The Stampede is Coming: A New Petascale Resource for the Open Science Community
|
|
|
- Lynette Preston
- 5 years ago
- Views:
Transcription
1 The Stampede is Coming: A New Petascale Resource for the Open Science Community Jay Boisseau Texas Advanced Computing Center boisseau@tacc.utexas.edu
2 Stampede: Solicitation US National Science Foundation (NSF) competition in 2011 for large HPC system To support open science across all domains of science and engineering To enable simulation-based & data-driven science Solicitation requirements & constraints $25M production system, plus up to $5M for innovative component Up to $6M/year for 4 years of O&M In production by January 2013 (fingers crossed)
3 Stampede: NSF HPC Context System must be integrated into XSEDE Allocations, integrated support, etc. Will effectively replace Ranger (TACC) and Kraken (NICS) HPC systems They expire in Februay 2013 (Ranger), June 2014 (Kraken) So probably had to bid at least 1½ - 2 PF Does not come with separate funding for networking, storage, visualization but all are required!
4 TACC s Stampede Project We wanted a comprehensive science system: Tremendous HPC capability, with powerful processors Support for HTC, big shared memory apps as well Powerful remote viz subsystem: 128 high-end GPUs Integration with archive, and (coming soon) TACC global work filesystem and other data systems Software complementing hardware to support both simulation-based and data-driven science People, training, and documentation to support diverse users, applications, and modes of computational science 4
5 Stampede: Background TACC evaluation Linux/x86 easiest path for XSEDE users Needed additional performance from innovative component community really needs >> 2PF due to lack of recent large-scale NSF HPC systems so, we considered acceleration options for more PFs Evaluated GPU and MIC decided on MIC Easier porting More programming options (x86) not just acceleration Leveraging x86 optimization experience More innovative? (Didn t exist yet )
6 Key Aspects of Acceleration We have lots of transistors Moore s law is holding; this isn t necessarily the problem. We don t really need lower power per transistor, we need lower power per *operation*. How to do this?
7 Intel s MIC Approach: Coprocessor, Not Just Accelerator Since days of RISC vs. CISC, Intel has mastered the art of figuring out what is important about a new processing technology, and saying why can t we do this in x86? Intel Many Integrated Core (MIC) architecture is (like GPUs) about large die, simpler circuit, much more parallelism and in the x86 line Easier to use (even as an accelerator) with standard, familiar tools (e.g. MPI, OpenMP) More flexible programming modes, models
 x86 cores that are simpler, but allow for more compute throughput Leverage (Intel s) existing x86 programming models Dedicate much of the silicon to")
8 Basic Design Ideas What is MIC? Leverage x86 architecture (CPU with many cores) x86 cores that are simpler, but allow for more compute throughput Leverage (Intel s) existing x86 programming models Dedicate much of the silicon to floating point ops., keep some cache(s) Keep cache-coherency protocol Increase floating-point throughput per core Implement as a separate device Strip expensive features (out-of-order execution, branch prediction, etc.) Widen SIMD registers for more throughput Fast (GDDR5) memory on card 8
9 Coprocessor vs. Accelerator Architecture: x86 vs. streaming processors HPC Programming model: Threading/MPI: Programming details coherent caches vs. shared memory and caches extension to C++/C/Fortran vs. CUDA/OpenCL OpenCL support OpenMP and Multithreading vs. threads in hardware MPI on host and/or MIC vs. MPI on host only offloaded regions vs. kernels Support for any code: serial, scripting, etc. Yes Native mode: Any code may be offloaded as a whole to the coprocessor No
10 What We Like about MIC Intel s MIC is based on x86 technology x86 cores w/ caches and cache coherency SIMD instruction set Programming for MIC is similar to programming for CPUs Familiar languages: C/C++ and Fortran Familiar parallel programming models: OpenMP & MPI MPI on host and on the coprocessor Any code can run on MIC, not just kernels Optimizing for MIC is similar to optimizing for CPUs Optimize once, run anywhere Our early MIC porting efforts for codes in the field are frequently doubling performance on Sandy Bridge.
11 TACC s Stampede: The Big Picture Dell, Intel, and Mellanox are vendor partners Almost 10 PF peak performance in initial system (2013) 2+ PF of Intel Xeon E5 (6400 dual-socket nodes) 7+ PF of Intel Xeon Phi (MIC) coprocessors (at least 6400) Special edition/release for this project 61 cores 14+ PB disk, 150+ GB/s I/O bandwidth 272+ TB RAM 56 Gb/s Mellanox FDR InfiniBand interconnect 16 x 1TB large shared memory nodes 128 Nvidia Kepler K20 GPUs for remote viz 182 racks, 6 MW power!
12 New Technologies/Milestones in the Stampede Project Density: surpasses 40KW/Cabinet New Dell node designs to support multiple 300W expansion cards in single node ~1U Total system power past 5 *megawatts* Thermal storage technology incorporated. Breakthrough price/performance and power/performance. Inclusion of Intel MIC; but we must program it. Application concurrency past 1 *million* threads per application
13 Stampede: How Will Users Use It? 2+ PF Xeon-only system (MPI, OpenMP) Many users will use it as an extremely powerful Sandy Bridge cluster and that s OK! They may also use the shared memory nodes, remote vis 7+ PF MIC-only system (MPI, OpenMP) Homogeneous codes can be run entirely on the MICs! ~10PF heterogeneous system (MPI, OpenMP) Run separate MPI tasks on Xeon vs. MIC; use OpenMP extensions for offload for hybrid programs
14 Will My Code Run on MIC? Yes That s the wrong question, it s: Will your code run *best* on MIC?, or Will you get great MIC performance without additional work?
15 Host-only Offload Symmetric Reverse Offload MIC Native Stampede Programming Five Possible Models
16 Key Questions Why do we need to use a thread-based programming model? MPI programming Where to place the MPI tasks? How to communicate between host and MIC?
17 Early MIC Programming Experiences at TACC Codes port easily Minutes to days depending mostly on library dependencies Performance can require real work While the sw environment continues to evolve Getting codes to run *at all* is almost too easy; really need to put in the effort to get what you expect Scalability is pretty good Multiple threads per core *really important* Getting your code to vectorize *really important*
18 Programming MIC with Threads Key aspects of the MIC coprocessor A lot of local memory, but even more cores 100+ threads or tasks on a MIC One MPI task per core? Probably not Severe limitation of the available memory per task Some GB of Memory & 100 tasks some ten s of MB per MPI task Threads (OpenMP, etc.) are a must on MIC
19 MIC Programming with OpenMP MIC specific pragma precedes OpenMP pragma Fortran:!dir$ omp offload target(mic) < > C: #pragma offload target(mic) < > All data transfer is handled by the compiler (optional keywords provide user control) Options for: Automatic data management Manual data management I/O from within offloaded region Data can stream through the MIC; no need to leave MIC to fetch new data Also very helpful when debugging (print statements) Offloading a subroutine and using MKL 19
20 Offloaded Execution Model MPI task execute on the host Directives offload OpenMP code sections to the MIC Communication between MPI tasks on hosts through MPI Communication between host and coprocessor through offload semantics Code modifications: Offload directives inserted before OpenMP parallel regions One executable (a.out) runs on host and coprocessor
21 MIC Training Offloading Basic Program Base program: #include <omp.h> #define N void foo(double *, double *, double *, int ); int main(){ int i; double a[n], b[n], c[n]; for(i=0;i<n;i++){ a[i]=i; b[i]=n-1-i;} } foo(a,b,c,n); Example program Offload engine is a device Objective: Offload foo Do OpenMP on device void foo(double *a, double *b, double *c, int n){ int i; for(i=0;i<n;i++) { c[i]=a[i]*2.0e0 + b[i]; } }
22 MIC Training Offloading Function Offload Function offload: Requirements #include <omp.h> #define N #pragma omp <offload_function_spec> void foo(double *, double *, double *, int ); int main(){ int i; double a[n], b[n], c[n]; for(i=0;i<n;i++){ a[i]=i; b[i]=n-1-i;} } #pragma omp <offload_this> foo(a,b,c,n); #pragma omp <offload_function_spec> void foo(double *a, double *b, double *c, int n){ int i; #pragma omp parallel for for(i=0;i<n;i++) { c[i]=a[i]*2.0e0 + b[i]; } } Direct compiler to offload function or block Decorate function and prototype Usual OpenMP directives on device
23 The Stampede is Coming Stampede has a *lot* of new technologies, and as such has a certain element of risk. However, as of now, we expect the early user/science period to begin in December. Full production by January 7 th (Base system at least). You might hear some more about this machine at SC12 in November. Thank to NSF, Intel, Dell

24 Ranger: 3000 ft 2 Datacenter Expansion Stampede: 8000 ft 2
25 Power/Physical Stampede will physically use U cabinets. Power density (after upgrade in 2015) will exceed 40kW per rack. Estimated 2015 peak power is 6.2MW.
26 Key Datacenter Features Thermal energy storage to reduce peak power charges Hot aisle containment to boost efficiency (and simply provide enough cooling). Total IT power to 9.5MW, total power ~12MW. Expand experiments in mineral oil cooling.
27 Stampede: Powered by Intel Xeon E5 and Xeon Phi TACC & Intel have provided open science clusters since 2001 x86 architecture has become dominant ISA in supercomputing Stampede needed to enable discoveries that require petaflops Xeon E5 enables more far performance for general applications Xeon Phi enables tremendous potential performance for highly parallel applications, with much easier porting than GPUs Thus, Stampede will preserve (and reward!) many years of x86 experience and expertise in scientific codes, while offering world-class performance






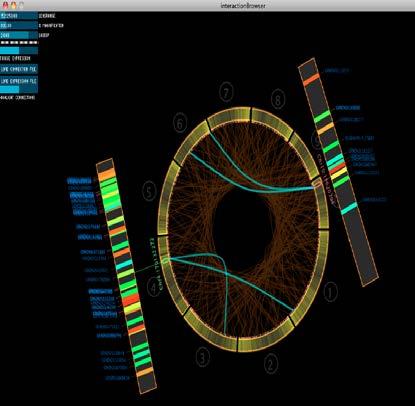
28 Stampede Will Enable New Scientific Discoveries Across Domains projects, by thousands of researchers
The Stampede is Coming Welcome to Stampede Introductory Training. Dan Stanzione Texas Advanced Computing Center
 The Stampede is Coming Welcome to Stampede Introductory Training Dan Stanzione Texas Advanced Computing Center dan@tacc.utexas.edu Thanks for Coming! Stampede is an exciting new system of incredible power.
The Stampede is Coming Welcome to Stampede Introductory Training Dan Stanzione Texas Advanced Computing Center dan@tacc.utexas.edu Thanks for Coming! Stampede is an exciting new system of incredible power.
Tutorial. Preparing for Stampede: Programming Heterogeneous Many-Core Supercomputers
 Tutorial Preparing for Stampede: Programming Heterogeneous Many-Core Supercomputers Dan Stanzione, Lars Koesterke, Bill Barth, Kent Milfeld dan/lars/bbarth/milfeld@tacc.utexas.edu XSEDE 12 July 16, 2012
Tutorial Preparing for Stampede: Programming Heterogeneous Many-Core Supercomputers Dan Stanzione, Lars Koesterke, Bill Barth, Kent Milfeld dan/lars/bbarth/milfeld@tacc.utexas.edu XSEDE 12 July 16, 2012
Parallel Programming on Ranger and Stampede
 Parallel Programming on Ranger and Stampede Steve Lantz Senior Research Associate Cornell CAC Parallel Computing at TACC: Ranger to Stampede Transition December 11, 2012 What is Stampede? NSF-funded XSEDE
Parallel Programming on Ranger and Stampede Steve Lantz Senior Research Associate Cornell CAC Parallel Computing at TACC: Ranger to Stampede Transition December 11, 2012 What is Stampede? NSF-funded XSEDE
Introduction to Xeon Phi. Bill Barth January 11, 2013
 Introduction to Xeon Phi Bill Barth January 11, 2013 What is it? Co-processor PCI Express card Stripped down Linux operating system Dense, simplified processor Many power-hungry operations removed Wider
Introduction to Xeon Phi Bill Barth January 11, 2013 What is it? Co-processor PCI Express card Stripped down Linux operating system Dense, simplified processor Many power-hungry operations removed Wider
Introduction to the Intel Xeon Phi on Stampede
 June 10, 2014 Introduction to the Intel Xeon Phi on Stampede John Cazes Texas Advanced Computing Center Stampede - High Level Overview Base Cluster (Dell/Intel/Mellanox): Intel Sandy Bridge processors
June 10, 2014 Introduction to the Intel Xeon Phi on Stampede John Cazes Texas Advanced Computing Center Stampede - High Level Overview Base Cluster (Dell/Intel/Mellanox): Intel Sandy Bridge processors
Resources Current and Future Systems. Timothy H. Kaiser, Ph.D.
 Resources Current and Future Systems Timothy H. Kaiser, Ph.D. tkaiser@mines.edu 1 Most likely talk to be out of date History of Top 500 Issues with building bigger machines Current and near future academic
Resources Current and Future Systems Timothy H. Kaiser, Ph.D. tkaiser@mines.edu 1 Most likely talk to be out of date History of Top 500 Issues with building bigger machines Current and near future academic
TACC s Stampede Project: Intel MIC for Simulation and Data-Intensive Computing
 TACC s Stampede Project: Intel MIC for Simulation and Data-Intensive Computing Jay Boisseau, Director April 17, 2012 TACC Vision & Strategy Provide the most powerful, capable computing technologies and
TACC s Stampede Project: Intel MIC for Simulation and Data-Intensive Computing Jay Boisseau, Director April 17, 2012 TACC Vision & Strategy Provide the most powerful, capable computing technologies and
Preparing for Highly Parallel, Heterogeneous Coprocessing
 Preparing for Highly Parallel, Heterogeneous Coprocessing Steve Lantz Senior Research Associate Cornell CAC Workshop: Parallel Computing on Ranger and Lonestar May 17, 2012 What Are We Talking About Here?
Preparing for Highly Parallel, Heterogeneous Coprocessing Steve Lantz Senior Research Associate Cornell CAC Workshop: Parallel Computing on Ranger and Lonestar May 17, 2012 What Are We Talking About Here?
Introduc)on to Xeon Phi
on to Xeon Phi") Introduc)on to Xeon Phi ACES Aus)n, TX Dec. 04 2013 Kent Milfeld, Luke Wilson, John McCalpin, Lars Koesterke TACC What is it? Co- processor PCI Express card Stripped down Linux opera)ng system Dense, simplified
Introduc)on to Xeon Phi ACES Aus)n, TX Dec. 04 2013 Kent Milfeld, Luke Wilson, John McCalpin, Lars Koesterke TACC What is it? Co- processor PCI Express card Stripped down Linux opera)ng system Dense, simplified
Resources Current and Future Systems. Timothy H. Kaiser, Ph.D.
 Resources Current and Future Systems Timothy H. Kaiser, Ph.D. tkaiser@mines.edu 1 Most likely talk to be out of date History of Top 500 Issues with building bigger machines Current and near future academic
Resources Current and Future Systems Timothy H. Kaiser, Ph.D. tkaiser@mines.edu 1 Most likely talk to be out of date History of Top 500 Issues with building bigger machines Current and near future academic
HPC Hardware Overview
 HPC Hardware Overview John Lockman III April 19, 2013 Texas Advanced Computing Center The University of Texas at Austin Outline Lonestar Dell blade-based system InfiniBand ( QDR) Intel Processors Longhorn
HPC Hardware Overview John Lockman III April 19, 2013 Texas Advanced Computing Center The University of Texas at Austin Outline Lonestar Dell blade-based system InfiniBand ( QDR) Intel Processors Longhorn
The Era of Heterogeneous Computing
 The Era of Heterogeneous Computing EU-US Summer School on High Performance Computing New York, NY, USA June 28, 2013 Lars Koesterke: Research Staff @ TACC Nomenclature Architecture Model -------------------------------------------------------
The Era of Heterogeneous Computing EU-US Summer School on High Performance Computing New York, NY, USA June 28, 2013 Lars Koesterke: Research Staff @ TACC Nomenclature Architecture Model -------------------------------------------------------
A Unified Approach to Heterogeneous Architectures Using the Uintah Framework
 DOE for funding the CSAFE project (97-10), DOE NETL, DOE NNSA NSF for funding via SDCI and PetaApps A Unified Approach to Heterogeneous Architectures Using the Uintah Framework Qingyu Meng, Alan Humphrey
DOE for funding the CSAFE project (97-10), DOE NETL, DOE NNSA NSF for funding via SDCI and PetaApps A Unified Approach to Heterogeneous Architectures Using the Uintah Framework Qingyu Meng, Alan Humphrey
Introduc)on to Xeon Phi
on to Xeon Phi") Introduc)on to Xeon Phi IXPUG 14 Lars Koesterke Acknowledgements Thanks/kudos to: Sponsor: National Science Foundation NSF Grant #OCI-1134872 Stampede Award, Enabling, Enhancing, and Extending Petascale
Introduc)on to Xeon Phi IXPUG 14 Lars Koesterke Acknowledgements Thanks/kudos to: Sponsor: National Science Foundation NSF Grant #OCI-1134872 Stampede Award, Enabling, Enhancing, and Extending Petascale
Intel Many Integrated Core (MIC) Matt Kelly & Ryan Rawlins
 Matt Kelly & Ryan Rawlins") Intel Many Integrated Core (MIC) Matt Kelly & Ryan Rawlins Outline History & Motivation Architecture Core architecture Network Topology Memory hierarchy Brief comparison to GPU & Tilera Programming Applications
Intel Many Integrated Core (MIC) Matt Kelly & Ryan Rawlins Outline History & Motivation Architecture Core architecture Network Topology Memory hierarchy Brief comparison to GPU & Tilera Programming Applications
Intel Knights Landing Hardware
 Intel Knights Landing Hardware TACC KNL Tutorial IXPUG Annual Meeting 2016 PRESENTED BY: John Cazes Lars Koesterke 1 Intel s Xeon Phi Architecture Leverages x86 architecture Simpler x86 cores, higher compute
Intel Knights Landing Hardware TACC KNL Tutorial IXPUG Annual Meeting 2016 PRESENTED BY: John Cazes Lars Koesterke 1 Intel s Xeon Phi Architecture Leverages x86 architecture Simpler x86 cores, higher compute
Preparing GPU-Accelerated Applications for the Summit Supercomputer
 Preparing GPU-Accelerated Applications for the Summit Supercomputer Fernanda Foertter HPC User Assistance Group Training Lead foertterfs@ornl.gov This research used resources of the Oak Ridge Leadership
Preparing GPU-Accelerated Applications for the Summit Supercomputer Fernanda Foertter HPC User Assistance Group Training Lead foertterfs@ornl.gov This research used resources of the Oak Ridge Leadership
GPUs and Emerging Architectures
 GPUs and Emerging Architectures Mike Giles mike.giles@maths.ox.ac.uk Mathematical Institute, Oxford University e-infrastructure South Consortium Oxford e-research Centre Emerging Architectures p. 1 CPUs
GPUs and Emerging Architectures Mike Giles mike.giles@maths.ox.ac.uk Mathematical Institute, Oxford University e-infrastructure South Consortium Oxford e-research Centre Emerging Architectures p. 1 CPUs
Introduction to Parallel Programming
 Introduction to Parallel Programming January 14, 2015 www.cac.cornell.edu What is Parallel Programming? Theoretically a very simple concept Use more than one processor to complete a task Operationally
Introduction to Parallel Programming January 14, 2015 www.cac.cornell.edu What is Parallel Programming? Theoretically a very simple concept Use more than one processor to complete a task Operationally
the Intel Xeon Phi coprocessor
 the Intel Xeon Phi coprocessor 1 Introduction about the Intel Xeon Phi coprocessor comparing Phi with CUDA the Intel Many Integrated Core architecture 2 Programming the Intel Xeon Phi Coprocessor with
the Intel Xeon Phi coprocessor 1 Introduction about the Intel Xeon Phi coprocessor comparing Phi with CUDA the Intel Many Integrated Core architecture 2 Programming the Intel Xeon Phi Coprocessor with
Intel Many Integrated Core (MIC) Architecture
 Architecture") Intel Many Integrated Core (MIC) Architecture Karl Solchenbach Director European Exascale Labs BMW2011, November 3, 2011 1 Notice and Disclaimers Notice: This document contains information on products
Intel Many Integrated Core (MIC) Architecture Karl Solchenbach Director European Exascale Labs BMW2011, November 3, 2011 1 Notice and Disclaimers Notice: This document contains information on products
Vincent C. Betro, R. Glenn Brook, & Ryan C. Hulguin XSEDE Xtreme Scaling Workshop Chicago, IL July 15-16, 2012
 Vincent C. Betro, R. Glenn Brook, & Ryan C. Hulguin XSEDE Xtreme Scaling Workshop Chicago, IL July 15-16, 2012 Outline NICS and AACE Architecture Overview Resources Native Mode Boltzmann BGK Solver Native/Offload
Vincent C. Betro, R. Glenn Brook, & Ryan C. Hulguin XSEDE Xtreme Scaling Workshop Chicago, IL July 15-16, 2012 Outline NICS and AACE Architecture Overview Resources Native Mode Boltzmann BGK Solver Native/Offload
Trends in HPC (hardware complexity and software challenges)
") Trends in HPC (hardware complexity and software challenges) Mike Giles Oxford e-research Centre Mathematical Institute MIT seminar March 13th, 2013 Mike Giles (Oxford) HPC Trends March 13th, 2013 1 / 18
Trends in HPC (hardware complexity and software challenges) Mike Giles Oxford e-research Centre Mathematical Institute MIT seminar March 13th, 2013 Mike Giles (Oxford) HPC Trends March 13th, 2013 1 / 18
n N c CIni.o ewsrg.au
 @NCInews NCI and Raijin National Computational Infrastructure 2 Our Partners General purpose, highly parallel processors High FLOPs/watt and FLOPs/$ Unit of execution Kernel Separate memory subsystem GPGPU
@NCInews NCI and Raijin National Computational Infrastructure 2 Our Partners General purpose, highly parallel processors High FLOPs/watt and FLOPs/$ Unit of execution Kernel Separate memory subsystem GPGPU
Architecture, Programming and Performance of MIC Phi Coprocessor
 Architecture, Programming and Performance of MIC Phi Coprocessor JanuszKowalik, Piotr Arłukowicz Professor (ret), The Boeing Company, Washington, USA Assistant professor, Faculty of Mathematics, Physics
Architecture, Programming and Performance of MIC Phi Coprocessor JanuszKowalik, Piotr Arłukowicz Professor (ret), The Boeing Company, Washington, USA Assistant professor, Faculty of Mathematics, Physics
An Introduction to the Intel Xeon Phi. Si Liu Feb 6, 2015
 Training Agenda Session 1: Introduction 8:00 9:45 Session 2: Native: MIC stand-alone 10:00-11:45 Lunch break Session 3: Offload: MIC as coprocessor 1:00 2:45 Session 4: Symmetric: MPI 3:00 4:45 1 Last
Training Agenda Session 1: Introduction 8:00 9:45 Session 2: Native: MIC stand-alone 10:00-11:45 Lunch break Session 3: Offload: MIC as coprocessor 1:00 2:45 Session 4: Symmetric: MPI 3:00 4:45 1 Last
HPC Architectures. Types of resource currently in use
 HPC Architectures Types of resource currently in use Reusing this material This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike 4.0 International License. http://creativecommons.org/licenses/by-nc-sa/4.0/deed.en_us
HPC Architectures Types of resource currently in use Reusing this material This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike 4.0 International License. http://creativecommons.org/licenses/by-nc-sa/4.0/deed.en_us
Introduction: Modern computer architecture. The stored program computer and its inherent bottlenecks Multi- and manycore chips and nodes
 Introduction: Modern computer architecture The stored program computer and its inherent bottlenecks Multi- and manycore chips and nodes Motivation: Multi-Cores where and why Introduction: Moore s law Intel
Introduction: Modern computer architecture The stored program computer and its inherent bottlenecks Multi- and manycore chips and nodes Motivation: Multi-Cores where and why Introduction: Moore s law Intel
Accelerator Programming Lecture 1
 Accelerator Programming Lecture 1 Manfred Liebmann Technische Universität München Chair of Optimal Control Center for Mathematical Sciences, M17 manfred.liebmann@tum.de January 11, 2016 Accelerator Programming
Accelerator Programming Lecture 1 Manfred Liebmann Technische Universität München Chair of Optimal Control Center for Mathematical Sciences, M17 manfred.liebmann@tum.de January 11, 2016 Accelerator Programming
HPC. Accelerating. HPC Advisory Council Lugano, CH March 15 th, Herbert Cornelius Intel
 15.03.2012 1 Accelerating HPC HPC Advisory Council Lugano, CH March 15 th, 2012 Herbert Cornelius Intel Legal Disclaimer 15.03.2012 2 INFORMATION IN THIS DOCUMENT IS PROVIDED IN CONNECTION WITH INTEL PRODUCTS.
15.03.2012 1 Accelerating HPC HPC Advisory Council Lugano, CH March 15 th, 2012 Herbert Cornelius Intel Legal Disclaimer 15.03.2012 2 INFORMATION IN THIS DOCUMENT IS PROVIDED IN CONNECTION WITH INTEL PRODUCTS.
Overview of Intel Xeon Phi Coprocessor
 Overview of Intel Xeon Phi Coprocessor Sept 20, 2013 Ritu Arora Texas Advanced Computing Center Email: rauta@tacc.utexas.edu This talk is only a trailer A comprehensive training on running and optimizing
Overview of Intel Xeon Phi Coprocessor Sept 20, 2013 Ritu Arora Texas Advanced Computing Center Email: rauta@tacc.utexas.edu This talk is only a trailer A comprehensive training on running and optimizing
Overview of Tianhe-2
 Overview of Tianhe-2 (MilkyWay-2) Supercomputer Yutong Lu School of Computer Science, National University of Defense Technology; State Key Laboratory of High Performance Computing, China ytlu@nudt.edu.cn
Overview of Tianhe-2 (MilkyWay-2) Supercomputer Yutong Lu School of Computer Science, National University of Defense Technology; State Key Laboratory of High Performance Computing, China ytlu@nudt.edu.cn
Achieving High Performance. Jim Cownie Principal Engineer SSG/DPD/TCAR Multicore Challenge 2013
 Achieving High Performance Jim Cownie Principal Engineer SSG/DPD/TCAR Multicore Challenge 2013 Does Instruction Set Matter? We find that ARM and x86 processors are simply engineering design points optimized
Achieving High Performance Jim Cownie Principal Engineer SSG/DPD/TCAR Multicore Challenge 2013 Does Instruction Set Matter? We find that ARM and x86 processors are simply engineering design points optimized
Intel Architecture for HPC
 Intel Architecture for HPC Georg Zitzlsberger georg.zitzlsberger@vsb.cz 1st of March 2018 Agenda Salomon Architectures Intel R Xeon R processors v3 (Haswell) Intel R Xeon Phi TM coprocessor (KNC) Ohter
Intel Architecture for HPC Georg Zitzlsberger georg.zitzlsberger@vsb.cz 1st of March 2018 Agenda Salomon Architectures Intel R Xeon R processors v3 (Haswell) Intel R Xeon Phi TM coprocessor (KNC) Ohter
Introduction CPS343. Spring Parallel and High Performance Computing. CPS343 (Parallel and HPC) Introduction Spring / 29
 Introduction Spring / 29") Introduction CPS343 Parallel and High Performance Computing Spring 2018 CPS343 (Parallel and HPC) Introduction Spring 2018 1 / 29 Outline 1 Preface Course Details Course Requirements 2 Background Definitions
Introduction CPS343 Parallel and High Performance Computing Spring 2018 CPS343 (Parallel and HPC) Introduction Spring 2018 1 / 29 Outline 1 Preface Course Details Course Requirements 2 Background Definitions
The Stampede Supercomputer
 The Stampede Supercomputer Niall Gaffney (Dan Stanzione, Karl Schulz, Bill Barth, Tommy Minyard) July 2013 Acknowledgements Thanks/kudos to: Sponsor: National Science Foundation NSF Grant #OCI-1134872
The Stampede Supercomputer Niall Gaffney (Dan Stanzione, Karl Schulz, Bill Barth, Tommy Minyard) July 2013 Acknowledgements Thanks/kudos to: Sponsor: National Science Foundation NSF Grant #OCI-1134872
Intel Xeon Phi Coprocessors
 Intel Xeon Phi Coprocessors Reference: Parallel Programming and Optimization with Intel Xeon Phi Coprocessors, by A. Vladimirov and V. Karpusenko, 2013 Ring Bus on Intel Xeon Phi Example with 8 cores Xeon
Intel Xeon Phi Coprocessors Reference: Parallel Programming and Optimization with Intel Xeon Phi Coprocessors, by A. Vladimirov and V. Karpusenko, 2013 Ring Bus on Intel Xeon Phi Example with 8 cores Xeon
Technology for a better society. hetcomp.com
 Technology for a better society hetcomp.com 1 J. Seland, C. Dyken, T. R. Hagen, A. R. Brodtkorb, J. Hjelmervik,E Bjønnes GPU Computing USIT Course Week 16th November 2011 hetcomp.com 2 9:30 10:15 Introduction
Technology for a better society hetcomp.com 1 J. Seland, C. Dyken, T. R. Hagen, A. R. Brodtkorb, J. Hjelmervik,E Bjønnes GPU Computing USIT Course Week 16th November 2011 hetcomp.com 2 9:30 10:15 Introduction
Introduction to the Xeon Phi programming model. Fabio AFFINITO, CINECA
 Introduction to the Xeon Phi programming model Fabio AFFINITO, CINECA What is a Xeon Phi? MIC = Many Integrated Core architecture by Intel Other names: KNF, KNC, Xeon Phi... Not a CPU (but somewhat similar
Introduction to the Xeon Phi programming model Fabio AFFINITO, CINECA What is a Xeon Phi? MIC = Many Integrated Core architecture by Intel Other names: KNF, KNC, Xeon Phi... Not a CPU (but somewhat similar
Introduction to Intel Xeon Phi programming techniques. Fabio Affinito Vittorio Ruggiero
 Introduction to Intel Xeon Phi programming techniques Fabio Affinito Vittorio Ruggiero Outline High level overview of the Intel Xeon Phi hardware and software stack Intel Xeon Phi programming paradigms:
Introduction to Intel Xeon Phi programming techniques Fabio Affinito Vittorio Ruggiero Outline High level overview of the Intel Xeon Phi hardware and software stack Intel Xeon Phi programming paradigms:
Netweb Technologies Delivers India s Fastest Hybrid Supercomputer with Breakthrough Performance
 white paper Intel, Netweb Technologies & Tyrone Netweb Technologies Delivers India s Fastest Hybrid Supercomputer with Breakthrough Performance Using the Intel Xeon processor and new Intel Xeon Phi coprocessor
white paper Intel, Netweb Technologies & Tyrone Netweb Technologies Delivers India s Fastest Hybrid Supercomputer with Breakthrough Performance Using the Intel Xeon processor and new Intel Xeon Phi coprocessor
Investigation of Intel MIC for implementation of Fast Fourier Transform
 Investigation of Intel MIC for implementation of Fast Fourier Transform Soren Goyal Department of Physics IIT Kanpur e-mail address: soren@iitk.ac.in The objective of the project was to run the code for
Investigation of Intel MIC for implementation of Fast Fourier Transform Soren Goyal Department of Physics IIT Kanpur e-mail address: soren@iitk.ac.in The objective of the project was to run the code for
Modern Processor Architectures. L25: Modern Compiler Design
 Modern Processor Architectures L25: Modern Compiler Design The 1960s - 1970s Instructions took multiple cycles Only one instruction in flight at once Optimisation meant minimising the number of instructions
Modern Processor Architectures L25: Modern Compiler Design The 1960s - 1970s Instructions took multiple cycles Only one instruction in flight at once Optimisation meant minimising the number of instructions
Overview of research activities Toward portability of performance
 Overview of research activities Toward portability of performance Do dynamically what can t be done statically Understand evolution of architectures Enable new programming models Put intelligence into
Overview of research activities Toward portability of performance Do dynamically what can t be done statically Understand evolution of architectures Enable new programming models Put intelligence into
Paving the Road to Exascale
 Paving the Road to Exascale Gilad Shainer August 2015, MVAPICH User Group (MUG) Meeting The Ever Growing Demand for Performance Performance Terascale Petascale Exascale 1 st Roadrunner 2000 2005 2010 2015
Paving the Road to Exascale Gilad Shainer August 2015, MVAPICH User Group (MUG) Meeting The Ever Growing Demand for Performance Performance Terascale Petascale Exascale 1 st Roadrunner 2000 2005 2010 2015
GPU Architecture. Alan Gray EPCC The University of Edinburgh
 GPU Architecture Alan Gray EPCC The University of Edinburgh Outline Why do we want/need accelerators such as GPUs? Architectural reasons for accelerator performance advantages Latest GPU Products From
GPU Architecture Alan Gray EPCC The University of Edinburgh Outline Why do we want/need accelerators such as GPUs? Architectural reasons for accelerator performance advantages Latest GPU Products From
HETEROGENEOUS HPC, ARCHITECTURAL OPTIMIZATION, AND NVLINK STEVE OBERLIN CTO, TESLA ACCELERATED COMPUTING NVIDIA
 HETEROGENEOUS HPC, ARCHITECTURAL OPTIMIZATION, AND NVLINK STEVE OBERLIN CTO, TESLA ACCELERATED COMPUTING NVIDIA STATE OF THE ART 2012 18,688 Tesla K20X GPUs 27 PetaFLOPS FLAGSHIP SCIENTIFIC APPLICATIONS
HETEROGENEOUS HPC, ARCHITECTURAL OPTIMIZATION, AND NVLINK STEVE OBERLIN CTO, TESLA ACCELERATED COMPUTING NVIDIA STATE OF THE ART 2012 18,688 Tesla K20X GPUs 27 PetaFLOPS FLAGSHIP SCIENTIFIC APPLICATIONS
Designing Optimized MPI Broadcast and Allreduce for Many Integrated Core (MIC) InfiniBand Clusters
 InfiniBand Clusters") Designing Optimized MPI Broadcast and Allreduce for Many Integrated Core (MIC) InfiniBand Clusters K. Kandalla, A. Venkatesh, K. Hamidouche, S. Potluri, D. Bureddy and D. K. Panda Presented by Dr. Xiaoyi
Designing Optimized MPI Broadcast and Allreduce for Many Integrated Core (MIC) InfiniBand Clusters K. Kandalla, A. Venkatesh, K. Hamidouche, S. Potluri, D. Bureddy and D. K. Panda Presented by Dr. Xiaoyi
Modern Processor Architectures (A compiler writer s perspective) L25: Modern Compiler Design
 L25: Modern Compiler Design") Modern Processor Architectures (A compiler writer s perspective) L25: Modern Compiler Design The 1960s - 1970s Instructions took multiple cycles Only one instruction in flight at once Optimisation meant
Modern Processor Architectures (A compiler writer s perspective) L25: Modern Compiler Design The 1960s - 1970s Instructions took multiple cycles Only one instruction in flight at once Optimisation meant
Interconnect Your Future
 Interconnect Your Future Gilad Shainer 2nd Annual MVAPICH User Group (MUG) Meeting, August 2014 Complete High-Performance Scalable Interconnect Infrastructure Comprehensive End-to-End Software Accelerators
Interconnect Your Future Gilad Shainer 2nd Annual MVAPICH User Group (MUG) Meeting, August 2014 Complete High-Performance Scalable Interconnect Infrastructure Comprehensive End-to-End Software Accelerators
ABySS Performance Benchmark and Profiling. May 2010
 ABySS Performance Benchmark and Profiling May 2010 Note The following research was performed under the HPC Advisory Council activities Participating vendors: AMD, Dell, Mellanox Compute resource - HPC
ABySS Performance Benchmark and Profiling May 2010 Note The following research was performed under the HPC Advisory Council activities Participating vendors: AMD, Dell, Mellanox Compute resource - HPC
Computer Architecture and Structured Parallel Programming James Reinders, Intel
 Computer Architecture and Structured Parallel Programming James Reinders, Intel Parallel Computing CIS 410/510 Department of Computer and Information Science Lecture 17 Manycore Computing and GPUs Computer
Computer Architecture and Structured Parallel Programming James Reinders, Intel Parallel Computing CIS 410/510 Department of Computer and Information Science Lecture 17 Manycore Computing and GPUs Computer
InfiniBand Strengthens Leadership as the Interconnect Of Choice By Providing Best Return on Investment. TOP500 Supercomputers, June 2014
 InfiniBand Strengthens Leadership as the Interconnect Of Choice By Providing Best Return on Investment TOP500 Supercomputers, June 2014 TOP500 Performance Trends 38% CAGR 78% CAGR Explosive high-performance
InfiniBand Strengthens Leadership as the Interconnect Of Choice By Providing Best Return on Investment TOP500 Supercomputers, June 2014 TOP500 Performance Trends 38% CAGR 78% CAGR Explosive high-performance
Advances of parallel computing. Kirill Bogachev May 2016
 Advances of parallel computing Kirill Bogachev May 2016 Demands in Simulations Field development relies more and more on static and dynamic modeling of the reservoirs that has come a long way from being
Advances of parallel computing Kirill Bogachev May 2016 Demands in Simulations Field development relies more and more on static and dynamic modeling of the reservoirs that has come a long way from being
Path to Exascale? Intel in Research and HPC 2012
 Path to Exascale? Intel in Research and HPC 2012 Intel s Investment in Manufacturing New Capacity for 14nm and Beyond D1X Oregon Development Fab Fab 42 Arizona High Volume Fab 22nm Fab Upgrades D1D Oregon
Path to Exascale? Intel in Research and HPC 2012 Intel s Investment in Manufacturing New Capacity for 14nm and Beyond D1X Oregon Development Fab Fab 42 Arizona High Volume Fab 22nm Fab Upgrades D1D Oregon
WVU RESEARCH COMPUTING INTRODUCTION. Introduction to WVU s Research Computing Services
 WVU RESEARCH COMPUTING INTRODUCTION Introduction to WVU s Research Computing Services WHO ARE WE? Division of Information Technology Services Funded through WVU Research Corporation Provide centralized
WVU RESEARCH COMPUTING INTRODUCTION Introduction to WVU s Research Computing Services WHO ARE WE? Division of Information Technology Services Funded through WVU Research Corporation Provide centralized
Intel High-Performance Computing. Technologies for Engineering
 6. LS-DYNA Anwenderforum, Frankenthal 2007 Keynote-Vorträge II Intel High-Performance Computing Technologies for Engineering H. Cornelius Intel GmbH A - II - 29 Keynote-Vorträge II 6. LS-DYNA Anwenderforum,
6. LS-DYNA Anwenderforum, Frankenthal 2007 Keynote-Vorträge II Intel High-Performance Computing Technologies for Engineering H. Cornelius Intel GmbH A - II - 29 Keynote-Vorträge II 6. LS-DYNA Anwenderforum,
Gateways to Discovery: Cyberinfrastructure for the Long Tail of Science
 Gateways to Discovery: Cyberinfrastructure for the Long Tail of Science ECSS Symposium, 12/16/14 M. L. Norman, R. L. Moore, D. Baxter, G. Fox (Indiana U), A Majumdar, P Papadopoulos, W Pfeiffer, R. S.
Gateways to Discovery: Cyberinfrastructure for the Long Tail of Science ECSS Symposium, 12/16/14 M. L. Norman, R. L. Moore, D. Baxter, G. Fox (Indiana U), A Majumdar, P Papadopoulos, W Pfeiffer, R. S.
Scalasca support for Intel Xeon Phi. Brian Wylie & Wolfgang Frings Jülich Supercomputing Centre Forschungszentrum Jülich, Germany
 Scalasca support for Intel Xeon Phi Brian Wylie & Wolfgang Frings Jülich Supercomputing Centre Forschungszentrum Jülich, Germany Overview Scalasca performance analysis toolset support for MPI & OpenMP
Scalasca support for Intel Xeon Phi Brian Wylie & Wolfgang Frings Jülich Supercomputing Centre Forschungszentrum Jülich, Germany Overview Scalasca performance analysis toolset support for MPI & OpenMP
General introduction: GPUs and the realm of parallel architectures
 General introduction: GPUs and the realm of parallel architectures GPU Computing Training August 17-19 th 2015 Jan Lemeire (jan.lemeire@vub.ac.be) Graduated as Engineer in 1994 at VUB Worked for 4 years
General introduction: GPUs and the realm of parallel architectures GPU Computing Training August 17-19 th 2015 Jan Lemeire (jan.lemeire@vub.ac.be) Graduated as Engineer in 1994 at VUB Worked for 4 years
Performance Optimizations via Connect-IB and Dynamically Connected Transport Service for Maximum Performance on LS-DYNA
 Performance Optimizations via Connect-IB and Dynamically Connected Transport Service for Maximum Performance on LS-DYNA Pak Lui, Gilad Shainer, Brian Klaff Mellanox Technologies Abstract From concept to
Performance Optimizations via Connect-IB and Dynamically Connected Transport Service for Maximum Performance on LS-DYNA Pak Lui, Gilad Shainer, Brian Klaff Mellanox Technologies Abstract From concept to
Introduc)on to Xeon Phi
on to Xeon Phi") Introduc)on to Xeon Phi MIC Training Event at TACC Lars Koesterke Xeon Phi MIC Xeon Phi = first product of Intel s Many Integrated Core (MIC) architecture Co- processor PCI Express card Stripped down Linux
Introduc)on to Xeon Phi MIC Training Event at TACC Lars Koesterke Xeon Phi MIC Xeon Phi = first product of Intel s Many Integrated Core (MIC) architecture Co- processor PCI Express card Stripped down Linux
Parallel Applications on Distributed Memory Systems. Le Yan HPC User LSU
 Parallel Applications on Distributed Memory Systems Le Yan HPC User Services @ LSU Outline Distributed memory systems Message Passing Interface (MPI) Parallel applications 6/3/2015 LONI Parallel Programming
Parallel Applications on Distributed Memory Systems Le Yan HPC User Services @ LSU Outline Distributed memory systems Message Passing Interface (MPI) Parallel applications 6/3/2015 LONI Parallel Programming
Oncilla - a Managed GAS Runtime for Accelerating Data Warehousing Queries
 Oncilla - a Managed GAS Runtime for Accelerating Data Warehousing Queries Jeffrey Young, Alex Merritt, Se Hoon Shon Advisor: Sudhakar Yalamanchili 4/16/13 Sponsors: Intel, NVIDIA, NSF 2 The Problem Big
Oncilla - a Managed GAS Runtime for Accelerating Data Warehousing Queries Jeffrey Young, Alex Merritt, Se Hoon Shon Advisor: Sudhakar Yalamanchili 4/16/13 Sponsors: Intel, NVIDIA, NSF 2 The Problem Big
Illinois Proposal Considerations Greg Bauer
 - 2016 Greg Bauer Support model Blue Waters provides traditional Partner Consulting as part of its User Services. Standard service requests for assistance with porting, debugging, allocation issues, and
- 2016 Greg Bauer Support model Blue Waters provides traditional Partner Consulting as part of its User Services. Standard service requests for assistance with porting, debugging, allocation issues, and
PORTING CP2K TO THE INTEL XEON PHI. ARCHER Technical Forum, Wed 30 th July Iain Bethune
 PORTING CP2K TO THE INTEL XEON PHI ARCHER Technical Forum, Wed 30 th July Iain Bethune (ibethune@epcc.ed.ac.uk) Outline Xeon Phi Overview Porting CP2K to Xeon Phi Performance Results Lessons Learned Further
PORTING CP2K TO THE INTEL XEON PHI ARCHER Technical Forum, Wed 30 th July Iain Bethune (ibethune@epcc.ed.ac.uk) Outline Xeon Phi Overview Porting CP2K to Xeon Phi Performance Results Lessons Learned Further
Lecture 9: MIMD Architectures
 Lecture 9: MIMD Architectures Introduction and classification Symmetric multiprocessors NUMA architecture Clusters Zebo Peng, IDA, LiTH 1 Introduction MIMD: a set of general purpose processors is connected
Lecture 9: MIMD Architectures Introduction and classification Symmetric multiprocessors NUMA architecture Clusters Zebo Peng, IDA, LiTH 1 Introduction MIMD: a set of general purpose processors is connected
Big Data Analytics Performance for Large Out-Of- Core Matrix Solvers on Advanced Hybrid Architectures
 Procedia Computer Science Volume 51, 2015, Pages 2774 2778 ICCS 2015 International Conference On Computational Science Big Data Analytics Performance for Large Out-Of- Core Matrix Solvers on Advanced Hybrid
Procedia Computer Science Volume 51, 2015, Pages 2774 2778 ICCS 2015 International Conference On Computational Science Big Data Analytics Performance for Large Out-Of- Core Matrix Solvers on Advanced Hybrid
OpenMP on Ranger and Stampede (with Labs)
") OpenMP on Ranger and Stampede (with Labs) Steve Lantz Senior Research Associate Cornell CAC Parallel Computing at TACC: Ranger to Stampede Transition November 6, 2012 Based on materials developed by Kent
OpenMP on Ranger and Stampede (with Labs) Steve Lantz Senior Research Associate Cornell CAC Parallel Computing at TACC: Ranger to Stampede Transition November 6, 2012 Based on materials developed by Kent
HPC Capabilities at Research Intensive Universities
 HPC Capabilities at Research Intensive Universities Purushotham (Puri) V. Bangalore Department of Computer and Information Sciences and UAB IT Research Computing UAB HPC Resources 24 nodes (192 cores)
HPC Capabilities at Research Intensive Universities Purushotham (Puri) V. Bangalore Department of Computer and Information Sciences and UAB IT Research Computing UAB HPC Resources 24 nodes (192 cores)
IBM CORAL HPC System Solution
 IBM CORAL HPC System Solution HPC and HPDA towards Cognitive, AI and Deep Learning Deep Learning AI / Deep Learning Strategy for Power Power AI Platform High Performance Data Analytics Big Data Strategy
IBM CORAL HPC System Solution HPC and HPDA towards Cognitive, AI and Deep Learning Deep Learning AI / Deep Learning Strategy for Power Power AI Platform High Performance Data Analytics Big Data Strategy
INTRODUCTION TO THE ARCHER KNIGHTS LANDING CLUSTER. Adrian
 INTRODUCTION TO THE ARCHER KNIGHTS LANDING CLUSTER Adrian Jackson adrianj@epcc.ed.ac.uk @adrianjhpc Processors The power used by a CPU core is proportional to Clock Frequency x Voltage 2 In the past, computers
INTRODUCTION TO THE ARCHER KNIGHTS LANDING CLUSTER Adrian Jackson adrianj@epcc.ed.ac.uk @adrianjhpc Processors The power used by a CPU core is proportional to Clock Frequency x Voltage 2 In the past, computers
Computing architectures Part 2 TMA4280 Introduction to Supercomputing
 Computing architectures Part 2 TMA4280 Introduction to Supercomputing NTNU, IMF January 16. 2017 1 Supercomputing What is the motivation for Supercomputing? Solve complex problems fast and accurately:
Computing architectures Part 2 TMA4280 Introduction to Supercomputing NTNU, IMF January 16. 2017 1 Supercomputing What is the motivation for Supercomputing? Solve complex problems fast and accurately:
This Unit: Putting It All Together. CIS 501 Computer Architecture. What is Computer Architecture? Sources
 This Unit: Putting It All Together CIS 501 Computer Architecture Unit 12: Putting It All Together: Anatomy of the XBox 360 Game Console Application OS Compiler Firmware CPU I/O Memory Digital Circuits
This Unit: Putting It All Together CIS 501 Computer Architecture Unit 12: Putting It All Together: Anatomy of the XBox 360 Game Console Application OS Compiler Firmware CPU I/O Memory Digital Circuits
NVIDIA Think about Computing as Heterogeneous One Leo Liao, 1/29/2106, NTU
 NVIDIA Think about Computing as Heterogeneous One Leo Liao, 1/29/2106, NTU GPGPU opens the door for co-design HPC, moreover middleware-support embedded system designs to harness the power of GPUaccelerated
NVIDIA Think about Computing as Heterogeneous One Leo Liao, 1/29/2106, NTU GPGPU opens the door for co-design HPC, moreover middleware-support embedded system designs to harness the power of GPUaccelerated
Programming Models for Multi- Threading. Brian Marshall, Advanced Research Computing
 Programming Models for Multi- Threading Brian Marshall, Advanced Research Computing Why Do Parallel Computing? Limits of single CPU computing performance available memory I/O rates Parallel computing allows
Programming Models for Multi- Threading Brian Marshall, Advanced Research Computing Why Do Parallel Computing? Limits of single CPU computing performance available memory I/O rates Parallel computing allows
Maximize Performance and Scalability of RADIOSS* Structural Analysis Software on Intel Xeon Processor E7 v2 Family-Based Platforms
 Maximize Performance and Scalability of RADIOSS* Structural Analysis Software on Family-Based Platforms Executive Summary Complex simulations of structural and systems performance, such as car crash simulations,
Maximize Performance and Scalability of RADIOSS* Structural Analysis Software on Family-Based Platforms Executive Summary Complex simulations of structural and systems performance, such as car crash simulations,
MELLANOX EDR UPDATE & GPUDIRECT MELLANOX SR. SE 정연구
 MELLANOX EDR UPDATE & GPUDIRECT MELLANOX SR. SE 정연구 Leading Supplier of End-to-End Interconnect Solutions Analyze Enabling the Use of Data Store ICs Comprehensive End-to-End InfiniBand and Ethernet Portfolio
MELLANOX EDR UPDATE & GPUDIRECT MELLANOX SR. SE 정연구 Leading Supplier of End-to-End Interconnect Solutions Analyze Enabling the Use of Data Store ICs Comprehensive End-to-End InfiniBand and Ethernet Portfolio
Interconnect Your Future
 #OpenPOWERSummit Interconnect Your Future Scot Schultz, Director HPC / Technical Computing Mellanox Technologies OpenPOWER Summit, San Jose CA March 2015 One-Generation Lead over the Competition Mellanox
#OpenPOWERSummit Interconnect Your Future Scot Schultz, Director HPC / Technical Computing Mellanox Technologies OpenPOWER Summit, San Jose CA March 2015 One-Generation Lead over the Competition Mellanox
It s a Multicore World. John Urbanic Pittsburgh Supercomputing Center
 It s a Multicore World John Urbanic Pittsburgh Supercomputing Center Waiting for Moore s Law to save your serial code start getting bleak in 2004 Source: published SPECInt data Moore s Law is not at all
It s a Multicore World John Urbanic Pittsburgh Supercomputing Center Waiting for Moore s Law to save your serial code start getting bleak in 2004 Source: published SPECInt data Moore s Law is not at all
IBM Power AC922 Server
 IBM Power AC922 Server The Best Server for Enterprise AI Highlights More accuracy - GPUs access system RAM for larger models Faster insights - significant deep learning speedups Rapid deployment - integrated
IBM Power AC922 Server The Best Server for Enterprise AI Highlights More accuracy - GPUs access system RAM for larger models Faster insights - significant deep learning speedups Rapid deployment - integrated
Unit 11: Putting it All Together: Anatomy of the XBox 360 Game Console
 Computer Architecture Unit 11: Putting it All Together: Anatomy of the XBox 360 Game Console Slides originally developed by Milo Martin & Amir Roth at University of Pennsylvania! Computer Architecture
Computer Architecture Unit 11: Putting it All Together: Anatomy of the XBox 360 Game Console Slides originally developed by Milo Martin & Amir Roth at University of Pennsylvania! Computer Architecture
FUSION PROCESSORS AND HPC
 FUSION PROCESSORS AND HPC Chuck Moore AMD Corporate Fellow & Technology Group CTO June 14, 2011 Fusion Processors and HPC Today: Multi-socket x86 CMPs + optional dgpu + high BW memory Fusion APUs (SPFP)
FUSION PROCESSORS AND HPC Chuck Moore AMD Corporate Fellow & Technology Group CTO June 14, 2011 Fusion Processors and HPC Today: Multi-socket x86 CMPs + optional dgpu + high BW memory Fusion APUs (SPFP)
OpenMP 4.0 (and now 5.0)
") OpenMP 4.0 (and now 5.0) John Urbanic Parallel Computing Scientist Pittsburgh Supercomputing Center Copyright 2018 Classic OpenMP OpenMP was designed to replace low-level and tedious solutions like POSIX
OpenMP 4.0 (and now 5.0) John Urbanic Parallel Computing Scientist Pittsburgh Supercomputing Center Copyright 2018 Classic OpenMP OpenMP was designed to replace low-level and tedious solutions like POSIX
CUDA. Matthew Joyner, Jeremy Williams
 CUDA Matthew Joyner, Jeremy Williams Agenda What is CUDA? CUDA GPU Architecture CPU/GPU Communication Coding in CUDA Use cases of CUDA Comparison to OpenCL What is CUDA? What is CUDA? CUDA is a parallel
CUDA Matthew Joyner, Jeremy Williams Agenda What is CUDA? CUDA GPU Architecture CPU/GPU Communication Coding in CUDA Use cases of CUDA Comparison to OpenCL What is CUDA? What is CUDA? CUDA is a parallel
IBM Power Systems HPC Cluster
 IBM Power Systems HPC Cluster Highlights Complete and fully Integrated HPC cluster for demanding workloads Modular and Extensible: match components & configurations to meet demands Integrated: racked &
IBM Power Systems HPC Cluster Highlights Complete and fully Integrated HPC cluster for demanding workloads Modular and Extensible: match components & configurations to meet demands Integrated: racked &
SAP HANA. Jake Klein/ SVP SAP HANA June, 2013
 SAP HANA Jake Klein/ SVP SAP HANA June, 2013 SAP 3 YEARS AGO Middleware BI / Analytics Core ERP + Suite 2013 WHERE ARE WE NOW? Cloud Mobile Applications SAP HANA Analytics D&T Changed Reality Disruptive
SAP HANA Jake Klein/ SVP SAP HANA June, 2013 SAP 3 YEARS AGO Middleware BI / Analytics Core ERP + Suite 2013 WHERE ARE WE NOW? Cloud Mobile Applications SAP HANA Analytics D&T Changed Reality Disruptive
Intra-MIC MPI Communication using MVAPICH2: Early Experience
 Intra-MIC MPI Communication using MVAPICH: Early Experience Sreeram Potluri, Karen Tomko, Devendar Bureddy, and Dhabaleswar K. Panda Department of Computer Science and Engineering Ohio State University
Intra-MIC MPI Communication using MVAPICH: Early Experience Sreeram Potluri, Karen Tomko, Devendar Bureddy, and Dhabaleswar K. Panda Department of Computer Science and Engineering Ohio State University
Overview. CS 472 Concurrent & Parallel Programming University of Evansville
 Overview CS 472 Concurrent & Parallel Programming University of Evansville Selection of slides from CIS 410/510 Introduction to Parallel Computing Department of Computer and Information Science, University
Overview CS 472 Concurrent & Parallel Programming University of Evansville Selection of slides from CIS 410/510 Introduction to Parallel Computing Department of Computer and Information Science, University
IBM Db2 Analytics Accelerator Version 7.1
 IBM Db2 Analytics Accelerator Version 7.1 Delivering new flexible, integrated deployment options Overview Ute Baumbach (bmb@de.ibm.com) 1 IBM Z Analytics Keep your data in place a different approach to
IBM Db2 Analytics Accelerator Version 7.1 Delivering new flexible, integrated deployment options Overview Ute Baumbach (bmb@de.ibm.com) 1 IBM Z Analytics Keep your data in place a different approach to
Introduction to CUDA Algoritmi e Calcolo Parallelo. Daniele Loiacono
 Introduction to CUDA Algoritmi e Calcolo Parallelo References q This set of slides is mainly based on: " CUDA Technical Training, Dr. Antonino Tumeo, Pacific Northwest National Laboratory " Slide of Applied
Introduction to CUDA Algoritmi e Calcolo Parallelo References q This set of slides is mainly based on: " CUDA Technical Training, Dr. Antonino Tumeo, Pacific Northwest National Laboratory " Slide of Applied
COMPUTING ELEMENT EVOLUTION AND ITS IMPACT ON SIMULATION CODES
 COMPUTING ELEMENT EVOLUTION AND ITS IMPACT ON SIMULATION CODES P(ND) 2-2 2014 Guillaume Colin de Verdière OCTOBER 14TH, 2014 P(ND)^2-2 PAGE 1 CEA, DAM, DIF, F-91297 Arpajon, France October 14th, 2014 Abstract:
COMPUTING ELEMENT EVOLUTION AND ITS IMPACT ON SIMULATION CODES P(ND) 2-2 2014 Guillaume Colin de Verdière OCTOBER 14TH, 2014 P(ND)^2-2 PAGE 1 CEA, DAM, DIF, F-91297 Arpajon, France October 14th, 2014 Abstract:
Performance Analysis of Memory Transfers and GEMM Subroutines on NVIDIA TESLA GPU Cluster
 Performance Analysis of Memory Transfers and GEMM Subroutines on NVIDIA TESLA GPU Cluster Veerendra Allada, Troy Benjegerdes Electrical and Computer Engineering, Ames Laboratory Iowa State University &
Performance Analysis of Memory Transfers and GEMM Subroutines on NVIDIA TESLA GPU Cluster Veerendra Allada, Troy Benjegerdes Electrical and Computer Engineering, Ames Laboratory Iowa State University &
Addressing the Increasing Challenges of Debugging on Accelerated HPC Systems. Ed Hinkel Senior Sales Engineer
 Addressing the Increasing Challenges of Debugging on Accelerated HPC Systems Ed Hinkel Senior Sales Engineer Agenda Overview - Rogue Wave & TotalView GPU Debugging with TotalView Nvdia CUDA Intel Phi 2
Addressing the Increasing Challenges of Debugging on Accelerated HPC Systems Ed Hinkel Senior Sales Engineer Agenda Overview - Rogue Wave & TotalView GPU Debugging with TotalView Nvdia CUDA Intel Phi 2
Isilon Performance. Name
 1 Isilon Performance Name 2 Agenda Architecture Overview Next Generation Hardware Performance Caching Performance Streaming Reads Performance Tuning OneFS Architecture Overview Copyright 2014 EMC Corporation.
1 Isilon Performance Name 2 Agenda Architecture Overview Next Generation Hardware Performance Caching Performance Streaming Reads Performance Tuning OneFS Architecture Overview Copyright 2014 EMC Corporation.
High performance Computing and O&G Challenges
 High performance Computing and O&G Challenges 2 Seismic exploration challenges High Performance Computing and O&G challenges Worldwide Context Seismic,sub-surface imaging Computing Power needs Accelerating
High performance Computing and O&G Challenges 2 Seismic exploration challenges High Performance Computing and O&G challenges Worldwide Context Seismic,sub-surface imaging Computing Power needs Accelerating
TECHNICAL GUIDELINES FOR APPLICANTS TO PRACE 13 th CALL (T ier-0)
") TECHNICAL GUIDELINES FOR APPLICANTS TO PRACE 13 th CALL (T ier-0) Contributing sites and the corresponding computer systems for this call are: BSC, Spain IBM System x idataplex CINECA, Italy Lenovo System
TECHNICAL GUIDELINES FOR APPLICANTS TO PRACE 13 th CALL (T ier-0) Contributing sites and the corresponding computer systems for this call are: BSC, Spain IBM System x idataplex CINECA, Italy Lenovo System
rabbit.engr.oregonstate.edu What is rabbit?
 1 rabbit.engr.oregonstate.edu Mike Bailey mjb@cs.oregonstate.edu rabbit.pptx What is rabbit? 2 NVIDIA Titan Black PCIe Bus 15 SMs 2880 CUDA cores 6 GB of memory OpenGL support OpenCL support Xeon system
1 rabbit.engr.oregonstate.edu Mike Bailey mjb@cs.oregonstate.edu rabbit.pptx What is rabbit? 2 NVIDIA Titan Black PCIe Bus 15 SMs 2880 CUDA cores 6 GB of memory OpenGL support OpenCL support Xeon system
This Unit: Putting It All Together. CIS 371 Computer Organization and Design. Sources. What is Computer Architecture?
 This Unit: Putting It All Together CIS 371 Computer Organization and Design Unit 15: Putting It All Together: Anatomy of the XBox 360 Game Console Application OS Compiler Firmware CPU I/O Memory Digital
This Unit: Putting It All Together CIS 371 Computer Organization and Design Unit 15: Putting It All Together: Anatomy of the XBox 360 Game Console Application OS Compiler Firmware CPU I/O Memory Digital
NAMD Performance Benchmark and Profiling. January 2015
 NAMD Performance Benchmark and Profiling January 2015 2 Note The following research was performed under the HPC Advisory Council activities Participating vendors: Intel, Dell, Mellanox Compute resource
NAMD Performance Benchmark and Profiling January 2015 2 Note The following research was performed under the HPC Advisory Council activities Participating vendors: Intel, Dell, Mellanox Compute resource