Introduction to tuning on many core platforms. Gilles Gouaillardet RIST
|
|
|
- Alan Fisher
- 5 years ago
- Views:
Transcription
1 Introduction to tuning on many core platforms Gilles Gouaillardet RIST
2 Agenda Why do we need many core platforms? Single-thread optimization Parallelization Conclusions
3 Why do we need many core platforms?
 Moore s")

4 Why many-core platforms? Von Neumann architecture (1945) Moore s law (1965) The number of transistors in a dense integrated circuit double approximately every two years

5 CPU trends past 40 years Sources: AMD
6 The free lunch is over Back in the days, Moore s law meant the processor frequency doubled every two years Memory bandwidth increased too upgrading hardware was enough to increase application performance Processor frequency cannot increase any more (physical, power and thermal constraints) More transistors means more and more capable cores Memory bandwidth and cache size keeps increasing Memory bandwidth and cache size per core tends to decrease
7 The road to exascale Exascale supercomputer using evolved technology would be too expensive too power hungry ( > 100 MW, acceptable is < 20 MW) Disruptive technology is needed FPGA? GPU? Many core?
8 Disruptive technology is needed for exascale Good compromise between absolute performance, performance per Watt, cost and programmability Many core is a popular option, easy programming is an important factor Sunway TaihuLight (RISC - #1 on Top500) KNL (x86_64 - #5 and #6 on Top500) Post K (ARMv8)
9 Challenges More, and more capable but slower cores Good algorithm is critical Parallelism is no more an option Instruction level parallelism (vectorization) Block level parallelism (MPI and/or OpenMP) Hierarchical memory Hyperthreading Code modernization is mandatory
10 Manycore tuning challenges With great computational power comes great algorithmic responsibility David E. Keyes (KAUST)
11 Single-thread optimization
12 Single thread optimization Maximum single thread performance can only be achieved with optimized code that fully exploits all the hardware features : Vectorization (Instruction Level Parallelism) use of all the Floating Points units (FMA) Maximize FLOP vs BYTES
 Usually write a line to the L1 cache n-ways associative memory Least Recently Used (LRU) policy is common Reuse data as much as")
13 Memory and caches Most architecture are based on cachecoherent memory Some exceptions : Cell and TaihuLight only have scratchpad memory a read instruction move a line into L1 cache (unless non temporal stores) Usually write a line to the L1 cache n-ways associative memory Least Recently Used (LRU) policy is common Reuse data as much as possible
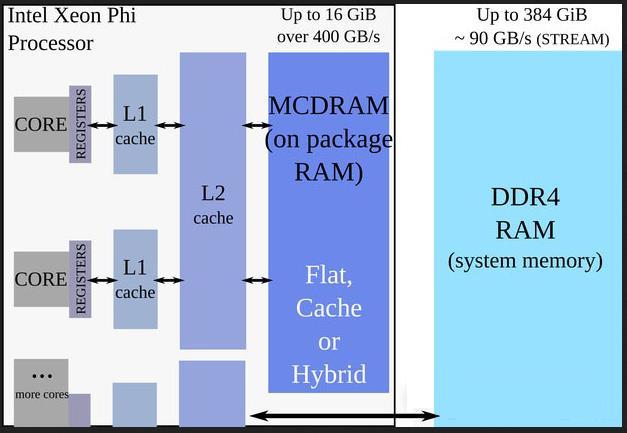
14 KNL memory configuration

15 Vectorization Scalar (one instruction produces one result) SIMD processing (one instruction can produce multiple results)
 for (j=1; j< n; j++) loop carried on for j")
16 When vectorize? Vectorization can be seen as instruction level parallelism Loop carried dependence prevent vectorization #define N 1024 double a[n][n]; for (i=1; i<n; i++) for (j=1; j< n; j++) loop carried on for j loop no loop-carried dependence in for i loop a[i][j] = a[i][j-1] + 1; #define N 1024 double a[n][n]; for (i=1; i<n; i++) for (j=1; j< n; j++) no loop-carried dependence in for j loop loop-carried dependence in for i loop a[i][j] = a[i-1][j] + 1;
17 Compilers are conservative If there might be some dependences, the compiler will not vectorize Compiler generated vectorization report are very valuable Developer knows best, if there is no dependence, then tell the compiler Compiler specific pragma Standard OpenMP 4 simd directive
 with only aligned access Remainder (scalar) aligned access but not a full vector Align data and inform the compiler to get rid of loop peeling (directive or")
18 Vectorized loop internals Aligned memory accesses are more efficient A loop is made of 3 phases Peeling (scalar) so aligned access can be used in the main body Main body (vectorized) with only aligned access Remainder (scalar) aligned access but not a full vector Align data and inform the compiler to get rid of loop peeling (directive or compiler option)
![Vectorized loop internals #define N 1020 double a[n], b[n], c[n]; for (int i=0; i<n; i++) a[i] = b[i] + c[i]; If 512 bits vectors, bump N to 1024](/docs-images/82/86058346/images/19-4.jpg "to get rid of the remainder integer, parameter :: N=1020, M=512 double precision :: a(n,m), b(n,m), c(n,m) do j=1,m do i=1,n a(i,j) = b(i,j) +")
![c(i,j) end do end do #define N 1020 double a[n], b[n]; double sum = 0; for (int i=0; i<n; i++) sum += a[i] * b[i]; If 512 bits vectors, bump N to](/docs-images/82/86058346/images/19-6.jpg "1024 to get rid of the remainder in the innermost loop If 512 bits vectors, bump N to 1024 and zero a[1020:1023] and b[1020:1023] to get rid of the")
19 Vectorized loop internals #define N 1020 double a[n], b[n], c[n]; for (int i=0; i<n; i++) a[i] = b[i] + c[i]; If 512 bits vectors, bump N to 1024 to get rid of the remainder integer, parameter :: N=1020, M=512 double precision :: a(n,m), b(n,m), c(n,m) do j=1,m do i=1,n a(i,j) = b(i,j) + c(i,j) end do end do #define N 1020 double a[n], b[n]; double sum = 0; for (int i=0; i<n; i++) sum += a[i] * b[i]; If 512 bits vectors, bump N to 1024 to get rid of the remainder in the innermost loop If 512 bits vectors, bump N to 1024 and zero a[1020:1023] and b[1020:1023] to get rid of the remainder
 #define N 1024 typedef struct { double x; double y; double z; }")
![point; point p[n]; /* x-translation */ for (int i=0; i<n; i++) p[i].x += 1.](/docs-images/82/86058346/images/20-4.jpg "0; Strided access : 1 cache line contains 2 or 3 useful double out of 8 A vector uses")
20 AoS vs SoA As taught in Object Oriented Programming classes, common data layout is Array of Structure (AoS) #define N 1024 typedef struct { double x; double y; double z; } point; point p[n]; /* x-translation */ for (int i=0; i<n; i++) p[i].x += 1.0; Strided access : 1 cache line contains 2 or 3 useful double out of 8 A vector uses data from 3 cache lines
 #define N 1024")
![typedef struct { double x[n]; double y[n];](/docs-images/82/86058346/images/21-3.jpg "double z[n]; } points; points p; /*")

21 AoS vs SoA Optimized data layout is Structure of Arrays (SoA) #define N 1024 typedef struct { double x[n]; double y[n]; double z[n]; } points; points p; /* x-translation */ for (int i=0; i<n; i++) p.x[i] += 1.0; Streaming access : 1 cache line contains 8 useful double
![Indirect access #define N 1024 double * a; int * indixes; for (int i=0; i<n; i++) a[indixes[i]]] += 1.](/docs-images/82/86058346/images/22-4.jpg "0; Data must be gathered/scattered from/to several cache lines Hardware support is available In the general case,")
22 Indirect access #define N 1024 double * a; int * indixes; for (int i=0; i<n; i++) a[indixes[i]]] += 1.0; Data must be gathered/scattered from/to several cache lines Hardware support is available In the general case, vectorization is incorrect!
23 Indirect access and collisions #define N 1024 double * a; int * indixes; for (int i=0; i<n; i++) a[indixes[i]]] += 1.0; If no conflict can occur, then compiler must be informed vectorization is safe Hardware support might be available for collision detection (AVX512-CD)
24 KNL High Bandwidth Memory KNL comes with 16 GB of MCDRAM / High Bandwidth Memory (HBM) Memory mode can be selected at boot time (and ideally on a per-job basis) Flat : NUMA node with 16 GB of HBM and standard memory Cache : only standard memory, HBM is transparently used as a L3 cache Hybrid (one portion is used as cache, the other as scratchpad)

, allocatable :: a(:)!")
25 KNL flat mode Command line # use only HBM $ numactl m 1 a.out Autohbw library $ export AUTO_HBW_SIZE=min_size[:max_size] $ LD_PRELOAD=libautohbw.so a.out # try HBM first, fallback to standard memory $ numactl preferred=1 a.out Fortran directive Memkind library real(r8), allocatable :: a(:)!dir$ attributes fastmem, align:64 :: a #include <hbwmalloc.h> double * d = hbw_malloc(n*sizeof(double)); allocate(a)

26 Arithmetic intensity Arithmetic intensity is the ratio FLOP per byte moved to/from memory Numerical intensity is based on algorithm, but it can be influenced by dataset

27 Roofline analysis Kernel with low arithmetic intensity are memory-bound Kernel with high arithmetic intensity are compute-bound Roofline analysis is a visual method to find how well the kernel is performing There are several roofs Memory type (L1 / L2 / HBM / standard memory Cpu features (no vectorization, vectorization, vectorization + FMA)

28 Roofline analysis w/ Intel Advisor 2017 Roofline model has to be built once per processor Vendor knows best Process fully automated from Advisor 2017 Update 2
![False sharing double local_value[num_threads];](/docs-images/82/86058346/images/29-1.jpg "#pragma omp parallel { int me =")
![omp_get_thread_num(); local_value[me] =](/docs-images/82/86058346/images/29-2.jpg "func(me); } typedef struct { double value;")
![double[7] padding; Different data from the same](/docs-images/82/86058346/images/29-3.jpg "cache line is used on different processors")

29 False sharing double local_value[num_threads]; #pragma omp parallel { int me = omp_get_thread_num(); local_value[me] = func(me); } typedef struct { double value; double[7] padding; Different data from the same cache line is used on different processors Excessive time is spent ensuring cache coherency Re-organize data so per thread data does not share any cache line (padding) } local_data;

30 n-way associative cache Since cache is not fully associative, all cache might not be used
31 Parallelization
32 Parallelization Free lunch is over, more cores are needed to keep application performances A lot more cores are available and must be effectively used to achieve greater performance Parallelization is now mandatory
33 Performance scaling Strong scaling how the solution time varies with the number of processors for a fixed total problem size? Ideally, adding processors decreases the time to solution. Weak scaling how the solution time varies with the number of processors for a fixed problem size per processor Ideally, the time to solution remains constant.
34 Amdahl s law (strong scaling) S latency is the theoretical speedup of the execution of the whole task; s is the speedup of the part of the task that benefits from improved system resources; p is the proportion of execution time that the part benefiting from improved resources originally occupied.
35 Gustafson s law (weak scaling) S latency is the theoretical speedup in latency of the execution of the whole task; s is the speedup in latency of the execution of the part of the task that benefits from the improvement of the resources of the system; p is the percentage of the execution workload of the whole task concerning the part that benefits from the improvement of the resources of the system before the improvement.
36 At a glance Amdahl s law we are fundamentally limited by the serial fraction Gustafson s law we need larger problems for larger numbers CPUs whilst we are still limited by the serial fraction, it becomes less important
37 Parallelization models MPI is the de facto standard for inter process communication Flat MPI is sometimes a good option, but beware of memory and wire-up overhead MPI+X is the general paradigm X is for intra node communications and can be OpenMP Pthreads PGAS (OpenSHMEM, Co-arrays, ) MPI (!)

![a[n], b[n], c[n]; for (int i=0; i<n; i++) a[i] = b[i] + c[i]; #define N 1024](/docs-images/82/86058346/images/38-4.jpg "double a[n], b[n], c[n]; #pragma omp parallel for for (int i=0; i<n; i++) a[i] =")
38 OpenMP OpenMP is a common parallelization paradigm used on shared memory node OpenMP is a set of directives to enable parallelization #define N 1024 double a[n], b[n], c[n]; for (int i=0; i<n; i++) a[i] = b[i] + c[i]; #define N 1024 double a[n], b[n], c[n]; #pragma omp parallel for for (int i=0; i<n; i++) a[i] = b[i] + c[i];
39 OpenMP limitations Most OpenMP parallelization focus only on loops OpenMP has an overhead (thread creation, synchronization, reduction) OpenMP was designed when memory was flat, today NUMA is very common. NUMA makes performance models hard to build OpenMP is generally best within a NUMA node natural when iterations are independent MPI communications within an OpenMP region is not natural
40 Hyperthreading A KNL core consists of 4 hardware threads Hardware threads share resources (cache, FPU, ) When a hardware thread is waiting for memory, an other hardware thread can be scheduled to perform some computation 2 hardware threads are enough to achieve maximum performances (4 on KNC) Best is to experiment with 1 and 2 threads per core, and choose the fastest option

41 Intel Thread Advisor Suitability report gives a speed-up estimation

42 Intel Thread Advisor Dependency analysis help predicting parallel data sharing problems (very slow, and only on annotated loops)
43 KNL cluster modes KNL cluster mode is selected at boot time (BIOS parameter) KNL modes influence cache coherency wiring and topology presented to the application. Commonly used modes are : Alltoall Quadrant SNC-4 SNC-2 Using the most appropriate mode is critical to achieve optimal performances The best mode depends on application and parallelization model Hopefully, KNL cluster mode can be selected on a per job basis

 SNC4 (4 sockets,")
44 KNL Cluster modes All2all/Quadrant (1 socket, 68 cores) SNC2 (2 sockets, cores) SNC4 (4 sockets, cores)
45 KNL cluster modes Rules of thumb AlltoAll : do not use it! SNC-4: 4 NUMA nodes, generally best with a multiple of 4 MPI tasks per node. Note 34 tiles do not split evenly into 4 quadrants! SNC-2: 2 NUMA nodes, generally best with a multiple of 2 MPI tasks per node Quadrant: flat memory, to be used if SNC-4/2 is not a fit
46 Problem sizing on KNL KNL has both ECC (standard) and MCDRAM (High Bandwidth) memory MCDRAM can be configured as cache or scratchpad Impact of performance can be significant If your app is cache-friendly, weak scale using all available memory If your app is not cache-friendly, it might be more effective to weak scale using only HBM
47 Is your app-cache friendly? In flat mode Run with HBM only Run with standard memory only In cache mode Increase dataset size to use all available memory Measure the drop in performance (if any) when using all the memory in cache mode
48 Conclusions
49 Conclusions Moore s law is yet still valid It used to mean free-lunch It now means more cores and more complex architectures, and that comes with new challenges Vectorization and parallelization are mandatory Tools are available to help We can help you too!
50 Questions? Regarding this presentation Need help with your research
Introduction to tuning on KNL platforms
 Introduction to tuning on KNL platforms Gilles Gouaillardet RIST gilles@rist.or.jp 1 Agenda Why do we need many core platforms? KNL architecture Single-thread optimization Parallelization Common pitfalls
Introduction to tuning on KNL platforms Gilles Gouaillardet RIST gilles@rist.or.jp 1 Agenda Why do we need many core platforms? KNL architecture Single-thread optimization Parallelization Common pitfalls
Introduction to tuning on KNL platforms
 Introduction to tuning on KNL platforms Gilles Gouaillardet RIST gilles@rist.or.jp 1 Agenda Why do we need many core platforms? KNL architecture Post-K overview Single-thread optimization Parallelization
Introduction to tuning on KNL platforms Gilles Gouaillardet RIST gilles@rist.or.jp 1 Agenda Why do we need many core platforms? KNL architecture Post-K overview Single-thread optimization Parallelization
Day 6: Optimization on Parallel Intel Architectures
 Day 6: Optimization on Parallel Intel Architectures Lecture day 6 Ryo Asai Colfax International colfaxresearch.com April 2017 colfaxresearch.com/ Welcome Colfax International, 2013 2017 Disclaimer 2 While
Day 6: Optimization on Parallel Intel Architectures Lecture day 6 Ryo Asai Colfax International colfaxresearch.com April 2017 colfaxresearch.com/ Welcome Colfax International, 2013 2017 Disclaimer 2 While
EARLY EVALUATION OF THE CRAY XC40 SYSTEM THETA
 EARLY EVALUATION OF THE CRAY XC40 SYSTEM THETA SUDHEER CHUNDURI, SCOTT PARKER, KEVIN HARMS, VITALI MOROZOV, CHRIS KNIGHT, KALYAN KUMARAN Performance Engineering Group Argonne Leadership Computing Facility
EARLY EVALUATION OF THE CRAY XC40 SYSTEM THETA SUDHEER CHUNDURI, SCOTT PARKER, KEVIN HARMS, VITALI MOROZOV, CHRIS KNIGHT, KALYAN KUMARAN Performance Engineering Group Argonne Leadership Computing Facility
CME 213 S PRING Eric Darve
 CME 213 S PRING 2017 Eric Darve Summary of previous lectures Pthreads: low-level multi-threaded programming OpenMP: simplified interface based on #pragma, adapted to scientific computing OpenMP for and
CME 213 S PRING 2017 Eric Darve Summary of previous lectures Pthreads: low-level multi-threaded programming OpenMP: simplified interface based on #pragma, adapted to scientific computing OpenMP for and
Computing architectures Part 2 TMA4280 Introduction to Supercomputing
 Computing architectures Part 2 TMA4280 Introduction to Supercomputing NTNU, IMF January 16. 2017 1 Supercomputing What is the motivation for Supercomputing? Solve complex problems fast and accurately:
Computing architectures Part 2 TMA4280 Introduction to Supercomputing NTNU, IMF January 16. 2017 1 Supercomputing What is the motivation for Supercomputing? Solve complex problems fast and accurately:
Parallel Numerical Algorithms
 Parallel Numerical Algorithms http://sudalab.is.s.u-tokyo.ac.jp/~reiji/pna16/ [ 9 ] Shared Memory Performance Parallel Numerical Algorithms / IST / UTokyo 1 PNA16 Lecture Plan General Topics 1. Architecture
Parallel Numerical Algorithms http://sudalab.is.s.u-tokyo.ac.jp/~reiji/pna16/ [ 9 ] Shared Memory Performance Parallel Numerical Algorithms / IST / UTokyo 1 PNA16 Lecture Plan General Topics 1. Architecture
CSCI 402: Computer Architectures. Parallel Processors (2) Fengguang Song Department of Computer & Information Science IUPUI.
 Fengguang Song Department of Computer & Information Science IUPUI.") CSCI 402: Computer Architectures Parallel Processors (2) Fengguang Song Department of Computer & Information Science IUPUI 6.6 - End Today s Contents GPU Cluster and its network topology The Roofline performance
CSCI 402: Computer Architectures Parallel Processors (2) Fengguang Song Department of Computer & Information Science IUPUI 6.6 - End Today s Contents GPU Cluster and its network topology The Roofline performance
Optimizing Fusion PIC Code XGC1 Performance on Cori Phase 2
 Optimizing Fusion PIC Code XGC1 Performance on Cori Phase 2 T. Koskela, J. Deslippe NERSC / LBNL tkoskela@lbl.gov June 23, 2017-1 - Thank you to all collaborators! LBNL Brian Friesen, Ankit Bhagatwala,
Optimizing Fusion PIC Code XGC1 Performance on Cori Phase 2 T. Koskela, J. Deslippe NERSC / LBNL tkoskela@lbl.gov June 23, 2017-1 - Thank you to all collaborators! LBNL Brian Friesen, Ankit Bhagatwala,
Parallel Computing. Hwansoo Han (SKKU)
") Parallel Computing Hwansoo Han (SKKU) Unicore Limitations Performance scaling stopped due to Power consumption Wire delay DRAM latency Limitation in ILP 10000 SPEC CINT2000 2 cores/chip Xeon 3.0GHz Core2duo
Parallel Computing Hwansoo Han (SKKU) Unicore Limitations Performance scaling stopped due to Power consumption Wire delay DRAM latency Limitation in ILP 10000 SPEC CINT2000 2 cores/chip Xeon 3.0GHz Core2duo
Fusion PIC Code Performance Analysis on the Cori KNL System. T. Koskela*, J. Deslippe*,! K. Raman**, B. Friesen*! *NERSC! ** Intel!
 Fusion PIC Code Performance Analysis on the Cori KNL System T. Koskela*, J. Deslippe*,! K. Raman**, B. Friesen*! *NERSC! ** Intel! tkoskela@lbl.gov May 18, 2017-1- Outline Introduc3on to magne3c fusion
Fusion PIC Code Performance Analysis on the Cori KNL System T. Koskela*, J. Deslippe*,! K. Raman**, B. Friesen*! *NERSC! ** Intel! tkoskela@lbl.gov May 18, 2017-1- Outline Introduc3on to magne3c fusion
Introduction to Parallel and Distributed Computing. Linh B. Ngo CPSC 3620
 Introduction to Parallel and Distributed Computing Linh B. Ngo CPSC 3620 Overview: What is Parallel Computing To be run using multiple processors A problem is broken into discrete parts that can be solved
Introduction to Parallel and Distributed Computing Linh B. Ngo CPSC 3620 Overview: What is Parallel Computing To be run using multiple processors A problem is broken into discrete parts that can be solved
A common scenario... Most of us have probably been here. Where did my performance go? It disappeared into overheads...
 OPENMP PERFORMANCE 2 A common scenario... So I wrote my OpenMP program, and I checked it gave the right answers, so I ran some timing tests, and the speedup was, well, a bit disappointing really. Now what?.
OPENMP PERFORMANCE 2 A common scenario... So I wrote my OpenMP program, and I checked it gave the right answers, so I ran some timing tests, and the speedup was, well, a bit disappointing really. Now what?.
Intel Knights Landing Hardware
 Intel Knights Landing Hardware TACC KNL Tutorial IXPUG Annual Meeting 2016 PRESENTED BY: John Cazes Lars Koesterke 1 Intel s Xeon Phi Architecture Leverages x86 architecture Simpler x86 cores, higher compute
Intel Knights Landing Hardware TACC KNL Tutorial IXPUG Annual Meeting 2016 PRESENTED BY: John Cazes Lars Koesterke 1 Intel s Xeon Phi Architecture Leverages x86 architecture Simpler x86 cores, higher compute
Carlo Cavazzoni, HPC department, CINECA
 Introduction to Shared memory architectures Carlo Cavazzoni, HPC department, CINECA Modern Parallel Architectures Two basic architectural scheme: Distributed Memory Shared Memory Now most computers have
Introduction to Shared memory architectures Carlo Cavazzoni, HPC department, CINECA Modern Parallel Architectures Two basic architectural scheme: Distributed Memory Shared Memory Now most computers have
27. Parallel Programming I
 760 27. Parallel Programming I Moore s Law and the Free Lunch, Hardware Architectures, Parallel Execution, Flynn s Taxonomy, Scalability: Amdahl and Gustafson, Data-parallelism, Task-parallelism, Scheduling
760 27. Parallel Programming I Moore s Law and the Free Lunch, Hardware Architectures, Parallel Execution, Flynn s Taxonomy, Scalability: Amdahl and Gustafson, Data-parallelism, Task-parallelism, Scheduling
SHARCNET Workshop on Parallel Computing. Hugh Merz Laurentian University May 2008
 SHARCNET Workshop on Parallel Computing Hugh Merz Laurentian University May 2008 What is Parallel Computing? A computational method that utilizes multiple processing elements to solve a problem in tandem
SHARCNET Workshop on Parallel Computing Hugh Merz Laurentian University May 2008 What is Parallel Computing? A computational method that utilizes multiple processing elements to solve a problem in tandem
1. Many Core vs Multi Core. 2. Performance Optimization Concepts for Many Core. 3. Performance Optimization Strategy for Many Core
 1. Many Core vs Multi Core 2. Performance Optimization Concepts for Many Core 3. Performance Optimization Strategy for Many Core 4. Example Case Studies NERSC s Cori will begin to transition the workload
1. Many Core vs Multi Core 2. Performance Optimization Concepts for Many Core 3. Performance Optimization Strategy for Many Core 4. Example Case Studies NERSC s Cori will begin to transition the workload
Parallel Algorithm Engineering
 Parallel Algorithm Engineering Kenneth S. Bøgh PhD Fellow Based on slides by Darius Sidlauskas Outline Background Current multicore architectures UMA vs NUMA The openmp framework and numa control Examples
Parallel Algorithm Engineering Kenneth S. Bøgh PhD Fellow Based on slides by Darius Sidlauskas Outline Background Current multicore architectures UMA vs NUMA The openmp framework and numa control Examples
Tools and techniques for optimization and debugging. Fabio Affinito October 2015
 Tools and techniques for optimization and debugging Fabio Affinito October 2015 Fundamentals of computer architecture Serial architectures Introducing the CPU It s a complex, modular object, made of different
Tools and techniques for optimization and debugging Fabio Affinito October 2015 Fundamentals of computer architecture Serial architectures Introducing the CPU It s a complex, modular object, made of different
CS 590: High Performance Computing. Parallel Computer Architectures. Lab 1 Starts Today. Already posted on Canvas (under Assignment) Let s look at it
 Let s look at it") Lab 1 Starts Today Already posted on Canvas (under Assignment) Let s look at it CS 590: High Performance Computing Parallel Computer Architectures Fengguang Song Department of Computer Science IUPUI 1
Lab 1 Starts Today Already posted on Canvas (under Assignment) Let s look at it CS 590: High Performance Computing Parallel Computer Architectures Fengguang Song Department of Computer Science IUPUI 1
Intel Xeon Phi архитектура, модели программирования, оптимизация.
 Нижний Новгород, 2017 Intel Xeon Phi архитектура, модели программирования, оптимизация. Дмитрий Прохоров, Дмитрий Рябцев, Intel Agenda What and Why Intel Xeon Phi Top 500 insights, roadmap, architecture
Нижний Новгород, 2017 Intel Xeon Phi архитектура, модели программирования, оптимизация. Дмитрий Прохоров, Дмитрий Рябцев, Intel Agenda What and Why Intel Xeon Phi Top 500 insights, roadmap, architecture
CS560 Lecture Parallel Architecture 1
 Parallel Architecture Announcements The RamCT merge is done! Please repost introductions. Manaf s office hours HW0 is due tomorrow night, please try RamCT submission HW1 has been posted Today Isoefficiency
Parallel Architecture Announcements The RamCT merge is done! Please repost introductions. Manaf s office hours HW0 is due tomorrow night, please try RamCT submission HW1 has been posted Today Isoefficiency
Outline. Motivation Parallel k-means Clustering Intel Computing Architectures Baseline Performance Performance Optimizations Future Trends
 Collaborators: Richard T. Mills, Argonne National Laboratory Sarat Sreepathi, Oak Ridge National Laboratory Forrest M. Hoffman, Oak Ridge National Laboratory Jitendra Kumar, Oak Ridge National Laboratory
Collaborators: Richard T. Mills, Argonne National Laboratory Sarat Sreepathi, Oak Ridge National Laboratory Forrest M. Hoffman, Oak Ridge National Laboratory Jitendra Kumar, Oak Ridge National Laboratory
The Art of Parallel Processing
 The Art of Parallel Processing Ahmad Siavashi April 2017 The Software Crisis As long as there were no machines, programming was no problem at all; when we had a few weak computers, programming became a
The Art of Parallel Processing Ahmad Siavashi April 2017 The Software Crisis As long as there were no machines, programming was no problem at all; when we had a few weak computers, programming became a
Lecture 13: Memory Consistency. + a Course-So-Far Review. Parallel Computer Architecture and Programming CMU , Spring 2013
 Lecture 13: Memory Consistency + a Course-So-Far Review Parallel Computer Architecture and Programming Today: what you should know Understand the motivation for relaxed consistency models Understand the
Lecture 13: Memory Consistency + a Course-So-Far Review Parallel Computer Architecture and Programming Today: what you should know Understand the motivation for relaxed consistency models Understand the
27. Parallel Programming I
 771 27. Parallel Programming I Moore s Law and the Free Lunch, Hardware Architectures, Parallel Execution, Flynn s Taxonomy, Scalability: Amdahl and Gustafson, Data-parallelism, Task-parallelism, Scheduling
771 27. Parallel Programming I Moore s Law and the Free Lunch, Hardware Architectures, Parallel Execution, Flynn s Taxonomy, Scalability: Amdahl and Gustafson, Data-parallelism, Task-parallelism, Scheduling
COSC 6385 Computer Architecture - Thread Level Parallelism (I)
") COSC 6385 Computer Architecture - Thread Level Parallelism (I) Edgar Gabriel Spring 2014 Long-term trend on the number of transistor per integrated circuit Number of transistors double every ~18 month
COSC 6385 Computer Architecture - Thread Level Parallelism (I) Edgar Gabriel Spring 2014 Long-term trend on the number of transistor per integrated circuit Number of transistors double every ~18 month
Multi-core processors are here, but how do you resolve data bottlenecks in native code?
 Multi-core processors are here, but how do you resolve data bottlenecks in native code? hint: it s all about locality Michael Wall October, 2008 part I of II: System memory 2 PDC 2008 October 2008 Session
Multi-core processors are here, but how do you resolve data bottlenecks in native code? hint: it s all about locality Michael Wall October, 2008 part I of II: System memory 2 PDC 2008 October 2008 Session
Introduction to Parallel Computing. CPS 5401 Fall 2014 Shirley Moore, Instructor October 13, 2014
 Introduction to Parallel Computing CPS 5401 Fall 2014 Shirley Moore, Instructor October 13, 2014 1 Definition of Parallel Computing Simultaneous use of multiple compute resources to solve a computational
Introduction to Parallel Computing CPS 5401 Fall 2014 Shirley Moore, Instructor October 13, 2014 1 Definition of Parallel Computing Simultaneous use of multiple compute resources to solve a computational
Efficient Parallel Programming on Xeon Phi for Exascale
 Efficient Parallel Programming on Xeon Phi for Exascale Eric Petit, Intel IPAG, Seminar at MDLS, Saclay, 29th November 2016 Legal Disclaimers Intel technologies features and benefits depend on system configuration
Efficient Parallel Programming on Xeon Phi for Exascale Eric Petit, Intel IPAG, Seminar at MDLS, Saclay, 29th November 2016 Legal Disclaimers Intel technologies features and benefits depend on system configuration
27. Parallel Programming I
 The Free Lunch 27. Parallel Programming I Moore s Law and the Free Lunch, Hardware Architectures, Parallel Execution, Flynn s Taxonomy, Scalability: Amdahl and Gustafson, Data-parallelism, Task-parallelism,
The Free Lunch 27. Parallel Programming I Moore s Law and the Free Lunch, Hardware Architectures, Parallel Execution, Flynn s Taxonomy, Scalability: Amdahl and Gustafson, Data-parallelism, Task-parallelism,
Instructor: Leopold Grinberg
 Part 1 : Roofline Model Instructor: Leopold Grinberg IBM, T.J. Watson Research Center, USA e-mail: leopoldgrinberg@us.ibm.com 1 ICSC 2014, Shanghai, China The Roofline Model DATA CALCULATIONS (+, -, /,
Part 1 : Roofline Model Instructor: Leopold Grinberg IBM, T.J. Watson Research Center, USA e-mail: leopoldgrinberg@us.ibm.com 1 ICSC 2014, Shanghai, China The Roofline Model DATA CALCULATIONS (+, -, /,
Bei Wang, Dmitry Prohorov and Carlos Rosales
 Bei Wang, Dmitry Prohorov and Carlos Rosales Aspects of Application Performance What are the Aspects of Performance Intel Hardware Features Omni-Path Architecture MCDRAM 3D XPoint Many-core Xeon Phi AVX-512
Bei Wang, Dmitry Prohorov and Carlos Rosales Aspects of Application Performance What are the Aspects of Performance Intel Hardware Features Omni-Path Architecture MCDRAM 3D XPoint Many-core Xeon Phi AVX-512
Towards modernisation of the Gadget code on many-core architectures Fabio Baruffa, Luigi Iapichino (LRZ)
") Towards modernisation of the Gadget code on many-core architectures Fabio Baruffa, Luigi Iapichino (LRZ) Overview Modernising P-Gadget3 for the Intel Xeon Phi : code features, challenges and strategy for
Towards modernisation of the Gadget code on many-core architectures Fabio Baruffa, Luigi Iapichino (LRZ) Overview Modernising P-Gadget3 for the Intel Xeon Phi : code features, challenges and strategy for
Parallel and High Performance Computing CSE 745
 Parallel and High Performance Computing CSE 745 1 Outline Introduction to HPC computing Overview Parallel Computer Memory Architectures Parallel Programming Models Designing Parallel Programs Parallel
Parallel and High Performance Computing CSE 745 1 Outline Introduction to HPC computing Overview Parallel Computer Memory Architectures Parallel Programming Models Designing Parallel Programs Parallel
Introduction to parallel computers and parallel programming. Introduction to parallel computersand parallel programming p. 1
 Introduction to parallel computers and parallel programming Introduction to parallel computersand parallel programming p. 1 Content A quick overview of morden parallel hardware Parallelism within a chip
Introduction to parallel computers and parallel programming Introduction to parallel computersand parallel programming p. 1 Content A quick overview of morden parallel hardware Parallelism within a chip
Lecture 2. Memory locality optimizations Address space organization
 Lecture 2 Memory locality optimizations Address space organization Announcements Office hours in EBU3B Room 3244 Mondays 3.00 to 4.00pm; Thurs 2:00pm-3:30pm Partners XSED Portal accounts Log in to Lilliput
Lecture 2 Memory locality optimizations Address space organization Announcements Office hours in EBU3B Room 3244 Mondays 3.00 to 4.00pm; Thurs 2:00pm-3:30pm Partners XSED Portal accounts Log in to Lilliput
Tools and techniques for optimization and debugging. Andrew Emerson, Fabio Affinito November 2017
 Tools and techniques for optimization and debugging Andrew Emerson, Fabio Affinito November 2017 Fundamentals of computer architecture Serial architectures Introducing the CPU It s a complex, modular object,
Tools and techniques for optimization and debugging Andrew Emerson, Fabio Affinito November 2017 Fundamentals of computer architecture Serial architectures Introducing the CPU It s a complex, modular object,
Visualizing and Finding Optimization Opportunities with Intel Advisor Roofline feature. Intel Software Developer Conference London, 2017
 Visualizing and Finding Optimization Opportunities with Intel Advisor Roofline feature Intel Software Developer Conference London, 2017 Agenda Vectorization is becoming more and more important What is
Visualizing and Finding Optimization Opportunities with Intel Advisor Roofline feature Intel Software Developer Conference London, 2017 Agenda Vectorization is becoming more and more important What is
Parallelism. CS6787 Lecture 8 Fall 2017
 Parallelism CS6787 Lecture 8 Fall 2017 So far We ve been talking about algorithms We ve been talking about ways to optimize their parameters But we haven t talked about the underlying hardware How does
Parallelism CS6787 Lecture 8 Fall 2017 So far We ve been talking about algorithms We ve been talking about ways to optimize their parameters But we haven t talked about the underlying hardware How does
Programming Models for Multi- Threading. Brian Marshall, Advanced Research Computing
 Programming Models for Multi- Threading Brian Marshall, Advanced Research Computing Why Do Parallel Computing? Limits of single CPU computing performance available memory I/O rates Parallel computing allows
Programming Models for Multi- Threading Brian Marshall, Advanced Research Computing Why Do Parallel Computing? Limits of single CPU computing performance available memory I/O rates Parallel computing allows
OpenACC. Introduction and Evolutions Sebastien Deldon, GPU Compiler engineer
 OpenACC Introduction and Evolutions Sebastien Deldon, GPU Compiler engineer 3 WAYS TO ACCELERATE APPLICATIONS Applications Libraries Compiler Directives Programming Languages Easy to use Most Performance
OpenACC Introduction and Evolutions Sebastien Deldon, GPU Compiler engineer 3 WAYS TO ACCELERATE APPLICATIONS Applications Libraries Compiler Directives Programming Languages Easy to use Most Performance
Parallel Computing. November 20, W.Homberg
 Mitglied der Helmholtz-Gemeinschaft Parallel Computing November 20, 2017 W.Homberg Why go parallel? Problem too large for single node Job requires more memory Shorter time to solution essential Better
Mitglied der Helmholtz-Gemeinschaft Parallel Computing November 20, 2017 W.Homberg Why go parallel? Problem too large for single node Job requires more memory Shorter time to solution essential Better
A common scenario... Most of us have probably been here. Where did my performance go? It disappeared into overheads...
 OPENMP PERFORMANCE 2 A common scenario... So I wrote my OpenMP program, and I checked it gave the right answers, so I ran some timing tests, and the speedup was, well, a bit disappointing really. Now what?.
OPENMP PERFORMANCE 2 A common scenario... So I wrote my OpenMP program, and I checked it gave the right answers, so I ran some timing tests, and the speedup was, well, a bit disappointing really. Now what?.
Intel Architecture for HPC
 Intel Architecture for HPC Georg Zitzlsberger georg.zitzlsberger@vsb.cz 1st of March 2018 Agenda Salomon Architectures Intel R Xeon R processors v3 (Haswell) Intel R Xeon Phi TM coprocessor (KNC) Ohter
Intel Architecture for HPC Georg Zitzlsberger georg.zitzlsberger@vsb.cz 1st of March 2018 Agenda Salomon Architectures Intel R Xeon R processors v3 (Haswell) Intel R Xeon Phi TM coprocessor (KNC) Ohter
CSC2/458 Parallel and Distributed Systems Machines and Models
 CSC2/458 Parallel and Distributed Systems Machines and Models Sreepathi Pai January 23, 2018 URCS Outline Recap Scalability Taxonomy of Parallel Machines Performance Metrics Outline Recap Scalability Taxonomy
CSC2/458 Parallel and Distributed Systems Machines and Models Sreepathi Pai January 23, 2018 URCS Outline Recap Scalability Taxonomy of Parallel Machines Performance Metrics Outline Recap Scalability Taxonomy
A Study of High Performance Computing and the Cray SV1 Supercomputer. Michael Sullivan TJHSST Class of 2004
 A Study of High Performance Computing and the Cray SV1 Supercomputer Michael Sullivan TJHSST Class of 2004 June 2004 0.1 Introduction A supercomputer is a device for turning compute-bound problems into
A Study of High Performance Computing and the Cray SV1 Supercomputer Michael Sullivan TJHSST Class of 2004 June 2004 0.1 Introduction A supercomputer is a device for turning compute-bound problems into
INTRODUCTION TO THE ARCHER KNIGHTS LANDING CLUSTER. Adrian
 INTRODUCTION TO THE ARCHER KNIGHTS LANDING CLUSTER Adrian Jackson adrianj@epcc.ed.ac.uk @adrianjhpc Processors The power used by a CPU core is proportional to Clock Frequency x Voltage 2 In the past, computers
INTRODUCTION TO THE ARCHER KNIGHTS LANDING CLUSTER Adrian Jackson adrianj@epcc.ed.ac.uk @adrianjhpc Processors The power used by a CPU core is proportional to Clock Frequency x Voltage 2 In the past, computers
NVIDIA Think about Computing as Heterogeneous One Leo Liao, 1/29/2106, NTU
 NVIDIA Think about Computing as Heterogeneous One Leo Liao, 1/29/2106, NTU GPGPU opens the door for co-design HPC, moreover middleware-support embedded system designs to harness the power of GPUaccelerated
NVIDIA Think about Computing as Heterogeneous One Leo Liao, 1/29/2106, NTU GPGPU opens the door for co-design HPC, moreover middleware-support embedded system designs to harness the power of GPUaccelerated
Introduction to Parallel Computing
 Portland State University ECE 588/688 Introduction to Parallel Computing Reference: Lawrence Livermore National Lab Tutorial https://computing.llnl.gov/tutorials/parallel_comp/ Copyright by Alaa Alameldeen
Portland State University ECE 588/688 Introduction to Parallel Computing Reference: Lawrence Livermore National Lab Tutorial https://computing.llnl.gov/tutorials/parallel_comp/ Copyright by Alaa Alameldeen
a. Assuming a perfect balance of FMUL and FADD instructions and no pipeline stalls, what would be the FLOPS rate of the FPU?
 CPS 540 Fall 204 Shirley Moore, Instructor Test November 9, 204 Answers Please show all your work.. Draw a sketch of the extended von Neumann architecture for a 4-core multicore processor with three levels
CPS 540 Fall 204 Shirley Moore, Instructor Test November 9, 204 Answers Please show all your work.. Draw a sketch of the extended von Neumann architecture for a 4-core multicore processor with three levels
NUMA-aware OpenMP Programming
 NUMA-aware OpenMP Programming Dirk Schmidl IT Center, RWTH Aachen University Member of the HPC Group schmidl@itc.rwth-aachen.de Christian Terboven IT Center, RWTH Aachen University Deputy lead of the HPC
NUMA-aware OpenMP Programming Dirk Schmidl IT Center, RWTH Aachen University Member of the HPC Group schmidl@itc.rwth-aachen.de Christian Terboven IT Center, RWTH Aachen University Deputy lead of the HPC
Intel Xeon Phi архитектура, модели программирования, оптимизация.
 Нижний Новгород, 2016 Intel Xeon Phi архитектура, модели программирования, оптимизация. Дмитрий Прохоров, Intel Agenda What and Why Intel Xeon Phi Top 500 insights, roadmap, architecture How Programming
Нижний Новгород, 2016 Intel Xeon Phi архитектура, модели программирования, оптимизация. Дмитрий Прохоров, Intel Agenda What and Why Intel Xeon Phi Top 500 insights, roadmap, architecture How Programming
Introduction to Parallel Programming
 Introduction to Parallel Programming January 14, 2015 www.cac.cornell.edu What is Parallel Programming? Theoretically a very simple concept Use more than one processor to complete a task Operationally
Introduction to Parallel Programming January 14, 2015 www.cac.cornell.edu What is Parallel Programming? Theoretically a very simple concept Use more than one processor to complete a task Operationally
Parallel Programming Libraries and implementations
 Parallel Programming Libraries and implementations Partners Funding Reusing this material This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike 4.0 International License.
Parallel Programming Libraries and implementations Partners Funding Reusing this material This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike 4.0 International License.
INTRODUCTION TO THE ARCHER KNIGHTS LANDING CLUSTER. Adrian
 INTRODUCTION TO THE ARCHER KNIGHTS LANDING CLUSTER Adrian Jackson a.jackson@epcc.ed.ac.uk @adrianjhpc Processors The power used by a CPU core is proportional to Clock Frequency x Voltage 2 In the past,
INTRODUCTION TO THE ARCHER KNIGHTS LANDING CLUSTER Adrian Jackson a.jackson@epcc.ed.ac.uk @adrianjhpc Processors The power used by a CPU core is proportional to Clock Frequency x Voltage 2 In the past,
Parallel Processing. Parallel Processing. 4 Optimization Techniques WS 2018/19
 Parallel Processing WS 2018/19 Universität Siegen rolanda.dwismuellera@duni-siegena.de Tel.: 0271/740-4050, Büro: H-B 8404 Stand: September 7, 2018 Betriebssysteme / verteilte Systeme Parallel Processing
Parallel Processing WS 2018/19 Universität Siegen rolanda.dwismuellera@duni-siegena.de Tel.: 0271/740-4050, Büro: H-B 8404 Stand: September 7, 2018 Betriebssysteme / verteilte Systeme Parallel Processing
Modern Processor Architectures (A compiler writer s perspective) L25: Modern Compiler Design
 L25: Modern Compiler Design") Modern Processor Architectures (A compiler writer s perspective) L25: Modern Compiler Design The 1960s - 1970s Instructions took multiple cycles Only one instruction in flight at once Optimisation meant
Modern Processor Architectures (A compiler writer s perspective) L25: Modern Compiler Design The 1960s - 1970s Instructions took multiple cycles Only one instruction in flight at once Optimisation meant
Multi-core Architectures. Dr. Yingwu Zhu
 Multi-core Architectures Dr. Yingwu Zhu What is parallel computing? Using multiple processors in parallel to solve problems more quickly than with a single processor Examples of parallel computing A cluster
Multi-core Architectures Dr. Yingwu Zhu What is parallel computing? Using multiple processors in parallel to solve problems more quickly than with a single processor Examples of parallel computing A cluster
Online Course Evaluation. What we will do in the last week?
 Online Course Evaluation Please fill in the online form The link will expire on April 30 (next Monday) So far 10 students have filled in the online form Thank you if you completed it. 1 What we will do
Online Course Evaluation Please fill in the online form The link will expire on April 30 (next Monday) So far 10 students have filled in the online form Thank you if you completed it. 1 What we will do
The Stampede is Coming: A New Petascale Resource for the Open Science Community
 The Stampede is Coming: A New Petascale Resource for the Open Science Community Jay Boisseau Texas Advanced Computing Center boisseau@tacc.utexas.edu Stampede: Solicitation US National Science Foundation
The Stampede is Coming: A New Petascale Resource for the Open Science Community Jay Boisseau Texas Advanced Computing Center boisseau@tacc.utexas.edu Stampede: Solicitation US National Science Foundation
Martin Kruliš, v
 Martin Kruliš 1 Optimizations in General Code And Compilation Memory Considerations Parallelism Profiling And Optimization Examples 2 Premature optimization is the root of all evil. -- D. Knuth Our goal
Martin Kruliš 1 Optimizations in General Code And Compilation Memory Considerations Parallelism Profiling And Optimization Examples 2 Premature optimization is the root of all evil. -- D. Knuth Our goal
Introduction to KNL and Parallel Computing
 Introduction to KNL and Parallel Computing Steve Lantz Senior Research Associate Cornell University Center for Advanced Computing (CAC) steve.lantz@cornell.edu High Performance Computing on Stampede 2,
Introduction to KNL and Parallel Computing Steve Lantz Senior Research Associate Cornell University Center for Advanced Computing (CAC) steve.lantz@cornell.edu High Performance Computing on Stampede 2,
Intel Advisor XE Future Release Threading Design & Prototyping Vectorization Assistant
 Intel Advisor XE Future Release Threading Design & Prototyping Vectorization Assistant Parallel is the Path Forward Intel Xeon and Intel Xeon Phi Product Families are both going parallel Intel Xeon processor
Intel Advisor XE Future Release Threading Design & Prototyping Vectorization Assistant Parallel is the Path Forward Intel Xeon and Intel Xeon Phi Product Families are both going parallel Intel Xeon processor
Introduction: Modern computer architecture. The stored program computer and its inherent bottlenecks Multi- and manycore chips and nodes
 Introduction: Modern computer architecture The stored program computer and its inherent bottlenecks Multi- and manycore chips and nodes Motivation: Multi-Cores where and why Introduction: Moore s law Intel
Introduction: Modern computer architecture The stored program computer and its inherent bottlenecks Multi- and manycore chips and nodes Motivation: Multi-Cores where and why Introduction: Moore s law Intel
HPC Architectures evolution: the case of Marconi, the new CINECA flagship system. Piero Lanucara
 HPC Architectures evolution: the case of Marconi, the new CINECA flagship system Piero Lanucara Many advantages as a supercomputing resource: Low energy consumption. Limited floor space requirements Fast
HPC Architectures evolution: the case of Marconi, the new CINECA flagship system Piero Lanucara Many advantages as a supercomputing resource: Low energy consumption. Limited floor space requirements Fast
Introduction to OpenMP
 Introduction to OpenMP Lecture 9: Performance tuning Sources of overhead There are 6 main causes of poor performance in shared memory parallel programs: sequential code communication load imbalance synchronisation
Introduction to OpenMP Lecture 9: Performance tuning Sources of overhead There are 6 main causes of poor performance in shared memory parallel programs: sequential code communication load imbalance synchronisation
Performance Optimization of Smoothed Particle Hydrodynamics for Multi/Many-Core Architectures
 Performance Optimization of Smoothed Particle Hydrodynamics for Multi/Many-Core Architectures Dr. Fabio Baruffa Dr. Luigi Iapichino Leibniz Supercomputing Centre fabio.baruffa@lrz.de Outline of the talk
Performance Optimization of Smoothed Particle Hydrodynamics for Multi/Many-Core Architectures Dr. Fabio Baruffa Dr. Luigi Iapichino Leibniz Supercomputing Centre fabio.baruffa@lrz.de Outline of the talk
COSC 6385 Computer Architecture - Multi Processor Systems
 COSC 6385 Computer Architecture - Multi Processor Systems Fall 2006 Classification of Parallel Architectures Flynn s Taxonomy SISD: Single instruction single data Classical von Neumann architecture SIMD:
COSC 6385 Computer Architecture - Multi Processor Systems Fall 2006 Classification of Parallel Architectures Flynn s Taxonomy SISD: Single instruction single data Classical von Neumann architecture SIMD:
Optimisation Myths and Facts as Seen in Statistical Physics
 Optimisation Myths and Facts as Seen in Statistical Physics Massimo Bernaschi Institute for Applied Computing National Research Council & Computer Science Department University La Sapienza Rome - ITALY
Optimisation Myths and Facts as Seen in Statistical Physics Massimo Bernaschi Institute for Applied Computing National Research Council & Computer Science Department University La Sapienza Rome - ITALY
Kevin O Leary, Intel Technical Consulting Engineer
 Kevin O Leary, Intel Technical Consulting Engineer Moore s Law Is Going Strong Hardware performance continues to grow exponentially We think we can continue Moore's Law for at least another 10 years."
Kevin O Leary, Intel Technical Consulting Engineer Moore s Law Is Going Strong Hardware performance continues to grow exponentially We think we can continue Moore's Law for at least another 10 years."
High Performance Computing (HPC) Introduction
 Introduction") High Performance Computing (HPC) Introduction Ontario Summer School on High Performance Computing Scott Northrup SciNet HPC Consortium Compute Canada June 25th, 2012 Outline 1 HPC Overview 2 Parallel Computing
High Performance Computing (HPC) Introduction Ontario Summer School on High Performance Computing Scott Northrup SciNet HPC Consortium Compute Canada June 25th, 2012 Outline 1 HPC Overview 2 Parallel Computing
Introduction to Parallel Programming
 Introduction to Parallel Programming Linda Woodard CAC 19 May 2010 Introduction to Parallel Computing on Ranger 5/18/2010 www.cac.cornell.edu 1 y What is Parallel Programming? Using more than one processor
Introduction to Parallel Programming Linda Woodard CAC 19 May 2010 Introduction to Parallel Computing on Ranger 5/18/2010 www.cac.cornell.edu 1 y What is Parallel Programming? Using more than one processor
OpenMP Programming. Prof. Thomas Sterling. High Performance Computing: Concepts, Methods & Means
 High Performance Computing: Concepts, Methods & Means OpenMP Programming Prof. Thomas Sterling Department of Computer Science Louisiana State University February 8 th, 2007 Topics Introduction Overview
High Performance Computing: Concepts, Methods & Means OpenMP Programming Prof. Thomas Sterling Department of Computer Science Louisiana State University February 8 th, 2007 Topics Introduction Overview
Advanced Parallel Programming I
 Advanced Parallel Programming I Alexander Leutgeb, RISC Software GmbH RISC Software GmbH Johannes Kepler University Linz 2016 22.09.2016 1 Levels of Parallelism RISC Software GmbH Johannes Kepler University
Advanced Parallel Programming I Alexander Leutgeb, RISC Software GmbH RISC Software GmbH Johannes Kepler University Linz 2016 22.09.2016 1 Levels of Parallelism RISC Software GmbH Johannes Kepler University
Performance and Energy Usage of Workloads on KNL and Haswell Architectures
 Performance and Energy Usage of Workloads on KNL and Haswell Architectures Tyler Allen 1 Christopher Daley 2 Doug Doerfler 2 Brian Austin 2 Nicholas Wright 2 1 Clemson University 2 National Energy Research
Performance and Energy Usage of Workloads on KNL and Haswell Architectures Tyler Allen 1 Christopher Daley 2 Doug Doerfler 2 Brian Austin 2 Nicholas Wright 2 1 Clemson University 2 National Energy Research
High Performance Computing: Architecture, Applications, and SE Issues. Peter Strazdins
 High Performance Computing: Architecture, Applications, and SE Issues Peter Strazdins Department of Computer Science, Australian National University e-mail: peter@cs.anu.edu.au May 17, 2004 COMP1800 Seminar2-1
High Performance Computing: Architecture, Applications, and SE Issues Peter Strazdins Department of Computer Science, Australian National University e-mail: peter@cs.anu.edu.au May 17, 2004 COMP1800 Seminar2-1
OpenMP: Open Multiprocessing
 OpenMP: Open Multiprocessing Erik Schnetter June 7, 2012, IHPC 2012, Iowa City Outline 1. Basic concepts, hardware architectures 2. OpenMP Programming 3. How to parallelise an existing code 4. Advanced
OpenMP: Open Multiprocessing Erik Schnetter June 7, 2012, IHPC 2012, Iowa City Outline 1. Basic concepts, hardware architectures 2. OpenMP Programming 3. How to parallelise an existing code 4. Advanced
Tutorial 11. Final Exam Review
 Tutorial 11 Final Exam Review Introduction Instruction Set Architecture: contract between programmer and designers (e.g.: IA-32, IA-64, X86-64) Computer organization: describe the functional units, cache
Tutorial 11 Final Exam Review Introduction Instruction Set Architecture: contract between programmer and designers (e.g.: IA-32, IA-64, X86-64) Computer organization: describe the functional units, cache
Serial. Parallel. CIT 668: System Architecture 2/14/2011. Topics. Serial and Parallel Computation. Parallel Computing
 CIT 668: System Architecture Parallel Computing Topics 1. What is Parallel Computing? 2. Why use Parallel Computing? 3. Types of Parallelism 4. Amdahl s Law 5. Flynn s Taxonomy of Parallel Computers 6.
CIT 668: System Architecture Parallel Computing Topics 1. What is Parallel Computing? 2. Why use Parallel Computing? 3. Types of Parallelism 4. Amdahl s Law 5. Flynn s Taxonomy of Parallel Computers 6.
PROGRAMOVÁNÍ V C++ CVIČENÍ. Michal Brabec
 PROGRAMOVÁNÍ V C++ CVIČENÍ Michal Brabec PARALLELISM CATEGORIES CPU? SSE Multiprocessor SIMT - GPU 2 / 17 PARALLELISM V C++ Weak support in the language itself, powerful libraries Many different parallelization
PROGRAMOVÁNÍ V C++ CVIČENÍ Michal Brabec PARALLELISM CATEGORIES CPU? SSE Multiprocessor SIMT - GPU 2 / 17 PARALLELISM V C++ Weak support in the language itself, powerful libraries Many different parallelization
FUSION PROCESSORS AND HPC
 FUSION PROCESSORS AND HPC Chuck Moore AMD Corporate Fellow & Technology Group CTO June 14, 2011 Fusion Processors and HPC Today: Multi-socket x86 CMPs + optional dgpu + high BW memory Fusion APUs (SPFP)
FUSION PROCESSORS AND HPC Chuck Moore AMD Corporate Fellow & Technology Group CTO June 14, 2011 Fusion Processors and HPC Today: Multi-socket x86 CMPs + optional dgpu + high BW memory Fusion APUs (SPFP)
Introduction to parallel computing
 Introduction to parallel computing 2. Parallel Hardware Zhiao Shi (modifications by Will French) Advanced Computing Center for Education & Research Vanderbilt University Motherboard Processor https://sites.google.com/
Introduction to parallel computing 2. Parallel Hardware Zhiao Shi (modifications by Will French) Advanced Computing Center for Education & Research Vanderbilt University Motherboard Processor https://sites.google.com/
Introduction to OpenMP. OpenMP basics OpenMP directives, clauses, and library routines
 Introduction to OpenMP Introduction OpenMP basics OpenMP directives, clauses, and library routines What is OpenMP? What does OpenMP stands for? What does OpenMP stands for? Open specifications for Multi
Introduction to OpenMP Introduction OpenMP basics OpenMP directives, clauses, and library routines What is OpenMP? What does OpenMP stands for? What does OpenMP stands for? Open specifications for Multi
VLPL-S Optimization on Knights Landing
 VLPL-S Optimization on Knights Landing 英特尔软件与服务事业部 周姗 2016.5 Agenda VLPL-S 性能分析 VLPL-S 性能优化 总结 2 VLPL-S Workload Descriptions VLPL-S is the in-house code from SJTU, paralleled with MPI and written in C++.
VLPL-S Optimization on Knights Landing 英特尔软件与服务事业部 周姗 2016.5 Agenda VLPL-S 性能分析 VLPL-S 性能优化 总结 2 VLPL-S Workload Descriptions VLPL-S is the in-house code from SJTU, paralleled with MPI and written in C++.
Optimising for the p690 memory system
 Optimising for the p690 memory Introduction As with all performance optimisation it is important to understand what is limiting the performance of a code. The Power4 is a very powerful micro-processor
Optimising for the p690 memory Introduction As with all performance optimisation it is important to understand what is limiting the performance of a code. The Power4 is a very powerful micro-processor
ECE 695 Numerical Simulations Lecture 3: Practical Assessment of Code Performance. Prof. Peter Bermel January 13, 2017
 ECE 695 Numerical Simulations Lecture 3: Practical Assessment of Code Performance Prof. Peter Bermel January 13, 2017 Outline Time Scaling Examples General performance strategies Computer architectures
ECE 695 Numerical Simulations Lecture 3: Practical Assessment of Code Performance Prof. Peter Bermel January 13, 2017 Outline Time Scaling Examples General performance strategies Computer architectures
MEMORY ON THE KNL. Adrian Some slides from Intel Presentations
 MEMORY ON THE KNL Adrian Jackson a.jackson@epcc.ed.ac.uk @adrianjhpc Some slides from Intel Presentations Memory Two levels of memory for KNL Main memory KNL has direct access to all of main memory Similar
MEMORY ON THE KNL Adrian Jackson a.jackson@epcc.ed.ac.uk @adrianjhpc Some slides from Intel Presentations Memory Two levels of memory for KNL Main memory KNL has direct access to all of main memory Similar
An Introduction to Parallel Programming
 An Introduction to Parallel Programming Ing. Andrea Marongiu (a.marongiu@unibo.it) Includes slides from Multicore Programming Primer course at Massachusetts Institute of Technology (MIT) by Prof. SamanAmarasinghe
An Introduction to Parallel Programming Ing. Andrea Marongiu (a.marongiu@unibo.it) Includes slides from Multicore Programming Primer course at Massachusetts Institute of Technology (MIT) by Prof. SamanAmarasinghe
Lecture 5. Performance programming for stencil methods Vectorization Computing with GPUs
 Lecture 5 Performance programming for stencil methods Vectorization Computing with GPUs Announcements Forge accounts: set up ssh public key, tcsh Turnin was enabled for Programming Lab #1: due at 9pm today,
Lecture 5 Performance programming for stencil methods Vectorization Computing with GPUs Announcements Forge accounts: set up ssh public key, tcsh Turnin was enabled for Programming Lab #1: due at 9pm today,
Intel Advisor XE. Vectorization Optimization. Optimization Notice
 Intel Advisor XE Vectorization Optimization 1 Performance is a Proven Game Changer It is driving disruptive change in multiple industries Protecting buildings from extreme events Sophisticated mechanics
Intel Advisor XE Vectorization Optimization 1 Performance is a Proven Game Changer It is driving disruptive change in multiple industries Protecting buildings from extreme events Sophisticated mechanics
High Performance Computing Systems
 High Performance Computing Systems Shared Memory Doug Shook Shared Memory Bottlenecks Trips to memory Cache coherence 2 Why Multicore? Shared memory systems used to be purely the domain of HPC... What
High Performance Computing Systems Shared Memory Doug Shook Shared Memory Bottlenecks Trips to memory Cache coherence 2 Why Multicore? Shared memory systems used to be purely the domain of HPC... What
Distributed Systems CS /640
 Distributed Systems CS 15-440/640 Programming Models Borrowed and adapted from our good friends at CMU-Doha, Qatar Majd F. Sakr, Mohammad Hammoud andvinay Kolar 1 Objectives Discussion on Programming Models
Distributed Systems CS 15-440/640 Programming Models Borrowed and adapted from our good friends at CMU-Doha, Qatar Majd F. Sakr, Mohammad Hammoud andvinay Kolar 1 Objectives Discussion on Programming Models
CSE 160 Lecture 10. Instruction level parallelism (ILP) Vectorization
 Vectorization") CSE 160 Lecture 10 Instruction level parallelism (ILP) Vectorization Announcements Quiz on Friday Signup for Friday labs sessions in APM 2013 Scott B. Baden / CSE 160 / Winter 2013 2 Particle simulation
CSE 160 Lecture 10 Instruction level parallelism (ILP) Vectorization Announcements Quiz on Friday Signup for Friday labs sessions in APM 2013 Scott B. Baden / CSE 160 / Winter 2013 2 Particle simulation
Test on Wednesday! Material covered since Monday, Feb 8 (no Linux, Git, C, MD, or compiling programs)
") Test on Wednesday! 50 minutes Closed notes, closed computer, closed everything Material covered since Monday, Feb 8 (no Linux, Git, C, MD, or compiling programs) Study notes and readings posted on course
Test on Wednesday! 50 minutes Closed notes, closed computer, closed everything Material covered since Monday, Feb 8 (no Linux, Git, C, MD, or compiling programs) Study notes and readings posted on course
The Era of Heterogeneous Computing
 The Era of Heterogeneous Computing EU-US Summer School on High Performance Computing New York, NY, USA June 28, 2013 Lars Koesterke: Research Staff @ TACC Nomenclature Architecture Model -------------------------------------------------------
The Era of Heterogeneous Computing EU-US Summer School on High Performance Computing New York, NY, USA June 28, 2013 Lars Koesterke: Research Staff @ TACC Nomenclature Architecture Model -------------------------------------------------------
Algorithms and Architecture. William D. Gropp Mathematics and Computer Science
 Algorithms and Architecture William D. Gropp Mathematics and Computer Science www.mcs.anl.gov/~gropp Algorithms What is an algorithm? A set of instructions to perform a task How do we evaluate an algorithm?
Algorithms and Architecture William D. Gropp Mathematics and Computer Science www.mcs.anl.gov/~gropp Algorithms What is an algorithm? A set of instructions to perform a task How do we evaluate an algorithm?
ECE 563 Second Exam, Spring 2014
 ECE 563 Second Exam, Spring 2014 Don t start working on this until I say so Your exam should have 8 pages total (including this cover sheet) and 11 questions. Each questions is worth 9 points. Please let
ECE 563 Second Exam, Spring 2014 Don t start working on this until I say so Your exam should have 8 pages total (including this cover sheet) and 11 questions. Each questions is worth 9 points. Please let
2006: Short-Range Molecular Dynamics on GPU. San Jose, CA September 22, 2010 Peng Wang, NVIDIA
 2006: Short-Range Molecular Dynamics on GPU San Jose, CA September 22, 2010 Peng Wang, NVIDIA Overview The LAMMPS molecular dynamics (MD) code Cell-list generation and force calculation Algorithm & performance
2006: Short-Range Molecular Dynamics on GPU San Jose, CA September 22, 2010 Peng Wang, NVIDIA Overview The LAMMPS molecular dynamics (MD) code Cell-list generation and force calculation Algorithm & performance