The Processor: Improving the performance - Control Hazards
|
|
|
- Joshua Berry
- 5 years ago
- Views:
Transcription
1 The Processor: Improving the performance - Control Hazards Wednesday 14 October 15 Many slides adapted from: and Design, Patterson & Hennessy 5th Edition, 2014, MK and from Prof. Mary Jane Irwin, PSU
2 Summary Previous Class Reducing pipeline data hazards Today: Reducing pipeline branch hazards Delayed Branch Branch Prediction Exceptions and Interrupts 2
3 Branch Hazards When the flow of instruction addresses is not sequential (i.e., PC = PC + 4); incurred by change of flow instructions Unconditional branches (j, jal, jr) Conditional branches (beq, bne) Exceptions Possible approaches Stall (impacts CPI) Move decision point as early in the pipeline as possible, thereby reducing the number of stall cycles Delay decision (requires compiler support) Predict and hope for the best! Control hazards occur less frequently than data hazards, but there is nothing as effective against control hazards as forwarding is for data hazards 3
4 Branch Instructions Cause Control Hazards Dependencies backward in time cause hazards I n s t r. O r d e r beq Inst_target Inst 3 Inst 4 IM Reg DM Reg IM Reg DM Reg IM Reg DM Reg IM Reg DM Reg 4
5 Pipelined Control (Simplified) 5
6 Branch Hazards nop instruction (or bubble) inserted between two instructions in the pipeline Keep the instructions earlier in the pipeline (later in the code) from progressing down the pipeline for a cycle ( bounce them in place with write control signals) Insert nop by zeroing control bits in the pipeline register at the appropriate stage Let the instructions later in the pipeline (earlier in the code) progress normally down the pipeline Flushes (or instruction squashing) were an instruction in the pipeline is replaced with a nop instruction (as done for instructions located sequentially after j instructions) Zero the control bits for the instruction to be flushed 6
7 One Way to Fix a Branch Control Hazard I n s t r. beq flush IM Reg DM Reg IM Reg DM Reg Fix branch hazard by waiting flush but affects CPI O r d e r flush flush beq target IM Reg DM Reg IM Reg DM Reg IM Reg DM Reg Inst 3 IM Reg DM 7

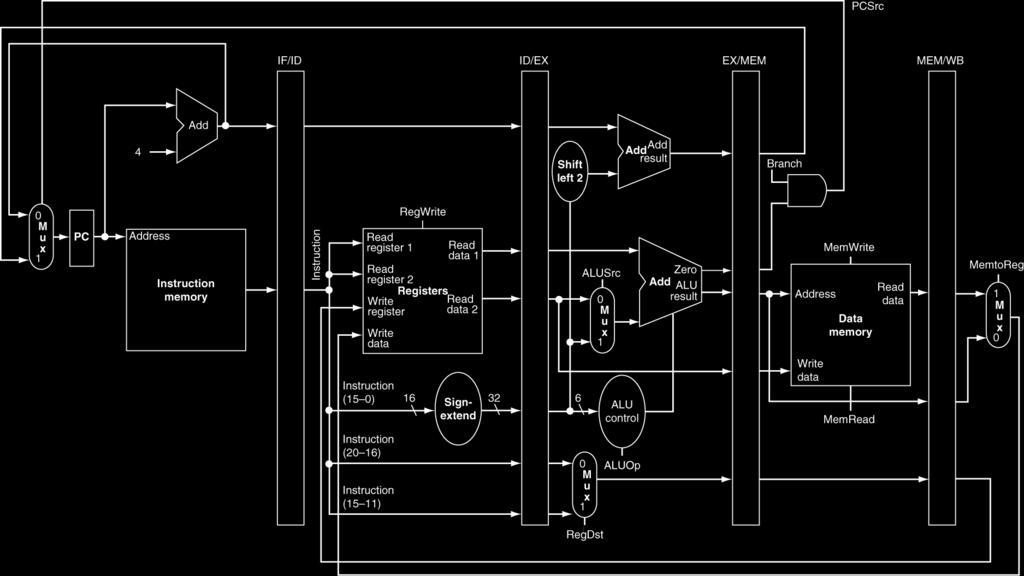
8 Pipelined Control (Simplified) 8
9 Branch Hazards Move branch decision hardware back to as early in the pipeline as possible i.e., during the decode cycle I n s t r. beq flush IM Reg DM Reg IM Reg DM Reg Fix remaining jump hazard by waiting flush O r d e r beq target One stall is still needed IM Reg DM Reg 9
10 Reducing the Delay of Branches Move the branch decision hardware back to the EX stage Add hardware to compute the branch target address and evaluate the branch decision to the ID stage Reduces the number of stall (flush) cycles to one like with jumps but now need to add forwarding hardware in ID stage For deeper pipelines, branch decision points can be even later in the pipeline, incurring more stalls 10
11 Delayed Branches If the branch hardware has been moved to the ID stage, then we can eliminate all branch stalls with delayed branches which are defined as always executing the next sequential instruction after the branch instruction the branch takes effect after that next instruction MIPS compiler moves an instruction to immediately after the branch that is not affected by the branch (a safe instruction) thereby hiding the branch delay With deeper pipelines, the branch delay grows requiring more than one delay slot Delayed branches have lost popularity compared to more expensive but more flexible (dynamic) hardware branch prediction Growth in available transistors has made hardware branch prediction relatively cheaper 11
12 Scheduling Branch Delay Slots A. From before branch B. From branch target C. From fall through add $1,$2,$3 bne $2,$0,40 delay slot sub $4,$5,$6 add $1,$2,$3 bne $2,$0,-40 delay slot add $1,$2,$3 bne $2,$0,40 delay slot sub $4,$5,$6 becomes becomes becomes sub $4,$5,$6 add $1,$2,$3 bne $2,$0,40 bne $2,$0,44 add $1,$2,$3 add $1,$2,$3 bne $2,$0,-36 sub $4,$5,$6 A is the best choice, fills delay slot and reduces IC sub $4,$5,$6 In B and C, the sub instruction may need to be copied, increasing IC In B and C, must be okay to execute sub when branch fails 12
13 Branch Prediction Longer pipelines can t readily determine branch outcome early Stall penalty becomes unacceptable Predict outcome of branch Only stall if prediction is wrong In MIPS pipeline Can predict branches not taken Fetch instruction after branch, with no delay 13
14 Static Branch Prediction Resolve branch hazards by assuming a given outcome and proceeding without waiting to see the actual branch outcome Predict not taken always predict branches will not be taken, continue to fetch from the sequential instruction stream, only when branch is taken does the pipeline stall If taken, flush instructions after the branch (earlier in the pipeline) ensure that those flushed instructions haven t changed the machine state restart the pipeline at the branch destination 14


15 MIPS with Predict Not Taken Prediction correct Prediction incorrect 15
16 Flushing with Misprediction (Not Taken) I n s t r. O r d e r 4 beq $1,$2,2 8 sub $4,$1,$5 flush 16 and $6,$1,$7 20 or r8,$1,$9 IM Reg DM Reg IM Reg DM Reg IM Reg DM Reg IM Reg DM Reg 16
17 Static Branch Prediction Predict not taken works well for top of the loop branching structures But such loops have jumps at the bottom of the loop to return to the top of the loop Loop: beq $1,$2,Out 1 nd loop instr... last loop instr j Loop Out: fall out instr Predict not taken doesn t work well for bottom of the loop branching structures Loop: 1 st loop instr 2 nd loop instr... last loop instr bne $1,$2,Loop fall out instr 17
18 More-Realistic Branch Prediction Static branch prediction Based on typical branch behavior Example: loop and if-statement branches Predict backward branches taken Predict forward branches not taken Dynamic branch prediction Hardware measures actual branch behavior e.g., record recent history of each branch Assume future behavior will continue the trend When wrong, stall while re-fetching, and update history 18
19 Dynamic Branch Prediction Dynamic prediction: Branch prediction buffer (aka branch history table) Indexed by recent branch instruction addresses Stores outcome (taken/not taken) To execute a branch Check table, expect the same outcome Start fetching from fall-through or target If wrong, flush pipeline and flip prediction 19
20 1-Bit Predictor: Shortcoming Inner loop branches mispredicted twice! outer: inner: beq,, inner beq,, outer Mispredict as taken on last iteration of inner loop Then mispredict as not taken on first iteration of inner loop next time around 20


21 2-Bit Predictor Only change prediction on two successive mispredictions 21
22 Exceptions and Interrupts Unexpected events requiring change in flow of control Different ISAs use the terms differently Exception Arises within the CPU e.g., undefined opcode, overflow, syscall, Interrupt From an external I/O controller Dealing with them without sacrificing performance is hard. 22
23 Handling Exceptions In MIPS, exceptions managed by a System Control Coprocessor (CP0) Save PC of offending (or interrupted) instruction In MIPS: Exception Program Counter (EPC) Save indication of the problem In MIPS: Cause register We ll assume 1-bit 0 for undefined opcode, 1 for overflow Jump to handler at
24 An Alternate Mechanism Vectored Interrupts Handler address determined by the cause Example: Undefined opcode: C Overflow: C : C Instructions either Deal with the interrupt, or Jump to real handler 24
25 Handler Actions Read cause, and transfer to relevant handler Determine action required If restartable Take corrective action Use EPC to return to program Otherwise Terminate program Report error using EPC, cause, 25
26 Exceptions in a Pipeline Another form of control hazard Consider overflow on add in EX stage add $1, $2, $1 Prevent $1 from being clobbered Complete previous instructions Flush add and subsequent instructions Set Cause and EPC register values Transfer control to handler Similar to mispredicted branch Use much of the same hardware 26
27 Exception Properties Restartable exceptions Pipeline can flush the instruction Handler executes, then returns to the instruction Refetched and executed from scratch PC saved in EPC register Identifies causing instruction Actually PC + 4 is saved Handler must adjust 27
28 Multiple Exceptions Pipelining overlaps multiple instructions Could have multiple exceptions at once Simple approach: deal with exception from earliest instruction Flush subsequent instructions Precise exceptions In complex pipelines Multiple instructions issued per cycle Out-of-order completion Maintaining precise exceptions is difficult! 28
29 Imprecise Exceptions Just stop pipeline and save state Including exception cause(s) Let the handler work out Which instruction(s) had exceptions Which to complete or flush May require manual completion Simplifies hardware, but more complex handler software Not feasible for complex multiple-issue out-of-order pipelines 29
30 Conclusion Must detect and resolve hazards Control hazards put the branch decision hardware in as early a stage in the pipeline as possible Stall (impacts CPI) Delay decision (requires compiler support) Static and dynamic prediction (requires hardware support) Pipelining complicates exception handling 30
31 Next Class Multiple issue processors Instruction-Level Parallelism (ILP) 31
32 The Processor: Improving the performance - Control Hazards Wednesday 14 October 15 Many slides adapted from: and Design, Patterson & Hennessy 5th Edition, 2014, MK and from Prof. Mary Jane Irwin, PSU
LECTURE 3: THE PROCESSOR
 LECTURE 3: THE PROCESSOR Abridged version of Patterson & Hennessy (2013):Ch.4 Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU
LECTURE 3: THE PROCESSOR Abridged version of Patterson & Hennessy (2013):Ch.4 Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU
Chapter 4 The Processor 1. Chapter 4B. The Processor
 Chapter 4 The Processor 1 Chapter 4B The Processor Chapter 4 The Processor 2 Control Hazards Branch determines flow of control Fetching next instruction depends on branch outcome Pipeline can t always
Chapter 4 The Processor 1 Chapter 4B The Processor Chapter 4 The Processor 2 Control Hazards Branch determines flow of control Fetching next instruction depends on branch outcome Pipeline can t always
Full Datapath. Chapter 4 The Processor 2
 Pipelining Full Datapath Chapter 4 The Processor 2 Datapath With Control Chapter 4 The Processor 3 Performance Issues Longest delay determines clock period Critical path: load instruction Instruction memory
Pipelining Full Datapath Chapter 4 The Processor 2 Datapath With Control Chapter 4 The Processor 3 Performance Issues Longest delay determines clock period Critical path: load instruction Instruction memory
Department of Computer and IT Engineering University of Kurdistan. Computer Architecture Pipelining. By: Dr. Alireza Abdollahpouri
 Department of Computer and IT Engineering University of Kurdistan Computer Architecture Pipelining By: Dr. Alireza Abdollahpouri Pipelined MIPS processor Any instruction set can be implemented in many
Department of Computer and IT Engineering University of Kurdistan Computer Architecture Pipelining By: Dr. Alireza Abdollahpouri Pipelined MIPS processor Any instruction set can be implemented in many
MIPS Pipelining. Computer Organization Architectures for Embedded Computing. Wednesday 8 October 14
 MIPS Pipelining Computer Organization Architectures for Embedded Computing Wednesday 8 October 14 Many slides adapted from: Computer Organization and Design, Patterson & Hennessy 4th Edition, 2011, MK
MIPS Pipelining Computer Organization Architectures for Embedded Computing Wednesday 8 October 14 Many slides adapted from: Computer Organization and Design, Patterson & Hennessy 4th Edition, 2011, MK
COMPUTER ORGANIZATION AND DESIGN
 COMPUTER ORGANIZATION AND DESIGN 5 Edition th The Hardware/Software Interface Chapter 4 The Processor 4.1 Introduction Introduction CPU performance factors Instruction count CPI and Cycle time Determined
COMPUTER ORGANIZATION AND DESIGN 5 Edition th The Hardware/Software Interface Chapter 4 The Processor 4.1 Introduction Introduction CPU performance factors Instruction count CPI and Cycle time Determined
Outline. A pipelined datapath Pipelined control Data hazards and forwarding Data hazards and stalls Branch (control) hazards Exception
 hazards Exception") Outline A pipelined datapath Pipelined control Data hazards and forwarding Data hazards and stalls Branch (control) hazards Exception 1 4 Which stage is the branch decision made? Case 1: 0 M u x 1 Add
Outline A pipelined datapath Pipelined control Data hazards and forwarding Data hazards and stalls Branch (control) hazards Exception 1 4 Which stage is the branch decision made? Case 1: 0 M u x 1 Add
COMPUTER ORGANIZATION AND DESI
 COMPUTER ORGANIZATION AND DESIGN 5 Edition th The Hardware/Software Interface Chapter 4 The Processor 4.1 Introduction Introduction CPU performance factors Instruction count Determined by ISA and compiler
COMPUTER ORGANIZATION AND DESIGN 5 Edition th The Hardware/Software Interface Chapter 4 The Processor 4.1 Introduction Introduction CPU performance factors Instruction count Determined by ISA and compiler
Computer Architecture Computer Science & Engineering. Chapter 4. The Processor BK TP.HCM
 Computer Architecture Computer Science & Engineering Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware
Computer Architecture Computer Science & Engineering Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware
Determined by ISA and compiler. We will examine two MIPS implementations. A simplified version A more realistic pipelined version
 MIPS Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware We will examine two MIPS implementations A simplified
MIPS Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware We will examine two MIPS implementations A simplified
Thomas Polzer Institut für Technische Informatik
 Thomas Polzer tpolzer@ecs.tuwien.ac.at Institut für Technische Informatik Pipelined laundry: overlapping execution Parallelism improves performance Four loads: Speedup = 8/3.5 = 2.3 Non-stop: Speedup =
Thomas Polzer tpolzer@ecs.tuwien.ac.at Institut für Technische Informatik Pipelined laundry: overlapping execution Parallelism improves performance Four loads: Speedup = 8/3.5 = 2.3 Non-stop: Speedup =
Chapter 4. The Processor
 Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware We will examine two MIPS implementations A simplified
Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware We will examine two MIPS implementations A simplified
EIE/ENE 334 Microprocessors
 EIE/ENE 334 Microprocessors Lecture 6: The Processor Week #06/07 : Dejwoot KHAWPARISUTH Adapted from Computer Organization and Design, 4 th Edition, Patterson & Hennessy, 2009, Elsevier (MK) http://webstaff.kmutt.ac.th/~dejwoot.kha/
EIE/ENE 334 Microprocessors Lecture 6: The Processor Week #06/07 : Dejwoot KHAWPARISUTH Adapted from Computer Organization and Design, 4 th Edition, Patterson & Hennessy, 2009, Elsevier (MK) http://webstaff.kmutt.ac.th/~dejwoot.kha/
CSEE 3827: Fundamentals of Computer Systems
 CSEE 3827: Fundamentals of Computer Systems Lecture 21 and 22 April 22 and 27, 2009 martha@cs.columbia.edu Amdahl s Law Be aware when optimizing... T = improved Taffected improvement factor + T unaffected
CSEE 3827: Fundamentals of Computer Systems Lecture 21 and 22 April 22 and 27, 2009 martha@cs.columbia.edu Amdahl s Law Be aware when optimizing... T = improved Taffected improvement factor + T unaffected
Chapter 4. The Processor
 Chapter 4 The Processor 4.1 Introduction Introduction CPU performance factors Instruction count CPI and Cycle time Determined by CPU hardware We will examine two MIPS implementations Determined by ISA
Chapter 4 The Processor 4.1 Introduction Introduction CPU performance factors Instruction count CPI and Cycle time Determined by CPU hardware We will examine two MIPS implementations Determined by ISA
Chapter 4. The Processor
 Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware We will examine two MIPS implementations A simplified
Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware We will examine two MIPS implementations A simplified
Lecture 9 Pipeline and Cache
 Lecture 9 Pipeline and Cache Peng Liu liupeng@zju.edu.cn 1 What makes it easy Pipelining Review all instructions are the same length just a few instruction formats memory operands appear only in loads
Lecture 9 Pipeline and Cache Peng Liu liupeng@zju.edu.cn 1 What makes it easy Pipelining Review all instructions are the same length just a few instruction formats memory operands appear only in loads
Pipelined Datapath. Reading. Sections Practice Problems: 1, 3, 8, 12 (2) Lecture notes from MKP, H. H. Lee and S.
 Lecture notes from MKP, H. H. Lee and S.") Pipelined Datapath Lecture notes from KP, H. H. Lee and S. Yalamanchili Sections 4.5 4. Practice Problems:, 3, 8, 2 ing (2) Pipeline Performance Assume time for stages is ps for register read or write
Pipelined Datapath Lecture notes from KP, H. H. Lee and S. Yalamanchili Sections 4.5 4. Practice Problems:, 3, 8, 2 ing (2) Pipeline Performance Assume time for stages is ps for register read or write
Chapter 4. The Processor
 Chapter 4 The Processor 1 Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware We will examine two MIPS implementations A
Chapter 4 The Processor 1 Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware We will examine two MIPS implementations A
COMPUTER ORGANIZATION AND DESIGN
 COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle
Pipelined Datapath. Reading. Sections Practice Problems: 1, 3, 8, 12
 Pipelined Datapath Lecture notes from KP, H. H. Lee and S. Yalamanchili Sections 4.5 4. Practice Problems:, 3, 8, 2 ing Note: Appendices A-E in the hardcopy text correspond to chapters 7- in the online
Pipelined Datapath Lecture notes from KP, H. H. Lee and S. Yalamanchili Sections 4.5 4. Practice Problems:, 3, 8, 2 ing Note: Appendices A-E in the hardcopy text correspond to chapters 7- in the online
Computer Organization and Structure. Bing-Yu Chen National Taiwan University
 Computer Organization and Structure Bing-Yu Chen National Taiwan University The Processor Logic Design Conventions Building a Datapath A Simple Implementation Scheme An Overview of Pipelining Pipelined
Computer Organization and Structure Bing-Yu Chen National Taiwan University The Processor Logic Design Conventions Building a Datapath A Simple Implementation Scheme An Overview of Pipelining Pipelined
Pipeline Hazards. Jin-Soo Kim Computer Systems Laboratory Sungkyunkwan University
 Pipeline Hazards Jin-Soo Kim (jinsookim@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu Hazards What are hazards? Situations that prevent starting the next instruction
Pipeline Hazards Jin-Soo Kim (jinsookim@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu Hazards What are hazards? Situations that prevent starting the next instruction
CENG 3420 Lecture 06: Pipeline
 CENG 3420 Lecture 06: Pipeline Bei Yu byu@cse.cuhk.edu.hk CENG3420 L06.1 Spring 2019 Outline q Pipeline Motivations q Pipeline Hazards q Exceptions q Background: Flip-Flop Control Signals CENG3420 L06.2
CENG 3420 Lecture 06: Pipeline Bei Yu byu@cse.cuhk.edu.hk CENG3420 L06.1 Spring 2019 Outline q Pipeline Motivations q Pipeline Hazards q Exceptions q Background: Flip-Flop Control Signals CENG3420 L06.2
Chapter 4. The Processor
 Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware We will examine two MIPS implementations A simplified
Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware We will examine two MIPS implementations A simplified
Computer Architecture Computer Science & Engineering. Chapter 4. The Processor BK TP.HCM
 Computer Architecture Computer Science & Engineering Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware
Computer Architecture Computer Science & Engineering Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface. 5 th. Edition. Chapter 4. The Processor
 COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle
MIPS An ISA for Pipelining
 Pipelining: Basic and Intermediate Concepts Slides by: Muhamed Mudawar CS 282 KAUST Spring 2010 Outline: MIPS An ISA for Pipelining 5 stage pipelining i Structural Hazards Data Hazards & Forwarding Branch
Pipelining: Basic and Intermediate Concepts Slides by: Muhamed Mudawar CS 282 KAUST Spring 2010 Outline: MIPS An ISA for Pipelining 5 stage pipelining i Structural Hazards Data Hazards & Forwarding Branch
The Processor (3) Jinkyu Jeong Computer Systems Laboratory Sungkyunkwan University
 Jinkyu Jeong Computer Systems Laboratory Sungkyunkwan University") The Processor (3) Jinkyu Jeong (jinkyu@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu EEE3050: Theory on Computer Architectures, Spring 2017, Jinkyu Jeong (jinkyu@skku.edu)
The Processor (3) Jinkyu Jeong (jinkyu@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu EEE3050: Theory on Computer Architectures, Spring 2017, Jinkyu Jeong (jinkyu@skku.edu)
Chapter 4. The Processor. Jiang Jiang
 Chapter 4 The Processor Jiang Jiang jiangjiang@ic.sjtu.edu.cn [Adapted from Computer Organization and Design, 4 th Edition, Patterson & Hennessy, 2008, MK] Chapter 4 The Processor 2 Introduction CPU performance
Chapter 4 The Processor Jiang Jiang jiangjiang@ic.sjtu.edu.cn [Adapted from Computer Organization and Design, 4 th Edition, Patterson & Hennessy, 2008, MK] Chapter 4 The Processor 2 Introduction CPU performance
Pipeline Overview. Dr. Jiang Li. Adapted from the slides provided by the authors. Jiang Li, Ph.D. Department of Computer Science
 Pipeline Overview Dr. Jiang Li Adapted from the slides provided by the authors Outline MIPS An ISA for Pipelining 5 stage pipelining Structural and Data Hazards Forwarding Branch Schemes Exceptions and
Pipeline Overview Dr. Jiang Li Adapted from the slides provided by the authors Outline MIPS An ISA for Pipelining 5 stage pipelining Structural and Data Hazards Forwarding Branch Schemes Exceptions and
1 Hazards COMP2611 Fall 2015 Pipelined Processor
 1 Hazards Dependences in Programs 2 Data dependence Example: lw $1, 200($2) add $3, $4, $1 add can t do ID (i.e., read register $1) until lw updates $1 Control dependence Example: bne $1, $2, target add
1 Hazards Dependences in Programs 2 Data dependence Example: lw $1, 200($2) add $3, $4, $1 add can t do ID (i.e., read register $1) until lw updates $1 Control dependence Example: bne $1, $2, target add
The Processor: Instruction-Level Parallelism
 The Processor: Instruction-Level Parallelism Computer Organization Architectures for Embedded Computing Tuesday 21 October 14 Many slides adapted from: Computer Organization and Design, Patterson & Hennessy
The Processor: Instruction-Level Parallelism Computer Organization Architectures for Embedded Computing Tuesday 21 October 14 Many slides adapted from: Computer Organization and Design, Patterson & Hennessy
There are different characteristics for exceptions. They are as follows:
 e-pg PATHSHALA- Computer Science Computer Architecture Module 15 Exception handling and floating point pipelines The objectives of this module are to discuss about exceptions and look at how the MIPS architecture
e-pg PATHSHALA- Computer Science Computer Architecture Module 15 Exception handling and floating point pipelines The objectives of this module are to discuss about exceptions and look at how the MIPS architecture
EI338: Computer Systems and Engineering (Computer Architecture & Operating Systems)
") EI338: Computer Systems and Engineering (Computer Architecture & Operating Systems) Chentao Wu 吴晨涛 Associate Professor Dept. of Computer Science and Engineering Shanghai Jiao Tong University SEIEE Building
EI338: Computer Systems and Engineering (Computer Architecture & Operating Systems) Chentao Wu 吴晨涛 Associate Professor Dept. of Computer Science and Engineering Shanghai Jiao Tong University SEIEE Building
Computer Architecture
 Lecture 3: Pipelining Iakovos Mavroidis Computer Science Department University of Crete 1 Previous Lecture Measurements and metrics : Performance, Cost, Dependability, Power Guidelines and principles in
Lecture 3: Pipelining Iakovos Mavroidis Computer Science Department University of Crete 1 Previous Lecture Measurements and metrics : Performance, Cost, Dependability, Power Guidelines and principles in
ECE473 Computer Architecture and Organization. Pipeline: Control Hazard
 Computer Architecture and Organization Pipeline: Control Hazard Lecturer: Prof. Yifeng Zhu Fall, 2015 Portions of these slides are derived from: Dave Patterson UCB Lec 15.1 Pipelining Outline Introduction
Computer Architecture and Organization Pipeline: Control Hazard Lecturer: Prof. Yifeng Zhu Fall, 2015 Portions of these slides are derived from: Dave Patterson UCB Lec 15.1 Pipelining Outline Introduction
3/12/2014. Single Cycle (Review) CSE 2021: Computer Organization. Single Cycle with Jump. Multi-Cycle Implementation. Why Multi-Cycle?
 CSE 2021: Computer Organization. Single Cycle with Jump. Multi-Cycle Implementation. Why Multi-Cycle?") CSE 2021: Computer Organization Single Cycle (Review) Lecture-10b CPU Design : Pipelining-1 Overview, Datapath and control Shakil M. Khan 2 Single Cycle with Jump Multi-Cycle Implementation Instruction:
CSE 2021: Computer Organization Single Cycle (Review) Lecture-10b CPU Design : Pipelining-1 Overview, Datapath and control Shakil M. Khan 2 Single Cycle with Jump Multi-Cycle Implementation Instruction:
COMPUTER ORGANIZATION AND DESIGN. 5 th Edition. The Hardware/Software Interface. Chapter 4. The Processor
 COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle
ECE232: Hardware Organization and Design
 ECE232: Hardware Organization and Design Lecture 17: Pipelining Wrapup Adapted from Computer Organization and Design, Patterson & Hennessy, UCB Outline The textbook includes lots of information Focus on
ECE232: Hardware Organization and Design Lecture 17: Pipelining Wrapup Adapted from Computer Organization and Design, Patterson & Hennessy, UCB Outline The textbook includes lots of information Focus on
Unresolved data hazards. CS2504, Spring'2007 Dimitris Nikolopoulos
 Unresolved data hazards 81 Unresolved data hazards Arithmetic instructions following a load, and reading the register updated by the load: if (ID/EX.MemRead and ((ID/EX.RegisterRt = IF/ID.RegisterRs) or
Unresolved data hazards 81 Unresolved data hazards Arithmetic instructions following a load, and reading the register updated by the load: if (ID/EX.MemRead and ((ID/EX.RegisterRt = IF/ID.RegisterRs) or
Some material adapted from Mohamed Younis, UMBC CMSC 611 Spr 2003 course slides Some material adapted from Hennessy & Patterson / 2003 Elsevier
 Some material adapted from Mohamed Younis, UMBC CMSC 611 Spr 2003 course slides Some material adapted from Hennessy & Patterson / 2003 Elsevier Science Cases that affect instruction execution semantics
Some material adapted from Mohamed Younis, UMBC CMSC 611 Spr 2003 course slides Some material adapted from Hennessy & Patterson / 2003 Elsevier Science Cases that affect instruction execution semantics
Lecture 3: The Processor (Chapter 4 of textbook) Chapter 4.1
 Chapter 4.1") Lecture 3: The Processor (Chapter 4 of textbook) Chapter 4.1 Introduction Chapter 4.1 Chapter 4.2 Review: MIPS (RISC) Design Principles Simplicity favors regularity fixed size instructions small number
Lecture 3: The Processor (Chapter 4 of textbook) Chapter 4.1 Introduction Chapter 4.1 Chapter 4.2 Review: MIPS (RISC) Design Principles Simplicity favors regularity fixed size instructions small number
Lecture 2: Processor and Pipelining 1
 The Simple BIG Picture! Chapter 3 Additional Slides The Processor and Pipelining CENG 6332 2 Datapath vs Control Datapath signals Control Points Controller Datapath: Storage, FU, interconnect sufficient
The Simple BIG Picture! Chapter 3 Additional Slides The Processor and Pipelining CENG 6332 2 Datapath vs Control Datapath signals Control Points Controller Datapath: Storage, FU, interconnect sufficient
Instr. execution impl. view
 Pipelining Sangyeun Cho Computer Science Department Instr. execution impl. view Single (long) cycle implementation Multi-cycle implementation Pipelined implementation Processing an instruction Fetch instruction
Pipelining Sangyeun Cho Computer Science Department Instr. execution impl. view Single (long) cycle implementation Multi-cycle implementation Pipelined implementation Processing an instruction Fetch instruction
CISC 662 Graduate Computer Architecture Lecture 6 - Hazards
 CISC 662 Graduate Computer Architecture Lecture 6 - Hazards Michela Taufer http://www.cis.udel.edu/~taufer/teaching/cis662f07 Powerpoint Lecture Notes from John Hennessy and David Patterson s: Computer
CISC 662 Graduate Computer Architecture Lecture 6 - Hazards Michela Taufer http://www.cis.udel.edu/~taufer/teaching/cis662f07 Powerpoint Lecture Notes from John Hennessy and David Patterson s: Computer
Pipelining. CSC Friday, November 6, 2015
 Pipelining CSC 211.01 Friday, November 6, 2015 Performance Issues Longest delay determines clock period Critical path: load instruction Instruction memory register file ALU data memory register file Not
Pipelining CSC 211.01 Friday, November 6, 2015 Performance Issues Longest delay determines clock period Critical path: load instruction Instruction memory register file ALU data memory register file Not
Chapter 4. Instruction Execution. Introduction. CPU Overview. Multiplexers. Chapter 4 The Processor 1. The Processor.
 COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 4 The Processor The Processor - Introduction
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 4 The Processor The Processor - Introduction
Control Hazards - branching causes problems since the pipeline can be filled with the wrong instructions.
 Control Hazards - branching causes problems since the pipeline can be filled with the wrong instructions Stage Instruction Fetch Instruction Decode Execution / Effective addr Memory access Write-back Abbreviation
Control Hazards - branching causes problems since the pipeline can be filled with the wrong instructions Stage Instruction Fetch Instruction Decode Execution / Effective addr Memory access Write-back Abbreviation
COMPUTER ORGANIZATION AND DESIGN. 5 th Edition. The Hardware/Software Interface. Chapter 4. The Processor
 COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 4 The Processor COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition The Processor - Introduction
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 4 The Processor COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition The Processor - Introduction
Pipelining - Part 2. CSE Computer Systems October 19, 2001
 Pipelining - Part 2 CSE 410 - Computer Systems October 19, 2001 Readings and References Reading Sections 6.4 through 6.6, Patterson and Hennessy, Computer Organization & Design Other References 19-Oct-2001
Pipelining - Part 2 CSE 410 - Computer Systems October 19, 2001 Readings and References Reading Sections 6.4 through 6.6, Patterson and Hennessy, Computer Organization & Design Other References 19-Oct-2001
Control Hazards. Prediction
 Control Hazards The nub of the problem: In what pipeline stage does the processor fetch the next instruction? If that instruction is a conditional branch, when does the processor know whether the conditional
Control Hazards The nub of the problem: In what pipeline stage does the processor fetch the next instruction? If that instruction is a conditional branch, when does the processor know whether the conditional
Lecture 3. Pipelining. Dr. Soner Onder CS 4431 Michigan Technological University 9/23/2009 1
 Lecture 3 Pipelining Dr. Soner Onder CS 4431 Michigan Technological University 9/23/2009 1 A "Typical" RISC ISA 32-bit fixed format instruction (3 formats) 32 32-bit GPR (R0 contains zero, DP take pair)
Lecture 3 Pipelining Dr. Soner Onder CS 4431 Michigan Technological University 9/23/2009 1 A "Typical" RISC ISA 32-bit fixed format instruction (3 formats) 32 32-bit GPR (R0 contains zero, DP take pair)
LECTURE 10. Pipelining: Advanced ILP
 LECTURE 10 Pipelining: Advanced ILP EXCEPTIONS An exception, or interrupt, is an event other than regular transfers of control (branches, jumps, calls, returns) that changes the normal flow of instruction
LECTURE 10 Pipelining: Advanced ILP EXCEPTIONS An exception, or interrupt, is an event other than regular transfers of control (branches, jumps, calls, returns) that changes the normal flow of instruction
Instruction-Level Parallelism and Its Exploitation (Part III) ECE 154B Dmitri Strukov
 ECE 154B Dmitri Strukov") Instruction-Level Parallelism and Its Exploitation (Part III) ECE 154B Dmitri Strukov Dealing With Control Hazards Simplest solution to stall pipeline until branch is resolved and target address is calculated
Instruction-Level Parallelism and Its Exploitation (Part III) ECE 154B Dmitri Strukov Dealing With Control Hazards Simplest solution to stall pipeline until branch is resolved and target address is calculated
Modern Computer Architecture
 Modern Computer Architecture Lecture2 Pipelining: Basic and Intermediate Concepts Hongbin Sun 国家集成电路人才培养基地 Xi an Jiaotong University Pipelining: Its Natural! Laundry Example Ann, Brian, Cathy, Dave each
Modern Computer Architecture Lecture2 Pipelining: Basic and Intermediate Concepts Hongbin Sun 国家集成电路人才培养基地 Xi an Jiaotong University Pipelining: Its Natural! Laundry Example Ann, Brian, Cathy, Dave each
Control Hazards. Branch Prediction
 Control Hazards The nub of the problem: In what pipeline stage does the processor fetch the next instruction? If that instruction is a conditional branch, when does the processor know whether the conditional
Control Hazards The nub of the problem: In what pipeline stage does the processor fetch the next instruction? If that instruction is a conditional branch, when does the processor know whether the conditional
Advanced Parallel Architecture Lessons 5 and 6. Annalisa Massini /2017
 Advanced Parallel Architecture Lessons 5 and 6 Annalisa Massini - Pipelining Hennessy, Patterson Computer architecture A quantitive approach Appendix C Sections C.1, C.2 Pipelining Pipelining is an implementation
Advanced Parallel Architecture Lessons 5 and 6 Annalisa Massini - Pipelining Hennessy, Patterson Computer architecture A quantitive approach Appendix C Sections C.1, C.2 Pipelining Pipelining is an implementation
5 th Edition. The Processor We will examine two MIPS implementations A simplified version A more realistic pipelined version
 COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface Chapter 4 5 th Edition Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface Chapter 4 5 th Edition Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined
Homework 5. Start date: March 24 Due date: 11:59PM on April 10, Monday night. CSCI 402: Computer Architectures
 Homework 5 Start date: March 24 Due date: 11:59PM on April 10, Monday night 4.1.1, 4.1.2 4.3 4.8.1, 4.8.2 4.9.1-4.9.4 4.13.1 4.16.1, 4.16.2 1 CSCI 402: Computer Architectures The Processor (4) Fengguang
Homework 5 Start date: March 24 Due date: 11:59PM on April 10, Monday night 4.1.1, 4.1.2 4.3 4.8.1, 4.8.2 4.9.1-4.9.4 4.13.1 4.16.1, 4.16.2 1 CSCI 402: Computer Architectures The Processor (4) Fengguang
Chapter 4 The Processor (Part 4)
") Department of Electr rical Eng ineering, Chapter 4 The Processor (Part 4) 王振傑 (Chen-Chieh Wang) ccwang@mail.ee.ncku.edu.tw ncku edu Depar rtment of Electr rical Engineering, Feng-Chia Unive ersity Outline
Department of Electr rical Eng ineering, Chapter 4 The Processor (Part 4) 王振傑 (Chen-Chieh Wang) ccwang@mail.ee.ncku.edu.tw ncku edu Depar rtment of Electr rical Engineering, Feng-Chia Unive ersity Outline
CMCS Mohamed Younis CMCS 611, Advanced Computer Architecture 1
 CMCS 611-101 Advanced Computer Architecture Lecture 8 Control Hazards and Exception Handling September 30, 2009 www.csee.umbc.edu/~younis/cmsc611/cmsc611.htm Mohamed Younis CMCS 611, Advanced Computer
CMCS 611-101 Advanced Computer Architecture Lecture 8 Control Hazards and Exception Handling September 30, 2009 www.csee.umbc.edu/~younis/cmsc611/cmsc611.htm Mohamed Younis CMCS 611, Advanced Computer
Complex Pipelines and Branch Prediction
 Complex Pipelines and Branch Prediction Daniel Sanchez Computer Science & Artificial Intelligence Lab M.I.T. L22-1 Processor Performance Time Program Instructions Program Cycles Instruction CPI Time Cycle
Complex Pipelines and Branch Prediction Daniel Sanchez Computer Science & Artificial Intelligence Lab M.I.T. L22-1 Processor Performance Time Program Instructions Program Cycles Instruction CPI Time Cycle
(Refer Slide Time: 00:02:04)
") Computer Architecture Prof. Anshul Kumar Department of Computer Science and Engineering Indian Institute of Technology, Delhi Lecture - 27 Pipelined Processor Design: Handling Control Hazards We have been
Computer Architecture Prof. Anshul Kumar Department of Computer Science and Engineering Indian Institute of Technology, Delhi Lecture - 27 Pipelined Processor Design: Handling Control Hazards We have been
CS 61C: Great Ideas in Computer Architecture Pipelining and Hazards
 CS 61C: Great Ideas in Computer Architecture Pipelining and Hazards Instructors: Vladimir Stojanovic and Nicholas Weaver http://inst.eecs.berkeley.edu/~cs61c/sp16 1 Pipelined Execution Representation Time
CS 61C: Great Ideas in Computer Architecture Pipelining and Hazards Instructors: Vladimir Stojanovic and Nicholas Weaver http://inst.eecs.berkeley.edu/~cs61c/sp16 1 Pipelined Execution Representation Time
ECE331: Hardware Organization and Design
 ECE331: Hardware Organization and Design Lecture 27: Midterm2 review Adapted from Computer Organization and Design, Patterson & Hennessy, UCB Midterm 2 Review Midterm will cover Section 1.6: Processor
ECE331: Hardware Organization and Design Lecture 27: Midterm2 review Adapted from Computer Organization and Design, Patterson & Hennessy, UCB Midterm 2 Review Midterm will cover Section 1.6: Processor
Minimizing Data hazard Stalls by Forwarding Data Hazard Classification Data Hazards Present in Current MIPS Pipeline
 Instruction Pipelining Review: MIPS In-Order Single-Issue Integer Pipeline Performance of Pipelines with Stalls Pipeline Hazards Structural hazards Data hazards Minimizing Data hazard Stalls by Forwarding
Instruction Pipelining Review: MIPS In-Order Single-Issue Integer Pipeline Performance of Pipelines with Stalls Pipeline Hazards Structural hazards Data hazards Minimizing Data hazard Stalls by Forwarding
Instruction Pipelining Review
 Instruction Pipelining Review Instruction pipelining is CPU implementation technique where multiple operations on a number of instructions are overlapped. An instruction execution pipeline involves a number
Instruction Pipelining Review Instruction pipelining is CPU implementation technique where multiple operations on a number of instructions are overlapped. An instruction execution pipeline involves a number
ELE 655 Microprocessor System Design
 ELE 655 Microprocessor System Design Section 2 Instruction Level Parallelism Class 1 Basic Pipeline Notes: Reg shows up two places but actually is the same register file Writes occur on the second half
ELE 655 Microprocessor System Design Section 2 Instruction Level Parallelism Class 1 Basic Pipeline Notes: Reg shows up two places but actually is the same register file Writes occur on the second half
Instruction Level Parallelism. Appendix C and Chapter 3, HP5e
 Instruction Level Parallelism Appendix C and Chapter 3, HP5e Outline Pipelining, Hazards Branch prediction Static and Dynamic Scheduling Speculation Compiler techniques, VLIW Limits of ILP. Implementation
Instruction Level Parallelism Appendix C and Chapter 3, HP5e Outline Pipelining, Hazards Branch prediction Static and Dynamic Scheduling Speculation Compiler techniques, VLIW Limits of ILP. Implementation
ECEN 651: Microprogrammed Control of Digital Systems Department of Electrical and Computer Engineering Texas A&M University
 ECEN 651: Microprogrammed Control of Digital Systems Department of Electrical and Computer Engineering Texas A&M University Prof. Mi Lu TA: Ehsan Rohani Laboratory Exercise #8 Dynamic Branch Prediction
ECEN 651: Microprogrammed Control of Digital Systems Department of Electrical and Computer Engineering Texas A&M University Prof. Mi Lu TA: Ehsan Rohani Laboratory Exercise #8 Dynamic Branch Prediction
Processor (II) - pipelining. Hwansoo Han
 - pipelining. Hwansoo Han") Processor (II) - pipelining Hwansoo Han Pipelining Analogy Pipelined laundry: overlapping execution Parallelism improves performance Four loads: Speedup = 8/3.5 =2.3 Non-stop: 2n/0.5n + 1.5 4 = number
Processor (II) - pipelining Hwansoo Han Pipelining Analogy Pipelined laundry: overlapping execution Parallelism improves performance Four loads: Speedup = 8/3.5 =2.3 Non-stop: 2n/0.5n + 1.5 4 = number
What about branches? Branch outcomes are not known until EXE What are our options?
 What about branches? Branch outcomes are not known until EXE What are our options? 1 Control Hazards 2 Today Quiz Control Hazards Midterm review Return your papers 3 Key Points: Control Hazards Control
What about branches? Branch outcomes are not known until EXE What are our options? 1 Control Hazards 2 Today Quiz Control Hazards Midterm review Return your papers 3 Key Points: Control Hazards Control
Pipelining Analogy. Pipelined laundry: overlapping execution. Parallelism improves performance. Four loads: Non-stop: Speedup = 8/3.5 = 2.3.
 Pipelining Analogy Pipelined laundry: overlapping execution Parallelism improves performance Four loads: Speedup = 8/3.5 = 2.3 Non-stop: Speedup =2n/05n+15 2n/0.5n 1.5 4 = number of stages 4.5 An Overview
Pipelining Analogy Pipelined laundry: overlapping execution Parallelism improves performance Four loads: Speedup = 8/3.5 = 2.3 Non-stop: Speedup =2n/05n+15 2n/0.5n 1.5 4 = number of stages 4.5 An Overview
Instruction-Level Parallelism Dynamic Branch Prediction. Reducing Branch Penalties
 Instruction-Level Parallelism Dynamic Branch Prediction CS448 1 Reducing Branch Penalties Last chapter static schemes Move branch calculation earlier in pipeline Static branch prediction Always taken,
Instruction-Level Parallelism Dynamic Branch Prediction CS448 1 Reducing Branch Penalties Last chapter static schemes Move branch calculation earlier in pipeline Static branch prediction Always taken,
Full Datapath. Chapter 4 The Processor 2
 Pipelining Full Datapath Chapter 4 The Processor 2 Datapath With Control Chapter 4 The Processor 3 Performance Issues Longest delay determines clock period Critical path: load instruction Instruction memory
Pipelining Full Datapath Chapter 4 The Processor 2 Datapath With Control Chapter 4 The Processor 3 Performance Issues Longest delay determines clock period Critical path: load instruction Instruction memory
CS311 Lecture: Pipelining and Superscalar Architectures
 Objectives: CS311 Lecture: Pipelining and Superscalar Architectures Last revised July 10, 2013 1. To introduce the basic concept of CPU speedup 2. To explain how data and branch hazards arise as a result
Objectives: CS311 Lecture: Pipelining and Superscalar Architectures Last revised July 10, 2013 1. To introduce the basic concept of CPU speedup 2. To explain how data and branch hazards arise as a result
CSE Lecture 13/14 In Class Handout For all of these problems: HAS NOT CANNOT Add Add Add must wait until $5 written by previous add;
 CSE 30321 Lecture 13/14 In Class Handout For the sequence of instructions shown below, show how they would progress through the pipeline. For all of these problems: - Stalls are indicated by placing the
CSE 30321 Lecture 13/14 In Class Handout For the sequence of instructions shown below, show how they would progress through the pipeline. For all of these problems: - Stalls are indicated by placing the
ECE 486/586. Computer Architecture. Lecture # 12
 ECE 486/586 Computer Architecture Lecture # 12 Spring 2015 Portland State University Lecture Topics Pipelining Control Hazards Delayed branch Branch stall impact Implementing the pipeline Detecting hazards
ECE 486/586 Computer Architecture Lecture # 12 Spring 2015 Portland State University Lecture Topics Pipelining Control Hazards Delayed branch Branch stall impact Implementing the pipeline Detecting hazards
Suggested Readings! Recap: Pipelining improves throughput! Processor comparison! Lecture 17" Short Pipelining Review! ! Readings!
 1! 2! Suggested Readings!! Readings!! H&P: Chapter 4.5-4.7!! (Over the next 3-4 lectures)! Lecture 17" Short Pipelining Review! 3! Processor components! Multicore processors and programming! Recap: Pipelining
1! 2! Suggested Readings!! Readings!! H&P: Chapter 4.5-4.7!! (Over the next 3-4 lectures)! Lecture 17" Short Pipelining Review! 3! Processor components! Multicore processors and programming! Recap: Pipelining
Instruction Level Parallelism. ILP, Loop level Parallelism Dependences, Hazards Speculation, Branch prediction
 Instruction Level Parallelism ILP, Loop level Parallelism Dependences, Hazards Speculation, Branch prediction Basic Block A straight line code sequence with no branches in except to the entry and no branches
Instruction Level Parallelism ILP, Loop level Parallelism Dependences, Hazards Speculation, Branch prediction Basic Block A straight line code sequence with no branches in except to the entry and no branches
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition. Chapter 4. The Processor
 COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 4 The Processor The Processor? Chapter 4 The Processor 2 Introduction We will learn How the ISA determines many aspects
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 4 The Processor The Processor? Chapter 4 The Processor 2 Introduction We will learn How the ISA determines many aspects
ECE260: Fundamentals of Computer Engineering
 Pipelining James Moscola Dept. of Engineering & Computer Science York College of Pennsylvania Based on Computer Organization and Design, 5th Edition by Patterson & Hennessy What is Pipelining? Pipelining
Pipelining James Moscola Dept. of Engineering & Computer Science York College of Pennsylvania Based on Computer Organization and Design, 5th Edition by Patterson & Hennessy What is Pipelining? Pipelining
Assignment 1 solutions
 Assignment solutions. The jal instruction does a jump identical to the j instruction (i.e., replacing the low order 28 bits of the with the ress in the instruction) and also writes the value of the + 4
Assignment solutions. The jal instruction does a jump identical to the j instruction (i.e., replacing the low order 28 bits of the with the ress in the instruction) and also writes the value of the + 4
CS 110 Computer Architecture. Pipelining. Guest Lecture: Shu Yin. School of Information Science and Technology SIST
 CS 110 Computer Architecture Pipelining Guest Lecture: Shu Yin http://shtech.org/courses/ca/ School of Information Science and Technology SIST ShanghaiTech University Slides based on UC Berkley's CS61C
CS 110 Computer Architecture Pipelining Guest Lecture: Shu Yin http://shtech.org/courses/ca/ School of Information Science and Technology SIST ShanghaiTech University Slides based on UC Berkley's CS61C
ECE 4750 Computer Architecture, Fall 2017 T13 Advanced Processors: Branch Prediction
 ECE 4750 Computer Architecture, Fall 2017 T13 Advanced Processors: Branch Prediction School of Electrical and Computer Engineering Cornell University revision: 2017-11-20-08-48 1 Branch Prediction Overview
ECE 4750 Computer Architecture, Fall 2017 T13 Advanced Processors: Branch Prediction School of Electrical and Computer Engineering Cornell University revision: 2017-11-20-08-48 1 Branch Prediction Overview
Quiz 5 Mini project #1 solution Mini project #2 assigned Stalling recap Branches!
 Control Hazards 1 Today Quiz 5 Mini project #1 solution Mini project #2 assigned Stalling recap Branches! 2 Key Points: Control Hazards Control hazards occur when we don t know which instruction to execute
Control Hazards 1 Today Quiz 5 Mini project #1 solution Mini project #2 assigned Stalling recap Branches! 2 Key Points: Control Hazards Control hazards occur when we don t know which instruction to execute
CS 152 Computer Architecture and Engineering. Lecture 5 - Pipelining II (Branches, Exceptions)
") CS 152 Computer Architecture and Engineering Lecture 5 - Pipelining II (Branches, Exceptions) John Wawrzynek Electrical Engineering and Computer Sciences University of California at Berkeley http://www.eecs.berkeley.edu/~johnw
CS 152 Computer Architecture and Engineering Lecture 5 - Pipelining II (Branches, Exceptions) John Wawrzynek Electrical Engineering and Computer Sciences University of California at Berkeley http://www.eecs.berkeley.edu/~johnw
4. The Processor Computer Architecture COMP SCI 2GA3 / SFWR ENG 2GA3. Emil Sekerinski, McMaster University, Fall Term 2015/16
 4. The Processor Computer Architecture COMP SCI 2GA3 / SFWR ENG 2GA3 Emil Sekerinski, McMaster University, Fall Term 2015/16 Instruction Execution Consider simplified MIPS: lw/sw rt, offset(rs) add/sub/and/or/slt
4. The Processor Computer Architecture COMP SCI 2GA3 / SFWR ENG 2GA3 Emil Sekerinski, McMaster University, Fall Term 2015/16 Instruction Execution Consider simplified MIPS: lw/sw rt, offset(rs) add/sub/and/or/slt
Data Hazards Compiler Scheduling Pipeline scheduling or instruction scheduling: Compiler generates code to eliminate hazard
 Data Hazards Compiler Scheduling Pipeline scheduling or instruction scheduling: Compiler generates code to eliminate hazard Consider: a = b + c; d = e - f; Assume loads have a latency of one clock cycle:
Data Hazards Compiler Scheduling Pipeline scheduling or instruction scheduling: Compiler generates code to eliminate hazard Consider: a = b + c; d = e - f; Assume loads have a latency of one clock cycle:
EITF20: Computer Architecture Part2.2.1: Pipeline-1
 EITF20: Computer Architecture Part2.2.1: Pipeline-1 Liang Liu liang.liu@eit.lth.se 1 Outline Reiteration Pipelining Harzards Structural hazards Data hazards Control hazards Implementation issues Multi-cycle
EITF20: Computer Architecture Part2.2.1: Pipeline-1 Liang Liu liang.liu@eit.lth.se 1 Outline Reiteration Pipelining Harzards Structural hazards Data hazards Control hazards Implementation issues Multi-cycle
COSC121: Computer Systems. ISA and Performance
 COSC121: Computer Systems. ISA and Performance Jeremy Bolton, PhD Assistant Teaching Professor Constructed using materials: - Patt and Patel Introduction to Computing Systems (2nd) - Patterson and Hennessy
COSC121: Computer Systems. ISA and Performance Jeremy Bolton, PhD Assistant Teaching Professor Constructed using materials: - Patt and Patel Introduction to Computing Systems (2nd) - Patterson and Hennessy
COMPUTER ORGANIZATION AND DESIGN
 ARM COMPUTER ORGANIZATION AND DESIGN Edition The Hardware/Software Interface Chapter 4 The Processor Modified and extended by R.J. Leduc - 2016 To understand this chapter, you will need to understand some
ARM COMPUTER ORGANIZATION AND DESIGN Edition The Hardware/Software Interface Chapter 4 The Processor Modified and extended by R.J. Leduc - 2016 To understand this chapter, you will need to understand some
EITF20: Computer Architecture Part2.2.1: Pipeline-1
 EITF20: Computer Architecture Part2.2.1: Pipeline-1 Liang Liu liang.liu@eit.lth.se 1 Outline Reiteration Pipelining Harzards Structural hazards Data hazards Control hazards Implementation issues Multi-cycle
EITF20: Computer Architecture Part2.2.1: Pipeline-1 Liang Liu liang.liu@eit.lth.se 1 Outline Reiteration Pipelining Harzards Structural hazards Data hazards Control hazards Implementation issues Multi-cycle
Chapter 4. The Processor
 Chapter 4 The Processor Recall. ISA? Instruction Fetch Instruction Decode Operand Fetch Execute Result Store Next Instruction Instruction Format or Encoding how is it decoded? Location of operands and
Chapter 4 The Processor Recall. ISA? Instruction Fetch Instruction Decode Operand Fetch Execute Result Store Next Instruction Instruction Format or Encoding how is it decoded? Location of operands and
Some material adapted from Mohamed Younis, UMBC CMSC 611 Spr 2003 course slides Some material adapted from Hennessy & Patterson / 2003 Elsevier
 Some material adapted from Mohamed Younis, UMBC CMSC 611 Spr 2003 course slides Some material adapted from Hennessy & Patterson / 2003 Elsevier Science 6 PM 7 8 9 10 11 Midnight Time 30 40 20 30 40 20
Some material adapted from Mohamed Younis, UMBC CMSC 611 Spr 2003 course slides Some material adapted from Hennessy & Patterson / 2003 Elsevier Science 6 PM 7 8 9 10 11 Midnight Time 30 40 20 30 40 20
Orange Coast College. Business Division. Computer Science Department. CS 116- Computer Architecture. Pipelining
 Orange Coast College Business Division Computer Science Department CS 116- Computer Architecture Pipelining Recall Pipelining is parallelizing execution Key to speedups in processors Split instruction
Orange Coast College Business Division Computer Science Department CS 116- Computer Architecture Pipelining Recall Pipelining is parallelizing execution Key to speedups in processors Split instruction
COMPUTER ORGANIZATION AND DESIGN. 5 th Edition. The Hardware/Software Interface. Chapter 4. The Processor
 COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle
Quiz 5 Mini project #1 solution Mini project #2 assigned Stalling recap Branches!
 Control Hazards 1 Today Quiz 5 Mini project #1 solution Mini project #2 assigned Stalling recap Branches! 2 Key Points: Control Hazards Control hazards occur when we don t know which instruction to execute
Control Hazards 1 Today Quiz 5 Mini project #1 solution Mini project #2 assigned Stalling recap Branches! 2 Key Points: Control Hazards Control hazards occur when we don t know which instruction to execute
Multi-cycle Instructions in the Pipeline (Floating Point)
") Lecture 6 Multi-cycle Instructions in the Pipeline (Floating Point) Introduction to instruction level parallelism Recap: Support of multi-cycle instructions in a pipeline (App A.5) Recap: Superpipelining
Lecture 6 Multi-cycle Instructions in the Pipeline (Floating Point) Introduction to instruction level parallelism Recap: Support of multi-cycle instructions in a pipeline (App A.5) Recap: Superpipelining