GPU A rchitectures Architectures Patrick Neill May
|
|
|
- Zoe Owen
- 5 years ago
- Views:
Transcription
1 GPU Architectures Patrick Neill May 30, 2014
2 Outline CPU versus GPU CUDA GPU Why are they different? Terminology Kepler/Maxwell Graphics Tiled deferred rendering Opportunities What skills you should know

3 CPU - Evolution Problem to solve over time
4 CPU - Priorities Latency Event driven programming Managing complex control flow Branch prediction Speculative execution Reduction of memory/hd access Large caches Small collection of active threads Anything greater than dual core is generally overkill Less space devoted to math


5 GPU - Evolution Problems over time
6 GPU - Priorities Parallelization Work-loads related to games are massively parallel 4K = 3840x2180 ~60fps ~= 500M threads per sec! Latency Trade-off Sacrifices immediate access to data Allow advanced batching and scheduling of data Computation Less complex control flow, more math Most space devoted d to math With a smart thread scheduler to keep it busy
7 Evolution of Modern GPU Fixed function (Geforce 256, Radeon R100) Hardware T&L Render Output Units/ Raster Operations Pipeline (ROPs) Programmability (Geforce 2 -> >7) Vertex, Pixel Evolved with DirectX SM versions, CG Unification (Geforce 8) Generic compute units Geometry shader Generalization (Fermi, Kepler, AMD GCN) Queuing, batching, advanced scheduling Compute focused
8 Future CPU GPU HPC Simpler more power efficient Integration of components Software/language needs Generalization Power efficiency Fast interconnects Heterogeneous computing
9 Why do you care? Companies try to leverage IP Obviously biased (except me of course, you can trust me ) Understand what architectures are best for the problem you need to solve N-Body = GPU GUI = CPU
10 CUDA Compute Unified Device Architecture NVIDIA invented parallel language OpenCL is similar Turns off graphics oriented features Disables: rasterizer, input assembler, output merger Turns on compute oriented features LD/ST to generic buffers Support for advanced scheduling features


11 CUDA Constructs Thread ~Work item Block/CTA ~Work group Gid Grid ~Index space
12 CUDA Constructs Thread Per-thread local memory Warp = 32 threads Share through local memory Block/CTA = Group of warps Shared mem per CTA: inter-cta sync/communication Grid = Group of CTAs that share the same kernel Global mem for cross-cta communication Defined by user (compute) Reflect communication
13 Warp
14 Compute - Integration Utilize existing libraries cufft (10x faster) cublas (6-17x faster) cusparse (8x faster) Application integration DIY Matlab Mathematica CUDA OpenCL DirectX Compute Source:
15 Compute - Integration OpenACC #include <stdio.h> #define N int main(void) { double pi = 0.0f; 0f; long i; #pragma acc region for for (i=0; i<n; i++) { double t= (double)((i+0.5)/n); pi +=4.0/(1.0+t*t); } } printf("pi=%16.15f\n",pi/n); return 0; cufft #define NX 64 #define NY 64 #define NZ 128 cuffthandle plan; cufftcomplex *data1 data1, *data2; cudamalloc((void**)&data1, sizeof(cufftcomplex)*nx*ny*nz); cudamalloc((void**)&data2, sizeof(cufftcomplex)*nx*ny*nz); /* Create a 3D FFT plan. */ cufftplan3d(&plan, NX, NY, NZ, CUFFT_C2C); /* Transform the first signal in place. */ cufftexecc2c(plan, data1, data1, CUFFT_FORWARD); /* Transform the second signal using the same plan. */ cufftexecc2c(plan, data2, data2, CUFFT_FORWARD); /* Destroy the cufft plan. */ cufftdestroy(plan); cudafree(data1); cudafree(data2);


16 Dynamic Parallelism Dynamic Parallelism Allow the GPU to create work for itself Remove CPU -> GPU sync points
17 Dynamic Parallelism
18 Why do you care? Constructs reflect: Warps Communication boundaries Read/write coherency Low level primitive HW operates on Blocks/CTAs are made up of integer # of warps AMD/Intel HPC chips are similar Use existing libraries Don t reinvent the wheel
19 GPU Yesterday Geforce 3 Source:
20 Kepler GK110




21 Kepler GPC Similar to a CPU core Stamp out for scaling Contains multiple SMXs Graphics Features Polymorph Engine Raster Engine Independent execution Compute Features Independent Kernels ~CTA (work group)




22 Kepler SMX Schedule threads efficiently Maximize Utilization 192 CUDA Cores 64 DP units 32 SFU 32 LD/ST Perfect utilization? 320 threads available per clock





23 Kepler Scheduler




24 Maxwell GM107



25 Maxwell GPC 5 SMMs per GPC Kepler had 2 SMXs ~90% perf of SMX But *much* smaller More power efficient Scheduling changes


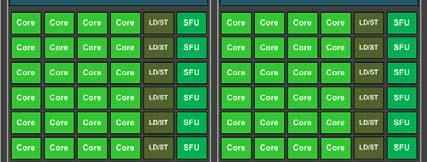






26 Maxwell GPC
27 Maxwell SMM Schedule threads efficiently Maximize Utilization 128 CUDA Cores 32 SFU 32 LD/ST Warps scheduling Each scheduler owns cores Own instruction buffer Still 2x dispatch unit
28 Maxwell Utilization Avoid Divergence! Shuffle your program to avoid divergence within a warp Size of CTA matters! Programmer thinks in CTAs, HW operates on warps CTA size 48 threads 32 thread warp architecture 48/32 = 1.5 warps, second warp is partially occupied Scheduler 2 dispatch units need two independent inst per warp Series of dependent instructions = Poor utilization
29 Maxwell Utilization Latency Memory access - ~10 cycles -> 800 cycles Cuda cores take a few cycles to complete Contention for limited resources 64K regs/sm * SM / 64 Warps * Warp / 32 Threads 32 regs/thread before # of warps/sm decrease High # of warps vital for high utilization Balance work-load Tex versus FP versus SFU versus LD/ST Avoid peak utilization of any one unit
 8.1 TFLOPs (10 TFLOPs boost) Intel Xeon E5-2690 371 GFLOPs (AVX) XBox One PS4 1.32 TFLOPs 1.")
30 Kepler SMX Each CUDA Core can do FMA = 2 FLOP 192 CUDA Cores per SMX, 15x2 SMX (Titan Z) FLOP/clock 705 Mhz (876 Mhz boost) 8.1 TFLOPs (10 TFLOPs boost) Intel Xeon E GFLOPs (AVX) XBox One PS TFLOPs 1.84 TFLOPs
31 Infiltrator Demo Tiled deferred shading Temporal anti-aliasing Tessellation and Displacement Millions of particles, colliding/lit by the environment Physically based materials/lighting (static GI)
32 Deferred shading Render to G-Buffer Material Normal Depth Defer shading Wait until all objects are rendered Use pixel position plus G-Buffer Shading done exactly once per pixel
33 Deferred shading
 + pixel pos Fetch list of lights hitting tile containing pixel Iterate")
34 Tiled Deferred Shading Render to G-Buffer (Materials, Normal, Depth) per pixel Segment screen into tiles (think parallel) DICE 2011 GDC presentation Compute light-tile intersection Output culled light list to buffer Perform per pixel light pass (Materials,Normal,Depth) + pixel pos Fetch list of lights hitting tile containing pixel Iterate + Light
35 Tiled Deferred Shading
36 Opportunities NVIDIA/AMD/Intel (Samsung/Qualcomm/Apple) Strong C/C++ Strong OS/Algorithms fundamentals Parallel Programming w/ emphasis on Performance Compiler experience a plus Graphics knowledge a plus Other industries Games Industry Seismic Processing Biochemistry simulations Weather/climate modeling CAD
37 Questions?
GPU ARCHITECTURE Chris Schultz, June 2017
 GPU ARCHITECTURE Chris Schultz, June 2017 MISC All of the opinions expressed in this presentation are my own and do not reflect any held by NVIDIA 2 OUTLINE CPU versus GPU Why are they different? CUDA
GPU ARCHITECTURE Chris Schultz, June 2017 MISC All of the opinions expressed in this presentation are my own and do not reflect any held by NVIDIA 2 OUTLINE CPU versus GPU Why are they different? CUDA
GPU ARCHITECTURE Chris Schultz, June 2017
 Chris Schultz, June 2017 MISC All of the opinions expressed in this presentation are my own and do not reflect any held by NVIDIA 2 OUTLINE Problems Solved Over Time versus Why are they different? Complex
Chris Schultz, June 2017 MISC All of the opinions expressed in this presentation are my own and do not reflect any held by NVIDIA 2 OUTLINE Problems Solved Over Time versus Why are they different? Complex
CS GPU and GPGPU Programming Lecture 8+9: GPU Architecture 7+8. Markus Hadwiger, KAUST
 CS 380 - GPU and GPGPU Programming Lecture 8+9: GPU Architecture 7+8 Markus Hadwiger, KAUST Reading Assignment #5 (until March 12) Read (required): Programming Massively Parallel Processors book, Chapter
CS 380 - GPU and GPGPU Programming Lecture 8+9: GPU Architecture 7+8 Markus Hadwiger, KAUST Reading Assignment #5 (until March 12) Read (required): Programming Massively Parallel Processors book, Chapter
GRAPHICS PROCESSING UNITS
 GRAPHICS PROCESSING UNITS Slides by: Pedro Tomás Additional reading: Computer Architecture: A Quantitative Approach, 5th edition, Chapter 4, John L. Hennessy and David A. Patterson, Morgan Kaufmann, 2011
GRAPHICS PROCESSING UNITS Slides by: Pedro Tomás Additional reading: Computer Architecture: A Quantitative Approach, 5th edition, Chapter 4, John L. Hennessy and David A. Patterson, Morgan Kaufmann, 2011
CUDA. Matthew Joyner, Jeremy Williams
 CUDA Matthew Joyner, Jeremy Williams Agenda What is CUDA? CUDA GPU Architecture CPU/GPU Communication Coding in CUDA Use cases of CUDA Comparison to OpenCL What is CUDA? What is CUDA? CUDA is a parallel
CUDA Matthew Joyner, Jeremy Williams Agenda What is CUDA? CUDA GPU Architecture CPU/GPU Communication Coding in CUDA Use cases of CUDA Comparison to OpenCL What is CUDA? What is CUDA? CUDA is a parallel
Antonio R. Miele Marco D. Santambrogio
 Advanced Topics on Heterogeneous System Architectures GPU Politecnico di Milano Seminar Room A. Alario 18 November, 2015 Antonio R. Miele Marco D. Santambrogio Politecnico di Milano 2 Introduction First
Advanced Topics on Heterogeneous System Architectures GPU Politecnico di Milano Seminar Room A. Alario 18 November, 2015 Antonio R. Miele Marco D. Santambrogio Politecnico di Milano 2 Introduction First
Threading Hardware in G80
 ing Hardware in G80 1 Sources Slides by ECE 498 AL : Programming Massively Parallel Processors : Wen-Mei Hwu John Nickolls, NVIDIA 2 3D 3D API: API: OpenGL OpenGL or or Direct3D Direct3D GPU Command &
ing Hardware in G80 1 Sources Slides by ECE 498 AL : Programming Massively Parallel Processors : Wen-Mei Hwu John Nickolls, NVIDIA 2 3D 3D API: API: OpenGL OpenGL or or Direct3D Direct3D GPU Command &
CS427 Multicore Architecture and Parallel Computing
 CS427 Multicore Architecture and Parallel Computing Lecture 6 GPU Architecture Li Jiang 2014/10/9 1 GPU Scaling A quiet revolution and potential build-up Calculation: 936 GFLOPS vs. 102 GFLOPS Memory Bandwidth:
CS427 Multicore Architecture and Parallel Computing Lecture 6 GPU Architecture Li Jiang 2014/10/9 1 GPU Scaling A quiet revolution and potential build-up Calculation: 936 GFLOPS vs. 102 GFLOPS Memory Bandwidth:
Portland State University ECE 588/688. Graphics Processors
 Portland State University ECE 588/688 Graphics Processors Copyright by Alaa Alameldeen 2018 Why Graphics Processors? Graphics programs have different characteristics from general purpose programs Highly
Portland State University ECE 588/688 Graphics Processors Copyright by Alaa Alameldeen 2018 Why Graphics Processors? Graphics programs have different characteristics from general purpose programs Highly
Graphics Hardware. Graphics Processing Unit (GPU) is a Subsidiary hardware. With massively multi-threaded many-core. Dedicated to 2D and 3D graphics
 is a Subsidiary hardware. With massively multi-threaded many-core. Dedicated to 2D and 3D graphics") Why GPU? Chapter 1 Graphics Hardware Graphics Processing Unit (GPU) is a Subsidiary hardware With massively multi-threaded many-core Dedicated to 2D and 3D graphics Special purpose low functionality, high
Why GPU? Chapter 1 Graphics Hardware Graphics Processing Unit (GPU) is a Subsidiary hardware With massively multi-threaded many-core Dedicated to 2D and 3D graphics Special purpose low functionality, high
Mattan Erez. The University of Texas at Austin
 EE382V (17325): Principles in Computer Architecture Parallelism and Locality Fall 2007 Lecture 12 GPU Architecture (NVIDIA G80) Mattan Erez The University of Texas at Austin Outline 3D graphics recap and
EE382V (17325): Principles in Computer Architecture Parallelism and Locality Fall 2007 Lecture 12 GPU Architecture (NVIDIA G80) Mattan Erez The University of Texas at Austin Outline 3D graphics recap and
Selecting the right Tesla/GTX GPU from a Drunken Baker's Dozen
 Selecting the right Tesla/GTX GPU from a Drunken Baker's Dozen GPU Computing Applications Here's what Nvidia says its Tesla K20(X) card excels at doing - Seismic processing, CFD, CAE, Financial computing,
Selecting the right Tesla/GTX GPU from a Drunken Baker's Dozen GPU Computing Applications Here's what Nvidia says its Tesla K20(X) card excels at doing - Seismic processing, CFD, CAE, Financial computing,
TUNING CUDA APPLICATIONS FOR MAXWELL
 TUNING CUDA APPLICATIONS FOR MAXWELL DA-07173-001_v6.5 August 2014 Application Note TABLE OF CONTENTS Chapter 1. Maxwell Tuning Guide... 1 1.1. NVIDIA Maxwell Compute Architecture... 1 1.2. CUDA Best Practices...2
TUNING CUDA APPLICATIONS FOR MAXWELL DA-07173-001_v6.5 August 2014 Application Note TABLE OF CONTENTS Chapter 1. Maxwell Tuning Guide... 1 1.1. NVIDIA Maxwell Compute Architecture... 1 1.2. CUDA Best Practices...2
CSCI 402: Computer Architectures. Parallel Processors (2) Fengguang Song Department of Computer & Information Science IUPUI.
 Fengguang Song Department of Computer & Information Science IUPUI.") CSCI 402: Computer Architectures Parallel Processors (2) Fengguang Song Department of Computer & Information Science IUPUI 6.6 - End Today s Contents GPU Cluster and its network topology The Roofline performance
CSCI 402: Computer Architectures Parallel Processors (2) Fengguang Song Department of Computer & Information Science IUPUI 6.6 - End Today s Contents GPU Cluster and its network topology The Roofline performance
1. Introduction 2. Methods for I/O Operations 3. Buses 4. Liquid Crystal Displays 5. Other Types of Displays 6. Graphics Adapters 7.
 1. Introduction 2. Methods for I/O Operations 3. Buses 4. Liquid Crystal Displays 5. Other Types of Displays 6. Graphics Adapters 7. Optical Discs 1 Structure of a Graphics Adapter Video Memory Graphics
1. Introduction 2. Methods for I/O Operations 3. Buses 4. Liquid Crystal Displays 5. Other Types of Displays 6. Graphics Adapters 7. Optical Discs 1 Structure of a Graphics Adapter Video Memory Graphics
Lecture 15: Introduction to GPU programming. Lecture 15: Introduction to GPU programming p. 1
 Lecture 15: Introduction to GPU programming Lecture 15: Introduction to GPU programming p. 1 Overview Hardware features of GPGPU Principles of GPU programming A good reference: David B. Kirk and Wen-mei
Lecture 15: Introduction to GPU programming Lecture 15: Introduction to GPU programming p. 1 Overview Hardware features of GPGPU Principles of GPU programming A good reference: David B. Kirk and Wen-mei
CSC573: TSHA Introduction to Accelerators
 CSC573: TSHA Introduction to Accelerators Sreepathi Pai September 5, 2017 URCS Outline Introduction to Accelerators GPU Architectures GPU Programming Models Outline Introduction to Accelerators GPU Architectures
CSC573: TSHA Introduction to Accelerators Sreepathi Pai September 5, 2017 URCS Outline Introduction to Accelerators GPU Architectures GPU Programming Models Outline Introduction to Accelerators GPU Architectures
Fundamental CUDA Optimization. NVIDIA Corporation
 Fundamental CUDA Optimization NVIDIA Corporation Outline Fermi/Kepler Architecture Kernel optimizations Launch configuration Global memory throughput Shared memory access Instruction throughput / control
Fundamental CUDA Optimization NVIDIA Corporation Outline Fermi/Kepler Architecture Kernel optimizations Launch configuration Global memory throughput Shared memory access Instruction throughput / control
TUNING CUDA APPLICATIONS FOR MAXWELL
 TUNING CUDA APPLICATIONS FOR MAXWELL DA-07173-001_v7.0 March 2015 Application Note TABLE OF CONTENTS Chapter 1. Maxwell Tuning Guide... 1 1.1. NVIDIA Maxwell Compute Architecture... 1 1.2. CUDA Best Practices...2
TUNING CUDA APPLICATIONS FOR MAXWELL DA-07173-001_v7.0 March 2015 Application Note TABLE OF CONTENTS Chapter 1. Maxwell Tuning Guide... 1 1.1. NVIDIA Maxwell Compute Architecture... 1 1.2. CUDA Best Practices...2
NVIDIA GTX200: TeraFLOPS Visual Computing. August 26, 2008 John Tynefield
 NVIDIA GTX200: TeraFLOPS Visual Computing August 26, 2008 John Tynefield 2 Outline Execution Model Architecture Demo 3 Execution Model 4 Software Architecture Applications DX10 OpenGL OpenCL CUDA C Host
NVIDIA GTX200: TeraFLOPS Visual Computing August 26, 2008 John Tynefield 2 Outline Execution Model Architecture Demo 3 Execution Model 4 Software Architecture Applications DX10 OpenGL OpenCL CUDA C Host
What is GPU? CS 590: High Performance Computing. GPU Architectures and CUDA Concepts/Terms
 CS 590: High Performance Computing GPU Architectures and CUDA Concepts/Terms Fengguang Song Department of Computer & Information Science IUPUI What is GPU? Conventional GPUs are used to generate 2D, 3D
CS 590: High Performance Computing GPU Architectures and CUDA Concepts/Terms Fengguang Song Department of Computer & Information Science IUPUI What is GPU? Conventional GPUs are used to generate 2D, 3D
CSE 591: GPU Programming. Introduction. Entertainment Graphics: Virtual Realism for the Masses. Computer games need to have: Klaus Mueller
 Entertainment Graphics: Virtual Realism for the Masses CSE 591: GPU Programming Introduction Computer games need to have: realistic appearance of characters and objects believable and creative shading,
Entertainment Graphics: Virtual Realism for the Masses CSE 591: GPU Programming Introduction Computer games need to have: realistic appearance of characters and objects believable and creative shading,
EE382N (20): Computer Architecture - Parallelism and Locality Spring 2015 Lecture 09 GPUs (II) Mattan Erez. The University of Texas at Austin
: Computer Architecture - Parallelism and Locality Spring 2015 Lecture 09 GPUs (II) Mattan Erez. The University of Texas at Austin") EE382 (20): Computer Architecture - ism and Locality Spring 2015 Lecture 09 GPUs (II) Mattan Erez The University of Texas at Austin 1 Recap 2 Streaming model 1. Use many slimmed down cores to run in parallel
EE382 (20): Computer Architecture - ism and Locality Spring 2015 Lecture 09 GPUs (II) Mattan Erez The University of Texas at Austin 1 Recap 2 Streaming model 1. Use many slimmed down cores to run in parallel
GPU Basics. Introduction to GPU. S. Sundar and M. Panchatcharam. GPU Basics. S. Sundar & M. Panchatcharam. Super Computing GPU.
 Basics of s Basics Introduction to Why vs CPU S. Sundar and Computing architecture August 9, 2014 1 / 70 Outline Basics of s Why vs CPU Computing architecture 1 2 3 of s 4 5 Why 6 vs CPU 7 Computing 8
Basics of s Basics Introduction to Why vs CPU S. Sundar and Computing architecture August 9, 2014 1 / 70 Outline Basics of s Why vs CPU Computing architecture 1 2 3 of s 4 5 Why 6 vs CPU 7 Computing 8
CME 213 S PRING Eric Darve
 CME 213 S PRING 2017 Eric Darve Summary of previous lectures Pthreads: low-level multi-threaded programming OpenMP: simplified interface based on #pragma, adapted to scientific computing OpenMP for and
CME 213 S PRING 2017 Eric Darve Summary of previous lectures Pthreads: low-level multi-threaded programming OpenMP: simplified interface based on #pragma, adapted to scientific computing OpenMP for and
Technology for a better society. hetcomp.com
 Technology for a better society hetcomp.com 1 J. Seland, C. Dyken, T. R. Hagen, A. R. Brodtkorb, J. Hjelmervik,E Bjønnes GPU Computing USIT Course Week 16th November 2011 hetcomp.com 2 9:30 10:15 Introduction
Technology for a better society hetcomp.com 1 J. Seland, C. Dyken, T. R. Hagen, A. R. Brodtkorb, J. Hjelmervik,E Bjønnes GPU Computing USIT Course Week 16th November 2011 hetcomp.com 2 9:30 10:15 Introduction
CSE 591/392: GPU Programming. Introduction. Klaus Mueller. Computer Science Department Stony Brook University
 CSE 591/392: GPU Programming Introduction Klaus Mueller Computer Science Department Stony Brook University First: A Big Word of Thanks! to the millions of computer game enthusiasts worldwide Who demand
CSE 591/392: GPU Programming Introduction Klaus Mueller Computer Science Department Stony Brook University First: A Big Word of Thanks! to the millions of computer game enthusiasts worldwide Who demand
HiPANQ Overview of NVIDIA GPU Architecture and Introduction to CUDA/OpenCL Programming, and Parallelization of LDPC codes.
 HiPANQ Overview of NVIDIA GPU Architecture and Introduction to CUDA/OpenCL Programming, and Parallelization of LDPC codes Ian Glendinning Outline NVIDIA GPU cards CUDA & OpenCL Parallel Implementation
HiPANQ Overview of NVIDIA GPU Architecture and Introduction to CUDA/OpenCL Programming, and Parallelization of LDPC codes Ian Glendinning Outline NVIDIA GPU cards CUDA & OpenCL Parallel Implementation
Challenges for GPU Architecture. Michael Doggett Graphics Architecture Group April 2, 2008
 Michael Doggett Graphics Architecture Group April 2, 2008 Graphics Processing Unit Architecture CPUs vsgpus AMD s ATI RADEON 2900 Programming Brook+, CAL, ShaderAnalyzer Architecture Challenges Accelerated
Michael Doggett Graphics Architecture Group April 2, 2008 Graphics Processing Unit Architecture CPUs vsgpus AMD s ATI RADEON 2900 Programming Brook+, CAL, ShaderAnalyzer Architecture Challenges Accelerated
Introduction to CUDA (1 of n*)
") Agenda Introduction to CUDA (1 of n*) GPU architecture review CUDA First of two or three dedicated classes Joseph Kider University of Pennsylvania CIS 565 - Spring 2011 * Where n is 2 or 3 Acknowledgements
Agenda Introduction to CUDA (1 of n*) GPU architecture review CUDA First of two or three dedicated classes Joseph Kider University of Pennsylvania CIS 565 - Spring 2011 * Where n is 2 or 3 Acknowledgements
Hybrid KAUST Many Cores and OpenACC. Alain Clo - KAUST Research Computing Saber Feki KAUST Supercomputing Lab Florent Lebeau - CAPS
 + Hybrid Computing @ KAUST Many Cores and OpenACC Alain Clo - KAUST Research Computing Saber Feki KAUST Supercomputing Lab Florent Lebeau - CAPS + Agenda Hybrid Computing n Hybrid Computing n From Multi-Physics
+ Hybrid Computing @ KAUST Many Cores and OpenACC Alain Clo - KAUST Research Computing Saber Feki KAUST Supercomputing Lab Florent Lebeau - CAPS + Agenda Hybrid Computing n Hybrid Computing n From Multi-Physics
The NVIDIA GeForce 8800 GPU
 The NVIDIA GeForce 8800 GPU August 2007 Erik Lindholm / Stuart Oberman Outline GeForce 8800 Architecture Overview Streaming Processor Array Streaming Multiprocessor Texture ROP: Raster Operation Pipeline
The NVIDIA GeForce 8800 GPU August 2007 Erik Lindholm / Stuart Oberman Outline GeForce 8800 Architecture Overview Streaming Processor Array Streaming Multiprocessor Texture ROP: Raster Operation Pipeline
Architectures. Michael Doggett Department of Computer Science Lund University 2009 Tomas Akenine-Möller and Michael Doggett 1
 Architectures Michael Doggett Department of Computer Science Lund University 2009 Tomas Akenine-Möller and Michael Doggett 1 Overview of today s lecture The idea is to cover some of the existing graphics
Architectures Michael Doggett Department of Computer Science Lund University 2009 Tomas Akenine-Möller and Michael Doggett 1 Overview of today s lecture The idea is to cover some of the existing graphics
Persistent RNNs. (stashing recurrent weights on-chip) Gregory Diamos. April 7, Baidu SVAIL
 Gregory Diamos. April 7, Baidu SVAIL") (stashing recurrent weights on-chip) Baidu SVAIL April 7, 2016 SVAIL Think hard AI. Goal Develop hard AI technologies that impact 100 million users. Deep Learning at SVAIL 100 GFLOP/s 1 laptop 6 TFLOP/s
(stashing recurrent weights on-chip) Baidu SVAIL April 7, 2016 SVAIL Think hard AI. Goal Develop hard AI technologies that impact 100 million users. Deep Learning at SVAIL 100 GFLOP/s 1 laptop 6 TFLOP/s
ASYNCHRONOUS SHADERS WHITE PAPER 0
 ASYNCHRONOUS SHADERS WHITE PAPER 0 INTRODUCTION GPU technology is constantly evolving to deliver more performance with lower cost and lower power consumption. Transistor scaling and Moore s Law have helped
ASYNCHRONOUS SHADERS WHITE PAPER 0 INTRODUCTION GPU technology is constantly evolving to deliver more performance with lower cost and lower power consumption. Transistor scaling and Moore s Law have helped
GPU! Advanced Topics on Heterogeneous System Architectures. Politecnico di Milano! Seminar Room, Bld 20! 11 December, 2017!
 Advanced Topics on Heterogeneous System Architectures GPU! Politecnico di Milano! Seminar Room, Bld 20! 11 December, 2017! Antonio R. Miele! Marco D. Santambrogio! Politecnico di Milano! 2 Introduction!
Advanced Topics on Heterogeneous System Architectures GPU! Politecnico di Milano! Seminar Room, Bld 20! 11 December, 2017! Antonio R. Miele! Marco D. Santambrogio! Politecnico di Milano! 2 Introduction!
ADVANCES IN EXTREME-SCALE APPLICATIONS ON GPU. Peng Wang HPC Developer Technology
 ADVANCES IN EXTREME-SCALE APPLICATIONS ON GPU Peng Wang HPC Developer Technology NVIDIA SuperPhones to SuperComputers Computers no longer get faster, just wider Architectural Features Common to All Processors
ADVANCES IN EXTREME-SCALE APPLICATIONS ON GPU Peng Wang HPC Developer Technology NVIDIA SuperPhones to SuperComputers Computers no longer get faster, just wider Architectural Features Common to All Processors
Introduction to Modern GPU Hardware
 The following content are extracted from the material in the references on last page. If any wrong citation or reference missing, please contact ldvan@cs.nctu.edu.tw. I will correct the error asap. This
The following content are extracted from the material in the references on last page. If any wrong citation or reference missing, please contact ldvan@cs.nctu.edu.tw. I will correct the error asap. This
Accelerator cards are typically PCIx cards that supplement a host processor, which they require to operate Today, the most common accelerators include
 3.1 Overview Accelerator cards are typically PCIx cards that supplement a host processor, which they require to operate Today, the most common accelerators include GPUs (Graphics Processing Units) AMD/ATI
3.1 Overview Accelerator cards are typically PCIx cards that supplement a host processor, which they require to operate Today, the most common accelerators include GPUs (Graphics Processing Units) AMD/ATI
Introduction to Multicore architecture. Tao Zhang Oct. 21, 2010
 Introduction to Multicore architecture Tao Zhang Oct. 21, 2010 Overview Part1: General multicore architecture Part2: GPU architecture Part1: General Multicore architecture Uniprocessor Performance (ECint)
Introduction to Multicore architecture Tao Zhang Oct. 21, 2010 Overview Part1: General multicore architecture Part2: GPU architecture Part1: General Multicore architecture Uniprocessor Performance (ECint)
CS 179 Lecture 4. GPU Compute Architecture
 CS 179 Lecture 4 GPU Compute Architecture 1 This is my first lecture ever Tell me if I m not speaking loud enough, going too fast/slow, etc. Also feel free to give me lecture feedback over email or at
CS 179 Lecture 4 GPU Compute Architecture 1 This is my first lecture ever Tell me if I m not speaking loud enough, going too fast/slow, etc. Also feel free to give me lecture feedback over email or at
Spring 2009 Prof. Hyesoon Kim
 Spring 2009 Prof. Hyesoon Kim Application Geometry Rasterizer CPU Each stage cane be also pipelined The slowest of the pipeline stage determines the rendering speed. Frames per second (fps) Executes on
Spring 2009 Prof. Hyesoon Kim Application Geometry Rasterizer CPU Each stage cane be also pipelined The slowest of the pipeline stage determines the rendering speed. Frames per second (fps) Executes on
CSCI-GA Graphics Processing Units (GPUs): Architecture and Programming Lecture 2: Hardware Perspective of GPUs
: Architecture and Programming Lecture 2: Hardware Perspective of GPUs") CSCI-GA.3033-004 Graphics Processing Units (GPUs): Architecture and Programming Lecture 2: Hardware Perspective of GPUs Mohamed Zahran (aka Z) mzahran@cs.nyu.edu http://www.mzahran.com History of GPUs
CSCI-GA.3033-004 Graphics Processing Units (GPUs): Architecture and Programming Lecture 2: Hardware Perspective of GPUs Mohamed Zahran (aka Z) mzahran@cs.nyu.edu http://www.mzahran.com History of GPUs
Windowing System on a 3D Pipeline. February 2005
 Windowing System on a 3D Pipeline February 2005 Agenda 1.Overview of the 3D pipeline 2.NVIDIA software overview 3.Strengths and challenges with using the 3D pipeline GeForce 6800 220M Transistors April
Windowing System on a 3D Pipeline February 2005 Agenda 1.Overview of the 3D pipeline 2.NVIDIA software overview 3.Strengths and challenges with using the 3D pipeline GeForce 6800 220M Transistors April
GPGPUs in HPC. VILLE TIMONEN Åbo Akademi University CSC
 GPGPUs in HPC VILLE TIMONEN Åbo Akademi University 2.11.2010 @ CSC Content Background How do GPUs pull off higher throughput Typical architecture Current situation & the future GPGPU languages A tale of
GPGPUs in HPC VILLE TIMONEN Åbo Akademi University 2.11.2010 @ CSC Content Background How do GPUs pull off higher throughput Typical architecture Current situation & the future GPGPU languages A tale of
Efficient and Scalable Shading for Many Lights
 Efficient and Scalable Shading for Many Lights 1. GPU Overview 2. Shading recap 3. Forward Shading 4. Deferred Shading 5. Tiled Deferred Shading 6. And more! First GPU Shaders Unified Shaders CUDA OpenCL
Efficient and Scalable Shading for Many Lights 1. GPU Overview 2. Shading recap 3. Forward Shading 4. Deferred Shading 5. Tiled Deferred Shading 6. And more! First GPU Shaders Unified Shaders CUDA OpenCL
CS 179: GPU Computing LECTURE 4: GPU MEMORY SYSTEMS
 CS 179: GPU Computing LECTURE 4: GPU MEMORY SYSTEMS 1 Last time Each block is assigned to and executed on a single streaming multiprocessor (SM). Threads execute in groups of 32 called warps. Threads in
CS 179: GPU Computing LECTURE 4: GPU MEMORY SYSTEMS 1 Last time Each block is assigned to and executed on a single streaming multiprocessor (SM). Threads execute in groups of 32 called warps. Threads in
Technical Report on IEIIT-CNR
 Technical Report on Architectural Evolution of NVIDIA GPUs for High-Performance Computing (IEIIT-CNR-150212) Angelo Corana (Decision Support Methods and Models Group) IEIIT-CNR Istituto di Elettronica
Technical Report on Architectural Evolution of NVIDIA GPUs for High-Performance Computing (IEIIT-CNR-150212) Angelo Corana (Decision Support Methods and Models Group) IEIIT-CNR Istituto di Elettronica
Graphics Processing Unit Architecture (GPU Arch)
") Graphics Processing Unit Architecture (GPU Arch) With a focus on NVIDIA GeForce 6800 GPU 1 What is a GPU From Wikipedia : A specialized processor efficient at manipulating and displaying computer graphics
Graphics Processing Unit Architecture (GPU Arch) With a focus on NVIDIA GeForce 6800 GPU 1 What is a GPU From Wikipedia : A specialized processor efficient at manipulating and displaying computer graphics
CUDA PROGRAMMING MODEL Chaithanya Gadiyam Swapnil S Jadhav
 CUDA PROGRAMMING MODEL Chaithanya Gadiyam Swapnil S Jadhav CMPE655 - Multiple Processor Systems Fall 2015 Rochester Institute of Technology Contents What is GPGPU? What s the need? CUDA-Capable GPU Architecture
CUDA PROGRAMMING MODEL Chaithanya Gadiyam Swapnil S Jadhav CMPE655 - Multiple Processor Systems Fall 2015 Rochester Institute of Technology Contents What is GPGPU? What s the need? CUDA-Capable GPU Architecture
EE382N (20): Computer Architecture - Parallelism and Locality Fall 2011 Lecture 18 GPUs (III)
: Computer Architecture - Parallelism and Locality Fall 2011 Lecture 18 GPUs (III)") EE382 (20): Computer Architecture - Parallelism and Locality Fall 2011 Lecture 18 GPUs (III) Mattan Erez The University of Texas at Austin EE382: Principles of Computer Architecture, Fall 2011 -- Lecture
EE382 (20): Computer Architecture - Parallelism and Locality Fall 2011 Lecture 18 GPUs (III) Mattan Erez The University of Texas at Austin EE382: Principles of Computer Architecture, Fall 2011 -- Lecture
Introduction to GPU hardware and to CUDA
 Introduction to GPU hardware and to CUDA Philip Blakely Laboratory for Scientific Computing, University of Cambridge Philip Blakely (LSC) GPU introduction 1 / 35 Course outline Introduction to GPU hardware
Introduction to GPU hardware and to CUDA Philip Blakely Laboratory for Scientific Computing, University of Cambridge Philip Blakely (LSC) GPU introduction 1 / 35 Course outline Introduction to GPU hardware
Real-Time Rendering Architectures
 Real-Time Rendering Architectures Mike Houston, AMD Part 1: throughput processing Three key concepts behind how modern GPU processing cores run code Knowing these concepts will help you: 1. Understand
Real-Time Rendering Architectures Mike Houston, AMD Part 1: throughput processing Three key concepts behind how modern GPU processing cores run code Knowing these concepts will help you: 1. Understand
Anatomy of AMD s TeraScale Graphics Engine
 Anatomy of AMD s TeraScale Graphics Engine Mike Houston Design Goals Focus on Efficiency f(perf/watt, Perf/$) Scale up processing power and AA performance Target >2x previous generation Enhance stream
Anatomy of AMD s TeraScale Graphics Engine Mike Houston Design Goals Focus on Efficiency f(perf/watt, Perf/$) Scale up processing power and AA performance Target >2x previous generation Enhance stream
Spring 2010 Prof. Hyesoon Kim. AMD presentations from Richard Huddy and Michael Doggett
 Spring 2010 Prof. Hyesoon Kim AMD presentations from Richard Huddy and Michael Doggett Radeon 2900 2600 2400 Stream Processors 320 120 40 SIMDs 4 3 2 Pipelines 16 8 4 Texture Units 16 8 4 Render Backens
Spring 2010 Prof. Hyesoon Kim AMD presentations from Richard Huddy and Michael Doggett Radeon 2900 2600 2400 Stream Processors 320 120 40 SIMDs 4 3 2 Pipelines 16 8 4 Texture Units 16 8 4 Render Backens
Parallel Computing: Parallel Architectures Jin, Hai
 Parallel Computing: Parallel Architectures Jin, Hai School of Computer Science and Technology Huazhong University of Science and Technology Peripherals Computer Central Processing Unit Main Memory Computer
Parallel Computing: Parallel Architectures Jin, Hai School of Computer Science and Technology Huazhong University of Science and Technology Peripherals Computer Central Processing Unit Main Memory Computer
Introduction to GPU Computing Using CUDA. Spring 2014 Westgid Seminar Series
 Introduction to GPU Computing Using CUDA Spring 2014 Westgid Seminar Series Scott Northrup SciNet www.scinethpc.ca (Slides http://support.scinet.utoronto.ca/ northrup/westgrid CUDA.pdf) March 12, 2014
Introduction to GPU Computing Using CUDA Spring 2014 Westgid Seminar Series Scott Northrup SciNet www.scinethpc.ca (Slides http://support.scinet.utoronto.ca/ northrup/westgrid CUDA.pdf) March 12, 2014
Finite Element Integration and Assembly on Modern Multi and Many-core Processors
 Finite Element Integration and Assembly on Modern Multi and Many-core Processors Krzysztof Banaś, Jan Bielański, Kazimierz Chłoń AGH University of Science and Technology, Mickiewicza 30, 30-059 Kraków,
Finite Element Integration and Assembly on Modern Multi and Many-core Processors Krzysztof Banaś, Jan Bielański, Kazimierz Chłoń AGH University of Science and Technology, Mickiewicza 30, 30-059 Kraków,
HPC Middle East. KFUPM HPC Workshop April Mohamed Mekias HPC Solutions Consultant. Introduction to CUDA programming
 KFUPM HPC Workshop April 29-30 2015 Mohamed Mekias HPC Solutions Consultant Introduction to CUDA programming 1 Agenda GPU Architecture Overview Tools of the Trade Introduction to CUDA C Patterns of Parallel
KFUPM HPC Workshop April 29-30 2015 Mohamed Mekias HPC Solutions Consultant Introduction to CUDA programming 1 Agenda GPU Architecture Overview Tools of the Trade Introduction to CUDA C Patterns of Parallel
Lecture 7: The Programmable GPU Core. Kayvon Fatahalian CMU : Graphics and Imaging Architectures (Fall 2011)
") Lecture 7: The Programmable GPU Core Kayvon Fatahalian CMU 15-869: Graphics and Imaging Architectures (Fall 2011) Today A brief history of GPU programmability Throughput processing core 101 A detailed
Lecture 7: The Programmable GPU Core Kayvon Fatahalian CMU 15-869: Graphics and Imaging Architectures (Fall 2011) Today A brief history of GPU programmability Throughput processing core 101 A detailed
Introduction to CUDA Algoritmi e Calcolo Parallelo. Daniele Loiacono
 Introduction to CUDA Algoritmi e Calcolo Parallelo References q This set of slides is mainly based on: " CUDA Technical Training, Dr. Antonino Tumeo, Pacific Northwest National Laboratory " Slide of Applied
Introduction to CUDA Algoritmi e Calcolo Parallelo References q This set of slides is mainly based on: " CUDA Technical Training, Dr. Antonino Tumeo, Pacific Northwest National Laboratory " Slide of Applied
Next-Generation Graphics on Larrabee. Tim Foley Intel Corp
 Next-Generation Graphics on Larrabee Tim Foley Intel Corp Motivation The killer app for GPGPU is graphics We ve seen Abstract models for parallel programming How those models map efficiently to Larrabee
Next-Generation Graphics on Larrabee Tim Foley Intel Corp Motivation The killer app for GPGPU is graphics We ve seen Abstract models for parallel programming How those models map efficiently to Larrabee
GPU for HPC. October 2010
 GPU for HPC Simone Melchionna Jonas Latt Francis Lapique October 2010 EPFL/ EDMX EPFL/EDMX EPFL/DIT simone.melchionna@epfl.ch jonas.latt@epfl.ch francis.lapique@epfl.ch 1 Moore s law: in the old days,
GPU for HPC Simone Melchionna Jonas Latt Francis Lapique October 2010 EPFL/ EDMX EPFL/EDMX EPFL/DIT simone.melchionna@epfl.ch jonas.latt@epfl.ch francis.lapique@epfl.ch 1 Moore s law: in the old days,
Trends in HPC (hardware complexity and software challenges)
") Trends in HPC (hardware complexity and software challenges) Mike Giles Oxford e-research Centre Mathematical Institute MIT seminar March 13th, 2013 Mike Giles (Oxford) HPC Trends March 13th, 2013 1 / 18
Trends in HPC (hardware complexity and software challenges) Mike Giles Oxford e-research Centre Mathematical Institute MIT seminar March 13th, 2013 Mike Giles (Oxford) HPC Trends March 13th, 2013 1 / 18
Introduction to GPU Computing Using CUDA. Spring 2014 Westgid Seminar Series
 Introduction to GPU Computing Using CUDA Spring 2014 Westgid Seminar Series Scott Northrup SciNet www.scinethpc.ca March 13, 2014 Outline 1 Heterogeneous Computing 2 GPGPU - Overview Hardware Software
Introduction to GPU Computing Using CUDA Spring 2014 Westgid Seminar Series Scott Northrup SciNet www.scinethpc.ca March 13, 2014 Outline 1 Heterogeneous Computing 2 GPGPU - Overview Hardware Software
NVidia s GPU Microarchitectures. By Stephen Lucas and Gerald Kotas
 NVidia s GPU Microarchitectures By Stephen Lucas and Gerald Kotas Intro Discussion Points - Difference between CPU and GPU - Use s of GPUS - Brie f History - Te sla Archite cture - Fermi Architecture -
NVidia s GPU Microarchitectures By Stephen Lucas and Gerald Kotas Intro Discussion Points - Difference between CPU and GPU - Use s of GPUS - Brie f History - Te sla Archite cture - Fermi Architecture -
CUFFT Library PG _V1.0 June, 2007
 PG-00000-003_V1.0 June, 2007 PG-00000-003_V1.0 Confidential Information Published by Corporation 2701 San Tomas Expressway Santa Clara, CA 95050 Notice This source code is subject to ownership rights under
PG-00000-003_V1.0 June, 2007 PG-00000-003_V1.0 Confidential Information Published by Corporation 2701 San Tomas Expressway Santa Clara, CA 95050 Notice This source code is subject to ownership rights under
Computer Architecture 计算机体系结构. Lecture 10. Data-Level Parallelism and GPGPU 第十讲 数据级并行化与 GPGPU. Chao Li, PhD. 李超博士
 Computer Architecture 计算机体系结构 Lecture 10. Data-Level Parallelism and GPGPU 第十讲 数据级并行化与 GPGPU Chao Li, PhD. 李超博士 SJTU-SE346, Spring 2017 Review Thread, Multithreading, SMT CMP and multicore Benefits of
Computer Architecture 计算机体系结构 Lecture 10. Data-Level Parallelism and GPGPU 第十讲 数据级并行化与 GPGPU Chao Li, PhD. 李超博士 SJTU-SE346, Spring 2017 Review Thread, Multithreading, SMT CMP and multicore Benefits of
COMP 605: Introduction to Parallel Computing Lecture : GPU Architecture
 COMP 605: Introduction to Parallel Computing Lecture : GPU Architecture Mary Thomas Department of Computer Science Computational Science Research Center (CSRC) San Diego State University (SDSU) Posted:
COMP 605: Introduction to Parallel Computing Lecture : GPU Architecture Mary Thomas Department of Computer Science Computational Science Research Center (CSRC) San Diego State University (SDSU) Posted:
Parallel Programming for Graphics
 Beyond Programmable Shading Course ACM SIGGRAPH 2010 Parallel Programming for Graphics Aaron Lefohn Advanced Rendering Technology (ART) Intel What s In This Talk? Overview of parallel programming models
Beyond Programmable Shading Course ACM SIGGRAPH 2010 Parallel Programming for Graphics Aaron Lefohn Advanced Rendering Technology (ART) Intel What s In This Talk? Overview of parallel programming models
GPU Architecture. Michael Doggett Department of Computer Science Lund university
 GPU Architecture Michael Doggett Department of Computer Science Lund university GPUs from my time at ATI R200 Xbox360 GPU R630 R610 R770 Let s start at the beginning... Graphics Hardware before GPUs 1970s
GPU Architecture Michael Doggett Department of Computer Science Lund university GPUs from my time at ATI R200 Xbox360 GPU R630 R610 R770 Let s start at the beginning... Graphics Hardware before GPUs 1970s
This Unit: Putting It All Together. CIS 501 Computer Architecture. What is Computer Architecture? Sources
 This Unit: Putting It All Together CIS 501 Computer Architecture Unit 12: Putting It All Together: Anatomy of the XBox 360 Game Console Application OS Compiler Firmware CPU I/O Memory Digital Circuits
This Unit: Putting It All Together CIS 501 Computer Architecture Unit 12: Putting It All Together: Anatomy of the XBox 360 Game Console Application OS Compiler Firmware CPU I/O Memory Digital Circuits
arxiv: v1 [physics.comp-ph] 4 Nov 2013
![arxiv: v1 [physics.comp-ph] 4 Nov 2013](/thumbs/74/70979601.jpg "arxiv: v1 [physics.comp-ph] 4 Nov 2013") arxiv:1311.0590v1 [physics.comp-ph] 4 Nov 2013 Performance of Kepler GTX Titan GPUs and Xeon Phi System, Weonjong Lee, and Jeonghwan Pak Lattice Gauge Theory Research Center, CTP, and FPRD, Department
arxiv:1311.0590v1 [physics.comp-ph] 4 Nov 2013 Performance of Kepler GTX Titan GPUs and Xeon Phi System, Weonjong Lee, and Jeonghwan Pak Lattice Gauge Theory Research Center, CTP, and FPRD, Department
GPU Fundamentals Jeff Larkin November 14, 2016
 GPU Fundamentals Jeff Larkin , November 4, 206 Who Am I? 2002 B.S. Computer Science Furman University 2005 M.S. Computer Science UT Knoxville 2002 Graduate Teaching Assistant 2005 Graduate
GPU Fundamentals Jeff Larkin , November 4, 206 Who Am I? 2002 B.S. Computer Science Furman University 2005 M.S. Computer Science UT Knoxville 2002 Graduate Teaching Assistant 2005 Graduate
GRAPHICS HARDWARE. Niels Joubert, 4th August 2010, CS147
 GRAPHICS HARDWARE Niels Joubert, 4th August 2010, CS147 Rendering Latest GPGPU Today Enabling Real Time Graphics Pipeline History Architecture Programming RENDERING PIPELINE Real-Time Graphics Vertices
GRAPHICS HARDWARE Niels Joubert, 4th August 2010, CS147 Rendering Latest GPGPU Today Enabling Real Time Graphics Pipeline History Architecture Programming RENDERING PIPELINE Real-Time Graphics Vertices
Directed Optimization On Stencil-based Computational Fluid Dynamics Application(s)
") Directed Optimization On Stencil-based Computational Fluid Dynamics Application(s) Islam Harb 08/21/2015 Agenda Motivation Research Challenges Contributions & Approach Results Conclusion Future Work 2
Directed Optimization On Stencil-based Computational Fluid Dynamics Application(s) Islam Harb 08/21/2015 Agenda Motivation Research Challenges Contributions & Approach Results Conclusion Future Work 2
CS195V Week 9. GPU Architecture and Other Shading Languages
 CS195V Week 9 GPU Architecture and Other Shading Languages GPU Architecture We will do a short overview of GPU hardware and architecture Relatively short journey into hardware, for more in depth information,
CS195V Week 9 GPU Architecture and Other Shading Languages GPU Architecture We will do a short overview of GPU hardware and architecture Relatively short journey into hardware, for more in depth information,
Introduction to CUDA
 Introduction to CUDA Oliver Meister November 7 th 2012 Tutorial Parallel Programming and High Performance Computing, November 7 th 2012 1 References D. Kirk, W. Hwu: Programming Massively Parallel Processors,
Introduction to CUDA Oliver Meister November 7 th 2012 Tutorial Parallel Programming and High Performance Computing, November 7 th 2012 1 References D. Kirk, W. Hwu: Programming Massively Parallel Processors,
Computer Architecture
 Jens Teubner Computer Architecture Summer 2017 1 Computer Architecture Jens Teubner, TU Dortmund jens.teubner@cs.tu-dortmund.de Summer 2017 Jens Teubner Computer Architecture Summer 2017 34 Part II Graphics
Jens Teubner Computer Architecture Summer 2017 1 Computer Architecture Jens Teubner, TU Dortmund jens.teubner@cs.tu-dortmund.de Summer 2017 Jens Teubner Computer Architecture Summer 2017 34 Part II Graphics
From Shader Code to a Teraflop: How GPU Shader Cores Work. Jonathan Ragan- Kelley (Slides by Kayvon Fatahalian)
") From Shader Code to a Teraflop: How GPU Shader Cores Work Jonathan Ragan- Kelley (Slides by Kayvon Fatahalian) 1 This talk Three major ideas that make GPU processing cores run fast Closer look at real
From Shader Code to a Teraflop: How GPU Shader Cores Work Jonathan Ragan- Kelley (Slides by Kayvon Fatahalian) 1 This talk Three major ideas that make GPU processing cores run fast Closer look at real
Tesla GPU Computing A Revolution in High Performance Computing
 Tesla GPU Computing A Revolution in High Performance Computing Gernot Ziegler, Developer Technology (Compute) (Material by Thomas Bradley) Agenda Tesla GPU Computing CUDA Fermi What is GPU Computing? Introduction
Tesla GPU Computing A Revolution in High Performance Computing Gernot Ziegler, Developer Technology (Compute) (Material by Thomas Bradley) Agenda Tesla GPU Computing CUDA Fermi What is GPU Computing? Introduction
Lecture 8: GPU Programming. CSE599G1: Spring 2017
 Lecture 8: GPU Programming CSE599G1: Spring 2017 Announcements Project proposal due on Thursday (4/28) 5pm. Assignment 2 will be out today, due in two weeks. Implement GPU kernels and use cublas library
Lecture 8: GPU Programming CSE599G1: Spring 2017 Announcements Project proposal due on Thursday (4/28) 5pm. Assignment 2 will be out today, due in two weeks. Implement GPU kernels and use cublas library
CUDA on ARM Update. Developing Accelerated Applications on ARM. Bas Aarts and Donald Becker
 CUDA on ARM Update Developing Accelerated Applications on ARM Bas Aarts and Donald Becker CUDA on ARM: a forward-looking development platform for high performance, energy efficient hybrid computing It
CUDA on ARM Update Developing Accelerated Applications on ARM Bas Aarts and Donald Becker CUDA on ARM: a forward-looking development platform for high performance, energy efficient hybrid computing It
ECE 574 Cluster Computing Lecture 16
 ECE 574 Cluster Computing Lecture 16 Vince Weaver http://web.eece.maine.edu/~vweaver vincent.weaver@maine.edu 26 March 2019 Announcements HW#7 posted HW#6 and HW#5 returned Don t forget project topics
ECE 574 Cluster Computing Lecture 16 Vince Weaver http://web.eece.maine.edu/~vweaver vincent.weaver@maine.edu 26 March 2019 Announcements HW#7 posted HW#6 and HW#5 returned Don t forget project topics
Real-Time Reyes: Programmable Pipelines and Research Challenges. Anjul Patney University of California, Davis
 Real-Time Reyes: Programmable Pipelines and Research Challenges Anjul Patney University of California, Davis Real-Time Reyes-Style Adaptive Surface Subdivision Anjul Patney and John D. Owens SIGGRAPH Asia
Real-Time Reyes: Programmable Pipelines and Research Challenges Anjul Patney University of California, Davis Real-Time Reyes-Style Adaptive Surface Subdivision Anjul Patney and John D. Owens SIGGRAPH Asia
GPU Architecture and Function. Michael Foster and Ian Frasch
 GPU Architecture and Function Michael Foster and Ian Frasch Overview What is a GPU? How is a GPU different from a CPU? The graphics pipeline History of the GPU GPU architecture Optimizations GPU performance
GPU Architecture and Function Michael Foster and Ian Frasch Overview What is a GPU? How is a GPU different from a CPU? The graphics pipeline History of the GPU GPU architecture Optimizations GPU performance
Unit 11: Putting it All Together: Anatomy of the XBox 360 Game Console
 Computer Architecture Unit 11: Putting it All Together: Anatomy of the XBox 360 Game Console Slides originally developed by Milo Martin & Amir Roth at University of Pennsylvania! Computer Architecture
Computer Architecture Unit 11: Putting it All Together: Anatomy of the XBox 360 Game Console Slides originally developed by Milo Martin & Amir Roth at University of Pennsylvania! Computer Architecture
2009: The GPU Computing Tipping Point. Jen-Hsun Huang, CEO
 2009: The GPU Computing Tipping Point Jen-Hsun Huang, CEO Someday, our graphics chips will have 1 TeraFLOPS of computing power, will be used for playing games to discovering cures for cancer to streaming
2009: The GPU Computing Tipping Point Jen-Hsun Huang, CEO Someday, our graphics chips will have 1 TeraFLOPS of computing power, will be used for playing games to discovering cures for cancer to streaming
PowerVR Hardware. Architecture Overview for Developers
 Public Imagination Technologies PowerVR Hardware Public. This publication contains proprietary information which is subject to change without notice and is supplied 'as is' without warranty of any kind.
Public Imagination Technologies PowerVR Hardware Public. This publication contains proprietary information which is subject to change without notice and is supplied 'as is' without warranty of any kind.
Graphics Architectures and OpenCL. Michael Doggett Department of Computer Science Lund university
 Graphics Architectures and OpenCL Michael Doggett Department of Computer Science Lund university Overview Parallelism Radeon 5870 Tiled Graphics Architectures Important when Memory and Bandwidth limited
Graphics Architectures and OpenCL Michael Doggett Department of Computer Science Lund university Overview Parallelism Radeon 5870 Tiled Graphics Architectures Important when Memory and Bandwidth limited
Accelerating High Performance Computing.
 Accelerating High Performance Computing http://www.nvidia.com/tesla Computing The 3 rd Pillar of Science Drug Design Molecular Dynamics Seismic Imaging Reverse Time Migration Automotive Design Computational
Accelerating High Performance Computing http://www.nvidia.com/tesla Computing The 3 rd Pillar of Science Drug Design Molecular Dynamics Seismic Imaging Reverse Time Migration Automotive Design Computational
Introduction to CUDA Algoritmi e Calcolo Parallelo. Daniele Loiacono
 Introduction to CUDA Algoritmi e Calcolo Parallelo References This set of slides is mainly based on: CUDA Technical Training, Dr. Antonino Tumeo, Pacific Northwest National Laboratory Slide of Applied
Introduction to CUDA Algoritmi e Calcolo Parallelo References This set of slides is mainly based on: CUDA Technical Training, Dr. Antonino Tumeo, Pacific Northwest National Laboratory Slide of Applied
Computer Architecture
 Computer Architecture Slide Sets WS 2013/2014 Prof. Dr. Uwe Brinkschulte M.Sc. Benjamin Betting Part 10 Thread and Task Level Parallelism Computer Architecture Part 10 page 1 of 36 Prof. Dr. Uwe Brinkschulte,
Computer Architecture Slide Sets WS 2013/2014 Prof. Dr. Uwe Brinkschulte M.Sc. Benjamin Betting Part 10 Thread and Task Level Parallelism Computer Architecture Part 10 page 1 of 36 Prof. Dr. Uwe Brinkschulte,
GPU Computation Strategies & Tricks. Ian Buck NVIDIA
 GPU Computation Strategies & Tricks Ian Buck NVIDIA Recent Trends 2 Compute is Cheap parallelism to keep 100s of ALUs per chip busy shading is highly parallel millions of fragments per frame 0.5mm 64-bit
GPU Computation Strategies & Tricks Ian Buck NVIDIA Recent Trends 2 Compute is Cheap parallelism to keep 100s of ALUs per chip busy shading is highly parallel millions of fragments per frame 0.5mm 64-bit
Current Trends in Computer Graphics Hardware
 Current Trends in Computer Graphics Hardware Dirk Reiners University of Louisiana Lafayette, LA Quick Introduction Assistant Professor in Computer Science at University of Louisiana, Lafayette (since 2006)
Current Trends in Computer Graphics Hardware Dirk Reiners University of Louisiana Lafayette, LA Quick Introduction Assistant Professor in Computer Science at University of Louisiana, Lafayette (since 2006)
Motivation Hardware Overview Programming model. GPU computing. Part 1: General introduction. Ch. Hoelbling. Wuppertal University
 Part 1: General introduction Ch. Hoelbling Wuppertal University Lattice Practices 2011 Outline 1 Motivation 2 Hardware Overview History Present Capabilities 3 Programming model Past: OpenGL Present: CUDA
Part 1: General introduction Ch. Hoelbling Wuppertal University Lattice Practices 2011 Outline 1 Motivation 2 Hardware Overview History Present Capabilities 3 Programming model Past: OpenGL Present: CUDA
Real - Time Rendering. Pipeline optimization. Michal Červeňanský Juraj Starinský
 Real - Time Rendering Pipeline optimization Michal Červeňanský Juraj Starinský Motivation Resolution 1600x1200, at 60 fps Hw power not enough Acceleration is still necessary 3.3.2010 2 Overview Application
Real - Time Rendering Pipeline optimization Michal Červeňanský Juraj Starinský Motivation Resolution 1600x1200, at 60 fps Hw power not enough Acceleration is still necessary 3.3.2010 2 Overview Application
Parallelizing Graphics Pipeline Execution (+ Basics of Characterizing a Rendering Workload)
") Lecture 2: Parallelizing Graphics Pipeline Execution (+ Basics of Characterizing a Rendering Workload) Visual Computing Systems Analyzing a 3D Graphics Workload Where is most of the work done? Memory Vertex
Lecture 2: Parallelizing Graphics Pipeline Execution (+ Basics of Characterizing a Rendering Workload) Visual Computing Systems Analyzing a 3D Graphics Workload Where is most of the work done? Memory Vertex
Tesla GPU Computing A Revolution in High Performance Computing
 Tesla GPU Computing A Revolution in High Performance Computing Mark Harris, NVIDIA Agenda Tesla GPU Computing CUDA Fermi What is GPU Computing? Introduction to Tesla CUDA Architecture Programming & Memory
Tesla GPU Computing A Revolution in High Performance Computing Mark Harris, NVIDIA Agenda Tesla GPU Computing CUDA Fermi What is GPU Computing? Introduction to Tesla CUDA Architecture Programming & Memory
Fundamental CUDA Optimization. NVIDIA Corporation
 Fundamental CUDA Optimization NVIDIA Corporation Outline! Fermi Architecture! Kernel optimizations! Launch configuration! Global memory throughput! Shared memory access! Instruction throughput / control
Fundamental CUDA Optimization NVIDIA Corporation Outline! Fermi Architecture! Kernel optimizations! Launch configuration! Global memory throughput! Shared memory access! Instruction throughput / control