Data-Level Parallelism in SIMD and Vector Architectures. Advanced Computer Architectures, Laura Pozzi & Cristina Silvano
|
|
|
- Rebecca Mills
- 5 years ago
- Views:
Transcription
1 Data-Level Parallelism in SIMD and Vector Architectures Advanced Computer Architectures, Laura Pozzi & Cristina Silvano 1
2 Current Trends in Architecture Cannot continue to leverage Instruction-Level parallelism (ILP) Beyond ILP: new models for managing parallelism: Data-level parallelism (DLP) Thread-level parallelism (TLP) Request-level parallelism (RLP) Advanced Computer Architectures, Laura Pozzi & Cristina Silvano 2
3 ILP, DLP Instead of going in the direction of complex out-of-order ILP processor An in-order vector processor can achieve the same performance, or more, by exploiting DLP (Data Level Parallelism) With more energy efficiency Advanced Computer Architectures, Laura Pozzi & Cristina Silvano 3
4 Flynn s Taxonomy SISD SIMD MISD Single instruction stream, single data stream - uniprocessors (including ILP processors) Single instruction stream, multiple data streams - Vector architectures - Multimedia extensions - Graphics processor units Multiple instruction streams, single data stream - No commercial implementation MIMD Multiple instruction streams, multiple data streams - Tightly-coupled MIMD (thread-level parallelism) - Loosely-coupled MIMD (request-level parallelism) Advanced Computer Architectures, Laura Pozzi & Cristina Silvano 4
5 SIMD and Vector Architectures Advanced Computer Architectures, Laura Pozzi & Cristina Silvano 5
6 Introduction to SIMD SIMD architectures can exploit significant data-level parallelism for: Matrix-oriented scientific computing Media-oriented image and sound processors SIMD is more energy efficient than MIMD Only needs to fetch one instruction per data operation Makes SIMD attractive for personal mobile devices SIMD allows programmer to continue to think sequentially (compared to MIMD) and achieve parallel speedups. Advanced Computer Architectures, Laura Pozzi & Cristina Silvano 6
7 SIMD Architecture Central controller broadcasts instructions to multiple processing elements (PEs) Array Controller Inter-PE Connection Network PE PE PE PE PE PE PE PE Control Data M e m M e m M e m M e m M e m M e m M e m M e m Only requires one controller for whole array Only requires storage for one copy of program All computations fully synchronized 7 Advanced Computer Architectures, Laura Pozzi & Cristina Silvano 7
8 Three variations of SIMD Machines 1. Vector architectures 2. SIMD extensions: x86 multimedia SIMD extensions: MMX 1996, SSE (Streaming SIMD Extension), AVX (Advanced Vector Extension) 3. Graphics Processor Units (GPUs) Advanced Computer Architectures, Laura Pozzi & Cristina Silvano 9
9 Vector Architectures Basic idea: Load sets of data elements into vector registers Operate on those registers Disperse the results back into memory A single instruction operates on vectors of data Synchronized units: single Program Counter Which results in dozens of register-to-register operations Used to hide memory latency (memory latency occurs one per vector load/store vs. one per element load/store). Leverage memory bandwidth Advanced Computer Architectures, Laura Pozzi & Cristina Silvano 10
10 Vector Architectures From Cray-1, 1976: Scalar Unit + Vector Extensions Load/Store Architecture Vector Registers Vector Instructions Hardwired Control Highly Pipelined Functional Units Interleaved Memory System No Data Caches No Virtual Memory 11 Advanced Computer Architectures, Laura Pozzi & Cristina Silvano 11
11 Vector Processing Vector processors have high-level operations that work on linear arrays of numbers: "vectors" SCALAR (1 operation) VECTOR (N operations) r1 r2 + r3 v1 v2 + v3 vector length add r3, r1, r2 add.vv v3, v1, v
12 Properties of Vector Processors Each result independent of previous result => long pipeline, compiler ensures no dependencies => high clock rate Vector instructions access memory with known pattern => highly interleaved memory => amortize memory latency of over 64 elements => no (data) caches required! (Do use instruction cache) Reduces branches and branch problems in pipelines Single vector instruction implies lots of work ( loop) => fewer instruction fetches 13 Advanced Computer Architectures, Laura Pozzi & Cristina Silvano 13
13 Styles of Vector Architectures Memory-memory vector processors: all vector operations are memory to memory Vector-register processors: all vector operations between vector registers (except load and store) Vector equivalent of load-store scalar architectures Includes all vector machines since late 1980s: Cray, Convex, Fujitsu, Hitachi, NEC 14 Advanced Computer Architectures, Laura Pozzi & Cristina Silvano 14
14 Components of Vector Processors Vector Register: fixed length bank holding a single vector has at least 2 read and 1 write ports typically 8-32 vector registers, each holding bit elements Vector Functional Units (FUs): fully pipelined, start new operation every clock typically 4 to 8 FUs: FP add, FP mult, FP reciprocal (1/X), integer add, logical, shift; may have multiple of same unit Vector Load-Store Units (LSUs): fully pipelined unit to load or store a vector; may have multiple LSUs Scalar Registers: single element for FP scalar or address Cross-bar to connect FUs, LSUs, registers 15 Advanced Computer Architectures, Laura Pozzi & Cristina Silvano 15
15 Scalar Registers vs Vector Registers 16 Scalar Registers: each register holds a 32-bit element 16 Vector Registers: each vector register holds VLRMAX elements, 32-bit per element 16
16 Vector Arithmetic Instructions 17
17 Example architecture: VMIPS Loosely based on Cray-1 Vector registers 8 registers. Each register holds a 64-element, 64 bits/element vector Register file has (at least) 16 read ports and 8 write ports Vector functional units Fully pipelined so they can start a new operation every cycle Vector load-store unit Fully pipelined, one word per clock cycle after initial memory latency Scalar registers 32 general-purpose registers 32 floating-point registers Advanced Computer Architectures, Laura Pozzi & Cristina Silvano 18

18 The basic structure of a vector architecture, VMIPS. This processor has a scalar architecture just like MIPS. There are also eight 64- element vector registers, and all the functional units are vector functional units. The vector and scalar registers have a significant number of read and write ports. Copyright 2011, Elsevier Inc. All rights Reserved. 19
19 20
20 Accommodating varying data sizes Vector processors are good for several applications (scientific applications, but also media applications) Because they can adapt to several width: a vector size can be seen as bit elements, or bit elements etc. Advanced Computer Architectures, Laura Pozzi & Cristina Silvano 21
21 DAXPY operation DAXPY operation, in scalar vs vector MIPS DAXPY stands for: double precision a X plus Y i.e. Y = a * X + Y for (i=0; i<64, i++){ Y[i]=a*X[i]+Y[i]; } Advanced Computer Architectures, Laura Pozzi & Cristina Silvano 22
22 Scalar version of DAXPY (assume that Rx and Ry are holding the addresses of X and Y) L.D F0, a ; load scalar a DADDIU R4, Rx, #512 ; last address to load Loop: L.D F2, 0(Rx) ; load X[i] MUL.D F2, F2, F0 ; a * X[i] L.D F4, 0(Rx) ; load Y[i] ADD.D F4, F4, F2 ; a * X[i] + Y[i] S.D F4, 0(Rx) ; store into Y[i] DADDIU Rx, Rx, #8 ; increment index to X DSUBU R20, R4, Rx ; compute bound BNEZ R20, Loop ; check if done 23
23 Scalar version of DAXPY (assume that Rx and Ry are holding the addresses of X and Y) L.D F0, a ; load scalar a DADDIU R4, Rx, #512 ; last address to load Loop: L.D F2, 0(Rx) ; load X[i] MUL.D F2, F2, F0 Scalar ; a * X[i] version of DAXPY: L.D F4, 0(Rx) 8 ; load instructions Y[i] per iteration ADD.D F4, F4, F2 ; a => * X[i] (64 + x Y[i] 8) + 2 = 514 S.D F4, 0(Rx) ; store instructions into Y[i] per loop plus stalls DADDIU Rx, Rx, #8 ; increment index to X DSUBU R20, R4, Rx ; compute bound BNEZ R20, Loop ; check if done 24
24 Analysis of scalar version (1) Loop: computation overhead L.D F2, 0(Rx) ; load X[i] MUL.D F2, F2, F0 ; a * X[i] L.D F4, 0(Rx) ; load Y[i] ADD.D F4, F4, F2 ; a * X[i] + Y[i] S.D F4, 0(Rx) ; store into Y[i] DADDIU Rx, Rx, #8 ; increment index to X DSUBU R20, R4, Rx ; compute bound BNEZ R20, Loop ; check if done 25
25 Analysis of scalar version (2) computation stall stall stall L.D F2, 0(Rx) ; load X[i] MUL.D F2, F2, F0 ; a * X[i] L.D F4, 0(Rx) ; load Y[i] ADD.D F4, F4, F2 ; a * X[i] + Y[i] S.D F4, 9(Rx) ; store into Y[i] Scalar version stalls at EVERY iteration 26
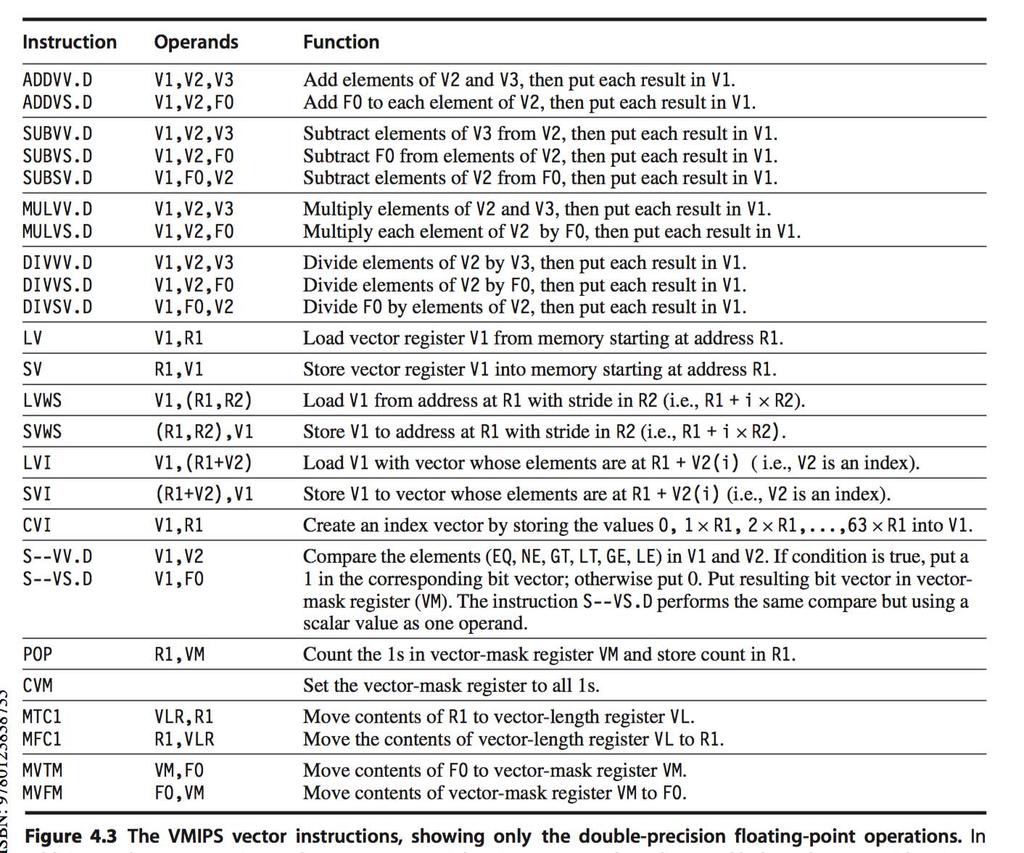
26 VMIPS Instructions ADDVV.D: add two vectors MULVS.D: multiply vector to a scalar LV/SV: vector load and vector store from memory address Vector processor version of DAXPY L.D F0,a ; load scalar a LV V1,Rx ; load vector X MULVS.D V2,V1,F0 ; vector-scalar multiply LV V3,Ry ; load vector Y ADDVV.D V4,V2,V3 ; add two vectors SV Ry,V4 ; store the result Requires 6 instructions per loop vs. almost 600 for MIPS: greatly decreased! 27
27 Analysis of advantages vs. scalar version Requires 6 instructions per loop vs. almost 600 instructions per loop for MIPS: greatly decreased! No branches anymore! The scalar version can try to get a similar effect by loop unrolling, but it cannot get the instruction count decrease. Pipeline stalls greatly decreased Vector version: must stall ONLY for THE FIRST vector element, after that, results can come out every clock cycle Advanced Computer Architectures, Laura Pozzi & Cristina Silvano 28
28 Operation Chaining Results from FU forwarded to next FU in the chain Concept of forwarding extended to vector registers: A vector operation can start as soon as the individual elements of its vector source operand become available Even though a pair of operations depend on one another, chaining allows the operations to proceed in parallel on separate elements of the vector Advanced Computer Architectures, Laura Pozzi & Cristina Silvano 29


29 Operation Chaining (2) Without chaining: must wait for last element of result to be written before starting dependent instruction With chaining: a dependent operation can start as soon as the individual elements of its vector source operand become available 30
30 Vector Execution Time Execution time depends on three factors: Length of operand vectors Structural hazards Data dependencies VMIPS functional units consume one element per clock cycle So, the execution time of one vector instruction is approximately the vector length Advanced Computer Architectures, Laura Pozzi & Cristina Silvano 31
31 Convoys Simplification: to introduce the notion of convoy Set of vector instructions that could potentially execute together (no structural hazards) Sequences with read-after-write dependency hazards can be in the same convoy via chaining Advanced Computer Architectures, Laura Pozzi & Cristina Silvano 32
32 Chimes Chime is a timing metric corresponding to the unit of time to execute one convoy m convoys execute in m chimes Simply stated: for a vector length of n, and m convoys in a program, n x m clock cycles are required Chime approximation ignores some processor-specific overheads Advanced Computer Architectures, Laura Pozzi & Cristina Silvano 33
33 Example LV V1,Rx ;load vector X MULVS.D V2,V1,F0 ;vector-scalar multiply LV V3,Ry ;load vector Y ADDVV.D V4,V2,V3 ;add two vectors SV Ry,V4 ;store the sum Convoys: 1 LV MULVS.D (chaining) 2 LV ADDVV.D (chaining) 3 SV (struct. hazards with 2 nd LV) 3 convoys (3 chimes); 2 FP ops per result; 1.5 cycles per FLOP For 64 element vectors, requires 64 x 3 = 192 clock cycles 34
34 Multiple Lanes Instead of generating an element per cycle in one lane, spread the elements of the two vector operands into multiple lanes to improve vector performance SINGLE ADD PIPELINE: 1 add per cycle 64 cycles for a vector of 64 elements FOUR ADDs PIPELINE: 4 adds per cycle 16 cycles for a vector of 64 elements 36

35 Multiple Lanes Vector Unit with 4 lanes Vector registers are divided across 4 lanes 37
36 Vector Length Control The Maximum Vector Length (MVL) is the physical length of vector registers in a machine (64 in our VMIPS example) What do you do when the vector length in a program is not exactly 64? Vector length smaller than 64 Vector length unknown at compile time and maybe greater than MVL Advanced Computer Architectures, Laura Pozzi & Cristina Silvano 38
37 Vector length smaller than 64 for (i=0; i<63; i=i+1) Y[i]=a * X[i] + Y[i]; for (i=0; i<31; i=i+1) Y[i]=a * X[i] + Y[i]; There is a special register, called vector-length register (VLR) The VLR controls the length of any vector operation (including vector load/store). It can be set to any value smaller than the MVL (64) Advanced Computer Architectures, Laura Pozzi & Cristina Silvano 39
38 Vector length unknown at compile time Restructure the code using a technique called strip mining: Sort of loop unrolling where the length of first segment is the remainder and all subsequent segments are of length MVL 40
39 Vector length unknown at compile time for (i=0; i<n; i=i+1) Y[i]=a * X[i] + Y[i]; Restructure the code using a technique called strip mining: Code generation technique such that each vector operation is done for a size less than or equal to MVL Sort of loop unrolling where the length of the first segment is (n mod MVL) and all subsequent segments are of length MVL < m > < MVL > < MVL > < MVL > < MVL > < MVL > < MVL > Advanced Computer Architecture, Laura Pozzi 41
![Vector length unknown at compile time for (i=0; i<n; i=i+1) Y[i]=a * X[i] + Y[i]; Restructure the code using a technique called strip mining low = 0; VL = (n % MVL); /*find odd-size piece using](/docs-images/87/96915225/images/40-0.jpg "modulo op % */ for (j = 0; j <= (n/mvl); j=j+1) { /*outer loop*/ for (i = low; i < (low+vl); i=i+1) /*runs for length VL*/ Y[i] = a * X[i] + Y[i] ; /*main operation*/ low = low + VL; /*start of next")
40 Vector length unknown at compile time for (i=0; i<n; i=i+1) Y[i]=a * X[i] + Y[i]; Restructure the code using a technique called strip mining low = 0; VL = (n % MVL); /*find odd-size piece using modulo op % */ for (j = 0; j <= (n/mvl); j=j+1) { /*outer loop*/ for (i = low; i < (low+vl); i=i+1) /*runs for length VL*/ Y[i] = a * X[i] + Y[i] ; /*main operation*/ low = low + VL; /*start of next vector*/ VL = MVL; /*reset the length to maximum vector length*/ } < m > < MVL > < MVL > < MVL > < MVL > < MVL > < MVL > Advanced Computer Architecture, Laura Pozzi 42
41 Vector Mask Registers for (i = 0; i < 64; i=i+1) if (X[i]!= 0) X[i] = X[i] Y[i]; Control Dependence in a loop This loop cannot normally be vectorized because of the if clause inside it Use vector mask register to disable some elements: The vector-mask control uses a Boolean vector of length MVL to control the execution of a vector instruction When vector mask registers are enabled, any vector instruction operates ONLY on the vector elements whose corresponding masks bits are set to 1 Advanced Computer Architectures, Laura Pozzi & Cristina Silvano 43
42 Vector Mask Registers for (i = 0; i < 64; i=i+1) if (X[i]!= 0) X[i] = X[i] Y[i]; This loop cannot normally be vectorized because of the if clause inside it Use vector mask register to disable elements: LV V1,Rx ;load vector X into V1 LV V2,Ry ;load vector Y into V2 L.D F0,#0 ;load FP zero into F0 SNEVS.D V1,F0 ;sets VM(i) to 1 if V1(i)!=F0 SUBVV.D V1,V1,V2 ;subtract under vector mask SV Rx,V1 ;store the result in X The cycles for non-executed operation elements are lost But the loop can still be vectorized! 44
43 Stride How do you do with non-adjacent memory elements? The stride is the distance separating memory elements that are to be gathered into a single register. LVWS V1, (r1, r2) When a matrix is allocated in memory, it is linearized and laid out in row-major order in C => the elements in the columns are not-adjacent in memory Advanced Computer Architectures, Laura Pozzi & Cristina Silvano 46
44 Stride When the elements of a matrix in the inner loop are accessed by column => they are separated in memory by a stride equal to the row size times 8 bytes per entry We need an instruction LVWS to load elements of a vector that are non-adjacent in memory from address R1 with stride R2: LVWS V1, (R1, R2) ; V1 <= M[R1 + i*r2] Example: LVWS V1, (C, 100) ; V1 <= M[C + i*100] while LV V2, B ; V2 <= M[B] Advanced Computer Architectures, Laura Pozzi & Cristina Silvano 47
45 Stride Consider: for (i = 0; i < 100; i=i+1) for (j = 0; j < 100; j=j+1) { A[i][j] = 0.0; for (k = 0; k < 100; k=k+1) A[i][j] = A[i][j] + B[i][k] * D[k][j]; } Must vectorize multiplication of rows of B with columns of D Use non-unit stride for columns of D Bank conflict (stall) occurs when the same bank is hit faster than bank busy time: #banks / LCM(stride,#banks) < bank busy time Copyright 2012, Elsevier Inc. All rights reserved. 48
46 Scatter-Gather Primary mechanism to support sparse matrices y using index vectors. Consider: for (i = 0; i < n; i=i+1) A[K[i]] = A[K[i]] + C[M[i]]; Use index vector K and M to indicate the nonzero elements of A and C (A and C must have the same number of nonzero elements). LV Vk, Rk ;load K LVI Va, (Ra+Vk) ;load A[K[]] LV Vm, Rm ;load M LVI Vc, (Rc+Vm) ;load C[M[]] ADDVV.D Va, Va, Vc ;add them SVI (Ra+Vk), Va ;store A[K[]] 49
47 SIMD Instruction Set Extensions Multimedia applications operate on data types narrower than the native word size Example: disconnect carry chains to partition adder Limitations, compared to vector instructions: Number of data operands encoded into op code No sophisticated addressing modes (strided, scattergather) No mask registers Copyright 2012, Elsevier Inc. All rights reserved. 51
48 SIMD Implementations Implementations: Intel MMX (1996) Eight 8-bit integer ops or four 16-bit integer ops Streaming SIMD Extensions (SSE) (1999) Eight 16-bit integer ops Four 32-bit integer/fp ops or two 64-bit integer/fp ops Advanced Vector Extensions (2010) Four 64-bit integer/fp ops Operands must be consecutive and aligned memory locations Copyright 2012, Elsevier Inc. All rights reserved. 52
! An alternate classification. Introduction. ! Vector architectures (slides 5 to 18) ! SIMD & extensions (slides 19 to 23)
 ! SIMD & extensions (slides 19 to 23)") Master Informatics Eng. Advanced Architectures 2015/16 A.J.Proença Data Parallelism 1 (vector, SIMD ext., GPU) (most slides are borrowed) Instruction and Data Streams An alternate classification Instruction
Master Informatics Eng. Advanced Architectures 2015/16 A.J.Proença Data Parallelism 1 (vector, SIMD ext., GPU) (most slides are borrowed) Instruction and Data Streams An alternate classification Instruction
Parallel Processing SIMD, Vector and GPU s
 Parallel Processing SIMD, Vector and GPU s EECS4201 Fall 2016 York University 1 Introduction Vector and array processors Chaining GPU 2 Flynn s taxonomy SISD: Single instruction operating on Single Data
Parallel Processing SIMD, Vector and GPU s EECS4201 Fall 2016 York University 1 Introduction Vector and array processors Chaining GPU 2 Flynn s taxonomy SISD: Single instruction operating on Single Data
Vector Architectures. Intensive Computation. Annalisa Massini 2017/2018
 Vector Architectures Intensive Computation Annalisa Massini 2017/2018 2 SIMD ARCHITECTURES 3 Computer Architecture - A Quantitative Approach, Fifth Edition Hennessy Patterson Chapter 4 - Data-Level Parallelism
Vector Architectures Intensive Computation Annalisa Massini 2017/2018 2 SIMD ARCHITECTURES 3 Computer Architecture - A Quantitative Approach, Fifth Edition Hennessy Patterson Chapter 4 - Data-Level Parallelism
EE 4683/5683: COMPUTER ARCHITECTURE
 EE 4683/5683: COMPUTER ARCHITECTURE Lecture 5B: Data Level Parallelism Avinash Kodi, kodi@ohio.edu Thanks to Morgan Kauffman and Krtse Asanovic Agenda 2 Flynn s Classification Data Level Parallelism Vector
EE 4683/5683: COMPUTER ARCHITECTURE Lecture 5B: Data Level Parallelism Avinash Kodi, kodi@ohio.edu Thanks to Morgan Kauffman and Krtse Asanovic Agenda 2 Flynn s Classification Data Level Parallelism Vector
UNIT III DATA-LEVEL PARALLELISM IN VECTOR, SIMD, AND GPU ARCHITECTURES
 UNIT III DATA-LEVEL PARALLELISM IN VECTOR, SIMD, AND GPU ARCHITECTURES Flynn s Taxonomy Single instruction stream, single data stream (SISD) Single instruction stream, multiple data streams (SIMD) o Vector
UNIT III DATA-LEVEL PARALLELISM IN VECTOR, SIMD, AND GPU ARCHITECTURES Flynn s Taxonomy Single instruction stream, single data stream (SISD) Single instruction stream, multiple data streams (SIMD) o Vector
COSC 6385 Computer Architecture. - Vector Processors
 COSC 6385 Computer Architecture - Vector Processors Spring 011 Vector Processors Chapter F of the 4 th edition (Chapter G of the 3 rd edition) Available in CD attached to the book Anybody having problems
COSC 6385 Computer Architecture - Vector Processors Spring 011 Vector Processors Chapter F of the 4 th edition (Chapter G of the 3 rd edition) Available in CD attached to the book Anybody having problems
Parallel Processing SIMD, Vector and GPU s
 Parallel Processing SIMD, ector and GPU s EECS4201 Comp. Architecture Fall 2017 York University 1 Introduction ector and array processors Chaining GPU 2 Flynn s taxonomy SISD: Single instruction operating
Parallel Processing SIMD, ector and GPU s EECS4201 Comp. Architecture Fall 2017 York University 1 Introduction ector and array processors Chaining GPU 2 Flynn s taxonomy SISD: Single instruction operating
Data-Level Parallelism in Vector and SIMD Architectures
 Data-Level Parallelism in Vector and SIMD Architectures Flynn Taxonomy of Computer Architectures (1972) It is based on parallelism of instruction streams and data streams SISD single instruction stream,
Data-Level Parallelism in Vector and SIMD Architectures Flynn Taxonomy of Computer Architectures (1972) It is based on parallelism of instruction streams and data streams SISD single instruction stream,
Data-Level Parallelism in Vector and SIMD Architectures
 Data-Level Parallelism in Vector and SIMD Architectures Flynn Taxonomy of Computer Architectures (1972) It is based on parallelism of instruction streams and data streams SISD single instruction stream,
Data-Level Parallelism in Vector and SIMD Architectures Flynn Taxonomy of Computer Architectures (1972) It is based on parallelism of instruction streams and data streams SISD single instruction stream,
Static Compiler Optimization Techniques
 Static Compiler Optimization Techniques We examined the following static ISA/compiler techniques aimed at improving pipelined CPU performance: Static pipeline scheduling. Loop unrolling. Static branch
Static Compiler Optimization Techniques We examined the following static ISA/compiler techniques aimed at improving pipelined CPU performance: Static pipeline scheduling. Loop unrolling. Static branch
Vector Processors. Abhishek Kulkarni Girish Subramanian
 Vector Processors Abhishek Kulkarni Girish Subramanian Classification of Parallel Architectures Hennessy and Patterson 1990; Sima, Fountain, and Kacsuk 1997 Why Vector Processors? Difficulties in exploiting
Vector Processors Abhishek Kulkarni Girish Subramanian Classification of Parallel Architectures Hennessy and Patterson 1990; Sima, Fountain, and Kacsuk 1997 Why Vector Processors? Difficulties in exploiting
Chapter 4 Data-Level Parallelism
 CS359: Computer Architecture Chapter 4 Data-Level Parallelism Yanyan Shen Department of Computer Science and Engineering Shanghai Jiao Tong University 1 Outline 4.1 Introduction 4.2 Vector Architecture
CS359: Computer Architecture Chapter 4 Data-Level Parallelism Yanyan Shen Department of Computer Science and Engineering Shanghai Jiao Tong University 1 Outline 4.1 Introduction 4.2 Vector Architecture
Lecture 21: Data Level Parallelism -- SIMD ISA Extensions for Multimedia and Roofline Performance Model
 Lecture 21: Data Level Parallelism -- SIMD ISA Extensions for Multimedia and Roofline Performance Model CSE 564 Computer Architecture Summer 2017 Department of Computer Science and Engineering Yonghong
Lecture 21: Data Level Parallelism -- SIMD ISA Extensions for Multimedia and Roofline Performance Model CSE 564 Computer Architecture Summer 2017 Department of Computer Science and Engineering Yonghong
CMPE 655 Multiple Processor Systems. SIMD/Vector Machines. Daniel Terrance Stephen Charles Rajkumar Ramadoss
 CMPE 655 Multiple Processor Systems SIMD/Vector Machines Daniel Terrance Stephen Charles Rajkumar Ramadoss SIMD Machines - Introduction Computers with an array of multiple processing elements (PE). Similar
CMPE 655 Multiple Processor Systems SIMD/Vector Machines Daniel Terrance Stephen Charles Rajkumar Ramadoss SIMD Machines - Introduction Computers with an array of multiple processing elements (PE). Similar
TDT 4260 lecture 9 spring semester 2015
 1 TDT 4260 lecture 9 spring semester 2015 Lasse Natvig, The CARD group Dept. of computer & information science NTNU 2 Lecture overview Repetition - CMP application classes - Vector MIPS Today Vector &
1 TDT 4260 lecture 9 spring semester 2015 Lasse Natvig, The CARD group Dept. of computer & information science NTNU 2 Lecture overview Repetition - CMP application classes - Vector MIPS Today Vector &
Introduction to Vector Processing
 Introduction to Vector Processing Motivation: Why vector Processing? Paper: VEC-1 Limits to Conventional Exploitation of ILP Flynn s 1972 Classification of Computer Architecture Data Parallelism and Architectures
Introduction to Vector Processing Motivation: Why vector Processing? Paper: VEC-1 Limits to Conventional Exploitation of ILP Flynn s 1972 Classification of Computer Architecture Data Parallelism and Architectures
ELE 455/555 Computer System Engineering. Section 4 Parallel Processing Class 1 Challenges
 ELE 455/555 Computer System Engineering Section 4 Class 1 Challenges Introduction Motivation Desire to provide more performance (processing) Scaling a single processor is limited Clock speeds Power concerns
ELE 455/555 Computer System Engineering Section 4 Class 1 Challenges Introduction Motivation Desire to provide more performance (processing) Scaling a single processor is limited Clock speeds Power concerns
Vector Processors. Kavitha Chandrasekar Sreesudhan Ramkumar
 Vector Processors Kavitha Chandrasekar Sreesudhan Ramkumar Agenda Why Vector processors Basic Vector Architecture Vector Execution time Vector load - store units and Vector memory systems Vector length
Vector Processors Kavitha Chandrasekar Sreesudhan Ramkumar Agenda Why Vector processors Basic Vector Architecture Vector Execution time Vector load - store units and Vector memory systems Vector length
Advanced Topics in Computer Architecture
 Advanced Topics in Computer Architecture Lecture 7 Data Level Parallelism: Vector Processors Marenglen Biba Department of Computer Science University of New York Tirana Cray I m certainly not inventing
Advanced Topics in Computer Architecture Lecture 7 Data Level Parallelism: Vector Processors Marenglen Biba Department of Computer Science University of New York Tirana Cray I m certainly not inventing
Advanced Computer Architecture
 Fiscal Year 2018 Ver. 2019-01-24a Course number: CSC.T433 School of Computing, Graduate major in Computer Science Advanced Computer Architecture 11. Multi-Processor: Distributed Memory and Shared Memory
Fiscal Year 2018 Ver. 2019-01-24a Course number: CSC.T433 School of Computing, Graduate major in Computer Science Advanced Computer Architecture 11. Multi-Processor: Distributed Memory and Shared Memory
Lecture 20: Data Level Parallelism -- Introduction and Vector Architecture
 Lecture 20: Data Level Parallelism -- Introduction and Vector Architecture CSE 564 Computer Architecture Summer 2017 Department of Computer Science and Engineering Yonghong Yan yan@oakland.edu www.secs.oakland.edu/~yan
Lecture 20: Data Level Parallelism -- Introduction and Vector Architecture CSE 564 Computer Architecture Summer 2017 Department of Computer Science and Engineering Yonghong Yan yan@oakland.edu www.secs.oakland.edu/~yan
Instruction and Data Streams
 Advaced Architectures Master Iformatics Eg. 2017/18 A.J.Proeça Data Parallelism 1 (vector & SIMD extesios) (most slides are borrowed) AJProeça, Advaced Architectures, MiEI, UMiho, 2017/18 1 Istructio ad
Advaced Architectures Master Iformatics Eg. 2017/18 A.J.Proeça Data Parallelism 1 (vector & SIMD extesios) (most slides are borrowed) AJProeça, Advaced Architectures, MiEI, UMiho, 2017/18 1 Istructio ad
CS 614 COMPUTER ARCHITECTURE II FALL 2005
 CS 614 COMPUTER ARCHITECTURE II FALL 2005 DUE : November 9, 2005 HOMEWORK III READ : - Portions of Chapters 5, 6, 7, 8, 9 and 14 of the Sima book and - Portions of Chapters 3, 4, Appendix A and Appendix
CS 614 COMPUTER ARCHITECTURE II FALL 2005 DUE : November 9, 2005 HOMEWORK III READ : - Portions of Chapters 5, 6, 7, 8, 9 and 14 of the Sima book and - Portions of Chapters 3, 4, Appendix A and Appendix
ILP Limit: Perfect/Infinite Hardware. Chapter 3: Limits of Instr Level Parallelism. ILP Limit: see Figure in book. Narrow Window Size
 Chapter 3: Limits of Instr Level Parallelism Ultimately, how much instruction level parallelism is there? Consider study by Wall (summarized in H & P) First, assume perfect/infinite hardware Then successively
Chapter 3: Limits of Instr Level Parallelism Ultimately, how much instruction level parallelism is there? Consider study by Wall (summarized in H & P) First, assume perfect/infinite hardware Then successively
Parallel Systems I The GPU architecture. Jan Lemeire
 Parallel Systems I The GPU architecture Jan Lemeire 2012-2013 Sequential program CPU pipeline Sequential pipelined execution Instruction-level parallelism (ILP): superscalar pipeline out-of-order execution
Parallel Systems I The GPU architecture Jan Lemeire 2012-2013 Sequential program CPU pipeline Sequential pipelined execution Instruction-level parallelism (ILP): superscalar pipeline out-of-order execution
Issues in Parallel Processing. Lecture for CPSC 5155 Edward Bosworth, Ph.D. Computer Science Department Columbus State University
 Issues in Parallel Processing Lecture for CPSC 5155 Edward Bosworth, Ph.D. Computer Science Department Columbus State University Introduction Goal: connecting multiple computers to get higher performance
Issues in Parallel Processing Lecture for CPSC 5155 Edward Bosworth, Ph.D. Computer Science Department Columbus State University Introduction Goal: connecting multiple computers to get higher performance
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface. 5 th. Edition. Chapter 6. Parallel Processors from Client to Cloud
 COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 6 Parallel Processors from Client to Cloud Introduction Goal: connecting multiple computers to get higher performance
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 6 Parallel Processors from Client to Cloud Introduction Goal: connecting multiple computers to get higher performance
Computer Architecture: SIMD and GPUs (Part I) Prof. Onur Mutlu Carnegie Mellon University
 Prof. Onur Mutlu Carnegie Mellon University") Computer Architecture: SIMD and GPUs (Part I) Prof. Onur Mutlu Carnegie Mellon University A Note on This Lecture These slides are partly from 18-447 Spring 2013, Computer Architecture, Lecture 15: Dataflow
Computer Architecture: SIMD and GPUs (Part I) Prof. Onur Mutlu Carnegie Mellon University A Note on This Lecture These slides are partly from 18-447 Spring 2013, Computer Architecture, Lecture 15: Dataflow
Chapter 04. Authors: John Hennessy & David Patterson. Copyright 2011, Elsevier Inc. All rights Reserved. 1
 Chapter 04 Authors: John Hennessy & David Patterson Copyright 2011, Elsevier Inc. All rights Reserved. 1 Figure 4.1 Potential speedup via parallelism from MIMD, SIMD, and both MIMD and SIMD over time for
Chapter 04 Authors: John Hennessy & David Patterson Copyright 2011, Elsevier Inc. All rights Reserved. 1 Figure 4.1 Potential speedup via parallelism from MIMD, SIMD, and both MIMD and SIMD over time for
Data-Parallel Architectures
 Data-Parallel Architectures Nima Honarmand Overview Data-Level Parallelism (DLP) vs. Thread-Level Parallelism (TLP) In DLP, parallelism arises from independent execution of the same code on a large number
Data-Parallel Architectures Nima Honarmand Overview Data-Level Parallelism (DLP) vs. Thread-Level Parallelism (TLP) In DLP, parallelism arises from independent execution of the same code on a large number
DATA-LEVEL PARALLELISM IN VECTOR, SIMD ANDGPU ARCHITECTURES(PART 2)
") 1 DATA-LEVEL PARALLELISM IN VECTOR, SIMD ANDGPU ARCHITECTURES(PART 2) Chapter 4 Appendix A (Computer Organization and Design Book) OUTLINE SIMD Instruction Set Extensions for Multimedia (4.3) Graphical
1 DATA-LEVEL PARALLELISM IN VECTOR, SIMD ANDGPU ARCHITECTURES(PART 2) Chapter 4 Appendix A (Computer Organization and Design Book) OUTLINE SIMD Instruction Set Extensions for Multimedia (4.3) Graphical
06-2 EE Lecture Transparency. Formatted 14:50, 4 December 1998 from lsli
 06-1 Vector Processors, Etc. 06-1 Some material from Appendix B of Hennessy and Patterson. Outline Memory Latency Hiding v. Reduction Program Characteristics Vector Processors Data Prefetch Processor /DRAM
06-1 Vector Processors, Etc. 06-1 Some material from Appendix B of Hennessy and Patterson. Outline Memory Latency Hiding v. Reduction Program Characteristics Vector Processors Data Prefetch Processor /DRAM
Computer Architecture 计算机体系结构. Lecture 10. Data-Level Parallelism and GPGPU 第十讲 数据级并行化与 GPGPU. Chao Li, PhD. 李超博士
 Computer Architecture 计算机体系结构 Lecture 10. Data-Level Parallelism and GPGPU 第十讲 数据级并行化与 GPGPU Chao Li, PhD. 李超博士 SJTU-SE346, Spring 2017 Review Thread, Multithreading, SMT CMP and multicore Benefits of
Computer Architecture 计算机体系结构 Lecture 10. Data-Level Parallelism and GPGPU 第十讲 数据级并行化与 GPGPU Chao Li, PhD. 李超博士 SJTU-SE346, Spring 2017 Review Thread, Multithreading, SMT CMP and multicore Benefits of
Adapted from instructor s. Organization and Design, 4th Edition, Patterson & Hennessy, 2008, MK]
![Adapted from instructor s. Organization and Design, 4th Edition, Patterson & Hennessy, 2008, MK]](/thumbs/83/88761675.jpg "Adapted from instructor s. Organization and Design, 4th Edition, Patterson & Hennessy, 2008, MK]") Review and Advanced d Concepts Adapted from instructor s supplementary material from Computer Organization and Design, 4th Edition, Patterson & Hennessy, 2008, MK] Pipelining Review PC IF/ID ID/EX EX/M
Review and Advanced d Concepts Adapted from instructor s supplementary material from Computer Organization and Design, 4th Edition, Patterson & Hennessy, 2008, MK] Pipelining Review PC IF/ID ID/EX EX/M
Hardware-based Speculation
 Hardware-based Speculation Hardware-based Speculation To exploit instruction-level parallelism, maintaining control dependences becomes an increasing burden. For a processor executing multiple instructions
Hardware-based Speculation Hardware-based Speculation To exploit instruction-level parallelism, maintaining control dependences becomes an increasing burden. For a processor executing multiple instructions
Computer Architecture A Quantitative Approach, Fifth Edition. Chapter 3. Instruction-Level Parallelism and Its Exploitation
 Computer Architecture A Quantitative Approach, Fifth Edition Chapter 3 Instruction-Level Parallelism and Its Exploitation Introduction Pipelining become universal technique in 1985 Overlaps execution of
Computer Architecture A Quantitative Approach, Fifth Edition Chapter 3 Instruction-Level Parallelism and Its Exploitation Introduction Pipelining become universal technique in 1985 Overlaps execution of
Chapter 3 Instruction-Level Parallelism and its Exploitation (Part 1)
") Chapter 3 Instruction-Level Parallelism and its Exploitation (Part 1) ILP vs. Parallel Computers Dynamic Scheduling (Section 3.4, 3.5) Dynamic Branch Prediction (Section 3.3) Hardware Speculation and Precise
Chapter 3 Instruction-Level Parallelism and its Exploitation (Part 1) ILP vs. Parallel Computers Dynamic Scheduling (Section 3.4, 3.5) Dynamic Branch Prediction (Section 3.3) Hardware Speculation and Precise
Adapted from David Patterson s slides on graduate computer architecture
 Mei Yang Adapted from David Patterson s slides on graduate computer architecture Introduction Basic Compiler Techniques for Exposing ILP Advanced Branch Prediction Dynamic Scheduling Hardware-Based Speculation
Mei Yang Adapted from David Patterson s slides on graduate computer architecture Introduction Basic Compiler Techniques for Exposing ILP Advanced Branch Prediction Dynamic Scheduling Hardware-Based Speculation
Asanovic/Devadas Spring Vector Computers. Krste Asanovic Laboratory for Computer Science Massachusetts Institute of Technology
 Vector Computers Krste Asanovic Laboratory for Computer Science Massachusetts Institute of Technology Supercomputers Definition of a supercomputer: Fastest machine in world at given task Any machine costing
Vector Computers Krste Asanovic Laboratory for Computer Science Massachusetts Institute of Technology Supercomputers Definition of a supercomputer: Fastest machine in world at given task Any machine costing
Pipelining and Vector Processing
 Chapter 8 Pipelining and Vector Processing 8 1 If the pipeline stages are heterogeneous, the slowest stage determines the flow rate of the entire pipeline. This leads to other stages idling. 8 2 Pipeline
Chapter 8 Pipelining and Vector Processing 8 1 If the pipeline stages are heterogeneous, the slowest stage determines the flow rate of the entire pipeline. This leads to other stages idling. 8 2 Pipeline
POLITECNICO DI MILANO. Advanced Topics on Heterogeneous System Architectures! Multiprocessors
 POLITECNICO DI MILANO Advanced Topics on Heterogeneous System Architectures! Multiprocessors Politecnico di Milano! Conference Room, Bld 20! 19 November, 2015! Antonio Miele! Marco Santambrogio! Politecnico
POLITECNICO DI MILANO Advanced Topics on Heterogeneous System Architectures! Multiprocessors Politecnico di Milano! Conference Room, Bld 20! 19 November, 2015! Antonio Miele! Marco Santambrogio! Politecnico
Pipelining and Vector Processing
 Pipelining and Vector Processing Chapter 8 S. Dandamudi Outline Basic concepts Handling resource conflicts Data hazards Handling branches Performance enhancements Example implementations Pentium PowerPC
Pipelining and Vector Processing Chapter 8 S. Dandamudi Outline Basic concepts Handling resource conflicts Data hazards Handling branches Performance enhancements Example implementations Pentium PowerPC
Multi-cycle Instructions in the Pipeline (Floating Point)
") Lecture 6 Multi-cycle Instructions in the Pipeline (Floating Point) Introduction to instruction level parallelism Recap: Support of multi-cycle instructions in a pipeline (App A.5) Recap: Superpipelining
Lecture 6 Multi-cycle Instructions in the Pipeline (Floating Point) Introduction to instruction level parallelism Recap: Support of multi-cycle instructions in a pipeline (App A.5) Recap: Superpipelining
7 Solutions. Solution 7.1. Solution 7.2
 7 Solutions Solution 7.1 There is no single right answer for this question. The purpose is to get students to think about parallelism present in their daily lives. The answer should have at least 10 activities
7 Solutions Solution 7.1 There is no single right answer for this question. The purpose is to get students to think about parallelism present in their daily lives. The answer should have at least 10 activities
ILP concepts (2.1) Basic compiler techniques (2.2) Reducing branch costs with prediction (2.3) Dynamic scheduling (2.4 and 2.5)
 Basic compiler techniques (2.2) Reducing branch costs with prediction (2.3) Dynamic scheduling (2.4 and 2.5)") Instruction-Level Parallelism and its Exploitation: PART 1 ILP concepts (2.1) Basic compiler techniques (2.2) Reducing branch costs with prediction (2.3) Dynamic scheduling (2.4 and 2.5) Project and Case
Instruction-Level Parallelism and its Exploitation: PART 1 ILP concepts (2.1) Basic compiler techniques (2.2) Reducing branch costs with prediction (2.3) Dynamic scheduling (2.4 and 2.5) Project and Case
ILP: Instruction Level Parallelism
 ILP: Instruction Level Parallelism Tassadaq Hussain Riphah International University Barcelona Supercomputing Center Universitat Politècnica de Catalunya Introduction Introduction Pipelining become universal
ILP: Instruction Level Parallelism Tassadaq Hussain Riphah International University Barcelona Supercomputing Center Universitat Politècnica de Catalunya Introduction Introduction Pipelining become universal
ESE 545 Computer Architecture. Data Level Parallelism (DLP), Vector Processing and Single-Instruction Multiple Data (SIMD) Computing
, Vector Processing and Single-Instruction Multiple Data (SIMD) Computing") Computer Architecture ESE 545 Computer Architecture Data Level Parallelism (DLP), Vector Processing and Single-Instruction Multiple Data (SIMD) Computing 1 Supercomputers Definition of a supercomputer:
Computer Architecture ESE 545 Computer Architecture Data Level Parallelism (DLP), Vector Processing and Single-Instruction Multiple Data (SIMD) Computing 1 Supercomputers Definition of a supercomputer:
CS152 Computer Architecture and Engineering CS252 Graduate Computer Architecture. VLIW, Vector, and Multithreaded Machines
 CS152 Computer Architecture and Engineering CS252 Graduate Computer Architecture VLIW, Vector, and Multithreaded Machines Assigned 3/24/2019 Problem Set #4 Due 4/5/2019 http://inst.eecs.berkeley.edu/~cs152/sp19
CS152 Computer Architecture and Engineering CS252 Graduate Computer Architecture VLIW, Vector, and Multithreaded Machines Assigned 3/24/2019 Problem Set #4 Due 4/5/2019 http://inst.eecs.berkeley.edu/~cs152/sp19
Online Course Evaluation. What we will do in the last week?
 Online Course Evaluation Please fill in the online form The link will expire on April 30 (next Monday) So far 10 students have filled in the online form Thank you if you completed it. 1 What we will do
Online Course Evaluation Please fill in the online form The link will expire on April 30 (next Monday) So far 10 students have filled in the online form Thank you if you completed it. 1 What we will do
Review of Last Lecture. CS 61C: Great Ideas in Computer Architecture. The Flynn Taxonomy, Intel SIMD Instructions. Great Idea #4: Parallelism.
 CS 61C: Great Ideas in Computer Architecture The Flynn Taxonomy, Intel SIMD Instructions Instructor: Justin Hsia 1 Review of Last Lecture Amdahl s Law limits benefits of parallelization Request Level Parallelism
CS 61C: Great Ideas in Computer Architecture The Flynn Taxonomy, Intel SIMD Instructions Instructor: Justin Hsia 1 Review of Last Lecture Amdahl s Law limits benefits of parallelization Request Level Parallelism
CS 61C: Great Ideas in Computer Architecture. The Flynn Taxonomy, Intel SIMD Instructions
 CS 61C: Great Ideas in Computer Architecture The Flynn Taxonomy, Intel SIMD Instructions Instructor: Justin Hsia 3/08/2013 Spring 2013 Lecture #19 1 Review of Last Lecture Amdahl s Law limits benefits
CS 61C: Great Ideas in Computer Architecture The Flynn Taxonomy, Intel SIMD Instructions Instructor: Justin Hsia 3/08/2013 Spring 2013 Lecture #19 1 Review of Last Lecture Amdahl s Law limits benefits
Copyright 2012, Elsevier Inc. All rights reserved.
 Computer Architecture A Quantitative Approach, Fifth Edition Chapter 1 Fundamentals of Quantitative Design and Analysis 1 Computer Technology Performance improvements: Improvements in semiconductor technology
Computer Architecture A Quantitative Approach, Fifth Edition Chapter 1 Fundamentals of Quantitative Design and Analysis 1 Computer Technology Performance improvements: Improvements in semiconductor technology
TDT4260/DT8803 COMPUTER ARCHITECTURE EXAM
 Norwegian University of Science and Technology Department of Computer and Information Science Page 1 of 13 Contact: Magnus Jahre (952 22 309) TDT4260/DT8803 COMPUTER ARCHITECTURE EXAM Monday 4. June Time:
Norwegian University of Science and Technology Department of Computer and Information Science Page 1 of 13 Contact: Magnus Jahre (952 22 309) TDT4260/DT8803 COMPUTER ARCHITECTURE EXAM Monday 4. June Time:
CS 152 Computer Architecture and Engineering. Lecture 17: Vector Computers
 CS 152 Computer Architecture and Engineering Lecture 17: Vector Computers Krste Asanovic Electrical Engineering and Computer Sciences University of California, Berkeley http://www.eecs.berkeley.edu/~krste
CS 152 Computer Architecture and Engineering Lecture 17: Vector Computers Krste Asanovic Electrical Engineering and Computer Sciences University of California, Berkeley http://www.eecs.berkeley.edu/~krste
CS 61C: Great Ideas in Computer Architecture. The Flynn Taxonomy, Intel SIMD Instructions
 CS 61C: Great Ideas in Computer Architecture The Flynn Taxonomy, Intel SIMD Instructions Guest Lecturer: Alan Christopher 3/08/2014 Spring 2014 -- Lecture #19 1 Neuromorphic Chips Researchers at IBM and
CS 61C: Great Ideas in Computer Architecture The Flynn Taxonomy, Intel SIMD Instructions Guest Lecturer: Alan Christopher 3/08/2014 Spring 2014 -- Lecture #19 1 Neuromorphic Chips Researchers at IBM and
Static vs. Dynamic Scheduling
 Static vs. Dynamic Scheduling Dynamic Scheduling Fast Requires complex hardware More power consumption May result in a slower clock Static Scheduling Done in S/W (compiler) Maybe not as fast Simpler processor
Static vs. Dynamic Scheduling Dynamic Scheduling Fast Requires complex hardware More power consumption May result in a slower clock Static Scheduling Done in S/W (compiler) Maybe not as fast Simpler processor
Computer Architecture Lecture 16: SIMD Processing (Vector and Array Processors)
") 18-447 Computer Architecture Lecture 16: SIMD Processing (Vector and Array Processors) Prof. Onur Mutlu Carnegie Mellon University Spring 2014, 2/24/2014 Lab 4 Reminder Lab 4a out Branch handling and branch
18-447 Computer Architecture Lecture 16: SIMD Processing (Vector and Array Processors) Prof. Onur Mutlu Carnegie Mellon University Spring 2014, 2/24/2014 Lab 4 Reminder Lab 4a out Branch handling and branch
POLITECNICO DI MILANO. Advanced Topics on Heterogeneous System Architectures! Multiprocessors
 POLITECNICO DI MILANO Advanced Topics on Heterogeneous System Architectures! Multiprocessors Politecnico di Milano! SeminarRoom, Bld 20! 30 November, 2017! Antonio Miele! Marco Santambrogio! Politecnico
POLITECNICO DI MILANO Advanced Topics on Heterogeneous System Architectures! Multiprocessors Politecnico di Milano! SeminarRoom, Bld 20! 30 November, 2017! Antonio Miele! Marco Santambrogio! Politecnico
COMPUTER ORGANIZATION AND DESIGN
 COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 6 Parallel Processors from Client to Cloud Introduction Goal: connecting multiple computers to get higher performance
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 6 Parallel Processors from Client to Cloud Introduction Goal: connecting multiple computers to get higher performance
Recall from Pipelining Review. Lecture 16: Instruction Level Parallelism and Dynamic Execution #1: Ideas to Reduce Stalls
 CS252 Graduate Computer Architecture Recall from Pipelining Review Lecture 16: Instruction Level Parallelism and Dynamic Execution #1: March 16, 2001 Prof. David A. Patterson Computer Science 252 Spring
CS252 Graduate Computer Architecture Recall from Pipelining Review Lecture 16: Instruction Level Parallelism and Dynamic Execution #1: March 16, 2001 Prof. David A. Patterson Computer Science 252 Spring
PIPELINE AND VECTOR PROCESSING
 PIPELINE AND VECTOR PROCESSING PIPELINING: Pipelining is a technique of decomposing a sequential process into sub operations, with each sub process being executed in a special dedicated segment that operates
PIPELINE AND VECTOR PROCESSING PIPELINING: Pipelining is a technique of decomposing a sequential process into sub operations, with each sub process being executed in a special dedicated segment that operates
Chapter 6 Solutions S-3
 6 Solutions Chapter 6 Solutions S-3 6.1 There is no single right answer for this question. The purpose is to get students to think about parallelism present in their daily lives. The answer should have
6 Solutions Chapter 6 Solutions S-3 6.1 There is no single right answer for this question. The purpose is to get students to think about parallelism present in their daily lives. The answer should have
Processor Architecture and Interconnect
 Processor Architecture and Interconnect What is Parallelism? Parallel processing is a term used to denote simultaneous computation in CPU for the purpose of measuring its computation speeds. Parallel Processing
Processor Architecture and Interconnect What is Parallelism? Parallel processing is a term used to denote simultaneous computation in CPU for the purpose of measuring its computation speeds. Parallel Processing
Good luck and have fun!
 Midterm Exam October 13, 2014 Name: Problem 1 2 3 4 total Points Exam rules: Time: 90 minutes. Individual test: No team work! Open book, open notes. No electronic devices, except an unprogrammed calculator.
Midterm Exam October 13, 2014 Name: Problem 1 2 3 4 total Points Exam rules: Time: 90 minutes. Individual test: No team work! Open book, open notes. No electronic devices, except an unprogrammed calculator.
Computer Architecture Practical 1 Pipelining
 Computer Architecture Issued: Monday 28 January 2008 Due: Friday 15 February 2008 at 4.30pm (at the ITO) This is the first of two practicals for the Computer Architecture module of CS3. Together the practicals
Computer Architecture Issued: Monday 28 January 2008 Due: Friday 15 February 2008 at 4.30pm (at the ITO) This is the first of two practicals for the Computer Architecture module of CS3. Together the practicals
Vector Processors and Graphics Processing Units (GPUs)
") Vector Processors and Graphics Processing Units (GPUs) Many slides from: Krste Asanovic Electrical Engineering and Computer Sciences University of California, Berkeley TA Evaluations Please fill out your
Vector Processors and Graphics Processing Units (GPUs) Many slides from: Krste Asanovic Electrical Engineering and Computer Sciences University of California, Berkeley TA Evaluations Please fill out your
CS 252 Graduate Computer Architecture. Lecture 7: Vector Computers
 CS 252 Graduate Computer Architecture Lecture 7: Vector Computers Krste Asanovic Electrical Engineering and Computer Sciences University of California, Berkeley http://www.eecs.berkeley.edu/~krste http://inst.cs.berkeley.edu/~cs252
CS 252 Graduate Computer Architecture Lecture 7: Vector Computers Krste Asanovic Electrical Engineering and Computer Sciences University of California, Berkeley http://www.eecs.berkeley.edu/~krste http://inst.cs.berkeley.edu/~cs252
ELEC 5200/6200 Computer Architecture and Design Fall 2016 Lecture 9: Instruction Level Parallelism
 ELEC 5200/6200 Computer Architecture and Design Fall 2016 Lecture 9: Instruction Level Parallelism Ujjwal Guin, Assistant Professor Department of Electrical and Computer Engineering Auburn University,
ELEC 5200/6200 Computer Architecture and Design Fall 2016 Lecture 9: Instruction Level Parallelism Ujjwal Guin, Assistant Professor Department of Electrical and Computer Engineering Auburn University,
Slide Set 8. for ENCM 501 in Winter Steve Norman, PhD, PEng
 Slide Set 8 for ENCM 501 in Winter 2018 Steve Norman, PhD, PEng Electrical & Computer Engineering Schulich School of Engineering University of Calgary March 2018 ENCM 501 Winter 2018 Slide Set 8 slide
Slide Set 8 for ENCM 501 in Winter 2018 Steve Norman, PhD, PEng Electrical & Computer Engineering Schulich School of Engineering University of Calgary March 2018 ENCM 501 Winter 2018 Slide Set 8 slide
Updated Exercises by Diana Franklin
 C-82 Appendix C Pipelining: Basic and Intermediate Concepts Updated Exercises by Diana Franklin C.1 [15/15/15/15/25/10/15] Use the following code fragment: Loop: LD R1,0(R2) ;load R1 from address
C-82 Appendix C Pipelining: Basic and Intermediate Concepts Updated Exercises by Diana Franklin C.1 [15/15/15/15/25/10/15] Use the following code fragment: Loop: LD R1,0(R2) ;load R1 from address
Unit 9 : Fundamentals of Parallel Processing
 Unit 9 : Fundamentals of Parallel Processing Lesson 1 : Types of Parallel Processing 1.1. Learning Objectives On completion of this lesson you will be able to : classify different types of parallel processing
Unit 9 : Fundamentals of Parallel Processing Lesson 1 : Types of Parallel Processing 1.1. Learning Objectives On completion of this lesson you will be able to : classify different types of parallel processing
SIMD Programming CS 240A, 2017
 SIMD Programming CS 240A, 2017 1 Flynn* Taxonomy, 1966 In 2013, SIMD and MIMD most common parallelism in architectures usually both in same system! Most common parallel processing programming style: Single
SIMD Programming CS 240A, 2017 1 Flynn* Taxonomy, 1966 In 2013, SIMD and MIMD most common parallelism in architectures usually both in same system! Most common parallel processing programming style: Single
4.10 Historical Perspective and References
 334 Chapter Four Data-Level Parallelism in Vector, SIMD, and GPU Architectures 4.10 Historical Perspective and References Section L.6 (available online) features a discussion on the Illiac IV (a representative
334 Chapter Four Data-Level Parallelism in Vector, SIMD, and GPU Architectures 4.10 Historical Perspective and References Section L.6 (available online) features a discussion on the Illiac IV (a representative
Announcements. Lecture Vector Processors. Review: Memory Consistency Problem. Review: Multi-core Processors. Readings for this lecture
 Announcements Readings for this lecture H&P 4 th edition, Appendix F Required paper Lecture 14: Vector Processors Department of Electrical Engineering Stanford University HW3 available on online Due on
Announcements Readings for this lecture H&P 4 th edition, Appendix F Required paper Lecture 14: Vector Processors Department of Electrical Engineering Stanford University HW3 available on online Due on
EC 513 Computer Architecture
 EC 513 Computer Architecture Complex Pipelining: Superscalar Prof. Michel A. Kinsy Summary Concepts Von Neumann architecture = stored-program computer architecture Self-Modifying Code Princeton architecture
EC 513 Computer Architecture Complex Pipelining: Superscalar Prof. Michel A. Kinsy Summary Concepts Von Neumann architecture = stored-program computer architecture Self-Modifying Code Princeton architecture
CS 590: High Performance Computing. Parallel Computer Architectures. Lab 1 Starts Today. Already posted on Canvas (under Assignment) Let s look at it
 Let s look at it") Lab 1 Starts Today Already posted on Canvas (under Assignment) Let s look at it CS 590: High Performance Computing Parallel Computer Architectures Fengguang Song Department of Computer Science IUPUI 1
Lab 1 Starts Today Already posted on Canvas (under Assignment) Let s look at it CS 590: High Performance Computing Parallel Computer Architectures Fengguang Song Department of Computer Science IUPUI 1
Fundamentals of Quantitative Design and Analysis
 Fundamentals of Quantitative Design and Analysis Dr. Jiang Li Adapted from the slides provided by the authors Computer Technology Performance improvements: Improvements in semiconductor technology Feature
Fundamentals of Quantitative Design and Analysis Dr. Jiang Li Adapted from the slides provided by the authors Computer Technology Performance improvements: Improvements in semiconductor technology Feature
Vector Processors. Department of Electrical Engineering Stanford University Lecture 14-1
 Lecture 14: Vector Processors Department of Electrical Engineering Stanford University http://eeclass.stanford.edu/ee382a Lecture 14-1 Announcements Readings for this lecture H&P 4 th edition, Appendix
Lecture 14: Vector Processors Department of Electrical Engineering Stanford University http://eeclass.stanford.edu/ee382a Lecture 14-1 Announcements Readings for this lecture H&P 4 th edition, Appendix
Flynn Taxonomy Data-Level Parallelism
 ecture 27 Computer Science 61C Spring 2017 March 22nd, 2017 Flynn Taxonomy Data-Level Parallelism 1 New-School Machine Structures (It s a bit more complicated!) Software Hardware Parallel Requests Assigned
ecture 27 Computer Science 61C Spring 2017 March 22nd, 2017 Flynn Taxonomy Data-Level Parallelism 1 New-School Machine Structures (It s a bit more complicated!) Software Hardware Parallel Requests Assigned
Computer Architecture A Quantitative Approach, Fifth Edition. Chapter 1. Copyright 2012, Elsevier Inc. All rights reserved. Computer Technology
 Computer Architecture A Quantitative Approach, Fifth Edition Chapter 1 Fundamentals of Quantitative Design and Analysis 1 Computer Technology Performance improvements: Improvements in semiconductor technology
Computer Architecture A Quantitative Approach, Fifth Edition Chapter 1 Fundamentals of Quantitative Design and Analysis 1 Computer Technology Performance improvements: Improvements in semiconductor technology
Advanced Computer Architecture CMSC 611 Homework 3. Due in class Oct 17 th, 2012
 Advanced Computer Architecture CMSC 611 Homework 3 Due in class Oct 17 th, 2012 (Show your work to receive partial credit) 1) For the following code snippet list the data dependencies and rewrite the code
Advanced Computer Architecture CMSC 611 Homework 3 Due in class Oct 17 th, 2012 (Show your work to receive partial credit) 1) For the following code snippet list the data dependencies and rewrite the code
NOW Handout Page 1. Alternative Model:Vector Processing. EECS 252 Graduate Computer Architecture. Lec10 Vector Processing. DLXV Vector Instructions
 Alternative Model:Vector Processing EECS 252 Graduate Computer Architecture Lec10 Vector Processing Vector processors have high-level operations that work on linear arrays of numbers: "vectors" SCALAR
Alternative Model:Vector Processing EECS 252 Graduate Computer Architecture Lec10 Vector Processing Vector processors have high-level operations that work on linear arrays of numbers: "vectors" SCALAR
CS 152 Computer Architecture and Engineering. Lecture 16: Graphics Processing Units (GPUs)
") CS 152 Computer Architecture and Engineering Lecture 16: Graphics Processing Units (GPUs) Dr. George Michelogiannakis EECS, University of California at Berkeley CRD, Lawrence Berkeley National Laboratory
CS 152 Computer Architecture and Engineering Lecture 16: Graphics Processing Units (GPUs) Dr. George Michelogiannakis EECS, University of California at Berkeley CRD, Lawrence Berkeley National Laboratory
Instruction-Level Parallelism and Its Exploitation
 Chapter 2 Instruction-Level Parallelism and Its Exploitation 1 Overview Instruction level parallelism Dynamic Scheduling Techniques es Scoreboarding Tomasulo s s Algorithm Reducing Branch Cost with Dynamic
Chapter 2 Instruction-Level Parallelism and Its Exploitation 1 Overview Instruction level parallelism Dynamic Scheduling Techniques es Scoreboarding Tomasulo s s Algorithm Reducing Branch Cost with Dynamic
Copyright 2012, Elsevier Inc. All rights reserved.
 Computer Architecture A Quantitative Approach, Fifth Edition Chapter 3 Instruction-Level Parallelism and Its Exploitation 1 Branch Prediction Basic 2-bit predictor: For each branch: Predict taken or not
Computer Architecture A Quantitative Approach, Fifth Edition Chapter 3 Instruction-Level Parallelism and Its Exploitation 1 Branch Prediction Basic 2-bit predictor: For each branch: Predict taken or not
Processor: Superscalars Dynamic Scheduling
 Processor: Superscalars Dynamic Scheduling Z. Jerry Shi Assistant Professor of Computer Science and Engineering University of Connecticut * Slides adapted from Blumrich&Gschwind/ELE475 03, Peh/ELE475 (Princeton),
Processor: Superscalars Dynamic Scheduling Z. Jerry Shi Assistant Professor of Computer Science and Engineering University of Connecticut * Slides adapted from Blumrich&Gschwind/ELE475 03, Peh/ELE475 (Princeton),
CSE 160 Lecture 10. Instruction level parallelism (ILP) Vectorization
 Vectorization") CSE 160 Lecture 10 Instruction level parallelism (ILP) Vectorization Announcements Quiz on Friday Signup for Friday labs sessions in APM 2013 Scott B. Baden / CSE 160 / Winter 2013 2 Particle simulation
CSE 160 Lecture 10 Instruction level parallelism (ILP) Vectorization Announcements Quiz on Friday Signup for Friday labs sessions in APM 2013 Scott B. Baden / CSE 160 / Winter 2013 2 Particle simulation
Page 1. Recall from Pipelining Review. Lecture 16: Instruction Level Parallelism and Dynamic Execution #1: Ideas to Reduce Stalls
 CS252 Graduate Computer Architecture Recall from Pipelining Review Lecture 16: Instruction Level Parallelism and Dynamic Execution #1: March 16, 2001 Prof. David A. Patterson Computer Science 252 Spring
CS252 Graduate Computer Architecture Recall from Pipelining Review Lecture 16: Instruction Level Parallelism and Dynamic Execution #1: March 16, 2001 Prof. David A. Patterson Computer Science 252 Spring
EE 4683/5683: COMPUTER ARCHITECTURE
 EE 4683/5683: COMPUTER ARCHITECTURE Lecture 4A: Instruction Level Parallelism - Static Scheduling Avinash Kodi, kodi@ohio.edu Agenda 2 Dependences RAW, WAR, WAW Static Scheduling Loop-carried Dependence
EE 4683/5683: COMPUTER ARCHITECTURE Lecture 4A: Instruction Level Parallelism - Static Scheduling Avinash Kodi, kodi@ohio.edu Agenda 2 Dependences RAW, WAR, WAW Static Scheduling Loop-carried Dependence
EECS4201 Computer Architecture
 Computer Architecture A Quantitative Approach, Fifth Edition Chapter 1 Fundamentals of Quantitative Design and Analysis These slides are based on the slides provided by the publisher. The slides will be
Computer Architecture A Quantitative Approach, Fifth Edition Chapter 1 Fundamentals of Quantitative Design and Analysis These slides are based on the slides provided by the publisher. The slides will be
CS152 Computer Architecture and Engineering VLIW, Vector, and Multithreaded Machines
 CS152 Computer Architecture and Engineering VLIW, Vector, and Multithreaded Machines Assigned April 7 Problem Set #5 Due April 21 http://inst.eecs.berkeley.edu/~cs152/sp09 The problem sets are intended
CS152 Computer Architecture and Engineering VLIW, Vector, and Multithreaded Machines Assigned April 7 Problem Set #5 Due April 21 http://inst.eecs.berkeley.edu/~cs152/sp09 The problem sets are intended
Several Common Compiler Strategies. Instruction scheduling Loop unrolling Static Branch Prediction Software Pipelining
 Several Common Compiler Strategies Instruction scheduling Loop unrolling Static Branch Prediction Software Pipelining Basic Instruction Scheduling Reschedule the order of the instructions to reduce the
Several Common Compiler Strategies Instruction scheduling Loop unrolling Static Branch Prediction Software Pipelining Basic Instruction Scheduling Reschedule the order of the instructions to reduce the
Pipelining and Exploiting Instruction-Level Parallelism (ILP)
") Pipelining and Exploiting Instruction-Level Parallelism (ILP) Pipelining and Instruction-Level Parallelism (ILP). Definition of basic instruction block Increasing Instruction-Level Parallelism (ILP) &
Pipelining and Exploiting Instruction-Level Parallelism (ILP) Pipelining and Instruction-Level Parallelism (ILP). Definition of basic instruction block Increasing Instruction-Level Parallelism (ILP) &
Instruction-Level Parallelism (ILP)
") Instruction Level Parallelism Instruction-Level Parallelism (ILP): overlap the execution of instructions to improve performance 2 approaches to exploit ILP: 1. Rely on hardware to help discover and exploit
Instruction Level Parallelism Instruction-Level Parallelism (ILP): overlap the execution of instructions to improve performance 2 approaches to exploit ILP: 1. Rely on hardware to help discover and exploit
CISC 662 Graduate Computer Architecture Lecture 13 - CPI < 1
 CISC 662 Graduate Computer Architecture Lecture 13 - CPI < 1 Michela Taufer http://www.cis.udel.edu/~taufer/teaching/cis662f07 Powerpoint Lecture Notes from John Hennessy and David Patterson s: Computer
CISC 662 Graduate Computer Architecture Lecture 13 - CPI < 1 Michela Taufer http://www.cis.udel.edu/~taufer/teaching/cis662f07 Powerpoint Lecture Notes from John Hennessy and David Patterson s: Computer
CS 152 Computer Architecture and Engineering. Lecture 16: Vector Computers
 CS 152 Computer Architecture and Engineering Lecture 16: Vector Computers Krste Asanovic Electrical Engineering and Computer Sciences University of California, Berkeley http://www.eecs.berkeley.edu/~krste
CS 152 Computer Architecture and Engineering Lecture 16: Vector Computers Krste Asanovic Electrical Engineering and Computer Sciences University of California, Berkeley http://www.eecs.berkeley.edu/~krste
Reduction of Data Hazards Stalls with Dynamic Scheduling So far we have dealt with data hazards in instruction pipelines by:
 Reduction of Data Hazards Stalls with Dynamic Scheduling So far we have dealt with data hazards in instruction pipelines by: Result forwarding (register bypassing) to reduce or eliminate stalls needed
Reduction of Data Hazards Stalls with Dynamic Scheduling So far we have dealt with data hazards in instruction pipelines by: Result forwarding (register bypassing) to reduce or eliminate stalls needed
CS 2410 Mid term (fall 2018)
") CS 2410 Mid term (fall 2018) Name: Question 1 (6+6+3=15 points): Consider two machines, the first being a 5-stage operating at 1ns clock and the second is a 12-stage operating at 0.7ns clock. Due to data
CS 2410 Mid term (fall 2018) Name: Question 1 (6+6+3=15 points): Consider two machines, the first being a 5-stage operating at 1ns clock and the second is a 12-stage operating at 0.7ns clock. Due to data
Computer Architecture and Engineering CS152 Quiz #4 April 11th, 2011 Professor Krste Asanović
 Computer Architecture and Engineering CS152 Quiz #4 April 11th, 2011 Professor Krste Asanović Name: This is a closed book, closed notes exam. 80 Minutes 17 Pages Notes: Not all questions are
Computer Architecture and Engineering CS152 Quiz #4 April 11th, 2011 Professor Krste Asanović Name: This is a closed book, closed notes exam. 80 Minutes 17 Pages Notes: Not all questions are
Instruction Level Parallelism
 Instruction Level Parallelism The potential overlap among instruction execution is called Instruction Level Parallelism (ILP) since instructions can be executed in parallel. There are mainly two approaches
Instruction Level Parallelism The potential overlap among instruction execution is called Instruction Level Parallelism (ILP) since instructions can be executed in parallel. There are mainly two approaches