Parallel Systems I The GPU architecture. Jan Lemeire
|
|
|
- Allen Briggs
- 5 years ago
- Views:
Transcription
1 Parallel Systems I The GPU architecture Jan Lemeire
2 Sequential program CPU pipeline Sequential pipelined execution Instruction-level parallelism (ILP): superscalar pipeline out-of-order execution Limitations: max ILP = 4 Reached Maximal clock frequency reached Branch prediction, caching, forwarding, More improvement possible? Computerarchitectuur
3 This is The End? Computerarchitectuur

4 Way out: parallel processors relying on explicit parallel software Computerarchitectuur
5 Chuck Moore, "DATA PROCESSING IN EXASCALE-CLASS COMPUTER SYSTEMS", The Salishan Conference on High Speed Computing, 2011.
 Courtesy")
6 Parallel processors GPUs (arrays) Courtesy of
7 Thus: The Future looks Parallel Computerarchitectuur

8 Conclusions Sequential world Changed into 20/12/2 8

9 Conclusions Parallel world 20/12/2 9



10 GPU vs CPU Peak Performance Trends Million triangles/second 3 Billion transistors GPU GPU peak performance has grown aggressively. Hardware has kept up with Moore s law ,000 triangles/second 800,000 transistors GPU Source : NVIDIA 10

11 Graphical Processing Units (GPUs) Many-core GPU 94 fps (AMD Tahiti Pro) GPU: 1-3 TeraFlop/second Multi-core CPU instead of GigaFlop/second for CPU Courtesy: John Owens igure 1.1. Enlarging Perform ance Gap betw een GPUs and CPUs. Computerarchitectuur
 that costed 3.")
12 Supercomputing for free FASTRA at university of Antwerp Collection of 8 graphical cards in PC FASTRA 8 cards = 8x128 processors = 4000 euro Similar performance as University s supercomputer (512 regular desktop PCs) that costed 3.5 million euro in 2005 Computerarchitectuur

13 Why are GPUs faster? Devote transistors to computation
14 GPU processor pipeline ±24 stages in-order execution!! no branch prediction!! no forwarding!! no register renaming!! Memory system: relatively small Until recently no caching On the other hand: much more registers (see later) New concepts: 1. Multithreading 2. SIMD Computerarchitectuur
15 Overhead Multithreading on CPU 1 process/thread active per core When activating another thread: context switch Stop program execution: flush pipeline (let all instructions finish) Save state of process/thread into Process Control Block : registers, program counter and operating system-specific data Restore state of activated thread Restart program execution and refill the pipeline Computerarchitectuur
16 Hardware threads In several modern CPUs typically 2HW threads Devote extra hardware for process state Context switch by hardware (almost) no overhead Within 1 cycle! Instructions in flight from different threads Computerarchitectuur
17 Multithreading Performing multiple threads of execution in parallel Replicate registers, PC, etc. Fast switching between threads Fine-grain multithreading Switch threads after each cycle Interleave instruction execution If one thread stalls, others are executed Coarse-grain multithreading Only switch on long stall (e.g., L2-cache miss) Simplifies hardware, but doesn t hide short stalls (eg, data hazards) 7.5 Hardware Multithreading Chapter 7 Multicores, Multiprocessors, and Clusters 17
18 Simultaneous Multithreading In multiple-issue dynamically scheduled processor Schedule instructions from multiple threads Instructions from independent threads execute when function units are available Within threads, dependencies handled by scheduling and register renaming Example: Intel Pentium-4 HT Two threads: duplicated registers, shared function units and caches Chapter 7 Multicores, Multiprocessors, and Clusters 18


19 Multithreading Example Chapter 7 Multicores, Multiprocessors, and Clusters 19
20 Benefits of fine-grained multithreading Independent instructions (no bubbles) More time between instructions: possibility for latency hiding Hide memory accesses If pipeline full Forwarding not necessary Branch prediction not necessary Computerarchitectuur
21 Instruction and Data Streams An alternate classification Instruction Streams Single Multiple Single SISD: Intel Pentium 4 MISD: No examples today Data Streams Multiple SIMD: SSE instructions of x86 MIMD: Intel Xeon e5345 SPMD: Single Program Multiple Data A parallel program on a MIMD computer Conditional code for different processors 7.6 SISD, MIMD, SIMD, SPMD, and Vector Chapter 7 Multicores, Multiprocessors, and Clusters 21

22 SIMD Operate elementwise on vectors of data E.g., MMX and SSE instructions in x86 Multiple data elements in 128-bit wide registers All processors execute the same instruction at the same time Each with different data address, etc. Simplifies synchronization Reduced instruction control hardware Works best for highly data-parallel applications Chapter 7 Multicores, Multiprocessors, and Clusters 22
23 Vector Processors Highly pipelined function units Stream data from/to vector registers to units Data collected from memory into registers Results stored from registers to memory Example: Vector extension to MIPS element registers (64-bit elements) Vector instructions lv, sv: load/store vector addv.d: add vectors of double addvs.d: add scalar to each element of vector of double Significantly reduces instruction-fetch bandwidth Chapter 7 Multicores, Multiprocessors, and Clusters 23
24 Example: DAXPY (Y = a X + Y) Conventional MIPS code l.d $f0,a($sp) ;load scalar a addiu r4,$s0,#512 ;upper bound of what to load loop: l.d $f2,0($s0) ;load x(i) mul.d $f2,$f2,$f0 ;a x(i) l.d $f4,0($s1) ;load y(i) add.d $f4,$f4,$f2 ;a x(i) + y(i) s.d $f4,0($s1) ;store into y(i) addiu $s0,$s0,#8 ;increment index to x addiu $s1,$s1,#8 ;increment index to y subu $t0,r4,$s0 ;compute bound bne $t0,$zero,loop ;check if done Vector MIPS code l.d $f0,a($sp) ;load scalar a lv $v1,0($s0) ;load vector x mulvs.d $v2,$v1,$f0 ;vector-scalar multiply lv $v3,0($s1) ;load vector y addv.d $v4,$v2,$v3 ;add y to product sv $v4,0($s1) ;store the result Chapter 7 Multicores, Multiprocessors, and Clusters 24
25 Vector vs. Scalar Vector architectures and compilers Simplify data-parallel programming Explicit statement of absence of loop-carried dependences Reduced checking in hardware Regular access patterns benefit from interleaved and burst memory Avoid control hazards by avoiding loops More general than ad-hoc media extensions (such as MMX, SSE) Better match with compiler technology Chapter 7 Multicores, Multiprocessors, and Clusters 25
26 Now: the GPU architecture Computerarchitectuur

27 1 Streaming Multiprocessor hardware threads grouped by 32 threads (warps), executing in lockstep (SIMD) In each cycle, a warp is selected of which the next instruction is put in the pipeline Ps: cache only in new models Computerarchitectuur
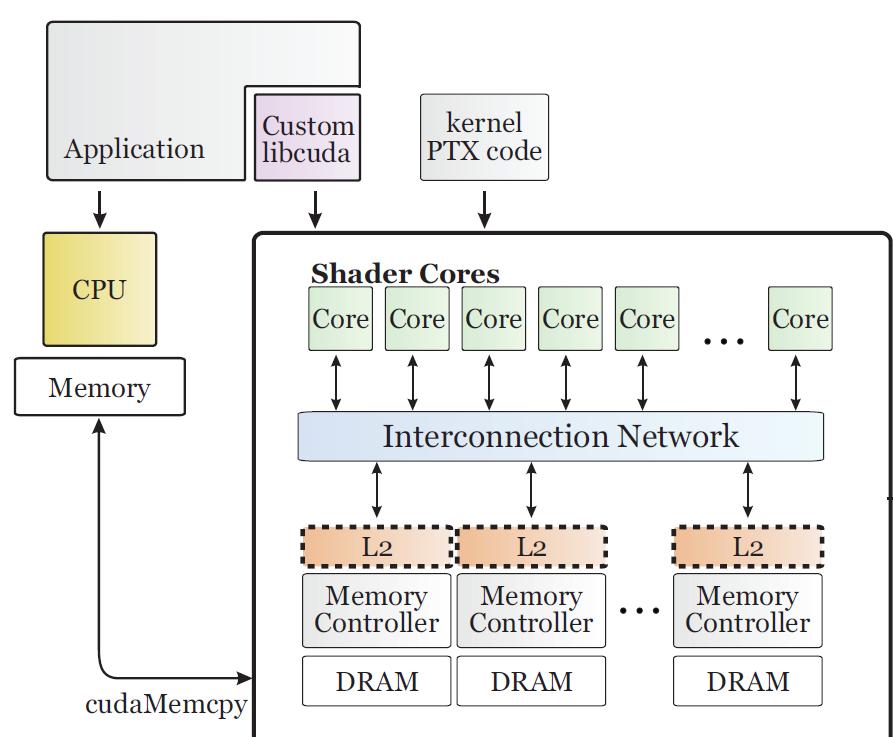
28 Computerarchitectuur
29 Peak GPU Performance GPUs consist of Streaming MultiProcessors (MPs) grouping a number of Scalar Processors (SPs) Nvidia GTX 280: 30MPs x 8 SPs/MP x 2FLOPs/instr/SP x 1 instr/clock x 1.3 GHz = 624 GFlops Nvidia Tesla C2050: 14 MPs x 32 SPs/MP x 2FLOPs/instr/SP x 1 instr/clock x 1.15 GHz (clocks per second) = 1030 GFlops Computerarchitectuur
30 Example: pixel transformation Kernel executed by each thread, each processing 1 pixel GPU = Zero-overhead thread processor usgn_8 transform(usgn_8 in, sgn_16 gain, sgn_16 gain_divide, sgn_8 offset) { sgn_32 x; x = (in * gain / gain_divide) + offset; } if (x < 0) x = 0; if (x > 255) x = 255; return x; Computerarchitectuur
31 Computerarchitectuur 31




32 Example: real-time image processing Images of 20MegaPixels Pixel rescaling lens correction pattern detection CPU gives only 4 fps next generation machines need 50fps Computerarchitectuur 32
33 CPU: 4 fps GPU: 70 fps Computerarchitectuur 33

34 However: processing power not for free Computerarchitectuur
35 Obstacle 1 Hard(er) to implement Computerarchitectuur 35
36 Obstacle 2 Hard(er) to get efficiency Computerarchitectuur 36
37 Computerarchitectuur


38 X86 to GPU GUDI - A combined GP- GPU/FPGA desktop system for accelerating image processing applications 18 mei 2011


39 Example 1: convolution Parallelism: +++ Locality: ++ Work/pixel: ++ GUDI - A combined GP- GPU/FPGA desktop system for accelerating image processing applications 23 september
Issues in Parallel Processing. Lecture for CPSC 5155 Edward Bosworth, Ph.D. Computer Science Department Columbus State University
 Issues in Parallel Processing Lecture for CPSC 5155 Edward Bosworth, Ph.D. Computer Science Department Columbus State University Introduction Goal: connecting multiple computers to get higher performance
Issues in Parallel Processing Lecture for CPSC 5155 Edward Bosworth, Ph.D. Computer Science Department Columbus State University Introduction Goal: connecting multiple computers to get higher performance
ELE 455/555 Computer System Engineering. Section 4 Parallel Processing Class 1 Challenges
 ELE 455/555 Computer System Engineering Section 4 Class 1 Challenges Introduction Motivation Desire to provide more performance (processing) Scaling a single processor is limited Clock speeds Power concerns
ELE 455/555 Computer System Engineering Section 4 Class 1 Challenges Introduction Motivation Desire to provide more performance (processing) Scaling a single processor is limited Clock speeds Power concerns
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface. 5 th. Edition. Chapter 6. Parallel Processors from Client to Cloud
 COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 6 Parallel Processors from Client to Cloud Introduction Goal: connecting multiple computers to get higher performance
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 6 Parallel Processors from Client to Cloud Introduction Goal: connecting multiple computers to get higher performance
Adapted from instructor s. Organization and Design, 4th Edition, Patterson & Hennessy, 2008, MK]
![Adapted from instructor s. Organization and Design, 4th Edition, Patterson & Hennessy, 2008, MK]](/thumbs/83/88761675.jpg "Adapted from instructor s. Organization and Design, 4th Edition, Patterson & Hennessy, 2008, MK]") Review and Advanced d Concepts Adapted from instructor s supplementary material from Computer Organization and Design, 4th Edition, Patterson & Hennessy, 2008, MK] Pipelining Review PC IF/ID ID/EX EX/M
Review and Advanced d Concepts Adapted from instructor s supplementary material from Computer Organization and Design, 4th Edition, Patterson & Hennessy, 2008, MK] Pipelining Review PC IF/ID ID/EX EX/M
COMPUTER ORGANIZATION AND DESIGN
 COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 6 Parallel Processors from Client to Cloud Introduction Goal: connecting multiple computers to get higher performance
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 6 Parallel Processors from Client to Cloud Introduction Goal: connecting multiple computers to get higher performance
Chapter 7. Multicores, Multiprocessors, and Clusters
 Chapter 7 Multicores, Multiprocessors, and Clusters Introduction Goal: connecting multiple computers to get higher performance Multiprocessors Scalability, availability, power efficiency Job-level (process-level)
Chapter 7 Multicores, Multiprocessors, and Clusters Introduction Goal: connecting multiple computers to get higher performance Multiprocessors Scalability, availability, power efficiency Job-level (process-level)
Chapter 7. Multicores, Multiprocessors, and
 Chapter 7 Multicores, Multiprocessors, and Clusters Introduction Goal: connecting multiple computers to get higher h performance Multiprocessors Scalability, availability, power efficiency Job-level (process-level)
Chapter 7 Multicores, Multiprocessors, and Clusters Introduction Goal: connecting multiple computers to get higher h performance Multiprocessors Scalability, availability, power efficiency Job-level (process-level)
General introduction: GPUs and the realm of parallel architectures
 General introduction: GPUs and the realm of parallel architectures GPU Computing Training August 17-19 th 2015 Jan Lemeire (jan.lemeire@vub.ac.be) Graduated as Engineer in 1994 at VUB Worked for 4 years
General introduction: GPUs and the realm of parallel architectures GPU Computing Training August 17-19 th 2015 Jan Lemeire (jan.lemeire@vub.ac.be) Graduated as Engineer in 1994 at VUB Worked for 4 years
Parallel computing and GPU introduction
 國立台灣大學 National Taiwan University Parallel computing and GPU introduction 黃子桓 tzhuan@gmail.com Agenda Parallel computing GPU introduction Interconnection networks Parallel benchmark Parallel programming
國立台灣大學 National Taiwan University Parallel computing and GPU introduction 黃子桓 tzhuan@gmail.com Agenda Parallel computing GPU introduction Interconnection networks Parallel benchmark Parallel programming
Multiple Issue and Static Scheduling. Multiple Issue. MSc Informatics Eng. Beyond Instruction-Level Parallelism
 Computing Systems & Performance Beyond Instruction-Level Parallelism MSc Informatics Eng. 2012/13 A.J.Proença From ILP to Multithreading and Shared Cache (most slides are borrowed) When exploiting ILP,
Computing Systems & Performance Beyond Instruction-Level Parallelism MSc Informatics Eng. 2012/13 A.J.Proença From ILP to Multithreading and Shared Cache (most slides are borrowed) When exploiting ILP,
CS 590: High Performance Computing. Parallel Computer Architectures. Lab 1 Starts Today. Already posted on Canvas (under Assignment) Let s look at it
 Let s look at it") Lab 1 Starts Today Already posted on Canvas (under Assignment) Let s look at it CS 590: High Performance Computing Parallel Computer Architectures Fengguang Song Department of Computer Science IUPUI 1
Lab 1 Starts Today Already posted on Canvas (under Assignment) Let s look at it CS 590: High Performance Computing Parallel Computer Architectures Fengguang Song Department of Computer Science IUPUI 1
Static Compiler Optimization Techniques
 Static Compiler Optimization Techniques We examined the following static ISA/compiler techniques aimed at improving pipelined CPU performance: Static pipeline scheduling. Loop unrolling. Static branch
Static Compiler Optimization Techniques We examined the following static ISA/compiler techniques aimed at improving pipelined CPU performance: Static pipeline scheduling. Loop unrolling. Static branch
Vector Processing. Computer Organization Architectures for Embedded Computing. Friday, 13 December 13
 Vector Processing Computer Organization Architectures for Embedded Computing Friday, 13 December 13 Many slides adapted from: Computer Organization and Design, Patterson & Hennessy 4th Edition, 2011, MK
Vector Processing Computer Organization Architectures for Embedded Computing Friday, 13 December 13 Many slides adapted from: Computer Organization and Design, Patterson & Hennessy 4th Edition, 2011, MK
Chapter 7. Multicores, Multiprocessors, and Clusters
 Chapter 7 Multicores, Multiprocessors, and Clusters Introduction Goal: connecting multiple computers to get higher performance Multiprocessors Scalability, availability, power efficiency Job-level (process-level)
Chapter 7 Multicores, Multiprocessors, and Clusters Introduction Goal: connecting multiple computers to get higher performance Multiprocessors Scalability, availability, power efficiency Job-level (process-level)
! An alternate classification. Introduction. ! Vector architectures (slides 5 to 18) ! SIMD & extensions (slides 19 to 23)
 ! SIMD & extensions (slides 19 to 23)") Master Informatics Eng. Advanced Architectures 2015/16 A.J.Proença Data Parallelism 1 (vector, SIMD ext., GPU) (most slides are borrowed) Instruction and Data Streams An alternate classification Instruction
Master Informatics Eng. Advanced Architectures 2015/16 A.J.Proença Data Parallelism 1 (vector, SIMD ext., GPU) (most slides are borrowed) Instruction and Data Streams An alternate classification Instruction
Course II Parallel Computer Architecture. Week 2-3 by Dr. Putu Harry Gunawan
 Course II Parallel Computer Architecture Week 2-3 by Dr. Putu Harry Gunawan www.phg-simulation-laboratory.com Review Review Review Review Review Review Review Review Review Review Review Review Processor
Course II Parallel Computer Architecture Week 2-3 by Dr. Putu Harry Gunawan www.phg-simulation-laboratory.com Review Review Review Review Review Review Review Review Review Review Review Review Processor
Advanced Computer Architecture
 Fiscal Year 2018 Ver. 2019-01-24a Course number: CSC.T433 School of Computing, Graduate major in Computer Science Advanced Computer Architecture 11. Multi-Processor: Distributed Memory and Shared Memory
Fiscal Year 2018 Ver. 2019-01-24a Course number: CSC.T433 School of Computing, Graduate major in Computer Science Advanced Computer Architecture 11. Multi-Processor: Distributed Memory and Shared Memory
Parallel Processing SIMD, Vector and GPU s cont.
 Parallel Processing SIMD, Vector and GPU s cont. EECS4201 Fall 2016 York University 1 Multithreading First, we start with multithreading Multithreading is used in GPU s 2 1 Thread Level Parallelism ILP
Parallel Processing SIMD, Vector and GPU s cont. EECS4201 Fall 2016 York University 1 Multithreading First, we start with multithreading Multithreading is used in GPU s 2 1 Thread Level Parallelism ILP
Parallel Systems Course: Chapter IV. GPU Programming. Jan Lemeire Dept. ETRO September 25th 2015
 Parallel Systems Course: Chapter IV Dept. ETRO September 25th 2015 GPU Message-passing Programming with Parallel CUDAMessagepassing Parallel Processing Processing Overview 1. GPUs for general purpose 2.
Parallel Systems Course: Chapter IV Dept. ETRO September 25th 2015 GPU Message-passing Programming with Parallel CUDAMessagepassing Parallel Processing Processing Overview 1. GPUs for general purpose 2.
Serial. Parallel. CIT 668: System Architecture 2/14/2011. Topics. Serial and Parallel Computation. Parallel Computing
 CIT 668: System Architecture Parallel Computing Topics 1. What is Parallel Computing? 2. Why use Parallel Computing? 3. Types of Parallelism 4. Amdahl s Law 5. Flynn s Taxonomy of Parallel Computers 6.
CIT 668: System Architecture Parallel Computing Topics 1. What is Parallel Computing? 2. Why use Parallel Computing? 3. Types of Parallelism 4. Amdahl s Law 5. Flynn s Taxonomy of Parallel Computers 6.
Online Course Evaluation. What we will do in the last week?
 Online Course Evaluation Please fill in the online form The link will expire on April 30 (next Monday) So far 10 students have filled in the online form Thank you if you completed it. 1 What we will do
Online Course Evaluation Please fill in the online form The link will expire on April 30 (next Monday) So far 10 students have filled in the online form Thank you if you completed it. 1 What we will do
Computer and Information Sciences College / Computer Science Department CS 207 D. Computer Architecture. Lecture 9: Multiprocessors
 Computer and Information Sciences College / Computer Science Department CS 207 D Computer Architecture Lecture 9: Multiprocessors Challenges of Parallel Processing First challenge is % of program inherently
Computer and Information Sciences College / Computer Science Department CS 207 D Computer Architecture Lecture 9: Multiprocessors Challenges of Parallel Processing First challenge is % of program inherently
! Readings! ! Room-level, on-chip! vs.!
 1! 2! Suggested Readings!! Readings!! H&P: Chapter 7 especially 7.1-7.8!! (Over next 2 weeks)!! Introduction to Parallel Computing!! https://computing.llnl.gov/tutorials/parallel_comp/!! POSIX Threads
1! 2! Suggested Readings!! Readings!! H&P: Chapter 7 especially 7.1-7.8!! (Over next 2 weeks)!! Introduction to Parallel Computing!! https://computing.llnl.gov/tutorials/parallel_comp/!! POSIX Threads
Processor Performance and Parallelism Y. K. Malaiya
 Processor Performance and Parallelism Y. K. Malaiya Processor Execution time The time taken by a program to execute is the product of n Number of machine instructions executed n Number of clock cycles
Processor Performance and Parallelism Y. K. Malaiya Processor Execution time The time taken by a program to execute is the product of n Number of machine instructions executed n Number of clock cycles
Parallel Systems Course: Chapter IV. GPU Programming. Jan Lemeire Dept. ETRO October 2017
 Parallel Systems Course: Chapter IV Dept. ETRO October 2017 GPU Message-passing Programming with Parallel CUDAMessagepassing Parallel Processing Processing Overview 1. GPUs for general purpose 2. GPU threads
Parallel Systems Course: Chapter IV Dept. ETRO October 2017 GPU Message-passing Programming with Parallel CUDAMessagepassing Parallel Processing Processing Overview 1. GPUs for general purpose 2. GPU threads
Data-Level Parallelism in SIMD and Vector Architectures. Advanced Computer Architectures, Laura Pozzi & Cristina Silvano
 Data-Level Parallelism in SIMD and Vector Architectures Advanced Computer Architectures, Laura Pozzi & Cristina Silvano 1 Current Trends in Architecture Cannot continue to leverage Instruction-Level parallelism
Data-Level Parallelism in SIMD and Vector Architectures Advanced Computer Architectures, Laura Pozzi & Cristina Silvano 1 Current Trends in Architecture Cannot continue to leverage Instruction-Level parallelism
Parallel Systems Course: Chapter IV Advanced Computer Architecture. GPU Programming. Jan Lemeire Dept. ETRO September 27th 2013
 Parallel Systems Course: Chapter IV Advanced Computer Architecture Dept. ETRO September 27th 2013 GPU Message-passing Programming with Parallel CUDAMessagepassing Parallel Processing Processing (jan.lemeire@vub.ac.be)
Parallel Systems Course: Chapter IV Advanced Computer Architecture Dept. ETRO September 27th 2013 GPU Message-passing Programming with Parallel CUDAMessagepassing Parallel Processing Processing (jan.lemeire@vub.ac.be)
Hardware-Based Speculation
 Hardware-Based Speculation Execute instructions along predicted execution paths but only commit the results if prediction was correct Instruction commit: allowing an instruction to update the register
Hardware-Based Speculation Execute instructions along predicted execution paths but only commit the results if prediction was correct Instruction commit: allowing an instruction to update the register
THREAD LEVEL PARALLELISM
 THREAD LEVEL PARALLELISM Mahdi Nazm Bojnordi Assistant Professor School of Computing University of Utah CS/ECE 6810: Computer Architecture Overview Announcement Homework 4 is due on Dec. 11 th This lecture
THREAD LEVEL PARALLELISM Mahdi Nazm Bojnordi Assistant Professor School of Computing University of Utah CS/ECE 6810: Computer Architecture Overview Announcement Homework 4 is due on Dec. 11 th This lecture
EE 4683/5683: COMPUTER ARCHITECTURE
 EE 4683/5683: COMPUTER ARCHITECTURE Lecture 5B: Data Level Parallelism Avinash Kodi, kodi@ohio.edu Thanks to Morgan Kauffman and Krtse Asanovic Agenda 2 Flynn s Classification Data Level Parallelism Vector
EE 4683/5683: COMPUTER ARCHITECTURE Lecture 5B: Data Level Parallelism Avinash Kodi, kodi@ohio.edu Thanks to Morgan Kauffman and Krtse Asanovic Agenda 2 Flynn s Classification Data Level Parallelism Vector
Multicore Hardware and Parallelism
 Multicore Hardware and Parallelism Minsoo Ryu Department of Computer Science and Engineering 2 1 Advent of Multicore Hardware 2 Multicore Processors 3 Amdahl s Law 4 Parallelism in Hardware 5 Q & A 2 3
Multicore Hardware and Parallelism Minsoo Ryu Department of Computer Science and Engineering 2 1 Advent of Multicore Hardware 2 Multicore Processors 3 Amdahl s Law 4 Parallelism in Hardware 5 Q & A 2 3
Computer Systems Architecture
 Computer Systems Architecture Lecture 24 Mahadevan Gomathisankaran April 29, 2010 04/29/2010 Lecture 24 CSCE 4610/5610 1 Reminder ABET Feedback: http://www.cse.unt.edu/exitsurvey.cgi?csce+4610+001 Student
Computer Systems Architecture Lecture 24 Mahadevan Gomathisankaran April 29, 2010 04/29/2010 Lecture 24 CSCE 4610/5610 1 Reminder ABET Feedback: http://www.cse.unt.edu/exitsurvey.cgi?csce+4610+001 Student
WHY PARALLEL PROCESSING? (CE-401)
") PARALLEL PROCESSING (CE-401) COURSE INFORMATION 2 + 1 credits (60 marks theory, 40 marks lab) Labs introduced for second time in PP history of SSUET Theory marks breakup: Midterm Exam: 15 marks Assignment:
PARALLEL PROCESSING (CE-401) COURSE INFORMATION 2 + 1 credits (60 marks theory, 40 marks lab) Labs introduced for second time in PP history of SSUET Theory marks breakup: Midterm Exam: 15 marks Assignment:
Computer Systems Architecture
 Computer Systems Architecture Lecture 23 Mahadevan Gomathisankaran April 27, 2010 04/27/2010 Lecture 23 CSCE 4610/5610 1 Reminder ABET Feedback: http://www.cse.unt.edu/exitsurvey.cgi?csce+4610+001 Student
Computer Systems Architecture Lecture 23 Mahadevan Gomathisankaran April 27, 2010 04/27/2010 Lecture 23 CSCE 4610/5610 1 Reminder ABET Feedback: http://www.cse.unt.edu/exitsurvey.cgi?csce+4610+001 Student
Parallel Processors. The dream of computer architects since 1950s: replicate processors to add performance vs. design a faster processor
 Multiprocessing Parallel Computers Definition: A parallel computer is a collection of processing elements that cooperate and communicate to solve large problems fast. Almasi and Gottlieb, Highly Parallel
Multiprocessing Parallel Computers Definition: A parallel computer is a collection of processing elements that cooperate and communicate to solve large problems fast. Almasi and Gottlieb, Highly Parallel
Motivation for Parallelism. Motivation for Parallelism. ILP Example: Loop Unrolling. Types of Parallelism
 Motivation for Parallelism Motivation for Parallelism The speed of an application is determined by more than just processor speed. speed Disk speed Network speed... Multiprocessors typically improve the
Motivation for Parallelism Motivation for Parallelism The speed of an application is determined by more than just processor speed. speed Disk speed Network speed... Multiprocessors typically improve the
Prof. Hakim Weatherspoon CS 3410, Spring 2015 Computer Science Cornell University. P & H Chapter 4.10, 1.7, 1.8, 5.10, 6
 Prof. Hakim Weatherspoon CS 3410, Spring 2015 Computer Science Cornell University P & H Chapter 4.10, 1.7, 1.8, 5.10, 6 Why do I need four computing cores on my phone?! Why do I need eight computing
Prof. Hakim Weatherspoon CS 3410, Spring 2015 Computer Science Cornell University P & H Chapter 4.10, 1.7, 1.8, 5.10, 6 Why do I need four computing cores on my phone?! Why do I need eight computing
Lecture 1: Introduction
 Contemporary Computer Architecture Instruction set architecture Lecture 1: Introduction CprE 581 Computer Systems Architecture, Fall 2016 Reading: Textbook, Ch. 1.1-1.7 Microarchitecture; examples: Pipeline
Contemporary Computer Architecture Instruction set architecture Lecture 1: Introduction CprE 581 Computer Systems Architecture, Fall 2016 Reading: Textbook, Ch. 1.1-1.7 Microarchitecture; examples: Pipeline
Lecture-13 (ROB and Multi-threading) CS422-Spring
 CS422-Spring") Lecture-13 (ROB and Multi-threading) CS422-Spring 2018 Biswa@CSE-IITK Cycle 62 (Scoreboard) vs 57 in Tomasulo Instruction status: Read Exec Write Exec Write Instruction j k Issue Oper Comp Result Issue
Lecture-13 (ROB and Multi-threading) CS422-Spring 2018 Biswa@CSE-IITK Cycle 62 (Scoreboard) vs 57 in Tomasulo Instruction status: Read Exec Write Exec Write Instruction j k Issue Oper Comp Result Issue
An Introduction to Parallel Architectures
 An Introduction to Parallel Architectures Andrea Marongiu a.marongiu@unibo.it Impact of Parallel Architectures From cell phones to supercomputers In regular CPUs as well as GPUs Parallel HW Processing
An Introduction to Parallel Architectures Andrea Marongiu a.marongiu@unibo.it Impact of Parallel Architectures From cell phones to supercomputers In regular CPUs as well as GPUs Parallel HW Processing
TDT 4260 lecture 7 spring semester 2015
 1 TDT 4260 lecture 7 spring semester 2015 Lasse Natvig, The CARD group Dept. of computer & information science NTNU 2 Lecture overview Repetition Superscalar processor (out-of-order) Dependencies/forwarding
1 TDT 4260 lecture 7 spring semester 2015 Lasse Natvig, The CARD group Dept. of computer & information science NTNU 2 Lecture overview Repetition Superscalar processor (out-of-order) Dependencies/forwarding
UNIT I (Two Marks Questions & Answers)
") UNIT I (Two Marks Questions & Answers) Discuss the different ways how instruction set architecture can be classified? Stack Architecture,Accumulator Architecture, Register-Memory Architecture,Register-
UNIT I (Two Marks Questions & Answers) Discuss the different ways how instruction set architecture can be classified? Stack Architecture,Accumulator Architecture, Register-Memory Architecture,Register-
Parallel Systems. Introduction. Principles of Parallel Programming, Calvin Lin & Lawrence Snyder, Chapters 1 & 2
 Parallel Systems Introduction Principles of Parallel Programming, Calvin Lin & Lawrence Snyder, Chapters 1 & 2 Jan Lemeire Parallel Systems September - December 2014 Goals of course Understand architecture
Parallel Systems Introduction Principles of Parallel Programming, Calvin Lin & Lawrence Snyder, Chapters 1 & 2 Jan Lemeire Parallel Systems September - December 2014 Goals of course Understand architecture
Introduction to GPU programming with CUDA
 Introduction to GPU programming with CUDA Dr. Juan C Zuniga University of Saskatchewan, WestGrid UBC Summer School, Vancouver. June 12th, 2018 Outline 1 Overview of GPU computing a. what is a GPU? b. GPU
Introduction to GPU programming with CUDA Dr. Juan C Zuniga University of Saskatchewan, WestGrid UBC Summer School, Vancouver. June 12th, 2018 Outline 1 Overview of GPU computing a. what is a GPU? b. GPU
Parallelism in Hardware
 Parallelism in Hardware Minsoo Ryu Department of Computer Science and Engineering 2 1 Advent of Multicore Hardware 2 Multicore Processors 3 Amdahl s Law 4 Parallelism in Hardware 5 Q & A 2 3 Moore s Law
Parallelism in Hardware Minsoo Ryu Department of Computer Science and Engineering 2 1 Advent of Multicore Hardware 2 Multicore Processors 3 Amdahl s Law 4 Parallelism in Hardware 5 Q & A 2 3 Moore s Law
Hardware-based Speculation
 Hardware-based Speculation Hardware-based Speculation To exploit instruction-level parallelism, maintaining control dependences becomes an increasing burden. For a processor executing multiple instructions
Hardware-based Speculation Hardware-based Speculation To exploit instruction-level parallelism, maintaining control dependences becomes an increasing burden. For a processor executing multiple instructions
Design of Digital Circuits Lecture 21: GPUs. Prof. Onur Mutlu ETH Zurich Spring May 2017
 Design of Digital Circuits Lecture 21: GPUs Prof. Onur Mutlu ETH Zurich Spring 2017 12 May 2017 Agenda for Today & Next Few Lectures Single-cycle Microarchitectures Multi-cycle and Microprogrammed Microarchitectures
Design of Digital Circuits Lecture 21: GPUs Prof. Onur Mutlu ETH Zurich Spring 2017 12 May 2017 Agenda for Today & Next Few Lectures Single-cycle Microarchitectures Multi-cycle and Microprogrammed Microarchitectures
NVIDIA GTX200: TeraFLOPS Visual Computing. August 26, 2008 John Tynefield
 NVIDIA GTX200: TeraFLOPS Visual Computing August 26, 2008 John Tynefield 2 Outline Execution Model Architecture Demo 3 Execution Model 4 Software Architecture Applications DX10 OpenGL OpenCL CUDA C Host
NVIDIA GTX200: TeraFLOPS Visual Computing August 26, 2008 John Tynefield 2 Outline Execution Model Architecture Demo 3 Execution Model 4 Software Architecture Applications DX10 OpenGL OpenCL CUDA C Host
45-year CPU Evolution: 1 Law -2 Equations
 4004 8086 PowerPC 601 Pentium 4 Prescott 1971 1978 1992 45-year CPU Evolution: 1 Law -2 Equations Daniel Etiemble LRI Université Paris Sud 2004 Xeon X7560 Power9 Nvidia Pascal 2010 2017 2016 Are there
4004 8086 PowerPC 601 Pentium 4 Prescott 1971 1978 1992 45-year CPU Evolution: 1 Law -2 Equations Daniel Etiemble LRI Université Paris Sud 2004 Xeon X7560 Power9 Nvidia Pascal 2010 2017 2016 Are there
Prof. Hakim Weatherspoon CS 3410, Spring 2015 Computer Science Cornell University
 Prof. Hakim Weatherspoon CS 3410, Spring 2015 Computer Science Cornell University Project3 Cache Race Games night Monday, May 4 th, 5pm Come, eat, drink, have fun and be merry! Location: B17 Upson Hall
Prof. Hakim Weatherspoon CS 3410, Spring 2015 Computer Science Cornell University Project3 Cache Race Games night Monday, May 4 th, 5pm Come, eat, drink, have fun and be merry! Location: B17 Upson Hall
Exploitation of instruction level parallelism
 Exploitation of instruction level parallelism Computer Architecture J. Daniel García Sánchez (coordinator) David Expósito Singh Francisco Javier García Blas ARCOS Group Computer Science and Engineering
Exploitation of instruction level parallelism Computer Architecture J. Daniel García Sánchez (coordinator) David Expósito Singh Francisco Javier García Blas ARCOS Group Computer Science and Engineering
CMSC 411 Computer Systems Architecture Lecture 13 Instruction Level Parallelism 6 (Limits to ILP & Threading)
") CMSC 411 Computer Systems Architecture Lecture 13 Instruction Level Parallelism 6 (Limits to ILP & Threading) Limits to ILP Conflicting studies of amount of ILP Benchmarks» vectorized Fortran FP vs. integer
CMSC 411 Computer Systems Architecture Lecture 13 Instruction Level Parallelism 6 (Limits to ILP & Threading) Limits to ILP Conflicting studies of amount of ILP Benchmarks» vectorized Fortran FP vs. integer
Introduction II. Overview
 Introduction II Overview Today we will introduce multicore hardware (we will introduce many-core hardware prior to learning OpenCL) We will also consider the relationship between computer hardware and
Introduction II Overview Today we will introduce multicore hardware (we will introduce many-core hardware prior to learning OpenCL) We will also consider the relationship between computer hardware and
ENGN1640: Design of Computing Systems Topic 06: Advanced Processor Design
 ENGN1640: Design of Computing Systems Topic 06: Advanced Processor Design Professor Sherief Reda http://scale.engin.brown.edu Electrical Sciences and Computer Engineering School of Engineering Brown University
ENGN1640: Design of Computing Systems Topic 06: Advanced Processor Design Professor Sherief Reda http://scale.engin.brown.edu Electrical Sciences and Computer Engineering School of Engineering Brown University
ILP: Instruction Level Parallelism
 ILP: Instruction Level Parallelism Tassadaq Hussain Riphah International University Barcelona Supercomputing Center Universitat Politècnica de Catalunya Introduction Introduction Pipelining become universal
ILP: Instruction Level Parallelism Tassadaq Hussain Riphah International University Barcelona Supercomputing Center Universitat Politècnica de Catalunya Introduction Introduction Pipelining become universal
Multiprocessors and Thread-Level Parallelism. Department of Electrical & Electronics Engineering, Amrita School of Engineering
 Multiprocessors and Thread-Level Parallelism Multithreading Increasing performance by ILP has the great advantage that it is reasonable transparent to the programmer, ILP can be quite limited or hard to
Multiprocessors and Thread-Level Parallelism Multithreading Increasing performance by ILP has the great advantage that it is reasonable transparent to the programmer, ILP can be quite limited or hard to
Lecture 26: Parallel Processing. Spring 2018 Jason Tang
 Lecture 26: Parallel Processing Spring 2018 Jason Tang 1 Topics Static multiple issue pipelines Dynamic multiple issue pipelines Hardware multithreading 2 Taxonomy of Parallel Architectures Flynn categories:
Lecture 26: Parallel Processing Spring 2018 Jason Tang 1 Topics Static multiple issue pipelines Dynamic multiple issue pipelines Hardware multithreading 2 Taxonomy of Parallel Architectures Flynn categories:
UNIT III DATA-LEVEL PARALLELISM IN VECTOR, SIMD, AND GPU ARCHITECTURES
 UNIT III DATA-LEVEL PARALLELISM IN VECTOR, SIMD, AND GPU ARCHITECTURES Flynn s Taxonomy Single instruction stream, single data stream (SISD) Single instruction stream, multiple data streams (SIMD) o Vector
UNIT III DATA-LEVEL PARALLELISM IN VECTOR, SIMD, AND GPU ARCHITECTURES Flynn s Taxonomy Single instruction stream, single data stream (SISD) Single instruction stream, multiple data streams (SIMD) o Vector
COSC 6385 Computer Architecture. - Vector Processors
 COSC 6385 Computer Architecture - Vector Processors Spring 011 Vector Processors Chapter F of the 4 th edition (Chapter G of the 3 rd edition) Available in CD attached to the book Anybody having problems
COSC 6385 Computer Architecture - Vector Processors Spring 011 Vector Processors Chapter F of the 4 th edition (Chapter G of the 3 rd edition) Available in CD attached to the book Anybody having problems
Lec 25: Parallel Processors. Announcements
 Lec 25: Parallel Processors Kavita Bala CS 340, Fall 2008 Computer Science Cornell University PA 3 out Hack n Seek Announcements The goal is to have fun with it Recitations today will talk about it Pizza
Lec 25: Parallel Processors Kavita Bala CS 340, Fall 2008 Computer Science Cornell University PA 3 out Hack n Seek Announcements The goal is to have fun with it Recitations today will talk about it Pizza
COSC 6385 Computer Architecture - Thread Level Parallelism (I)
") COSC 6385 Computer Architecture - Thread Level Parallelism (I) Edgar Gabriel Spring 2014 Long-term trend on the number of transistor per integrated circuit Number of transistors double every ~18 month
COSC 6385 Computer Architecture - Thread Level Parallelism (I) Edgar Gabriel Spring 2014 Long-term trend on the number of transistor per integrated circuit Number of transistors double every ~18 month
Multicore and Parallel Processing
 Multicore and Parallel Processing Hakim Weatherspoon CS 3410, Spring 2012 Computer Science Cornell University P & H Chapter 4.10 11, 7.1 6 xkcd/619 2 Pitfall: Amdahl s Law Execution time after improvement
Multicore and Parallel Processing Hakim Weatherspoon CS 3410, Spring 2012 Computer Science Cornell University P & H Chapter 4.10 11, 7.1 6 xkcd/619 2 Pitfall: Amdahl s Law Execution time after improvement
 Exploring different level of parallelism Instruction-level parallelism (ILP): how many of the operations/instructions in a computer program can be performed simultaneously 1. e = a + b 2. f = c + d 3.
Exploring different level of parallelism Instruction-level parallelism (ILP): how many of the operations/instructions in a computer program can be performed simultaneously 1. e = a + b 2. f = c + d 3.
CS 152, Spring 2011 Section 10
 CS 152, Spring 2011 Section 10 Christopher Celio University of California, Berkeley Agenda Stuff (Quiz 4 Prep) http://3dimensionaljigsaw.wordpress.com/2008/06/18/physics-based-games-the-new-genre/ Intel
CS 152, Spring 2011 Section 10 Christopher Celio University of California, Berkeley Agenda Stuff (Quiz 4 Prep) http://3dimensionaljigsaw.wordpress.com/2008/06/18/physics-based-games-the-new-genre/ Intel
TDT Coarse-Grained Multithreading. Review on ILP. Multi-threaded execution. Contents. Fine-Grained Multithreading
 Review on ILP TDT 4260 Chap 5 TLP & Hierarchy What is ILP? Let the compiler find the ILP Advantages? Disadvantages? Let the HW find the ILP Advantages? Disadvantages? Contents Multi-threading Chap 3.5
Review on ILP TDT 4260 Chap 5 TLP & Hierarchy What is ILP? Let the compiler find the ILP Advantages? Disadvantages? Let the HW find the ILP Advantages? Disadvantages? Contents Multi-threading Chap 3.5
Chapter 4 Data-Level Parallelism
 CS359: Computer Architecture Chapter 4 Data-Level Parallelism Yanyan Shen Department of Computer Science and Engineering Shanghai Jiao Tong University 1 Outline 4.1 Introduction 4.2 Vector Architecture
CS359: Computer Architecture Chapter 4 Data-Level Parallelism Yanyan Shen Department of Computer Science and Engineering Shanghai Jiao Tong University 1 Outline 4.1 Introduction 4.2 Vector Architecture
Computer Architecture
 Computer Architecture Slide Sets WS 2013/2014 Prof. Dr. Uwe Brinkschulte M.Sc. Benjamin Betting Part 10 Thread and Task Level Parallelism Computer Architecture Part 10 page 1 of 36 Prof. Dr. Uwe Brinkschulte,
Computer Architecture Slide Sets WS 2013/2014 Prof. Dr. Uwe Brinkschulte M.Sc. Benjamin Betting Part 10 Thread and Task Level Parallelism Computer Architecture Part 10 page 1 of 36 Prof. Dr. Uwe Brinkschulte,
Multi-cycle Instructions in the Pipeline (Floating Point)
") Lecture 6 Multi-cycle Instructions in the Pipeline (Floating Point) Introduction to instruction level parallelism Recap: Support of multi-cycle instructions in a pipeline (App A.5) Recap: Superpipelining
Lecture 6 Multi-cycle Instructions in the Pipeline (Floating Point) Introduction to instruction level parallelism Recap: Support of multi-cycle instructions in a pipeline (App A.5) Recap: Superpipelining
5DV118 Computer Organization and Architecture Umeå University Department of Computing Science Stephen J. Hegner. Topic 7: Support for Parallelism
 5DV118 Computer Organization and Architecture Umeå University Department of Computing Science Stephen J. Hegner Topic 7: Support for Parallelism These slides are mostly taken verbatim, or with minor changes,
5DV118 Computer Organization and Architecture Umeå University Department of Computing Science Stephen J. Hegner Topic 7: Support for Parallelism These slides are mostly taken verbatim, or with minor changes,
GP-GPU. General Purpose Programming on the Graphics Processing Unit
 GP-GPU General Purpose Programming on the Graphics Processing Unit Goals Learn modern GPU architectures and its advantage and disadvantage as compared to modern CPUs Learn how to effectively program the
GP-GPU General Purpose Programming on the Graphics Processing Unit Goals Learn modern GPU architectures and its advantage and disadvantage as compared to modern CPUs Learn how to effectively program the
Multithreaded Processors. Department of Electrical Engineering Stanford University
 Lecture 12: Multithreaded Processors Department of Electrical Engineering Stanford University http://eeclass.stanford.edu/ee382a Lecture 12-1 The Big Picture Previous lectures: Core design for single-thread
Lecture 12: Multithreaded Processors Department of Electrical Engineering Stanford University http://eeclass.stanford.edu/ee382a Lecture 12-1 The Big Picture Previous lectures: Core design for single-thread
DATA-LEVEL PARALLELISM IN VECTOR, SIMD ANDGPU ARCHITECTURES(PART 2)
") 1 DATA-LEVEL PARALLELISM IN VECTOR, SIMD ANDGPU ARCHITECTURES(PART 2) Chapter 4 Appendix A (Computer Organization and Design Book) OUTLINE SIMD Instruction Set Extensions for Multimedia (4.3) Graphical
1 DATA-LEVEL PARALLELISM IN VECTOR, SIMD ANDGPU ARCHITECTURES(PART 2) Chapter 4 Appendix A (Computer Organization and Design Book) OUTLINE SIMD Instruction Set Extensions for Multimedia (4.3) Graphical
Parallel Computing: Parallel Architectures Jin, Hai
 Parallel Computing: Parallel Architectures Jin, Hai School of Computer Science and Technology Huazhong University of Science and Technology Peripherals Computer Central Processing Unit Main Memory Computer
Parallel Computing: Parallel Architectures Jin, Hai School of Computer Science and Technology Huazhong University of Science and Technology Peripherals Computer Central Processing Unit Main Memory Computer
The Processor: Instruction-Level Parallelism
 The Processor: Instruction-Level Parallelism Computer Organization Architectures for Embedded Computing Tuesday 21 October 14 Many slides adapted from: Computer Organization and Design, Patterson & Hennessy
The Processor: Instruction-Level Parallelism Computer Organization Architectures for Embedded Computing Tuesday 21 October 14 Many slides adapted from: Computer Organization and Design, Patterson & Hennessy
CSCI 402: Computer Architectures. Parallel Processors (2) Fengguang Song Department of Computer & Information Science IUPUI.
 Fengguang Song Department of Computer & Information Science IUPUI.") CSCI 402: Computer Architectures Parallel Processors (2) Fengguang Song Department of Computer & Information Science IUPUI 6.6 - End Today s Contents GPU Cluster and its network topology The Roofline performance
CSCI 402: Computer Architectures Parallel Processors (2) Fengguang Song Department of Computer & Information Science IUPUI 6.6 - End Today s Contents GPU Cluster and its network topology The Roofline performance
EN164: Design of Computing Systems Topic 08: Parallel Processor Design (introduction)
") EN164: Design of Computing Systems Topic 08: Parallel Processor Design (introduction) Professor Sherief Reda http://scale.engin.brown.edu Electrical Sciences and Computer Engineering School of Engineering
EN164: Design of Computing Systems Topic 08: Parallel Processor Design (introduction) Professor Sherief Reda http://scale.engin.brown.edu Electrical Sciences and Computer Engineering School of Engineering
Computing architectures Part 2 TMA4280 Introduction to Supercomputing
 Computing architectures Part 2 TMA4280 Introduction to Supercomputing NTNU, IMF January 16. 2017 1 Supercomputing What is the motivation for Supercomputing? Solve complex problems fast and accurately:
Computing architectures Part 2 TMA4280 Introduction to Supercomputing NTNU, IMF January 16. 2017 1 Supercomputing What is the motivation for Supercomputing? Solve complex problems fast and accurately:
Multi-Processors and GPU
 Multi-Processors and GPU Philipp Koehn 7 December 2016 Predicted CPU Clock Speed 1 Clock speed 1971: 740 khz, 2016: 28.7 GHz Source: Horowitz "The Singularity is Near" (2005) Actual CPU Clock Speed 2 Clock
Multi-Processors and GPU Philipp Koehn 7 December 2016 Predicted CPU Clock Speed 1 Clock speed 1971: 740 khz, 2016: 28.7 GHz Source: Horowitz "The Singularity is Near" (2005) Actual CPU Clock Speed 2 Clock
CS6303 Computer Architecture Regulation 2013 BE-Computer Science and Engineering III semester 2 MARKS
 CS6303 Computer Architecture Regulation 2013 BE-Computer Science and Engineering III semester 2 MARKS UNIT-I OVERVIEW & INSTRUCTIONS 1. What are the eight great ideas in computer architecture? The eight
CS6303 Computer Architecture Regulation 2013 BE-Computer Science and Engineering III semester 2 MARKS UNIT-I OVERVIEW & INSTRUCTIONS 1. What are the eight great ideas in computer architecture? The eight
Processor (IV) - advanced ILP. Hwansoo Han
 - advanced ILP. Hwansoo Han") Processor (IV) - advanced ILP Hwansoo Han Instruction-Level Parallelism (ILP) Pipelining: executing multiple instructions in parallel To increase ILP Deeper pipeline Less work per stage shorter clock cycle
Processor (IV) - advanced ILP Hwansoo Han Instruction-Level Parallelism (ILP) Pipelining: executing multiple instructions in parallel To increase ILP Deeper pipeline Less work per stage shorter clock cycle
A taxonomy of computer architectures
 A taxonomy of computer architectures 53 We have considered different types of architectures, and it is worth considering some way to classify them. Indeed, there exists a famous taxonomy of the various
A taxonomy of computer architectures 53 We have considered different types of architectures, and it is worth considering some way to classify them. Indeed, there exists a famous taxonomy of the various
Chapter 6. Parallel Processors from Client to Cloud. Copyright 2014 Elsevier Inc. All rights reserved.
 Chapter 6 Parallel Processors from Client to Cloud FIGURE 6.1 Hardware/software categorization and examples of application perspective on concurrency versus hardware perspective on parallelism. 2 FIGURE
Chapter 6 Parallel Processors from Client to Cloud FIGURE 6.1 Hardware/software categorization and examples of application perspective on concurrency versus hardware perspective on parallelism. 2 FIGURE
CISC 662 Graduate Computer Architecture Lecture 13 - Limits of ILP
 CISC 662 Graduate Computer Architecture Lecture 13 - Limits of ILP Michela Taufer http://www.cis.udel.edu/~taufer/teaching/cis662f07 Powerpoint Lecture Notes from John Hennessy and David Patterson s: Computer
CISC 662 Graduate Computer Architecture Lecture 13 - Limits of ILP Michela Taufer http://www.cis.udel.edu/~taufer/teaching/cis662f07 Powerpoint Lecture Notes from John Hennessy and David Patterson s: Computer
GRAPHICS PROCESSING UNITS
 GRAPHICS PROCESSING UNITS Slides by: Pedro Tomás Additional reading: Computer Architecture: A Quantitative Approach, 5th edition, Chapter 4, John L. Hennessy and David A. Patterson, Morgan Kaufmann, 2011
GRAPHICS PROCESSING UNITS Slides by: Pedro Tomás Additional reading: Computer Architecture: A Quantitative Approach, 5th edition, Chapter 4, John L. Hennessy and David A. Patterson, Morgan Kaufmann, 2011
Handout 2 ILP: Part B
 Handout 2 ILP: Part B Review from Last Time #1 Leverage Implicit Parallelism for Performance: Instruction Level Parallelism Loop unrolling by compiler to increase ILP Branch prediction to increase ILP
Handout 2 ILP: Part B Review from Last Time #1 Leverage Implicit Parallelism for Performance: Instruction Level Parallelism Loop unrolling by compiler to increase ILP Branch prediction to increase ILP
INSTITUTO SUPERIOR TÉCNICO. Architectures for Embedded Computing
 UNIVERSIDADE TÉCNICA DE LISBOA INSTITUTO SUPERIOR TÉCNICO Departamento de Engenharia Informática Architectures for Embedded Computing MEIC-A, MEIC-T, MERC Lecture Slides Version 3.0 - English Lecture 12
UNIVERSIDADE TÉCNICA DE LISBOA INSTITUTO SUPERIOR TÉCNICO Departamento de Engenharia Informática Architectures for Embedded Computing MEIC-A, MEIC-T, MERC Lecture Slides Version 3.0 - English Lecture 12
DEPARTMENT OF ELECTRONICS & COMMUNICATION ENGINEERING QUESTION BANK
 DEPARTMENT OF ELECTRONICS & COMMUNICATION ENGINEERING QUESTION BANK SUBJECT : CS6303 / COMPUTER ARCHITECTURE SEM / YEAR : VI / III year B.E. Unit I OVERVIEW AND INSTRUCTIONS Part A Q.No Questions BT Level
DEPARTMENT OF ELECTRONICS & COMMUNICATION ENGINEERING QUESTION BANK SUBJECT : CS6303 / COMPUTER ARCHITECTURE SEM / YEAR : VI / III year B.E. Unit I OVERVIEW AND INSTRUCTIONS Part A Q.No Questions BT Level
Computer Architecture A Quantitative Approach, Fifth Edition. Chapter 3. Instruction-Level Parallelism and Its Exploitation
 Computer Architecture A Quantitative Approach, Fifth Edition Chapter 3 Instruction-Level Parallelism and Its Exploitation Introduction Pipelining become universal technique in 1985 Overlaps execution of
Computer Architecture A Quantitative Approach, Fifth Edition Chapter 3 Instruction-Level Parallelism and Its Exploitation Introduction Pipelining become universal technique in 1985 Overlaps execution of
Keywords and Review Questions
 Keywords and Review Questions lec1: Keywords: ISA, Moore s Law Q1. Who are the people credited for inventing transistor? Q2. In which year IC was invented and who was the inventor? Q3. What is ISA? Explain
Keywords and Review Questions lec1: Keywords: ISA, Moore s Law Q1. Who are the people credited for inventing transistor? Q2. In which year IC was invented and who was the inventor? Q3. What is ISA? Explain
Computer and Information Sciences College / Computer Science Department CS 207 D. Computer Architecture. Lecture 9: Multiprocessors
 Computer and Information Sciences College / Computer Science Department CS 207 D Computer Architecture Lecture 9: Multiprocessors Challenges of Parallel Processing First challenge is % of program inherently
Computer and Information Sciences College / Computer Science Department CS 207 D Computer Architecture Lecture 9: Multiprocessors Challenges of Parallel Processing First challenge is % of program inherently
Introduction: Modern computer architecture. The stored program computer and its inherent bottlenecks Multi- and manycore chips and nodes
 Introduction: Modern computer architecture The stored program computer and its inherent bottlenecks Multi- and manycore chips and nodes Motivation: Multi-Cores where and why Introduction: Moore s law Intel
Introduction: Modern computer architecture The stored program computer and its inherent bottlenecks Multi- and manycore chips and nodes Motivation: Multi-Cores where and why Introduction: Moore s law Intel
CUDA PROGRAMMING MODEL Chaithanya Gadiyam Swapnil S Jadhav
 CUDA PROGRAMMING MODEL Chaithanya Gadiyam Swapnil S Jadhav CMPE655 - Multiple Processor Systems Fall 2015 Rochester Institute of Technology Contents What is GPGPU? What s the need? CUDA-Capable GPU Architecture
CUDA PROGRAMMING MODEL Chaithanya Gadiyam Swapnil S Jadhav CMPE655 - Multiple Processor Systems Fall 2015 Rochester Institute of Technology Contents What is GPGPU? What s the need? CUDA-Capable GPU Architecture
Vector Processors. Abhishek Kulkarni Girish Subramanian
 Vector Processors Abhishek Kulkarni Girish Subramanian Classification of Parallel Architectures Hennessy and Patterson 1990; Sima, Fountain, and Kacsuk 1997 Why Vector Processors? Difficulties in exploiting
Vector Processors Abhishek Kulkarni Girish Subramanian Classification of Parallel Architectures Hennessy and Patterson 1990; Sima, Fountain, and Kacsuk 1997 Why Vector Processors? Difficulties in exploiting
Advanced d Instruction Level Parallelism. Computer Systems Laboratory Sungkyunkwan University
 Advanced d Instruction ti Level Parallelism Jin-Soo Kim (jinsookim@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu ILP Instruction-Level Parallelism (ILP) Pipelining:
Advanced d Instruction ti Level Parallelism Jin-Soo Kim (jinsookim@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu ILP Instruction-Level Parallelism (ILP) Pipelining:
UC Berkeley CS61C : Machine Structures
 inst.eecs.berkeley.edu/~cs61c Review! UC Berkeley CS61C : Machine Structures Lecture 28 Intra-machine Parallelism Parallelism is necessary for performance! It looks like itʼs It is the future of computing!
inst.eecs.berkeley.edu/~cs61c Review! UC Berkeley CS61C : Machine Structures Lecture 28 Intra-machine Parallelism Parallelism is necessary for performance! It looks like itʼs It is the future of computing!
Copyright 2012, Elsevier Inc. All rights reserved.
 Computer Architecture A Quantitative Approach, Fifth Edition Chapter 3 Instruction-Level Parallelism and Its Exploitation 1 Branch Prediction Basic 2-bit predictor: For each branch: Predict taken or not
Computer Architecture A Quantitative Approach, Fifth Edition Chapter 3 Instruction-Level Parallelism and Its Exploitation 1 Branch Prediction Basic 2-bit predictor: For each branch: Predict taken or not
Fundamentals of Computer Design
 Fundamentals of Computer Design Computer Architecture J. Daniel García Sánchez (coordinator) David Expósito Singh Francisco Javier García Blas ARCOS Group Computer Science and Engineering Department University
Fundamentals of Computer Design Computer Architecture J. Daniel García Sánchez (coordinator) David Expósito Singh Francisco Javier García Blas ARCOS Group Computer Science and Engineering Department University
CS 614 COMPUTER ARCHITECTURE II FALL 2005
 CS 614 COMPUTER ARCHITECTURE II FALL 2005 DUE : November 9, 2005 HOMEWORK III READ : - Portions of Chapters 5, 6, 7, 8, 9 and 14 of the Sima book and - Portions of Chapters 3, 4, Appendix A and Appendix
CS 614 COMPUTER ARCHITECTURE II FALL 2005 DUE : November 9, 2005 HOMEWORK III READ : - Portions of Chapters 5, 6, 7, 8, 9 and 14 of the Sima book and - Portions of Chapters 3, 4, Appendix A and Appendix
Review of Last Lecture. CS 61C: Great Ideas in Computer Architecture. The Flynn Taxonomy, Intel SIMD Instructions. Great Idea #4: Parallelism.
 CS 61C: Great Ideas in Computer Architecture The Flynn Taxonomy, Intel SIMD Instructions Instructor: Justin Hsia 1 Review of Last Lecture Amdahl s Law limits benefits of parallelization Request Level Parallelism
CS 61C: Great Ideas in Computer Architecture The Flynn Taxonomy, Intel SIMD Instructions Instructor: Justin Hsia 1 Review of Last Lecture Amdahl s Law limits benefits of parallelization Request Level Parallelism
Multiprocessors. Flynn Taxonomy. Classifying Multiprocessors. why would you want a multiprocessor? more is better? Cache Cache Cache.
 Multiprocessors why would you want a multiprocessor? Multiprocessors and Multithreading more is better? Cache Cache Cache Classifying Multiprocessors Flynn Taxonomy Flynn Taxonomy Interconnection Network
Multiprocessors why would you want a multiprocessor? Multiprocessors and Multithreading more is better? Cache Cache Cache Classifying Multiprocessors Flynn Taxonomy Flynn Taxonomy Interconnection Network