Portable and Productive Performance with OpenACC Compilers and Tools. Luiz DeRose Sr. Principal Engineer Programming Environments Director Cray Inc.
|
|
|
- Briana Tucker
- 5 years ago
- Views:
Transcription

1 Portable and Productive Performance with OpenACC Compilers and Tools Luiz DeRose Sr. Principal Engineer Programming Environments Director Cray Inc. 1































2 Cray: Leadership in Computational Research Earth Sciences Academic Research We provide a complete turn key solution to help solve challenges in science and engineering that require supercomputing National Defense Energy Research 2
3 The New Generation of Supercomputers Hybrid multicore has arrived and is here to stay Fat nodes are getting fatter Accelerators have leapt into the Top500 Programming accelerators efficiently is challenging Three levels of parallelism required MPI between nodes or sockets Shared memory programming on the node Vectorization for low level looping structures Need a hybrid programming model to support these new systems Need a high level programming environment Compilers, tools, & libraries 3



4 The Cray XK7 Hybrid Architecture NVIDIA Kepler GPUs AMD Interlagos CPU Cray Gemini interconnect high bandwidth/low latency scalability Unified X86/GPU programming environment Fully compatible with Cray XE6 product line Fully upgradeable from Cray XT/XE systems 4

 to expand its Cray XC30 supercomputer with NVIDIA Kepler GPUs.")
5 Major Hybrid Multi Petaflop Systems Blue Waters: Sustained Petascale Performance Production Science at Full Scale 244 Cray XE Cabinets + 32 Cray XK Cabinets 11.5 Petaflops 1.5 Petabytes of total memory 25 Petabytes Storage Cray s scalable Linux Environment HPC-focused GPU/CPU Programming Environment Titan: A Jaguar-Size System with GPUs 200 cabinets 18,688 compute nodes 25x32x24 3D torus (22.5 TB/s global BW) 128 I/O blades ( GB/s bidir) 1,278 TB of memory 4,352 sq. ft. Piz Daint CRAY has signed a contract with the Swiss National Supercomputing Centre (CSCS) to expand its Cray XC30 supercomputer with NVIDIA Kepler GPUs. When the upgrade is completed, the Centre s Cray XC system, will be the first petascale supercomputer in Switzerland. 5
6 Cray s Vision for Accelerated Computing Most important hurdle for widespread adoption of accelerated computing in HPC is programming difficulty Need a single programming model that is portable across machine types Portable expression of heterogeneity and multi-level parallelism Programming model and optimization should not be significantly difference for accelerated nodes and multi-core x86 processors Allow users to maintain a single code base Cray s approach to Accelerator Programming is to provide an ease of use tightly coupled high level programming environment with compilers, libraries, and tools that can hide the complexity of the system Ease of use is possible with Compiler making it feasible for users to write applications in Fortran, C, and C++ Tools to help users port and optimize for hybrid systems Auto-tuned scientific libraries 6
7 Programming for a Node with Accelerator Fortran, C, and C++ compilers Directives to drive compiler optimization Compiler does the heavy lifting to split off the work destined for the accelerator and perform the necessary data transfers Compiler optimizations to take advantage of accelerator and multi-core X86 hardware appropriately Advanced users can mix CUDA functions with compiler-generated accelerator code Debugger support with DDT and TotalView Cray Reveal, built upon an internal compiler database containing a representation of the application Source code browsing tool that provides interface between the user, the compiler, and the performance analysis tool Scoping tool to help users port and optimize applications Performance measurement and analysis information for identification of main loops of the code to focus refactoring Scientific Libraries support Auto-tuned libraries (using Cray Auto-Tuning Framework) 7

8 OpenACC Accelerator Programming Model Why a new model? There are already many ways to program: CUDA and OpenCL All are quite low-level and closely coupled to the GPU PGI CUDA Fortran: still CUDA just in a better base language User needs to write specialized kernels: Hard to write and debug Hard to optimize for specific GPU Hard to update (porting/functionality) OpenACC Directives provide high-level approach Simple programming model for hybrid systems Easier to maintain/port/extend code Non-executable statements (comments, pragmas) The same source code can be compiled for multicore CPU Based on the work in the OpenMP Accelerator Subcommittee PGI accelerator directives, CAPS HMPP First steps in the right direction Needed standardization Possible performance sacrifice A small performance gap is acceptable (do you still hand-code in assembly?) Goal is to provide at least 80% of the performance obtained with hand coded CUDA Compiler support: all complete in 2012 Cray CCE: complete in the 8.1 release PGI Accelerator version 12.6 onwards CAPS Full support in version 1.3 8
9 The Cray Compilation Environment Cray technology focused on scientific applications Takes advantage of automatic vectorization Takes advantage of automatic shared memory parallelization OpenACC 1.0 compliant (working on OpenACC 2.0) CCE Identifies parallel loops within code regions Splits the code into accelerator and host portions Workshares loops running on accelerator Make use of MIMD and SIMD style parallelism Data movement allocates/frees GPU memory at start/end of region moves data to/from GPU Compiles to PTX not CUDA Single object file Debuggers see original program not CUDA intermediate 9
10 Steps to Create a Hybrid Code 1. Identify possible accelerator kernels Determine where to add additional levels of parallelism Assumes MPI application is functioning correctly on X86 Find top serial work-intensive loops (perftools + CCE loop work estimates) 2. Perform parallel analysis, scoping and vectorization Split loop work among threads Do parallel analysis and restructuring on targeted high level loops Use CCE loopmark feedback, Reveal loopmark and source browsing 3. Move to OpenMP and then to OpenACC Add parallel directives and acceleration extensions Insert OpenMP directives (Reveal scoping assistance) Run on X86 to verify application and check for performance improvements Convert desired OpenMP directives to OpenACC 4. Analyze performance from optimizations 10








11 Moving to a Hybrid or Many-core Environment New analysis and code restructuring assistant Key Features Uses both the performance toolset and CCE s program library functionality to provide static and runtime analysis information Annotated source code with compiler optimization information Provides feedback on critical dependencies that prevent optimizations Assists user with the code optimization phase by correlating source code with analysis to help identify which areas are key candidates for optimization Scoping analysis Identifies shared, private and ambiguous arrays Allows user to privatize ambiguous arrays Allows user to override dependency analysis Source code navigation Uses performance data collected through CrayPat 11

12 Reveal with Loop Work Estimates 12




13 Visualize Loopmark with Performance Information Performance feedback Loopmark and optimization annotations Compiler feedback 13


14 Compiler Messages Explanations Integrated message explain support 14



15 View Pseudo Code for Inlined Functions Expand to see pseudo code Inlined call sites marked 15





16 Scoping Assistance Review Scoping Results Parallelization inhibitor messages are provided to assist user with analysis Loops with scoping information are highlighted red needs user assistance User addresses parallelization issues for unresolved variables 16



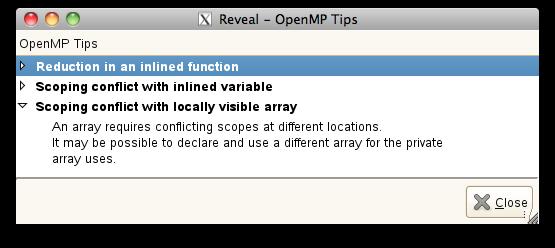


17 Scoping Assistance User Resolves Issues Use Reveal s OpenMP parallelization tips Click on variable to view all occurrences in loop 17





18 Scoping Assistance Generate Directive Automatically Reveal generates generate example OpenMP OpenMP directive directive 18
19 OpenACC Debugging On device debugging with Allinea DDT Variables arrays, pointers, full F90 and C support Set breakpoints and step warps and blocks Requires Cray compiler for on-device debugging Other compilers to follow Identical to CUDA Full warp/block/kernel controls OpenACC DIRECTIVES FOR ACCELERATORS Step host & device View variables Set breakpoints Compatibility with Cray CCE 8.x OpenACC 19
20 Cray Performance Tools Scaling (running big jobs with a large number of GPUs) Results summarized and consolidated in one place Statistics for the whole application Performance statistics mapped back to the user source by line number Performance statistics grouped by accelerator directive Single report can include statistics for both the host and the accelerator Single tool for GPU and CPU performance analysis Performance statistics Includes accelerator time, host time, and amount of data copied to/from the accelerator Kernel level statistics Accelerator hardware counters 20

21 Cray Apprentice2 Overview with GPU Data 21

22 Accelerator Statistics View from Apprentice2 22

23 Call Tree with GPU regions 23
24 What is Cray Libsci_acc? Provide basic scientific libraries optimized for hybrid systems Incorporate the existing GPU libraries into Cray libsci Independent to, but fully compatible with OpenACC Multiple use case support Get the base use of accelerators with no code change Get extreme performance of GPU with or without code change Provide additional performance and usability Two interfaces Simple interface Auto-adaptation Base performance of GPU with minimal (or no) code change Target for anybody: non-gpu users and non-gpu expert Expert interface Advanced performance of the GPU with controls for data movement Target for CUDA, OpenACC, and GPU experts Does not imply that the expert interfaces are always needed to get great performance 24
25 Adaptation in the Simple Interface You can pass either host pointers or device pointers with the simple interface A is in host memory dgetrf(m, N, A, lda, ipiv, &info) Performs hybrid operation on GPU if problem is too small, performs host operation Pass Device memory dgetrf(m, N, d_a, lda, ipiv, &info) Performs hybrid operation on GPU BLAS 1 and 2 performs computation local to the data location CPU-GPU data transfer is too expensive to exploit hybrid execution 25





26 Libsci_acc: Simple Interface for BLAS3 and LAPACK User Application dgemm_(); where is the data? On Host Large enough? Libsci DGEMM On GPU Libsci_acc DGEMM_ACC Libsci_acc Hybrid DGEMM 26

27 Case Study: the Himeno Benchmark Parallel 3D Poisson equation solver Iterative loop evaluating 19-point stencil Memory intensive, memory bandwidth bound Fortran, C, MPI and OpenMP implementations available from Strong scaling benchmark XL configuration: 1024 x 512 x 512 global volume Expect halo exchanges to become significant Use asynchronous GPU data transfers and kernel launches to help avoid this 27
28 Porting Himeno to the Cray XK6 Several versions tested, with communication implemented in MPI and Fortran coarrays GPU version using OpenACC accelerator directives Total number of accelerator directives: 27 plus 18 "end" directives Arrays reside permanently on the GPU memory Data transfers between host and GPU are: Communication buffers for the halo exchange Control value Cray XK6 timings compared to best Cray XE6 results (hybrid MPI/OpenMP) 28
29 Performance (TFlop/s) Himeno performance XK6 GPU is about 1.6x faster than XE6 OpenACC async implementation is ~ 8% faster than OpenACC blocking Himeno Benchmark - XL configuration 5.0 XE6 MPI/OMP XK6 async XK6 blocking Number of nodes 29
30 CloverLeaf 2D hydro code, with several stencil-type operations Developed by AWE Using to explore programming models to be released as Open Source to the Mantevo project hosted by Sandia (miniapps) Current performance for 87 steps Mesh CUDA OpenACC 960x x
31 GAMESS Computational chemistry package suite developed and maintained by the Gordon Group at Iowa State University ijk-tuples kernel - Source changes CUDA lines of hand-coded CUDA OpenACC approximately 75 directives added to the original source Performance of ijk-tuples on 16 XK6 Nodes with Fermi CPU Only (16 ranks per node) 311 Seconds CUDA 134 seconds OpenACC 138 seconds CUDA was only ~3% faster than OpenACC Performance of ijk-tuples on 16 XK6 Nodes with Kepler CPU Only (16 ranks per node) 311 Seconds CUDA 76.6 seconds OpenACC 68.1 seconds OpenACC was ~12.5% faster than CUDA!! 31
32 Summary Cray provides a high level programming environment for accelerated Computing Fortran, C, and C++ compilers OpenACC directives to drive compiler optimization Compiler optimizations to take advantage of accelerator and multi-core X86 hardware appropriately Cray Reveal Scoping analysis tool to assist user in understanding their code and taking full advantage of SW and HW system Cray Performance Measurement and Analysis toolkit Single tool for GPU and CPU performance analysis with statistics for the whole application Parallel Debugger support with DDT or TotalView Auto-tuned Scientific Libraries support Getting performance from the system no assembly required 32
Productive Performance on the Cray XK System Using OpenACC Compilers and Tools
 Productive Performance on the Cray XK System Using OpenACC Compilers and Tools Luiz DeRose Sr. Principal Engineer Programming Environments Director Cray Inc. 1 The New Generation of Supercomputers Hybrid
Productive Performance on the Cray XK System Using OpenACC Compilers and Tools Luiz DeRose Sr. Principal Engineer Programming Environments Director Cray Inc. 1 The New Generation of Supercomputers Hybrid
Portable and Productive Performance on Hybrid Systems with libsci_acc Luiz DeRose Sr. Principal Engineer Programming Environments Director Cray Inc.
 Portable and Productive Performance on Hybrid Systems with libsci_acc Luiz DeRose Sr. Principal Engineer Programming Environments Director Cray Inc. 1 What is Cray Libsci_acc? Provide basic scientific
Portable and Productive Performance on Hybrid Systems with libsci_acc Luiz DeRose Sr. Principal Engineer Programming Environments Director Cray Inc. 1 What is Cray Libsci_acc? Provide basic scientific
An Introduction to OpenACC
 An Introduction to OpenACC Alistair Hart Cray Exascale Research Initiative Europe 3 Timetable Day 1: Wednesday 29th August 2012 13:00 Welcome and overview 13:15 Session 1: An Introduction to OpenACC 13:15
An Introduction to OpenACC Alistair Hart Cray Exascale Research Initiative Europe 3 Timetable Day 1: Wednesday 29th August 2012 13:00 Welcome and overview 13:15 Session 1: An Introduction to OpenACC 13:15
A High Level Programming Environment for Accelerated Computing. Luiz DeRose Sr. Principal Engineer Programming Environments Director Cray Inc.
 A High Level Programming Environment for Accelerated Computing Luiz DeRose Sr. Principal Engineer Programming Environments Director Cray Inc. Outline Motivation Cray XK6 Overview Why a new programming
A High Level Programming Environment for Accelerated Computing Luiz DeRose Sr. Principal Engineer Programming Environments Director Cray Inc. Outline Motivation Cray XK6 Overview Why a new programming
CRAY XK6 REDEFINING SUPERCOMPUTING. - Sanjana Rakhecha - Nishad Nerurkar
 CRAY XK6 REDEFINING SUPERCOMPUTING - Sanjana Rakhecha - Nishad Nerurkar CONTENTS Introduction History Specifications Cray XK6 Architecture Performance Industry acceptance and applications Summary INTRODUCTION
CRAY XK6 REDEFINING SUPERCOMPUTING - Sanjana Rakhecha - Nishad Nerurkar CONTENTS Introduction History Specifications Cray XK6 Architecture Performance Industry acceptance and applications Summary INTRODUCTION
Hybrid multicore supercomputing and GPU acceleration with next-generation Cray systems
 Hybrid multicore supercomputing and GPU acceleration with next-generation Cray systems Alistair Hart Cray Exascale Research Initiative Europe T-Systems HPCN workshop DLR Braunschweig 26.May.11 ahart@cray.com
Hybrid multicore supercomputing and GPU acceleration with next-generation Cray systems Alistair Hart Cray Exascale Research Initiative Europe T-Systems HPCN workshop DLR Braunschweig 26.May.11 ahart@cray.com
Titan - Early Experience with the Titan System at Oak Ridge National Laboratory
 Office of Science Titan - Early Experience with the Titan System at Oak Ridge National Laboratory Buddy Bland Project Director Oak Ridge Leadership Computing Facility November 13, 2012 ORNL s Titan Hybrid
Office of Science Titan - Early Experience with the Titan System at Oak Ridge National Laboratory Buddy Bland Project Director Oak Ridge Leadership Computing Facility November 13, 2012 ORNL s Titan Hybrid
Adrian Tate XK6 / openacc workshop Manno, Mar
 Adrian Tate XK6 / openacc workshop Manno, Mar6-7 2012 1 Overview & Philosophy Two modes of usage Contents Present contents Upcoming releases Optimization of libsci_acc Autotuning Adaptation Asynchronous
Adrian Tate XK6 / openacc workshop Manno, Mar6-7 2012 1 Overview & Philosophy Two modes of usage Contents Present contents Upcoming releases Optimization of libsci_acc Autotuning Adaptation Asynchronous
GPU Debugging Made Easy. David Lecomber CTO, Allinea Software
 GPU Debugging Made Easy David Lecomber CTO, Allinea Software david@allinea.com Allinea Software HPC development tools company Leading in HPC software tools market Wide customer base Blue-chip engineering,
GPU Debugging Made Easy David Lecomber CTO, Allinea Software david@allinea.com Allinea Software HPC development tools company Leading in HPC software tools market Wide customer base Blue-chip engineering,
The Cray Programming Environment. An Introduction
 The Cray Programming Environment An Introduction Vision Cray systems are designed to be High Productivity as well as High Performance Computers The Cray Programming Environment (PE) provides a simple consistent
The Cray Programming Environment An Introduction Vision Cray systems are designed to be High Productivity as well as High Performance Computers The Cray Programming Environment (PE) provides a simple consistent
Alistair Hart, Roberto Ansaloni, Alan Gray, Kevin Stratford (EPCC) ( Cray Exascale Research Initiative Europe)
 ( Cray Exascale Research Initiative Europe)") Alistair Hart, Roberto Ansaloni, Alan Gray, Kevin Stratford (EPCC) ( Cray Exascale Research Initiative Europe) UKGPUCC3 Goodenough College, London Wed. 14.Dec.11 ahart@cray.com Contents The Now: the new
Alistair Hart, Roberto Ansaloni, Alan Gray, Kevin Stratford (EPCC) ( Cray Exascale Research Initiative Europe) UKGPUCC3 Goodenough College, London Wed. 14.Dec.11 ahart@cray.com Contents The Now: the new
Addressing Performance and Programmability Challenges in Current and Future Supercomputers
 Addressing Performance and Programmability Challenges in Current and Future Supercomputers Luiz DeRose Sr. Principal Engineer Programming Environments Director Cray Inc. VI-HPS - SC'13 Luiz DeRose 2013
Addressing Performance and Programmability Challenges in Current and Future Supercomputers Luiz DeRose Sr. Principal Engineer Programming Environments Director Cray Inc. VI-HPS - SC'13 Luiz DeRose 2013
The challenges of new, efficient computer architectures, and how they can be met with a scalable software development strategy.! Thomas C.
 The challenges of new, efficient computer architectures, and how they can be met with a scalable software development strategy! Thomas C. Schulthess ENES HPC Workshop, Hamburg, March 17, 2014 T. Schulthess!1
The challenges of new, efficient computer architectures, and how they can be met with a scalable software development strategy! Thomas C. Schulthess ENES HPC Workshop, Hamburg, March 17, 2014 T. Schulthess!1
CUDA. Matthew Joyner, Jeremy Williams
 CUDA Matthew Joyner, Jeremy Williams Agenda What is CUDA? CUDA GPU Architecture CPU/GPU Communication Coding in CUDA Use cases of CUDA Comparison to OpenCL What is CUDA? What is CUDA? CUDA is a parallel
CUDA Matthew Joyner, Jeremy Williams Agenda What is CUDA? CUDA GPU Architecture CPU/GPU Communication Coding in CUDA Use cases of CUDA Comparison to OpenCL What is CUDA? What is CUDA? CUDA is a parallel
John Levesque Nov 16, 2001
 1 We see that the GPU is the best device available for us today to be able to get to the performance we want and meet our users requirements for a very high performance node with very high memory bandwidth.
1 We see that the GPU is the best device available for us today to be able to get to the performance we want and meet our users requirements for a very high performance node with very high memory bandwidth.
Addressing the Increasing Challenges of Debugging on Accelerated HPC Systems. Ed Hinkel Senior Sales Engineer
 Addressing the Increasing Challenges of Debugging on Accelerated HPC Systems Ed Hinkel Senior Sales Engineer Agenda Overview - Rogue Wave & TotalView GPU Debugging with TotalView Nvdia CUDA Intel Phi 2
Addressing the Increasing Challenges of Debugging on Accelerated HPC Systems Ed Hinkel Senior Sales Engineer Agenda Overview - Rogue Wave & TotalView GPU Debugging with TotalView Nvdia CUDA Intel Phi 2
Preparing GPU-Accelerated Applications for the Summit Supercomputer
 Preparing GPU-Accelerated Applications for the Summit Supercomputer Fernanda Foertter HPC User Assistance Group Training Lead foertterfs@ornl.gov This research used resources of the Oak Ridge Leadership
Preparing GPU-Accelerated Applications for the Summit Supercomputer Fernanda Foertter HPC User Assistance Group Training Lead foertterfs@ornl.gov This research used resources of the Oak Ridge Leadership
Piz Daint: Application driven co-design of a supercomputer based on Cray s adaptive system design
 Piz Daint: Application driven co-design of a supercomputer based on Cray s adaptive system design Sadaf Alam & Thomas Schulthess CSCS & ETHzürich CUG 2014 * Timelines & releases are not precise Top 500
Piz Daint: Application driven co-design of a supercomputer based on Cray s adaptive system design Sadaf Alam & Thomas Schulthess CSCS & ETHzürich CUG 2014 * Timelines & releases are not precise Top 500
CloverLeaf: Preparing Hydrodynamics Codes for Exascale
 CloverLeaf: Preparing Hydrodynamics Codes for Exascale Andrew Mallinson Andy.Mallinson@awe.co.uk www.awe.co.uk British Crown Owned Copyright [2013]/AWE Agenda AWE & Uni. of Warwick introduction Problem
CloverLeaf: Preparing Hydrodynamics Codes for Exascale Andrew Mallinson Andy.Mallinson@awe.co.uk www.awe.co.uk British Crown Owned Copyright [2013]/AWE Agenda AWE & Uni. of Warwick introduction Problem
The Titan Tools Experience
 The Titan Tools Experience Michael J. Brim, Ph.D. Computer Science Research, CSMD/NCCS Petascale Tools Workshop 213 Madison, WI July 15, 213 Overview of Titan Cray XK7 18,688+ compute nodes 16-core AMD
The Titan Tools Experience Michael J. Brim, Ph.D. Computer Science Research, CSMD/NCCS Petascale Tools Workshop 213 Madison, WI July 15, 213 Overview of Titan Cray XK7 18,688+ compute nodes 16-core AMD
OpenACC Course. Office Hour #2 Q&A
 OpenACC Course Office Hour #2 Q&A Q1: How many threads does each GPU core have? A: GPU cores execute arithmetic instructions. Each core can execute one single precision floating point instruction per cycle
OpenACC Course Office Hour #2 Q&A Q1: How many threads does each GPU core have? A: GPU cores execute arithmetic instructions. Each core can execute one single precision floating point instruction per cycle
The Arm Technology Ecosystem: Current Products and Future Outlook
 The Arm Technology Ecosystem: Current Products and Future Outlook Dan Ernst, PhD Advanced Technology Cray, Inc. Why is an Ecosystem Important? An Ecosystem is a collection of common material Developed
The Arm Technology Ecosystem: Current Products and Future Outlook Dan Ernst, PhD Advanced Technology Cray, Inc. Why is an Ecosystem Important? An Ecosystem is a collection of common material Developed
Debugging CUDA Applications with Allinea DDT. Ian Lumb Sr. Systems Engineer, Allinea Software Inc.
 Debugging CUDA Applications with Allinea DDT Ian Lumb Sr. Systems Engineer, Allinea Software Inc. ilumb@allinea.com GTC 2013, San Jose, March 20, 2013 Embracing GPUs GPUs a rival to traditional processors
Debugging CUDA Applications with Allinea DDT Ian Lumb Sr. Systems Engineer, Allinea Software Inc. ilumb@allinea.com GTC 2013, San Jose, March 20, 2013 Embracing GPUs GPUs a rival to traditional processors
The Eclipse Parallel Tools Platform
 May 1, 2012 Toward an Integrated Development Environment for Improved Software Engineering on Crays Agenda 1. What is the Eclipse Parallel Tools Platform (PTP) 2. Tour of features available in Eclipse/PTP
May 1, 2012 Toward an Integrated Development Environment for Improved Software Engineering on Crays Agenda 1. What is the Eclipse Parallel Tools Platform (PTP) 2. Tour of features available in Eclipse/PTP
Hybrid KAUST Many Cores and OpenACC. Alain Clo - KAUST Research Computing Saber Feki KAUST Supercomputing Lab Florent Lebeau - CAPS
 + Hybrid Computing @ KAUST Many Cores and OpenACC Alain Clo - KAUST Research Computing Saber Feki KAUST Supercomputing Lab Florent Lebeau - CAPS + Agenda Hybrid Computing n Hybrid Computing n From Multi-Physics
+ Hybrid Computing @ KAUST Many Cores and OpenACC Alain Clo - KAUST Research Computing Saber Feki KAUST Supercomputing Lab Florent Lebeau - CAPS + Agenda Hybrid Computing n Hybrid Computing n From Multi-Physics
Portable and Productive Performance on Hybrid Systems with OpenACC Compilers and Tools
 Portable and Productive Performance on Hybrid Systems with OpenACC Compilers and Tools Luiz DeRose Sr. Principal Engineer Programming Environments Director Cray Inc. Major Hybrid Multi Petaflop Systems
Portable and Productive Performance on Hybrid Systems with OpenACC Compilers and Tools Luiz DeRose Sr. Principal Engineer Programming Environments Director Cray Inc. Major Hybrid Multi Petaflop Systems
User Training Cray XC40 IITM, Pune
 User Training Cray XC40 IITM, Pune Sudhakar Yerneni, Raviteja K, Nachiket Manapragada, etc. 1 Cray XC40 Architecture & Packaging 3 Cray XC Series Building Blocks XC40 System Compute Blade 4 Compute Nodes
User Training Cray XC40 IITM, Pune Sudhakar Yerneni, Raviteja K, Nachiket Manapragada, etc. 1 Cray XC40 Architecture & Packaging 3 Cray XC Series Building Blocks XC40 System Compute Blade 4 Compute Nodes
Operational Robustness of Accelerator Aware MPI
 Operational Robustness of Accelerator Aware MPI Sadaf Alam Swiss National Supercomputing Centre (CSSC) Switzerland 2nd Annual MVAPICH User Group (MUG) Meeting, 2014 Computing Systems @ CSCS http://www.cscs.ch/computers
Operational Robustness of Accelerator Aware MPI Sadaf Alam Swiss National Supercomputing Centre (CSSC) Switzerland 2nd Annual MVAPICH User Group (MUG) Meeting, 2014 Computing Systems @ CSCS http://www.cscs.ch/computers
Steve Scott, Tesla CTO SC 11 November 15, 2011
 Steve Scott, Tesla CTO SC 11 November 15, 2011 What goal do these products have in common? Performance / W Exaflop Expectations First Exaflop Computer K Computer ~10 MW CM5 ~200 KW Not constant size, cost
Steve Scott, Tesla CTO SC 11 November 15, 2011 What goal do these products have in common? Performance / W Exaflop Expectations First Exaflop Computer K Computer ~10 MW CM5 ~200 KW Not constant size, cost
Porting COSMO to Hybrid Architectures
 Porting COSMO to Hybrid Architectures T. Gysi 1, O. Fuhrer 2, C. Osuna 3, X. Lapillonne 3, T. Diamanti 3, B. Cumming 4, T. Schroeder 5, P. Messmer 5, T. Schulthess 4,6,7 [1] Supercomputing Systems AG,
Porting COSMO to Hybrid Architectures T. Gysi 1, O. Fuhrer 2, C. Osuna 3, X. Lapillonne 3, T. Diamanti 3, B. Cumming 4, T. Schroeder 5, P. Messmer 5, T. Schulthess 4,6,7 [1] Supercomputing Systems AG,
Early Experiences Writing Performance Portable OpenMP 4 Codes
 Early Experiences Writing Performance Portable OpenMP 4 Codes Verónica G. Vergara Larrea Wayne Joubert M. Graham Lopez Oscar Hernandez Oak Ridge National Laboratory Problem statement APU FPGA neuromorphic
Early Experiences Writing Performance Portable OpenMP 4 Codes Verónica G. Vergara Larrea Wayne Joubert M. Graham Lopez Oscar Hernandez Oak Ridge National Laboratory Problem statement APU FPGA neuromorphic
INTRODUCTION TO OPENACC. Analyzing and Parallelizing with OpenACC, Feb 22, 2017
 INTRODUCTION TO OPENACC Analyzing and Parallelizing with OpenACC, Feb 22, 2017 Objective: Enable you to to accelerate your applications with OpenACC. 2 Today s Objectives Understand what OpenACC is and
INTRODUCTION TO OPENACC Analyzing and Parallelizing with OpenACC, Feb 22, 2017 Objective: Enable you to to accelerate your applications with OpenACC. 2 Today s Objectives Understand what OpenACC is and
PERFORMANCE PORTABILITY WITH OPENACC. Jeff Larkin, NVIDIA, November 2015
 PERFORMANCE PORTABILITY WITH OPENACC Jeff Larkin, NVIDIA, November 2015 TWO TYPES OF PORTABILITY FUNCTIONAL PORTABILITY PERFORMANCE PORTABILITY The ability for a single code to run anywhere. The ability
PERFORMANCE PORTABILITY WITH OPENACC Jeff Larkin, NVIDIA, November 2015 TWO TYPES OF PORTABILITY FUNCTIONAL PORTABILITY PERFORMANCE PORTABILITY The ability for a single code to run anywhere. The ability
Adapting Numerical Weather Prediction codes to heterogeneous architectures: porting the COSMO model to GPUs
 Adapting Numerical Weather Prediction codes to heterogeneous architectures: porting the COSMO model to GPUs O. Fuhrer, T. Gysi, X. Lapillonne, C. Osuna, T. Dimanti, T. Schultess and the HP2C team Eidgenössisches
Adapting Numerical Weather Prediction codes to heterogeneous architectures: porting the COSMO model to GPUs O. Fuhrer, T. Gysi, X. Lapillonne, C. Osuna, T. Dimanti, T. Schultess and the HP2C team Eidgenössisches
Introduction to Parallel and Distributed Computing. Linh B. Ngo CPSC 3620
 Introduction to Parallel and Distributed Computing Linh B. Ngo CPSC 3620 Overview: What is Parallel Computing To be run using multiple processors A problem is broken into discrete parts that can be solved
Introduction to Parallel and Distributed Computing Linh B. Ngo CPSC 3620 Overview: What is Parallel Computing To be run using multiple processors A problem is broken into discrete parts that can be solved
Illinois Proposal Considerations Greg Bauer
 - 2016 Greg Bauer Support model Blue Waters provides traditional Partner Consulting as part of its User Services. Standard service requests for assistance with porting, debugging, allocation issues, and
- 2016 Greg Bauer Support model Blue Waters provides traditional Partner Consulting as part of its User Services. Standard service requests for assistance with porting, debugging, allocation issues, and
OpenACC programming for GPGPUs: Rotor wake simulation
 DLR.de Chart 1 OpenACC programming for GPGPUs: Rotor wake simulation Melven Röhrig-Zöllner, Achim Basermann Simulations- und Softwaretechnik DLR.de Chart 2 Outline Hardware-Architecture (CPU+GPU) GPU computing
DLR.de Chart 1 OpenACC programming for GPGPUs: Rotor wake simulation Melven Röhrig-Zöllner, Achim Basermann Simulations- und Softwaretechnik DLR.de Chart 2 Outline Hardware-Architecture (CPU+GPU) GPU computing
NVIDIA Think about Computing as Heterogeneous One Leo Liao, 1/29/2106, NTU
 NVIDIA Think about Computing as Heterogeneous One Leo Liao, 1/29/2106, NTU GPGPU opens the door for co-design HPC, moreover middleware-support embedded system designs to harness the power of GPUaccelerated
NVIDIA Think about Computing as Heterogeneous One Leo Liao, 1/29/2106, NTU GPGPU opens the door for co-design HPC, moreover middleware-support embedded system designs to harness the power of GPUaccelerated
The Uintah Framework: A Unified Heterogeneous Task Scheduling and Runtime System
 The Uintah Framework: A Unified Heterogeneous Task Scheduling and Runtime System Alan Humphrey, Qingyu Meng, Martin Berzins Scientific Computing and Imaging Institute & University of Utah I. Uintah Overview
The Uintah Framework: A Unified Heterogeneous Task Scheduling and Runtime System Alan Humphrey, Qingyu Meng, Martin Berzins Scientific Computing and Imaging Institute & University of Utah I. Uintah Overview
Using the Cray Programming Environment to Convert an all MPI code to a Hybrid-Multi-core Ready Application
 Using the Cray Programming Environment to Convert an all MPI code to a Hybrid-Multi-core Ready Application John Levesque Cray s Supercomputing Center of Excellence The Target ORNL s Titan System Upgrade
Using the Cray Programming Environment to Convert an all MPI code to a Hybrid-Multi-core Ready Application John Levesque Cray s Supercomputing Center of Excellence The Target ORNL s Titan System Upgrade
Cray Scientific Libraries: Overview and Performance. Cray XE6 Performance Workshop University of Reading Nov 2012
 Cray Scientific Libraries: Overview and Performance Cray XE6 Performance Workshop University of Reading 20-22 Nov 2012 Contents LibSci overview and usage BFRAME / CrayBLAS LAPACK ScaLAPACK FFTW / CRAFFT
Cray Scientific Libraries: Overview and Performance Cray XE6 Performance Workshop University of Reading 20-22 Nov 2012 Contents LibSci overview and usage BFRAME / CrayBLAS LAPACK ScaLAPACK FFTW / CRAFFT
OpenACC/CUDA/OpenMP... 1 Languages and Libraries... 3 Multi-GPU support... 4 How OpenACC Works... 4
 OpenACC Course Class #1 Q&A Contents OpenACC/CUDA/OpenMP... 1 Languages and Libraries... 3 Multi-GPU support... 4 How OpenACC Works... 4 OpenACC/CUDA/OpenMP Q: Is OpenACC an NVIDIA standard or is it accepted
OpenACC Course Class #1 Q&A Contents OpenACC/CUDA/OpenMP... 1 Languages and Libraries... 3 Multi-GPU support... 4 How OpenACC Works... 4 OpenACC/CUDA/OpenMP Q: Is OpenACC an NVIDIA standard or is it accepted
GpuWrapper: A Portable API for Heterogeneous Programming at CGG
 GpuWrapper: A Portable API for Heterogeneous Programming at CGG Victor Arslan, Jean-Yves Blanc, Gina Sitaraman, Marc Tchiboukdjian, Guillaume Thomas-Collignon March 2 nd, 2016 GpuWrapper: Objectives &
GpuWrapper: A Portable API for Heterogeneous Programming at CGG Victor Arslan, Jean-Yves Blanc, Gina Sitaraman, Marc Tchiboukdjian, Guillaume Thomas-Collignon March 2 nd, 2016 GpuWrapper: Objectives &
It s not my fault! Finding errors in parallel codes 找並行程序的錯誤
 It s not my fault! Finding errors in parallel codes 找並行程序的錯誤 David Abramson Minh Dinh (UQ) Chao Jin (UQ) Research Computing Centre, University of Queensland, Brisbane Australia Luiz DeRose (Cray) Bob Moench
It s not my fault! Finding errors in parallel codes 找並行程序的錯誤 David Abramson Minh Dinh (UQ) Chao Jin (UQ) Research Computing Centre, University of Queensland, Brisbane Australia Luiz DeRose (Cray) Bob Moench
Optimising the Mantevo benchmark suite for multi- and many-core architectures
 Optimising the Mantevo benchmark suite for multi- and many-core architectures Simon McIntosh-Smith Department of Computer Science University of Bristol 1 Bristol's rich heritage in HPC The University of
Optimising the Mantevo benchmark suite for multi- and many-core architectures Simon McIntosh-Smith Department of Computer Science University of Bristol 1 Bristol's rich heritage in HPC The University of
Heidi Poxon Cray Inc.
 Heidi Poxon Topics GPU support in the Cray performance tools CUDA proxy MPI support for GPUs (GPU-to-GPU) 2 3 Programming Models Supported for the GPU Goal is to provide whole program analysis for programs
Heidi Poxon Topics GPU support in the Cray performance tools CUDA proxy MPI support for GPUs (GPU-to-GPU) 2 3 Programming Models Supported for the GPU Goal is to provide whole program analysis for programs
RAMSES on the GPU: An OpenACC-Based Approach
 RAMSES on the GPU: An OpenACC-Based Approach Claudio Gheller (ETHZ-CSCS) Giacomo Rosilho de Souza (EPFL Lausanne) Romain Teyssier (University of Zurich) Markus Wetzstein (ETHZ-CSCS) PRACE-2IP project EU
RAMSES on the GPU: An OpenACC-Based Approach Claudio Gheller (ETHZ-CSCS) Giacomo Rosilho de Souza (EPFL Lausanne) Romain Teyssier (University of Zurich) Markus Wetzstein (ETHZ-CSCS) PRACE-2IP project EU
8/19/13. Blue Waters User Monthly Teleconference
 8/19/13 Blue Waters User Monthly Teleconference Extreme Scaling Workshop 2013 Successful workshop in Boulder. Presentations from 4 groups with allocations on Blue Waters. Industry representatives were
8/19/13 Blue Waters User Monthly Teleconference Extreme Scaling Workshop 2013 Successful workshop in Boulder. Presentations from 4 groups with allocations on Blue Waters. Industry representatives were
Programming Environment 4/11/2015
 Programming Environment 4/11/2015 1 Vision Cray systems are designed to be High Productivity as well as High Performance Computers The Cray Programming Environment (PE) provides a simple consistent interface
Programming Environment 4/11/2015 1 Vision Cray systems are designed to be High Productivity as well as High Performance Computers The Cray Programming Environment (PE) provides a simple consistent interface
The Cray Programming Environment. An Introduction
 The Cray Programming Environment An Introduction Vision Cray systems are designed to be High Productivity as well as High Performance Computers The Cray Programming Environment (PE) provides a simple consistent
The Cray Programming Environment An Introduction Vision Cray systems are designed to be High Productivity as well as High Performance Computers The Cray Programming Environment (PE) provides a simple consistent
Exascale Challenges and Applications Initiatives for Earth System Modeling
 Exascale Challenges and Applications Initiatives for Earth System Modeling Workshop on Weather and Climate Prediction on Next Generation Supercomputers 22-25 October 2012 Tom Edwards tedwards@cray.com
Exascale Challenges and Applications Initiatives for Earth System Modeling Workshop on Weather and Climate Prediction on Next Generation Supercomputers 22-25 October 2012 Tom Edwards tedwards@cray.com
Understanding Dynamic Parallelism
 Understanding Dynamic Parallelism Know your code and know yourself Presenter: Mark O Connor, VP Product Management Agenda Introduction and Background Fixing a Dynamic Parallelism Bug Understanding Dynamic
Understanding Dynamic Parallelism Know your code and know yourself Presenter: Mark O Connor, VP Product Management Agenda Introduction and Background Fixing a Dynamic Parallelism Bug Understanding Dynamic
Cray RS Programming Environment
 Cray RS Programming Environment Gail Alverson Cray Inc. Cray Proprietary Red Storm Red Storm is a supercomputer system leveraging over 10,000 AMD Opteron processors connected by an innovative high speed,
Cray RS Programming Environment Gail Alverson Cray Inc. Cray Proprietary Red Storm Red Storm is a supercomputer system leveraging over 10,000 AMD Opteron processors connected by an innovative high speed,
GPU Computing with NVIDIA s new Kepler Architecture
 GPU Computing with NVIDIA s new Kepler Architecture Axel Koehler Sr. Solution Architect HPC HPC Advisory Council Meeting, March 13-15 2013, Lugano 1 NVIDIA: Parallel Computing Company GPUs: GeForce, Quadro,
GPU Computing with NVIDIA s new Kepler Architecture Axel Koehler Sr. Solution Architect HPC HPC Advisory Council Meeting, March 13-15 2013, Lugano 1 NVIDIA: Parallel Computing Company GPUs: GeForce, Quadro,
CUDA Development Using NVIDIA Nsight, Eclipse Edition. David Goodwin
 CUDA Development Using NVIDIA Nsight, Eclipse Edition David Goodwin NVIDIA Nsight Eclipse Edition CUDA Integrated Development Environment Project Management Edit Build Debug Profile SC'12 2 Powered By
CUDA Development Using NVIDIA Nsight, Eclipse Edition David Goodwin NVIDIA Nsight Eclipse Edition CUDA Integrated Development Environment Project Management Edit Build Debug Profile SC'12 2 Powered By
Finite Element Integration and Assembly on Modern Multi and Many-core Processors
 Finite Element Integration and Assembly on Modern Multi and Many-core Processors Krzysztof Banaś, Jan Bielański, Kazimierz Chłoń AGH University of Science and Technology, Mickiewicza 30, 30-059 Kraków,
Finite Element Integration and Assembly on Modern Multi and Many-core Processors Krzysztof Banaś, Jan Bielański, Kazimierz Chłoń AGH University of Science and Technology, Mickiewicza 30, 30-059 Kraków,
It s a Multicore World. John Urbanic Pittsburgh Supercomputing Center
 It s a Multicore World John Urbanic Pittsburgh Supercomputing Center Waiting for Moore s Law to save your serial code start getting bleak in 2004 Source: published SPECInt data Moore s Law is not at all
It s a Multicore World John Urbanic Pittsburgh Supercomputing Center Waiting for Moore s Law to save your serial code start getting bleak in 2004 Source: published SPECInt data Moore s Law is not at all
Cray XC Scalability and the Aries Network Tony Ford
 Cray XC Scalability and the Aries Network Tony Ford June 29, 2017 Exascale Scalability Which scalability metrics are important for Exascale? Performance (obviously!) What are the contributing factors?
Cray XC Scalability and the Aries Network Tony Ford June 29, 2017 Exascale Scalability Which scalability metrics are important for Exascale? Performance (obviously!) What are the contributing factors?
Steps to create a hybrid code
 Steps to create a hybrid code Alistair Hart Cray Exascale Research Initiative Europe 29-30.Aug.12 PRACE training course, Edinburgh 1 Contents This lecture is all about finding as much parallelism as you
Steps to create a hybrid code Alistair Hart Cray Exascale Research Initiative Europe 29-30.Aug.12 PRACE training course, Edinburgh 1 Contents This lecture is all about finding as much parallelism as you
The Red Storm System: Architecture, System Update and Performance Analysis
 The Red Storm System: Architecture, System Update and Performance Analysis Douglas Doerfler, Jim Tomkins Sandia National Laboratories Center for Computation, Computers, Information and Mathematics LACSI
The Red Storm System: Architecture, System Update and Performance Analysis Douglas Doerfler, Jim Tomkins Sandia National Laboratories Center for Computation, Computers, Information and Mathematics LACSI
Lattice Simulations using OpenACC compilers. Pushan Majumdar (Indian Association for the Cultivation of Science, Kolkata)
") Lattice Simulations using OpenACC compilers Pushan Majumdar (Indian Association for the Cultivation of Science, Kolkata) OpenACC is a programming standard for parallel computing developed by Cray, CAPS,
Lattice Simulations using OpenACC compilers Pushan Majumdar (Indian Association for the Cultivation of Science, Kolkata) OpenACC is a programming standard for parallel computing developed by Cray, CAPS,
Present and Future Leadership Computers at OLCF
 Present and Future Leadership Computers at OLCF Al Geist ORNL Corporate Fellow DOE Data/Viz PI Meeting January 13-15, 2015 Walnut Creek, CA ORNL is managed by UT-Battelle for the US Department of Energy
Present and Future Leadership Computers at OLCF Al Geist ORNL Corporate Fellow DOE Data/Viz PI Meeting January 13-15, 2015 Walnut Creek, CA ORNL is managed by UT-Battelle for the US Department of Energy
CS500 SMARTER CLUSTER SUPERCOMPUTERS
 CS500 SMARTER CLUSTER SUPERCOMPUTERS OVERVIEW Extending the boundaries of what you can achieve takes reliable computing tools matched to your workloads. That s why we tailor the Cray CS500 cluster supercomputer
CS500 SMARTER CLUSTER SUPERCOMPUTERS OVERVIEW Extending the boundaries of what you can achieve takes reliable computing tools matched to your workloads. That s why we tailor the Cray CS500 cluster supercomputer
Porting a parallel rotor wake simulation to GPGPU accelerators using OpenACC
 DLR.de Chart 1 Porting a parallel rotor wake simulation to GPGPU accelerators using OpenACC Melven Röhrig-Zöllner DLR, Simulations- und Softwaretechnik DLR.de Chart 2 Outline Hardware-Architecture (CPU+GPU)
DLR.de Chart 1 Porting a parallel rotor wake simulation to GPGPU accelerators using OpenACC Melven Röhrig-Zöllner DLR, Simulations- und Softwaretechnik DLR.de Chart 2 Outline Hardware-Architecture (CPU+GPU)
arxiv: v1 [hep-lat] 12 Nov 2013
![arxiv: v1 [hep-lat] 12 Nov 2013](/thumbs/87/96002319.jpg "arxiv: v1 [hep-lat] 12 Nov 2013") Lattice Simulations using OpenACC compilers arxiv:13112719v1 [hep-lat] 12 Nov 2013 Indian Association for the Cultivation of Science, Kolkata E-mail: tppm@iacsresin OpenACC compilers allow one to use Graphics
Lattice Simulations using OpenACC compilers arxiv:13112719v1 [hep-lat] 12 Nov 2013 Indian Association for the Cultivation of Science, Kolkata E-mail: tppm@iacsresin OpenACC compilers allow one to use Graphics
Analyzing the Performance of IWAVE on a Cluster using HPCToolkit
 Analyzing the Performance of IWAVE on a Cluster using HPCToolkit John Mellor-Crummey and Laksono Adhianto Department of Computer Science Rice University {johnmc,laksono}@rice.edu TRIP Meeting March 30,
Analyzing the Performance of IWAVE on a Cluster using HPCToolkit John Mellor-Crummey and Laksono Adhianto Department of Computer Science Rice University {johnmc,laksono}@rice.edu TRIP Meeting March 30,
OpenACC 2.6 Proposed Features
 OpenACC 2.6 Proposed Features OpenACC.org June, 2017 1 Introduction This document summarizes features and changes being proposed for the next version of the OpenACC Application Programming Interface, tentatively
OpenACC 2.6 Proposed Features OpenACC.org June, 2017 1 Introduction This document summarizes features and changes being proposed for the next version of the OpenACC Application Programming Interface, tentatively
GPGPUs in HPC. VILLE TIMONEN Åbo Akademi University CSC
 GPGPUs in HPC VILLE TIMONEN Åbo Akademi University 2.11.2010 @ CSC Content Background How do GPUs pull off higher throughput Typical architecture Current situation & the future GPGPU languages A tale of
GPGPUs in HPC VILLE TIMONEN Åbo Akademi University 2.11.2010 @ CSC Content Background How do GPUs pull off higher throughput Typical architecture Current situation & the future GPGPU languages A tale of
HETEROGENEOUS HPC, ARCHITECTURAL OPTIMIZATION, AND NVLINK STEVE OBERLIN CTO, TESLA ACCELERATED COMPUTING NVIDIA
 HETEROGENEOUS HPC, ARCHITECTURAL OPTIMIZATION, AND NVLINK STEVE OBERLIN CTO, TESLA ACCELERATED COMPUTING NVIDIA STATE OF THE ART 2012 18,688 Tesla K20X GPUs 27 PetaFLOPS FLAGSHIP SCIENTIFIC APPLICATIONS
HETEROGENEOUS HPC, ARCHITECTURAL OPTIMIZATION, AND NVLINK STEVE OBERLIN CTO, TESLA ACCELERATED COMPUTING NVIDIA STATE OF THE ART 2012 18,688 Tesla K20X GPUs 27 PetaFLOPS FLAGSHIP SCIENTIFIC APPLICATIONS
Overview. Lecture 1: an introduction to CUDA. Hardware view. Hardware view. hardware view software view CUDA programming
 Overview Lecture 1: an introduction to CUDA Mike Giles mike.giles@maths.ox.ac.uk hardware view software view Oxford University Mathematical Institute Oxford e-research Centre Lecture 1 p. 1 Lecture 1 p.
Overview Lecture 1: an introduction to CUDA Mike Giles mike.giles@maths.ox.ac.uk hardware view software view Oxford University Mathematical Institute Oxford e-research Centre Lecture 1 p. 1 Lecture 1 p.
Lecture 20: Distributed Memory Parallelism. William Gropp
 Lecture 20: Distributed Parallelism William Gropp www.cs.illinois.edu/~wgropp A Very Short, Very Introductory Introduction We start with a short introduction to parallel computing from scratch in order
Lecture 20: Distributed Parallelism William Gropp www.cs.illinois.edu/~wgropp A Very Short, Very Introductory Introduction We start with a short introduction to parallel computing from scratch in order
The Cray Rainier System: Integrated Scalar/Vector Computing
 THE SUPERCOMPUTER COMPANY The Cray Rainier System: Integrated Scalar/Vector Computing Per Nyberg 11 th ECMWF Workshop on HPC in Meteorology Topics Current Product Overview Cray Technology Strengths Rainier
THE SUPERCOMPUTER COMPANY The Cray Rainier System: Integrated Scalar/Vector Computing Per Nyberg 11 th ECMWF Workshop on HPC in Meteorology Topics Current Product Overview Cray Technology Strengths Rainier
Intel C++ Compiler User's Guide With Support For The Streaming Simd Extensions 2
 Intel C++ Compiler User's Guide With Support For The Streaming Simd Extensions 2 This release of the Intel C++ Compiler 16.0 product is a Pre-Release, and as such is 64 architecture processor supporting
Intel C++ Compiler User's Guide With Support For The Streaming Simd Extensions 2 This release of the Intel C++ Compiler 16.0 product is a Pre-Release, and as such is 64 architecture processor supporting
GPU Architecture. Alan Gray EPCC The University of Edinburgh
 GPU Architecture Alan Gray EPCC The University of Edinburgh Outline Why do we want/need accelerators such as GPUs? Architectural reasons for accelerator performance advantages Latest GPU Products From
GPU Architecture Alan Gray EPCC The University of Edinburgh Outline Why do we want/need accelerators such as GPUs? Architectural reasons for accelerator performance advantages Latest GPU Products From
Experiences with ENZO on the Intel Many Integrated Core Architecture
 Experiences with ENZO on the Intel Many Integrated Core Architecture Dr. Robert Harkness National Institute for Computational Sciences April 10th, 2012 Overview ENZO applications at petascale ENZO and
Experiences with ENZO on the Intel Many Integrated Core Architecture Dr. Robert Harkness National Institute for Computational Sciences April 10th, 2012 Overview ENZO applications at petascale ENZO and
It s a Multicore World. John Urbanic Pittsburgh Supercomputing Center Parallel Computing Scientist
 It s a Multicore World John Urbanic Pittsburgh Supercomputing Center Parallel Computing Scientist Waiting for Moore s Law to save your serial code started getting bleak in 2004 Source: published SPECInt
It s a Multicore World John Urbanic Pittsburgh Supercomputing Center Parallel Computing Scientist Waiting for Moore s Law to save your serial code started getting bleak in 2004 Source: published SPECInt
Our Workshop Environment
 Our Workshop Environment John Urbanic Parallel Computing Scientist Pittsburgh Supercomputing Center Copyright 2015 Our Environment Today Your laptops or workstations: only used for portal access Blue Waters
Our Workshop Environment John Urbanic Parallel Computing Scientist Pittsburgh Supercomputing Center Copyright 2015 Our Environment Today Your laptops or workstations: only used for portal access Blue Waters
HPC future trends from a science perspective
 HPC future trends from a science perspective Simon McIntosh-Smith University of Bristol HPC Research Group simonm@cs.bris.ac.uk 1 Business as usual? We've all got used to new machines being relatively
HPC future trends from a science perspective Simon McIntosh-Smith University of Bristol HPC Research Group simonm@cs.bris.ac.uk 1 Business as usual? We've all got used to new machines being relatively
Parallel Programming and Debugging with CUDA C. Geoff Gerfin Sr. System Software Engineer
 Parallel Programming and Debugging with CUDA C Geoff Gerfin Sr. System Software Engineer CUDA - NVIDIA s Architecture for GPU Computing Broad Adoption Over 250M installed CUDA-enabled GPUs GPU Computing
Parallel Programming and Debugging with CUDA C Geoff Gerfin Sr. System Software Engineer CUDA - NVIDIA s Architecture for GPU Computing Broad Adoption Over 250M installed CUDA-enabled GPUs GPU Computing
IBM CORAL HPC System Solution
 IBM CORAL HPC System Solution HPC and HPDA towards Cognitive, AI and Deep Learning Deep Learning AI / Deep Learning Strategy for Power Power AI Platform High Performance Data Analytics Big Data Strategy
IBM CORAL HPC System Solution HPC and HPDA towards Cognitive, AI and Deep Learning Deep Learning AI / Deep Learning Strategy for Power Power AI Platform High Performance Data Analytics Big Data Strategy
Parallel Programming. Libraries and Implementations
 Parallel Programming Libraries and Implementations Reusing this material This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike 4.0 International License. http://creativecommons.org/licenses/by-nc-sa/4.0/deed.en_us
Parallel Programming Libraries and Implementations Reusing this material This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike 4.0 International License. http://creativecommons.org/licenses/by-nc-sa/4.0/deed.en_us
OpenACC Accelerator Directives. May 3, 2013
 OpenACC Accelerator Directives May 3, 2013 OpenACC is... An API Inspired by OpenMP Implemented by Cray, PGI, CAPS Includes functions to query device(s) Evolving Plan to integrate into OpenMP Support of
OpenACC Accelerator Directives May 3, 2013 OpenACC is... An API Inspired by OpenMP Implemented by Cray, PGI, CAPS Includes functions to query device(s) Evolving Plan to integrate into OpenMP Support of
Trends in HPC (hardware complexity and software challenges)
") Trends in HPC (hardware complexity and software challenges) Mike Giles Oxford e-research Centre Mathematical Institute MIT seminar March 13th, 2013 Mike Giles (Oxford) HPC Trends March 13th, 2013 1 / 18
Trends in HPC (hardware complexity and software challenges) Mike Giles Oxford e-research Centre Mathematical Institute MIT seminar March 13th, 2013 Mike Giles (Oxford) HPC Trends March 13th, 2013 1 / 18
Accelerator programming with OpenACC
 ..... Accelerator programming with OpenACC Colaboratorio Nacional de Computación Avanzada Jorge Castro jcastro@cenat.ac.cr 2018. Agenda 1 Introduction 2 OpenACC life cycle 3 Hands on session Profiling
..... Accelerator programming with OpenACC Colaboratorio Nacional de Computación Avanzada Jorge Castro jcastro@cenat.ac.cr 2018. Agenda 1 Introduction 2 OpenACC life cycle 3 Hands on session Profiling
Thinking Outside of the Tera-Scale Box. Piotr Luszczek
 Thinking Outside of the Tera-Scale Box Piotr Luszczek Brief History of Tera-flop: 1997 1997 ASCI Red Brief History of Tera-flop: 2007 Intel Polaris 2007 1997 ASCI Red Brief History of Tera-flop: GPGPU
Thinking Outside of the Tera-Scale Box Piotr Luszczek Brief History of Tera-flop: 1997 1997 ASCI Red Brief History of Tera-flop: 2007 Intel Polaris 2007 1997 ASCI Red Brief History of Tera-flop: GPGPU
Quantum ESPRESSO on GPU accelerated systems
 Quantum ESPRESSO on GPU accelerated systems Massimiliano Fatica, Everett Phillips, Josh Romero - NVIDIA Filippo Spiga - University of Cambridge/ARM (UK) MaX International Conference, Trieste, Italy, January
Quantum ESPRESSO on GPU accelerated systems Massimiliano Fatica, Everett Phillips, Josh Romero - NVIDIA Filippo Spiga - University of Cambridge/ARM (UK) MaX International Conference, Trieste, Italy, January
Directed Optimization On Stencil-based Computational Fluid Dynamics Application(s)
") Directed Optimization On Stencil-based Computational Fluid Dynamics Application(s) Islam Harb 08/21/2015 Agenda Motivation Research Challenges Contributions & Approach Results Conclusion Future Work 2
Directed Optimization On Stencil-based Computational Fluid Dynamics Application(s) Islam Harb 08/21/2015 Agenda Motivation Research Challenges Contributions & Approach Results Conclusion Future Work 2
OpenACC2 vs.openmp4. James Lin 1,2 and Satoshi Matsuoka 2
 2014@San Jose Shanghai Jiao Tong University Tokyo Institute of Technology OpenACC2 vs.openmp4 he Strong, the Weak, and the Missing to Develop Performance Portable Applica>ons on GPU and Xeon Phi James
2014@San Jose Shanghai Jiao Tong University Tokyo Institute of Technology OpenACC2 vs.openmp4 he Strong, the Weak, and the Missing to Develop Performance Portable Applica>ons on GPU and Xeon Phi James
Programming NVIDIA GPUs with OpenACC Directives
 Programming NVIDIA GPUs with OpenACC Directives Michael Wolfe michael.wolfe@pgroup.com http://www.pgroup.com/accelerate Programming NVIDIA GPUs with OpenACC Directives Michael Wolfe mwolfe@nvidia.com http://www.pgroup.com/accelerate
Programming NVIDIA GPUs with OpenACC Directives Michael Wolfe michael.wolfe@pgroup.com http://www.pgroup.com/accelerate Programming NVIDIA GPUs with OpenACC Directives Michael Wolfe mwolfe@nvidia.com http://www.pgroup.com/accelerate
GPU computing at RZG overview & some early performance results. Markus Rampp
 GPU computing at RZG overview & some early performance results Markus Rampp Introduction Outline Hydra configuration overview GPU software environment Benchmarking and porting activities Team Renate Dohmen
GPU computing at RZG overview & some early performance results Markus Rampp Introduction Outline Hydra configuration overview GPU software environment Benchmarking and porting activities Team Renate Dohmen
Lecture 1: an introduction to CUDA
 Lecture 1: an introduction to CUDA Mike Giles mike.giles@maths.ox.ac.uk Oxford University Mathematical Institute Oxford e-research Centre Lecture 1 p. 1 Overview hardware view software view CUDA programming
Lecture 1: an introduction to CUDA Mike Giles mike.giles@maths.ox.ac.uk Oxford University Mathematical Institute Oxford e-research Centre Lecture 1 p. 1 Overview hardware view software view CUDA programming
Developing, Debugging, and Optimizing GPU Codes for High Performance Computing with Allinea Forge
 Developing, Debugging, and Optimizing GPU Codes for High Performance Computing with Allinea Forge Ryan Hulguin Applications Engineer ryan.hulguin@arm.com Agenda Introduction Overview of Allinea Products
Developing, Debugging, and Optimizing GPU Codes for High Performance Computing with Allinea Forge Ryan Hulguin Applications Engineer ryan.hulguin@arm.com Agenda Introduction Overview of Allinea Products
Performance Tools for Technical Computing
 Christian Terboven terboven@rz.rwth-aachen.de Center for Computing and Communication RWTH Aachen University Intel Software Conference 2010 April 13th, Barcelona, Spain Agenda o Motivation and Methodology
Christian Terboven terboven@rz.rwth-aachen.de Center for Computing and Communication RWTH Aachen University Intel Software Conference 2010 April 13th, Barcelona, Spain Agenda o Motivation and Methodology
Experiences with CUDA & OpenACC from porting ACME to GPUs
 Experiences with CUDA & OpenACC from porting ACME to GPUs Matthew Norman Irina Demeshko Jeffrey Larkin Aaron Vose Mark Taylor ORNL is managed by UT-Battelle for the US Department of Energy ORNL Sandia
Experiences with CUDA & OpenACC from porting ACME to GPUs Matthew Norman Irina Demeshko Jeffrey Larkin Aaron Vose Mark Taylor ORNL is managed by UT-Battelle for the US Department of Energy ORNL Sandia
CMSC 714 Lecture 6 MPI vs. OpenMP and OpenACC. Guest Lecturer: Sukhyun Song (original slides by Alan Sussman)
") CMSC 714 Lecture 6 MPI vs. OpenMP and OpenACC Guest Lecturer: Sukhyun Song (original slides by Alan Sussman) Parallel Programming with Message Passing and Directives 2 MPI + OpenMP Some applications can
CMSC 714 Lecture 6 MPI vs. OpenMP and OpenACC Guest Lecturer: Sukhyun Song (original slides by Alan Sussman) Parallel Programming with Message Passing and Directives 2 MPI + OpenMP Some applications can
CSCS Proposal writing webinar Technical review. 12th April 2015 CSCS
 CSCS Proposal writing webinar Technical review 12th April 2015 CSCS Agenda Tips for new applicants CSCS overview Allocation process Guidelines Basic concepts Performance tools Demo Q&A open discussion
CSCS Proposal writing webinar Technical review 12th April 2015 CSCS Agenda Tips for new applicants CSCS overview Allocation process Guidelines Basic concepts Performance tools Demo Q&A open discussion
Particle-in-Cell Simulations on Modern Computing Platforms. Viktor K. Decyk and Tajendra V. Singh UCLA
 Particle-in-Cell Simulations on Modern Computing Platforms Viktor K. Decyk and Tajendra V. Singh UCLA Outline of Presentation Abstraction of future computer hardware PIC on GPUs OpenCL and Cuda Fortran
Particle-in-Cell Simulations on Modern Computing Platforms Viktor K. Decyk and Tajendra V. Singh UCLA Outline of Presentation Abstraction of future computer hardware PIC on GPUs OpenCL and Cuda Fortran
How to Write Code that Will Survive the Many-Core Revolution
 How to Write Code that Will Survive the Many-Core Revolution Write Once, Deploy Many(-Cores) Guillaume BARAT, EMEA Sales Manager CAPS worldwide ecosystem Customers Business Partners Involved in many European
How to Write Code that Will Survive the Many-Core Revolution Write Once, Deploy Many(-Cores) Guillaume BARAT, EMEA Sales Manager CAPS worldwide ecosystem Customers Business Partners Involved in many European
Overview of Tianhe-2
 Overview of Tianhe-2 (MilkyWay-2) Supercomputer Yutong Lu School of Computer Science, National University of Defense Technology; State Key Laboratory of High Performance Computing, China ytlu@nudt.edu.cn
Overview of Tianhe-2 (MilkyWay-2) Supercomputer Yutong Lu School of Computer Science, National University of Defense Technology; State Key Laboratory of High Performance Computing, China ytlu@nudt.edu.cn
Chapter 3 Parallel Software
 Chapter 3 Parallel Software Part I. Preliminaries Chapter 1. What Is Parallel Computing? Chapter 2. Parallel Hardware Chapter 3. Parallel Software Chapter 4. Parallel Applications Chapter 5. Supercomputers
Chapter 3 Parallel Software Part I. Preliminaries Chapter 1. What Is Parallel Computing? Chapter 2. Parallel Hardware Chapter 3. Parallel Software Chapter 4. Parallel Applications Chapter 5. Supercomputers