Improving Http-Server Performance by Adapted Multithreading
|
|
|
- Juliana Ramsey
- 5 years ago
- Views:
Transcription
1 Improving Http-Server Performance by Adapted Multithreading Jörg Keller LG Technische Informatik II FernUniversität Hagen Hagen, Germany Olaf Monien Thilo Lardon Computertechnik Füllenbachstrasse Düsseldorf, Germany olaf@monien.net ABSTRACT It is wellknown that http servers can be programmed easier by using multithreading, i.e. each connection is dealt with by a separate thread. It is also known, e.g. from massively parallel programming, that multithreading can be used to hide the long latency of a remote memory access. However, the two techniques do not readily complement each other because context switches do not necessarily occur when latencies would suggest them. We present an http server that combines these two features: as soon as an event with a longer latency is encountered, such as the server cannot send all data with one buffer, the context is switched. The implementation is based on the replacement of threads in the http library Indy by an own implementation that allows explicit context switch as in fibers. We benchmark our http server with the apache benchmark against the original thread-based implementation, with different file sizes and different load levels. We find that if the server s network connection is fully utilized, our implementation needs about one third of CPU time to handle the same throughput. If the network connection is not the bottleneck, then our implementation achieves a 26% higher throughput, given a 100% CPU utilization in both servers. The application of fiber-based multithreading is a technique similar to using assembler: it is not feasible on a large scale, but use in a library provides enormous performance benefits transparently to the user. KEY WORDS Multithreading, Parallel Processing, Web Technologies, Performance Evaluation 1 Introduction An http server is an important software application on todays server (hardware) platforms, which possesses an enormous amount of parallelism. It handles multiple often thousands of connections simultaneously. Hence, it is appropriate to program them in a parallel manner: each connection is handled by its own thread. Moreover, the performance requirements (especially concerning the throughput) are high. Hence we concentrate on how to improve web server performance. Work done as part of Master s thesis at FernUniversität. In each thread, events with a long latency can occur. An example is a connecting client that requests a file, which can be (almost) arbitrarily large, while it has to be transferred via a send buffer that has a fixed finite size. Thus, the data to be sent will not fit completely in the buffer. In this case the thread must wait until the buffer content has been sent over the network before it can fill the buffer again with the remaining data. These latencies can potentially be hidden by a context switch to execute another thread while the former thread is waiting. However, for typical thread packages, the application has no possibility to enforce a context switch at a particular instant. In addition, although thread switch time in modern operating systems has become quite small compared to process switch time, the context switch time for threads is still rather long in comparison to the latencies incurred. Therefore, the gain would be quite small. Latency hiding by multithreading has been explored e.g. in the context of the massively-parallel Cray T3E architecture [1, 2]. There, the calls for a remote memory access were detected during compilation and extended with a context-switch. Also, the standard POSIX thread calls were replaced by inserting code of a re-implementation that delivered a much higher performance. This was achieved by keeping the context as small as possible, avoiding operating system calls, and inlining the context-switch code. The latter measure had the advantage that by a compile-time analysis, only parts of the context that are needed in the next section must be loaded, and only parts of the context that were changed in the last section must be stored. We try to use this idea in the area of http servers. As we want to initiate a context switch at particular places, we look at fibers 1 as used by the Windows operating system, that are related to coroutines which were popular in the eighties [3]. As the Windows fibers are not fast enough, we do a re-implementation (see Section 2). We integrate our fibers into a multithreaded http server of the open source protocol suite Indy [4] and show that only a handful of code modifications are necessary (see Section 3). We evaluate our concept by measuring performance of our http server and the unmodified http server of the Indy suite (see Section 4). We also compare these results to the popular apache http server. 1 Fibers are similar to threads, but the user can specify when a fiber shall transfer control to another fiber.
2 Figure 1. Class concept of EMUfibers While our concept may seem quite specialized, we once again mention that web applications are a major application area, and that the changes to the http server code happen in the Indy library linked to the application. The changes to Indy are minor. The fiber implementation itself is a library of its own. Our idea in a sense is similar to using assembler: this is not feasible on a large scale, but still done in libraries when performance is a serious issue. The implementation within a library also allows to apply the same idea in other performance sensitive fields as well, may it be in the same library or by applying this technique to another library. Finally, in contrast to the idea by Grävinghoff, we do not need specialized compiler tools. Therefore we can rely on standard compilers and enjoy all their possibilities for optimization as well. 2 Re-Implementing Fibers Fibers in the Windows operating system have some disadvantages. First, their documentation is not very good. Second, creating or destructing a larger number of fibers produces a high CPU load, which is not desired because this frequently will happen in an http server, although the concept of thread pools partially alleviates this disadvantage. Third, the fibers are not object-oriented, while the http server we want to use them is written in Delphi, Borland s object-oriented development tool based on the Pascal programming language. Therefore, we decided to implement a fiber class ourselves. We call these EMUfibers in tribute to the EMU system [1] that inspired them. Necessary was to create code for creating and destructing a fiber, a yield-call that switches context from the current fiber so that another fiber can continue, and a manager that schedules the fibers. Additionally, calls for synchronization are implemented, so that the fibers can access the graphical user interface, which in Delphi runs under the MainThread and is not thread-safe. The software construction is shown in Figure 1. During initialization, we create one Manager in- Figure 2. Flow diagramm of EMUfiber control stance. The manager maintains two lists: SuspendedFibers and TerminatedFibers. The former contains all fibers to be executed, and the latter contains all fibers that have terminated but are not yet freed, e.g. because another fiber might need some result data from them. The manager also starts and controls one or several threads, onto which the EMUfibers from the list SuspendedFibers are scheduled. See Figure 2 for a complete flow diagramm. A thread which is given an EMUfiber first checks whether the fiber is ready to run, i.e. in state Yielded. If so, it is unyielded and executed until the fiber terminates or calls the Yield function. In the former case, the fiber is transferred to the list TerminatedFibers, or freed if it is not to provide any result to another fiber. In the latter case, it is transferred to the list SuspendedFibers. If the application creates a new EMUfiber, it is in state Suspended. If the fiber is resumed by the application, then it takes state Yielded. In both states, the fiber is in list SuspendedFibers. The difference between these two states is due to compatibility with Windows threads. In our application, a newly created fiber is immediately resumed, and never suspended. With a call to UnYield, the state changes to Executing. For a complete state diagramm, see Figure 3. The Yield and Unyield methods were programmed in Delphi inline assembler for performance reasons. As the methods are normals procedure calls, most of the context, ie. the registers, need not be saved explicitly. As the thread where the fiber is executed in remains the same, this is possible. Additionally, the base and stack pointers of the fiber and the thread and the return address

3 Creating 1000 EMUFibers (Stack size: 4000 byte) EMUFibers created in 8,58 ms. Destroying 1000 EMUFibers EMUFibers destroxed in 9,02 ms. Figure 3. State Diagramm of an EMUfiber must be stored. Hence, the fiber context is very small. The Yield method consists of about 20 assembler instructions, which is much faster than current thread implementations. The scheduling strategy used is a simple first-in-firstout strategy. Besides the obvious performance advantage, we believe this strategy to be sufficient in our application environment, for the following reasons. First, almost all fibers deal with a client connection, and therefore have identical priorities. If there are many connections, then the probability is quite small that a fiber is scheduled again while its send buffer is not yet cleared. This normally only happens if the communication bandwidth is the bottleneck. In the case that the communication bandwidth is sufficient, then fibers may still experience differing times to clear their buffers because some of them are subject to bandwidth bottlenecks on the side of their client (or in the network). Then a further increase in throughput might be possible if fibers whose connections experience a higher bandwidth get higher priority. As, however, the penalty for scheduling a fiber and immediately yielding it again is quite small, we believe this increase to be small. The detailed description of the procedures implemented, together with the assembler code listing, can be found in [5], or obtained by contacting the authors. 3 Integration into an http Server The Indy (Internet direct) library [4] provides implementations for a number of internet protocols, among them http, both for the server and the client side. It is open source and included in Delphi. As Delphi is available for Linux under the name Kylix, our code can also be used for that operating system after a small number of operating-system specific changes. The http server in Indy uses two types of threads: a socalled ListenerThread waits for incoming connections on port 80, and a so-called PeerThread is created for each new connection. The latter handles the communication between the server and the client, and is terminated upon the end of the connection. The exchange of the threads for our fibers is simplified by the fact that the Indy library does not use the Delphi threads directly but uses a derivation. By changing only a few code lines, our fibers can be used. What remains to be done is the insertion of Yield statements at the appropriate places. In fact, only one statement must be added, namely during the write of a data stream. If the data does Creating 1000 WinFibers WinFibers created in 12,96 ms. Destroying 1000 WinFibers WinFibers destroxed in 31,91 ms. Figure 4. Comparing EMUfibers and Windows fibers Figure 5. Benchmarking EMUfibers against threads not fit into the buffer, then the context is switched by calling Yield. Then the socket responsible for sending the data gets time to transmit the buffer content, until the fiber is scheduled again. An additional, although minor, problem is that the ListenerThread, which is now a fiber, blocks until a new connection is recognized, and hence no other fibers could be executed. A simple solution is to use two scheduler threads, of which one blocks with the Listener fiber, and the other executes the remaining fibers. We have created a web server executable, that listens on two ports. Port 80 is used for the http server with our fibers, port 8080 is used for the original http server with threads. The server creates a simple graphical user interface for display in the client browser. 4 Experiments We first compare the performance of our fiber implementation against the original Windows fibers with the help of a simple test programm that only creates and destroys fibers. We find that creation and destruction of 1000 EMUfibers takes only 66.2% and 28.3%, respectively, of the time that Windows fibers need, see Figure 4. Then, we compare EMUfibers against threads. There, creation of 1000 EMUthreads needs only 7.8% of the time for threads, see Figure 5.

4 Figure 6. Example output of the Apache benchmark Now, we compare a http server based on our fiber implementation with the original multithreaded http server of the Indy suite. The platform uses an AMD K6-III processor at 400 MHz with 512 MByte memory, running under the Windows NT4 Server operating system. We use the Apache Benchmark ab [6]. For our tests, we use two files of sizes 10,541 bytes (Haewelmann.html) and 4 bytes (echo, generated by the server s echo function) respectively, to reflect the varying file sizes on the web. The first file reflects a typical html page, while the second reflects the answer to a generated request. Note that the transferred amount of data is about 100 bytes more because of the http protocol overhead. We also experimented with a file of about 800 KBytes (changes.html), but there the data transfer times dominate. Consequently, the differences between the two http servers diminish. For each server and each file, we performed the following tests: Either a local client or a 10 MBit network connection was used. Concurrency levels of 1, 10, and 50 were used. In the Apache Benchmark, the concurrency level denotes the number of requests that are posed in a very short time before a response is expected. This is used to simulate multiple clients. Figure 6 depicts a sample output of ab. If a local client is used, the communication bandwidth is not the limit. Hence, if the concurrency is high enough, the server CPU will be fully utilized. In this case, we compare the throughputs achieved by the two servers. If a network connection is used, it will saturate when the concurrency is high enough. In this case we compare the CPU utilizations, and in addition the throughput to check whether a lower CPU utilization sacrifices performance. For the situation of a local client, we find that our throughput is 26% and 50% higher, respectively, for the two files, if the concurrency is at least 5, to achieve 100% CPU utilization; see Figure 8. For the situation of a network connection, we find that our CPU utilization is 40% and 80%, respectively, of the other http server s, if the concurrency is at least 5, to achieve 100% network utilization; see Figure 9. At the same time we find that our throughput is identical for the larger file and about 30% higher for the short file; see Figure 10. This indicates that the original http server was not able to fully utilize the network bandwidth in this case due to local performance problems (its CPU utilization is about 90%). It hence seems that our implementation may be especially suited for large numbers of short requests. Last, we compare our implementation against the Apache web server , which is one of the most popular open source products for web servers. As server platform, we use an 1.3 GHz Celeron processor with 1 GByte memory, running under the Windows 2000 professional operating system. We apply the apache benchmark with the file haewelmann.html and concurrency 2 5 for a local client, because this file represents a typical web page size, and the differences between the servers should be most prominent without the influence of network bandwidth. Figure 7 depicts that the EMUfiber-based web server achieves a throughput which is slightly higher than the Apache web server. The original Indy web server achieves about 3,000 KByte/sec, as to be expected in similarity to Figure 8. Note that this comparison still is somewhat unfair towards our implementation, as the Apache web server is a product designed solely for that purpose, i.e. a stand-alone standard web server, while the Indy suite contains a custom http server, i.e. an http server that is easily embeddable into a larger application (see also section 5 for an example). 2 For Windows 2000 professional, there seems to be a limitation of the allowed number of requests to 5. Higher concurrency values lead to request rejection.
![[3] C.D. Marlin, Coroutines, (Berlin: Springer-Verlag, 1980). [4] Indy Pit Crew, Indy, http://www.indyproject.org/ indy.html, 2003. [5] O.](/docs-images/93/114333597/images/5-0.jpg "Monien, Implementation of an Http Server with Increased Latency Tolerance on IA32 Plattform (Master s Thesis in German), (Hagen: FernUniversität, 2003).")
5 [3] C.D. Marlin, Coroutines, (Berlin: Springer-Verlag, 1980). [4] Indy Pit Crew, Indy, indy.html, [5] O. Monien, Implementation of an Http Server with Increased Latency Tolerance on IA32 Plattform (Master s Thesis in German), (Hagen: FernUniversität, 2003). [6] Apache Software Foundation, Apache http Server Project, Figure 7. Comparison with Apache web server [7] Atozed Software Ltd., IntraWeb, intraweb, Yet, in the latter case, efficiency of the http server software may be more important because the hardware for an application containing a web server often is less powerful than the hardware solely bought for running a web server. 5 Conclusions We presented a re-implementation of Windows fibers, usable under the Windows and under the Linux operating systems. We presented how to easily modify the open source http server library Indy to replace threads for our fibers. We benchmarked our server against the original Indy server. We found that it achieves lower CPU utilization in a setting where the network connection is the bottleneck, and that it achieves higher throughput in a setting where the processing power is the bottleneck. For short requests, it even achieves both. We also compared our solution to the apache web server and achieved comparable throughput. While our solution is not the method of choice for use on a large scale, it is well suited for use in a software library setting. In this sense it resembles the use of assembler: use it in libraries where performance counts. The proposed solution is to be included as an optional module in the next revision of the Indy suite, and on that basis, in IntraWeb [7], a commercial software package for the construction of web-based applications. References [1] A. Grävinghoff, On the Realization of Fine-Grained Multithreading in Software (PdD Thesis) (Hagen: FernUniversität, 2002). [2] A. Grävinghoff and J. Keller, Fine-Grained Multithreading on the Cray T3E, in High-Performance Computing in Science and Engineering, (Berlin: Springer-Verlag, 2000)

 with a")


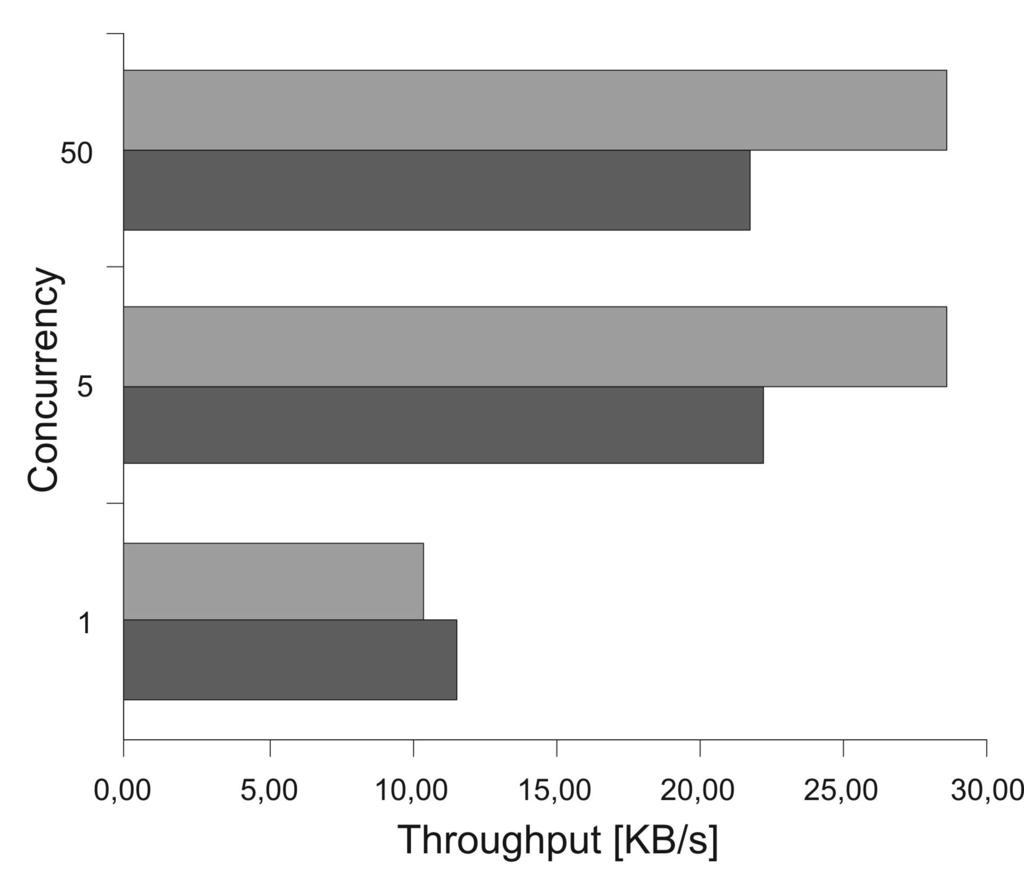
6 Figure 8. Throughput for Haewelmann (left) and echo (right) with a local client Figure 9. CPU load for Haewelmann (left) and echo (right) over a 10MBit connection Figure 10. Throughput for Haewelmann (left) and echo (right) over a 10MBit connection
Utilizing Linux Kernel Components in K42 K42 Team modified October 2001
 K42 Team modified October 2001 This paper discusses how K42 uses Linux-kernel components to support a wide range of hardware, a full-featured TCP/IP stack and Linux file-systems. An examination of the
K42 Team modified October 2001 This paper discusses how K42 uses Linux-kernel components to support a wide range of hardware, a full-featured TCP/IP stack and Linux file-systems. An examination of the
Motivation. Threads. Multithreaded Server Architecture. Thread of execution. Chapter 4
 Motivation Threads Chapter 4 Most modern applications are multithreaded Threads run within application Multiple tasks with the application can be implemented by separate Update display Fetch data Spell
Motivation Threads Chapter 4 Most modern applications are multithreaded Threads run within application Multiple tasks with the application can be implemented by separate Update display Fetch data Spell
6.1 Multiprocessor Computing Environment
 6 Parallel Computing 6.1 Multiprocessor Computing Environment The high-performance computing environment used in this book for optimization of very large building structures is the Origin 2000 multiprocessor,
6 Parallel Computing 6.1 Multiprocessor Computing Environment The high-performance computing environment used in this book for optimization of very large building structures is the Origin 2000 multiprocessor,
1. Memory technology & Hierarchy
 1 Memory technology & Hierarchy Caching and Virtual Memory Parallel System Architectures Andy D Pimentel Caches and their design cf Henessy & Patterson, Chap 5 Caching - summary Caches are small fast memories
1 Memory technology & Hierarchy Caching and Virtual Memory Parallel System Architectures Andy D Pimentel Caches and their design cf Henessy & Patterson, Chap 5 Caching - summary Caches are small fast memories
SEDA: An Architecture for Well-Conditioned, Scalable Internet Services
 SEDA: An Architecture for Well-Conditioned, Scalable Internet Services Matt Welsh, David Culler, and Eric Brewer Computer Science Division University of California, Berkeley Operating Systems Principles
SEDA: An Architecture for Well-Conditioned, Scalable Internet Services Matt Welsh, David Culler, and Eric Brewer Computer Science Division University of California, Berkeley Operating Systems Principles
Agenda. Threads. Single and Multi-threaded Processes. What is Thread. CSCI 444/544 Operating Systems Fall 2008
 Agenda Threads CSCI 444/544 Operating Systems Fall 2008 Thread concept Thread vs process Thread implementation - user-level - kernel-level - hybrid Inter-process (inter-thread) communication What is Thread
Agenda Threads CSCI 444/544 Operating Systems Fall 2008 Thread concept Thread vs process Thread implementation - user-level - kernel-level - hybrid Inter-process (inter-thread) communication What is Thread
CS555: Distributed Systems [Fall 2017] Dept. Of Computer Science, Colorado State University
![CS555: Distributed Systems [Fall 2017] Dept. Of Computer Science, Colorado State University](/thumbs/92/108913314.jpg "CS555: Distributed Systems [Fall 2017] Dept. Of Computer Science, Colorado State University") CS 555: DISTRIBUTED SYSTEMS [THREADS] Shrideep Pallickara Computer Science Colorado State University Frequently asked questions from the previous class survey Shuffle less/shuffle better Which actions?
CS 555: DISTRIBUTED SYSTEMS [THREADS] Shrideep Pallickara Computer Science Colorado State University Frequently asked questions from the previous class survey Shuffle less/shuffle better Which actions?
A New Approach to Determining the Time-Stamping Counter's Overhead on the Pentium Pro Processors *
 A New Approach to Determining the Time-Stamping Counter's Overhead on the Pentium Pro Processors * Hsin-Ta Chiao and Shyan-Ming Yuan Department of Computer and Information Science National Chiao Tung University
A New Approach to Determining the Time-Stamping Counter's Overhead on the Pentium Pro Processors * Hsin-Ta Chiao and Shyan-Ming Yuan Department of Computer and Information Science National Chiao Tung University
POSIX Threads: a first step toward parallel programming. George Bosilca
 POSIX Threads: a first step toward parallel programming George Bosilca bosilca@icl.utk.edu Process vs. Thread A process is a collection of virtual memory space, code, data, and system resources. A thread
POSIX Threads: a first step toward parallel programming George Bosilca bosilca@icl.utk.edu Process vs. Thread A process is a collection of virtual memory space, code, data, and system resources. A thread
What s in a traditional process? Concurrency/Parallelism. What s needed? CSE 451: Operating Systems Autumn 2012
 What s in a traditional process? CSE 451: Operating Systems Autumn 2012 Ed Lazowska lazowska @cs.washi ngton.edu Allen Center 570 A process consists of (at least): An, containing the code (instructions)
What s in a traditional process? CSE 451: Operating Systems Autumn 2012 Ed Lazowska lazowska @cs.washi ngton.edu Allen Center 570 A process consists of (at least): An, containing the code (instructions)
What s in a process?
 CSE 451: Operating Systems Winter 2015 Module 5 Threads Mark Zbikowski mzbik@cs.washington.edu Allen Center 476 2013 Gribble, Lazowska, Levy, Zahorjan What s in a process? A process consists of (at least):
CSE 451: Operating Systems Winter 2015 Module 5 Threads Mark Zbikowski mzbik@cs.washington.edu Allen Center 476 2013 Gribble, Lazowska, Levy, Zahorjan What s in a process? A process consists of (at least):
Capriccio : Scalable Threads for Internet Services
 Capriccio : Scalable Threads for Internet Services - Ron von Behren &et al - University of California, Berkeley. Presented By: Rajesh Subbiah Background Each incoming request is dispatched to a separate
Capriccio : Scalable Threads for Internet Services - Ron von Behren &et al - University of California, Berkeley. Presented By: Rajesh Subbiah Background Each incoming request is dispatched to a separate
殷亚凤. Processes. Distributed Systems [3]
![殷亚凤. Processes. Distributed Systems [3]](/thumbs/95/125078038.jpg "殷亚凤. Processes. Distributed Systems [3]") Processes Distributed Systems [3] 殷亚凤 Email: yafeng@nju.edu.cn Homepage: http://cs.nju.edu.cn/yafeng/ Room 301, Building of Computer Science and Technology Review Architectural Styles: Layered style, Object-based,
Processes Distributed Systems [3] 殷亚凤 Email: yafeng@nju.edu.cn Homepage: http://cs.nju.edu.cn/yafeng/ Room 301, Building of Computer Science and Technology Review Architectural Styles: Layered style, Object-based,
Distributed Scheduling for the Sombrero Single Address Space Distributed Operating System
 Distributed Scheduling for the Sombrero Single Address Space Distributed Operating System Donald S. Miller Department of Computer Science and Engineering Arizona State University Tempe, AZ, USA Alan C.
Distributed Scheduling for the Sombrero Single Address Space Distributed Operating System Donald S. Miller Department of Computer Science and Engineering Arizona State University Tempe, AZ, USA Alan C.
Threads. Computer Systems. 5/12/2009 cse threads Perkins, DW Johnson and University of Washington 1
 Threads CSE 410, Spring 2009 Computer Systems http://www.cs.washington.edu/410 5/12/2009 cse410-20-threads 2006-09 Perkins, DW Johnson and University of Washington 1 Reading and References Reading» Read
Threads CSE 410, Spring 2009 Computer Systems http://www.cs.washington.edu/410 5/12/2009 cse410-20-threads 2006-09 Perkins, DW Johnson and University of Washington 1 Reading and References Reading» Read
Operating Systems 2010/2011
 Operating Systems 2010/2011 Input/Output Systems part 1 (ch13) Shudong Chen 1 Objectives Discuss the principles of I/O hardware and its complexity Explore the structure of an operating system s I/O subsystem
Operating Systems 2010/2011 Input/Output Systems part 1 (ch13) Shudong Chen 1 Objectives Discuss the principles of I/O hardware and its complexity Explore the structure of an operating system s I/O subsystem
Multiprocessor Systems
 White Paper: Virtex-II Series R WP162 (v1.1) April 10, 2003 Multiprocessor Systems By: Jeremy Kowalczyk With the availability of the Virtex-II Pro devices containing more than one Power PC processor and
White Paper: Virtex-II Series R WP162 (v1.1) April 10, 2003 Multiprocessor Systems By: Jeremy Kowalczyk With the availability of the Virtex-II Pro devices containing more than one Power PC processor and
Processes and Threads. Processes: Review
 Processes and Threads Processes and their scheduling Threads and scheduling Multiprocessor scheduling Distributed Scheduling/migration Lecture 3, page 1 Processes: Review Multiprogramming versus multiprocessing
Processes and Threads Processes and their scheduling Threads and scheduling Multiprocessor scheduling Distributed Scheduling/migration Lecture 3, page 1 Processes: Review Multiprogramming versus multiprocessing
ASYNCHRONOUS SHADERS WHITE PAPER 0
 ASYNCHRONOUS SHADERS WHITE PAPER 0 INTRODUCTION GPU technology is constantly evolving to deliver more performance with lower cost and lower power consumption. Transistor scaling and Moore s Law have helped
ASYNCHRONOUS SHADERS WHITE PAPER 0 INTRODUCTION GPU technology is constantly evolving to deliver more performance with lower cost and lower power consumption. Transistor scaling and Moore s Law have helped
3.1 Introduction. Computers perform operations concurrently
 PROCESS CONCEPTS 1 3.1 Introduction Computers perform operations concurrently For example, compiling a program, sending a file to a printer, rendering a Web page, playing music and receiving e-mail Processes
PROCESS CONCEPTS 1 3.1 Introduction Computers perform operations concurrently For example, compiling a program, sending a file to a printer, rendering a Web page, playing music and receiving e-mail Processes
Multimedia Systems 2011/2012
 Multimedia Systems 2011/2012 System Architecture Prof. Dr. Paul Müller University of Kaiserslautern Department of Computer Science Integrated Communication Systems ICSY http://www.icsy.de Sitemap 2 Hardware
Multimedia Systems 2011/2012 System Architecture Prof. Dr. Paul Müller University of Kaiserslautern Department of Computer Science Integrated Communication Systems ICSY http://www.icsy.de Sitemap 2 Hardware
DISTRIBUTED HIGH-SPEED COMPUTING OF MULTIMEDIA DATA
 DISTRIBUTED HIGH-SPEED COMPUTING OF MULTIMEDIA DATA M. GAUS, G. R. JOUBERT, O. KAO, S. RIEDEL AND S. STAPEL Technical University of Clausthal, Department of Computer Science Julius-Albert-Str. 4, 38678
DISTRIBUTED HIGH-SPEED COMPUTING OF MULTIMEDIA DATA M. GAUS, G. R. JOUBERT, O. KAO, S. RIEDEL AND S. STAPEL Technical University of Clausthal, Department of Computer Science Julius-Albert-Str. 4, 38678
Page 1. Analogy: Problems: Operating Systems Lecture 7. Operating Systems Lecture 7
 Os-slide#1 /*Sequential Producer & Consumer*/ int i=0; repeat forever Gather material for item i; Produce item i; Use item i; Discard item i; I=I+1; end repeat Analogy: Manufacturing and distribution Print
Os-slide#1 /*Sequential Producer & Consumer*/ int i=0; repeat forever Gather material for item i; Produce item i; Use item i; Discard item i; I=I+1; end repeat Analogy: Manufacturing and distribution Print
Execution architecture concepts
 by Gerrit Muller Buskerud University College e-mail: gaudisite@gmail.com www.gaudisite.nl Abstract The execution architecture determines largely the realtime and performance behavior of a system. Hard
by Gerrit Muller Buskerud University College e-mail: gaudisite@gmail.com www.gaudisite.nl Abstract The execution architecture determines largely the realtime and performance behavior of a system. Hard
Chapter 4: Threads. Overview Multithreading Models Thread Libraries Threading Issues Operating System Examples Windows XP Threads Linux Threads
 Chapter 4: Threads Overview Multithreading Models Thread Libraries Threading Issues Operating System Examples Windows XP Threads Linux Threads Chapter 4: Threads Objectives To introduce the notion of a
Chapter 4: Threads Overview Multithreading Models Thread Libraries Threading Issues Operating System Examples Windows XP Threads Linux Threads Chapter 4: Threads Objectives To introduce the notion of a
Chapter 7 The Potential of Special-Purpose Hardware
 Chapter 7 The Potential of Special-Purpose Hardware The preceding chapters have described various implementation methods and performance data for TIGRE. This chapter uses those data points to propose architecture
Chapter 7 The Potential of Special-Purpose Hardware The preceding chapters have described various implementation methods and performance data for TIGRE. This chapter uses those data points to propose architecture
OS structure. Process management. Major OS components. CSE 451: Operating Systems Spring Module 3 Operating System Components and Structure
 CSE 451: Operating Systems Spring 2012 Module 3 Operating System Components and Structure Ed Lazowska lazowska@cs.washington.edu Allen Center 570 The OS sits between application programs and the it mediates
CSE 451: Operating Systems Spring 2012 Module 3 Operating System Components and Structure Ed Lazowska lazowska@cs.washington.edu Allen Center 570 The OS sits between application programs and the it mediates
Last Class: OS and Computer Architecture. Last Class: OS and Computer Architecture
 Last Class: OS and Computer Architecture System bus Network card CPU, memory, I/O devices, network card, system bus Lecture 4, page 1 Last Class: OS and Computer Architecture OS Service Protection Interrupts
Last Class: OS and Computer Architecture System bus Network card CPU, memory, I/O devices, network card, system bus Lecture 4, page 1 Last Class: OS and Computer Architecture OS Service Protection Interrupts
! Readings! ! Room-level, on-chip! vs.!
 1! 2! Suggested Readings!! Readings!! H&P: Chapter 7 especially 7.1-7.8!! (Over next 2 weeks)!! Introduction to Parallel Computing!! https://computing.llnl.gov/tutorials/parallel_comp/!! POSIX Threads
1! 2! Suggested Readings!! Readings!! H&P: Chapter 7 especially 7.1-7.8!! (Over next 2 weeks)!! Introduction to Parallel Computing!! https://computing.llnl.gov/tutorials/parallel_comp/!! POSIX Threads
AC59/AT59/AC110/AT110 OPERATING SYSTEMS & SYSTEMS SOFTWARE DEC 2015
 Q.2 a. Explain the following systems: (9) i. Batch processing systems ii. Time sharing systems iii. Real-time operating systems b. Draw the process state diagram. (3) c. What resources are used when a
Q.2 a. Explain the following systems: (9) i. Batch processing systems ii. Time sharing systems iii. Real-time operating systems b. Draw the process state diagram. (3) c. What resources are used when a
Improving the Database Logging Performance of the Snort Network Intrusion Detection Sensor
 -0- Improving the Database Logging Performance of the Snort Network Intrusion Detection Sensor Lambert Schaelicke, Matthew R. Geiger, Curt J. Freeland Department of Computer Science and Engineering University
-0- Improving the Database Logging Performance of the Snort Network Intrusion Detection Sensor Lambert Schaelicke, Matthew R. Geiger, Curt J. Freeland Department of Computer Science and Engineering University
Introduction to Asynchronous Programming Fall 2014
 CS168 Computer Networks Fonseca Introduction to Asynchronous Programming Fall 2014 Contents 1 Introduction 1 2 The Models 1 3 The Motivation 3 4 Event-Driven Programming 4 5 select() to the rescue 5 1
CS168 Computer Networks Fonseca Introduction to Asynchronous Programming Fall 2014 Contents 1 Introduction 1 2 The Models 1 3 The Motivation 3 4 Event-Driven Programming 4 5 select() to the rescue 5 1
Parallel Processing SIMD, Vector and GPU s cont.
 Parallel Processing SIMD, Vector and GPU s cont. EECS4201 Fall 2016 York University 1 Multithreading First, we start with multithreading Multithreading is used in GPU s 2 1 Thread Level Parallelism ILP
Parallel Processing SIMD, Vector and GPU s cont. EECS4201 Fall 2016 York University 1 Multithreading First, we start with multithreading Multithreading is used in GPU s 2 1 Thread Level Parallelism ILP
SMD149 - Operating Systems
 SMD149 - Operating Systems Roland Parviainen November 3, 2005 1 / 45 Outline Overview 2 / 45 Process (tasks) are necessary for concurrency Instance of a program in execution Next invocation of the program
SMD149 - Operating Systems Roland Parviainen November 3, 2005 1 / 45 Outline Overview 2 / 45 Process (tasks) are necessary for concurrency Instance of a program in execution Next invocation of the program
in Berlin (Germany) Sponsored by Motorola Semiconductor NEC Electronics (Europe) Siemens Semiconductors Organized by
 Sponsored by Motorola Semiconductor NEC Electronics (Europe) Siemens Semiconductors Organized by") 4 th international CAN Conference icc 1997 in Berlin (Germany) Sponsored by Motorola Semiconductor NEC Electronics (Europe) Siemens Semiconductors Organized by CAN in Automation (CiA) international users
4 th international CAN Conference icc 1997 in Berlin (Germany) Sponsored by Motorola Semiconductor NEC Electronics (Europe) Siemens Semiconductors Organized by CAN in Automation (CiA) international users
Measurement-based Analysis of TCP/IP Processing Requirements
 Measurement-based Analysis of TCP/IP Processing Requirements Srihari Makineni Ravi Iyer Communications Technology Lab Intel Corporation {srihari.makineni, ravishankar.iyer}@intel.com Abstract With the
Measurement-based Analysis of TCP/IP Processing Requirements Srihari Makineni Ravi Iyer Communications Technology Lab Intel Corporation {srihari.makineni, ravishankar.iyer}@intel.com Abstract With the
Computer Systems A Programmer s Perspective 1 (Beta Draft)
") Computer Systems A Programmer s Perspective 1 (Beta Draft) Randal E. Bryant David R. O Hallaron August 1, 2001 1 Copyright c 2001, R. E. Bryant, D. R. O Hallaron. All rights reserved. 2 Contents Preface
Computer Systems A Programmer s Perspective 1 (Beta Draft) Randal E. Bryant David R. O Hallaron August 1, 2001 1 Copyright c 2001, R. E. Bryant, D. R. O Hallaron. All rights reserved. 2 Contents Preface
Processes. 4: Threads. Problem needs > 1 independent sequential process? Example: Web Server. Last Modified: 9/17/2002 2:27:59 PM
 Processes 4: Threads Last Modified: 9/17/2002 2:27:59 PM Recall: A process includes Address space (Code, Data, Heap, Stack) Register values (including the PC) Resources allocated to the process Memory,
Processes 4: Threads Last Modified: 9/17/2002 2:27:59 PM Recall: A process includes Address space (Code, Data, Heap, Stack) Register values (including the PC) Resources allocated to the process Memory,
Multiprocessing and Scalability. A.R. Hurson Computer Science and Engineering The Pennsylvania State University
 A.R. Hurson Computer Science and Engineering The Pennsylvania State University 1 Large-scale multiprocessor systems have long held the promise of substantially higher performance than traditional uniprocessor
A.R. Hurson Computer Science and Engineering The Pennsylvania State University 1 Large-scale multiprocessor systems have long held the promise of substantially higher performance than traditional uniprocessor
Questions answered in this lecture: CS 537 Lecture 19 Threads and Cooperation. What s in a process? Organizing a Process
 Questions answered in this lecture: CS 537 Lecture 19 Threads and Cooperation Why are threads useful? How does one use POSIX pthreads? Michael Swift 1 2 What s in a process? Organizing a Process A process
Questions answered in this lecture: CS 537 Lecture 19 Threads and Cooperation Why are threads useful? How does one use POSIX pthreads? Michael Swift 1 2 What s in a process? Organizing a Process A process
10/10/ Gribble, Lazowska, Levy, Zahorjan 2. 10/10/ Gribble, Lazowska, Levy, Zahorjan 4
 What s in a process? CSE 451: Operating Systems Autumn 2010 Module 5 Threads Ed Lazowska lazowska@cs.washington.edu Allen Center 570 A process consists of (at least): An, containing the code (instructions)
What s in a process? CSE 451: Operating Systems Autumn 2010 Module 5 Threads Ed Lazowska lazowska@cs.washington.edu Allen Center 570 A process consists of (at least): An, containing the code (instructions)
CPS221 Lecture: Threads
 Objectives CPS221 Lecture: Threads 1. To introduce threads in the context of processes 2. To introduce UML Activity Diagrams last revised 9/5/12 Materials: 1. Diagram showing state of memory for a process
Objectives CPS221 Lecture: Threads 1. To introduce threads in the context of processes 2. To introduce UML Activity Diagrams last revised 9/5/12 Materials: 1. Diagram showing state of memory for a process
Data Replication in Offline Web Applications:
 Data Replication in Offline Web Applications: Optimizing Persistence, Synchronization and Conflict Resolution Master Thesis Computer Science May 4, 2013 Samuel Esposito - 1597183 Primary supervisor: Prof.dr.
Data Replication in Offline Web Applications: Optimizing Persistence, Synchronization and Conflict Resolution Master Thesis Computer Science May 4, 2013 Samuel Esposito - 1597183 Primary supervisor: Prof.dr.
Exercise (could be a quiz) Solution. Concurrent Programming. Roadmap. Tevfik Koşar. CSE 421/521 - Operating Systems Fall Lecture - IV Threads
 Solution. Concurrent Programming. Roadmap. Tevfik Koşar. CSE 421/521 - Operating Systems Fall Lecture - IV Threads") Exercise (could be a quiz) 1 2 Solution CSE 421/521 - Operating Systems Fall 2013 Lecture - IV Threads Tevfik Koşar 3 University at Buffalo September 12 th, 2013 4 Roadmap Threads Why do we need them?
Exercise (could be a quiz) 1 2 Solution CSE 421/521 - Operating Systems Fall 2013 Lecture - IV Threads Tevfik Koşar 3 University at Buffalo September 12 th, 2013 4 Roadmap Threads Why do we need them?
Threads. Raju Pandey Department of Computer Sciences University of California, Davis Spring 2011
 Threads Raju Pandey Department of Computer Sciences University of California, Davis Spring 2011 Threads Effectiveness of parallel computing depends on the performance of the primitives used to express
Threads Raju Pandey Department of Computer Sciences University of California, Davis Spring 2011 Threads Effectiveness of parallel computing depends on the performance of the primitives used to express
Threads Chapter 5 1 Chapter 5
 Threads Chapter 5 1 Chapter 5 Process Characteristics Concept of Process has two facets. A Process is: A Unit of resource ownership: a virtual address space for the process image control of some resources
Threads Chapter 5 1 Chapter 5 Process Characteristics Concept of Process has two facets. A Process is: A Unit of resource ownership: a virtual address space for the process image control of some resources
An implementation model of rendezvous communication
 G.Winskel Eds. Appears in Seminar on Concurrency S.D.Brookds, A.W.Roscoe, and Lecture Notes in Computer Science 197 Springer-Verlag, 1985 An implementation model of rendezvous communication Luca Cardelli
G.Winskel Eds. Appears in Seminar on Concurrency S.D.Brookds, A.W.Roscoe, and Lecture Notes in Computer Science 197 Springer-Verlag, 1985 An implementation model of rendezvous communication Luca Cardelli
Issues in Multiprocessors
 Issues in Multiprocessors Which programming model for interprocessor communication shared memory regular loads & stores SPARCCenter, SGI Challenge, Cray T3D, Convex Exemplar, KSR-1&2, today s CMPs message
Issues in Multiprocessors Which programming model for interprocessor communication shared memory regular loads & stores SPARCCenter, SGI Challenge, Cray T3D, Convex Exemplar, KSR-1&2, today s CMPs message
OS Design Approaches. Roadmap. OS Design Approaches. Tevfik Koşar. Operating System Design and Implementation
 CSE 421/521 - Operating Systems Fall 2012 Lecture - II OS Structures Roadmap OS Design and Implementation Different Design Approaches Major OS Components!! Memory management! CPU Scheduling! I/O Management
CSE 421/521 - Operating Systems Fall 2012 Lecture - II OS Structures Roadmap OS Design and Implementation Different Design Approaches Major OS Components!! Memory management! CPU Scheduling! I/O Management
Hierarchical PLABs, CLABs, TLABs in Hotspot
 Hierarchical s, CLABs, s in Hotspot Christoph M. Kirsch ck@cs.uni-salzburg.at Hannes Payer hpayer@cs.uni-salzburg.at Harald Röck hroeck@cs.uni-salzburg.at Abstract Thread-local allocation buffers (s) are
Hierarchical s, CLABs, s in Hotspot Christoph M. Kirsch ck@cs.uni-salzburg.at Hannes Payer hpayer@cs.uni-salzburg.at Harald Röck hroeck@cs.uni-salzburg.at Abstract Thread-local allocation buffers (s) are
Concurrent Programming Synchronisation. CISTER Summer Internship 2017
 1 Concurrent Programming Synchronisation CISTER Summer Internship 2017 Luís Nogueira lmn@isep.ipp.pt 2 Introduction Multitasking Concept of overlapping the computation of a program with another one Central
1 Concurrent Programming Synchronisation CISTER Summer Internship 2017 Luís Nogueira lmn@isep.ipp.pt 2 Introduction Multitasking Concept of overlapping the computation of a program with another one Central
A Scalable Multiprocessor for Real-time Signal Processing
 A Scalable Multiprocessor for Real-time Signal Processing Daniel Scherrer, Hans Eberle Institute for Computer Systems, Swiss Federal Institute of Technology CH-8092 Zurich, Switzerland {scherrer, eberle}@inf.ethz.ch
A Scalable Multiprocessor for Real-time Signal Processing Daniel Scherrer, Hans Eberle Institute for Computer Systems, Swiss Federal Institute of Technology CH-8092 Zurich, Switzerland {scherrer, eberle}@inf.ethz.ch
What is this? How do UVMs work?
 An introduction to UVMs What is this? UVM support is a unique Xenomai feature, which allows running a nearly complete realtime system embodied into a single multi threaded Linux process in user space,
An introduction to UVMs What is this? UVM support is a unique Xenomai feature, which allows running a nearly complete realtime system embodied into a single multi threaded Linux process in user space,
Computer Architecture
 Computer Architecture Slide Sets WS 2013/2014 Prof. Dr. Uwe Brinkschulte M.Sc. Benjamin Betting Part 10 Thread and Task Level Parallelism Computer Architecture Part 10 page 1 of 36 Prof. Dr. Uwe Brinkschulte,
Computer Architecture Slide Sets WS 2013/2014 Prof. Dr. Uwe Brinkschulte M.Sc. Benjamin Betting Part 10 Thread and Task Level Parallelism Computer Architecture Part 10 page 1 of 36 Prof. Dr. Uwe Brinkschulte,
AN 831: Intel FPGA SDK for OpenCL
 AN 831: Intel FPGA SDK for OpenCL Host Pipelined Multithread Subscribe Send Feedback Latest document on the web: PDF HTML Contents Contents 1 Intel FPGA SDK for OpenCL Host Pipelined Multithread...3 1.1
AN 831: Intel FPGA SDK for OpenCL Host Pipelined Multithread Subscribe Send Feedback Latest document on the web: PDF HTML Contents Contents 1 Intel FPGA SDK for OpenCL Host Pipelined Multithread...3 1.1
Kylix. Technical Overview of the Kylix Compiler. Introduction. Table of Contents
 Technical Overview of the Kylix Compiler by John Ray Thomas / RAD Tools Product Manager Borland Software Corporation Table of Contents Introduction 1 Native Code Compiler for GNU/Linux 2 Optimizing ELF
Technical Overview of the Kylix Compiler by John Ray Thomas / RAD Tools Product Manager Borland Software Corporation Table of Contents Introduction 1 Native Code Compiler for GNU/Linux 2 Optimizing ELF
CSC Operating Systems Fall Lecture - II OS Structures. Tevfik Ko!ar. Louisiana State University. August 27 th, 2009.
 CSC 4103 - Operating Systems Fall 2009 Lecture - II OS Structures Tevfik Ko!ar Louisiana State University August 27 th, 2009 1 Announcements TA Changed. New TA: Praveenkumar Kondikoppa Email: pkondi1@lsu.edu
CSC 4103 - Operating Systems Fall 2009 Lecture - II OS Structures Tevfik Ko!ar Louisiana State University August 27 th, 2009 1 Announcements TA Changed. New TA: Praveenkumar Kondikoppa Email: pkondi1@lsu.edu
Announcements. Computer System Organization. Roadmap. Major OS Components. Processes. Tevfik Ko!ar. CSC Operating Systems Fall 2009
 CSC 4103 - Operating Systems Fall 2009 Lecture - II OS Structures Tevfik Ko!ar TA Changed. New TA: Praveenkumar Kondikoppa Email: pkondi1@lsu.edu Announcements All of you should be now in the class mailing
CSC 4103 - Operating Systems Fall 2009 Lecture - II OS Structures Tevfik Ko!ar TA Changed. New TA: Praveenkumar Kondikoppa Email: pkondi1@lsu.edu Announcements All of you should be now in the class mailing
The Public Shared Objects Run-Time System
 The Public Shared Objects Run-Time System Stefan Lüpke, Jürgen W. Quittek, Torsten Wiese E-mail: wiese@tu-harburg.d400.de Arbeitsbereich Technische Informatik 2, Technische Universität Hamburg-Harburg
The Public Shared Objects Run-Time System Stefan Lüpke, Jürgen W. Quittek, Torsten Wiese E-mail: wiese@tu-harburg.d400.de Arbeitsbereich Technische Informatik 2, Technische Universität Hamburg-Harburg
LINUX OPERATING SYSTEM Submitted in partial fulfillment of the requirement for the award of degree of Bachelor of Technology in Computer Science
 A Seminar report On LINUX OPERATING SYSTEM Submitted in partial fulfillment of the requirement for the award of degree of Bachelor of Technology in Computer Science SUBMITTED TO: www.studymafia.org SUBMITTED
A Seminar report On LINUX OPERATING SYSTEM Submitted in partial fulfillment of the requirement for the award of degree of Bachelor of Technology in Computer Science SUBMITTED TO: www.studymafia.org SUBMITTED
B.H.GARDI COLLEGE OF ENGINEERING & TECHNOLOGY (MCA Dept.) Parallel Database Database Management System - 2
 Parallel Database Database Management System - 2") Introduction :- Today single CPU based architecture is not capable enough for the modern database that are required to handle more demanding and complex requirements of the users, for example, high performance,
Introduction :- Today single CPU based architecture is not capable enough for the modern database that are required to handle more demanding and complex requirements of the users, for example, high performance,
Mobile Communications Chapter 9: Mobile Transport Layer
 Prof. Dr.-Ing Jochen H. Schiller Inst. of Computer Science Freie Universität Berlin Germany Mobile Communications Chapter 9: Mobile Transport Layer Motivation, TCP-mechanisms Classical approaches (Indirect
Prof. Dr.-Ing Jochen H. Schiller Inst. of Computer Science Freie Universität Berlin Germany Mobile Communications Chapter 9: Mobile Transport Layer Motivation, TCP-mechanisms Classical approaches (Indirect
Multiprocessor scheduling
 Chapter 10 Multiprocessor scheduling When a computer system contains multiple processors, a few new issues arise. Multiprocessor systems can be categorized into the following: Loosely coupled or distributed.
Chapter 10 Multiprocessor scheduling When a computer system contains multiple processors, a few new issues arise. Multiprocessor systems can be categorized into the following: Loosely coupled or distributed.
TIXway IRT Lab Evaluation
 08.08.2012 TIXway IRT Lab Evaluation Matthias Hammer, NT Madeleine Keltsch, NT Copyright Notice This document and all contents are protected by copyright law. IRT reserves all its rights. You may not alter
08.08.2012 TIXway IRT Lab Evaluation Matthias Hammer, NT Madeleine Keltsch, NT Copyright Notice This document and all contents are protected by copyright law. IRT reserves all its rights. You may not alter
Unit 2 : Computer and Operating System Structure
 Unit 2 : Computer and Operating System Structure Lesson 1 : Interrupts and I/O Structure 1.1. Learning Objectives On completion of this lesson you will know : what interrupt is the causes of occurring
Unit 2 : Computer and Operating System Structure Lesson 1 : Interrupts and I/O Structure 1.1. Learning Objectives On completion of this lesson you will know : what interrupt is the causes of occurring
Contents Overview of the Compression Server White Paper... 5 Business Problem... 7
 P6 Professional Compression Server White Paper for On-Premises Version 17 July 2017 Contents Overview of the Compression Server White Paper... 5 Business Problem... 7 P6 Compression Server vs. Citrix...
P6 Professional Compression Server White Paper for On-Premises Version 17 July 2017 Contents Overview of the Compression Server White Paper... 5 Business Problem... 7 P6 Compression Server vs. Citrix...
1 Multiprocessors. 1.1 Kinds of Processes. COMP 242 Class Notes Section 9: Multiprocessor Operating Systems
 COMP 242 Class Notes Section 9: Multiprocessor Operating Systems 1 Multiprocessors As we saw earlier, a multiprocessor consists of several processors sharing a common memory. The memory is typically divided
COMP 242 Class Notes Section 9: Multiprocessor Operating Systems 1 Multiprocessors As we saw earlier, a multiprocessor consists of several processors sharing a common memory. The memory is typically divided
Outline. Threads. Single and Multithreaded Processes. Benefits of Threads. Eike Ritter 1. Modified: October 16, 2012
 Eike Ritter 1 Modified: October 16, 2012 Lecture 8: Operating Systems with C/C++ School of Computer Science, University of Birmingham, UK 1 Based on material by Matt Smart and Nick Blundell Outline 1 Concurrent
Eike Ritter 1 Modified: October 16, 2012 Lecture 8: Operating Systems with C/C++ School of Computer Science, University of Birmingham, UK 1 Based on material by Matt Smart and Nick Blundell Outline 1 Concurrent
Distributed Computing: PVM, MPI, and MOSIX. Multiple Processor Systems. Dr. Shaaban. Judd E.N. Jenne
 Distributed Computing: PVM, MPI, and MOSIX Multiple Processor Systems Dr. Shaaban Judd E.N. Jenne May 21, 1999 Abstract: Distributed computing is emerging as the preferred means of supporting parallel
Distributed Computing: PVM, MPI, and MOSIX Multiple Processor Systems Dr. Shaaban Judd E.N. Jenne May 21, 1999 Abstract: Distributed computing is emerging as the preferred means of supporting parallel
Dr Markus Hagenbuchner CSCI319. Distributed Systems Chapter 3 - Processes
 Dr Markus Hagenbuchner markus@uow.edu.au CSCI319 Distributed Systems Chapter 3 - Processes CSCI319 Chapter 3 Page: 1 Processes Lecture notes based on the textbook by Tannenbaum Study objectives: 1. Understand
Dr Markus Hagenbuchner markus@uow.edu.au CSCI319 Distributed Systems Chapter 3 - Processes CSCI319 Chapter 3 Page: 1 Processes Lecture notes based on the textbook by Tannenbaum Study objectives: 1. Understand
Last Class: CPU Scheduling. Pre-emptive versus non-preemptive schedulers Goals for Scheduling: CS377: Operating Systems.
 Last Class: CPU Scheduling Pre-emptive versus non-preemptive schedulers Goals for Scheduling: Minimize average response time Maximize throughput Share CPU equally Other goals? Scheduling Algorithms: Selecting
Last Class: CPU Scheduling Pre-emptive versus non-preemptive schedulers Goals for Scheduling: Minimize average response time Maximize throughput Share CPU equally Other goals? Scheduling Algorithms: Selecting
Outline EEL 5764 Graduate Computer Architecture. Chapter 3 Limits to ILP and Simultaneous Multithreading. Overcoming Limits - What do we need??
 Outline EEL 7 Graduate Computer Architecture Chapter 3 Limits to ILP and Simultaneous Multithreading! Limits to ILP! Thread Level Parallelism! Multithreading! Simultaneous Multithreading Ann Gordon-Ross
Outline EEL 7 Graduate Computer Architecture Chapter 3 Limits to ILP and Simultaneous Multithreading! Limits to ILP! Thread Level Parallelism! Multithreading! Simultaneous Multithreading Ann Gordon-Ross
Introducing the Cray XMT. Petr Konecny May 4 th 2007
 Introducing the Cray XMT Petr Konecny May 4 th 2007 Agenda Origins of the Cray XMT Cray XMT system architecture Cray XT infrastructure Cray Threadstorm processor Shared memory programming model Benefits/drawbacks/solutions
Introducing the Cray XMT Petr Konecny May 4 th 2007 Agenda Origins of the Cray XMT Cray XMT system architecture Cray XT infrastructure Cray Threadstorm processor Shared memory programming model Benefits/drawbacks/solutions
PROCESSES AND THREADS THREADING MODELS. CS124 Operating Systems Winter , Lecture 8
 PROCESSES AND THREADS THREADING MODELS CS124 Operating Systems Winter 2016-2017, Lecture 8 2 Processes and Threads As previously described, processes have one sequential thread of execution Increasingly,
PROCESSES AND THREADS THREADING MODELS CS124 Operating Systems Winter 2016-2017, Lecture 8 2 Processes and Threads As previously described, processes have one sequential thread of execution Increasingly,
CSCI 4717 Computer Architecture
 CSCI 4717/5717 Computer Architecture Topic: Symmetric Multiprocessors & Clusters Reading: Stallings, Sections 18.1 through 18.4 Classifications of Parallel Processing M. Flynn classified types of parallel
CSCI 4717/5717 Computer Architecture Topic: Symmetric Multiprocessors & Clusters Reading: Stallings, Sections 18.1 through 18.4 Classifications of Parallel Processing M. Flynn classified types of parallel
Computer Networks/DV2 Lab
 Computer Networks/DV2 Lab Room: BB 219 Additional Information: http://ti.uni-due.de/ti/en/education/teaching/ss18/netlab 1. Practical Training: Network planning and installation of a file server 2. Practical
Computer Networks/DV2 Lab Room: BB 219 Additional Information: http://ti.uni-due.de/ti/en/education/teaching/ss18/netlab 1. Practical Training: Network planning and installation of a file server 2. Practical
Operating Systems 2 nd semester 2016/2017. Chapter 4: Threads
 Operating Systems 2 nd semester 2016/2017 Chapter 4: Threads Mohamed B. Abubaker Palestine Technical College Deir El-Balah Note: Adapted from the resources of textbox Operating System Concepts, 9 th edition
Operating Systems 2 nd semester 2016/2017 Chapter 4: Threads Mohamed B. Abubaker Palestine Technical College Deir El-Balah Note: Adapted from the resources of textbox Operating System Concepts, 9 th edition
CS533 Concepts of Operating Systems. Jonathan Walpole
 CS533 Concepts of Operating Systems Jonathan Walpole SEDA: An Architecture for Well- Conditioned Scalable Internet Services Overview What does well-conditioned mean? Internet service architectures - thread
CS533 Concepts of Operating Systems Jonathan Walpole SEDA: An Architecture for Well- Conditioned Scalable Internet Services Overview What does well-conditioned mean? Internet service architectures - thread
Chapter 2. Parallel Hardware and Parallel Software. An Introduction to Parallel Programming. The Von Neuman Architecture
 An Introduction to Parallel Programming Peter Pacheco Chapter 2 Parallel Hardware and Parallel Software 1 The Von Neuman Architecture Control unit: responsible for deciding which instruction in a program
An Introduction to Parallel Programming Peter Pacheco Chapter 2 Parallel Hardware and Parallel Software 1 The Von Neuman Architecture Control unit: responsible for deciding which instruction in a program
Process Description and Control
 Process Description and Control 1 Process:the concept Process = a program in execution Example processes: OS kernel OS shell Program executing after compilation www-browser Process management by OS : Allocate
Process Description and Control 1 Process:the concept Process = a program in execution Example processes: OS kernel OS shell Program executing after compilation www-browser Process management by OS : Allocate
CHAPTER 3 - PROCESS CONCEPT
 CHAPTER 3 - PROCESS CONCEPT 1 OBJECTIVES Introduce a process a program in execution basis of all computation Describe features of processes: scheduling, creation, termination, communication Explore interprocess
CHAPTER 3 - PROCESS CONCEPT 1 OBJECTIVES Introduce a process a program in execution basis of all computation Describe features of processes: scheduling, creation, termination, communication Explore interprocess
Module 1. Introduction:
 Module 1 Introduction: Operating system is the most fundamental of all the system programs. It is a layer of software on top of the hardware which constitutes the system and manages all parts of the system.
Module 1 Introduction: Operating system is the most fundamental of all the system programs. It is a layer of software on top of the hardware which constitutes the system and manages all parts of the system.
Optimizing the use of the Hard Disk in MapReduce Frameworks for Multi-core Architectures*
 Optimizing the use of the Hard Disk in MapReduce Frameworks for Multi-core Architectures* Tharso Ferreira 1, Antonio Espinosa 1, Juan Carlos Moure 2 and Porfidio Hernández 2 Computer Architecture and Operating
Optimizing the use of the Hard Disk in MapReduce Frameworks for Multi-core Architectures* Tharso Ferreira 1, Antonio Espinosa 1, Juan Carlos Moure 2 and Porfidio Hernández 2 Computer Architecture and Operating
Sistemi in Tempo Reale
 Laurea Specialistica in Ingegneria dell'automazione Sistemi in Tempo Reale Giuseppe Lipari Introduzione alla concorrenza Fundamentals Algorithm: It is the logical procedure to solve a certain problem It
Laurea Specialistica in Ingegneria dell'automazione Sistemi in Tempo Reale Giuseppe Lipari Introduzione alla concorrenza Fundamentals Algorithm: It is the logical procedure to solve a certain problem It
Capriccio: Scalable Threads for Internet Services
 Capriccio: Scalable Threads for Internet Services Rob von Behren, Jeremy Condit, Feng Zhou, Geroge Necula and Eric Brewer University of California at Berkeley Presenter: Cong Lin Outline Part I Motivation
Capriccio: Scalable Threads for Internet Services Rob von Behren, Jeremy Condit, Feng Zhou, Geroge Necula and Eric Brewer University of California at Berkeley Presenter: Cong Lin Outline Part I Motivation
Threads. Still Chapter 2 (Based on Silberchatz s text and Nachos Roadmap.) 3/9/2003 B.Ramamurthy 1
 3/9/2003 B.Ramamurthy 1") Threads Still Chapter 2 (Based on Silberchatz s text and Nachos Roadmap.) 3/9/2003 B.Ramamurthy 1 Single and Multithreaded Processes Thread specific Data (TSD) Code 3/9/2003 B.Ramamurthy 2 User Threads
Threads Still Chapter 2 (Based on Silberchatz s text and Nachos Roadmap.) 3/9/2003 B.Ramamurthy 1 Single and Multithreaded Processes Thread specific Data (TSD) Code 3/9/2003 B.Ramamurthy 2 User Threads
Open Packet Processing Acceleration Nuzzo, Craig,
 Open Packet Processing Acceleration Nuzzo, Craig, cnuzz2@uis.edu Summary The amount of data in our world is growing rapidly, this is obvious. However, the behind the scenes impacts of this growth may not
Open Packet Processing Acceleration Nuzzo, Craig, cnuzz2@uis.edu Summary The amount of data in our world is growing rapidly, this is obvious. However, the behind the scenes impacts of this growth may not
Extended Dataflow Model For Automated Parallel Execution Of Algorithms
 Extended Dataflow Model For Automated Parallel Execution Of Algorithms Maik Schumann, Jörg Bargenda, Edgar Reetz and Gerhard Linß Department of Quality Assurance and Industrial Image Processing Ilmenau
Extended Dataflow Model For Automated Parallel Execution Of Algorithms Maik Schumann, Jörg Bargenda, Edgar Reetz and Gerhard Linß Department of Quality Assurance and Industrial Image Processing Ilmenau
CS533 Concepts of Operating Systems. Jonathan Walpole
 CS533 Concepts of Operating Systems Jonathan Walpole Improving IPC by Kernel Design & The Performance of Micro- Kernel Based Systems The IPC Dilemma IPC is very import in µ-kernel design - Increases modularity,
CS533 Concepts of Operating Systems Jonathan Walpole Improving IPC by Kernel Design & The Performance of Micro- Kernel Based Systems The IPC Dilemma IPC is very import in µ-kernel design - Increases modularity,
Asynchronous Events on Linux
 Asynchronous Events on Linux Frederic.Rossi@Ericsson.CA Open System Lab Systems Research June 25, 2002 Ericsson Research Canada Introduction Linux performs well as a general purpose OS but doesn t satisfy
Asynchronous Events on Linux Frederic.Rossi@Ericsson.CA Open System Lab Systems Research June 25, 2002 Ericsson Research Canada Introduction Linux performs well as a general purpose OS but doesn t satisfy
COMP 321: Introduction to Computer Systems
 Assigned: 3/29/18, Due: 4/19/18 Important: This project may be done individually or in pairs. Be sure to carefully read the course policies for assignments (including the honor code policy) on the assignments
Assigned: 3/29/18, Due: 4/19/18 Important: This project may be done individually or in pairs. Be sure to carefully read the course policies for assignments (including the honor code policy) on the assignments
Computer Architecture: Multithreading (I) Prof. Onur Mutlu Carnegie Mellon University
 Prof. Onur Mutlu Carnegie Mellon University") Computer Architecture: Multithreading (I) Prof. Onur Mutlu Carnegie Mellon University A Note on This Lecture These slides are partly from 18-742 Fall 2012, Parallel Computer Architecture, Lecture 9: Multithreading
Computer Architecture: Multithreading (I) Prof. Onur Mutlu Carnegie Mellon University A Note on This Lecture These slides are partly from 18-742 Fall 2012, Parallel Computer Architecture, Lecture 9: Multithreading
CHAPTER 1 INTRODUCTION
 1 CHAPTER 1 INTRODUCTION 1.1 Advance Encryption Standard (AES) Rijndael algorithm is symmetric block cipher that can process data blocks of 128 bits, using cipher keys with lengths of 128, 192, and 256
1 CHAPTER 1 INTRODUCTION 1.1 Advance Encryption Standard (AES) Rijndael algorithm is symmetric block cipher that can process data blocks of 128 bits, using cipher keys with lengths of 128, 192, and 256
Reliable Stream Analysis on the Internet of Things
 Reliable Stream Analysis on the Internet of Things ECE6102 Course Project Team IoT Submitted April 30, 2014 1 1. Introduction Team IoT is interested in developing a distributed system that supports live
Reliable Stream Analysis on the Internet of Things ECE6102 Course Project Team IoT Submitted April 30, 2014 1 1. Introduction Team IoT is interested in developing a distributed system that supports live
A THREAD IMPLEMENTATION PROJECT SUPPORTING AN OPERATING SYSTEMS COURSE
 A THREAD IMPLEMENTATION PROJECT SUPPORTING AN OPERATING SYSTEMS COURSE Tom Bennet Department of Computer Science Mississippi College Clinton, MS 39058 601 924 6622 bennet@mc.edu ABSTRACT This paper describes
A THREAD IMPLEMENTATION PROJECT SUPPORTING AN OPERATING SYSTEMS COURSE Tom Bennet Department of Computer Science Mississippi College Clinton, MS 39058 601 924 6622 bennet@mc.edu ABSTRACT This paper describes
QLIKVIEW SCALABILITY BENCHMARK WHITE PAPER
 QLIKVIEW SCALABILITY BENCHMARK WHITE PAPER Hardware Sizing Using Amazon EC2 A QlikView Scalability Center Technical White Paper June 2013 qlikview.com Table of Contents Executive Summary 3 A Challenge
QLIKVIEW SCALABILITY BENCHMARK WHITE PAPER Hardware Sizing Using Amazon EC2 A QlikView Scalability Center Technical White Paper June 2013 qlikview.com Table of Contents Executive Summary 3 A Challenge
Java Virtual Machine
 Evaluation of Java Thread Performance on Two Dierent Multithreaded Kernels Yan Gu B. S. Lee Wentong Cai School of Applied Science Nanyang Technological University Singapore 639798 guyan@cais.ntu.edu.sg,
Evaluation of Java Thread Performance on Two Dierent Multithreaded Kernels Yan Gu B. S. Lee Wentong Cai School of Applied Science Nanyang Technological University Singapore 639798 guyan@cais.ntu.edu.sg,
Part IV. Chapter 15 - Introduction to MIMD Architectures
 D. Sima, T. J. Fountain, P. Kacsuk dvanced Computer rchitectures Part IV. Chapter 15 - Introduction to MIMD rchitectures Thread and process-level parallel architectures are typically realised by MIMD (Multiple
D. Sima, T. J. Fountain, P. Kacsuk dvanced Computer rchitectures Part IV. Chapter 15 - Introduction to MIMD rchitectures Thread and process-level parallel architectures are typically realised by MIMD (Multiple
EECS 570 Final Exam - SOLUTIONS Winter 2015
 EECS 570 Final Exam - SOLUTIONS Winter 2015 Name: unique name: Sign the honor code: I have neither given nor received aid on this exam nor observed anyone else doing so. Scores: # Points 1 / 21 2 / 32
EECS 570 Final Exam - SOLUTIONS Winter 2015 Name: unique name: Sign the honor code: I have neither given nor received aid on this exam nor observed anyone else doing so. Scores: # Points 1 / 21 2 / 32
Chapter 8 & Chapter 9 Main Memory & Virtual Memory
 Chapter 8 & Chapter 9 Main Memory & Virtual Memory 1. Various ways of organizing memory hardware. 2. Memory-management techniques: 1. Paging 2. Segmentation. Introduction Memory consists of a large array
Chapter 8 & Chapter 9 Main Memory & Virtual Memory 1. Various ways of organizing memory hardware. 2. Memory-management techniques: 1. Paging 2. Segmentation. Introduction Memory consists of a large array