Intuitive distributed algorithms. with F#
|
|
|
- Amos Hampton
- 5 years ago
- Views:
Transcription
1 Intuitive distributed algorithms with F# Natallia Dzenisenka
2 A tour of a variety of intuitivedistributed algorithms used in practical distributed systems. and how to prototype with F# for better understanding
3 Why distributed algorithms?

4 Sorting algorithms
5 Not everyone needs to know... But it can be really useful

6 Things Will Break
7 No blind troubleshooting

8 TUNING
9 Edge cases or even create your own new Distributed System *** *** WARNING!

10 Riak

11 Cassandra
12 HBase
13 Abstract words actually mean concrete algorithms

14 Liveness Safety

15
16 No To Be Or Not To Be Will show algorithms that provide different types of guarantees for different purposes
17 System should be ready for events, changes and failures! A node can die Node can join Recover from failure [FAILURE DETECTION] [GOSSIP, ANTI-ENTROPY] [SNAPSHOTS, CHECKPOINTING] And a whole bunch of other things!
18 üintro Ø Consistency Levels o Gossip o Consensus o Snapshot o Failure Detectors o Distributed Broadcast o Summary Contents
19 Consistency Levels
20 $100 $100 Balance = $100 $100 $100 Good situation! $100

21 $100 $100 Balance = 100$ $100 $100 $0 Bad situation $0 balance
22 Good news: we can choose the level of consistency
23 More consistency Less availability
24 Let s look at different consistency levels and how they affect a distributed system
25 The weakest consistency level Writer client x Writes to any node x X x x x Reads from any node Reader client
26 Weak Consistency Advantages: Trade-off: High availability, low latency Low consistency High propagation time No guarantee of successful update propagation
27 Reducing propagation latency Writer client x Writes to any node x X x x x x Reads from any node Reader client
28 NODE FAILS
29 Hinted Handoff Writer client x Writes to any node x X x x x x Hinted handoff Reads from any node * Faster update propagation after failures Reader client

30 Coordinator fails Hint file corrupted
31 Read Repair Writer client x Writes to any node x X x x x x Read repair Hash gathering Reads from any node Reader client
32 Can we get stronger consistency?
33 Quorum Writer client x Writes to any node x X x x x x Reads from any node Reader client
34 Quorum W number of replicas where clients synchronously writes R number of replicas from which client reads N number of replicas [WRITE QUORUM] [READ QUORUM] W > N/2 W + R > N By following the rule we ensure that at least 1 replica will return fresh data during read operations.

35 Quintuplets and approximate estimation of Cassandra partition size
36 How to prevent inconsistency?
37 Centralization
38 Consensus to be continued
39 Consistency levels in real distributed systems Cassandra and Riak use weak consistency level protocol for metadata exchange, hinted-handoff andread repair techniques to improve consistency. You can choose read and write quorums in Cassandra. HBase uses master/slave asynchronous replication. Zookeeper writes are also performed by master.
40 ü Intro ü Consistency Levels Ø Gossip o Consensus o Snapshot o Failure Detectors o Distributed Broadcast o Summary Contents
41 Gossip
42 Common use cases of Gossip Failure detection: determining which nodes are down Solving inconsistency Metadata exchange: Cluster membership: i.e. changes in distributed DB topology new, failed or recovered nodes Many more
43 Use Gossip when system needs to be... Fast and scalable Fault-tolerant Extremely decentralized Or when it has huge number of nodes
44 General gossip Endless process when each node periodically selects N others nodes and sends information to them
45 General gossip Node #1 Node #2 Node #3 Node #4 Node #5 List of known nodes: #2 #3 #4 #5 List of known nodes: #1 #3 #4 #5 List of known nodes: #1 #2 #4 #5 List of known nodes: #1 #2 #3 #5 List of known nodes: #1 #2 #3 #4
46 Key: 42 Value: status: green Key: 42 Value: status: red
47 Key: 42 Value: status: green Timestamp: Key: 42 Value: status: red Timestamp:
48 Anti-entropy repair Solves the state of inconsistently replicated data

49 Writer client x Read runs on reads Read repair x X Hash gatherig x x x Reader client Anti-entropy can run constantly, periodically or can be initiated manually.
50 Merkle trees for Anti-entropy Tree data structure which has hashes of data on the leaves and hashes of children on nonleaves. Cassandra, Riak and DynamoDB use anti-entropy technique using Merkle trees. In case of hash inequality - exchange of actual data takes place
51 Merkle trees Cassandra Short-lived in-memory Riak On-disk persistent

52 Rumor mongering Step 1 Step 2 Message: Node #5 is down! Message: Node #5 is down! Message: Node #5 is down! Message: Node #5 is down!
53 Real world use cases of Gossip Riak - Communicates ring state and bucket properties around thecluster Cassandra - Propagates information about database topology and other metadata - For failure detection Consul - To discover new members and failures and to perform reliable and fast event broadcasts for events like leader election. Uses SERF (based on SWIM: Scalable Weakly-consistent Infection-style Process Group Membership Protocol ) Amazon S3 - Topropagate server state tothe system
54 NOT gossip: one node is overloaded
55 Trade-offs with Gossip Propagation latency may be high Risk of spreading wrong information Weak consistency
56 General Gossip example
57
58 CODE
59 üintro üconsistency Levels ügossip Ø Consensus o Snapshot o Failure Detectors o Distributed Broadcast o Summary Contents

60 Consensus
61 In a fully asynchronous system there is no consensus solution that can tolerate one or more crash failures even when only requiring the non triviality property - Fischer Lynch Paterson [FLP] result
62 Real world applications of Consensus Distributed coordination services, i.e. log coordination Locking protocols State machine and primary-backup replication Distributed transaction resolution Agreement to move to the next stage of a distributed algorithm Leader election for higher-level protocols Many more
63 PAXOS a protocol for state-machine replication in an asynchronous environment that admits crash-failures
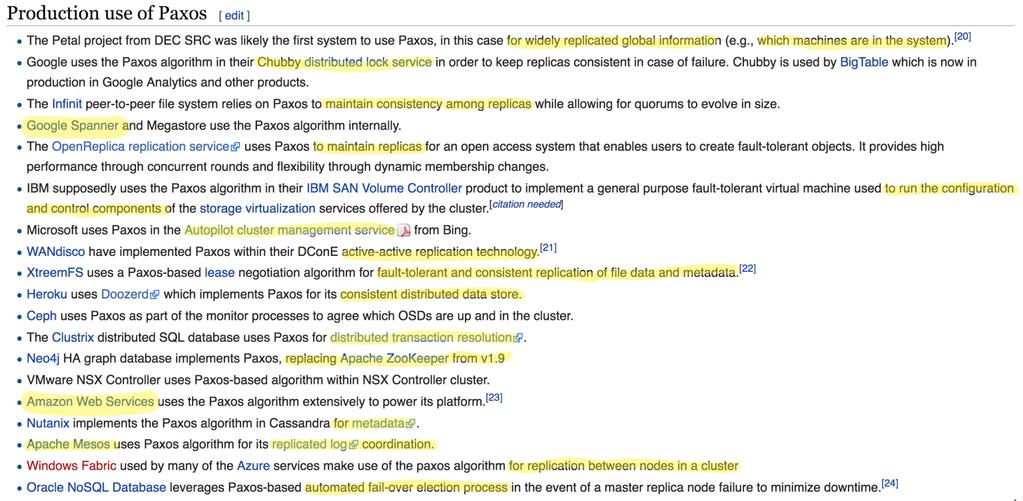
64

65



66 Proposers Acceptors Learners
67 Prepare request Proposer chooses a new proposal number N Proposer asks acceptors to: 1. Promise to never accept a proposal # < N 2. Return a highest accepted proposal # < N
68 Accept request If majority of acceptors responded, X = value of the highest # proposal received from acceptors Proposer issues an accept request: With a Proposal Number N And a value X Accept Request
69 Multi Paxos Deciding on one value - running one round of Basic Paxos Deciding on a sequence of values - running Paxos many times...right?
70 Multi Paxos Deciding on one value - running one round of Basic Paxos Deciding on a sequence of values - running Paxos many times Almost. We can optimize consecutive Paxos rounds by skipping prepare phase, assuming a stable leader
71
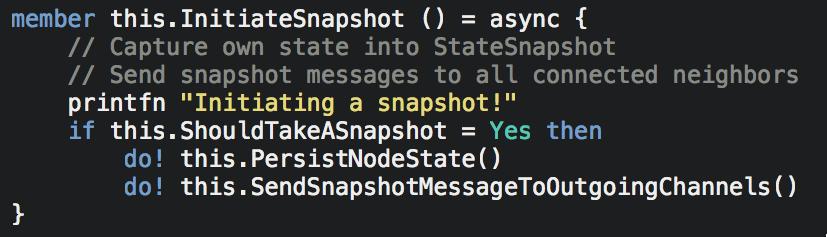
 Auxiliary acceptors in case of acceptor failures")
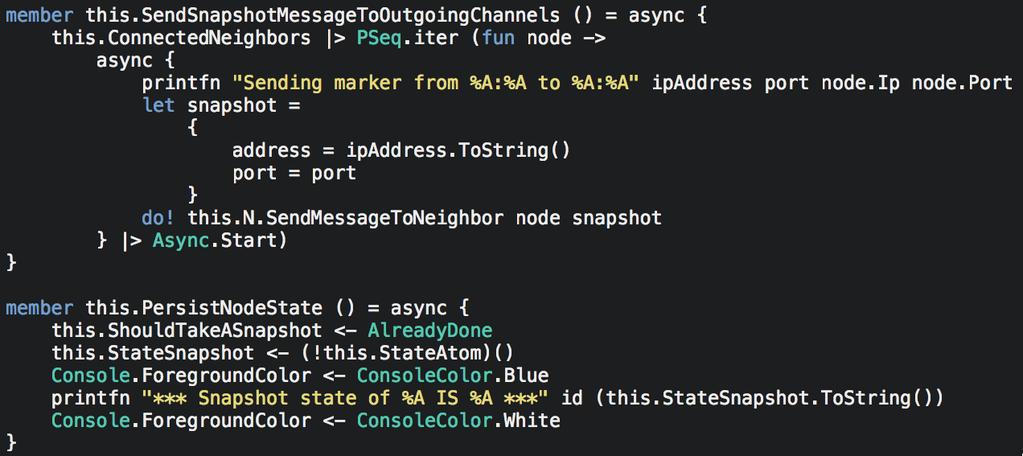
72 To tolerate f failures: Cheap Paxos Based on Multi-Paxos f + 1 acceptors (not 2f + 1, like in traditional Paxos) Auxiliary acceptors in case of acceptor failures

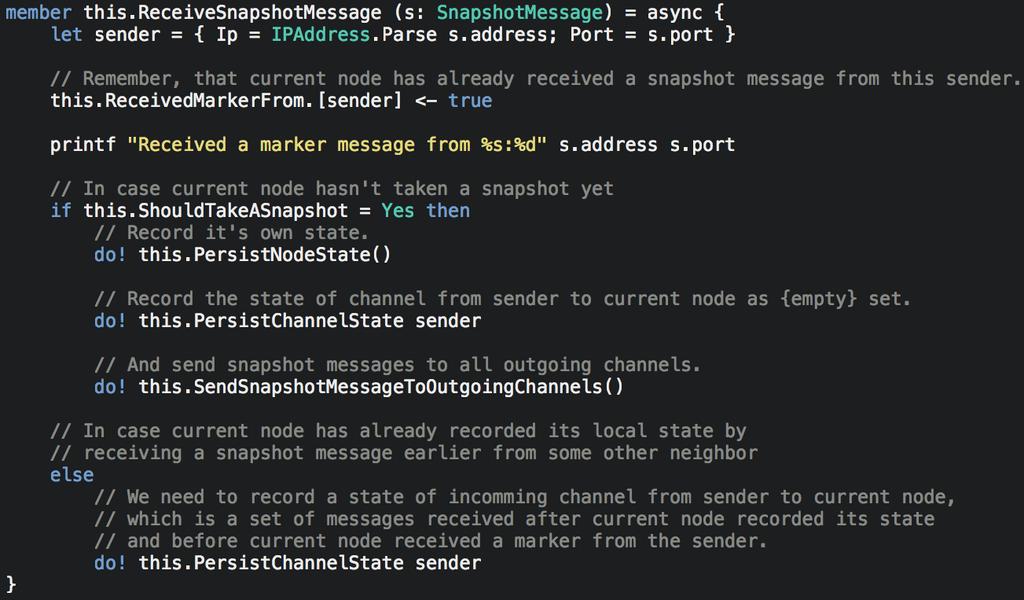
73 Fast Paxos Based on Multi-Paxos Reduces end-to-end message delays for a replica to learn a chosen value Needs 3f + 1 acceptors instead of 2f + 1
74 Vertical Paxos Reconfigurable Enables reconfiguration while state machine is deciding on commands Uses auxiliary master for reconfiguration ops A special case of Primary-Backup protocol

75
76 ZAB Zookeeper s Atomic Broadcast A bit stricter ordering guarantees If leader fails, new leader cannot arbitrarily reorder uncommitted state updates, or apply them starting from a different initial state
77 ü Intro ü Consistency Levels ü Gossip ü Consensus Ø Snapshot o Failure Detectors o Distributed Broadcast o Summary Contents
78 Snapshots
79 Prototyping a Chandy-Lamport Snapshot in F#
80
81
82
83

84
85 Assumes that channels are FIFO All nodes can reach each other All nodes are available Basic Messages for regular data Marker Messages for snapshots Any node can initiate a snapshot at any moment
86 Initial state of the system Lena $50 Maggie $0 Natasha $75
87 Lena $45 $5 Maggie $0 $10 Natasha $65
88 $45 Lena $45 marker marker $5 Maggie $0 $10 Natasha $65
89 $45 Lena $45 marker Lena Maggie = {empty} marker Maggie $0 $0 $10 Network delay for $10 marker Natasha $70
90 $45 Maggie Lena = {empty} Lena $45 marker Lena Maggie = {empty} Lena Natasha = {empty} Maggie Natasha = {empty} Maggie $0 $10 marker Natasha $70 $0 Network delay for $10 message $70
91 $45 Maggie Lena = {empty} $45 Lena $45 marker Lena Maggie = {empty} Messages to snapshot: $10 Maggie $0 marker Natasha $70 Lena Natasha = {empty} Maggie Natasha = {empty} $0 $70
92 Maggie Lena = {empty} $45 Lena $45 Natasha Lena = { empty} Lena Maggie = {empty} Natasha Maggie = { $10 } Lena Natasha = {empty} Maggie Natasha = {empty} Maggie $0 Natasha $70 $0 $70
93
94 CODE
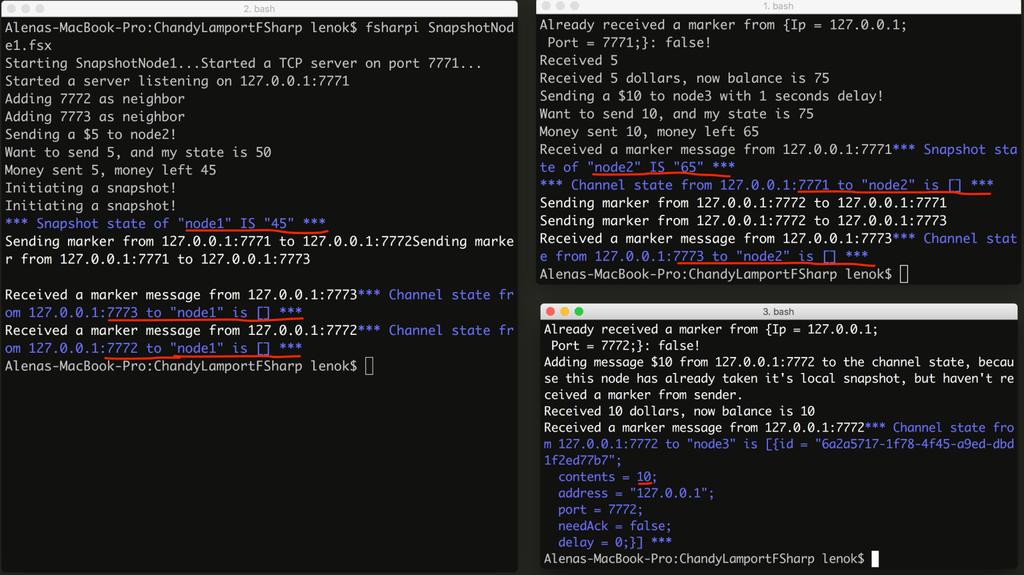
95
96 ü Intro ü Consistency Levels ü Gossip ü Consensus ü Snapshot Ø Failure Detectors o Distributed Broadcast o Summary Contents
97 Failure detectors
98 Failure detectors are critical for: Leader election Agreement (e.g. Paxos) Reliable Broadcast And more
99 How are faults detected?
100 Heartbeat failure detection #1 #2 300 ms 300 ms 300 ms I am healthy! I am healthy! I am healthy! 300 ms 300 ms 300 ms Node failed No message 500 ms Suspected Nodes List: #1
101 Completeness Strong Eventually all failed processes are suspected by all correct once. #4 Weak Eventually all failed processes are suspected by at least one correct one. #4 #2 Failed: #2, #3 #2 Failed: none #1 Failed: #2, #3 #3 #5 Failed: #2, #3 #1 Failed: #4 #3 #5 Failed: #2, #3
102 Detects every process as failed #2 #4 #1 Failed: #2, #3, #4, #5 #3 #5
103 Accuracy Strong Weak Eventually strong Eventually weak We can say that accuracy Restricts the mistake or Limits number of false positives or, more precisely Limits number of nodes that are mistakenly suspected by the correct nodes
104 Accuracy Strong All correct processes are never suspected #4 Weak At least 1 correct process is never suspected #4 #2 Failed: none #2 Failed: #1, #2 #1 Failed: #2 #3 #5 Failed: #3 #1 Failed: #4 #3 #5 Failed: #3 * Correct node #5 isn t in any suspected list ever
105 Accuracy Eventual Strong After some point in time, all correct processes are never suspected #4 Eventual Weak After some point in time, at least 1 correct process is never suspected #4 #2 Failed: none #2 Failed: #1, #2 #1 Failed: #2 #3 #5 Failed: #3 #1 Failed: #4 #3 #5 Failed: #3 * Nodes could have had wrong suspicions in the past

106 Failure detector classes
107 Perfect Failure Detector Strong Completeness + Strong Accuracy Possible only in synchronous system Uses timeouts (waiting time for a heartbeat arrival)

108
109 Eventually Perfect Failure Detector Strong Completeness + Eventual Strong Accuracy Timeouts are adjusted to be maximum or average Eventually timeout will be that big that all assumptions will be correct
110 Eventually Perfect Failure Detector #1 #2 300 ms I am healthy! 300 ms Node failed No message 700 ms #1 Node recovered Timeout to wait: 300 ms List of suspected nodes: #1 300 ms I am healthy! Timeout to wait: 700 ms List of suspected nodes: none
111 Failure Detectors in Consensus
112 Failure detectors are present in almost every distributed system
113

114 SWIM Scalable Weakly-consistent Infection-style process group Membership protocol Strong completeness and configurable accuracy 1. Initiator picks random node from its membership list and sends a message to it. 2. Ifa chosen node doesn t send acknowledgement after some time, initiator sends ping request to other M randomly selected nodes to ask to send message to suspicious node. 3. All nodes try toget acknowledgement from suspicious node and forward it tothe initiator. If none of the M nodes gets an acknowledgement, initiator marks the node as dead and disseminates about failed node. Choosing bigger number M of nodes you make accuracybigger.
115 ü Intro ü Consistency Levels ü Gossip ü Consensus ü Snapshot ü Failure Detectors Ø Distributed Broadcast o Summary Contents
116 Distributed Broadcast Sending message to every node in the cluster
117 Messages can be lost Nodes can fail Various broadcast algorithms help us to choose between consistency of the system and its availability.
118 Best-effort Broadcast Ensures the delivery of the message to all of the correct processes if sender doesn t fail during message exchange. Messages are sent using perfect point-to-point connection (no message loss, no duplicates). #3 #1 X = 15 X = 15 #5 X = 15 X = 15 #2 #4
119 Reliable Broadcast If any correct node delivers the message, all correct nodes should deliver the message Normal scenario results in O(N) messages Worst-case scenario (when processes fail one after another) O(N) steps with O(N 2 ) messages. Uses failure detector
120 Message has sender ID #1 Sender:#1 X = 15 #3 Sender: #1 X = 15 #5 Sender:#1 X=15 X = 15 Sender:#1 X=15 X = 15 #2 #4
121 Nodes constantly check sender #3 #1 Are you ok? #5 #2 #4
122 If failure detected message is relayed #1 #3 Sender: #5 X = 15 #5 Sender: #5 X = 15 Sender: #5 X = 15 #2 #4 They can even fail one by one, other nodes will detect failure and relay message
123 If failure detector marks sender failed when it s not, unnecessary messages would be sent, that would impact performance, not correctness. However, ifprocess will not indicatefailure, then needed messages won t be sent.
124 Some reliable broadcasts do not use failure detectors What if a node processes a message, and then fails?...
125 Uniform Reliable Broadcast If any node (doesn t matter correct or crashed) delivers the message, all correct nodes should deliver the message. Works with failure detector, this way nodes don t wait for the reply from failed nodes forever.
126 All-Ack Algorithm Node that initiated the broadcast sends messages to all of nodes. Each node that gets the message, relays it and considers pending for now. Got x = 15 from: #1 #3 X=15 #1 X = 15 #5 X = 15 #2 Got X = 15 from: #1 X = 15 #4 Got X = 15 from: #1 Got X = 15 from: #1
127 Each node keeps track of nodes from which it received current message. Got x=15 from: #5 #1 X = 15 Got x=15 from: #1, #5 #3 X = 15 Got x=15 from: #1 #5 X = 15 X = 15 #2 Got x=15 from: #1, #5 #4 Got x=15 from: #1, #5 When process gets current message from all of the correct nodes, it considers message delivered.
128 ü Intro ü Consistency Levels ü Gossip ü Consensus ü Snapshot ü Failure Detectors ü Distributed Broadcast Ø Summary Contents

129 Now I know distributed algorithms
130 Thank you and reach out! Natallia Dzenisenka
Distributed systems. Lecture 6: distributed transactions, elections, consensus and replication. Malte Schwarzkopf
 Distributed systems Lecture 6: distributed transactions, elections, consensus and replication Malte Schwarzkopf Last time Saw how we can build ordered multicast Messages between processes in a group Need
Distributed systems Lecture 6: distributed transactions, elections, consensus and replication Malte Schwarzkopf Last time Saw how we can build ordered multicast Messages between processes in a group Need
CS Amazon Dynamo
 CS 5450 Amazon Dynamo Amazon s Architecture Dynamo The platform for Amazon's e-commerce services: shopping chart, best seller list, produce catalog, promotional items etc. A highly available, distributed
CS 5450 Amazon Dynamo Amazon s Architecture Dynamo The platform for Amazon's e-commerce services: shopping chart, best seller list, produce catalog, promotional items etc. A highly available, distributed
Transactions. CS 475, Spring 2018 Concurrent & Distributed Systems
 Transactions CS 475, Spring 2018 Concurrent & Distributed Systems Review: Transactions boolean transfermoney(person from, Person to, float amount){ if(from.balance >= amount) { from.balance = from.balance
Transactions CS 475, Spring 2018 Concurrent & Distributed Systems Review: Transactions boolean transfermoney(person from, Person to, float amount){ if(from.balance >= amount) { from.balance = from.balance
Last time. Distributed systems Lecture 6: Elections, distributed transactions, and replication. DrRobert N. M. Watson
 Distributed systems Lecture 6: Elections, distributed transactions, and replication DrRobert N. M. Watson 1 Last time Saw how we can build ordered multicast Messages between processes in a group Need to
Distributed systems Lecture 6: Elections, distributed transactions, and replication DrRobert N. M. Watson 1 Last time Saw how we can build ordered multicast Messages between processes in a group Need to
Distributed Systems. 10. Consensus: Paxos. Paul Krzyzanowski. Rutgers University. Fall 2017
 Distributed Systems 10. Consensus: Paxos Paul Krzyzanowski Rutgers University Fall 2017 1 Consensus Goal Allow a group of processes to agree on a result All processes must agree on the same value The value
Distributed Systems 10. Consensus: Paxos Paul Krzyzanowski Rutgers University Fall 2017 1 Consensus Goal Allow a group of processes to agree on a result All processes must agree on the same value The value
Agreement and Consensus. SWE 622, Spring 2017 Distributed Software Engineering
 Agreement and Consensus SWE 622, Spring 2017 Distributed Software Engineering Today General agreement problems Fault tolerance limitations of 2PC 3PC Paxos + ZooKeeper 2 Midterm Recap 200 GMU SWE 622 Midterm
Agreement and Consensus SWE 622, Spring 2017 Distributed Software Engineering Today General agreement problems Fault tolerance limitations of 2PC 3PC Paxos + ZooKeeper 2 Midterm Recap 200 GMU SWE 622 Midterm
Recovering from a Crash. Three-Phase Commit
 Recovering from a Crash If INIT : abort locally and inform coordinator If Ready, contact another process Q and examine Q s state Lecture 18, page 23 Three-Phase Commit Two phase commit: problem if coordinator
Recovering from a Crash If INIT : abort locally and inform coordinator If Ready, contact another process Q and examine Q s state Lecture 18, page 23 Three-Phase Commit Two phase commit: problem if coordinator
Consensus and related problems
 Consensus and related problems Today l Consensus l Google s Chubby l Paxos for Chubby Consensus and failures How to make process agree on a value after one or more have proposed what the value should be?
Consensus and related problems Today l Consensus l Google s Chubby l Paxos for Chubby Consensus and failures How to make process agree on a value after one or more have proposed what the value should be?
Dynamo: Key-Value Cloud Storage
 Dynamo: Key-Value Cloud Storage Brad Karp UCL Computer Science CS M038 / GZ06 22 nd February 2016 Context: P2P vs. Data Center (key, value) Storage Chord and DHash intended for wide-area peer-to-peer systems
Dynamo: Key-Value Cloud Storage Brad Karp UCL Computer Science CS M038 / GZ06 22 nd February 2016 Context: P2P vs. Data Center (key, value) Storage Chord and DHash intended for wide-area peer-to-peer systems
Consensus a classic problem. Consensus, impossibility results and Paxos. Distributed Consensus. Asynchronous networks.
 Consensus, impossibility results and Paxos Ken Birman Consensus a classic problem Consensus abstraction underlies many distributed systems and protocols N processes They start execution with inputs {0,1}
Consensus, impossibility results and Paxos Ken Birman Consensus a classic problem Consensus abstraction underlies many distributed systems and protocols N processes They start execution with inputs {0,1}
CS /15/16. Paul Krzyzanowski 1. Question 1. Distributed Systems 2016 Exam 2 Review. Question 3. Question 2. Question 5.
 Question 1 What makes a message unstable? How does an unstable message become stable? Distributed Systems 2016 Exam 2 Review Paul Krzyzanowski Rutgers University Fall 2016 In virtual sychrony, a message
Question 1 What makes a message unstable? How does an unstable message become stable? Distributed Systems 2016 Exam 2 Review Paul Krzyzanowski Rutgers University Fall 2016 In virtual sychrony, a message
Distributed Systems Consensus
 Distributed Systems Consensus Amir H. Payberah amir@sics.se Amirkabir University of Technology (Tehran Polytechnic) Amir H. Payberah (Tehran Polytechnic) Consensus 1393/6/31 1 / 56 What is the Problem?
Distributed Systems Consensus Amir H. Payberah amir@sics.se Amirkabir University of Technology (Tehran Polytechnic) Amir H. Payberah (Tehran Polytechnic) Consensus 1393/6/31 1 / 56 What is the Problem?
Exam 2 Review. October 29, Paul Krzyzanowski 1
 Exam 2 Review October 29, 2015 2013 Paul Krzyzanowski 1 Question 1 Why did Dropbox add notification servers to their architecture? To avoid the overhead of clients polling the servers periodically to check
Exam 2 Review October 29, 2015 2013 Paul Krzyzanowski 1 Question 1 Why did Dropbox add notification servers to their architecture? To avoid the overhead of clients polling the servers periodically to check
 Paxos applied
Paxos applied Replication in Distributed Systems
 Replication in Distributed Systems Replication Basics Multiple copies of data kept in different nodes A set of replicas holding copies of a data Nodes can be physically very close or distributed all over
Replication in Distributed Systems Replication Basics Multiple copies of data kept in different nodes A set of replicas holding copies of a data Nodes can be physically very close or distributed all over
Consensus, impossibility results and Paxos. Ken Birman
 Consensus, impossibility results and Paxos Ken Birman Consensus a classic problem Consensus abstraction underlies many distributed systems and protocols N processes They start execution with inputs {0,1}
Consensus, impossibility results and Paxos Ken Birman Consensus a classic problem Consensus abstraction underlies many distributed systems and protocols N processes They start execution with inputs {0,1}
Horizontal or vertical scalability? Horizontal scaling is challenging. Today. Scaling Out Key-Value Storage
 Horizontal or vertical scalability? Scaling Out Key-Value Storage COS 418: Distributed Systems Lecture 8 Kyle Jamieson Vertical Scaling Horizontal Scaling [Selected content adapted from M. Freedman, B.
Horizontal or vertical scalability? Scaling Out Key-Value Storage COS 418: Distributed Systems Lecture 8 Kyle Jamieson Vertical Scaling Horizontal Scaling [Selected content adapted from M. Freedman, B.
Failure Tolerance. Distributed Systems Santa Clara University
 Failure Tolerance Distributed Systems Santa Clara University Distributed Checkpointing Distributed Checkpointing Capture the global state of a distributed system Chandy and Lamport: Distributed snapshot
Failure Tolerance Distributed Systems Santa Clara University Distributed Checkpointing Distributed Checkpointing Capture the global state of a distributed system Chandy and Lamport: Distributed snapshot
Dynamo. Smruti R. Sarangi. Department of Computer Science Indian Institute of Technology New Delhi, India. Motivation System Architecture Evaluation
 Dynamo Smruti R. Sarangi Department of Computer Science Indian Institute of Technology New Delhi, India Smruti R. Sarangi Leader Election 1/20 Outline Motivation 1 Motivation 2 3 Smruti R. Sarangi Leader
Dynamo Smruti R. Sarangi Department of Computer Science Indian Institute of Technology New Delhi, India Smruti R. Sarangi Leader Election 1/20 Outline Motivation 1 Motivation 2 3 Smruti R. Sarangi Leader
Failures, Elections, and Raft
 Failures, Elections, and Raft CS 8 XI Copyright 06 Thomas W. Doeppner, Rodrigo Fonseca. All rights reserved. Distributed Banking SFO add interest based on current balance PVD deposit $000 CS 8 XI Copyright
Failures, Elections, and Raft CS 8 XI Copyright 06 Thomas W. Doeppner, Rodrigo Fonseca. All rights reserved. Distributed Banking SFO add interest based on current balance PVD deposit $000 CS 8 XI Copyright
10. Replication. Motivation
 10. Replication Page 1 10. Replication Motivation Reliable and high-performance computation on a single instance of a data object is prone to failure. Replicate data to overcome single points of failure
10. Replication Page 1 10. Replication Motivation Reliable and high-performance computation on a single instance of a data object is prone to failure. Replicate data to overcome single points of failure
DYNAMO: AMAZON S HIGHLY AVAILABLE KEY-VALUE STORE. Presented by Byungjin Jun
 DYNAMO: AMAZON S HIGHLY AVAILABLE KEY-VALUE STORE Presented by Byungjin Jun 1 What is Dynamo for? Highly available key-value storages system Simple primary-key only interface Scalable and Reliable Tradeoff:
DYNAMO: AMAZON S HIGHLY AVAILABLE KEY-VALUE STORE Presented by Byungjin Jun 1 What is Dynamo for? Highly available key-value storages system Simple primary-key only interface Scalable and Reliable Tradeoff:
HT-Paxos: High Throughput State-Machine Replication Protocol for Large Clustered Data Centers
 1 HT-Paxos: High Throughput State-Machine Replication Protocol for Large Clustered Data Centers Vinit Kumar 1 and Ajay Agarwal 2 1 Associate Professor with the Krishna Engineering College, Ghaziabad, India.
1 HT-Paxos: High Throughput State-Machine Replication Protocol for Large Clustered Data Centers Vinit Kumar 1 and Ajay Agarwal 2 1 Associate Professor with the Krishna Engineering College, Ghaziabad, India.
Distributed Systems. 09. State Machine Replication & Virtual Synchrony. Paul Krzyzanowski. Rutgers University. Fall Paul Krzyzanowski
 Distributed Systems 09. State Machine Replication & Virtual Synchrony Paul Krzyzanowski Rutgers University Fall 2016 1 State machine replication 2 State machine replication We want high scalability and
Distributed Systems 09. State Machine Replication & Virtual Synchrony Paul Krzyzanowski Rutgers University Fall 2016 1 State machine replication 2 State machine replication We want high scalability and
Proseminar Distributed Systems Summer Semester Paxos algorithm. Stefan Resmerita
 Proseminar Distributed Systems Summer Semester 2016 Paxos algorithm stefan.resmerita@cs.uni-salzburg.at The Paxos algorithm Family of protocols for reaching consensus among distributed agents Agents may
Proseminar Distributed Systems Summer Semester 2016 Paxos algorithm stefan.resmerita@cs.uni-salzburg.at The Paxos algorithm Family of protocols for reaching consensus among distributed agents Agents may
AGREEMENT PROTOCOLS. Paxos -a family of protocols for solving consensus
 AGREEMENT PROTOCOLS Paxos -a family of protocols for solving consensus OUTLINE History of the Paxos algorithm Paxos Algorithm Family Implementation in existing systems References HISTORY OF THE PAXOS ALGORITHM
AGREEMENT PROTOCOLS Paxos -a family of protocols for solving consensus OUTLINE History of the Paxos algorithm Paxos Algorithm Family Implementation in existing systems References HISTORY OF THE PAXOS ALGORITHM
FAQs Snapshots and locks Vector Clock
 //08 CS5 Introduction to Big - FALL 08 W.B.0.0 CS5 Introduction to Big //08 CS5 Introduction to Big - FALL 08 W.B. FAQs Snapshots and locks Vector Clock PART. LARGE SCALE DATA STORAGE SYSTEMS NO SQL DATA
//08 CS5 Introduction to Big - FALL 08 W.B.0.0 CS5 Introduction to Big //08 CS5 Introduction to Big - FALL 08 W.B. FAQs Snapshots and locks Vector Clock PART. LARGE SCALE DATA STORAGE SYSTEMS NO SQL DATA
Today: Fault Tolerance. Fault Tolerance
 Today: Fault Tolerance Agreement in presence of faults Two army problem Byzantine generals problem Reliable communication Distributed commit Two phase commit Three phase commit Paxos Failure recovery Checkpointing
Today: Fault Tolerance Agreement in presence of faults Two army problem Byzantine generals problem Reliable communication Distributed commit Two phase commit Three phase commit Paxos Failure recovery Checkpointing
Distributed Systems. coordination Johan Montelius ID2201. Distributed Systems ID2201
 Distributed Systems ID2201 coordination Johan Montelius 1 Coordination Coordinating several threads in one node is a problem, coordination in a network is of course worse: failure of nodes and networks
Distributed Systems ID2201 coordination Johan Montelius 1 Coordination Coordinating several threads in one node is a problem, coordination in a network is of course worse: failure of nodes and networks
Dynamo: Amazon s Highly Available Key-Value Store
 Dynamo: Amazon s Highly Available Key-Value Store DeCandia et al. Amazon.com Presented by Sushil CS 5204 1 Motivation A storage system that attains high availability, performance and durability Decentralized
Dynamo: Amazon s Highly Available Key-Value Store DeCandia et al. Amazon.com Presented by Sushil CS 5204 1 Motivation A storage system that attains high availability, performance and durability Decentralized
CMPSCI 677 Operating Systems Spring Lecture 14: March 9
 CMPSCI 677 Operating Systems Spring 2014 Lecture 14: March 9 Lecturer: Prashant Shenoy Scribe: Nikita Mehra 14.1 Distributed Snapshot Algorithm A distributed snapshot algorithm captures a consistent global
CMPSCI 677 Operating Systems Spring 2014 Lecture 14: March 9 Lecturer: Prashant Shenoy Scribe: Nikita Mehra 14.1 Distributed Snapshot Algorithm A distributed snapshot algorithm captures a consistent global
Today: Fault Tolerance
 Today: Fault Tolerance Agreement in presence of faults Two army problem Byzantine generals problem Reliable communication Distributed commit Two phase commit Three phase commit Paxos Failure recovery Checkpointing
Today: Fault Tolerance Agreement in presence of faults Two army problem Byzantine generals problem Reliable communication Distributed commit Two phase commit Three phase commit Paxos Failure recovery Checkpointing
Scaling Out Key-Value Storage
 Scaling Out Key-Value Storage COS 418: Distributed Systems Logan Stafman [Adapted from K. Jamieson, M. Freedman, B. Karp] Horizontal or vertical scalability? Vertical Scaling Horizontal Scaling 2 Horizontal
Scaling Out Key-Value Storage COS 418: Distributed Systems Logan Stafman [Adapted from K. Jamieson, M. Freedman, B. Karp] Horizontal or vertical scalability? Vertical Scaling Horizontal Scaling 2 Horizontal
Presented By: Devarsh Patel
 : Amazon s Highly Available Key-value Store Presented By: Devarsh Patel CS5204 Operating Systems 1 Introduction Amazon s e-commerce platform Requires performance, reliability and efficiency To support
: Amazon s Highly Available Key-value Store Presented By: Devarsh Patel CS5204 Operating Systems 1 Introduction Amazon s e-commerce platform Requires performance, reliability and efficiency To support
Paxos Made Simple. Leslie Lamport, 2001
 Paxos Made Simple Leslie Lamport, 2001 The Problem Reaching consensus on a proposed value, among a collection of processes Safety requirements: Only a value that has been proposed may be chosen Only a
Paxos Made Simple Leslie Lamport, 2001 The Problem Reaching consensus on a proposed value, among a collection of processes Safety requirements: Only a value that has been proposed may be chosen Only a
Introduction to Distributed Systems Seif Haridi
 Introduction to Distributed Systems Seif Haridi haridi@kth.se What is a distributed system? A set of nodes, connected by a network, which appear to its users as a single coherent system p1 p2. pn send
Introduction to Distributed Systems Seif Haridi haridi@kth.se What is a distributed system? A set of nodes, connected by a network, which appear to its users as a single coherent system p1 p2. pn send
CS455: Introduction to Distributed Systems [Spring 2018] Dept. Of Computer Science, Colorado State University
![CS455: Introduction to Distributed Systems [Spring 2018] Dept. Of Computer Science, Colorado State University](/thumbs/89/97640828.jpg "CS455: Introduction to Distributed Systems [Spring 2018] Dept. Of Computer Science, Colorado State University") CS 455: INTRODUCTION TO DISTRIBUTED SYSTEMS [ELECTION ALGORITHMS] Shrideep Pallickara Computer Science Colorado State University Frequently asked questions from the previous class survey Does a process
CS 455: INTRODUCTION TO DISTRIBUTED SYSTEMS [ELECTION ALGORITHMS] Shrideep Pallickara Computer Science Colorado State University Frequently asked questions from the previous class survey Does a process
Recall our 2PC commit problem. Recall our 2PC commit problem. Doing failover correctly isn t easy. Consensus I. FLP Impossibility, Paxos
 Consensus I Recall our 2PC commit problem FLP Impossibility, Paxos Client C 1 C à TC: go! COS 418: Distributed Systems Lecture 7 Michael Freedman Bank A B 2 TC à A, B: prepare! 3 A, B à P: yes or no 4
Consensus I Recall our 2PC commit problem FLP Impossibility, Paxos Client C 1 C à TC: go! COS 418: Distributed Systems Lecture 7 Michael Freedman Bank A B 2 TC à A, B: prepare! 3 A, B à P: yes or no 4
There is a tempta7on to say it is really used, it must be good
 Notes from reviews Dynamo Evalua7on doesn t cover all design goals (e.g. incremental scalability, heterogeneity) Is it research? Complexity? How general? Dynamo Mo7va7on Normal database not the right fit
Notes from reviews Dynamo Evalua7on doesn t cover all design goals (e.g. incremental scalability, heterogeneity) Is it research? Complexity? How general? Dynamo Mo7va7on Normal database not the right fit
Distributed Systems 8L for Part IB
 Distributed Systems 8L for Part IB Handout 3 Dr. Steven Hand 1 Distributed Mutual Exclusion In first part of course, saw need to coordinate concurrent processes / threads In particular considered how to
Distributed Systems 8L for Part IB Handout 3 Dr. Steven Hand 1 Distributed Mutual Exclusion In first part of course, saw need to coordinate concurrent processes / threads In particular considered how to
Distributed Consensus Protocols
 Distributed Consensus Protocols ABSTRACT In this paper, I compare Paxos, the most popular and influential of distributed consensus protocols, and Raft, a fairly new protocol that is considered to be a
Distributed Consensus Protocols ABSTRACT In this paper, I compare Paxos, the most popular and influential of distributed consensus protocols, and Raft, a fairly new protocol that is considered to be a
To do. Consensus and related problems. q Failure. q Raft
 Consensus and related problems To do q Failure q Consensus and related problems q Raft Consensus We have seen protocols tailored for individual types of consensus/agreements Which process can enter the
Consensus and related problems To do q Failure q Consensus and related problems q Raft Consensus We have seen protocols tailored for individual types of consensus/agreements Which process can enter the
CS 138: Dynamo. CS 138 XXIV 1 Copyright 2017 Thomas W. Doeppner. All rights reserved.
 CS 138: Dynamo CS 138 XXIV 1 Copyright 2017 Thomas W. Doeppner. All rights reserved. Dynamo Highly available and scalable distributed data store Manages state of services that have high reliability and
CS 138: Dynamo CS 138 XXIV 1 Copyright 2017 Thomas W. Doeppner. All rights reserved. Dynamo Highly available and scalable distributed data store Manages state of services that have high reliability and
Spotify. Scaling storage to million of users world wide. Jimmy Mårdell October 14, 2014
 Cassandra @ Spotify Scaling storage to million of users world wide! Jimmy Mårdell October 14, 2014 2 About me Jimmy Mårdell Tech Product Owner in the Cassandra team 4 years at Spotify
Cassandra @ Spotify Scaling storage to million of users world wide! Jimmy Mårdell October 14, 2014 2 About me Jimmy Mårdell Tech Product Owner in the Cassandra team 4 years at Spotify
Recap. CSE 486/586 Distributed Systems Google Chubby Lock Service. Recap: First Requirement. Recap: Second Requirement. Recap: Strengthening P2
 Recap CSE 486/586 Distributed Systems Google Chubby Lock Service Steve Ko Computer Sciences and Engineering University at Buffalo Paxos is a consensus algorithm. Proposers? Acceptors? Learners? A proposer
Recap CSE 486/586 Distributed Systems Google Chubby Lock Service Steve Ko Computer Sciences and Engineering University at Buffalo Paxos is a consensus algorithm. Proposers? Acceptors? Learners? A proposer
CAP Theorem, BASE & DynamoDB
 Indian Institute of Science Bangalore, India भ रत य व ज ञ न स स थ न ब गल र, भ रत DS256:Jan18 (3:1) Department of Computational and Data Sciences CAP Theorem, BASE & DynamoDB Yogesh Simmhan Yogesh Simmhan
Indian Institute of Science Bangalore, India भ रत य व ज ञ न स स थ न ब गल र, भ रत DS256:Jan18 (3:1) Department of Computational and Data Sciences CAP Theorem, BASE & DynamoDB Yogesh Simmhan Yogesh Simmhan
Paxos and Raft (Lecture 21, cs262a) Ion Stoica, UC Berkeley November 7, 2016
 Ion Stoica, UC Berkeley November 7, 2016") Paxos and Raft (Lecture 21, cs262a) Ion Stoica, UC Berkeley November 7, 2016 Bezos mandate for service-oriented-architecture (~2002) 1. All teams will henceforth expose their data and functionality through
Paxos and Raft (Lecture 21, cs262a) Ion Stoica, UC Berkeley November 7, 2016 Bezos mandate for service-oriented-architecture (~2002) 1. All teams will henceforth expose their data and functionality through
ZooKeeper & Curator. CS 475, Spring 2018 Concurrent & Distributed Systems
 ZooKeeper & Curator CS 475, Spring 2018 Concurrent & Distributed Systems Review: Agreement In distributed systems, we have multiple nodes that need to all agree that some object has some state Examples:
ZooKeeper & Curator CS 475, Spring 2018 Concurrent & Distributed Systems Review: Agreement In distributed systems, we have multiple nodes that need to all agree that some object has some state Examples:
CS October 2017
 Atomic Transactions Transaction An operation composed of a number of discrete steps. Distributed Systems 11. Distributed Commit Protocols All the steps must be completed for the transaction to be committed.
Atomic Transactions Transaction An operation composed of a number of discrete steps. Distributed Systems 11. Distributed Commit Protocols All the steps must be completed for the transaction to be committed.
FAULT TOLERANT LEADER ELECTION IN DISTRIBUTED SYSTEMS
 FAULT TOLERANT LEADER ELECTION IN DISTRIBUTED SYSTEMS Marius Rafailescu The Faculty of Automatic Control and Computers, POLITEHNICA University, Bucharest ABSTRACT There are many distributed systems which
FAULT TOLERANT LEADER ELECTION IN DISTRIBUTED SYSTEMS Marius Rafailescu The Faculty of Automatic Control and Computers, POLITEHNICA University, Bucharest ABSTRACT There are many distributed systems which
Distributed Commit in Asynchronous Systems
 Distributed Commit in Asynchronous Systems Minsoo Ryu Department of Computer Science and Engineering 2 Distributed Commit Problem - Either everybody commits a transaction, or nobody - This means consensus!
Distributed Commit in Asynchronous Systems Minsoo Ryu Department of Computer Science and Engineering 2 Distributed Commit Problem - Either everybody commits a transaction, or nobody - This means consensus!
Practical Byzantine Fault Tolerance. Miguel Castro and Barbara Liskov
 Practical Byzantine Fault Tolerance Miguel Castro and Barbara Liskov Outline 1. Introduction to Byzantine Fault Tolerance Problem 2. PBFT Algorithm a. Models and overview b. Three-phase protocol c. View-change
Practical Byzantine Fault Tolerance Miguel Castro and Barbara Liskov Outline 1. Introduction to Byzantine Fault Tolerance Problem 2. PBFT Algorithm a. Models and overview b. Three-phase protocol c. View-change
Coordination 1. To do. Mutual exclusion Election algorithms Next time: Global state. q q q
 Coordination 1 To do q q q Mutual exclusion Election algorithms Next time: Global state Coordination and agreement in US Congress 1798-2015 Process coordination How can processes coordinate their action?
Coordination 1 To do q q q Mutual exclusion Election algorithms Next time: Global state Coordination and agreement in US Congress 1798-2015 Process coordination How can processes coordinate their action?
Distributed Systems 11. Consensus. Paul Krzyzanowski
 Distributed Systems 11. Consensus Paul Krzyzanowski pxk@cs.rutgers.edu 1 Consensus Goal Allow a group of processes to agree on a result All processes must agree on the same value The value must be one
Distributed Systems 11. Consensus Paul Krzyzanowski pxk@cs.rutgers.edu 1 Consensus Goal Allow a group of processes to agree on a result All processes must agree on the same value The value must be one
Agreement in Distributed Systems CS 188 Distributed Systems February 19, 2015
 Agreement in Distributed Systems CS 188 Distributed Systems February 19, 2015 Page 1 Introduction We frequently want to get a set of nodes in a distributed system to agree Commitment protocols and mutual
Agreement in Distributed Systems CS 188 Distributed Systems February 19, 2015 Page 1 Introduction We frequently want to get a set of nodes in a distributed system to agree Commitment protocols and mutual
Data Consistency and Blockchain. Bei Chun Zhou (BlockChainZ)
") Data Consistency and Blockchain Bei Chun Zhou (BlockChainZ) beichunz@cn.ibm.com 1 Data Consistency Point-in-time consistency Transaction consistency Application consistency 2 Strong Consistency ACID Atomicity.
Data Consistency and Blockchain Bei Chun Zhou (BlockChainZ) beichunz@cn.ibm.com 1 Data Consistency Point-in-time consistency Transaction consistency Application consistency 2 Strong Consistency ACID Atomicity.
Recap. CSE 486/586 Distributed Systems Paxos. Paxos. Brief History. Brief History. Brief History C 1
 Recap Distributed Systems Steve Ko Computer Sciences and Engineering University at Buffalo Facebook photo storage CDN (hot), Haystack (warm), & f4 (very warm) Haystack RAID-6, per stripe: 10 data disks,
Recap Distributed Systems Steve Ko Computer Sciences and Engineering University at Buffalo Facebook photo storage CDN (hot), Haystack (warm), & f4 (very warm) Haystack RAID-6, per stripe: 10 data disks,
CS 655 Advanced Topics in Distributed Systems
 Presented by : Walid Budgaga CS 655 Advanced Topics in Distributed Systems Computer Science Department Colorado State University 1 Outline Problem Solution Approaches Comparison Conclusion 2 Problem 3
Presented by : Walid Budgaga CS 655 Advanced Topics in Distributed Systems Computer Science Department Colorado State University 1 Outline Problem Solution Approaches Comparison Conclusion 2 Problem 3
Replicated State Machine in Wide-area Networks
 Replicated State Machine in Wide-area Networks Yanhua Mao CSE223A WI09 1 Building replicated state machine with consensus General approach to replicate stateful deterministic services Provide strong consistency
Replicated State Machine in Wide-area Networks Yanhua Mao CSE223A WI09 1 Building replicated state machine with consensus General approach to replicate stateful deterministic services Provide strong consistency
Lecture XII: Replication
 Lecture XII: Replication CMPT 401 Summer 2007 Dr. Alexandra Fedorova Replication 2 Why Replicate? (I) Fault-tolerance / High availability As long as one replica is up, the service is available Assume each
Lecture XII: Replication CMPT 401 Summer 2007 Dr. Alexandra Fedorova Replication 2 Why Replicate? (I) Fault-tolerance / High availability As long as one replica is up, the service is available Assume each
Coordinating distributed systems part II. Marko Vukolić Distributed Systems and Cloud Computing
 Coordinating distributed systems part II Marko Vukolić Distributed Systems and Cloud Computing Last Time Coordinating distributed systems part I Zookeeper At the heart of Zookeeper is the ZAB atomic broadcast
Coordinating distributed systems part II Marko Vukolić Distributed Systems and Cloud Computing Last Time Coordinating distributed systems part I Zookeeper At the heart of Zookeeper is the ZAB atomic broadcast
Cassandra - A Decentralized Structured Storage System. Avinash Lakshman and Prashant Malik Facebook
 Cassandra - A Decentralized Structured Storage System Avinash Lakshman and Prashant Malik Facebook Agenda Outline Data Model System Architecture Implementation Experiments Outline Extension of Bigtable
Cassandra - A Decentralized Structured Storage System Avinash Lakshman and Prashant Malik Facebook Agenda Outline Data Model System Architecture Implementation Experiments Outline Extension of Bigtable
Recap. CSE 486/586 Distributed Systems Case Study: Amazon Dynamo. Amazon Dynamo. Amazon Dynamo. Necessary Pieces? Overview of Key Design Techniques
 Recap CSE 486/586 Distributed Systems Case Study: Amazon Dynamo Steve Ko Computer Sciences and Engineering University at Buffalo CAP Theorem? Consistency, Availability, Partition Tolerance P then C? A?
Recap CSE 486/586 Distributed Systems Case Study: Amazon Dynamo Steve Ko Computer Sciences and Engineering University at Buffalo CAP Theorem? Consistency, Availability, Partition Tolerance P then C? A?
Practical Byzantine Fault Tolerance. Castro and Liskov SOSP 99
 Practical Byzantine Fault Tolerance Castro and Liskov SOSP 99 Why this paper? Kind of incredible that it s even possible Let alone a practical NFS implementation with it So far we ve only considered fail-stop
Practical Byzantine Fault Tolerance Castro and Liskov SOSP 99 Why this paper? Kind of incredible that it s even possible Let alone a practical NFS implementation with it So far we ve only considered fail-stop
EECS 498 Introduction to Distributed Systems
 EECS 498 Introduction to Distributed Systems Fall 2017 Harsha V. Madhyastha Dynamo Recap Consistent hashing 1-hop DHT enabled by gossip Execution of reads and writes Coordinated by first available successor
EECS 498 Introduction to Distributed Systems Fall 2017 Harsha V. Madhyastha Dynamo Recap Consistent hashing 1-hop DHT enabled by gossip Execution of reads and writes Coordinated by first available successor
Chapter 4: Distributed Systems: Replication and Consistency. Fall 2013 Jussi Kangasharju
 Chapter 4: Distributed Systems: Replication and Consistency Fall 2013 Jussi Kangasharju Chapter Outline n Replication n Consistency models n Distribution protocols n Consistency protocols 2 Data Replication
Chapter 4: Distributed Systems: Replication and Consistency Fall 2013 Jussi Kangasharju Chapter Outline n Replication n Consistency models n Distribution protocols n Consistency protocols 2 Data Replication
BIG DATA AND CONSISTENCY. Amy Babay
 BIG DATA AND CONSISTENCY Amy Babay Outline Big Data What is it? How is it used? What problems need to be solved? Replication What are the options? Can we use this to solve Big Data s problems? Putting
BIG DATA AND CONSISTENCY Amy Babay Outline Big Data What is it? How is it used? What problems need to be solved? Replication What are the options? Can we use this to solve Big Data s problems? Putting
Replication. Feb 10, 2016 CPSC 416
 Replication Feb 10, 2016 CPSC 416 How d we get here? Failures & single systems; fault tolerance techniques added redundancy (ECC memory, RAID, etc.) Conceptually, ECC & RAID both put a master in front
Replication Feb 10, 2016 CPSC 416 How d we get here? Failures & single systems; fault tolerance techniques added redundancy (ECC memory, RAID, etc.) Conceptually, ECC & RAID both put a master in front
Large-Scale Key-Value Stores Eventual Consistency Marco Serafini
 Large-Scale Key-Value Stores Eventual Consistency Marco Serafini COMPSCI 590S Lecture 13 Goals of Key-Value Stores Export simple API put(key, value) get(key) Simpler and faster than a DBMS Less complexity,
Large-Scale Key-Value Stores Eventual Consistency Marco Serafini COMPSCI 590S Lecture 13 Goals of Key-Value Stores Export simple API put(key, value) get(key) Simpler and faster than a DBMS Less complexity,
Distributed Data Management Replication
 Felix Naumann F-2.03/F-2.04, Campus II Hasso Plattner Institut Distributing Data Motivation Scalability (Elasticity) If data volume, processing, or access exhausts one machine, you might want to spread
Felix Naumann F-2.03/F-2.04, Campus II Hasso Plattner Institut Distributing Data Motivation Scalability (Elasticity) If data volume, processing, or access exhausts one machine, you might want to spread
CSE-E5430 Scalable Cloud Computing Lecture 10
 CSE-E5430 Scalable Cloud Computing Lecture 10 Keijo Heljanko Department of Computer Science School of Science Aalto University keijo.heljanko@aalto.fi 23.11-2015 1/29 Exam Registering for the exam is obligatory,
CSE-E5430 Scalable Cloud Computing Lecture 10 Keijo Heljanko Department of Computer Science School of Science Aalto University keijo.heljanko@aalto.fi 23.11-2015 1/29 Exam Registering for the exam is obligatory,
Recall: Primary-Backup. State machine replication. Extend PB for high availability. Consensus 2. Mechanism: Replicate and separate servers
 Replicated s, RAFT COS 8: Distributed Systems Lecture 8 Recall: Primary-Backup Mechanism: Replicate and separate servers Goal #: Provide a highly reliable service Goal #: Servers should behave just like
Replicated s, RAFT COS 8: Distributed Systems Lecture 8 Recall: Primary-Backup Mechanism: Replicate and separate servers Goal #: Provide a highly reliable service Goal #: Servers should behave just like
Two phase commit protocol. Two phase commit protocol. Recall: Linearizability (Strong Consistency) Consensus
 Consensus") Recall: Linearizability (Strong Consistency) Consensus COS 518: Advanced Computer Systems Lecture 4 Provide behavior of a single copy of object: Read should urn the most recent write Subsequent reads should
Recall: Linearizability (Strong Consistency) Consensus COS 518: Advanced Computer Systems Lecture 4 Provide behavior of a single copy of object: Read should urn the most recent write Subsequent reads should
Introduction to riak_ensemble. Joseph Blomstedt Basho Technologies
 Introduction to riak_ensemble Joseph Blomstedt (@jtuple) Basho Technologies riak_ensemble Paxos framework for scalable consistent system 2 node node node node node node node node 3 What about state? 4
Introduction to riak_ensemble Joseph Blomstedt (@jtuple) Basho Technologies riak_ensemble Paxos framework for scalable consistent system 2 node node node node node node node node 3 What about state? 4
Semi-Passive Replication in the Presence of Byzantine Faults
 Semi-Passive Replication in the Presence of Byzantine Faults HariGovind V. Ramasamy Adnan Agbaria William H. Sanders University of Illinois at Urbana-Champaign 1308 W. Main Street, Urbana IL 61801, USA
Semi-Passive Replication in the Presence of Byzantine Faults HariGovind V. Ramasamy Adnan Agbaria William H. Sanders University of Illinois at Urbana-Champaign 1308 W. Main Street, Urbana IL 61801, USA
How VoltDB does Transactions
 TEHNIL NOTE How does Transactions Note to readers: Some content about read-only transaction coordination in this document is out of date due to changes made in v6.4 as a result of Jepsen testing. Updates
TEHNIL NOTE How does Transactions Note to readers: Some content about read-only transaction coordination in this document is out of date due to changes made in v6.4 as a result of Jepsen testing. Updates
EECS 498 Introduction to Distributed Systems
 EECS 498 Introduction to Distributed Systems Fall 2017 Harsha V. Madhyastha Replicated State Machines Logical clocks Primary/ Backup Paxos? 0 1 (N-1)/2 No. of tolerable failures October 11, 2017 EECS 498
EECS 498 Introduction to Distributed Systems Fall 2017 Harsha V. Madhyastha Replicated State Machines Logical clocks Primary/ Backup Paxos? 0 1 (N-1)/2 No. of tolerable failures October 11, 2017 EECS 498
SpecPaxos. James Connolly && Harrison Davis
 SpecPaxos James Connolly && Harrison Davis Overview Background Fast Paxos Traditional Paxos Implementations Data Centers Mostly-Ordered-Multicast Network layer Speculative Paxos Protocol Application layer
SpecPaxos James Connolly && Harrison Davis Overview Background Fast Paxos Traditional Paxos Implementations Data Centers Mostly-Ordered-Multicast Network layer Speculative Paxos Protocol Application layer
Distributed Synchronization. EECS 591 Farnam Jahanian University of Michigan
 Distributed Synchronization EECS 591 Farnam Jahanian University of Michigan Reading List Tanenbaum Chapter 5.1, 5.4 and 5.5 Clock Synchronization Distributed Election Mutual Exclusion Clock Synchronization
Distributed Synchronization EECS 591 Farnam Jahanian University of Michigan Reading List Tanenbaum Chapter 5.1, 5.4 and 5.5 Clock Synchronization Distributed Election Mutual Exclusion Clock Synchronization
Basic vs. Reliable Multicast
 Basic vs. Reliable Multicast Basic multicast does not consider process crashes. Reliable multicast does. So far, we considered the basic versions of ordered multicasts. What about the reliable versions?
Basic vs. Reliable Multicast Basic multicast does not consider process crashes. Reliable multicast does. So far, we considered the basic versions of ordered multicasts. What about the reliable versions?
Mencius: Another Paxos Variant???
 Mencius: Another Paxos Variant??? Authors: Yanhua Mao, Flavio P. Junqueira, Keith Marzullo Presented by Isaiah Mayerchak & Yijia Liu State Machine Replication in WANs WAN = Wide Area Network Goals: Web
Mencius: Another Paxos Variant??? Authors: Yanhua Mao, Flavio P. Junqueira, Keith Marzullo Presented by Isaiah Mayerchak & Yijia Liu State Machine Replication in WANs WAN = Wide Area Network Goals: Web
Distributed Systems. Lec 9: Distributed File Systems NFS, AFS. Slide acks: Dave Andersen
 Distributed Systems Lec 9: Distributed File Systems NFS, AFS Slide acks: Dave Andersen (http://www.cs.cmu.edu/~dga/15-440/f10/lectures/08-distfs1.pdf) 1 VFS and FUSE Primer Some have asked for some background
Distributed Systems Lec 9: Distributed File Systems NFS, AFS Slide acks: Dave Andersen (http://www.cs.cmu.edu/~dga/15-440/f10/lectures/08-distfs1.pdf) 1 VFS and FUSE Primer Some have asked for some background
CSE 5306 Distributed Systems
 CSE 5306 Distributed Systems Fault Tolerance Jia Rao http://ranger.uta.edu/~jrao/ 1 Failure in Distributed Systems Partial failure Happens when one component of a distributed system fails Often leaves
CSE 5306 Distributed Systems Fault Tolerance Jia Rao http://ranger.uta.edu/~jrao/ 1 Failure in Distributed Systems Partial failure Happens when one component of a distributed system fails Often leaves
Applications of Paxos Algorithm
 Applications of Paxos Algorithm Gurkan Solmaz COP 6938 - Cloud Computing - Fall 2012 Department of Electrical Engineering and Computer Science University of Central Florida - Orlando, FL Oct 15, 2012 1
Applications of Paxos Algorithm Gurkan Solmaz COP 6938 - Cloud Computing - Fall 2012 Department of Electrical Engineering and Computer Science University of Central Florida - Orlando, FL Oct 15, 2012 1
Paxos and Distributed Transactions
 Paxos and Distributed Transactions INF 5040 autumn 2016 lecturer: Roman Vitenberg Paxos what is it? The most commonly used consensus algorithm A fundamental building block for data centers Distributed
Paxos and Distributed Transactions INF 5040 autumn 2016 lecturer: Roman Vitenberg Paxos what is it? The most commonly used consensus algorithm A fundamental building block for data centers Distributed
TAPIR. By Irene Zhang, Naveen Sharma, Adriana Szekeres, Arvind Krishnamurthy, and Dan Ports Presented by Todd Charlton
 TAPIR By Irene Zhang, Naveen Sharma, Adriana Szekeres, Arvind Krishnamurthy, and Dan Ports Presented by Todd Charlton Outline Problem Space Inconsistent Replication TAPIR Evaluation Conclusion Problem
TAPIR By Irene Zhang, Naveen Sharma, Adriana Szekeres, Arvind Krishnamurthy, and Dan Ports Presented by Todd Charlton Outline Problem Space Inconsistent Replication TAPIR Evaluation Conclusion Problem
Eventual Consistency. Eventual Consistency
 Eventual Consistency Many systems: one or few processes perform updates How frequently should these updates be made available to other read-only processes? Examples: DNS: single naming authority per domain
Eventual Consistency Many systems: one or few processes perform updates How frequently should these updates be made available to other read-only processes? Examples: DNS: single naming authority per domain
Scaling KVS. CS6450: Distributed Systems Lecture 14. Ryan Stutsman
 Scaling KVS CS6450: Distributed Systems Lecture 14 Ryan Stutsman Material taken/derived from Princeton COS-418 materials created by Michael Freedman and Kyle Jamieson at Princeton University. Licensed
Scaling KVS CS6450: Distributed Systems Lecture 14 Ryan Stutsman Material taken/derived from Princeton COS-418 materials created by Michael Freedman and Kyle Jamieson at Princeton University. Licensed
Tools for Social Networking Infrastructures
 Tools for Social Networking Infrastructures 1 Cassandra - a decentralised structured storage system Problem : Facebook Inbox Search hundreds of millions of users distributed infrastructure inbox changes
Tools for Social Networking Infrastructures 1 Cassandra - a decentralised structured storage system Problem : Facebook Inbox Search hundreds of millions of users distributed infrastructure inbox changes
Designing for Understandability: the Raft Consensus Algorithm. Diego Ongaro John Ousterhout Stanford University
 Designing for Understandability: the Raft Consensus Algorithm Diego Ongaro John Ousterhout Stanford University Algorithms Should Be Designed For... Correctness? Efficiency? Conciseness? Understandability!
Designing for Understandability: the Raft Consensus Algorithm Diego Ongaro John Ousterhout Stanford University Algorithms Should Be Designed For... Correctness? Efficiency? Conciseness? Understandability!
Extend PB for high availability. PB high availability via 2PC. Recall: Primary-Backup. Putting it all together for SMR:
 Putting it all together for SMR: Two-Phase Commit, Leader Election RAFT COS 8: Distributed Systems Lecture Recall: Primary-Backup Mechanism: Replicate and separate servers Goal #: Provide a highly reliable
Putting it all together for SMR: Two-Phase Commit, Leader Election RAFT COS 8: Distributed Systems Lecture Recall: Primary-Backup Mechanism: Replicate and separate servers Goal #: Provide a highly reliable
Distributed Consensus: Making Impossible Possible
 Distributed Consensus: Making Impossible Possible Heidi Howard PhD Student @ University of Cambridge heidi.howard@cl.cam.ac.uk @heidiann360 hh360.user.srcf.net Sometimes inconsistency is not an option
Distributed Consensus: Making Impossible Possible Heidi Howard PhD Student @ University of Cambridge heidi.howard@cl.cam.ac.uk @heidiann360 hh360.user.srcf.net Sometimes inconsistency is not an option
CSE 544 Principles of Database Management Systems. Alvin Cheung Fall 2015 Lecture 14 Distributed Transactions
 CSE 544 Principles of Database Management Systems Alvin Cheung Fall 2015 Lecture 14 Distributed Transactions Transactions Main issues: Concurrency control Recovery from failures 2 Distributed Transactions
CSE 544 Principles of Database Management Systems Alvin Cheung Fall 2015 Lecture 14 Distributed Transactions Transactions Main issues: Concurrency control Recovery from failures 2 Distributed Transactions
Recap. CSE 486/586 Distributed Systems Case Study: Amazon Dynamo. Amazon Dynamo. Amazon Dynamo. Necessary Pieces? Overview of Key Design Techniques
 Recap Distributed Systems Case Study: Amazon Dynamo CAP Theorem? Consistency, Availability, Partition Tolerance P then C? A? Eventual consistency? Availability and partition tolerance over consistency
Recap Distributed Systems Case Study: Amazon Dynamo CAP Theorem? Consistency, Availability, Partition Tolerance P then C? A? Eventual consistency? Availability and partition tolerance over consistency
Apache Cassandra - A Decentralized Structured Storage System
 Apache Cassandra - A Decentralized Structured Storage System Avinash Lakshman Prashant Malik from Facebook Presented by: Oded Naor Acknowledgments Some slides are based on material from: Idit Keidar, Topics
Apache Cassandra - A Decentralized Structured Storage System Avinash Lakshman Prashant Malik from Facebook Presented by: Oded Naor Acknowledgments Some slides are based on material from: Idit Keidar, Topics
Lecture XIII: Replication-II
 Lecture XIII: Replication-II CMPT 401 Summer 2007 Dr. Alexandra Fedorova Outline Google File System A real replicated file system Paxos Harp A consensus algorithm used in real systems A replicated research
Lecture XIII: Replication-II CMPT 401 Summer 2007 Dr. Alexandra Fedorova Outline Google File System A real replicated file system Paxos Harp A consensus algorithm used in real systems A replicated research
Comparative Analysis of Big Data Stream Processing Systems
 Comparative Analysis of Big Data Stream Processing Systems Farouk Salem School of Science Thesis submitted for examination for the degree of Master of Science in Technology. Espoo 22 June, 2016 Thesis
Comparative Analysis of Big Data Stream Processing Systems Farouk Salem School of Science Thesis submitted for examination for the degree of Master of Science in Technology. Espoo 22 June, 2016 Thesis
Replication and Consistency. Fall 2010 Jussi Kangasharju
 Replication and Consistency Fall 2010 Jussi Kangasharju Chapter Outline Replication Consistency models Distribution protocols Consistency protocols 2 Data Replication user B user C user A object object
Replication and Consistency Fall 2010 Jussi Kangasharju Chapter Outline Replication Consistency models Distribution protocols Consistency protocols 2 Data Replication user B user C user A object object
Distributed Systems (5DV147)
") Distributed Systems (5DV147) Replication and consistency Fall 2013 1 Replication 2 What is replication? Introduction Make different copies of data ensuring that all copies are identical Immutable data
Distributed Systems (5DV147) Replication and consistency Fall 2013 1 Replication 2 What is replication? Introduction Make different copies of data ensuring that all copies are identical Immutable data
Last Class: Clock Synchronization. Today: More Canonical Problems
 Last Class: Clock Synchronization Logical clocks Vector clocks Global state Lecture 12, page 1 Today: More Canonical Problems Distributed snapshot and termination detection Election algorithms Bully algorithm
Last Class: Clock Synchronization Logical clocks Vector clocks Global state Lecture 12, page 1 Today: More Canonical Problems Distributed snapshot and termination detection Election algorithms Bully algorithm