Intel Xeon Phi архитектура, модели программирования, оптимизация.
|
|
|
- Brianna Gardner
- 6 years ago
- Views:
Transcription


1 Нижний Новгород, 2016 Intel Xeon Phi архитектура, модели программирования, оптимизация. Дмитрий Прохоров, Intel
2 Agenda What and Why Intel Xeon Phi Top 500 insights, roadmap, architecture How Programming models - positioning and spectrum How Fast Optimization and Tools 2





3 If you were plowing a field, which would you rather use two strong oxen, or 1024 chickens? 3

4 What and Why HPC High-Performance Computing the use of super computers and parallel processing techniques for solving complex computational problems. 4

5 What and Why TOP 500 Today s Future of tomorrow s mainstream HPC 5
6 What and Why TOP 500 Highlights Performance Projection 6

7 What and Why TOP 500 Highlights Top 10 list 7

8 What and Why TOP 500 Highlights Accelerators in Power Efficiency 8

9 What and Why TOP 500 Highlights Accelerators/Coprocessors N V I d I a 9

10 What and Why Intel May Integrated Core (MIC) architecture Larrabee + TerraFlops Research Chip + Competition with NVidia on Accelerators 10



11 What and Why Parallelization and vectorization Scalar Vector Parallel Parallel + Vector 11

12 What and Why Xeon VS Xeon Phi 12

13 13
14 14
15 15
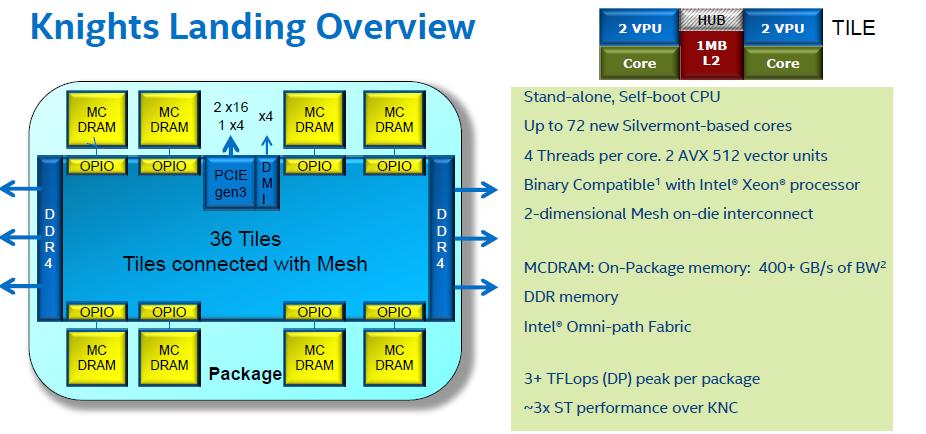
16 KNL Mesh Interconnect: All-to-All EDC Tile OPIO OPIO PCIe OPIO OPIO EDC Tile IIO EDC Tile EDC Tile 3 Address uniformly hashed across all distributed directories Tile Tile Tile 1 4 Tile Tile Tile Tile Tile Tile Tile Tile Tile Typical Read L2 miss DDR imc Tile Tile Tile Tile imc DDR 1. L2 miss encountered Tile Tile Tile Tile Tile Tile Tile Tile Tile Tile Tile Tile 2. Send request to the distributed directory Tile Tile Tile Tile Tile Tile EDC EDC Misc EDC EDC 2 3. Miss in the directory. Forward to memory OPIO OPIO OPIO OPIO 4. Memory sends the data to the requestor 16
17 KNL Mesh Interconnect: Quadrant Chip divided into four OPIO OPIO PCIe OPIO OPIO Quadrants EDC EDC IIO EDC EDC Tile Tile Tile Tile Tile Tile Tile 1 4 Tile Tile Tile Tile Tile Tile Tile Tile Tile 2 3 Directory for an address resides in the same Quadrant as the memory location SW Transparent DDR imc Tile Tile Tile Tile imc Tile Tile Tile Tile Tile Tile DDR Typical Read L2 miss Tile Tile Tile Tile Tile Tile 1. L2 miss encountered Tile Tile Tile Tile Tile Tile 2. Send request to the distributed directory EDC EDC Misc EDC EDC 3. Miss in the directory. Forward to memory OPIO OPIO OPIO OPIO 4. Memory sends the data to the requestor 17
18 KNL Mesh Interconnect: Sub-NUMA Clustering OPIO OPIO OPIO OPIO PCIe EDC EDC IIO EDC EDC Tile Tile Tile Tile Each Quadrant (Cluster) exposed as a separate NUMA domain to OS 3 Analogous to 4S Xeon DDR Tile Tile Tile Tile Tile Tile Tile Tile Tile Tile Tile Tile imc Tile Tile Tile Tile imc DDR SW Visible Typical Read L2 miss Tile Tile Tile Tile Tile Tile 1. L2 miss encountered Tile Tile Tile Tile Tile Tile 2. Send request to the distributed directory Tile Tile Tile Tile Tile Tile EDC EDC Misc EDC EDC 3. Miss in the directory. Forward to memory 4. Memory sends the data to the requestor OPIO OPIO OPIO OPIO 18
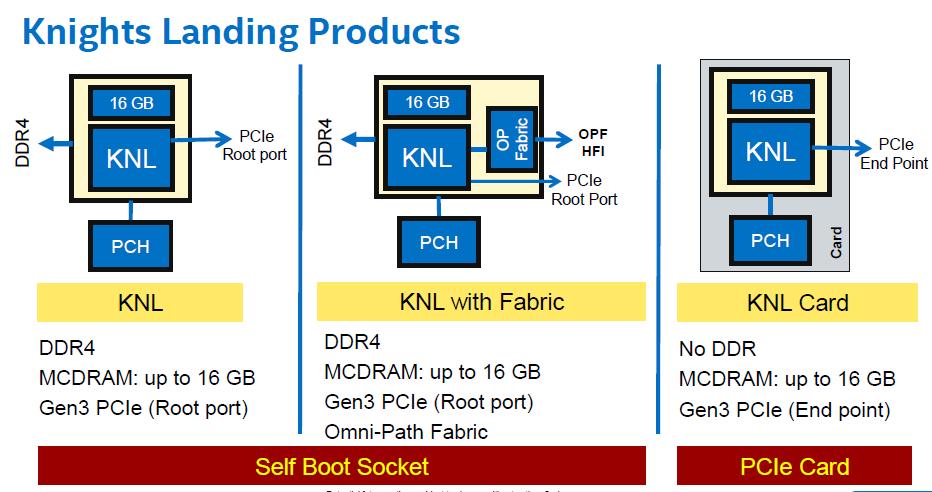
19 19
20 20
21 21
22 Cori Supercomputer at NERSC (National Energy Research Scientific Computing Center at LBNL/DOE) became the first publically announced Knights Landing based system, with over 9,300 nodes slated to be deployed in mid-2016 Trinity Supercomputer at NNSA (National Nuclear Security Administration) is a $174 million deal awarded to Cray that will feature Haswell and Knights Landing, with acceptance phases in both late-2015 and Expecting over 50 system providers for the KNL host processor, in addition to many more PCIe*-card based solutions. >100 Petaflops of committed customer deals to date The DOE* and Argonne* awarded Intel contracts for two systems (Theta and Aurora) as a part of the CORAL* program, with a combined value of over $200 million. Intel is teaming with Cray* on both systems. Scheduled for 2016, Theta is the first system with greater than 8.5 petaflop/s and more than 2,500 nodes, featuring the Intel Xeon Phi processor (Knights Landing), Cray* Aries* interconnect and Cray s* XC* supercomputing platform. Scheduled for 2018, Aurora is the second and largest system with petaflop/s and approximately 50,000 nodes, featuring the next-generation Intel Xeon Phi processor (Knights Hill), 2nd generation Intel Omni-Path fabric, Cray s* Shasta* platform, and a new memory hierarchy composed of Intel Lustre, Burst Buffer Storage, and persistent memory through high bandwidth on-package memory 22

23 How Programming models 23

24 How Positioning works: Adoption for Coprocessors in TOP
25 How Positioning works: Adoption speed for Coprocessors in TOP
26 How KNL positioning Massive thread and data parallelism and massive memory bandwidth with good ST performance in a ISA compatible standard CPU form factor Out-of-box performance on throughput workloads about the same as Xeon, with potential for > 2X in performance when optimized for vectors, threads and memory BW. Code Base Programming mode Compilers, Tools & Libraries Same programming model, tools, compilers and libraries as Xeon. Boots standard OS, runs all legacy code Xeon KNL 26
27 How Programming models on Xeon Phi Native (Xeon Phi) Offload (Xeon -> Xeon Phi) 27
28 How Programming models on Xeon Phi: native Recompilation, with xmic-avx512 Vectorization: increased efficiency, use of new instructions MCDRAM and memory tuning: tile, 1GB pages 28

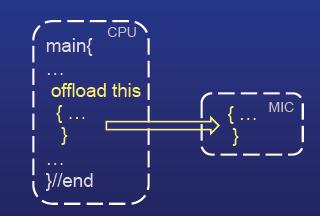
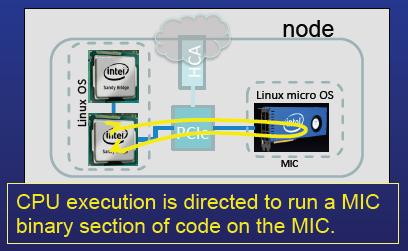
29 How Offload programming model 29
30 How Offload with pragma target in OpenMP
31 How Programming models on Xeon Phi : offload Applicable for coprocessor cards mostly Cost for data transfers Three ways to use: OpenMP 4.0 target directives MKL Automatic offload Direct calls to the offload APIs (COI), and those built on it (e.g., HStreams) Offload over fabric implementation for self-boot 31
32 How Fast Optimization BKMs Optimization techniques are the same as for Xeon and helping both Loop unrolling to feed vectorization Loop reorganization to avoid strides Be careful with no dependency pragmas Data layout changes for more efficient cache usage Moving to hybrid MPI+OpenMP from pure MPI Avoid data replication, inner node communication, increased MPI buffer size NUMA-awareness for sub-numa clustering mode MPI/thread pinning with parallel data initialization Eliminating syncs on barriers where possible The more threads the more barrier cost 32
33 How Fast Tools Intel Hardware Features Omni-Path Architectur e MCDRAM 3D XPoint Many-core Xeon Phi AVX-512 Distributed memory Memory I/O Threading CPU Core Message size Rank placement Rank Imbalance RTL Overhead Pt2Pt ->collective Ops Network Bandwidth Latency Bandwidth NUMA File I/O I/O latency I/O waits System-wide I/O Threaded/serial ratio Thread Imbalance RTL overhead (scheduling, forking) Synchronization uarch issues (IPC) FPU usage efficiency Vectorization Cluster Node Core

34 How Fast Tools Intel Hardware Features Omni-Path Intel ITAC Message size Rank placement Rank Imbalance RTL Overhead Pt2Pt ->collective Ops Network Bandwidth MCDRAM 3D X Many-core Intel VTune Amplifier Xeon Phi Distributed memory Memory I/O Threading CPU Core Latency Bandwidth NUMA File I/O I/O latency I/O waits System-wide I/O Threaded/serial ratio Thread Imbalance RTL overhead (scheduling, forking) Synchronization Intel Parallel Studio XE Cluster Edition covers all aspects of distributed application performance in synergy with Intel HW and Runtimes uarch issues (IPC) FPU usage efficiency Cluster Node Core AVX Intel Advisor

35 How Fast Tools - Workflow Intel Confidential 35
36 How Fast Tools: Intel MPI Performance Snapshot Performance Triage Orchestrator How to tune for efficient utilization of hardware capabilities Scalability 32K ranks (~0.8Gb trace size per 1K ranks) Performance characterization Intel MPI internal statistics and Intel MPI imbalance (unproductive wait-time) time Guidance to ITAC if MPI-bound OpenMP* imbalance (unproductive wait-time) time Guidance to VTune Amplifier OpenMP* efficiency analysis if bottleneck Basic memory efficiency and footprint information Guidance to VTune Memory Access Analysis if memory-bound GFLOPs
 Performance characterization Intel MPI internal statistics and Intel MPI imbalance (unproductive wait-time) time Guidance to ITAC if MPI-bound OpenMP* imbalance")
37 How Fast Tools: Intel MPI Performance Snapshot Performance Triage Orchestrator How to tune for efficient utilization of hardware capabilities Scalability 32K ranks (~0.8Gb trace size per 1K ranks) Performance characterization Intel MPI internal statistics and Intel MPI imbalance (unproductive wait-time) time Guidance to ITAC if MPI-bound OpenMP* imbalance (unproductive wait-time) time Guidance to VTune Amplifier OpenMP* efficiency analysis if bottleneck Basic memory efficiency and footprint information Guidance to VTune Memory Access Analysis if memory-bound GFLOPs
38 How Fast Tools: Intel Trace Analyzer and Collector Inter-node Summary page Time interval shown Aggregation of shown data Tagging & Filtering Idealizer Compare Perf. Assistant Settings Imbalance Diagram Compare the event timelines of two communication profiles Blue = computation Red = communication Chart showing how the MPI processes interact


39 How Fast Tools: Intel Trace Analyzer and Collector Inter-node Compare the event timelines of two communication profiles Blue = computation Red = communication Chart showing how the MPI processes interact

40 How Fast Tools: VTune Amplifier exploring scalability, threading/cpu utilization Is serial time of my application significant to prevent scaling? How efficient is my parallelization towards ideal parallel execution? How much theoretical gain I can get if invest in tuning? What regions are more perspective to invest? Links to grid view for more details on inefficiency 40
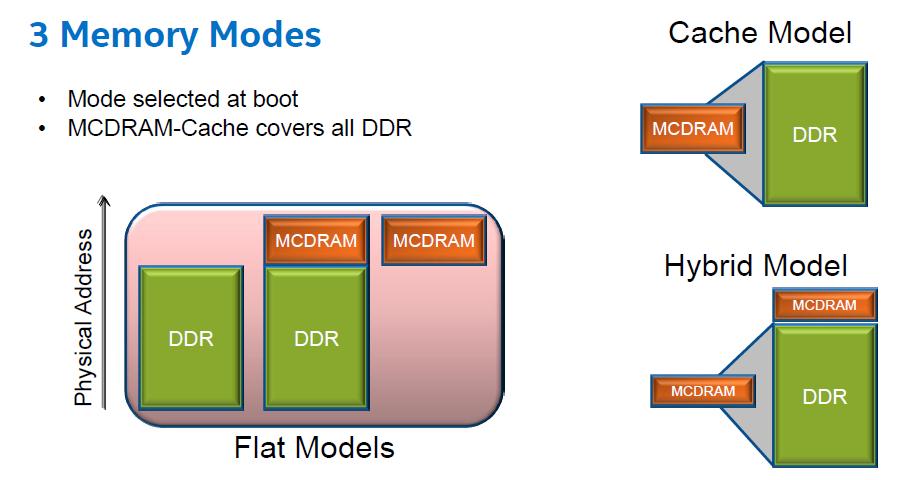
41 How Fast Tools: High Bandwidth Memory Analysis on KNL with VTune Memory Bandwidth often is a limiting factor of compute intensive applications on multi-core systems MCDRAM High Bandwidth Memory with much greater bandwidth speedup to alleviate this problem Limited MCDRAM size might require selective data object placement to HBM (for flat and hybrid MCDRAM modes) Memory Access analysis helps to identify memory objects for HBM placement to benefit the most 3/18/

42 How Fast Tools: High Bandwidth Memory Analysis on KNL with VTune Explore DRAM Bandwidth histogram to see if the app is bandwidth bound Significant portion of application time spent in high memory bandwidth utilization The app may benefit from MCDRAM 3/18/


43 How Fast Tools: High Bandwidth Memory Analysis on KNL with VTune Investigate the memory allocations inducing bandwidth Bandwidth Domain/Bandwidth Utilization Type/Memory Object/Allocation Stack grouping with expansion by DRAM/High and sorting by L2 Miss Count Focus on allocations inducing L2 misses Allocation stack shows the allocation place in user s code 3/18/


44 How Fast Tools: High Bandwidth Memory Analysis on KNL with VTune Allocate object using High Bandwidth Memory Specifying a custom memory allocator class for stored vector elements 3/18/



45 How Fast Tools: High Bandwidth Memory Analysis on KNL with VTune DRAM bandwidth significantly decreased reducing DRAM memory access stalls 3/18/





46 How Fast Tools: Vector Advisor explore vectorization 1. Compiler diagnostics + Performance Data + SIMD efficiency information Intel Advisor s Vectorization Advisor fills a gap in code performance analysis. It can guide the informed user to better exploit the 2. Guidance: detect problem vector capabilities and of modern recommend how processors to fix it and coprocessors 3. Accurate Trip Counts: understand parallelism granularity and overheads Dr. Luigi Iapichino Scientific Computing Expert Leibniz Supercomputing Centre 4. Loop-Carried Dependency Analysis 5. Memory Access Patterns Analysis 46
47 Summary Many-core-based architectures play main role to achieve Exascale and further Intel Many Integrated Core (MIC) offers competitive performance on well-known HPC programming models KNL is a step forward in this direction with More cores, faster ST High Bandwidth Memory Self-boot with better performance/watt and no data transfer cost 47

48 Intel Confidential
Intel Xeon Phi архитектура, модели программирования, оптимизация.
 Нижний Новгород, 2017 Intel Xeon Phi архитектура, модели программирования, оптимизация. Дмитрий Прохоров, Дмитрий Рябцев, Intel Agenda What and Why Intel Xeon Phi Top 500 insights, roadmap, architecture
Нижний Новгород, 2017 Intel Xeon Phi архитектура, модели программирования, оптимизация. Дмитрий Прохоров, Дмитрий Рябцев, Intel Agenda What and Why Intel Xeon Phi Top 500 insights, roadmap, architecture
Bei Wang, Dmitry Prohorov and Carlos Rosales
 Bei Wang, Dmitry Prohorov and Carlos Rosales Aspects of Application Performance What are the Aspects of Performance Intel Hardware Features Omni-Path Architecture MCDRAM 3D XPoint Many-core Xeon Phi AVX-512
Bei Wang, Dmitry Prohorov and Carlos Rosales Aspects of Application Performance What are the Aspects of Performance Intel Hardware Features Omni-Path Architecture MCDRAM 3D XPoint Many-core Xeon Phi AVX-512
Efficient Parallel Programming on Xeon Phi for Exascale
 Efficient Parallel Programming on Xeon Phi for Exascale Eric Petit, Intel IPAG, Seminar at MDLS, Saclay, 29th November 2016 Legal Disclaimers Intel technologies features and benefits depend on system configuration
Efficient Parallel Programming on Xeon Phi for Exascale Eric Petit, Intel IPAG, Seminar at MDLS, Saclay, 29th November 2016 Legal Disclaimers Intel technologies features and benefits depend on system configuration
Performance Profiler. Klaus-Dieter Oertel Intel-SSG-DPD IT4I HPC Workshop, Ostrava,
 Performance Profiler Klaus-Dieter Oertel Intel-SSG-DPD IT4I HPC Workshop, Ostrava, 08-09-2016 Faster, Scalable Code, Faster Intel VTune Amplifier Performance Profiler Get Faster Code Faster With Accurate
Performance Profiler Klaus-Dieter Oertel Intel-SSG-DPD IT4I HPC Workshop, Ostrava, 08-09-2016 Faster, Scalable Code, Faster Intel VTune Amplifier Performance Profiler Get Faster Code Faster With Accurate
EARLY EVALUATION OF THE CRAY XC40 SYSTEM THETA
 EARLY EVALUATION OF THE CRAY XC40 SYSTEM THETA SUDHEER CHUNDURI, SCOTT PARKER, KEVIN HARMS, VITALI MOROZOV, CHRIS KNIGHT, KALYAN KUMARAN Performance Engineering Group Argonne Leadership Computing Facility
EARLY EVALUATION OF THE CRAY XC40 SYSTEM THETA SUDHEER CHUNDURI, SCOTT PARKER, KEVIN HARMS, VITALI MOROZOV, CHRIS KNIGHT, KALYAN KUMARAN Performance Engineering Group Argonne Leadership Computing Facility
Munara Tolubaeva Technical Consulting Engineer. 3D XPoint is a trademark of Intel Corporation in the U.S. and/or other countries.
 Munara Tolubaeva Technical Consulting Engineer 3D XPoint is a trademark of Intel Corporation in the U.S. and/or other countries. notices and disclaimers Intel technologies features and benefits depend
Munara Tolubaeva Technical Consulting Engineer 3D XPoint is a trademark of Intel Corporation in the U.S. and/or other countries. notices and disclaimers Intel technologies features and benefits depend
Performance analysis tools: Intel VTuneTM Amplifier and Advisor. Dr. Luigi Iapichino
 Performance analysis tools: Intel VTuneTM Amplifier and Advisor Dr. Luigi Iapichino luigi.iapichino@lrz.de Which tool do I use in my project? A roadmap to optimisation After having considered the MPI layer,
Performance analysis tools: Intel VTuneTM Amplifier and Advisor Dr. Luigi Iapichino luigi.iapichino@lrz.de Which tool do I use in my project? A roadmap to optimisation After having considered the MPI layer,
NERSC Site Update. National Energy Research Scientific Computing Center Lawrence Berkeley National Laboratory. Richard Gerber
 NERSC Site Update National Energy Research Scientific Computing Center Lawrence Berkeley National Laboratory Richard Gerber NERSC Senior Science Advisor High Performance Computing Department Head Cori
NERSC Site Update National Energy Research Scientific Computing Center Lawrence Berkeley National Laboratory Richard Gerber NERSC Senior Science Advisor High Performance Computing Department Head Cori
Performance and Energy Usage of Workloads on KNL and Haswell Architectures
 Performance and Energy Usage of Workloads on KNL and Haswell Architectures Tyler Allen 1 Christopher Daley 2 Doug Doerfler 2 Brian Austin 2 Nicholas Wright 2 1 Clemson University 2 National Energy Research
Performance and Energy Usage of Workloads on KNL and Haswell Architectures Tyler Allen 1 Christopher Daley 2 Doug Doerfler 2 Brian Austin 2 Nicholas Wright 2 1 Clemson University 2 National Energy Research
Agenda. Optimization Notice Copyright 2017, Intel Corporation. All rights reserved. *Other names and brands may be claimed as the property of others.
 Agenda VTune Amplifier XE OpenMP* Analysis: answering on customers questions about performance in the same language a program was written in Concepts, metrics and technology inside VTune Amplifier XE OpenMP
Agenda VTune Amplifier XE OpenMP* Analysis: answering on customers questions about performance in the same language a program was written in Concepts, metrics and technology inside VTune Amplifier XE OpenMP
Intel VTune Amplifier XE. Dr. Michael Klemm Software and Services Group Developer Relations Division
 Intel VTune Amplifier XE Dr. Michael Klemm Software and Services Group Developer Relations Division Legal Disclaimer & Optimization Notice INFORMATION IN THIS DOCUMENT IS PROVIDED AS IS. NO LICENSE, EXPRESS
Intel VTune Amplifier XE Dr. Michael Klemm Software and Services Group Developer Relations Division Legal Disclaimer & Optimization Notice INFORMATION IN THIS DOCUMENT IS PROVIDED AS IS. NO LICENSE, EXPRESS
Intel Many Integrated Core (MIC) Architecture
 Architecture") Intel Many Integrated Core (MIC) Architecture Karl Solchenbach Director European Exascale Labs BMW2011, November 3, 2011 1 Notice and Disclaimers Notice: This document contains information on products
Intel Many Integrated Core (MIC) Architecture Karl Solchenbach Director European Exascale Labs BMW2011, November 3, 2011 1 Notice and Disclaimers Notice: This document contains information on products
Performance optimization of the Smoothed Particle Hydrodynamics code Gadget3 on 2nd generation Intel Xeon Phi
 Performance optimization of the Smoothed Particle Hydrodynamics code Gadget3 on 2nd generation Intel Xeon Phi Dr. Luigi Iapichino Leibniz Supercomputing Centre Supercomputing 2017 Intel booth, Nerve Center
Performance optimization of the Smoothed Particle Hydrodynamics code Gadget3 on 2nd generation Intel Xeon Phi Dr. Luigi Iapichino Leibniz Supercomputing Centre Supercomputing 2017 Intel booth, Nerve Center
IFS RAPS14 benchmark on 2 nd generation Intel Xeon Phi processor
 IFS RAPS14 benchmark on 2 nd generation Intel Xeon Phi processor D.Sc. Mikko Byckling 17th Workshop on High Performance Computing in Meteorology October 24 th 2016, Reading, UK Legal Disclaimer & Optimization
IFS RAPS14 benchmark on 2 nd generation Intel Xeon Phi processor D.Sc. Mikko Byckling 17th Workshop on High Performance Computing in Meteorology October 24 th 2016, Reading, UK Legal Disclaimer & Optimization
INTRODUCTION TO THE ARCHER KNIGHTS LANDING CLUSTER. Adrian
 INTRODUCTION TO THE ARCHER KNIGHTS LANDING CLUSTER Adrian Jackson adrianj@epcc.ed.ac.uk @adrianjhpc Processors The power used by a CPU core is proportional to Clock Frequency x Voltage 2 In the past, computers
INTRODUCTION TO THE ARCHER KNIGHTS LANDING CLUSTER Adrian Jackson adrianj@epcc.ed.ac.uk @adrianjhpc Processors The power used by a CPU core is proportional to Clock Frequency x Voltage 2 In the past, computers
Intel Many Integrated Core (MIC) Matt Kelly & Ryan Rawlins
 Matt Kelly & Ryan Rawlins") Intel Many Integrated Core (MIC) Matt Kelly & Ryan Rawlins Outline History & Motivation Architecture Core architecture Network Topology Memory hierarchy Brief comparison to GPU & Tilera Programming Applications
Intel Many Integrated Core (MIC) Matt Kelly & Ryan Rawlins Outline History & Motivation Architecture Core architecture Network Topology Memory hierarchy Brief comparison to GPU & Tilera Programming Applications
HPC Architectures. Types of resource currently in use
 HPC Architectures Types of resource currently in use Reusing this material This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike 4.0 International License. http://creativecommons.org/licenses/by-nc-sa/4.0/deed.en_us
HPC Architectures Types of resource currently in use Reusing this material This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike 4.0 International License. http://creativecommons.org/licenses/by-nc-sa/4.0/deed.en_us
Outline. Motivation Parallel k-means Clustering Intel Computing Architectures Baseline Performance Performance Optimizations Future Trends
 Collaborators: Richard T. Mills, Argonne National Laboratory Sarat Sreepathi, Oak Ridge National Laboratory Forrest M. Hoffman, Oak Ridge National Laboratory Jitendra Kumar, Oak Ridge National Laboratory
Collaborators: Richard T. Mills, Argonne National Laboratory Sarat Sreepathi, Oak Ridge National Laboratory Forrest M. Hoffman, Oak Ridge National Laboratory Jitendra Kumar, Oak Ridge National Laboratory
Performance Optimization of Smoothed Particle Hydrodynamics for Multi/Many-Core Architectures
 Performance Optimization of Smoothed Particle Hydrodynamics for Multi/Many-Core Architectures Dr. Fabio Baruffa Dr. Luigi Iapichino Leibniz Supercomputing Centre fabio.baruffa@lrz.de Outline of the talk
Performance Optimization of Smoothed Particle Hydrodynamics for Multi/Many-Core Architectures Dr. Fabio Baruffa Dr. Luigi Iapichino Leibniz Supercomputing Centre fabio.baruffa@lrz.de Outline of the talk
INTRODUCTION TO THE ARCHER KNIGHTS LANDING CLUSTER. Adrian
 INTRODUCTION TO THE ARCHER KNIGHTS LANDING CLUSTER Adrian Jackson a.jackson@epcc.ed.ac.uk @adrianjhpc Processors The power used by a CPU core is proportional to Clock Frequency x Voltage 2 In the past,
INTRODUCTION TO THE ARCHER KNIGHTS LANDING CLUSTER Adrian Jackson a.jackson@epcc.ed.ac.uk @adrianjhpc Processors The power used by a CPU core is proportional to Clock Frequency x Voltage 2 In the past,
VLPL-S Optimization on Knights Landing
 VLPL-S Optimization on Knights Landing 英特尔软件与服务事业部 周姗 2016.5 Agenda VLPL-S 性能分析 VLPL-S 性能优化 总结 2 VLPL-S Workload Descriptions VLPL-S is the in-house code from SJTU, paralleled with MPI and written in C++.
VLPL-S Optimization on Knights Landing 英特尔软件与服务事业部 周姗 2016.5 Agenda VLPL-S 性能分析 VLPL-S 性能优化 总结 2 VLPL-S Workload Descriptions VLPL-S is the in-house code from SJTU, paralleled with MPI and written in C++.
The Intel Xeon PHI Architecture
 The Intel Xeon PHI Architecture (codename Knights Landing ) Dr. Christopher Dahnken Senior Application Engineer Software and Services Group Legal Disclaimer & Optimization Notice INFORMATION IN THIS DOCUMENT
The Intel Xeon PHI Architecture (codename Knights Landing ) Dr. Christopher Dahnken Senior Application Engineer Software and Services Group Legal Disclaimer & Optimization Notice INFORMATION IN THIS DOCUMENT
Intel VTune Amplifier XE for Tuning of HPC Applications Intel Software Developer Conference Frankfurt, 2017 Klaus-Dieter Oertel, Intel
 Intel VTune Amplifier XE for Tuning of HPC Applications Intel Software Developer Conference Frankfurt, 2017 Klaus-Dieter Oertel, Intel Agenda Which performance analysis tool should I use first? Intel Application
Intel VTune Amplifier XE for Tuning of HPC Applications Intel Software Developer Conference Frankfurt, 2017 Klaus-Dieter Oertel, Intel Agenda Which performance analysis tool should I use first? Intel Application
Using Intel VTune Amplifier XE for High Performance Computing
 Using Intel VTune Amplifier XE for High Performance Computing Vladimir Tsymbal Performance, Analysis and Threading Lab 1 The Majority of all HPC-Systems are Clusters Interconnect I/O I/O... I/O I/O Message
Using Intel VTune Amplifier XE for High Performance Computing Vladimir Tsymbal Performance, Analysis and Threading Lab 1 The Majority of all HPC-Systems are Clusters Interconnect I/O I/O... I/O I/O Message
Tools for Intel Xeon Phi: VTune & Advisor Dr. Fabio Baruffa - LRZ,
 Tools for Intel Xeon Phi: VTune & Advisor Dr. Fabio Baruffa - fabio.baruffa@lrz.de LRZ, 27.6.- 29.6.2016 Architecture Overview Intel Xeon Processor Intel Xeon Phi Coprocessor, 1st generation Intel Xeon
Tools for Intel Xeon Phi: VTune & Advisor Dr. Fabio Baruffa - fabio.baruffa@lrz.de LRZ, 27.6.- 29.6.2016 Architecture Overview Intel Xeon Processor Intel Xeon Phi Coprocessor, 1st generation Intel Xeon
What s P. Thierry
 What s new@intel P. Thierry Principal Engineer, Intel Corp philippe.thierry@intel.com CPU trend Memory update Software Characterization in 30 mn 10 000 feet view CPU : Range of few TF/s and
What s new@intel P. Thierry Principal Engineer, Intel Corp philippe.thierry@intel.com CPU trend Memory update Software Characterization in 30 mn 10 000 feet view CPU : Range of few TF/s and
Kevin O Leary, Intel Technical Consulting Engineer
 Kevin O Leary, Intel Technical Consulting Engineer Moore s Law Is Going Strong Hardware performance continues to grow exponentially We think we can continue Moore's Law for at least another 10 years."
Kevin O Leary, Intel Technical Consulting Engineer Moore s Law Is Going Strong Hardware performance continues to grow exponentially We think we can continue Moore's Law for at least another 10 years."
Introduction to tuning on KNL platforms
 Introduction to tuning on KNL platforms Gilles Gouaillardet RIST gilles@rist.or.jp 1 Agenda Why do we need many core platforms? KNL architecture Single-thread optimization Parallelization Common pitfalls
Introduction to tuning on KNL platforms Gilles Gouaillardet RIST gilles@rist.or.jp 1 Agenda Why do we need many core platforms? KNL architecture Single-thread optimization Parallelization Common pitfalls
Intel Architecture for HPC
 Intel Architecture for HPC Georg Zitzlsberger georg.zitzlsberger@vsb.cz 1st of March 2018 Agenda Salomon Architectures Intel R Xeon R processors v3 (Haswell) Intel R Xeon Phi TM coprocessor (KNC) Ohter
Intel Architecture for HPC Georg Zitzlsberger georg.zitzlsberger@vsb.cz 1st of March 2018 Agenda Salomon Architectures Intel R Xeon R processors v3 (Haswell) Intel R Xeon Phi TM coprocessor (KNC) Ohter
arxiv: v2 [hep-lat] 3 Nov 2016
![arxiv: v2 [hep-lat] 3 Nov 2016](/thumbs/90/103721354.jpg "arxiv: v2 [hep-lat] 3 Nov 2016") MILC staggered conjugate gradient performance on Intel KNL arxiv:1611.00728v2 [hep-lat] 3 Nov 2016 Department of Physics, Indiana University, Bloomington IN 47405, USA E-mail: ruizli@umail.iu.edu Carleton
MILC staggered conjugate gradient performance on Intel KNL arxiv:1611.00728v2 [hep-lat] 3 Nov 2016 Department of Physics, Indiana University, Bloomington IN 47405, USA E-mail: ruizli@umail.iu.edu Carleton
Intel Knights Landing Hardware
 Intel Knights Landing Hardware TACC KNL Tutorial IXPUG Annual Meeting 2016 PRESENTED BY: John Cazes Lars Koesterke 1 Intel s Xeon Phi Architecture Leverages x86 architecture Simpler x86 cores, higher compute
Intel Knights Landing Hardware TACC KNL Tutorial IXPUG Annual Meeting 2016 PRESENTED BY: John Cazes Lars Koesterke 1 Intel s Xeon Phi Architecture Leverages x86 architecture Simpler x86 cores, higher compute
Towards modernisation of the Gadget code on many-core architectures Fabio Baruffa, Luigi Iapichino (LRZ)
") Towards modernisation of the Gadget code on many-core architectures Fabio Baruffa, Luigi Iapichino (LRZ) Overview Modernising P-Gadget3 for the Intel Xeon Phi : code features, challenges and strategy for
Towards modernisation of the Gadget code on many-core architectures Fabio Baruffa, Luigi Iapichino (LRZ) Overview Modernising P-Gadget3 for the Intel Xeon Phi : code features, challenges and strategy for
Introduction to tuning on KNL platforms
 Introduction to tuning on KNL platforms Gilles Gouaillardet RIST gilles@rist.or.jp 1 Agenda Why do we need many core platforms? KNL architecture Post-K overview Single-thread optimization Parallelization
Introduction to tuning on KNL platforms Gilles Gouaillardet RIST gilles@rist.or.jp 1 Agenda Why do we need many core platforms? KNL architecture Post-K overview Single-thread optimization Parallelization
IHK/McKernel: A Lightweight Multi-kernel Operating System for Extreme-Scale Supercomputing
 : A Lightweight Multi-kernel Operating System for Extreme-Scale Supercomputing Balazs Gerofi Exascale System Software Team, RIKEN Center for Computational Science 218/Nov/15 SC 18 Intel Extreme Computing
: A Lightweight Multi-kernel Operating System for Extreme-Scale Supercomputing Balazs Gerofi Exascale System Software Team, RIKEN Center for Computational Science 218/Nov/15 SC 18 Intel Extreme Computing
Knights Corner: Your Path to Knights Landing
 Knights Corner: Your Path to Knights Landing James Reinders, Intel Wednesday, September 17, 2014; 9-10am PDT Photo (c) 2014, James Reinders; used with permission; Yosemite Half Dome rising through forest
Knights Corner: Your Path to Knights Landing James Reinders, Intel Wednesday, September 17, 2014; 9-10am PDT Photo (c) 2014, James Reinders; used with permission; Yosemite Half Dome rising through forest
Toward portable I/O performance by leveraging system abstractions of deep memory and interconnect hierarchies
 Toward portable I/O performance by leveraging system abstractions of deep memory and interconnect hierarchies François Tessier, Venkatram Vishwanath, Paul Gressier Argonne National Laboratory, USA Wednesday
Toward portable I/O performance by leveraging system abstractions of deep memory and interconnect hierarchies François Tessier, Venkatram Vishwanath, Paul Gressier Argonne National Laboratory, USA Wednesday
Capability Models for Manycore Memory Systems: A Case-Study with Xeon Phi KNL
 SABELA RAMOS, TORSTEN HOEFLER Capability Models for Manycore Memory Systems: A Case-Study with Xeon Phi KNL spcl.inf.ethz.ch Microarchitectures are becoming more and more complex CPU L1 CPU L1 CPU L1 CPU
SABELA RAMOS, TORSTEN HOEFLER Capability Models for Manycore Memory Systems: A Case-Study with Xeon Phi KNL spcl.inf.ethz.ch Microarchitectures are becoming more and more complex CPU L1 CPU L1 CPU L1 CPU
NVIDIA Think about Computing as Heterogeneous One Leo Liao, 1/29/2106, NTU
 NVIDIA Think about Computing as Heterogeneous One Leo Liao, 1/29/2106, NTU GPGPU opens the door for co-design HPC, moreover middleware-support embedded system designs to harness the power of GPUaccelerated
NVIDIA Think about Computing as Heterogeneous One Leo Liao, 1/29/2106, NTU GPGPU opens the door for co-design HPC, moreover middleware-support embedded system designs to harness the power of GPUaccelerated
Reusing this material
 XEON PHI BASICS Reusing this material This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike 4.0 International License. http://creativecommons.org/licenses/by-nc-sa/4.0/deed.en_us
XEON PHI BASICS Reusing this material This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike 4.0 International License. http://creativecommons.org/licenses/by-nc-sa/4.0/deed.en_us
Intel Architecture and Tools Jureca Tuning for the platform II. Dr. Heinrich Bockhorst Intel SSG/DPD/ Date:
 Intel Architecture and Tools Jureca Tuning for the platform II Dr. Heinrich Bockhorst Intel SSG/DPD/ Date: 23.11.2017 Agenda Introduction Processor Architecture Overview Composer XE Compiler Intel Python
Intel Architecture and Tools Jureca Tuning for the platform II Dr. Heinrich Bockhorst Intel SSG/DPD/ Date: 23.11.2017 Agenda Introduction Processor Architecture Overview Composer XE Compiler Intel Python
Introduction to tuning on many core platforms. Gilles Gouaillardet RIST
 Introduction to tuning on many core platforms Gilles Gouaillardet RIST gilles@rist.or.jp Agenda Why do we need many core platforms? Single-thread optimization Parallelization Conclusions Why do we need
Introduction to tuning on many core platforms Gilles Gouaillardet RIST gilles@rist.or.jp Agenda Why do we need many core platforms? Single-thread optimization Parallelization Conclusions Why do we need
GPU Architecture. Alan Gray EPCC The University of Edinburgh
 GPU Architecture Alan Gray EPCC The University of Edinburgh Outline Why do we want/need accelerators such as GPUs? Architectural reasons for accelerator performance advantages Latest GPU Products From
GPU Architecture Alan Gray EPCC The University of Edinburgh Outline Why do we want/need accelerators such as GPUs? Architectural reasons for accelerator performance advantages Latest GPU Products From
Cray XC Scalability and the Aries Network Tony Ford
 Cray XC Scalability and the Aries Network Tony Ford June 29, 2017 Exascale Scalability Which scalability metrics are important for Exascale? Performance (obviously!) What are the contributing factors?
Cray XC Scalability and the Aries Network Tony Ford June 29, 2017 Exascale Scalability Which scalability metrics are important for Exascale? Performance (obviously!) What are the contributing factors?
Short Talk: System abstractions to facilitate data movement in supercomputers with deep memory and interconnect hierarchy
 Short Talk: System abstractions to facilitate data movement in supercomputers with deep memory and interconnect hierarchy François Tessier, Venkatram Vishwanath Argonne National Laboratory, USA July 19,
Short Talk: System abstractions to facilitate data movement in supercomputers with deep memory and interconnect hierarchy François Tessier, Venkatram Vishwanath Argonne National Laboratory, USA July 19,
Dmitry Durnov 15 February 2017
 Cовременные тенденции разработки высокопроизводительных приложений Dmitry Durnov 15 February 2017 Agenda Modern cluster architecture Node level Cluster level Programming models Tools 2/20/2017 2 Modern
Cовременные тенденции разработки высокопроизводительных приложений Dmitry Durnov 15 February 2017 Agenda Modern cluster architecture Node level Cluster level Programming models Tools 2/20/2017 2 Modern
1. Many Core vs Multi Core. 2. Performance Optimization Concepts for Many Core. 3. Performance Optimization Strategy for Many Core
 1. Many Core vs Multi Core 2. Performance Optimization Concepts for Many Core 3. Performance Optimization Strategy for Many Core 4. Example Case Studies NERSC s Cori will begin to transition the workload
1. Many Core vs Multi Core 2. Performance Optimization Concepts for Many Core 3. Performance Optimization Strategy for Many Core 4. Example Case Studies NERSC s Cori will begin to transition the workload
Intel profiling tools and roofline model. Dr. Luigi Iapichino
 Intel profiling tools and roofline model Dr. Luigi Iapichino luigi.iapichino@lrz.de Which tool do I use in my project? A roadmap to optimization (and to the next hour) We will focus on tools developed
Intel profiling tools and roofline model Dr. Luigi Iapichino luigi.iapichino@lrz.de Which tool do I use in my project? A roadmap to optimization (and to the next hour) We will focus on tools developed
Intel VTune Amplifier XE
 Intel VTune Amplifier XE Vladimir Tsymbal Performance, Analysis and Threading Lab 1 Agenda Intel VTune Amplifier XE Overview Features Data collectors Analysis types Key Concepts Collecting performance
Intel VTune Amplifier XE Vladimir Tsymbal Performance, Analysis and Threading Lab 1 Agenda Intel VTune Amplifier XE Overview Features Data collectors Analysis types Key Concepts Collecting performance
arxiv: v1 [hep-lat] 1 Dec 2017
![arxiv: v1 [hep-lat] 1 Dec 2017](/thumbs/77/76587427.jpg "arxiv: v1 [hep-lat] 1 Dec 2017") arxiv:1712.00143v1 [hep-lat] 1 Dec 2017 MILC Code Performance on High End CPU and GPU Supercomputer Clusters Carleton DeTar 1, Steven Gottlieb 2,, Ruizi Li 2,, and Doug Toussaint 3 1 Department of Physics
arxiv:1712.00143v1 [hep-lat] 1 Dec 2017 MILC Code Performance on High End CPU and GPU Supercomputer Clusters Carleton DeTar 1, Steven Gottlieb 2,, Ruizi Li 2,, and Doug Toussaint 3 1 Department of Physics
Double Rewards of Porting Scientific Applications to the Intel MIC Architecture
 Double Rewards of Porting Scientific Applications to the Intel MIC Architecture Troy A. Porter Hansen Experimental Physics Laboratory and Kavli Institute for Particle Astrophysics and Cosmology Stanford
Double Rewards of Porting Scientific Applications to the Intel MIC Architecture Troy A. Porter Hansen Experimental Physics Laboratory and Kavli Institute for Particle Astrophysics and Cosmology Stanford
PORTING CP2K TO THE INTEL XEON PHI. ARCHER Technical Forum, Wed 30 th July Iain Bethune
 PORTING CP2K TO THE INTEL XEON PHI ARCHER Technical Forum, Wed 30 th July Iain Bethune (ibethune@epcc.ed.ac.uk) Outline Xeon Phi Overview Porting CP2K to Xeon Phi Performance Results Lessons Learned Further
PORTING CP2K TO THE INTEL XEON PHI ARCHER Technical Forum, Wed 30 th July Iain Bethune (ibethune@epcc.ed.ac.uk) Outline Xeon Phi Overview Porting CP2K to Xeon Phi Performance Results Lessons Learned Further
Dr Christopher Dahnken. SSG DRD EMEA Datacenter
 Dr Christopher Dahnken SSG DRD EMEA Datacenter Legal Disclaimer & Optimization Notice INFORMATION IN THIS DOCUMENT IS PROVIDED AS IS. NO LICENSE, EXPRESS OR IMPLIED, BY ESTOPPEL OR OTHERWISE, TO ANY INTELLECTUAL
Dr Christopher Dahnken SSG DRD EMEA Datacenter Legal Disclaimer & Optimization Notice INFORMATION IN THIS DOCUMENT IS PROVIDED AS IS. NO LICENSE, EXPRESS OR IMPLIED, BY ESTOPPEL OR OTHERWISE, TO ANY INTELLECTUAL
Managing HPC Active Archive Storage with HPSS RAIT at Oak Ridge National Laboratory
 Managing HPC Active Archive Storage with HPSS RAIT at Oak Ridge National Laboratory Quinn Mitchell HPC UNIX/LINUX Storage Systems ORNL is managed by UT-Battelle for the US Department of Energy U.S. Department
Managing HPC Active Archive Storage with HPSS RAIT at Oak Ridge National Laboratory Quinn Mitchell HPC UNIX/LINUX Storage Systems ORNL is managed by UT-Battelle for the US Department of Energy U.S. Department
Cori (2016) and Beyond Ensuring NERSC Users Stay Productive
 and Beyond Ensuring NERSC Users Stay Productive") Cori (2016) and Beyond Ensuring NERSC Users Stay Productive Nicholas J. Wright! Advanced Technologies Group Lead! Heterogeneous Mul-- Core 4 Workshop 17 September 2014-1 - NERSC Systems Today Edison: 2.39PF,
Cori (2016) and Beyond Ensuring NERSC Users Stay Productive Nicholas J. Wright! Advanced Technologies Group Lead! Heterogeneous Mul-- Core 4 Workshop 17 September 2014-1 - NERSC Systems Today Edison: 2.39PF,
Intel Advisor XE Future Release Threading Design & Prototyping Vectorization Assistant
 Intel Advisor XE Future Release Threading Design & Prototyping Vectorization Assistant Parallel is the Path Forward Intel Xeon and Intel Xeon Phi Product Families are both going parallel Intel Xeon processor
Intel Advisor XE Future Release Threading Design & Prototyping Vectorization Assistant Parallel is the Path Forward Intel Xeon and Intel Xeon Phi Product Families are both going parallel Intel Xeon processor
April 2 nd, Bob Burroughs Director, HPC Solution Sales
 April 2 nd, 2019 Bob Burroughs Director, HPC Solution Sales Today - Introducing 2 nd Generation Intel Xeon Scalable Processors how Intel Speeds HPC performance Work Time System Peak Efficiency Software
April 2 nd, 2019 Bob Burroughs Director, HPC Solution Sales Today - Introducing 2 nd Generation Intel Xeon Scalable Processors how Intel Speeds HPC performance Work Time System Peak Efficiency Software
Scalasca support for Intel Xeon Phi. Brian Wylie & Wolfgang Frings Jülich Supercomputing Centre Forschungszentrum Jülich, Germany
 Scalasca support for Intel Xeon Phi Brian Wylie & Wolfgang Frings Jülich Supercomputing Centre Forschungszentrum Jülich, Germany Overview Scalasca performance analysis toolset support for MPI & OpenMP
Scalasca support for Intel Xeon Phi Brian Wylie & Wolfgang Frings Jülich Supercomputing Centre Forschungszentrum Jülich, Germany Overview Scalasca performance analysis toolset support for MPI & OpenMP
Tutorial: Analyzing MPI Applications. Intel Trace Analyzer and Collector Intel VTune Amplifier XE
 Tutorial: Analyzing MPI Applications Intel Trace Analyzer and Collector Intel VTune Amplifier XE Contents Legal Information... 3 1. Overview... 4 1.1. Prerequisites... 5 1.1.1. Required Software... 5 1.1.2.
Tutorial: Analyzing MPI Applications Intel Trace Analyzer and Collector Intel VTune Amplifier XE Contents Legal Information... 3 1. Overview... 4 1.1. Prerequisites... 5 1.1.1. Required Software... 5 1.1.2.
KNL tools. Dr. Fabio Baruffa
 KNL tools Dr. Fabio Baruffa fabio.baruffa@lrz.de 2 Which tool do I use? A roadmap to optimization We will focus on tools developed by Intel, available to users of the LRZ systems. Again, we will skip the
KNL tools Dr. Fabio Baruffa fabio.baruffa@lrz.de 2 Which tool do I use? A roadmap to optimization We will focus on tools developed by Intel, available to users of the LRZ systems. Again, we will skip the
Resources Current and Future Systems. Timothy H. Kaiser, Ph.D.
 Resources Current and Future Systems Timothy H. Kaiser, Ph.D. tkaiser@mines.edu 1 Most likely talk to be out of date History of Top 500 Issues with building bigger machines Current and near future academic
Resources Current and Future Systems Timothy H. Kaiser, Ph.D. tkaiser@mines.edu 1 Most likely talk to be out of date History of Top 500 Issues with building bigger machines Current and near future academic
Scientific Computing with Intel Xeon Phi Coprocessors
 Scientific Computing with Intel Xeon Phi Coprocessors Andrey Vladimirov Colfax International HPC Advisory Council Stanford Conference 2015 Compututing with Xeon Phi Welcome Colfax International, 2014 Contents
Scientific Computing with Intel Xeon Phi Coprocessors Andrey Vladimirov Colfax International HPC Advisory Council Stanford Conference 2015 Compututing with Xeon Phi Welcome Colfax International, 2014 Contents
Optimization of the Gadget code and energy measurements on second-generation Intel Xeon Phi
 Optimization of the Gadget code and energy measurements on second-generation Intel Xeon Phi Dr. Luigi Iapichino Leibniz Supercomputing Centre IXPUG 2018 Spring conference luigi.iapichino@lrz.de Work main
Optimization of the Gadget code and energy measurements on second-generation Intel Xeon Phi Dr. Luigi Iapichino Leibniz Supercomputing Centre IXPUG 2018 Spring conference luigi.iapichino@lrz.de Work main
Introduction: Modern computer architecture. The stored program computer and its inherent bottlenecks Multi- and manycore chips and nodes
 Introduction: Modern computer architecture The stored program computer and its inherent bottlenecks Multi- and manycore chips and nodes Motivation: Multi-Cores where and why Introduction: Moore s law Intel
Introduction: Modern computer architecture The stored program computer and its inherent bottlenecks Multi- and manycore chips and nodes Motivation: Multi-Cores where and why Introduction: Moore s law Intel
Jackson Marusarz Intel Corporation
 Jackson Marusarz Intel Corporation Intel VTune Amplifier Quick Introduction Get the Data You Need Hotspot (Statistical call tree), Call counts (Statistical) Thread Profiling Concurrency and Lock & Waits
Jackson Marusarz Intel Corporation Intel VTune Amplifier Quick Introduction Get the Data You Need Hotspot (Statistical call tree), Call counts (Statistical) Thread Profiling Concurrency and Lock & Waits
A Study of High Performance Computing and the Cray SV1 Supercomputer. Michael Sullivan TJHSST Class of 2004
 A Study of High Performance Computing and the Cray SV1 Supercomputer Michael Sullivan TJHSST Class of 2004 June 2004 0.1 Introduction A supercomputer is a device for turning compute-bound problems into
A Study of High Performance Computing and the Cray SV1 Supercomputer Michael Sullivan TJHSST Class of 2004 June 2004 0.1 Introduction A supercomputer is a device for turning compute-bound problems into
Trends of Network Topology on Supercomputers. Michihiro Koibuchi National Institute of Informatics, Japan 2018/11/27
 Trends of Network Topology on Supercomputers Michihiro Koibuchi National Institute of Informatics, Japan 2018/11/27 From Graph Golf to Real Interconnection Networks Case 1: On-chip Networks Case 2: Supercomputer
Trends of Network Topology on Supercomputers Michihiro Koibuchi National Institute of Informatics, Japan 2018/11/27 From Graph Golf to Real Interconnection Networks Case 1: On-chip Networks Case 2: Supercomputer
Experiences with ENZO on the Intel Many Integrated Core Architecture
 Experiences with ENZO on the Intel Many Integrated Core Architecture Dr. Robert Harkness National Institute for Computational Sciences April 10th, 2012 Overview ENZO applications at petascale ENZO and
Experiences with ENZO on the Intel Many Integrated Core Architecture Dr. Robert Harkness National Institute for Computational Sciences April 10th, 2012 Overview ENZO applications at petascale ENZO and
Performance Optimization of Smoothed Particle Hydrodynamics for Multi/Many-Core Architectures
 Performance Optimization of Smoothed Particle Hydrodynamics for Multi/Many-Core Architectures Dr. Fabio Baruffa Leibniz Supercomputing Centre fabio.baruffa@lrz.de MC² Series: Colfax Research Webinar, http://mc2series.com
Performance Optimization of Smoothed Particle Hydrodynamics for Multi/Many-Core Architectures Dr. Fabio Baruffa Leibniz Supercomputing Centre fabio.baruffa@lrz.de MC² Series: Colfax Research Webinar, http://mc2series.com
AUTOMATIC SMT THREADING
 AUTOMATIC SMT THREADING FOR OPENMP APPLICATIONS ON THE INTEL XEON PHI CO-PROCESSOR WIM HEIRMAN 1,2 TREVOR E. CARLSON 1 KENZO VAN CRAEYNEST 1 IBRAHIM HUR 2 AAMER JALEEL 2 LIEVEN EECKHOUT 1 1 GHENT UNIVERSITY
AUTOMATIC SMT THREADING FOR OPENMP APPLICATIONS ON THE INTEL XEON PHI CO-PROCESSOR WIM HEIRMAN 1,2 TREVOR E. CARLSON 1 KENZO VAN CRAEYNEST 1 IBRAHIM HUR 2 AAMER JALEEL 2 LIEVEN EECKHOUT 1 1 GHENT UNIVERSITY
IXPUG 16. Dmitry Durnov, Intel MPI team
 IXPUG 16 Dmitry Durnov, Intel MPI team Agenda - Intel MPI 2017 Beta U1 product availability - New features overview - Competitive results - Useful links - Q/A 2 Intel MPI 2017 Beta U1 is available! Key
IXPUG 16 Dmitry Durnov, Intel MPI team Agenda - Intel MPI 2017 Beta U1 product availability - New features overview - Competitive results - Useful links - Q/A 2 Intel MPI 2017 Beta U1 is available! Key
Accelerating Insights In the Technical Computing Transformation
 Accelerating Insights In the Technical Computing Transformation Dr. Rajeeb Hazra Vice President, Data Center Group General Manager, Technical Computing Group June 2014 TOP500 Highlights Intel Xeon Phi
Accelerating Insights In the Technical Computing Transformation Dr. Rajeeb Hazra Vice President, Data Center Group General Manager, Technical Computing Group June 2014 TOP500 Highlights Intel Xeon Phi
Profiling: Understand Your Application
 Profiling: Understand Your Application Michal Merta michal.merta@vsb.cz 1st of March 2018 Agenda Hardware events based sampling Some fundamental bottlenecks Overview of profiling tools perf tools Intel
Profiling: Understand Your Application Michal Merta michal.merta@vsb.cz 1st of March 2018 Agenda Hardware events based sampling Some fundamental bottlenecks Overview of profiling tools perf tools Intel
David R. Mackay, Ph.D. Libraries play an important role in threading software to run faster on Intel multi-core platforms.
 Whitepaper Introduction A Library Based Approach to Threading for Performance David R. Mackay, Ph.D. Libraries play an important role in threading software to run faster on Intel multi-core platforms.
Whitepaper Introduction A Library Based Approach to Threading for Performance David R. Mackay, Ph.D. Libraries play an important role in threading software to run faster on Intel multi-core platforms.
HPC Architectures evolution: the case of Marconi, the new CINECA flagship system. Piero Lanucara
 HPC Architectures evolution: the case of Marconi, the new CINECA flagship system Piero Lanucara Many advantages as a supercomputing resource: Low energy consumption. Limited floor space requirements Fast
HPC Architectures evolution: the case of Marconi, the new CINECA flagship system Piero Lanucara Many advantages as a supercomputing resource: Low energy consumption. Limited floor space requirements Fast
Interconnect Your Future
 Interconnect Your Future Smart Interconnect for Next Generation HPC Platforms Gilad Shainer, August 2016, 4th Annual MVAPICH User Group (MUG) Meeting Mellanox Connects the World s Fastest Supercomputer
Interconnect Your Future Smart Interconnect for Next Generation HPC Platforms Gilad Shainer, August 2016, 4th Annual MVAPICH User Group (MUG) Meeting Mellanox Connects the World s Fastest Supercomputer
On the Use of Burst Buffers for Accelerating Data-Intensive Scientific Workflows
 On the Use of Burst Buffers for Accelerating Data-Intensive Scientific Workflows Rafael Ferreira da Silva, Scott Callaghan, Ewa Deelman 12 th Workflows in Support of Large-Scale Science (WORKS) SuperComputing
On the Use of Burst Buffers for Accelerating Data-Intensive Scientific Workflows Rafael Ferreira da Silva, Scott Callaghan, Ewa Deelman 12 th Workflows in Support of Large-Scale Science (WORKS) SuperComputing
Introduction to Performance Tuning & Optimization Tools
 Introduction to Performance Tuning & Optimization Tools a[i] a[i+1] + a[i+2] a[i+3] b[i] b[i+1] b[i+2] b[i+3] = a[i]+b[i] a[i+1]+b[i+1] a[i+2]+b[i+2] a[i+3]+b[i+3] Ian A. Cosden, Ph.D. Manager, HPC Software
Introduction to Performance Tuning & Optimization Tools a[i] a[i+1] + a[i+2] a[i+3] b[i] b[i+1] b[i+2] b[i+3] = a[i]+b[i] a[i+1]+b[i+1] a[i+2]+b[i+2] a[i+3]+b[i+3] Ian A. Cosden, Ph.D. Manager, HPC Software
Parallel Programming on Ranger and Stampede
 Parallel Programming on Ranger and Stampede Steve Lantz Senior Research Associate Cornell CAC Parallel Computing at TACC: Ranger to Stampede Transition December 11, 2012 What is Stampede? NSF-funded XSEDE
Parallel Programming on Ranger and Stampede Steve Lantz Senior Research Associate Cornell CAC Parallel Computing at TACC: Ranger to Stampede Transition December 11, 2012 What is Stampede? NSF-funded XSEDE
Intel Many-Core Processor Architecture for High Performance Computing
 Intel Many-Core Processor Architecture for High Performance Computing Andrey Semin Principal Engineer, Intel IXPUG, Moscow June 1, 2017 Legal INFORMATION IN THIS DOCUMENT IS PROVIDED IN CONNECTION WITH
Intel Many-Core Processor Architecture for High Performance Computing Andrey Semin Principal Engineer, Intel IXPUG, Moscow June 1, 2017 Legal INFORMATION IN THIS DOCUMENT IS PROVIDED IN CONNECTION WITH
Simplified and Effective Serial and Parallel Performance Optimization
 HPC Code Modernization Workshop at LRZ Simplified and Effective Serial and Parallel Performance Optimization Performance tuning Using Intel VTune Performance Profiler Performance Tuning Methodology Goal:
HPC Code Modernization Workshop at LRZ Simplified and Effective Serial and Parallel Performance Optimization Performance tuning Using Intel VTune Performance Profiler Performance Tuning Methodology Goal:
Cray Performance Tools Enhancements for Next Generation Systems Heidi Poxon
 Cray Performance Tools Enhancements for Next Generation Systems Heidi Poxon Agenda Cray Performance Tools Overview Recent Enhancements Support for Cray systems with KNL 2 Cray Performance Analysis Tools
Cray Performance Tools Enhancements for Next Generation Systems Heidi Poxon Agenda Cray Performance Tools Overview Recent Enhancements Support for Cray systems with KNL 2 Cray Performance Analysis Tools
Computer Architecture and Structured Parallel Programming James Reinders, Intel
 Computer Architecture and Structured Parallel Programming James Reinders, Intel Parallel Computing CIS 410/510 Department of Computer and Information Science Lecture 17 Manycore Computing and GPUs Computer
Computer Architecture and Structured Parallel Programming James Reinders, Intel Parallel Computing CIS 410/510 Department of Computer and Information Science Lecture 17 Manycore Computing and GPUs Computer
ECE 574 Cluster Computing Lecture 23
 ECE 574 Cluster Computing Lecture 23 Vince Weaver http://www.eece.maine.edu/~vweaver vincent.weaver@maine.edu 1 December 2015 Announcements Project presentations next week There is a final. time. Maybe
ECE 574 Cluster Computing Lecture 23 Vince Weaver http://www.eece.maine.edu/~vweaver vincent.weaver@maine.edu 1 December 2015 Announcements Project presentations next week There is a final. time. Maybe
Introduction to Xeon Phi. Bill Barth January 11, 2013
 Introduction to Xeon Phi Bill Barth January 11, 2013 What is it? Co-processor PCI Express card Stripped down Linux operating system Dense, simplified processor Many power-hungry operations removed Wider
Introduction to Xeon Phi Bill Barth January 11, 2013 What is it? Co-processor PCI Express card Stripped down Linux operating system Dense, simplified processor Many power-hungry operations removed Wider
Deep Learning with Intel DAAL
 Deep Learning with Intel DAAL on Knights Landing Processor David Ojika dave.n.ojika@cern.ch March 22, 2017 Outline Introduction and Motivation Intel Knights Landing Processor Intel Data Analytics and Acceleration
Deep Learning with Intel DAAL on Knights Landing Processor David Ojika dave.n.ojika@cern.ch March 22, 2017 Outline Introduction and Motivation Intel Knights Landing Processor Intel Data Analytics and Acceleration
Lecture 10: Cache Coherence. Parallel Computer Architecture and Programming CMU / 清华 大学, Summer 2017
 Lecture 10: Cache Coherence Parallel Computer Architecture and Programming CMU / 清华 大学, Summer 2017 Course schedule (where we are) Week 1: How parallel hardware works: types of parallel execution in modern
Lecture 10: Cache Coherence Parallel Computer Architecture and Programming CMU / 清华 大学, Summer 2017 Course schedule (where we are) Week 1: How parallel hardware works: types of parallel execution in modern
Addressing the Increasing Challenges of Debugging on Accelerated HPC Systems. Ed Hinkel Senior Sales Engineer
 Addressing the Increasing Challenges of Debugging on Accelerated HPC Systems Ed Hinkel Senior Sales Engineer Agenda Overview - Rogue Wave & TotalView GPU Debugging with TotalView Nvdia CUDA Intel Phi 2
Addressing the Increasing Challenges of Debugging on Accelerated HPC Systems Ed Hinkel Senior Sales Engineer Agenda Overview - Rogue Wave & TotalView GPU Debugging with TotalView Nvdia CUDA Intel Phi 2
CSCI 402: Computer Architectures. Parallel Processors (2) Fengguang Song Department of Computer & Information Science IUPUI.
 Fengguang Song Department of Computer & Information Science IUPUI.") CSCI 402: Computer Architectures Parallel Processors (2) Fengguang Song Department of Computer & Information Science IUPUI 6.6 - End Today s Contents GPU Cluster and its network topology The Roofline performance
CSCI 402: Computer Architectures Parallel Processors (2) Fengguang Song Department of Computer & Information Science IUPUI 6.6 - End Today s Contents GPU Cluster and its network topology The Roofline performance
Benchmark results on Knight Landing (KNL) architecture
 architecture") Benchmark results on Knight Landing (KNL) architecture Domenico Guida, CINECA SCAI (Bologna) Giorgio Amati, CINECA SCAI (Roma) Roma 23/10/2017 KNL, BDW, SKL A1 BDW A2 KNL A3 SKL cores per node 2 x 18 @2.3
Benchmark results on Knight Landing (KNL) architecture Domenico Guida, CINECA SCAI (Bologna) Giorgio Amati, CINECA SCAI (Roma) Roma 23/10/2017 KNL, BDW, SKL A1 BDW A2 KNL A3 SKL cores per node 2 x 18 @2.3
INTEL HPC DEVELOPER CONFERENCE FUEL YOUR INSIGHT
 INTEL HPC DEVELOPER CONFERENCE FUEL YOUR INSIGHT INTEL HPC DEVELOPER CONFERENCE FUEL YOUR INSIGHT UPDATE ON OPENSWR: A SCALABLE HIGH- PERFORMANCE SOFTWARE RASTERIZER FOR SCIVIS Jefferson Amstutz Intel
INTEL HPC DEVELOPER CONFERENCE FUEL YOUR INSIGHT INTEL HPC DEVELOPER CONFERENCE FUEL YOUR INSIGHT UPDATE ON OPENSWR: A SCALABLE HIGH- PERFORMANCE SOFTWARE RASTERIZER FOR SCIVIS Jefferson Amstutz Intel
Introduction to KNL and Parallel Computing
 Introduction to KNL and Parallel Computing Steve Lantz Senior Research Associate Cornell University Center for Advanced Computing (CAC) steve.lantz@cornell.edu High Performance Computing on Stampede 2,
Introduction to KNL and Parallel Computing Steve Lantz Senior Research Associate Cornell University Center for Advanced Computing (CAC) steve.lantz@cornell.edu High Performance Computing on Stampede 2,
HPC-BLAST Scalable Sequence Analysis for the Intel Many Integrated Core Future
 HPC-BLAST Scalable Sequence Analysis for the Intel Many Integrated Core Future Dr. R. Glenn Brook & Shane Sawyer Joint Institute For Computational Sciences University of Tennessee, Knoxville Dr. Bhanu
HPC-BLAST Scalable Sequence Analysis for the Intel Many Integrated Core Future Dr. R. Glenn Brook & Shane Sawyer Joint Institute For Computational Sciences University of Tennessee, Knoxville Dr. Bhanu
The knight makes his play for the crown Phi & Omni-Path Glenn Rosenberg Computer Insights UK 2016
 The knight makes his play for the crown Phi & Omni-Path Glenn Rosenberg Computer Insights UK 2016 2016 Supermicro 15 Minutes Two Swim Lanes Intel Phi Roadmap & SKUs Phi in the TOP500 Use Cases Supermicro
The knight makes his play for the crown Phi & Omni-Path Glenn Rosenberg Computer Insights UK 2016 2016 Supermicro 15 Minutes Two Swim Lanes Intel Phi Roadmap & SKUs Phi in the TOP500 Use Cases Supermicro
NEXTGenIO Performance Tools for In-Memory I/O
 NEXTGenIO Performance Tools for In- I/O holger.brunst@tu-dresden.de ZIH, Technische Universität Dresden 22 nd -23 rd March 2017 Credits Intro slides by Adrian Jackson (EPCC) A new hierarchy New non-volatile
NEXTGenIO Performance Tools for In- I/O holger.brunst@tu-dresden.de ZIH, Technische Universität Dresden 22 nd -23 rd March 2017 Credits Intro slides by Adrian Jackson (EPCC) A new hierarchy New non-volatile
Achieving High Performance. Jim Cownie Principal Engineer SSG/DPD/TCAR Multicore Challenge 2013
 Achieving High Performance Jim Cownie Principal Engineer SSG/DPD/TCAR Multicore Challenge 2013 Does Instruction Set Matter? We find that ARM and x86 processors are simply engineering design points optimized
Achieving High Performance Jim Cownie Principal Engineer SSG/DPD/TCAR Multicore Challenge 2013 Does Instruction Set Matter? We find that ARM and x86 processors are simply engineering design points optimized
Welcome. Virtual tutorial starts at BST
 Welcome Virtual tutorial starts at 15.00 BST Using KNL on ARCHER Adrian Jackson With thanks to: adrianj@epcc.ed.ac.uk @adrianjhpc Harvey Richardson from Cray Slides from Intel Xeon Phi Knights Landing
Welcome Virtual tutorial starts at 15.00 BST Using KNL on ARCHER Adrian Jackson With thanks to: adrianj@epcc.ed.ac.uk @adrianjhpc Harvey Richardson from Cray Slides from Intel Xeon Phi Knights Landing
Introduction to Intel Xeon Phi programming techniques. Fabio Affinito Vittorio Ruggiero
 Introduction to Intel Xeon Phi programming techniques Fabio Affinito Vittorio Ruggiero Outline High level overview of the Intel Xeon Phi hardware and software stack Intel Xeon Phi programming paradigms:
Introduction to Intel Xeon Phi programming techniques Fabio Affinito Vittorio Ruggiero Outline High level overview of the Intel Xeon Phi hardware and software stack Intel Xeon Phi programming paradigms:
HPC future trends from a science perspective
 HPC future trends from a science perspective Simon McIntosh-Smith University of Bristol HPC Research Group simonm@cs.bris.ac.uk 1 Business as usual? We've all got used to new machines being relatively
HPC future trends from a science perspective Simon McIntosh-Smith University of Bristol HPC Research Group simonm@cs.bris.ac.uk 1 Business as usual? We've all got used to new machines being relatively
Performance of deal.ii on a node
 Performance of deal.ii on a node Bruno Turcksin Texas A&M University, Dept. of Mathematics Bruno Turcksin Deal.II on a node 1/37 Outline 1 Introduction 2 Architecture 3 Paralution 4 Other Libraries 5 Conclusions
Performance of deal.ii on a node Bruno Turcksin Texas A&M University, Dept. of Mathematics Bruno Turcksin Deal.II on a node 1/37 Outline 1 Introduction 2 Architecture 3 Paralution 4 Other Libraries 5 Conclusions
Toward Automated Application Profiling on Cray Systems
 Toward Automated Application Profiling on Cray Systems Charlene Yang, Brian Friesen, Thorsten Kurth, Brandon Cook NERSC at LBNL Samuel Williams CRD at LBNL I have a dream.. M.L.K. Collect performance data:
Toward Automated Application Profiling on Cray Systems Charlene Yang, Brian Friesen, Thorsten Kurth, Brandon Cook NERSC at LBNL Samuel Williams CRD at LBNL I have a dream.. M.L.K. Collect performance data: