Algorithms for Scalable Synchronization on Shared Memory Multiprocessors by John M. Mellor Crummey Michael L. Scott
|
|
|
- Jessica Woods
- 6 years ago
- Views:
Transcription
1 Algorithms for Scalable Synchronization on Shared Memory Multiprocessors by John M. Mellor Crummey Michael L. Scott Presentation by Joe Izraelevitz Tim Kopp
2 Synchronization Primitives Spin Locks Used for mutual exclusion around critical sequential sections Spin locks used for nonscheduled processes, basic primitive for building complicated locks Barriers Used to ensure all threads have left a parallel section Similar to pthreads join()
3 Spin Locks: Evaluation Fairness Spin Locks Starvation Test and Set FIFO Ordering Ticket Lock Scalability Network load Space Hardware Requirements Cache Coherence Instruction Set Overhead Array based Queuing Lock MCS Lock
4 Test and Set Lock type lock = (unlocked, locked) procedure acquirelock (L : lock) delay : integer = 1 while (testandset (L) == locked) // returns old value pause delay // pause for short time delay = delay*2 // exponential back off procedure releaselock (L : lock) lock = unlocked
5 Spin Locks: Evaluation Fairness Starvation FIFO Ordering Scalability Network load Space Hardware Requirements Cache Coherence Instruction Set Overhead Improvements Backoff Exponential test and test_and_set


6 Ticket Lock Note: Global Variable Increment
7 Ticket Lock type lock = record nextticket : integer = 0 // the next ticket to be issued nowserving : integer = 0 // ticket number of thread with lock procedure acquirelock (L : lock) myticket : integer = fetchandincrement(l->nextticket) // returns old value, arithmetic overflow is harmless loop pause (myticket (L->nowserving) ) // consume this many units of time // on most machines subtraction works correctly // despite overflow if (L->nowserving == myticket) return procedure releaselock (L : lock) L->nowserving = L->nowserving + 1
8 Spin Locks: Evaluation Fairness Starvation FIFO Ordering Scalability Network load Space Hardware Requirements Cache Coherence Instruction Set Overhead Improvements Backoff Exponential Proportional
9 Array Based Queuing Lock Note: Dynamically Assigned Slot Notify next using array
10 Array Based Queuing Lock (Andersen) type lock : record slots : array [0...numprocs-1] of (haslock, mustwait) = (haslock, mustwait, mustwait,... mustwait) // each element of slots should lie in a different memory module or cache line nextslot : integer = 0 // function argument myplace points to a private variable in an enclosing scope procedure acquirelock (L : lock, myplace : integer) myplace = fetchandincrement (L->nextslot) // returns old value, this provides my assigned slot to spin on if (myplace mod numprocs == 0) // decrement periodically to avoid overflow atomicadd (L->nextslot, -numprocs) myplace = myplace mod numprocs repeat while (L->slots[myplace] == mustwait) // spin until L->slots[myplace]==haslock L->slots[myplace] == mustwait // init for next time procedure releaselock (L : lock, myplace : integer) L->slots[(myplace+1) mod numprocs] = haslock // give lock to next thread
11 Spin Locks: Evaluation Fairness Starvation FIFO Ordering Scalability Network load Space Hardware Requirements Cache Coherence Instruction Set Overhead


12 MCS Lock I'm so dizzy! Note: Statically Assigned Slot Notify next using linked list
13 MCS Lock type qnode = record next : qnode locked : Boolean type lock = qnode // parameter I below points to a qnode record allocated in an enclosing scope in shared // memory locally accessible to the invoking processor procedure acquirelock (L : lock, I : qnode) I->next = nil predecessor : qnode = fetchandstore (L, I) if (predecessor!= nil) // queue was non empty I->locked = true predecessor->next = I repeat while (I->locked) // spin on local qnode procedure releaselock (L : lock, I : qnode) if (I->next == nil ) // no known successor if ( compareandswap (L, I, nil) ) return // compareandswap succeeds if no thread has enqueued, we can exit // else, we spin until next thread registers with us, then unlock it and exit repeat while (I->next == nil) I->next->locked = false
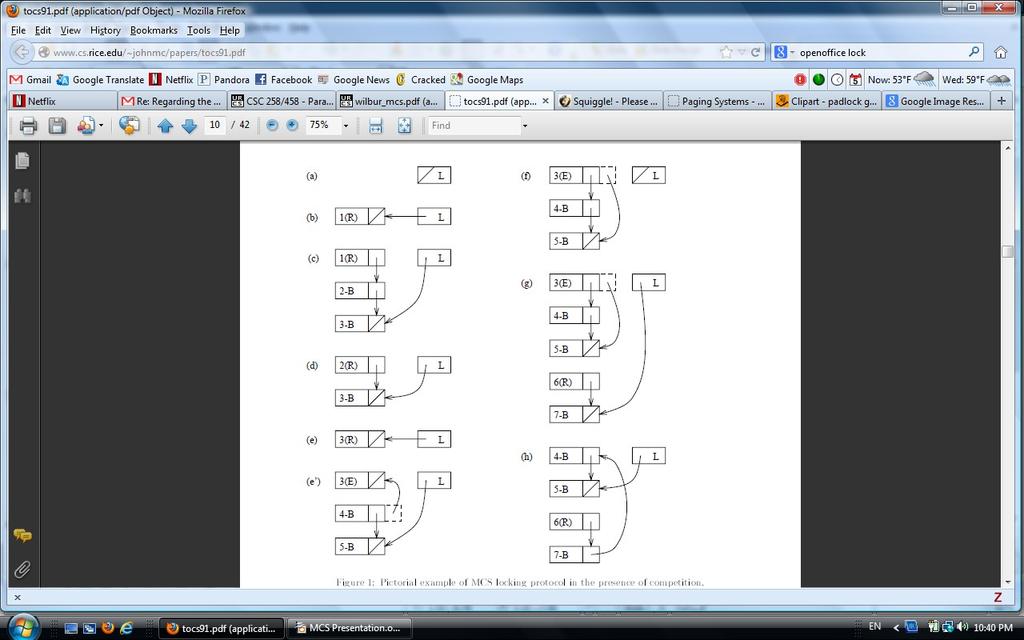
14 MCS Lock
15 Spin Locks: Evaluation Fairness Starvation FIFO Ordering Scalability Network load Space Hardware Requirements Cache Coherence Instruction Set Overhead
16 Advantage Comparison Lock FIFO Network Traffic Space Instruction Set Overhead Ratio (single CPU compared to TSL) Test and Set No O(n*t) O(k) test_and_set 1.0 Ticket Yes O(n*t) O(k) fetch_and_ increment 1.11 Array Queue Yes O(n) O(#cpus) fetch_and_ add 1.88 MCS Yes O(n) O(n) compare_ and_swap 2.04 * n = number of threads contending for lock t = number of polls made in spin k = constant
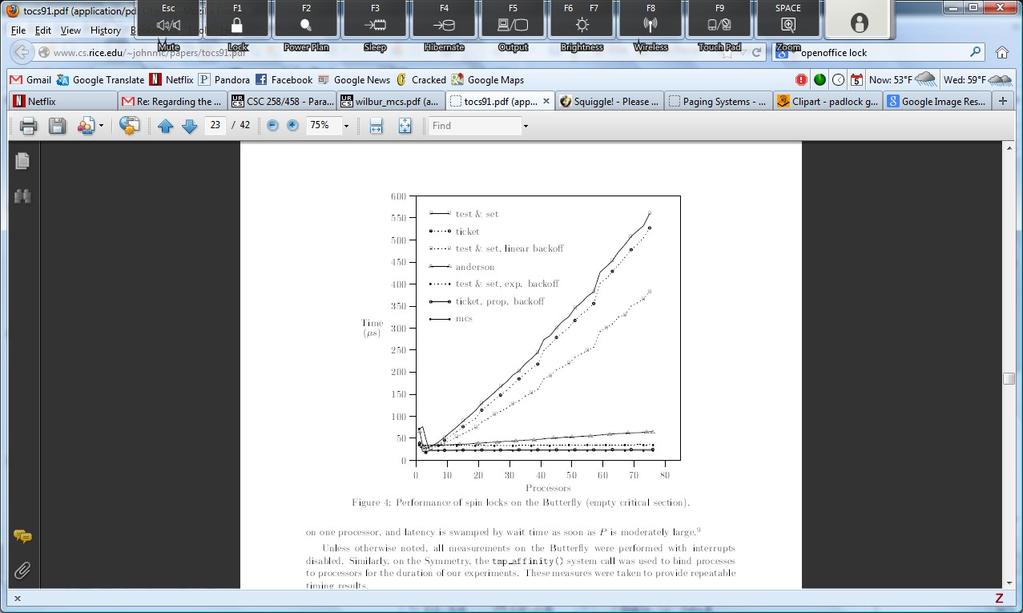
17 Speed Comparison
18 Overhead Comparison
19 Barriers

20 Centralized Barrier (Naive)

21 Centralized Barrier (Sense Reversal)
22 Centralized Barrier Ops on critical path = O(P) Space = O(1) Network transactions = O(P) with broadcast coherent caches, unbounded otherwise fetch_and_increment needed
23 Centralized Barrier Pros Simple Less traffic on broadcast-based cache-coherent architectures Constant Space Cons Many busy-wait accesses significant network traffic Memory contention Cache thrashing Does not scale

24 Software-Combining Tree Barrier
25 Software Combining Tree Barrier Nodes scattered across different memory units or cache lines Ops on critical path = O(log P) Space = O(P) Network transactions = O(P) with broadcast coherent caches, unbounded otherwise fetch_and_increment needed
26 Software Combining Tree Barrier Pros Significant decrease in memory contention Prevents tree saturation in multistage interconnects Cons Processors spin on memory locations that cannot be statically determined Processors spin on memory locations that other processes spin on
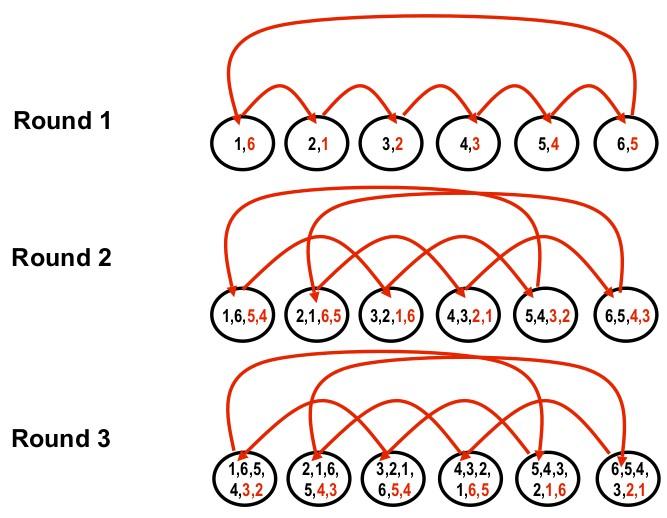
27 Dissemination Barrier
28 Dissemination Barrier Uses two sets of variables to avoid double spinning Network transactions = O(P log P) Ops in critical path = O(log P) Space = O(P log P) No need for fetch_and_φ instructions
29 Dissemination Barrier Pros All spinning is local Eliminates remote spinning Cons With distributed shared memory and no coherent caches, must scatter state across memory banks
30 Tournament Barrier Combining tree of fan-in two Rather than waiting on a node, losers drop out and wait on shared variable Winners statically determined Tournament winner changes shared state
31 Tournament Barrier Network transactions = O(P) Ops in critical path = O(log P) Space = O(P) or O(P log P) No need for fetch_and_φ instructions
32 Tournament Barrier Pros Efficient when broadcast is used for cache consistency Eliminates remote spinning Cons Heavy interconnect traffic if no coherent caches

33 MCS Barrier - Arrival

34 MCS Barrier - Wake
35 MCS Barrier Network transactions = 2p-2 = O(P), theoretical minimum without broadcast Space = O(P) Ops on critical path = O(log P) No need for fetch_and_φ instructions
36 MCS Barrier With coherent caches, could replace wakeup with spin on global variable Minimal network traffic
37 Advantage Comparison Barrier Critical Path Length # of Network Transactions Space Instruction Set Centralized (count) O(P) O(P) or Unbounded O(1) fetch_and_ increment Software Combining Tree Dissemination O(log P) O(P) or Unbounded O(P) fetch_and_ increment O(log P) O(P log P) O(P log P) Atomic read/write Tournament O(log P) O(P) O(P log P) Atomic read/write MCS Tree O(log P) O(P) O(P) Atomic read/write
38 Speed Comparison (Non Cache Coherent)
39 Speed Comparison (Cache Coherent)
40 Questions?
41 Images Cited The Electronic Avenue Inc. Employee and Guest Pagers. (2013). (Pager on image) Finding the Humor. (2013). (Now Serving image) Genex Disability. (2013). (Please take a number image) Open Clip Art. (2013). (Lock image) Mellor Crummey, John. Comp 422 Lecture Slides, Rice University (Dissemination Barrier Image) Mellor Crummey, John M. and Michael L. Scott. Algorithms for Scalable Synchronization on Shared Memory Multiprocessors. ACM Trans. on Computer Systems. February (Algorithm Comparison Charts) PRLOG. Fajitas and Ritas Keeps Customers Festive with GuestCall paging from HME Wireless. (2010). (Pager off image)
Hardware: BBN Butterfly
 Algorithms for Scalable Synchronization on Shared-Memory Multiprocessors John M. Mellor-Crummey and Michael L. Scott Presented by Charles Lehner and Matt Graichen Hardware: BBN Butterfly shared-memory
Algorithms for Scalable Synchronization on Shared-Memory Multiprocessors John M. Mellor-Crummey and Michael L. Scott Presented by Charles Lehner and Matt Graichen Hardware: BBN Butterfly shared-memory
Algorithms for Scalable Lock Synchronization on Shared-memory Multiprocessors
 Algorithms for Scalable Lock Synchronization on Shared-memory Multiprocessors John Mellor-Crummey Department of Computer Science Rice University johnmc@cs.rice.edu COMP 422 Lecture 18 17 March 2009 Summary
Algorithms for Scalable Lock Synchronization on Shared-memory Multiprocessors John Mellor-Crummey Department of Computer Science Rice University johnmc@cs.rice.edu COMP 422 Lecture 18 17 March 2009 Summary
Algorithms for Scalable Lock Synchronization on Shared-memory Multiprocessors
 Algorithms for Scalable Lock Synchronization on Shared-memory Multiprocessors John Mellor-Crummey Department of Computer Science Rice University johnmc@rice.edu COMP 422/534 Lecture 21 30 March 2017 Summary
Algorithms for Scalable Lock Synchronization on Shared-memory Multiprocessors John Mellor-Crummey Department of Computer Science Rice University johnmc@rice.edu COMP 422/534 Lecture 21 30 March 2017 Summary
Advance Operating Systems (CS202) Locks Discussion
 Locks Discussion") Advance Operating Systems (CS202) Locks Discussion Threads Locks Spin Locks Array-based Locks MCS Locks Sequential Locks Road Map Threads Global variables and static objects are shared Stored in the static
Advance Operating Systems (CS202) Locks Discussion Threads Locks Spin Locks Array-based Locks MCS Locks Sequential Locks Road Map Threads Global variables and static objects are shared Stored in the static
Lecture 9: Multiprocessor OSs & Synchronization. CSC 469H1F Fall 2006 Angela Demke Brown
 Lecture 9: Multiprocessor OSs & Synchronization CSC 469H1F Fall 2006 Angela Demke Brown The Problem Coordinated management of shared resources Resources may be accessed by multiple threads Need to control
Lecture 9: Multiprocessor OSs & Synchronization CSC 469H1F Fall 2006 Angela Demke Brown The Problem Coordinated management of shared resources Resources may be accessed by multiple threads Need to control
Synchronization. Jinkyu Jeong Computer Systems Laboratory Sungkyunkwan University
 Synchronization Jinkyu Jeong (jinkyu@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu Types of Synchronization Mutual Exclusion Locks Event Synchronization Global or group-based
Synchronization Jinkyu Jeong (jinkyu@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu Types of Synchronization Mutual Exclusion Locks Event Synchronization Global or group-based
Synchronization. Jinkyu Jeong Computer Systems Laboratory Sungkyunkwan University
 Synchronization Jinkyu Jeong (jinkyu@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu SSE3054: Multicore Systems, Spring 2017, Jinkyu Jeong (jinkyu@skku.edu) Types of Synchronization
Synchronization Jinkyu Jeong (jinkyu@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu SSE3054: Multicore Systems, Spring 2017, Jinkyu Jeong (jinkyu@skku.edu) Types of Synchronization
Conventions. Barrier Methods. How it Works. Centralized Barrier. Enhancements. Pitfalls
 Conventions Barrier Methods Based on Algorithms for Scalable Synchronization on Shared Memory Multiprocessors, by John Mellor- Crummey and Michael Scott Presentation by Jonathan Pearson In code snippets,
Conventions Barrier Methods Based on Algorithms for Scalable Synchronization on Shared Memory Multiprocessors, by John Mellor- Crummey and Michael Scott Presentation by Jonathan Pearson In code snippets,
Adaptive Lock. Madhav Iyengar < >, Nathaniel Jeffries < >
 Adaptive Lock Madhav Iyengar < miyengar@andrew.cmu.edu >, Nathaniel Jeffries < njeffrie@andrew.cmu.edu > ABSTRACT Busy wait synchronization, the spinlock, is the primitive at the core of all other synchronization
Adaptive Lock Madhav Iyengar < miyengar@andrew.cmu.edu >, Nathaniel Jeffries < njeffrie@andrew.cmu.edu > ABSTRACT Busy wait synchronization, the spinlock, is the primitive at the core of all other synchronization
CSC2/458 Parallel and Distributed Systems Scalable Synchronization
 CSC2/458 Parallel and Distributed Systems Scalable Synchronization Sreepathi Pai February 20, 2018 URCS Outline Scalable Locking Barriers Outline Scalable Locking Barriers An alternative lock ticket lock
CSC2/458 Parallel and Distributed Systems Scalable Synchronization Sreepathi Pai February 20, 2018 URCS Outline Scalable Locking Barriers Outline Scalable Locking Barriers An alternative lock ticket lock
250P: Computer Systems Architecture. Lecture 14: Synchronization. Anton Burtsev March, 2019
 250P: Computer Systems Architecture Lecture 14: Synchronization Anton Burtsev March, 2019 Coherence and Synchronization Topics: synchronization primitives (Sections 5.4-5.5) 2 Constructing Locks Applications
250P: Computer Systems Architecture Lecture 14: Synchronization Anton Burtsev March, 2019 Coherence and Synchronization Topics: synchronization primitives (Sections 5.4-5.5) 2 Constructing Locks Applications
Advanced Operating Systems (CS 202) Memory Consistency, Cache Coherence and Synchronization
 Memory Consistency, Cache Coherence and Synchronization") Advanced Operating Systems (CS 202) Memory Consistency, Cache Coherence and Synchronization (some cache coherence slides adapted from Ian Watson; some memory consistency slides from Sarita Adve) Classic
Advanced Operating Systems (CS 202) Memory Consistency, Cache Coherence and Synchronization (some cache coherence slides adapted from Ian Watson; some memory consistency slides from Sarita Adve) Classic
The need for atomicity This code sequence illustrates the need for atomicity. Explain.
 Lock Implementations [ 8.1] Recall the three kinds of synchronization from Lecture 6: Point-to-point Lock Performance metrics for lock implementations Uncontended latency Traffic o Time to acquire a lock
Lock Implementations [ 8.1] Recall the three kinds of synchronization from Lecture 6: Point-to-point Lock Performance metrics for lock implementations Uncontended latency Traffic o Time to acquire a lock
Role of Synchronization. CS 258 Parallel Computer Architecture Lecture 23. Hardware-Software Trade-offs in Synchronization and Data Layout
 CS 28 Parallel Computer Architecture Lecture 23 Hardware-Software Trade-offs in Synchronization and Data Layout April 21, 2008 Prof John D. Kubiatowicz http://www.cs.berkeley.edu/~kubitron/cs28 Role of
CS 28 Parallel Computer Architecture Lecture 23 Hardware-Software Trade-offs in Synchronization and Data Layout April 21, 2008 Prof John D. Kubiatowicz http://www.cs.berkeley.edu/~kubitron/cs28 Role of
CS377P Programming for Performance Multicore Performance Synchronization
 CS377P Programming for Performance Multicore Performance Synchronization Sreepathi Pai UTCS October 21, 2015 Outline 1 Synchronization Primitives 2 Blocking, Lock-free and Wait-free Algorithms 3 Transactional
CS377P Programming for Performance Multicore Performance Synchronization Sreepathi Pai UTCS October 21, 2015 Outline 1 Synchronization Primitives 2 Blocking, Lock-free and Wait-free Algorithms 3 Transactional
A simple correctness proof of the MCS contention-free lock. Theodore Johnson. Krishna Harathi. University of Florida. Abstract
 A simple correctness proof of the MCS contention-free lock Theodore Johnson Krishna Harathi Computer and Information Sciences Department University of Florida Abstract Mellor-Crummey and Scott present
A simple correctness proof of the MCS contention-free lock Theodore Johnson Krishna Harathi Computer and Information Sciences Department University of Florida Abstract Mellor-Crummey and Scott present
Scalable Reader-Writer Synchronization for Shared-Memory Multiprocessors
 Scalable Reader-Writer Synchronization for Shared-Memory Multiprocessors John M. Mellor-Crummey' (johnmcgrice.edu) Center for Research on Parallel Computation Rice University, P.O. Box 1892 Houston, TX
Scalable Reader-Writer Synchronization for Shared-Memory Multiprocessors John M. Mellor-Crummey' (johnmcgrice.edu) Center for Research on Parallel Computation Rice University, P.O. Box 1892 Houston, TX
Multiprocessor Systems. Chapter 8, 8.1
 Multiprocessor Systems Chapter 8, 8.1 1 Learning Outcomes An understanding of the structure and limits of multiprocessor hardware. An appreciation of approaches to operating system support for multiprocessor
Multiprocessor Systems Chapter 8, 8.1 1 Learning Outcomes An understanding of the structure and limits of multiprocessor hardware. An appreciation of approaches to operating system support for multiprocessor
Advanced Operating Systems (CS 202) Memory Consistency, Cache Coherence and Synchronization
 Memory Consistency, Cache Coherence and Synchronization") Advanced Operating Systems (CS 202) Memory Consistency, Cache Coherence and Synchronization Jan, 27, 2017 (some cache coherence slides adapted from Ian Watson; some memory consistency slides from Sarita
Advanced Operating Systems (CS 202) Memory Consistency, Cache Coherence and Synchronization Jan, 27, 2017 (some cache coherence slides adapted from Ian Watson; some memory consistency slides from Sarita
Spinlocks. Spinlocks. Message Systems, Inc. April 8, 2011
 Spinlocks Samy Al Bahra Devon H. O Dell Message Systems, Inc. April 8, 2011 Introduction Mutexes A mutex is an object which implements acquire and relinquish operations such that the execution following
Spinlocks Samy Al Bahra Devon H. O Dell Message Systems, Inc. April 8, 2011 Introduction Mutexes A mutex is an object which implements acquire and relinquish operations such that the execution following
Agenda. Lecture. Next discussion papers. Bottom-up motivation Shared memory primitives Shared memory synchronization Barriers and locks
 Agenda Lecture Bottom-up motivation Shared memory primitives Shared memory synchronization Barriers and locks Next discussion papers Selecting Locking Primitives for Parallel Programming Selecting Locking
Agenda Lecture Bottom-up motivation Shared memory primitives Shared memory synchronization Barriers and locks Next discussion papers Selecting Locking Primitives for Parallel Programming Selecting Locking
Lecture 19: Synchronization. CMU : Parallel Computer Architecture and Programming (Spring 2012)
") Lecture 19: Synchronization CMU 15-418: Parallel Computer Architecture and Programming (Spring 2012) Announcements Assignment 4 due tonight at 11:59 PM Synchronization primitives (that we have or will
Lecture 19: Synchronization CMU 15-418: Parallel Computer Architecture and Programming (Spring 2012) Announcements Assignment 4 due tonight at 11:59 PM Synchronization primitives (that we have or will
GLocks: Efficient Support for Highly- Contended Locks in Many-Core CMPs
 GLocks: Efficient Support for Highly- Contended Locks in Many-Core CMPs Authors: Jos e L. Abell an, Juan Fern andez and Manuel E. Acacio Presenter: Guoliang Liu Outline Introduction Motivation Background
GLocks: Efficient Support for Highly- Contended Locks in Many-Core CMPs Authors: Jos e L. Abell an, Juan Fern andez and Manuel E. Acacio Presenter: Guoliang Liu Outline Introduction Motivation Background
Advanced Operating Systems (CS 202)
") Advanced Operating Systems (CS 202) Memory Consistency, Cache Coherence and Synchronization (Part II) Jan, 30, 2017 (some cache coherence slides adapted from Ian Watson; some memory consistency slides
Advanced Operating Systems (CS 202) Memory Consistency, Cache Coherence and Synchronization (Part II) Jan, 30, 2017 (some cache coherence slides adapted from Ian Watson; some memory consistency slides
6.852: Distributed Algorithms Fall, Class 15
 6.852: Distributed Algorithms Fall, 2009 Class 15 Today s plan z z z z z Pragmatic issues for shared-memory multiprocessors Practical mutual exclusion algorithms Test-and-set locks Ticket locks Queue locks
6.852: Distributed Algorithms Fall, 2009 Class 15 Today s plan z z z z z Pragmatic issues for shared-memory multiprocessors Practical mutual exclusion algorithms Test-and-set locks Ticket locks Queue locks
Synchronization. Coherency protocols guarantee that a reading processor (thread) sees the most current update to shared data.
 sees the most current update to shared data.") Synchronization Coherency protocols guarantee that a reading processor (thread) sees the most current update to shared data. Coherency protocols do not: make sure that only one thread accesses shared data
Synchronization Coherency protocols guarantee that a reading processor (thread) sees the most current update to shared data. Coherency protocols do not: make sure that only one thread accesses shared data
The complete license text can be found at
 SMP & Locking These slides are made distributed under the Creative Commons Attribution 3.0 License, unless otherwise noted on individual slides. You are free: to Share to copy, distribute and transmit
SMP & Locking These slides are made distributed under the Creative Commons Attribution 3.0 License, unless otherwise noted on individual slides. You are free: to Share to copy, distribute and transmit
Module 7: Synchronization Lecture 13: Introduction to Atomic Primitives. The Lecture Contains: Synchronization. Waiting Algorithms.
 The Lecture Contains: Synchronization Waiting Algorithms Implementation Hardwired Locks Software Locks Hardware Support Atomic Exchange Test & Set Fetch & op Compare & Swap Traffic of Test & Set Backoff
The Lecture Contains: Synchronization Waiting Algorithms Implementation Hardwired Locks Software Locks Hardware Support Atomic Exchange Test & Set Fetch & op Compare & Swap Traffic of Test & Set Backoff
CS758 Synchronization. CS758 Multicore Programming (Wood) Synchronization
 Synchronization") CS758 Synchronization 1 Shared Memory Primitives CS758 Multicore Programming (Wood) Performance Tuning 2 Shared Memory Primitives Create thread Ask operating system to create a new thread Threads starts
CS758 Synchronization 1 Shared Memory Primitives CS758 Multicore Programming (Wood) Performance Tuning 2 Shared Memory Primitives Create thread Ask operating system to create a new thread Threads starts
Distributed Systems Synchronization. Marcus Völp 2007
 Distributed Systems Synchronization Marcus Völp 2007 1 Purpose of this Lecture Synchronization Locking Analysis / Comparison Distributed Operating Systems 2007 Marcus Völp 2 Overview Introduction Hardware
Distributed Systems Synchronization Marcus Völp 2007 1 Purpose of this Lecture Synchronization Locking Analysis / Comparison Distributed Operating Systems 2007 Marcus Völp 2 Overview Introduction Hardware
Lecture 18: Coherence and Synchronization. Topics: directory-based coherence protocols, synchronization primitives (Sections
 Lecture 18: Coherence and Synchronization Topics: directory-based coherence protocols, synchronization primitives (Sections 5.1-5.5) 1 Cache Coherence Protocols Directory-based: A single location (directory)
Lecture 18: Coherence and Synchronization Topics: directory-based coherence protocols, synchronization primitives (Sections 5.1-5.5) 1 Cache Coherence Protocols Directory-based: A single location (directory)
1) If a location is initialized to 0, what will the first invocation of TestAndSet on that location return?
 If a location is initialized to 0, what will the first invocation of TestAndSet on that location return?") Synchronization Part 1: Synchronization - Locks Dekker s Algorithm and the Bakery Algorithm provide software-only synchronization. Thanks to advancements in hardware, synchronization approaches have been
Synchronization Part 1: Synchronization - Locks Dekker s Algorithm and the Bakery Algorithm provide software-only synchronization. Thanks to advancements in hardware, synchronization approaches have been
Multiprocessor Synchronization
 Multiprocessor Synchronization Material in this lecture in Henessey and Patterson, Chapter 8 pgs. 694-708 Some material from David Patterson s slides for CS 252 at Berkeley 1 Multiprogramming and Multiprocessing
Multiprocessor Synchronization Material in this lecture in Henessey and Patterson, Chapter 8 pgs. 694-708 Some material from David Patterson s slides for CS 252 at Berkeley 1 Multiprogramming and Multiprocessing
Distributed Operating Systems
 Distributed Operating Systems Synchronization in Parallel Systems Marcus Völp 2009 1 Topics Synchronization Locking Analysis / Comparison Distributed Operating Systems 2009 Marcus Völp 2 Overview Introduction
Distributed Operating Systems Synchronization in Parallel Systems Marcus Völp 2009 1 Topics Synchronization Locking Analysis / Comparison Distributed Operating Systems 2009 Marcus Völp 2 Overview Introduction
AST: scalable synchronization Supervisors guide 2002
 AST: scalable synchronization Supervisors guide 00 tim.harris@cl.cam.ac.uk These are some notes about the topics that I intended the questions to draw on. Do let me know if you find the questions unclear
AST: scalable synchronization Supervisors guide 00 tim.harris@cl.cam.ac.uk These are some notes about the topics that I intended the questions to draw on. Do let me know if you find the questions unclear
Lecture 19: Coherence and Synchronization. Topics: synchronization primitives (Sections )
") Lecture 19: Coherence and Synchronization Topics: synchronization primitives (Sections 5.4-5.5) 1 Caching Locks Spin lock: to acquire a lock, a process may enter an infinite loop that keeps attempting
Lecture 19: Coherence and Synchronization Topics: synchronization primitives (Sections 5.4-5.5) 1 Caching Locks Spin lock: to acquire a lock, a process may enter an infinite loop that keeps attempting
1 Process Coordination
 COMP 730 (242) Class Notes Section 5: Process Coordination 1 Process Coordination Process coordination consists of synchronization and mutual exclusion, which were discussed earlier. We will now study
COMP 730 (242) Class Notes Section 5: Process Coordination 1 Process Coordination Process coordination consists of synchronization and mutual exclusion, which were discussed earlier. We will now study
Scalable Locking. Adam Belay
 Scalable Locking Adam Belay Problem: Locks can ruin performance 12 finds/sec 9 6 Locking overhead dominates 3 0 0 6 12 18 24 30 36 42 48 Cores Problem: Locks can ruin performance the locks
Scalable Locking Adam Belay Problem: Locks can ruin performance 12 finds/sec 9 6 Locking overhead dominates 3 0 0 6 12 18 24 30 36 42 48 Cores Problem: Locks can ruin performance the locks
Resource management. Real-Time Systems. Resource management. Resource management
 Real-Time Systems Specification Implementation Verification Mutual exclusion is a general problem that exists at several levels in a real-time system. Shared resources internal to the the run-time system:
Real-Time Systems Specification Implementation Verification Mutual exclusion is a general problem that exists at several levels in a real-time system. Shared resources internal to the the run-time system:
Locks Chapter 4. Overview. Introduction Spin Locks. Queue locks. Roger Wattenhofer. Test-and-Set & Test-and-Test-and-Set Backoff lock
 Locks Chapter 4 Roger Wattenhofer ETH Zurich Distributed Computing www.disco.ethz.ch Overview Introduction Spin Locks Test-and-Set & Test-and-Test-and-Set Backoff lock Queue locks 4/2 1 Introduction: From
Locks Chapter 4 Roger Wattenhofer ETH Zurich Distributed Computing www.disco.ethz.ch Overview Introduction Spin Locks Test-and-Set & Test-and-Test-and-Set Backoff lock Queue locks 4/2 1 Introduction: From
Distributed Operating Systems
 Distributed Operating Systems Synchronization in Parallel Systems Marcus Völp 203 Topics Synchronization Locks Performance Distributed Operating Systems 203 Marcus Völp 2 Overview Introduction Hardware
Distributed Operating Systems Synchronization in Parallel Systems Marcus Völp 203 Topics Synchronization Locks Performance Distributed Operating Systems 203 Marcus Völp 2 Overview Introduction Hardware
Synchronization. Erik Hagersten Uppsala University Sweden. Components of a Synchronization Even. Need to introduce synchronization.
 Synchronization sum := thread_create Execution on a sequentially consistent shared-memory machine: Erik Hagersten Uppsala University Sweden while (sum < threshold) sum := sum while + (sum < threshold)
Synchronization sum := thread_create Execution on a sequentially consistent shared-memory machine: Erik Hagersten Uppsala University Sweden while (sum < threshold) sum := sum while + (sum < threshold)
CPSC/ECE 3220 Summer 2018 Exam 2 No Electronics.
 CPSC/ECE 3220 Summer 2018 Exam 2 No Electronics. Name: Write one of the words or terms from the following list into the blank appearing to the left of the appropriate definition. Note that there are more
CPSC/ECE 3220 Summer 2018 Exam 2 No Electronics. Name: Write one of the words or terms from the following list into the blank appearing to the left of the appropriate definition. Note that there are more
Models of concurrency & synchronization algorithms
 Models of concurrency & synchronization algorithms Lecture 3 of TDA383/DIT390 (Concurrent Programming) Carlo A. Furia Chalmers University of Technology University of Gothenburg SP3 2016/2017 Today s menu
Models of concurrency & synchronization algorithms Lecture 3 of TDA383/DIT390 (Concurrent Programming) Carlo A. Furia Chalmers University of Technology University of Gothenburg SP3 2016/2017 Today s menu
Priority Inheritance Spin Locks for Multiprocessor Real-Time Systems
 Priority Inheritance Spin Locks for Multiprocessor Real-Time Systems Cai-Dong Wang, Hiroaki Takada, and Ken Sakamura Department of Information Science, Faculty of Science, University of Tokyo 7-3-1 Hongo,
Priority Inheritance Spin Locks for Multiprocessor Real-Time Systems Cai-Dong Wang, Hiroaki Takada, and Ken Sakamura Department of Information Science, Faculty of Science, University of Tokyo 7-3-1 Hongo,
Spin Locks and Contention. Companion slides for The Art of Multiprocessor Programming by Maurice Herlihy & Nir Shavit
 Spin Locks and Contention Companion slides for The Art of Multiprocessor Programming by Maurice Herlihy & Nir Shavit Focus so far: Correctness and Progress Models Accurate (we never lied to you) But idealized
Spin Locks and Contention Companion slides for The Art of Multiprocessor Programming by Maurice Herlihy & Nir Shavit Focus so far: Correctness and Progress Models Accurate (we never lied to you) But idealized
Real-Time Systems. Lecture #4. Professor Jan Jonsson. Department of Computer Science and Engineering Chalmers University of Technology
 Real-Time Systems Lecture #4 Professor Jan Jonsson Department of Computer Science and Engineering Chalmers University of Technology Real-Time Systems Specification Resource management Mutual exclusion
Real-Time Systems Lecture #4 Professor Jan Jonsson Department of Computer Science and Engineering Chalmers University of Technology Real-Time Systems Specification Resource management Mutual exclusion
Introduction to OS Synchronization MOS 2.3
 Introduction to OS Synchronization MOS 2.3 Mahmoud El-Gayyar elgayyar@ci.suez.edu.eg Mahmoud El-Gayyar / Introduction to OS 1 Challenge How can we help processes synchronize with each other? E.g., how
Introduction to OS Synchronization MOS 2.3 Mahmoud El-Gayyar elgayyar@ci.suez.edu.eg Mahmoud El-Gayyar / Introduction to OS 1 Challenge How can we help processes synchronize with each other? E.g., how
CS 333 Introduction to Operating Systems. Class 3 Threads & Concurrency. Jonathan Walpole Computer Science Portland State University
 CS 333 Introduction to Operating Systems Class 3 Threads & Concurrency Jonathan Walpole Computer Science Portland State University 1 Process creation in UNIX All processes have a unique process id getpid(),
CS 333 Introduction to Operating Systems Class 3 Threads & Concurrency Jonathan Walpole Computer Science Portland State University 1 Process creation in UNIX All processes have a unique process id getpid(),
CS Advanced Operating Systems Structures and Implementation Lecture 8. Synchronization Continued. Goals for Today. Synchronization Scheduling
 Goals for Today CS194-24 Advanced Operating Systems Structures and Implementation Lecture 8 Synchronization Continued Synchronization Scheduling Interactive is important! Ask Questions! February 25 th,
Goals for Today CS194-24 Advanced Operating Systems Structures and Implementation Lecture 8 Synchronization Continued Synchronization Scheduling Interactive is important! Ask Questions! February 25 th,
Spin Locks and Contention Management
 Chapter 7 Spin Locks and Contention Management 7.1 Introduction We now turn our attention to the performance of mutual exclusion protocols on realistic architectures. Any mutual exclusion protocol poses
Chapter 7 Spin Locks and Contention Management 7.1 Introduction We now turn our attention to the performance of mutual exclusion protocols on realistic architectures. Any mutual exclusion protocol poses
Last Class: CPU Scheduling! Adjusting Priorities in MLFQ!
 Last Class: CPU Scheduling! Scheduling Algorithms: FCFS Round Robin SJF Multilevel Feedback Queues Lottery Scheduling Review questions: How does each work? Advantages? Disadvantages? Lecture 7, page 1
Last Class: CPU Scheduling! Scheduling Algorithms: FCFS Round Robin SJF Multilevel Feedback Queues Lottery Scheduling Review questions: How does each work? Advantages? Disadvantages? Lecture 7, page 1
Readers-Writers Problem. Implementing shared locks. shared locks (continued) Review: Test-and-set spinlock. Review: Test-and-set on alpha
 Review: Test-and-set spinlock. Review: Test-and-set on alpha") Readers-Writers Problem Implementing shared locks Multiple threads may access data - Readers will only observe, not modify data - Writers will change the data Goal: allow multiple readers or one single
Readers-Writers Problem Implementing shared locks Multiple threads may access data - Readers will only observe, not modify data - Writers will change the data Goal: allow multiple readers or one single
MULTIPROCESSORS AND THREAD LEVEL PARALLELISM
 UNIT III MULTIPROCESSORS AND THREAD LEVEL PARALLELISM 1. Symmetric Shared Memory Architectures: The Symmetric Shared Memory Architecture consists of several processors with a single physical memory shared
UNIT III MULTIPROCESSORS AND THREAD LEVEL PARALLELISM 1. Symmetric Shared Memory Architectures: The Symmetric Shared Memory Architecture consists of several processors with a single physical memory shared
Amdahl's Law in the Multicore Era
 Amdahl's Law in the Multicore Era Explain intuitively why in the asymmetric model, the speedup actually decreases past a certain point of increasing r. The limiting factor of these improved equations and
Amdahl's Law in the Multicore Era Explain intuitively why in the asymmetric model, the speedup actually decreases past a certain point of increasing r. The limiting factor of these improved equations and
Lecture: Coherence and Synchronization. Topics: synchronization primitives, consistency models intro (Sections )
") Lecture: Coherence and Synchronization Topics: synchronization primitives, consistency models intro (Sections 5.4-5.5) 1 Performance Improvements What determines performance on a multiprocessor: What fraction
Lecture: Coherence and Synchronization Topics: synchronization primitives, consistency models intro (Sections 5.4-5.5) 1 Performance Improvements What determines performance on a multiprocessor: What fraction
Multiprocessors II: CC-NUMA DSM. CC-NUMA for Large Systems
 Multiprocessors II: CC-NUMA DSM DSM cache coherence the hardware stuff Today s topics: what happens when we lose snooping new issues: global vs. local cache line state enter the directory issues of increasing
Multiprocessors II: CC-NUMA DSM DSM cache coherence the hardware stuff Today s topics: what happens when we lose snooping new issues: global vs. local cache line state enter the directory issues of increasing
Operating Systems. Lecture 4 - Concurrency and Synchronization. Master of Computer Science PUF - Hồ Chí Minh 2016/2017
 Operating Systems Lecture 4 - Concurrency and Synchronization Adrien Krähenbühl Master of Computer Science PUF - Hồ Chí Minh 2016/2017 Mutual exclusion Hardware solutions Semaphores IPC: Message passing
Operating Systems Lecture 4 - Concurrency and Synchronization Adrien Krähenbühl Master of Computer Science PUF - Hồ Chí Minh 2016/2017 Mutual exclusion Hardware solutions Semaphores IPC: Message passing
Shared Memory Programming Models I
 Shared Memory Programming Models I Peter Bastian / Stefan Lang Interdisciplinary Center for Scientific Computing (IWR) University of Heidelberg INF 368, Room 532 D-69120 Heidelberg phone: 06221/54-8264
Shared Memory Programming Models I Peter Bastian / Stefan Lang Interdisciplinary Center for Scientific Computing (IWR) University of Heidelberg INF 368, Room 532 D-69120 Heidelberg phone: 06221/54-8264
CS 333 Introduction to Operating Systems. Class 3 Threads & Concurrency. Jonathan Walpole Computer Science Portland State University
 CS 333 Introduction to Operating Systems Class 3 Threads & Concurrency Jonathan Walpole Computer Science Portland State University 1 The Process Concept 2 The Process Concept Process a program in execution
CS 333 Introduction to Operating Systems Class 3 Threads & Concurrency Jonathan Walpole Computer Science Portland State University 1 The Process Concept 2 The Process Concept Process a program in execution
Computer Engineering II Solution to Exercise Sheet Chapter 10
 Distributed Computing FS 2017 Prof. R. Wattenhofer Computer Engineering II Solution to Exercise Sheet Chapter 10 Quiz 1 Quiz a) The AtomicBoolean utilizes an atomic version of getandset() implemented in
Distributed Computing FS 2017 Prof. R. Wattenhofer Computer Engineering II Solution to Exercise Sheet Chapter 10 Quiz 1 Quiz a) The AtomicBoolean utilizes an atomic version of getandset() implemented in
Semaphore. Originally called P() and V() wait (S) { while S <= 0 ; // no-op S--; } signal (S) { S++; }
 and V() wait (S) { while S <= 0 ; // no-op S--; } signal (S) { S++; }") Semaphore Semaphore S integer variable Two standard operations modify S: wait() and signal() Originally called P() and V() Can only be accessed via two indivisible (atomic) operations wait (S) { while
Semaphore Semaphore S integer variable Two standard operations modify S: wait() and signal() Originally called P() and V() Can only be accessed via two indivisible (atomic) operations wait (S) { while
Concurrent programming: From theory to practice. Concurrent Algorithms 2015 Vasileios Trigonakis
 oncurrent programming: From theory to practice oncurrent Algorithms 2015 Vasileios Trigonakis From theory to practice Theoretical (design) Practical (design) Practical (implementation) 2 From theory to
oncurrent programming: From theory to practice oncurrent Algorithms 2015 Vasileios Trigonakis From theory to practice Theoretical (design) Practical (design) Practical (implementation) 2 From theory to
Mutual Exclusion Algorithms with Constant RMR Complexity and Wait-Free Exit Code
 Mutual Exclusion Algorithms with Constant RMR Complexity and Wait-Free Exit Code Rotem Dvir 1 and Gadi Taubenfeld 2 1 The Interdisciplinary Center, P.O.Box 167, Herzliya 46150, Israel rotem.dvir@gmail.com
Mutual Exclusion Algorithms with Constant RMR Complexity and Wait-Free Exit Code Rotem Dvir 1 and Gadi Taubenfeld 2 1 The Interdisciplinary Center, P.O.Box 167, Herzliya 46150, Israel rotem.dvir@gmail.com
Multiprocessor System. Multiprocessor Systems. Bus Based UMA. Types of Multiprocessors (MPs) Cache Consistency. Bus Based UMA. Chapter 8, 8.
 Cache Consistency. Bus Based UMA. Chapter 8, 8.") Multiprocessor System Multiprocessor Systems Chapter 8, 8.1 We will look at shared-memory multiprocessors More than one processor sharing the same memory A single CPU can only go so fast Use more than
Multiprocessor System Multiprocessor Systems Chapter 8, 8.1 We will look at shared-memory multiprocessors More than one processor sharing the same memory A single CPU can only go so fast Use more than
Multiprocessor Systems. COMP s1
 Multiprocessor Systems 1 Multiprocessor System We will look at shared-memory multiprocessors More than one processor sharing the same memory A single CPU can only go so fast Use more than one CPU to improve
Multiprocessor Systems 1 Multiprocessor System We will look at shared-memory multiprocessors More than one processor sharing the same memory A single CPU can only go so fast Use more than one CPU to improve
Operating Systems. Operating Systems Summer 2017 Sina Meraji U of T
 Operating Systems Operating Systems Summer 2017 Sina Meraji U of T More Special Instructions Swap (or Exchange) instruction Operates on two words atomically Can also be used to solve critical section problem
Operating Systems Operating Systems Summer 2017 Sina Meraji U of T More Special Instructions Swap (or Exchange) instruction Operates on two words atomically Can also be used to solve critical section problem
Introduction. Coherency vs Consistency. Lec-11. Multi-Threading Concepts: Coherency, Consistency, and Synchronization
 Lec-11 Multi-Threading Concepts: Coherency, Consistency, and Synchronization Coherency vs Consistency Memory coherency and consistency are major concerns in the design of shared-memory systems. Consistency
Lec-11 Multi-Threading Concepts: Coherency, Consistency, and Synchronization Coherency vs Consistency Memory coherency and consistency are major concerns in the design of shared-memory systems. Consistency
Reactive Synchronization Algorithms for Multiprocessors
 Synchronization Algorithms for Multiprocessors Beng-Hong Lim and Anant Agarwal Laboratory for Computer Science Massachusetts Institute of Technology Cambridge, MA 039 Abstract Synchronization algorithms
Synchronization Algorithms for Multiprocessors Beng-Hong Lim and Anant Agarwal Laboratory for Computer Science Massachusetts Institute of Technology Cambridge, MA 039 Abstract Synchronization algorithms
Chapter 8. Multiprocessors. In-Cheol Park Dept. of EE, KAIST
 Chapter 8. Multiprocessors In-Cheol Park Dept. of EE, KAIST Can the rapid rate of uniprocessor performance growth be sustained indefinitely? If the pace does slow down, multiprocessor architectures will
Chapter 8. Multiprocessors In-Cheol Park Dept. of EE, KAIST Can the rapid rate of uniprocessor performance growth be sustained indefinitely? If the pace does slow down, multiprocessor architectures will
Lecture: Coherence, Synchronization. Topics: directory-based coherence, synchronization primitives (Sections )
") Lecture: Coherence, Synchronization Topics: directory-based coherence, synchronization primitives (Sections 5.1-5.5) 1 Cache Coherence Protocols Directory-based: A single location (directory) keeps track
Lecture: Coherence, Synchronization Topics: directory-based coherence, synchronization primitives (Sections 5.1-5.5) 1 Cache Coherence Protocols Directory-based: A single location (directory) keeps track
Threading and Synchronization. Fahd Albinali
 Threading and Synchronization Fahd Albinali Parallelism Parallelism and Pseudoparallelism Why parallelize? Finding parallelism Advantages: better load balancing, better scalability Disadvantages: process/thread
Threading and Synchronization Fahd Albinali Parallelism Parallelism and Pseudoparallelism Why parallelize? Finding parallelism Advantages: better load balancing, better scalability Disadvantages: process/thread
Chapter 5: Process Synchronization. Operating System Concepts 9 th Edition
 Chapter 5: Process Synchronization Silberschatz, Galvin and Gagne 2013 Chapter 5: Process Synchronization Background The Critical-Section Problem Peterson s Solution Synchronization Hardware Mutex Locks
Chapter 5: Process Synchronization Silberschatz, Galvin and Gagne 2013 Chapter 5: Process Synchronization Background The Critical-Section Problem Peterson s Solution Synchronization Hardware Mutex Locks
Spin Locks and Contention
 Spin Locks and Contention Companion slides for The Art of Multiprocessor Programming by Maurice Herlihy & Nir Shavit Modified for Software1 students by Lior Wolf and Mati Shomrat Kinds of Architectures
Spin Locks and Contention Companion slides for The Art of Multiprocessor Programming by Maurice Herlihy & Nir Shavit Modified for Software1 students by Lior Wolf and Mati Shomrat Kinds of Architectures
G52CON: Concepts of Concurrency
 G52CON: Concepts of Concurrency Lecture 11: Semaphores I" Brian Logan School of Computer Science bsl@cs.nott.ac.uk Outline of this lecture" problems with Peterson s algorithm semaphores implementing semaphores
G52CON: Concepts of Concurrency Lecture 11: Semaphores I" Brian Logan School of Computer Science bsl@cs.nott.ac.uk Outline of this lecture" problems with Peterson s algorithm semaphores implementing semaphores
Introduction to Operating Systems
 Introduction to Operating Systems Lecture 4: Process Synchronization MING GAO SE@ecnu (for course related communications) mgao@sei.ecnu.edu.cn Mar. 18, 2015 Outline 1 The synchronization problem 2 A roadmap
Introduction to Operating Systems Lecture 4: Process Synchronization MING GAO SE@ecnu (for course related communications) mgao@sei.ecnu.edu.cn Mar. 18, 2015 Outline 1 The synchronization problem 2 A roadmap
C09: Process Synchronization
 CISC 7310X C09: Process Synchronization Hui Chen Department of Computer & Information Science CUNY Brooklyn College 3/29/2018 CUNY Brooklyn College 1 Outline Race condition and critical regions The bounded
CISC 7310X C09: Process Synchronization Hui Chen Department of Computer & Information Science CUNY Brooklyn College 3/29/2018 CUNY Brooklyn College 1 Outline Race condition and critical regions The bounded
Whatever can go wrong will go wrong. attributed to Edward A. Murphy. Murphy was an optimist. authors of lock-free programs LOCK FREE KERNEL
 Whatever can go wrong will go wrong. attributed to Edward A. Murphy Murphy was an optimist. authors of lock-free programs LOCK FREE KERNEL 251 Literature Maurice Herlihy and Nir Shavit. The Art of Multiprocessor
Whatever can go wrong will go wrong. attributed to Edward A. Murphy Murphy was an optimist. authors of lock-free programs LOCK FREE KERNEL 251 Literature Maurice Herlihy and Nir Shavit. The Art of Multiprocessor
Non-blocking Array-based Algorithms for Stacks and Queues. Niloufar Shafiei
 Non-blocking Array-based Algorithms for Stacks and Queues Niloufar Shafiei Outline Introduction Concurrent stacks and queues Contributions New algorithms New algorithms using bounded counter values Correctness
Non-blocking Array-based Algorithms for Stacks and Queues Niloufar Shafiei Outline Introduction Concurrent stacks and queues Contributions New algorithms New algorithms using bounded counter values Correctness
Chapter 5. Multiprocessors and Thread-Level Parallelism
 Computer Architecture A Quantitative Approach, Fifth Edition Chapter 5 Multiprocessors and Thread-Level Parallelism 1 Introduction Thread-Level parallelism Have multiple program counters Uses MIMD model
Computer Architecture A Quantitative Approach, Fifth Edition Chapter 5 Multiprocessors and Thread-Level Parallelism 1 Introduction Thread-Level parallelism Have multiple program counters Uses MIMD model
Today: Synchronization. Recap: Synchronization
 Today: Synchronization Synchronization Mutual exclusion Critical sections Example: Too Much Milk Locks Synchronization primitives are required to ensure that only one thread executes in a critical section
Today: Synchronization Synchronization Mutual exclusion Critical sections Example: Too Much Milk Locks Synchronization primitives are required to ensure that only one thread executes in a critical section
Locking. Part 2, Chapter 11. Roger Wattenhofer. ETH Zurich Distributed Computing
 Locking Part 2, Chapter 11 Roger Wattenhofer ETH Zurich Distributed Computing www.disco.ethz.ch Overview Introduction Spin Locks Test-and-Set & Test-and-Test-and-Set Backoff lock Queue locks 11/2 Introduction:
Locking Part 2, Chapter 11 Roger Wattenhofer ETH Zurich Distributed Computing www.disco.ethz.ch Overview Introduction Spin Locks Test-and-Set & Test-and-Test-and-Set Backoff lock Queue locks 11/2 Introduction:
CSE 451: Operating Systems Winter Lecture 7 Synchronization. Steve Gribble. Synchronization. Threads cooperate in multithreaded programs
 CSE 451: Operating Systems Winter 2005 Lecture 7 Synchronization Steve Gribble Synchronization Threads cooperate in multithreaded programs to share resources, access shared data structures e.g., threads
CSE 451: Operating Systems Winter 2005 Lecture 7 Synchronization Steve Gribble Synchronization Threads cooperate in multithreaded programs to share resources, access shared data structures e.g., threads
CS 162 Operating Systems and Systems Programming Professor: Anthony D. Joseph Spring Lecture 8: Semaphores, Monitors, & Condition Variables
 CS 162 Operating Systems and Systems Programming Professor: Anthony D. Joseph Spring 2004 Lecture 8: Semaphores, Monitors, & Condition Variables 8.0 Main Points: Definition of semaphores Example of use
CS 162 Operating Systems and Systems Programming Professor: Anthony D. Joseph Spring 2004 Lecture 8: Semaphores, Monitors, & Condition Variables 8.0 Main Points: Definition of semaphores Example of use
l12 handout.txt l12 handout.txt Printed by Michael Walfish Feb 24, 11 12:57 Page 1/5 Feb 24, 11 12:57 Page 2/5
 Feb 24, 11 12:57 Page 1/5 1 Handout for CS 372H 2 Class 12 3 24 February 2011 4 5 1. CAS / CMPXCHG 6 7 Useful operation: compare and swap, known as CAS. Says: "atomically 8 check whether a given memory
Feb 24, 11 12:57 Page 1/5 1 Handout for CS 372H 2 Class 12 3 24 February 2011 4 5 1. CAS / CMPXCHG 6 7 Useful operation: compare and swap, known as CAS. Says: "atomically 8 check whether a given memory
Parallel Computer Architecture Spring Distributed Shared Memory Architectures & Directory-Based Memory Coherence
 Parallel Computer Architecture Spring 2018 Distributed Shared Memory Architectures & Directory-Based Memory Coherence Nikos Bellas Computer and Communications Engineering Department University of Thessaly
Parallel Computer Architecture Spring 2018 Distributed Shared Memory Architectures & Directory-Based Memory Coherence Nikos Bellas Computer and Communications Engineering Department University of Thessaly
CHAPTER 6: PROCESS SYNCHRONIZATION
 CHAPTER 6: PROCESS SYNCHRONIZATION The slides do not contain all the information and cannot be treated as a study material for Operating System. Please refer the text book for exams. TOPICS Background
CHAPTER 6: PROCESS SYNCHRONIZATION The slides do not contain all the information and cannot be treated as a study material for Operating System. Please refer the text book for exams. TOPICS Background
Spin Locks and Contention. Companion slides for The Art of Multiprocessor Programming by Maurice Herlihy & Nir Shavit
 Spin Locks and Contention Companion slides for The Art of Multiprocessor Programming by Maurice Herlihy & Nir Shavit Real world concurrency Understanding hardware architecture What is contention How to
Spin Locks and Contention Companion slides for The Art of Multiprocessor Programming by Maurice Herlihy & Nir Shavit Real world concurrency Understanding hardware architecture What is contention How to
Learning Outcomes. Concurrency and Synchronisation. Textbook. Concurrency Example. Inter- Thread and Process Communication. Sections & 2.
 Learning Outcomes Concurrency and Synchronisation Understand concurrency is an issue in operating systems and multithreaded applications Know the concept of a critical region. Understand how mutual exclusion
Learning Outcomes Concurrency and Synchronisation Understand concurrency is an issue in operating systems and multithreaded applications Know the concept of a critical region. Understand how mutual exclusion
Lecture. DM510 - Operating Systems, Weekly Notes, Week 11/12, 2018
 Lecture In the lecture on March 13 we will mainly discuss Chapter 6 (Process Scheduling). Examples will be be shown for the simulation of the Dining Philosopher problem, a solution with monitors will also
Lecture In the lecture on March 13 we will mainly discuss Chapter 6 (Process Scheduling). Examples will be be shown for the simulation of the Dining Philosopher problem, a solution with monitors will also
Concurrency and Synchronisation
 Concurrency and Synchronisation 1 Learning Outcomes Understand concurrency is an issue in operating systems and multithreaded applications Know the concept of a critical region. Understand how mutual exclusion
Concurrency and Synchronisation 1 Learning Outcomes Understand concurrency is an issue in operating systems and multithreaded applications Know the concept of a critical region. Understand how mutual exclusion
CS 333 Introduction to Operating Systems Class 4 Concurrent Programming and Synchronization Primitives
 CS 333 Introduction to Operating Systems Class 4 Concurrent Programming and Synchronization Primitives Jonathan Walpole Computer Science Portland State University 1 What does a typical thread API look
CS 333 Introduction to Operating Systems Class 4 Concurrent Programming and Synchronization Primitives Jonathan Walpole Computer Science Portland State University 1 What does a typical thread API look
Lesson 6: Process Synchronization
 Lesson 6: Process Synchronization Chapter 5: Process Synchronization Background The Critical-Section Problem Peterson s Solution Synchronization Hardware Mutex Locks Semaphores Classic Problems of Synchronization
Lesson 6: Process Synchronization Chapter 5: Process Synchronization Background The Critical-Section Problem Peterson s Solution Synchronization Hardware Mutex Locks Semaphores Classic Problems of Synchronization
SHARED-MEMORY COMMUNICATION
 SHARED-MEMORY COMMUNICATION IMPLICITELY VIA MEMORY PROCESSORS SHARE SOME MEMORY COMMUNICATION IS IMPLICIT THROUGH LOADS AND STORES NEED TO SYNCHRONIZE NEED TO KNOW HOW THE HARDWARE INTERLEAVES ACCESSES
SHARED-MEMORY COMMUNICATION IMPLICITELY VIA MEMORY PROCESSORS SHARE SOME MEMORY COMMUNICATION IS IMPLICIT THROUGH LOADS AND STORES NEED TO SYNCHRONIZE NEED TO KNOW HOW THE HARDWARE INTERLEAVES ACCESSES
EN164: Design of Computing Systems Lecture 34: Misc Multi-cores and Multi-processors
 EN164: Design of Computing Systems Lecture 34: Misc Multi-cores and Multi-processors Professor Sherief Reda http://scale.engin.brown.edu Electrical Sciences and Computer Engineering School of Engineering
EN164: Design of Computing Systems Lecture 34: Misc Multi-cores and Multi-processors Professor Sherief Reda http://scale.engin.brown.edu Electrical Sciences and Computer Engineering School of Engineering
Programming Languages
 Programming Languages Tevfik Koşar Lecture - XXVI April 27 th, 2006 1 Roadmap Shared Memory Synchronization Spin Locks Barriers Semaphores Monitors 2 1 Memory Architectures Distributed Memory Shared Memory
Programming Languages Tevfik Koşar Lecture - XXVI April 27 th, 2006 1 Roadmap Shared Memory Synchronization Spin Locks Barriers Semaphores Monitors 2 1 Memory Architectures Distributed Memory Shared Memory
EE382 Processor Design. Processor Issues for MP
 EE382 Processor Design Winter 1998 Chapter 8 Lectures Multiprocessors, Part I EE 382 Processor Design Winter 98/99 Michael Flynn 1 Processor Issues for MP Initialization Interrupts Virtual Memory TLB Coherency
EE382 Processor Design Winter 1998 Chapter 8 Lectures Multiprocessors, Part I EE 382 Processor Design Winter 98/99 Michael Flynn 1 Processor Issues for MP Initialization Interrupts Virtual Memory TLB Coherency
M4 Parallelism. Implementation of Locks Cache Coherence
 M4 Parallelism Implementation of Locks Cache Coherence Outline Parallelism Flynn s classification Vector Processing Subword Parallelism Symmetric Multiprocessors, Distributed Memory Machines Shared Memory
M4 Parallelism Implementation of Locks Cache Coherence Outline Parallelism Flynn s classification Vector Processing Subword Parallelism Symmetric Multiprocessors, Distributed Memory Machines Shared Memory
Multiprocessor Cache Coherence. Chapter 5. Memory System is Coherent If... From ILP to TLP. Enforcing Cache Coherence. Multiprocessor Types
 Chapter 5 Multiprocessor Cache Coherence Thread-Level Parallelism 1: read 2: read 3: write??? 1 4 From ILP to TLP Memory System is Coherent If... ILP became inefficient in terms of Power consumption Silicon
Chapter 5 Multiprocessor Cache Coherence Thread-Level Parallelism 1: read 2: read 3: write??? 1 4 From ILP to TLP Memory System is Coherent If... ILP became inefficient in terms of Power consumption Silicon
Synchronization. CS61, Lecture 18. Prof. Stephen Chong November 3, 2011
 Synchronization CS61, Lecture 18 Prof. Stephen Chong November 3, 2011 Announcements Assignment 5 Tell us your group by Sunday Nov 6 Due Thursday Nov 17 Talks of interest in next two days Towards Predictable,
Synchronization CS61, Lecture 18 Prof. Stephen Chong November 3, 2011 Announcements Assignment 5 Tell us your group by Sunday Nov 6 Due Thursday Nov 17 Talks of interest in next two days Towards Predictable,