ASPERA HIGH-SPEED TRANSFER. Moving the world s data at maximum speed
|
|
|
- Ariel May
- 6 years ago
- Views:
Transcription

1 ASPERA HIGH-SPEED TRANSFER Moving the world s data at maximum speed
2 ASPERA HIGH-SPEED FILE TRANSFER 80 GBIT/S OVER IP USING DPDK Performance, Code, and Architecture Charles Shiflett Developer of next-generation FASP us. IBM. com asperasoft.com 2
3 RAPID PROTYPING OF BARE METAL SOLUTIONS Benefits of using DPDK Lightweight API that exposes Network and Acceleration Cards Rapid Iteration on high performance transport designs as compared to equivalent code developed as Kernel Module Set of performance best practices - Time, Locking, Memory Alignment, and Synchronization - Avoids libc and system call interaction when possible NUMA aware solution Framework for High Performance Userland Direct I/O 3
4 FASP NX DESIGN GOAL Goal is to bring industry closer to the data they are using both within the data center and across the globe. Effectively utilize PCIe based IO on Intel Server platform. Solve storage bottleneck using Direct I/O w/ multiple controllers Solve network bottleneck using DPDK and link aggregation Provide a secure transport solution using Intel AES-NI GCM Significantly reduce time spent getting your data set to the CPU 4


5 HARDWARE CONFIGURATION 2x Intel Xeon E v3 5x Intel DC P3700 NVMe SSD 2x Intel XL GbE Ethernet QSFP+ 5
6 ASPERA S MISSION Creating next-generation transport technologies that move the world s digital assets at maximum speed, regardless of file size, transfer distance and network conditions. 6

7 CHALLENGES WITH TCP AND ALTERNATIVE TECHNOLOGIES Distance degrades conditions on all networks Latency (or Round Trip Times) increase Packet losses increase Fast networks just as prone to degradation TCP performance degrades with distance Throughput bottleneck becomes more severe with increased latency and packet loss TCP does not scale with bandwidth TCP designed for low bandwidth Adding more bandwidth does not improve throughput Alternative Technologies TCP-based - Network latency and packet loss must be low UDP traffic blasters - Inefficient and waste bandwidth Data caching - Inappropriate for many large file transfer workflows Modified TCP - Improves on TCP performance but insufficient for fast networks Data compression - Time consuming and impractical for certain file types CDNs & co-lo build outs - High overhead and expensive to scale 7

8 FASP : HIGH-PERFORMANCE TRANSPORT Maximum transfer speed Optimal end-to-end throughput efficiency Transfer performance scales with bandwidth independent of transfer distance and resilient to packet loss Congestion Avoidance and Policy Control Automatic, full utilization of available bandwidth On-the-fly prioritization and bandwidth allocation Uncompromising security and reliability Secure, user/endpoint authentication AES-128 cryptography in transit and at-rest Scalable management, monitoring and control Real-time progress, performance and bandwidth utilization Detailed transfer history, logging, and manifest Low Overhead Less than 0.1% overhead on 30% packet loss High performance with large files or large sets of small files Resulting in Transfers up to thousands of times faster than FTP Precise and predictable transfer times Extreme scalability (concurrency and throughput) 8
 FASP (Intel Xeon E5-2697 v3) Results from SC 14 showing the relative performance of Network Transfer")
9 LAN TRANSFER RESULTS IN GBIT PER SECOND Disk to Disk Wire Utilization w/o disk 10 0 SSH AES-128 CTR FTP iperf FASP 4x10Gbit (Intel Xeon E v2) FASP (Intel Xeon E v3) Results from SC 14 showing the relative performance of Network Transfer Technologies 9

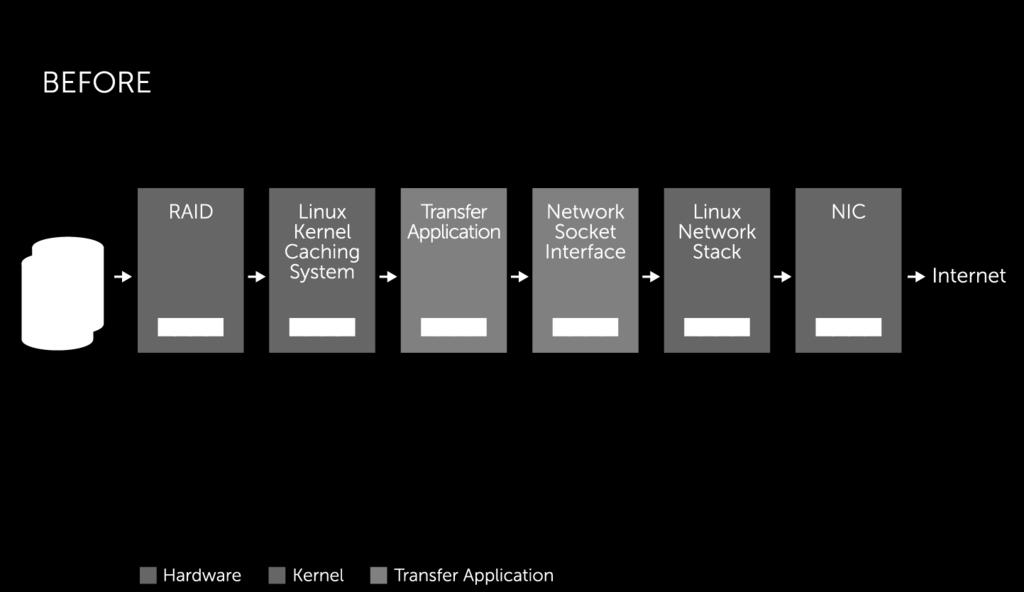
10 TYPICAL TRANSFER APPLICATION 10

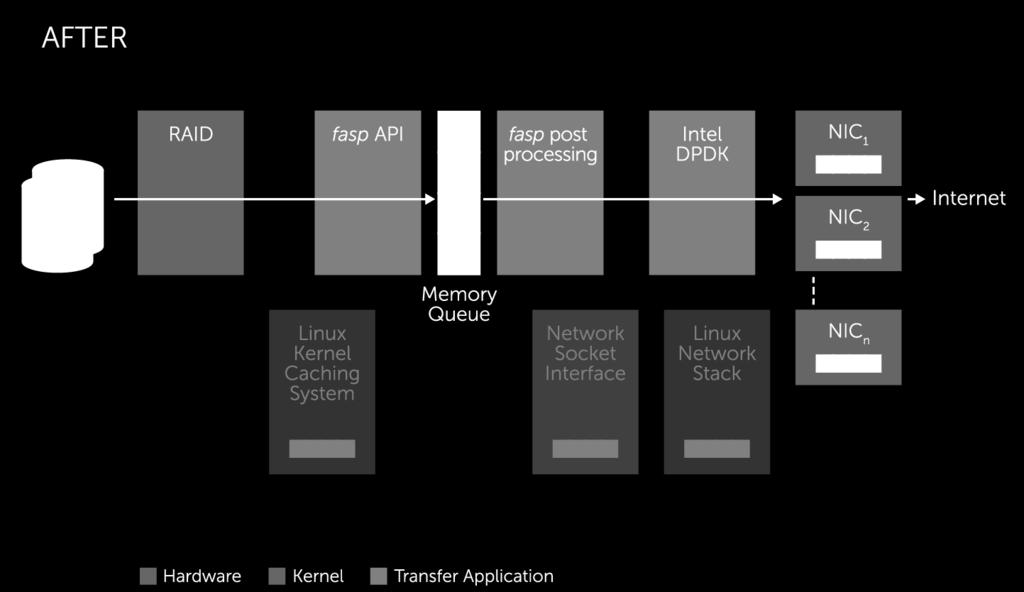
11 ASPERA NEXT GENERATION FASP 11
12 AVOIDING STALLS Synchronization primitives aligned to cache-line, lockless. Example for circular buffer queues; Dequeue, claim block: block_id = sync_fetch_and_add ( &sess->block_tail, 1 ) % block_count; Dequeue, consume block: while (! sync_val_compare_and_swap( &sess->block[block_id].state, 0, 1) ) PAUSE; Zero copy paradigm critical to good memory performance. Memory copies are VERY expensive! Memory copies should be avoided at all costs, writes to Memory must be page aligned to avoid read of destination cacheline Solution is to operate on datasets which fit into L3 cache. New tools provide better insight into L3 cache utilization such that code can be optimized. Low latency direct I/O. Intel DDIO critical in bringing data into L3 from Storage, Network Adapters, and PCIe Accelerators. DPDK provides framework for operating on data streamed into L3 cache Avoid TLB misses by using Hugepages Avoid NUMA issues and minimize thread preemption. Userland IO drivers where possible. 12


13 EXAMPLE OF ALIGNED/UNALIGNED MEMORY COPY 5.7 GB/S copy performance constrained by RFO 9.0 GB/s copy avoids RFO, close to per core limit * Per channel results via Intel Performance Counter Monitor 13
 Nb_rx_desc %")
14 OPTIMIZING NETWORK THROUGHPUT Create network queues which fit into L3. Each queue tied to a specific core. Experiment with values to minimize memory, while retaining useful properties: Should support bulk allocation MAX_RX_BURST < rx_free_thresh < nb_rx_desc (set when assigning queue to port) Nb_rx_desc % rx_free_thresh == 0 Ideally pkts_in_cache % nb_pkts == 0 and nb_pkts == 2^n-1 PTHRESH/HTHRESH/WTHRESH values feel like black magic, but can have a huge effect on performance. Start by copying values from example applications. 14
15 IMPROVING STORAGE THROUGHPUT Traditional storage is built around the idea of moving slow data from disk to memory and then from memory to application. Memory is used to cache data to improve access speeds. Cache structure quickly becomes a bottleneck as transfer speeds exceed 10 gbit/s. While individual spinning disks are slow, JBOD s of 100 s of disk have very high aggregate bandwidth Modern SSDs (especially NVMe) is very fast. Two solutions for fast data Use XFS with direct IO (and/or MMAP) Have shown performance at about 40gbit/s with hardware raid and direct attach disks. Have shown performance at about 70gbit/s with NVMe SSD. Limited by how many devices you can connect to PCIe data link. Clustered parallel storage Aspera is targeting IBM GPFS (Spectrum) or Lustre based solutions Individual nodes can be slow, but by aggregating nodes high performance is achieved Both offer direct I/O solutions 15
16 DC P3700 PERFORMANCE (SINGLE DRIVE) MB/s MB/s MB/s Write Synchronous Read Async Read (AIO) Performance relative to block size (SI Units in MB) 16
17 ENCRYPTION IS NOT A BOTTLENECK WITH HW AES-GCM 2.5 AES 128 GCM Encryption Rate in GB/s per Core Core i7 X GHz Xeon E v2 2.60GHz Xeon E v3 2.60GHz 17
18 NEW ON THE WIRE PROTOCOL Built around AES-128 GCM, which is similar to DTLS ( Datagram TLS ). AES-128 GCM { uint64 IV; uint8[] payload; uint8[16] MAC; } DTLSRecord { ContentType type; ProtocolVersion version; uint16 epoch; uint48 sequence_number; uint16 length; uint8_t[length] payload; } MAC { uint8[16] hash; } FASP4 { uint16 stream_id; uint8 ver_and_pkt_type; uint40 sequence_number; uint8[] payload; uint8[16] hash; // optional } In the same way it is possible to encapsulate FASP NX header in UDP, will also support Encapsulating FASP4 in DTLS. 18


19 EXAMPLE TRANSFER SESSION USING FASP NX API 19
20 FASP NX API S Native FASP NX API Share hugepage sized regions of memory with client application Usable from VM or Native machine Enables Zero Copy transfer solutions of non file data Dynamically set rate policy, destination IP, and so on. Traditional Aspera (ascp) command line tools Similar command line to SCP, with FASP NX performance. Existing Aspera API Faspmgmt Web Services Rest based Queries 20
21 FUTURE DIRECTION Aspera s Goal: Transfer Solution to Petascale Datasets - 1 SI Terabyte in 2 Minutes - 1 SI Petabyte in 1⅜ Days - Performance improvements expected to scale relative to PCIe interconnect. Better integration with storage systems - Take advantage of native APIs to avoid kernel cache. Better integration with network hardware - Expected to show 100gbit/s transfers using Mellanox ConnectX -4 - Query network switch and routers? Support wider use cases - Compression, Forward Error Correcting Codecs, Berkeley Sockets API 21


22 THANK YOU CHARLES SHIFLETT us.ibm.com
ASPERA HIGH-SPEED TRANSFER. Moving the world s data at maximum speed
 ASPERA HIGH-SPEED TRANSFER Moving the world s data at maximum speed ASPERA HIGH-SPEED FILE TRANSFER Aspera FASP Data Transfer at 80 Gbps Elimina8ng tradi8onal bo
ASPERA HIGH-SPEED TRANSFER Moving the world s data at maximum speed ASPERA HIGH-SPEED FILE TRANSFER Aspera FASP Data Transfer at 80 Gbps Elimina8ng tradi8onal bo
Disclaimer This presentation may contain product features that are currently under development. This overview of new technology represents no commitme
 NET1343BU NSX Performance Samuel Kommu #VMworld #NET1343BU Disclaimer This presentation may contain product features that are currently under development. This overview of new technology represents no
NET1343BU NSX Performance Samuel Kommu #VMworld #NET1343BU Disclaimer This presentation may contain product features that are currently under development. This overview of new technology represents no
Fast packet processing in the cloud. Dániel Géhberger Ericsson Research
 Fast packet processing in the cloud Dániel Géhberger Ericsson Research Outline Motivation Service chains Hardware related topics, acceleration Virtualization basics Software performance and acceleration
Fast packet processing in the cloud Dániel Géhberger Ericsson Research Outline Motivation Service chains Hardware related topics, acceleration Virtualization basics Software performance and acceleration
Application Acceleration Beyond Flash Storage
 Application Acceleration Beyond Flash Storage Session 303C Mellanox Technologies Flash Memory Summit July 2014 Accelerating Applications, Step-by-Step First Steps Make compute fast Moore s Law Make storage
Application Acceleration Beyond Flash Storage Session 303C Mellanox Technologies Flash Memory Summit July 2014 Accelerating Applications, Step-by-Step First Steps Make compute fast Moore s Law Make storage
Learning with Purpose
 Network Measurement for 100Gbps Links Using Multicore Processors Xiaoban Wu, Dr. Peilong Li, Dr. Yongyi Ran, Prof. Yan Luo Department of Electrical and Computer Engineering University of Massachusetts
Network Measurement for 100Gbps Links Using Multicore Processors Xiaoban Wu, Dr. Peilong Li, Dr. Yongyi Ran, Prof. Yan Luo Department of Electrical and Computer Engineering University of Massachusetts
RoCE vs. iwarp Competitive Analysis
 WHITE PAPER February 217 RoCE vs. iwarp Competitive Analysis Executive Summary...1 RoCE s Advantages over iwarp...1 Performance and Benchmark Examples...3 Best Performance for Virtualization...5 Summary...6
WHITE PAPER February 217 RoCE vs. iwarp Competitive Analysis Executive Summary...1 RoCE s Advantages over iwarp...1 Performance and Benchmark Examples...3 Best Performance for Virtualization...5 Summary...6
TRANSFORMING CLOUD INFRASTRUCTURE TO SUPPORT BIG DATA STORAGE AND WORKFLOWS
 TRANSFORMING CLOUD INFRASTRUCTURE TO SUPPORT BIG DATA STORAGE AND WORKFLOWS PRESENTER AND AGENDA PRESENTER Jay Migliaccio Director Cloud platforms and Services jay@asperasoft.com AGENDA Aspera Intro Big
TRANSFORMING CLOUD INFRASTRUCTURE TO SUPPORT BIG DATA STORAGE AND WORKFLOWS PRESENTER AND AGENDA PRESENTER Jay Migliaccio Director Cloud platforms and Services jay@asperasoft.com AGENDA Aspera Intro Big
Scaling Internet TV Content Delivery ALEX GUTARIN DIRECTOR OF ENGINEERING, NETFLIX
 Scaling Internet TV Content Delivery ALEX GUTARIN DIRECTOR OF ENGINEERING, NETFLIX Inventing Internet TV Available in more than 190 countries 104+ million subscribers Lots of Streaming == Lots of Traffic
Scaling Internet TV Content Delivery ALEX GUTARIN DIRECTOR OF ENGINEERING, NETFLIX Inventing Internet TV Available in more than 190 countries 104+ million subscribers Lots of Streaming == Lots of Traffic
OpenFlow Software Switch & Intel DPDK. performance analysis
 OpenFlow Software Switch & Intel DPDK performance analysis Agenda Background Intel DPDK OpenFlow 1.3 implementation sketch Prototype design and setup Results Future work, optimization ideas OF 1.3 prototype
OpenFlow Software Switch & Intel DPDK performance analysis Agenda Background Intel DPDK OpenFlow 1.3 implementation sketch Prototype design and setup Results Future work, optimization ideas OF 1.3 prototype
Ultra high-speed transmission technology for wide area data movement
 Ultra high-speed transmission technology for wide area data movement Michelle Munson, president & co-founder Aspera Outline Business motivation Moving ever larger file sets over commodity IP networks (public,
Ultra high-speed transmission technology for wide area data movement Michelle Munson, president & co-founder Aspera Outline Business motivation Moving ever larger file sets over commodity IP networks (public,
End-to-End Adaptive Packet Aggregation for High-Throughput I/O Bus Network Using Ethernet
 Hot Interconnects 2014 End-to-End Adaptive Packet Aggregation for High-Throughput I/O Bus Network Using Ethernet Green Platform Research Laboratories, NEC, Japan J. Suzuki, Y. Hayashi, M. Kan, S. Miyakawa,
Hot Interconnects 2014 End-to-End Adaptive Packet Aggregation for High-Throughput I/O Bus Network Using Ethernet Green Platform Research Laboratories, NEC, Japan J. Suzuki, Y. Hayashi, M. Kan, S. Miyakawa,
A High-Performance Storage and Ultra- High-Speed File Transfer Solution for Collaborative Life Sciences Research
 A High-Performance Storage and Ultra- High-Speed File Transfer Solution for Collaborative Life Sciences Research Storage Platforms with Aspera Overview A growing number of organizations with data-intensive
A High-Performance Storage and Ultra- High-Speed File Transfer Solution for Collaborative Life Sciences Research Storage Platforms with Aspera Overview A growing number of organizations with data-intensive
Meltdown and Spectre Interconnect Performance Evaluation Jan Mellanox Technologies
 Meltdown and Spectre Interconnect Evaluation Jan 2018 1 Meltdown and Spectre - Background Most modern processors perform speculative execution This speculation can be measured, disclosing information about
Meltdown and Spectre Interconnect Evaluation Jan 2018 1 Meltdown and Spectre - Background Most modern processors perform speculative execution This speculation can be measured, disclosing information about
Network Design Considerations for Grid Computing
 Network Design Considerations for Grid Computing Engineering Systems How Bandwidth, Latency, and Packet Size Impact Grid Job Performance by Erik Burrows, Engineering Systems Analyst, Principal, Broadcom
Network Design Considerations for Grid Computing Engineering Systems How Bandwidth, Latency, and Packet Size Impact Grid Job Performance by Erik Burrows, Engineering Systems Analyst, Principal, Broadcom
TLDK Overview. Transport Layer Development Kit Keith Wiles April Contributions from Ray Kinsella & Konstantin Ananyev
 TLDK Overview Transport Layer Development Kit Keith Wiles April 2017 Contributions from Ray Kinsella & Konstantin Ananyev Notices and Disclaimers Intel technologies features and benefits depend on system
TLDK Overview Transport Layer Development Kit Keith Wiles April 2017 Contributions from Ray Kinsella & Konstantin Ananyev Notices and Disclaimers Intel technologies features and benefits depend on system
TLDK Overview. Transport Layer Development Kit Ray Kinsella February ray.kinsella [at] intel.com IRC: mortderire
![TLDK Overview. Transport Layer Development Kit Ray Kinsella February ray.kinsella [at] intel.com IRC: mortderire](/thumbs/90/102424037.jpg "TLDK Overview. Transport Layer Development Kit Ray Kinsella February ray.kinsella [at] intel.com IRC: mortderire") TLDK Overview Transport Layer Development Kit Ray Kinsella February 2017 Email : ray.kinsella [at] intel.com IRC: mortderire Contributions from Keith Wiles & Konstantin Ananyev Legal Disclaimer General
TLDK Overview Transport Layer Development Kit Ray Kinsella February 2017 Email : ray.kinsella [at] intel.com IRC: mortderire Contributions from Keith Wiles & Konstantin Ananyev Legal Disclaimer General
IBM POWER8 100 GigE Adapter Best Practices
 Introduction IBM POWER8 100 GigE Adapter Best Practices With higher network speeds in new network adapters, achieving peak performance requires careful tuning of the adapters and workloads using them.
Introduction IBM POWER8 100 GigE Adapter Best Practices With higher network speeds in new network adapters, achieving peak performance requires careful tuning of the adapters and workloads using them.
Networking at the Speed of Light
 Networking at the Speed of Light Dror Goldenberg VP Software Architecture MaRS Workshop April 2017 Cloud The Software Defined Data Center Resource virtualization Efficient services VM, Containers uservices
Networking at the Speed of Light Dror Goldenberg VP Software Architecture MaRS Workshop April 2017 Cloud The Software Defined Data Center Resource virtualization Efficient services VM, Containers uservices
Ziye Yang. NPG, DCG, Intel
 Ziye Yang NPG, DCG, Intel Agenda What is SPDK? Accelerated NVMe-oF via SPDK Conclusion 2 Agenda What is SPDK? Accelerated NVMe-oF via SPDK Conclusion 3 Storage Performance Development Kit Scalable and
Ziye Yang NPG, DCG, Intel Agenda What is SPDK? Accelerated NVMe-oF via SPDK Conclusion 2 Agenda What is SPDK? Accelerated NVMe-oF via SPDK Conclusion 3 Storage Performance Development Kit Scalable and
Evolution of the netmap architecture
 L < > T H local Evolution of the netmap architecture Evolution of the netmap architecture -- Page 1/21 Evolution of the netmap architecture Luigi Rizzo, Università di Pisa http://info.iet.unipi.it/~luigi/vale/
L < > T H local Evolution of the netmap architecture Evolution of the netmap architecture -- Page 1/21 Evolution of the netmap architecture Luigi Rizzo, Università di Pisa http://info.iet.unipi.it/~luigi/vale/
2017 Storage Developer Conference. Mellanox Technologies. All Rights Reserved.
 Ethernet Storage Fabrics Using RDMA with Fast NVMe-oF Storage to Reduce Latency and Improve Efficiency Kevin Deierling & Idan Burstein Mellanox Technologies 1 Storage Media Technology Storage Media Access
Ethernet Storage Fabrics Using RDMA with Fast NVMe-oF Storage to Reduce Latency and Improve Efficiency Kevin Deierling & Idan Burstein Mellanox Technologies 1 Storage Media Technology Storage Media Access
Enabling High Performance Bulk Data Transfers With SSH
 Enabling High Performance Bulk Data Transfers With SSH Chris Rapier Benjamin Bennett TIP 08 Moving Data Still crazy after all these years Multiple solutions exist Protocols UDT, SABUL, etc Implementations
Enabling High Performance Bulk Data Transfers With SSH Chris Rapier Benjamin Bennett TIP 08 Moving Data Still crazy after all these years Multiple solutions exist Protocols UDT, SABUL, etc Implementations
FUJITSU Software Interstage Information Integrator V11
 FUJITSU Software V11 An Innovative WAN optimization solution to bring out maximum network performance October, 2013 Fujitsu Limited Contents Overview Key technologies Supported network characteristics
FUJITSU Software V11 An Innovative WAN optimization solution to bring out maximum network performance October, 2013 Fujitsu Limited Contents Overview Key technologies Supported network characteristics
Advanced Computer Networks. End Host Optimization
 Oriana Riva, Department of Computer Science ETH Zürich 263 3501 00 End Host Optimization Patrick Stuedi Spring Semester 2017 1 Today End-host optimizations: NUMA-aware networking Kernel-bypass Remote Direct
Oriana Riva, Department of Computer Science ETH Zürich 263 3501 00 End Host Optimization Patrick Stuedi Spring Semester 2017 1 Today End-host optimizations: NUMA-aware networking Kernel-bypass Remote Direct
Comparison of SSL/TLS libraries based on Algorithms/languages supported, Platform, Protocols and Performance. By Akshay Thorat
 Comparison of SSL/TLS libraries based on Algorithms/languages supported, Platform, Protocols and Performance By Akshay Thorat Table of Contents TLS - Why is it needed? Introduction- SSL/TLS evolution Libraries
Comparison of SSL/TLS libraries based on Algorithms/languages supported, Platform, Protocols and Performance By Akshay Thorat Table of Contents TLS - Why is it needed? Introduction- SSL/TLS evolution Libraries
PacketShader: A GPU-Accelerated Software Router
 PacketShader: A GPU-Accelerated Software Router Sangjin Han In collaboration with: Keon Jang, KyoungSoo Park, Sue Moon Advanced Networking Lab, CS, KAIST Networked and Distributed Computing Systems Lab,
PacketShader: A GPU-Accelerated Software Router Sangjin Han In collaboration with: Keon Jang, KyoungSoo Park, Sue Moon Advanced Networking Lab, CS, KAIST Networked and Distributed Computing Systems Lab,
SSH Bulk Transfer Performance. Allan Jude --
 SSH Bulk Transfer Performance Allan Jude -- allanjude@freebsd.org Introduction 15 Years as FreeBSD Server Admin FreeBSD src/doc committer (ZFS, bhyve, ucl, xo) FreeBSD Core Team (July 2016-2018) Co-Author
SSH Bulk Transfer Performance Allan Jude -- allanjude@freebsd.org Introduction 15 Years as FreeBSD Server Admin FreeBSD src/doc committer (ZFS, bhyve, ucl, xo) FreeBSD Core Team (July 2016-2018) Co-Author
SPDK China Summit Ziye Yang. Senior Software Engineer. Network Platforms Group, Intel Corporation
 SPDK China Summit 2018 Ziye Yang Senior Software Engineer Network Platforms Group, Intel Corporation Agenda SPDK programming framework Accelerated NVMe-oF via SPDK Conclusion 2 Agenda SPDK programming
SPDK China Summit 2018 Ziye Yang Senior Software Engineer Network Platforms Group, Intel Corporation Agenda SPDK programming framework Accelerated NVMe-oF via SPDK Conclusion 2 Agenda SPDK programming
PM Support in Linux and Windows. Dr. Stephen Bates, CTO, Eideticom Neal Christiansen, Principal Development Lead, Microsoft
 PM Support in Linux and Windows Dr. Stephen Bates, CTO, Eideticom Neal Christiansen, Principal Development Lead, Microsoft Windows Support for Persistent Memory 2 Availability of Windows PM Support Client
PM Support in Linux and Windows Dr. Stephen Bates, CTO, Eideticom Neal Christiansen, Principal Development Lead, Microsoft Windows Support for Persistent Memory 2 Availability of Windows PM Support Client
A closer look at network structure:
 T1: Introduction 1.1 What is computer network? Examples of computer network The Internet Network structure: edge and core 1.2 Why computer networks 1.3 The way networks work 1.4 Performance metrics: Delay,
T1: Introduction 1.1 What is computer network? Examples of computer network The Internet Network structure: edge and core 1.2 Why computer networks 1.3 The way networks work 1.4 Performance metrics: Delay,
Be Fast, Cheap and in Control with SwitchKV. Xiaozhou Li
 Be Fast, Cheap and in Control with SwitchKV Xiaozhou Li Goal: fast and cost-efficient key-value store Store, retrieve, manage key-value objects Get(key)/Put(key,value)/Delete(key) Target: cluster-level
Be Fast, Cheap and in Control with SwitchKV Xiaozhou Li Goal: fast and cost-efficient key-value store Store, retrieve, manage key-value objects Get(key)/Put(key,value)/Delete(key) Target: cluster-level
IBM Aspera Direct-to- Cloud Storage
 IBM Aspera Direct-to- Cloud Storage A technical whitepaper on the state-of-the art in high-speed transport direct-to-cloud storage and support for third-party cloud storage platforms Contents: 1 Overview
IBM Aspera Direct-to- Cloud Storage A technical whitepaper on the state-of-the art in high-speed transport direct-to-cloud storage and support for third-party cloud storage platforms Contents: 1 Overview
Next Steps Spring 2011 Lecture #18. Multi-hop Networks. Network Reliability. Have: digital point-to-point. Want: many interconnected points
 Next Steps Have: digital point-to-point We ve worked on link signaling, reliability, sharing Want: many interconnected points 6.02 Spring 2011 Lecture #18 multi-hop networks: design criteria network topologies
Next Steps Have: digital point-to-point We ve worked on link signaling, reliability, sharing Want: many interconnected points 6.02 Spring 2011 Lecture #18 multi-hop networks: design criteria network topologies
G-NET: Effective GPU Sharing In NFV Systems
 G-NET: Effective Sharing In NFV Systems Kai Zhang*, Bingsheng He^, Jiayu Hu #, Zeke Wang^, Bei Hua #, Jiayi Meng #, Lishan Yang # *Fudan University ^National University of Singapore #University of Science
G-NET: Effective Sharing In NFV Systems Kai Zhang*, Bingsheng He^, Jiayu Hu #, Zeke Wang^, Bei Hua #, Jiayi Meng #, Lishan Yang # *Fudan University ^National University of Singapore #University of Science
Extremely Fast Distributed Storage for Cloud Service Providers
 Solution brief Intel Storage Builders StorPool Storage Intel SSD DC S3510 Series Intel Xeon Processor E3 and E5 Families Intel Ethernet Converged Network Adapter X710 Family Extremely Fast Distributed
Solution brief Intel Storage Builders StorPool Storage Intel SSD DC S3510 Series Intel Xeon Processor E3 and E5 Families Intel Ethernet Converged Network Adapter X710 Family Extremely Fast Distributed
FAQ. Release rc2
 FAQ Release 19.02.0-rc2 January 15, 2019 CONTENTS 1 What does EAL: map_all_hugepages(): open failed: Permission denied Cannot init memory mean? 2 2 If I want to change the number of hugepages allocated,
FAQ Release 19.02.0-rc2 January 15, 2019 CONTENTS 1 What does EAL: map_all_hugepages(): open failed: Permission denied Cannot init memory mean? 2 2 If I want to change the number of hugepages allocated,
EXTENDING AN ASYNCHRONOUS MESSAGING LIBRARY USING AN RDMA-ENABLED INTERCONNECT. Konstantinos Alexopoulos ECE NTUA CSLab
 EXTENDING AN ASYNCHRONOUS MESSAGING LIBRARY USING AN RDMA-ENABLED INTERCONNECT Konstantinos Alexopoulos ECE NTUA CSLab MOTIVATION HPC, Multi-node & Heterogeneous Systems Communication with low latency
EXTENDING AN ASYNCHRONOUS MESSAGING LIBRARY USING AN RDMA-ENABLED INTERCONNECT Konstantinos Alexopoulos ECE NTUA CSLab MOTIVATION HPC, Multi-node & Heterogeneous Systems Communication with low latency
Highly Scalable, Non-RDMA NVMe Fabric. Bob Hansen,, VP System Architecture
 A Cost Effective,, High g Performance,, Highly Scalable, Non-RDMA NVMe Fabric Bob Hansen,, VP System Architecture bob@apeirondata.com Storage Developers Conference, September 2015 Agenda 3 rd Platform
A Cost Effective,, High g Performance,, Highly Scalable, Non-RDMA NVMe Fabric Bob Hansen,, VP System Architecture bob@apeirondata.com Storage Developers Conference, September 2015 Agenda 3 rd Platform
LANCOM Techpaper Routing Performance
 LANCOM Techpaper Routing Performance Applications for communications and entertainment are increasingly based on IP networks. In order to ensure that the necessary bandwidth performance can be provided
LANCOM Techpaper Routing Performance Applications for communications and entertainment are increasingly based on IP networks. In order to ensure that the necessary bandwidth performance can be provided
Advanced Computer Networks. Flow Control
 Advanced Computer Networks 263 3501 00 Flow Control Patrick Stuedi Spring Semester 2017 1 Oriana Riva, Department of Computer Science ETH Zürich Last week TCP in Datacenters Avoid incast problem - Reduce
Advanced Computer Networks 263 3501 00 Flow Control Patrick Stuedi Spring Semester 2017 1 Oriana Riva, Department of Computer Science ETH Zürich Last week TCP in Datacenters Avoid incast problem - Reduce
Lightstreamer. The Streaming-Ajax Revolution. Product Insight
 Lightstreamer The Streaming-Ajax Revolution Product Insight 1 Agenda Paradigms for the Real-Time Web (four models explained) Requirements for a Good Comet Solution Introduction to Lightstreamer Lightstreamer
Lightstreamer The Streaming-Ajax Revolution Product Insight 1 Agenda Paradigms for the Real-Time Web (four models explained) Requirements for a Good Comet Solution Introduction to Lightstreamer Lightstreamer
All product specifications are subject to change without notice.
 MSI N3000 series is cost-benefit rackmount network security. Basing on Intel Xeon E3-1200 v3/v4/v5 series CPU and Xeon D-1500 series SoC which is to help enterprise to be flexibly applied to various network
MSI N3000 series is cost-benefit rackmount network security. Basing on Intel Xeon E3-1200 v3/v4/v5 series CPU and Xeon D-1500 series SoC which is to help enterprise to be flexibly applied to various network
Performance Optimizations via Connect-IB and Dynamically Connected Transport Service for Maximum Performance on LS-DYNA
 Performance Optimizations via Connect-IB and Dynamically Connected Transport Service for Maximum Performance on LS-DYNA Pak Lui, Gilad Shainer, Brian Klaff Mellanox Technologies Abstract From concept to
Performance Optimizations via Connect-IB and Dynamically Connected Transport Service for Maximum Performance on LS-DYNA Pak Lui, Gilad Shainer, Brian Klaff Mellanox Technologies Abstract From concept to
Flavors of Memory supported by Linux, their use and benefit. Christoph Lameter, Ph.D,
 Flavors of Memory supported by Linux, their use and benefit Christoph Lameter, Ph.D, Twitter: @qant Flavors Of Memory The term computer memory is a simple term but there are numerous nuances
Flavors of Memory supported by Linux, their use and benefit Christoph Lameter, Ph.D, Twitter: @qant Flavors Of Memory The term computer memory is a simple term but there are numerous nuances
A New Internet? RIPE76 - Marseille May Jordi Palet
 A New Internet? RIPE76 - Marseille May 2018 Jordi Palet (jordi.palet@theipv6company.com) -1 (a quick) Introduction to HTTP/2, QUIC and DOH and more RIPE76 - Marseille May 2018 Jordi Palet (jordi.palet@theipv6company.com)
A New Internet? RIPE76 - Marseille May 2018 Jordi Palet (jordi.palet@theipv6company.com) -1 (a quick) Introduction to HTTP/2, QUIC and DOH and more RIPE76 - Marseille May 2018 Jordi Palet (jordi.palet@theipv6company.com)
Introduction to VoIP. Cisco Networking Academy Program Cisco Systems, Inc. All rights reserved. Cisco Public. IP Telephony
 Introduction to VoIP Cisco Networking Academy Program 1 Requirements of Voice in an IP Internetwork 2 IP Internetwork IP is connectionless. IP provides multiple paths from source to destination. 3 Packet
Introduction to VoIP Cisco Networking Academy Program 1 Requirements of Voice in an IP Internetwork 2 IP Internetwork IP is connectionless. IP provides multiple paths from source to destination. 3 Packet
DPDK Vhost/Virtio Performance Report Release 18.05
 DPDK Vhost/Virtio Performance Report Test Date: Jun 1 2018 Author: Intel DPDK Validation Team Revision History Date Revision Comment Jun 1st, 2018 1.0 Initial document for release 2 Release 18.02 Contents
DPDK Vhost/Virtio Performance Report Test Date: Jun 1 2018 Author: Intel DPDK Validation Team Revision History Date Revision Comment Jun 1st, 2018 1.0 Initial document for release 2 Release 18.02 Contents
DDN. DDN Updates. Data DirectNeworks Japan, Inc Shuichi Ihara. DDN Storage 2017 DDN Storage
 DDN DDN Updates Data DirectNeworks Japan, Inc Shuichi Ihara DDN A Broad Range of Technologies to Best Address Your Needs Protection Security Data Distribution and Lifecycle Management Open Monitoring Your
DDN DDN Updates Data DirectNeworks Japan, Inc Shuichi Ihara DDN A Broad Range of Technologies to Best Address Your Needs Protection Security Data Distribution and Lifecycle Management Open Monitoring Your
VirtuLocity VLN Software Acceleration Service Virtualized acceleration wherever and whenever you need it
 VirtuLocity VLN Software Acceleration Service Virtualized acceleration wherever and whenever you need it Bandwidth Optimization with Adaptive Congestion Avoidance for WAN Connections model and supports
VirtuLocity VLN Software Acceleration Service Virtualized acceleration wherever and whenever you need it Bandwidth Optimization with Adaptive Congestion Avoidance for WAN Connections model and supports
VALE: a switched ethernet for virtual machines
 L < > T H local VALE VALE -- Page 1/23 VALE: a switched ethernet for virtual machines Luigi Rizzo, Giuseppe Lettieri Università di Pisa http://info.iet.unipi.it/~luigi/vale/ Motivation Make sw packet processing
L < > T H local VALE VALE -- Page 1/23 VALE: a switched ethernet for virtual machines Luigi Rizzo, Giuseppe Lettieri Università di Pisa http://info.iet.unipi.it/~luigi/vale/ Motivation Make sw packet processing
Delay Controlled Elephant Flow Rerouting in Software Defined Network
 1st International Conference on Advanced Information Technologies (ICAIT), Nov. 1-2, 2017, Yangon, Myanmar Delay Controlled Elephant Flow Rerouting in Software Defined Network Hnin Thiri Zaw, Aung Htein
1st International Conference on Advanced Information Technologies (ICAIT), Nov. 1-2, 2017, Yangon, Myanmar Delay Controlled Elephant Flow Rerouting in Software Defined Network Hnin Thiri Zaw, Aung Htein
Fast and Easy Persistent Storage for Docker* Containers with Storidge and Intel
 Solution brief Intel Storage Builders Storidge ContainerIO TM Intel Xeon Processor Scalable Family Intel SSD DC Family for PCIe*/NVMe Fast and Easy Persistent Storage for Docker* Containers with Storidge
Solution brief Intel Storage Builders Storidge ContainerIO TM Intel Xeon Processor Scalable Family Intel SSD DC Family for PCIe*/NVMe Fast and Easy Persistent Storage for Docker* Containers with Storidge
PCI Express x8 Single Port SFP+ 10 Gigabit Server Adapter (Intel 82599ES Based) Single-Port 10 Gigabit SFP+ Ethernet Server Adapters Provide Ultimate
 Single-Port 10 Gigabit SFP+ Ethernet Server Adapters Provide Ultimate") NIC-PCIE-1SFP+-PLU PCI Express x8 Single Port SFP+ 10 Gigabit Server Adapter (Intel 82599ES Based) Single-Port 10 Gigabit SFP+ Ethernet Server Adapters Provide Ultimate Flexibility and Scalability in Virtual
NIC-PCIE-1SFP+-PLU PCI Express x8 Single Port SFP+ 10 Gigabit Server Adapter (Intel 82599ES Based) Single-Port 10 Gigabit SFP+ Ethernet Server Adapters Provide Ultimate Flexibility and Scalability in Virtual
Evaluating the Impact of RDMA on Storage I/O over InfiniBand
 Evaluating the Impact of RDMA on Storage I/O over InfiniBand J Liu, DK Panda and M Banikazemi Computer and Information Science IBM T J Watson Research Center The Ohio State University Presentation Outline
Evaluating the Impact of RDMA on Storage I/O over InfiniBand J Liu, DK Panda and M Banikazemi Computer and Information Science IBM T J Watson Research Center The Ohio State University Presentation Outline
DPDK Vhost/Virtio Performance Report Release 18.11
 DPDK Vhost/Virtio Performance Report Test Date: December 3st 2018 Author: Intel DPDK Validation Team Revision History Date Revision Comment December 3st, 2018 1.0 Initial document for release 2 Contents
DPDK Vhost/Virtio Performance Report Test Date: December 3st 2018 Author: Intel DPDK Validation Team Revision History Date Revision Comment December 3st, 2018 1.0 Initial document for release 2 Contents
IBM V7000 Unified R1.4.2 Asynchronous Replication Performance Reference Guide
 V7 Unified Asynchronous Replication Performance Reference Guide IBM V7 Unified R1.4.2 Asynchronous Replication Performance Reference Guide Document Version 1. SONAS / V7 Unified Asynchronous Replication
V7 Unified Asynchronous Replication Performance Reference Guide IBM V7 Unified R1.4.2 Asynchronous Replication Performance Reference Guide Document Version 1. SONAS / V7 Unified Asynchronous Replication
What s Wrong with the Operating System Interface? Collin Lee and John Ousterhout
 What s Wrong with the Operating System Interface? Collin Lee and John Ousterhout Goals for the OS Interface More convenient abstractions than hardware interface Manage shared resources Provide near-hardware
What s Wrong with the Operating System Interface? Collin Lee and John Ousterhout Goals for the OS Interface More convenient abstractions than hardware interface Manage shared resources Provide near-hardware
Be Fast, Cheap and in Control with SwitchKV Xiaozhou Li
 Be Fast, Cheap and in Control with SwitchKV Xiaozhou Li Raghav Sethi Michael Kaminsky David G. Andersen Michael J. Freedman Goal: fast and cost-effective key-value store Target: cluster-level storage for
Be Fast, Cheap and in Control with SwitchKV Xiaozhou Li Raghav Sethi Michael Kaminsky David G. Andersen Michael J. Freedman Goal: fast and cost-effective key-value store Target: cluster-level storage for
Mellanox InfiniBand Solutions Accelerate Oracle s Data Center and Cloud Solutions
 Mellanox InfiniBand Solutions Accelerate Oracle s Data Center and Cloud Solutions Providing Superior Server and Storage Performance, Efficiency and Return on Investment As Announced and Demonstrated at
Mellanox InfiniBand Solutions Accelerate Oracle s Data Center and Cloud Solutions Providing Superior Server and Storage Performance, Efficiency and Return on Investment As Announced and Demonstrated at
URDMA: RDMA VERBS OVER DPDK
 13 th ANNUAL WORKSHOP 2017 URDMA: RDMA VERBS OVER DPDK Patrick MacArthur, Ph.D. Candidate University of New Hampshire March 28, 2017 ACKNOWLEDGEMENTS urdma was initially developed during an internship
13 th ANNUAL WORKSHOP 2017 URDMA: RDMA VERBS OVER DPDK Patrick MacArthur, Ph.D. Candidate University of New Hampshire March 28, 2017 ACKNOWLEDGEMENTS urdma was initially developed during an internship
What s New in VMware vsphere 4.1 Performance. VMware vsphere 4.1
 What s New in VMware vsphere 4.1 Performance VMware vsphere 4.1 T E C H N I C A L W H I T E P A P E R Table of Contents Scalability enhancements....................................................................
What s New in VMware vsphere 4.1 Performance VMware vsphere 4.1 T E C H N I C A L W H I T E P A P E R Table of Contents Scalability enhancements....................................................................
LS-DYNA Best-Practices: Networking, MPI and Parallel File System Effect on LS-DYNA Performance
 11 th International LS-DYNA Users Conference Computing Technology LS-DYNA Best-Practices: Networking, MPI and Parallel File System Effect on LS-DYNA Performance Gilad Shainer 1, Tong Liu 2, Jeff Layton
11 th International LS-DYNA Users Conference Computing Technology LS-DYNA Best-Practices: Networking, MPI and Parallel File System Effect on LS-DYNA Performance Gilad Shainer 1, Tong Liu 2, Jeff Layton
Session based high bandwidth throughput testing
 Universiteit van Amsterdam System and Network Engineering Research Project 2 Session based high bandwidth throughput testing Bram ter Borch bram.terborch@os3.nl 29 August 2017 Abstract To maximize and
Universiteit van Amsterdam System and Network Engineering Research Project 2 Session based high bandwidth throughput testing Bram ter Borch bram.terborch@os3.nl 29 August 2017 Abstract To maximize and
Lighting the Blue Touchpaper for UK e-science - Closing Conference of ESLEA Project The George Hotel, Edinburgh, UK March, 2007
 Working with 1 Gigabit Ethernet 1, The School of Physics and Astronomy, The University of Manchester, Manchester, M13 9PL UK E-mail: R.Hughes-Jones@manchester.ac.uk Stephen Kershaw The School of Physics
Working with 1 Gigabit Ethernet 1, The School of Physics and Astronomy, The University of Manchester, Manchester, M13 9PL UK E-mail: R.Hughes-Jones@manchester.ac.uk Stephen Kershaw The School of Physics
Scalable Distributed Training with Parameter Hub: a whirlwind tour
 Scalable Distributed Training with Parameter Hub: a whirlwind tour TVM Stack Optimization High-Level Differentiable IR Tensor Expression IR AutoTVM LLVM, CUDA, Metal VTA AutoVTA Edge FPGA Cloud FPGA ASIC
Scalable Distributed Training with Parameter Hub: a whirlwind tour TVM Stack Optimization High-Level Differentiable IR Tensor Expression IR AutoTVM LLVM, CUDA, Metal VTA AutoVTA Edge FPGA Cloud FPGA ASIC
FlashGrid Software Enables Converged and Hyper-Converged Appliances for Oracle* RAC
 white paper FlashGrid Software Intel SSD DC P3700/P3600/P3500 Topic: Hyper-converged Database/Storage FlashGrid Software Enables Converged and Hyper-Converged Appliances for Oracle* RAC Abstract FlashGrid
white paper FlashGrid Software Intel SSD DC P3700/P3600/P3500 Topic: Hyper-converged Database/Storage FlashGrid Software Enables Converged and Hyper-Converged Appliances for Oracle* RAC Abstract FlashGrid
Advanced Network Design
 Advanced Network Design Organization Whoami, Book, Wikipedia www.cs.uchicago.edu/~nugent/cspp54015 Grading Homework/project: 60% Midterm: 15% Final: 20% Class participation: 5% Interdisciplinary Course
Advanced Network Design Organization Whoami, Book, Wikipedia www.cs.uchicago.edu/~nugent/cspp54015 Grading Homework/project: 60% Midterm: 15% Final: 20% Class participation: 5% Interdisciplinary Course
The Exascale Architecture
 The Exascale Architecture Richard Graham HPC Advisory Council China 2013 Overview Programming-model challenges for Exascale Challenges for scaling MPI to Exascale InfiniBand enhancements Dynamically Connected
The Exascale Architecture Richard Graham HPC Advisory Council China 2013 Overview Programming-model challenges for Exascale Challenges for scaling MPI to Exascale InfiniBand enhancements Dynamically Connected
Keeping up with the hardware
 Keeping up with the hardware Challenges in scaling I/O performance Jonathan Davies XenServer System Performance Lead XenServer Engineering, Citrix Cambridge, UK 18 Aug 2015 Jonathan Davies (Citrix) Keeping
Keeping up with the hardware Challenges in scaling I/O performance Jonathan Davies XenServer System Performance Lead XenServer Engineering, Citrix Cambridge, UK 18 Aug 2015 Jonathan Davies (Citrix) Keeping
Much Faster Networking
 Much Faster Networking David Riddoch driddoch@solarflare.com Copyright 2016 Solarflare Communications, Inc. All rights reserved. What is kernel bypass? The standard receive path The standard receive path
Much Faster Networking David Riddoch driddoch@solarflare.com Copyright 2016 Solarflare Communications, Inc. All rights reserved. What is kernel bypass? The standard receive path The standard receive path
CHAPTER 3 GRID MONITORING AND RESOURCE SELECTION
 31 CHAPTER 3 GRID MONITORING AND RESOURCE SELECTION This chapter introduces the Grid monitoring with resource metrics and network metrics. This chapter also discusses various network monitoring tools and
31 CHAPTER 3 GRID MONITORING AND RESOURCE SELECTION This chapter introduces the Grid monitoring with resource metrics and network metrics. This chapter also discusses various network monitoring tools and
N V M e o v e r F a b r i c s -
 N V M e o v e r F a b r i c s - H i g h p e r f o r m a n c e S S D s n e t w o r k e d f o r c o m p o s a b l e i n f r a s t r u c t u r e Rob Davis, VP Storage Technology, Mellanox OCP Evolution Server
N V M e o v e r F a b r i c s - H i g h p e r f o r m a n c e S S D s n e t w o r k e d f o r c o m p o s a b l e i n f r a s t r u c t u r e Rob Davis, VP Storage Technology, Mellanox OCP Evolution Server
Achieve Optimal Network Throughput on the Cisco UCS S3260 Storage Server
 White Paper Achieve Optimal Network Throughput on the Cisco UCS S3260 Storage Server Executive Summary This document describes the network I/O performance characteristics of the Cisco UCS S3260 Storage
White Paper Achieve Optimal Network Throughput on the Cisco UCS S3260 Storage Server Executive Summary This document describes the network I/O performance characteristics of the Cisco UCS S3260 Storage
A Next Generation Home Access Point and Router
 A Next Generation Home Access Point and Router Product Marketing Manager Network Communication Technology and Application of the New Generation Points of Discussion Why Do We Need a Next Gen Home Router?
A Next Generation Home Access Point and Router Product Marketing Manager Network Communication Technology and Application of the New Generation Points of Discussion Why Do We Need a Next Gen Home Router?
Communication has significant impact on application performance. Interconnection networks therefore have a vital role in cluster systems.
 Cluster Networks Introduction Communication has significant impact on application performance. Interconnection networks therefore have a vital role in cluster systems. As usual, the driver is performance
Cluster Networks Introduction Communication has significant impact on application performance. Interconnection networks therefore have a vital role in cluster systems. As usual, the driver is performance
SONAS Best Practices and options for CIFS Scalability
 COMMON INTERNET FILE SYSTEM (CIFS) FILE SERVING...2 MAXIMUM NUMBER OF ACTIVE CONCURRENT CIFS CONNECTIONS...2 SONAS SYSTEM CONFIGURATION...4 SONAS Best Practices and options for CIFS Scalability A guide
COMMON INTERNET FILE SYSTEM (CIFS) FILE SERVING...2 MAXIMUM NUMBER OF ACTIVE CONCURRENT CIFS CONNECTIONS...2 SONAS SYSTEM CONFIGURATION...4 SONAS Best Practices and options for CIFS Scalability A guide
Messaging Overview. Introduction. Gen-Z Messaging
 Page 1 of 6 Messaging Overview Introduction Gen-Z is a new data access technology that not only enhances memory and data storage solutions, but also provides a framework for both optimized and traditional
Page 1 of 6 Messaging Overview Introduction Gen-Z is a new data access technology that not only enhances memory and data storage solutions, but also provides a framework for both optimized and traditional
ARISTA: Improving Application Performance While Reducing Complexity
 ARISTA: Improving Application Performance While Reducing Complexity October 2008 1.0 Problem Statement #1... 1 1.1 Problem Statement #2... 1 1.2 Previous Options: More Servers and I/O Adapters... 1 1.3
ARISTA: Improving Application Performance While Reducing Complexity October 2008 1.0 Problem Statement #1... 1 1.1 Problem Statement #2... 1 1.2 Previous Options: More Servers and I/O Adapters... 1 1.3
InfiniBand Networked Flash Storage
 InfiniBand Networked Flash Storage Superior Performance, Efficiency and Scalability Motti Beck Director Enterprise Market Development, Mellanox Technologies Flash Memory Summit 2016 Santa Clara, CA 1 17PB
InfiniBand Networked Flash Storage Superior Performance, Efficiency and Scalability Motti Beck Director Enterprise Market Development, Mellanox Technologies Flash Memory Summit 2016 Santa Clara, CA 1 17PB
Sybase Adaptive Server Enterprise on Linux
 Sybase Adaptive Server Enterprise on Linux A Technical White Paper May 2003 Information Anywhere EXECUTIVE OVERVIEW ARCHITECTURE OF ASE Dynamic Performance Security Mission-Critical Computing Advanced
Sybase Adaptive Server Enterprise on Linux A Technical White Paper May 2003 Information Anywhere EXECUTIVE OVERVIEW ARCHITECTURE OF ASE Dynamic Performance Security Mission-Critical Computing Advanced
Emerging Technologies for HPC Storage
 Emerging Technologies for HPC Storage Dr. Wolfgang Mertz CTO EMEA Unstructured Data Solutions June 2018 The very definition of HPC is expanding Blazing Fast Speed Accessibility and flexibility 2 Traditional
Emerging Technologies for HPC Storage Dr. Wolfgang Mertz CTO EMEA Unstructured Data Solutions June 2018 The very definition of HPC is expanding Blazing Fast Speed Accessibility and flexibility 2 Traditional
CERN openlab Summer 2006: Networking Overview
 CERN openlab Summer 2006: Networking Overview Martin Swany, Ph.D. Assistant Professor, Computer and Information Sciences, U. Delaware, USA Visiting Helsinki Institute of Physics (HIP) at CERN swany@cis.udel.edu,
CERN openlab Summer 2006: Networking Overview Martin Swany, Ph.D. Assistant Professor, Computer and Information Sciences, U. Delaware, USA Visiting Helsinki Institute of Physics (HIP) at CERN swany@cis.udel.edu,
Chapter 5.6 Network and Multiplayer
 Chapter 5.6 Network and Multiplayer Multiplayer Modes: Event Timing Turn-Based Easy to implement Any connection type Real-Time Difficult to implement Latency sensitive 2 Multiplayer Modes: Shared I/O Input
Chapter 5.6 Network and Multiplayer Multiplayer Modes: Event Timing Turn-Based Easy to implement Any connection type Real-Time Difficult to implement Latency sensitive 2 Multiplayer Modes: Shared I/O Input
DPDK Performance Report Release Test Date: Nov 16 th 2016
 Test Date: Nov 16 th 2016 Revision History Date Revision Comment Nov 16 th, 2016 1.0 Initial document for release 2 Contents Audience and Purpose... 4 Test setup:... 4 Intel Xeon Processor E5-2699 v4 (55M
Test Date: Nov 16 th 2016 Revision History Date Revision Comment Nov 16 th, 2016 1.0 Initial document for release 2 Contents Audience and Purpose... 4 Test setup:... 4 Intel Xeon Processor E5-2699 v4 (55M
Virtualization, Xen and Denali
 Virtualization, Xen and Denali Susmit Shannigrahi November 9, 2011 Susmit Shannigrahi () Virtualization, Xen and Denali November 9, 2011 1 / 70 Introduction Virtualization is the technology to allow two
Virtualization, Xen and Denali Susmit Shannigrahi November 9, 2011 Susmit Shannigrahi () Virtualization, Xen and Denali November 9, 2011 1 / 70 Introduction Virtualization is the technology to allow two
ASN Configuration Best Practices
 ASN Configuration Best Practices Managed machine Generally used CPUs and RAM amounts are enough for the managed machine: CPU still allows us to read and write data faster than real IO subsystem allows.
ASN Configuration Best Practices Managed machine Generally used CPUs and RAM amounts are enough for the managed machine: CPU still allows us to read and write data faster than real IO subsystem allows.
Accelerating Real-Time Big Data. Breaking the limitations of captive NVMe storage
 Accelerating Real-Time Big Data Breaking the limitations of captive NVMe storage 18M IOPs in 2u Agenda Everything related to storage is changing! The 3rd Platform NVM Express architected for solid state
Accelerating Real-Time Big Data Breaking the limitations of captive NVMe storage 18M IOPs in 2u Agenda Everything related to storage is changing! The 3rd Platform NVM Express architected for solid state
Maximum Performance. How to get it and how to avoid pitfalls. Christoph Lameter, PhD
 Maximum Performance How to get it and how to avoid pitfalls Christoph Lameter, PhD cl@linux.com Performance Just push a button? Systems are optimized by default for good general performance in all areas.
Maximum Performance How to get it and how to avoid pitfalls Christoph Lameter, PhD cl@linux.com Performance Just push a button? Systems are optimized by default for good general performance in all areas.
WhitePaper: XipLink Real-Time Optimizations
 WhitePaper: XipLink Real-Time Optimizations XipLink Real Time Optimizations Header Compression, Packet Coalescing and Packet Prioritization Overview XipLink Real Time ( XRT ) is an optimization capability
WhitePaper: XipLink Real-Time Optimizations XipLink Real Time Optimizations Header Compression, Packet Coalescing and Packet Prioritization Overview XipLink Real Time ( XRT ) is an optimization capability
High Performance Transactions in Deuteronomy
 High Performance Transactions in Deuteronomy Justin Levandoski, David Lomet, Sudipta Sengupta, Ryan Stutsman, and Rui Wang Microsoft Research Overview Deuteronomy: componentized DB stack Separates transaction,
High Performance Transactions in Deuteronomy Justin Levandoski, David Lomet, Sudipta Sengupta, Ryan Stutsman, and Rui Wang Microsoft Research Overview Deuteronomy: componentized DB stack Separates transaction,
vswitch Acceleration with Hardware Offloading CHEN ZHIHUI JUNE 2018
 x vswitch Acceleration with Hardware Offloading CHEN ZHIHUI JUNE 2018 Current Network Solution for Virtualization Control Plane Control Plane virtio virtio user space PF VF2 user space TAP1 SW Datapath
x vswitch Acceleration with Hardware Offloading CHEN ZHIHUI JUNE 2018 Current Network Solution for Virtualization Control Plane Control Plane virtio virtio user space PF VF2 user space TAP1 SW Datapath
IBM InfoSphere Streams v4.0 Performance Best Practices
 Henry May IBM InfoSphere Streams v4.0 Performance Best Practices Abstract Streams v4.0 introduces powerful high availability features. Leveraging these requires careful consideration of performance related
Henry May IBM InfoSphere Streams v4.0 Performance Best Practices Abstract Streams v4.0 introduces powerful high availability features. Leveraging these requires careful consideration of performance related
Deep Learning Performance and Cost Evaluation
 Micron 5210 ION Quad-Level Cell (QLC) SSDs vs 7200 RPM HDDs in Centralized NAS Storage Repositories A Technical White Paper Don Wang, Rene Meyer, Ph.D. info@ AMAX Corporation Publish date: October 25,
Micron 5210 ION Quad-Level Cell (QLC) SSDs vs 7200 RPM HDDs in Centralized NAS Storage Repositories A Technical White Paper Don Wang, Rene Meyer, Ph.D. info@ AMAX Corporation Publish date: October 25,
NVMe Over Fabrics: Scaling Up With The Storage Performance Development Kit
 NVMe Over Fabrics: Scaling Up With The Storage Performance Development Kit Ben Walker Data Center Group Intel Corporation 2018 Storage Developer Conference. Intel Corporation. All Rights Reserved. 1 Notices
NVMe Over Fabrics: Scaling Up With The Storage Performance Development Kit Ben Walker Data Center Group Intel Corporation 2018 Storage Developer Conference. Intel Corporation. All Rights Reserved. 1 Notices
Database Acceleration Solution Using FPGAs and Integrated Flash Storage
 Database Acceleration Solution Using FPGAs and Integrated Flash Storage HK Verma, Xilinx Inc. August 2017 1 FPGA Analytics in Flash Storage System In-memory or Flash storage based DB reduce disk access
Database Acceleration Solution Using FPGAs and Integrated Flash Storage HK Verma, Xilinx Inc. August 2017 1 FPGA Analytics in Flash Storage System In-memory or Flash storage based DB reduce disk access
Got Loss? Get zovn! Daniel Crisan, Robert Birke, Gilles Cressier, Cyriel Minkenberg, and Mitch Gusat. ACM SIGCOMM 2013, August, Hong Kong, China
 Got Loss? Get zovn! Daniel Crisan, Robert Birke, Gilles Cressier, Cyriel Minkenberg, and Mitch Gusat ACM SIGCOMM 2013, 12-16 August, Hong Kong, China Virtualized Server 1 Application Performance in Virtualized
Got Loss? Get zovn! Daniel Crisan, Robert Birke, Gilles Cressier, Cyriel Minkenberg, and Mitch Gusat ACM SIGCOMM 2013, 12-16 August, Hong Kong, China Virtualized Server 1 Application Performance in Virtualized
CCNA 1 Chapter 7 v5.0 Exam Answers 2013
 CCNA 1 Chapter 7 v5.0 Exam Answers 2013 1 A PC is downloading a large file from a server. The TCP window is 1000 bytes. The server is sending the file using 100-byte segments. How many segments will the
CCNA 1 Chapter 7 v5.0 Exam Answers 2013 1 A PC is downloading a large file from a server. The TCP window is 1000 bytes. The server is sending the file using 100-byte segments. How many segments will the
THE STORAGE PERFORMANCE DEVELOPMENT KIT AND NVME-OF
 14th ANNUAL WORKSHOP 2018 THE STORAGE PERFORMANCE DEVELOPMENT KIT AND NVME-OF Paul Luse Intel Corporation Apr 2018 AGENDA Storage Performance Development Kit What is SPDK? The SPDK Community Why are so
14th ANNUAL WORKSHOP 2018 THE STORAGE PERFORMANCE DEVELOPMENT KIT AND NVME-OF Paul Luse Intel Corporation Apr 2018 AGENDA Storage Performance Development Kit What is SPDK? The SPDK Community Why are so
Chelsio Communications. Meeting Today s Datacenter Challenges. Produced by Tabor Custom Publishing in conjunction with: CUSTOM PUBLISHING
 Meeting Today s Datacenter Challenges Produced by Tabor Custom Publishing in conjunction with: 1 Introduction In this era of Big Data, today s HPC systems are faced with unprecedented growth in the complexity
Meeting Today s Datacenter Challenges Produced by Tabor Custom Publishing in conjunction with: 1 Introduction In this era of Big Data, today s HPC systems are faced with unprecedented growth in the complexity
Ronald van der Pol
 Ronald van der Pol Contributors! " Ronald van der Pol! " Freek Dijkstra! " Pieter de Boer! " Igor Idziejczak! " Mark Meijerink! " Hanno Pet! " Peter Tavenier Outline! " Network bandwidth
Ronald van der Pol Contributors! " Ronald van der Pol! " Freek Dijkstra! " Pieter de Boer! " Igor Idziejczak! " Mark Meijerink! " Hanno Pet! " Peter Tavenier Outline! " Network bandwidth