MSCOCO Keypoints Challenge Megvii (Face++)
|
|
|
- Ambrose Poole
- 6 years ago
- Views:
Transcription

1 MSCOCO Keypoints Challenge 2017 Megvii (Face++)







2 Team members(keypoints & Detection): Yilun Chen* Zhicheng Wang* Xiangyu Peng Zhiqiang Zhang Gang Yu Chao Peng Tete Xiao Zeming Li Xiangyu Zhang Yuning Jiang Jian Sun Megvii (Face++)
![Results COCO 17 & 16 Keypoints AP AP 50 AP 75 AP M AP L AR AR 50 AR 75 AR M AR L CMU-Pose [1] 0.605 0.834 0.664 0.551 0.681 0.659 0.864 0.713 0.594 0.748 G-RMI [2] 0.598 0.81 0.651 0.567 0.667 0.](/docs-images/75/72913666/images/3-3.jpg "664 0.865 0.712 0.618 0.726 Ours 0.726 0.905 0.791 0.684 0.788 0.788 0.943 0.846 0.746 0.846 [1] Cao, Zhe, et al. \"Realtime Multi-Person 2D Pose Estimation using Part Affinity Fields.\" (2016).")
3 Results COCO 17 & 16 Keypoints AP AP 50 AP 75 AP M AP L AR AR 50 AR 75 AR M AR L CMU-Pose [1] G-RMI [2] Ours [1] Cao, Zhe, et al. "Realtime Multi-Person 2D Pose Estimation using Part Affinity Fields." (2016). [2] Papandreou, George, et al. "Towards Accurate Multi-person Pose Estimation in the Wild." (2017). Note: [1] and [2] are evaluated on COCO 2016 test challenge dataset, while ours method is evaluated on COCO 2017 test challenge dataset.
4 Overview Top-down Pipeline Network Design Is Hourglass good for COCO keypoint? Motivation: How human locate keypoints? Our Network Architecture Techniques & Experiments Conclusion
5 Overview Top-down Pipeline
6 MegDet Top-Down pipeline
7 Top-Down pipeline MegDet crop
8 Top-Down pipeline MegDet crop Single Person Pose Estimation Network
9 Person Detector Our person detector is based on MegDet trained on 80-class labeled data, without specific training for person. (Human detection AP is 62.0) Human AP(area = all) Human AP(area = medium) Human AP(area = large)
10 Overview Top-down Pipeline Network Design
11 Overview Top-down Pipeline Network Design Is Hourglass good for COCO keypoint?
12 Is Hourglass good for COCO keypoint models input size FLOPs param_dim param_size depth_conv_fc AP Hourglass [2] 1-stage 256x G 3M 12MB ResNet-50-FPN [1] 256x G 24M 93MB ResNet-FPN-like [1] network works better than hourglass-like [2] network (1-stage) of the same FLOPs. [1] Lin, Tsung-Yi, et al. "Feature Pyramid Networks for Object Detection." arxiv preprint arxiv: (2016). [2] Newell, Alejandro, Kaiyu Yang, and Jia Deng. "Stacked hourglass networks for human pose estimation." European Conference on Computer Vision
 8.3G 0.924 0.754 4-stage hourglass(256*192) 10.5G 0.924 0.752 Two stages are enough for keypoint localization for better trade-off.")
13 Is Hourglass good for COCO keypoint Model FLOPs Pckh-0.5 (MPI val) (COCO val) 1-stage hourglass(256*192) 3.9G stage hourglass(256*192) 6.1G stage hourglass(256*192) 8.3G stage hourglass(256*192) 10.5G Two stages are enough for keypoint localization for better trade-off. More stages (stages larger than 2) are not good at high-precision localization, for OKS Guess: Hourglass stages harm the spatial resolution.
14 Overview Top-down Pipeline Network Design Is Hourglass good for COCO keypoint? Motivation: How human locates keypoints?



15 Motivation: How human locate keypoints? Nose Left elbow Right hand Visible easy keypoints context Left knee What? enlarge view Right knee Visible hard keypoints Left hip context easy visible parts hard visible parts Invisible part What? enlarge view hard to distinguish? Right shoulder
16 Network s Design Goal Visible easy part Visible hard part Invisible part Input image receptive view getting larger & more context Output image
17 Overview Top-down Pipeline Network Design Is Hourglass good for COCO keypoint? Motivation: How human locate keypoints? Our Network Architecture

 and visible hard parts (deep layers) GlobalNet: to locate hard parts")
18 Network Architecture Network Design Principles: Follow the human perspective locate visible easy parts => locate visible hard parts => locate invisible parts Two stages VisibleNet: to locate the both the easy parts (earlier layers) and visible hard parts (deep layers) GlobalNet: to locate hard parts as well
19 Overview Top-down Pipeline Network Design Is Hourglass good for COCO keypoint? Motivation: How human locate keypoint? Our Network Architecture Techniques & Experiments
20 Techniques & Experiments AP% (COCO minival) AP% (COCO minival) Baseline (ResNet-50-FPN) (256x192) 67.1 Our network (ResNet-50) (256x192) 69.0 Our network (Inception-ResNet) (384x288) Large Batch 73.0 Our network (ResNet-50) (384x288) 71.0 More ablation experiments on our network will come soon in our CVPR submission.
21 Techniques & Experiments Data augmentation (+0.4AP) Crop augmentation Random scales(0.7~ 1.35) Rotation(-45º ~ 45º)
22 Techniques & Experiments Data augmentation (+0.4AP) Crop augmentation Random scales(0.7~ 1.35) Rotation(-45º ~ 45º) Large Batch (+0.4~0.7AP)
23 Techniques & Experiments Data augmentation (+0.4AP) Crop augmentation Random scales(0.7~ 1.35) Rotation(-45º ~ 45º) Large Batch (+0.4~0.7AP) Segmentation supervision(+0.2~0.6ap) Enhance the network s ability to distinguish the detected person from crowded scene.
24 Techniques & Experiments Data augmentation (+0.4AP) Crop augmentation Random scales(0.7~ 1.35) Rotation(-45º ~ 45º) Large Batch (+0.4~0.7AP) Segmentation supervision(+0.2~0.6ap) Enhance the network s ability to distinguish the detected person from crowded scene. Ensemble(+1.1~1.5AP) Heatmap merge AP% (COCO minival) AP% (COCO challenge) Our network with all techniques
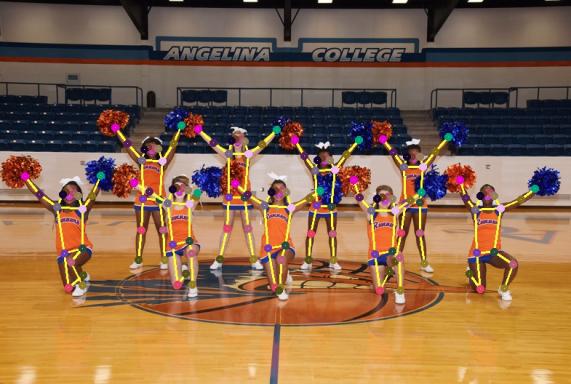



25 Illustrative results of our method
26 Conclusion The two-stage network design is crucial. VisibleNet: locates both the visible easy parts (earlier layers) and visible hard parts (deep layers) GlobalNet: locates invisible parts Data augmentation is the key to enhance robustness of network, especially in CNN. Large batch technique is not only applicable in object detection, but also in keypoint. Segmentation supervision is also an universe skill in training CNN.
27 We @Seattle
28 Thanks & Questions
Cascaded Pyramid Network for Multi-Person Pose Estimation
 Cascaded Pyramid Network for Multi-Person Pose Estimation Gang YU yugang@megvii.com Megvii (Face++) Team members: Yilun Chen* Zhicheng Wang* Xiangyu Peng Zhiqiang Zhang Gang Yu Jian Sun (https://arxiv.org/abs/1711.07319)
Cascaded Pyramid Network for Multi-Person Pose Estimation Gang YU yugang@megvii.com Megvii (Face++) Team members: Yilun Chen* Zhicheng Wang* Xiangyu Peng Zhiqiang Zhang Gang Yu Jian Sun (https://arxiv.org/abs/1711.07319)
arxiv: v2 [cs.cv] 8 Apr 2018
![arxiv: v2 [cs.cv] 8 Apr 2018](/thumbs/80/82499963.jpg "arxiv: v2 [cs.cv] 8 Apr 2018") Cascaded Pyramid Network for Multi-Person Pose Estimation Yilun Chen Zhicheng Wang Yuxiang Peng 1 Zhiqiang Zhang 2 Gang Yu Jian Sun 1 Tsinghua University 2 HuaZhong University of Science and Technology
Cascaded Pyramid Network for Multi-Person Pose Estimation Yilun Chen Zhicheng Wang Yuxiang Peng 1 Zhiqiang Zhang 2 Gang Yu Jian Sun 1 Tsinghua University 2 HuaZhong University of Science and Technology
Team G-RMI: Google Research & Machine Intelligence
 Team G-RMI: Google Research & Machine Intelligence Alireza Fathi (alirezafathi@google.com) Nori Kanazawa, Kai Yang, George Papandreou, Tyler Zhu, Jonathan Huang, Vivek Rathod, Chen Sun, Kevin Murphy, et
Team G-RMI: Google Research & Machine Intelligence Alireza Fathi (alirezafathi@google.com) Nori Kanazawa, Kai Yang, George Papandreou, Tyler Zhu, Jonathan Huang, Vivek Rathod, Chen Sun, Kevin Murphy, et
R-FCN++: Towards Accurate Region-Based Fully Convolutional Networks for Object Detection
 The Thirty-Second AAAI Conference on Artificial Intelligence (AAAI-18) R-FCN++: Towards Accurate Region-Based Fully Convolutional Networks for Object Detection Zeming Li, 1 Yilun Chen, 2 Gang Yu, 2 Yangdong
The Thirty-Second AAAI Conference on Artificial Intelligence (AAAI-18) R-FCN++: Towards Accurate Region-Based Fully Convolutional Networks for Object Detection Zeming Li, 1 Yilun Chen, 2 Gang Yu, 2 Yangdong
Realtime Multi-Person 2D Pose Estimation using Part Affinity Fields
 Realtime Multi-Person 2D Pose Estimation using Part Affinity Fields Authors: Zhe Cao, Tomas Simon, Shih-En Wei, Yaser Sheikh Presented by: Suraj Kesavan, Priscilla Jennifer ECS 289G: Visual Recognition
Realtime Multi-Person 2D Pose Estimation using Part Affinity Fields Authors: Zhe Cao, Tomas Simon, Shih-En Wei, Yaser Sheikh Presented by: Suraj Kesavan, Priscilla Jennifer ECS 289G: Visual Recognition
Classifying a specific image region using convolutional nets with an ROI mask as input
 Classifying a specific image region using convolutional nets with an ROI mask as input 1 Sagi Eppel Abstract Convolutional neural nets (CNN) are the leading computer vision method for classifying images.
Classifying a specific image region using convolutional nets with an ROI mask as input 1 Sagi Eppel Abstract Convolutional neural nets (CNN) are the leading computer vision method for classifying images.
arxiv: v2 [cs.cv] 19 Apr 2018
![arxiv: v2 [cs.cv] 19 Apr 2018](/thumbs/83/87325597.jpg "arxiv: v2 [cs.cv] 19 Apr 2018") arxiv:1804.06215v2 [cs.cv] 19 Apr 2018 DetNet: A Backbone network for Object Detection Zeming Li 1, Chao Peng 2, Gang Yu 2, Xiangyu Zhang 2, Yangdong Deng 1, Jian Sun 2 1 School of Software, Tsinghua University,
arxiv:1804.06215v2 [cs.cv] 19 Apr 2018 DetNet: A Backbone network for Object Detection Zeming Li 1, Chao Peng 2, Gang Yu 2, Xiangyu Zhang 2, Yangdong Deng 1, Jian Sun 2 1 School of Software, Tsinghua University,
arxiv: v1 [cs.cv] 29 Nov 2018
![arxiv: v1 [cs.cv] 29 Nov 2018](/thumbs/93/114181352.jpg "arxiv: v1 [cs.cv] 29 Nov 2018") Grid R-CNN Xin Lu 1 Buyu Li 1 Yuxin Yue 1 Quanquan Li 1 Junjie Yan 1 1 SenseTime Group Limited {luxin,libuyu,yueyuxin,liquanquan,yanjunjie}@sensetime.com arxiv:1811.12030v1 [cs.cv] 29 Nov 2018 Abstract
Grid R-CNN Xin Lu 1 Buyu Li 1 Yuxin Yue 1 Quanquan Li 1 Junjie Yan 1 1 SenseTime Group Limited {luxin,libuyu,yueyuxin,liquanquan,yanjunjie}@sensetime.com arxiv:1811.12030v1 [cs.cv] 29 Nov 2018 Abstract
arxiv: v2 [cs.cv] 23 Jan 2019
![arxiv: v2 [cs.cv] 23 Jan 2019](/thumbs/96/128286896.jpg "arxiv: v2 [cs.cv] 23 Jan 2019") CrowdPose: Efficient Crowded Scenes Pose Estimation and A New Benchmark Jiefeng Li 1, Can Wang 1, Hao Zhu 1, Yihuan Mao 2, Hao-Shu Fang 1, Cewu Lu 1 1 Shanghai Jiao Tong University, 2 Tsinghua University
CrowdPose: Efficient Crowded Scenes Pose Estimation and A New Benchmark Jiefeng Li 1, Can Wang 1, Hao Zhu 1, Yihuan Mao 2, Hao-Shu Fang 1, Cewu Lu 1 1 Shanghai Jiao Tong University, 2 Tsinghua University
Simple Baselines for Human Pose Estimation and Tracking
 Simple Baselines for Human Pose Estimation and Tracking Bin Xiao 1, Haiping Wu 2, and Yichen Wei 1 1 Microsoft Research Asia, 2 University of Electronic Science and Technology of China {Bin.Xiao, v-haipwu,
Simple Baselines for Human Pose Estimation and Tracking Bin Xiao 1, Haiping Wu 2, and Yichen Wei 1 1 Microsoft Research Asia, 2 University of Electronic Science and Technology of China {Bin.Xiao, v-haipwu,
arxiv: v5 [cs.cv] 4 Feb 2018
![arxiv: v5 [cs.cv] 4 Feb 2018](/thumbs/78/77842416.jpg "arxiv: v5 [cs.cv] 4 Feb 2018") RMPE: Regional Multi-Person Pose Estimation Hao-Shu Fang 1, Shuqin Xie 1, Yu-Wing Tai 2, Cewu Lu 1 1 Shanghai Jiao Tong University, China 2 Tencent YouTu fhaoshu@gmail.com qweasdshu@sjtu.edu.cn yuwingtai@tencent.com
RMPE: Regional Multi-Person Pose Estimation Hao-Shu Fang 1, Shuqin Xie 1, Yu-Wing Tai 2, Cewu Lu 1 1 Shanghai Jiao Tong University, China 2 Tencent YouTu fhaoshu@gmail.com qweasdshu@sjtu.edu.cn yuwingtai@tencent.com
SEMANTIC SEGMENTATION AVIRAM BAR HAIM & IRIS TAL
 SEMANTIC SEGMENTATION AVIRAM BAR HAIM & IRIS TAL IMAGE DESCRIPTIONS IN THE WILD (IDW-CNN) LARGE KERNEL MATTERS (GCN) DEEP LEARNING SEMINAR, TAU NOVEMBER 2017 TOPICS IDW-CNN: Improving Semantic Segmentation
SEMANTIC SEGMENTATION AVIRAM BAR HAIM & IRIS TAL IMAGE DESCRIPTIONS IN THE WILD (IDW-CNN) LARGE KERNEL MATTERS (GCN) DEEP LEARNING SEMINAR, TAU NOVEMBER 2017 TOPICS IDW-CNN: Improving Semantic Segmentation
Multi-scale Adaptive Structure Network for Human Pose Estimation from Color Images
 Multi-scale Adaptive Structure Network for Human Pose Estimation from Color Images Wenlin Zhuang 1, Cong Peng 2, Siyu Xia 1, and Yangang, Wang 1 1 School of Automation, Southeast University, Nanjing, China
Multi-scale Adaptive Structure Network for Human Pose Estimation from Color Images Wenlin Zhuang 1, Cong Peng 2, Siyu Xia 1, and Yangang, Wang 1 1 School of Automation, Southeast University, Nanjing, China
Towards 3D Human Pose Estimation in the Wild: a Weakly-supervised Approach
 Towards 3D Human Pose Estimation in the Wild: a Weakly-supervised Approach Xingyi Zhou, Qixing Huang, Xiao Sun, Xiangyang Xue, Yichen Wei UT Austin & MSRA & Fudan Human Pose Estimation Pose representation
Towards 3D Human Pose Estimation in the Wild: a Weakly-supervised Approach Xingyi Zhou, Qixing Huang, Xiao Sun, Xiangyang Xue, Yichen Wei UT Austin & MSRA & Fudan Human Pose Estimation Pose representation
SSD: Single Shot MultiBox Detector. Author: Wei Liu et al. Presenter: Siyu Jiang
 SSD: Single Shot MultiBox Detector Author: Wei Liu et al. Presenter: Siyu Jiang Outline 1. Motivations 2. Contributions 3. Methodology 4. Experiments 5. Conclusions 6. Extensions Motivation Motivation
SSD: Single Shot MultiBox Detector Author: Wei Liu et al. Presenter: Siyu Jiang Outline 1. Motivations 2. Contributions 3. Methodology 4. Experiments 5. Conclusions 6. Extensions Motivation Motivation
Channel Locality Block: A Variant of Squeeze-and-Excitation
 Channel Locality Block: A Variant of Squeeze-and-Excitation 1 st Huayu Li Northern Arizona University Flagstaff, United State Northern Arizona University hl459@nau.edu arxiv:1901.01493v1 [cs.lg] 6 Jan
Channel Locality Block: A Variant of Squeeze-and-Excitation 1 st Huayu Li Northern Arizona University Flagstaff, United State Northern Arizona University hl459@nau.edu arxiv:1901.01493v1 [cs.lg] 6 Jan
arxiv: v1 [cs.cv] 26 Jul 2018
![arxiv: v1 [cs.cv] 26 Jul 2018](/thumbs/88/117269915.jpg "arxiv: v1 [cs.cv] 26 Jul 2018") A Better Baseline for AVA Rohit Girdhar João Carreira Carl Doersch Andrew Zisserman DeepMind Carnegie Mellon University University of Oxford arxiv:1807.10066v1 [cs.cv] 26 Jul 2018 Abstract We introduce
A Better Baseline for AVA Rohit Girdhar João Carreira Carl Doersch Andrew Zisserman DeepMind Carnegie Mellon University University of Oxford arxiv:1807.10066v1 [cs.cv] 26 Jul 2018 Abstract We introduce
arxiv: v2 [cs.cv] 22 Nov 2017
![arxiv: v2 [cs.cv] 22 Nov 2017](/thumbs/86/93068521.jpg "arxiv: v2 [cs.cv] 22 Nov 2017") Face Attention Network: An Effective Face Detector for the Occluded Faces Jianfeng Wang College of Software, Beihang University Beijing, China wjfwzzc@buaa.edu.cn Ye Yuan Megvii Inc. (Face++) Beijing,
Face Attention Network: An Effective Face Detector for the Occluded Faces Jianfeng Wang College of Software, Beihang University Beijing, China wjfwzzc@buaa.edu.cn Ye Yuan Megvii Inc. (Face++) Beijing,
A Cascaded Inception of Inception Network with Attention Modulated Feature Fusion for Human Pose Estimation
 A Cascaded Inception of Inception Network with Attention Modulated Feature Fusion for Human Pose Estimation Submission ID: 2065 Abstract Accurate keypoint localization of human pose needs diversified features:
A Cascaded Inception of Inception Network with Attention Modulated Feature Fusion for Human Pose Estimation Submission ID: 2065 Abstract Accurate keypoint localization of human pose needs diversified features:
JIAN SUN (
 JIAN SUN (www.jiansun.org) CONTACT INFO Email: sunjian@megvii.com Birth date: Oct 30, 1976 Homepage: www.jiansun.org ADDRESS 3F Tower A, Raycom Info Tech Park No.2 Kexueyuan South Road Haidian District,
JIAN SUN (www.jiansun.org) CONTACT INFO Email: sunjian@megvii.com Birth date: Oct 30, 1976 Homepage: www.jiansun.org ADDRESS 3F Tower A, Raycom Info Tech Park No.2 Kexueyuan South Road Haidian District,
arxiv: v1 [cs.cv] 16 Nov 2015
![arxiv: v1 [cs.cv] 16 Nov 2015](/thumbs/85/92600288.jpg "arxiv: v1 [cs.cv] 16 Nov 2015") Coarse-to-fine Face Alignment with Multi-Scale Local Patch Regression Zhiao Huang hza@megvii.com Erjin Zhou zej@megvii.com Zhimin Cao czm@megvii.com arxiv:1511.04901v1 [cs.cv] 16 Nov 2015 Abstract Facial
Coarse-to-fine Face Alignment with Multi-Scale Local Patch Regression Zhiao Huang hza@megvii.com Erjin Zhou zej@megvii.com Zhimin Cao czm@megvii.com arxiv:1511.04901v1 [cs.cv] 16 Nov 2015 Abstract Facial
Human Pose Estimation with Deep Learning. Wei Yang
 Human Pose Estimation with Deep Learning Wei Yang Applications Understand Activities Family Robots American Heist (2014) - The Bank Robbery Scene 2 What do we need to know to recognize a crime scene? 3
Human Pose Estimation with Deep Learning Wei Yang Applications Understand Activities Family Robots American Heist (2014) - The Bank Robbery Scene 2 What do we need to know to recognize a crime scene? 3
Cascade Region Regression for Robust Object Detection
 Large Scale Visual Recognition Challenge 2015 (ILSVRC2015) Cascade Region Regression for Robust Object Detection Jiankang Deng, Shaoli Huang, Jing Yang, Hui Shuai, Zhengbo Yu, Zongguang Lu, Qiang Ma, Yali
Large Scale Visual Recognition Challenge 2015 (ILSVRC2015) Cascade Region Regression for Robust Object Detection Jiankang Deng, Shaoli Huang, Jing Yang, Hui Shuai, Zhengbo Yu, Zongguang Lu, Qiang Ma, Yali
Mask R-CNN. presented by Jiageng Zhang, Jingyao Zhan, Yunhan Ma
 Mask R-CNN presented by Jiageng Zhang, Jingyao Zhan, Yunhan Ma Mask R-CNN Background Related Work Architecture Experiment Mask R-CNN Background Related Work Architecture Experiment Background From left
Mask R-CNN presented by Jiageng Zhang, Jingyao Zhan, Yunhan Ma Mask R-CNN Background Related Work Architecture Experiment Mask R-CNN Background Related Work Architecture Experiment Background From left
arxiv: v1 [cs.cv] 29 Sep 2016
![arxiv: v1 [cs.cv] 29 Sep 2016](/thumbs/76/73787064.jpg "arxiv: v1 [cs.cv] 29 Sep 2016") arxiv:1609.09545v1 [cs.cv] 29 Sep 2016 Two-stage Convolutional Part Heatmap Regression for the 1st 3D Face Alignment in the Wild (3DFAW) Challenge Adrian Bulat and Georgios Tzimiropoulos Computer Vision
arxiv:1609.09545v1 [cs.cv] 29 Sep 2016 Two-stage Convolutional Part Heatmap Regression for the 1st 3D Face Alignment in the Wild (3DFAW) Challenge Adrian Bulat and Georgios Tzimiropoulos Computer Vision
A Cascaded Inception of Inception Network with Attention Modulated Feature Fusion for Human Pose Estimation
 The Thirty-Second AAAI Conference on Artificial Intelligence (AAAI-18) A Cascaded Inception of Inception Network with Attention Modulated Feature Fusion for Human Pose Estimation Wentao Liu, 1,2 Jie Chen,
The Thirty-Second AAAI Conference on Artificial Intelligence (AAAI-18) A Cascaded Inception of Inception Network with Attention Modulated Feature Fusion for Human Pose Estimation Wentao Liu, 1,2 Jie Chen,
arxiv: v4 [cs.cv] 2 Sep 2017
![arxiv: v4 [cs.cv] 2 Sep 2017](/thumbs/81/83455566.jpg "arxiv: v4 [cs.cv] 2 Sep 2017") RMPE: Regional Multi-Person Pose Estimation Hao-Shu Fang 1, Shuqin Xie 1, Yu-Wing Tai 2, Cewu Lu 1 1 Shanghai Jiao Tong University, China 2 Tencent YouTu fhaoshu@gmail.com qweasdshu@sjtu.edu.cn yuwingtai@tencent.com
RMPE: Regional Multi-Person Pose Estimation Hao-Shu Fang 1, Shuqin Xie 1, Yu-Wing Tai 2, Cewu Lu 1 1 Shanghai Jiao Tong University, China 2 Tencent YouTu fhaoshu@gmail.com qweasdshu@sjtu.edu.cn yuwingtai@tencent.com
Mask R-CNN. Kaiming He, Georgia, Gkioxari, Piotr Dollar, Ross Girshick Presenters: Xiaokang Wang, Mengyao Shi Feb. 13, 2018
 Mask R-CNN Kaiming He, Georgia, Gkioxari, Piotr Dollar, Ross Girshick Presenters: Xiaokang Wang, Mengyao Shi Feb. 13, 2018 1 Common computer vision tasks Image Classification: one label is generated for
Mask R-CNN Kaiming He, Georgia, Gkioxari, Piotr Dollar, Ross Girshick Presenters: Xiaokang Wang, Mengyao Shi Feb. 13, 2018 1 Common computer vision tasks Image Classification: one label is generated for
Efficient Segmentation-Aided Text Detection For Intelligent Robots
 Efficient Segmentation-Aided Text Detection For Intelligent Robots Junting Zhang, Yuewei Na, Siyang Li, C.-C. Jay Kuo University of Southern California Outline Problem Definition and Motivation Related
Efficient Segmentation-Aided Text Detection For Intelligent Robots Junting Zhang, Yuewei Na, Siyang Li, C.-C. Jay Kuo University of Southern California Outline Problem Definition and Motivation Related
An Analysis of Scale Invariance in Object Detection SNIP
 An Analysis of Scale Invariance in Object Detection SNIP Bharat Singh Larry S. Davis University of Maryland, College Park {bharat,lsd}@cs.umd.edu Abstract An analysis of different techniques for recognizing
An Analysis of Scale Invariance in Object Detection SNIP Bharat Singh Larry S. Davis University of Maryland, College Park {bharat,lsd}@cs.umd.edu Abstract An analysis of different techniques for recognizing
arxiv: v2 [cs.cv] 3 Feb 2019
![arxiv: v2 [cs.cv] 3 Feb 2019](/thumbs/95/123524922.jpg "arxiv: v2 [cs.cv] 3 Feb 2019") arxiv:1901.08043v [cs.cv] 3 Feb 019 Bottom-up Object Detection by Grouping Extreme and Center Points Xingyi Zhou UT Austin Jiacheng Zhuo UT Austin Philipp Kra henbu hl UT Austin zhouxy@cs.utexas.edu jzhuo@cs.utexas.edu
arxiv:1901.08043v [cs.cv] 3 Feb 019 Bottom-up Object Detection by Grouping Extreme and Center Points Xingyi Zhou UT Austin Jiacheng Zhuo UT Austin Philipp Kra henbu hl UT Austin zhouxy@cs.utexas.edu jzhuo@cs.utexas.edu
Inception and Residual Networks. Hantao Zhang. Deep Learning with Python.
 Inception and Residual Networks Hantao Zhang Deep Learning with Python https://en.wikipedia.org/wiki/residual_neural_network Deep Neural Network Progress from Large Scale Visual Recognition Challenge (ILSVRC)
Inception and Residual Networks Hantao Zhang Deep Learning with Python https://en.wikipedia.org/wiki/residual_neural_network Deep Neural Network Progress from Large Scale Visual Recognition Challenge (ILSVRC)
Stereo Human Keypoint Estimation
 Stereo Human Keypoint Estimation Kyle Brown Stanford University Stanford Intelligent Systems Laboratory kjbrown7@stanford.edu Abstract The goal of this project is to accurately estimate human keypoint
Stereo Human Keypoint Estimation Kyle Brown Stanford University Stanford Intelligent Systems Laboratory kjbrown7@stanford.edu Abstract The goal of this project is to accurately estimate human keypoint
ECE 6554:Advanced Computer Vision Pose Estimation
 ECE 6554:Advanced Computer Vision Pose Estimation Sujay Yadawadkar, Virginia Tech, Agenda: Pose Estimation: Part Based Models for Pose Estimation Pose Estimation with Convolutional Neural Networks (Deep
ECE 6554:Advanced Computer Vision Pose Estimation Sujay Yadawadkar, Virginia Tech, Agenda: Pose Estimation: Part Based Models for Pose Estimation Pose Estimation with Convolutional Neural Networks (Deep
Improving Face Recognition by Exploring Local Features with Visual Attention
 Improving Face Recognition by Exploring Local Features with Visual Attention Yichun Shi and Anil K. Jain Michigan State University Difficulties of Face Recognition Large variations in unconstrained face
Improving Face Recognition by Exploring Local Features with Visual Attention Yichun Shi and Anil K. Jain Michigan State University Difficulties of Face Recognition Large variations in unconstrained face
YOLO9000: Better, Faster, Stronger
 YOLO9000: Better, Faster, Stronger Date: January 24, 2018 Prepared by Haris Khan (University of Toronto) Haris Khan CSC2548: Machine Learning in Computer Vision 1 Overview 1. Motivation for one-shot object
YOLO9000: Better, Faster, Stronger Date: January 24, 2018 Prepared by Haris Khan (University of Toronto) Haris Khan CSC2548: Machine Learning in Computer Vision 1 Overview 1. Motivation for one-shot object
FishNet: A Versatile Backbone for Image, Region, and Pixel Level Prediction
 FishNet: A Versatile Backbone for Image, Region, and Pixel Level Prediction Shuyang Sun 1, Jiangmiao Pang 3, Jianping Shi 2, Shuai Yi 2, Wanli Ouyang 1 1 The University of Sydney 2 SenseTime Research 3
FishNet: A Versatile Backbone for Image, Region, and Pixel Level Prediction Shuyang Sun 1, Jiangmiao Pang 3, Jianping Shi 2, Shuai Yi 2, Wanli Ouyang 1 1 The University of Sydney 2 SenseTime Research 3
An Analysis of Scale Invariance in Object Detection SNIP
 An Analysis of Scale Invariance in Object Detection SNIP Bharat Singh Larry S. Davis University of Maryland, College Park {bharat,lsd}@cs.umd.edu Abstract An analysis of different techniques for recognizing
An Analysis of Scale Invariance in Object Detection SNIP Bharat Singh Larry S. Davis University of Maryland, College Park {bharat,lsd}@cs.umd.edu Abstract An analysis of different techniques for recognizing
DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution and Fully Connected CRFs
 DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution and Fully Connected CRFs Zhipeng Yan, Moyuan Huang, Hao Jiang 5/1/2017 1 Outline Background semantic segmentation Objective,
DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution and Fully Connected CRFs Zhipeng Yan, Moyuan Huang, Hao Jiang 5/1/2017 1 Outline Background semantic segmentation Objective,
Amodal and Panoptic Segmentation. Stephanie Liu, Andrew Zhou
 Amodal and Panoptic Segmentation Stephanie Liu, Andrew Zhou This lecture: 1. 2. 3. 4. Semantic Amodal Segmentation Cityscapes Dataset ADE20K Dataset Panoptic Segmentation Semantic Amodal Segmentation Yan
Amodal and Panoptic Segmentation Stephanie Liu, Andrew Zhou This lecture: 1. 2. 3. 4. Semantic Amodal Segmentation Cityscapes Dataset ADE20K Dataset Panoptic Segmentation Semantic Amodal Segmentation Yan
Content-Based Image Recovery
 Content-Based Image Recovery Hong-Yu Zhou and Jianxin Wu National Key Laboratory for Novel Software Technology Nanjing University, China zhouhy@lamda.nju.edu.cn wujx2001@nju.edu.cn Abstract. We propose
Content-Based Image Recovery Hong-Yu Zhou and Jianxin Wu National Key Laboratory for Novel Software Technology Nanjing University, China zhouhy@lamda.nju.edu.cn wujx2001@nju.edu.cn Abstract. We propose
Multi-Scale Structure-Aware Network for Human Pose Estimation
 Multi-Scale Structure-Aware Network for Human Pose Estimation Lipeng Ke 1, Ming-Ching Chang 2, Honggang Qi 1, and Siwei Lyu 2 1 University of Chinese Academy of Sciences, Beijing, China 2 University at
Multi-Scale Structure-Aware Network for Human Pose Estimation Lipeng Ke 1, Ming-Ching Chang 2, Honggang Qi 1, and Siwei Lyu 2 1 University of Chinese Academy of Sciences, Beijing, China 2 University at
arxiv: v2 [cs.cv] 16 Sep 2018
![arxiv: v2 [cs.cv] 16 Sep 2018](/thumbs/90/104336455.jpg "arxiv: v2 [cs.cv] 16 Sep 2018") Dual Attention Network for Scene Segmentation Jun Fu, Jing Liu, Haijie Tian, Zhiwei Fang, Hanqing Lu CASIA IVA {jun.fu, jliu, zhiwei.fang, luhq}@nlpr.ia.ac.cn,{hjtian bit}@63.com arxiv:809.0983v [cs.cv]
Dual Attention Network for Scene Segmentation Jun Fu, Jing Liu, Haijie Tian, Zhiwei Fang, Hanqing Lu CASIA IVA {jun.fu, jliu, zhiwei.fang, luhq}@nlpr.ia.ac.cn,{hjtian bit}@63.com arxiv:809.0983v [cs.cv]
Multi-Scale Structure-Aware Network for Human Pose Estimation
 Multi-Scale Structure-Aware Network for Human Pose Estimation Lipeng Ke 1, Ming-Ching Chang 2, Honggang Qi 1, Siwei Lyu 2 1 University of Chinese Academy of Sciences, Beijing, China 2 University at Albany,
Multi-Scale Structure-Aware Network for Human Pose Estimation Lipeng Ke 1, Ming-Ching Chang 2, Honggang Qi 1, Siwei Lyu 2 1 University of Chinese Academy of Sciences, Beijing, China 2 University at Albany,
CornerNet: Detecting Objects as Paired Keypoints
 CornerNet: Detecting Objects as Paired Keypoints Hei Law Jia Deng more efficient. One-stage detectors place anchor boxes densely over an image and generate final box predictions by scoring anchor boxes
CornerNet: Detecting Objects as Paired Keypoints Hei Law Jia Deng more efficient. One-stage detectors place anchor boxes densely over an image and generate final box predictions by scoring anchor boxes
Deep Residual Learning
 Deep Residual Learning MSRA @ ILSVRC & COCO 2015 competitions Kaiming He with Xiangyu Zhang, Shaoqing Ren, Jifeng Dai, & Jian Sun Microsoft Research Asia (MSRA) MSRA @ ILSVRC & COCO 2015 Competitions 1st
Deep Residual Learning MSRA @ ILSVRC & COCO 2015 competitions Kaiming He with Xiangyu Zhang, Shaoqing Ren, Jifeng Dai, & Jian Sun Microsoft Research Asia (MSRA) MSRA @ ILSVRC & COCO 2015 Competitions 1st
arxiv: v2 [cs.cv] 23 Nov 2017
![arxiv: v2 [cs.cv] 23 Nov 2017](/thumbs/75/71682984.jpg "arxiv: v2 [cs.cv] 23 Nov 2017") Light-Head R-CNN: In Defense of Two-Stage Object Detector Zeming Li 1, Chao Peng 2, Gang Yu 2, Xiangyu Zhang 2, Yangdong Deng 1, Jian Sun 2 1 School of Software, Tsinghua University, {lizm15@mails.tsinghua.edu.cn,
Light-Head R-CNN: In Defense of Two-Stage Object Detector Zeming Li 1, Chao Peng 2, Gang Yu 2, Xiangyu Zhang 2, Yangdong Deng 1, Jian Sun 2 1 School of Software, Tsinghua University, {lizm15@mails.tsinghua.edu.cn,
Integral Human Pose Regression
 Integral Human Pose Regression Xiao Sun 1, Bin Xiao 1, Fangyin Wei 2, Shuang Liang 3, and Yichen Wei 1 1 Microsoft Research, Beijing, China {xias, Bin.Xiao, yichenw}@microsoft.com 2 Peking University,
Integral Human Pose Regression Xiao Sun 1, Bin Xiao 1, Fangyin Wei 2, Shuang Liang 3, and Yichen Wei 1 1 Microsoft Research, Beijing, China {xias, Bin.Xiao, yichenw}@microsoft.com 2 Peking University,
Improved Face Detection and Alignment using Cascade Deep Convolutional Network
 Improved Face Detection and Alignment using Cascade Deep Convolutional Network Weilin Cong, Sanyuan Zhao, Hui Tian, and Jianbing Shen Beijing Key Laboratory of Intelligent Information Technology, School
Improved Face Detection and Alignment using Cascade Deep Convolutional Network Weilin Cong, Sanyuan Zhao, Hui Tian, and Jianbing Shen Beijing Key Laboratory of Intelligent Information Technology, School
Holistic 3D Scene Parsing and Reconstruction from a Single RGB Image. Supplementary Material
 Holistic 3D Scene Parsing and Reconstruction from a Single RGB Image Supplementary Material Siyuan Huang 1,2, Siyuan Qi 1,2, Yixin Zhu 1,2, Yinxue Xiao 1, Yuanlu Xu 1,2, and Song-Chun Zhu 1,2 1 University
Holistic 3D Scene Parsing and Reconstruction from a Single RGB Image Supplementary Material Siyuan Huang 1,2, Siyuan Qi 1,2, Yixin Zhu 1,2, Yinxue Xiao 1, Yuanlu Xu 1,2, and Song-Chun Zhu 1,2 1 University
Proceedings of the International MultiConference of Engineers and Computer Scientists 2018 Vol I IMECS 2018, March 14-16, 2018, Hong Kong
 , March 14-16, 2018, Hong Kong , March 14-16, 2018, Hong Kong , March 14-16, 2018, Hong Kong , March 14-16, 2018, Hong Kong TABLE I CLASSIFICATION ACCURACY OF DIFFERENT PRE-TRAINED MODELS ON THE TEST DATA
, March 14-16, 2018, Hong Kong , March 14-16, 2018, Hong Kong , March 14-16, 2018, Hong Kong , March 14-16, 2018, Hong Kong TABLE I CLASSIFICATION ACCURACY OF DIFFERENT PRE-TRAINED MODELS ON THE TEST DATA
Person Part Segmentation based on Weak Supervision
 JIANG, CHI: PERSON PART SEGMENTATION BASED ON WEAK SUPERVISION 1 Person Part Segmentation based on Weak Supervision Yalong Jiang 1 yalong.jiang@connect.polyu.hk Zheru Chi 1 chi.zheru@polyu.edu.hk 1 Department
JIANG, CHI: PERSON PART SEGMENTATION BASED ON WEAK SUPERVISION 1 Person Part Segmentation based on Weak Supervision Yalong Jiang 1 yalong.jiang@connect.polyu.hk Zheru Chi 1 chi.zheru@polyu.edu.hk 1 Department
arxiv: v1 [cs.cv] 11 Jul 2018
![arxiv: v1 [cs.cv] 11 Jul 2018](/thumbs/87/96473743.jpg "arxiv: v1 [cs.cv] 11 Jul 2018") arxiv:1807.04067v1 [cs.cv] 11 Jul 2018 MultiPoseNet: Fast Multi-Person Pose Estimation using Pose Residual Network Muhammed Kocabas 1, M. Salih Karagoz 1, Emre Akbas 1 1 Department of Computer Engineering,
arxiv:1807.04067v1 [cs.cv] 11 Jul 2018 MultiPoseNet: Fast Multi-Person Pose Estimation using Pose Residual Network Muhammed Kocabas 1, M. Salih Karagoz 1, Emre Akbas 1 1 Department of Computer Engineering,
arxiv: v2 [cs.cv] 30 Sep 2018
![arxiv: v2 [cs.cv] 30 Sep 2018](/thumbs/94/120109326.jpg "arxiv: v2 [cs.cv] 30 Sep 2018") A Detection and Segmentation Architecture for Skin Lesion Segmentation on Dermoscopy Images arxiv:1809.03917v2 [cs.cv] 30 Sep 2018 Chengyao Qian, Ting Liu, Hao Jiang, Zhe Wang, Pengfei Wang, Mingxin Guan
A Detection and Segmentation Architecture for Skin Lesion Segmentation on Dermoscopy Images arxiv:1809.03917v2 [cs.cv] 30 Sep 2018 Chengyao Qian, Ting Liu, Hao Jiang, Zhe Wang, Pengfei Wang, Mingxin Guan
arxiv: v2 [cs.cv] 26 Mar 2018
![arxiv: v2 [cs.cv] 26 Mar 2018](/thumbs/85/92916828.jpg "arxiv: v2 [cs.cv] 26 Mar 2018") Repulsion Loss: Detecting Pedestrians in a Crowd Xinlong Wang 1 Tete Xiao 2 Yuning Jiang 3 Shuai Shao 3 Jian Sun 3 Chunhua Shen 4 arxiv:1711.07752v2 [cs.cv] 26 Mar 2018 1 Tongji University 1452405wxl@tongji.edu.cn
Repulsion Loss: Detecting Pedestrians in a Crowd Xinlong Wang 1 Tete Xiao 2 Yuning Jiang 3 Shuai Shao 3 Jian Sun 3 Chunhua Shen 4 arxiv:1711.07752v2 [cs.cv] 26 Mar 2018 1 Tongji University 1452405wxl@tongji.edu.cn
arxiv: v1 [cs.cv] 2 Aug 2018
![arxiv: v1 [cs.cv] 2 Aug 2018](/thumbs/93/114042775.jpg "arxiv: v1 [cs.cv] 2 Aug 2018") arxiv:1808.00897v1 [cs.cv] 2 Aug 2018 BiSeNet: Bilateral Segmentation Network for Real-time Semantic Segmentation Changqian Yu 1[0000 0002 4488 4157], Jingbo Wang 2[0000 0001 9700 6262], Chao Peng 3[0000
arxiv:1808.00897v1 [cs.cv] 2 Aug 2018 BiSeNet: Bilateral Segmentation Network for Real-time Semantic Segmentation Changqian Yu 1[0000 0002 4488 4157], Jingbo Wang 2[0000 0001 9700 6262], Chao Peng 3[0000
3 Object Detection. BVM 2018 Tutorial: Advanced Deep Learning Methods. Paul F. Jaeger, Division of Medical Image Computing
 3 Object Detection BVM 2018 Tutorial: Advanced Deep Learning Methods Paul F. Jaeger, of Medical Image Computing What is object detection? classification segmentation obj. detection (1 label per pixel)
3 Object Detection BVM 2018 Tutorial: Advanced Deep Learning Methods Paul F. Jaeger, of Medical Image Computing What is object detection? classification segmentation obj. detection (1 label per pixel)
arxiv: v1 [cs.cv] 19 Feb 2019
![arxiv: v1 [cs.cv] 19 Feb 2019](/thumbs/88/117177831.jpg "arxiv: v1 [cs.cv] 19 Feb 2019") Detector-in-Detector: Multi-Level Analysis for Human-Parts Xiaojie Li 1[0000 0001 6449 2727], Lu Yang 2[0000 0003 3857 3982], Qing Song 2[0000000346162200], and Fuqiang Zhou 1[0000 0001 9341 9342] arxiv:1902.07017v1
Detector-in-Detector: Multi-Level Analysis for Human-Parts Xiaojie Li 1[0000 0001 6449 2727], Lu Yang 2[0000 0003 3857 3982], Qing Song 2[0000000346162200], and Fuqiang Zhou 1[0000 0001 9341 9342] arxiv:1902.07017v1
arxiv: v3 [cs.cv] 20 Mar 2018
![arxiv: v3 [cs.cv] 20 Mar 2018](/thumbs/77/75966172.jpg "arxiv: v3 [cs.cv] 20 Mar 2018") arxiv:1711.08229v3 [cs.cv] 20 Mar 2018 Integral Human Pose Regression Xiao Sun 1, Bin Xiao 1, Fangyin Wei 2, Shuang Liang 3, Yichen Wei 1 1 Microsoft Research, 2 Peking University, 3 Tongji University
arxiv:1711.08229v3 [cs.cv] 20 Mar 2018 Integral Human Pose Regression Xiao Sun 1, Bin Xiao 1, Fangyin Wei 2, Shuang Liang 3, Yichen Wei 1 1 Microsoft Research, 2 Peking University, 3 Tongji University
arxiv: v2 [cs.cv] 13 Mar 2019
![arxiv: v2 [cs.cv] 13 Mar 2019](/thumbs/94/121711710.jpg "arxiv: v2 [cs.cv] 13 Mar 2019") An End-to-End Network for Panoptic Segmentation Huanyu Liu 1, Chao Peng 2, Changqian Yu 3, Jingbo Wang 4, Xu Liu 5, Gang Yu 2, Wei Jiang 1 1 Zhejiang University, 2 Megvii Inc. (Face++), 3 Huazhong University
An End-to-End Network for Panoptic Segmentation Huanyu Liu 1, Chao Peng 2, Changqian Yu 3, Jingbo Wang 4, Xu Liu 5, Gang Yu 2, Wei Jiang 1 1 Zhejiang University, 2 Megvii Inc. (Face++), 3 Huazhong University
arxiv: v2 [cs.cv] 14 Apr 2017
![arxiv: v2 [cs.cv] 14 Apr 2017](/thumbs/76/73596867.jpg "arxiv: v2 [cs.cv] 14 Apr 2017") Towards Accurate Multi-person Pose Estimation in the Wild George Papandreou, Tyler Zhu, Nori Kanazawa, Alexander Toshev, Jonathan Tompson, Chris Bregler, Kevin Murphy Google, Inc. [gpapan, tylerzhu, kanazawa,
Towards Accurate Multi-person Pose Estimation in the Wild George Papandreou, Tyler Zhu, Nori Kanazawa, Alexander Toshev, Jonathan Tompson, Chris Bregler, Kevin Murphy Google, Inc. [gpapan, tylerzhu, kanazawa,
DeepIM: Deep Iterative Matching for 6D Pose Estimation - Supplementary Material
 DeepIM: Deep Iterative Matching for 6D Pose Estimation - Supplementary Material Yi Li 1, Gu Wang 1, Xiangyang Ji 1, Yu Xiang 2, and Dieter Fox 2 1 Tsinghua University, BNRist 2 University of Washington
DeepIM: Deep Iterative Matching for 6D Pose Estimation - Supplementary Material Yi Li 1, Gu Wang 1, Xiangyang Ji 1, Yu Xiang 2, and Dieter Fox 2 1 Tsinghua University, BNRist 2 University of Washington
arxiv: v1 [cs.cv] 19 Mar 2018
![arxiv: v1 [cs.cv] 19 Mar 2018](/thumbs/78/77646221.jpg "arxiv: v1 [cs.cv] 19 Mar 2018") arxiv:1803.07066v1 [cs.cv] 19 Mar 2018 Learning Region Features for Object Detection Jiayuan Gu 1, Han Hu 2, Liwei Wang 1, Yichen Wei 2 and Jifeng Dai 2 1 Key Laboratory of Machine Perception, School of
arxiv:1803.07066v1 [cs.cv] 19 Mar 2018 Learning Region Features for Object Detection Jiayuan Gu 1, Han Hu 2, Liwei Wang 1, Yichen Wei 2 and Jifeng Dai 2 1 Key Laboratory of Machine Perception, School of
A FRAMEWORK OF EXTRACTING MULTI-SCALE FEATURES USING MULTIPLE CONVOLUTIONAL NEURAL NETWORKS. Kuan-Chuan Peng and Tsuhan Chen
 A FRAMEWORK OF EXTRACTING MULTI-SCALE FEATURES USING MULTIPLE CONVOLUTIONAL NEURAL NETWORKS Kuan-Chuan Peng and Tsuhan Chen School of Electrical and Computer Engineering, Cornell University, Ithaca, NY
A FRAMEWORK OF EXTRACTING MULTI-SCALE FEATURES USING MULTIPLE CONVOLUTIONAL NEURAL NETWORKS Kuan-Chuan Peng and Tsuhan Chen School of Electrical and Computer Engineering, Cornell University, Ithaca, NY
[Supplementary Material] Improving Occlusion and Hard Negative Handling for Single-Stage Pedestrian Detectors
![[Supplementary Material] Improving Occlusion and Hard Negative Handling for Single-Stage Pedestrian Detectors](/thumbs/89/97941029.jpg "[Supplementary Material] Improving Occlusion and Hard Negative Handling for Single-Stage Pedestrian Detectors") [Supplementary Material] Improving Occlusion and Hard Negative Handling for Single-Stage Pedestrian Detectors Junhyug Noh Soochan Lee Beomsu Kim Gunhee Kim Department of Computer Science and Engineering
[Supplementary Material] Improving Occlusion and Hard Negative Handling for Single-Stage Pedestrian Detectors Junhyug Noh Soochan Lee Beomsu Kim Gunhee Kim Department of Computer Science and Engineering
3D Pose Estimation using Synthetic Data over Monocular Depth Images
 3D Pose Estimation using Synthetic Data over Monocular Depth Images Wei Chen cwind@stanford.edu Xiaoshi Wang xiaoshiw@stanford.edu Abstract We proposed an approach for human pose estimation over monocular
3D Pose Estimation using Synthetic Data over Monocular Depth Images Wei Chen cwind@stanford.edu Xiaoshi Wang xiaoshiw@stanford.edu Abstract We proposed an approach for human pose estimation over monocular
arxiv: v2 [cs.cv] 10 Oct 2018
![arxiv: v2 [cs.cv] 10 Oct 2018](/thumbs/92/109817158.jpg "arxiv: v2 [cs.cv] 10 Oct 2018") Net: An Accurate and Efficient Single-Shot Object Detector for Autonomous Driving Qijie Zhao 1, Tao Sheng 1, Yongtao Wang 1, Feng Ni 1, Ling Cai 2 1 Institute of Computer Science and Technology, Peking
Net: An Accurate and Efficient Single-Shot Object Detector for Autonomous Driving Qijie Zhao 1, Tao Sheng 1, Yongtao Wang 1, Feng Ni 1, Ling Cai 2 1 Institute of Computer Science and Technology, Peking
Human Pose Estimation using Global and Local Normalization. Ke Sun, Cuiling Lan, Junliang Xing, Wenjun Zeng, Dong Liu, Jingdong Wang
 Human Pose Estimation using Global and Local Normalization Ke Sun, Cuiling Lan, Junliang Xing, Wenjun Zeng, Dong Liu, Jingdong Wang Overview of the supplementary material In this supplementary material,
Human Pose Estimation using Global and Local Normalization Ke Sun, Cuiling Lan, Junliang Xing, Wenjun Zeng, Dong Liu, Jingdong Wang Overview of the supplementary material In this supplementary material,
arxiv: v1 [cs.cv] 28 Nov 2018 Abstract
![arxiv: v1 [cs.cv] 28 Nov 2018 Abstract](/thumbs/91/104752316.jpg "arxiv: v1 [cs.cv] 28 Nov 2018 Abstract") CCNet: Criss-Cross Attention for Semantic Segmentation Zilong Huang 1, Xinggang Wang 1, Lichao Huang 2, Chang Huang 2, Yunchao Wei 3, Wenyu Liu 1 1 School of EIC, Huazhong University of Science and Technology
CCNet: Criss-Cross Attention for Semantic Segmentation Zilong Huang 1, Xinggang Wang 1, Lichao Huang 2, Chang Huang 2, Yunchao Wei 3, Wenyu Liu 1 1 School of EIC, Huazhong University of Science and Technology
Efficient Online Multi-Person 2D Pose Tracking with Recurrent Spatio-Temporal Affinity Fields
 Efficient Online Multi-Person 2D Pose Tracking with Recurrent Spatio-Temporal Affinity Fields Yaadhav Raaj Haroon Idrees Gines Hidalgo Yaser Sheikh The Robotics Institute, Carnegie Mellon University {raaj@cmu.edu,
Efficient Online Multi-Person 2D Pose Tracking with Recurrent Spatio-Temporal Affinity Fields Yaadhav Raaj Haroon Idrees Gines Hidalgo Yaser Sheikh The Robotics Institute, Carnegie Mellon University {raaj@cmu.edu,
Mask R-CNN. By Kaiming He, Georgia Gkioxari, Piotr Dollar and Ross Girshick Presented By Aditya Sanghi
 Mask R-CNN By Kaiming He, Georgia Gkioxari, Piotr Dollar and Ross Girshick Presented By Aditya Sanghi Types of Computer Vision Tasks http://cs231n.stanford.edu/ Semantic vs Instance Segmentation Image
Mask R-CNN By Kaiming He, Georgia Gkioxari, Piotr Dollar and Ross Girshick Presented By Aditya Sanghi Types of Computer Vision Tasks http://cs231n.stanford.edu/ Semantic vs Instance Segmentation Image
arxiv: v1 [cs.cv] 16 Nov 2018
![arxiv: v1 [cs.cv] 16 Nov 2018](/thumbs/90/103928298.jpg "arxiv: v1 [cs.cv] 16 Nov 2018") Improving Rotated Text Detection with Rotation Region Proposal Networks Jing Huang 1, Viswanath Sivakumar 1, Mher Mnatsakanyan 1,2 and Guan Pang 1 1 Facebook Inc. 2 University of California, Berkeley November
Improving Rotated Text Detection with Rotation Region Proposal Networks Jing Huang 1, Viswanath Sivakumar 1, Mher Mnatsakanyan 1,2 and Guan Pang 1 1 Facebook Inc. 2 University of California, Berkeley November
arxiv: v1 [cs.cv] 15 May 2018
![arxiv: v1 [cs.cv] 15 May 2018](/thumbs/96/126610205.jpg "arxiv: v1 [cs.cv] 15 May 2018") A DEEPLY-RECURSIVE CONVOLUTIONAL NETWORK FOR CROWD COUNTING Xinghao Ding, Zhirui Lin, Fujin He, Yu Wang, Yue Huang Fujian Key Laboratory of Sensing and Computing for Smart City, Xiamen University, China
A DEEPLY-RECURSIVE CONVOLUTIONAL NETWORK FOR CROWD COUNTING Xinghao Ding, Zhirui Lin, Fujin He, Yu Wang, Yue Huang Fujian Key Laboratory of Sensing and Computing for Smart City, Xiamen University, China
Associative Embedding: End-to-End Learning for Joint Detection and Grouping
 Associative Embedding: End-to-End Learning for Joint Detection and Grouping Alejandro Newell Computer Science and Engineering University of Michigan Ann Arbor, MI alnewell@umich.edu Zhiao Huang* Institute
Associative Embedding: End-to-End Learning for Joint Detection and Grouping Alejandro Newell Computer Science and Engineering University of Michigan Ann Arbor, MI alnewell@umich.edu Zhiao Huang* Institute
arxiv: v1 [cs.cv] 31 Mar 2017
![arxiv: v1 [cs.cv] 31 Mar 2017](/thumbs/80/81467687.jpg "arxiv: v1 [cs.cv] 31 Mar 2017") End-to-End Spatial Transform Face Detection and Recognition Liying Chi Zhejiang University charrin0531@gmail.com Hongxin Zhang Zhejiang University zhx@cad.zju.edu.cn Mingxiu Chen Rokid.inc cmxnono@rokid.com
End-to-End Spatial Transform Face Detection and Recognition Liying Chi Zhejiang University charrin0531@gmail.com Hongxin Zhang Zhejiang University zhx@cad.zju.edu.cn Mingxiu Chen Rokid.inc cmxnono@rokid.com
An Anchor-Free Region Proposal Network for Faster R-CNN based Text Detection Approaches
 An Anchor-Free Region Proposal Network for Faster R-CNN based Text Detection Approaches Zhuoyao Zhong 1,2,*, Lei Sun 2, Qiang Huo 2 1 School of EIE., South China University of Technology, Guangzhou, China
An Anchor-Free Region Proposal Network for Faster R-CNN based Text Detection Approaches Zhuoyao Zhong 1,2,*, Lei Sun 2, Qiang Huo 2 1 School of EIE., South China University of Technology, Guangzhou, China
Learning Deep Representations for Visual Recognition
 Learning Deep Representations for Visual Recognition CVPR 2018 Tutorial Kaiming He Facebook AI Research (FAIR) Deep Learning is Representation Learning Representation Learning: worth a conference name
Learning Deep Representations for Visual Recognition CVPR 2018 Tutorial Kaiming He Facebook AI Research (FAIR) Deep Learning is Representation Learning Representation Learning: worth a conference name
REGION AVERAGE POOLING FOR CONTEXT-AWARE OBJECT DETECTION
 REGION AVERAGE POOLING FOR CONTEXT-AWARE OBJECT DETECTION Kingsley Kuan 1, Gaurav Manek 1, Jie Lin 1, Yuan Fang 1, Vijay Chandrasekhar 1,2 Institute for Infocomm Research, A*STAR, Singapore 1 Nanyang Technological
REGION AVERAGE POOLING FOR CONTEXT-AWARE OBJECT DETECTION Kingsley Kuan 1, Gaurav Manek 1, Jie Lin 1, Yuan Fang 1, Vijay Chandrasekhar 1,2 Institute for Infocomm Research, A*STAR, Singapore 1 Nanyang Technological
arxiv: v1 [cs.cv] 23 Mar 2018
![arxiv: v1 [cs.cv] 23 Mar 2018](/thumbs/85/93001669.jpg "arxiv: v1 [cs.cv] 23 Mar 2018") Pyramid Stereo Matching Network Jia-Ren Chang Yong-Sheng Chen Department of Computer Science, National Chiao Tung University, Taiwan {followwar.cs00g, yschen}@nctu.edu.tw arxiv:03.0669v [cs.cv] 3 Mar 0
Pyramid Stereo Matching Network Jia-Ren Chang Yong-Sheng Chen Department of Computer Science, National Chiao Tung University, Taiwan {followwar.cs00g, yschen}@nctu.edu.tw arxiv:03.0669v [cs.cv] 3 Mar 0
arxiv: v1 [cs.cv] 30 Jul 2018
![arxiv: v1 [cs.cv] 30 Jul 2018](/thumbs/92/108811191.jpg "arxiv: v1 [cs.cv] 30 Jul 2018") Acquisition of Localization Confidence for Accurate Object Detection Borui Jiang 1,3, Ruixuan Luo 1,3, Jiayuan Mao 2,4, Tete Xiao 1,3, and Yuning Jiang 4 arxiv:1807.11590v1 [cs.cv] 30 Jul 2018 1 School
Acquisition of Localization Confidence for Accurate Object Detection Borui Jiang 1,3, Ruixuan Luo 1,3, Jiayuan Mao 2,4, Tete Xiao 1,3, and Yuning Jiang 4 arxiv:1807.11590v1 [cs.cv] 30 Jul 2018 1 School
SNIPER: Efficient Multi-Scale Training
 SNIPER: Efficient Multi-Scale Training Bharat Singh Mahyar Najibi Larry S. Davis University of Maryland, College Park {bharat,najibi,lsd}@cs.umd.edu Abstract We present SNIPER, an algorithm for performing
SNIPER: Efficient Multi-Scale Training Bharat Singh Mahyar Najibi Larry S. Davis University of Maryland, College Park {bharat,najibi,lsd}@cs.umd.edu Abstract We present SNIPER, an algorithm for performing
arxiv: v2 [cs.cv] 23 Jan 2019
![arxiv: v2 [cs.cv] 23 Jan 2019](/thumbs/88/114974572.jpg "arxiv: v2 [cs.cv] 23 Jan 2019") COCO AP Consistent Optimization for Single-Shot Object Detection Tao Kong 1 Fuchun Sun 1 Huaping Liu 1 Yuning Jiang 2 Jianbo Shi 3 1 Department of Computer Science and Technology, Tsinghua University,
COCO AP Consistent Optimization for Single-Shot Object Detection Tao Kong 1 Fuchun Sun 1 Huaping Liu 1 Yuning Jiang 2 Jianbo Shi 3 1 Department of Computer Science and Technology, Tsinghua University,
Todo before next class
 Todo before next class Each project group should submit a short project report (4 pages presentation slides) including 1. Problem definition 2. Related work 3. Preliminary results 4. Future plan Submission:
Todo before next class Each project group should submit a short project report (4 pages presentation slides) including 1. Problem definition 2. Related work 3. Preliminary results 4. Future plan Submission:
Lecture 7: Semantic Segmentation
 Semantic Segmentation CSED703R: Deep Learning for Visual Recognition (207F) Segmenting images based on its semantic notion Lecture 7: Semantic Segmentation Bohyung Han Computer Vision Lab. bhhanpostech.ac.kr
Semantic Segmentation CSED703R: Deep Learning for Visual Recognition (207F) Segmenting images based on its semantic notion Lecture 7: Semantic Segmentation Bohyung Han Computer Vision Lab. bhhanpostech.ac.kr
Detecting Faces Using Inside Cascaded Contextual CNN
 Detecting Faces Using Inside Cascaded Contextual CNN Kaipeng Zhang 1, Zhanpeng Zhang 2, Hao Wang 1, Zhifeng Li 1, Yu Qiao 3, Wei Liu 1 1 Tencent AI Lab 2 SenseTime Group Limited 3 Guangdong Provincial
Detecting Faces Using Inside Cascaded Contextual CNN Kaipeng Zhang 1, Zhanpeng Zhang 2, Hao Wang 1, Zhifeng Li 1, Yu Qiao 3, Wei Liu 1 1 Tencent AI Lab 2 SenseTime Group Limited 3 Guangdong Provincial
Cascade Multi-view Hourglass Model for Robust 3D Face Alignment
 Cascade Multi-view Hourglass Model for Robust 3D Face Alignment Jiankang Deng 1, Yuxiang Zhou 1, Shiyang Cheng 1, and Stefanos Zaferiou 1,2 1 Department of Computing, Imperial College London, UK 2 Centre
Cascade Multi-view Hourglass Model for Robust 3D Face Alignment Jiankang Deng 1, Yuxiang Zhou 1, Shiyang Cheng 1, and Stefanos Zaferiou 1,2 1 Department of Computing, Imperial College London, UK 2 Centre
Panoptic Feature Pyramid Networks
 Panoptic Feature Pyramid Networks Alexander Kirillov Ross Girshick Kaiming He Piotr Dollár Facebook AI Research (FAIR) Abstract arxiv:1901.02446v2 [cs.cv] 10 Apr 2019 The recently introduced panoptic segmentation
Panoptic Feature Pyramid Networks Alexander Kirillov Ross Girshick Kaiming He Piotr Dollár Facebook AI Research (FAIR) Abstract arxiv:1901.02446v2 [cs.cv] 10 Apr 2019 The recently introduced panoptic segmentation
arxiv: v1 [cs.cv] 11 May 2018
![arxiv: v1 [cs.cv] 11 May 2018](/thumbs/88/115835402.jpg "arxiv: v1 [cs.cv] 11 May 2018") Weakly and Semi Supervised Human Body Part Parsing via Pose-Guided Knowledge Transfer Hao-Shu Fang 1, Guansong Lu 1, Xiaolin Fang 2, Jianwen Xie 3, Yu-Wing Tai 4, Cewu Lu 1 1 Shanghai Jiao Tong University,
Weakly and Semi Supervised Human Body Part Parsing via Pose-Guided Knowledge Transfer Hao-Shu Fang 1, Guansong Lu 1, Xiaolin Fang 2, Jianwen Xie 3, Yu-Wing Tai 4, Cewu Lu 1 1 Shanghai Jiao Tong University,
arxiv: v1 [cs.cv] 11 Apr 2018
![arxiv: v1 [cs.cv] 11 Apr 2018](/thumbs/89/99253021.jpg "arxiv: v1 [cs.cv] 11 Apr 2018") arxiv:1804.03821v1 [cs.cv] 11 Apr 2018 ExFuse: Enhancing Feature Fusion for Semantic Segmentation Zhenli Zhang 1, Xiangyu Zhang 2, Chao Peng 2, Dazhi Cheng 3, Jian Sun 2 1 Fudan University, 2 Megvii Inc.
arxiv:1804.03821v1 [cs.cv] 11 Apr 2018 ExFuse: Enhancing Feature Fusion for Semantic Segmentation Zhenli Zhang 1, Xiangyu Zhang 2, Chao Peng 2, Dazhi Cheng 3, Jian Sun 2 1 Fudan University, 2 Megvii Inc.
Finding Tiny Faces Supplementary Materials
 Finding Tiny Faces Supplementary Materials Peiyun Hu, Deva Ramanan Robotics Institute Carnegie Mellon University {peiyunh,deva}@cs.cmu.edu 1. Error analysis Quantitative analysis We plot the distribution
Finding Tiny Faces Supplementary Materials Peiyun Hu, Deva Ramanan Robotics Institute Carnegie Mellon University {peiyunh,deva}@cs.cmu.edu 1. Error analysis Quantitative analysis We plot the distribution
arxiv: v3 [cs.cv] 17 May 2018
![arxiv: v3 [cs.cv] 17 May 2018](/thumbs/79/79331767.jpg "arxiv: v3 [cs.cv] 17 May 2018") FSSD: Feature Fusion Single Shot Multibox Detector Zuo-Xin Li Fu-Qiang Zhou Key Laboratory of Precision Opto-mechatronics Technology, Ministry of Education, Beihang University, Beijing 100191, China {lizuoxin,
FSSD: Feature Fusion Single Shot Multibox Detector Zuo-Xin Li Fu-Qiang Zhou Key Laboratory of Precision Opto-mechatronics Technology, Ministry of Education, Beihang University, Beijing 100191, China {lizuoxin,
Detecting and Parsing of Visual Objects: Humans and Animals. Alan Yuille (UCLA)
") Detecting and Parsing of Visual Objects: Humans and Animals Alan Yuille (UCLA) Summary This talk describes recent work on detection and parsing visual objects. The methods represent objects in terms of
Detecting and Parsing of Visual Objects: Humans and Animals Alan Yuille (UCLA) Summary This talk describes recent work on detection and parsing visual objects. The methods represent objects in terms of
arxiv: v1 [cs.cv] 14 Jul 2017
![arxiv: v1 [cs.cv] 14 Jul 2017](/thumbs/74/70463879.jpg "arxiv: v1 [cs.cv] 14 Jul 2017") Temporal Modeling Approaches for Large-scale Youtube-8M Video Understanding Fu Li, Chuang Gan, Xiao Liu, Yunlong Bian, Xiang Long, Yandong Li, Zhichao Li, Jie Zhou, Shilei Wen Baidu IDL & Tsinghua University
Temporal Modeling Approaches for Large-scale Youtube-8M Video Understanding Fu Li, Chuang Gan, Xiao Liu, Yunlong Bian, Xiang Long, Yandong Li, Zhichao Li, Jie Zhou, Shilei Wen Baidu IDL & Tsinghua University
Geometry-aware Traffic Flow Analysis by Detection and Tracking
 Geometry-aware Traffic Flow Analysis by Detection and Tracking 1,2 Honghui Shi, 1 Zhonghao Wang, 1,2 Yang Zhang, 1,3 Xinchao Wang, 1 Thomas Huang 1 IFP Group, Beckman Institute at UIUC, 2 IBM Research,
Geometry-aware Traffic Flow Analysis by Detection and Tracking 1,2 Honghui Shi, 1 Zhonghao Wang, 1,2 Yang Zhang, 1,3 Xinchao Wang, 1 Thomas Huang 1 IFP Group, Beckman Institute at UIUC, 2 IBM Research,
JOINT DETECTION AND SEGMENTATION WITH DEEP HIERARCHICAL NETWORKS. Zhao Chen Machine Learning Intern, NVIDIA
 JOINT DETECTION AND SEGMENTATION WITH DEEP HIERARCHICAL NETWORKS Zhao Chen Machine Learning Intern, NVIDIA ABOUT ME 5th year PhD student in physics @ Stanford by day, deep learning computer vision scientist
JOINT DETECTION AND SEGMENTATION WITH DEEP HIERARCHICAL NETWORKS Zhao Chen Machine Learning Intern, NVIDIA ABOUT ME 5th year PhD student in physics @ Stanford by day, deep learning computer vision scientist
arxiv: v2 [cs.cv] 2 Jun 2018
![arxiv: v2 [cs.cv] 2 Jun 2018](/thumbs/87/95225561.jpg "arxiv: v2 [cs.cv] 2 Jun 2018") Beyond Trade-off: Accelerate FCN-based Face Detector with Higher Accuracy Guanglu Song, Yu Liu 2, Ming Jiang, Yujie Wang, Junjie Yan 3, Biao Leng Beihang University, 2 The Chinese University of Hong Kong,
Beyond Trade-off: Accelerate FCN-based Face Detector with Higher Accuracy Guanglu Song, Yu Liu 2, Ming Jiang, Yujie Wang, Junjie Yan 3, Biao Leng Beihang University, 2 The Chinese University of Hong Kong,
THE task of human pose estimation is to determine the. Knowledge-Guided Deep Fractal Neural Networks for Human Pose Estimation
 1 Knowledge-Guided Deep Fractal Neural Networks for Human Pose Estimation Guanghan Ning, Student Member, IEEE, Zhi Zhang, Student Member, IEEE, and Zhihai He, Fellow, IEEE arxiv:1705.02407v2 [cs.cv] 8
1 Knowledge-Guided Deep Fractal Neural Networks for Human Pose Estimation Guanghan Ning, Student Member, IEEE, Zhi Zhang, Student Member, IEEE, and Zhihai He, Fellow, IEEE arxiv:1705.02407v2 [cs.cv] 8
MoFA: Model-based Deep Convolutional Face Autoencoder for Unsupervised Monocular Reconstruction
 MoFA: Model-based Deep Convolutional Face Autoencoder for Unsupervised Monocular Reconstruction Ayush Tewari Michael Zollhofer Hyeongwoo Kim Pablo Garrido Florian Bernard Patrick Perez Christian Theobalt
MoFA: Model-based Deep Convolutional Face Autoencoder for Unsupervised Monocular Reconstruction Ayush Tewari Michael Zollhofer Hyeongwoo Kim Pablo Garrido Florian Bernard Patrick Perez Christian Theobalt
Instance-aware Semantic Segmentation via Multi-task Network Cascades
 Instance-aware Semantic Segmentation via Multi-task Network Cascades Jifeng Dai, Kaiming He, Jian Sun Microsoft research 2016 Yotam Gil Amit Nativ Agenda Introduction Highlights Implementation Further
Instance-aware Semantic Segmentation via Multi-task Network Cascades Jifeng Dai, Kaiming He, Jian Sun Microsoft research 2016 Yotam Gil Amit Nativ Agenda Introduction Highlights Implementation Further
When Big Datasets are Not Enough: The need for visual virtual worlds.
 When Big Datasets are Not Enough: The need for visual virtual worlds. Alan Yuille Bloomberg Distinguished Professor Departments of Cognitive Science and Computer Science Johns Hopkins University Computational
When Big Datasets are Not Enough: The need for visual virtual worlds. Alan Yuille Bloomberg Distinguished Professor Departments of Cognitive Science and Computer Science Johns Hopkins University Computational