Lecture 23: Thread Level Parallelism -- Introduction, SMP and Snooping Cache Coherence Protocol
|
|
|
- Oscar Stafford
- 6 years ago
- Views:
Transcription
1 Lecture 23: Thread Level Parallelism -- Introduction, SMP and Snooping Cache Coherence Protocol CSE 564 Computer Architecture Summer 2017 Department of Computer Science and Engineering Yonghong Yan
2 CSE 564 Class Contents Introduction to Computer Architecture (CA) Quantitative Analysis, Trend and Performance of CA Chapter 1 Instruction Set Principles and Examples Appendix A Pipelining and Implementation, RISC-V ISA and Implementation Appendix C, RISC-V (riscv.org) and UCB RISC-V impl Memory System (Technology, Cache Organization and Optimization, Virtual Memory) Appendix B and Chapter 2 Midterm covered till Memory Tech and Cache Organization Instruction Level Parallelism (Dynamic Scheduling, Branch Prediction, Hardware Speculation, Superscalar, VLIW and SMT) Chapter 3 Data Level Parallelism (Vector, SIMD, and GPU) Chapter 4 Thread Level Parallelism Chapter 5 2
3 Topics for Thread Level Parallelism (TLP) Parallelism (centered around ) Instruction Level Parallelism Data Level Parallelism Thread Level Parallelism TLP Introduction 5.1 SMP and Snooping Cache Coherence Protocol 5.2 Distributed Shared-Memory and Directory-Based Coherence 5.4 Synchronization Basics and Memory Consistency Model 5.5, 5.6 Others 3
4 Acknowledge and Copyright Slides adapted from UC Berkeley course Computer Science 252: Graduate Computer Architecture of David E. Culler Copyright(C) 2005 UCB UC Berkeley course Computer Science 252, Graduate Computer Architecture Spring 2012 of John Kubiatowicz Copyright(C) 2012 UCB Computer Science 152: Computer Architecture and Engineering, Spring 2016 by Dr. George Michelogiannakis from UC Berkeley Arvind (MIT), Krste Asanovic (MIT/UCB), Joel Emer (Intel/MIT), James Hoe (CMU), John Kubiatowicz (UCB), and David Patterson (UCB) UH Edgar Gabrial, Computer Architecture Course: www2.cs.uh.edu/~gabriel/courses/cosc6385_s16/index.shtml 4

5 Moore s Law Long-term trend on the density of transistor per integrated circuit Number of transistors/in 2 double every ~18-24 month 5
6 What do we do with that many transistors? Optimizing the execution of a single instruction stream through Pipelining» Overlap the execution of multiple instructions» Example: all RISC architectures; Intel x86 underneath the hood Out-of-order execution:» Allow instructions to overtake each other in accordance with code dependencies (RAW, WAW, WAR)» Example: all commercial processors (Intel, AMD, IBM, Oracle) Branch prediction and speculative execution:» Reduce the number of stall cycles due to unresolved branches» Example: (nearly) all commercial processors 6
7 What do we do with that many transistors? (II) Multi-issue processors:» Allow multiple instructions to start execution per clock cycle» Superscalar (Intel x86, AMD, ) vs. VLIW architectures VLIW/EPIC architectures:» Allow compilers to indicate independent instructions per issue packet» Example: Intel Itanium SIMD units:» Allow for the efficient expression and execution of vector operations» Example: Vector, SSE - SSE4, AVX instructions Everything we have learned so far 7
8 Limitations of optimizing a single instruction stream Problem: within a single instruction stream we do not find enough independent instructions to execute simultaneously due to data dependencies limitations of speculative execution across multiple branches difficulties to detect memory dependencies among instruction (alias analysis) Consequence: significant number of functional units are idling at any given time Question: Can we maybe execute instructions from another instructions stream Another thread? Another process? 8
9 Thread-level parallelism Problems for executing instructions from multiple threads at the same time The instructions in each thread might use the same register names Each thread has its own program counter Virtual memory management allows for the execution of multiple threads and sharing of the main memory When to switch between different threads: Fine grain multithreading: switches between every instruction Course grain multithreading: switches only on costly stalls (e.g. level 2 cache misses) 9
10 Time (processor cycle) Convert Thread-level parallelism to instruction-level parallelism Superscalar Fine-Grained Coarse-Grained Simultaneous Multithreading Thread 1 Thread 2 Thread 3 Thread 4 Thread 5 Idle slot 10
11 ILP to Do TLP: e.g. Simultaneous Multi- Threading Works well if Number of compute intensive threads does not exceed the number of threads supported in SMT Threads have highly different characteristics (e.g. one thread doing mostly integer operations, another mainly doing floating point operations) Does not work well if Threads try to utilize the same function units» e.g. a dual processor system, each processor supporting 2 threads simultaneously (OS thinks there are 4 processors)» 2 compute intensive application processes might end up on the same processor instead of different processors (OS does not see the difference between SMT and real processors!) 11

12 Power, Frequency and ILP Moore s Law to processor speed (frequency) CPU frequency increase was flattened around Two main reasons: 1. Limited ILP and 2. Power consumption and heat dissipation Note: Even Moore s Law is ending around 2021: semiconductors/devices/ transistors-could-stopshrinking-in /moores-law-is-deadnow-what/ timworstall/2016/07/26/ economics-is-important-theend-of-moores-law 12
13 History Past (2000) and Today 13

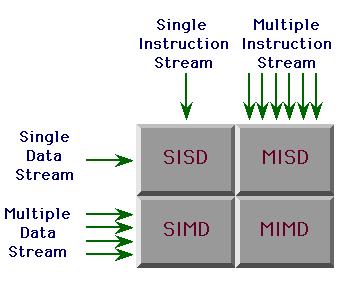
14 Flynn s Taxonomy 14
15 Examples of MIMD Machines Symmetric Shared-Memory Multiprocessor (SMP) Multiple processors in box with shared memory communication Current Multicore chips like this Every processor runs copy of OS Distributed/Non-uniform Shared- Memory Multiprocessor Multiple processors» Each with local memory» general scalable network Extremely light OS on node provides simple services» Scheduling/synchronization Network-accessible host for I/O Cluster Many independent machine connected with general network Communication through messages P P P P Bus Memory P/M P/M P/M P/M P/M P/M P/M P/M P/M P/M P/M P/M P/M P/M P/M P/M Network Host 15
16 Symmetric (Shared-Memory) Multiprocessors (SMP) Small numbers of cores Typically eight or fewer, and no more than 32 in most cases Share a single centralized memory that all processors have equal access to, Hence the term symmetric. All existing multicores are SMPs. Also called uniform memory access (UMA) multiprocessors all processors have a uniform latency 16
 Each processor may has local")
17 Distributed Shared-Memory Multiprocessor Large processor count 64 to 1000s Distributed memory Remote vs local memory Long vs short latency High vs low latency Interconnection network Bandwidth, topology, etc Nonuniform memory access (NUMA) Each processor may has local I/O 20
18 Distributed Shared-Memory Multiprocessor (NUMA) Reduces the memory bottleneck compared to SMPs More difficult to program efficiently E.g. first touch policy: data item will be located in the memory of the processor which uses a data item first To reduce effects of non-uniform memory access, caches are often used ccnuma: cache-coherent non-uniform memory access architectures Largest example as of today: SGI Origin with 512 processors 21
19 Shared-Memory Multiprocessor SMP and DSM are all shared memory multiprocessors UMA or NUMA Multicore are SMP shared memory Most multi-cpu machines are DSM NUMA Shared Address Space (Virtual Address Space) Not always shared memory 22
20 Bus-Based Symmetric Shared Memory Still an important architecture even on chip (until very recently) Building blocks for larger systems; arriving to desktop Attractive as throughput servers and for parallel programs Fine-grain resource sharing Uniform access via loads/stores Automatic data movement and coherent replication in caches Cheap and powerful extension Normal uniprocessor mechanisms to access data Key is extension of memory hierarchy to support multiple processors P 1 P n $ $ Bus Mem I/O devices 23
21 Performance Metrics (I) Speedup: how much faster does a problem run on p processors compared to 1 processor? S( p) = Optimal: S(p) = p (linear speedup) Parallel Efficiency: Speedup normalized by the number of processors Optimal: E(p) = 1.0 T T E( p) = total total (1) ( p) S( p) p 24
22 Amdahl s Law (I) Most applications have a (small) sequential fraction, which limits the speedup T = T + T = ft + ( 1 f ) T total sequential parallel Total Total f: fraction of the code which can only be executed sequentially S( p) = ( f Ttotal (1) 1 f + ) T p 1 1 f + p Assumes the problem size is constant In most applications, the sequential part is independent of the problem size The part which can be executed in parallel depends. total (1) = f 25
23 Challenges of Parallel Processing 1. Limited parallelism available in programs Amdahl s Law 0.25% can be sequential 26
24 Cache in Shared Memory System (UMA or NUMA) P 1 Switch P n Scale (Interleaved) First-level $ P 1 P n (Interleaved) Main memory $ Inter connection network $ Shared Cache Mem Mem UMA P 1 P n Mem $ Mem $ NUMA Inter connection network 28
25 Caches and Cache Coherence Caches play key role in all cases Reduce average data access time Reduce bandwidth demands placed on shared interconnect Private processor caches create a problem Copies of a variable can be present in multiple caches A write by one processor may not become visible to others» They ll keep accessing stale value in their caches Cache coherence problem What do we do about it? Organize the mem hierarchy to make it go away Detect and take actions to eliminate the problem 29
26 int count = 5; int * u= &count;. a1 = *u; b1 = *u Example Cache Coherence Problem a2 = *u a3 = *u; *u = 7; u :5 Memory Things to note: Processors see different values for u after event 3 With write back caches, value written back to memory depends on happenstance of which cache flushes or writes back value and when Processes accessing main memory may see very stale value Unacceptable to programs, and frequent! 1 P 1 u =? P 2 P 3 u =? 4 $ $ 5 $ u :5 2 I/O devices u :5 u =
27 Cache coherence (II) Typical solution: Caches keep track on whether a data item is shared between multiple processes Upon modification of a shared data item, notification of other caches has to occur Other caches will have to reload the shared data item on the next access into their cache Cache coherence is only an issue in case multiple tasks access the same item Multiple threads Multiple processes have a joint shared memory segment Process is being migrated from one CPU to another 31
28 Cache Coherence Protocols Snooping Protocols Send all requests for data to all processors, the address Processors snoop a bus to see if they have a copy and respond accordingly Requires broadcast, since caching information is at processors Works well with bus (natural broadcast medium) Dominates for centralized shared memory machines Directory-Based Protocols Keep track of what is being shared in centralized location Distributed memory => distributed directory for scalability (avoids bottlenecks) Send point-to-point requests to processors via network Scales better than Snooping Commonly used for distributed shared memory machines 32
29 Snoopy Cache-Coherence Protocols State P 1 Bus snoop P n Address Data $ $ Mem I/O devices Cache-memory transaction Works because bus is a broadcast medium & Caches know what they have Cache Controller snoops all transactions on the shared bus relevant transaction if for a block it contains take action to ensure coherence» invalidate, update, or supply value depends on state of the block and the protocol 33
30 Basic Snoopy Protocols Write Invalidate Protocol: Multiple readers, single writer Write to shared data: an invalidate is sent to all caches which snoop and invalidate any copies Read Miss:» Write-through: memory is always up-to-date» Write-back: snoop in caches to find most recent copy Write Update Protocol (typically write through): Write to shared data: broadcast on bus, processors snoop, and update any copies Read miss: memory is always up-to-date Write serialization: bus serializes requests! Bus is single point of arbitration 34
31 Write Invalidate Protocol Basic Bus-Based Protocol Each processor has cache, state All transactions over bus snooped Writes invalidate all other caches can have multiple simultaneous readers of block,but write invalidates them Two states per block in each cache as in uniprocessor state of a block is a p-vector of states Hardware state bits associated with blocks that are in the cache other blocks can be seen as being in invalid (not-present) state in that cache State Tag Data P 1 Mem PrRd / BusRd V I State Tag Data P n $ $ Bus I/O devices PrRd/ -- PrWr / BusWr BusWr / - PrWr / BusWr 35
32 Example: Write Invalidate u :5 P 1 P 2 P 3 u =? u =? 4 $ $ 5 $ u :7 3 u :5 u = 7 1 u :5 u = 7 Memory 2 I/O devices 36
33 Write-Update (Broadcast) Update all the cached copies of a data item when that item is written. Even a processor may not need the updated copy in the future Consumes considerably more bandwidth Recent multiprocessors have opted to implement a write invalidate protocol P 1 P 2 P 3 u =? u =? 3 4 $ $ 5 $ u :5 u=7 u :5 u = 7 1 u :5 u = 7 Memory 2 I/O devices 37
34 Implementation of Cache Coherence Protocol -- 1 Memory Written by CPU 0 Cache Cache CPU 0 CPU 1 Invalidated by CPU 0 When data are coherent, the cache block is shared Memory could be the last level shared cache, e.g. shared L3 1. When there is a write by CPU 0, Invalidate the shared copies in the cache of other processors/cores Copy in CPU 0 s cache is exclusive/unshared, CPU 0 is the owner of the block For write-through cache, data is also written to the memory» Memory has the latest For write-back cache: data in memory is obsoleted For snooping protocol, invalidate signals are broadcasted by CPU 0» CPU 0 broadcasts; and CPU 1 snoops, compares and invalidates 38
35 Implementation of Cache Coherence Protocol -- 2 Memory Owned by CPU 0 Cache Cache CPU 0 CPU 1 Read/write miss CPU 0 owned the block (exclusive or unshared) 2. When there is a read/write by CPU 1 or others à Miss since already invalidated For write-through cache: read from memory For write-back cache: supply from CPU 0 and abort memory access For snooping: CPU 1 broadcasts mem request because of a miss; CPU 0 snoops, compares and provides cache block (aborts the memory request) 39
: Events Changing the state of the selected cache block, as")
36 Finite State Machine (FSM) for Implementation Mathematical model of computation used to design both computer programs and sequential logic circuits Events trigger state change Snooping protocol FSM Implemented as part of cache controller Responds to requests from the processor in the core and from the bus (or other broadcast medium): Events Changing the state of the selected cache block, as well as using the bus to access data or to invalidate it: Change state and action 40
37 An Example Snoopy Protocol Invalidation protocol, write-back cache Each block of memory is in one state: Clean in all caches and up-to-date in memory (Shared) OR Dirty in exactly one cache (Exclusive) OR Not in any caches Each cache block is in one state (track these): Shared : block can be read OR Exclusive : cache has only copy, its writeable, and dirty OR Invalid : block contains no data Read misses: cause all caches to snoop bus Writes to clean line are treated as misses 41

38 State Table of Snoopy Protocol 42
39 Snoopy-Cache State Machine-I State machine for CPU requests for each cache block Invalid CPU Read Place read miss on bus CPU read hit Shared (read/only) CPU Write Place Write Miss on bus CPU Read miss Place read miss on bus CPU read hit CPU write hit Exclusive (read/write) CPU Write miss Place Write Miss on Bus CPU Write Miss Write back cache block Place write miss on bus 43
40 Snoopy-Cache State Machine-II State machine for bus requests for each cache block Invalid Write miss for this block Invalidate for this block Shared (read/only) Write Back Block; (abort memory access) Write Back Block; (abort memory access) Read miss Write miss for this block Exclusive (read/write) Read miss for this block 44
41 Snoopy-Cache State Machine-III State machine for CPU requests for each cache block and for bus requests for each cache block Write miss for this block Write Back Block; (abort memory access) CPU read hit CPU write hit Write miss for this block Invalid CPU Read Place read miss CPU Write on bus Place Write Miss on bus Exclusive (read/write) CPU read miss Write back block, Place read miss on bus CPU Read hit Shared (read/only) CPU Read miss Place read miss on bus CPU Write Place Write Miss on Bus Read miss for this block Write Back Block; (abort memory access) CPU Write Miss Write back cache block Place write miss on bus 45
42 Example Processor 1 Processor 2 Bus Memory P1 P2 Bus Memory step State Addr Value State Addr Value Action Proc. Addr Value Addr Value P1: Write 10 to A1 P1: Read A1 P2: Read A1 P2: Write 20 to A1 P2: Write 40 to A2 Assumes initial cache state Remote Write CPU Read hit is invalid and A1 and A2 map to same cache block, but A1!= A2 Invalid Read miss on bus Write Remote miss on bus Write Write Back Remote Read Write Back Shared CPU Write Place Write Miss on Bus CPU Read Miss CPU read hit CPU write hit Exclusive CPU Write Miss Write Back 46
43 Example: Step 1 P1 P2 Bus Memory step State Addr Value State Addr Value Action Proc. Addr Value Addr Value P1: Write 10 to A1 Excl. A1 10 WrMs P1 A1 P1: Read A1 P2: Read A1 P2: Write 20 to A1 P2: Write 40 to A2 Assumes initial cache state Remote Write CPU Read hit is invalid and A1 and A2 map to same cache block, but A1!= A2. Active arrow = Invalid Read miss on bus Write Remote miss on bus Write Write Back Remote Read Write Back Shared CPU Read Miss CPU Write Place Write Miss on Bus CPU read hit CPU write hit Exclusive CPU Write Miss Write Back 47
44 Example: Step 2 P1 P2 Bus Memory step State Addr Value State Addr Value Action Proc. Addr Value Addr Value P1: Write 10 to A1 Excl. A1 10 WrMs P1 A1 P1: Read A1 Excl. A1 10 P2: Read A1 P2: Write 20 to A1 P2: Write 40 to A2 Assumes initial cache state Remote Write CPU Read hit is invalid and A1 and A2 map to same cache block, but A1!= A2 Invalid Read miss on bus Write Remote miss on bus Write Write Back Remote Read Write Back Shared CPU Read Miss CPU Write Place Write Miss on Bus CPU read hit CPU write hit Exclusive CPU Write Miss Write Back 48
45 Example: Step 3 P1 P2 Bus Memory step State Addr Value State Addr Value Action Proc. Addr Value Addr Value P1: Write 10 to A1 Excl. A1 10 WrMs P1 A1 P1: Read A1 Excl. A1 10 P2: Read A1 Shar. A1 RdMs P2 A1 Shar. A1 10 WrBk P1 A1 10 A1 10 Shar. A1 10 RdDa P2 A1 10 A1 10 P2: Write 20 to A1 10 P2: Write 40 to A Assumes initial cache state Remote Write CPU Read hit is invalid and A1 and A2 map to same cache block, but A1!= A2. Invalid Read miss on bus Write Remote miss on bus Write Write Back Remote Read Write Back Shared CPU Read Miss CPU Write Place Write Miss on Bus CPU read hit CPU write hit Exclusive CPU Write Miss Write Back 49
46 Example: Step 4 P1 P2 Bus Memory step State Addr Value State Addr Value Action Proc. Addr Value Addr Value P1: Write 10 to A1 Excl. A1 10 WrMs P1 A1 P1: Read A1 Excl. A1 10 P2: Read A1 Shar. A1 RdMs P2 A1 Shar. A1 10 WrBk P1 A1 10 A1 10 Shar. A1 10 RdDa P2 A1 10 A1 10 P2: Write 20 to A1 Inv. Excl. A1 20 WrMs P2 A1 A1 10 P2: Write 40 to A Assumes initial cache state Remote Write CPU Read hit is invalid and A1 and A2 map to same cache block, but A1!= A2 Invalid Read miss on bus Write Remote miss on bus Write Write Back Remote Read Write Back Shared CPU Read Miss CPU Write Place Write Miss on Bus CPU read hit CPU write hit Exclusive CPU Write Miss Write Back 50
47 Example: Step 5 P1 P2 Bus Memory step State Addr Value State Addr Value Action Proc. Addr Value Addr Value P1: Write 10 to A1 Excl. A1 10 WrMs P1 A1 P1: Read A1 Excl. A1 10 P2: Read A1 Shar. A1 RdMs P2 A1 Shar. A1 10 WrBk P1 A1 10 A1 10 Shar. A1 10 RdDa P2 A1 10 A1 10 P2: Write 20 to A1 Inv. Excl. A1 20 WrMs P2 A1 A1 10 P2: Write 40 to A2 WrMs P2 A2 A1 10 Excl. A2 40 WrBk P2 A1 20 A1 20 Assumes initial cache state Remote Write CPU Read hit is invalid and A1 and A2 map to same cache block, but A1!= A2 Invalid Read miss on bus Write Remote miss on bus Write Remote Read Write Back Write Back Shared CPU Read Miss CPU Write Place Write Miss on Bus CPU read hit CPU write hit Exclusive CPU Write Miss Write Back 51
48 Snooping Cache Variations Basic Protocol Berkeley Protocol Illinois Protocol MESI Protocol Exclusive Shared Invalid Owned Exclusive Owned Shared Shared Invalid Private Dirty Modfied (private,!=memory) Private Clean Exclusive (private,=memory) Shared (shared,=memory) Shared Invalid Invalid Owner can update via bus invalidate operation Owner must write back when replaced in cache If read sourced from memory, then Private Clean if read sourced from other cache, then Shared Can write in cache if held private clean or dirty 52
49 Shared Memory Multiprocessor Memory Bus M 1 Snoopy Cache Physical Memory M 2 Snoopy Cache M 3 Snoopy Cache DMA DISKS Use snoopy mechanism to keep all processors view of memory coherent 53
50 Cache Line for Snooping Cache tags for implementing snooping Compares the addresses on the bus with the tags of the cache line Valid bit for being invalidated State bit for shared/exclusive We will use write-back cache Lower bandwidth requirement than write-through cache Dirty bit for write-back Write-buffer complicates things 54
51 Categories of cache misses Up to now: Compulsory Misses: first access to a block cannot be in the cache (cold start misses) Capacity Misses: cache cannot contain all blocks required for the execution Conflict Misses: cache block has to be discarded because of block replacement strategy In multi-processor systems: Coherence Misses: cache block has to be discarded because another processor modified the content» true sharing miss: another processor modified the content of the request element» false sharing miss: another processor invalidated the block, although the actual item of interest is unchanged. 70
52 False Sharing state line addr data0 data1... datan A cache line contains more than one word Cache-coherence is done at the line-level and not word-level Suppose M1 writes wordi and M2 writes wordk and both words have the same line address. What can happen? 71 71
53 Example: True v. False Sharing v. Hit? Assume x1 and x2 in same cache line. P1 and P2 both read x1 and x2 before. Time P1 P2 True, False, Hit? Why? 1 Write x1 2 Read x2 3 Write x1 4 Write x2 5 Read x2 True miss; invalidate x1 in P2 False miss; x1 irrelevant to P2 False miss; x1 irrelevant to P2 True miss; x2 not writeable True miss; invalidate x2 in P
54 Performance Coherence influences cache miss rate Coherence misses» True sharing misses Write to shared block (transmission of invalidation) Read an invalidated block» False sharing misses Read an unmodified word in an invalidated block 73

55 Performance Study: Commercial Workload 74

56 Performance Study: Commercial Workload 75

57 Performance Study: Commercial Workload 76

58 Performance Study: Commercial Workload 77
COSC 6385 Computer Architecture - Thread Level Parallelism (I)
") COSC 6385 Computer Architecture - Thread Level Parallelism (I) Edgar Gabriel Spring 2014 Long-term trend on the number of transistor per integrated circuit Number of transistors double every ~18 month
COSC 6385 Computer Architecture - Thread Level Parallelism (I) Edgar Gabriel Spring 2014 Long-term trend on the number of transistor per integrated circuit Number of transistors double every ~18 month
ESE 545 Computer Architecture Symmetric Multiprocessors and Snoopy Cache Coherence Protocols CA SMP and cache coherence
 Computer Architecture ESE 545 Computer Architecture Symmetric Multiprocessors and Snoopy Cache Coherence Protocols 1 Shared Memory Multiprocessor Memory Bus P 1 Snoopy Cache Physical Memory P 2 Snoopy
Computer Architecture ESE 545 Computer Architecture Symmetric Multiprocessors and Snoopy Cache Coherence Protocols 1 Shared Memory Multiprocessor Memory Bus P 1 Snoopy Cache Physical Memory P 2 Snoopy
Lecture 24: Thread Level Parallelism -- Distributed Shared Memory and Directory-based Coherence Protocol
 Lecture 24: Thread Level Parallelism -- Distributed Shared Memory and Directory-based Coherence Protocol CSE 564 Computer Architecture Fall 2016 Department of Computer Science and Engineering Yonghong
Lecture 24: Thread Level Parallelism -- Distributed Shared Memory and Directory-based Coherence Protocol CSE 564 Computer Architecture Fall 2016 Department of Computer Science and Engineering Yonghong
Computer Architecture. A Quantitative Approach, Fifth Edition. Chapter 5. Multiprocessors and Thread-Level Parallelism
 Computer Architecture A Quantitative Approach, Fifth Edition Chapter 5 Multiprocessors and Thread-Level Parallelism 1 Introduction Thread-Level parallelism Have multiple program counters Uses MIMD model
Computer Architecture A Quantitative Approach, Fifth Edition Chapter 5 Multiprocessors and Thread-Level Parallelism 1 Introduction Thread-Level parallelism Have multiple program counters Uses MIMD model
Thread- Level Parallelism. ECE 154B Dmitri Strukov
 Thread- Level Parallelism ECE 154B Dmitri Strukov Introduc?on Thread- Level parallelism Have mul?ple program counters and resources Uses MIMD model Targeted for?ghtly- coupled shared- memory mul?processors
Thread- Level Parallelism ECE 154B Dmitri Strukov Introduc?on Thread- Level parallelism Have mul?ple program counters and resources Uses MIMD model Targeted for?ghtly- coupled shared- memory mul?processors
CS252 Spring 2017 Graduate Computer Architecture. Lecture 12: Cache Coherence
 CS252 Spring 2017 Graduate Computer Architecture Lecture 12: Cache Coherence Lisa Wu, Krste Asanovic http://inst.eecs.berkeley.edu/~cs252/sp17 WU UCB CS252 SP17 Last Time in Lecture 11 Memory Systems DRAM
CS252 Spring 2017 Graduate Computer Architecture Lecture 12: Cache Coherence Lisa Wu, Krste Asanovic http://inst.eecs.berkeley.edu/~cs252/sp17 WU UCB CS252 SP17 Last Time in Lecture 11 Memory Systems DRAM
COEN-4730 Computer Architecture Lecture 08 Thread Level Parallelism and Coherence
 1 COEN-4730 Computer Architecture Lecture 08 Thread Level Parallelism and Coherence Cristinel Ababei Dept. of Electrical and Computer Engineering Marquette University Credits: Slides adapted from presentations
1 COEN-4730 Computer Architecture Lecture 08 Thread Level Parallelism and Coherence Cristinel Ababei Dept. of Electrical and Computer Engineering Marquette University Credits: Slides adapted from presentations
Parallel Computers. CPE 631 Session 20: Multiprocessors. Flynn s Tahonomy (1972) Why Multiprocessors?
 Why Multiprocessors?") Parallel Computers CPE 63 Session 20: Multiprocessors Department of Electrical and Computer Engineering University of Alabama in Huntsville Definition: A parallel computer is a collection of processing
Parallel Computers CPE 63 Session 20: Multiprocessors Department of Electrical and Computer Engineering University of Alabama in Huntsville Definition: A parallel computer is a collection of processing
Lecture 30: Multiprocessors Flynn Categories, Large vs. Small Scale, Cache Coherency Professor Randy H. Katz Computer Science 252 Spring 1996
 Lecture 30: Multiprocessors Flynn Categories, Large vs. Small Scale, Cache Coherency Professor Randy H. Katz Computer Science 252 Spring 1996 RHK.S96 1 Flynn Categories SISD (Single Instruction Single
Lecture 30: Multiprocessors Flynn Categories, Large vs. Small Scale, Cache Coherency Professor Randy H. Katz Computer Science 252 Spring 1996 RHK.S96 1 Flynn Categories SISD (Single Instruction Single
Computer Systems Architecture
 Computer Systems Architecture Lecture 24 Mahadevan Gomathisankaran April 29, 2010 04/29/2010 Lecture 24 CSCE 4610/5610 1 Reminder ABET Feedback: http://www.cse.unt.edu/exitsurvey.cgi?csce+4610+001 Student
Computer Systems Architecture Lecture 24 Mahadevan Gomathisankaran April 29, 2010 04/29/2010 Lecture 24 CSCE 4610/5610 1 Reminder ABET Feedback: http://www.cse.unt.edu/exitsurvey.cgi?csce+4610+001 Student
Aleksandar Milenkovich 1
 Parallel Computers Lecture 8: Multiprocessors Aleksandar Milenkovic, milenka@ece.uah.edu Electrical and Computer Engineering University of Alabama in Huntsville Definition: A parallel computer is a collection
Parallel Computers Lecture 8: Multiprocessors Aleksandar Milenkovic, milenka@ece.uah.edu Electrical and Computer Engineering University of Alabama in Huntsville Definition: A parallel computer is a collection
Multiprocessors & Thread Level Parallelism
 Multiprocessors & Thread Level Parallelism COE 403 Computer Architecture Prof. Muhamed Mudawar Computer Engineering Department King Fahd University of Petroleum and Minerals Presentation Outline Introduction
Multiprocessors & Thread Level Parallelism COE 403 Computer Architecture Prof. Muhamed Mudawar Computer Engineering Department King Fahd University of Petroleum and Minerals Presentation Outline Introduction
Aleksandar Milenkovic, Electrical and Computer Engineering University of Alabama in Huntsville
 Lecture 18: Multiprocessors Aleksandar Milenkovic, milenka@ece.uah.edu Electrical and Computer Engineering University of Alabama in Huntsville Parallel Computers Definition: A parallel computer is a collection
Lecture 18: Multiprocessors Aleksandar Milenkovic, milenka@ece.uah.edu Electrical and Computer Engineering University of Alabama in Huntsville Parallel Computers Definition: A parallel computer is a collection
CISC 662 Graduate Computer Architecture Lectures 15 and 16 - Multiprocessors and Thread-Level Parallelism
 CISC 662 Graduate Computer Architecture Lectures 15 and 16 - Multiprocessors and Thread-Level Parallelism Michela Taufer http://www.cis.udel.edu/~taufer/teaching/cis662f07 Powerpoint Lecture Notes from
CISC 662 Graduate Computer Architecture Lectures 15 and 16 - Multiprocessors and Thread-Level Parallelism Michela Taufer http://www.cis.udel.edu/~taufer/teaching/cis662f07 Powerpoint Lecture Notes from
3/13/2008 Csci 211 Lecture %/year. Manufacturer/Year. Processors/chip Threads/Processor. Threads/chip 3/13/2008 Csci 211 Lecture 8 4
 Outline CSCI Computer System Architecture Lec 8 Multiprocessor Introduction Xiuzhen Cheng Department of Computer Sciences The George Washington University MP Motivation SISD v. SIMD v. MIMD Centralized
Outline CSCI Computer System Architecture Lec 8 Multiprocessor Introduction Xiuzhen Cheng Department of Computer Sciences The George Washington University MP Motivation SISD v. SIMD v. MIMD Centralized
Multiprocessors and Thread-Level Parallelism. Department of Electrical & Electronics Engineering, Amrita School of Engineering
 Multiprocessors and Thread-Level Parallelism Multithreading Increasing performance by ILP has the great advantage that it is reasonable transparent to the programmer, ILP can be quite limited or hard to
Multiprocessors and Thread-Level Parallelism Multithreading Increasing performance by ILP has the great advantage that it is reasonable transparent to the programmer, ILP can be quite limited or hard to
Review: Multiprocessor. CPE 631 Session 21: Multiprocessors (Part 2) Potential HW Coherency Solutions. Bus Snooping Topology
 Potential HW Coherency Solutions. Bus Snooping Topology") Review: Multiprocessor CPE 631 Session 21: Multiprocessors (Part 2) Department of Electrical and Computer Engineering University of Alabama in Huntsville Basic issues and terminology Communication: share
Review: Multiprocessor CPE 631 Session 21: Multiprocessors (Part 2) Department of Electrical and Computer Engineering University of Alabama in Huntsville Basic issues and terminology Communication: share
Handout 3 Multiprocessor and thread level parallelism
 Handout 3 Multiprocessor and thread level parallelism Outline Review MP Motivation SISD v SIMD (SIMT) v MIMD Centralized vs Distributed Memory MESI and Directory Cache Coherency Synchronization and Relaxed
Handout 3 Multiprocessor and thread level parallelism Outline Review MP Motivation SISD v SIMD (SIMT) v MIMD Centralized vs Distributed Memory MESI and Directory Cache Coherency Synchronization and Relaxed
Computer Systems Architecture
 Computer Systems Architecture Lecture 23 Mahadevan Gomathisankaran April 27, 2010 04/27/2010 Lecture 23 CSCE 4610/5610 1 Reminder ABET Feedback: http://www.cse.unt.edu/exitsurvey.cgi?csce+4610+001 Student
Computer Systems Architecture Lecture 23 Mahadevan Gomathisankaran April 27, 2010 04/27/2010 Lecture 23 CSCE 4610/5610 1 Reminder ABET Feedback: http://www.cse.unt.edu/exitsurvey.cgi?csce+4610+001 Student
Fall 2012 EE 6633: Architecture of Parallel Computers Lecture 4: Shared Address Multiprocessors Acknowledgement: Dave Patterson, UC Berkeley
 Fall 2012 EE 6633: Architecture of Parallel Computers Lecture 4: Shared Address Multiprocessors Acknowledgement: Dave Patterson, UC Berkeley Avinash Kodi Department of Electrical Engineering & Computer
Fall 2012 EE 6633: Architecture of Parallel Computers Lecture 4: Shared Address Multiprocessors Acknowledgement: Dave Patterson, UC Berkeley Avinash Kodi Department of Electrical Engineering & Computer
COSC4201 Multiprocessors
 COSC4201 Multiprocessors Prof. Mokhtar Aboelaze Parts of these slides are taken from Notes by Prof. David Patterson (UCB) Multiprocessing We are dedicating all of our future product development to multicore
COSC4201 Multiprocessors Prof. Mokhtar Aboelaze Parts of these slides are taken from Notes by Prof. David Patterson (UCB) Multiprocessing We are dedicating all of our future product development to multicore
Parallel Computer Architecture Spring Shared Memory Multiprocessors Memory Coherence
 Parallel Computer Architecture Spring 2018 Shared Memory Multiprocessors Memory Coherence Nikos Bellas Computer and Communications Engineering Department University of Thessaly Parallel Computer Architecture
Parallel Computer Architecture Spring 2018 Shared Memory Multiprocessors Memory Coherence Nikos Bellas Computer and Communications Engineering Department University of Thessaly Parallel Computer Architecture
Page 1. Instruction-Level Parallelism (ILP) CISC 662 Graduate Computer Architecture Lectures 16 and 17 - Multiprocessors and Thread-Level Parallelism
 CISC 662 Graduate Computer Architecture Lectures 16 and 17 - Multiprocessors and Thread-Level Parallelism") CISC 662 Graduate Computer Architecture Lectures 16 and 17 - Multiprocessors and Thread-Level Parallelism Michela Taufer Powerpoint Lecture Notes from John Hennessy and David Patterson s: Computer Architecture,
CISC 662 Graduate Computer Architecture Lectures 16 and 17 - Multiprocessors and Thread-Level Parallelism Michela Taufer Powerpoint Lecture Notes from John Hennessy and David Patterson s: Computer Architecture,
Multiple Issue and Static Scheduling. Multiple Issue. MSc Informatics Eng. Beyond Instruction-Level Parallelism
 Computing Systems & Performance Beyond Instruction-Level Parallelism MSc Informatics Eng. 2012/13 A.J.Proença From ILP to Multithreading and Shared Cache (most slides are borrowed) When exploiting ILP,
Computing Systems & Performance Beyond Instruction-Level Parallelism MSc Informatics Eng. 2012/13 A.J.Proença From ILP to Multithreading and Shared Cache (most slides are borrowed) When exploiting ILP,
Chap. 4 Multiprocessors and Thread-Level Parallelism
 Chap. 4 Multiprocessors and Thread-Level Parallelism Uniprocessor performance Performance (vs. VAX-11/780) 10000 1000 100 10 From Hennessy and Patterson, Computer Architecture: A Quantitative Approach,
Chap. 4 Multiprocessors and Thread-Level Parallelism Uniprocessor performance Performance (vs. VAX-11/780) 10000 1000 100 10 From Hennessy and Patterson, Computer Architecture: A Quantitative Approach,
Multiprocessors 1. Outline
 Multiprocessors 1 Outline Multiprocessing Coherence Write Consistency Snooping Building Blocks Snooping protocols and examples Coherence traffic and performance on MP Directory-based protocols and examples
Multiprocessors 1 Outline Multiprocessing Coherence Write Consistency Snooping Building Blocks Snooping protocols and examples Coherence traffic and performance on MP Directory-based protocols and examples
Chapter Seven. Idea: create powerful computers by connecting many smaller ones
 Chapter Seven Multiprocessors Idea: create powerful computers by connecting many smaller ones good news: works for timesharing (better than supercomputer) vector processing may be coming back bad news:
Chapter Seven Multiprocessors Idea: create powerful computers by connecting many smaller ones good news: works for timesharing (better than supercomputer) vector processing may be coming back bad news:
Multiprocessor Cache Coherence. Chapter 5. Memory System is Coherent If... From ILP to TLP. Enforcing Cache Coherence. Multiprocessor Types
 Chapter 5 Multiprocessor Cache Coherence Thread-Level Parallelism 1: read 2: read 3: write??? 1 4 From ILP to TLP Memory System is Coherent If... ILP became inefficient in terms of Power consumption Silicon
Chapter 5 Multiprocessor Cache Coherence Thread-Level Parallelism 1: read 2: read 3: write??? 1 4 From ILP to TLP Memory System is Coherent If... ILP became inefficient in terms of Power consumption Silicon
Page 1. Lecture 12: Multiprocessor 2: Snooping Protocol, Directory Protocol, Synchronization, Consistency. Bus Snooping Topology
 CS252 Graduate Computer Architecture Lecture 12: Multiprocessor 2: Snooping Protocol, Directory Protocol, Synchronization, Consistency Review: Multiprocessor Basic issues and terminology Communication:
CS252 Graduate Computer Architecture Lecture 12: Multiprocessor 2: Snooping Protocol, Directory Protocol, Synchronization, Consistency Review: Multiprocessor Basic issues and terminology Communication:
Cache Coherence. CMU : Parallel Computer Architecture and Programming (Spring 2012)
") Cache Coherence CMU 15-418: Parallel Computer Architecture and Programming (Spring 2012) Shared memory multi-processor Processors read and write to shared variables - More precisely: processors issues
Cache Coherence CMU 15-418: Parallel Computer Architecture and Programming (Spring 2012) Shared memory multi-processor Processors read and write to shared variables - More precisely: processors issues
Chapter 6: Multiprocessors and Thread-Level Parallelism
 Chapter 6: Multiprocessors and Thread-Level Parallelism 1 Parallel Architectures 2 Flynn s Four Categories SISD (Single Instruction Single Data) Uniprocessors MISD (Multiple Instruction Single Data)???;
Chapter 6: Multiprocessors and Thread-Level Parallelism 1 Parallel Architectures 2 Flynn s Four Categories SISD (Single Instruction Single Data) Uniprocessors MISD (Multiple Instruction Single Data)???;
MULTIPROCESSORS AND THREAD-LEVEL. B649 Parallel Architectures and Programming
 MULTIPROCESSORS AND THREAD-LEVEL PARALLELISM B649 Parallel Architectures and Programming Motivation behind Multiprocessors Limitations of ILP (as already discussed) Growing interest in servers and server-performance
MULTIPROCESSORS AND THREAD-LEVEL PARALLELISM B649 Parallel Architectures and Programming Motivation behind Multiprocessors Limitations of ILP (as already discussed) Growing interest in servers and server-performance
MULTIPROCESSORS AND THREAD-LEVEL PARALLELISM. B649 Parallel Architectures and Programming
 MULTIPROCESSORS AND THREAD-LEVEL PARALLELISM B649 Parallel Architectures and Programming Motivation behind Multiprocessors Limitations of ILP (as already discussed) Growing interest in servers and server-performance
MULTIPROCESSORS AND THREAD-LEVEL PARALLELISM B649 Parallel Architectures and Programming Motivation behind Multiprocessors Limitations of ILP (as already discussed) Growing interest in servers and server-performance
CS 152 Computer Architecture and Engineering. Lecture 19: Directory-Based Cache Protocols
 CS 152 Computer Architecture and Engineering Lecture 19: Directory-Based Cache Protocols Krste Asanovic Electrical Engineering and Computer Sciences University of California, Berkeley http://www.eecs.berkeley.edu/~krste
CS 152 Computer Architecture and Engineering Lecture 19: Directory-Based Cache Protocols Krste Asanovic Electrical Engineering and Computer Sciences University of California, Berkeley http://www.eecs.berkeley.edu/~krste
CS 152 Computer Architecture and Engineering. Lecture 19: Directory-Based Cache Protocols
 CS 152 Computer Architecture and Engineering Lecture 19: Directory-Based Protocols Dr. George Michelogiannakis EECS, University of California at Berkeley CRD, Lawrence Berkeley National Laboratory http://inst.eecs.berkeley.edu/~cs152
CS 152 Computer Architecture and Engineering Lecture 19: Directory-Based Protocols Dr. George Michelogiannakis EECS, University of California at Berkeley CRD, Lawrence Berkeley National Laboratory http://inst.eecs.berkeley.edu/~cs152
Chapter 5. Multiprocessors and Thread-Level Parallelism
 Computer Architecture A Quantitative Approach, Fifth Edition Chapter 5 Multiprocessors and Thread-Level Parallelism 1 Introduction Thread-Level parallelism Have multiple program counters Uses MIMD model
Computer Architecture A Quantitative Approach, Fifth Edition Chapter 5 Multiprocessors and Thread-Level Parallelism 1 Introduction Thread-Level parallelism Have multiple program counters Uses MIMD model
CS 152 Computer Architecture and Engineering
 CS 152 Computer Architecture and Engineering Lecture 18: Directory-Based Cache Protocols John Wawrzynek EECS, University of California at Berkeley http://inst.eecs.berkeley.edu/~cs152 Administrivia 2 Recap:
CS 152 Computer Architecture and Engineering Lecture 18: Directory-Based Cache Protocols John Wawrzynek EECS, University of California at Berkeley http://inst.eecs.berkeley.edu/~cs152 Administrivia 2 Recap:
CS 152 Computer Architecture and Engineering. Lecture 19: Directory-Based Cache Protocols
 CS 152 Computer Architecture and Engineering Lecture 19: Directory-Based Cache Protocols Krste Asanovic Electrical Engineering and Computer Sciences University of California, Berkeley http://www.eecs.berkeley.edu/~krste
CS 152 Computer Architecture and Engineering Lecture 19: Directory-Based Cache Protocols Krste Asanovic Electrical Engineering and Computer Sciences University of California, Berkeley http://www.eecs.berkeley.edu/~krste
Multiprocessors. Flynn Taxonomy. Classifying Multiprocessors. why would you want a multiprocessor? more is better? Cache Cache Cache.
 Multiprocessors why would you want a multiprocessor? Multiprocessors and Multithreading more is better? Cache Cache Cache Classifying Multiprocessors Flynn Taxonomy Flynn Taxonomy Interconnection Network
Multiprocessors why would you want a multiprocessor? Multiprocessors and Multithreading more is better? Cache Cache Cache Classifying Multiprocessors Flynn Taxonomy Flynn Taxonomy Interconnection Network
EITF20: Computer Architecture Part 5.2.1: IO and MultiProcessor
 EITF20: Computer Architecture Part 5.2.1: IO and MultiProcessor Liang Liu liang.liu@eit.lth.se 1 Outline Reiteration I/O MultiProcessor Summary 2 Virtual memory benifits Using physical memory efficiently
EITF20: Computer Architecture Part 5.2.1: IO and MultiProcessor Liang Liu liang.liu@eit.lth.se 1 Outline Reiteration I/O MultiProcessor Summary 2 Virtual memory benifits Using physical memory efficiently
Cache Coherence in Bus-Based Shared Memory Multiprocessors
 Cache Coherence in Bus-Based Shared Memory Multiprocessors Shared Memory Multiprocessors Variations Cache Coherence in Shared Memory Multiprocessors A Coherent Memory System: Intuition Formal Definition
Cache Coherence in Bus-Based Shared Memory Multiprocessors Shared Memory Multiprocessors Variations Cache Coherence in Shared Memory Multiprocessors A Coherent Memory System: Intuition Formal Definition
Lecture 10: Cache Coherence: Part I. Parallel Computer Architecture and Programming CMU , Spring 2013
 Lecture 10: Cache Coherence: Part I Parallel Computer Architecture and Programming Cache design review Let s say your code executes int x = 1; (Assume for simplicity x corresponds to the address 0x12345604
Lecture 10: Cache Coherence: Part I Parallel Computer Architecture and Programming Cache design review Let s say your code executes int x = 1; (Assume for simplicity x corresponds to the address 0x12345604
COSC 6385 Computer Architecture - Multi Processor Systems
 COSC 6385 Computer Architecture - Multi Processor Systems Fall 2006 Classification of Parallel Architectures Flynn s Taxonomy SISD: Single instruction single data Classical von Neumann architecture SIMD:
COSC 6385 Computer Architecture - Multi Processor Systems Fall 2006 Classification of Parallel Architectures Flynn s Taxonomy SISD: Single instruction single data Classical von Neumann architecture SIMD:
Lecture 10: Cache Coherence: Part I. Parallel Computer Architecture and Programming CMU /15-618, Spring 2015
 Lecture 10: Cache Coherence: Part I Parallel Computer Architecture and Programming CMU 15-418/15-618, Spring 2015 Tunes Marble House The Knife (Silent Shout) Before starting The Knife, we were working
Lecture 10: Cache Coherence: Part I Parallel Computer Architecture and Programming CMU 15-418/15-618, Spring 2015 Tunes Marble House The Knife (Silent Shout) Before starting The Knife, we were working
Chapter 5. Multiprocessors and Thread-Level Parallelism
 Computer Architecture A Quantitative Approach, Fifth Edition Chapter 5 Multiprocessors and Thread-Level Parallelism 1 Introduction Thread-Level parallelism Have multiple program counters Uses MIMD model
Computer Architecture A Quantitative Approach, Fifth Edition Chapter 5 Multiprocessors and Thread-Level Parallelism 1 Introduction Thread-Level parallelism Have multiple program counters Uses MIMD model
10 Parallel Organizations: Multiprocessor / Multicore / Multicomputer Systems
 1 License: http://creativecommons.org/licenses/by-nc-nd/3.0/ 10 Parallel Organizations: Multiprocessor / Multicore / Multicomputer Systems To enhance system performance and, in some cases, to increase
1 License: http://creativecommons.org/licenses/by-nc-nd/3.0/ 10 Parallel Organizations: Multiprocessor / Multicore / Multicomputer Systems To enhance system performance and, in some cases, to increase
Computing architectures Part 2 TMA4280 Introduction to Supercomputing
 Computing architectures Part 2 TMA4280 Introduction to Supercomputing NTNU, IMF January 16. 2017 1 Supercomputing What is the motivation for Supercomputing? Solve complex problems fast and accurately:
Computing architectures Part 2 TMA4280 Introduction to Supercomputing NTNU, IMF January 16. 2017 1 Supercomputing What is the motivation for Supercomputing? Solve complex problems fast and accurately:
CMSC 611: Advanced. Distributed & Shared Memory
 CMSC 611: Advanced Computer Architecture Distributed & Shared Memory Centralized Shared Memory MIMD Processors share a single centralized memory through a bus interconnect Feasible for small processor
CMSC 611: Advanced Computer Architecture Distributed & Shared Memory Centralized Shared Memory MIMD Processors share a single centralized memory through a bus interconnect Feasible for small processor
CS 152 Computer Architecture and Engineering CS252 Graduate Computer Architecture. Lecture 18 Cache Coherence
 CS 152 Computer Architecture and Engineering CS252 Graduate Computer Architecture Lecture 18 Cache Coherence Krste Asanovic Electrical Engineering and Computer Sciences University of California at Berkeley
CS 152 Computer Architecture and Engineering CS252 Graduate Computer Architecture Lecture 18 Cache Coherence Krste Asanovic Electrical Engineering and Computer Sciences University of California at Berkeley
Limitations of parallel processing
 Your professor du jour: Steve Gribble gribble@cs.washington.edu 323B Sieg Hall all material in this lecture in Henessey and Patterson, Chapter 8 635-640 645, 646 654-665 11/8/00 CSE 471 Multiprocessors
Your professor du jour: Steve Gribble gribble@cs.washington.edu 323B Sieg Hall all material in this lecture in Henessey and Patterson, Chapter 8 635-640 645, 646 654-665 11/8/00 CSE 471 Multiprocessors
INSTITUTO SUPERIOR TÉCNICO. Architectures for Embedded Computing
 UNIVERSIDADE TÉCNICA DE LISBOA INSTITUTO SUPERIOR TÉCNICO Departamento de Engenharia Informática Architectures for Embedded Computing MEIC-A, MEIC-T, MERC Lecture Slides Version 3.0 - English Lecture 11
UNIVERSIDADE TÉCNICA DE LISBOA INSTITUTO SUPERIOR TÉCNICO Departamento de Engenharia Informática Architectures for Embedded Computing MEIC-A, MEIC-T, MERC Lecture Slides Version 3.0 - English Lecture 11
Chapter 6. Parallel Processors from Client to Cloud Part 2 COMPUTER ORGANIZATION AND DESIGN. Homogeneous & Heterogeneous Multicore Architectures
 COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 6 Parallel Processors from Client to Cloud Part 2 Homogeneous & Heterogeneous Multicore Architectures Intel XEON 22nm
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 6 Parallel Processors from Client to Cloud Part 2 Homogeneous & Heterogeneous Multicore Architectures Intel XEON 22nm
CS 590: High Performance Computing. Parallel Computer Architectures. Lab 1 Starts Today. Already posted on Canvas (under Assignment) Let s look at it
 Let s look at it") Lab 1 Starts Today Already posted on Canvas (under Assignment) Let s look at it CS 590: High Performance Computing Parallel Computer Architectures Fengguang Song Department of Computer Science IUPUI 1
Lab 1 Starts Today Already posted on Canvas (under Assignment) Let s look at it CS 590: High Performance Computing Parallel Computer Architectures Fengguang Song Department of Computer Science IUPUI 1
CMSC 611: Advanced Computer Architecture
 CMSC 611: Advanced Computer Architecture Shared Memory Most slides adapted from David Patterson. Some from Mohomed Younis Interconnection Networks Massively processor networks (MPP) Thousands of nodes
CMSC 611: Advanced Computer Architecture Shared Memory Most slides adapted from David Patterson. Some from Mohomed Younis Interconnection Networks Massively processor networks (MPP) Thousands of nodes
Lecture 17: Multiprocessors: Size, Consitency. Review: Networking Summary
 Lecture 17: Multiprocessors: Size, Consitency Professor David A. Patterson Computer Science 252 Spring 1998 DAP Spr. 98 UCB 1 Review: Networking Summary Protocols allow hetereogeneous networking Protocols
Lecture 17: Multiprocessors: Size, Consitency Professor David A. Patterson Computer Science 252 Spring 1998 DAP Spr. 98 UCB 1 Review: Networking Summary Protocols allow hetereogeneous networking Protocols
Dr. George Michelogiannakis. EECS, University of California at Berkeley CRD, Lawrence Berkeley National Laboratory
 CS 152 Computer Architecture and Engineering Lecture 18: Snoopy Caches Dr. George Michelogiannakis EECS, University of California at Berkeley CRD, Lawrence Berkeley National Laboratory http://inst.eecs.berkeley.edu/~cs152!
CS 152 Computer Architecture and Engineering Lecture 18: Snoopy Caches Dr. George Michelogiannakis EECS, University of California at Berkeley CRD, Lawrence Berkeley National Laboratory http://inst.eecs.berkeley.edu/~cs152!
Serial. Parallel. CIT 668: System Architecture 2/14/2011. Topics. Serial and Parallel Computation. Parallel Computing
 CIT 668: System Architecture Parallel Computing Topics 1. What is Parallel Computing? 2. Why use Parallel Computing? 3. Types of Parallelism 4. Amdahl s Law 5. Flynn s Taxonomy of Parallel Computers 6.
CIT 668: System Architecture Parallel Computing Topics 1. What is Parallel Computing? 2. Why use Parallel Computing? 3. Types of Parallelism 4. Amdahl s Law 5. Flynn s Taxonomy of Parallel Computers 6.
Parallel Architecture. Hwansoo Han
 Parallel Architecture Hwansoo Han Performance Curve 2 Unicore Limitations Performance scaling stopped due to: Power Wire delay DRAM latency Limitation in ILP 3 Power Consumption (watts) 4 Wire Delay Range
Parallel Architecture Hwansoo Han Performance Curve 2 Unicore Limitations Performance scaling stopped due to: Power Wire delay DRAM latency Limitation in ILP 3 Power Consumption (watts) 4 Wire Delay Range
Computer and Information Sciences College / Computer Science Department CS 207 D. Computer Architecture. Lecture 9: Multiprocessors
 Computer and Information Sciences College / Computer Science Department CS 207 D Computer Architecture Lecture 9: Multiprocessors Challenges of Parallel Processing First challenge is % of program inherently
Computer and Information Sciences College / Computer Science Department CS 207 D Computer Architecture Lecture 9: Multiprocessors Challenges of Parallel Processing First challenge is % of program inherently
Lecture 24: Virtual Memory, Multiprocessors
 Lecture 24: Virtual Memory, Multiprocessors Today s topics: Virtual memory Multiprocessors, cache coherence 1 Virtual Memory Processes deal with virtual memory they have the illusion that a very large
Lecture 24: Virtual Memory, Multiprocessors Today s topics: Virtual memory Multiprocessors, cache coherence 1 Virtual Memory Processes deal with virtual memory they have the illusion that a very large
Chapter-4 Multiprocessors and Thread-Level Parallelism
 Chapter-4 Multiprocessors and Thread-Level Parallelism We have seen the renewed interest in developing multiprocessors in early 2000: - The slowdown in uniprocessor performance due to the diminishing returns
Chapter-4 Multiprocessors and Thread-Level Parallelism We have seen the renewed interest in developing multiprocessors in early 2000: - The slowdown in uniprocessor performance due to the diminishing returns
COSC4201. Multiprocessors and Thread Level Parallelism. Prof. Mokhtar Aboelaze York University
 COSC4201 Multiprocessors and Thread Level Parallelism Prof. Mokhtar Aboelaze York University COSC 4201 1 Introduction Why multiprocessor The turning away from the conventional organization came in the
COSC4201 Multiprocessors and Thread Level Parallelism Prof. Mokhtar Aboelaze York University COSC 4201 1 Introduction Why multiprocessor The turning away from the conventional organization came in the
Lecture 24: Multiprocessing Computer Architecture and Systems Programming ( )
") Systems Group Department of Computer Science ETH Zürich Lecture 24: Multiprocessing Computer Architecture and Systems Programming (252-0061-00) Timothy Roscoe Herbstsemester 2012 Most of the rest of this
Systems Group Department of Computer Science ETH Zürich Lecture 24: Multiprocessing Computer Architecture and Systems Programming (252-0061-00) Timothy Roscoe Herbstsemester 2012 Most of the rest of this
Shared Symmetric Memory Systems
 Shared Symmetric Memory Systems Computer Architecture J. Daniel García Sánchez (coordinator) David Expósito Singh Francisco Javier García Blas ARCOS Group Computer Science and Engineering Department University
Shared Symmetric Memory Systems Computer Architecture J. Daniel García Sánchez (coordinator) David Expósito Singh Francisco Javier García Blas ARCOS Group Computer Science and Engineering Department University
CSE 392/CS 378: High-performance Computing - Principles and Practice
 CSE 392/CS 378: High-performance Computing - Principles and Practice Parallel Computer Architectures A Conceptual Introduction for Software Developers Jim Browne browne@cs.utexas.edu Parallel Computer
CSE 392/CS 378: High-performance Computing - Principles and Practice Parallel Computer Architectures A Conceptual Introduction for Software Developers Jim Browne browne@cs.utexas.edu Parallel Computer
Advanced Parallel Programming I
 Advanced Parallel Programming I Alexander Leutgeb, RISC Software GmbH RISC Software GmbH Johannes Kepler University Linz 2016 22.09.2016 1 Levels of Parallelism RISC Software GmbH Johannes Kepler University
Advanced Parallel Programming I Alexander Leutgeb, RISC Software GmbH RISC Software GmbH Johannes Kepler University Linz 2016 22.09.2016 1 Levels of Parallelism RISC Software GmbH Johannes Kepler University
CS 654 Computer Architecture Summary. Peter Kemper
 CS 654 Computer Architecture Summary Peter Kemper Chapters in Hennessy & Patterson Ch 1: Fundamentals Ch 2: Instruction Level Parallelism Ch 3: Limits on ILP Ch 4: Multiprocessors & TLP Ap A: Pipelining
CS 654 Computer Architecture Summary Peter Kemper Chapters in Hennessy & Patterson Ch 1: Fundamentals Ch 2: Instruction Level Parallelism Ch 3: Limits on ILP Ch 4: Multiprocessors & TLP Ap A: Pipelining
Computer Science 146. Computer Architecture
 Computer Architecture Spring 24 Harvard University Instructor: Prof. dbrooks@eecs.harvard.edu Lecture 2: More Multiprocessors Computation Taxonomy SISD SIMD MISD MIMD ILP Vectors, MM-ISAs Shared Memory
Computer Architecture Spring 24 Harvard University Instructor: Prof. dbrooks@eecs.harvard.edu Lecture 2: More Multiprocessors Computation Taxonomy SISD SIMD MISD MIMD ILP Vectors, MM-ISAs Shared Memory
CS 152 Computer Architecture and Engineering. Lecture 7 - Memory Hierarchy-II
 CS 152 Computer Architecture and Engineering Lecture 7 - Memory Hierarchy-II Krste Asanovic Electrical Engineering and Computer Sciences University of California at Berkeley http://www.eecs.berkeley.edu/~krste!
CS 152 Computer Architecture and Engineering Lecture 7 - Memory Hierarchy-II Krste Asanovic Electrical Engineering and Computer Sciences University of California at Berkeley http://www.eecs.berkeley.edu/~krste!
CSE502 Graduate Computer Architecture. Lec 22 Goodbye to Computer Architecture and Review
 CSE502 Graduate Computer Architecture Lec 22 Goodbye to Computer Architecture and Review Larry Wittie Computer Science, StonyBrook University http://www.cs.sunysb.edu/~cse502 and ~lw Slides adapted from
CSE502 Graduate Computer Architecture Lec 22 Goodbye to Computer Architecture and Review Larry Wittie Computer Science, StonyBrook University http://www.cs.sunysb.edu/~cse502 and ~lw Slides adapted from
Modern CPU Architectures
 Modern CPU Architectures Alexander Leutgeb, RISC Software GmbH RISC Software GmbH Johannes Kepler University Linz 2014 16.04.2014 1 Motivation for Parallelism I CPU History RISC Software GmbH Johannes
Modern CPU Architectures Alexander Leutgeb, RISC Software GmbH RISC Software GmbH Johannes Kepler University Linz 2014 16.04.2014 1 Motivation for Parallelism I CPU History RISC Software GmbH Johannes
UNIT I (Two Marks Questions & Answers)
") UNIT I (Two Marks Questions & Answers) Discuss the different ways how instruction set architecture can be classified? Stack Architecture,Accumulator Architecture, Register-Memory Architecture,Register-
UNIT I (Two Marks Questions & Answers) Discuss the different ways how instruction set architecture can be classified? Stack Architecture,Accumulator Architecture, Register-Memory Architecture,Register-
Outline. EEL 5764 Graduate Computer Architecture. Chapter 4 - Multiprocessors and TLP. Déjà vu all over again?
 Outline EEL 5764 Graduate Computer Architecture Chapter 4 - Multiprocessors and TLP Ann Gordon-Ross Electrical and Computer Engineering University of Florida MP Motivation ID v. IMD v. MIMD Centralized
Outline EEL 5764 Graduate Computer Architecture Chapter 4 - Multiprocessors and TLP Ann Gordon-Ross Electrical and Computer Engineering University of Florida MP Motivation ID v. IMD v. MIMD Centralized
EN164: Design of Computing Systems Topic 08: Parallel Processor Design (introduction)
") EN164: Design of Computing Systems Topic 08: Parallel Processor Design (introduction) Professor Sherief Reda http://scale.engin.brown.edu Electrical Sciences and Computer Engineering School of Engineering
EN164: Design of Computing Systems Topic 08: Parallel Processor Design (introduction) Professor Sherief Reda http://scale.engin.brown.edu Electrical Sciences and Computer Engineering School of Engineering
WHY PARALLEL PROCESSING? (CE-401)
") PARALLEL PROCESSING (CE-401) COURSE INFORMATION 2 + 1 credits (60 marks theory, 40 marks lab) Labs introduced for second time in PP history of SSUET Theory marks breakup: Midterm Exam: 15 marks Assignment:
PARALLEL PROCESSING (CE-401) COURSE INFORMATION 2 + 1 credits (60 marks theory, 40 marks lab) Labs introduced for second time in PP history of SSUET Theory marks breakup: Midterm Exam: 15 marks Assignment:
Page 1. SMP Review. Multiprocessors. Bus Based Coherence. Bus Based Coherence. Characteristics. Cache coherence. Cache coherence
 SMP Review Multiprocessors Today s topics: SMP cache coherence general cache coherence issues snooping protocols Improved interaction lots of questions warning I m going to wait for answers granted it
SMP Review Multiprocessors Today s topics: SMP cache coherence general cache coherence issues snooping protocols Improved interaction lots of questions warning I m going to wait for answers granted it
Introducing Multi-core Computing / Hyperthreading
 Introducing Multi-core Computing / Hyperthreading Clock Frequency with Time 3/9/2017 2 Why multi-core/hyperthreading? Difficult to make single-core clock frequencies even higher Deeply pipelined circuits:
Introducing Multi-core Computing / Hyperthreading Clock Frequency with Time 3/9/2017 2 Why multi-core/hyperthreading? Difficult to make single-core clock frequencies even higher Deeply pipelined circuits:
Comp. Org II, Spring
 Lecture 11 Parallel Processor Architectures Flynn s taxonomy from 1972 Parallel Processing & computers 8th edition: Ch 17 & 18 Earlier editions contain only Parallel Processing (Sta09 Fig 17.1) 2 Parallel
Lecture 11 Parallel Processor Architectures Flynn s taxonomy from 1972 Parallel Processing & computers 8th edition: Ch 17 & 18 Earlier editions contain only Parallel Processing (Sta09 Fig 17.1) 2 Parallel
Multi-core Architectures. Dr. Yingwu Zhu
 Multi-core Architectures Dr. Yingwu Zhu What is parallel computing? Using multiple processors in parallel to solve problems more quickly than with a single processor Examples of parallel computing A cluster
Multi-core Architectures Dr. Yingwu Zhu What is parallel computing? Using multiple processors in parallel to solve problems more quickly than with a single processor Examples of parallel computing A cluster
MULTIPROCESSORS AND THREAD-LEVEL PARALLELISM (PART 1)
") 1 MULTIPROCESSORS AND THREAD-LEVEL PARALLELISM (PART 1) Chapter 5 Appendix F Appendix I OUTLINE Introduction (5.1) Multiprocessor Architecture Challenges in Parallel Processing Centralized Shared Memory
1 MULTIPROCESSORS AND THREAD-LEVEL PARALLELISM (PART 1) Chapter 5 Appendix F Appendix I OUTLINE Introduction (5.1) Multiprocessor Architecture Challenges in Parallel Processing Centralized Shared Memory
Introduction to Multiprocessors (Part II) Cristina Silvano Politecnico di Milano
 Cristina Silvano Politecnico di Milano") Introduction to Multiprocessors (Part II) Cristina Silvano Politecnico di Milano Outline The problem of cache coherence Snooping protocols Directory-based protocols Prof. Cristina Silvano, Politecnico
Introduction to Multiprocessors (Part II) Cristina Silvano Politecnico di Milano Outline The problem of cache coherence Snooping protocols Directory-based protocols Prof. Cristina Silvano, Politecnico
Parallel Processing & Multicore computers
 Lecture 11 Parallel Processing & Multicore computers 8th edition: Ch 17 & 18 Earlier editions contain only Parallel Processing Parallel Processor Architectures Flynn s taxonomy from 1972 (Sta09 Fig 17.1)
Lecture 11 Parallel Processing & Multicore computers 8th edition: Ch 17 & 18 Earlier editions contain only Parallel Processing Parallel Processor Architectures Flynn s taxonomy from 1972 (Sta09 Fig 17.1)
Flynn s Classification
 Flynn s Classification SISD (Single Instruction Single Data) Uniprocessors MISD (Multiple Instruction Single Data) No machine is built yet for this type SIMD (Single Instruction Multiple Data) Examples:
Flynn s Classification SISD (Single Instruction Single Data) Uniprocessors MISD (Multiple Instruction Single Data) No machine is built yet for this type SIMD (Single Instruction Multiple Data) Examples:
Lecture 14: Multithreading
 CS 152 Computer Architecture and Engineering Lecture 14: Multithreading John Wawrzynek Electrical Engineering and Computer Sciences University of California, Berkeley http://www.eecs.berkeley.edu/~johnw
CS 152 Computer Architecture and Engineering Lecture 14: Multithreading John Wawrzynek Electrical Engineering and Computer Sciences University of California, Berkeley http://www.eecs.berkeley.edu/~johnw
CS 152 Computer Architecture and Engineering. Lecture 18: Multithreading
 CS 152 Computer Architecture and Engineering Lecture 18: Multithreading Krste Asanovic Electrical Engineering and Computer Sciences University of California, Berkeley http://www.eecs.berkeley.edu/~krste
CS 152 Computer Architecture and Engineering Lecture 18: Multithreading Krste Asanovic Electrical Engineering and Computer Sciences University of California, Berkeley http://www.eecs.berkeley.edu/~krste
Comp. Org II, Spring
 Lecture 11 Parallel Processing & computers 8th edition: Ch 17 & 18 Earlier editions contain only Parallel Processing Parallel Processor Architectures Flynn s taxonomy from 1972 (Sta09 Fig 17.1) Computer
Lecture 11 Parallel Processing & computers 8th edition: Ch 17 & 18 Earlier editions contain only Parallel Processing Parallel Processor Architectures Flynn s taxonomy from 1972 (Sta09 Fig 17.1) Computer
Motivation for Parallelism. Motivation for Parallelism. ILP Example: Loop Unrolling. Types of Parallelism
 Motivation for Parallelism Motivation for Parallelism The speed of an application is determined by more than just processor speed. speed Disk speed Network speed... Multiprocessors typically improve the
Motivation for Parallelism Motivation for Parallelism The speed of an application is determined by more than just processor speed. speed Disk speed Network speed... Multiprocessors typically improve the
DEPARTMENT OF COMPUTER SCIENCE AND ENGINEERING UNIT-1
 DEPARTMENT OF COMPUTER SCIENCE AND ENGINEERING Year & Semester : III/VI Section : CSE-1 & CSE-2 Subject Code : CS2354 Subject Name : Advanced Computer Architecture Degree & Branch : B.E C.S.E. UNIT-1 1.
DEPARTMENT OF COMPUTER SCIENCE AND ENGINEERING Year & Semester : III/VI Section : CSE-1 & CSE-2 Subject Code : CS2354 Subject Name : Advanced Computer Architecture Degree & Branch : B.E C.S.E. UNIT-1 1.
Processor Architecture
 Processor Architecture Shared Memory Multiprocessors M. Schölzel The Coherence Problem s may contain local copies of the same memory address without proper coordination they work independently on their
Processor Architecture Shared Memory Multiprocessors M. Schölzel The Coherence Problem s may contain local copies of the same memory address without proper coordination they work independently on their
Overview: Shared Memory Hardware. Shared Address Space Systems. Shared Address Space and Shared Memory Computers. Shared Memory Hardware
 Overview: Shared Memory Hardware Shared Address Space Systems overview of shared address space systems example: cache hierarchy of the Intel Core i7 cache coherency protocols: basic ideas, invalidate and
Overview: Shared Memory Hardware Shared Address Space Systems overview of shared address space systems example: cache hierarchy of the Intel Core i7 cache coherency protocols: basic ideas, invalidate and
Overview: Shared Memory Hardware
 Overview: Shared Memory Hardware overview of shared address space systems example: cache hierarchy of the Intel Core i7 cache coherency protocols: basic ideas, invalidate and update protocols false sharing
Overview: Shared Memory Hardware overview of shared address space systems example: cache hierarchy of the Intel Core i7 cache coherency protocols: basic ideas, invalidate and update protocols false sharing
Multi-core Architectures. Dr. Yingwu Zhu
 Multi-core Architectures Dr. Yingwu Zhu Outline Parallel computing? Multi-core architectures Memory hierarchy Vs. SMT Cache coherence What is parallel computing? Using multiple processors in parallel to
Multi-core Architectures Dr. Yingwu Zhu Outline Parallel computing? Multi-core architectures Memory hierarchy Vs. SMT Cache coherence What is parallel computing? Using multiple processors in parallel to
Parallel Processing. Computer Architecture. Computer Architecture. Outline. Multiple Processor Organization
 Computer Architecture Computer Architecture Prof. Dr. Nizamettin AYDIN naydin@yildiz.edu.tr nizamettinaydin@gmail.com Parallel Processing http://www.yildiz.edu.tr/~naydin 1 2 Outline Multiple Processor
Computer Architecture Computer Architecture Prof. Dr. Nizamettin AYDIN naydin@yildiz.edu.tr nizamettinaydin@gmail.com Parallel Processing http://www.yildiz.edu.tr/~naydin 1 2 Outline Multiple Processor
Computer Architecture Spring 2016
 Computer Architecture Spring 2016 Lecture 19: Multiprocessing Shuai Wang Department of Computer Science and Technology Nanjing University [Slides adapted from CSE 502 Stony Brook University] Getting More
Computer Architecture Spring 2016 Lecture 19: Multiprocessing Shuai Wang Department of Computer Science and Technology Nanjing University [Slides adapted from CSE 502 Stony Brook University] Getting More
Lecture 11: Snooping Cache Coherence: Part II. CMU : Parallel Computer Architecture and Programming (Spring 2012)
") Lecture 11: Snooping Cache Coherence: Part II CMU 15-418: Parallel Computer Architecture and Programming (Spring 2012) Announcements Assignment 2 due tonight 11:59 PM - Recall 3-late day policy Assignment
Lecture 11: Snooping Cache Coherence: Part II CMU 15-418: Parallel Computer Architecture and Programming (Spring 2012) Announcements Assignment 2 due tonight 11:59 PM - Recall 3-late day policy Assignment
CS/ECE 757: Advanced Computer Architecture II (Parallel Computer Architecture) Symmetric Multiprocessors Part 1 (Chapter 5)
 Symmetric Multiprocessors Part 1 (Chapter 5)") CS/ECE 757: Advanced Computer Architecture II (Parallel Computer Architecture) Symmetric Multiprocessors Part 1 (Chapter 5) Copyright 2001 Mark D. Hill University of Wisconsin-Madison Slides are derived
CS/ECE 757: Advanced Computer Architecture II (Parallel Computer Architecture) Symmetric Multiprocessors Part 1 (Chapter 5) Copyright 2001 Mark D. Hill University of Wisconsin-Madison Slides are derived
Multicore Workshop. Cache Coherency. Mark Bull David Henty. EPCC, University of Edinburgh
 Multicore Workshop Cache Coherency Mark Bull David Henty EPCC, University of Edinburgh Symmetric MultiProcessing 2 Each processor in an SMP has equal access to all parts of memory same latency and bandwidth
Multicore Workshop Cache Coherency Mark Bull David Henty EPCC, University of Edinburgh Symmetric MultiProcessing 2 Each processor in an SMP has equal access to all parts of memory same latency and bandwidth
EECS 452 Lecture 9 TLP Thread-Level Parallelism
 EECS 452 Lecture 9 TLP Thread-Level Parallelism Instructor: Gokhan Memik EECS Dept., Northwestern University The lecture is adapted from slides by Iris Bahar (Brown), James Hoe (CMU), and John Shen (CMU
EECS 452 Lecture 9 TLP Thread-Level Parallelism Instructor: Gokhan Memik EECS Dept., Northwestern University The lecture is adapted from slides by Iris Bahar (Brown), James Hoe (CMU), and John Shen (CMU
Module 5: Performance Issues in Shared Memory and Introduction to Coherence Lecture 10: Introduction to Coherence. The Lecture Contains:
 The Lecture Contains: Four Organizations Hierarchical Design Cache Coherence Example What Went Wrong? Definitions Ordering Memory op Bus-based SMP s file:///d /...audhary,%20dr.%20sanjeev%20k%20aggrwal%20&%20dr.%20rajat%20moona/multi-core_architecture/lecture10/10_1.htm[6/14/2012
The Lecture Contains: Four Organizations Hierarchical Design Cache Coherence Example What Went Wrong? Definitions Ordering Memory op Bus-based SMP s file:///d /...audhary,%20dr.%20sanjeev%20k%20aggrwal%20&%20dr.%20rajat%20moona/multi-core_architecture/lecture10/10_1.htm[6/14/2012
CS 152 Computer Architecture and Engineering. Lecture 19: Directory- Based Cache Protocols. Recap: Snoopy Cache Protocols
 CS 152 Computer Architecture and Engineering Lecture 19: Directory- Based Protocols Krste Asanovic Electrical Engineering and Computer Sciences University of California, Berkeley hap://www.eecs.berkeley.edu/~krste
CS 152 Computer Architecture and Engineering Lecture 19: Directory- Based Protocols Krste Asanovic Electrical Engineering and Computer Sciences University of California, Berkeley hap://www.eecs.berkeley.edu/~krste