Paving the Road to Exascale
|
|
|
- Cuthbert Simpson
- 6 years ago
- Views:
Transcription
")
1 Paving the Road to Exascale Gilad Shainer August 2015, MVAPICH User Group (MUG) Meeting




2 The Ever Growing Demand for Performance Performance Terascale Petascale Exascale 1 st Roadrunner Technology Development SMP to Clusters Single-Core to Multi-Core 2015 Mellanox Technologies 2




3 The Road to Exascale Computing Cluster Multi-Core Co-Design 2015 Mellanox Technologies 3








4 Co-Design Architecture From Discrete to System Focused Discrete Level System Level 2015 Mellanox Technologies 4

5 Exascale will be Enabled via Co-Design Architecture Software Hardware Hardware Hardware (e.g. GPU-Direct) Software Software (e.g. OpenUCX) Industry Users Academia Standard, Open Source, Eco-System Programmable, Configurable, Innovative 2015 Mellanox Technologies 5
6 Software-Hardware Co-Design? Example: Breaking the Latency Wall Network 10 years ago Communication Framework Network Today Communication Framework Co-Design Network Future Communication Framework ~10 microsecond ~100s microsecond ~0.1 microsecond ~10s microsecond ~0.1 microsecond ~1s microsecond Today: Network devices are in 100ns latency today Challenge: How to enable the next order of magnitude performance improvement? Solution: Co-Design - mapping the communication frameworks on all active devices Result: reduce HPC communication frameworks latency by an order of magnitude Co-Design Architecture Paves the Road to Exascale Performance 2015 Mellanox Technologies 6
7 The Road to Exascale Co-Design System Architecture The road to Exascale requires order of magnitude performance improvements Co-Design architecture enables all active devices to become co-processors Compute Communication Management Compute Compute Compute CPU CPU GPU FPGA HCA Data Switch Data Mapping Communication Frameworks on All Active Devices 2015 Mellanox Technologies 7



8 Co-Design Architecture Co-Design Co-Design Compute Compute Compute Co-Design CPU GPU FPGA HCA Data Co-Design Switch Data 2015 Mellanox Technologies 8
9 The Elements of the Co-Design Architecture Applications (Innovations, Scalability, Performance) Communication Frameworks (MPI, SHMEM/PGAS) Offloading Technologies Software-Defined X Direct Communications Flexibility Offloading Technologies RDMA GPUDirect Programmability Heterogeneous System Virtualization Backward and future Compatibility Co-Design Implementation Via Offloading Technologies 2015 Mellanox Technologies 9
10 Mellanox Co-Design Architecture (Collaborative Effort) Communication Frameworks (MPI, SHMEM/PGAS) Applications Transport RDMA SRIOV Collectives Peer-Direct GPU-Direct More Future The Only Approach to Deliver 10X Performance Improvements 2015 Mellanox Technologies 10






11 Mellanox InfiniBand Proven and Most Scalable HPC Interconnect Summit System Sierra System Paving the Road to Exascale 2015 Mellanox Technologies 11



 36 EDR")



 Optical Cables")
12 High-Performance Designed 100Gb/s Interconnect Solutions 100Gb/s Adapter, 0.7us latency 150 million messages per second (10 / 25 / 40 / 50 / 56 / 100Gb/s) 36 EDR (100Gb/s) Ports, <90ns Latency Throughput of 7.2Tb/s GbE Ports, 64 25/50GbE Ports (10 / 25 / 40 / 50 / 100GbE) Throughput of 6.4Tb/s Copper (Passive, Active) Optical Cables (VCSEL) Silicon Photonics 2015 Mellanox Technologies 12
 149.5 Million/sec 105 Million/sec 35.")
13 InfiniBand Adapters Performance Comparison Mellanox Adapters ConnectX-4 Connect-IB ConnectX-3 Pro Single Port Performance EDR 100G FDR 56G FDR 56G Uni-Directional Throughput 100 Gb/s Gb/s 51.1 Gb/s Bi-Directional Throughput 195 Gb/s Gb/s 98.4 Gb/s Latency 0.61 us 0.63 us 0.64 us Message Rate (Uni-Directional) Million/sec 105 Million/sec 35.9 Million/sec 2015 Mellanox Technologies 13


14 EDR InfiniBand Performance Commercial Applications 40% 25% 15% 2015 Mellanox Technologies 14






15 EDR InfiniBand Performance Weather Simulation Weather Research and Forecasting Model Optimization effort with the HPCAC EDR InfiniBand delivers 28% higher performance 32-node cluster Performance advantage increase with system size 2015 Mellanox Technologies 15



16 Lenovo EDR InfiniBand System (TOP500) LENOX EDR InfiniBand connected system at the Lenovo HPC innovation center EDR InfiniBand provides >20% higher performance versus over FDR on Graph500 At 128nodes 2015 Mellanox Technologies 16
17 Unified Communication X Framework (UCX) The Next Generation HPC Software Framework To Meet the Needs of Future Systems / Applications 2015 Mellanox Technologies 17




18 Exascale Co-Design Collaboration The Next Generation HPC Software Framework Collaborative Effort Industry, National Laboratories and Academia 2015 Mellanox Technologies 18


, GPUs Co-design of Exascale Network APIs 2015")
19 UCX Framework Mission Collaboration between industry, laboratories, and academia Create open-source production grade communication framework for HPC applications To enable the highest performance through co-design of software-hardware interfaces To unify industry - national laboratories - academia efforts API Exposes broad semantics that target data centric and HPC programming models and applications Performance oriented Optimization for low-software overheads in communication path allows near native-level performance Production quality Developed, maintained, tested, and used by industry and researcher community Community driven Collaboration between industry, laboratories, and academia Research The framework concepts and ideas are driven by research in academia, laboratories, and industry Cross platform Support for Infiniband, Cray, various shared memory (x86-64 and Power), GPUs Co-design of Exascale Network APIs 2015 Mellanox Technologies 19



20 The UCX Framework UC-S for Services This framework provides basic infrastructure for component based programming, memory management, and useful system utilities Functionality: Platform abstractions and data structures UC-T for Transport Low-level API that expose basic network operations supported by underlying hardware Functionality: work request setup and instantiation of operations UC-P for Protocols High-level API uses UCT framework to construct protocols commonly found in applications Functionality: Multi-rail, device selection, pending queue, rendezvous, tag-matching, software-atomics, etc Mellanox Technologies 20

21 UCX High-level Overview 2015 Mellanox Technologies 21
22 Collaboration Mellanox co-designs network interface and contributes MXM technology Infrastructure, transport, shared memory, protocols, integration with OpenMPI/SHMEM, MPICH ORNL co-designs network interface and contributes UCCS project InfiniBand optimizations, Cray devices, shared memory NVIDIA co-designs high-quality support for GPU devices GPU-Direct, GDR copy, etc. IBM co-designs network interface and contributes ideas and concepts from PAMI UH/UTK focus on integration with their research platforms 2015 Mellanox Technologies 22
23 UCX Performance 2015 Mellanox Technologies 23
24 Mellanox Multi-Host Technology Next Generation Data Center Architecture 2015 Mellanox Technologies 24


25 New Compute Rack / Data Center Architecture NIC CPU Scalable Data Center with Multi-Host Flexible, configurable, application optimized Optimized top-of-rack switches Takes advantage of high-throughput network Server Traditional Data Center Expensive design for fixed data centers Requires many ports on top-of-rack switch Dedicated NIC / cable per server CPU Slots NIC Server The Network is The Computer 2015 Mellanox Technologies 25

26 Multi-Host Dramatically Reduces Server Cost Traditional 4-Way SMP Machine CPU CPU Proprietary Cache Coherent Bus Multi-Host 4-Socket Architecture CPU CPU CPU CPU CPU CPU Modern CPUs with 8-20 cores don t require expensive SMP architectures. Additional parallelism achieved with higher level network based distributed programming techniques such as Hadoop Map-Reduce Expensive 4-Way CPU Massive but unused cache-coherent domain High overhead but un-necessary CPU bus High pin count,high power, complex layout Asymmetric (NUMA) of data access Low cost single-socket CPU Clean, simple, cost-effective, software transparent Cache coherent domain: Multi-Core CPU Eliminates pins, Lower power, Simpler layout Symmetric Data Access 2015 Mellanox Technologies 26









27 ConnectX-4 on Facebook OCP Multi-Host Platform (Yosemite) ConnectX-4 Multi-Host Adapter Compute Slots The Next Generation Compute and Storage Rack Design 2015 Mellanox Technologies 27
28 Summary Paving the Road to Exascale Computing 2015 Mellanox Technologies 28
29 End-to-End Interconnect Solutions for All Platforms Highest Performance and Scalability for X86, Power, GPU, ARM and FPGA-based Compute and Storage Platforms 10, 20, 25, 40, 50, 56 and 100Gb/s Speeds X86 Open POWER GPU ARM FPGA Smart Interconnect to Unleash The Power of All Compute Architectures 2015 Mellanox Technologies 29



30 Technology Roadmap One-Generation Lead over the Competition Mellanox 20Gbs 40Gbs 56Gbs 100Gbs 200Gbs Terascale Petascale Exascale 3 rd TOP Virginia Tech (Apple) 1 st Roadrunner Mellanox Connected Mellanox Technologies 30
31 Thank You
MELLANOX EDR UPDATE & GPUDIRECT MELLANOX SR. SE 정연구
 MELLANOX EDR UPDATE & GPUDIRECT MELLANOX SR. SE 정연구 Leading Supplier of End-to-End Interconnect Solutions Analyze Enabling the Use of Data Store ICs Comprehensive End-to-End InfiniBand and Ethernet Portfolio
MELLANOX EDR UPDATE & GPUDIRECT MELLANOX SR. SE 정연구 Leading Supplier of End-to-End Interconnect Solutions Analyze Enabling the Use of Data Store ICs Comprehensive End-to-End InfiniBand and Ethernet Portfolio
Interconnect Your Future
 Interconnect Your Future Gilad Shainer 2nd Annual MVAPICH User Group (MUG) Meeting, August 2014 Complete High-Performance Scalable Interconnect Infrastructure Comprehensive End-to-End Software Accelerators
Interconnect Your Future Gilad Shainer 2nd Annual MVAPICH User Group (MUG) Meeting, August 2014 Complete High-Performance Scalable Interconnect Infrastructure Comprehensive End-to-End Software Accelerators
High Performance Computing
 High Performance Computing Dror Goldenberg, HPCAC Switzerland Conference March 2015 End-to-End Interconnect Solutions for All Platforms Highest Performance and Scalability for X86, Power, GPU, ARM and
High Performance Computing Dror Goldenberg, HPCAC Switzerland Conference March 2015 End-to-End Interconnect Solutions for All Platforms Highest Performance and Scalability for X86, Power, GPU, ARM and
Interconnect Your Future
 Interconnect Your Future Smart Interconnect for Next Generation HPC Platforms Gilad Shainer, August 2016, 4th Annual MVAPICH User Group (MUG) Meeting Mellanox Connects the World s Fastest Supercomputer
Interconnect Your Future Smart Interconnect for Next Generation HPC Platforms Gilad Shainer, August 2016, 4th Annual MVAPICH User Group (MUG) Meeting Mellanox Connects the World s Fastest Supercomputer
Interconnect Your Future
 #OpenPOWERSummit Interconnect Your Future Scot Schultz, Director HPC / Technical Computing Mellanox Technologies OpenPOWER Summit, San Jose CA March 2015 One-Generation Lead over the Competition Mellanox
#OpenPOWERSummit Interconnect Your Future Scot Schultz, Director HPC / Technical Computing Mellanox Technologies OpenPOWER Summit, San Jose CA March 2015 One-Generation Lead over the Competition Mellanox
In-Network Computing. Paving the Road to Exascale. 5th Annual MVAPICH User Group (MUG) Meeting, August 2017
 Meeting, August 2017") In-Network Computing Paving the Road to Exascale 5th Annual MVAPICH User Group (MUG) Meeting, August 2017 Exponential Data Growth The Need for Intelligent and Faster Interconnect CPU-Centric (Onload) Data-Centric
In-Network Computing Paving the Road to Exascale 5th Annual MVAPICH User Group (MUG) Meeting, August 2017 Exponential Data Growth The Need for Intelligent and Faster Interconnect CPU-Centric (Onload) Data-Centric
The Future of High Performance Interconnects
 The Future of High Performance Interconnects Ashrut Ambastha HPC Advisory Council Perth, Australia :: August 2017 When Algorithms Go Rogue 2017 Mellanox Technologies 2 When Algorithms Go Rogue 2017 Mellanox
The Future of High Performance Interconnects Ashrut Ambastha HPC Advisory Council Perth, Australia :: August 2017 When Algorithms Go Rogue 2017 Mellanox Technologies 2 When Algorithms Go Rogue 2017 Mellanox
Interconnect Your Future
 Interconnect Your Future Paving the Road to Exascale August 2017 Exponential Data Growth The Need for Intelligent and Faster Interconnect CPU-Centric (Onload) Data-Centric (Offload) Must Wait for the Data
Interconnect Your Future Paving the Road to Exascale August 2017 Exponential Data Growth The Need for Intelligent and Faster Interconnect CPU-Centric (Onload) Data-Centric (Offload) Must Wait for the Data
Solutions for Scalable HPC
 Solutions for Scalable HPC Scot Schultz, Director HPC/Technical Computing HPC Advisory Council Stanford Conference Feb 2014 Leading Supplier of End-to-End Interconnect Solutions Comprehensive End-to-End
Solutions for Scalable HPC Scot Schultz, Director HPC/Technical Computing HPC Advisory Council Stanford Conference Feb 2014 Leading Supplier of End-to-End Interconnect Solutions Comprehensive End-to-End
Interconnect Your Future Enabling the Best Datacenter Return on Investment. TOP500 Supercomputers, November 2017
 Interconnect Your Future Enabling the Best Datacenter Return on Investment TOP500 Supercomputers, November 2017 InfiniBand Accelerates Majority of New Systems on TOP500 InfiniBand connects 77% of new HPC
Interconnect Your Future Enabling the Best Datacenter Return on Investment TOP500 Supercomputers, November 2017 InfiniBand Accelerates Majority of New Systems on TOP500 InfiniBand connects 77% of new HPC
UCX: An Open Source Framework for HPC Network APIs and Beyond
 UCX: An Open Source Framework for HPC Network APIs and Beyond Presented by: Pavel Shamis / Pasha ORNL is managed by UT-Battelle for the US Department of Energy Co-Design Collaboration The Next Generation
UCX: An Open Source Framework for HPC Network APIs and Beyond Presented by: Pavel Shamis / Pasha ORNL is managed by UT-Battelle for the US Department of Energy Co-Design Collaboration The Next Generation
Interconnect Your Future
 Interconnect Your Future Paving the Path to Exascale November 2017 Mellanox Accelerates Leading HPC and AI Systems Summit CORAL System Sierra CORAL System Fastest Supercomputer in Japan Fastest Supercomputer
Interconnect Your Future Paving the Path to Exascale November 2017 Mellanox Accelerates Leading HPC and AI Systems Summit CORAL System Sierra CORAL System Fastest Supercomputer in Japan Fastest Supercomputer
The Future of Interconnect Technology
 The Future of Interconnect Technology Michael Kagan, CTO HPC Advisory Council Stanford, 2014 Exponential Data Growth Best Interconnect Required 44X 0.8 Zetabyte 2009 35 Zetabyte 2020 2014 Mellanox Technologies
The Future of Interconnect Technology Michael Kagan, CTO HPC Advisory Council Stanford, 2014 Exponential Data Growth Best Interconnect Required 44X 0.8 Zetabyte 2009 35 Zetabyte 2020 2014 Mellanox Technologies
Building the Most Efficient Machine Learning System
 Building the Most Efficient Machine Learning System Mellanox The Artificial Intelligence Interconnect Company June 2017 Mellanox Overview Company Headquarters Yokneam, Israel Sunnyvale, California Worldwide
Building the Most Efficient Machine Learning System Mellanox The Artificial Intelligence Interconnect Company June 2017 Mellanox Overview Company Headquarters Yokneam, Israel Sunnyvale, California Worldwide
Building the Most Efficient Machine Learning System
 Building the Most Efficient Machine Learning System Mellanox The Artificial Intelligence Interconnect Company June 2017 Mellanox Overview Company Headquarters Yokneam, Israel Sunnyvale, California Worldwide
Building the Most Efficient Machine Learning System Mellanox The Artificial Intelligence Interconnect Company June 2017 Mellanox Overview Company Headquarters Yokneam, Israel Sunnyvale, California Worldwide
Unified Communication X (UCX)
") Unified Communication X (UCX) Pavel Shamis / Pasha ARM Research SC 18 UCF Consortium Mission: Collaboration between industry, laboratories, and academia to create production grade communication frameworks
Unified Communication X (UCX) Pavel Shamis / Pasha ARM Research SC 18 UCF Consortium Mission: Collaboration between industry, laboratories, and academia to create production grade communication frameworks
In-Network Computing. Paving the Road to Exascale. June 2017
 In-Network Computing Paving the Road to Exascale June 2017 Exponential Data Growth The Need for Intelligent and Faster Interconnect -Centric (Onload) Data-Centric (Offload) Must Wait for the Data Creates
In-Network Computing Paving the Road to Exascale June 2017 Exponential Data Growth The Need for Intelligent and Faster Interconnect -Centric (Onload) Data-Centric (Offload) Must Wait for the Data Creates
Paving the Road to Exascale Computing. Yossi Avni
 Paving the Road to Exascale Computing Yossi Avni HPC@mellanox.com Connectivity Solutions for Efficient Computing Enterprise HPC High-end HPC HPC Clouds ICs Mellanox Interconnect Networking Solutions Adapter
Paving the Road to Exascale Computing Yossi Avni HPC@mellanox.com Connectivity Solutions for Efficient Computing Enterprise HPC High-end HPC HPC Clouds ICs Mellanox Interconnect Networking Solutions Adapter
In-Network Computing. Sebastian Kalcher, Senior System Engineer HPC. May 2017
 In-Network Computing Sebastian Kalcher, Senior System Engineer HPC May 2017 Exponential Data Growth The Need for Intelligent and Faster Interconnect CPU-Centric (Onload) Data-Centric (Offload) Must Wait
In-Network Computing Sebastian Kalcher, Senior System Engineer HPC May 2017 Exponential Data Growth The Need for Intelligent and Faster Interconnect CPU-Centric (Onload) Data-Centric (Offload) Must Wait
Interconnect Your Future Paving the Road to Exascale
 Interconnect Your Future Paving the Road to Exascale CHPC, December 2017 90% of the World Data was Created in the Last 2 Years 2017 Mellanox Technologies 2 The Future Depends on Fastest Interconnects 1Gb/s
Interconnect Your Future Paving the Road to Exascale CHPC, December 2017 90% of the World Data was Created in the Last 2 Years 2017 Mellanox Technologies 2 The Future Depends on Fastest Interconnects 1Gb/s
2008 International ANSYS Conference
 2008 International ANSYS Conference Maximizing Productivity With InfiniBand-Based Clusters Gilad Shainer Director of Technical Marketing Mellanox Technologies 2008 ANSYS, Inc. All rights reserved. 1 ANSYS,
2008 International ANSYS Conference Maximizing Productivity With InfiniBand-Based Clusters Gilad Shainer Director of Technical Marketing Mellanox Technologies 2008 ANSYS, Inc. All rights reserved. 1 ANSYS,
The Road to ExaScale. Advances in High-Performance Interconnect Infrastructure. September 2011
 The Road to ExaScale Advances in High-Performance Interconnect Infrastructure September 2011 diego@mellanox.com ExaScale Computing Ambitious Challenges Foster Progress Demand Research Institutes, Universities
The Road to ExaScale Advances in High-Performance Interconnect Infrastructure September 2011 diego@mellanox.com ExaScale Computing Ambitious Challenges Foster Progress Demand Research Institutes, Universities
Birds of a Feather Presentation
 Mellanox InfiniBand QDR 4Gb/s The Fabric of Choice for High Performance Computing Gilad Shainer, shainer@mellanox.com June 28 Birds of a Feather Presentation InfiniBand Technology Leadership Industry Standard
Mellanox InfiniBand QDR 4Gb/s The Fabric of Choice for High Performance Computing Gilad Shainer, shainer@mellanox.com June 28 Birds of a Feather Presentation InfiniBand Technology Leadership Industry Standard
VPI / InfiniBand. Performance Accelerated Mellanox InfiniBand Adapters Provide Advanced Data Center Performance, Efficiency and Scalability
 VPI / InfiniBand Performance Accelerated Mellanox InfiniBand Adapters Provide Advanced Data Center Performance, Efficiency and Scalability Mellanox enables the highest data center performance with its
VPI / InfiniBand Performance Accelerated Mellanox InfiniBand Adapters Provide Advanced Data Center Performance, Efficiency and Scalability Mellanox enables the highest data center performance with its
Performance Accelerated Mellanox InfiniBand Adapters Provide Advanced Data Center Performance, Efficiency and Scalability
 Performance Accelerated Mellanox InfiniBand Adapters Provide Advanced Data Center Performance, Efficiency and Scalability Mellanox InfiniBand Host Channel Adapters (HCA) enable the highest data center
Performance Accelerated Mellanox InfiniBand Adapters Provide Advanced Data Center Performance, Efficiency and Scalability Mellanox InfiniBand Host Channel Adapters (HCA) enable the highest data center
VPI / InfiniBand. Performance Accelerated Mellanox InfiniBand Adapters Provide Advanced Data Center Performance, Efficiency and Scalability
 VPI / InfiniBand Performance Accelerated Mellanox InfiniBand Adapters Provide Advanced Data Center Performance, Efficiency and Scalability Mellanox enables the highest data center performance with its
VPI / InfiniBand Performance Accelerated Mellanox InfiniBand Adapters Provide Advanced Data Center Performance, Efficiency and Scalability Mellanox enables the highest data center performance with its
InfiniBand Strengthens Leadership as the Interconnect Of Choice By Providing Best Return on Investment. TOP500 Supercomputers, June 2014
 InfiniBand Strengthens Leadership as the Interconnect Of Choice By Providing Best Return on Investment TOP500 Supercomputers, June 2014 TOP500 Performance Trends 38% CAGR 78% CAGR Explosive high-performance
InfiniBand Strengthens Leadership as the Interconnect Of Choice By Providing Best Return on Investment TOP500 Supercomputers, June 2014 TOP500 Performance Trends 38% CAGR 78% CAGR Explosive high-performance
Future Routing Schemes in Petascale clusters
 Future Routing Schemes in Petascale clusters Gilad Shainer, Mellanox, USA Ola Torudbakken, Sun Microsystems, Norway Richard Graham, Oak Ridge National Laboratory, USA Birds of a Feather Presentation Abstract
Future Routing Schemes in Petascale clusters Gilad Shainer, Mellanox, USA Ola Torudbakken, Sun Microsystems, Norway Richard Graham, Oak Ridge National Laboratory, USA Birds of a Feather Presentation Abstract
Performance Optimizations via Connect-IB and Dynamically Connected Transport Service for Maximum Performance on LS-DYNA
 Performance Optimizations via Connect-IB and Dynamically Connected Transport Service for Maximum Performance on LS-DYNA Pak Lui, Gilad Shainer, Brian Klaff Mellanox Technologies Abstract From concept to
Performance Optimizations via Connect-IB and Dynamically Connected Transport Service for Maximum Performance on LS-DYNA Pak Lui, Gilad Shainer, Brian Klaff Mellanox Technologies Abstract From concept to
The Exascale Architecture
 The Exascale Architecture Richard Graham HPC Advisory Council China 2013 Overview Programming-model challenges for Exascale Challenges for scaling MPI to Exascale InfiniBand enhancements Dynamically Connected
The Exascale Architecture Richard Graham HPC Advisory Council China 2013 Overview Programming-model challenges for Exascale Challenges for scaling MPI to Exascale InfiniBand enhancements Dynamically Connected
IBM CORAL HPC System Solution
 IBM CORAL HPC System Solution HPC and HPDA towards Cognitive, AI and Deep Learning Deep Learning AI / Deep Learning Strategy for Power Power AI Platform High Performance Data Analytics Big Data Strategy
IBM CORAL HPC System Solution HPC and HPDA towards Cognitive, AI and Deep Learning Deep Learning AI / Deep Learning Strategy for Power Power AI Platform High Performance Data Analytics Big Data Strategy
Application Acceleration Beyond Flash Storage
 Application Acceleration Beyond Flash Storage Session 303C Mellanox Technologies Flash Memory Summit July 2014 Accelerating Applications, Step-by-Step First Steps Make compute fast Moore s Law Make storage
Application Acceleration Beyond Flash Storage Session 303C Mellanox Technologies Flash Memory Summit July 2014 Accelerating Applications, Step-by-Step First Steps Make compute fast Moore s Law Make storage
Maximizing Cluster Scalability for LS-DYNA
 Maximizing Cluster Scalability for LS-DYNA Pak Lui 1, David Cho 1, Gerald Lotto 1, Gilad Shainer 1 1 Mellanox Technologies, Inc. Sunnyvale, CA, USA 1 Abstract High performance network interconnect is an
Maximizing Cluster Scalability for LS-DYNA Pak Lui 1, David Cho 1, Gerald Lotto 1, Gilad Shainer 1 1 Mellanox Technologies, Inc. Sunnyvale, CA, USA 1 Abstract High performance network interconnect is an
The Effect of In-Network Computing-Capable Interconnects on the Scalability of CAE Simulations
 The Effect of In-Network Computing-Capable Interconnects on the Scalability of CAE Simulations Ophir Maor HPC Advisory Council ophir@hpcadvisorycouncil.com The HPC-AI Advisory Council World-wide HPC non-profit
The Effect of In-Network Computing-Capable Interconnects on the Scalability of CAE Simulations Ophir Maor HPC Advisory Council ophir@hpcadvisorycouncil.com The HPC-AI Advisory Council World-wide HPC non-profit
Mellanox Technologies Maximize Cluster Performance and Productivity. Gilad Shainer, October, 2007
 Mellanox Technologies Maximize Cluster Performance and Productivity Gilad Shainer, shainer@mellanox.com October, 27 Mellanox Technologies Hardware OEMs Servers And Blades Applications End-Users Enterprise
Mellanox Technologies Maximize Cluster Performance and Productivity Gilad Shainer, shainer@mellanox.com October, 27 Mellanox Technologies Hardware OEMs Servers And Blades Applications End-Users Enterprise
Ethernet. High-Performance Ethernet Adapter Cards
 High-Performance Ethernet Adapter Cards Supporting Virtualization, Overlay Networks, CPU Offloads and RDMA over Converged Ethernet (RoCE), and Enabling Data Center Efficiency and Scalability Ethernet Mellanox
High-Performance Ethernet Adapter Cards Supporting Virtualization, Overlay Networks, CPU Offloads and RDMA over Converged Ethernet (RoCE), and Enabling Data Center Efficiency and Scalability Ethernet Mellanox
Messaging Overview. Introduction. Gen-Z Messaging
 Page 1 of 6 Messaging Overview Introduction Gen-Z is a new data access technology that not only enhances memory and data storage solutions, but also provides a framework for both optimized and traditional
Page 1 of 6 Messaging Overview Introduction Gen-Z is a new data access technology that not only enhances memory and data storage solutions, but also provides a framework for both optimized and traditional
LAMMPS-KOKKOS Performance Benchmark and Profiling. September 2015
 LAMMPS-KOKKOS Performance Benchmark and Profiling September 2015 2 Note The following research was performed under the HPC Advisory Council activities Participating vendors: Intel, Dell, Mellanox, NVIDIA
LAMMPS-KOKKOS Performance Benchmark and Profiling September 2015 2 Note The following research was performed under the HPC Advisory Council activities Participating vendors: Intel, Dell, Mellanox, NVIDIA
NAMD Performance Benchmark and Profiling. January 2015
 NAMD Performance Benchmark and Profiling January 2015 2 Note The following research was performed under the HPC Advisory Council activities Participating vendors: Intel, Dell, Mellanox Compute resource
NAMD Performance Benchmark and Profiling January 2015 2 Note The following research was performed under the HPC Advisory Council activities Participating vendors: Intel, Dell, Mellanox Compute resource
Gen-Z Memory-Driven Computing
 Gen-Z Memory-Driven Computing Our vision for the future of computing Patrick Demichel Distinguished Technologist Explosive growth of data More Data Need answers FAST! Value of Analyzed Data 2005 0.1ZB
Gen-Z Memory-Driven Computing Our vision for the future of computing Patrick Demichel Distinguished Technologist Explosive growth of data More Data Need answers FAST! Value of Analyzed Data 2005 0.1ZB
The Impact of Inter-node Latency versus Intra-node Latency on HPC Applications The 23 rd IASTED International Conference on PDCS 2011
 The Impact of Inter-node Latency versus Intra-node Latency on HPC Applications The 23 rd IASTED International Conference on PDCS 2011 HPC Scale Working Group, Dec 2011 Gilad Shainer, Pak Lui, Tong Liu,
The Impact of Inter-node Latency versus Intra-node Latency on HPC Applications The 23 rd IASTED International Conference on PDCS 2011 HPC Scale Working Group, Dec 2011 Gilad Shainer, Pak Lui, Tong Liu,
UCX: An Open Source Framework for HPC Network APIs and Beyond
 UCX: An Open Source Framework for HPC Network APIs and Beyond Pavel Shamis, Manjunath Gorentla Venkata, M. Graham Lopez, Matthew B. Baker, Oscar Hernandez, Yossi Itigin, Mike Dubman, Gilad Shainer, Richard
UCX: An Open Source Framework for HPC Network APIs and Beyond Pavel Shamis, Manjunath Gorentla Venkata, M. Graham Lopez, Matthew B. Baker, Oscar Hernandez, Yossi Itigin, Mike Dubman, Gilad Shainer, Richard
ROCm: An open platform for GPU computing exploration
 UCX-ROCm: ROCm Integration into UCX {Khaled Hamidouche, Brad Benton}@AMD Research ROCm: An open platform for GPU computing exploration 1 JUNE, 2018 ISC ROCm Software Platform An Open Source foundation
UCX-ROCm: ROCm Integration into UCX {Khaled Hamidouche, Brad Benton}@AMD Research ROCm: An open platform for GPU computing exploration 1 JUNE, 2018 ISC ROCm Software Platform An Open Source foundation
Accelerating Ceph with Flash and High Speed Networks
 Accelerating Ceph with Flash and High Speed Networks Dror Goldenberg VP Software Architecture Santa Clara, CA 1 The New Open Cloud Era Compute Software Defined Network Object, Block Software Defined Storage
Accelerating Ceph with Flash and High Speed Networks Dror Goldenberg VP Software Architecture Santa Clara, CA 1 The New Open Cloud Era Compute Software Defined Network Object, Block Software Defined Storage
Chelsio Communications. Meeting Today s Datacenter Challenges. Produced by Tabor Custom Publishing in conjunction with: CUSTOM PUBLISHING
 Meeting Today s Datacenter Challenges Produced by Tabor Custom Publishing in conjunction with: 1 Introduction In this era of Big Data, today s HPC systems are faced with unprecedented growth in the complexity
Meeting Today s Datacenter Challenges Produced by Tabor Custom Publishing in conjunction with: 1 Introduction In this era of Big Data, today s HPC systems are faced with unprecedented growth in the complexity
Preparing GPU-Accelerated Applications for the Summit Supercomputer
 Preparing GPU-Accelerated Applications for the Summit Supercomputer Fernanda Foertter HPC User Assistance Group Training Lead foertterfs@ornl.gov This research used resources of the Oak Ridge Leadership
Preparing GPU-Accelerated Applications for the Summit Supercomputer Fernanda Foertter HPC User Assistance Group Training Lead foertterfs@ornl.gov This research used resources of the Oak Ridge Leadership
High Performance Interconnects: Landscape, Assessments & Rankings
 High Performance Interconnects: Landscape, Assessments & Rankings Dan Olds Partner, OrionX April 12, 2017 Specialized 100G InfiniBand MPI Multi-Rack OPA Single-Rack HPI market segment 100G 40G 10G TCP/IP
High Performance Interconnects: Landscape, Assessments & Rankings Dan Olds Partner, OrionX April 12, 2017 Specialized 100G InfiniBand MPI Multi-Rack OPA Single-Rack HPI market segment 100G 40G 10G TCP/IP
N V M e o v e r F a b r i c s -
 N V M e o v e r F a b r i c s - H i g h p e r f o r m a n c e S S D s n e t w o r k e d f o r c o m p o s a b l e i n f r a s t r u c t u r e Rob Davis, VP Storage Technology, Mellanox OCP Evolution Server
N V M e o v e r F a b r i c s - H i g h p e r f o r m a n c e S S D s n e t w o r k e d f o r c o m p o s a b l e i n f r a s t r u c t u r e Rob Davis, VP Storage Technology, Mellanox OCP Evolution Server
MM5 Modeling System Performance Research and Profiling. March 2009
 MM5 Modeling System Performance Research and Profiling March 2009 Note The following research was performed under the HPC Advisory Council activities AMD, Dell, Mellanox HPC Advisory Council Cluster Center
MM5 Modeling System Performance Research and Profiling March 2009 Note The following research was performed under the HPC Advisory Council activities AMD, Dell, Mellanox HPC Advisory Council Cluster Center
InfiniBand Strengthens Leadership as The High-Speed Interconnect Of Choice
 InfiniBand Strengthens Leadership as The High-Speed Interconnect Of Choice Providing the Best Return on Investment by Delivering the Highest System Efficiency and Utilization Top500 Supercomputers June
InfiniBand Strengthens Leadership as The High-Speed Interconnect Of Choice Providing the Best Return on Investment by Delivering the Highest System Efficiency and Utilization Top500 Supercomputers June
EC-Bench: Benchmarking Onload and Offload Erasure Coders on Modern Hardware Architectures
 EC-Bench: Benchmarking Onload and Offload Erasure Coders on Modern Hardware Architectures Haiyang Shi, Xiaoyi Lu, and Dhabaleswar K. (DK) Panda {shi.876, lu.932, panda.2}@osu.edu The Ohio State University
EC-Bench: Benchmarking Onload and Offload Erasure Coders on Modern Hardware Architectures Haiyang Shi, Xiaoyi Lu, and Dhabaleswar K. (DK) Panda {shi.876, lu.932, panda.2}@osu.edu The Ohio State University
Design challenges of Highperformance. MPI over InfiniBand. Presented by Karthik
 Design challenges of Highperformance and Scalable MPI over InfiniBand Presented by Karthik Presentation Overview In depth analysis of High-Performance and scalable MPI with Reduced Memory Usage Zero Copy
Design challenges of Highperformance and Scalable MPI over InfiniBand Presented by Karthik Presentation Overview In depth analysis of High-Performance and scalable MPI with Reduced Memory Usage Zero Copy
IO virtualization. Michael Kagan Mellanox Technologies
 IO virtualization Michael Kagan Mellanox Technologies IO Virtualization Mission non-stop s to consumers Flexibility assign IO resources to consumer as needed Agility assignment of IO resources to consumer
IO virtualization Michael Kagan Mellanox Technologies IO Virtualization Mission non-stop s to consumers Flexibility assign IO resources to consumer as needed Agility assignment of IO resources to consumer
2-Port 40 Gb InfiniBand Expansion Card (CFFh) for IBM BladeCenter IBM BladeCenter at-a-glance guide
 for IBM BladeCenter IBM BladeCenter at-a-glance guide") 2-Port 40 Gb InfiniBand Expansion Card (CFFh) for IBM BladeCenter IBM BladeCenter at-a-glance guide The 2-Port 40 Gb InfiniBand Expansion Card (CFFh) for IBM BladeCenter is a dual port InfiniBand Host
2-Port 40 Gb InfiniBand Expansion Card (CFFh) for IBM BladeCenter IBM BladeCenter at-a-glance guide The 2-Port 40 Gb InfiniBand Expansion Card (CFFh) for IBM BladeCenter is a dual port InfiniBand Host
Mapping MPI+X Applications to Multi-GPU Architectures
 Mapping MPI+X Applications to Multi-GPU Architectures A Performance-Portable Approach Edgar A. León Computer Scientist San Jose, CA March 28, 2018 GPU Technology Conference This work was performed under
Mapping MPI+X Applications to Multi-GPU Architectures A Performance-Portable Approach Edgar A. León Computer Scientist San Jose, CA March 28, 2018 GPU Technology Conference This work was performed under
Oncilla - a Managed GAS Runtime for Accelerating Data Warehousing Queries
 Oncilla - a Managed GAS Runtime for Accelerating Data Warehousing Queries Jeffrey Young, Alex Merritt, Se Hoon Shon Advisor: Sudhakar Yalamanchili 4/16/13 Sponsors: Intel, NVIDIA, NSF 2 The Problem Big
Oncilla - a Managed GAS Runtime for Accelerating Data Warehousing Queries Jeffrey Young, Alex Merritt, Se Hoon Shon Advisor: Sudhakar Yalamanchili 4/16/13 Sponsors: Intel, NVIDIA, NSF 2 The Problem Big
Enabling Efficient Use of UPC and OpenSHMEM PGAS models on GPU Clusters
 Enabling Efficient Use of UPC and OpenSHMEM PGAS models on GPU Clusters Presentation at GTC 2014 by Dhabaleswar K. (DK) Panda The Ohio State University E-mail: panda@cse.ohio-state.edu http://www.cse.ohio-state.edu/~panda
Enabling Efficient Use of UPC and OpenSHMEM PGAS models on GPU Clusters Presentation at GTC 2014 by Dhabaleswar K. (DK) Panda The Ohio State University E-mail: panda@cse.ohio-state.edu http://www.cse.ohio-state.edu/~panda
Introduction to Infiniband
 Introduction to Infiniband FRNOG 22, April 4 th 2014 Yael Shenhav, Sr. Director of EMEA, APAC FAE, Application Engineering The InfiniBand Architecture Industry standard defined by the InfiniBand Trade
Introduction to Infiniband FRNOG 22, April 4 th 2014 Yael Shenhav, Sr. Director of EMEA, APAC FAE, Application Engineering The InfiniBand Architecture Industry standard defined by the InfiniBand Trade
ABySS Performance Benchmark and Profiling. May 2010
 ABySS Performance Benchmark and Profiling May 2010 Note The following research was performed under the HPC Advisory Council activities Participating vendors: AMD, Dell, Mellanox Compute resource - HPC
ABySS Performance Benchmark and Profiling May 2010 Note The following research was performed under the HPC Advisory Council activities Participating vendors: AMD, Dell, Mellanox Compute resource - HPC
High Performance MPI on IBM 12x InfiniBand Architecture
 High Performance MPI on IBM 12x InfiniBand Architecture Abhinav Vishnu, Brad Benton 1 and Dhabaleswar K. Panda {vishnu, panda} @ cse.ohio-state.edu {brad.benton}@us.ibm.com 1 1 Presentation Road-Map Introduction
High Performance MPI on IBM 12x InfiniBand Architecture Abhinav Vishnu, Brad Benton 1 and Dhabaleswar K. Panda {vishnu, panda} @ cse.ohio-state.edu {brad.benton}@us.ibm.com 1 1 Presentation Road-Map Introduction
GROMACS (GPU) Performance Benchmark and Profiling. February 2016
 Performance Benchmark and Profiling. February 2016") GROMACS (GPU) Performance Benchmark and Profiling February 2016 2 Note The following research was performed under the HPC Advisory Council activities Participating vendors: Dell, Mellanox, NVIDIA Compute
GROMACS (GPU) Performance Benchmark and Profiling February 2016 2 Note The following research was performed under the HPC Advisory Council activities Participating vendors: Dell, Mellanox, NVIDIA Compute
OPEN MPI WITH RDMA SUPPORT AND CUDA. Rolf vandevaart, NVIDIA
 OPEN MPI WITH RDMA SUPPORT AND CUDA Rolf vandevaart, NVIDIA OVERVIEW What is CUDA-aware History of CUDA-aware support in Open MPI GPU Direct RDMA support Tuning parameters Application example Future work
OPEN MPI WITH RDMA SUPPORT AND CUDA Rolf vandevaart, NVIDIA OVERVIEW What is CUDA-aware History of CUDA-aware support in Open MPI GPU Direct RDMA support Tuning parameters Application example Future work
IBM Power Advanced Compute (AC) AC922 Server
 AC922 Server") IBM Power Advanced Compute (AC) AC922 Server The Best Server for Enterprise AI Highlights IBM Power Systems Accelerated Compute (AC922) server is an acceleration superhighway to enterprise- class AI. A
IBM Power Advanced Compute (AC) AC922 Server The Best Server for Enterprise AI Highlights IBM Power Systems Accelerated Compute (AC922) server is an acceleration superhighway to enterprise- class AI. A
Corporate Update. Enabling The Use of Data January Mellanox Technologies
 Corporate Update Enabling The Use of Data January 2018 Safe Harbor Statement These slides and the accompanying oral presentation contain forward-looking statements and information. The use of words such
Corporate Update Enabling The Use of Data January 2018 Safe Harbor Statement These slides and the accompanying oral presentation contain forward-looking statements and information. The use of words such
LS-DYNA Best-Practices: Networking, MPI and Parallel File System Effect on LS-DYNA Performance
 11 th International LS-DYNA Users Conference Computing Technology LS-DYNA Best-Practices: Networking, MPI and Parallel File System Effect on LS-DYNA Performance Gilad Shainer 1, Tong Liu 2, Jeff Layton
11 th International LS-DYNA Users Conference Computing Technology LS-DYNA Best-Practices: Networking, MPI and Parallel File System Effect on LS-DYNA Performance Gilad Shainer 1, Tong Liu 2, Jeff Layton
RapidIO.org Update. Mar RapidIO.org 1
 RapidIO.org Update rickoco@rapidio.org Mar 2015 2015 RapidIO.org 1 Outline RapidIO Overview & Markets Data Center & HPC Communications Infrastructure Industrial Automation Military & Aerospace RapidIO.org
RapidIO.org Update rickoco@rapidio.org Mar 2015 2015 RapidIO.org 1 Outline RapidIO Overview & Markets Data Center & HPC Communications Infrastructure Industrial Automation Military & Aerospace RapidIO.org
The Stampede is Coming: A New Petascale Resource for the Open Science Community
 The Stampede is Coming: A New Petascale Resource for the Open Science Community Jay Boisseau Texas Advanced Computing Center boisseau@tacc.utexas.edu Stampede: Solicitation US National Science Foundation
The Stampede is Coming: A New Petascale Resource for the Open Science Community Jay Boisseau Texas Advanced Computing Center boisseau@tacc.utexas.edu Stampede: Solicitation US National Science Foundation
Scaling to Petaflop. Ola Torudbakken Distinguished Engineer. Sun Microsystems, Inc
 Scaling to Petaflop Ola Torudbakken Distinguished Engineer Sun Microsystems, Inc HPC Market growth is strong CAGR increased from 9.2% (2006) to 15.5% (2007) Market in 2007 doubled from 2003 (Source: IDC
Scaling to Petaflop Ola Torudbakken Distinguished Engineer Sun Microsystems, Inc HPC Market growth is strong CAGR increased from 9.2% (2006) to 15.5% (2007) Market in 2007 doubled from 2003 (Source: IDC
Accelerating Hadoop Applications with the MapR Distribution Using Flash Storage and High-Speed Ethernet
 WHITE PAPER Accelerating Hadoop Applications with the MapR Distribution Using Flash Storage and High-Speed Ethernet Contents Background... 2 The MapR Distribution... 2 Mellanox Ethernet Solution... 3 Test
WHITE PAPER Accelerating Hadoop Applications with the MapR Distribution Using Flash Storage and High-Speed Ethernet Contents Background... 2 The MapR Distribution... 2 Mellanox Ethernet Solution... 3 Test
Deep Learning mit PowerAI - Ein Überblick
 Stephen Lutz Deep Learning mit PowerAI - Open Group Master Certified IT Specialist Technical Sales IBM Cognitive Infrastructure IBM Germany Ein Überblick Stephen.Lutz@de.ibm.com What s that? and what s
Stephen Lutz Deep Learning mit PowerAI - Open Group Master Certified IT Specialist Technical Sales IBM Cognitive Infrastructure IBM Germany Ein Überblick Stephen.Lutz@de.ibm.com What s that? and what s
NAMD Performance Benchmark and Profiling. November 2010
 NAMD Performance Benchmark and Profiling November 2010 Note The following research was performed under the HPC Advisory Council activities Participating vendors: HP, Mellanox Compute resource - HPC Advisory
NAMD Performance Benchmark and Profiling November 2010 Note The following research was performed under the HPC Advisory Council activities Participating vendors: HP, Mellanox Compute resource - HPC Advisory
LAMMPSCUDA GPU Performance. April 2011
 LAMMPSCUDA GPU Performance April 2011 Note The following research was performed under the HPC Advisory Council activities Participating vendors: Dell, Intel, Mellanox Compute resource - HPC Advisory Council
LAMMPSCUDA GPU Performance April 2011 Note The following research was performed under the HPC Advisory Council activities Participating vendors: Dell, Intel, Mellanox Compute resource - HPC Advisory Council
2017 Storage Developer Conference. Mellanox Technologies. All Rights Reserved.
 Ethernet Storage Fabrics Using RDMA with Fast NVMe-oF Storage to Reduce Latency and Improve Efficiency Kevin Deierling & Idan Burstein Mellanox Technologies 1 Storage Media Technology Storage Media Access
Ethernet Storage Fabrics Using RDMA with Fast NVMe-oF Storage to Reduce Latency and Improve Efficiency Kevin Deierling & Idan Burstein Mellanox Technologies 1 Storage Media Technology Storage Media Access
By John Kim, Chair SNIA Ethernet Storage Forum. Several technology changes are collectively driving the need for faster networking speeds.
 A quiet revolutation is taking place in networking speeds for servers and storage, one that is converting 1Gb and 10 Gb connections to 25Gb, 50Gb and 100 Gb connections in order to support faster servers,
A quiet revolutation is taking place in networking speeds for servers and storage, one that is converting 1Gb and 10 Gb connections to 25Gb, 50Gb and 100 Gb connections in order to support faster servers,
A unified multicore programming model
 A unified multicore programming model Simplifying multicore migration By Sven Brehmer Abstract There are a number of different multicore architectures and programming models available, making it challenging
A unified multicore programming model Simplifying multicore migration By Sven Brehmer Abstract There are a number of different multicore architectures and programming models available, making it challenging
Exploiting Full Potential of GPU Clusters with InfiniBand using MVAPICH2-GDR
 Exploiting Full Potential of GPU Clusters with InfiniBand using MVAPICH2-GDR Presentation at Mellanox Theater () Dhabaleswar K. (DK) Panda - The Ohio State University panda@cse.ohio-state.edu Outline Communication
Exploiting Full Potential of GPU Clusters with InfiniBand using MVAPICH2-GDR Presentation at Mellanox Theater () Dhabaleswar K. (DK) Panda - The Ohio State University panda@cse.ohio-state.edu Outline Communication
Scheduling Strategies for HPC as a Service (HPCaaS) for Bio-Science Applications
 for Bio-Science Applications") Scheduling Strategies for HPC as a Service (HPCaaS) for Bio-Science Applications Sep 2009 Gilad Shainer, Tong Liu (Mellanox); Jeffrey Layton (Dell); Joshua Mora (AMD) High Performance Interconnects for
Scheduling Strategies for HPC as a Service (HPCaaS) for Bio-Science Applications Sep 2009 Gilad Shainer, Tong Liu (Mellanox); Jeffrey Layton (Dell); Joshua Mora (AMD) High Performance Interconnects for
SR-IOV Support for Virtualization on InfiniBand Clusters: Early Experience
 SR-IOV Support for Virtualization on InfiniBand Clusters: Early Experience Jithin Jose, Mingzhe Li, Xiaoyi Lu, Krishna Kandalla, Mark Arnold and Dhabaleswar K. (DK) Panda Network-Based Computing Laboratory
SR-IOV Support for Virtualization on InfiniBand Clusters: Early Experience Jithin Jose, Mingzhe Li, Xiaoyi Lu, Krishna Kandalla, Mark Arnold and Dhabaleswar K. (DK) Panda Network-Based Computing Laboratory
Introduction to High-Speed InfiniBand Interconnect
 Introduction to High-Speed InfiniBand Interconnect 2 What is InfiniBand? Industry standard defined by the InfiniBand Trade Association Originated in 1999 InfiniBand specification defines an input/output
Introduction to High-Speed InfiniBand Interconnect 2 What is InfiniBand? Industry standard defined by the InfiniBand Trade Association Originated in 1999 InfiniBand specification defines an input/output
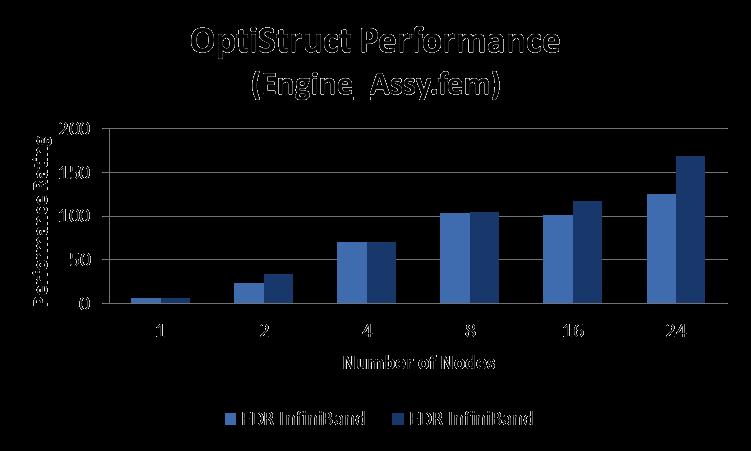
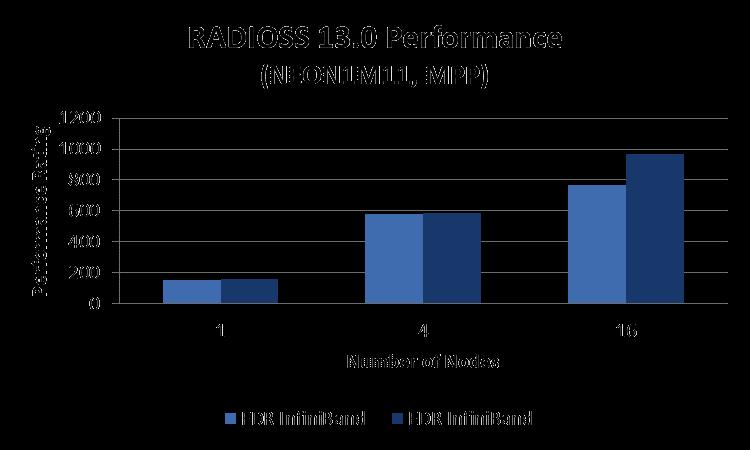
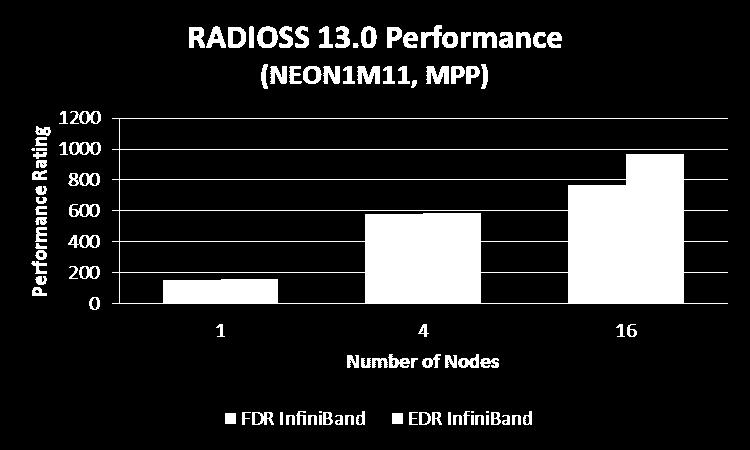
Altair OptiStruct 13.0 Performance Benchmark and Profiling. May 2015
 Altair OptiStruct 13.0 Performance Benchmark and Profiling May 2015 Note The following research was performed under the HPC Advisory Council activities Participating vendors: Intel, Dell, Mellanox Compute
Altair OptiStruct 13.0 Performance Benchmark and Profiling May 2015 Note The following research was performed under the HPC Advisory Council activities Participating vendors: Intel, Dell, Mellanox Compute
Memory Scalability Evaluation of the Next-Generation Intel Bensley Platform with InfiniBand
 Memory Scalability Evaluation of the Next-Generation Intel Bensley Platform with InfiniBand Matthew Koop, Wei Huang, Ahbinav Vishnu, Dhabaleswar K. Panda Network-Based Computing Laboratory Department of
Memory Scalability Evaluation of the Next-Generation Intel Bensley Platform with InfiniBand Matthew Koop, Wei Huang, Ahbinav Vishnu, Dhabaleswar K. Panda Network-Based Computing Laboratory Department of
Single-Points of Performance
 Single-Points of Performance Mellanox Technologies Inc. 29 Stender Way, Santa Clara, CA 9554 Tel: 48-97-34 Fax: 48-97-343 http://www.mellanox.com High-performance computations are rapidly becoming a critical
Single-Points of Performance Mellanox Technologies Inc. 29 Stender Way, Santa Clara, CA 9554 Tel: 48-97-34 Fax: 48-97-343 http://www.mellanox.com High-performance computations are rapidly becoming a critical
Gen-Z Overview. 1. Introduction. 2. Background. 3. A better way to access data. 4. Why a memory-semantic fabric
 Gen-Z Overview 1. Introduction Gen-Z is a new data access technology that will allow business and technology leaders, to overcome current challenges with the existing computer architecture and provide
Gen-Z Overview 1. Introduction Gen-Z is a new data access technology that will allow business and technology leaders, to overcome current challenges with the existing computer architecture and provide
How to Network Flash Storage Efficiently at Hyperscale. Flash Memory Summit 2017 Santa Clara, CA 1
 How to Network Flash Storage Efficiently at Hyperscale Manoj Wadekar Michael Kagan Flash Memory Summit 2017 Santa Clara, CA 1 ebay Hyper scale Infrastructure Search Front-End & Product Hadoop Object Store
How to Network Flash Storage Efficiently at Hyperscale Manoj Wadekar Michael Kagan Flash Memory Summit 2017 Santa Clara, CA 1 ebay Hyper scale Infrastructure Search Front-End & Product Hadoop Object Store
Latest Advances in MVAPICH2 MPI Library for NVIDIA GPU Clusters with InfiniBand
 Latest Advances in MVAPICH2 MPI Library for NVIDIA GPU Clusters with InfiniBand Presentation at GTC 2014 by Dhabaleswar K. (DK) Panda The Ohio State University E-mail: panda@cse.ohio-state.edu http://www.cse.ohio-state.edu/~panda
Latest Advances in MVAPICH2 MPI Library for NVIDIA GPU Clusters with InfiniBand Presentation at GTC 2014 by Dhabaleswar K. (DK) Panda The Ohio State University E-mail: panda@cse.ohio-state.edu http://www.cse.ohio-state.edu/~panda
Optimizing LS-DYNA Productivity in Cluster Environments
 10 th International LS-DYNA Users Conference Computing Technology Optimizing LS-DYNA Productivity in Cluster Environments Gilad Shainer and Swati Kher Mellanox Technologies Abstract Increasing demand for
10 th International LS-DYNA Users Conference Computing Technology Optimizing LS-DYNA Productivity in Cluster Environments Gilad Shainer and Swati Kher Mellanox Technologies Abstract Increasing demand for
MPI Optimizations via MXM and FCA for Maximum Performance on LS-DYNA
 MPI Optimizations via MXM and FCA for Maximum Performance on LS-DYNA Gilad Shainer 1, Tong Liu 1, Pak Lui 1, Todd Wilde 1 1 Mellanox Technologies Abstract From concept to engineering, and from design to
MPI Optimizations via MXM and FCA for Maximum Performance on LS-DYNA Gilad Shainer 1, Tong Liu 1, Pak Lui 1, Todd Wilde 1 1 Mellanox Technologies Abstract From concept to engineering, and from design to
OpenFabrics Interface WG A brief introduction. Paul Grun co chair OFI WG Cray, Inc.
 OpenFabrics Interface WG A brief introduction Paul Grun co chair OFI WG Cray, Inc. OFI WG a brief overview and status report 1. Keep everybody on the same page, and 2. An example of a possible model for
OpenFabrics Interface WG A brief introduction Paul Grun co chair OFI WG Cray, Inc. OFI WG a brief overview and status report 1. Keep everybody on the same page, and 2. An example of a possible model for
HPC Saudi Jeffrey A. Nichols Associate Laboratory Director Computing and Computational Sciences. Presented to: March 14, 2017
 Creating an Exascale Ecosystem for Science Presented to: HPC Saudi 2017 Jeffrey A. Nichols Associate Laboratory Director Computing and Computational Sciences March 14, 2017 ORNL is managed by UT-Battelle
Creating an Exascale Ecosystem for Science Presented to: HPC Saudi 2017 Jeffrey A. Nichols Associate Laboratory Director Computing and Computational Sciences March 14, 2017 ORNL is managed by UT-Battelle
Networking at the Speed of Light
 Networking at the Speed of Light Dror Goldenberg VP Software Architecture MaRS Workshop April 2017 Cloud The Software Defined Data Center Resource virtualization Efficient services VM, Containers uservices
Networking at the Speed of Light Dror Goldenberg VP Software Architecture MaRS Workshop April 2017 Cloud The Software Defined Data Center Resource virtualization Efficient services VM, Containers uservices
OpenPOWER Innovations for HPC. IBM Research. IWOPH workshop, ISC, Germany June 21, Christoph Hagleitner,
 IWOPH workshop, ISC, Germany June 21, 2017 OpenPOWER Innovations for HPC IBM Research Christoph Hagleitner, hle@zurich.ibm.com IBM Research - Zurich Lab IBM Research - Zurich Established in 1956 45+ different
IWOPH workshop, ISC, Germany June 21, 2017 OpenPOWER Innovations for HPC IBM Research Christoph Hagleitner, hle@zurich.ibm.com IBM Research - Zurich Lab IBM Research - Zurich Established in 1956 45+ different
SNAP Performance Benchmark and Profiling. April 2014
 SNAP Performance Benchmark and Profiling April 2014 Note The following research was performed under the HPC Advisory Council activities Participating vendors: HP, Mellanox For more information on the supporting
SNAP Performance Benchmark and Profiling April 2014 Note The following research was performed under the HPC Advisory Council activities Participating vendors: HP, Mellanox For more information on the supporting
Mellanox InfiniBand Solutions Accelerate Oracle s Data Center and Cloud Solutions
 Mellanox InfiniBand Solutions Accelerate Oracle s Data Center and Cloud Solutions Providing Superior Server and Storage Performance, Efficiency and Return on Investment As Announced and Demonstrated at
Mellanox InfiniBand Solutions Accelerate Oracle s Data Center and Cloud Solutions Providing Superior Server and Storage Performance, Efficiency and Return on Investment As Announced and Demonstrated at
Voltaire Making Applications Run Faster
 Voltaire Making Applications Run Faster Asaf Somekh Director, Marketing Voltaire, Inc. Agenda HPC Trends InfiniBand Voltaire Grid Backbone Deployment examples About Voltaire HPC Trends Clusters are the
Voltaire Making Applications Run Faster Asaf Somekh Director, Marketing Voltaire, Inc. Agenda HPC Trends InfiniBand Voltaire Grid Backbone Deployment examples About Voltaire HPC Trends Clusters are the
Université IBM i 2017
 Université IBM i 2017 17 et 18 mai IBM Client Center de Bois-Colombes S24 Architecture IBM POWER: tendances et stratégies Jeudi 18 mai 11h00-12h30 Jean-Luc Bonhommet IBM AGENDA IBM Power Systems - IBM
Université IBM i 2017 17 et 18 mai IBM Client Center de Bois-Colombes S24 Architecture IBM POWER: tendances et stratégies Jeudi 18 mai 11h00-12h30 Jean-Luc Bonhommet IBM AGENDA IBM Power Systems - IBM
How Might Recently Formed System Interconnect Consortia Affect PM? Doug Voigt, SNIA TC
 How Might Recently Formed System Interconnect Consortia Affect PM? Doug Voigt, SNIA TC Three Consortia Formed in Oct 2016 Gen-Z Open CAPI CCIX complex to rack scale memory fabric Cache coherent accelerator
How Might Recently Formed System Interconnect Consortia Affect PM? Doug Voigt, SNIA TC Three Consortia Formed in Oct 2016 Gen-Z Open CAPI CCIX complex to rack scale memory fabric Cache coherent accelerator
GPUs and Emerging Architectures
 GPUs and Emerging Architectures Mike Giles mike.giles@maths.ox.ac.uk Mathematical Institute, Oxford University e-infrastructure South Consortium Oxford e-research Centre Emerging Architectures p. 1 CPUs
GPUs and Emerging Architectures Mike Giles mike.giles@maths.ox.ac.uk Mathematical Institute, Oxford University e-infrastructure South Consortium Oxford e-research Centre Emerging Architectures p. 1 CPUs
10-Gigabit iwarp Ethernet: Comparative Performance Analysis with InfiniBand and Myrinet-10G
 10-Gigabit iwarp Ethernet: Comparative Performance Analysis with InfiniBand and Myrinet-10G Mohammad J. Rashti and Ahmad Afsahi Queen s University Kingston, ON, Canada 2007 Workshop on Communication Architectures
10-Gigabit iwarp Ethernet: Comparative Performance Analysis with InfiniBand and Myrinet-10G Mohammad J. Rashti and Ahmad Afsahi Queen s University Kingston, ON, Canada 2007 Workshop on Communication Architectures
Coupling GPUDirect RDMA and InfiniBand Hardware Multicast Technologies for Streaming Applications
 Coupling GPUDirect RDMA and InfiniBand Hardware Multicast Technologies for Streaming Applications GPU Technology Conference GTC 2016 by Dhabaleswar K. (DK) Panda The Ohio State University E-mail: panda@cse.ohio-state.edu
Coupling GPUDirect RDMA and InfiniBand Hardware Multicast Technologies for Streaming Applications GPU Technology Conference GTC 2016 by Dhabaleswar K. (DK) Panda The Ohio State University E-mail: panda@cse.ohio-state.edu
LiMIC: Support for High-Performance MPI Intra-Node Communication on Linux Cluster
 LiMIC: Support for High-Performance MPI Intra-Node Communication on Linux Cluster H. W. Jin, S. Sur, L. Chai, and D. K. Panda Network-Based Computing Laboratory Department of Computer Science and Engineering
LiMIC: Support for High-Performance MPI Intra-Node Communication on Linux Cluster H. W. Jin, S. Sur, L. Chai, and D. K. Panda Network-Based Computing Laboratory Department of Computer Science and Engineering