Chapter 2. Parallel Architectures
|
|
|
- Paula Wilkinson
- 6 years ago
- Views:
Transcription
1 Chapter 2 Parallel Architectures
2 2.1 Hardware-Architecture Flynn s Classification The most well known and simple classification scheme differentiates according to the multiplicity of instruction and data streams. The combination yields four classes: SD (single data) SI (single instruction) SISD: Von-Neumann- Computer MI (multiple instruction) MISD: Data flow machines MD (multiple data) SIMD: Vector computer, (Cray-1, CM2, MasPar, some GPUs) MIMD: Multiprocessor systems, Distributed Systems (Cray T3E, Cluster, most current computers..) 2-2
3 Flynn s Classification scheme Instructions CU ALU Instructions Data Instructions Instructions Instructions CU1 CU2 CUn Instructions Instructions Instructions ALU1 ALU2 ALUn Data Data Instructions Memory SISD CU Instructions Instructions Instructions ALU1 ALU2 ALUn Data Data Data Memory SIMD Memory MISD Instructions Instructions Instructions CU1 CU2 CUn Instructions Instructions Instructions ALU1 ALU2 ALUn Data Data Data Memory MIMD 2-3
: Access to memory module is independent of")
4 MIMD Machines a) Multiprocessor systems (shared memory systems, tightly coupled systems) All processors have access to common memory modules via a common communication network CPU1 CPU2 CPU3 CPU4 Interconnection network Memory 1 Memory 2 Memory 3 Further distinction according to the accessibility of the memory modules: uniform memory access (UMA): Access to memory module is independent of address of processor an memory module non-uniform memory access (NUMA): Memory access depends on addresses involved. 2-4

5 MIMD Machines b) Multicomputer systems (message passing systems, loosely coupled systems) Each processor has its own private memory with exclusive access Data exchange takes place by sending messages across an interconnection network. Memory 1 Memory 2 Memory 3 Memory 4 CPU1 CPU2 CPU3 CPU4 Interconnection network 2-5
6 Pragmatic Classification (Parallel Computer) Parallel Computer Cluster Computer Metacomputer Tightly Coupled Constellations Vector Pile of PCs NOW WS Farms/cycle- Stealing Beowulf NT/Windows Clusters DSM SHMEM- NUMA 2-6
7 2.2 Interconnection networks General Criteria Extendibility Arbitrary increments Performance Short paths between all processors High bandwidth Short delay Cost Proportional to number of wires and to number of access points Reliability Existence of redundant data paths Functionality Buffering Routing Group communication 2-7
8 Topological Performance Aspects Node degree Def: Number of directly connected neighbor nodes Goal : constant, small (cost, scalability) Diameter Def: Maximum path length between two arbitrary nodes Goal : small (low maximum message delay) Edge connectivity Def: Minimum number of edges to be removed in order to partition the network Goal : high (bandwidth, fault tolerance, parallelism) Bisection bandwidth Def: Minimum sum of bandwidth of all sets of edges, which partition the network in two equal halves when removed Goal: high (bandwidth, fault tolerance, parallelism) 2-8
9 2.2.1 Static Networks Connectivity spectrum of static networks Ring Hypercube Completely meshed up No. of links n n /2 log 2 n n ( n -1) / 2 Accesses/Processors 2 log 2 n n -1 Diameter n /2 log 2 n 1 2-9
10 Grid Structures 4x4-Grid 4x4-Torus Properties Constant node degree Extendibility in small increments Good support of algorithms with local communication structure (modeling of physical processes, e.g. LaPlace heat distribution) 2-10

11 Hypercube Hypercube of dimension 4 Properties: Logarithmic diameter Extendibility in powers of 2 Variable node degree Connection Machine CM
12 Trees Binary tree X-Tree Properties: Logarithmic diameter Extendibility in powers of 2 Node degree at most 3 (at most 5, respectively) Poor bisection bandwidth No parallel data paths (binary tree) 2-12

13 Fat Tree n-ary Tree Higher Capacity (factor n) closer to the root removes bottleneck 16x Connection Machine CM-5 4x 1x 2-13
14 Cube Connected Cycles CCC(d) d-dimensional Hypercube, where each node is replaced by a ring of size d. Each of these d nodes has two links in the ring and one more to one of the d hypercube dimensions Cube Connected Cycles of dimension 3 (CCC(3)) Properties: Logarithmic diameter Constant node degree (3) Extendibility only in powers of
15 Butterfly-Graph Properties: Logarithmic diameter Extendibility in powers of 2 Constant node degree
16 Overview: Properties Graph Number of nodes Number of edges Max. Node degree Diameter d 1 a2 a d a k k = 1 a Grid G( ) d k = 1 ( a 1) k i k a i 2d d ( a k 1) k= 1 a a a d Torus T( ) 1 2 d k = 1 a k d d k = 1 a k 2d d a k / 2 k = 1 Hypercube H(d) d 2 d2 d 1 d d Cube Connected Cycles CCC(d) d d 1 d2 3d2 3 2d + d /
17 2.2.2 Dynamic Interconnection networks All components have access to a joint network. Connections are switched on request. Switchable network Scheme of a dynamic network There are basically three different classes Bus Crossbar switch Multistage networks 2-17
18 Bus-like Networks cost effective blocking extendible suitable for small number of components Single bus M M M M P P P P B us Multibus for multiprocessor architecture M M M M P P P P B 1 B 2 B m 2-18
19 Crossbar switch expensive non-blocking, highly performant fixed number of access points realizable only for small networks due to quadratically growing costs M M M M M M M M P P P P P P P P Interprocessor connection P P P P P P P P Connection between processors and memory modules 2-19
20 2.2.3 Multistage Networks Small crossbar switches (e.g. 2x2) serve as cells that are connected in stages to build larger networks. Properties partially blocking extendible (a) (b) (c) (d) Elementary switching states: through (a), cross (b), upper (c) and lower (d) broadcast 2-20
21 Example: Omega-Network Target address determines selection of output for each stage (0: up, 1: down) 2-21
22 Example: Banyan-Network
23 Dynamic Networks: Properties Classes of dynamic interconnection networks with their basic properties in comparison: Bus Multistage Network Crossbar switch Latency (distance) 1 log n 1 Bandwidth per access point 1/n < 1 1 Switching cost n n log n n 2 Wiring cost 1 n log n n Asymptotic growth of cost and performance features of dynamic interconnection networks 2-23
24 2.2.4 Local Networks mostly bus-like or ring-like topologies diverse media (e.g. coaxial cable, twisted pair, optical fiber, infrared, radio) diverse protocols (e.g. IEEE (Ethernet, Fast- Ethernet, Gigabit-Ethernet), IEEE (Token-Ring), FDDI, ATM, IEEE (Wlan/WiFi), IEEE (Bluetooth), IEEE (WiMAX)) compute nodes typically heterogeneous regarding performance manufacturer operating system mostly hierarchical heterogeneous structure of subnetworks (structured networks) 2-24
25 Typical Intranet print and other servers Web server Local area network server Desktop computers server File server the rest of the Internet router/firewall print other servers 2-25
. The component computer nodes can but need not to be spatially tightly coupled.")
26 2.3 Cluster Architectures A Cluster is the collection of usually complete autonomous computers (Workstations, PCs) to build a parallel computer. (Some cluster nodes share infrastructure such as power supply, case, fans). The component computer nodes can but need not to be spatially tightly coupled. The coupling is realized by a high speed network. Networks (typically) used: Ethernet (Fast, Gigabit, 10 Gigabit, ) Myrinet SCI (Scalable Coherent Interface) Infiniband Source: Supermicro 2-26
27 Linux-Cluster (History) 1995 Beowulf-Cluster (NASA) PentiumPro/II as nodes, FastEthernet, MPI 1997 Avalon (Los Alamos) 70 Alpha-Processors 1998 Ad-hoc-Cluster of 560 nodes for one night (Paderborn) 1999 Siemens hpcline 192 Pentium II (Paderborn) 2000 Cplant-Cluster (Sandia National Laboratories) 1000 Alpha-Prozessoren 2001 Locus Supercluster 1416 Prozessoren 2002 Linux NetworX 2304 Prozessoren (Xeon). 2-27


28 Avalon-Cluster (Los Alamos Nat. Lab.) 140 Alpha-Processors 2-28


29 World record 1998: 560 nodes running Linux WDR-Computer night 1998, HNF / Uni Paderborn Spontaneously connected heterogeneous cluster of private PCs brought by visitors. Network: Gigabit-/Fast Ethernet 2-29



30 Supercomputer (Cluster) ASCI White ASCI Q ASCI Blue Pacific 2-30
31 Networks for Cluster Fast Ethernet Bandwidth: 100 Mb/s Latency: ca. 80 µsec (userlevel to userlevel) Was highly prevalent (low cost) Gigabit-Ethernet Bandwidth: 1 Gb/s Latency: ca. 80 µsec (userlevel to userlevel, raw: 1-12 µsec) Today widespread (159 of Top500, Nov 2012) 10 Gigabit-Ethernet Bandwidth: 10 Gbit/s Latency: ca. 80 µsec (userlevel to userlevel, raw: 2-4 µsec) Already in use (30 of Top500, Nov 2012) 2-31


32 Myrinet Bandwidth: 4 Gb/s Real : 495 MB/s Latency: ca. 5 µsec Point-to-Point Message Passing Switch-based Still used (3 in Top 500, Nov 2012, using 10G Myrinet) 2-32
33 Scalable Coherent Interface SCI = Scalable Coherent Interface, ANSI/IEEE bit global address space (16-bit node ID, 48-bit local memory). Guaranteed data transport by packet-based handshake protocol. Interfaces with two unidirectional Links that can work simultaneously. Parallel copper or serial optical fibers. Low latency (<2μs). Supports shared memory and message passing. Defines Cache coherence protocol (not available everywhere). 2-33

 (Data from Dolphin Inc.")
34 Scalable Coherent Interface (SCI) Standard IEEE 1594 Bandwidth: 667MB/s Real : 386MB/s Latency: 1,4 msec Shared Memory in HW Usually 2D/3D-Torus Scarcely used (last time Nov in Top500) (Data from Dolphin Inc.) 2-34
35 SCI Nodes 1: Request Multiplxer. Bypass FIFO Output FIFO Request Output FIFO Response Input FIFO Request Input FIFO Response 2: Request Echo SCI out Multiplexer Bypass FIFO Address Dec. SCI in Address Dec. 4: Response Echo Intput FIFO Request Intput FIFO Response Output FIFO Request Output FIFO Response 3: Response 2-35
36 SCI-NUMA Processor Processor Processor Processor L1 L2 L1 L2 Cache L1 L2 L1 L2 Cache Processor Bus Processor Bus SCI Cache SCI Cache Memory SCI Memory SCI Bridge Bridge SCI-Ring 2-36
37 SCI for PC-Cluster (Dolphin-Adapter) Processor Processor Processor Processor L1 L2 L1 L2 Cache L1 L2 L1 L2 Cache Processor Bus Bus Bridge I/O Bus Processor Bus Bus Bridge I/O Bus Memory SCI Memory SCI Bridge Bridge SCI-Ring 2-37
.")
38 Example: SCI-Cluster (Uni Paderborn) 96 Dual processor-pcs (Pentium III, 850 MHz) with total 48 GB memory, connected as SCI-Rings (16x6-Torus). NUMA-Architecture: Hardware access to remote memory Siemens hpc-line 2-38


39 SCI-Cluster (KBS, TU Berlin) Linux-Cluster 16 Dualprocessor-nodes with 1,7 GHz P4 1 GB memory 2D-Torus SCI (Scalable Coherent Interface) 2-39
40 SCI address translation Process 1 on node A Process 2 on node B 32 bit virtual address space MMU address translation 32 bit physical address space Real memory I/O-window SCI address translation 48 bit global SCI address space 2-40
 Source: top500.")
41 Infiniband New standard for coupling devices and compute nodes (replacement for system busses like PCI) single link: 2,5 GBit/sec Up to 12 links in parallel Most used today (224 of Top500, Nov 2012, different configurations) Source: top500.org 2-41

42 Infiniband Current technology for building HPC- Cluster 2.5 Gbps per Link ca. 2 µsec Latency 2-42
43 Virtual Interface Architecture To standardize the diversity of high performance network protocols, an industry consortium, consisting of Microsoft, Compaq (now HP) and Intel defined the Virtual Interface Architecture (VIA). Central element is the concept of a user-level interface, that allows direct access to the network interface bypassing the operating system. Examples: Active Messages (UCB); Fast Messages (UIUC); U-Net (Cornell); BIP (Univ. Lyon, France); User Process Operating System Network Interface source: M. Baker 2-43
44 Virtual Interface Architecture Application OS Communication Interface (Sockets, MPI,...) VI User Agent user mode kernel mode VI Kernel Agent Open/Connect/ Register Memory S E N D R E C E I V E S E N D R E C E I V E Send/Receive S E N D R E C E I V E C O M P L E T I O N VI Network Adapter 2-44
45 Virtual Interface Architecture Application OS Communication Interface (Sockets, MPI,...) VI User Agent user mode kernel mode VI Kernel Agent Open/Connect/ Register Memory S E N D R E C E I V E S E N D R E C E I V E Send/Receive S E N D R E C E I V E C O M P L E T I O N VI Network Adapter 2-45
46 2.4 Architectural Trends in HPC Cost saving by usage of mass products Usage of top-of-line standard processor Usage of top-of-line standard interconnect SMPs/multicore/manycore-processors as nodes Assemble such nodes to build arbitrarily large clusters P P M P P M P P M P P... P P M M P P P P P P P P P P Interconnection Network 2-46

47 Top 500: Architecture 2-47
48 Notion of "Constellation" Nodes of parallel computer consist of many processors (SMP) or multicore processors Thus, we have two layers of parallelism: the "Intranode-parallelism" and the "Internode parallelism" In the TOP500 terminology there is a distinction between Cluster and Constellation, depending on what form parallelism is dominant: If a machine has more processor cores per node than nodes at all, it is called Constellation. If a machine has more nodes than processor cores per node, than it is called Cluster. 2-48

49 Top 500: Processor Types 2-49

50 Top 500: Coprocessors 2-50

51 Top 500: Processor Family 2-51

52 Top 500: Operating system families 2-52
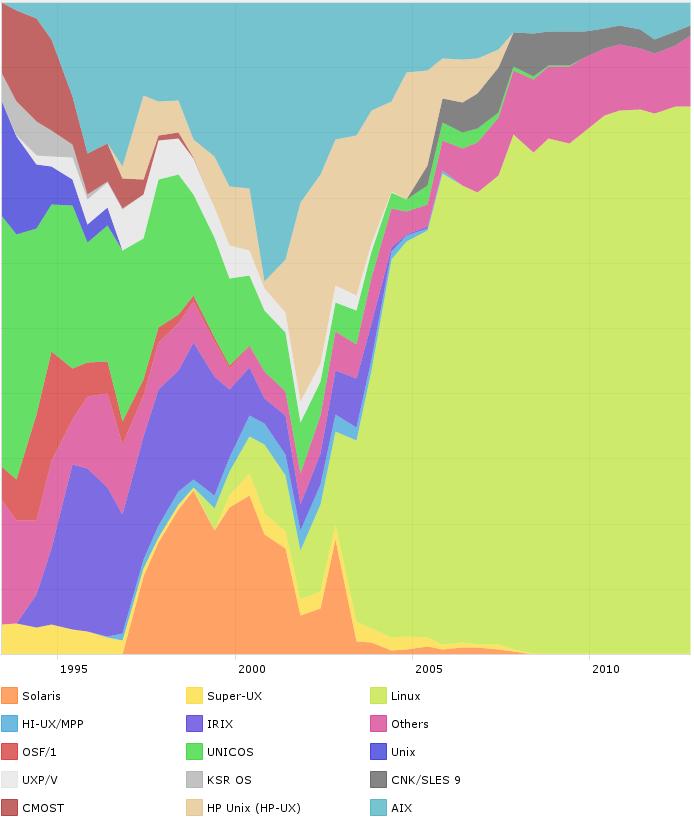
53 HPC-Operating systems 2-53

54 Top 500: Interconnect 2-54

55 Top 500: Geographical Regions 2-55


56 Moore s law Number of transistors per chip doubles (roughly) every 18 months. Source: Wikipedia 2-56
57 Transistors per processor Processor Year of introduction Transistor count Intel ,300 Intel ,500 MOS ,510 Zilog Z ,500 Intel ,000 Intel ,000 Motorola ,000 Intel ,000 Motorola ,000 Intel ,180,000 Motorola ~1,200,
58 Transistors per processor Processor Year of introduction Transistor count Intel Pentium ,100,000 Intel Pentium Pro ,500,000 AMD K ,800,000 AMD K ,000,000 Intel Pentium ,000,000 AMD K ,900,000 AMD K8 Dual Core ,000,000 IBM Power ,000,000 AMD Opteron (6 core) ,000,000 Intel Xeon EX (10 core) ,600,000,000 Intel Itanium (8 core) ,100,000,

59 Xeon EX (Westmere EX) with 10 Cores Source: computerbase.de 2-59

60 Intel Single Chip Cloud Computer: 48 Cores Source: Intel 2-60
61 Performance of Top
62 Top 500: Forecast 2-62
63 2.4 Software Architecture of Distributed Systems Applications should be supported in a transparent way, i.e., we need a software infrastructure that hides the distribution to a high degree. Parallel distributed Application??? Computer Computer Computer Computer Interconnection network 2-63
64 Two Architectural Approaches for Distributed Systems Distributed Operating System The operating system itself provides the necessary functionality Parallel Application Distributed Operating System Computer Computer Computer Computer Interconnection network Network Operating System The local operating systems are complemented by an additional layer (Network OS, Middleware) that provides distributed functions Parallel Application Network Operating System loc. OS loc. OS loc. OS loc. OS Computer Computer Computer Computer Interconnection network 2-64
65 General OS Architecture (Microkernel) Control OS user interface Application Services Operation and management of real and logical resources Process area OS-Kernel Hardware Kernel interface Process management Interaction Kernel area 2-65
66 Architecture of local OS User processes OS-Processes Kernel interface OS kernel Hardware 2-66
67 Architecture of distributed OS User processes Node boundary OS-Processes OS-Kernel Hardware OS-Kernel Hardware Interconnect 2-67
68 Process communication A B A C Communication object B A B Send(C,..) Receive(C,..) Kernel C 2-68
69 Distributed OS: Architectural Variants To overcome the node boundaries in distributed systems for interaction, we need communication operations that are either integrated in the kernel (kernel federation) or as a component outside the kernel (process federation). When using the kernel federation the "distributedness" is hidden behind the kernel interface. Kernel calls can refer to any object in the system regardless of its physical location. The federation of all kernels is called the federated kernel. The process federation leaves the kernel interface untouched. The local kernel is not aware of being part of a distributed system. This way, existing OS can be extended to become distributed OS. 2-69
70 Kernel federation Node boundaries Process Process Comm. software loc. OS-Kernel Federated kernel Comm. software loc. OS-Kernel 2-70
71 Process federation Node boundaries Process Process Comm. software Comm. software OS-Kernel OS-Kernel 2-71
72 Features of Distributed OS Multiprocessor- OS Distribute d OS Network- OS All nodes have the same OS? yes yes no How many copies of OS? 1 n n Shared ready queue? yes no no Communication Shared memory Message exchange Message exchange / Shared files 2-72
73 Transparency I Transparency is the property that the user (almost) does not realize the distributedness of the system. Transparency is the main challenge when building distributed systems. Access transparency Access to remote objects in the same way as to local ones Location transparency Name transparency Objects are addressed using names that are independent of their locations User mobility If the user changes his location he can address the objects with the same name as before. Replication transparency If for performance improvement (temporary) copies of data are generated, the consistency is taken care of automatically. 2-73
74 Transparency II Failure transparency Failures of components should not be noticeable. Migration transparency Migration of objects should not be noticeable. Concurrency transparency The fact that that many users access objects from different locations concurrently must not lead to problems or faults. Scalability transparency Adding more nodes to the system during operation should be possible. Algorithms should cope with the growth of the system. Performance transparency No performance penalties due to uneven load distribution. 2-74
75 References Erich Strohmaier, Jack J. Dongarra, Hans W. Meuer, and Horst D. Simon: Recent Trends in the Marketplace of High Performance Computing, Gregory Pfister: In Search of Clusters (2nd ed.), Prentice-Hall, 1998 Thorsten v.eicken, Werner Vogels: Evolution of the Virtual Interface Architecture, IEEE Computer, Nov Hans Werner Meuer: The TOP500 Project: Looking Back over 15 Years of Supercomputing Experience David Culler, J.P. Singh, Anoop Gupta: Parallel Computer Architecture: A Hardware/Software Approach. Morgan Kaufmann, 1999 Hesham El-Rewini und Mostafa Abd-El-Barr: Advanced Computer Architecture and Parallel Processing: Advanced Computer Architecture v. 2; John Wiley & Sons, 2005 V. Rajaraman und C.Siva Ram Murthy: Parallel Computers: Architecture and Programming; Prentice-Hall,
COSC 6374 Parallel Computation. Parallel Computer Architectures
 OS 6374 Parallel omputation Parallel omputer Architectures Some slides on network topologies based on a similar presentation by Michael Resch, University of Stuttgart Spring 2010 Flynn s Taxonomy SISD:
OS 6374 Parallel omputation Parallel omputer Architectures Some slides on network topologies based on a similar presentation by Michael Resch, University of Stuttgart Spring 2010 Flynn s Taxonomy SISD:
COSC 6374 Parallel Computation. Parallel Computer Architectures
 OS 6374 Parallel omputation Parallel omputer Architectures Some slides on network topologies based on a similar presentation by Michael Resch, University of Stuttgart Edgar Gabriel Fall 2015 Flynn s Taxonomy
OS 6374 Parallel omputation Parallel omputer Architectures Some slides on network topologies based on a similar presentation by Michael Resch, University of Stuttgart Edgar Gabriel Fall 2015 Flynn s Taxonomy
BlueGene/L. Computer Science, University of Warwick. Source: IBM
 BlueGene/L Source: IBM 1 BlueGene/L networking BlueGene system employs various network types. Central is the torus interconnection network: 3D torus with wrap-around. Each node connects to six neighbours
BlueGene/L Source: IBM 1 BlueGene/L networking BlueGene system employs various network types. Central is the torus interconnection network: 3D torus with wrap-around. Each node connects to six neighbours
Advanced Parallel Architecture. Annalisa Massini /2017
 Advanced Parallel Architecture Annalisa Massini - 2016/2017 References Advanced Computer Architecture and Parallel Processing H. El-Rewini, M. Abd-El-Barr, John Wiley and Sons, 2005 Parallel computing
Advanced Parallel Architecture Annalisa Massini - 2016/2017 References Advanced Computer Architecture and Parallel Processing H. El-Rewini, M. Abd-El-Barr, John Wiley and Sons, 2005 Parallel computing
Lecture 2 Parallel Programming Platforms
 Lecture 2 Parallel Programming Platforms Flynn s Taxonomy In 1966, Michael Flynn classified systems according to numbers of instruction streams and the number of data stream. Data stream Single Multiple
Lecture 2 Parallel Programming Platforms Flynn s Taxonomy In 1966, Michael Flynn classified systems according to numbers of instruction streams and the number of data stream. Data stream Single Multiple
Communication has significant impact on application performance. Interconnection networks therefore have a vital role in cluster systems.
 Cluster Networks Introduction Communication has significant impact on application performance. Interconnection networks therefore have a vital role in cluster systems. As usual, the driver is performance
Cluster Networks Introduction Communication has significant impact on application performance. Interconnection networks therefore have a vital role in cluster systems. As usual, the driver is performance
Scalability and Classifications
 Scalability and Classifications 1 Types of Parallel Computers MIMD and SIMD classifications shared and distributed memory multicomputers distributed shared memory computers 2 Network Topologies static
Scalability and Classifications 1 Types of Parallel Computers MIMD and SIMD classifications shared and distributed memory multicomputers distributed shared memory computers 2 Network Topologies static
CS 770G - Parallel Algorithms in Scientific Computing Parallel Architectures. May 7, 2001 Lecture 2
 CS 770G - arallel Algorithms in Scientific Computing arallel Architectures May 7, 2001 Lecture 2 References arallel Computer Architecture: A Hardware / Software Approach Culler, Singh, Gupta, Morgan Kaufmann
CS 770G - arallel Algorithms in Scientific Computing arallel Architectures May 7, 2001 Lecture 2 References arallel Computer Architecture: A Hardware / Software Approach Culler, Singh, Gupta, Morgan Kaufmann
CS Parallel Algorithms in Scientific Computing
 CS 775 - arallel Algorithms in Scientific Computing arallel Architectures January 2, 2004 Lecture 2 References arallel Computer Architecture: A Hardware / Software Approach Culler, Singh, Gupta, Morgan
CS 775 - arallel Algorithms in Scientific Computing arallel Architectures January 2, 2004 Lecture 2 References arallel Computer Architecture: A Hardware / Software Approach Culler, Singh, Gupta, Morgan
Interconnection Network
 Interconnection Network Jinkyu Jeong (jinkyu@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu SSE3054: Multicore Systems, Spring 2017, Jinkyu Jeong (jinkyu@skku.edu) Topics
Interconnection Network Jinkyu Jeong (jinkyu@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu SSE3054: Multicore Systems, Spring 2017, Jinkyu Jeong (jinkyu@skku.edu) Topics
Interconnection Network. Jinkyu Jeong Computer Systems Laboratory Sungkyunkwan University
 Interconnection Network Jinkyu Jeong (jinkyu@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu Topics Taxonomy Metric Topologies Characteristics Cost Performance 2 Interconnection
Interconnection Network Jinkyu Jeong (jinkyu@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu Topics Taxonomy Metric Topologies Characteristics Cost Performance 2 Interconnection
Overview. Processor organizations Types of parallel machines. Real machines
 Course Outline Introduction in algorithms and applications Parallel machines and architectures Overview of parallel machines, trends in top-500, clusters, DAS Programming methods, languages, and environments
Course Outline Introduction in algorithms and applications Parallel machines and architectures Overview of parallel machines, trends in top-500, clusters, DAS Programming methods, languages, and environments
Chapter 1. Introduction: Part I. Jens Saak Scientific Computing II 7/348
 Chapter 1 Introduction: Part I Jens Saak Scientific Computing II 7/348 Why Parallel Computing? 1. Problem size exceeds desktop capabilities. Jens Saak Scientific Computing II 8/348 Why Parallel Computing?
Chapter 1 Introduction: Part I Jens Saak Scientific Computing II 7/348 Why Parallel Computing? 1. Problem size exceeds desktop capabilities. Jens Saak Scientific Computing II 8/348 Why Parallel Computing?
COSC 6385 Computer Architecture - Multi Processor Systems
 COSC 6385 Computer Architecture - Multi Processor Systems Fall 2006 Classification of Parallel Architectures Flynn s Taxonomy SISD: Single instruction single data Classical von Neumann architecture SIMD:
COSC 6385 Computer Architecture - Multi Processor Systems Fall 2006 Classification of Parallel Architectures Flynn s Taxonomy SISD: Single instruction single data Classical von Neumann architecture SIMD:
Computer parallelism Flynn s categories
 04 Multi-processors 04.01-04.02 Taxonomy and communication Parallelism Taxonomy Communication alessandro bogliolo isti information science and technology institute 1/9 Computer parallelism Flynn s categories
04 Multi-processors 04.01-04.02 Taxonomy and communication Parallelism Taxonomy Communication alessandro bogliolo isti information science and technology institute 1/9 Computer parallelism Flynn s categories
Parallel Architectures
 Parallel Architectures Part 1: The rise of parallel machines Intel Core i7 4 CPU cores 2 hardware thread per core (8 cores ) Lab Cluster Intel Xeon 4/10/16/18 CPU cores 2 hardware thread per core (8/20/32/36
Parallel Architectures Part 1: The rise of parallel machines Intel Core i7 4 CPU cores 2 hardware thread per core (8 cores ) Lab Cluster Intel Xeon 4/10/16/18 CPU cores 2 hardware thread per core (8/20/32/36
Non-Uniform Memory Access (NUMA) Architecture and Multicomputers
 Architecture and Multicomputers") Non-Uniform Memory Access (NUMA) Architecture and Multicomputers Parallel and Distributed Computing Department of Computer Science and Engineering (DEI) Instituto Superior Técnico February 29, 2016 CPD
Non-Uniform Memory Access (NUMA) Architecture and Multicomputers Parallel and Distributed Computing Department of Computer Science and Engineering (DEI) Instituto Superior Técnico February 29, 2016 CPD
Real Parallel Computers
 Real Parallel Computers Modular data centers Background Information Recent trends in the marketplace of high performance computing Strohmaier, Dongarra, Meuer, Simon Parallel Computing 2005 Short history
Real Parallel Computers Modular data centers Background Information Recent trends in the marketplace of high performance computing Strohmaier, Dongarra, Meuer, Simon Parallel Computing 2005 Short history
Real Parallel Computers
 Real Parallel Computers Modular data centers Overview Short history of parallel machines Cluster computing Blue Gene supercomputer Performance development, top-500 DAS: Distributed supercomputing Short
Real Parallel Computers Modular data centers Overview Short history of parallel machines Cluster computing Blue Gene supercomputer Performance development, top-500 DAS: Distributed supercomputing Short
What is Parallel Computing?
 What is Parallel Computing? Parallel Computing is several processing elements working simultaneously to solve a problem faster. 1/33 What is Parallel Computing? Parallel Computing is several processing
What is Parallel Computing? Parallel Computing is several processing elements working simultaneously to solve a problem faster. 1/33 What is Parallel Computing? Parallel Computing is several processing
Non-Uniform Memory Access (NUMA) Architecture and Multicomputers
 Architecture and Multicomputers") Non-Uniform Memory Access (NUMA) Architecture and Multicomputers Parallel and Distributed Computing Department of Computer Science and Engineering (DEI) Instituto Superior Técnico September 26, 2011 CPD
Non-Uniform Memory Access (NUMA) Architecture and Multicomputers Parallel and Distributed Computing Department of Computer Science and Engineering (DEI) Instituto Superior Técnico September 26, 2011 CPD
Parallel Architecture. Sathish Vadhiyar
 Parallel Architecture Sathish Vadhiyar Motivations of Parallel Computing Faster execution times From days or months to hours or seconds E.g., climate modelling, bioinformatics Large amount of data dictate
Parallel Architecture Sathish Vadhiyar Motivations of Parallel Computing Faster execution times From days or months to hours or seconds E.g., climate modelling, bioinformatics Large amount of data dictate
Computing architectures Part 2 TMA4280 Introduction to Supercomputing
 Computing architectures Part 2 TMA4280 Introduction to Supercomputing NTNU, IMF January 16. 2017 1 Supercomputing What is the motivation for Supercomputing? Solve complex problems fast and accurately:
Computing architectures Part 2 TMA4280 Introduction to Supercomputing NTNU, IMF January 16. 2017 1 Supercomputing What is the motivation for Supercomputing? Solve complex problems fast and accurately:
Non-Uniform Memory Access (NUMA) Architecture and Multicomputers
 Architecture and Multicomputers") Non-Uniform Memory Access (NUMA) Architecture and Multicomputers Parallel and Distributed Computing MSc in Information Systems and Computer Engineering DEA in Computational Engineering Department of Computer
Non-Uniform Memory Access (NUMA) Architecture and Multicomputers Parallel and Distributed Computing MSc in Information Systems and Computer Engineering DEA in Computational Engineering Department of Computer
10 Parallel Organizations: Multiprocessor / Multicore / Multicomputer Systems
 1 License: http://creativecommons.org/licenses/by-nc-nd/3.0/ 10 Parallel Organizations: Multiprocessor / Multicore / Multicomputer Systems To enhance system performance and, in some cases, to increase
1 License: http://creativecommons.org/licenses/by-nc-nd/3.0/ 10 Parallel Organizations: Multiprocessor / Multicore / Multicomputer Systems To enhance system performance and, in some cases, to increase
Parallel Architectures
 Parallel Architectures CPS343 Parallel and High Performance Computing Spring 2018 CPS343 (Parallel and HPC) Parallel Architectures Spring 2018 1 / 36 Outline 1 Parallel Computer Classification Flynn s
Parallel Architectures CPS343 Parallel and High Performance Computing Spring 2018 CPS343 (Parallel and HPC) Parallel Architectures Spring 2018 1 / 36 Outline 1 Parallel Computer Classification Flynn s
Chapter 9 Multiprocessors
 ECE200 Computer Organization Chapter 9 Multiprocessors David H. lbonesi and the University of Rochester Henk Corporaal, TU Eindhoven, Netherlands Jari Nurmi, Tampere University of Technology, Finland University
ECE200 Computer Organization Chapter 9 Multiprocessors David H. lbonesi and the University of Rochester Henk Corporaal, TU Eindhoven, Netherlands Jari Nurmi, Tampere University of Technology, Finland University
SMD149 - Operating Systems - Multiprocessing
 SMD149 - Operating Systems - Multiprocessing Roland Parviainen December 1, 2005 1 / 55 Overview Introduction Multiprocessor systems Multiprocessor, operating system and memory organizations 2 / 55 Introduction
SMD149 - Operating Systems - Multiprocessing Roland Parviainen December 1, 2005 1 / 55 Overview Introduction Multiprocessor systems Multiprocessor, operating system and memory organizations 2 / 55 Introduction
Overview. SMD149 - Operating Systems - Multiprocessing. Multiprocessing architecture. Introduction SISD. Flynn s taxonomy
 Overview SMD149 - Operating Systems - Multiprocessing Roland Parviainen Multiprocessor systems Multiprocessor, operating system and memory organizations December 1, 2005 1/55 2/55 Multiprocessor system
Overview SMD149 - Operating Systems - Multiprocessing Roland Parviainen Multiprocessor systems Multiprocessor, operating system and memory organizations December 1, 2005 1/55 2/55 Multiprocessor system
Distributed Systems. 01. Introduction. Paul Krzyzanowski. Rutgers University. Fall 2013
 Distributed Systems 01. Introduction Paul Krzyzanowski Rutgers University Fall 2013 September 9, 2013 CS 417 - Paul Krzyzanowski 1 What can we do now that we could not do before? 2 Technology advances
Distributed Systems 01. Introduction Paul Krzyzanowski Rutgers University Fall 2013 September 9, 2013 CS 417 - Paul Krzyzanowski 1 What can we do now that we could not do before? 2 Technology advances
Parallel Computing Platforms
 Parallel Computing Platforms Jinkyu Jeong (jinkyu@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu SSE3054: Multicore Systems, Spring 2017, Jinkyu Jeong (jinkyu@skku.edu)
Parallel Computing Platforms Jinkyu Jeong (jinkyu@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu SSE3054: Multicore Systems, Spring 2017, Jinkyu Jeong (jinkyu@skku.edu)
Parallel Computing Platforms. Jinkyu Jeong Computer Systems Laboratory Sungkyunkwan University
 Parallel Computing Platforms Jinkyu Jeong (jinkyu@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu Elements of a Parallel Computer Hardware Multiple processors Multiple
Parallel Computing Platforms Jinkyu Jeong (jinkyu@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu Elements of a Parallel Computer Hardware Multiple processors Multiple
Lecture 9: MIMD Architectures
 Lecture 9: MIMD Architectures Introduction and classification Symmetric multiprocessors NUMA architecture Clusters Zebo Peng, IDA, LiTH 1 Introduction MIMD: a set of general purpose processors is connected
Lecture 9: MIMD Architectures Introduction and classification Symmetric multiprocessors NUMA architecture Clusters Zebo Peng, IDA, LiTH 1 Introduction MIMD: a set of general purpose processors is connected
Lecture 9: MIMD Architecture
 Lecture 9: MIMD Architecture Introduction and classification Symmetric multiprocessors NUMA architecture Cluster machines Zebo Peng, IDA, LiTH 1 Introduction MIMD: a set of general purpose processors is
Lecture 9: MIMD Architecture Introduction and classification Symmetric multiprocessors NUMA architecture Cluster machines Zebo Peng, IDA, LiTH 1 Introduction MIMD: a set of general purpose processors is
PARALLEL COMPUTER ARCHITECTURES
 8 ARALLEL COMUTER ARCHITECTURES 1 CU Shared memory (a) (b) Figure 8-1. (a) A multiprocessor with 16 CUs sharing a common memory. (b) An image partitioned into 16 sections, each being analyzed by a different
8 ARALLEL COMUTER ARCHITECTURES 1 CU Shared memory (a) (b) Figure 8-1. (a) A multiprocessor with 16 CUs sharing a common memory. (b) An image partitioned into 16 sections, each being analyzed by a different
4. Networks. in parallel computers. Advances in Computer Architecture
 4. Networks in parallel computers Advances in Computer Architecture System architectures for parallel computers Control organization Single Instruction stream Multiple Data stream (SIMD) All processors
4. Networks in parallel computers Advances in Computer Architecture System architectures for parallel computers Control organization Single Instruction stream Multiple Data stream (SIMD) All processors
Crossbar switch. Chapter 2: Concepts and Architectures. Traditional Computer Architecture. Computer System Architectures. Flynn Architectures (2)
") Chapter 2: Concepts and Architectures Computer System Architectures Disk(s) CPU I/O Memory Traditional Computer Architecture Flynn, 1966+1972 classification of computer systems in terms of instruction
Chapter 2: Concepts and Architectures Computer System Architectures Disk(s) CPU I/O Memory Traditional Computer Architecture Flynn, 1966+1972 classification of computer systems in terms of instruction
Parallel Computer Architectures. Lectured by: Phạm Trần Vũ Prepared by: Thoại Nam
 Parallel Computer Architectures Lectured by: Phạm Trần Vũ Prepared by: Thoại Nam Outline Flynn s Taxonomy Classification of Parallel Computers Based on Architectures Flynn s Taxonomy Based on notions of
Parallel Computer Architectures Lectured by: Phạm Trần Vũ Prepared by: Thoại Nam Outline Flynn s Taxonomy Classification of Parallel Computers Based on Architectures Flynn s Taxonomy Based on notions of
CSE Introduction to Parallel Processing. Chapter 4. Models of Parallel Processing
 Dr Izadi CSE-4533 Introduction to Parallel Processing Chapter 4 Models of Parallel Processing Elaborate on the taxonomy of parallel processing from chapter Introduce abstract models of shared and distributed
Dr Izadi CSE-4533 Introduction to Parallel Processing Chapter 4 Models of Parallel Processing Elaborate on the taxonomy of parallel processing from chapter Introduce abstract models of shared and distributed
06-Dec-17. Credits:4. Notes by Pritee Parwekar,ANITS 06-Dec-17 1
 Credits:4 1 Understand the Distributed Systems and the challenges involved in Design of the Distributed Systems. Understand how communication is created and synchronized in Distributed systems Design and
Credits:4 1 Understand the Distributed Systems and the challenges involved in Design of the Distributed Systems. Understand how communication is created and synchronized in Distributed systems Design and
BİL 542 Parallel Computing
 BİL 542 Parallel Computing 1 Chapter 1 Parallel Programming 2 Why Use Parallel Computing? Main Reasons: Save time and/or money: In theory, throwing more resources at a task will shorten its time to completion,
BİL 542 Parallel Computing 1 Chapter 1 Parallel Programming 2 Why Use Parallel Computing? Main Reasons: Save time and/or money: In theory, throwing more resources at a task will shorten its time to completion,
CS550. TA: TBA Office: xxx Office hours: TBA. Blackboard:
 CS550 Advanced Operating Systems (Distributed Operating Systems) Instructor: Xian-He Sun Email: sun@iit.edu, Phone: (312) 567-5260 Office hours: 1:30pm-2:30pm Tuesday, Thursday at SB229C, or by appointment
CS550 Advanced Operating Systems (Distributed Operating Systems) Instructor: Xian-He Sun Email: sun@iit.edu, Phone: (312) 567-5260 Office hours: 1:30pm-2:30pm Tuesday, Thursday at SB229C, or by appointment
Parallel Processors. The dream of computer architects since 1950s: replicate processors to add performance vs. design a faster processor
 Multiprocessing Parallel Computers Definition: A parallel computer is a collection of processing elements that cooperate and communicate to solve large problems fast. Almasi and Gottlieb, Highly Parallel
Multiprocessing Parallel Computers Definition: A parallel computer is a collection of processing elements that cooperate and communicate to solve large problems fast. Almasi and Gottlieb, Highly Parallel
Parallel Systems Prof. James L. Frankel Harvard University. Version of 6:50 PM 4-Dec-2018 Copyright 2018, 2017 James L. Frankel. All rights reserved.
 Parallel Systems Prof. James L. Frankel Harvard University Version of 6:50 PM 4-Dec-2018 Copyright 2018, 2017 James L. Frankel. All rights reserved. Architectures SISD (Single Instruction, Single Data)
Parallel Systems Prof. James L. Frankel Harvard University Version of 6:50 PM 4-Dec-2018 Copyright 2018, 2017 James L. Frankel. All rights reserved. Architectures SISD (Single Instruction, Single Data)
Multiprocessors - Flynn s Taxonomy (1966)
") Multiprocessors - Flynn s Taxonomy (1966) Single Instruction stream, Single Data stream (SISD) Conventional uniprocessor Although ILP is exploited Single Program Counter -> Single Instruction stream The
Multiprocessors - Flynn s Taxonomy (1966) Single Instruction stream, Single Data stream (SISD) Conventional uniprocessor Although ILP is exploited Single Program Counter -> Single Instruction stream The
MIMD Overview. Intel Paragon XP/S Overview. XP/S Usage. XP/S Nodes and Interconnection. ! Distributed-memory MIMD multicomputer
 MIMD Overview Intel Paragon XP/S Overview! MIMDs in the 1980s and 1990s! Distributed-memory multicomputers! Intel Paragon XP/S! Thinking Machines CM-5! IBM SP2! Distributed-memory multicomputers with hardware
MIMD Overview Intel Paragon XP/S Overview! MIMDs in the 1980s and 1990s! Distributed-memory multicomputers! Intel Paragon XP/S! Thinking Machines CM-5! IBM SP2! Distributed-memory multicomputers with hardware
SHARED MEMORY VS DISTRIBUTED MEMORY
 OVERVIEW Important Processor Organizations 3 SHARED MEMORY VS DISTRIBUTED MEMORY Classical parallel algorithms were discussed using the shared memory paradigm. In shared memory parallel platform processors
OVERVIEW Important Processor Organizations 3 SHARED MEMORY VS DISTRIBUTED MEMORY Classical parallel algorithms were discussed using the shared memory paradigm. In shared memory parallel platform processors
WHY PARALLEL PROCESSING? (CE-401)
") PARALLEL PROCESSING (CE-401) COURSE INFORMATION 2 + 1 credits (60 marks theory, 40 marks lab) Labs introduced for second time in PP history of SSUET Theory marks breakup: Midterm Exam: 15 marks Assignment:
PARALLEL PROCESSING (CE-401) COURSE INFORMATION 2 + 1 credits (60 marks theory, 40 marks lab) Labs introduced for second time in PP history of SSUET Theory marks breakup: Midterm Exam: 15 marks Assignment:
EE 4683/5683: COMPUTER ARCHITECTURE
 3/3/205 EE 4683/5683: COMPUTER ARCHITECTURE Lecture 8: Interconnection Networks Avinash Kodi, kodi@ohio.edu Agenda 2 Interconnection Networks Performance Metrics Topology 3/3/205 IN Performance Metrics
3/3/205 EE 4683/5683: COMPUTER ARCHITECTURE Lecture 8: Interconnection Networks Avinash Kodi, kodi@ohio.edu Agenda 2 Interconnection Networks Performance Metrics Topology 3/3/205 IN Performance Metrics
CS252 Graduate Computer Architecture Lecture 14. Multiprocessor Networks March 9 th, 2011
 CS252 Graduate Computer Architecture Lecture 14 Multiprocessor Networks March 9 th, 2011 John Kubiatowicz Electrical Engineering and Computer Sciences University of California, Berkeley http://www.eecs.berkeley.edu/~kubitron/cs252
CS252 Graduate Computer Architecture Lecture 14 Multiprocessor Networks March 9 th, 2011 John Kubiatowicz Electrical Engineering and Computer Sciences University of California, Berkeley http://www.eecs.berkeley.edu/~kubitron/cs252
Introduction to parallel computing
 Introduction to parallel computing 2. Parallel Hardware Zhiao Shi (modifications by Will French) Advanced Computing Center for Education & Research Vanderbilt University Motherboard Processor https://sites.google.com/
Introduction to parallel computing 2. Parallel Hardware Zhiao Shi (modifications by Will French) Advanced Computing Center for Education & Research Vanderbilt University Motherboard Processor https://sites.google.com/
COSC 6385 Computer Architecture - Thread Level Parallelism (I)
") COSC 6385 Computer Architecture - Thread Level Parallelism (I) Edgar Gabriel Spring 2014 Long-term trend on the number of transistor per integrated circuit Number of transistors double every ~18 month
COSC 6385 Computer Architecture - Thread Level Parallelism (I) Edgar Gabriel Spring 2014 Long-term trend on the number of transistor per integrated circuit Number of transistors double every ~18 month
CCS HPC. Interconnection Network. PC MPP (Massively Parallel Processor) MPP IBM
 MPP IBM") CCS HC taisuke@cs.tsukuba.ac.jp 1 2 CU memoryi/o 2 2 4single chipmulti-core CU 10 C CM (Massively arallel rocessor) M IBM BlueGene/L 65536 Interconnection Network 3 4 (distributed memory system) (shared
CCS HC taisuke@cs.tsukuba.ac.jp 1 2 CU memoryi/o 2 2 4single chipmulti-core CU 10 C CM (Massively arallel rocessor) M IBM BlueGene/L 65536 Interconnection Network 3 4 (distributed memory system) (shared
Lecture 9: MIMD Architectures
 Lecture 9: MIMD Architectures Introduction and classification Symmetric multiprocessors NUMA architecture Clusters Zebo Peng, IDA, LiTH 1 Introduction A set of general purpose processors is connected together.
Lecture 9: MIMD Architectures Introduction and classification Symmetric multiprocessors NUMA architecture Clusters Zebo Peng, IDA, LiTH 1 Introduction A set of general purpose processors is connected together.
Convergence of Parallel Architecture
 Parallel Computing Convergence of Parallel Architecture Hwansoo Han History Parallel architectures tied closely to programming models Divergent architectures, with no predictable pattern of growth Uncertainty
Parallel Computing Convergence of Parallel Architecture Hwansoo Han History Parallel architectures tied closely to programming models Divergent architectures, with no predictable pattern of growth Uncertainty
Parallel Computer Architecture II
 Parallel Computer Architecture II Stefan Lang Interdisciplinary Center for Scientific Computing (IWR) University of Heidelberg INF 368, Room 532 D-692 Heidelberg phone: 622/54-8264 email: Stefan.Lang@iwr.uni-heidelberg.de
Parallel Computer Architecture II Stefan Lang Interdisciplinary Center for Scientific Computing (IWR) University of Heidelberg INF 368, Room 532 D-692 Heidelberg phone: 622/54-8264 email: Stefan.Lang@iwr.uni-heidelberg.de
Computer and Information Sciences College / Computer Science Department CS 207 D. Computer Architecture. Lecture 9: Multiprocessors
 Computer and Information Sciences College / Computer Science Department CS 207 D Computer Architecture Lecture 9: Multiprocessors Challenges of Parallel Processing First challenge is % of program inherently
Computer and Information Sciences College / Computer Science Department CS 207 D Computer Architecture Lecture 9: Multiprocessors Challenges of Parallel Processing First challenge is % of program inherently
Lecture 26: Interconnects. James C. Hoe Department of ECE Carnegie Mellon University
 18 447 Lecture 26: Interconnects James C. Hoe Department of ECE Carnegie Mellon University 18 447 S18 L26 S1, James C. Hoe, CMU/ECE/CALCM, 2018 Housekeeping Your goal today get an overview of parallel
18 447 Lecture 26: Interconnects James C. Hoe Department of ECE Carnegie Mellon University 18 447 S18 L26 S1, James C. Hoe, CMU/ECE/CALCM, 2018 Housekeeping Your goal today get an overview of parallel
Interconnection Network
 Interconnection Network Recap: Generic Parallel Architecture A generic modern multiprocessor Network Mem Communication assist (CA) $ P Node: processor(s), memory system, plus communication assist Network
Interconnection Network Recap: Generic Parallel Architecture A generic modern multiprocessor Network Mem Communication assist (CA) $ P Node: processor(s), memory system, plus communication assist Network
CS4230 Parallel Programming. Lecture 3: Introduction to Parallel Architectures 8/28/12. Homework 1: Parallel Programming Basics
 CS4230 Parallel Programming Lecture 3: Introduction to Parallel Architectures Mary Hall August 28, 2012 Homework 1: Parallel Programming Basics Due before class, Thursday, August 30 Turn in electronically
CS4230 Parallel Programming Lecture 3: Introduction to Parallel Architectures Mary Hall August 28, 2012 Homework 1: Parallel Programming Basics Due before class, Thursday, August 30 Turn in electronically
SMP and ccnuma Multiprocessor Systems. Sharing of Resources in Parallel and Distributed Computing Systems
 Reference Papers on SMP/NUMA Systems: EE 657, Lecture 5 September 14, 2007 SMP and ccnuma Multiprocessor Systems Professor Kai Hwang USC Internet and Grid Computing Laboratory Email: kaihwang@usc.edu [1]
Reference Papers on SMP/NUMA Systems: EE 657, Lecture 5 September 14, 2007 SMP and ccnuma Multiprocessor Systems Professor Kai Hwang USC Internet and Grid Computing Laboratory Email: kaihwang@usc.edu [1]
What are Clusters? Why Clusters? - a Short History
 What are Clusters? Our definition : A parallel machine built of commodity components and running commodity software Cluster consists of nodes with one or more processors (CPUs), memory that is shared by
What are Clusters? Our definition : A parallel machine built of commodity components and running commodity software Cluster consists of nodes with one or more processors (CPUs), memory that is shared by
3/24/2014 BIT 325 PARALLEL PROCESSING ASSESSMENT. Lecture Notes:
 BIT 325 PARALLEL PROCESSING ASSESSMENT CA 40% TESTS 30% PRESENTATIONS 10% EXAM 60% CLASS TIME TABLE SYLLUBUS & RECOMMENDED BOOKS Parallel processing Overview Clarification of parallel machines Some General
BIT 325 PARALLEL PROCESSING ASSESSMENT CA 40% TESTS 30% PRESENTATIONS 10% EXAM 60% CLASS TIME TABLE SYLLUBUS & RECOMMENDED BOOKS Parallel processing Overview Clarification of parallel machines Some General
Client Server & Distributed System. A Basic Introduction
 Client Server & Distributed System A Basic Introduction 1 Client Server Architecture A network architecture in which each computer or process on the network is either a client or a server. Source: http://webopedia.lycos.com
Client Server & Distributed System A Basic Introduction 1 Client Server Architecture A network architecture in which each computer or process on the network is either a client or a server. Source: http://webopedia.lycos.com
Introduction to High-Performance Computing
 Introduction to High-Performance Computing Simon D. Levy BIOL 274 17 November 2010 Chapter 12 12.1: Concurrent Processing High-Performance Computing A fancy term for computers significantly faster than
Introduction to High-Performance Computing Simon D. Levy BIOL 274 17 November 2010 Chapter 12 12.1: Concurrent Processing High-Performance Computing A fancy term for computers significantly faster than
ECE/CS 757: Advanced Computer Architecture II Interconnects
 ECE/CS 757: Advanced Computer Architecture II Interconnects Instructor:Mikko H Lipasti Spring 2017 University of Wisconsin-Madison Lecture notes created by Natalie Enright Jerger Lecture Outline Introduction
ECE/CS 757: Advanced Computer Architecture II Interconnects Instructor:Mikko H Lipasti Spring 2017 University of Wisconsin-Madison Lecture notes created by Natalie Enright Jerger Lecture Outline Introduction
MULTIPROCESSORS AND THREAD-LEVEL. B649 Parallel Architectures and Programming
 MULTIPROCESSORS AND THREAD-LEVEL PARALLELISM B649 Parallel Architectures and Programming Motivation behind Multiprocessors Limitations of ILP (as already discussed) Growing interest in servers and server-performance
MULTIPROCESSORS AND THREAD-LEVEL PARALLELISM B649 Parallel Architectures and Programming Motivation behind Multiprocessors Limitations of ILP (as already discussed) Growing interest in servers and server-performance
MULTIPROCESSORS AND THREAD-LEVEL PARALLELISM. B649 Parallel Architectures and Programming
 MULTIPROCESSORS AND THREAD-LEVEL PARALLELISM B649 Parallel Architectures and Programming Motivation behind Multiprocessors Limitations of ILP (as already discussed) Growing interest in servers and server-performance
MULTIPROCESSORS AND THREAD-LEVEL PARALLELISM B649 Parallel Architectures and Programming Motivation behind Multiprocessors Limitations of ILP (as already discussed) Growing interest in servers and server-performance
Types of Parallel Computers
 slides1-22 Two principal types: Types of Parallel Computers Shared memory multiprocessor Distributed memory multicomputer slides1-23 Shared Memory Multiprocessor Conventional Computer slides1-24 Consists
slides1-22 Two principal types: Types of Parallel Computers Shared memory multiprocessor Distributed memory multicomputer slides1-23 Shared Memory Multiprocessor Conventional Computer slides1-24 Consists
Parallel Architectures
 Parallel Architectures Instructor: Tsung-Che Chiang tcchiang@ieee.org Department of Science and Information Engineering National Taiwan Normal University Introduction In the roughly three decades between
Parallel Architectures Instructor: Tsung-Che Chiang tcchiang@ieee.org Department of Science and Information Engineering National Taiwan Normal University Introduction In the roughly three decades between
Three basic multiprocessing issues
 Three basic multiprocessing issues 1. artitioning. The sequential program must be partitioned into subprogram units or tasks. This is done either by the programmer or by the compiler. 2. Scheduling. Associated
Three basic multiprocessing issues 1. artitioning. The sequential program must be partitioned into subprogram units or tasks. This is done either by the programmer or by the compiler. 2. Scheduling. Associated
Lecture 7: Parallel Processing
 Lecture 7: Parallel Processing Introduction and motivation Architecture classification Performance evaluation Interconnection network Zebo Peng, IDA, LiTH 1 Performance Improvement Reduction of instruction
Lecture 7: Parallel Processing Introduction and motivation Architecture classification Performance evaluation Interconnection network Zebo Peng, IDA, LiTH 1 Performance Improvement Reduction of instruction
Chapter 18 Parallel Processing
 Chapter 18 Parallel Processing Multiple Processor Organization Single instruction, single data stream - SISD Single instruction, multiple data stream - SIMD Multiple instruction, single data stream - MISD
Chapter 18 Parallel Processing Multiple Processor Organization Single instruction, single data stream - SISD Single instruction, multiple data stream - SIMD Multiple instruction, single data stream - MISD
Computer Architecture
 Computer Architecture Chapter 7 Parallel Processing 1 Parallelism Instruction-level parallelism (Ch.6) pipeline superscalar latency issues hazards Processor-level parallelism (Ch.7) array/vector of processors
Computer Architecture Chapter 7 Parallel Processing 1 Parallelism Instruction-level parallelism (Ch.6) pipeline superscalar latency issues hazards Processor-level parallelism (Ch.7) array/vector of processors
Interconnection networks
 Interconnection networks When more than one processor needs to access a memory structure, interconnection networks are needed to route data from processors to memories (concurrent access to a shared memory
Interconnection networks When more than one processor needs to access a memory structure, interconnection networks are needed to route data from processors to memories (concurrent access to a shared memory
Cluster Network Products
 Cluster Network Products Cluster interconnects include, among others: Gigabit Ethernet Myrinet Quadrics InfiniBand 1 Interconnects in Top500 list 11/2009 2 Interconnects in Top500 list 11/2008 3 Cluster
Cluster Network Products Cluster interconnects include, among others: Gigabit Ethernet Myrinet Quadrics InfiniBand 1 Interconnects in Top500 list 11/2009 2 Interconnects in Top500 list 11/2008 3 Cluster
Outline Marquette University
 COEN-4710 Computer Hardware Lecture 1 Computer Abstractions and Technology (Ch.1) Cristinel Ababei Department of Electrical and Computer Engineering Credits: Slides adapted primarily from presentations
COEN-4710 Computer Hardware Lecture 1 Computer Abstractions and Technology (Ch.1) Cristinel Ababei Department of Electrical and Computer Engineering Credits: Slides adapted primarily from presentations
InfiniBand Experiences of PC²
 InfiniBand Experiences of PC² Dr. Jens Simon simon@upb.de Paderborn Center for Parallel Computing (PC²) Universität Paderborn hpcline-infotag, 18. Mai 2004 PC² - Paderborn Center for Parallel Computing
InfiniBand Experiences of PC² Dr. Jens Simon simon@upb.de Paderborn Center for Parallel Computing (PC²) Universität Paderborn hpcline-infotag, 18. Mai 2004 PC² - Paderborn Center for Parallel Computing
Dheeraj Bhardwaj May 12, 2003
 HPC Systems and Models Dheeraj Bhardwaj Department of Computer Science & Engineering Indian Institute of Technology, Delhi 110 016 India http://www.cse.iitd.ac.in/~dheerajb 1 Sequential Computers Traditional
HPC Systems and Models Dheeraj Bhardwaj Department of Computer Science & Engineering Indian Institute of Technology, Delhi 110 016 India http://www.cse.iitd.ac.in/~dheerajb 1 Sequential Computers Traditional
Distributed Systems. Thoai Nam Faculty of Computer Science and Engineering HCMC University of Technology
 Distributed Systems Thoai Nam Faculty of Computer Science and Engineering HCMC University of Technology Chapter 1: Introduction Distributed Systems Hardware & software Transparency Scalability Distributed
Distributed Systems Thoai Nam Faculty of Computer Science and Engineering HCMC University of Technology Chapter 1: Introduction Distributed Systems Hardware & software Transparency Scalability Distributed
Networks. Distributed Systems. Philipp Kupferschmied. Universität Karlsruhe, System Architecture Group. May 6th, 2009
 Networks Distributed Systems Philipp Kupferschmied Universität Karlsruhe, System Architecture Group May 6th, 2009 Philipp Kupferschmied Networks 1/ 41 1 Communication Basics Introduction Layered Communication
Networks Distributed Systems Philipp Kupferschmied Universität Karlsruhe, System Architecture Group May 6th, 2009 Philipp Kupferschmied Networks 1/ 41 1 Communication Basics Introduction Layered Communication
Outline. Distributed Shared Memory. Shared Memory. ECE574 Cluster Computing. Dichotomy of Parallel Computing Platforms (Continued)
") Cluster Computing Dichotomy of Parallel Computing Platforms (Continued) Lecturer: Dr Yifeng Zhu Class Review Interconnections Crossbar» Example: myrinet Multistage» Example: Omega network Outline Flynn
Cluster Computing Dichotomy of Parallel Computing Platforms (Continued) Lecturer: Dr Yifeng Zhu Class Review Interconnections Crossbar» Example: myrinet Multistage» Example: Omega network Outline Flynn
Serial. Parallel. CIT 668: System Architecture 2/14/2011. Topics. Serial and Parallel Computation. Parallel Computing
 CIT 668: System Architecture Parallel Computing Topics 1. What is Parallel Computing? 2. Why use Parallel Computing? 3. Types of Parallelism 4. Amdahl s Law 5. Flynn s Taxonomy of Parallel Computers 6.
CIT 668: System Architecture Parallel Computing Topics 1. What is Parallel Computing? 2. Why use Parallel Computing? 3. Types of Parallelism 4. Amdahl s Law 5. Flynn s Taxonomy of Parallel Computers 6.
CSC630/CSC730: Parallel Computing
 CSC630/CSC730: Parallel Computing Parallel Computing Platforms Chapter 2 (2.4.1 2.4.4) Dr. Joe Zhang PDC-4: Topology 1 Content Parallel computing platforms Logical organization (a programmer s view) Control
CSC630/CSC730: Parallel Computing Parallel Computing Platforms Chapter 2 (2.4.1 2.4.4) Dr. Joe Zhang PDC-4: Topology 1 Content Parallel computing platforms Logical organization (a programmer s view) Control
Parallel Processors. Session 1 Introduction
 Parallel Processors Session 1 Introduction Applications of Parallel Processors Structural Analysis Weather Forecasting Petroleum Exploration Fusion Energy Research Medical Diagnosis Aerodynamics Simulations
Parallel Processors Session 1 Introduction Applications of Parallel Processors Structural Analysis Weather Forecasting Petroleum Exploration Fusion Energy Research Medical Diagnosis Aerodynamics Simulations
Non-uniform memory access machine or (NUMA) is a system where the memory access time to any region of memory is not the same for all processors.
 is a system where the memory access time to any region of memory is not the same for all processors.") CS 320 Ch. 17 Parallel Processing Multiple Processor Organization The author makes the statement: "Processors execute programs by executing machine instructions in a sequence one at a time." He also says
CS 320 Ch. 17 Parallel Processing Multiple Processor Organization The author makes the statement: "Processors execute programs by executing machine instructions in a sequence one at a time." He also says
Interconnect Technology and Computational Speed
 Interconnect Technology and Computational Speed From Chapter 1 of B. Wilkinson et al., PARAL- LEL PROGRAMMING. Techniques and Applications Using Networked Workstations and Parallel Computers, augmented
Interconnect Technology and Computational Speed From Chapter 1 of B. Wilkinson et al., PARAL- LEL PROGRAMMING. Techniques and Applications Using Networked Workstations and Parallel Computers, augmented
Top500 Supercomputer list
 Top500 Supercomputer list Tends to represent parallel computers, so distributed systems such as SETI@Home are neglected. Does not consider storage or I/O issues Both custom designed machines and commodity
Top500 Supercomputer list Tends to represent parallel computers, so distributed systems such as SETI@Home are neglected. Does not consider storage or I/O issues Both custom designed machines and commodity
ARCHITECTURAL CLASSIFICATION. Mariam A. Salih
 ARCHITECTURAL CLASSIFICATION Mariam A. Salih Basic types of architectural classification FLYNN S TAXONOMY OF COMPUTER ARCHITECTURE FENG S CLASSIFICATION Handler Classification Other types of architectural
ARCHITECTURAL CLASSIFICATION Mariam A. Salih Basic types of architectural classification FLYNN S TAXONOMY OF COMPUTER ARCHITECTURE FENG S CLASSIFICATION Handler Classification Other types of architectural
CSCI 4717 Computer Architecture
 CSCI 4717/5717 Computer Architecture Topic: Symmetric Multiprocessors & Clusters Reading: Stallings, Sections 18.1 through 18.4 Classifications of Parallel Processing M. Flynn classified types of parallel
CSCI 4717/5717 Computer Architecture Topic: Symmetric Multiprocessors & Clusters Reading: Stallings, Sections 18.1 through 18.4 Classifications of Parallel Processing M. Flynn classified types of parallel
Multiprocessors & Thread Level Parallelism
 Multiprocessors & Thread Level Parallelism COE 403 Computer Architecture Prof. Muhamed Mudawar Computer Engineering Department King Fahd University of Petroleum and Minerals Presentation Outline Introduction
Multiprocessors & Thread Level Parallelism COE 403 Computer Architecture Prof. Muhamed Mudawar Computer Engineering Department King Fahd University of Petroleum and Minerals Presentation Outline Introduction
TDT Appendix E Interconnection Networks
 TDT 4260 Appendix E Interconnection Networks Review Advantages of a snooping coherency protocol? Disadvantages of a snooping coherency protocol? Advantages of a directory coherency protocol? Disadvantages
TDT 4260 Appendix E Interconnection Networks Review Advantages of a snooping coherency protocol? Disadvantages of a snooping coherency protocol? Advantages of a directory coherency protocol? Disadvantages
Introduction to Multiprocessors (Part I) Prof. Cristina Silvano Politecnico di Milano
 Prof. Cristina Silvano Politecnico di Milano") Introduction to Multiprocessors (Part I) Prof. Cristina Silvano Politecnico di Milano Outline Key issues to design multiprocessors Interconnection network Centralized shared-memory architectures Distributed
Introduction to Multiprocessors (Part I) Prof. Cristina Silvano Politecnico di Milano Outline Key issues to design multiprocessors Interconnection network Centralized shared-memory architectures Distributed
Chapter 11. Introduction to Multiprocessors
 Chapter 11 Introduction to Multiprocessors 11.1 Introduction A multiple processor system consists of two or more processors that are connected in a manner that allows them to share the simultaneous (parallel)
Chapter 11 Introduction to Multiprocessors 11.1 Introduction A multiple processor system consists of two or more processors that are connected in a manner that allows them to share the simultaneous (parallel)
Low Cost Supercomputing. Rajkumar Buyya, Monash University, Melbourne, Australia. Parallel Processing on Linux Clusters
 N Low Cost Supercomputing o Parallel Processing on Linux Clusters Rajkumar Buyya, Monash University, Melbourne, Australia. rajkumar@ieee.org http://www.dgs.monash.edu.au/~rajkumar Agenda Cluster? Enabling
N Low Cost Supercomputing o Parallel Processing on Linux Clusters Rajkumar Buyya, Monash University, Melbourne, Australia. rajkumar@ieee.org http://www.dgs.monash.edu.au/~rajkumar Agenda Cluster? Enabling
Concepts of Distributed Systems 2006/2007
 Concepts of Distributed Systems 2006/2007 Introduction & overview Johan Lukkien 1 Introduction & overview Communication Distributed OS & Processes Synchronization Security Consistency & replication Programme
Concepts of Distributed Systems 2006/2007 Introduction & overview Johan Lukkien 1 Introduction & overview Communication Distributed OS & Processes Synchronization Security Consistency & replication Programme
Multiprocessors and Thread Level Parallelism Chapter 4, Appendix H CS448. The Greed for Speed
 Multiprocessors and Thread Level Parallelism Chapter 4, Appendix H CS448 1 The Greed for Speed Two general approaches to making computers faster Faster uniprocessor All the techniques we ve been looking
Multiprocessors and Thread Level Parallelism Chapter 4, Appendix H CS448 1 The Greed for Speed Two general approaches to making computers faster Faster uniprocessor All the techniques we ve been looking
CS4961 Parallel Programming. Lecture 3: Introduction to Parallel Architectures 8/30/11. Administrative UPDATE. Mary Hall August 30, 2011
 CS4961 Parallel Programming Lecture 3: Introduction to Parallel Architectures Administrative UPDATE Nikhil office hours: - Monday, 2-3 PM, MEB 3115 Desk #12 - Lab hours on Tuesday afternoons during programming
CS4961 Parallel Programming Lecture 3: Introduction to Parallel Architectures Administrative UPDATE Nikhil office hours: - Monday, 2-3 PM, MEB 3115 Desk #12 - Lab hours on Tuesday afternoons during programming
Physical Organization of Parallel Platforms. Alexandre David
 Physical Organization of Parallel Platforms Alexandre David 1.2.05 1 Static vs. Dynamic Networks 13-02-2008 Alexandre David, MVP'08 2 Interconnection networks built using links and switches. How to connect:
Physical Organization of Parallel Platforms Alexandre David 1.2.05 1 Static vs. Dynamic Networks 13-02-2008 Alexandre David, MVP'08 2 Interconnection networks built using links and switches. How to connect:
TDP3471 Distributed and Parallel Computing
 TDP3471 Distributed and Parallel Computing Lecture 1 Dr. Ian Chai ianchai@mmu.edu.my FIT Building: Room BR1024 Office : 03-8312-5379 Schedule for Dr. Ian (including consultation hours) available at http://pesona.mmu.edu.my/~ianchai/schedule.pdf
TDP3471 Distributed and Parallel Computing Lecture 1 Dr. Ian Chai ianchai@mmu.edu.my FIT Building: Room BR1024 Office : 03-8312-5379 Schedule for Dr. Ian (including consultation hours) available at http://pesona.mmu.edu.my/~ianchai/schedule.pdf