Lecture 27: Pot-Pourri. Today s topics: Shared memory vs message-passing Simultaneous multi-threading (SMT) GPUs Disks and reliability
|
|
|
- Jesse Parker
- 6 years ago
- Views:
Transcription
1 Lecture 27: Pot-Pourri Today s topics: Shared memory vs message-passing Simultaneous multi-threading (SMT) GPUs Disks and reliability 1
2 Shared-Memory Vs. Message-Passing Shared-memory: Well-understood programming model Communication is implicit and hardware handles protection Hardware-controlled caching Message-passing: No cache coherence simpler hardware Explicit communication easier for the programmer to restructure code Software-controlled caching Sender can initiate data transfer 2
3 Ocean Kernel Procedure Solve(A) begin diff = done = 0; while (!done) do diff = 0; for i 1 to n do for j 1 to n do temp = A[i,j]; A[i,j] 0.2 * (A[i,j] + neighbors); diff += abs(a[i,j] temp); end for end for if (diff < TOL) then done = 1; end while end procedure.. Row 1 Row k Row 2k Row 3k 3
4 Shared Address Space Model int n, nprocs; float **A, diff; LOCKDEC(diff_lock); BARDEC(bar1); main() begin read(n); read(nprocs); A G_MALLOC(); initialize (A); CREATE (nprocs,solve,a); WAIT_FOR_END (nprocs); end main procedure Solve(A) int i, j, pid, done=0; float temp, mydiff=0; int mymin = 1 + (pid * n/procs); int mymax = mymin + n/nprocs -1; while (!done) do mydiff = diff = 0; BARRIER(bar1,nprocs); for i mymin to mymax for j 1 to n do endfor endfor LOCK(diff_lock); diff += mydiff; UNLOCK(diff_lock); BARRIER (bar1, nprocs); if (diff < TOL) then done = 1; BARRIER (bar1, nprocs); endwhile 4
5 Message Passing Model main() read(n); read(nprocs); CREATE (nprocs-1, Solve); Solve(); WAIT_FOR_END (nprocs-1); procedure Solve() int i, j, pid, nn = n/nprocs, done=0; float temp, tempdiff, mydiff = 0; mya malloc( ) initialize(mya); while (!done) do mydiff = 0; if (pid!= 0) SEND(&myA[1,0], n, pid-1, ROW); if (pid!= nprocs-1) SEND(&myA[nn,0], n, pid+1, ROW); if (pid!= 0) RECEIVE(&myA[0,0], n, pid-1, ROW); if (pid!= nprocs-1) RECEIVE(&myA[nn+1,0], n, pid+1, ROW); for i 1 to nn do for j 1 to n do endfor endfor if (pid!= 0) SEND(mydiff, 1, 0, DIFF); RECEIVE(done, 1, 0, DONE); else for i 1 to nprocs-1 do RECEIVE(tempdiff, 1, *, DIFF); mydiff += tempdiff; endfor if (mydiff < TOL) done = 1; for i 1 to nprocs-1 do SEND(done, 1, I, DONE); endfor endif endwhile 5
6 Multithreading Within a Processor Until now, we have executed multiple threads of an application on different processors can multiple threads execute concurrently on the same processor? Why is this desireable? inexpensive one CPU, no external interconnects no remote or coherence misses (more capacity misses) Why does this make sense? most processors can t find enough work peak IPC is 6, average IPC is 1.5! threads can share resources we can increase threads without a corresponding linear increase in area 6
7 How are Resources Shared? Each box represents an issue slot for a functional unit. Peak thruput is 4 IPC. Thread 1 Thread 2 Cycles Thread 3 Thread 4 Superscalar Fine-Grained Multithreading Simultaneous Multithreading Idle Superscalar processor has high under-utilization not enough work every cycle, especially when there is a cache miss Fine-grained multithreading can only issue instructions from a single thread in a cycle can not find max work every cycle, but cache misses can be tolerated Simultaneous multithreading can issue instructions from any thread every cycle has the highest probability of finding work for every issue slot 7
8 Performance Implications of SMT Single thread performance is likely to go down (caches, branch predictors, registers, etc. are shared) this effect can be mitigated by trying to prioritize one thread With eight threads in a processor with many resources, SMT yields throughput improvements of roughly 2-4 8
9 SIMD Processors Single instruction, multiple data Such processors offer energy efficiency because a single instruction fetch can trigger many data operations Such data parallelism may be useful for many image/sound and numerical applications 9
10 GPUs Initially developed as graphics accelerators; now viewed as one of the densest compute engines available Many on-going efforts to run non-graphics workloads on GPUs, i.e., use them as general-purpose GPUs or GPGPUs C/C++ based programming platforms enable wider use of GPGPUs CUDA from NVidia and OpenCL from an industry consortium A heterogeneous system has a regular host CPU and a GPU that handles (say) CUDA code (they can both be on the same chip) 10
11 The GPU Architecture SIMT single instruction, multiple thread; a GPU has many SIMT cores A large data-parallel operation is partitioned into many thread blocks (one per SIMT core); a thread block is partitioned into many warps (one warp running at a time in the SIMT core); a warp is partitioned across many in-order pipelines (each is called a SIMD lane) A SIMT core can have multiple active warps at a time, i.e., the SIMT core stores the registers for each warp; warps can be context-switched at low cost; a warp scheduler keeps track of runnable warps and schedules a new warp if the currently running warp stalls 11
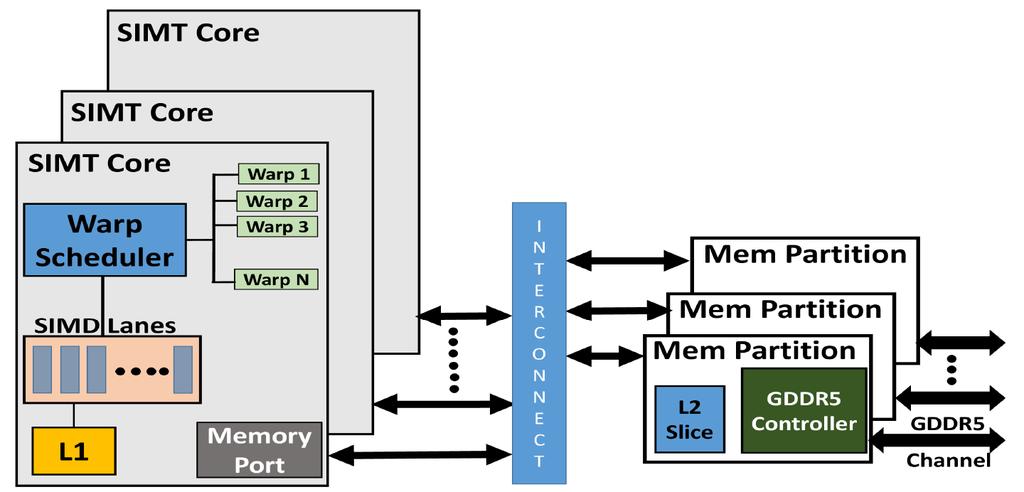
12 The GPU Architecture 12
13 Architecture Features Simple in-order pipelines that rely on thread-level parallelism to hide long latencies Many registers (~1K) per in-order pipeline (lane) to support many active warps When a branch is encountered, some of the lanes proceed along the then case depending on their data values; later, the other lanes evaluate the else case; a branch cuts the data-level parallelism by half (branch divergence) When a load/store is encountered, the requests from all lanes are coalesced into a few 128B cache line requests; each request may return at a different time (mem divergence) 13
14 GPU Memory Hierarchy Each SIMT core has a private L1 cache (shared by the warps on that core) A large L2 is shared by all SIMT cores; each L2 bank services a subset of all addresses Each L2 partition is connected to its own memory controller and memory channel The GDDR5 memory system runs at higher frequencies, and uses chips with more banks, wide IO, and better power delivery networks A portion of GDDR5 memory is private to the GPU and the rest is accessible to the host CPU (the GPU performs copies) 14
15 Role of Disks Activities external to the CPU/memory are typically orders of magnitude slower Example: while CPU performance has improved by 50% per year, disk latencies have improved by 10% every year Typical strategy on I/O: switch contexts and work on something else Other metrics, such as bandwidth, reliability, availability, and capacity, often receive more attention than performance 15
16 Magnetic Disks A magnetic disk consists of 1-12 platters (metal or glass disk covered with magnetic recording material on both sides), with diameters between inches Each platter is comprised of concentric tracks (5-30K) and each track is divided into sectors ( per track, each about 512 bytes) A movable arm holds the read/write heads for each disk surface and moves them all in tandem a cylinder of data is accessible at a time 16
17 Disk Latency To read/write data, the arm has to be placed on the correct track this seek time usually takes 5 to 12 ms on average can take less if there is spatial locality Rotational latency is the time taken to rotate the correct sector under the head average is typically more than 2 ms (15,000 RPM) Transfer time is the time taken to transfer a block of bits out of the disk and is typically 3 65 MB/second A disk controller maintains a disk cache (spatial locality can be exploited) and sets up the transfer on the bus (controller overhead) 17
18 Defining Reliability and Availability A system toggles between Service accomplishment: service matches specifications Service interruption: service deviates from specs The toggle is caused by failures and restorations Reliability measures continuous service accomplishment and is usually expressed as mean time to failure (MTTF) Availability measures fraction of time that service matches specifications, expressed as MTTF / (MTTF + MTTR) 18
19 RAID Reliability and availability are important metrics for disks RAID: redundant array of inexpensive (independent) disks Redundancy can deal with one or more failures Each sector of a disk records check information that allows it to determine if the disk has an error or not (in other words, redundancy already exists within a disk) When the disk read flags an error, we turn elsewhere for correct data 19
20 RAID 0 and RAID 1 RAID 0 has no additional redundancy (misnomer) it uses an array of disks and stripes (interleaves) data across the arrays to improve parallelism and throughput RAID 1 mirrors or shadows every disk every write happens to two disks Reads to the mirror may happen only when the primary disk fails or, you may try to read both together and the quicker response is accepted Expensive solution: high reliability at twice the cost 20
21 RAID 3 Data is bit-interleaved across several disks and a separate disk maintains parity information for a set of bits For example: with 8 disks, bit 0 is in disk-0, bit 1 is in disk-1,, bit 7 is in disk-7; disk-8 maintains parity for all 8 bits For any read, 8 disks must be accessed (as we usually read more than a byte at a time) and for any write, 9 disks must be accessed as parity has to be re-calculated High throughput for a single request, low cost for redundancy (overhead: 12.5%), low task-level parallelism 21
22 RAID 4 and RAID 5 Data is block interleaved this allows us to get all our data from a single disk on a read in case of a disk error, read all 9 disks Block interleaving reduces thruput for a single request (as only a single disk drive is servicing the request), but improves task-level parallelism as other disk drives are free to service other requests On a write, we access the disk that stores the data and the parity disk parity information can be updated simply by checking if the new data differs from the old data 22
23 RAID 5 If we have a single disk for parity, multiple writes can not happen in parallel (as all writes must update parity info) RAID 5 distributes the parity block to allow simultaneous writes 23
24 RAID Summary RAID 1-5 can tolerate a single fault mirroring (RAID 1) has a 100% overhead, while parity (RAID 3, 4, 5) has modest overhead Can tolerate multiple faults by having multiple check functions each additional check can cost an additional disk (RAID 6) RAID 6 and RAID 2 (memory-style ECC) are not commercially employed 24
25 Memory Protection Most common approach: SECDED single error correction, double error detection an 8-bit code for every 64-bit word -- can correct a single error in any 64-bit word also used in caches Extends a 64-bit memory channel to a 72-bit channel and requires ECC DIMMs (e.g., a word is fetched from 9 chips instead of 8) Chipkill is a form of error protection where failures in an entire memory chip can be corrected 25
26 Computation Errors TMR Errors in ALUs and cores are typically handled by performing the computation n times and voting for the correct answer n=3 is common and is referred to as triple modular redundancy 26
27 Title Bullet 27
Lecture 27: Multiprocessors. Today s topics: Shared memory vs message-passing Simultaneous multi-threading (SMT) GPUs
 GPUs") Lecture 27: Multiprocessors Today s topics: Shared memory vs message-passing Simultaneous multi-threading (SMT) GPUs 1 Shared-Memory Vs. Message-Passing Shared-memory: Well-understood programming model
Lecture 27: Multiprocessors Today s topics: Shared memory vs message-passing Simultaneous multi-threading (SMT) GPUs 1 Shared-Memory Vs. Message-Passing Shared-memory: Well-understood programming model
Lecture: Storage, GPUs. Topics: disks, RAID, reliability, GPUs (Appendix D, Ch 4)
") Lecture: Storage, GPUs Topics: disks, RAID, reliability, GPUs (Appendix D, Ch 4) 1 Magnetic Disks A magnetic disk consists of 1-12 platters (metal or glass disk covered with magnetic recording material
Lecture: Storage, GPUs Topics: disks, RAID, reliability, GPUs (Appendix D, Ch 4) 1 Magnetic Disks A magnetic disk consists of 1-12 platters (metal or glass disk covered with magnetic recording material
Lecture 26: Multiprocessors. Today s topics: Synchronization Consistency Shared memory vs message-passing
 Lecture 26: Multiprocessors Today s topics: Synchronization Consistency Shared memory vs message-passing 1 Constructing Locks Applications have phases (consisting of many instructions) that must be executed
Lecture 26: Multiprocessors Today s topics: Synchronization Consistency Shared memory vs message-passing 1 Constructing Locks Applications have phases (consisting of many instructions) that must be executed
Lecture 18: Shared-Memory Multiprocessors. Topics: coherence protocols for symmetric shared-memory multiprocessors (Sections
 Lecture 18: Shared-Memory Multiprocessors Topics: coherence protocols for symmetric shared-memory multiprocessors (Sections 4.1-4.2) 1 Ocean Kernel Procedure Solve(A) begin diff = done = 0; while (!done)
Lecture 18: Shared-Memory Multiprocessors Topics: coherence protocols for symmetric shared-memory multiprocessors (Sections 4.1-4.2) 1 Ocean Kernel Procedure Solve(A) begin diff = done = 0; while (!done)
Lecture 17: Multiprocessors. Topics: multiprocessor intro and taxonomy, symmetric shared-memory multiprocessors (Sections )
") Lecture 17: Multiprocessors Topics: multiprocessor intro and taxonomy, symmetric shared-memory multiprocessors (Sections 4.1-4.2) 1 Taxonomy SISD: single instruction and single data stream: uniprocessor
Lecture 17: Multiprocessors Topics: multiprocessor intro and taxonomy, symmetric shared-memory multiprocessors (Sections 4.1-4.2) 1 Taxonomy SISD: single instruction and single data stream: uniprocessor
Lecture 26: Multiprocessors. Today s topics: Directory-based coherence Synchronization Consistency Shared memory vs message-passing
 Lecture 26: Multiprocessors Today s topics: Directory-based coherence Synchronization Consistency Shared memory vs message-passing 1 Cache Coherence Protocols Directory-based: A single location (directory)
Lecture 26: Multiprocessors Today s topics: Directory-based coherence Synchronization Consistency Shared memory vs message-passing 1 Cache Coherence Protocols Directory-based: A single location (directory)
Lecture: Memory Technology Innovations
 Lecture: Memory Technology Innovations Topics: state-of-the-art and upcoming changes: buffer chips, 3D stacking, non-volatile cells, photonics Multiprocessor intro 1 Modern Memory System...... PROC.. 4
Lecture: Memory Technology Innovations Topics: state-of-the-art and upcoming changes: buffer chips, 3D stacking, non-volatile cells, photonics Multiprocessor intro 1 Modern Memory System...... PROC.. 4
Lecture: Memory, Coherence Protocols. Topics: wrap-up of memory systems, intro to multi-thread programming models
 Lecture: Memory, Coherence Protocols Topics: wrap-up of memory systems, intro to multi-thread programming models 1 Refresh Every DRAM cell must be refreshed within a 64 ms window A row read/write automatically
Lecture: Memory, Coherence Protocols Topics: wrap-up of memory systems, intro to multi-thread programming models 1 Refresh Every DRAM cell must be refreshed within a 64 ms window A row read/write automatically
Lecture: Coherence Protocols. Topics: wrap-up of memory systems, multi-thread programming models, snooping-based protocols
 Lecture: Coherence Protocols Topics: wrap-up of memory systems, multi-thread programming models, snooping-based protocols 1 Future Memory Trends pin count is not increasing High memory bandwidth requires
Lecture: Coherence Protocols Topics: wrap-up of memory systems, multi-thread programming models, snooping-based protocols 1 Future Memory Trends pin count is not increasing High memory bandwidth requires
Lecture: Memory, Coherence Protocols. Topics: wrap-up of memory systems, multi-thread programming models, snooping-based protocols
 Lecture: Memory, Coherence Protocols Topics: wrap-up of memory systems, multi-thread programming models, snooping-based protocols 1 Modern Memory System...... PROC.. 4 DDR3 channels 64-bit data channels
Lecture: Memory, Coherence Protocols Topics: wrap-up of memory systems, multi-thread programming models, snooping-based protocols 1 Modern Memory System...... PROC.. 4 DDR3 channels 64-bit data channels
Lecture 23: Storage Systems. Topics: disk access, bus design, evaluation metrics, RAID (Sections )
") Lecture 23: Storage Systems Topics: disk access, bus design, evaluation metrics, RAID (Sections 7.1-7.9) 1 Role of I/O Activities external to the CPU are typically orders of magnitude slower Example: while
Lecture 23: Storage Systems Topics: disk access, bus design, evaluation metrics, RAID (Sections 7.1-7.9) 1 Role of I/O Activities external to the CPU are typically orders of magnitude slower Example: while
Lecture: Coherence Protocols. Topics: wrap-up of memory systems, multi-thread programming models, snooping-based protocols
 Lecture: Coherence Protocols Topics: wrap-up of memory systems, multi-thread programming models, snooping-based protocols 1 Future Memory Trends pin count is not increasing High memory bandwidth requires
Lecture: Coherence Protocols Topics: wrap-up of memory systems, multi-thread programming models, snooping-based protocols 1 Future Memory Trends pin count is not increasing High memory bandwidth requires
Lecture 25: Interconnection Networks, Disks. Topics: flow control, router microarchitecture, RAID
 Lecture 25: Interconnection Networks, Disks Topics: flow control, router microarchitecture, RAID 1 Virtual Channel Flow Control Each switch has multiple virtual channels per phys. channel Each virtual
Lecture 25: Interconnection Networks, Disks Topics: flow control, router microarchitecture, RAID 1 Virtual Channel Flow Control Each switch has multiple virtual channels per phys. channel Each virtual
Flynn's Classification
 Multiprocessors Oracles's SPARC M7-32 core, 64MB L3 cache (8 x 8 MB), 1.6TB/s. 256 KB of 4-way SA L2 ICache, 0.5 TB/s per cluster. 2 cores share 256 KB, 8-way SA L2 DCache, 0.5 TB/s. Flynn's Classification
Multiprocessors Oracles's SPARC M7-32 core, 64MB L3 cache (8 x 8 MB), 1.6TB/s. 256 KB of 4-way SA L2 ICache, 0.5 TB/s per cluster. 2 cores share 256 KB, 8-way SA L2 DCache, 0.5 TB/s. Flynn's Classification
Lecture 1: Introduction
 Lecture 1: Introduction ourse organization: 13 lectures on parallel architectures ~5 lectures on cache coherence, consistency ~3 lectures on TM ~2 lectures on interconnection networks ~2 lectures on large
Lecture 1: Introduction ourse organization: 13 lectures on parallel architectures ~5 lectures on cache coherence, consistency ~3 lectures on TM ~2 lectures on interconnection networks ~2 lectures on large
Lecture 2: Parallel Programs. Topics: consistency, parallel applications, parallelization process
 Lecture 2: Parallel Programs Topics: consistency, parallel applications, parallelization process 1 Sequential Consistency A multiprocessor is sequentially consistent if the result of the execution is achievable
Lecture 2: Parallel Programs Topics: consistency, parallel applications, parallelization process 1 Sequential Consistency A multiprocessor is sequentially consistent if the result of the execution is achievable
Lecture: Networks, Disks, Datacenters, GPUs. Topics: networks wrap-up, disks and reliability, datacenters, GPU intro (Sections
 Lecture: Networks, Disks, Datacenters, GPUs Topics: networks wrap-up, disks and reliability, datacenters, GPU intro (Sections 6.1-6.7, App D, Ch 4) 1 Packets/Flits A message is broken into multiple packets
Lecture: Networks, Disks, Datacenters, GPUs Topics: networks wrap-up, disks and reliability, datacenters, GPU intro (Sections 6.1-6.7, App D, Ch 4) 1 Packets/Flits A message is broken into multiple packets
Parallelization of an Example Program
 Parallelization of an Example Program [ 2.3] In this lecture, we will consider a parallelization of the kernel of the Ocean application. Goals: Illustrate parallel programming in a low-level parallel language.
Parallelization of an Example Program [ 2.3] In this lecture, we will consider a parallelization of the kernel of the Ocean application. Goals: Illustrate parallel programming in a low-level parallel language.
I/O CANNOT BE IGNORED
 LECTURE 13 I/O I/O CANNOT BE IGNORED Assume a program requires 100 seconds, 90 seconds for main memory, 10 seconds for I/O. Assume main memory access improves by ~10% per year and I/O remains the same.
LECTURE 13 I/O I/O CANNOT BE IGNORED Assume a program requires 100 seconds, 90 seconds for main memory, 10 seconds for I/O. Assume main memory access improves by ~10% per year and I/O remains the same.
Simulating ocean currents
 Simulating ocean currents We will study a parallel application that simulates ocean currents. Goal: Simulate the motion of water currents in the ocean. Important to climate modeling. Motion depends on
Simulating ocean currents We will study a parallel application that simulates ocean currents. Goal: Simulate the motion of water currents in the ocean. Important to climate modeling. Motion depends on
I/O CANNOT BE IGNORED
 LECTURE 13 I/O I/O CANNOT BE IGNORED Assume a program requires 100 seconds, 90 seconds for main memory, 10 seconds for I/O. Assume main memory access improves by ~10% per year and I/O remains the same.
LECTURE 13 I/O I/O CANNOT BE IGNORED Assume a program requires 100 seconds, 90 seconds for main memory, 10 seconds for I/O. Assume main memory access improves by ~10% per year and I/O remains the same.
Lect. 2: Types of Parallelism
 Lect. 2: Types of Parallelism Parallelism in Hardware (Uniprocessor) Parallelism in a Uniprocessor Pipelining Superscalar, VLIW etc. SIMD instructions, Vector processors, GPUs Multiprocessor Symmetric
Lect. 2: Types of Parallelism Parallelism in Hardware (Uniprocessor) Parallelism in a Uniprocessor Pipelining Superscalar, VLIW etc. SIMD instructions, Vector processors, GPUs Multiprocessor Symmetric
Lecture 11: SMT and Caching Basics. Today: SMT, cache access basics (Sections 3.5, 5.1)
") Lecture 11: SMT and Caching Basics Today: SMT, cache access basics (Sections 3.5, 5.1) 1 Thread-Level Parallelism Motivation: a single thread leaves a processor under-utilized for most of the time by doubling
Lecture 11: SMT and Caching Basics Today: SMT, cache access basics (Sections 3.5, 5.1) 1 Thread-Level Parallelism Motivation: a single thread leaves a processor under-utilized for most of the time by doubling
Lecture: SMT, Cache Hierarchies. Topics: SMT processors, cache access basics and innovations (Sections B.1-B.3, 2.1)
") Lecture: SMT, Cache Hierarchies Topics: SMT processors, cache access basics and innovations (Sections B.1-B.3, 2.1) 1 Thread-Level Parallelism Motivation: a single thread leaves a processor under-utilized
Lecture: SMT, Cache Hierarchies Topics: SMT processors, cache access basics and innovations (Sections B.1-B.3, 2.1) 1 Thread-Level Parallelism Motivation: a single thread leaves a processor under-utilized
ECE7660 Parallel Computer Architecture. Perspective on Parallel Programming
 ECE7660 Parallel Computer Architecture Perspective on Parallel Programming Outline Motivating Problems (application case studies) Process of creating a parallel program What a simple parallel program looks
ECE7660 Parallel Computer Architecture Perspective on Parallel Programming Outline Motivating Problems (application case studies) Process of creating a parallel program What a simple parallel program looks
Chapter 6. Storage and Other I/O Topics
 Chapter 6 Storage and Other I/O Topics Introduction I/O devices can be characterized by Behaviour: input, output, storage Partner: human or machine Data rate: bytes/sec, transfers/sec I/O bus connections
Chapter 6 Storage and Other I/O Topics Introduction I/O devices can be characterized by Behaviour: input, output, storage Partner: human or machine Data rate: bytes/sec, transfers/sec I/O bus connections
Parallelization Principles. Sathish Vadhiyar
 Parallelization Principles Sathish Vadhiyar Parallel Programming and Challenges Recall the advantages and motivation of parallelism But parallel programs incur overheads not seen in sequential programs
Parallelization Principles Sathish Vadhiyar Parallel Programming and Challenges Recall the advantages and motivation of parallelism But parallel programs incur overheads not seen in sequential programs
Parallel Processing SIMD, Vector and GPU s cont.
 Parallel Processing SIMD, Vector and GPU s cont. EECS4201 Fall 2016 York University 1 Multithreading First, we start with multithreading Multithreading is used in GPU s 2 1 Thread Level Parallelism ILP
Parallel Processing SIMD, Vector and GPU s cont. EECS4201 Fall 2016 York University 1 Multithreading First, we start with multithreading Multithreading is used in GPU s 2 1 Thread Level Parallelism ILP
Virtual Memory. Reading. Sections 5.4, 5.5, 5.6, 5.8, 5.10 (2) Lecture notes from MKP and S. Yalamanchili
 Lecture notes from MKP and S. Yalamanchili") Virtual Memory Lecture notes from MKP and S. Yalamanchili Sections 5.4, 5.5, 5.6, 5.8, 5.10 Reading (2) 1 The Memory Hierarchy ALU registers Cache Memory Memory Memory Managed by the compiler Memory Managed
Virtual Memory Lecture notes from MKP and S. Yalamanchili Sections 5.4, 5.5, 5.6, 5.8, 5.10 Reading (2) 1 The Memory Hierarchy ALU registers Cache Memory Memory Memory Managed by the compiler Memory Managed
Appendix D: Storage Systems
 Appendix D: Storage Systems Instructor: Josep Torrellas CS433 Copyright Josep Torrellas 1999, 2001, 2002, 2013 1 Storage Systems : Disks Used for long term storage of files temporarily store parts of pgm
Appendix D: Storage Systems Instructor: Josep Torrellas CS433 Copyright Josep Torrellas 1999, 2001, 2002, 2013 1 Storage Systems : Disks Used for long term storage of files temporarily store parts of pgm
UNIVERSITY OF MASSACHUSETTS Dept. of Electrical & Computer Engineering. Computer Architecture ECE 568
 UNIVERSITY OF MASSACHUSETTS Dept. of Electrical & Computer Engineering Computer Architecture ECE 568 Part 6 Input/Output Israel Koren ECE568/Koren Part.6. CPU performance keeps increasing 26 72-core Xeon
UNIVERSITY OF MASSACHUSETTS Dept. of Electrical & Computer Engineering Computer Architecture ECE 568 Part 6 Input/Output Israel Koren ECE568/Koren Part.6. CPU performance keeps increasing 26 72-core Xeon
Storage Systems : Disks and SSDs. Manu Awasthi CASS 2018
 Storage Systems : Disks and SSDs Manu Awasthi CASS 2018 Why study storage? Scalable High Performance Main Memory System Using Phase-Change Memory Technology, Qureshi et al, ISCA 2009 Trends Total amount
Storage Systems : Disks and SSDs Manu Awasthi CASS 2018 Why study storage? Scalable High Performance Main Memory System Using Phase-Change Memory Technology, Qureshi et al, ISCA 2009 Trends Total amount
Lecture: SMT, Cache Hierarchies. Topics: memory dependence wrap-up, SMT processors, cache access basics (Sections B.1-B.3, 2.1)
") Lecture: SMT, Cache Hierarchies Topics: memory dependence wrap-up, SMT processors, cache access basics (Sections B.1-B.3, 2.1) 1 Problem 3 Consider the following LSQ and when operands are available. Estimate
Lecture: SMT, Cache Hierarchies Topics: memory dependence wrap-up, SMT processors, cache access basics (Sections B.1-B.3, 2.1) 1 Problem 3 Consider the following LSQ and when operands are available. Estimate
Portland State University ECE 588/688. Graphics Processors
 Portland State University ECE 588/688 Graphics Processors Copyright by Alaa Alameldeen 2018 Why Graphics Processors? Graphics programs have different characteristics from general purpose programs Highly
Portland State University ECE 588/688 Graphics Processors Copyright by Alaa Alameldeen 2018 Why Graphics Processors? Graphics programs have different characteristics from general purpose programs Highly
Page 1. Magnetic Disk Purpose Long term, nonvolatile storage Lowest level in the memory hierarchy. Typical Disk Access Time
 Review: Major Components of a Computer Processor Control Datapath Cache Memory Main Memory Secondary Memory (Disk) Devices Output Input Magnetic Disk Purpose Long term, nonvolatile storage Lowest level
Review: Major Components of a Computer Processor Control Datapath Cache Memory Main Memory Secondary Memory (Disk) Devices Output Input Magnetic Disk Purpose Long term, nonvolatile storage Lowest level
Storage Systems. Storage Systems
 Storage Systems Storage Systems We already know about four levels of storage: Registers Cache Memory Disk But we've been a little vague on how these devices are interconnected In this unit, we study Input/output
Storage Systems Storage Systems We already know about four levels of storage: Registers Cache Memory Disk But we've been a little vague on how these devices are interconnected In this unit, we study Input/output
Storage. Hwansoo Han
 Storage Hwansoo Han I/O Devices I/O devices can be characterized by Behavior: input, out, storage Partner: human or machine Data rate: bytes/sec, transfers/sec I/O bus connections 2 I/O System Characteristics
Storage Hwansoo Han I/O Devices I/O devices can be characterized by Behavior: input, out, storage Partner: human or machine Data rate: bytes/sec, transfers/sec I/O bus connections 2 I/O System Characteristics
Administrivia. CMSC 411 Computer Systems Architecture Lecture 19 Storage Systems, cont. Disks (cont.) Disks - review
 Disks - review") Administrivia CMSC 411 Computer Systems Architecture Lecture 19 Storage Systems, cont. Homework #4 due Thursday answers posted soon after Exam #2 on Thursday, April 24 on memory hierarchy (Unit 4) and
Administrivia CMSC 411 Computer Systems Architecture Lecture 19 Storage Systems, cont. Homework #4 due Thursday answers posted soon after Exam #2 on Thursday, April 24 on memory hierarchy (Unit 4) and
Computer Organization and Structure. Bing-Yu Chen National Taiwan University
 Computer Organization and Structure Bing-Yu Chen National Taiwan University Storage and Other I/O Topics I/O Performance Measures Types and Characteristics of I/O Devices Buses Interfacing I/O Devices
Computer Organization and Structure Bing-Yu Chen National Taiwan University Storage and Other I/O Topics I/O Performance Measures Types and Characteristics of I/O Devices Buses Interfacing I/O Devices
Lecture: SMT, Cache Hierarchies. Topics: memory dependence wrap-up, SMT processors, cache access basics and innovations (Sections B.1-B.3, 2.
 Lecture: SMT, Cache Hierarchies Topics: memory dependence wrap-up, SMT processors, cache access basics and innovations (Sections B.1-B.3, 2.1) 1 Problem 0 Consider the following LSQ and when operands are
Lecture: SMT, Cache Hierarchies Topics: memory dependence wrap-up, SMT processors, cache access basics and innovations (Sections B.1-B.3, 2.1) 1 Problem 0 Consider the following LSQ and when operands are
UNIVERSITY OF MASSACHUSETTS Dept. of Electrical & Computer Engineering. Computer Architecture ECE 568
 UNIVERSITY OF MASSACHUSETTS Dept. of Electrical & Computer Engineering Computer Architecture ECE 568 Part 6 Input/Output Israel Koren ECE568/Koren Part.6. Motivation: Why Care About I/O? CPU Performance:
UNIVERSITY OF MASSACHUSETTS Dept. of Electrical & Computer Engineering Computer Architecture ECE 568 Part 6 Input/Output Israel Koren ECE568/Koren Part.6. Motivation: Why Care About I/O? CPU Performance:
Lecture: SMT, Cache Hierarchies. Topics: memory dependence wrap-up, SMT processors, cache access basics and innovations (Sections B.1-B.3, 2.
 Lecture: SMT, Cache Hierarchies Topics: memory dependence wrap-up, SMT processors, cache access basics and innovations (Sections B.1-B.3, 2.1) 1 Problem 1 Consider the following LSQ and when operands are
Lecture: SMT, Cache Hierarchies Topics: memory dependence wrap-up, SMT processors, cache access basics and innovations (Sections B.1-B.3, 2.1) 1 Problem 1 Consider the following LSQ and when operands are
Adapted from instructor s supplementary material from Computer. Patterson & Hennessy, 2008, MK]
![Adapted from instructor s supplementary material from Computer. Patterson & Hennessy, 2008, MK]](/thumbs/80/82108809.jpg "Adapted from instructor s supplementary material from Computer. Patterson & Hennessy, 2008, MK]") Lecture 17 Adapted from instructor s supplementary material from Computer Organization and Design, 4th Edition, Patterson & Hennessy, 2008, MK] SRAM / / Flash / RRAM / HDD SRAM / / Flash / RRAM/ HDD SRAM
Lecture 17 Adapted from instructor s supplementary material from Computer Organization and Design, 4th Edition, Patterson & Hennessy, 2008, MK] SRAM / / Flash / RRAM / HDD SRAM / / Flash / RRAM/ HDD SRAM
Storage systems. Computer Systems Architecture CMSC 411 Unit 6 Storage Systems. (Hard) Disks. Disk and Tape Technologies. Disks (cont.
 Disks. Disk and Tape Technologies. Disks (cont.") Computer Systems Architecture CMSC 4 Unit 6 Storage Systems Alan Sussman November 23, 2004 Storage systems We already know about four levels of storage: registers cache memory disk but we've been a little
Computer Systems Architecture CMSC 4 Unit 6 Storage Systems Alan Sussman November 23, 2004 Storage systems We already know about four levels of storage: registers cache memory disk but we've been a little
Storage System COSC UCB
 Storage System COSC4201 1 1999 UCB I/O and Disks Over the years much less attention was paid to I/O compared with CPU design. As frustrating as a CPU crash is, disk crash is a lot worse. Disks are mechanical
Storage System COSC4201 1 1999 UCB I/O and Disks Over the years much less attention was paid to I/O compared with CPU design. As frustrating as a CPU crash is, disk crash is a lot worse. Disks are mechanical
Modern Processor Architectures. L25: Modern Compiler Design
 Modern Processor Architectures L25: Modern Compiler Design The 1960s - 1970s Instructions took multiple cycles Only one instruction in flight at once Optimisation meant minimising the number of instructions
Modern Processor Architectures L25: Modern Compiler Design The 1960s - 1970s Instructions took multiple cycles Only one instruction in flight at once Optimisation meant minimising the number of instructions
Final Lecture. A few minutes to wrap up and add some perspective
 Final Lecture A few minutes to wrap up and add some perspective 1 2 Instant replay The quarter was split into roughly three parts and a coda. The 1st part covered instruction set architectures the connection
Final Lecture A few minutes to wrap up and add some perspective 1 2 Instant replay The quarter was split into roughly three parts and a coda. The 1st part covered instruction set architectures the connection
Adapted from David Patterson s slides on graduate computer architecture
 Mei Yang Adapted from David Patterson s slides on graduate computer architecture Introduction Ten Advanced Optimizations of Cache Performance Memory Technology and Optimizations Virtual Memory and Virtual
Mei Yang Adapted from David Patterson s slides on graduate computer architecture Introduction Ten Advanced Optimizations of Cache Performance Memory Technology and Optimizations Virtual Memory and Virtual
Some material adapted from Mohamed Younis, UMBC CMSC 611 Spr 2003 course slides Some material adapted from Hennessy & Patterson / 2003 Elsevier
 Some material adapted from Mohamed Younis, UMBC CMSC 6 Spr 23 course slides Some material adapted from Hennessy & Patterson / 23 Elsevier Science Characteristics IBM 39 IBM UltraStar Integral 82 Disk diameter
Some material adapted from Mohamed Younis, UMBC CMSC 6 Spr 23 course slides Some material adapted from Hennessy & Patterson / 23 Elsevier Science Characteristics IBM 39 IBM UltraStar Integral 82 Disk diameter
Course II Parallel Computer Architecture. Week 2-3 by Dr. Putu Harry Gunawan
 Course II Parallel Computer Architecture Week 2-3 by Dr. Putu Harry Gunawan www.phg-simulation-laboratory.com Review Review Review Review Review Review Review Review Review Review Review Review Processor
Course II Parallel Computer Architecture Week 2-3 by Dr. Putu Harry Gunawan www.phg-simulation-laboratory.com Review Review Review Review Review Review Review Review Review Review Review Review Processor
Chapter 6 Storage and Other I/O Topics
 Department of Electr rical Eng ineering, Chapter 6 Storage and Other I/O Topics 王振傑 (Chen-Chieh Wang) ccwang@mail.ee.ncku.edu.tw ncku edu Feng-Chia Unive ersity Outline 6.1 Introduction 6.2 Dependability,
Department of Electr rical Eng ineering, Chapter 6 Storage and Other I/O Topics 王振傑 (Chen-Chieh Wang) ccwang@mail.ee.ncku.edu.tw ncku edu Feng-Chia Unive ersity Outline 6.1 Introduction 6.2 Dependability,
Chapter 6. Storage and Other I/O Topics. ICE3003: Computer Architecture Fall 2012 Euiseong Seo
 Chapter 6 Storage and Other I/O Topics 1 Introduction I/O devices can be characterized by Behaviour: input, output, storage Partner: human or machine Data rate: bytes/sec, transfers/sec I/O bus connections
Chapter 6 Storage and Other I/O Topics 1 Introduction I/O devices can be characterized by Behaviour: input, output, storage Partner: human or machine Data rate: bytes/sec, transfers/sec I/O bus connections
Copyright 2012, Elsevier Inc. All rights reserved.
 Computer Architecture A Quantitative Approach, Fifth Edition Chapter 2 Memory Hierarchy Design 1 Introduction Programmers want unlimited amounts of memory with low latency Fast memory technology is more
Computer Architecture A Quantitative Approach, Fifth Edition Chapter 2 Memory Hierarchy Design 1 Introduction Programmers want unlimited amounts of memory with low latency Fast memory technology is more
UNIVERSITY OF MASSACHUSETTS Dept. of Electrical & Computer Engineering. Computer Architecture ECE 568
 UNIVERSITY OF MASSACHUSETTS Dept of Electrical & Computer Engineering Computer Architecture ECE 568 art 5 Input/Output Israel Koren ECE568/Koren art5 CU performance keeps increasing 26 72-core Xeon hi
UNIVERSITY OF MASSACHUSETTS Dept of Electrical & Computer Engineering Computer Architecture ECE 568 art 5 Input/Output Israel Koren ECE568/Koren art5 CU performance keeps increasing 26 72-core Xeon hi
GPU Performance Optimisation. Alan Gray EPCC The University of Edinburgh
 GPU Performance Optimisation EPCC The University of Edinburgh Hardware NVIDIA accelerated system: Memory Memory GPU vs CPU: Theoretical Peak capabilities NVIDIA Fermi AMD Magny-Cours (6172) Cores 448 (1.15GHz)
GPU Performance Optimisation EPCC The University of Edinburgh Hardware NVIDIA accelerated system: Memory Memory GPU vs CPU: Theoretical Peak capabilities NVIDIA Fermi AMD Magny-Cours (6172) Cores 448 (1.15GHz)
Input/Output. Today. Next. Principles of I/O hardware & software I/O software layers Disks. Protection & Security
 Input/Output Today Principles of I/O hardware & software I/O software layers Disks Next Protection & Security Operating Systems and I/O Two key operating system goals Control I/O devices Provide a simple,
Input/Output Today Principles of I/O hardware & software I/O software layers Disks Next Protection & Security Operating Systems and I/O Two key operating system goals Control I/O devices Provide a simple,
Chapter 6. Storage and Other I/O Topics
 Chapter 6 Storage and Other I/O Topics Introduction I/O devices can be characterized by Behaviour: input, output, storage Partner: human or machine Data rate: bytes/sec, transfers/sec I/O bus connections
Chapter 6 Storage and Other I/O Topics Introduction I/O devices can be characterized by Behaviour: input, output, storage Partner: human or machine Data rate: bytes/sec, transfers/sec I/O bus connections
Mass-Storage Structure
 CS 4410 Operating Systems Mass-Storage Structure Summer 2011 Cornell University 1 Today How is data saved in the hard disk? Magnetic disk Disk speed parameters Disk Scheduling RAID Structure 2 Secondary
CS 4410 Operating Systems Mass-Storage Structure Summer 2011 Cornell University 1 Today How is data saved in the hard disk? Magnetic disk Disk speed parameters Disk Scheduling RAID Structure 2 Secondary
Copyright 2012, Elsevier Inc. All rights reserved.
 Computer Architecture A Quantitative Approach, Fifth Edition Chapter 2 Memory Hierarchy Design 1 Introduction Introduction Programmers want unlimited amounts of memory with low latency Fast memory technology
Computer Architecture A Quantitative Approach, Fifth Edition Chapter 2 Memory Hierarchy Design 1 Introduction Introduction Programmers want unlimited amounts of memory with low latency Fast memory technology
Computer Architecture. A Quantitative Approach, Fifth Edition. Chapter 2. Memory Hierarchy Design. Copyright 2012, Elsevier Inc. All rights reserved.
 Computer Architecture A Quantitative Approach, Fifth Edition Chapter 2 Memory Hierarchy Design 1 Programmers want unlimited amounts of memory with low latency Fast memory technology is more expensive per
Computer Architecture A Quantitative Approach, Fifth Edition Chapter 2 Memory Hierarchy Design 1 Programmers want unlimited amounts of memory with low latency Fast memory technology is more expensive per
Concepts Introduced. I/O Cannot Be Ignored. Typical Collection of I/O Devices. I/O Issues
 Concepts Introduced I/O Cannot Be Ignored Assume a program requires 100 seconds, 90 seconds for accessing main memory and 10 seconds for I/O. I/O introduction magnetic disks ash memory communication with
Concepts Introduced I/O Cannot Be Ignored Assume a program requires 100 seconds, 90 seconds for accessing main memory and 10 seconds for I/O. I/O introduction magnetic disks ash memory communication with
250P: Computer Systems Architecture. Lecture 9: Out-of-order execution (continued) Anton Burtsev February, 2019
 Anton Burtsev February, 2019") 250P: Computer Systems Architecture Lecture 9: Out-of-order execution (continued) Anton Burtsev February, 2019 The Alpha 21264 Out-of-Order Implementation Reorder Buffer (ROB) Branch prediction and instr
250P: Computer Systems Architecture Lecture 9: Out-of-order execution (continued) Anton Burtsev February, 2019 The Alpha 21264 Out-of-Order Implementation Reorder Buffer (ROB) Branch prediction and instr
Lecture 23. Finish-up buses Storage
 Lecture 23 Finish-up buses Storage 1 Example Bus Problems, cont. 2) Assume the following system: A CPU and memory share a 32-bit bus running at 100MHz. The memory needs 50ns to access a 64-bit value from
Lecture 23 Finish-up buses Storage 1 Example Bus Problems, cont. 2) Assume the following system: A CPU and memory share a 32-bit bus running at 100MHz. The memory needs 50ns to access a 64-bit value from
Introduction to GPU programming with CUDA
 Introduction to GPU programming with CUDA Dr. Juan C Zuniga University of Saskatchewan, WestGrid UBC Summer School, Vancouver. June 12th, 2018 Outline 1 Overview of GPU computing a. what is a GPU? b. GPU
Introduction to GPU programming with CUDA Dr. Juan C Zuniga University of Saskatchewan, WestGrid UBC Summer School, Vancouver. June 12th, 2018 Outline 1 Overview of GPU computing a. what is a GPU? b. GPU
I/O, Disks, and RAID Yi Shi Fall Xi an Jiaotong University
 I/O, Disks, and RAID Yi Shi Fall 2017 Xi an Jiaotong University Goals for Today Disks How does a computer system permanently store data? RAID How to make storage both efficient and reliable? 2 What does
I/O, Disks, and RAID Yi Shi Fall 2017 Xi an Jiaotong University Goals for Today Disks How does a computer system permanently store data? RAID How to make storage both efficient and reliable? 2 What does
Computer Architecture Computer Science & Engineering. Chapter 6. Storage and Other I/O Topics BK TP.HCM
 Computer Architecture Computer Science & Engineering Chapter 6 Storage and Other I/O Topics Introduction I/O devices can be characterized by Behaviour: input, output, storage Partner: human or machine
Computer Architecture Computer Science & Engineering Chapter 6 Storage and Other I/O Topics Introduction I/O devices can be characterized by Behaviour: input, output, storage Partner: human or machine
Parallel Programming Principle and Practice. Lecture 9 Introduction to GPGPUs and CUDA Programming Model
 Parallel Programming Principle and Practice Lecture 9 Introduction to GPGPUs and CUDA Programming Model Outline Introduction to GPGPUs and Cuda Programming Model The Cuda Thread Hierarchy / Memory Hierarchy
Parallel Programming Principle and Practice Lecture 9 Introduction to GPGPUs and CUDA Programming Model Outline Introduction to GPGPUs and Cuda Programming Model The Cuda Thread Hierarchy / Memory Hierarchy
LECTURE 5: MEMORY HIERARCHY DESIGN
 LECTURE 5: MEMORY HIERARCHY DESIGN Abridged version of Hennessy & Patterson (2012):Ch.2 Introduction Programmers want unlimited amounts of memory with low latency Fast memory technology is more expensive
LECTURE 5: MEMORY HIERARCHY DESIGN Abridged version of Hennessy & Patterson (2012):Ch.2 Introduction Programmers want unlimited amounts of memory with low latency Fast memory technology is more expensive
CSCI-GA Database Systems Lecture 8: Physical Schema: Storage
 CSCI-GA.2433-001 Database Systems Lecture 8: Physical Schema: Storage Mohamed Zahran (aka Z) mzahran@cs.nyu.edu http://www.mzahran.com View 1 View 2 View 3 Conceptual Schema Physical Schema 1. Create a
CSCI-GA.2433-001 Database Systems Lecture 8: Physical Schema: Storage Mohamed Zahran (aka Z) mzahran@cs.nyu.edu http://www.mzahran.com View 1 View 2 View 3 Conceptual Schema Physical Schema 1. Create a
Lecture 13. Storage, Network and Other Peripherals
 Lecture 13 Storage, Network and Other Peripherals 1 I/O Systems Processor interrupts Cache Processor & I/O Communication Memory - I/O Bus Main Memory I/O Controller I/O Controller I/O Controller Disk Disk
Lecture 13 Storage, Network and Other Peripherals 1 I/O Systems Processor interrupts Cache Processor & I/O Communication Memory - I/O Bus Main Memory I/O Controller I/O Controller I/O Controller Disk Disk
Parallel Computing: Parallel Architectures Jin, Hai
 Parallel Computing: Parallel Architectures Jin, Hai School of Computer Science and Technology Huazhong University of Science and Technology Peripherals Computer Central Processing Unit Main Memory Computer
Parallel Computing: Parallel Architectures Jin, Hai School of Computer Science and Technology Huazhong University of Science and Technology Peripherals Computer Central Processing Unit Main Memory Computer
Introduction I/O 1. I/O devices can be characterized by Behavior: input, output, storage Partner: human or machine Data rate: bytes/sec, transfers/sec
 Introduction I/O 1 I/O devices can be characterized by Behavior: input, output, storage Partner: human or machine Data rate: bytes/sec, transfers/sec I/O bus connections I/O Device Summary I/O 2 I/O System
Introduction I/O 1 I/O devices can be characterized by Behavior: input, output, storage Partner: human or machine Data rate: bytes/sec, transfers/sec I/O bus connections I/O Device Summary I/O 2 I/O System
Two hours. No special instructions. UNIVERSITY OF MANCHESTER SCHOOL OF COMPUTER SCIENCE. Date. Time
 Two hours No special instructions. UNIVERSITY OF MANCHESTER SCHOOL OF COMPUTER SCIENCE System Architecture Date Time Please answer any THREE Questions from the FOUR questions provided Use a SEPARATE answerbook
Two hours No special instructions. UNIVERSITY OF MANCHESTER SCHOOL OF COMPUTER SCIENCE System Architecture Date Time Please answer any THREE Questions from the FOUR questions provided Use a SEPARATE answerbook
Computer Architecture A Quantitative Approach, Fifth Edition. Chapter 2. Memory Hierarchy Design. Copyright 2012, Elsevier Inc. All rights reserved.
 Computer Architecture A Quantitative Approach, Fifth Edition Chapter 2 Memory Hierarchy Design 1 Introduction Programmers want unlimited amounts of memory with low latency Fast memory technology is more
Computer Architecture A Quantitative Approach, Fifth Edition Chapter 2 Memory Hierarchy Design 1 Introduction Programmers want unlimited amounts of memory with low latency Fast memory technology is more
Memory Technology. Chapter 5. Principle of Locality. Chapter 5 Large and Fast: Exploiting Memory Hierarchy 1
 COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface Chapter 5 Large and Fast: Exploiting Memory Hierarchy 5 th Edition Memory Technology Static RAM (SRAM) 0.5ns 2.5ns, $2000 $5000 per GB Dynamic
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface Chapter 5 Large and Fast: Exploiting Memory Hierarchy 5 th Edition Memory Technology Static RAM (SRAM) 0.5ns 2.5ns, $2000 $5000 per GB Dynamic
Storage Systems : Disks and SSDs. Manu Awasthi July 6 th 2018 Computer Architecture Summer School 2018
 Storage Systems : Disks and SSDs Manu Awasthi July 6 th 2018 Computer Architecture Summer School 2018 Why study storage? Scalable High Performance Main Memory System Using Phase-Change Memory Technology,
Storage Systems : Disks and SSDs Manu Awasthi July 6 th 2018 Computer Architecture Summer School 2018 Why study storage? Scalable High Performance Main Memory System Using Phase-Change Memory Technology,
Computer System Architecture
 CSC 203 1.5 Computer System Architecture Department of Statistics and Computer Science University of Sri Jayewardenepura Secondary Memory 2 Technologies Magnetic storage Floppy, Zip disk, Hard drives,
CSC 203 1.5 Computer System Architecture Department of Statistics and Computer Science University of Sri Jayewardenepura Secondary Memory 2 Technologies Magnetic storage Floppy, Zip disk, Hard drives,
Thomas Polzer Institut für Technische Informatik
 Thomas Polzer tpolzer@ecs.tuwien.ac.at Institut für Technische Informatik Processor Interrupts Cache Memory I/O bus Main memory I/O controller I/O controller I/O controller Disk Disk Graphics output Network
Thomas Polzer tpolzer@ecs.tuwien.ac.at Institut für Technische Informatik Processor Interrupts Cache Memory I/O bus Main memory I/O controller I/O controller I/O controller Disk Disk Graphics output Network
Lecture 13: Memory Consistency. + a Course-So-Far Review. Parallel Computer Architecture and Programming CMU , Spring 2013
 Lecture 13: Memory Consistency + a Course-So-Far Review Parallel Computer Architecture and Programming Today: what you should know Understand the motivation for relaxed consistency models Understand the
Lecture 13: Memory Consistency + a Course-So-Far Review Parallel Computer Architecture and Programming Today: what you should know Understand the motivation for relaxed consistency models Understand the
CSE325 Principles of Operating Systems. Mass-Storage Systems. David P. Duggan. April 19, 2011
 CSE325 Principles of Operating Systems Mass-Storage Systems David P. Duggan dduggan@sandia.gov April 19, 2011 Outline Storage Devices Disk Scheduling FCFS SSTF SCAN, C-SCAN LOOK, C-LOOK Redundant Arrays
CSE325 Principles of Operating Systems Mass-Storage Systems David P. Duggan dduggan@sandia.gov April 19, 2011 Outline Storage Devices Disk Scheduling FCFS SSTF SCAN, C-SCAN LOOK, C-LOOK Redundant Arrays
Components of the Virtual Memory System
 Components of the Virtual Memory System Arrows indicate what happens on a lw virtual page number (VPN) page offset virtual address TLB physical address PPN page offset page table tag index block offset
Components of the Virtual Memory System Arrows indicate what happens on a lw virtual page number (VPN) page offset virtual address TLB physical address PPN page offset page table tag index block offset
CS6303 Computer Architecture Regulation 2013 BE-Computer Science and Engineering III semester 2 MARKS
 CS6303 Computer Architecture Regulation 2013 BE-Computer Science and Engineering III semester 2 MARKS UNIT-I OVERVIEW & INSTRUCTIONS 1. What are the eight great ideas in computer architecture? The eight
CS6303 Computer Architecture Regulation 2013 BE-Computer Science and Engineering III semester 2 MARKS UNIT-I OVERVIEW & INSTRUCTIONS 1. What are the eight great ideas in computer architecture? The eight
CDA3101 Recitation Section 13
 CDA3101 Recitation Section 13 Storage + Bus + Multicore and some exam tips Hard Disks Traditional disk performance is limited by the moving parts. Some disk terms Disk Performance Platters - the surfaces
CDA3101 Recitation Section 13 Storage + Bus + Multicore and some exam tips Hard Disks Traditional disk performance is limited by the moving parts. Some disk terms Disk Performance Platters - the surfaces
Chapter 6. Storage and Other I/O Topics
 Chapter 6 Storage and Other I/O Topics Introduction I/O devices can be characterized by Behavior: input, output, storage Partner: human or machine Data rate: bytes/sec, transfers/sec I/O bus connections
Chapter 6 Storage and Other I/O Topics Introduction I/O devices can be characterized by Behavior: input, output, storage Partner: human or machine Data rate: bytes/sec, transfers/sec I/O bus connections
Warps and Reduction Algorithms
 Warps and Reduction Algorithms 1 more on Thread Execution block partitioning into warps single-instruction, multiple-thread, and divergence 2 Parallel Reduction Algorithms computing the sum or the maximum
Warps and Reduction Algorithms 1 more on Thread Execution block partitioning into warps single-instruction, multiple-thread, and divergence 2 Parallel Reduction Algorithms computing the sum or the maximum
Fundamental Optimizations in CUDA Peng Wang, Developer Technology, NVIDIA
 Fundamental Optimizations in CUDA Peng Wang, Developer Technology, NVIDIA Optimization Overview GPU architecture Kernel optimization Memory optimization Latency optimization Instruction optimization CPU-GPU
Fundamental Optimizations in CUDA Peng Wang, Developer Technology, NVIDIA Optimization Overview GPU architecture Kernel optimization Memory optimization Latency optimization Instruction optimization CPU-GPU
Module 1: Basics and Background Lecture 4: Memory and Disk Accesses. The Lecture Contains: Memory organisation. Memory hierarchy. Disks.
 The Lecture Contains: Memory organisation Example of memory hierarchy Memory hierarchy Disks Disk access Disk capacity Disk access time Typical disk parameters Access times file:///c /Documents%20and%20Settings/iitkrana1/My%20Documents/Google%20Talk%20Received%20Files/ist_data/lecture4/4_1.htm[6/14/2012
The Lecture Contains: Memory organisation Example of memory hierarchy Memory hierarchy Disks Disk access Disk capacity Disk access time Typical disk parameters Access times file:///c /Documents%20and%20Settings/iitkrana1/My%20Documents/Google%20Talk%20Received%20Files/ist_data/lecture4/4_1.htm[6/14/2012
EI338: Computer Systems and Engineering (Computer Architecture & Operating Systems)
") EI338: Computer Systems and Engineering (Computer Architecture & Operating Systems) Chentao Wu 吴晨涛 Associate Professor Dept. of Computer Science and Engineering Shanghai Jiao Tong University SEIEE Building
EI338: Computer Systems and Engineering (Computer Architecture & Operating Systems) Chentao Wu 吴晨涛 Associate Professor Dept. of Computer Science and Engineering Shanghai Jiao Tong University SEIEE Building
Database Systems. November 2, 2011 Lecture #7. topobo (mit)
") Database Systems November 2, 2011 Lecture #7 1 topobo (mit) 1 Announcement Assignment #2 due today Assignment #3 out today & due on 11/16. Midterm exam in class next week. Cover Chapters 1, 2,
Database Systems November 2, 2011 Lecture #7 1 topobo (mit) 1 Announcement Assignment #2 due today Assignment #3 out today & due on 11/16. Midterm exam in class next week. Cover Chapters 1, 2,
ENGN1640: Design of Computing Systems Topic 06: Advanced Processor Design
 ENGN1640: Design of Computing Systems Topic 06: Advanced Processor Design Professor Sherief Reda http://scale.engin.brown.edu Electrical Sciences and Computer Engineering School of Engineering Brown University
ENGN1640: Design of Computing Systems Topic 06: Advanced Processor Design Professor Sherief Reda http://scale.engin.brown.edu Electrical Sciences and Computer Engineering School of Engineering Brown University
Fundamental CUDA Optimization. NVIDIA Corporation
 Fundamental CUDA Optimization NVIDIA Corporation Outline Fermi/Kepler Architecture Kernel optimizations Launch configuration Global memory throughput Shared memory access Instruction throughput / control
Fundamental CUDA Optimization NVIDIA Corporation Outline Fermi/Kepler Architecture Kernel optimizations Launch configuration Global memory throughput Shared memory access Instruction throughput / control
Multithreaded Processors. Department of Electrical Engineering Stanford University
 Lecture 12: Multithreaded Processors Department of Electrical Engineering Stanford University http://eeclass.stanford.edu/ee382a Lecture 12-1 The Big Picture Previous lectures: Core design for single-thread
Lecture 12: Multithreaded Processors Department of Electrical Engineering Stanford University http://eeclass.stanford.edu/ee382a Lecture 12-1 The Big Picture Previous lectures: Core design for single-thread
Definition of RAID Levels
 RAID The basic idea of RAID (Redundant Array of Independent Disks) is to combine multiple inexpensive disk drives into an array of disk drives to obtain performance, capacity and reliability that exceeds
RAID The basic idea of RAID (Redundant Array of Independent Disks) is to combine multiple inexpensive disk drives into an array of disk drives to obtain performance, capacity and reliability that exceeds
UC Santa Barbara. Operating Systems. Christopher Kruegel Department of Computer Science UC Santa Barbara
 Operating Systems Christopher Kruegel Department of Computer Science http://www.cs.ucsb.edu/~chris/ Input and Output Input/Output Devices The OS is responsible for managing I/O devices Issue requests Manage
Operating Systems Christopher Kruegel Department of Computer Science http://www.cs.ucsb.edu/~chris/ Input and Output Input/Output Devices The OS is responsible for managing I/O devices Issue requests Manage
CSE 451: Operating Systems Winter Redundant Arrays of Inexpensive Disks (RAID) and OS structure. Gary Kimura
 and OS structure. Gary Kimura") CSE 451: Operating Systems Winter 2013 Redundant Arrays of Inexpensive Disks (RAID) and OS structure Gary Kimura The challenge Disk transfer rates are improving, but much less fast than CPU performance
CSE 451: Operating Systems Winter 2013 Redundant Arrays of Inexpensive Disks (RAID) and OS structure Gary Kimura The challenge Disk transfer rates are improving, but much less fast than CPU performance
GPU Fundamentals Jeff Larkin November 14, 2016
 GPU Fundamentals Jeff Larkin , November 4, 206 Who Am I? 2002 B.S. Computer Science Furman University 2005 M.S. Computer Science UT Knoxville 2002 Graduate Teaching Assistant 2005 Graduate
GPU Fundamentals Jeff Larkin , November 4, 206 Who Am I? 2002 B.S. Computer Science Furman University 2005 M.S. Computer Science UT Knoxville 2002 Graduate Teaching Assistant 2005 Graduate
High Performance Computing on GPUs using NVIDIA CUDA
 High Performance Computing on GPUs using NVIDIA CUDA Slides include some material from GPGPU tutorial at SIGGRAPH2007: http://www.gpgpu.org/s2007 1 Outline Motivation Stream programming Simplified HW and
High Performance Computing on GPUs using NVIDIA CUDA Slides include some material from GPGPU tutorial at SIGGRAPH2007: http://www.gpgpu.org/s2007 1 Outline Motivation Stream programming Simplified HW and
The Memory Hierarchy 10/25/16
 The Memory Hierarchy 10/25/16 Transition First half of course: hardware focus How the hardware is constructed How the hardware works How to interact with hardware Second half: performance and software
The Memory Hierarchy 10/25/16 Transition First half of course: hardware focus How the hardware is constructed How the hardware works How to interact with hardware Second half: performance and software
Computer Architecture and System Software Lecture 09: Memory Hierarchy. Instructor: Rob Bergen Applied Computer Science University of Winnipeg
 Computer Architecture and System Software Lecture 09: Memory Hierarchy Instructor: Rob Bergen Applied Computer Science University of Winnipeg Announcements Midterm returned + solutions in class today SSD
Computer Architecture and System Software Lecture 09: Memory Hierarchy Instructor: Rob Bergen Applied Computer Science University of Winnipeg Announcements Midterm returned + solutions in class today SSD
CUDA PROGRAMMING MODEL Chaithanya Gadiyam Swapnil S Jadhav
 CUDA PROGRAMMING MODEL Chaithanya Gadiyam Swapnil S Jadhav CMPE655 - Multiple Processor Systems Fall 2015 Rochester Institute of Technology Contents What is GPGPU? What s the need? CUDA-Capable GPU Architecture
CUDA PROGRAMMING MODEL Chaithanya Gadiyam Swapnil S Jadhav CMPE655 - Multiple Processor Systems Fall 2015 Rochester Institute of Technology Contents What is GPGPU? What s the need? CUDA-Capable GPU Architecture