Kinetic drive. Bingzhe Li
|
|
|
- Garey Dawson
- 6 years ago
- Views:
Transcription
1 Kinetic drive Bingzhe Li

2 Consumption has changed It s an object storage world, unprecedented growth and scale In total, a complete redefinition of the storage stack
 and enable rapid response to a growing cloud storage infrastructure. http://www.")
3 What s Kinetic drive Kinetic drive is the world s first Ethernet-connected HDD with an open source object API designed specifically for hyperscale and scale-out environments. Seagate Kinetic HDD simplifies storage hardware and software architectures to reduce Total Cost of Ownership(TCO) and enable rapid response to a growing cloud storage infrastructure.
4 Kinetic drive features New class of Ethernet drives 2 Ethernet ports instead of 2 SAS ports Key/Value interface instead of SCSI Standard form-factor Open source key/value API and libraries

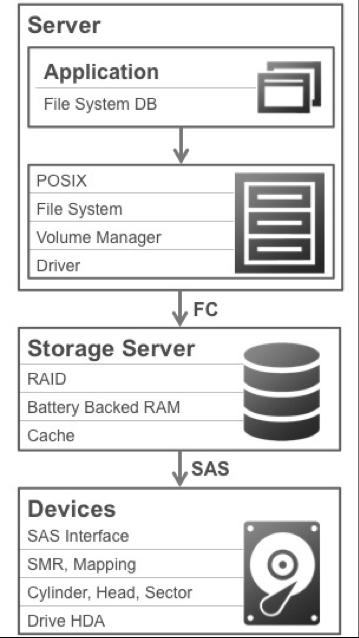
5 HDD Form Factor and Connector Kinetic chassis conform to dimensions for the HDD drive form factor. Kinetic drives repurposes the standard SAS HDD connector. The connector is defined by and conforms to the dimensions and specifications of SFF Rev 2.3. Its placement in the drive form factor is identical to SAS drives.

6 First Generation Kinetic HDD The first Kinetic drive is a 4TB, 5900 rpm, 3.5" hard disk drive (HDD). Compared to its conventional sister drive, the Kinetic drive implements the Kinetic API that enables key-value object storage. The Kinetic drive replaces the Serial Advance Technology Attachment (SATA) or Serial Attached SCSI (SAS) interface connections with the two 1-Gbps SGMII Ethernet ports, which enables direct network attached connectivity. The Ethernet interface allows communication between drives and direct communication to the datacenter, eliminating the need for Storage Servers for datacenter storage racks.
7 The Seagate Kinetic Open Storage Data Center vs. the Traditional Model VS.
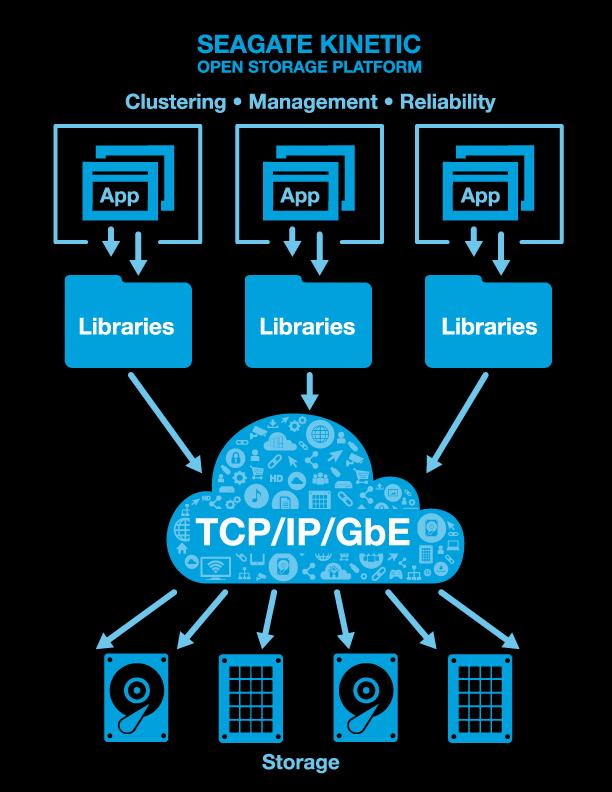
8 Basic architecture
9 Advantages of kinetic drive Performance Scalability Simplicity TCO(Total cost of ownership)

10 From Ali Fenn's and James Hugher s presentation in SNIA's DSI Conference - Santa Clara - April 2014

11 From Ali Fenn's and James Hugher s presentation in SNIA's DSI Conference - Santa Clara - April 2014

12 From Ali Fenn's and James Hugher s presentation in SNIA's DSI Conference - Santa Clara - April 2014
13 P2P operation example copydrive (see src/copydrive.cc) This example uses the P2P push functionality to copy an entire keyspace from one drive to one or more other drives. For example, to run a pipeline that looks like A -> B -> C you could call it like so:./copydrive A 8123 B 8123 C 4444
14 Goals of the kinetic API Data movement get/put/delete/getnext/getprevious Multiple masters Cluster-able 3 rd party copy Management
15 Software applications OpenStack Swift Distributed Hash Tables Hadoop Distributed File system Basho Riak CS netic+open+storage+documentation+wiki
16 OpenStack Kinetic drive

17 OpenStack Swift OpenStack Swift enables an object storage system that is highly scalable and durable. Swift allows the ability to store, retrieve, and delete objects in containers using a RESTful HTTP API. The key terminologies used for Swift are: Proxy Server - Scalable API request handler, determines storage node distribution of objects based on URL Partitions - A complete and non-overlapping set of key ranges such that each object, container and account is a member of exactly one partition as per the value of its key Ring - Maps each partition to a set of devices Objects - Key-value entries in the object store Containers - Groups of objects Accounts - Groups of containers Object Server - Service that provides access to object methods Container Server - Service that provides access to container methods Account Server - Service that provides access to account methods
 are embedded within the Proxy Server acting as a logical construct.")
18 Kinetic Implementation Swift clusters using Kinetic drives allow access to any drives and, thus, any object. For the current Kinetic integration, a fraction of Object Server commands (Object Daemon) are embedded within the Proxy Server acting as a logical construct.

19 Heterogeneous Clusters Keeping Object Server operations within the Proxy Server conservatively integrates the Kinetic ecosystem with the current Swift ecosystem and potentially provides backward compatibility with existing Swift deployments. The additional value gained by this implementation is allowing the Proxy Servers to use existing protocol, while reducing the amount of I/O from the Object Servers. A possible heterogenous cluster with Kinetic and Non-Kinetic Zones are shown below.

20 Future possibilities Current Kinetic replication process involves P2P Copy, where the Kinetic drives can copy objects from other Kinetic drives. Future potential goals for complete Kinetic integration would be to eliminate the Proxy Server restrictions of Zone accesses, such that the Proxy Servers can access all drives from any Zone. In this situation, the Client can make a single connection to a Proxy Server and obtain access to objects from all Zones
21 From Ali Fenn's presentation in OpenStack Summit - Paris - November 2014 RaliQuest, York Street Strategy
22 Distributed Hash Tables
23 Distributed Hash Tables (DHT) provides a lookup service by storing key-value pairs in a decentralized distributed system. The benefits of DHTs are: Highly scalable by automatically distributing loads to new nodes Distributed storage of objects with known names Self-organizing with no need of a central server Robust against node failure except for bootstrap nodes Bootstrap node provides initial configuration information to newly joining nodes so that they may successfully join the overlay network Data is automatically sent away from failed nodes The disadvantages to DHTs are: Searching feature based on hash algorithm, where very similar data values can be at totally different nodes. Security problems with secure routing and difficulty in verifying data integrity.
24 Node failure/removal In the case of a node failure or removal, the data must be replicated on to the next successor node for survival.
25 Node Lookup Since node 14 does not exist in the ring, the data stored for node 14 will be in the next successor, which in this case is node 15.
26 Kinetic Open Storage Implementation DHT can be implemented with Kinetic drives with the use of an integrated Kinetic API that can directly store the key/value objects onto the drives. The use of Kinetic drives eliminates the need for servers to communicate with the drive.
27 Hadoop Distributed File System
28

29 Kinetic Open Storage Integration HDFS is integrated with Kinetic drives by providing a plug-in for the HDFS Client to communicate with the Kinetic drives. The integration of HDFS with Kinetic drives are independent of the Hadoop ecosystem and is designed to allow the client to choose whether to use the Default File System or the Kinetic File System for the HDFS application. With the Kinetic File System plug-in, the HDFS client no longer needs to communicate with the Datanode in order to communication with the storage devices. When needed, the HDFS client will communicate with the Namenode to obtain information about the file system's namespace and client's accessibility, before directly connecting to the Kinetic drives. The image on the right shows the architecture for the HDFS Kinetic integration.

30 Mixed With the use current HDFS architecture and conventional drives, when Datanodes fail, the drives attached to the nodes also fail and become no longer accessible. Having no Datanodes with the use of Kinetic drives, this allows failures to happen only at the drive level, which reduces chances of inaccessible data in a large scale environment. The comparison between conventional and Kinetic drives in HDFS are shown below.
31 Basho Riak+Kinetic drive Riak is a distributed NoSQL key-value data store with extra query capabilities that offers high availability, fault tolerance, operational simplicity, and scalability.
32

33 Traditional Riak CS (Cloud Storage) is a highly scalable, open source distributed key/value store built on top of Basho Riak, designed to be used for public or private clouds, and for applications and services with high reliability demands. Riak CS API allow RESTful Get, Put and Delete operations for objects and buckets, along with a Map-Reduce function. The Riak CS API shards larges object sizes into 1MB chunks of key/value objects, which is sent to the Riak cluster to be streamed, stored, and replicated in the Ring.

34 Kinetic Implementation Replacing the drives in the Riak Node within The Ring with Kinetic drives allow access to any drives, thus any object. Integrating Kinetic drives to the Riak CS ecosystem allows the elimination of the object servers in the Riak Nodes, such any Riak CS API Server can access all the drives in any node. In the Riak Ring, the Object Server takes responsibility of a limited number of drives within the Riak Node, which restricts other Object Servers from accessing those drives for service client requests. The elimination of Object Servers can potentially allow any Riak CS Server Node to communicate with all Riak Nodes, thus access to all the drives. Data replication can potentially be performed using P2P Copy, such that Kinetic drives can communicate with each other independent of their Riak Node locations, with the absence of the Object Servers.
35 Evaluating the performance of Seagate Kinetic Drive Technology and its integration into the CERN EOS storage system Ivana Pejeva August 2015 CERN openlab Summer Student Report 2015
36 Goals of the project Goal: Performance evaluation of Seagate Kinetic drive technology and its integration into the CERN EOS storage system. CERN openlab is a unique public-private partnership that accelerates the development of cutting-edge solutions for the worldwide LHC community and wider scientific research EOS[1], a multi-petabyte disk storage [1]"Exabyte Scale Storage at CERN", Andreas J. Peters, Lukasz Janyst

37 EOS Storage System Three components: Management server(mgm) Message queue(mq) File storage services(fst) DAS vs. Ethernet Drive tech: Scalability DAS only support limited number of drives Ethernet is scaled independently

38 Kinetic Integration with EOS 32+4 encoding 10+2 encoding For comparisons a conventional EOS configuration (EOS DEV) with directly attached disks was tested storing two replicas on two individual FSTs. All FSTs were connected via 10GE.
39 Performance Benchmarks The graph for the 1 GE client shows that a plateau of upload rate (~ MB/s) is reached for files larger than 64MB. There is a systematic few percent decrease of performance of Kinetic-10:2 vs. the conventional disk layout DEV. And a second few percent effect when changing from Kinetic- 10:2 to Kinetic-32:4. These effects are only visible for file sizes larger than 64MB
40 For a 10 GE client a plateau is reached with files larger than 256MB (~ MB/s). There is no visible difference between the DEV and Kinetic-10:2 configuration, while the Kinetic-32:4 configuration involves a systematic performance loss around 10% for large files.
41 Thanks!
Kinetic Open Storage Platform: Enabling Break-through Economics in Scale-out Object Storage PRESENTATION TITLE GOES HERE Ali Fenn & James Hughes
 Kinetic Open Storage Platform: Enabling Break-through Economics in Scale-out Object Storage PRESENTATION TITLE GOES HERE Ali Fenn & James Hughes Seagate Technology 2020: 7.3 Zettabytes 56% of total = in
Kinetic Open Storage Platform: Enabling Break-through Economics in Scale-out Object Storage PRESENTATION TITLE GOES HERE Ali Fenn & James Hughes Seagate Technology 2020: 7.3 Zettabytes 56% of total = in
November 7, DAN WILSON Global Operations Architecture, Concur. OpenStack Summit Hong Kong JOE ARNOLD
 November 7, 2013 DAN WILSON Global Operations Architecture, Concur dan.wilson@concur.com @tweetdanwilson OpenStack Summit Hong Kong JOE ARNOLD CEO, SwiftStack joe@swiftstack.com @joearnold Introduction
November 7, 2013 DAN WILSON Global Operations Architecture, Concur dan.wilson@concur.com @tweetdanwilson OpenStack Summit Hong Kong JOE ARNOLD CEO, SwiftStack joe@swiftstack.com @joearnold Introduction
Decentralized Distributed Storage System for Big Data
 Decentralized Distributed Storage System for Big Presenter: Wei Xie -Intensive Scalable Computing Laboratory(DISCL) Computer Science Department Texas Tech University Outline Trends in Big and Cloud Storage
Decentralized Distributed Storage System for Big Presenter: Wei Xie -Intensive Scalable Computing Laboratory(DISCL) Computer Science Department Texas Tech University Outline Trends in Big and Cloud Storage
Seagate Kinetic Open Storage Platform. Mayur Shetty - Senior Solutions Architect
 Seagate Kinetic Open Storage Platform Mayur Shetty - Senior Solutions Architect 2 Application Clustering Management Interconnect App App LibKinetic App A D App No. 77103, LibKinetic effective Jan. 18,
Seagate Kinetic Open Storage Platform Mayur Shetty - Senior Solutions Architect 2 Application Clustering Management Interconnect App App LibKinetic App A D App No. 77103, LibKinetic effective Jan. 18,
CIS 601 Graduate Seminar. Dr. Sunnie S. Chung Dhruv Patel ( ) Kalpesh Sharma ( )
 Kalpesh Sharma ( )") Guide: CIS 601 Graduate Seminar Presented By: Dr. Sunnie S. Chung Dhruv Patel (2652790) Kalpesh Sharma (2660576) Introduction Background Parallel Data Warehouse (PDW) Hive MongoDB Client-side Shared SQL
Guide: CIS 601 Graduate Seminar Presented By: Dr. Sunnie S. Chung Dhruv Patel (2652790) Kalpesh Sharma (2660576) Introduction Background Parallel Data Warehouse (PDW) Hive MongoDB Client-side Shared SQL
CPSC 426/526. Cloud Computing. Ennan Zhai. Computer Science Department Yale University
 CPSC 426/526 Cloud Computing Ennan Zhai Computer Science Department Yale University Recall: Lec-7 In the lec-7, I talked about: - P2P vs Enterprise control - Firewall - NATs - Software defined network
CPSC 426/526 Cloud Computing Ennan Zhai Computer Science Department Yale University Recall: Lec-7 In the lec-7, I talked about: - P2P vs Enterprise control - Firewall - NATs - Software defined network
Cloud Computing and Hadoop Distributed File System. UCSB CS170, Spring 2018
 Cloud Computing and Hadoop Distributed File System UCSB CS70, Spring 08 Cluster Computing Motivations Large-scale data processing on clusters Scan 000 TB on node @ 00 MB/s = days Scan on 000-node cluster
Cloud Computing and Hadoop Distributed File System UCSB CS70, Spring 08 Cluster Computing Motivations Large-scale data processing on clusters Scan 000 TB on node @ 00 MB/s = days Scan on 000-node cluster
A BigData Tour HDFS, Ceph and MapReduce
 A BigData Tour HDFS, Ceph and MapReduce These slides are possible thanks to these sources Jonathan Drusi - SCInet Toronto Hadoop Tutorial, Amir Payberah - Course in Data Intensive Computing SICS; Yahoo!
A BigData Tour HDFS, Ceph and MapReduce These slides are possible thanks to these sources Jonathan Drusi - SCInet Toronto Hadoop Tutorial, Amir Payberah - Course in Data Intensive Computing SICS; Yahoo!
Integrated hardware-software solution developed on ARM architecture. CS3 Conference Krakow, January 30th 2018
 Integrated hardware-software solution developed on ARM architecture CS3 Conference Krakow, January 30th 2018 Why Object Storage Data doubles every 2 year...growing at a faster pace and is mainly unstructured
Integrated hardware-software solution developed on ARM architecture CS3 Conference Krakow, January 30th 2018 Why Object Storage Data doubles every 2 year...growing at a faster pace and is mainly unstructured
Accelerate MySQL for Demanding OLAP and OLTP Use Cases with Apache Ignite. Peter Zaitsev, Denis Magda Santa Clara, California April 25th, 2017
 Accelerate MySQL for Demanding OLAP and OLTP Use Cases with Apache Ignite Peter Zaitsev, Denis Magda Santa Clara, California April 25th, 2017 About the Presentation Problems Existing Solutions Denis Magda
Accelerate MySQL for Demanding OLAP and OLTP Use Cases with Apache Ignite Peter Zaitsev, Denis Magda Santa Clara, California April 25th, 2017 About the Presentation Problems Existing Solutions Denis Magda
The Datacentered Future Greg Huff CTO, LSI Corporation
 The Datacentered Future Greg Huff CTO, LSI Corporation 1 Tremendous Growth in Connected Data Sources, Consumption Devices, and Services 2 Nearly limitless data depth and breadth needed Execution of millions
The Datacentered Future Greg Huff CTO, LSI Corporation 1 Tremendous Growth in Connected Data Sources, Consumption Devices, and Services 2 Nearly limitless data depth and breadth needed Execution of millions
Flash Storage Complementing a Data Lake for Real-Time Insight
 Flash Storage Complementing a Data Lake for Real-Time Insight Dr. Sanhita Sarkar Global Director, Analytics Software Development August 7, 2018 Agenda 1 2 3 4 5 Delivering insight along the entire spectrum
Flash Storage Complementing a Data Lake for Real-Time Insight Dr. Sanhita Sarkar Global Director, Analytics Software Development August 7, 2018 Agenda 1 2 3 4 5 Delivering insight along the entire spectrum
We are ready to serve Latest Testing Trends, Are you ready to learn?? New Batches Info
 We are ready to serve Latest Testing Trends, Are you ready to learn?? New Batches Info START DATE : TIMINGS : DURATION : TYPE OF BATCH : FEE : FACULTY NAME : LAB TIMINGS : PH NO: 9963799240, 040-40025423
We are ready to serve Latest Testing Trends, Are you ready to learn?? New Batches Info START DATE : TIMINGS : DURATION : TYPE OF BATCH : FEE : FACULTY NAME : LAB TIMINGS : PH NO: 9963799240, 040-40025423
Introduction to Hadoop. Owen O Malley Yahoo!, Grid Team
 Introduction to Hadoop Owen O Malley Yahoo!, Grid Team owen@yahoo-inc.com Who Am I? Yahoo! Architect on Hadoop Map/Reduce Design, review, and implement features in Hadoop Working on Hadoop full time since
Introduction to Hadoop Owen O Malley Yahoo!, Grid Team owen@yahoo-inc.com Who Am I? Yahoo! Architect on Hadoop Map/Reduce Design, review, and implement features in Hadoop Working on Hadoop full time since
Distributed Filesystem
 Distributed Filesystem 1 How do we get data to the workers? NAS Compute Nodes SAN 2 Distributing Code! Don t move data to workers move workers to the data! - Store data on the local disks of nodes in the
Distributed Filesystem 1 How do we get data to the workers? NAS Compute Nodes SAN 2 Distributing Code! Don t move data to workers move workers to the data! - Store data on the local disks of nodes in the
Hadoop/MapReduce Computing Paradigm
 Hadoop/Reduce Computing Paradigm 1 Large-Scale Data Analytics Reduce computing paradigm (E.g., Hadoop) vs. Traditional database systems vs. Database Many enterprises are turning to Hadoop Especially applications
Hadoop/Reduce Computing Paradigm 1 Large-Scale Data Analytics Reduce computing paradigm (E.g., Hadoop) vs. Traditional database systems vs. Database Many enterprises are turning to Hadoop Especially applications
Ceph vs Swift Performance Evaluation on a Small Cluster. edupert monthly call Jul 24, 2014
 Ceph vs Swift Performance Evaluation on a Small Cluster edupert monthly call July, 24th 2014 About me Vincenzo Pii Researcher @ Leading research initiative on Cloud Storage Under the theme IaaS More on
Ceph vs Swift Performance Evaluation on a Small Cluster edupert monthly call July, 24th 2014 About me Vincenzo Pii Researcher @ Leading research initiative on Cloud Storage Under the theme IaaS More on
Hadoop and HDFS Overview. Madhu Ankam
 Hadoop and HDFS Overview Madhu Ankam Why Hadoop We are gathering more data than ever Examples of data : Server logs Web logs Financial transactions Analytics Emails and text messages Social media like
Hadoop and HDFS Overview Madhu Ankam Why Hadoop We are gathering more data than ever Examples of data : Server logs Web logs Financial transactions Analytics Emails and text messages Social media like
relational Relational to Riak Why Move From Relational to Riak? Introduction High Availability Riak At-a-Glance
 WHITEPAPER Relational to Riak relational Introduction This whitepaper looks at why companies choose Riak over a relational database. We focus specifically on availability, scalability, and the / data model.
WHITEPAPER Relational to Riak relational Introduction This whitepaper looks at why companies choose Riak over a relational database. We focus specifically on availability, scalability, and the / data model.
HDFS Architecture. Gregory Kesden, CSE-291 (Storage Systems) Fall 2017
 Fall 2017") HDFS Architecture Gregory Kesden, CSE-291 (Storage Systems) Fall 2017 Based Upon: http://hadoop.apache.org/docs/r3.0.0-alpha1/hadoopproject-dist/hadoop-hdfs/hdfsdesign.html Assumptions At scale, hardware
HDFS Architecture Gregory Kesden, CSE-291 (Storage Systems) Fall 2017 Based Upon: http://hadoop.apache.org/docs/r3.0.0-alpha1/hadoopproject-dist/hadoop-hdfs/hdfsdesign.html Assumptions At scale, hardware
Chapter 5. The MapReduce Programming Model and Implementation
 Chapter 5. The MapReduce Programming Model and Implementation - Traditional computing: data-to-computing (send data to computing) * Data stored in separate repository * Data brought into system for computing
Chapter 5. The MapReduce Programming Model and Implementation - Traditional computing: data-to-computing (send data to computing) * Data stored in separate repository * Data brought into system for computing
Evaluation of the Huawei UDS cloud storage system for CERN specific data
 th International Conference on Computing in High Energy and Nuclear Physics (CHEP3) IOP Publishing Journal of Physics: Conference Series 53 (4) 44 doi:.88/74-6596/53/4/44 Evaluation of the Huawei UDS cloud
th International Conference on Computing in High Energy and Nuclear Physics (CHEP3) IOP Publishing Journal of Physics: Conference Series 53 (4) 44 doi:.88/74-6596/53/4/44 Evaluation of the Huawei UDS cloud
PRESENTATION TITLE GOES HERE. Understanding Architectural Trade-offs in Object Storage Technologies
 Object Storage 201 PRESENTATION TITLE GOES HERE Understanding Architectural Trade-offs in Object Storage Technologies SNIA Legal Notice The material contained in this tutorial is copyrighted by the SNIA
Object Storage 201 PRESENTATION TITLE GOES HERE Understanding Architectural Trade-offs in Object Storage Technologies SNIA Legal Notice The material contained in this tutorial is copyrighted by the SNIA
SUSE OpenStack Cloud Production Deployment Architecture. Guide. Solution Guide Cloud Computing.
 SUSE OpenStack Cloud Production Deployment Architecture Guide Solution Guide Cloud Computing Table of Contents page Introduction... 2 High Availability Configuration...6 Network Topography...8 Services
SUSE OpenStack Cloud Production Deployment Architecture Guide Solution Guide Cloud Computing Table of Contents page Introduction... 2 High Availability Configuration...6 Network Topography...8 Services
Simplifying Collaboration in the Cloud
 Simplifying Collaboration in the Cloud WOS and IRODS Data Grid Dave Fellinger dfellinger@ddn.com Innovating in Storage DDN Firsts: Streaming ingest from satellite with guaranteed bandwidth Continuous service
Simplifying Collaboration in the Cloud WOS and IRODS Data Grid Dave Fellinger dfellinger@ddn.com Innovating in Storage DDN Firsts: Streaming ingest from satellite with guaranteed bandwidth Continuous service
A brief history on Hadoop
 Hadoop Basics A brief history on Hadoop 2003 - Google launches project Nutch to handle billions of searches and indexing millions of web pages. Oct 2003 - Google releases papers with GFS (Google File System)
Hadoop Basics A brief history on Hadoop 2003 - Google launches project Nutch to handle billions of searches and indexing millions of web pages. Oct 2003 - Google releases papers with GFS (Google File System)
Data Sheet FUJITSU Storage ETERNUS CD10000 S2 Hyperscale Storage
 Data Sheet FUJITSU Storage ETERNUS CD10000 S2 Hyperscale Storage Data Sheet FUJITSU Storage ETERNUS CD10000 S2 Hyperscale Storage The hyper-scale, software-defined storage system for the cloud ETERNUS
Data Sheet FUJITSU Storage ETERNUS CD10000 S2 Hyperscale Storage Data Sheet FUJITSU Storage ETERNUS CD10000 S2 Hyperscale Storage The hyper-scale, software-defined storage system for the cloud ETERNUS
April Final Quiz COSC MapReduce Programming a) Explain briefly the main ideas and components of the MapReduce programming model.
 Explain briefly the main ideas and components of the MapReduce programming model.") 1. MapReduce Programming a) Explain briefly the main ideas and components of the MapReduce programming model. MapReduce is a framework for processing big data which processes data in two phases, a Map
1. MapReduce Programming a) Explain briefly the main ideas and components of the MapReduce programming model. MapReduce is a framework for processing big data which processes data in two phases, a Map
EsgynDB Enterprise 2.0 Platform Reference Architecture
 EsgynDB Enterprise 2.0 Platform Reference Architecture This document outlines a Platform Reference Architecture for EsgynDB Enterprise, built on Apache Trafodion (Incubating) implementation with licensed
EsgynDB Enterprise 2.0 Platform Reference Architecture This document outlines a Platform Reference Architecture for EsgynDB Enterprise, built on Apache Trafodion (Incubating) implementation with licensed
DEMYSTIFYING BIG DATA WITH RIAK USE CASES. Martin Schneider Basho Technologies!
 DEMYSTIFYING BIG DATA WITH RIAK USE CASES Martin Schneider Basho Technologies! Agenda Defining Big Data in Regards to Riak A Series of Trade-Offs Use Cases Q & A About Basho & Riak Basho Technologies is
DEMYSTIFYING BIG DATA WITH RIAK USE CASES Martin Schneider Basho Technologies! Agenda Defining Big Data in Regards to Riak A Series of Trade-Offs Use Cases Q & A About Basho & Riak Basho Technologies is
Konstantin Shvachko, Hairong Kuang, Sanjay Radia, Robert Chansler Yahoo! Sunnyvale, California USA {Shv, Hairong, SRadia,
 Konstantin Shvachko, Hairong Kuang, Sanjay Radia, Robert Chansler Yahoo! Sunnyvale, California USA {Shv, Hairong, SRadia, Chansler}@Yahoo-Inc.com Presenter: Alex Hu } Introduction } Architecture } File
Konstantin Shvachko, Hairong Kuang, Sanjay Radia, Robert Chansler Yahoo! Sunnyvale, California USA {Shv, Hairong, SRadia, Chansler}@Yahoo-Inc.com Presenter: Alex Hu } Introduction } Architecture } File
powered by Cloudian and Veritas
 Lenovo Storage DX8200C powered by Cloudian and Veritas On-site data protection for Amazon S3-compliant cloud storage. assistance from Lenovo s world-class support organization, which is rated #1 for overall
Lenovo Storage DX8200C powered by Cloudian and Veritas On-site data protection for Amazon S3-compliant cloud storage. assistance from Lenovo s world-class support organization, which is rated #1 for overall
virtual machine block storage with the ceph distributed storage system sage weil xensummit august 28, 2012
 virtual machine block storage with the ceph distributed storage system sage weil xensummit august 28, 2012 outline why you should care what is it, what it does how it works, how you can use it architecture
virtual machine block storage with the ceph distributed storage system sage weil xensummit august 28, 2012 outline why you should care what is it, what it does how it works, how you can use it architecture
Enterprise Ceph: Everyway, your way! Amit Dell Kyle Red Hat Red Hat Summit June 2016
 Enterprise Ceph: Everyway, your way! Amit Bhutani @ Dell Kyle Bader @ Red Hat Red Hat Summit June 2016 Agenda Overview of Ceph Components and Architecture Evolution of Ceph in Dell-Red Hat Joint OpenStack
Enterprise Ceph: Everyway, your way! Amit Bhutani @ Dell Kyle Bader @ Red Hat Red Hat Summit June 2016 Agenda Overview of Ceph Components and Architecture Evolution of Ceph in Dell-Red Hat Joint OpenStack
Agenda. AWS Database Services Traditional vs AWS Data services model Amazon RDS Redshift DynamoDB ElastiCache
 Databases on AWS 2017 Amazon Web Services, Inc. and its affiliates. All rights served. May not be copied, modified, or distributed in whole or in part without the express consent of Amazon Web Services,
Databases on AWS 2017 Amazon Web Services, Inc. and its affiliates. All rights served. May not be copied, modified, or distributed in whole or in part without the express consent of Amazon Web Services,
Toward Energy-efficient and Fault-tolerant Consistent Hashing based Data Store. Wei Xie TTU CS Department Seminar, 3/7/2017
 Toward Energy-efficient and Fault-tolerant Consistent Hashing based Data Store Wei Xie TTU CS Department Seminar, 3/7/2017 1 Outline General introduction Study 1: Elastic Consistent Hashing based Store
Toward Energy-efficient and Fault-tolerant Consistent Hashing based Data Store Wei Xie TTU CS Department Seminar, 3/7/2017 1 Outline General introduction Study 1: Elastic Consistent Hashing based Store
Using Cloud Services behind SGI DMF
 Using Cloud Services behind SGI DMF Greg Banks Principal Engineer, Storage SW 2013 SGI Overview Cloud Storage SGI Objectstore Design Features & Non-Features Future Directions Cloud Storage
Using Cloud Services behind SGI DMF Greg Banks Principal Engineer, Storage SW 2013 SGI Overview Cloud Storage SGI Objectstore Design Features & Non-Features Future Directions Cloud Storage
BUSINESS DATA LAKE FADI FAKHOURI, SR. SYSTEMS ENGINEER, ISILON SPECIALIST. Copyright 2016 EMC Corporation. All rights reserved.
 BUSINESS DATA LAKE FADI FAKHOURI, SR. SYSTEMS ENGINEER, ISILON SPECIALIST 1 UNSTRUCTURED DATA GROWTH 75% 78% 80% 2015 71 EB 2016 106 EB 2017 133 EB Total Capacity Shipped, Worldwide % of Unstructured Data
BUSINESS DATA LAKE FADI FAKHOURI, SR. SYSTEMS ENGINEER, ISILON SPECIALIST 1 UNSTRUCTURED DATA GROWTH 75% 78% 80% 2015 71 EB 2016 106 EB 2017 133 EB Total Capacity Shipped, Worldwide % of Unstructured Data
CS60021: Scalable Data Mining. Sourangshu Bhattacharya
 CS60021: Scalable Data Mining Sourangshu Bhattacharya In this Lecture: Outline: HDFS Motivation HDFS User commands HDFS System architecture HDFS Implementation details Sourangshu Bhattacharya Computer
CS60021: Scalable Data Mining Sourangshu Bhattacharya In this Lecture: Outline: HDFS Motivation HDFS User commands HDFS System architecture HDFS Implementation details Sourangshu Bhattacharya Computer
CS 655 Advanced Topics in Distributed Systems
 Presented by : Walid Budgaga CS 655 Advanced Topics in Distributed Systems Computer Science Department Colorado State University 1 Outline Problem Solution Approaches Comparison Conclusion 2 Problem 3
Presented by : Walid Budgaga CS 655 Advanced Topics in Distributed Systems Computer Science Department Colorado State University 1 Outline Problem Solution Approaches Comparison Conclusion 2 Problem 3
Enosis: Bridging the Semantic Gap between
 Enosis: Bridging the Semantic Gap between File-based and Object-based Data Models Anthony Kougkas - akougkas@hawk.iit.edu, Hariharan Devarajan, Xian-He Sun Outline Introduction Background Approach Evaluation
Enosis: Bridging the Semantic Gap between File-based and Object-based Data Models Anthony Kougkas - akougkas@hawk.iit.edu, Hariharan Devarajan, Xian-He Sun Outline Introduction Background Approach Evaluation
UNIFY DATA AT MEMORY SPEED. Haoyuan (HY) Li, Alluxio Inc. VAULT Conference 2017
 Li, Alluxio Inc. VAULT Conference 2017") UNIFY DATA AT MEMORY SPEED Haoyuan (HY) Li, CEO @ Alluxio Inc. VAULT Conference 2017 March 2017 HISTORY Started at UC Berkeley AMPLab In Summer 2012 Originally named as Tachyon Rebranded to Alluxio in
UNIFY DATA AT MEMORY SPEED Haoyuan (HY) Li, CEO @ Alluxio Inc. VAULT Conference 2017 March 2017 HISTORY Started at UC Berkeley AMPLab In Summer 2012 Originally named as Tachyon Rebranded to Alluxio in
White Paper. Nexenta Replicast
 White Paper Nexenta Replicast By Caitlin Bestler, September 2013 Table of Contents Overview... 3 Nexenta Replicast Description... 3 Send Once, Receive Many... 4 Distributed Storage Basics... 7 Nexenta
White Paper Nexenta Replicast By Caitlin Bestler, September 2013 Table of Contents Overview... 3 Nexenta Replicast Description... 3 Send Once, Receive Many... 4 Distributed Storage Basics... 7 Nexenta
Ambry: LinkedIn s Scalable Geo- Distributed Object Store
 Ambry: LinkedIn s Scalable Geo- Distributed Object Store Shadi A. Noghabi *, Sriram Subramanian +, Priyesh Narayanan +, Sivabalan Narayanan +, Gopalakrishna Holla +, Mammad Zadeh +, Tianwei Li +, Indranil
Ambry: LinkedIn s Scalable Geo- Distributed Object Store Shadi A. Noghabi *, Sriram Subramanian +, Priyesh Narayanan +, Sivabalan Narayanan +, Gopalakrishna Holla +, Mammad Zadeh +, Tianwei Li +, Indranil
CompSci 356: Computer Network Architectures Lecture 21: Overlay Networks Chap 9.4. Xiaowei Yang
 CompSci 356: Computer Network Architectures Lecture 21: Overlay Networks Chap 9.4 Xiaowei Yang xwy@cs.duke.edu Overview Problem Evolving solutions IP multicast Proxy caching Content distribution networks
CompSci 356: Computer Network Architectures Lecture 21: Overlay Networks Chap 9.4 Xiaowei Yang xwy@cs.duke.edu Overview Problem Evolving solutions IP multicast Proxy caching Content distribution networks
Hadoop An Overview. - Socrates CCDH
 Hadoop An Overview - Socrates CCDH What is Big Data? Volume Not Gigabyte. Terabyte, Petabyte, Exabyte, Zettabyte - Due to handheld gadgets,and HD format images and videos - In total data, 90% of them collected
Hadoop An Overview - Socrates CCDH What is Big Data? Volume Not Gigabyte. Terabyte, Petabyte, Exabyte, Zettabyte - Due to handheld gadgets,and HD format images and videos - In total data, 90% of them collected
CLOUD-SCALE FILE SYSTEMS
 Data Management in the Cloud CLOUD-SCALE FILE SYSTEMS 92 Google File System (GFS) Designing a file system for the Cloud design assumptions design choices Architecture GFS Master GFS Chunkservers GFS Clients
Data Management in the Cloud CLOUD-SCALE FILE SYSTEMS 92 Google File System (GFS) Designing a file system for the Cloud design assumptions design choices Architecture GFS Master GFS Chunkservers GFS Clients
Home of Redis. April 24, 2017
 Home of Redis April 24, 2017 Introduction to Redis and Redis Labs Redis with MySQL Data Structures in Redis Benefits of Redis e 2 Redis and Redis Labs Open source. The leading in-memory database platform,
Home of Redis April 24, 2017 Introduction to Redis and Redis Labs Redis with MySQL Data Structures in Redis Benefits of Redis e 2 Redis and Redis Labs Open source. The leading in-memory database platform,
MySQL High Availability
 MySQL High Availability InnoDB Cluster and NDB Cluster Ted Wennmark ted.wennmark@oracle.com Copyright 2016, Oracle and/or its its affiliates. All All rights reserved. Safe Harbor Statement The following
MySQL High Availability InnoDB Cluster and NDB Cluster Ted Wennmark ted.wennmark@oracle.com Copyright 2016, Oracle and/or its its affiliates. All All rights reserved. Safe Harbor Statement The following
Big Data in OpenStack Storage
 Big Data in OpenStack Storage Ivan Tomašić, Aleksandra Rashkovska, Matjaž Depolli, Roman Trobec Department of Communication Systems Jožef Stefan Institute, Ljubljana, Slovenia Outline Introduction Swift
Big Data in OpenStack Storage Ivan Tomašić, Aleksandra Rashkovska, Matjaž Depolli, Roman Trobec Department of Communication Systems Jožef Stefan Institute, Ljubljana, Slovenia Outline Introduction Swift
Introduction to MapReduce. Instructor: Dr. Weikuan Yu Computer Sci. & Software Eng.
 Introduction to MapReduce Instructor: Dr. Weikuan Yu Computer Sci. & Software Eng. Before MapReduce Large scale data processing was difficult! Managing hundreds or thousands of processors Managing parallelization
Introduction to MapReduce Instructor: Dr. Weikuan Yu Computer Sci. & Software Eng. Before MapReduce Large scale data processing was difficult! Managing hundreds or thousands of processors Managing parallelization
Datacenter replication solution with quasardb
 Datacenter replication solution with quasardb Technical positioning paper April 2017 Release v1.3 www.quasardb.net Contact: sales@quasardb.net Quasardb A datacenter survival guide quasardb INTRODUCTION
Datacenter replication solution with quasardb Technical positioning paper April 2017 Release v1.3 www.quasardb.net Contact: sales@quasardb.net Quasardb A datacenter survival guide quasardb INTRODUCTION
Scality RING on Cisco UCS: Store File, Object, and OpenStack Data at Scale
 Scality RING on Cisco UCS: Store File, Object, and OpenStack Data at Scale What You Will Learn Cisco and Scality provide a joint solution for storing and protecting file, object, and OpenStack data at
Scality RING on Cisco UCS: Store File, Object, and OpenStack Data at Scale What You Will Learn Cisco and Scality provide a joint solution for storing and protecting file, object, and OpenStack data at
Lecture 11 Hadoop & Spark
 Lecture 11 Hadoop & Spark Dr. Wilson Rivera ICOM 6025: High Performance Computing Electrical and Computer Engineering Department University of Puerto Rico Outline Distributed File Systems Hadoop Ecosystem
Lecture 11 Hadoop & Spark Dr. Wilson Rivera ICOM 6025: High Performance Computing Electrical and Computer Engineering Department University of Puerto Rico Outline Distributed File Systems Hadoop Ecosystem
Mixing and matching virtual and physical HPC clusters. Paolo Anedda
 Mixing and matching virtual and physical HPC clusters Paolo Anedda paolo.anedda@crs4.it HPC 2010 - Cetraro 22/06/2010 1 Outline Introduction Scalability Issues System architecture Conclusions & Future
Mixing and matching virtual and physical HPC clusters Paolo Anedda paolo.anedda@crs4.it HPC 2010 - Cetraro 22/06/2010 1 Outline Introduction Scalability Issues System architecture Conclusions & Future
Achieving Horizontal Scalability. Alain Houf Sales Engineer
 Achieving Horizontal Scalability Alain Houf Sales Engineer Scale Matters InterSystems IRIS Database Platform lets you: Scale up and scale out Scale users and scale data Mix and match a variety of approaches
Achieving Horizontal Scalability Alain Houf Sales Engineer Scale Matters InterSystems IRIS Database Platform lets you: Scale up and scale out Scale users and scale data Mix and match a variety of approaches
Cisco and Cloudera Deliver WorldClass Solutions for Powering the Enterprise Data Hub alerts, etc. Organizations need the right technology and infrastr
 Solution Overview Cisco UCS Integrated Infrastructure for Big Data and Analytics with Cloudera Enterprise Bring faster performance and scalability for big data analytics. Highlights Proven platform for
Solution Overview Cisco UCS Integrated Infrastructure for Big Data and Analytics with Cloudera Enterprise Bring faster performance and scalability for big data analytics. Highlights Proven platform for
March 10, Distributed Hash-based Lookup. for Peer-to-Peer Systems. Sandeep Shelke Shrirang Shirodkar MTech I CSE
 for for March 10, 2006 Agenda for Peer-to-Peer Sytems Initial approaches to Their Limitations CAN - Applications of CAN Design Details Benefits for Distributed and a decentralized architecture No centralized
for for March 10, 2006 Agenda for Peer-to-Peer Sytems Initial approaches to Their Limitations CAN - Applications of CAN Design Details Benefits for Distributed and a decentralized architecture No centralized
Ghislain Fourny. Big Data 5. Column stores
 Ghislain Fourny Big Data 5. Column stores 1 Introduction 2 Relational model 3 Relational model Schema 4 Issues with relational databases (RDBMS) Small scale Single machine 5 Can we fix a RDBMS? Scale up
Ghislain Fourny Big Data 5. Column stores 1 Introduction 2 Relational model 3 Relational model Schema 4 Issues with relational databases (RDBMS) Small scale Single machine 5 Can we fix a RDBMS? Scale up
NOSQL OPERATIONAL CHECKLIST
 WHITEPAPER NOSQL NOSQL OPERATIONAL CHECKLIST NEW APPLICATION REQUIREMENTS ARE DRIVING A DATABASE REVOLUTION There is a new breed of high volume, highly distributed, and highly complex applications that
WHITEPAPER NOSQL NOSQL OPERATIONAL CHECKLIST NEW APPLICATION REQUIREMENTS ARE DRIVING A DATABASE REVOLUTION There is a new breed of high volume, highly distributed, and highly complex applications that
Ghislain Fourny. Big Data 5. Wide column stores
 Ghislain Fourny Big Data 5. Wide column stores Data Technology Stack User interfaces Querying Data stores Indexing Processing Validation Data models Syntax Encoding Storage 2 Where we are User interfaces
Ghislain Fourny Big Data 5. Wide column stores Data Technology Stack User interfaces Querying Data stores Indexing Processing Validation Data models Syntax Encoding Storage 2 Where we are User interfaces
Distributed File Systems II
 Distributed File Systems II To do q Very-large scale: Google FS, Hadoop FS, BigTable q Next time: Naming things GFS A radically new environment NFS, etc. Independence Small Scale Variety of workloads Cooperation
Distributed File Systems II To do q Very-large scale: Google FS, Hadoop FS, BigTable q Next time: Naming things GFS A radically new environment NFS, etc. Independence Small Scale Variety of workloads Cooperation
Big Data: Tremendous challenges, great solutions
 Big Data: Tremendous challenges, great solutions Luc Bougé ENS Rennes Alexandru Costan INSA Rennes Gabriel Antoniu INRIA Rennes Survive the data deluge! Équipe KerData 1 Big Data? 2 Big Picture The digital
Big Data: Tremendous challenges, great solutions Luc Bougé ENS Rennes Alexandru Costan INSA Rennes Gabriel Antoniu INRIA Rennes Survive the data deluge! Équipe KerData 1 Big Data? 2 Big Picture The digital
Ceph Software Defined Storage Appliance
 Ceph Software Defined Storage Appliance Unified distributed data storage cluster with self-healing, auto-balancing and no single point of failure Lowest power consumption in the industry: 70% power saving
Ceph Software Defined Storage Appliance Unified distributed data storage cluster with self-healing, auto-balancing and no single point of failure Lowest power consumption in the industry: 70% power saving
Data Infrastructure at LinkedIn. Shirshanka Das XLDB 2011
 Data Infrastructure at LinkedIn Shirshanka Das XLDB 2011 1 Me UCLA Ph.D. 2005 (Distributed protocols in content delivery networks) PayPal (Web frameworks and Session Stores) Yahoo! (Serving Infrastructure,
Data Infrastructure at LinkedIn Shirshanka Das XLDB 2011 1 Me UCLA Ph.D. 2005 (Distributed protocols in content delivery networks) PayPal (Web frameworks and Session Stores) Yahoo! (Serving Infrastructure,
Yuval Carmel Tel-Aviv University "Advanced Topics in Storage Systems" - Spring 2013
 Yuval Carmel Tel-Aviv University "Advanced Topics in About & Keywords Motivation & Purpose Assumptions Architecture overview & Comparison Measurements How does it fit in? The Future 2 About & Keywords
Yuval Carmel Tel-Aviv University "Advanced Topics in About & Keywords Motivation & Purpose Assumptions Architecture overview & Comparison Measurements How does it fit in? The Future 2 About & Keywords
MI-PDB, MIE-PDB: Advanced Database Systems
 MI-PDB, MIE-PDB: Advanced Database Systems http://www.ksi.mff.cuni.cz/~svoboda/courses/2015-2-mie-pdb/ Lecture 10: MapReduce, Hadoop 26. 4. 2016 Lecturer: Martin Svoboda svoboda@ksi.mff.cuni.cz Author:
MI-PDB, MIE-PDB: Advanced Database Systems http://www.ksi.mff.cuni.cz/~svoboda/courses/2015-2-mie-pdb/ Lecture 10: MapReduce, Hadoop 26. 4. 2016 Lecturer: Martin Svoboda svoboda@ksi.mff.cuni.cz Author:
Cloud Computing at Yahoo! Thomas Kwan Director, Research Operations Yahoo! Labs
 Cloud Computing at Yahoo! Thomas Kwan Director, Research Operations Yahoo! Labs Overview Cloud Strategy Cloud Services Cloud Research Partnerships - 2 - Yahoo! Cloud Strategy 1. Optimizing for Yahoo-scale
Cloud Computing at Yahoo! Thomas Kwan Director, Research Operations Yahoo! Labs Overview Cloud Strategy Cloud Services Cloud Research Partnerships - 2 - Yahoo! Cloud Strategy 1. Optimizing for Yahoo-scale
Open vstorage RedHat Ceph Architectural Comparison
 Open vstorage RedHat Ceph Architectural Comparison Open vstorage is the World s fastest Distributed Block Store that spans across different Datacenter. It combines ultrahigh performance and low latency
Open vstorage RedHat Ceph Architectural Comparison Open vstorage is the World s fastest Distributed Block Store that spans across different Datacenter. It combines ultrahigh performance and low latency
Big Data and Object Storage
 Big Data and Object Storage or where to store the cold and small data? Sven Bauernfeind Computacenter AG & Co. ohg, Consultancy Germany 28.02.2018 Munich Volume, Variety & Velocity + Analytics Velocity
Big Data and Object Storage or where to store the cold and small data? Sven Bauernfeind Computacenter AG & Co. ohg, Consultancy Germany 28.02.2018 Munich Volume, Variety & Velocity + Analytics Velocity
Systems Infrastructure for Data Science. Web Science Group Uni Freiburg WS 2013/14
 Systems Infrastructure for Data Science Web Science Group Uni Freiburg WS 2013/14 MapReduce & Hadoop The new world of Big Data (programming model) Overview of this Lecture Module Background Cluster File
Systems Infrastructure for Data Science Web Science Group Uni Freiburg WS 2013/14 MapReduce & Hadoop The new world of Big Data (programming model) Overview of this Lecture Module Background Cluster File
Scaling Out Key-Value Storage
 Scaling Out Key-Value Storage COS 418: Distributed Systems Logan Stafman [Adapted from K. Jamieson, M. Freedman, B. Karp] Horizontal or vertical scalability? Vertical Scaling Horizontal Scaling 2 Horizontal
Scaling Out Key-Value Storage COS 418: Distributed Systems Logan Stafman [Adapted from K. Jamieson, M. Freedman, B. Karp] Horizontal or vertical scalability? Vertical Scaling Horizontal Scaling 2 Horizontal
Hadoop 2.x Core: YARN, Tez, and Spark. Hortonworks Inc All Rights Reserved
 Hadoop 2.x Core: YARN, Tez, and Spark YARN Hadoop Machine Types top-of-rack switches core switch client machines have client-side software used to access a cluster to process data master nodes run Hadoop
Hadoop 2.x Core: YARN, Tez, and Spark YARN Hadoop Machine Types top-of-rack switches core switch client machines have client-side software used to access a cluster to process data master nodes run Hadoop
Data Analysis Using MapReduce in Hadoop Environment
 Data Analysis Using MapReduce in Hadoop Environment Muhammad Khairul Rijal Muhammad*, Saiful Adli Ismail, Mohd Nazri Kama, Othman Mohd Yusop, Azri Azmi Advanced Informatics School (UTM AIS), Universiti
Data Analysis Using MapReduce in Hadoop Environment Muhammad Khairul Rijal Muhammad*, Saiful Adli Ismail, Mohd Nazri Kama, Othman Mohd Yusop, Azri Azmi Advanced Informatics School (UTM AIS), Universiti
MapReduce. U of Toronto, 2014
 MapReduce U of Toronto, 2014 http://www.google.org/flutrends/ca/ (2012) Average Searches Per Day: 5,134,000,000 2 Motivation Process lots of data Google processed about 24 petabytes of data per day in
MapReduce U of Toronto, 2014 http://www.google.org/flutrends/ca/ (2012) Average Searches Per Day: 5,134,000,000 2 Motivation Process lots of data Google processed about 24 petabytes of data per day in
Cisco UCS Mini Software-Defined Storage with StorMagic SvSAN for Remote Offices
 Solution Overview Cisco UCS Mini Software-Defined Storage with StorMagic SvSAN for Remote Offices BENEFITS Cisco UCS and StorMagic SvSAN deliver a solution to the edge: Single addressable storage pool
Solution Overview Cisco UCS Mini Software-Defined Storage with StorMagic SvSAN for Remote Offices BENEFITS Cisco UCS and StorMagic SvSAN deliver a solution to the edge: Single addressable storage pool
Accelerate MySQL for Demanding OLAP and OLTP Use Case with Apache Ignite December 7, 2016
 Accelerate MySQL for Demanding OLAP and OLTP Use Case with Apache Ignite December 7, 2016 Nikita Ivanov CTO and Co-Founder GridGain Systems Peter Zaitsev CEO and Co-Founder Percona About the Presentation
Accelerate MySQL for Demanding OLAP and OLTP Use Case with Apache Ignite December 7, 2016 Nikita Ivanov CTO and Co-Founder GridGain Systems Peter Zaitsev CEO and Co-Founder Percona About the Presentation
MapReduce & HyperDex. Kathleen Durant PhD Lecture 21 CS 3200 Northeastern University
 MapReduce & HyperDex Kathleen Durant PhD Lecture 21 CS 3200 Northeastern University 1 Distributing Processing Mantra Scale out, not up. Assume failures are common. Move processing to the data. Process
MapReduce & HyperDex Kathleen Durant PhD Lecture 21 CS 3200 Northeastern University 1 Distributing Processing Mantra Scale out, not up. Assume failures are common. Move processing to the data. Process
Cluster Setup and Distributed File System
 Cluster Setup and Distributed File System R&D Storage for the R&D Storage Group People Involved Gaetano Capasso - INFN-Naples Domenico Del Prete INFN-Naples Diacono Domenico INFN-Bari Donvito Giacinto
Cluster Setup and Distributed File System R&D Storage for the R&D Storage Group People Involved Gaetano Capasso - INFN-Naples Domenico Del Prete INFN-Naples Diacono Domenico INFN-Bari Donvito Giacinto
NetApp Solutions for Hadoop Reference Architecture
 White Paper NetApp Solutions for Hadoop Reference Architecture Gus Horn, Iyer Venkatesan, NetApp April 2014 WP-7196 Abstract Today s businesses need to store, control, and analyze the unprecedented complexity,
White Paper NetApp Solutions for Hadoop Reference Architecture Gus Horn, Iyer Venkatesan, NetApp April 2014 WP-7196 Abstract Today s businesses need to store, control, and analyze the unprecedented complexity,
Jai Menon and the rest of the team IBM Research Autonomic Storage Systems April 11, 2002
 Jai Menon and the rest of the team IBM Research Autonomic Storage Systems April 11, 2002 Copyright IBM Corporation 2000. All rights reserved. Presentation File Name Why do we need Autonomic Storage? Storage
Jai Menon and the rest of the team IBM Research Autonomic Storage Systems April 11, 2002 Copyright IBM Corporation 2000. All rights reserved. Presentation File Name Why do we need Autonomic Storage? Storage
Big Data 7. Resource Management
 Ghislain Fourny Big Data 7. Resource Management artjazz / 123RF Stock Photo Data Technology Stack User interfaces Querying Data stores Indexing Processing Validation Data models Syntax Encoding Storage
Ghislain Fourny Big Data 7. Resource Management artjazz / 123RF Stock Photo Data Technology Stack User interfaces Querying Data stores Indexing Processing Validation Data models Syntax Encoding Storage
EMC Forum EMC ViPR and ECS: A Lap Around Software-Defined Services
 EMC Forum 2014 Copyright 2014 EMC Corporation. All rights reserved. 1 EMC ViPR and ECS: A Lap Around Software-Defined Services 2 Session Agenda Market Dynamics EMC ViPR Overview What s New in ViPR Controller
EMC Forum 2014 Copyright 2014 EMC Corporation. All rights reserved. 1 EMC ViPR and ECS: A Lap Around Software-Defined Services 2 Session Agenda Market Dynamics EMC ViPR Overview What s New in ViPR Controller
PLATFORM AND SOFTWARE AS A SERVICE THE MAPREDUCE PROGRAMMING MODEL AND IMPLEMENTATIONS
 PLATFORM AND SOFTWARE AS A SERVICE THE MAPREDUCE PROGRAMMING MODEL AND IMPLEMENTATIONS By HAI JIN, SHADI IBRAHIM, LI QI, HAIJUN CAO, SONG WU and XUANHUA SHI Prepared by: Dr. Faramarz Safi Islamic Azad
PLATFORM AND SOFTWARE AS A SERVICE THE MAPREDUCE PROGRAMMING MODEL AND IMPLEMENTATIONS By HAI JIN, SHADI IBRAHIM, LI QI, HAIJUN CAO, SONG WU and XUANHUA SHI Prepared by: Dr. Faramarz Safi Islamic Azad
Content Overlays. Nick Feamster CS 7260 March 12, 2007
 Content Overlays Nick Feamster CS 7260 March 12, 2007 Content Overlays Distributed content storage and retrieval Two primary approaches: Structured overlay Unstructured overlay Today s paper: Chord Not
Content Overlays Nick Feamster CS 7260 March 12, 2007 Content Overlays Distributed content storage and retrieval Two primary approaches: Structured overlay Unstructured overlay Today s paper: Chord Not
Highly accurate simulations of big-data clusters for system planning and optimization
 White Paper Highly accurate simulations of big-data clusters for system planning and optimization Intel CoFluent Technology for Big Data Intel Rack Scale Design Using Intel CoFluent Technology for Big
White Paper Highly accurate simulations of big-data clusters for system planning and optimization Intel CoFluent Technology for Big Data Intel Rack Scale Design Using Intel CoFluent Technology for Big
Time-Series Data in MongoDB on a Budget. Peter Schwaller Senior Director Server Engineering, Percona Santa Clara, California April 23th 25th, 2018
 Time-Series Data in MongoDB on a Budget Peter Schwaller Senior Director Server Engineering, Percona Santa Clara, California April 23th 25th, 2018 TIME SERIES DATA in MongoDB on a Budget Click to add text
Time-Series Data in MongoDB on a Budget Peter Schwaller Senior Director Server Engineering, Percona Santa Clara, California April 23th 25th, 2018 TIME SERIES DATA in MongoDB on a Budget Click to add text
A New Key-value Data Store For Heterogeneous Storage Architecture Intel APAC R&D Ltd.
 A New Key-value Data Store For Heterogeneous Storage Architecture Intel APAC R&D Ltd. 1 Agenda Introduction Background and Motivation Hybrid Key-Value Data Store Architecture Overview Design details Performance
A New Key-value Data Store For Heterogeneous Storage Architecture Intel APAC R&D Ltd. 1 Agenda Introduction Background and Motivation Hybrid Key-Value Data Store Architecture Overview Design details Performance
Distributed Databases: SQL vs NoSQL
 Distributed Databases: SQL vs NoSQL Seda Unal, Yuchen Zheng April 23, 2017 1 Introduction Distributed databases have become increasingly popular in the era of big data because of their advantages over
Distributed Databases: SQL vs NoSQL Seda Unal, Yuchen Zheng April 23, 2017 1 Introduction Distributed databases have become increasingly popular in the era of big data because of their advantages over
OpenSFS Test Cluster Donation. Dr. Nihat Altiparmak, Assistant Professor Computer Engineering & Computer Science Department University of Louisville
 OpenSFS Test Cluster Donation Dr. Nihat Altiparmak, Assistant Professor Computer Engineering & Computer Science Department University of Louisville 4/24/2018 Donation Details Jan 5, 2018 OpenSFS announced
OpenSFS Test Cluster Donation Dr. Nihat Altiparmak, Assistant Professor Computer Engineering & Computer Science Department University of Louisville 4/24/2018 Donation Details Jan 5, 2018 OpenSFS announced
Department of Computer Science University of Cyprus EPL646 Advanced Topics in Databases. Lecture 14
 Department of Computer Science University of Cyprus EPL646 Advanced Topics in Databases Lecture 14 Big Data Management IV: Big-data Infrastructures (Background, IO, From NFS to HFDS) Chapter 14-15: Abideboul
Department of Computer Science University of Cyprus EPL646 Advanced Topics in Databases Lecture 14 Big Data Management IV: Big-data Infrastructures (Background, IO, From NFS to HFDS) Chapter 14-15: Abideboul
50 Must Read Hadoop Interview Questions & Answers
 50 Must Read Hadoop Interview Questions & Answers Whizlabs Dec 29th, 2017 Big Data Are you planning to land a job with big data and data analytics? Are you worried about cracking the Hadoop job interview?
50 Must Read Hadoop Interview Questions & Answers Whizlabs Dec 29th, 2017 Big Data Are you planning to land a job with big data and data analytics? Are you worried about cracking the Hadoop job interview?
Optimizing the Data Center with an End to End Solutions Approach
 Optimizing the Data Center with an End to End Solutions Approach Adam Roberts Chief Solutions Architect, Director of Technical Marketing ESS SanDisk Corporation Flash Memory Summit 11-13 August 2015 August
Optimizing the Data Center with an End to End Solutions Approach Adam Roberts Chief Solutions Architect, Director of Technical Marketing ESS SanDisk Corporation Flash Memory Summit 11-13 August 2015 August
Scale-out Storage Solution and Challenges Mahadev Gaonkar igate
 Scale-out Solution and Challenges Mahadev Gaonkar igate 2013 Developer Conference. igate. All Rights Reserved. Table of Content Overview of Scale-out Scale-out NAS Solution Architecture IO Workload Distribution
Scale-out Solution and Challenges Mahadev Gaonkar igate 2013 Developer Conference. igate. All Rights Reserved. Table of Content Overview of Scale-out Scale-out NAS Solution Architecture IO Workload Distribution
Evaluation and Integration of OCP Servers from Software Perspective. Internet Initiative Japan Inc. Takashi Sogabe
 Evaluation and Integration of OCP Servers from Software Perspective Internet Initiative Japan Inc. Takashi Sogabe Who am I? Takashi Sogabe @rev4t Software Engineer, Internet Initiative Japan Inc. Focusing
Evaluation and Integration of OCP Servers from Software Perspective Internet Initiative Japan Inc. Takashi Sogabe Who am I? Takashi Sogabe @rev4t Software Engineer, Internet Initiative Japan Inc. Focusing
Rapid Automated Indication of Link-Loss
 Rapid Automated Indication of Link-Loss Fast recovery of failures is becoming a hot topic of discussion for many of today s Big Data applications such as Hadoop, HBase, Cassandra, MongoDB, MySQL, MemcacheD
Rapid Automated Indication of Link-Loss Fast recovery of failures is becoming a hot topic of discussion for many of today s Big Data applications such as Hadoop, HBase, Cassandra, MongoDB, MySQL, MemcacheD
5 reasons why choosing Apache Cassandra is planning for a multi-cloud future
 White Paper 5 reasons why choosing Apache Cassandra is planning for a multi-cloud future Abstract We have been hearing for several years now that multi-cloud deployment is something that is highly desirable,
White Paper 5 reasons why choosing Apache Cassandra is planning for a multi-cloud future Abstract We have been hearing for several years now that multi-cloud deployment is something that is highly desirable,
HADOOP FRAMEWORK FOR BIG DATA
 HADOOP FRAMEWORK FOR BIG DATA Mr K. Srinivas Babu 1,Dr K. Rameshwaraiah 2 1 Research Scholar S V University, Tirupathi 2 Professor and Head NNRESGI, Hyderabad Abstract - Data has to be stored for further
HADOOP FRAMEWORK FOR BIG DATA Mr K. Srinivas Babu 1,Dr K. Rameshwaraiah 2 1 Research Scholar S V University, Tirupathi 2 Professor and Head NNRESGI, Hyderabad Abstract - Data has to be stored for further
Google File System. Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung Google fall DIP Heerak lim, Donghun Koo
 Google File System Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung Google 2017 fall DIP Heerak lim, Donghun Koo 1 Agenda Introduction Design overview Systems interactions Master operation Fault tolerance
Google File System Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung Google 2017 fall DIP Heerak lim, Donghun Koo 1 Agenda Introduction Design overview Systems interactions Master operation Fault tolerance
Handling Big Data an overview of mass storage technologies
 SS Data & Handling Big Data an overview of mass storage technologies Łukasz Janyst CERN IT Department CH-1211 Genève 23 Switzerland www.cern.ch/it GridKA School 2013 Karlsruhe, 26.08.2013 What is Big Data?
SS Data & Handling Big Data an overview of mass storage technologies Łukasz Janyst CERN IT Department CH-1211 Genève 23 Switzerland www.cern.ch/it GridKA School 2013 Karlsruhe, 26.08.2013 What is Big Data?