Advanced cache optimizations. ECE 154B Dmitri Strukov
|
|
|
- Gregory Chapman
- 6 years ago
- Views:
Transcription
1 Advanced cache optimizations ECE 154B Dmitri Strukov
2 Advanced Cache Optimization 1) Way prediction 2) Victim cache 3) Critical word first and early restart 4) Merging write buffer 5) Nonblocking cache 6) Pipelined cache 7) Multibanked cache 8) Compiler optimizations 9) Prefetching
3 #1: Way Prediction How to combine fast hit time of Direct Mapped and have the lower conflict misses of 2-way SA cache? Way prediction: keep extra bits in cache to predict the way, or block within the set, of next cache access. Multiplexor is set early to select desired block, only 1 tag comparison performed that clock cycle in parallel with reading the cache data Miss 1 st check other blocks for matches in next clock cycle Hit Time Way-Miss Hit Time Miss Penalty Accuracy 85% Drawback: CPU pipeline is hard if hit takes 1 or 2 cycles Used for instruction caches vs. L1 data caches Also used on MIPS R10K for off-chip L2 unified cache, way-prediction table on-chip
4 2-Way Set-Associative Cache Not a on a critical path anymore Set index = (Block address) MOD (Number of sets in cache)

5 #2: Victim Cache - Efficient for thrashing problem in direct mapped caches - Remove 20%-90% cache misses to L1 cache - L1 and Victim cache are exclusive - Miss to L1 but hit in VC; miss in L1 and VC
6 #3: Early Restart and Critical Word First Don t wait for full block before restarting CPU Early restart As soon as the requested word of the block arrives, send it to the CPU and let the CPU continue execution Critical Word First Request the missed word first from memory and send it to the CPU as soon as it arrives; let the CPU continue execution while filling the rest of the words in the block Long blocks more popular today Critical Word 1 st Widely used block
7 #4: Merging Write Buffer Write buffer to allow processor to continue while waiting to write to memory If buffer contains modified blocks, the addresses can be checked to see if address of new data matches the address of a valid write buffer entry If so, new data are combined with that entry Increases block size of write for write-through cache of writes to sequential words, bytes since multiword writes more efficient to memory The Sun T1 (Niagara) processor, among many others, uses write merging

8 Merging Write Buffer Example Figure 2.7 To illustrate write merging, the write buffer on top does not use it while the write buffer on the bottom does. The four writes are merged into a single buffer entry with write merging; without it, the buffer is full even though three-fourths of each entry is wasted. The buffer has four entries, and each entry holds four 64-bit words. The address for each entry is on the left, with a valid bit (V) indicating whether the next sequential 8 bytes in this entry are occupied. (Without write merging, the words to the right in the upper part of the figure would only be used for instructions that wrote multiple words at the same time.) Interesting issue with conflicting design objectives, i.e. ejecting as soon as possible vs. keeping longer for merging
9 #5: Nonblocking Cache: Basic Idea
10 Nonblocking Cache Non-blocking cache or lockup-free cache allow data cache to continue to supply cache hits during a miss hit under miss reduces the effective miss penalty by working during miss vs. ignoring CPU requests hit under multiple miss or miss under miss may further lower the effective miss penalty by overlapping multiple misses Pentium Pro allows 4 outstanding memory misses (Cray X1E vector supercomputer allows 2,048 outstanding memory misses)
 is 256 KB with a 10 clock cycle access latency.")
11 Non Blocking Cache Figure 2.5 The effectiveness of a nonblocking cache is evaluated by allowing 1, 2, or 64 hits under a cache miss with 9 SPECINT (on the left) and 9 SPECFP (on the right) benchmarks. The data memory system modeled after the Intel i7 consists of a 32KB L1 cache with a four cycle access latency. The L2 cache (shared with instructions) is 256 KB with a 10 clock cycle access latency. The L3 is 2 MB and a 36-cycle access latency. All the caches are eight-way set associative and have a 64-byte block size. Allowing one hit under miss reduces the miss penalty by 9% for the integer benchmarks and 12.5% for the floating point. Allowing a second hit improves these results to 10% and 16%, and allowing 64 results in little additional improvement.
12 Nonblocking Cache Implementation requires out-of-order execution significantly increases the complexity of the cache controller as there can be multiple outstanding memory accesses requires pipelined or banked memory system (otherwise cannot support)
13 Nonblocking Cache Example Maximum number of outstanding references to maintain peak bandwidth for a system? - sustained transfer rate 16GB/sec - memory access 36ns - block size 64 bytes - 50% need not be issued
14 Nonblocking Cache Example Maximum number of outstanding references to maintain peak bandwidth for a system? - sustained transfer rate 16GB/sec - memory access 36ns - block size 64 bytes - 50% need not be issued Answer: (16*10)^9/64 *36 * 10^-9*2 = 18
15 Writing to Cache Read vs. Write Writes are longer than reads!
16 #6: Pipelining Cache Writes
17 #7: Increasing Cache Bandwidth via Multiple Banks Rather than treat the cache as a single monolithic block, divide into independent banks that can support simultaneous accesses 4 in L1 and 8 in L2 for Intel core i7 Banking works best when accesses naturally spread themselves across banks mapping of addresses to banks affects behavior of memory system Simple mapping that works well is sequential interleaving Spread block addresses sequentially across banks E,g, if there 4 banks, Bank 0 has all blocks whose address modulo 4 is 0; bank 1 has all blocks whose address modulo 4 is 1;

18 #8: Compiler Optimizations
19 Loop Interchange
20 Loop Fusion
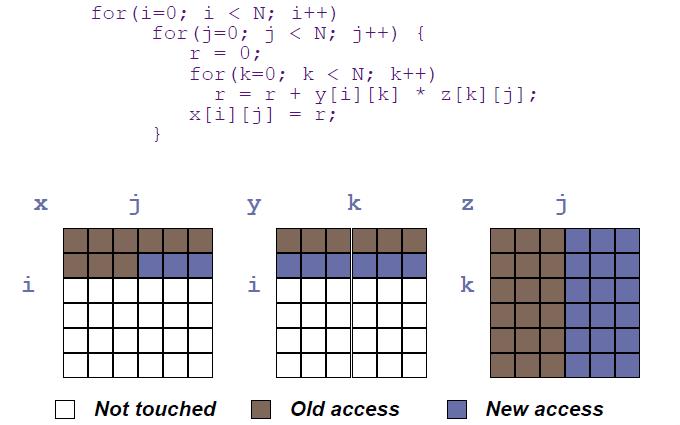
21 Blocking
22 Blocking
23 #9: Prefetching
24 Issues in Prefetching
25 Hardware Instruction Prefetching

26 Hardware Data Prefetching
27 Software Prefetching
28 Software Prefetching Issues
29 Summary
30 Acknowledgements Some of the slides contain material developed and copyrighted by Arvind, Emer (MIT), Asanovic (UCB/MIT) and instructor material for the textbook 30
Chapter-5 Memory Hierarchy Design
 Chapter-5 Memory Hierarchy Design Unlimited amount of fast memory - Economical solution is memory hierarchy - Locality - Cost performance Principle of locality - most programs do not access all code or
Chapter-5 Memory Hierarchy Design Unlimited amount of fast memory - Economical solution is memory hierarchy - Locality - Cost performance Principle of locality - most programs do not access all code or
Memory Hierarchy Computing Systems & Performance MSc Informatics Eng. Memory Hierarchy (most slides are borrowed)
") Computing Systems & Performance Memory Hierarchy MSc Informatics Eng. 2011/12 A.J.Proença Memory Hierarchy (most slides are borrowed) AJProença, Computer Systems & Performance, MEI, UMinho, 2011/12 1 2
Computing Systems & Performance Memory Hierarchy MSc Informatics Eng. 2011/12 A.J.Proença Memory Hierarchy (most slides are borrowed) AJProença, Computer Systems & Performance, MEI, UMinho, 2011/12 1 2
Memory Hierarchy Computing Systems & Performance MSc Informatics Eng. Memory Hierarchy (most slides are borrowed)
") Computing Systems & Performance Memory Hierarchy MSc Informatics Eng. 2012/13 A.J.Proença Memory Hierarchy (most slides are borrowed) AJProença, Computer Systems & Performance, MEI, UMinho, 2012/13 1 2
Computing Systems & Performance Memory Hierarchy MSc Informatics Eng. 2012/13 A.J.Proença Memory Hierarchy (most slides are borrowed) AJProença, Computer Systems & Performance, MEI, UMinho, 2012/13 1 2
Memory Hierarchy Basics
 Computer Architecture A Quantitative Approach, Fifth Edition Chapter 2 Memory Hierarchy Design 1 Memory Hierarchy Basics Six basic cache optimizations: Larger block size Reduces compulsory misses Increases
Computer Architecture A Quantitative Approach, Fifth Edition Chapter 2 Memory Hierarchy Design 1 Memory Hierarchy Basics Six basic cache optimizations: Larger block size Reduces compulsory misses Increases
Memory Hierarchy Basics. Ten Advanced Optimizations. Small and Simple
 Memory Hierarchy Basics Six basic cache optimizations: Larger block size Reduces compulsory misses Increases capacity and conflict misses, increases miss penalty Larger total cache capacity to reduce miss
Memory Hierarchy Basics Six basic cache optimizations: Larger block size Reduces compulsory misses Increases capacity and conflict misses, increases miss penalty Larger total cache capacity to reduce miss
EITF20: Computer Architecture Part4.1.1: Cache - 2
 EITF20: Computer Architecture Part4.1.1: Cache - 2 Liang Liu liang.liu@eit.lth.se 1 Outline Reiteration Cache performance optimization Bandwidth increase Reduce hit time Reduce miss penalty Reduce miss
EITF20: Computer Architecture Part4.1.1: Cache - 2 Liang Liu liang.liu@eit.lth.se 1 Outline Reiteration Cache performance optimization Bandwidth increase Reduce hit time Reduce miss penalty Reduce miss
Advanced optimizations of cache performance ( 2.2)
") Advanced optimizations of cache performance ( 2.2) 30 1. Small and Simple Caches to reduce hit time Critical timing path: address tag memory, then compare tags, then select set Lower associativity Direct-mapped
Advanced optimizations of cache performance ( 2.2) 30 1. Small and Simple Caches to reduce hit time Critical timing path: address tag memory, then compare tags, then select set Lower associativity Direct-mapped
EITF20: Computer Architecture Part4.1.1: Cache - 2
 EITF20: Computer Architecture Part4.1.1: Cache - 2 Liang Liu liang.liu@eit.lth.se 1 Outline Reiteration Cache performance optimization Bandwidth increase Reduce hit time Reduce miss penalty Reduce miss
EITF20: Computer Architecture Part4.1.1: Cache - 2 Liang Liu liang.liu@eit.lth.se 1 Outline Reiteration Cache performance optimization Bandwidth increase Reduce hit time Reduce miss penalty Reduce miss
TDT Coarse-Grained Multithreading. Review on ILP. Multi-threaded execution. Contents. Fine-Grained Multithreading
 Review on ILP TDT 4260 Chap 5 TLP & Hierarchy What is ILP? Let the compiler find the ILP Advantages? Disadvantages? Let the HW find the ILP Advantages? Disadvantages? Contents Multi-threading Chap 3.5
Review on ILP TDT 4260 Chap 5 TLP & Hierarchy What is ILP? Let the compiler find the ILP Advantages? Disadvantages? Let the HW find the ILP Advantages? Disadvantages? Contents Multi-threading Chap 3.5
Lecture-18 (Cache Optimizations) CS422-Spring
 CS422-Spring") Lecture-18 (Cache Optimizations) CS422-Spring 2018 Biswa@CSE-IITK Compiler Optimizations Loop interchange Merging Loop fusion Blocking Refer H&P: You need it for PA3 and PA4 too. CS422: Spring 2018 Biswabandan
Lecture-18 (Cache Optimizations) CS422-Spring 2018 Biswa@CSE-IITK Compiler Optimizations Loop interchange Merging Loop fusion Blocking Refer H&P: You need it for PA3 and PA4 too. CS422: Spring 2018 Biswabandan
LRU. Pseudo LRU A B C D E F G H A B C D E F G H H H C. Copyright 2012, Elsevier Inc. All rights reserved.
 LRU A list to keep track of the order of access to every block in the set. The least recently used block is replaced (if needed). How many bits we need for that? 27 Pseudo LRU A B C D E F G H A B C D E
LRU A list to keep track of the order of access to every block in the set. The least recently used block is replaced (if needed). How many bits we need for that? 27 Pseudo LRU A B C D E F G H A B C D E
COSC 6385 Computer Architecture - Memory Hierarchy Design (III)
") COSC 6385 Computer Architecture - Memory Hierarchy Design (III) Fall 2006 Reducing cache miss penalty Five techniques Multilevel caches Critical word first and early restart Giving priority to read misses
COSC 6385 Computer Architecture - Memory Hierarchy Design (III) Fall 2006 Reducing cache miss penalty Five techniques Multilevel caches Critical word first and early restart Giving priority to read misses
CS 152 Computer Architecture and Engineering. Lecture 8 - Memory Hierarchy-III
 CS 152 Computer Architecture and Engineering Lecture 8 - Memory Hierarchy-III Krste Asanovic Electrical Engineering and Computer Sciences University of California at Berkeley http://www.eecs.berkeley.edu/~krste
CS 152 Computer Architecture and Engineering Lecture 8 - Memory Hierarchy-III Krste Asanovic Electrical Engineering and Computer Sciences University of California at Berkeley http://www.eecs.berkeley.edu/~krste
Memory Hierarchy. Advanced Optimizations. Slides contents from:
 Memory Hierarchy Advanced Optimizations Slides contents from: Hennessy & Patterson, 5ed. Appendix B and Chapter 2. David Wentzlaff, ELE 475 Computer Architecture. MJT, High Performance Computing, NPTEL.
Memory Hierarchy Advanced Optimizations Slides contents from: Hennessy & Patterson, 5ed. Appendix B and Chapter 2. David Wentzlaff, ELE 475 Computer Architecture. MJT, High Performance Computing, NPTEL.
Lec 11 How to improve cache performance
 Lec 11 How to improve cache performance How to Improve Cache Performance? AMAT = HitTime + MissRate MissPenalty 1. Reduce the time to hit in the cache.--4 small and simple caches, avoiding address translation,
Lec 11 How to improve cache performance How to Improve Cache Performance? AMAT = HitTime + MissRate MissPenalty 1. Reduce the time to hit in the cache.--4 small and simple caches, avoiding address translation,
Cache Optimisation. sometime he thought that there must be a better way
 Cache sometime he thought that there must be a better way 2 Cache 1. Reduce miss rate a) Increase block size b) Increase cache size c) Higher associativity d) compiler optimisation e) Parallelism f) prefetching
Cache sometime he thought that there must be a better way 2 Cache 1. Reduce miss rate a) Increase block size b) Increase cache size c) Higher associativity d) compiler optimisation e) Parallelism f) prefetching
CISC 662 Graduate Computer Architecture Lecture 18 - Cache Performance. Why More on Memory Hierarchy?
 CISC 662 Graduate Computer Architecture Lecture 18 - Cache Performance Michela Taufer Powerpoint Lecture Notes from John Hennessy and David Patterson s: Computer Architecture, 4th edition ---- Additional
CISC 662 Graduate Computer Architecture Lecture 18 - Cache Performance Michela Taufer Powerpoint Lecture Notes from John Hennessy and David Patterson s: Computer Architecture, 4th edition ---- Additional
CS 152 Computer Architecture and Engineering. Lecture 8 - Memory Hierarchy-III
 CS 152 Computer Architecture and Engineering Lecture 8 - Memory Hierarchy-III Krste Asanovic Electrical Engineering and Computer Sciences University of California at Berkeley http://www.eecs.berkeley.edu/~krste
CS 152 Computer Architecture and Engineering Lecture 8 - Memory Hierarchy-III Krste Asanovic Electrical Engineering and Computer Sciences University of California at Berkeley http://www.eecs.berkeley.edu/~krste
NOW Handout Page # Why More on Memory Hierarchy? CISC 662 Graduate Computer Architecture Lecture 18 - Cache Performance
 CISC 66 Graduate Computer Architecture Lecture 8 - Cache Performance Michela Taufer Performance Why More on Memory Hierarchy?,,, Processor Memory Processor-Memory Performance Gap Growing Powerpoint Lecture
CISC 66 Graduate Computer Architecture Lecture 8 - Cache Performance Michela Taufer Performance Why More on Memory Hierarchy?,,, Processor Memory Processor-Memory Performance Gap Growing Powerpoint Lecture
Outline. 1 Reiteration. 2 Cache performance optimization. 3 Bandwidth increase. 4 Reduce hit time. 5 Reduce miss penalty. 6 Reduce miss rate
 Outline Lecture 7: EITF20 Computer Architecture Anders Ardö EIT Electrical and Information Technology, Lund University November 21, 2012 A. Ardö, EIT Lecture 7: EITF20 Computer Architecture November 21,
Outline Lecture 7: EITF20 Computer Architecture Anders Ardö EIT Electrical and Information Technology, Lund University November 21, 2012 A. Ardö, EIT Lecture 7: EITF20 Computer Architecture November 21,
COSC 6385 Computer Architecture. - Memory Hierarchies (II)
") COSC 6385 Computer Architecture - Memory Hierarchies (II) Fall 2008 Cache Performance Avg. memory access time = Hit time + Miss rate x Miss penalty with Hit time: time to access a data item which is available
COSC 6385 Computer Architecture - Memory Hierarchies (II) Fall 2008 Cache Performance Avg. memory access time = Hit time + Miss rate x Miss penalty with Hit time: time to access a data item which is available
CS 152 Computer Architecture and Engineering. Lecture 8 - Memory Hierarchy-III
 CS 152 Computer Architecture and Engineering Lecture 8 - Memory Hierarchy-III Krste Asanovic Electrical Engineering and Computer Sciences University of California at Berkeley http://www.eecs.berkeley.edu/~krste!
CS 152 Computer Architecture and Engineering Lecture 8 - Memory Hierarchy-III Krste Asanovic Electrical Engineering and Computer Sciences University of California at Berkeley http://www.eecs.berkeley.edu/~krste!
MEMORY HIERARCHY DESIGN. B649 Parallel Architectures and Programming
 MEMORY HIERARCHY DESIGN B649 Parallel Architectures and Programming Basic Optimizations Average memory access time = Hit time + Miss rate Miss penalty Larger block size to reduce miss rate Larger caches
MEMORY HIERARCHY DESIGN B649 Parallel Architectures and Programming Basic Optimizations Average memory access time = Hit time + Miss rate Miss penalty Larger block size to reduce miss rate Larger caches
A Cache Hierarchy in a Computer System
 A Cache Hierarchy in a Computer System Ideally one would desire an indefinitely large memory capacity such that any particular... word would be immediately available... We are... forced to recognize the
A Cache Hierarchy in a Computer System Ideally one would desire an indefinitely large memory capacity such that any particular... word would be immediately available... We are... forced to recognize the
Memory hier ar hier ch ar y ch rev re i v e i w e ECE 154B Dmitri Struko Struk v o
 Memory hierarchy review ECE 154B Dmitri Strukov Outline Cache motivation Cache basics Opteron example Cache performance Six basic optimizations Virtual memory Processor DRAM gap (latency) Four issue superscalar
Memory hierarchy review ECE 154B Dmitri Strukov Outline Cache motivation Cache basics Opteron example Cache performance Six basic optimizations Virtual memory Processor DRAM gap (latency) Four issue superscalar
Memory hierarchy review. ECE 154B Dmitri Strukov
 Memory hierarchy review ECE 154B Dmitri Strukov Outline Cache motivation Cache basics Six basic optimizations Virtual memory Cache performance Opteron example Processor-DRAM gap in latency Q1. How to deal
Memory hierarchy review ECE 154B Dmitri Strukov Outline Cache motivation Cache basics Six basic optimizations Virtual memory Cache performance Opteron example Processor-DRAM gap in latency Q1. How to deal
Computer Architecture A Quantitative Approach, Fifth Edition. Chapter 2. Memory Hierarchy Design. Copyright 2012, Elsevier Inc. All rights reserved.
 Computer Architecture A Quantitative Approach, Fifth Edition Chapter 2 Memory Hierarchy Design 1 Introduction Programmers want unlimited amounts of memory with low latency Fast memory technology is more
Computer Architecture A Quantitative Approach, Fifth Edition Chapter 2 Memory Hierarchy Design 1 Introduction Programmers want unlimited amounts of memory with low latency Fast memory technology is more
Copyright 2012, Elsevier Inc. All rights reserved.
 Computer Architecture A Quantitative Approach, Fifth Edition Chapter 2 Memory Hierarchy Design 1 Introduction Introduction Programmers want unlimited amounts of memory with low latency Fast memory technology
Computer Architecture A Quantitative Approach, Fifth Edition Chapter 2 Memory Hierarchy Design 1 Introduction Introduction Programmers want unlimited amounts of memory with low latency Fast memory technology
Computer Architecture. A Quantitative Approach, Fifth Edition. Chapter 2. Memory Hierarchy Design. Copyright 2012, Elsevier Inc. All rights reserved.
 Computer Architecture A Quantitative Approach, Fifth Edition Chapter 2 Memory Hierarchy Design 1 Programmers want unlimited amounts of memory with low latency Fast memory technology is more expensive per
Computer Architecture A Quantitative Approach, Fifth Edition Chapter 2 Memory Hierarchy Design 1 Programmers want unlimited amounts of memory with low latency Fast memory technology is more expensive per
Copyright 2012, Elsevier Inc. All rights reserved.
 Computer Architecture A Quantitative Approach, Fifth Edition Chapter 2 Memory Hierarchy Design 1 Introduction Programmers want unlimited amounts of memory with low latency Fast memory technology is more
Computer Architecture A Quantitative Approach, Fifth Edition Chapter 2 Memory Hierarchy Design 1 Introduction Programmers want unlimited amounts of memory with low latency Fast memory technology is more
EITF20: Computer Architecture Part 5.1.1: Virtual Memory
 EITF20: Computer Architecture Part 5.1.1: Virtual Memory Liang Liu liang.liu@eit.lth.se 1 Outline Reiteration Cache optimization Virtual memory Case study AMD Opteron Summary 2 Memory hierarchy 3 Cache
EITF20: Computer Architecture Part 5.1.1: Virtual Memory Liang Liu liang.liu@eit.lth.se 1 Outline Reiteration Cache optimization Virtual memory Case study AMD Opteron Summary 2 Memory hierarchy 3 Cache
Graduate Computer Architecture. Handout 4B Cache optimizations and inside DRAM
 Graduate Computer Architecture Handout 4B Cache optimizations and inside DRAM Outline 11 Advanced Cache Optimizations What inside DRAM? Summary 2018/1/15 2 Why More on Memory Hierarchy? 100,000 10,000
Graduate Computer Architecture Handout 4B Cache optimizations and inside DRAM Outline 11 Advanced Cache Optimizations What inside DRAM? Summary 2018/1/15 2 Why More on Memory Hierarchy? 100,000 10,000
LECTURE 5: MEMORY HIERARCHY DESIGN
 LECTURE 5: MEMORY HIERARCHY DESIGN Abridged version of Hennessy & Patterson (2012):Ch.2 Introduction Programmers want unlimited amounts of memory with low latency Fast memory technology is more expensive
LECTURE 5: MEMORY HIERARCHY DESIGN Abridged version of Hennessy & Patterson (2012):Ch.2 Introduction Programmers want unlimited amounts of memory with low latency Fast memory technology is more expensive
Lecture 20: Memory Hierarchy Main Memory and Enhancing its Performance. Grinch-Like Stuff
 Lecture 20: ory Hierarchy Main ory and Enhancing its Performance Professor Alvin R. Lebeck Computer Science 220 Fall 1999 HW #4 Due November 12 Projects Finish reading Chapter 5 Grinch-Like Stuff CPS 220
Lecture 20: ory Hierarchy Main ory and Enhancing its Performance Professor Alvin R. Lebeck Computer Science 220 Fall 1999 HW #4 Due November 12 Projects Finish reading Chapter 5 Grinch-Like Stuff CPS 220
Computer Architecture Spring 2016
 Computer Architecture Spring 2016 Lecture 08: Caches III Shuai Wang Department of Computer Science and Technology Nanjing University Improve Cache Performance Average memory access time (AMAT): AMAT =
Computer Architecture Spring 2016 Lecture 08: Caches III Shuai Wang Department of Computer Science and Technology Nanjing University Improve Cache Performance Average memory access time (AMAT): AMAT =
Some material adapted from Mohamed Younis, UMBC CMSC 611 Spr 2003 course slides Some material adapted from Hennessy & Patterson / 2003 Elsevier
 Some material adapted from Mohamed Younis, UMBC CMSC 611 Spr 2003 course slides Some material adapted from Hennessy & Patterson / 2003 Elsevier Science CPUtime = IC CPI Execution + Memory accesses Instruction
Some material adapted from Mohamed Younis, UMBC CMSC 611 Spr 2003 course slides Some material adapted from Hennessy & Patterson / 2003 Elsevier Science CPUtime = IC CPI Execution + Memory accesses Instruction
5008: Computer Architecture
 5008: Computer Architecture Chapter 5 Memory Hierarchy Design CA Lecture10 - memory hierarchy design (cwliu@twins.ee.nctu.edu.tw) 10-1 Outline 11 Advanced Cache Optimizations Memory Technology and DRAM
5008: Computer Architecture Chapter 5 Memory Hierarchy Design CA Lecture10 - memory hierarchy design (cwliu@twins.ee.nctu.edu.tw) 10-1 Outline 11 Advanced Cache Optimizations Memory Technology and DRAM
Adapted from David Patterson s slides on graduate computer architecture
 Mei Yang Adapted from David Patterson s slides on graduate computer architecture Introduction Ten Advanced Optimizations of Cache Performance Memory Technology and Optimizations Virtual Memory and Virtual
Mei Yang Adapted from David Patterson s slides on graduate computer architecture Introduction Ten Advanced Optimizations of Cache Performance Memory Technology and Optimizations Virtual Memory and Virtual
Types of Cache Misses: The Three C s
 Types of Cache Misses: The Three C s 1 Compulsory: On the first access to a block; the block must be brought into the cache; also called cold start misses, or first reference misses. 2 Capacity: Occur
Types of Cache Misses: The Three C s 1 Compulsory: On the first access to a block; the block must be brought into the cache; also called cold start misses, or first reference misses. 2 Capacity: Occur
Why memory hierarchy? Memory hierarchy. Memory hierarchy goals. CS2410: Computer Architecture. L1 cache design. Sangyeun Cho
 Why memory hierarchy? L1 cache design Sangyeun Cho Computer Science Department Memory hierarchy Memory hierarchy goals Smaller Faster More expensive per byte CPU Regs L1 cache L2 cache SRAM SRAM To provide
Why memory hierarchy? L1 cache design Sangyeun Cho Computer Science Department Memory hierarchy Memory hierarchy goals Smaller Faster More expensive per byte CPU Regs L1 cache L2 cache SRAM SRAM To provide
Graduate Computer Architecture. Handout 4B Cache optimizations and inside DRAM
 Graduate Computer Architecture Handout 4B Cache optimizations and inside DRAM Outline 11 Advanced Cache Optimizations What inside DRAM? Summary 2012/11/21 2 Why More on Memory Hierarchy? 100,000 10,000
Graduate Computer Architecture Handout 4B Cache optimizations and inside DRAM Outline 11 Advanced Cache Optimizations What inside DRAM? Summary 2012/11/21 2 Why More on Memory Hierarchy? 100,000 10,000
Classification Steady-State Cache Misses: Techniques To Improve Cache Performance:
 #1 Lec # 9 Winter 2003 1-21-2004 Classification Steady-State Cache Misses: The Three C s of cache Misses: Compulsory Misses Capacity Misses Conflict Misses Techniques To Improve Cache Performance: Reduce
#1 Lec # 9 Winter 2003 1-21-2004 Classification Steady-State Cache Misses: The Three C s of cache Misses: Compulsory Misses Capacity Misses Conflict Misses Techniques To Improve Cache Performance: Reduce
Chapter 02. Authors: John Hennessy & David Patterson. Copyright 2011, Elsevier Inc. All rights Reserved. 1
 Chapter 02 Authors: John Hennessy & David Patterson Copyright 2011, Elsevier Inc. All rights Reserved. 1 Figure 2.1 The levels in a typical memory hierarchy in a server computer shown on top (a) and in
Chapter 02 Authors: John Hennessy & David Patterson Copyright 2011, Elsevier Inc. All rights Reserved. 1 Figure 2.1 The levels in a typical memory hierarchy in a server computer shown on top (a) and in
Advanced cache memory optimizations
 Advanced cache memory optimizations Computer Architecture J. Daniel García Sánchez (coordinator) David Expósito Singh Francisco Javier García Blas ARCOS Group Computer Science and Engineering Department
Advanced cache memory optimizations Computer Architecture J. Daniel García Sánchez (coordinator) David Expósito Singh Francisco Javier García Blas ARCOS Group Computer Science and Engineering Department
EI338: Computer Systems and Engineering (Computer Architecture & Operating Systems)
") EI338: Computer Systems and Engineering (Computer Architecture & Operating Systems) Chentao Wu 吴晨涛 Associate Professor Dept. of Computer Science and Engineering Shanghai Jiao Tong University SEIEE Building
EI338: Computer Systems and Engineering (Computer Architecture & Operating Systems) Chentao Wu 吴晨涛 Associate Professor Dept. of Computer Science and Engineering Shanghai Jiao Tong University SEIEE Building
COSC 6385 Computer Architecture - Memory Hierarchies (II)
") COSC 6385 Computer Architecture - Memory Hierarchies (II) Edgar Gabriel Spring 2018 Types of cache misses Compulsory Misses: first access to a block cannot be in the cache (cold start misses) Capacity
COSC 6385 Computer Architecture - Memory Hierarchies (II) Edgar Gabriel Spring 2018 Types of cache misses Compulsory Misses: first access to a block cannot be in the cache (cold start misses) Capacity
Lecture 9: Improving Cache Performance: Reduce miss rate Reduce miss penalty Reduce hit time
 Lecture 9: Improving Cache Performance: Reduce miss rate Reduce miss penalty Reduce hit time Review ABC of Cache: Associativity Block size Capacity Cache organization Direct-mapped cache : A =, S = C/B
Lecture 9: Improving Cache Performance: Reduce miss rate Reduce miss penalty Reduce hit time Review ABC of Cache: Associativity Block size Capacity Cache organization Direct-mapped cache : A =, S = C/B
Lecture 19: Memory Hierarchy Five Ways to Reduce Miss Penalty (Second Level Cache) Admin
 Admin") Lecture 19: Memory Hierarchy Five Ways to Reduce Miss Penalty (Second Level Cache) Professor Alvin R. Lebeck Computer Science 220 Fall 1999 Exam Average 76 90-100 4 80-89 3 70-79 3 60-69 5 < 60 1 Admin
Lecture 19: Memory Hierarchy Five Ways to Reduce Miss Penalty (Second Level Cache) Professor Alvin R. Lebeck Computer Science 220 Fall 1999 Exam Average 76 90-100 4 80-89 3 70-79 3 60-69 5 < 60 1 Admin
Memory Hierarchies. Instructor: Dmitri A. Gusev. Fall Lecture 10, October 8, CS 502: Computers and Communications Technology
 Memory Hierarchies Instructor: Dmitri A. Gusev Fall 2007 CS 502: Computers and Communications Technology Lecture 10, October 8, 2007 Memories SRAM: value is stored on a pair of inverting gates very fast
Memory Hierarchies Instructor: Dmitri A. Gusev Fall 2007 CS 502: Computers and Communications Technology Lecture 10, October 8, 2007 Memories SRAM: value is stored on a pair of inverting gates very fast
Advanced Computer Architecture- 06CS81-Memory Hierarchy Design
 Advanced Computer Architecture- 06CS81-Memory Hierarchy Design AMAT and Processor Performance AMAT = Average Memory Access Time Miss-oriented Approach to Memory Access CPIExec includes ALU and Memory instructions
Advanced Computer Architecture- 06CS81-Memory Hierarchy Design AMAT and Processor Performance AMAT = Average Memory Access Time Miss-oriented Approach to Memory Access CPIExec includes ALU and Memory instructions
Reducing Hit Times. Critical Influence on cycle-time or CPI. small is always faster and can be put on chip
 Reducing Hit Times Critical Influence on cycle-time or CPI Keep L1 small and simple small is always faster and can be put on chip interesting compromise is to keep the tags on chip and the block data off
Reducing Hit Times Critical Influence on cycle-time or CPI Keep L1 small and simple small is always faster and can be put on chip interesting compromise is to keep the tags on chip and the block data off
Copyright 2012, Elsevier Inc. All rights reserved.
 Computer Architecture A Quantitative Approach, Fifth Edition Chapter 2 Memory Hierarchy Design Edited by Mansour Al Zuair 1 Introduction Programmers want unlimited amounts of memory with low latency Fast
Computer Architecture A Quantitative Approach, Fifth Edition Chapter 2 Memory Hierarchy Design Edited by Mansour Al Zuair 1 Introduction Programmers want unlimited amounts of memory with low latency Fast
Cache Performance! ! Memory system and processor performance:! ! Improving memory hierarchy performance:! CPU time = IC x CPI x Clock time
 Cache Performance!! Memory system and processor performance:! CPU time = IC x CPI x Clock time CPU performance eqn. CPI = CPI ld/st x IC ld/st IC + CPI others x IC others IC CPI ld/st = Pipeline time +
Cache Performance!! Memory system and processor performance:! CPU time = IC x CPI x Clock time CPU performance eqn. CPI = CPI ld/st x IC ld/st IC + CPI others x IC others IC CPI ld/st = Pipeline time +
Reducing Miss Penalty: Read Priority over Write on Miss. Improving Cache Performance. Non-blocking Caches to reduce stalls on misses
 Improving Cache Performance 1. Reduce the miss rate, 2. Reduce the miss penalty, or 3. Reduce the time to hit in the. Reducing Miss Penalty: Read Priority over Write on Miss Write buffers may offer RAW
Improving Cache Performance 1. Reduce the miss rate, 2. Reduce the miss penalty, or 3. Reduce the time to hit in the. Reducing Miss Penalty: Read Priority over Write on Miss Write buffers may offer RAW
Improving Cache Performance. Dr. Yitzhak Birk Electrical Engineering Department, Technion
 Improving Cache Performance Dr. Yitzhak Birk Electrical Engineering Department, Technion 1 Cache Performance CPU time = (CPU execution clock cycles + Memory stall clock cycles) x clock cycle time Memory
Improving Cache Performance Dr. Yitzhak Birk Electrical Engineering Department, Technion 1 Cache Performance CPU time = (CPU execution clock cycles + Memory stall clock cycles) x clock cycle time Memory
Improving Cache Performance. Reducing Misses. How To Reduce Misses? 3Cs Absolute Miss Rate. 1. Reduce the miss rate, Classifying Misses: 3 Cs
 Improving Cache Performance 1. Reduce the miss rate, 2. Reduce the miss penalty, or 3. Reduce the time to hit in the. Reducing Misses Classifying Misses: 3 Cs! Compulsory The first access to a block is
Improving Cache Performance 1. Reduce the miss rate, 2. Reduce the miss penalty, or 3. Reduce the time to hit in the. Reducing Misses Classifying Misses: 3 Cs! Compulsory The first access to a block is
Advanced Caching Techniques
 Advanced Caching Approaches to improving memory system performance eliminate memory operations decrease the number of misses decrease the miss penalty decrease the cache/memory access times hide memory
Advanced Caching Approaches to improving memory system performance eliminate memory operations decrease the number of misses decrease the miss penalty decrease the cache/memory access times hide memory
Memory Hierarchies 2009 DAT105
 Memory Hierarchies Cache performance issues (5.1) Virtual memory (C.4) Cache performance improvement techniques (5.2) Hit-time improvement techniques Miss-rate improvement techniques Miss-penalty improvement
Memory Hierarchies Cache performance issues (5.1) Virtual memory (C.4) Cache performance improvement techniques (5.2) Hit-time improvement techniques Miss-rate improvement techniques Miss-penalty improvement
COSC4201. Chapter 5. Memory Hierarchy Design. Prof. Mokhtar Aboelaze York University
 COSC4201 Chapter 5 Memory Hierarchy Design Prof. Mokhtar Aboelaze York University 1 Memory Hierarchy The gap between CPU performance and main memory has been widening with higher performance CPUs creating
COSC4201 Chapter 5 Memory Hierarchy Design Prof. Mokhtar Aboelaze York University 1 Memory Hierarchy The gap between CPU performance and main memory has been widening with higher performance CPUs creating
Lecture 18: Memory Hierarchy Main Memory and Enhancing its Performance Professor Randy H. Katz Computer Science 252 Spring 1996
 Lecture 18: Memory Hierarchy Main Memory and Enhancing its Performance Professor Randy H. Katz Computer Science 252 Spring 1996 RHK.S96 1 Review: Reducing Miss Penalty Summary Five techniques Read priority
Lecture 18: Memory Hierarchy Main Memory and Enhancing its Performance Professor Randy H. Katz Computer Science 252 Spring 1996 RHK.S96 1 Review: Reducing Miss Penalty Summary Five techniques Read priority
Pollard s Attempt to Explain Cache Memory
 Pollard s Attempt to Explain Cache Start with (Very) Basic Block Diagram CPU (Actual work done here) (Starting and ending data stored here, along with program) Organization of : Designer s choice 1 Problem
Pollard s Attempt to Explain Cache Start with (Very) Basic Block Diagram CPU (Actual work done here) (Starting and ending data stored here, along with program) Organization of : Designer s choice 1 Problem
Cache Performance! ! Memory system and processor performance:! ! Improving memory hierarchy performance:! CPU time = IC x CPI x Clock time
 Cache Performance!! Memory system and processor performance:! CPU time = IC x CPI x Clock time CPU performance eqn. CPI = CPI ld/st x IC ld/st IC + CPI others x IC others IC CPI ld/st = Pipeline time +
Cache Performance!! Memory system and processor performance:! CPU time = IC x CPI x Clock time CPU performance eqn. CPI = CPI ld/st x IC ld/st IC + CPI others x IC others IC CPI ld/st = Pipeline time +
Lecture 11. Virtual Memory Review: Memory Hierarchy
 Lecture 11 Virtual Memory Review: Memory Hierarchy 1 Administration Homework 4 -Due 12/21 HW 4 Use your favorite language to write a cache simulator. Input: address trace, cache size, block size, associativity
Lecture 11 Virtual Memory Review: Memory Hierarchy 1 Administration Homework 4 -Due 12/21 HW 4 Use your favorite language to write a cache simulator. Input: address trace, cache size, block size, associativity
Announcements. ! Previous lecture. Caches. Inf3 Computer Architecture
 Announcements! Previous lecture Caches Inf3 Computer Architecture - 2016-2017 1 Recap: Memory Hierarchy Issues! Block size: smallest unit that is managed at each level E.g., 64B for cache lines, 4KB for
Announcements! Previous lecture Caches Inf3 Computer Architecture - 2016-2017 1 Recap: Memory Hierarchy Issues! Block size: smallest unit that is managed at each level E.g., 64B for cache lines, 4KB for
Chapter 2: Memory Hierarchy Design Part 2
 Chapter 2: Memory Hierarchy Design Part 2 Introduction (Section 2.1, Appendix B) Caches Review of basics (Section 2.1, Appendix B) Advanced methods (Section 2.3) Main Memory Virtual Memory Fundamental
Chapter 2: Memory Hierarchy Design Part 2 Introduction (Section 2.1, Appendix B) Caches Review of basics (Section 2.1, Appendix B) Advanced methods (Section 2.3) Main Memory Virtual Memory Fundamental
Memory Hierarchy 3 Cs and 6 Ways to Reduce Misses
 Memory Hierarchy 3 Cs and 6 Ways to Reduce Misses Soner Onder Michigan Technological University Randy Katz & David A. Patterson University of California, Berkeley Four Questions for Memory Hierarchy Designers
Memory Hierarchy 3 Cs and 6 Ways to Reduce Misses Soner Onder Michigan Technological University Randy Katz & David A. Patterson University of California, Berkeley Four Questions for Memory Hierarchy Designers
CSE 502 Graduate Computer Architecture. Lec Advanced Memory Hierarchy
 CSE 502 Graduate Computer Architecture Lec 19-20 Advanced Memory Hierarchy Larry Wittie Computer Science, StonyBrook University http://www.cs.sunysb.edu/~cse502 and ~lw Slides adapted from David Patterson,
CSE 502 Graduate Computer Architecture Lec 19-20 Advanced Memory Hierarchy Larry Wittie Computer Science, StonyBrook University http://www.cs.sunysb.edu/~cse502 and ~lw Slides adapted from David Patterson,
CS3350B Computer Architecture
 CS335B Computer Architecture Winter 25 Lecture 32: Exploiting Memory Hierarchy: How? Marc Moreno Maza wwwcsduwoca/courses/cs335b [Adapted from lectures on Computer Organization and Design, Patterson &
CS335B Computer Architecture Winter 25 Lecture 32: Exploiting Memory Hierarchy: How? Marc Moreno Maza wwwcsduwoca/courses/cs335b [Adapted from lectures on Computer Organization and Design, Patterson &
Advanced Caching Techniques
 Advanced Caching Approaches to improving memory system performance eliminate memory accesses/operations decrease the number of misses decrease the miss penalty decrease the cache/memory access times hide
Advanced Caching Approaches to improving memory system performance eliminate memory accesses/operations decrease the number of misses decrease the miss penalty decrease the cache/memory access times hide
Chapter Seven. Large & Fast: Exploring Memory Hierarchy
 Chapter Seven Large & Fast: Exploring Memory Hierarchy 1 Memories: Review SRAM (Static Random Access Memory): value is stored on a pair of inverting gates very fast but takes up more space than DRAM DRAM
Chapter Seven Large & Fast: Exploring Memory Hierarchy 1 Memories: Review SRAM (Static Random Access Memory): value is stored on a pair of inverting gates very fast but takes up more space than DRAM DRAM
DECstation 5000 Miss Rates. Cache Performance Measures. Example. Cache Performance Improvements. Types of Cache Misses. Cache Performance Equations
 DECstation 5 Miss Rates Cache Performance Measures % 3 5 5 5 KB KB KB 8 KB 6 KB 3 KB KB 8 KB Cache size Direct-mapped cache with 3-byte blocks Percentage of instruction references is 75% Instr. Cache Data
DECstation 5 Miss Rates Cache Performance Measures % 3 5 5 5 KB KB KB 8 KB 6 KB 3 KB KB 8 KB Cache size Direct-mapped cache with 3-byte blocks Percentage of instruction references is 75% Instr. Cache Data
Lecture notes for CS Chapter 2, part 1 10/23/18
 Chapter 2: Memory Hierarchy Design Part 2 Introduction (Section 2.1, Appendix B) Caches Review of basics (Section 2.1, Appendix B) Advanced methods (Section 2.3) Main Memory Virtual Memory Fundamental
Chapter 2: Memory Hierarchy Design Part 2 Introduction (Section 2.1, Appendix B) Caches Review of basics (Section 2.1, Appendix B) Advanced methods (Section 2.3) Main Memory Virtual Memory Fundamental
CS 252 Graduate Computer Architecture. Lecture 8: Memory Hierarchy
 CS 252 Graduate Computer Architecture Lecture 8: Memory Hierarchy Krste Asanovic Electrical Engineering and Computer Sciences University of California, Berkeley http://www.eecs.berkeley.edu/~krste http://inst.cs.berkeley.edu/~cs252
CS 252 Graduate Computer Architecture Lecture 8: Memory Hierarchy Krste Asanovic Electrical Engineering and Computer Sciences University of California, Berkeley http://www.eecs.berkeley.edu/~krste http://inst.cs.berkeley.edu/~cs252
The Alpha Microprocessor: Out-of-Order Execution at 600 Mhz. R. E. Kessler COMPAQ Computer Corporation Shrewsbury, MA
 The Alpha 21264 Microprocessor: Out-of-Order ution at 600 Mhz R. E. Kessler COMPAQ Computer Corporation Shrewsbury, MA 1 Some Highlights z Continued Alpha performance leadership y 600 Mhz operation in
The Alpha 21264 Microprocessor: Out-of-Order ution at 600 Mhz R. E. Kessler COMPAQ Computer Corporation Shrewsbury, MA 1 Some Highlights z Continued Alpha performance leadership y 600 Mhz operation in
Cache Performance and Memory Management: From Absolute Addresses to Demand Paging. Cache Performance
 6.823, L11--1 Cache Performance and Memory Management: From Absolute Addresses to Demand Paging Asanovic Laboratory for Computer Science M.I.T. http://www.csg.lcs.mit.edu/6.823 Cache Performance 6.823,
6.823, L11--1 Cache Performance and Memory Management: From Absolute Addresses to Demand Paging Asanovic Laboratory for Computer Science M.I.T. http://www.csg.lcs.mit.edu/6.823 Cache Performance 6.823,
Advanced Caching Techniques (2) Department of Electrical Engineering Stanford University
 Department of Electrical Engineering Stanford University") Lecture 4: Advanced Caching Techniques (2) Department of Electrical Engineering Stanford University http://eeclass.stanford.edu/ee282 Lecture 4-1 Announcements HW1 is out (handout and online) Due on 10/15
Lecture 4: Advanced Caching Techniques (2) Department of Electrical Engineering Stanford University http://eeclass.stanford.edu/ee282 Lecture 4-1 Announcements HW1 is out (handout and online) Due on 10/15
CACHE MEMORIES ADVANCED COMPUTER ARCHITECTURES. Slides by: Pedro Tomás
 CACHE MEMORIES Slides by: Pedro Tomás Additional reading: Computer Architecture: A Quantitative Approach, 5th edition, Chapter 2 and Appendix B, John L. Hennessy and David A. Patterson, Morgan Kaufmann,
CACHE MEMORIES Slides by: Pedro Tomás Additional reading: Computer Architecture: A Quantitative Approach, 5th edition, Chapter 2 and Appendix B, John L. Hennessy and David A. Patterson, Morgan Kaufmann,
CSE 502 Graduate Computer Architecture. Lec Advanced Memory Hierarchy and Application Tuning
 CSE 502 Graduate Computer Architecture Lec 25-26 Advanced Memory Hierarchy and Application Tuning Larry Wittie Computer Science, StonyBrook University http://www.cs.sunysb.edu/~cse502 and ~lw Slides adapted
CSE 502 Graduate Computer Architecture Lec 25-26 Advanced Memory Hierarchy and Application Tuning Larry Wittie Computer Science, StonyBrook University http://www.cs.sunysb.edu/~cse502 and ~lw Slides adapted
L2 cache provides additional on-chip caching space. L2 cache captures misses from L1 cache. Summary
 HY425 Lecture 13: Improving Cache Performance Dimitrios S. Nikolopoulos University of Crete and FORTH-ICS November 25, 2011 Dimitrios S. Nikolopoulos HY425 Lecture 13: Improving Cache Performance 1 / 40
HY425 Lecture 13: Improving Cache Performance Dimitrios S. Nikolopoulos University of Crete and FORTH-ICS November 25, 2011 Dimitrios S. Nikolopoulos HY425 Lecture 13: Improving Cache Performance 1 / 40
High Performance Computer Architecture Prof. Ajit Pal Department of Computer Science and Engineering Indian Institute of Technology, Kharagpur
 High Performance Computer Architecture Prof. Ajit Pal Department of Computer Science and Engineering Indian Institute of Technology, Kharagpur Lecture - 26 Cache Optimization Techniques (Contd.) (Refer
High Performance Computer Architecture Prof. Ajit Pal Department of Computer Science and Engineering Indian Institute of Technology, Kharagpur Lecture - 26 Cache Optimization Techniques (Contd.) (Refer
Cache Performance (H&P 5.3; 5.5; 5.6)
") Cache Performance (H&P 5.3; 5.5; 5.6) Memory system and processor performance: CPU time = IC x CPI x Clock time CPU performance eqn. CPI = CPI ld/st x IC ld/st IC + CPI others x IC others IC CPI ld/st
Cache Performance (H&P 5.3; 5.5; 5.6) Memory system and processor performance: CPU time = IC x CPI x Clock time CPU performance eqn. CPI = CPI ld/st x IC ld/st IC + CPI others x IC others IC CPI ld/st
Locality. Cache. Direct Mapped Cache. Direct Mapped Cache
 Locality A principle that makes having a memory hierarchy a good idea If an item is referenced, temporal locality: it will tend to be referenced again soon spatial locality: nearby items will tend to be
Locality A principle that makes having a memory hierarchy a good idea If an item is referenced, temporal locality: it will tend to be referenced again soon spatial locality: nearby items will tend to be
EE 660: Computer Architecture Advanced Caches
 EE 660: Computer Architecture Advanced Caches Yao Zheng Department of Electrical Engineering University of Hawaiʻi at Mānoa Based on the slides of Prof. David Wentzlaff Agenda Review Three C s Basic Cache
EE 660: Computer Architecture Advanced Caches Yao Zheng Department of Electrical Engineering University of Hawaiʻi at Mānoa Based on the slides of Prof. David Wentzlaff Agenda Review Three C s Basic Cache
The Alpha Microprocessor: Out-of-Order Execution at 600 MHz. Some Highlights
 The Alpha 21264 Microprocessor: Out-of-Order ution at 600 MHz R. E. Kessler Compaq Computer Corporation Shrewsbury, MA 1 Some Highlights Continued Alpha performance leadership 600 MHz operation in 0.35u
The Alpha 21264 Microprocessor: Out-of-Order ution at 600 MHz R. E. Kessler Compaq Computer Corporation Shrewsbury, MA 1 Some Highlights Continued Alpha performance leadership 600 MHz operation in 0.35u
Chapter 2: Memory Hierarchy Design Part 2
 Chapter 2: Memory Hierarchy Design Part 2 Introduction (Section 2.1, Appendix B) Caches Review of basics (Section 2.1, Appendix B) Advanced methods (Section 2.3) Main Memory Virtual Memory Fundamental
Chapter 2: Memory Hierarchy Design Part 2 Introduction (Section 2.1, Appendix B) Caches Review of basics (Section 2.1, Appendix B) Advanced methods (Section 2.3) Main Memory Virtual Memory Fundamental
Cray XE6 Performance Workshop
 Cray XE6 Performance Workshop Mark Bull David Henty EPCC, University of Edinburgh Overview Why caches are needed How caches work Cache design and performance. 2 1 The memory speed gap Moore s Law: processors
Cray XE6 Performance Workshop Mark Bull David Henty EPCC, University of Edinburgh Overview Why caches are needed How caches work Cache design and performance. 2 1 The memory speed gap Moore s Law: processors
Cache in a Memory Hierarchy
 Cache in a Memory Hierarchy Paulo J. D. Domingues Curso de Especialização em Informática Universidade do Minho pado@clix.pt Abstract: In the past two decades, the steady increase on processor performance
Cache in a Memory Hierarchy Paulo J. D. Domingues Curso de Especialização em Informática Universidade do Minho pado@clix.pt Abstract: In the past two decades, the steady increase on processor performance
Memory Cache. Memory Locality. Cache Organization -- Overview L1 Data Cache
 Memory Cache Memory Locality cpu cache memory Memory hierarchies take advantage of memory locality. Memory locality is the principle that future memory accesses are near past accesses. Memory hierarchies
Memory Cache Memory Locality cpu cache memory Memory hierarchies take advantage of memory locality. Memory locality is the principle that future memory accesses are near past accesses. Memory hierarchies
EECS 322 Computer Architecture Superpipline and the Cache
 EECS 322 Computer Architecture Superpipline and the Cache Instructor: Francis G. Wolff wolff@eecs.cwru.edu Case Western Reserve University This presentation uses powerpoint animation: please viewshow Summary:
EECS 322 Computer Architecture Superpipline and the Cache Instructor: Francis G. Wolff wolff@eecs.cwru.edu Case Western Reserve University This presentation uses powerpoint animation: please viewshow Summary:
! 11 Advanced Cache Optimizations! Memory Technology and DRAM optimizations! Virtual Machines
 Outline EEL 5764 Graduate Computer Architecture 11 Advanced Cache Optimizations Memory Technology and DRAM optimizations Virtual Machines Chapter 5 Advanced Memory Hierarchy Ann Gordon-Ross Electrical
Outline EEL 5764 Graduate Computer Architecture 11 Advanced Cache Optimizations Memory Technology and DRAM optimizations Virtual Machines Chapter 5 Advanced Memory Hierarchy Ann Gordon-Ross Electrical
CS 152 Computer Architecture and Engineering. Lecture 7 - Memory Hierarchy-II
 CS 152 Computer Architecture and Engineering Lecture 7 - Memory Hierarchy-II Krste Asanovic Electrical Engineering and Computer Sciences University of California at Berkeley http://www.eecs.berkeley.edu/~krste
CS 152 Computer Architecture and Engineering Lecture 7 - Memory Hierarchy-II Krste Asanovic Electrical Engineering and Computer Sciences University of California at Berkeley http://www.eecs.berkeley.edu/~krste
Chapter 7 Large and Fast: Exploiting Memory Hierarchy. Memory Hierarchy. Locality. Memories: Review
 Memories: Review Chapter 7 Large and Fast: Exploiting Hierarchy DRAM (Dynamic Random Access ): value is stored as a charge on capacitor that must be periodically refreshed, which is why it is called dynamic
Memories: Review Chapter 7 Large and Fast: Exploiting Hierarchy DRAM (Dynamic Random Access ): value is stored as a charge on capacitor that must be periodically refreshed, which is why it is called dynamic
Lecture 11 Reducing Cache Misses. Computer Architectures S
 Lecture 11 Reducing Cache Misses Computer Architectures 521480S Reducing Misses Classifying Misses: 3 Cs Compulsory The first access to a block is not in the cache, so the block must be brought into the
Lecture 11 Reducing Cache Misses Computer Architectures 521480S Reducing Misses Classifying Misses: 3 Cs Compulsory The first access to a block is not in the cache, so the block must be brought into the
Chapter Seven. Memories: Review. Exploiting Memory Hierarchy CACHE MEMORY AND VIRTUAL MEMORY
 Chapter Seven CACHE MEMORY AND VIRTUAL MEMORY 1 Memories: Review SRAM: value is stored on a pair of inverting gates very fast but takes up more space than DRAM (4 to 6 transistors) DRAM: value is stored
Chapter Seven CACHE MEMORY AND VIRTUAL MEMORY 1 Memories: Review SRAM: value is stored on a pair of inverting gates very fast but takes up more space than DRAM (4 to 6 transistors) DRAM: value is stored
CMSC 611: Advanced Computer Architecture. Cache and Memory
 CMSC 611: Advanced Computer Architecture Cache and Memory Classification of Cache Misses Compulsory The first access to a block is never in the cache. Also called cold start misses or first reference misses.
CMSC 611: Advanced Computer Architecture Cache and Memory Classification of Cache Misses Compulsory The first access to a block is never in the cache. Also called cold start misses or first reference misses.
Computer Systems Architecture I. CSE 560M Lecture 17 Guest Lecturer: Shakir James
 Computer Systems Architecture I CSE 560M Lecture 17 Guest Lecturer: Shakir James Plan for Today Announcements and Reminders Project demos in three weeks (Nov. 23 rd ) Questions Today s discussion: Improving
Computer Systems Architecture I CSE 560M Lecture 17 Guest Lecturer: Shakir James Plan for Today Announcements and Reminders Project demos in three weeks (Nov. 23 rd ) Questions Today s discussion: Improving
Chapter Seven Morgan Kaufmann Publishers
 Chapter Seven Memories: Review SRAM: value is stored on a pair of inverting gates very fast but takes up more space than DRAM (4 to 6 transistors) DRAM: value is stored as a charge on capacitor (must be
Chapter Seven Memories: Review SRAM: value is stored on a pair of inverting gates very fast but takes up more space than DRAM (4 to 6 transistors) DRAM: value is stored as a charge on capacitor (must be
Cache performance Outline
 Cache performance 1 Outline Metrics Performance characterization Cache optimization techniques 2 Page 1 Cache Performance metrics (1) Miss rate: Neglects cycle time implications Average memory access time
Cache performance 1 Outline Metrics Performance characterization Cache optimization techniques 2 Page 1 Cache Performance metrics (1) Miss rate: Neglects cycle time implications Average memory access time
Name: 1. Caches a) The average memory access time (AMAT) can be modeled using the following formula: AMAT = Hit time + Miss rate * Miss penalty
 The average memory access time (AMAT) can be modeled using the following formula: AMAT = Hit time + Miss rate * Miss penalty") 1. Caches a) The average memory access time (AMAT) can be modeled using the following formula: ( 3 Pts) AMAT Hit time + Miss rate * Miss penalty Name and explain (briefly) one technique for each of the
1. Caches a) The average memory access time (AMAT) can be modeled using the following formula: ( 3 Pts) AMAT Hit time + Miss rate * Miss penalty Name and explain (briefly) one technique for each of the
Chapter 5 Memory Hierarchy Design. In-Cheol Park Dept. of EE, KAIST
 Chapter 5 Memory Hierarchy Design In-Cheol Park Dept. of EE, KAIST Why cache? Microprocessor performance increment: 55% per year Memory performance increment: 7% per year Principles of locality Spatial
Chapter 5 Memory Hierarchy Design In-Cheol Park Dept. of EE, KAIST Why cache? Microprocessor performance increment: 55% per year Memory performance increment: 7% per year Principles of locality Spatial