Memory Consistency. Challenges. Program order Memory access order
|
|
|
- Caren Underwood
- 6 years ago
- Views:
Transcription
1 Memory Consistency
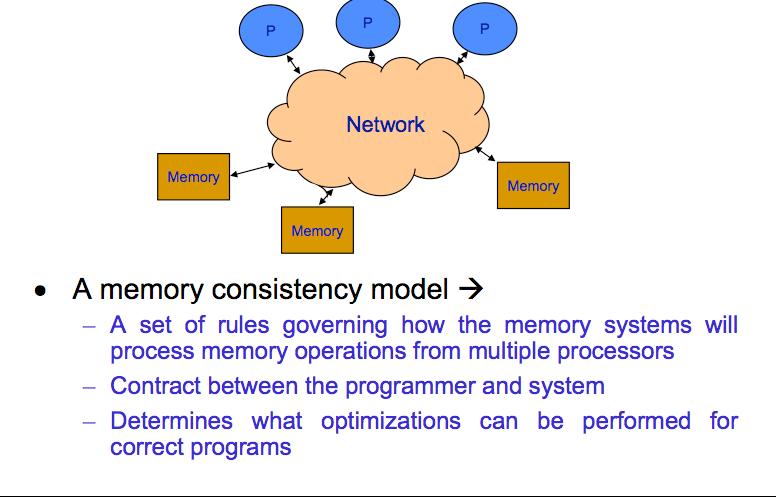
2 Memory Consistency
3 Memory Consistency Reads and writes of the shared memory face consistency problem Need to achieve controlled consistency in memory events Shared memory behavior determined by: Program order Memory access order Challenges Modern processors reorder operations Compiler optimizations (scalar replacement, instruction rescheduling
4 Basic Concept On a multiprocessor: Concurrent instruction streams (threads) on different processors Memory events performed by one process may create data to be used by another Events: read and write Memory consistency model specifies how the memory events initiated by one process should be observed by other processes Event ordering Declare which memory access is allowed, which process should wait for a later access when processes compete
5 Uniprocessor vs. Multiprocessor Model
6 Understanding Program Order Initially X = 2 P1 P2.... r0=read(x) r1=read(x) r0=r0+1 r1=r1+1 Write(r0,X) Write(r1,X).. Possible execution sequences: P1:r0=Read(X) P2:r1=Read(X) P2:r1=Read(X) P2:r1=r1+1 P1:r0=r0+1 P2:Write(r1,X) P1:Write(r0,X) P1:r0=Read(X) P2:r1=r1+1 P1:r0=r0+1 P2:Write(r1,X) P1:Write(r0,X) x=3 x=4
7 Interleaving P1 a. A=1; b. Print B,C; P2 c. B=1; d. Print A,C; switch P3 e. C=1; f. Print A,B; A, B, C shared variables (initially 0) Shared Memory Program orders of individual instruction streams may need to be modified because of interaction among them Finding optimum global memory order is an NP hard problem
8 Example P1 a. A=1; b. Print B,C; P2 c. B=1; d. Print A,C; switch P3 e. C=1; f. Print A,B; A, B, C shared variables (initially 0) Shared Memory Concatenate program orders in P1, P2 and P3 6-tuple binary strings (64 output combinations) (a,b,c,d,e,f) => (001011) (in order execution) (a,c,e,b,d,f) => (111111) (in order execution) (b,d,f,e,a,c) => (000000) (out of order execution) 6! (720 possible permutations)
9 Mutual exclusion problem mutual exclusion problem in concurrent programming allow two threads to share a single-use resource without conflict, using only shared memory for communication. avoid the strict alternation of a naive turntaking algorithm
10 Definition If two processes attempt to enter a critical section at the same time, allow only one process in, based on whose turn it is. If one process is already in the critical section, the other process will wait for the first process to exit. How would you implement this without mutual exclusion, freedom from deadlock, and freedom from starvation.
11 Solution: Dekker s Algorithm This is done by the use of two flags f0 and f1 which indicate an intention to enter the critical section and a turn variable which indicates who has priority between the two processes.
12 flag[0] := false flag[1] := false turn := 0 // or 1 P0 flag[0] := true while flag[1] = true { if turn 0 { flag[0] := false while turn 0 { } flag[0] := true } } // critical section... turn := 1 flag[0] := false // remainder // section P1 flag[1] := true while flag[0] = true { if turn 1 { flag[1] := false while turn 1 { } flag[1] := true } } // critical section... turn := 0 flag[1] := false // remainder // section
13 Disadvantages limited to two processes makes use of busy waiting instead of process suspension. Modern CPUs execute their instructions in an out-of-order fashion, even memory accesses can be reordered
14 Peterson s Algorithm flag[0] = 0; flag[1] = 0; turn; P0 flag[0] = 1; turn = 1; while (flag[1] == 1 && turn == 1) { // busy wait } // critical section... // end of critical section flag[0] = 0; P1 flag[1] = 1; turn = 0; while (flag[0] == 1 && turn == 0) { // busy wait } // critical section... // end of critical section flag[1] = 0;
15 Lamport's bakery algorithm a bakery with a numbering machine the 'customers' will be threads, identified by the letter i, obtained from a global variable. more than one thread might get the same number // declaration and initial values of global variables Entering: array [1..NUM_THREADS] of bool = {false}; Number: array [1.. NUM_THREADS] of integer = {0}; 1 lock(integer i) { 2 Entering[i] = true; 3 Number[i] = 1 + max(number[1],..., Number[NUM_THREADS]); 4 Entering[i] = false; 5 for (j = 1; j <= NUM_THREADS; j++) { 6 // Wait until thread j receives its number: 7 while (Entering[j]) { /* nothing */ } 8 // Wait until all threads with smaller numbers or with the same 9 // number, but with higher priority, finish their work: 10 while ((Number[j]!= 0) && ((Number[j], j) < (Number[i], i))) { 11 /* nothing */ 12 } 13 } 14 } 15 unlock(integer i) { 16 Number[i] = 0; 17 } 18 Thread(integer i) { 19 while (true) { 20 lock(i); 21 // The critical section goes here unlock(i); 23 // non-critical section } 25 }
16 Models Strict Consistency: Read always returns with most recent Write to same address Sequential Consistency: The result of any execution appears as the interleaving of individual programs strictly in sequential program order Processor Consistency: Writes issued by each processor are in program order, but writes from different processors can be out of order (Goodman) Weak Consistency: Programmer uses synch operations to enforce sequential consistency (Dubois) Reads from each processor is not restricted More opportunities for pipelining
17 Relationship to Cache Coherence Protocol Cache coherence protocol must observe the constraints imposed by the memory consistency model Ex: Read hit in a cache Reading without waiting for the completion of a previous write my violate sequential consistency Cache coherence protocol provides a mechanism to propagate the newly written value Memory consistency model places an additional constraint on when the value can be propagated to a given processor
18 Latency Tolerance Scalable systems Distributed shared memory architecture Access to remote memory: long latency Processor speed vs. the memory and interconnect Need for Latency reduction, avoidance, hiding
19 Latency Avoidance Organize user applications at architectural, compiler or application levels to achieve program/data locality Possible when applications exhibit: Temporal or spatial locality How do you enhance locality?
20 Locality Enhancement Architectural support: Cache coherency protocols, memory consistency models, fast message passing, etc. User support High Performance Fortran: program instructs compiler how to allocate the data (example?) Software support Compiler performs certain transformations Example?
21 Latency Reduction What if locality is limited? Data access is dynamically changing? For ex: sorting algorithms We need latency reduction mechanisms Target communication subsystem Interconnect Network interface Fast communication software Cluster: TCP, UDP, etc
22 Latency Hiding Hide communication latency within computation Overlapping techniques Prefetching techniques Hide read latency Distributed coherent caches Reduce cache misses Shorten time to retrieve clean copy Multiple context processors Switch from one context to another when long-latency operations is encountered (hardware supported multithreading)
23 Memory Delays SMP high in multiprocessors due to added contention for shared resources such as a shared bus and memory modules Distributed are even more pronounced in distributed-memory multiprocessors where memory requests may need to be satisfied across an interconnection network. By masking some or all of these significant memory latencies, prefetching can be an effective means of speeding up multiprocessor applications
24 Data Prefetching Overlapping computation with memory accesses Rather than waiting for a cache miss to perform a memory fetch, data prefetching anticipates such misses and issues a fetch to the memory system in advance of the actual memory reference.
25 Cache Hierarchy Popular latency reducing technique But still common for scientific programs to spend more than half their run times stalled on memory requests partially a result of the on demand fetch policy fetch data into the cache from main memory only after the processor has requested a word and found it absent from the cache.
26 Why do scientific applications exhibit poor cache utilization? Is something wrong with the principle of locality? The traversal of large data arrays is often at the heart of this problem. Temporal locality in array computations once an element has been used to compute a result, it is often not referenced again before it is displaced from the cache to make room for additional array elements. Sequential array accesses patterns exhibit a high degree of spatial locality, many other types of array access patterns do not. For example, in a language which stores matrices in row-major order, a row-wise traversal of a matrix will result in consecutively referenced elements being widely separated in memory. Such strided reference patterns result in low spatial locality if the stride is greater than the cache block size. In this case, only one word per cache block is actually used while the remainder of the block remains untouched even though cache space has been allocated for it.
27 Memory references r1,r2 and r3 not in the cache Time: Computation and memory references satisfied within the cache hierarchy main memory access time
28 Challenges Cache pollution Data arrives early enough to hide all of the memory latency Data must be held in the processor cache for some period of time before it is used by the processor. During this time, the prefetched data are exposed to the cache replacement policy and may be evicted from the cache before use. Moreover, the prefetched data may displace data in the cache that is currently in use by the processor. Memory bandwidth Back to figure: No prefetch: the three memory requests occur within the first 31 time units of program startup, With prefetch: these requests are compressed into a period of 19 time units. By removing processor stall cycles, prefetching effectively increases the frequency of memory requests issued by the processor. Memory systems must be designed to match this higher bandwidth to avoid becoming saturated and nullifying the benefits of prefetching.
29 Spatial Locality Block transfer is a way of prefetching (1960s) Software prefetching later (1980s)
30 Binding Prefetch Non-blocking load instructions these instructions are issued in advance of the actual use to take advantage of the parallelism between the processor and memory subsystem. Rather than loading data into the cache, however, the specified word is placed directly into a processor register. the value of the prefetched variable is bound to a named location at the time the prefetch is issued.
31 Software-Initiated Data Prefetching Some form of fetch instruction can be as simple as a load into a processor register Fetches are non-blocking memory operations Allow prefetches to bypass other outstanding memory operations in the cache. Fetch instructions cannot cause exceptions The hardware required to implement softwareinitiated prefetching is modest
32 Prefetch Challenges prefetch scheduling. judicious placement of fetch instructions within the target application. not possible to precisely predict when to schedule a prefetch so that data arrives in the cache at the moment it will be requested by the processor uncertainties not predictable at compile time careful consideration when statically scheduling prefetch instructions. may be added by the programmer or by the compiler during an optimization pass. programming effort?
33 Suitable spots for Fetch most often used within loops responsible for large array calculations. common in scientific codes, exhibit poor cache utilization predictable array referencing patterns.


34 Example: How to solve these two issues? software piplining assume a four-word cache block Issues: Cache misses during the first iteration Unnecessary prefetches in the last iteration of the unrolled loop
35 Assumptions implicit assumption Prefetching one iteration ahead of the data s actual use is sufficient to hide the latency What if the loops contain small computational bodies. Define prefetch distance initiate prefetches d iterations before the data is referenced How do you determine d? Let l be the average cache miss latency, measured in processor cycles, s be the estimated cycle time of the shortest possible execution path through one loop iteration, including the prefetch overhead. d
36 Revisiting the example let us assume an average miss latency of 100 processor cycles and a loop iteration time of 45 cycles d=3 (handle a prefetch distance of three)
37 Case Study Given a distributed-shared multiprocessor let s define a remote access cache (RAC) Assume that RAC is located at the network interface of each node Motivation: prefetched remote data could be accessed at a speed comparable to that of local memory while the processor cache hierarchy was reserved for demand-fetched data. Which one is better: Having RAC or pretefetching data directly into the processor cache hierarchy? Despite significantly increasing cache contention and reducing overall cache space, The latter approach results in higher cache hit rates, dominant performance factor.
38 Case Study Transfer of individual cache blocks across the interconnection network of a multiprocessor yields low network efficiency what if we propose transferring prefetched data in larger units? Method: a compiler schedules a single prefetch command before the loop is entered rather than software pipelining prefetches within a loop. transfer of large blocks of remote memory used within the loop body prefetched into local memory to prevent excessive cache pollution. Issues: binding prefetch since data stored in a processor s local memory are not exposed to any coherency policy imposes constraints on the use of prefetched data which, in turn, limits the amount of remote data that can be prefetched.
39 What about besides the loops? Prefetching is normally restricted to loops array accesses whose indices are linear functions of the loop indices compiler must be able to predict memory access patterns when scheduling prefetches. such loops are relatively common in scientific codes but far less so in general applications. Irregular data structures difficult to reliably predict when a particular data will be accessed once a cache block has been accessed, there is less of a chance that several successive cache blocks will also be requested when data structures such as graphs and linked lists are used. comparatively high temporal locality result in high cache utilization thereby diminishing the benefit of prefetching.
40 What is the overhead of fetch instructions? require extra execution cycles fetch source addresses must be calculated and stored in the processor to avoid recalculation for the matching load or store instruction. How: Register space Problem: compiler will have less register space to allocate to other active variables. fetch instructions increase register pressure It gets worse when the prefetch distance is greater than one multiple prefetch addresses code expansion may degrade instruction cache performance. software-initiated prefetching is done statically unable to detect when a prefetched block has been prematurely evicted and needs to be re-fetched.
41 Hardware-Initiated Data Prefetching Prefetching capabilities without the need for programmer or compiler intervention. No changes to existing executables instruction overhead completely eliminated. can take advantage of run-time information to potentially make prefetching more effective.
42 Cache Blocks Typically: fetch data from main memory into the processor cache in units of cache blocks. multiple word cache blocks are themselves a form of data prefetching. large cache blocks Effective prefetching vs cache pollution. What is the complication for SMPs with private caches false sharing: when two or more processors wish to access different words within the same cache block and at least one of the accesses is a store. cache coherence traffic is generated to ensure that the changes made to a block by a store operation are seen by all processors caching the block. Unnecessary traffic Increasing the cache block size increases the likelihood of such occurances How do we take advantage of spatial locality without introducing some of the problems associated with large cache blocks?
43 Sequential prefetching one block lookahead (OBL) approach initiates a prefetch for block b+1 when block b is accessed. How is it different from doubling the block size? prefetched blocks are treated separately with regard to the cache replacement and coherency policies.
44 OBL: Case Study Assume that a large block contains one word which is frequently referenced and several other words which are not in use. Assume that an LRU replacement policy is used, What is the implication? the entire block will be retained even though only a portion of the block s data is actually in use. How do we solve? Replace large block with two smaller blocks, one of them could be evicted to make room for more active data. use of smaller cache blocks reduces the probability of false sharing
45 OBL implementations Based on what type of access to block b initiates the prefetch of b+1 prefetch on miss Initiates a prefetch for block b+1 whenever an access for block b results in a cache miss. If b+1 is already cached, no memory access is initiated tagged prefetch algorithms Associates a tag bit with every memory block. Use this bit to detect when a block is demand-fetched or when a prefetched block is referenced for the first time. Then, next sequential block is fetched. Which one is better in terms of reducing miss rate? Prefetch on miss vs tagged prefetch?


46 Prefetch on miss vs tagged prefetch Accessing three contiguous blocks strictly sequential access pattern:
47 Shortcoming of the OBL prefetch may not be initiated far enough in advance of the actual use to avoid a processor memory stall. A sequential access stream resulting from a tight loop, for example, may not allow sufficient time between the use of blocks b and b+1 to completely hide the memory latency.
48 How do you solve this shortcoming? Increase the number of blocks prefetched after a demand fetch from one to d As each prefetched block, b, is accessed for the first time, the cache is interrogated to check if blocks b+1,... b+d are present in the cache What if d=1? What kind of prefetching is this? Tagged
49 Another technique with d-prefetch dprefetchedblocks are brought into a FIFO stream buffer before being brought into the cache. As each buffer entry is referenced, it is brought into the cache while the remaining blocks are moved up in the queue and a new block is prefetched into the tail position. If a miss occurs in the cache and the desired block is also not found at the head of the stream buffer, the buffer is flushed. Advantage: prefetched data are not placed directly into the cache, avoids cache pollution. Disadvantage: requires that prefetched blocks be accessed in a strictly sequential order to take advantage of the stream buffer.
50 Tradeoffs of d-prefetching? Good: increasing the degree of prefetching reduces miss rates in sections of code that show a high degree of spatial locality Bad additional traffic and cache pollution are generated by sequential prefetching during program phases that show little spatial locality. What if are able to vary the d
51 Adaptive sequential prefetching d is matched to the degree of spatial locality exhibited by the program at a particular point in time. a prefetch efficiency metric is periodically calculated Prefetch efficiency ratio of useful prefetches to total prefetches a useful prefetch occurs whenever a prefetched block results in a cache hit. d is initialized to one, incremented whenever efficiency exceeds a predetermined upper threshold decremented whenever the efficiency drops below a lower threshold If d=0, no prefetching Which one is better? adaptive or tagged prefetching? Miss ratio vs Memory traffic and contention
52 Sequential prefetching summary Does sequential prefetching require changes to existing executables? What about the hardware complexity? Which one offers both simplicity and performance? TAGGED Compared to software-initiated prefetching, what might be the problem? tend to generate more unnecessary prefetches. Non-sequential access patterns are not good Ex: such as scalar references or array accesses with large strides, will result in unnecessary prefetch requests do not exhibit the spatial locality upon which sequential prefetching is based. To enable prefetching of strided and other irregular data access patterns, several more elaborate hardware prefetching techniques have been proposed.
53 Prefetching with arbitrary strides Reference Prediction Table State: initial, transient, steady
54 RPT Entries State Transition

55 Matrix Multiplication Assume that starting addresses a=10000 b=20000 c=30000, and 1 word cache block After the first iteration of inner loop

56 Matrix Multiplication After the second iteration of inner loop Hits/misses?

57 Matrix Multiplication After the third iteration b and c hits provided that a prefetch of distance one is enough
58 RPT Limitations Prefetch distance to one loop iteration Loop entrance : miss Loop exit: unnecessary prefetch How can we solve this? Use longer distance Prefetch address = effective address + (stride x distance ) with lookahead program counter (LA-PC)
59 Summary Prefetches timely, useful, and introduce little overhead. Reduce secondary effects in the memory system strategies are diverse and no single strategy provides optimal performance
60 Summary Prefetching schemes are diverse. To help categorize a particular approach it is useful to answer three basic questions concerning the prefetching mechanism: 1) When are prefetches initiated, 2) Where are prefetched data placed, 3) What is the unit of prefetch?
61 Software vs Hardware Prefetching Prefetch instructions actually increase the amount of work done by the processor. Hardware-based prefetching techniques do not require the use of explicit fetch instructions. hardware monitors the processor in an attempt to infer prefetching opportunities. no instruction overhead generates more unnecessary prefetches than software-initiated schemes. need to speculate on future memory accesses without the benefit of compile-time information Cache pollution Consume memory bandwidth
62 Conclusions Prefetches can be initiated either by explicit fetch operation within a program (software initiated) logic that monitors the processor s referencing pattern (hardwareinitiated). Prefetches must be timely. issued too early chance that the prefetched data will displace other useful data or be displaced itself before use. issued too late may not arrive before the actual memory reference and introduce stalls Prefetches must be precise. The software approach issues prefetches only for data that is likely to be used Hardware schemes tend to fetch more data unnecessarily.
63 Conclusions The decision of where to place prefetched data in the memory hierarchy higher level of the memory hierarchy to provide a performance benefit. The majority of schemes prefetched data in some type of cache memory. Prefetched data in processor registers binding and additional constraints must be imposed on the use of the data. Finally, multiprocessor systems can introduce additional levels into the memory hierarchy which must be taken into consideration.
64 Conclusions Data can be prefetched in units of single words, cache blocks or larger blocks of memory. determined by the organization of the underlying cache and memory system. Uniprocessors and SMPs Cache blocks appropriate Distributed memory multiprocessor larger memory blocks to amortize the cost of initiating a data transfer across an interconnection network
A Survey of Data Prefetching Techniques
 A Survey of Data Prefetching Techniques Technical Report No: HPPC-96-05 October 1996 Steve VanderWiel David J. Lilja High-Performance Parallel Computing Research Group Department of Electrical Engineering
A Survey of Data Prefetching Techniques Technical Report No: HPPC-96-05 October 1996 Steve VanderWiel David J. Lilja High-Performance Parallel Computing Research Group Department of Electrical Engineering
Comprehensive Review of Data Prefetching Mechanisms
 86 Sneha Chhabra, Raman Maini Comprehensive Review of Data Prefetching Mechanisms 1 Sneha Chhabra, 2 Raman Maini 1 University College of Engineering, Punjabi University, Patiala 2 Associate Professor,
86 Sneha Chhabra, Raman Maini Comprehensive Review of Data Prefetching Mechanisms 1 Sneha Chhabra, 2 Raman Maini 1 University College of Engineering, Punjabi University, Patiala 2 Associate Professor,
Data Prefetch Mechanisms
 Data Prefetch Mechanisms STEVEN P. VANDERWIEL IBM Server Group AND DAVID J. LILJA University of Minnesota The expanding gap between microprocessor and DRAM performance has necessitated the use of increasingly
Data Prefetch Mechanisms STEVEN P. VANDERWIEL IBM Server Group AND DAVID J. LILJA University of Minnesota The expanding gap between microprocessor and DRAM performance has necessitated the use of increasingly
The Impact of Parallel Loop Scheduling Strategies on Prefetching in a Shared-Memory Multiprocessor
 IEEE Transactions on Parallel and Distributed Systems, Vol. 5, No. 6, June 1994, pp. 573-584.. The Impact of Parallel Loop Scheduling Strategies on Prefetching in a Shared-Memory Multiprocessor David J.
IEEE Transactions on Parallel and Distributed Systems, Vol. 5, No. 6, June 1994, pp. 573-584.. The Impact of Parallel Loop Scheduling Strategies on Prefetching in a Shared-Memory Multiprocessor David J.
EECS 470. Lecture 15. Prefetching. Fall 2018 Jon Beaumont. History Table. Correlating Prediction Table
 Lecture 15 History Table Correlating Prediction Table Prefetching Latest A0 A0,A1 A3 11 Fall 2018 Jon Beaumont A1 http://www.eecs.umich.edu/courses/eecs470 Prefetch A3 Slides developed in part by Profs.
Lecture 15 History Table Correlating Prediction Table Prefetching Latest A0 A0,A1 A3 11 Fall 2018 Jon Beaumont A1 http://www.eecs.umich.edu/courses/eecs470 Prefetch A3 Slides developed in part by Profs.
Module 10: "Design of Shared Memory Multiprocessors" Lecture 20: "Performance of Coherence Protocols" MOESI protocol.
 MOESI protocol Dragon protocol State transition Dragon example Design issues General issues Evaluating protocols Protocol optimizations Cache size Cache line size Impact on bus traffic Large cache line
MOESI protocol Dragon protocol State transition Dragon example Design issues General issues Evaluating protocols Protocol optimizations Cache size Cache line size Impact on bus traffic Large cache line
Announcements. ! Previous lecture. Caches. Inf3 Computer Architecture
 Announcements! Previous lecture Caches Inf3 Computer Architecture - 2016-2017 1 Recap: Memory Hierarchy Issues! Block size: smallest unit that is managed at each level E.g., 64B for cache lines, 4KB for
Announcements! Previous lecture Caches Inf3 Computer Architecture - 2016-2017 1 Recap: Memory Hierarchy Issues! Block size: smallest unit that is managed at each level E.g., 64B for cache lines, 4KB for
CSC 631: High-Performance Computer Architecture
 CSC 631: High-Performance Computer Architecture Spring 2017 Lecture 10: Memory Part II CSC 631: High-Performance Computer Architecture 1 Two predictable properties of memory references: Temporal Locality:
CSC 631: High-Performance Computer Architecture Spring 2017 Lecture 10: Memory Part II CSC 631: High-Performance Computer Architecture 1 Two predictable properties of memory references: Temporal Locality:
Introduction. Stream processor: high computation to bandwidth ratio To make legacy hardware more like stream processor: We study the bandwidth problem
 Introduction Stream processor: high computation to bandwidth ratio To make legacy hardware more like stream processor: Increase computation power Make the best use of available bandwidth We study the bandwidth
Introduction Stream processor: high computation to bandwidth ratio To make legacy hardware more like stream processor: Increase computation power Make the best use of available bandwidth We study the bandwidth
Cache Performance (H&P 5.3; 5.5; 5.6)
") Cache Performance (H&P 5.3; 5.5; 5.6) Memory system and processor performance: CPU time = IC x CPI x Clock time CPU performance eqn. CPI = CPI ld/st x IC ld/st IC + CPI others x IC others IC CPI ld/st
Cache Performance (H&P 5.3; 5.5; 5.6) Memory system and processor performance: CPU time = IC x CPI x Clock time CPU performance eqn. CPI = CPI ld/st x IC ld/st IC + CPI others x IC others IC CPI ld/st
Computer Architecture Spring 2016
 omputer Architecture Spring 2016 Lecture 09: Prefetching Shuai Wang Department of omputer Science and Technology Nanjing University Prefetching(1/3) Fetch block ahead of demand Target compulsory, capacity,
omputer Architecture Spring 2016 Lecture 09: Prefetching Shuai Wang Department of omputer Science and Technology Nanjing University Prefetching(1/3) Fetch block ahead of demand Target compulsory, capacity,
A Survey of prefetching techniques
 A Survey of prefetching techniques Nir Oren July 18, 2000 Abstract As the gap between processor and memory speeds increases, memory latencies have become a critical bottleneck for computer performance.
A Survey of prefetching techniques Nir Oren July 18, 2000 Abstract As the gap between processor and memory speeds increases, memory latencies have become a critical bottleneck for computer performance.
Selective Fill Data Cache
 Selective Fill Data Cache Rice University ELEC525 Final Report Anuj Dharia, Paul Rodriguez, Ryan Verret Abstract Here we present an architecture for improving data cache miss rate. Our enhancement seeks
Selective Fill Data Cache Rice University ELEC525 Final Report Anuj Dharia, Paul Rodriguez, Ryan Verret Abstract Here we present an architecture for improving data cache miss rate. Our enhancement seeks
10/16/2017. Miss Rate: ABC. Classifying Misses: 3C Model (Hill) Reducing Conflict Misses: Victim Buffer. Overlapping Misses: Lockup Free Cache
 Reducing Conflict Misses: Victim Buffer. Overlapping Misses: Lockup Free Cache") Classifying Misses: 3C Model (Hill) Divide cache misses into three categories Compulsory (cold): never seen this address before Would miss even in infinite cache Capacity: miss caused because cache is
Classifying Misses: 3C Model (Hill) Divide cache misses into three categories Compulsory (cold): never seen this address before Would miss even in infinite cache Capacity: miss caused because cache is
Chapter 2: Memory Hierarchy Design Part 2
 Chapter 2: Memory Hierarchy Design Part 2 Introduction (Section 2.1, Appendix B) Caches Review of basics (Section 2.1, Appendix B) Advanced methods (Section 2.3) Main Memory Virtual Memory Fundamental
Chapter 2: Memory Hierarchy Design Part 2 Introduction (Section 2.1, Appendix B) Caches Review of basics (Section 2.1, Appendix B) Advanced methods (Section 2.3) Main Memory Virtual Memory Fundamental
Lecture 13: Memory Consistency. + a Course-So-Far Review. Parallel Computer Architecture and Programming CMU , Spring 2013
 Lecture 13: Memory Consistency + a Course-So-Far Review Parallel Computer Architecture and Programming Today: what you should know Understand the motivation for relaxed consistency models Understand the
Lecture 13: Memory Consistency + a Course-So-Far Review Parallel Computer Architecture and Programming Today: what you should know Understand the motivation for relaxed consistency models Understand the
Computer Systems Architecture I. CSE 560M Lecture 17 Guest Lecturer: Shakir James
 Computer Systems Architecture I CSE 560M Lecture 17 Guest Lecturer: Shakir James Plan for Today Announcements and Reminders Project demos in three weeks (Nov. 23 rd ) Questions Today s discussion: Improving
Computer Systems Architecture I CSE 560M Lecture 17 Guest Lecturer: Shakir James Plan for Today Announcements and Reminders Project demos in three weeks (Nov. 23 rd ) Questions Today s discussion: Improving
Chapter 5. Topics in Memory Hierachy. Computer Architectures. Tien-Fu Chen. National Chung Cheng Univ.
 Computer Architectures Chapter 5 Tien-Fu Chen National Chung Cheng Univ. Chap5-0 Topics in Memory Hierachy! Memory Hierachy Features: temporal & spatial locality Common: Faster -> more expensive -> smaller!
Computer Architectures Chapter 5 Tien-Fu Chen National Chung Cheng Univ. Chap5-0 Topics in Memory Hierachy! Memory Hierachy Features: temporal & spatial locality Common: Faster -> more expensive -> smaller!
Why memory hierarchy? Memory hierarchy. Memory hierarchy goals. CS2410: Computer Architecture. L1 cache design. Sangyeun Cho
 Why memory hierarchy? L1 cache design Sangyeun Cho Computer Science Department Memory hierarchy Memory hierarchy goals Smaller Faster More expensive per byte CPU Regs L1 cache L2 cache SRAM SRAM To provide
Why memory hierarchy? L1 cache design Sangyeun Cho Computer Science Department Memory hierarchy Memory hierarchy goals Smaller Faster More expensive per byte CPU Regs L1 cache L2 cache SRAM SRAM To provide
SPIN, PETERSON AND BAKERY LOCKS
 Concurrent Programs reasoning about their execution proving correctness start by considering execution sequences CS4021/4521 2018 jones@scss.tcd.ie School of Computer Science and Statistics, Trinity College
Concurrent Programs reasoning about their execution proving correctness start by considering execution sequences CS4021/4521 2018 jones@scss.tcd.ie School of Computer Science and Statistics, Trinity College
Techniques for Efficient Processing in Runahead Execution Engines
 Techniques for Efficient Processing in Runahead Execution Engines Onur Mutlu Hyesoon Kim Yale N. Patt Depment of Electrical and Computer Engineering University of Texas at Austin {onur,hyesoon,patt}@ece.utexas.edu
Techniques for Efficient Processing in Runahead Execution Engines Onur Mutlu Hyesoon Kim Yale N. Patt Depment of Electrical and Computer Engineering University of Texas at Austin {onur,hyesoon,patt}@ece.utexas.edu
Module 5: Performance Issues in Shared Memory and Introduction to Coherence Lecture 9: Performance Issues in Shared Memory. The Lecture Contains:
 The Lecture Contains: Data Access and Communication Data Access Artifactual Comm. Capacity Problem Temporal Locality Spatial Locality 2D to 4D Conversion Transfer Granularity Worse: False Sharing Contention
The Lecture Contains: Data Access and Communication Data Access Artifactual Comm. Capacity Problem Temporal Locality Spatial Locality 2D to 4D Conversion Transfer Granularity Worse: False Sharing Contention
Cache Performance and Memory Management: From Absolute Addresses to Demand Paging. Cache Performance
 6.823, L11--1 Cache Performance and Memory Management: From Absolute Addresses to Demand Paging Asanovic Laboratory for Computer Science M.I.T. http://www.csg.lcs.mit.edu/6.823 Cache Performance 6.823,
6.823, L11--1 Cache Performance and Memory Management: From Absolute Addresses to Demand Paging Asanovic Laboratory for Computer Science M.I.T. http://www.csg.lcs.mit.edu/6.823 Cache Performance 6.823,
Cache Performance! ! Memory system and processor performance:! ! Improving memory hierarchy performance:! CPU time = IC x CPI x Clock time
 Cache Performance!! Memory system and processor performance:! CPU time = IC x CPI x Clock time CPU performance eqn. CPI = CPI ld/st x IC ld/st IC + CPI others x IC others IC CPI ld/st = Pipeline time +
Cache Performance!! Memory system and processor performance:! CPU time = IC x CPI x Clock time CPU performance eqn. CPI = CPI ld/st x IC ld/st IC + CPI others x IC others IC CPI ld/st = Pipeline time +
Improving Cache Performance and Memory Management: From Absolute Addresses to Demand Paging. Highly-Associative Caches
 Improving Cache Performance and Memory Management: From Absolute Addresses to Demand Paging 6.823, L8--1 Asanovic Laboratory for Computer Science M.I.T. http://www.csg.lcs.mit.edu/6.823 Highly-Associative
Improving Cache Performance and Memory Management: From Absolute Addresses to Demand Paging 6.823, L8--1 Asanovic Laboratory for Computer Science M.I.T. http://www.csg.lcs.mit.edu/6.823 Highly-Associative
Computer System Architecture Final Examination Spring 2002
 Computer System Architecture 6.823 Final Examination Spring 2002 Name: This is an open book, open notes exam. 180 Minutes 22 Pages Notes: Not all questions are of equal difficulty, so look over the entire
Computer System Architecture 6.823 Final Examination Spring 2002 Name: This is an open book, open notes exam. 180 Minutes 22 Pages Notes: Not all questions are of equal difficulty, so look over the entire
Advanced optimizations of cache performance ( 2.2)
") Advanced optimizations of cache performance ( 2.2) 30 1. Small and Simple Caches to reduce hit time Critical timing path: address tag memory, then compare tags, then select set Lower associativity Direct-mapped
Advanced optimizations of cache performance ( 2.2) 30 1. Small and Simple Caches to reduce hit time Critical timing path: address tag memory, then compare tags, then select set Lower associativity Direct-mapped
Chapter 2: Memory Hierarchy Design Part 2
 Chapter 2: Memory Hierarchy Design Part 2 Introduction (Section 2.1, Appendix B) Caches Review of basics (Section 2.1, Appendix B) Advanced methods (Section 2.3) Main Memory Virtual Memory Fundamental
Chapter 2: Memory Hierarchy Design Part 2 Introduction (Section 2.1, Appendix B) Caches Review of basics (Section 2.1, Appendix B) Advanced methods (Section 2.3) Main Memory Virtual Memory Fundamental
Memory Hierarchy Basics
 Computer Architecture A Quantitative Approach, Fifth Edition Chapter 2 Memory Hierarchy Design 1 Memory Hierarchy Basics Six basic cache optimizations: Larger block size Reduces compulsory misses Increases
Computer Architecture A Quantitative Approach, Fifth Edition Chapter 2 Memory Hierarchy Design 1 Memory Hierarchy Basics Six basic cache optimizations: Larger block size Reduces compulsory misses Increases
Memory Hierarchy. Slides contents from:
 Memory Hierarchy Slides contents from: Hennessy & Patterson, 5ed Appendix B and Chapter 2 David Wentzlaff, ELE 475 Computer Architecture MJT, High Performance Computing, NPTEL Memory Performance Gap Memory
Memory Hierarchy Slides contents from: Hennessy & Patterson, 5ed Appendix B and Chapter 2 David Wentzlaff, ELE 475 Computer Architecture MJT, High Performance Computing, NPTEL Memory Performance Gap Memory
Compiler Assisted Cache Prefetch Using Procedure Call Hierarchy
 Louisiana State University LSU Digital Commons LSU Master's Theses Graduate School 2006 Compiler Assisted Cache Prefetch Using Procedure Call Hierarchy Sheela A. Doshi Louisiana State University and Agricultural
Louisiana State University LSU Digital Commons LSU Master's Theses Graduate School 2006 Compiler Assisted Cache Prefetch Using Procedure Call Hierarchy Sheela A. Doshi Louisiana State University and Agricultural
Lecture notes for CS Chapter 2, part 1 10/23/18
 Chapter 2: Memory Hierarchy Design Part 2 Introduction (Section 2.1, Appendix B) Caches Review of basics (Section 2.1, Appendix B) Advanced methods (Section 2.3) Main Memory Virtual Memory Fundamental
Chapter 2: Memory Hierarchy Design Part 2 Introduction (Section 2.1, Appendix B) Caches Review of basics (Section 2.1, Appendix B) Advanced methods (Section 2.3) Main Memory Virtual Memory Fundamental
TDT Coarse-Grained Multithreading. Review on ILP. Multi-threaded execution. Contents. Fine-Grained Multithreading
 Review on ILP TDT 4260 Chap 5 TLP & Hierarchy What is ILP? Let the compiler find the ILP Advantages? Disadvantages? Let the HW find the ILP Advantages? Disadvantages? Contents Multi-threading Chap 3.5
Review on ILP TDT 4260 Chap 5 TLP & Hierarchy What is ILP? Let the compiler find the ILP Advantages? Disadvantages? Let the HW find the ILP Advantages? Disadvantages? Contents Multi-threading Chap 3.5
MULTIPROCESSORS AND THREAD LEVEL PARALLELISM
 UNIT III MULTIPROCESSORS AND THREAD LEVEL PARALLELISM 1. Symmetric Shared Memory Architectures: The Symmetric Shared Memory Architecture consists of several processors with a single physical memory shared
UNIT III MULTIPROCESSORS AND THREAD LEVEL PARALLELISM 1. Symmetric Shared Memory Architectures: The Symmetric Shared Memory Architecture consists of several processors with a single physical memory shared
LRU. Pseudo LRU A B C D E F G H A B C D E F G H H H C. Copyright 2012, Elsevier Inc. All rights reserved.
 LRU A list to keep track of the order of access to every block in the set. The least recently used block is replaced (if needed). How many bits we need for that? 27 Pseudo LRU A B C D E F G H A B C D E
LRU A list to keep track of the order of access to every block in the set. The least recently used block is replaced (if needed). How many bits we need for that? 27 Pseudo LRU A B C D E F G H A B C D E
CS 136: Advanced Architecture. Review of Caches
 1 / 30 CS 136: Advanced Architecture Review of Caches 2 / 30 Why Caches? Introduction Basic goal: Size of cheapest memory... At speed of most expensive Locality makes it work Temporal locality: If you
1 / 30 CS 136: Advanced Architecture Review of Caches 2 / 30 Why Caches? Introduction Basic goal: Size of cheapest memory... At speed of most expensive Locality makes it work Temporal locality: If you
Review: Creating a Parallel Program. Programming for Performance
 Review: Creating a Parallel Program Can be done by programmer, compiler, run-time system or OS Steps for creating parallel program Decomposition Assignment of tasks to processes Orchestration Mapping (C)
Review: Creating a Parallel Program Can be done by programmer, compiler, run-time system or OS Steps for creating parallel program Decomposition Assignment of tasks to processes Orchestration Mapping (C)
EECS 570 Final Exam - SOLUTIONS Winter 2015
 EECS 570 Final Exam - SOLUTIONS Winter 2015 Name: unique name: Sign the honor code: I have neither given nor received aid on this exam nor observed anyone else doing so. Scores: # Points 1 / 21 2 / 32
EECS 570 Final Exam - SOLUTIONS Winter 2015 Name: unique name: Sign the honor code: I have neither given nor received aid on this exam nor observed anyone else doing so. Scores: # Points 1 / 21 2 / 32
MULTIPROCESSORS AND THREAD-LEVEL. B649 Parallel Architectures and Programming
 MULTIPROCESSORS AND THREAD-LEVEL PARALLELISM B649 Parallel Architectures and Programming Motivation behind Multiprocessors Limitations of ILP (as already discussed) Growing interest in servers and server-performance
MULTIPROCESSORS AND THREAD-LEVEL PARALLELISM B649 Parallel Architectures and Programming Motivation behind Multiprocessors Limitations of ILP (as already discussed) Growing interest in servers and server-performance
Computer Architecture Spring 2016
 Computer Architecture Spring 2016 Lecture 08: Caches III Shuai Wang Department of Computer Science and Technology Nanjing University Improve Cache Performance Average memory access time (AMAT): AMAT =
Computer Architecture Spring 2016 Lecture 08: Caches III Shuai Wang Department of Computer Science and Technology Nanjing University Improve Cache Performance Average memory access time (AMAT): AMAT =
Memory Hierarchy Computing Systems & Performance MSc Informatics Eng. Memory Hierarchy (most slides are borrowed)
") Computing Systems & Performance Memory Hierarchy MSc Informatics Eng. 2012/13 A.J.Proença Memory Hierarchy (most slides are borrowed) AJProença, Computer Systems & Performance, MEI, UMinho, 2012/13 1 2
Computing Systems & Performance Memory Hierarchy MSc Informatics Eng. 2012/13 A.J.Proença Memory Hierarchy (most slides are borrowed) AJProença, Computer Systems & Performance, MEI, UMinho, 2012/13 1 2
SAMPLE MIDTERM QUESTIONS
 SAMPLE MIDTERM QUESTIONS CS 143A Notes: 1. These questions are just for you to have some questions to practice. 2. There is no guarantee that there will be any similarities between these questions and
SAMPLE MIDTERM QUESTIONS CS 143A Notes: 1. These questions are just for you to have some questions to practice. 2. There is no guarantee that there will be any similarities between these questions and
CS 426 Parallel Computing. Parallel Computing Platforms
 CS 426 Parallel Computing Parallel Computing Platforms Ozcan Ozturk http://www.cs.bilkent.edu.tr/~ozturk/cs426/ Slides are adapted from ``Introduction to Parallel Computing'' Topic Overview Implicit Parallelism:
CS 426 Parallel Computing Parallel Computing Platforms Ozcan Ozturk http://www.cs.bilkent.edu.tr/~ozturk/cs426/ Slides are adapted from ``Introduction to Parallel Computing'' Topic Overview Implicit Parallelism:
CACHE MEMORIES ADVANCED COMPUTER ARCHITECTURES. Slides by: Pedro Tomás
 CACHE MEMORIES Slides by: Pedro Tomás Additional reading: Computer Architecture: A Quantitative Approach, 5th edition, Chapter 2 and Appendix B, John L. Hennessy and David A. Patterson, Morgan Kaufmann,
CACHE MEMORIES Slides by: Pedro Tomás Additional reading: Computer Architecture: A Quantitative Approach, 5th edition, Chapter 2 and Appendix B, John L. Hennessy and David A. Patterson, Morgan Kaufmann,
MULTIPROCESSORS AND THREAD-LEVEL PARALLELISM. B649 Parallel Architectures and Programming
 MULTIPROCESSORS AND THREAD-LEVEL PARALLELISM B649 Parallel Architectures and Programming Motivation behind Multiprocessors Limitations of ILP (as already discussed) Growing interest in servers and server-performance
MULTIPROCESSORS AND THREAD-LEVEL PARALLELISM B649 Parallel Architectures and Programming Motivation behind Multiprocessors Limitations of ILP (as already discussed) Growing interest in servers and server-performance
Lecture: Cache Hierarchies. Topics: cache innovations (Sections B.1-B.3, 2.1)
") Lecture: Cache Hierarchies Topics: cache innovations (Sections B.1-B.3, 2.1) 1 Types of Cache Misses Compulsory misses: happens the first time a memory word is accessed the misses for an infinite cache
Lecture: Cache Hierarchies Topics: cache innovations (Sections B.1-B.3, 2.1) 1 Types of Cache Misses Compulsory misses: happens the first time a memory word is accessed the misses for an infinite cache
Advanced Caching Techniques (2) Department of Electrical Engineering Stanford University
 Department of Electrical Engineering Stanford University") Lecture 4: Advanced Caching Techniques (2) Department of Electrical Engineering Stanford University http://eeclass.stanford.edu/ee282 Lecture 4-1 Announcements HW1 is out (handout and online) Due on 10/15
Lecture 4: Advanced Caching Techniques (2) Department of Electrical Engineering Stanford University http://eeclass.stanford.edu/ee282 Lecture 4-1 Announcements HW1 is out (handout and online) Due on 10/15
Module 14: "Directory-based Cache Coherence" Lecture 31: "Managing Directory Overhead" Directory-based Cache Coherence: Replacement of S blocks
 Directory-based Cache Coherence: Replacement of S blocks Serialization VN deadlock Starvation Overflow schemes Sparse directory Remote access cache COMA Latency tolerance Page migration Queue lock in hardware
Directory-based Cache Coherence: Replacement of S blocks Serialization VN deadlock Starvation Overflow schemes Sparse directory Remote access cache COMA Latency tolerance Page migration Queue lock in hardware
Memory Hierarchy Basics. Ten Advanced Optimizations. Small and Simple
 Memory Hierarchy Basics Six basic cache optimizations: Larger block size Reduces compulsory misses Increases capacity and conflict misses, increases miss penalty Larger total cache capacity to reduce miss
Memory Hierarchy Basics Six basic cache optimizations: Larger block size Reduces compulsory misses Increases capacity and conflict misses, increases miss penalty Larger total cache capacity to reduce miss
1. Memory technology & Hierarchy
 1. Memory technology & Hierarchy Back to caching... Advances in Computer Architecture Andy D. Pimentel Caches in a multi-processor context Dealing with concurrent updates Multiprocessor architecture In
1. Memory technology & Hierarchy Back to caching... Advances in Computer Architecture Andy D. Pimentel Caches in a multi-processor context Dealing with concurrent updates Multiprocessor architecture In
Efficient Prefetching with Hybrid Schemes and Use of Program Feedback to Adjust Prefetcher Aggressiveness
 Journal of Instruction-Level Parallelism 13 (11) 1-14 Submitted 3/1; published 1/11 Efficient Prefetching with Hybrid Schemes and Use of Program Feedback to Adjust Prefetcher Aggressiveness Santhosh Verma
Journal of Instruction-Level Parallelism 13 (11) 1-14 Submitted 3/1; published 1/11 Efficient Prefetching with Hybrid Schemes and Use of Program Feedback to Adjust Prefetcher Aggressiveness Santhosh Verma
Cache Coherence. CMU : Parallel Computer Architecture and Programming (Spring 2012)
") Cache Coherence CMU 15-418: Parallel Computer Architecture and Programming (Spring 2012) Shared memory multi-processor Processors read and write to shared variables - More precisely: processors issues
Cache Coherence CMU 15-418: Parallel Computer Architecture and Programming (Spring 2012) Shared memory multi-processor Processors read and write to shared variables - More precisely: processors issues
Main Points of the Computer Organization and System Software Module
 Main Points of the Computer Organization and System Software Module You can find below the topics we have covered during the COSS module. Reading the relevant parts of the textbooks is essential for a
Main Points of the Computer Organization and System Software Module You can find below the topics we have covered during the COSS module. Reading the relevant parts of the textbooks is essential for a
ECE/CS 757: Homework 1
 ECE/CS 757: Homework 1 Cores and Multithreading 1. A CPU designer has to decide whether or not to add a new micoarchitecture enhancement to improve performance (ignoring power costs) of a block (coarse-grain)
ECE/CS 757: Homework 1 Cores and Multithreading 1. A CPU designer has to decide whether or not to add a new micoarchitecture enhancement to improve performance (ignoring power costs) of a block (coarse-grain)
1/19/2009. Data Locality. Exploiting Locality: Caches
 Spring 2009 Prof. Hyesoon Kim Thanks to Prof. Loh & Prof. Prvulovic Data Locality Temporal: if data item needed now, it is likely to be needed again in near future Spatial: if data item needed now, nearby
Spring 2009 Prof. Hyesoon Kim Thanks to Prof. Loh & Prof. Prvulovic Data Locality Temporal: if data item needed now, it is likely to be needed again in near future Spatial: if data item needed now, nearby
Like scalar processor Processes individual data items Item may be single integer or floating point number. - 1 of 15 - Superscalar Architectures
 Superscalar Architectures Have looked at examined basic architecture concepts Starting with simple machines Introduced concepts underlying RISC machines From characteristics of RISC instructions Found
Superscalar Architectures Have looked at examined basic architecture concepts Starting with simple machines Introduced concepts underlying RISC machines From characteristics of RISC instructions Found
CHAPTER 4 MEMORY HIERARCHIES TYPICAL MEMORY HIERARCHY TYPICAL MEMORY HIERARCHY: THE PYRAMID CACHE PERFORMANCE MEMORY HIERARCHIES CACHE DESIGN
 CHAPTER 4 TYPICAL MEMORY HIERARCHY MEMORY HIERARCHIES MEMORY HIERARCHIES CACHE DESIGN TECHNIQUES TO IMPROVE CACHE PERFORMANCE VIRTUAL MEMORY SUPPORT PRINCIPLE OF LOCALITY: A PROGRAM ACCESSES A RELATIVELY
CHAPTER 4 TYPICAL MEMORY HIERARCHY MEMORY HIERARCHIES MEMORY HIERARCHIES CACHE DESIGN TECHNIQUES TO IMPROVE CACHE PERFORMANCE VIRTUAL MEMORY SUPPORT PRINCIPLE OF LOCALITY: A PROGRAM ACCESSES A RELATIVELY
Motivations. Shared Memory Consistency Models. Optimizations for Performance. Memory Consistency
 Shared Memory Consistency Models Authors : Sarita.V.Adve and Kourosh Gharachorloo Presented by Arrvindh Shriraman Motivations Programmer is required to reason about consistency to ensure data race conditions
Shared Memory Consistency Models Authors : Sarita.V.Adve and Kourosh Gharachorloo Presented by Arrvindh Shriraman Motivations Programmer is required to reason about consistency to ensure data race conditions
Memory Hierarchy Computing Systems & Performance MSc Informatics Eng. Memory Hierarchy (most slides are borrowed)
") Computing Systems & Performance Memory Hierarchy MSc Informatics Eng. 2011/12 A.J.Proença Memory Hierarchy (most slides are borrowed) AJProença, Computer Systems & Performance, MEI, UMinho, 2011/12 1 2
Computing Systems & Performance Memory Hierarchy MSc Informatics Eng. 2011/12 A.J.Proença Memory Hierarchy (most slides are borrowed) AJProença, Computer Systems & Performance, MEI, UMinho, 2011/12 1 2
I/O Buffering and Streaming
 I/O Buffering and Streaming I/O Buffering and Caching I/O accesses are reads or writes (e.g., to files) Application access is arbitary (offset, len) Convert accesses to read/write of fixed-size blocks
I/O Buffering and Streaming I/O Buffering and Caching I/O accesses are reads or writes (e.g., to files) Application access is arbitary (offset, len) Convert accesses to read/write of fixed-size blocks
Chapter 6 Memory 11/3/2015. Chapter 6 Objectives. 6.2 Types of Memory. 6.1 Introduction
 Chapter 6 Objectives Chapter 6 Memory Master the concepts of hierarchical memory organization. Understand how each level of memory contributes to system performance, and how the performance is measured.
Chapter 6 Objectives Chapter 6 Memory Master the concepts of hierarchical memory organization. Understand how each level of memory contributes to system performance, and how the performance is measured.
Computer Architecture A Quantitative Approach, Fifth Edition. Chapter 2. Memory Hierarchy Design. Copyright 2012, Elsevier Inc. All rights reserved.
 Computer Architecture A Quantitative Approach, Fifth Edition Chapter 2 Memory Hierarchy Design 1 Introduction Programmers want unlimited amounts of memory with low latency Fast memory technology is more
Computer Architecture A Quantitative Approach, Fifth Edition Chapter 2 Memory Hierarchy Design 1 Introduction Programmers want unlimited amounts of memory with low latency Fast memory technology is more
Motivation for Parallelism. Motivation for Parallelism. ILP Example: Loop Unrolling. Types of Parallelism
 Motivation for Parallelism Motivation for Parallelism The speed of an application is determined by more than just processor speed. speed Disk speed Network speed... Multiprocessors typically improve the
Motivation for Parallelism Motivation for Parallelism The speed of an application is determined by more than just processor speed. speed Disk speed Network speed... Multiprocessors typically improve the
SPECULATIVE MULTITHREADED ARCHITECTURES
 2 SPECULATIVE MULTITHREADED ARCHITECTURES In this Chapter, the execution model of the speculative multithreading paradigm is presented. This execution model is based on the identification of pairs of instructions
2 SPECULATIVE MULTITHREADED ARCHITECTURES In this Chapter, the execution model of the speculative multithreading paradigm is presented. This execution model is based on the identification of pairs of instructions
Donn Morrison Department of Computer Science. TDT4255 Memory hierarchies
 TDT4255 Lecture 10: Memory hierarchies Donn Morrison Department of Computer Science 2 Outline Chapter 5 - Memory hierarchies (5.1-5.5) Temporal and spacial locality Hits and misses Direct-mapped, set associative,
TDT4255 Lecture 10: Memory hierarchies Donn Morrison Department of Computer Science 2 Outline Chapter 5 - Memory hierarchies (5.1-5.5) Temporal and spacial locality Hits and misses Direct-mapped, set associative,
Lecture: Large Caches, Virtual Memory. Topics: cache innovations (Sections 2.4, B.4, B.5)
") Lecture: Large Caches, Virtual Memory Topics: cache innovations (Sections 2.4, B.4, B.5) 1 More Cache Basics caches are split as instruction and data; L2 and L3 are unified The /L2 hierarchy can be inclusive,
Lecture: Large Caches, Virtual Memory Topics: cache innovations (Sections 2.4, B.4, B.5) 1 More Cache Basics caches are split as instruction and data; L2 and L3 are unified The /L2 hierarchy can be inclusive,
Cache Optimisation. sometime he thought that there must be a better way
 Cache sometime he thought that there must be a better way 2 Cache 1. Reduce miss rate a) Increase block size b) Increase cache size c) Higher associativity d) compiler optimisation e) Parallelism f) prefetching
Cache sometime he thought that there must be a better way 2 Cache 1. Reduce miss rate a) Increase block size b) Increase cache size c) Higher associativity d) compiler optimisation e) Parallelism f) prefetching
Cache Performance! ! Memory system and processor performance:! ! Improving memory hierarchy performance:! CPU time = IC x CPI x Clock time
 Cache Performance!! Memory system and processor performance:! CPU time = IC x CPI x Clock time CPU performance eqn. CPI = CPI ld/st x IC ld/st IC + CPI others x IC others IC CPI ld/st = Pipeline time +
Cache Performance!! Memory system and processor performance:! CPU time = IC x CPI x Clock time CPU performance eqn. CPI = CPI ld/st x IC ld/st IC + CPI others x IC others IC CPI ld/st = Pipeline time +
Multiprocessors and Locking
 Types of Multiprocessors (MPs) Uniform memory-access (UMA) MP Access to all memory occurs at the same speed for all processors. Multiprocessors and Locking COMP9242 2008/S2 Week 12 Part 1 Non-uniform memory-access
Types of Multiprocessors (MPs) Uniform memory-access (UMA) MP Access to all memory occurs at the same speed for all processors. Multiprocessors and Locking COMP9242 2008/S2 Week 12 Part 1 Non-uniform memory-access
Page 1. Multilevel Memories (Improving performance using a little cash )
") Page 1 Multilevel Memories (Improving performance using a little cash ) 1 Page 2 CPU-Memory Bottleneck CPU Memory Performance of high-speed computers is usually limited by memory bandwidth & latency Latency
Page 1 Multilevel Memories (Improving performance using a little cash ) 1 Page 2 CPU-Memory Bottleneck CPU Memory Performance of high-speed computers is usually limited by memory bandwidth & latency Latency
CSc33200: Operating Systems, CS-CCNY, Fall 2003 Jinzhong Niu December 10, Review
 CSc33200: Operating Systems, CS-CCNY, Fall 2003 Jinzhong Niu December 10, 2003 Review 1 Overview 1.1 The definition, objectives and evolution of operating system An operating system exploits and manages
CSc33200: Operating Systems, CS-CCNY, Fall 2003 Jinzhong Niu December 10, 2003 Review 1 Overview 1.1 The definition, objectives and evolution of operating system An operating system exploits and manages
When Caches Aren t Enough: Data Prefetching Techniques
 Computing Practices When Caches Aren t Enough: Data Prefetching Techniques With data prefetching, memory systems call data into the cache before the processor needs it, thereby reducing memory-access latency.
Computing Practices When Caches Aren t Enough: Data Prefetching Techniques With data prefetching, memory systems call data into the cache before the processor needs it, thereby reducing memory-access latency.
Introduction to OpenMP. Lecture 10: Caches
 Introduction to OpenMP Lecture 10: Caches Overview Why caches are needed How caches work Cache design and performance. The memory speed gap Moore s Law: processors speed doubles every 18 months. True for
Introduction to OpenMP Lecture 10: Caches Overview Why caches are needed How caches work Cache design and performance. The memory speed gap Moore s Law: processors speed doubles every 18 months. True for
NOW Handout Page 1. Memory Consistency Model. Background for Debate on Memory Consistency Models. Multiprogrammed Uniprocessor Mem.
 Memory Consistency Model Background for Debate on Memory Consistency Models CS 258, Spring 99 David E. Culler Computer Science Division U.C. Berkeley for a SAS specifies constraints on the order in which
Memory Consistency Model Background for Debate on Memory Consistency Models CS 258, Spring 99 David E. Culler Computer Science Division U.C. Berkeley for a SAS specifies constraints on the order in which
COSC 6385 Computer Architecture. - Memory Hierarchies (II)
") COSC 6385 Computer Architecture - Memory Hierarchies (II) Fall 2008 Cache Performance Avg. memory access time = Hit time + Miss rate x Miss penalty with Hit time: time to access a data item which is available
COSC 6385 Computer Architecture - Memory Hierarchies (II) Fall 2008 Cache Performance Avg. memory access time = Hit time + Miss rate x Miss penalty with Hit time: time to access a data item which is available
Chapter 5 Concurrency: Mutual Exclusion and Synchronization
 Operating Systems: Internals and Design Principles Chapter 5 Concurrency: Mutual Exclusion and Synchronization Seventh Edition By William Stallings Designing correct routines for controlling concurrent
Operating Systems: Internals and Design Principles Chapter 5 Concurrency: Mutual Exclusion and Synchronization Seventh Edition By William Stallings Designing correct routines for controlling concurrent
Lecture 10: Cache Coherence: Part I. Parallel Computer Architecture and Programming CMU , Spring 2013
 Lecture 10: Cache Coherence: Part I Parallel Computer Architecture and Programming Cache design review Let s say your code executes int x = 1; (Assume for simplicity x corresponds to the address 0x12345604
Lecture 10: Cache Coherence: Part I Parallel Computer Architecture and Programming Cache design review Let s say your code executes int x = 1; (Assume for simplicity x corresponds to the address 0x12345604
SRAMs to Memory. Memory Hierarchy. Locality. Low Power VLSI System Design Lecture 10: Low Power Memory Design
 SRAMs to Memory Low Power VLSI System Design Lecture 0: Low Power Memory Design Prof. R. Iris Bahar October, 07 Last lecture focused on the SRAM cell and the D or D memory architecture built from these
SRAMs to Memory Low Power VLSI System Design Lecture 0: Low Power Memory Design Prof. R. Iris Bahar October, 07 Last lecture focused on the SRAM cell and the D or D memory architecture built from these
Handout 3 Multiprocessor and thread level parallelism
 Handout 3 Multiprocessor and thread level parallelism Outline Review MP Motivation SISD v SIMD (SIMT) v MIMD Centralized vs Distributed Memory MESI and Directory Cache Coherency Synchronization and Relaxed
Handout 3 Multiprocessor and thread level parallelism Outline Review MP Motivation SISD v SIMD (SIMT) v MIMD Centralized vs Distributed Memory MESI and Directory Cache Coherency Synchronization and Relaxed
EC 513 Computer Architecture
 EC 513 Computer Architecture Cache Organization Prof. Michel A. Kinsy The course has 4 modules Module 1 Instruction Set Architecture (ISA) Simple Pipelining and Hazards Module 2 Superscalar Architectures
EC 513 Computer Architecture Cache Organization Prof. Michel A. Kinsy The course has 4 modules Module 1 Instruction Set Architecture (ISA) Simple Pipelining and Hazards Module 2 Superscalar Architectures
Memory Systems and Compiler Support for MPSoC Architectures. Mahmut Kandemir and Nikil Dutt. Cap. 9
 Memory Systems and Compiler Support for MPSoC Architectures Mahmut Kandemir and Nikil Dutt Cap. 9 Fernando Moraes 28/maio/2013 1 MPSoC - Vantagens MPSoC architecture has several advantages over a conventional
Memory Systems and Compiler Support for MPSoC Architectures Mahmut Kandemir and Nikil Dutt Cap. 9 Fernando Moraes 28/maio/2013 1 MPSoC - Vantagens MPSoC architecture has several advantages over a conventional
CS6303 Computer Architecture Regulation 2013 BE-Computer Science and Engineering III semester 2 MARKS
 CS6303 Computer Architecture Regulation 2013 BE-Computer Science and Engineering III semester 2 MARKS UNIT-I OVERVIEW & INSTRUCTIONS 1. What are the eight great ideas in computer architecture? The eight
CS6303 Computer Architecture Regulation 2013 BE-Computer Science and Engineering III semester 2 MARKS UNIT-I OVERVIEW & INSTRUCTIONS 1. What are the eight great ideas in computer architecture? The eight
Topics to be covered. EEC 581 Computer Architecture. Virtual Memory. Memory Hierarchy Design (II)
") EEC 581 Computer Architecture Memory Hierarchy Design (II) Department of Electrical Engineering and Computer Science Cleveland State University Topics to be covered Cache Penalty Reduction Techniques Victim
EEC 581 Computer Architecture Memory Hierarchy Design (II) Department of Electrical Engineering and Computer Science Cleveland State University Topics to be covered Cache Penalty Reduction Techniques Victim
6x86 PROCESSOR Superscalar, Superpipelined, Sixth-generation, x86 Compatible CPU
 1-6x86 PROCESSOR Superscalar, Superpipelined, Sixth-generation, x86 Compatible CPU Product Overview Introduction 1. ARCHITECTURE OVERVIEW The Cyrix 6x86 CPU is a leader in the sixth generation of high
1-6x86 PROCESSOR Superscalar, Superpipelined, Sixth-generation, x86 Compatible CPU Product Overview Introduction 1. ARCHITECTURE OVERVIEW The Cyrix 6x86 CPU is a leader in the sixth generation of high
CSL373: Lecture 5 Deadlocks (no process runnable) + Scheduling (> 1 process runnable)
 + Scheduling (> 1 process runnable)") CSL373: Lecture 5 Deadlocks (no process runnable) + Scheduling (> 1 process runnable) Past & Present Have looked at two constraints: Mutual exclusion constraint between two events is a requirement that
CSL373: Lecture 5 Deadlocks (no process runnable) + Scheduling (> 1 process runnable) Past & Present Have looked at two constraints: Mutual exclusion constraint between two events is a requirement that
2 Improved Direct-Mapped Cache Performance by the Addition of a Small Fully-Associative Cache and Prefetch Buffers [1]
![2 Improved Direct-Mapped Cache Performance by the Addition of a Small Fully-Associative Cache and Prefetch Buffers [1]](/thumbs/73/69207197.jpg "2 Improved Direct-Mapped Cache Performance by the Addition of a Small Fully-Associative Cache and Prefetch Buffers [1]") EE482: Advanced Computer Organization Lecture #7 Processor Architecture Stanford University Tuesday, June 6, 2000 Memory Systems and Memory Latency Lecture #7: Wednesday, April 19, 2000 Lecturer: Brian
EE482: Advanced Computer Organization Lecture #7 Processor Architecture Stanford University Tuesday, June 6, 2000 Memory Systems and Memory Latency Lecture #7: Wednesday, April 19, 2000 Lecturer: Brian
Pick a time window size w. In time span w, are there, Multiple References, to nearby addresses: Spatial Locality
 Pick a time window size w. In time span w, are there, Multiple References, to nearby addresses: Spatial Locality Repeated References, to a set of locations: Temporal Locality Take advantage of behavior
Pick a time window size w. In time span w, are there, Multiple References, to nearby addresses: Spatial Locality Repeated References, to a set of locations: Temporal Locality Take advantage of behavior
Multiprocessors and Thread-Level Parallelism. Department of Electrical & Electronics Engineering, Amrita School of Engineering
 Multiprocessors and Thread-Level Parallelism Multithreading Increasing performance by ILP has the great advantage that it is reasonable transparent to the programmer, ILP can be quite limited or hard to
Multiprocessors and Thread-Level Parallelism Multithreading Increasing performance by ILP has the great advantage that it is reasonable transparent to the programmer, ILP can be quite limited or hard to
Lecture 13: March 25
 CISC 879 Software Support for Multicore Architectures Spring 2007 Lecture 13: March 25 Lecturer: John Cavazos Scribe: Ying Yu 13.1. Bryan Youse-Optimization of Sparse Matrix-Vector Multiplication on Emerging
CISC 879 Software Support for Multicore Architectures Spring 2007 Lecture 13: March 25 Lecturer: John Cavazos Scribe: Ying Yu 13.1. Bryan Youse-Optimization of Sparse Matrix-Vector Multiplication on Emerging
Show Me the $... Performance And Caches
 Show Me the $... Performance And Caches 1 CPU-Cache Interaction (5-stage pipeline) PCen 0x4 Add bubble PC addr inst hit? Primary Instruction Cache IR D To Memory Control Decode, Register Fetch E A B MD1
Show Me the $... Performance And Caches 1 CPU-Cache Interaction (5-stage pipeline) PCen 0x4 Add bubble PC addr inst hit? Primary Instruction Cache IR D To Memory Control Decode, Register Fetch E A B MD1
Memory Hierarchy. Advanced Optimizations. Slides contents from:
 Memory Hierarchy Advanced Optimizations Slides contents from: Hennessy & Patterson, 5ed. Appendix B and Chapter 2. David Wentzlaff, ELE 475 Computer Architecture. MJT, High Performance Computing, NPTEL.
Memory Hierarchy Advanced Optimizations Slides contents from: Hennessy & Patterson, 5ed. Appendix B and Chapter 2. David Wentzlaff, ELE 475 Computer Architecture. MJT, High Performance Computing, NPTEL.
Portland State University ECE 587/687. Caches and Memory-Level Parallelism
 Portland State University ECE 587/687 Caches and Memory-Level Parallelism Revisiting Processor Performance Program Execution Time = (CPU clock cycles + Memory stall cycles) x clock cycle time For each
Portland State University ECE 587/687 Caches and Memory-Level Parallelism Revisiting Processor Performance Program Execution Time = (CPU clock cycles + Memory stall cycles) x clock cycle time For each
Performance of Computer Systems. CSE 586 Computer Architecture. Review. ISA s (RISC, CISC, EPIC) Basic Pipeline Model.
 Basic Pipeline Model.") Performance of Computer Systems CSE 586 Computer Architecture Review Jean-Loup Baer http://www.cs.washington.edu/education/courses/586/00sp Performance metrics Use (weighted) arithmetic means for execution
Performance of Computer Systems CSE 586 Computer Architecture Review Jean-Loup Baer http://www.cs.washington.edu/education/courses/586/00sp Performance metrics Use (weighted) arithmetic means for execution
ABSTRACT. PANT, SALIL MOHAN Slipstream-mode Prefetching in CMP s: Peformance Comparison and Evaluation. (Under the direction of Dr. Greg Byrd).
.") ABSTRACT PANT, SALIL MOHAN Slipstream-mode Prefetching in CMP s: Peformance Comparison and Evaluation. (Under the direction of Dr. Greg Byrd). With the increasing gap between processor speeds and memory,
ABSTRACT PANT, SALIL MOHAN Slipstream-mode Prefetching in CMP s: Peformance Comparison and Evaluation. (Under the direction of Dr. Greg Byrd). With the increasing gap between processor speeds and memory,
Chapter 2. Parallel Hardware and Parallel Software. An Introduction to Parallel Programming. The Von Neuman Architecture
 An Introduction to Parallel Programming Peter Pacheco Chapter 2 Parallel Hardware and Parallel Software 1 The Von Neuman Architecture Control unit: responsible for deciding which instruction in a program
An Introduction to Parallel Programming Peter Pacheco Chapter 2 Parallel Hardware and Parallel Software 1 The Von Neuman Architecture Control unit: responsible for deciding which instruction in a program
Chapter 5 Asynchronous Concurrent Execution
 Chapter 5 Asynchronous Concurrent Execution Outline 5.1 Introduction 5.2 Mutual Exclusion 5.2.1 Java Multithreading Case Study 5.2.2 Critical Sections 5.2.3 Mutual Exclusion Primitives 5.3 Implementing
Chapter 5 Asynchronous Concurrent Execution Outline 5.1 Introduction 5.2 Mutual Exclusion 5.2.1 Java Multithreading Case Study 5.2.2 Critical Sections 5.2.3 Mutual Exclusion Primitives 5.3 Implementing
VIRTUAL MEMORY READING: CHAPTER 9
 VIRTUAL MEMORY READING: CHAPTER 9 9 MEMORY HIERARCHY Core! Processor! Core! Caching! Main! Memory! (DRAM)!! Caching!! Secondary Storage (SSD)!!!! Secondary Storage (Disk)! L cache exclusive to a single
VIRTUAL MEMORY READING: CHAPTER 9 9 MEMORY HIERARCHY Core! Processor! Core! Caching! Main! Memory! (DRAM)!! Caching!! Secondary Storage (SSD)!!!! Secondary Storage (Disk)! L cache exclusive to a single
CS 152 Computer Architecture and Engineering. Lecture 8 - Memory Hierarchy-III
 CS 152 Computer Architecture and Engineering Lecture 8 - Memory Hierarchy-III Krste Asanovic Electrical Engineering and Computer Sciences University of California at Berkeley http://www.eecs.berkeley.edu/~krste
CS 152 Computer Architecture and Engineering Lecture 8 - Memory Hierarchy-III Krste Asanovic Electrical Engineering and Computer Sciences University of California at Berkeley http://www.eecs.berkeley.edu/~krste
CS252 Graduate Computer Architecture Multiprocessors and Multithreading Solutions November 14, 2007
 CS252 Graduate Computer Architecture Multiprocessors and Multithreading Solutions November 14, 2007 Problem 1: Directory-based Cache Coherence Problem 1.A Cache State Transitions Complete Table 1. No.
CS252 Graduate Computer Architecture Multiprocessors and Multithreading Solutions November 14, 2007 Problem 1: Directory-based Cache Coherence Problem 1.A Cache State Transitions Complete Table 1. No.
CS 614 COMPUTER ARCHITECTURE II FALL 2005
 CS 614 COMPUTER ARCHITECTURE II FALL 2005 DUE : November 9, 2005 HOMEWORK III READ : - Portions of Chapters 5, 6, 7, 8, 9 and 14 of the Sima book and - Portions of Chapters 3, 4, Appendix A and Appendix
CS 614 COMPUTER ARCHITECTURE II FALL 2005 DUE : November 9, 2005 HOMEWORK III READ : - Portions of Chapters 5, 6, 7, 8, 9 and 14 of the Sima book and - Portions of Chapters 3, 4, Appendix A and Appendix