Crossing the Chasm: Sneaking a parallel file system into Hadoop
|
|
|
- Shanon Chambers
- 6 years ago
- Views:
Transcription
1 Crossing the Chasm: Sneaking a parallel file system into Hadoop Wittawat Tantisiriroj Swapnil Patil, Garth Gibson PARALLEL DATA LABORATORY Carnegie Mellon University
2 In this work Compare and contrast large storage system architectures Internet services High performance computing Can we use a parallel file system for Internet service applications? Hadoop, an Internet service software stack HDFS, an Internet service file system for Hadoop PVFS, a parallel file system 2
3 Today s Internet services Applications are becoming data-intensive Large input data set (e.g. the entire web) Distributed, parallel application execution Distributed file system is a key component Define new semantics for anticipated workloads Atomic append in Google FS Write-once in HDFS Commodity hardware and network Handle failures through replication 3
4 The HPC world Equally large applications Large input data set (e.g. astronomy data) Parallel execution on large clusters Use parallel file systems for scalable I/O e.g. IBM s GPFS, Sun s Lustre FS, PanFS, and Parallel Virtual File System (PVFS) 4
5 Why use parallel file systems? Handle a wide variety of workloads High concurrent reads and writes Small file support, scalable metadata Offer performance vs. reliability tradeoff RAID-5 (e.g., PanFS) Mirroring Failover (e.g., LustreFS) Standard Unix FS interface & POSIX semantics pnfs standard (NFS v4.1) 5
6 Outline A basic shim layer & preliminary evaluation Three add-on features in a shim layer Evaluation 6
7 HDFS & PVFS: high level design Meta-data servers Store all file system metadata Handle all metadata operations Data servers Store actual file system data Handle all read and write operations Files are divided into chunks Chunks of a file are distributed across servers 7
8 PVFS shim layer under Hadoop Hadoop applications Hadoop framework Extensible file system API HDFS client library PVFS shim layer Unmodified PVFS client library (C) Unmodified PVFS HDFS servers servers Forward requests to and respond from PVFS client library using Java Native Interface (JNI) Client Server 8
9 Preliminary Evaluation Text search ( grep ) common workloads in Internet service applications Search for a rare pattern in 100-byte records 64GB data set 32 nodes Each node servers as storage and compute nodes 9


10 Vanilla PVFS is disappointing 2.5 times slower 10
11 Outline A basic shim layer & preliminary evaluation Three add-on features in a shim layer Readahead buffer File layout information Replication Evaluation 11
12 Read operation in Hadoop Typical read workload: Small (less than 128 KB) Sequential through an entire chunk HDFS prefetches an entire chunk No cache coherence issue with its write-once semantic 12
13 Readahead buffer PVFS has no client buffer cache Avoid a cache coherence issue with concurrent writes Readahead buffer can be added to PVFS shim layer In Hadoop, a file can become immutable after it is closed No need for cache coherence mechanism 13


14 PVFS with 4MB buffer still quite slow 14
15 Outline A basic shim layer & preliminary evaluation Three add-on features in a shim layer Readahead buffer File layout information Replication Evaluation 15
16 Collocation in Hadoop File layout information Describe where chunks are located Collocate computation and data Ship computation to where data is located Reduce network traffic 16
17 Hadoop without collocation Computation Chunk1 Chunk2 Chunk3 Compute Node 3 data transfers over network Storage Node Chunk1 Chunk2 Chunk3 Chunk 3 Node A Chunk 1 Node B Chunk 2 Node C 17
18 Hadoop with collocation Computation Chunk1 Chunk2 Chunk3 Compute Node no data transfer over network Storage Node Chunk3 Chunk1 Chunk2 Chunk 3 Node A Chunk 1 Node B Chunk 2 Node C 18
19 Expose file layout information File layout information in PVFS Stored as extended attributes Different format from Hadoop format A shim layer converts file layout information from PVFS format to Hadoop format Enable Hadoop to collocate computation and data 19


20 PVFS with file layout information comparable performance 20
21 Outline A basic shim layer & preliminary evaluation Three add-on features in a shim layer Readahead buffer File layout information Replication Evaluation 21
22 Replication in HDFS Rack-awareness replication By default, 3 copies for each file (triplication) 1.Write to a local storage node 2.Write to a storage node in the local rack 3.Write to a storage node in the other rack 22
23 Replication in PVFS No replication in the public release of PVFS Rely on hardware based reliability solutions Per server RAID inside logical storage devices Replication can be added in a shim layer Write each file to three servers No reconstruction/recovery in the prototype 23
24 PVFS with replication Hadoop applications Hadoop framework Extensible file system API PVFS shim layer Unmodified PVFS client library (C) Unmodified PVFS server Unmodified PVFS server Unmodified PVFS server 24
25 PVFS shim layer under Hadoop Hadoop applications Hadoop framework Extensible file system API ~1,700 lines of code PVFS shim layer Readahead buffer HDFS client library HDFS servers PVFS shim layer Unmodified PVFS client library (C) Unmodified PVFS servers File layout info Replication Client Server 25
26 Outline A basic shim layer & preliminary evaluation Three add-on features in a shim layer Evaluation Micro-benchmark (non MapReduce) MapReduce benchmark 26
27 Micro-benchmark Cluster configuration 16 nodes Pentium D dual-core 3.0GHz 4 GB Memory One 7200 rpm SATA 160 GB (8 MB buffer) Gigabit Ethernet Use file system API directly without Hadoop involvement 27


28 N clients, each reads 1/N of single file Round-robin file layout in PVFS helps avoid contention 28
29 Why is PVFS better in this case? Without scheduling, clients read in a uniform pattern Client1 reads A1 then A4 Client2 reads A2 then A5 Client3 reads A3 then A6 PVFS Round-robin placement HDFS Random placement A1 A4 A2 A5 A3 A6 A1 A3 A2 A5 A4 A6 Contention 29
30 HDFS with Hadoop s scheduling Example 1: Client1 reads A1 then A4 Client2 reads A2 then A5 Client3 reads A6 then A3 A1 A3 A2 A5 A4 A6 Example 2: Client1 reads A1 then A3 Client2 reads A2 then A5 Client3 reads A4 then A6 A1 A3 A2 A5 A4 A6 30


31 Read with Hadoop s scheduling Hadoop s scheduling can mask a problem with a non-uniform file layout in HDFS 31


32 N clients write to n distinct files By writing one of three copies locally, HDFS write throughout grows linearly 32


33 Concurrent writes to a single file By allowing concurrent writes in PVFS, copy completes faster by using multiple writers 33
34 Outline A basic shim layer & preliminary evaluation Three add-on features in a shim layer Evaluation Micro-benchmark (non MapReduce) MapReduce benchmark 34
35 MapReduce benchmark setting Yahoo! M45 cluster Use nodes Xeon quad-core 1.86 GHz with 6GB Memory One 7200 rpm SATA 750 GB (8 MB buffer) Gigabit Ethernet Use Hadoop framework for MapReduce processing 35
36 MapReduce benchmark Grep: Search for a rare pattern in hundred million 100-byte records (100GB) Sort: Sort hundred million 100-byte records (100GB) Never-Ending Language Learning (NELL): (J. Betteridge, CMU) Count the numbers of selected phrases in 37GB data-set 36
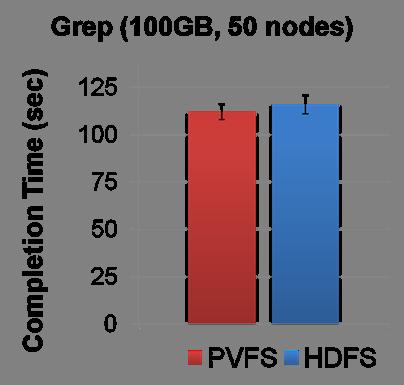
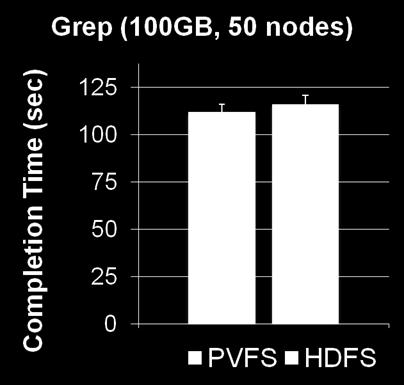
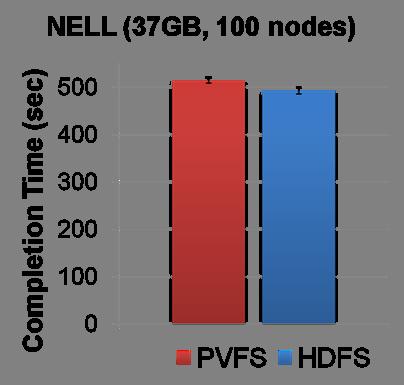
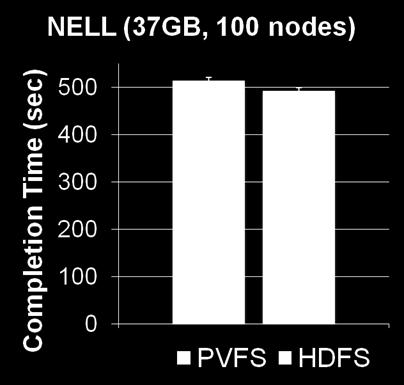
37 Read-Intensive Benchmark PVFS s performance is similar to HDFS 37


38 Write-Intensive Benchmark By writing one of three copies locally, HDFS does better than PVFS 38
39 Summary PVFS can be tuned to deliver promising performance for Hadoop applications Simple shim layer in Hadoop No modification to PVFS PVFS can expose file layout information Enable Hadoop to collocate computation and data Hadoop application can benefit from concurrent writing supported by parallel file systems 39
40 Acknowledgements Sam Lang and Rob Ross for help with PVFS internals Yahoo! for the M45 cluster Julio Lopez for help with M45 and Hadoop Justin Betteridge, Le Zhao, Jamie Callan, Shay Cohen, Noah Smith, U Kang and Christos Faloutsos for their scientific applications 40
Crossing the Chasm: Sneaking a parallel file system into Hadoop
 Crossing the Chasm: Sneaking a parallel file system into Hadoop Wittawat Tantisiriroj Swapnil Patil, Garth Gibson PARALLEL DATA LABORATORY Carnegie Mellon University In this work Compare and contrast large
Crossing the Chasm: Sneaking a parallel file system into Hadoop Wittawat Tantisiriroj Swapnil Patil, Garth Gibson PARALLEL DATA LABORATORY Carnegie Mellon University In this work Compare and contrast large
Data-intensive File Systems for Internet Services: A Rose by Any Other Name... (CMU-PDL )
") Carnegie Mellon University Research Showcase @ CMU Parallel Data Laboratory Research Centers and Institutes 10-2008 Data-intensive File Systems for Internet Services: A Rose by Any Other Name... (CMU-PDL-08-114)
Carnegie Mellon University Research Showcase @ CMU Parallel Data Laboratory Research Centers and Institutes 10-2008 Data-intensive File Systems for Internet Services: A Rose by Any Other Name... (CMU-PDL-08-114)
The Hadoop Distributed File System Konstantin Shvachko Hairong Kuang Sanjay Radia Robert Chansler
 The Hadoop Distributed File System Konstantin Shvachko Hairong Kuang Sanjay Radia Robert Chansler MSST 10 Hadoop in Perspective Hadoop scales computation capacity, storage capacity, and I/O bandwidth by
The Hadoop Distributed File System Konstantin Shvachko Hairong Kuang Sanjay Radia Robert Chansler MSST 10 Hadoop in Perspective Hadoop scales computation capacity, storage capacity, and I/O bandwidth by
DiskReduce: Making Room for More Data on DISCs. Wittawat Tantisiriroj
 DiskReduce: Making Room for More Data on DISCs Wittawat Tantisiriroj Lin Xiao, Bin Fan, and Garth Gibson PARALLEL DATA LABORATORY Carnegie Mellon University GFS/HDFS Triplication GFS & HDFS triplicate
DiskReduce: Making Room for More Data on DISCs Wittawat Tantisiriroj Lin Xiao, Bin Fan, and Garth Gibson PARALLEL DATA LABORATORY Carnegie Mellon University GFS/HDFS Triplication GFS & HDFS triplicate
Published by: PIONEER RESEARCH & DEVELOPMENT GROUP (www.prdg.org)
") Need to reinvent the storage stack in cloud computing Sagar Wadhwa 1, Dr. Naveen Hemrajani 2 1 M.Tech Scholar, Suresh Gyan Vihar University, Jaipur, Rajasthan, India 2 Profesor, Suresh Gyan Vihar University,
Need to reinvent the storage stack in cloud computing Sagar Wadhwa 1, Dr. Naveen Hemrajani 2 1 M.Tech Scholar, Suresh Gyan Vihar University, Jaipur, Rajasthan, India 2 Profesor, Suresh Gyan Vihar University,
YCSB++ Benchmarking Tool Performance Debugging Advanced Features of Scalable Table Stores
 YCSB++ Benchmarking Tool Performance Debugging Advanced Features of Scalable Table Stores Swapnil Patil Milo Polte, Wittawat Tantisiriroj, Kai Ren, Lin Xiao, Julio Lopez, Garth Gibson, Adam Fuchs *, Billie
YCSB++ Benchmarking Tool Performance Debugging Advanced Features of Scalable Table Stores Swapnil Patil Milo Polte, Wittawat Tantisiriroj, Kai Ren, Lin Xiao, Julio Lopez, Garth Gibson, Adam Fuchs *, Billie
System that permanently stores data Usually layered on top of a lower-level physical storage medium Divided into logical units called files
 System that permanently stores data Usually layered on top of a lower-level physical storage medium Divided into logical units called files Addressable by a filename ( foo.txt ) Usually supports hierarchical
System that permanently stores data Usually layered on top of a lower-level physical storage medium Divided into logical units called files Addressable by a filename ( foo.txt ) Usually supports hierarchical
18-hdfs-gfs.txt Thu Oct 27 10:05: Notes on Parallel File Systems: HDFS & GFS , Fall 2011 Carnegie Mellon University Randal E.
 18-hdfs-gfs.txt Thu Oct 27 10:05:07 2011 1 Notes on Parallel File Systems: HDFS & GFS 15-440, Fall 2011 Carnegie Mellon University Randal E. Bryant References: Ghemawat, Gobioff, Leung, "The Google File
18-hdfs-gfs.txt Thu Oct 27 10:05:07 2011 1 Notes on Parallel File Systems: HDFS & GFS 15-440, Fall 2011 Carnegie Mellon University Randal E. Bryant References: Ghemawat, Gobioff, Leung, "The Google File
Structuring PLFS for Extensibility
 Structuring PLFS for Extensibility Chuck Cranor, Milo Polte, Garth Gibson PARALLEL DATA LABORATORY Carnegie Mellon University What is PLFS? Parallel Log Structured File System Interposed filesystem b/w
Structuring PLFS for Extensibility Chuck Cranor, Milo Polte, Garth Gibson PARALLEL DATA LABORATORY Carnegie Mellon University What is PLFS? Parallel Log Structured File System Interposed filesystem b/w
DiskReduce: Making Room for More Data on DISCs. Wittawat Tantisiriroj
 DiskReduce: Making Room for More Data on DISCs Wittawat Tantisiriroj Lin Xiao, in Fan, and Garth Gibson PARALLEL DATA LAORATORY Carnegie Mellon University GFS/HDFS Triplication GFS & HDFS triplicate every
DiskReduce: Making Room for More Data on DISCs Wittawat Tantisiriroj Lin Xiao, in Fan, and Garth Gibson PARALLEL DATA LAORATORY Carnegie Mellon University GFS/HDFS Triplication GFS & HDFS triplicate every
Analytics in the cloud
 Analytics in the cloud Dow we really need to reinvent the storage stack? R. Ananthanarayanan, Karan Gupta, Prashant Pandey, Himabindu Pucha, Prasenjit Sarkar, Mansi Shah, Renu Tewari Image courtesy NASA
Analytics in the cloud Dow we really need to reinvent the storage stack? R. Ananthanarayanan, Karan Gupta, Prashant Pandey, Himabindu Pucha, Prasenjit Sarkar, Mansi Shah, Renu Tewari Image courtesy NASA
CA485 Ray Walshe Google File System
 Google File System Overview Google File System is scalable, distributed file system on inexpensive commodity hardware that provides: Fault Tolerance File system runs on hundreds or thousands of storage
Google File System Overview Google File System is scalable, distributed file system on inexpensive commodity hardware that provides: Fault Tolerance File system runs on hundreds or thousands of storage
Cloud Computing at Yahoo! Thomas Kwan Director, Research Operations Yahoo! Labs
 Cloud Computing at Yahoo! Thomas Kwan Director, Research Operations Yahoo! Labs Overview Cloud Strategy Cloud Services Cloud Research Partnerships - 2 - Yahoo! Cloud Strategy 1. Optimizing for Yahoo-scale
Cloud Computing at Yahoo! Thomas Kwan Director, Research Operations Yahoo! Labs Overview Cloud Strategy Cloud Services Cloud Research Partnerships - 2 - Yahoo! Cloud Strategy 1. Optimizing for Yahoo-scale
18-hdfs-gfs.txt Thu Nov 01 09:53: Notes on Parallel File Systems: HDFS & GFS , Fall 2012 Carnegie Mellon University Randal E.
 18-hdfs-gfs.txt Thu Nov 01 09:53:32 2012 1 Notes on Parallel File Systems: HDFS & GFS 15-440, Fall 2012 Carnegie Mellon University Randal E. Bryant References: Ghemawat, Gobioff, Leung, "The Google File
18-hdfs-gfs.txt Thu Nov 01 09:53:32 2012 1 Notes on Parallel File Systems: HDFS & GFS 15-440, Fall 2012 Carnegie Mellon University Randal E. Bryant References: Ghemawat, Gobioff, Leung, "The Google File
Distributed Filesystem
 Distributed Filesystem 1 How do we get data to the workers? NAS Compute Nodes SAN 2 Distributing Code! Don t move data to workers move workers to the data! - Store data on the local disks of nodes in the
Distributed Filesystem 1 How do we get data to the workers? NAS Compute Nodes SAN 2 Distributing Code! Don t move data to workers move workers to the data! - Store data on the local disks of nodes in the
Yuval Carmel Tel-Aviv University "Advanced Topics in Storage Systems" - Spring 2013
 Yuval Carmel Tel-Aviv University "Advanced Topics in About & Keywords Motivation & Purpose Assumptions Architecture overview & Comparison Measurements How does it fit in? The Future 2 About & Keywords
Yuval Carmel Tel-Aviv University "Advanced Topics in About & Keywords Motivation & Purpose Assumptions Architecture overview & Comparison Measurements How does it fit in? The Future 2 About & Keywords
Hadoop File System S L I D E S M O D I F I E D F R O M P R E S E N T A T I O N B Y B. R A M A M U R T H Y 11/15/2017
 Hadoop File System 1 S L I D E S M O D I F I E D F R O M P R E S E N T A T I O N B Y B. R A M A M U R T H Y Moving Computation is Cheaper than Moving Data Motivation: Big Data! What is BigData? - Google
Hadoop File System 1 S L I D E S M O D I F I E D F R O M P R E S E N T A T I O N B Y B. R A M A M U R T H Y Moving Computation is Cheaper than Moving Data Motivation: Big Data! What is BigData? - Google
Distributed File Systems II
 Distributed File Systems II To do q Very-large scale: Google FS, Hadoop FS, BigTable q Next time: Naming things GFS A radically new environment NFS, etc. Independence Small Scale Variety of workloads Cooperation
Distributed File Systems II To do q Very-large scale: Google FS, Hadoop FS, BigTable q Next time: Naming things GFS A radically new environment NFS, etc. Independence Small Scale Variety of workloads Cooperation
The Fusion Distributed File System
 Slide 1 / 44 The Fusion Distributed File System Dongfang Zhao February 2015 Slide 2 / 44 Outline Introduction FusionFS System Architecture Metadata Management Data Movement Implementation Details Unique
Slide 1 / 44 The Fusion Distributed File System Dongfang Zhao February 2015 Slide 2 / 44 Outline Introduction FusionFS System Architecture Metadata Management Data Movement Implementation Details Unique
Log-structured files for fast checkpointing
 Log-structured files for fast checkpointing Milo Polte Jiri Simsa, Wittawat Tantisiriroj,Shobhit Dayal, Mikhail Chainani, Dilip Kumar Uppugandla, Garth Gibson PARALLEL DATA LABORATORY Carnegie Mellon University
Log-structured files for fast checkpointing Milo Polte Jiri Simsa, Wittawat Tantisiriroj,Shobhit Dayal, Mikhail Chainani, Dilip Kumar Uppugandla, Garth Gibson PARALLEL DATA LABORATORY Carnegie Mellon University
CSE 124: Networked Services Lecture-16
 Fall 2010 CSE 124: Networked Services Lecture-16 Instructor: B. S. Manoj, Ph.D http://cseweb.ucsd.edu/classes/fa10/cse124 11/23/2010 CSE 124 Networked Services Fall 2010 1 Updates PlanetLab experiments
Fall 2010 CSE 124: Networked Services Lecture-16 Instructor: B. S. Manoj, Ph.D http://cseweb.ucsd.edu/classes/fa10/cse124 11/23/2010 CSE 124 Networked Services Fall 2010 1 Updates PlanetLab experiments
CSE 124: Networked Services Fall 2009 Lecture-19
 CSE 124: Networked Services Fall 2009 Lecture-19 Instructor: B. S. Manoj, Ph.D http://cseweb.ucsd.edu/classes/fa09/cse124 Some of these slides are adapted from various sources/individuals including but
CSE 124: Networked Services Fall 2009 Lecture-19 Instructor: B. S. Manoj, Ph.D http://cseweb.ucsd.edu/classes/fa09/cse124 Some of these slides are adapted from various sources/individuals including but
Distributed Systems 16. Distributed File Systems II
 Distributed Systems 16. Distributed File Systems II Paul Krzyzanowski pxk@cs.rutgers.edu 1 Review NFS RPC-based access AFS Long-term caching CODA Read/write replication & disconnected operation DFS AFS
Distributed Systems 16. Distributed File Systems II Paul Krzyzanowski pxk@cs.rutgers.edu 1 Review NFS RPC-based access AFS Long-term caching CODA Read/write replication & disconnected operation DFS AFS
Accelerating Parallel Analysis of Scientific Simulation Data via Zazen
 Accelerating Parallel Analysis of Scientific Simulation Data via Zazen Tiankai Tu, Charles A. Rendleman, Patrick J. Miller, Federico Sacerdoti, Ron O. Dror, and David E. Shaw D. E. Shaw Research Motivation
Accelerating Parallel Analysis of Scientific Simulation Data via Zazen Tiankai Tu, Charles A. Rendleman, Patrick J. Miller, Federico Sacerdoti, Ron O. Dror, and David E. Shaw D. E. Shaw Research Motivation
CLOUD-SCALE FILE SYSTEMS
 Data Management in the Cloud CLOUD-SCALE FILE SYSTEMS 92 Google File System (GFS) Designing a file system for the Cloud design assumptions design choices Architecture GFS Master GFS Chunkservers GFS Clients
Data Management in the Cloud CLOUD-SCALE FILE SYSTEMS 92 Google File System (GFS) Designing a file system for the Cloud design assumptions design choices Architecture GFS Master GFS Chunkservers GFS Clients
Introduction to Hadoop. Owen O Malley Yahoo!, Grid Team
 Introduction to Hadoop Owen O Malley Yahoo!, Grid Team owen@yahoo-inc.com Who Am I? Yahoo! Architect on Hadoop Map/Reduce Design, review, and implement features in Hadoop Working on Hadoop full time since
Introduction to Hadoop Owen O Malley Yahoo!, Grid Team owen@yahoo-inc.com Who Am I? Yahoo! Architect on Hadoop Map/Reduce Design, review, and implement features in Hadoop Working on Hadoop full time since
The Google File System
 The Google File System Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung December 2003 ACM symposium on Operating systems principles Publisher: ACM Nov. 26, 2008 OUTLINE INTRODUCTION DESIGN OVERVIEW
The Google File System Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung December 2003 ACM symposium on Operating systems principles Publisher: ACM Nov. 26, 2008 OUTLINE INTRODUCTION DESIGN OVERVIEW
Cloud Computing CS
 Cloud Computing CS 15-319 Distributed File Systems and Cloud Storage Part I Lecture 12, Feb 22, 2012 Majd F. Sakr, Mohammad Hammoud and Suhail Rehman 1 Today Last two sessions Pregel, Dryad and GraphLab
Cloud Computing CS 15-319 Distributed File Systems and Cloud Storage Part I Lecture 12, Feb 22, 2012 Majd F. Sakr, Mohammad Hammoud and Suhail Rehman 1 Today Last two sessions Pregel, Dryad and GraphLab
Write a technical report Present your results Write a workshop/conference paper (optional) Could be a real system, simulation and/or theoretical
 Could be a real system, simulation and/or theoretical") Identify a problem Review approaches to the problem Propose a novel approach to the problem Define, design, prototype an implementation to evaluate your approach Could be a real system, simulation and/or
Identify a problem Review approaches to the problem Propose a novel approach to the problem Define, design, prototype an implementation to evaluate your approach Could be a real system, simulation and/or
Parallel File Systems for HPC
 Introduction to Scuola Internazionale Superiore di Studi Avanzati Trieste November 2008 Advanced School in High Performance and Grid Computing Outline 1 The Need for 2 The File System 3 Cluster & A typical
Introduction to Scuola Internazionale Superiore di Studi Avanzati Trieste November 2008 Advanced School in High Performance and Grid Computing Outline 1 The Need for 2 The File System 3 Cluster & A typical
Data Management. Parallel Filesystems. Dr David Henty HPC Training and Support
 Data Management Dr David Henty HPC Training and Support d.henty@epcc.ed.ac.uk +44 131 650 5960 Overview Lecture will cover Why is IO difficult Why is parallel IO even worse Lustre GPFS Performance on ARCHER
Data Management Dr David Henty HPC Training and Support d.henty@epcc.ed.ac.uk +44 131 650 5960 Overview Lecture will cover Why is IO difficult Why is parallel IO even worse Lustre GPFS Performance on ARCHER
Name: Instructions. Problem 1 : Short answer. [48 points] CMU / Storage Systems 23 Feb 2011 Spring 2012 Exam 1
![Name: Instructions. Problem 1 : Short answer. [48 points] CMU / Storage Systems 23 Feb 2011 Spring 2012 Exam 1](/thumbs/95/126247775.jpg "Name: Instructions. Problem 1 : Short answer. [48 points] CMU / Storage Systems 23 Feb 2011 Spring 2012 Exam 1") CMU 18-746/15-746 Storage Systems 23 Feb 2011 Spring 2012 Exam 1 Instructions Name: There are three (3) questions on the exam. You may find questions that could have several answers and require an explanation
CMU 18-746/15-746 Storage Systems 23 Feb 2011 Spring 2012 Exam 1 Instructions Name: There are three (3) questions on the exam. You may find questions that could have several answers and require an explanation
Qing Zheng Lin Xiao, Kai Ren, Garth Gibson
 Qing Zheng Lin Xiao, Kai Ren, Garth Gibson File System Architecture APP APP APP APP APP APP APP APP metadata operations Metadata Service I/O operations [flat namespace] Low-level Storage Infrastructure
Qing Zheng Lin Xiao, Kai Ren, Garth Gibson File System Architecture APP APP APP APP APP APP APP APP metadata operations Metadata Service I/O operations [flat namespace] Low-level Storage Infrastructure
EsgynDB Enterprise 2.0 Platform Reference Architecture
 EsgynDB Enterprise 2.0 Platform Reference Architecture This document outlines a Platform Reference Architecture for EsgynDB Enterprise, built on Apache Trafodion (Incubating) implementation with licensed
EsgynDB Enterprise 2.0 Platform Reference Architecture This document outlines a Platform Reference Architecture for EsgynDB Enterprise, built on Apache Trafodion (Incubating) implementation with licensed
NFS, GPFS, PVFS, Lustre Batch-scheduled systems: Clusters, Grids, and Supercomputers Programming paradigm: HPC, MTC, and HTC
 Segregated storage and compute NFS, GPFS, PVFS, Lustre Batch-scheduled systems: Clusters, Grids, and Supercomputers Programming paradigm: HPC, MTC, and HTC Co-located storage and compute HDFS, GFS Data
Segregated storage and compute NFS, GPFS, PVFS, Lustre Batch-scheduled systems: Clusters, Grids, and Supercomputers Programming paradigm: HPC, MTC, and HTC Co-located storage and compute HDFS, GFS Data
COS 318: Operating Systems. NSF, Snapshot, Dedup and Review
 COS 318: Operating Systems NSF, Snapshot, Dedup and Review Topics! NFS! Case Study: NetApp File System! Deduplication storage system! Course review 2 Network File System! Sun introduced NFS v2 in early
COS 318: Operating Systems NSF, Snapshot, Dedup and Review Topics! NFS! Case Study: NetApp File System! Deduplication storage system! Course review 2 Network File System! Sun introduced NFS v2 in early
Google is Really Different.
 COMP 790-088 -- Distributed File Systems Google File System 7 Google is Really Different. Huge Datacenters in 5+ Worldwide Locations Datacenters house multiple server clusters Coming soon to Lenior, NC
COMP 790-088 -- Distributed File Systems Google File System 7 Google is Really Different. Huge Datacenters in 5+ Worldwide Locations Datacenters house multiple server clusters Coming soon to Lenior, NC
CPSC 426/526. Cloud Computing. Ennan Zhai. Computer Science Department Yale University
 CPSC 426/526 Cloud Computing Ennan Zhai Computer Science Department Yale University Recall: Lec-7 In the lec-7, I talked about: - P2P vs Enterprise control - Firewall - NATs - Software defined network
CPSC 426/526 Cloud Computing Ennan Zhai Computer Science Department Yale University Recall: Lec-7 In the lec-7, I talked about: - P2P vs Enterprise control - Firewall - NATs - Software defined network
The Last Bottleneck: How Parallel I/O can improve application performance
 The Last Bottleneck: How Parallel I/O can improve application performance HPC ADVISORY COUNCIL STANFORD WORKSHOP; DECEMBER 6 TH 2011 REX TANAKIT DIRECTOR OF INDUSTRY SOLUTIONS AGENDA Panasas Overview Who
The Last Bottleneck: How Parallel I/O can improve application performance HPC ADVISORY COUNCIL STANFORD WORKSHOP; DECEMBER 6 TH 2011 REX TANAKIT DIRECTOR OF INDUSTRY SOLUTIONS AGENDA Panasas Overview Who
Two-Choice Randomized Dynamic I/O Scheduler for Object Storage Systems. Dong Dai, Yong Chen, Dries Kimpe, and Robert Ross
 Two-Choice Randomized Dynamic I/O Scheduler for Object Storage Systems Dong Dai, Yong Chen, Dries Kimpe, and Robert Ross Parallel Object Storage Many HPC systems utilize object storage: PVFS, Lustre, PanFS,
Two-Choice Randomized Dynamic I/O Scheduler for Object Storage Systems Dong Dai, Yong Chen, Dries Kimpe, and Robert Ross Parallel Object Storage Many HPC systems utilize object storage: PVFS, Lustre, PanFS,
HDF5 I/O Performance. HDF and HDF-EOS Workshop VI December 5, 2002
 HDF5 I/O Performance HDF and HDF-EOS Workshop VI December 5, 2002 1 Goal of this talk Give an overview of the HDF5 Library tuning knobs for sequential and parallel performance 2 Challenging task HDF5 Library
HDF5 I/O Performance HDF and HDF-EOS Workshop VI December 5, 2002 1 Goal of this talk Give an overview of the HDF5 Library tuning knobs for sequential and parallel performance 2 Challenging task HDF5 Library
pnfs, POSIX, and MPI-IO: A Tale of Three Semantics
 Dean Hildebrand Research Staff Member PDSW 2009 pnfs, POSIX, and MPI-IO: A Tale of Three Semantics Dean Hildebrand, Roger Haskin Arifa Nisar IBM Almaden Northwestern University Agenda Motivation pnfs HPC
Dean Hildebrand Research Staff Member PDSW 2009 pnfs, POSIX, and MPI-IO: A Tale of Three Semantics Dean Hildebrand, Roger Haskin Arifa Nisar IBM Almaden Northwestern University Agenda Motivation pnfs HPC
CS 345A Data Mining. MapReduce
 CS 345A Data Mining MapReduce Single-node architecture CPU Machine Learning, Statistics Memory Classical Data Mining Disk Commodity Clusters Web data sets can be very large Tens to hundreds of terabytes
CS 345A Data Mining MapReduce Single-node architecture CPU Machine Learning, Statistics Memory Classical Data Mining Disk Commodity Clusters Web data sets can be very large Tens to hundreds of terabytes
CSE 153 Design of Operating Systems
 CSE 153 Design of Operating Systems Winter 2018 Lecture 22: File system optimizations and advanced topics There s more to filesystems J Standard Performance improvement techniques Alternative important
CSE 153 Design of Operating Systems Winter 2018 Lecture 22: File system optimizations and advanced topics There s more to filesystems J Standard Performance improvement techniques Alternative important
YCSB++ benchmarking tool Performance debugging advanced features of scalable table stores
 YCSB++ benchmarking tool Performance debugging advanced features of scalable table stores Swapnil Patil M. Polte, W. Tantisiriroj, K. Ren, L.Xiao, J. Lopez, G.Gibson, A. Fuchs *, B. Rinaldi * Carnegie
YCSB++ benchmarking tool Performance debugging advanced features of scalable table stores Swapnil Patil M. Polte, W. Tantisiriroj, K. Ren, L.Xiao, J. Lopez, G.Gibson, A. Fuchs *, B. Rinaldi * Carnegie
The Google File System
 The Google File System Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung SOSP 2003 presented by Kun Suo Outline GFS Background, Concepts and Key words Example of GFS Operations Some optimizations in
The Google File System Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung SOSP 2003 presented by Kun Suo Outline GFS Background, Concepts and Key words Example of GFS Operations Some optimizations in
WHITEPAPER. Improve Hadoop Performance with Memblaze PBlaze SSD
 Improve Hadoop Performance with Memblaze PBlaze SSD Improve Hadoop Performance with Memblaze PBlaze SSD Exclusive Summary We live in the data age. It s not easy to measure the total volume of data stored
Improve Hadoop Performance with Memblaze PBlaze SSD Improve Hadoop Performance with Memblaze PBlaze SSD Exclusive Summary We live in the data age. It s not easy to measure the total volume of data stored
Google File System. Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung Google fall DIP Heerak lim, Donghun Koo
 Google File System Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung Google 2017 fall DIP Heerak lim, Donghun Koo 1 Agenda Introduction Design overview Systems interactions Master operation Fault tolerance
Google File System Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung Google 2017 fall DIP Heerak lim, Donghun Koo 1 Agenda Introduction Design overview Systems interactions Master operation Fault tolerance
The Google File System
 The Google File System By Ghemawat, Gobioff and Leung Outline Overview Assumption Design of GFS System Interactions Master Operations Fault Tolerance Measurements Overview GFS: Scalable distributed file
The Google File System By Ghemawat, Gobioff and Leung Outline Overview Assumption Design of GFS System Interactions Master Operations Fault Tolerance Measurements Overview GFS: Scalable distributed file
COSC 6397 Big Data Analytics. Distributed File Systems (II) Edgar Gabriel Fall HDFS Basics
 Edgar Gabriel Fall HDFS Basics") COSC 6397 Big Data Analytics Distributed File Systems (II) Edgar Gabriel Fall 2018 HDFS Basics An open-source implementation of Google File System Assume that node failure rate is high Assumes a small
COSC 6397 Big Data Analytics Distributed File Systems (II) Edgar Gabriel Fall 2018 HDFS Basics An open-source implementation of Google File System Assume that node failure rate is high Assumes a small
The Last Bottleneck: How Parallel I/O can attenuate Amdahl's Law
 The Last Bottleneck: How Parallel I/O can attenuate Amdahl's Law ERESEARCH AUSTRALASIA, NOVEMBER 2011 REX TANAKIT DIRECTOR OF INDUSTRY SOLUTIONS AGENDA Parallel System Parallel processing goes mainstream
The Last Bottleneck: How Parallel I/O can attenuate Amdahl's Law ERESEARCH AUSTRALASIA, NOVEMBER 2011 REX TANAKIT DIRECTOR OF INDUSTRY SOLUTIONS AGENDA Parallel System Parallel processing goes mainstream
The Google File System
 The Google File System Sanjay Ghemawat, Howard Gobioff, Shun-Tak Leung ACM SIGOPS 2003 {Google Research} Vaibhav Bajpai NDS Seminar 2011 Looking Back time Classics Sun NFS (1985) CMU Andrew FS (1988) Fault
The Google File System Sanjay Ghemawat, Howard Gobioff, Shun-Tak Leung ACM SIGOPS 2003 {Google Research} Vaibhav Bajpai NDS Seminar 2011 Looking Back time Classics Sun NFS (1985) CMU Andrew FS (1988) Fault
Parallel Storage Systems for Large-Scale Machines
 Parallel Storage Systems for Large-Scale Machines Doctoral Showcase Christos FILIPPIDIS (cfjs@outlook.com) Department of Informatics and Telecommunications, National and Kapodistrian University of Athens
Parallel Storage Systems for Large-Scale Machines Doctoral Showcase Christos FILIPPIDIS (cfjs@outlook.com) Department of Informatics and Telecommunications, National and Kapodistrian University of Athens
CSE6230 Fall Parallel I/O. Fang Zheng
 CSE6230 Fall 2012 Parallel I/O Fang Zheng 1 Credits Some materials are taken from Rob Latham s Parallel I/O in Practice talk http://www.spscicomp.org/scicomp14/talks/l atham.pdf 2 Outline I/O Requirements
CSE6230 Fall 2012 Parallel I/O Fang Zheng 1 Credits Some materials are taken from Rob Latham s Parallel I/O in Practice talk http://www.spscicomp.org/scicomp14/talks/l atham.pdf 2 Outline I/O Requirements
BeoLink.org. Design and build an inexpensive DFS. Fabrizio Manfredi Furuholmen. FrOSCon August 2008
 Design and build an inexpensive DFS Fabrizio Manfredi Furuholmen FrOSCon August 2008 Agenda Overview Introduction Old way openafs New way Hadoop CEPH Conclusion Overview Why Distributed File system? Handle
Design and build an inexpensive DFS Fabrizio Manfredi Furuholmen FrOSCon August 2008 Agenda Overview Introduction Old way openafs New way Hadoop CEPH Conclusion Overview Why Distributed File system? Handle
The Google File System
 The Google File System Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung Google SOSP 03, October 19 22, 2003, New York, USA Hyeon-Gyu Lee, and Yeong-Jae Woo Memory & Storage Architecture Lab. School
The Google File System Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung Google SOSP 03, October 19 22, 2003, New York, USA Hyeon-Gyu Lee, and Yeong-Jae Woo Memory & Storage Architecture Lab. School
The Google File System
 October 13, 2010 Based on: S. Ghemawat, H. Gobioff, and S.-T. Leung: The Google file system, in Proceedings ACM SOSP 2003, Lake George, NY, USA, October 2003. 1 Assumptions Interface Architecture Single
October 13, 2010 Based on: S. Ghemawat, H. Gobioff, and S.-T. Leung: The Google file system, in Proceedings ACM SOSP 2003, Lake George, NY, USA, October 2003. 1 Assumptions Interface Architecture Single
Distributed File Systems
 Distributed File Systems Today l Basic distributed file systems l Two classical examples Next time l Naming things xkdc Distributed File Systems " A DFS supports network-wide sharing of files and devices
Distributed File Systems Today l Basic distributed file systems l Two classical examples Next time l Naming things xkdc Distributed File Systems " A DFS supports network-wide sharing of files and devices
The Google File System
 The Google File System Sanjay Ghemawat, Howard Gobioff and Shun Tak Leung Google* Shivesh Kumar Sharma fl4164@wayne.edu Fall 2015 004395771 Overview Google file system is a scalable distributed file system
The Google File System Sanjay Ghemawat, Howard Gobioff and Shun Tak Leung Google* Shivesh Kumar Sharma fl4164@wayne.edu Fall 2015 004395771 Overview Google file system is a scalable distributed file system
Let s Make Parallel File System More Parallel
 Let s Make Parallel File System More Parallel [LA-UR-15-25811] Qing Zheng 1, Kai Ren 1, Garth Gibson 1, Bradley W. Settlemyer 2 1 Carnegie MellonUniversity 2 Los AlamosNationalLaboratory HPC defined by
Let s Make Parallel File System More Parallel [LA-UR-15-25811] Qing Zheng 1, Kai Ren 1, Garth Gibson 1, Bradley W. Settlemyer 2 1 Carnegie MellonUniversity 2 Los AlamosNationalLaboratory HPC defined by
BIG DATA AND HADOOP ON THE ZFS STORAGE APPLIANCE
 BIG DATA AND HADOOP ON THE ZFS STORAGE APPLIANCE BRETT WENINGER, MANAGING DIRECTOR 10/21/2014 ADURANT APPROACH TO BIG DATA Align to Un/Semi-structured Data Instead of Big Scale out will become Big Greatest
BIG DATA AND HADOOP ON THE ZFS STORAGE APPLIANCE BRETT WENINGER, MANAGING DIRECTOR 10/21/2014 ADURANT APPROACH TO BIG DATA Align to Un/Semi-structured Data Instead of Big Scale out will become Big Greatest
Database Architecture 2 & Storage. Instructor: Matei Zaharia cs245.stanford.edu
 Database Architecture 2 & Storage Instructor: Matei Zaharia cs245.stanford.edu Summary from Last Time System R mostly matched the architecture of a modern RDBMS» SQL» Many storage & access methods» Cost-based
Database Architecture 2 & Storage Instructor: Matei Zaharia cs245.stanford.edu Summary from Last Time System R mostly matched the architecture of a modern RDBMS» SQL» Many storage & access methods» Cost-based
CSE 124: Networked Services Lecture-17
 Fall 2010 CSE 124: Networked Services Lecture-17 Instructor: B. S. Manoj, Ph.D http://cseweb.ucsd.edu/classes/fa10/cse124 11/30/2010 CSE 124 Networked Services Fall 2010 1 Updates PlanetLab experiments
Fall 2010 CSE 124: Networked Services Lecture-17 Instructor: B. S. Manoj, Ph.D http://cseweb.ucsd.edu/classes/fa10/cse124 11/30/2010 CSE 124 Networked Services Fall 2010 1 Updates PlanetLab experiments
Feedback on BeeGFS. A Parallel File System for High Performance Computing
 Feedback on BeeGFS A Parallel File System for High Performance Computing Philippe Dos Santos et Georges Raseev FR 2764 Fédération de Recherche LUmière MATière December 13 2016 LOGO CNRS LOGO IO December
Feedback on BeeGFS A Parallel File System for High Performance Computing Philippe Dos Santos et Georges Raseev FR 2764 Fédération de Recherche LUmière MATière December 13 2016 LOGO CNRS LOGO IO December
Hadoop/MapReduce Computing Paradigm
 Hadoop/Reduce Computing Paradigm 1 Large-Scale Data Analytics Reduce computing paradigm (E.g., Hadoop) vs. Traditional database systems vs. Database Many enterprises are turning to Hadoop Especially applications
Hadoop/Reduce Computing Paradigm 1 Large-Scale Data Analytics Reduce computing paradigm (E.g., Hadoop) vs. Traditional database systems vs. Database Many enterprises are turning to Hadoop Especially applications
Lecture 2 Distributed Filesystems
 Lecture 2 Distributed Filesystems 922EU3870 Cloud Computing and Mobile Platforms, Autumn 2009 2009/9/21 Ping Yeh ( 葉平 ), Google, Inc. Outline Get to know the numbers Filesystems overview Distributed file
Lecture 2 Distributed Filesystems 922EU3870 Cloud Computing and Mobile Platforms, Autumn 2009 2009/9/21 Ping Yeh ( 葉平 ), Google, Inc. Outline Get to know the numbers Filesystems overview Distributed file
CS 470 Spring Distributed Web and File Systems. Mike Lam, Professor. Content taken from the following:
 CS 470 Spring 2018 Mike Lam, Professor Distributed Web and File Systems Content taken from the following: "Distributed Systems: Principles and Paradigms" by Andrew S. Tanenbaum and Maarten Van Steen (Chapters
CS 470 Spring 2018 Mike Lam, Professor Distributed Web and File Systems Content taken from the following: "Distributed Systems: Principles and Paradigms" by Andrew S. Tanenbaum and Maarten Van Steen (Chapters
BlobSeer: Bringing High Throughput under Heavy Concurrency to Hadoop Map/Reduce Applications
 Author manuscript, published in "24th IEEE International Parallel and Distributed Processing Symposium (IPDPS 21) (21)" DOI : 1.119/IPDPS.21.547433 BlobSeer: Bringing High Throughput under Heavy Concurrency
Author manuscript, published in "24th IEEE International Parallel and Distributed Processing Symposium (IPDPS 21) (21)" DOI : 1.119/IPDPS.21.547433 BlobSeer: Bringing High Throughput under Heavy Concurrency
Bigtable. A Distributed Storage System for Structured Data. Presenter: Yunming Zhang Conglong Li. Saturday, September 21, 13
 Bigtable A Distributed Storage System for Structured Data Presenter: Yunming Zhang Conglong Li References SOCC 2010 Key Note Slides Jeff Dean Google Introduction to Distributed Computing, Winter 2008 University
Bigtable A Distributed Storage System for Structured Data Presenter: Yunming Zhang Conglong Li References SOCC 2010 Key Note Slides Jeff Dean Google Introduction to Distributed Computing, Winter 2008 University
MapReduce. U of Toronto, 2014
 MapReduce U of Toronto, 2014 http://www.google.org/flutrends/ca/ (2012) Average Searches Per Day: 5,134,000,000 2 Motivation Process lots of data Google processed about 24 petabytes of data per day in
MapReduce U of Toronto, 2014 http://www.google.org/flutrends/ca/ (2012) Average Searches Per Day: 5,134,000,000 2 Motivation Process lots of data Google processed about 24 petabytes of data per day in
Shared Parallel Filesystems in Heterogeneous Linux Multi-Cluster Environments
 LCI HPC Revolution 2005 26 April 2005 Shared Parallel Filesystems in Heterogeneous Linux Multi-Cluster Environments Matthew Woitaszek matthew.woitaszek@colorado.edu Collaborators Organizations National
LCI HPC Revolution 2005 26 April 2005 Shared Parallel Filesystems in Heterogeneous Linux Multi-Cluster Environments Matthew Woitaszek matthew.woitaszek@colorado.edu Collaborators Organizations National
Fault Tolerance Design for Hadoop MapReduce on Gfarm Distributed Filesystem
 Fault Tolerance Design for Hadoop MapReduce on Gfarm Distributed Filesystem Marilia Melo 1,a) Osamu Tatebe 1,b) Abstract: Many distributed file systems that have been designed to use MapReduce, such as
Fault Tolerance Design for Hadoop MapReduce on Gfarm Distributed Filesystem Marilia Melo 1,a) Osamu Tatebe 1,b) Abstract: Many distributed file systems that have been designed to use MapReduce, such as
Introduction to High Performance Parallel I/O
 Introduction to High Performance Parallel I/O Richard Gerber Deputy Group Lead NERSC User Services August 30, 2013-1- Some slides from Katie Antypas I/O Needs Getting Bigger All the Time I/O needs growing
Introduction to High Performance Parallel I/O Richard Gerber Deputy Group Lead NERSC User Services August 30, 2013-1- Some slides from Katie Antypas I/O Needs Getting Bigger All the Time I/O needs growing
TITLE: PRE-REQUISITE THEORY. 1. Introduction to Hadoop. 2. Cluster. Implement sort algorithm and run it using HADOOP
 TITLE: Implement sort algorithm and run it using HADOOP PRE-REQUISITE Preliminary knowledge of clusters and overview of Hadoop and its basic functionality. THEORY 1. Introduction to Hadoop The Apache Hadoop
TITLE: Implement sort algorithm and run it using HADOOP PRE-REQUISITE Preliminary knowledge of clusters and overview of Hadoop and its basic functionality. THEORY 1. Introduction to Hadoop The Apache Hadoop
Hadoop Distributed File System(HDFS)
") Hadoop Distributed File System(HDFS) Bu eğitim sunumları İstanbul Kalkınma Ajansı nın 2016 yılı Yenilikçi ve Yaratıcı İstanbul Mali Destek Programı kapsamında yürütülmekte olan TR10/16/YNY/0036 no lu İstanbul
Hadoop Distributed File System(HDFS) Bu eğitim sunumları İstanbul Kalkınma Ajansı nın 2016 yılı Yenilikçi ve Yaratıcı İstanbul Mali Destek Programı kapsamında yürütülmekte olan TR10/16/YNY/0036 no lu İstanbul
Cluster Setup and Distributed File System
 Cluster Setup and Distributed File System R&D Storage for the R&D Storage Group People Involved Gaetano Capasso - INFN-Naples Domenico Del Prete INFN-Naples Diacono Domenico INFN-Bari Donvito Giacinto
Cluster Setup and Distributed File System R&D Storage for the R&D Storage Group People Involved Gaetano Capasso - INFN-Naples Domenico Del Prete INFN-Naples Diacono Domenico INFN-Bari Donvito Giacinto
NPTEL Course Jan K. Gopinath Indian Institute of Science
 Storage Systems NPTEL Course Jan 2012 (Lecture 39) K. Gopinath Indian Institute of Science Google File System Non-Posix scalable distr file system for large distr dataintensive applications performance,
Storage Systems NPTEL Course Jan 2012 (Lecture 39) K. Gopinath Indian Institute of Science Google File System Non-Posix scalable distr file system for large distr dataintensive applications performance,
Introduction to Cloud Computing
 Introduction to Cloud Computing Distributed File Systems 15 319, spring 2010 12 th Lecture, Feb 18 th Majd F. Sakr Lecture Motivation Quick Refresher on Files and File Systems Understand the importance
Introduction to Cloud Computing Distributed File Systems 15 319, spring 2010 12 th Lecture, Feb 18 th Majd F. Sakr Lecture Motivation Quick Refresher on Files and File Systems Understand the importance
Evaluating Algorithms for Shared File Pointer Operations in MPI I/O
 Evaluating Algorithms for Shared File Pointer Operations in MPI I/O Ketan Kulkarni and Edgar Gabriel Parallel Software Technologies Laboratory, Department of Computer Science, University of Houston {knkulkarni,gabriel}@cs.uh.edu
Evaluating Algorithms for Shared File Pointer Operations in MPI I/O Ketan Kulkarni and Edgar Gabriel Parallel Software Technologies Laboratory, Department of Computer Science, University of Houston {knkulkarni,gabriel}@cs.uh.edu
Georgia Institute of Technology ECE6102 4/20/2009 David Colvin, Jimmy Vuong
 Georgia Institute of Technology ECE6102 4/20/2009 David Colvin, Jimmy Vuong Relatively recent; still applicable today GFS: Google s storage platform for the generation and processing of data used by services
Georgia Institute of Technology ECE6102 4/20/2009 David Colvin, Jimmy Vuong Relatively recent; still applicable today GFS: Google s storage platform for the generation and processing of data used by services
GFS Overview. Design goals/priorities Design for big-data workloads Huge files, mostly appends, concurrency, huge bandwidth Design for failures
 GFS Overview Design goals/priorities Design for big-data workloads Huge files, mostly appends, concurrency, huge bandwidth Design for failures Interface: non-posix New op: record appends (atomicity matters,
GFS Overview Design goals/priorities Design for big-data workloads Huge files, mostly appends, concurrency, huge bandwidth Design for failures Interface: non-posix New op: record appends (atomicity matters,
Google File System. By Dinesh Amatya
 Google File System By Dinesh Amatya Google File System (GFS) Sanjay Ghemawat, Howard Gobioff, Shun-Tak Leung designed and implemented to meet rapidly growing demand of Google's data processing need a scalable
Google File System By Dinesh Amatya Google File System (GFS) Sanjay Ghemawat, Howard Gobioff, Shun-Tak Leung designed and implemented to meet rapidly growing demand of Google's data processing need a scalable
NFS, GPFS, PVFS, Lustre Batch-scheduled systems: Clusters, Grids, and Supercomputers Programming paradigm: HPC, MTC, and HTC
 Segregated storage and compute NFS, GPFS, PVFS, Lustre Batch-scheduled systems: Clusters, Grids, and Supercomputers Programming paradigm: HPC, MTC, and HTC Co-located storage and compute HDFS, GFS Data
Segregated storage and compute NFS, GPFS, PVFS, Lustre Batch-scheduled systems: Clusters, Grids, and Supercomputers Programming paradigm: HPC, MTC, and HTC Co-located storage and compute HDFS, GFS Data
In search of an API for scalable file systems: Under the table or above it?
 In search of an API for scalable file systems: Under the table or above it? Swapnil Patil, Garth A. Gibson, Gregory R. Ganger, Julio Lopez, Milo Polte, Wittawat Tantisiroj, and Lin Xiao Carnegie Mellon
In search of an API for scalable file systems: Under the table or above it? Swapnil Patil, Garth A. Gibson, Gregory R. Ganger, Julio Lopez, Milo Polte, Wittawat Tantisiroj, and Lin Xiao Carnegie Mellon
Enabling Active Storage on Parallel I/O Software Stacks. Seung Woo Son Mathematics and Computer Science Division
 Enabling Active Storage on Parallel I/O Software Stacks Seung Woo Son sson@mcs.anl.gov Mathematics and Computer Science Division MSST 2010, Incline Village, NV May 7, 2010 Performing analysis on large
Enabling Active Storage on Parallel I/O Software Stacks Seung Woo Son sson@mcs.anl.gov Mathematics and Computer Science Division MSST 2010, Incline Village, NV May 7, 2010 Performing analysis on large
BigData and Map Reduce VITMAC03
 BigData and Map Reduce VITMAC03 1 Motivation Process lots of data Google processed about 24 petabytes of data per day in 2009. A single machine cannot serve all the data You need a distributed system to
BigData and Map Reduce VITMAC03 1 Motivation Process lots of data Google processed about 24 petabytes of data per day in 2009. A single machine cannot serve all the data You need a distributed system to
Data Analytics and Storage System (DASS) Mixing POSIX and Hadoop Architectures. 13 November 2016
 Mixing POSIX and Hadoop Architectures. 13 November 2016") National Aeronautics and Space Administration Data Analytics and Storage System (DASS) Mixing POSIX and Hadoop Architectures 13 November 2016 Carrie Spear (carrie.e.spear@nasa.gov) HPC Architect/Contractor
National Aeronautics and Space Administration Data Analytics and Storage System (DASS) Mixing POSIX and Hadoop Architectures 13 November 2016 Carrie Spear (carrie.e.spear@nasa.gov) HPC Architect/Contractor
COSC 6374 Parallel Computation. Parallel I/O (I) I/O basics. Concept of a clusters
 I/O basics. Concept of a clusters") COSC 6374 Parallel I/O (I) I/O basics Fall 2010 Concept of a clusters Processor 1 local disks Compute node message passing network administrative network Memory Processor 2 Network card 1 Network card
COSC 6374 Parallel I/O (I) I/O basics Fall 2010 Concept of a clusters Processor 1 local disks Compute node message passing network administrative network Memory Processor 2 Network card 1 Network card
The Google File System. Alexandru Costan
 1 The Google File System Alexandru Costan Actions on Big Data 2 Storage Analysis Acquisition Handling the data stream Data structured unstructured semi-structured Results Transactions Outline File systems
1 The Google File System Alexandru Costan Actions on Big Data 2 Storage Analysis Acquisition Handling the data stream Data structured unstructured semi-structured Results Transactions Outline File systems
DISTRIBUTED FILE SYSTEMS CARSTEN WEINHOLD
 Department of Computer Science Institute of System Architecture, Operating Systems Group DISTRIBUTED FILE SYSTEMS CARSTEN WEINHOLD OUTLINE Classical distributed file systems NFS: Sun Network File System
Department of Computer Science Institute of System Architecture, Operating Systems Group DISTRIBUTED FILE SYSTEMS CARSTEN WEINHOLD OUTLINE Classical distributed file systems NFS: Sun Network File System
Quobyte The Data Center File System QUOBYTE INC.
 Quobyte The Data Center File System QUOBYTE INC. The Quobyte Data Center File System All Workloads Consolidate all application silos into a unified highperformance file, block, and object storage (POSIX
Quobyte The Data Center File System QUOBYTE INC. The Quobyte Data Center File System All Workloads Consolidate all application silos into a unified highperformance file, block, and object storage (POSIX
Extreme computing Infrastructure
 Outline Extreme computing School of Informatics University of Edinburgh Replication and fault tolerance Virtualisation Parallelism and parallel/concurrent programming Services So, you want to build a cloud
Outline Extreme computing School of Informatics University of Edinburgh Replication and fault tolerance Virtualisation Parallelism and parallel/concurrent programming Services So, you want to build a cloud
DISTRIBUTED FILE SYSTEMS CARSTEN WEINHOLD
 Department of Computer Science Institute of System Architecture, Operating Systems Group DISTRIBUTED FILE SYSTEMS CARSTEN WEINHOLD OUTLINE Classical distributed file systems NFS: Sun Network File System
Department of Computer Science Institute of System Architecture, Operating Systems Group DISTRIBUTED FILE SYSTEMS CARSTEN WEINHOLD OUTLINE Classical distributed file systems NFS: Sun Network File System
August Li Qiang, Huang Qiulan, Sun Gongxing IHEP-CC. Supported by the National Natural Science Fund
 August 15 2016 Li Qiang, Huang Qiulan, Sun Gongxing IHEP-CC Supported by the National Natural Science Fund The Current Computing System What is Hadoop? Why Hadoop? The New Computing System with Hadoop
August 15 2016 Li Qiang, Huang Qiulan, Sun Gongxing IHEP-CC Supported by the National Natural Science Fund The Current Computing System What is Hadoop? Why Hadoop? The New Computing System with Hadoop
Today CSCI Coda. Naming: Volumes. Coda GFS PAST. Instructor: Abhishek Chandra. Main Goals: Volume is a subtree in the naming space
 Today CSCI 5105 Coda GFS PAST Instructor: Abhishek Chandra 2 Coda Main Goals: Availability: Work in the presence of disconnection Scalability: Support large number of users Successor of Andrew File System
Today CSCI 5105 Coda GFS PAST Instructor: Abhishek Chandra 2 Coda Main Goals: Availability: Work in the presence of disconnection Scalability: Support large number of users Successor of Andrew File System
COS 318: Operating Systems. Journaling, NFS and WAFL
 COS 318: Operating Systems Journaling, NFS and WAFL Jaswinder Pal Singh Computer Science Department Princeton University (http://www.cs.princeton.edu/courses/cos318/) Topics Journaling and LFS Network
COS 318: Operating Systems Journaling, NFS and WAFL Jaswinder Pal Singh Computer Science Department Princeton University (http://www.cs.princeton.edu/courses/cos318/) Topics Journaling and LFS Network
MixApart: Decoupled Analytics for Shared Storage Systems. Madalin Mihailescu, Gokul Soundararajan, Cristiana Amza University of Toronto and NetApp
 MixApart: Decoupled Analytics for Shared Storage Systems Madalin Mihailescu, Gokul Soundararajan, Cristiana Amza University of Toronto and NetApp Hadoop Pig, Hive Hadoop + Enterprise storage?! Shared storage
MixApart: Decoupled Analytics for Shared Storage Systems Madalin Mihailescu, Gokul Soundararajan, Cristiana Amza University of Toronto and NetApp Hadoop Pig, Hive Hadoop + Enterprise storage?! Shared storage
Outline 1 Motivation 2 Theory of a non-blocking benchmark 3 The benchmark and results 4 Future work
 Using Non-blocking Operations in HPC to Reduce Execution Times David Buettner, Julian Kunkel, Thomas Ludwig Euro PVM/MPI September 8th, 2009 Outline 1 Motivation 2 Theory of a non-blocking benchmark 3
Using Non-blocking Operations in HPC to Reduce Execution Times David Buettner, Julian Kunkel, Thomas Ludwig Euro PVM/MPI September 8th, 2009 Outline 1 Motivation 2 Theory of a non-blocking benchmark 3
MOHA: Many-Task Computing Framework on Hadoop
 Apache: Big Data North America 2017 @ Miami MOHA: Many-Task Computing Framework on Hadoop Soonwook Hwang Korea Institute of Science and Technology Information May 18, 2017 Table of Contents Introduction
Apache: Big Data North America 2017 @ Miami MOHA: Many-Task Computing Framework on Hadoop Soonwook Hwang Korea Institute of Science and Technology Information May 18, 2017 Table of Contents Introduction
Google File System, Replication. Amin Vahdat CSE 123b May 23, 2006
 Google File System, Replication Amin Vahdat CSE 123b May 23, 2006 Annoucements Third assignment available today Due date June 9, 5 pm Final exam, June 14, 11:30-2:30 Google File System (thanks to Mahesh
Google File System, Replication Amin Vahdat CSE 123b May 23, 2006 Annoucements Third assignment available today Due date June 9, 5 pm Final exam, June 14, 11:30-2:30 Google File System (thanks to Mahesh