PageVault: Securing Off-Chip Memory Using Page-Based Authen?ca?on. Blaise-Pascal Tine Sudhakar Yalamanchili
|
|
|
- Audrey Marshall
- 5 years ago
- Views:
Transcription

1 PageVault: Securing Off-Chip Memory Using Page-Based Authen?ca?on Blaise-Pascal Tine Sudhakar Yalamanchili

2 Outline Background: Memory Security Motivation Proposed Solution Implementation Evaluation Conclusion
3 Background Cloud Computing Threat Model Compute as a service deals with sensitive content trading, banking, medical, legal, search, etc. Offloading data + computation

")
 Hardware")
4 Background Cloud Computing Threat Model Data encryption (SSL) Compute Sandboxing (Intel SGX) Hardware Security: Admin? Admin
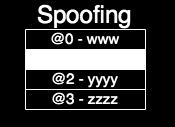


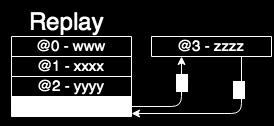

5 Background Memory Attacks Snooping Spoofing Splicing Replay Authentication Encryption


6 Background Hash Generation Generate unique seed Create nonce from seed Hash block using nonce Store MAC for integrity check Where to store? - CPU area limited - Store it in memory - Still secure?


7 Background Merkle Tree Authentication Generate MAC for each block Build binary hash tree Store tree nodes in memory Store root on chip Integrity Check Fetch block Fetch partial tree Re-compute root Storage Overhead Large User Data = 8 * 64B = 512B Meta Data = 14 * 16B = 224B
![Motivation Authentication Cost Memory overhead GMT 41% BMT 23% SGX 55% Runtime overhead GMT [1] 150% BMT [2] 13% SGX](/docs-images/83/87689741/images/8-1.jpg "[3] <5% Processor cost 32KB counter cache GMT BMT SGX User blocks 59% 77% 45% MACs 0% 20% 5% Counters 1% 2% 0% Hash")
![Tree 40% 1% 50% Meta-Data 41% 23% 55% - 8GB DRAM - 128bit MAC [1] C, Yan. D. Englender, M. Prulovic, et al.](/docs-images/83/87689741/images/8-2.jpg "ISCA 06 [2] B. Rogers, Raleigh, S. Chhabra, M. Prvulovic et al. ISCA 07 [3] S.")
8 Motivation Authentication Cost Memory overhead GMT 41% BMT 23% SGX 55% Runtime overhead GMT [1] 150% BMT [2] 13% SGX [3] <5% Processor cost 32KB counter cache GMT BMT SGX User blocks 59% 77% 45% MACs 0% 20% 5% Counters 1% 2% 0% Hash Tree 40% 1% 50% Meta-Data 41% 23% 55% - 8GB DRAM - 128bit MAC [1] C, Yan. D. Englender, M. Prulovic, et al. ISCA 06 [2] B. Rogers, Raleigh, S. Chhabra, M. Prvulovic et al. ISCA 07 [3] S. Gueron, Cryptology eprint Archive, Report 2016/204
9 Proposed Solution Key Insight Access the memory at larger block granularity Potential Benefits Reduce storage overhead Reduce memory traffic Reduce runtime overhead Challenges Maintain Security Cache Pollution? User Data = 8 * 64B = 512B Meta Data = * * 16B = = 64B 32B 160B
![Proposed Solution Aggregate Message Authentication [1] Use XOR to combine blocks: - Aggregate MAC = MAC 0 MAC 1 The aggregate MAC is secure if both operands are unique MACs are unique spatially](/docs-images/83/87689741/images/10-1.jpg "- Seed s block address MACs are unique temporally - Seed s block counter A partition is a set of consecutive blocks protected by a single aggregate MAC [1] J. Katz and A. Y. Lindell.")
10 Proposed Solution Aggregate Message Authentication [1] Use XOR to combine blocks: - Aggregate MAC = MAC 0 MAC 1 The aggregate MAC is secure if both operands are unique MACs are unique spatially - Seed s block address MACs are unique temporally - Seed s block counter A partition is a set of consecutive blocks protected by a single aggregate MAC [1] J. Katz and A. Y. Lindell. CT-RSA-2008
11 Proposed Solution Read Transaction A single MAC protect all blocks in a page partition Fetch all blocks in the page partition on read access Compute the MAC of each fetched block Compute the aggregate MAC Compare with cached MAC
12 Proposed Solution Write Transaction Operates at block granularity Reduce memory traffic Clear aggregate MAC after each read Compute MAC of dirty block Writeback the dirty block Append to aggregate MAC - Aggregate MAC = Hash(block)

13 Implementation Handling Partial Read Requests Aggregate MAC only protects off-chip blocks Need to track which blocks are off-chip Where to store tracking info? Use counter cache - Counter cache access latency - Counter overflow Use LLC lookup transaction - Group blocks from same partition into same set - Shift index region of block address left - Return full partition status mask (e.g. 4-bit register) Partition size = 4
14 Implementation Handling Cache Eviction Evicting block in currently accessed partition - Will invalidate the partition on-chip status - Add lookup logic to pick from next partition in set Evicting Clean Blocks - Aggregate MAC should be updated - Need to recompute block MAC - No need to send the block off-chip


15 Implementation PageVault Architecture Vault controller Counter cache MAC cache HMAC engine AES engine Command Queue
16 Evaluation Simulation Manifold Full System Simulator 3 Ghz 4-OoO-cores 32K-L1 2MB-L2 DramSim2-8GB - DDR3-1.25ns - 2 channels GCM-AES cycles - 16 stages HMAC-SHA1-8 cycles bit MACs 8 KB counter cache 8 KB MAC cache Splash2, Parsec, GraphBig benchmarks Metrics Runtime/Storage overhead
17 Evaluation Systems Configuration NOEA: Baseline system with no protection GMT: Galois Merkle Tree (vanilla) BMT: Bonsai Merkle Tree (state of the art) SGX: Intel SGX (applied) PMT2: PageVault with 2 blocks per partition PMT4: PageVault with 4 blocks per partition PMT8: PageVault with 8 blocks per partition
18 Results Memory Overhead Meta-data overhead reduction: from 23% to 8% - Using 128-bit MACs to protect 8GB user data Can reach down to 5% for higher partition size (8) User data occupancy above 90% Why? MACs reduction by 1/N GMT BMT SGX PMT2 PMT4 PMT8 User Data 59% 77% 45% 86% 91% 94% MAC s 0% 20% 5% 11% 6% 3% Counters 1% 2% 0% 2% 2% 2% Hash Tre 40% 1% 50% 1% 1% 1% Meta-D ata 41% 23% 55% 15% 8% 5%


19 Results Execution Time: up to 10-12% improvement bodytrack, Lu-c outperform NOEA Parsec GraphBIG & Splash2 Parsec and Splash2 Performance Exploits Prefetched blocks reuse - Accuracy above 85% MAC cache efficiency - Hit rate above 70% Reduced Hash Processing Time


20 Results GraphBIG Prefetch Accuracy Good prefetch accuracy in LLC (~80%) DFS has high cache misses due to sync variables Parsec & Splash2


21 Results GraphBIG Memory Traffic Off-chip read traffic degrades by 15% The write traffic shows similar degradation - Due to synchronization variables creating cache pollution.

22 Results GraphBIG Memory Traffic Off-chip traffic degrades by 15% Traffic comes from hash tree traffic for counters

23 Results Reducing the Partition Size Improve runtime by 8% Less cache pollution But? - 2x Memory overhead - from 8% to 15% Adaptive resizing - Compiler driven - Hardware driven use block counters history
24 Conclusion A cost efficient memory protection Exploits AMAC properties Significant reduction of storage overhead Total runtime execution is improved Increase compute capacity of the secure system Adaptive Compression scheme
25 Thank You!

26 Results Counter Cache Hit Rate
27 Results Runtime Effect on 8KB vs 16KB MAC cache Runtime Effect on Partition Size
![BMT [Brian 07] Counter Based Encryption Hash tree covers counters](/docs-images/83/87689741/images/28-1.jpg "MACs authenticate data.")

28 BMT [Brian 07] Counter Based Encryption Hash tree covers counters MACs authenticate data. Runtime overhead ~13% Storage overhead ~53% Prior Work GMT [Chenyu 06] Counter Based Encryption Hash tree covers data Hash tree covers counters Runtime overhead ~151% Storage overhead ~134%


29 Background Basic Direct Encryption Encrypt block using key AES is very slow! Counter Mode Encryption Generate unique seed Create pad from seed Encrypt block using pad Cache the pad for decryption Can fetch block while accessing cache

30 Evaluation Benchmarks GraphBIG has 100x more traffic than Splash2 Parsec and Splash2 GraphBIG

 Parsec &")
31 Results Splash/Parsec Prefetch Accuracy Good prefetch accuracy in LLC (~85%) Average miss rate reduction (10%) Parsec & Splash2


32 Results Splash/Parsec Memory Traffic Off-chip read traffic is reduced by 10% The write traffic shows similar reduction
33 Background Bonsai Merkle Tree Tree covers counters only Counters are small Tree overhead reduced MAC overhead still large bit MAC > 25% bit MAC > 31% bit MAC > 38% Compression? - bits shuffling - hardware cost - B. Rogers et al. ISCA 07 User Data = 8 * 64B = 512B Meta Data = 10 * 16B = 160B
Silent Shredder: Zero-Cost Shredding For Secure Non-Volatile Main Memory Controllers
 Silent Shredder: Zero-Cost Shredding For Secure Non-Volatile Main Memory Controllers 1 ASPLOS 2016 2-6 th April Amro Awad (NC State University) Pratyusa Manadhata (Hewlett Packard Labs) Yan Solihin (NC
Silent Shredder: Zero-Cost Shredding For Secure Non-Volatile Main Memory Controllers 1 ASPLOS 2016 2-6 th April Amro Awad (NC State University) Pratyusa Manadhata (Hewlett Packard Labs) Yan Solihin (NC
Ming Ming Wong Jawad Haj-Yahya Anupam Chattopadhyay
 Hardware and Architectural Support for Security and Privacy (HASP 18), June 2, 2018, Los Angeles, CA, USA Ming Ming Wong Jawad Haj-Yahya Anupam Chattopadhyay Computing and Engineering (SCSE) Nanyang Technological
Hardware and Architectural Support for Security and Privacy (HASP 18), June 2, 2018, Los Angeles, CA, USA Ming Ming Wong Jawad Haj-Yahya Anupam Chattopadhyay Computing and Engineering (SCSE) Nanyang Technological
Intel Software Guard Extensions (Intel SGX) Memory Encryption Engine (MEE) Shay Gueron
 Memory Encryption Engine (MEE) Shay Gueron") Real World Cryptography Conference 2016 6-8 January 2016, Stanford, CA, USA Intel Software Guard Extensions (Intel SGX) Memory Encryption Engine (MEE) Shay Gueron Intel Corp., Intel Development Center,
Real World Cryptography Conference 2016 6-8 January 2016, Stanford, CA, USA Intel Software Guard Extensions (Intel SGX) Memory Encryption Engine (MEE) Shay Gueron Intel Corp., Intel Development Center,
Using Address Independent Seed Encryption and Bonsai Merkle Trees to Make Secure Processors OS- and Performance-Friendly
 Using Address Independent Seed Encryption and Bonsai Merkle Trees to Make Secure Processors OS- and Performance-Friendly Brian Rogers, Siddhartha Chhabra, Yan Solihin Dept. of Electrical and Computer Engineering
Using Address Independent Seed Encryption and Bonsai Merkle Trees to Make Secure Processors OS- and Performance-Friendly Brian Rogers, Siddhartha Chhabra, Yan Solihin Dept. of Electrical and Computer Engineering
Authenticated Storage Using Small Trusted Hardware Hsin-Jung Yang, Victor Costan, Nickolai Zeldovich, and Srini Devadas
 Authenticated Storage Using Small Trusted Hardware Hsin-Jung Yang, Victor Costan, Nickolai Zeldovich, and Srini Devadas Massachusetts Institute of Technology November 8th, CCSW 2013 Cloud Storage Model
Authenticated Storage Using Small Trusted Hardware Hsin-Jung Yang, Victor Costan, Nickolai Zeldovich, and Srini Devadas Massachusetts Institute of Technology November 8th, CCSW 2013 Cloud Storage Model
WALL: A Writeback-Aware LLC Management for PCM-based Main Memory Systems
 : A Writeback-Aware LLC Management for PCM-based Main Memory Systems Bahareh Pourshirazi *, Majed Valad Beigi, Zhichun Zhu *, and Gokhan Memik * University of Illinois at Chicago Northwestern University
: A Writeback-Aware LLC Management for PCM-based Main Memory Systems Bahareh Pourshirazi *, Majed Valad Beigi, Zhichun Zhu *, and Gokhan Memik * University of Illinois at Chicago Northwestern University
Donn Morrison Department of Computer Science. TDT4255 Memory hierarchies
 TDT4255 Lecture 10: Memory hierarchies Donn Morrison Department of Computer Science 2 Outline Chapter 5 - Memory hierarchies (5.1-5.5) Temporal and spacial locality Hits and misses Direct-mapped, set associative,
TDT4255 Lecture 10: Memory hierarchies Donn Morrison Department of Computer Science 2 Outline Chapter 5 - Memory hierarchies (5.1-5.5) Temporal and spacial locality Hits and misses Direct-mapped, set associative,
Secure Hierarchy-Aware Cache Replacement Policy (SHARP): Defending Against Cache-Based Side Channel Attacks
: Defending Against Cache-Based Side Channel Attacks") : Defending Against Cache-Based Side Channel Attacks Mengjia Yan, Bhargava Gopireddy, Thomas Shull, Josep Torrellas University of Illinois at Urbana-Champaign http://iacoma.cs.uiuc.edu Presented by Mengjia
: Defending Against Cache-Based Side Channel Attacks Mengjia Yan, Bhargava Gopireddy, Thomas Shull, Josep Torrellas University of Illinois at Urbana-Champaign http://iacoma.cs.uiuc.edu Presented by Mengjia
Data Criticality in Network-On-Chip Design. Joshua San Miguel Natalie Enright Jerger
 Data Criticality in Network-On-Chip Design Joshua San Miguel Natalie Enright Jerger Network-On-Chip Efficiency Efficiency is the ability to produce results with the least amount of waste. Wasted time Wasted
Data Criticality in Network-On-Chip Design Joshua San Miguel Natalie Enright Jerger Network-On-Chip Efficiency Efficiency is the ability to produce results with the least amount of waste. Wasted time Wasted
The Reuse Cache Downsizing the Shared Last-Level Cache! Jorge Albericio 1, Pablo Ibáñez 2, Víctor Viñals 2, and José M. Llabería 3!!!
 The Reuse Cache Downsizing the Shared Last-Level Cache! Jorge Albericio 1, Pablo Ibáñez 2, Víctor Viñals 2, and José M. Llabería 3!!! 1 2 3 Modern CMPs" Intel e5 2600 (2013)! SLLC" AMD Orochi (2012)! SLLC"
The Reuse Cache Downsizing the Shared Last-Level Cache! Jorge Albericio 1, Pablo Ibáñez 2, Víctor Viñals 2, and José M. Llabería 3!!! 1 2 3 Modern CMPs" Intel e5 2600 (2013)! SLLC" AMD Orochi (2012)! SLLC"
Flexible Cache Error Protection using an ECC FIFO
 Flexible Cache Error Protection using an ECC FIFO Doe Hyun Yoon and Mattan Erez Dept Electrical and Computer Engineering The University of Texas at Austin 1 ECC FIFO Goal: to reduce on-chip ECC overhead
Flexible Cache Error Protection using an ECC FIFO Doe Hyun Yoon and Mattan Erez Dept Electrical and Computer Engineering The University of Texas at Austin 1 ECC FIFO Goal: to reduce on-chip ECC overhead
Memory Defenses. The Elevation from Obscurity to Headlines. Rajeev Balasubramonian School of Computing, University of Utah
 Memory Defenses The Elevation from Obscurity to Headlines Rajeev Balasubramonian School of Computing, University of Utah Image sources: pinterest, gizmodo 2 Spectre Overview Victim Code x is controlled
Memory Defenses The Elevation from Obscurity to Headlines Rajeev Balasubramonian School of Computing, University of Utah Image sources: pinterest, gizmodo 2 Spectre Overview Victim Code x is controlled
Enabling Transparent Memory-Compression for Commodity Memory Systems
 Enabling Transparent Memory-Compression for Commodity Memory Systems Vinson Young *, Sanjay Kariyappa *, Moinuddin K. Qureshi Georgia Institute of Technology {vyoung,sanjaykariyappa,moin}@gatech.edu Abstract
Enabling Transparent Memory-Compression for Commodity Memory Systems Vinson Young *, Sanjay Kariyappa *, Moinuddin K. Qureshi Georgia Institute of Technology {vyoung,sanjaykariyappa,moin}@gatech.edu Abstract
arxiv: v1 [cs.dc] 3 Jan 2019
![arxiv: v1 [cs.dc] 3 Jan 2019](/thumbs/93/111392665.jpg "arxiv: v1 [cs.dc] 3 Jan 2019") A Secure and Persistent Memory System for Non-volatile Memory Pengfei Zuo *, Yu Hua *, Yuan Xie * Huazhong University of Science and Technology University of California, Santa Barbara arxiv:1901.00620v1
A Secure and Persistent Memory System for Non-volatile Memory Pengfei Zuo *, Yu Hua *, Yuan Xie * Huazhong University of Science and Technology University of California, Santa Barbara arxiv:1901.00620v1
EFFICIENTLY ENABLING CONVENTIONAL BLOCK SIZES FOR VERY LARGE DIE- STACKED DRAM CACHES
 EFFICIENTLY ENABLING CONVENTIONAL BLOCK SIZES FOR VERY LARGE DIE- STACKED DRAM CACHES MICRO 2011 @ Porte Alegre, Brazil Gabriel H. Loh [1] and Mark D. Hill [2][1] December 2011 [1] AMD Research [2] University
EFFICIENTLY ENABLING CONVENTIONAL BLOCK SIZES FOR VERY LARGE DIE- STACKED DRAM CACHES MICRO 2011 @ Porte Alegre, Brazil Gabriel H. Loh [1] and Mark D. Hill [2][1] December 2011 [1] AMD Research [2] University
and data combined) is equal to 7% of the number of instructions. Miss Rate with Second- Level Cache, Direct- Mapped Speed
 is equal to 7% of the number of instructions. Miss Rate with Second- Level Cache, Direct- Mapped Speed") 5.3 By convention, a cache is named according to the amount of data it contains (i.e., a 4 KiB cache can hold 4 KiB of data); however, caches also require SRAM to store metadata such as tags and valid
5.3 By convention, a cache is named according to the amount of data it contains (i.e., a 4 KiB cache can hold 4 KiB of data); however, caches also require SRAM to store metadata such as tags and valid
Efficient Memory Integrity Verification and Encryption for Secure Processors
 Efficient Memory Integrity Verification and Encryption for Secure Processors G. Edward Suh, Dwaine Clarke, Blaise Gassend, Marten van Dijk, Srinivas Devadas Massachusetts Institute of Technology New Security
Efficient Memory Integrity Verification and Encryption for Secure Processors G. Edward Suh, Dwaine Clarke, Blaise Gassend, Marten van Dijk, Srinivas Devadas Massachusetts Institute of Technology New Security
Chapter 2: Memory Hierarchy Design Part 2
 Chapter 2: Memory Hierarchy Design Part 2 Introduction (Section 2.1, Appendix B) Caches Review of basics (Section 2.1, Appendix B) Advanced methods (Section 2.3) Main Memory Virtual Memory Fundamental
Chapter 2: Memory Hierarchy Design Part 2 Introduction (Section 2.1, Appendix B) Caches Review of basics (Section 2.1, Appendix B) Advanced methods (Section 2.3) Main Memory Virtual Memory Fundamental
Chapter 2: Memory Hierarchy Design Part 2
 Chapter 2: Memory Hierarchy Design Part 2 Introduction (Section 2.1, Appendix B) Caches Review of basics (Section 2.1, Appendix B) Advanced methods (Section 2.3) Main Memory Virtual Memory Fundamental
Chapter 2: Memory Hierarchy Design Part 2 Introduction (Section 2.1, Appendix B) Caches Review of basics (Section 2.1, Appendix B) Advanced methods (Section 2.3) Main Memory Virtual Memory Fundamental
Logical Diagram of a Set-associative Cache Accessing a Cache
 Introduction Memory Hierarchy Why memory subsystem design is important CPU speeds increase 25%-30% per year DRAM speeds increase 2%-11% per year Levels of memory with different sizes & speeds close to
Introduction Memory Hierarchy Why memory subsystem design is important CPU speeds increase 25%-30% per year DRAM speeds increase 2%-11% per year Levels of memory with different sizes & speeds close to
Lecture notes for CS Chapter 2, part 1 10/23/18
 Chapter 2: Memory Hierarchy Design Part 2 Introduction (Section 2.1, Appendix B) Caches Review of basics (Section 2.1, Appendix B) Advanced methods (Section 2.3) Main Memory Virtual Memory Fundamental
Chapter 2: Memory Hierarchy Design Part 2 Introduction (Section 2.1, Appendix B) Caches Review of basics (Section 2.1, Appendix B) Advanced methods (Section 2.3) Main Memory Virtual Memory Fundamental
Introduction. Memory Hierarchy
 Introduction Why memory subsystem design is important CPU speeds increase 25%-30% per year DRAM speeds increase 2%-11% per year 1 Memory Hierarchy Levels of memory with different sizes & speeds close to
Introduction Why memory subsystem design is important CPU speeds increase 25%-30% per year DRAM speeds increase 2%-11% per year 1 Memory Hierarchy Levels of memory with different sizes & speeds close to
L2 cache provides additional on-chip caching space. L2 cache captures misses from L1 cache. Summary
 HY425 Lecture 13: Improving Cache Performance Dimitrios S. Nikolopoulos University of Crete and FORTH-ICS November 25, 2011 Dimitrios S. Nikolopoulos HY425 Lecture 13: Improving Cache Performance 1 / 40
HY425 Lecture 13: Improving Cache Performance Dimitrios S. Nikolopoulos University of Crete and FORTH-ICS November 25, 2011 Dimitrios S. Nikolopoulos HY425 Lecture 13: Improving Cache Performance 1 / 40
Mo Money, No Problems: Caches #2...
 Mo Money, No Problems: Caches #2... 1 Reminder: Cache Terms... Cache: A small and fast memory used to increase the performance of accessing a big and slow memory Uses temporal locality: The tendency to
Mo Money, No Problems: Caches #2... 1 Reminder: Cache Terms... Cache: A small and fast memory used to increase the performance of accessing a big and slow memory Uses temporal locality: The tendency to
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface. 5 th. Edition. Chapter 5. Large and Fast: Exploiting Memory Hierarchy
 COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 5 Large and Fast: Exploiting Memory Hierarchy Principle of Locality Programs access a small proportion of their address
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 5 Large and Fast: Exploiting Memory Hierarchy Principle of Locality Programs access a small proportion of their address
STLAC: A Spatial and Temporal Locality-Aware Cache and Networkon-Chip
 STLAC: A Spatial and Temporal Locality-Aware Cache and Networkon-Chip Codesign for Tiled Manycore Systems Mingyu Wang and Zhaolin Li Institute of Microelectronics, Tsinghua University, Beijing 100084,
STLAC: A Spatial and Temporal Locality-Aware Cache and Networkon-Chip Codesign for Tiled Manycore Systems Mingyu Wang and Zhaolin Li Institute of Microelectronics, Tsinghua University, Beijing 100084,
Memory Mapped ECC Low-Cost Error Protection for Last Level Caches. Doe Hyun Yoon Mattan Erez
 Memory Mapped ECC Low-Cost Error Protection for Last Level Caches Doe Hyun Yoon Mattan Erez 1-Slide Summary Reliability issues in caches Increasing soft error rate (SER) Cost increases with error protection
Memory Mapped ECC Low-Cost Error Protection for Last Level Caches Doe Hyun Yoon Mattan Erez 1-Slide Summary Reliability issues in caches Increasing soft error rate (SER) Cost increases with error protection
CS3350B Computer Architecture
 CS335B Computer Architecture Winter 25 Lecture 32: Exploiting Memory Hierarchy: How? Marc Moreno Maza wwwcsduwoca/courses/cs335b [Adapted from lectures on Computer Organization and Design, Patterson &
CS335B Computer Architecture Winter 25 Lecture 32: Exploiting Memory Hierarchy: How? Marc Moreno Maza wwwcsduwoca/courses/cs335b [Adapted from lectures on Computer Organization and Design, Patterson &
Memory Hierarchy. Slides contents from:
 Memory Hierarchy Slides contents from: Hennessy & Patterson, 5ed Appendix B and Chapter 2 David Wentzlaff, ELE 475 Computer Architecture MJT, High Performance Computing, NPTEL Memory Performance Gap Memory
Memory Hierarchy Slides contents from: Hennessy & Patterson, 5ed Appendix B and Chapter 2 David Wentzlaff, ELE 475 Computer Architecture MJT, High Performance Computing, NPTEL Memory Performance Gap Memory
I, J A[I][J] / /4 8000/ I, J A(J, I) Chapter 5 Solutions S-3.
![I, J A[I][J] / /4 8000/ I, J A(J, I) Chapter 5 Solutions S-3.](/thumbs/81/83055456.jpg "I, J A[I][J] / /4 8000/ I, J A(J, I) Chapter 5 Solutions S-3.") 5 Solutions Chapter 5 Solutions S-3 5.1 5.1.1 4 5.1.2 I, J 5.1.3 A[I][J] 5.1.4 3596 8 800/4 2 8 8/4 8000/4 5.1.5 I, J 5.1.6 A(J, I) 5.2 5.2.1 Word Address Binary Address Tag Index Hit/Miss 5.2.2 3 0000
5 Solutions Chapter 5 Solutions S-3 5.1 5.1.1 4 5.1.2 I, J 5.1.3 A[I][J] 5.1.4 3596 8 800/4 2 8 8/4 8000/4 5.1.5 I, J 5.1.6 A(J, I) 5.2 5.2.1 Word Address Binary Address Tag Index Hit/Miss 5.2.2 3 0000
Agenda. EE 260: Introduction to Digital Design Memory. Naive Register File. Agenda. Memory Arrays: SRAM. Memory Arrays: Register File
 EE 260: Introduction to Digital Design Technology Yao Zheng Department of Electrical Engineering University of Hawaiʻi at Mānoa 2 Technology Naive Register File Write Read clk Decoder Read Write 3 4 Arrays:
EE 260: Introduction to Digital Design Technology Yao Zheng Department of Electrical Engineering University of Hawaiʻi at Mānoa 2 Technology Naive Register File Write Read clk Decoder Read Write 3 4 Arrays:
Memory Management Outline. Operating Systems. Motivation. Paging Implementation. Accessing Invalid Pages. Performance of Demand Paging
 Memory Management Outline Operating Systems Processes (done) Memory Management Basic (done) Paging (done) Virtual memory Virtual Memory (Chapter.) Motivation Logical address space larger than physical
Memory Management Outline Operating Systems Processes (done) Memory Management Basic (done) Paging (done) Virtual memory Virtual Memory (Chapter.) Motivation Logical address space larger than physical
Design and Implementation of the Ascend Secure Processor. Ling Ren, Christopher W. Fletcher, Albert Kwon, Marten van Dijk, Srinivas Devadas
 Design and Implementation of the Ascend Secure Processor Ling Ren, Christopher W. Fletcher, Albert Kwon, Marten van Dijk, Srinivas Devadas Agenda Motivation Ascend Overview ORAM for obfuscation Ascend:
Design and Implementation of the Ascend Secure Processor Ling Ren, Christopher W. Fletcher, Albert Kwon, Marten van Dijk, Srinivas Devadas Agenda Motivation Ascend Overview ORAM for obfuscation Ascend:
Chapter Seven. Memories: Review. Exploiting Memory Hierarchy CACHE MEMORY AND VIRTUAL MEMORY
 Chapter Seven CACHE MEMORY AND VIRTUAL MEMORY 1 Memories: Review SRAM: value is stored on a pair of inverting gates very fast but takes up more space than DRAM (4 to 6 transistors) DRAM: value is stored
Chapter Seven CACHE MEMORY AND VIRTUAL MEMORY 1 Memories: Review SRAM: value is stored on a pair of inverting gates very fast but takes up more space than DRAM (4 to 6 transistors) DRAM: value is stored
Comparing Memory Systems for Chip Multiprocessors
 Comparing Memory Systems for Chip Multiprocessors Jacob Leverich Hideho Arakida, Alex Solomatnikov, Amin Firoozshahian, Mark Horowitz, Christos Kozyrakis Computer Systems Laboratory Stanford University
Comparing Memory Systems for Chip Multiprocessors Jacob Leverich Hideho Arakida, Alex Solomatnikov, Amin Firoozshahian, Mark Horowitz, Christos Kozyrakis Computer Systems Laboratory Stanford University
CSE502: Computer Architecture CSE 502: Computer Architecture
 CSE 502: Computer Architecture Memory Hierarchy & Caches Motivation 10000 Performance 1000 100 10 Processor Memory 1 1985 1990 1995 2000 2005 2010 Want memory to appear: As fast as CPU As large as required
CSE 502: Computer Architecture Memory Hierarchy & Caches Motivation 10000 Performance 1000 100 10 Processor Memory 1 1985 1990 1995 2000 2005 2010 Want memory to appear: As fast as CPU As large as required
Cache Memory COE 403. Computer Architecture Prof. Muhamed Mudawar. Computer Engineering Department King Fahd University of Petroleum and Minerals
 Cache Memory COE 403 Computer Architecture Prof. Muhamed Mudawar Computer Engineering Department King Fahd University of Petroleum and Minerals Presentation Outline The Need for Cache Memory The Basics
Cache Memory COE 403 Computer Architecture Prof. Muhamed Mudawar Computer Engineering Department King Fahd University of Petroleum and Minerals Presentation Outline The Need for Cache Memory The Basics
Low-Cost Inter-Linked Subarrays (LISA) Enabling Fast Inter-Subarray Data Movement in DRAM
 Enabling Fast Inter-Subarray Data Movement in DRAM") Low-Cost Inter-Linked ubarrays (LIA) Enabling Fast Inter-ubarray Data Movement in DRAM Kevin Chang rashant Nair, Donghyuk Lee, augata Ghose, Moinuddin Qureshi, and Onur Mutlu roblem: Inefficient Bulk Data
Low-Cost Inter-Linked ubarrays (LIA) Enabling Fast Inter-ubarray Data Movement in DRAM Kevin Chang rashant Nair, Donghyuk Lee, augata Ghose, Moinuddin Qureshi, and Onur Mutlu roblem: Inefficient Bulk Data
Decoupled Compressed Cache: Exploiting Spatial Locality for Energy-Optimized Compressed Caching
 Decoupled Compressed Cache: Exploiting Spatial Locality for Energy-Optimized Compressed Caching Somayeh Sardashti and David A. Wood University of Wisconsin-Madison 1 Please find the power point presentation
Decoupled Compressed Cache: Exploiting Spatial Locality for Energy-Optimized Compressed Caching Somayeh Sardashti and David A. Wood University of Wisconsin-Madison 1 Please find the power point presentation
The Ascend Secure Processor. Christopher Fletcher MIT
 The Ascend Secure Processor Christopher Fletcher MIT 1 Joint work with Srini Devadas, Marten van Dijk Ling Ren, Albert Kwon, Xiangyao Yu Elaine Shi & Emil Stefanov David Wentzlaff & Princeton Team (Mike,
The Ascend Secure Processor Christopher Fletcher MIT 1 Joint work with Srini Devadas, Marten van Dijk Ling Ren, Albert Kwon, Xiangyao Yu Elaine Shi & Emil Stefanov David Wentzlaff & Princeton Team (Mike,
10/16/2017. Miss Rate: ABC. Classifying Misses: 3C Model (Hill) Reducing Conflict Misses: Victim Buffer. Overlapping Misses: Lockup Free Cache
 Reducing Conflict Misses: Victim Buffer. Overlapping Misses: Lockup Free Cache") Classifying Misses: 3C Model (Hill) Divide cache misses into three categories Compulsory (cold): never seen this address before Would miss even in infinite cache Capacity: miss caused because cache is
Classifying Misses: 3C Model (Hill) Divide cache misses into three categories Compulsory (cold): never seen this address before Would miss even in infinite cache Capacity: miss caused because cache is
1/19/2009. Data Locality. Exploiting Locality: Caches
 Spring 2009 Prof. Hyesoon Kim Thanks to Prof. Loh & Prof. Prvulovic Data Locality Temporal: if data item needed now, it is likely to be needed again in near future Spatial: if data item needed now, nearby
Spring 2009 Prof. Hyesoon Kim Thanks to Prof. Loh & Prof. Prvulovic Data Locality Temporal: if data item needed now, it is likely to be needed again in near future Spatial: if data item needed now, nearby
Caches. Han Wang CS 3410, Spring 2012 Computer Science Cornell University. See P&H 5.1, 5.2 (except writes)
") Caches Han Wang CS 3410, Spring 2012 Computer Science Cornell University See P&H 5.1, 5.2 (except writes) This week: Announcements PA2 Work-in-progress submission Next six weeks: Two labs and two projects
Caches Han Wang CS 3410, Spring 2012 Computer Science Cornell University See P&H 5.1, 5.2 (except writes) This week: Announcements PA2 Work-in-progress submission Next six weeks: Two labs and two projects
Key Point. What are Cache lines
 Caching 1 Key Point What are Cache lines Tags Index offset How do we find data in the cache? How do we tell if it s the right data? What decisions do we need to make in designing a cache? What are possible
Caching 1 Key Point What are Cache lines Tags Index offset How do we find data in the cache? How do we tell if it s the right data? What decisions do we need to make in designing a cache? What are possible
Dynamic Performance Tuning for Speculative Threads
 Dynamic Performance Tuning for Speculative Threads Yangchun Luo, Venkatesan Packirisamy, Nikhil Mungre, Ankit Tarkas, Wei-Chung Hsu, and Antonia Zhai Dept. of Computer Science and Engineering Dept. of
Dynamic Performance Tuning for Speculative Threads Yangchun Luo, Venkatesan Packirisamy, Nikhil Mungre, Ankit Tarkas, Wei-Chung Hsu, and Antonia Zhai Dept. of Computer Science and Engineering Dept. of
Sharing-aware Efficient Private Caching in Many-core Server Processors
 17 IEEE 35th International Conference on Computer Design Sharing-aware Efficient Private Caching in Many-core Server Processors Sudhanshu Shukla Mainak Chaudhuri Department of Computer Science and Engineering,
17 IEEE 35th International Conference on Computer Design Sharing-aware Efficient Private Caching in Many-core Server Processors Sudhanshu Shukla Mainak Chaudhuri Department of Computer Science and Engineering,
Chapter 8. Virtual Memory
 Operating System Chapter 8. Virtual Memory Lynn Choi School of Electrical Engineering Motivated by Memory Hierarchy Principles of Locality Speed vs. size vs. cost tradeoff Locality principle Spatial Locality:
Operating System Chapter 8. Virtual Memory Lynn Choi School of Electrical Engineering Motivated by Memory Hierarchy Principles of Locality Speed vs. size vs. cost tradeoff Locality principle Spatial Locality:
Recap: Machine Organization
 ECE232: Hardware Organization and Design Part 14: Hierarchy Chapter 5 (4 th edition), 7 (3 rd edition) http://www.ecs.umass.edu/ece/ece232/ Adapted from Computer Organization and Design, Patterson & Hennessy,
ECE232: Hardware Organization and Design Part 14: Hierarchy Chapter 5 (4 th edition), 7 (3 rd edition) http://www.ecs.umass.edu/ece/ece232/ Adapted from Computer Organization and Design, Patterson & Hennessy,
Why memory hierarchy? Memory hierarchy. Memory hierarchy goals. CS2410: Computer Architecture. L1 cache design. Sangyeun Cho
 Why memory hierarchy? L1 cache design Sangyeun Cho Computer Science Department Memory hierarchy Memory hierarchy goals Smaller Faster More expensive per byte CPU Regs L1 cache L2 cache SRAM SRAM To provide
Why memory hierarchy? L1 cache design Sangyeun Cho Computer Science Department Memory hierarchy Memory hierarchy goals Smaller Faster More expensive per byte CPU Regs L1 cache L2 cache SRAM SRAM To provide
CANDY: Enabling Coherent DRAM Caches for Multi-Node Systems
 CANDY: Enabling Coherent DRAM Caches for Multi-Node Systems Chiachen Chou Aamer Jaleel Moinuddin K. Qureshi School of Electrical and Computer Engineering Georgia Institute of Technology {cc.chou, moin}@ece.gatech.edu
CANDY: Enabling Coherent DRAM Caches for Multi-Node Systems Chiachen Chou Aamer Jaleel Moinuddin K. Qureshi School of Electrical and Computer Engineering Georgia Institute of Technology {cc.chou, moin}@ece.gatech.edu
Rethinking On-chip DRAM Cache for Simultaneous Performance and Energy Optimization
 Rethinking On-chip DRAM Cache for Simultaneous Performance and Energy Optimization Fazal Hameed and Jeronimo Castrillon Center for Advancing Electronics Dresden (cfaed), Technische Universität Dresden,
Rethinking On-chip DRAM Cache for Simultaneous Performance and Energy Optimization Fazal Hameed and Jeronimo Castrillon Center for Advancing Electronics Dresden (cfaed), Technische Universität Dresden,
5 Solutions. Solution a. no solution provided. b. no solution provided
 5 Solutions Solution 5.1 5.1.1 5.1.2 5.1.3 5.1.4 5.1.5 5.1.6 S2 Chapter 5 Solutions Solution 5.2 5.2.1 4 5.2.2 a. I, J b. B[I][0] 5.2.3 a. A[I][J] b. A[J][I] 5.2.4 a. 3596 = 8 800/4 2 8 8/4 + 8000/4 b.
5 Solutions Solution 5.1 5.1.1 5.1.2 5.1.3 5.1.4 5.1.5 5.1.6 S2 Chapter 5 Solutions Solution 5.2 5.2.1 4 5.2.2 a. I, J b. B[I][0] 5.2.3 a. A[I][J] b. A[J][I] 5.2.4 a. 3596 = 8 800/4 2 8 8/4 + 8000/4 b.
EE 457 Unit 7b. Main Memory Organization
 1 EE 457 Unit 7b Main Memory Organization 2 Motivation Organize main memory to Facilitate byte-addressability while maintaining Efficient fetching of the words in a cache block Low order interleaving (L.O.I)
1 EE 457 Unit 7b Main Memory Organization 2 Motivation Organize main memory to Facilitate byte-addressability while maintaining Efficient fetching of the words in a cache block Low order interleaving (L.O.I)
Design Space Exploration and Optimization of Path Oblivious RAM in Secure Processors
 Design Space Exploration and Optimization of Path Oblivious RAM in Secure Processors Ling Ren, Xiangyao Yu, Christopher W. Fletcher, Marten van Dijk and Srinivas Devadas MIT CSAIL, Cambridge, MA, USA {renling,
Design Space Exploration and Optimization of Path Oblivious RAM in Secure Processors Ling Ren, Xiangyao Yu, Christopher W. Fletcher, Marten van Dijk and Srinivas Devadas MIT CSAIL, Cambridge, MA, USA {renling,
M7: Next Generation SPARC. Hotchips 26 August 12, Stephen Phillips Senior Director, SPARC Architecture Oracle
 M7: Next Generation SPARC Hotchips 26 August 12, 2014 Stephen Phillips Senior Director, SPARC Architecture Oracle Safe Harbor Statement The following is intended to outline our general product direction.
M7: Next Generation SPARC Hotchips 26 August 12, 2014 Stephen Phillips Senior Director, SPARC Architecture Oracle Safe Harbor Statement The following is intended to outline our general product direction.
The Salsa20 Family of Stream Ciphers
 The Salsa20 Family of Stream Ciphers Based on [Bernstein, 2008] Erin Hales, Gregor Matl, Simon-Philipp Merz Introduction to Cryptology November 13, 2017 From a security perspective, if you re connected,
The Salsa20 Family of Stream Ciphers Based on [Bernstein, 2008] Erin Hales, Gregor Matl, Simon-Philipp Merz Introduction to Cryptology November 13, 2017 From a security perspective, if you re connected,
The Memory Hierarchy. Cache, Main Memory, and Virtual Memory (Part 2)
") The Memory Hierarchy Cache, Main Memory, and Virtual Memory (Part 2) Lecture for CPSC 5155 Edward Bosworth, Ph.D. Computer Science Department Columbus State University Cache Line Replacement The cache
The Memory Hierarchy Cache, Main Memory, and Virtual Memory (Part 2) Lecture for CPSC 5155 Edward Bosworth, Ph.D. Computer Science Department Columbus State University Cache Line Replacement The cache
Multilevel Memories. Joel Emer Computer Science and Artificial Intelligence Laboratory Massachusetts Institute of Technology
 1 Multilevel Memories Computer Science and Artificial Intelligence Laboratory Massachusetts Institute of Technology Based on the material prepared by Krste Asanovic and Arvind CPU-Memory Bottleneck 6.823
1 Multilevel Memories Computer Science and Artificial Intelligence Laboratory Massachusetts Institute of Technology Based on the material prepared by Krste Asanovic and Arvind CPU-Memory Bottleneck 6.823
Accelerating Pointer Chasing in 3D-Stacked Memory: Challenges, Mechanisms, Evaluation Kevin Hsieh
 Accelerating Pointer Chasing in 3D-Stacked : Challenges, Mechanisms, Evaluation Kevin Hsieh Samira Khan, Nandita Vijaykumar, Kevin K. Chang, Amirali Boroumand, Saugata Ghose, Onur Mutlu Executive Summary
Accelerating Pointer Chasing in 3D-Stacked : Challenges, Mechanisms, Evaluation Kevin Hsieh Samira Khan, Nandita Vijaykumar, Kevin K. Chang, Amirali Boroumand, Saugata Ghose, Onur Mutlu Executive Summary
A Comparison of Capacity Management Schemes for Shared CMP Caches
 A Comparison of Capacity Management Schemes for Shared CMP Caches Carole-Jean Wu and Margaret Martonosi Princeton University 7 th Annual WDDD 6/22/28 Motivation P P1 P1 Pn L1 L1 L1 L1 Last Level On-Chip
A Comparison of Capacity Management Schemes for Shared CMP Caches Carole-Jean Wu and Margaret Martonosi Princeton University 7 th Annual WDDD 6/22/28 Motivation P P1 P1 Pn L1 L1 L1 L1 Last Level On-Chip
Chapter 6 Caches. Computer System. Alpha Chip Photo. Topics. Memory Hierarchy Locality of Reference SRAM Caches Direct Mapped Associative
 Chapter 6 s Topics Memory Hierarchy Locality of Reference SRAM s Direct Mapped Associative Computer System Processor interrupt On-chip cache s s Memory-I/O bus bus Net cache Row cache Disk cache Memory
Chapter 6 s Topics Memory Hierarchy Locality of Reference SRAM s Direct Mapped Associative Computer System Processor interrupt On-chip cache s s Memory-I/O bus bus Net cache Row cache Disk cache Memory
Exploration of Cache Coherent CPU- FPGA Heterogeneous System
 Exploration of Cache Coherent CPU- FPGA Heterogeneous System Wei Zhang Department of Electronic and Computer Engineering Hong Kong University of Science and Technology 1 Outline ointroduction to FPGA-based
Exploration of Cache Coherent CPU- FPGA Heterogeneous System Wei Zhang Department of Electronic and Computer Engineering Hong Kong University of Science and Technology 1 Outline ointroduction to FPGA-based
Tiered-Latency DRAM: A Low Latency and A Low Cost DRAM Architecture
 Tiered-Latency DRAM: A Low Latency and A Low Cost DRAM Architecture Donghyuk Lee, Yoongu Kim, Vivek Seshadri, Jamie Liu, Lavanya Subramanian, Onur Mutlu Carnegie Mellon University HPCA - 2013 Executive
Tiered-Latency DRAM: A Low Latency and A Low Cost DRAM Architecture Donghyuk Lee, Yoongu Kim, Vivek Seshadri, Jamie Liu, Lavanya Subramanian, Onur Mutlu Carnegie Mellon University HPCA - 2013 Executive
MARACAS: A Real-Time Multicore VCPU Scheduling Framework
 : A Real-Time Framework Computer Science Department Boston University Overview 1 2 3 4 5 6 7 Motivation platforms are gaining popularity in embedded and real-time systems concurrent workload support less
: A Real-Time Framework Computer Science Department Boston University Overview 1 2 3 4 5 6 7 Motivation platforms are gaining popularity in embedded and real-time systems concurrent workload support less
Achieving Out-of-Order Performance with Almost In-Order Complexity
 Achieving Out-of-Order Performance with Almost In-Order Complexity Comprehensive Examination Part II By Raj Parihar Background Info: About the Paper Title Achieving Out-of-Order Performance with Almost
Achieving Out-of-Order Performance with Almost In-Order Complexity Comprehensive Examination Part II By Raj Parihar Background Info: About the Paper Title Achieving Out-of-Order Performance with Almost
Data Integrity. Modified by: Dr. Ramzi Saifan
 Data Integrity Modified by: Dr. Ramzi Saifan Encryption/Decryption Provides message confidentiality. Does it provide message authentication? 2 Message Authentication Bob receives a message m from Alice,
Data Integrity Modified by: Dr. Ramzi Saifan Encryption/Decryption Provides message confidentiality. Does it provide message authentication? 2 Message Authentication Bob receives a message m from Alice,
Lec 13: Linking and Memory. Kavita Bala CS 3410, Fall 2008 Computer Science Cornell University. Announcements
 Lec 13: Linking and Memory Kavita Bala CS 3410, Fall 2008 Computer Science Cornell University PA 2 is out Due on Oct 22 nd Announcements Prelim Oct 23 rd, 7:30-9:30/10:00 All content up to Lecture on Oct
Lec 13: Linking and Memory Kavita Bala CS 3410, Fall 2008 Computer Science Cornell University PA 2 is out Due on Oct 22 nd Announcements Prelim Oct 23 rd, 7:30-9:30/10:00 All content up to Lecture on Oct
Lecture 6: Symmetric Cryptography. CS 5430 February 21, 2018
 Lecture 6: Symmetric Cryptography CS 5430 February 21, 2018 The Big Picture Thus Far Attacks are perpetrated by threats that inflict harm by exploiting vulnerabilities which are controlled by countermeasures.
Lecture 6: Symmetric Cryptography CS 5430 February 21, 2018 The Big Picture Thus Far Attacks are perpetrated by threats that inflict harm by exploiting vulnerabilities which are controlled by countermeasures.
Computer Architecture Memory hierarchies and caches
 Computer Architecture Memory hierarchies and caches S Coudert and R Pacalet January 23, 2019 Outline Introduction Localities principles Direct-mapped caches Increasing block size Set-associative caches
Computer Architecture Memory hierarchies and caches S Coudert and R Pacalet January 23, 2019 Outline Introduction Localities principles Direct-mapped caches Increasing block size Set-associative caches
Introduction to OpenMP. Lecture 10: Caches
 Introduction to OpenMP Lecture 10: Caches Overview Why caches are needed How caches work Cache design and performance. The memory speed gap Moore s Law: processors speed doubles every 18 months. True for
Introduction to OpenMP Lecture 10: Caches Overview Why caches are needed How caches work Cache design and performance. The memory speed gap Moore s Law: processors speed doubles every 18 months. True for
Chapter 5 Large and Fast: Exploiting Memory Hierarchy (Part 1)
") Department of Electr rical Eng ineering, Chapter 5 Large and Fast: Exploiting Memory Hierarchy (Part 1) 王振傑 (Chen-Chieh Wang) ccwang@mail.ee.ncku.edu.tw ncku edu Depar rtment of Electr rical Engineering,
Department of Electr rical Eng ineering, Chapter 5 Large and Fast: Exploiting Memory Hierarchy (Part 1) 王振傑 (Chen-Chieh Wang) ccwang@mail.ee.ncku.edu.tw ncku edu Depar rtment of Electr rical Engineering,
TDT Coarse-Grained Multithreading. Review on ILP. Multi-threaded execution. Contents. Fine-Grained Multithreading
 Review on ILP TDT 4260 Chap 5 TLP & Hierarchy What is ILP? Let the compiler find the ILP Advantages? Disadvantages? Let the HW find the ILP Advantages? Disadvantages? Contents Multi-threading Chap 3.5
Review on ILP TDT 4260 Chap 5 TLP & Hierarchy What is ILP? Let the compiler find the ILP Advantages? Disadvantages? Let the HW find the ILP Advantages? Disadvantages? Contents Multi-threading Chap 3.5
Banshee: Bandwidth-Efficient DRAM Caching via Software/Hardware Cooperation!
 Banshee: Bandwidth-Efficient DRAM Caching via Software/Hardware Cooperation! Xiangyao Yu 1, Christopher Hughes 2, Nadathur Satish 2, Onur Mutlu 3, Srinivas Devadas 1 1 MIT 2 Intel Labs 3 ETH Zürich 1 High-Bandwidth
Banshee: Bandwidth-Efficient DRAM Caching via Software/Hardware Cooperation! Xiangyao Yu 1, Christopher Hughes 2, Nadathur Satish 2, Onur Mutlu 3, Srinivas Devadas 1 1 MIT 2 Intel Labs 3 ETH Zürich 1 High-Bandwidth
Caches and Memory Hierarchy: Review. UCSB CS240A, Fall 2017
 Caches and Memory Hierarchy: Review UCSB CS24A, Fall 27 Motivation Most applications in a single processor runs at only - 2% of the processor peak Most of the single processor performance loss is in the
Caches and Memory Hierarchy: Review UCSB CS24A, Fall 27 Motivation Most applications in a single processor runs at only - 2% of the processor peak Most of the single processor performance loss is in the
Securing the Frisbee Multicast Disk Loader
 Securing the Frisbee Multicast Disk Loader Robert Ricci, Jonathon Duerig University of Utah 1 What is Frisbee? 2 Frisbee is Emulab s tool to install whole disk images from a server to many clients using
Securing the Frisbee Multicast Disk Loader Robert Ricci, Jonathon Duerig University of Utah 1 What is Frisbee? 2 Frisbee is Emulab s tool to install whole disk images from a server to many clients using
Lecture 14: Memory Hierarchy. James C. Hoe Department of ECE Carnegie Mellon University
 18 447 Lecture 14: Memory Hierarchy James C. Hoe Department of ECE Carnegie Mellon University 18 447 S18 L14 S1, James C. Hoe, CMU/ECE/CALCM, 2018 Your goal today Housekeeping understand memory system
18 447 Lecture 14: Memory Hierarchy James C. Hoe Department of ECE Carnegie Mellon University 18 447 S18 L14 S1, James C. Hoe, CMU/ECE/CALCM, 2018 Your goal today Housekeeping understand memory system
PageForge: A Near-Memory Content- Aware Page-Merging Architecture
 PageForge: A Near-Memory Content- Aware Page-Merging Architecture Dimitrios Skarlatos, Nam Sung Kim, and Josep Torrellas University of Illinois at Urbana-Champaign MICRO-50 @ Boston Motivation: Server
PageForge: A Near-Memory Content- Aware Page-Merging Architecture Dimitrios Skarlatos, Nam Sung Kim, and Josep Torrellas University of Illinois at Urbana-Champaign MICRO-50 @ Boston Motivation: Server
Chapter 6 Objectives
 Chapter 6 Memory Chapter 6 Objectives Master the concepts of hierarchical memory organization. Understand how each level of memory contributes to system performance, and how the performance is measured.
Chapter 6 Memory Chapter 6 Objectives Master the concepts of hierarchical memory organization. Understand how each level of memory contributes to system performance, and how the performance is measured.
Chapter 5A. Large and Fast: Exploiting Memory Hierarchy
 Chapter 5A Large and Fast: Exploiting Memory Hierarchy Memory Technology Static RAM (SRAM) Fast, expensive Dynamic RAM (DRAM) In between Magnetic disk Slow, inexpensive Ideal memory Access time of SRAM
Chapter 5A Large and Fast: Exploiting Memory Hierarchy Memory Technology Static RAM (SRAM) Fast, expensive Dynamic RAM (DRAM) In between Magnetic disk Slow, inexpensive Ideal memory Access time of SRAM
CSAIL. Computer Science and Artificial Intelligence Laboratory. Massachusetts Institute of Technology
 CSAIL Computer Science and Artificial Intelligence Laboratory Massachusetts Institute of Technology Efficient Memory Integrity Verification and Encryption for Secure Processors G. Edward Suh, Dwaine Clarke,
CSAIL Computer Science and Artificial Intelligence Laboratory Massachusetts Institute of Technology Efficient Memory Integrity Verification and Encryption for Secure Processors G. Edward Suh, Dwaine Clarke,
Caches 3/23/17. Agenda. The Dataflow Model (of a Computer)
") Agenda Caches Samira Khan March 23, 2017 Review from last lecture Data flow model Memory hierarchy More Caches The Dataflow Model (of a Computer) Von Neumann model: An instruction is fetched and executed
Agenda Caches Samira Khan March 23, 2017 Review from last lecture Data flow model Memory hierarchy More Caches The Dataflow Model (of a Computer) Von Neumann model: An instruction is fetched and executed
ZSIM: FAST AND ACCURATE MICROARCHITECTURAL SIMULATION OF THOUSAND-CORE SYSTEMS
 ZSIM: FAST AND ACCURATE MICROARCHITECTURAL SIMULATION OF THOUSAND-CORE SYSTEMS DANIEL SANCHEZ MIT CHRISTOS KOZYRAKIS STANFORD ISCA-40 JUNE 27, 2013 Introduction 2 Current detailed simulators are slow (~200
ZSIM: FAST AND ACCURATE MICROARCHITECTURAL SIMULATION OF THOUSAND-CORE SYSTEMS DANIEL SANCHEZ MIT CHRISTOS KOZYRAKIS STANFORD ISCA-40 JUNE 27, 2013 Introduction 2 Current detailed simulators are slow (~200
Caches. Samira Khan March 23, 2017
 Caches Samira Khan March 23, 2017 Agenda Review from last lecture Data flow model Memory hierarchy More Caches The Dataflow Model (of a Computer) Von Neumann model: An instruction is fetched and executed
Caches Samira Khan March 23, 2017 Agenda Review from last lecture Data flow model Memory hierarchy More Caches The Dataflow Model (of a Computer) Von Neumann model: An instruction is fetched and executed
Martin Kruliš, v
 Martin Kruliš 1 Optimizations in General Code And Compilation Memory Considerations Parallelism Profiling And Optimization Examples 2 Premature optimization is the root of all evil. -- D. Knuth Our goal
Martin Kruliš 1 Optimizations in General Code And Compilation Memory Considerations Parallelism Profiling And Optimization Examples 2 Premature optimization is the root of all evil. -- D. Knuth Our goal
Hashes, MACs & Passwords. Tom Chothia Computer Security Lecture 5
 Hashes, MACs & Passwords Tom Chothia Computer Security Lecture 5 Today s Lecture Hashes and Message Authentication Codes Properties of Hashes and MACs CBC-MAC, MAC -> HASH (slow), SHA1, SHA2, SHA3 HASH
Hashes, MACs & Passwords Tom Chothia Computer Security Lecture 5 Today s Lecture Hashes and Message Authentication Codes Properties of Hashes and MACs CBC-MAC, MAC -> HASH (slow), SHA1, SHA2, SHA3 HASH
Oasis: An Active Storage Framework for Object Storage Platform
 Oasis: An Active Storage Framework for Object Storage Platform Yulai Xie 1, Dan Feng 1, Darrell D. E. Long 2, Yan Li 2 1 School of Computer, Huazhong University of Science and Technology Wuhan National
Oasis: An Active Storage Framework for Object Storage Platform Yulai Xie 1, Dan Feng 1, Darrell D. E. Long 2, Yan Li 2 1 School of Computer, Huazhong University of Science and Technology Wuhan National
Performance analysis basics
 Performance analysis basics Christian Iwainsky Iwainsky@rz.rwth-aachen.de 25.3.2010 1 Overview 1. Motivation 2. Performance analysis basics 3. Measurement Techniques 2 Why bother with performance analysis
Performance analysis basics Christian Iwainsky Iwainsky@rz.rwth-aachen.de 25.3.2010 1 Overview 1. Motivation 2. Performance analysis basics 3. Measurement Techniques 2 Why bother with performance analysis
ZSIM: FAST AND ACCURATE MICROARCHITECTURAL SIMULATION OF THOUSAND-CORE SYSTEMS
 ZSIM: FAST AND ACCURATE MICROARCHITECTURAL SIMULATION OF THOUSAND-CORE SYSTEMS DANIEL SANCHEZ MIT CHRISTOS KOZYRAKIS STANFORD ISCA-40 JUNE 27, 2013 Introduction 2 Current detailed simulators are slow (~200
ZSIM: FAST AND ACCURATE MICROARCHITECTURAL SIMULATION OF THOUSAND-CORE SYSTEMS DANIEL SANCHEZ MIT CHRISTOS KOZYRAKIS STANFORD ISCA-40 JUNE 27, 2013 Introduction 2 Current detailed simulators are slow (~200
ELIMINATING ON-CHIP TRAFFIC WASTE: ARE WE THERE YET? ROBERT SMOLINSKI
 ELIMINATING ON-CHIP TRAFFIC WASTE: ARE WE THERE YET? BY ROBERT SMOLINSKI THESIS Submitted in partial fulfillment of the requirements for the degree of Master of Science in Computer Science in the Graduate
ELIMINATING ON-CHIP TRAFFIC WASTE: ARE WE THERE YET? BY ROBERT SMOLINSKI THESIS Submitted in partial fulfillment of the requirements for the degree of Master of Science in Computer Science in the Graduate
Computer Architecture and System Software Lecture 09: Memory Hierarchy. Instructor: Rob Bergen Applied Computer Science University of Winnipeg
 Computer Architecture and System Software Lecture 09: Memory Hierarchy Instructor: Rob Bergen Applied Computer Science University of Winnipeg Announcements Midterm returned + solutions in class today SSD
Computer Architecture and System Software Lecture 09: Memory Hierarchy Instructor: Rob Bergen Applied Computer Science University of Winnipeg Announcements Midterm returned + solutions in class today SSD
An Adaptive Filtering Mechanism for Energy Efficient Data Prefetching
 18th Asia and South Pacific Design Automation Conference January 22-25, 2013 - Yokohama, Japan An Adaptive Filtering Mechanism for Energy Efficient Data Prefetching Xianglei Dang, Xiaoyin Wang, Dong Tong,
18th Asia and South Pacific Design Automation Conference January 22-25, 2013 - Yokohama, Japan An Adaptive Filtering Mechanism for Energy Efficient Data Prefetching Xianglei Dang, Xiaoyin Wang, Dong Tong,
Caches and Memory Hierarchy: Review. UCSB CS240A, Winter 2016
 Caches and Memory Hierarchy: Review UCSB CS240A, Winter 2016 1 Motivation Most applications in a single processor runs at only 10-20% of the processor peak Most of the single processor performance loss
Caches and Memory Hierarchy: Review UCSB CS240A, Winter 2016 1 Motivation Most applications in a single processor runs at only 10-20% of the processor peak Most of the single processor performance loss
Profiling-Based L1 Data Cache Bypassing to Improve GPU Performance and Energy Efficiency
 Profiling-Based L1 Data Cache Bypassing to Improve GPU Performance and Energy Efficiency Yijie Huangfu and Wei Zhang Department of Electrical and Computer Engineering Virginia Commonwealth University {huangfuy2,wzhang4}@vcu.edu
Profiling-Based L1 Data Cache Bypassing to Improve GPU Performance and Energy Efficiency Yijie Huangfu and Wei Zhang Department of Electrical and Computer Engineering Virginia Commonwealth University {huangfuy2,wzhang4}@vcu.edu
Eleos: Exit-Less OS Services for SGX Enclaves
 Eleos: Exit-Less OS Services for SGX Enclaves Meni Orenbach Marina Minkin Pavel Lifshits Mark Silberstein Accelerated Computing Systems Lab Haifa, Israel What do we do? Improve performance: I/O intensive
Eleos: Exit-Less OS Services for SGX Enclaves Meni Orenbach Marina Minkin Pavel Lifshits Mark Silberstein Accelerated Computing Systems Lab Haifa, Israel What do we do? Improve performance: I/O intensive
Token Coherence. Milo M. K. Martin Dissertation Defense
 Token Coherence Milo M. K. Martin Dissertation Defense Wisconsin Multifacet Project http://www.cs.wisc.edu/multifacet/ University of Wisconsin Madison (C) 2003 Milo Martin Overview Technology and software
Token Coherence Milo M. K. Martin Dissertation Defense Wisconsin Multifacet Project http://www.cs.wisc.edu/multifacet/ University of Wisconsin Madison (C) 2003 Milo Martin Overview Technology and software
Doppelgänger: A Cache for Approximate Computing
 Doppelgänger: A Cache for Approximate Computing ABSTRACT Joshua San Miguel University of Toronto joshua.sanmiguel@mail.utoronto.ca Andreas Moshovos University of Toronto moshovos@eecg.toronto.edu Modern
Doppelgänger: A Cache for Approximate Computing ABSTRACT Joshua San Miguel University of Toronto joshua.sanmiguel@mail.utoronto.ca Andreas Moshovos University of Toronto moshovos@eecg.toronto.edu Modern
Advanced Caching Techniques (2) Department of Electrical Engineering Stanford University
 Department of Electrical Engineering Stanford University") Lecture 4: Advanced Caching Techniques (2) Department of Electrical Engineering Stanford University http://eeclass.stanford.edu/ee282 Lecture 4-1 Announcements HW1 is out (handout and online) Due on 10/15
Lecture 4: Advanced Caching Techniques (2) Department of Electrical Engineering Stanford University http://eeclass.stanford.edu/ee282 Lecture 4-1 Announcements HW1 is out (handout and online) Due on 10/15
Chapter 5. Large and Fast: Exploiting Memory Hierarchy
 Chapter 5 Large and Fast: Exploiting Memory Hierarchy Principle of Locality Programs access a small proportion of their address space at any time Temporal locality Items accessed recently are likely to
Chapter 5 Large and Fast: Exploiting Memory Hierarchy Principle of Locality Programs access a small proportion of their address space at any time Temporal locality Items accessed recently are likely to
Memory Hierarchy Computing Systems & Performance MSc Informatics Eng. Memory Hierarchy (most slides are borrowed)
") Computing Systems & Performance Memory Hierarchy MSc Informatics Eng. 2011/12 A.J.Proença Memory Hierarchy (most slides are borrowed) AJProença, Computer Systems & Performance, MEI, UMinho, 2011/12 1 2
Computing Systems & Performance Memory Hierarchy MSc Informatics Eng. 2011/12 A.J.Proença Memory Hierarchy (most slides are borrowed) AJProença, Computer Systems & Performance, MEI, UMinho, 2011/12 1 2
ECE 571 Advanced Microprocessor-Based Design Lecture 13
 ECE 571 Advanced Microprocessor-Based Design Lecture 13 Vince Weaver http://web.eece.maine.edu/~vweaver vincent.weaver@maine.edu 21 March 2017 Announcements More on HW#6 When ask for reasons why cache
ECE 571 Advanced Microprocessor-Based Design Lecture 13 Vince Weaver http://web.eece.maine.edu/~vweaver vincent.weaver@maine.edu 21 March 2017 Announcements More on HW#6 When ask for reasons why cache