Accelerating Parallel Analysis of Scientific Simulation Data via Zazen
|
|
|
- Adam Mosley
- 5 years ago
- Views:
Transcription
1 Accelerating Parallel Analysis of Scientific Simulation Data via Zazen Tiankai Tu, Charles A. Rendleman, Patrick J. Miller, Federico Sacerdoti, Ron O. Dror, and David E. Shaw D. E. Shaw Research


2 Motivation Goal: To model biological processes that occur on the millisecond time scale 2 Approach: A specialized, massively parallel supercomputer called Anton (2009 ACM Gordon Bell Award for Special Achievement)
3 3 Millisecond-scale MD Trajectories A biomolecular system: 25 K atoms Position and velocity: 24 bytes/atom Frame size: 0.6 MB/frame Simulation length: 1x 10-3 s Output interval: 10 x s Number of frames: 100 M frames
4 4 Part I: How We Analyze Simulation Data in Parallel
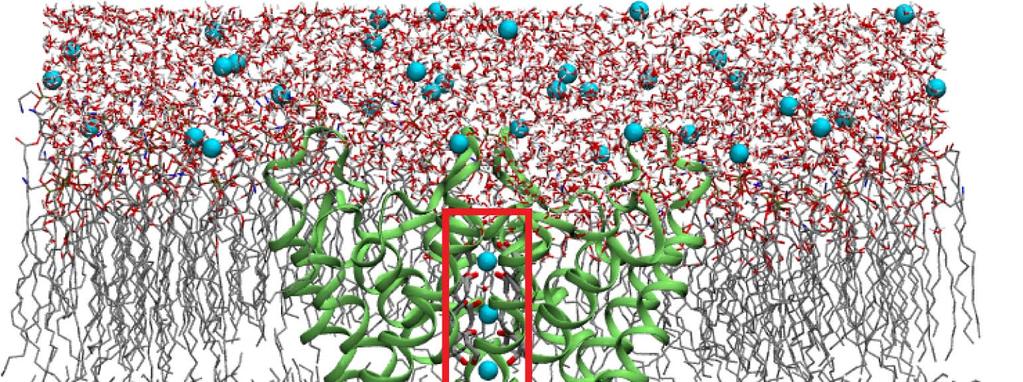
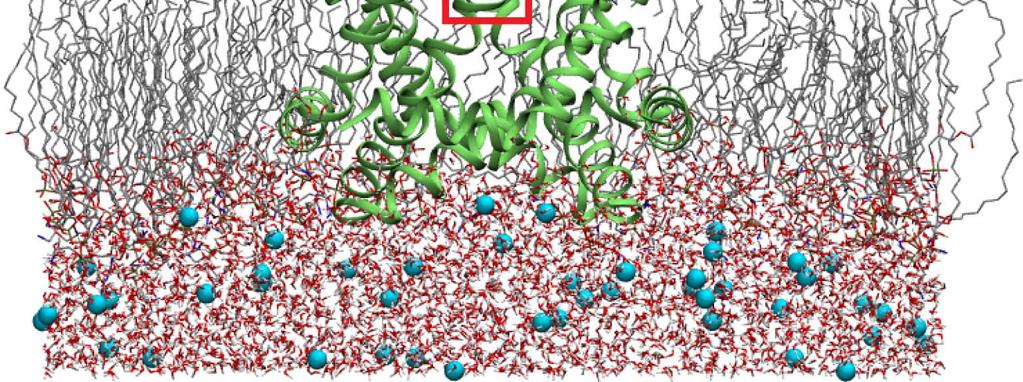
5 5 An MD Trajectory Analysis Example: Ion Permeation
6 6 A Hypothetic Trajectory 20,000 atoms in total; two ions of interest Ion A Ion B
7 7 Ion State Transition S Above channel Into channel from below S Inside channel Into channel from above S Below channel
8 8 Typical Sequential Analysis Maintain a main-memory resident data structure to record states and positions Process frames in ascending simulated physical time order Strong inter-frame data dependence: Data analysis tightly coupled with data acquisition
9 9 Problems with Sequential Analysis Millisecond-scale trajectory size : 60 TB Local disk read bandwidth : 100 MB / s Time to fetch data to memory : 1 week Analysis time : Varied Time to perform data analysis : Weeks Sequential analysis lack the computational, memory, and I/O capabilities!
10 10 A Parallel Data Analysis Model Specify which frames to be accessed Decouple data acquisition from data analysis Trajectory definition Stage1: Per-frame data acquisition Stage 2: Cross-frame data analysis
11 Trajectory Definition Every other frame in the trajectory Ion A Ion B 11

12 Per-frame Data Acquisition (stage 1) P0 P Ion A Ion B 12
13 Cross-frame Data Analysis (stage 2) Analyze ion A on P0 and ion B on P1 in parallel Ion A Ion B 13
14 Inspiration: Google s MapReduce Output file Output file Google File System Input files Input files Input files map(...) map(...) map(...) K1: {v1 i } K2: {v2 i } K1: {v1 j } K2: {v2 j } K1: {v1 k } K2: {v2 k } K1: {v1 j, v1 i, v1 k } K2: {v2 k, v2 j, v2 i } reduce(k1,...) reduce(k2,...) 14
15 Trajectory Analysis Cast Into MapReduce 15 Per-frame data acquisition (stage 1): map() Cross-frame data analysis (stage 2): reduce() Key-value pairs: connecting stage1 and stage2 Keys: categorical identifiers or names Values: including timestamps Examples: (ion_id j, (t k, x ik, y jk, z jk )) Key Value
16 16 The HiMach Library A MapReduce-style API that allows users to write Python programs to analyze MD trajectories A parallel runtime that executes HiMach user programs in parallel on a Linux cluster automatically Performance results on a Linux cluster: 2 orders of magnitude faster on 512 cores than on a single core


17 Typical Simulation Analysis Storage Infrastructure Analysis cluster Analysis node Analysis node Parallel analysis programs Local disks Local disks File servers I/O node Parallel supercomputer 17
18 18 Part II: How We Overcome the I/O Bottleneck in Parallel Analysis
19 19 Trajectory Characteristics A large number of small frames Write once, read many Distinguishable by unique integer sequence numbers Amenable to out-of-order parallel access in the map phase
20 20 Our Main Idea At simulation time, actively cache frames in the local disks of the analysis nodes as the frames become available At analysis time, fetch data from local disk caches in parallel
21 21 Limitations Require large aggregate disk capacity on the analysis cluster Assume relatively low average simulation data output rate
22 22 An Example Analysis node 0 Merged bitmap Remote bitmap Local bitmap / Analysis node Merged bitmap Remote bitmap Local bitmap / bodhi bodhi sim0 sim1 sim0 sim1 seq 0 2 f0 f2 seq 1 3 f1 f3 NFS server / sim0 sim1 f0 f1 f2 f3
23 23 How to guarantee that each frame is read by one and only one node in the face of node failure and recovery? The Zazen Protocol
24 The Zazen Protocol Execute a distributed consensus protocol before performing actual disk I/O Assign data retrieval tasks in a locationaware manner Read data from local disks if the data are already cached Fetch missing data from file servers No metadata servers to keep record of who has what 24
25 25 The Zazen Protocol (cont d) Bitmaps: a compact structure for recording the presence or non-presence of a cached copy All-to-all reduction algorithms: an efficient mechanism for inter-processor collective communications (used an MPI library in practice)
26 26 Implementation The Bodhi library Zazen cluster Analysis node Analysis node Parallel analysis programs (HiMach jobs) The Bodhi server The Zazen protocol Bodhi library Bodhi server Zazen protocol Bodhi library Bodhi server File servers Bodhi library I/O node Parallel supercomputer
27 Performance Evaluation 27
28 28 Experiment Setup A Linux cluster with 100 nodes Two Intel Xeon 2.33 GHz quad-core processors per node Four 500 GB 7200-RPM SATA disks organized in RAID 0 per node 16 GB physical memory per node CentOS 4.6 with a Linux kernel of Nodes connected to a Gigabit Ethernet core switch Common accesses to NFS directories exported by a number of enterprise storage servers
29 Fixed-Problem-Size Scalability Execution time of the Zazen protocol to assign the I/O tasks of reading 1 billion frames Time (s) Number of nodes 29
30 Fixed-Cluster-Size Scalability Execution time of the Zazen protocol on 100 nodes assigning different number of frames 1E+02 1E+01 Time (s) 1E+00 1E-01 1E-02 1E-03 1E+03 1E+04 1E+05 1E+06 1E+07 1E+08 1E+09 Number of frames 30
31 31 Efficiency I: Achieving Better I/O BW One Bodhi daemon per user process One Bodhi daemon per analysis node 25 1-GB MB 20 GB/s MB 2-MB GB/s Application read processes per node Application read processes per node
32 Efficiency II: Comparison w. NFS/PFS NFS (v3) on separate enterprise storage servers Dual quad-core 2.8-GHz Opteron processors, 16 GB memory, 48 SATA disks organized in RAID 6 Four 1 GigE connection to the core switch of the 100-node cluster PVFS2 (2.8.1) on the same 100 analysis nodes I/O (data) server and metadata server on all nodes File I/O performed via the PVFS2 Linux kernel interface Hadoop/HDFS (0.19.1) on the same 100 nodes Data stored via HDFS s C library interface, block sizes set to be equal to file sizes, three replications per file Data accessed via a read-only Hadoop MapReduce Java program (with a number of best-effort optimizations) 32
33 Efficiency II: Outperforming NFS/PFS I/O bandwidth of reading files of different sizes 25 NFS PVFS2 Hadoop/HDFS Zazen 20 GB/s MB 64 MB 256 MB 1 GB File size for read 33
34 34 Efficiency II: Outperforming NFS/PFS Time to read one terabyte of data 1E+05 1E+04 NFS PVFS2 Hadoop/HDFS Zazen Time (s) 1E+03 1E+02 1E+01 2 MB 64 MB 256 MB 1 GB File size for read
35 35 Read Perf. under Writes (1GB/s) File size for writes No writes 1 GB files 256 MB files 64 MB files 2 MB files Normalized performance MB 64 MB 256 MB 1 GB File size for reads
36 End-to-End Performance A HiMach analysis program called water residence on 100 nodes 2.5 million small frame files (430 KB each) 10,000 Time (s) 1, NFS Zazen Memory Application processes per node 36
37 Robustness Worst case execution time is T(1 + δ (B/b) ) The water-residence program re-executed with varying number of nodes powered off 1,600 1,400 1,200 Theoretical worst case Actual running time Time (s) 1, % 10% 20% 30% 40% 50% Node failure rate 37
38 Summary Zazen accelerates order-independent, parallel data access by (1) actively caching simulation output, and (2) executing an efficient distributed consensus protocol. Simple and robust Scalable on a large number of nodes Much higher performance than NFS/PFS * Applicable to a certain class of timedependent simulation datasets * 38
Fault-Tolerant Parallel Analysis of Millisecond-scale Molecular Dynamics Trajectories. Tiankai Tu D. E. Shaw Research
 Fault-Tolerant Parallel Analysis of Millisecond-scale Molecular Dynamics Trajectories Tiankai Tu D. E. Shaw Research Anton: A Special-Purpose Parallel Machine for MD Simulations 2 Routine Data Analysis
Fault-Tolerant Parallel Analysis of Millisecond-scale Molecular Dynamics Trajectories Tiankai Tu D. E. Shaw Research Anton: A Special-Purpose Parallel Machine for MD Simulations 2 Routine Data Analysis
Accelerating Parallel Analysis of Scientific Simulation Data via Zazen
 Accelerating Parallel Analysis of Scientific Simulation Data via Zazen Tiankai Tu, 1 Charles A. Rendleman, 1 Patrick J. Miller, 1 Federico Sacerdoti, 1 Ron O. Dror, 1 and David. E. Shaw 1,2,3 1. D. E.
Accelerating Parallel Analysis of Scientific Simulation Data via Zazen Tiankai Tu, 1 Charles A. Rendleman, 1 Patrick J. Miller, 1 Federico Sacerdoti, 1 Ron O. Dror, 1 and David. E. Shaw 1,2,3 1. D. E.
Crossing the Chasm: Sneaking a parallel file system into Hadoop
 Crossing the Chasm: Sneaking a parallel file system into Hadoop Wittawat Tantisiriroj Swapnil Patil, Garth Gibson PARALLEL DATA LABORATORY Carnegie Mellon University In this work Compare and contrast large
Crossing the Chasm: Sneaking a parallel file system into Hadoop Wittawat Tantisiriroj Swapnil Patil, Garth Gibson PARALLEL DATA LABORATORY Carnegie Mellon University In this work Compare and contrast large
Crossing the Chasm: Sneaking a parallel file system into Hadoop
 Crossing the Chasm: Sneaking a parallel file system into Hadoop Wittawat Tantisiriroj Swapnil Patil, Garth Gibson PARALLEL DATA LABORATORY Carnegie Mellon University In this work Compare and contrast large
Crossing the Chasm: Sneaking a parallel file system into Hadoop Wittawat Tantisiriroj Swapnil Patil, Garth Gibson PARALLEL DATA LABORATORY Carnegie Mellon University In this work Compare and contrast large
Sun Lustre Storage System Simplifying and Accelerating Lustre Deployments
 Sun Lustre Storage System Simplifying and Accelerating Lustre Deployments Torben Kling-Petersen, PhD Presenter s Name Principle Field Title andengineer Division HPC &Cloud LoB SunComputing Microsystems
Sun Lustre Storage System Simplifying and Accelerating Lustre Deployments Torben Kling-Petersen, PhD Presenter s Name Principle Field Title andengineer Division HPC &Cloud LoB SunComputing Microsystems
Parallel File Systems for HPC
 Introduction to Scuola Internazionale Superiore di Studi Avanzati Trieste November 2008 Advanced School in High Performance and Grid Computing Outline 1 The Need for 2 The File System 3 Cluster & A typical
Introduction to Scuola Internazionale Superiore di Studi Avanzati Trieste November 2008 Advanced School in High Performance and Grid Computing Outline 1 The Need for 2 The File System 3 Cluster & A typical
The Hadoop Distributed File System Konstantin Shvachko Hairong Kuang Sanjay Radia Robert Chansler
 The Hadoop Distributed File System Konstantin Shvachko Hairong Kuang Sanjay Radia Robert Chansler MSST 10 Hadoop in Perspective Hadoop scales computation capacity, storage capacity, and I/O bandwidth by
The Hadoop Distributed File System Konstantin Shvachko Hairong Kuang Sanjay Radia Robert Chansler MSST 10 Hadoop in Perspective Hadoop scales computation capacity, storage capacity, and I/O bandwidth by
MOHA: Many-Task Computing Framework on Hadoop
 Apache: Big Data North America 2017 @ Miami MOHA: Many-Task Computing Framework on Hadoop Soonwook Hwang Korea Institute of Science and Technology Information May 18, 2017 Table of Contents Introduction
Apache: Big Data North America 2017 @ Miami MOHA: Many-Task Computing Framework on Hadoop Soonwook Hwang Korea Institute of Science and Technology Information May 18, 2017 Table of Contents Introduction
CA485 Ray Walshe Google File System
 Google File System Overview Google File System is scalable, distributed file system on inexpensive commodity hardware that provides: Fault Tolerance File system runs on hundreds or thousands of storage
Google File System Overview Google File System is scalable, distributed file system on inexpensive commodity hardware that provides: Fault Tolerance File system runs on hundreds or thousands of storage
REMEM: REmote MEMory as Checkpointing Storage
 REMEM: REmote MEMory as Checkpointing Storage Hui Jin Illinois Institute of Technology Xian-He Sun Illinois Institute of Technology Yong Chen Oak Ridge National Laboratory Tao Ke Illinois Institute of
REMEM: REmote MEMory as Checkpointing Storage Hui Jin Illinois Institute of Technology Xian-He Sun Illinois Institute of Technology Yong Chen Oak Ridge National Laboratory Tao Ke Illinois Institute of
Shared Parallel Filesystems in Heterogeneous Linux Multi-Cluster Environments
 LCI HPC Revolution 2005 26 April 2005 Shared Parallel Filesystems in Heterogeneous Linux Multi-Cluster Environments Matthew Woitaszek matthew.woitaszek@colorado.edu Collaborators Organizations National
LCI HPC Revolution 2005 26 April 2005 Shared Parallel Filesystems in Heterogeneous Linux Multi-Cluster Environments Matthew Woitaszek matthew.woitaszek@colorado.edu Collaborators Organizations National
High Performance Computing (HPC) Prepared By: Abdussamad Muntahi Muhammad Rahman
 Prepared By: Abdussamad Muntahi Muhammad Rahman") High Performance Computing (HPC) Prepared By: Abdussamad Muntahi Muhammad Rahman 1 2 Introduction to High Performance Computing (HPC) Introduction High-speed computing. Originally pertaining only to supercomputers
High Performance Computing (HPC) Prepared By: Abdussamad Muntahi Muhammad Rahman 1 2 Introduction to High Performance Computing (HPC) Introduction High-speed computing. Originally pertaining only to supercomputers
EMC Backup and Recovery for Microsoft SQL Server
 EMC Backup and Recovery for Microsoft SQL Server Enabled by Microsoft SQL Native Backup Reference Copyright 2010 EMC Corporation. All rights reserved. Published February, 2010 EMC believes the information
EMC Backup and Recovery for Microsoft SQL Server Enabled by Microsoft SQL Native Backup Reference Copyright 2010 EMC Corporation. All rights reserved. Published February, 2010 EMC believes the information
Hadoop File System S L I D E S M O D I F I E D F R O M P R E S E N T A T I O N B Y B. R A M A M U R T H Y 11/15/2017
 Hadoop File System 1 S L I D E S M O D I F I E D F R O M P R E S E N T A T I O N B Y B. R A M A M U R T H Y Moving Computation is Cheaper than Moving Data Motivation: Big Data! What is BigData? - Google
Hadoop File System 1 S L I D E S M O D I F I E D F R O M P R E S E N T A T I O N B Y B. R A M A M U R T H Y Moving Computation is Cheaper than Moving Data Motivation: Big Data! What is BigData? - Google
Cloud Computing and Hadoop Distributed File System. UCSB CS170, Spring 2018
 Cloud Computing and Hadoop Distributed File System UCSB CS70, Spring 08 Cluster Computing Motivations Large-scale data processing on clusters Scan 000 TB on node @ 00 MB/s = days Scan on 000-node cluster
Cloud Computing and Hadoop Distributed File System UCSB CS70, Spring 08 Cluster Computing Motivations Large-scale data processing on clusters Scan 000 TB on node @ 00 MB/s = days Scan on 000-node cluster
High Performance Data Analytics for Numerical Simulations. Bruno Raffin DataMove
 High Performance Data Analytics for Numerical Simulations Bruno Raffin DataMove bruno.raffin@inria.fr April 2016 About this Talk HPC for analyzing the results of large scale parallel numerical simulations
High Performance Data Analytics for Numerical Simulations Bruno Raffin DataMove bruno.raffin@inria.fr April 2016 About this Talk HPC for analyzing the results of large scale parallel numerical simulations
Distributed File Systems II
 Distributed File Systems II To do q Very-large scale: Google FS, Hadoop FS, BigTable q Next time: Naming things GFS A radically new environment NFS, etc. Independence Small Scale Variety of workloads Cooperation
Distributed File Systems II To do q Very-large scale: Google FS, Hadoop FS, BigTable q Next time: Naming things GFS A radically new environment NFS, etc. Independence Small Scale Variety of workloads Cooperation
The Fusion Distributed File System
 Slide 1 / 44 The Fusion Distributed File System Dongfang Zhao February 2015 Slide 2 / 44 Outline Introduction FusionFS System Architecture Metadata Management Data Movement Implementation Details Unique
Slide 1 / 44 The Fusion Distributed File System Dongfang Zhao February 2015 Slide 2 / 44 Outline Introduction FusionFS System Architecture Metadata Management Data Movement Implementation Details Unique
Coordinating Parallel HSM in Object-based Cluster Filesystems
 Coordinating Parallel HSM in Object-based Cluster Filesystems Dingshan He, Xianbo Zhang, David Du University of Minnesota Gary Grider Los Alamos National Lab Agenda Motivations Parallel archiving/retrieving
Coordinating Parallel HSM in Object-based Cluster Filesystems Dingshan He, Xianbo Zhang, David Du University of Minnesota Gary Grider Los Alamos National Lab Agenda Motivations Parallel archiving/retrieving
BeoLink.org. Design and build an inexpensive DFS. Fabrizio Manfredi Furuholmen. FrOSCon August 2008
 Design and build an inexpensive DFS Fabrizio Manfredi Furuholmen FrOSCon August 2008 Agenda Overview Introduction Old way openafs New way Hadoop CEPH Conclusion Overview Why Distributed File system? Handle
Design and build an inexpensive DFS Fabrizio Manfredi Furuholmen FrOSCon August 2008 Agenda Overview Introduction Old way openafs New way Hadoop CEPH Conclusion Overview Why Distributed File system? Handle
Structuring PLFS for Extensibility
 Structuring PLFS for Extensibility Chuck Cranor, Milo Polte, Garth Gibson PARALLEL DATA LABORATORY Carnegie Mellon University What is PLFS? Parallel Log Structured File System Interposed filesystem b/w
Structuring PLFS for Extensibility Chuck Cranor, Milo Polte, Garth Gibson PARALLEL DATA LABORATORY Carnegie Mellon University What is PLFS? Parallel Log Structured File System Interposed filesystem b/w
Xyratex ClusterStor6000 & OneStor
 Xyratex ClusterStor6000 & OneStor Proseminar Ein-/Ausgabe Stand der Wissenschaft von Tim Reimer Structure OneStor OneStorSP OneStorAP ''Green'' Advancements ClusterStor6000 About Scale-Out Storage Architecture
Xyratex ClusterStor6000 & OneStor Proseminar Ein-/Ausgabe Stand der Wissenschaft von Tim Reimer Structure OneStor OneStorSP OneStorAP ''Green'' Advancements ClusterStor6000 About Scale-Out Storage Architecture
Assessing performance in HP LeftHand SANs
 Assessing performance in HP LeftHand SANs HP LeftHand Starter, Virtualization, and Multi-Site SANs deliver reliable, scalable, and predictable performance White paper Introduction... 2 The advantages of
Assessing performance in HP LeftHand SANs HP LeftHand Starter, Virtualization, and Multi-Site SANs deliver reliable, scalable, and predictable performance White paper Introduction... 2 The advantages of
GFS: The Google File System
 GFS: The Google File System Brad Karp UCL Computer Science CS GZ03 / M030 24 th October 2014 Motivating Application: Google Crawl the whole web Store it all on one big disk Process users searches on one
GFS: The Google File System Brad Karp UCL Computer Science CS GZ03 / M030 24 th October 2014 Motivating Application: Google Crawl the whole web Store it all on one big disk Process users searches on one
CIS 601 Graduate Seminar. Dr. Sunnie S. Chung Dhruv Patel ( ) Kalpesh Sharma ( )
 Kalpesh Sharma ( )") Guide: CIS 601 Graduate Seminar Presented By: Dr. Sunnie S. Chung Dhruv Patel (2652790) Kalpesh Sharma (2660576) Introduction Background Parallel Data Warehouse (PDW) Hive MongoDB Client-side Shared SQL
Guide: CIS 601 Graduate Seminar Presented By: Dr. Sunnie S. Chung Dhruv Patel (2652790) Kalpesh Sharma (2660576) Introduction Background Parallel Data Warehouse (PDW) Hive MongoDB Client-side Shared SQL
DiskReduce: Making Room for More Data on DISCs. Wittawat Tantisiriroj
 DiskReduce: Making Room for More Data on DISCs Wittawat Tantisiriroj Lin Xiao, Bin Fan, and Garth Gibson PARALLEL DATA LABORATORY Carnegie Mellon University GFS/HDFS Triplication GFS & HDFS triplicate
DiskReduce: Making Room for More Data on DISCs Wittawat Tantisiriroj Lin Xiao, Bin Fan, and Garth Gibson PARALLEL DATA LABORATORY Carnegie Mellon University GFS/HDFS Triplication GFS & HDFS triplicate
W b b 2.0. = = Data Ex E pl p o l s o io i n
 Hypertable Doug Judd Zvents, Inc. Background Web 2.0 = Data Explosion Web 2.0 Mt. Web 2.0 Traditional Tools Don t Scale Well Designed for a single machine Typical scaling solutions ad-hoc manual/static
Hypertable Doug Judd Zvents, Inc. Background Web 2.0 = Data Explosion Web 2.0 Mt. Web 2.0 Traditional Tools Don t Scale Well Designed for a single machine Typical scaling solutions ad-hoc manual/static
Map-Reduce. Marco Mura 2010 March, 31th
 Map-Reduce Marco Mura (mura@di.unipi.it) 2010 March, 31th This paper is a note from the 2009-2010 course Strumenti di programmazione per sistemi paralleli e distribuiti and it s based by the lessons of
Map-Reduce Marco Mura (mura@di.unipi.it) 2010 March, 31th This paper is a note from the 2009-2010 course Strumenti di programmazione per sistemi paralleli e distribuiti and it s based by the lessons of
Introduction to Hadoop. Owen O Malley Yahoo!, Grid Team
 Introduction to Hadoop Owen O Malley Yahoo!, Grid Team owen@yahoo-inc.com Who Am I? Yahoo! Architect on Hadoop Map/Reduce Design, review, and implement features in Hadoop Working on Hadoop full time since
Introduction to Hadoop Owen O Malley Yahoo!, Grid Team owen@yahoo-inc.com Who Am I? Yahoo! Architect on Hadoop Map/Reduce Design, review, and implement features in Hadoop Working on Hadoop full time since
A Robust Cloud-based Service Architecture for Multimedia Streaming Using Hadoop
 A Robust Cloud-based Service Architecture for Multimedia Streaming Using Hadoop Myoungjin Kim 1, Seungho Han 1, Jongjin Jung 3, Hanku Lee 1,2,*, Okkyung Choi 2 1 Department of Internet and Multimedia Engineering,
A Robust Cloud-based Service Architecture for Multimedia Streaming Using Hadoop Myoungjin Kim 1, Seungho Han 1, Jongjin Jung 3, Hanku Lee 1,2,*, Okkyung Choi 2 1 Department of Internet and Multimedia Engineering,
Big Data Programming: an Introduction. Spring 2015, X. Zhang Fordham Univ.
 Big Data Programming: an Introduction Spring 2015, X. Zhang Fordham Univ. Outline What the course is about? scope Introduction to big data programming Opportunity and challenge of big data Origin of Hadoop
Big Data Programming: an Introduction Spring 2015, X. Zhang Fordham Univ. Outline What the course is about? scope Introduction to big data programming Opportunity and challenge of big data Origin of Hadoop
Evaluating Cloud Storage Strategies. James Bottomley; CTO, Server Virtualization
 Evaluating Cloud Storage Strategies James Bottomley; CTO, Server Virtualization Introduction to Storage Attachments: - Local (Direct cheap) SAS, SATA - Remote (SAN, NAS expensive) FC net Types - Block
Evaluating Cloud Storage Strategies James Bottomley; CTO, Server Virtualization Introduction to Storage Attachments: - Local (Direct cheap) SAS, SATA - Remote (SAN, NAS expensive) FC net Types - Block
called Hadoop Distribution file System (HDFS). HDFS is designed to run on clusters of commodity hardware and is capable of handling large files. A fil
. HDFS is designed to run on clusters of commodity hardware and is capable of handling large files. A fil") Parallel Genome-Wide Analysis With Central And Graphic Processing Units Muhamad Fitra Kacamarga mkacamarga@binus.edu James W. Baurley baurley@binus.edu Bens Pardamean bpardamean@binus.edu Abstract The
Parallel Genome-Wide Analysis With Central And Graphic Processing Units Muhamad Fitra Kacamarga mkacamarga@binus.edu James W. Baurley baurley@binus.edu Bens Pardamean bpardamean@binus.edu Abstract The
SGI Overview. HPC User Forum Dearborn, Michigan September 17 th, 2012
 SGI Overview HPC User Forum Dearborn, Michigan September 17 th, 2012 SGI Market Strategy HPC Commercial Scientific Modeling & Simulation Big Data Hadoop In-memory Analytics Archive Cloud Public Private
SGI Overview HPC User Forum Dearborn, Michigan September 17 th, 2012 SGI Market Strategy HPC Commercial Scientific Modeling & Simulation Big Data Hadoop In-memory Analytics Archive Cloud Public Private
Accelerating Big Data: Using SanDisk SSDs for Apache HBase Workloads
 WHITE PAPER Accelerating Big Data: Using SanDisk SSDs for Apache HBase Workloads December 2014 Western Digital Technologies, Inc. 951 SanDisk Drive, Milpitas, CA 95035 www.sandisk.com Table of Contents
WHITE PAPER Accelerating Big Data: Using SanDisk SSDs for Apache HBase Workloads December 2014 Western Digital Technologies, Inc. 951 SanDisk Drive, Milpitas, CA 95035 www.sandisk.com Table of Contents
MapReduce. U of Toronto, 2014
 MapReduce U of Toronto, 2014 http://www.google.org/flutrends/ca/ (2012) Average Searches Per Day: 5,134,000,000 2 Motivation Process lots of data Google processed about 24 petabytes of data per day in
MapReduce U of Toronto, 2014 http://www.google.org/flutrends/ca/ (2012) Average Searches Per Day: 5,134,000,000 2 Motivation Process lots of data Google processed about 24 petabytes of data per day in
Distributed Filesystem
 Distributed Filesystem 1 How do we get data to the workers? NAS Compute Nodes SAN 2 Distributing Code! Don t move data to workers move workers to the data! - Store data on the local disks of nodes in the
Distributed Filesystem 1 How do we get data to the workers? NAS Compute Nodes SAN 2 Distributing Code! Don t move data to workers move workers to the data! - Store data on the local disks of nodes in the
Hadoop/MapReduce Computing Paradigm
 Hadoop/Reduce Computing Paradigm 1 Large-Scale Data Analytics Reduce computing paradigm (E.g., Hadoop) vs. Traditional database systems vs. Database Many enterprises are turning to Hadoop Especially applications
Hadoop/Reduce Computing Paradigm 1 Large-Scale Data Analytics Reduce computing paradigm (E.g., Hadoop) vs. Traditional database systems vs. Database Many enterprises are turning to Hadoop Especially applications
An Introduction to GPFS
 IBM High Performance Computing July 2006 An Introduction to GPFS gpfsintro072506.doc Page 2 Contents Overview 2 What is GPFS? 3 The file system 3 Application interfaces 4 Performance and scalability 4
IBM High Performance Computing July 2006 An Introduction to GPFS gpfsintro072506.doc Page 2 Contents Overview 2 What is GPFS? 3 The file system 3 Application interfaces 4 Performance and scalability 4
TITLE: PRE-REQUISITE THEORY. 1. Introduction to Hadoop. 2. Cluster. Implement sort algorithm and run it using HADOOP
 TITLE: Implement sort algorithm and run it using HADOOP PRE-REQUISITE Preliminary knowledge of clusters and overview of Hadoop and its basic functionality. THEORY 1. Introduction to Hadoop The Apache Hadoop
TITLE: Implement sort algorithm and run it using HADOOP PRE-REQUISITE Preliminary knowledge of clusters and overview of Hadoop and its basic functionality. THEORY 1. Introduction to Hadoop The Apache Hadoop
WHITE PAPER AGILOFT SCALABILITY AND REDUNDANCY
 WHITE PAPER AGILOFT SCALABILITY AND REDUNDANCY Table of Contents Introduction 3 Performance on Hosted Server 3 Figure 1: Real World Performance 3 Benchmarks 3 System configuration used for benchmarks 3
WHITE PAPER AGILOFT SCALABILITY AND REDUNDANCY Table of Contents Introduction 3 Performance on Hosted Server 3 Figure 1: Real World Performance 3 Benchmarks 3 System configuration used for benchmarks 3
NFS, GPFS, PVFS, Lustre Batch-scheduled systems: Clusters, Grids, and Supercomputers Programming paradigm: HPC, MTC, and HTC
 Segregated storage and compute NFS, GPFS, PVFS, Lustre Batch-scheduled systems: Clusters, Grids, and Supercomputers Programming paradigm: HPC, MTC, and HTC Co-located storage and compute HDFS, GFS Data
Segregated storage and compute NFS, GPFS, PVFS, Lustre Batch-scheduled systems: Clusters, Grids, and Supercomputers Programming paradigm: HPC, MTC, and HTC Co-located storage and compute HDFS, GFS Data
IME (Infinite Memory Engine) Extreme Application Acceleration & Highly Efficient I/O Provisioning
 Extreme Application Acceleration & Highly Efficient I/O Provisioning") IME (Infinite Memory Engine) Extreme Application Acceleration & Highly Efficient I/O Provisioning September 22 nd 2015 Tommaso Cecchi 2 What is IME? This breakthrough, software defined storage application
IME (Infinite Memory Engine) Extreme Application Acceleration & Highly Efficient I/O Provisioning September 22 nd 2015 Tommaso Cecchi 2 What is IME? This breakthrough, software defined storage application
MATE-EC2: A Middleware for Processing Data with Amazon Web Services
 MATE-EC2: A Middleware for Processing Data with Amazon Web Services Tekin Bicer David Chiu* and Gagan Agrawal Department of Compute Science and Engineering Ohio State University * School of Engineering
MATE-EC2: A Middleware for Processing Data with Amazon Web Services Tekin Bicer David Chiu* and Gagan Agrawal Department of Compute Science and Engineering Ohio State University * School of Engineering
Ioan Raicu. Everyone else. More information at: Background? What do you want to get out of this course?
 Ioan Raicu More information at: http://www.cs.iit.edu/~iraicu/ Everyone else Background? What do you want to get out of this course? 2 Data Intensive Computing is critical to advancing modern science Applies
Ioan Raicu More information at: http://www.cs.iit.edu/~iraicu/ Everyone else Background? What do you want to get out of this course? 2 Data Intensive Computing is critical to advancing modern science Applies
The advantages of architecting an open iscsi SAN
 Storage as it should be The advantages of architecting an open iscsi SAN Pete Caviness Lefthand Networks, 5500 Flatiron Parkway, Boulder CO 80301, Ph: +1-303-217-9043, FAX: +1-303-217-9020 e-mail: pete.caviness@lefthandnetworks.com
Storage as it should be The advantages of architecting an open iscsi SAN Pete Caviness Lefthand Networks, 5500 Flatiron Parkway, Boulder CO 80301, Ph: +1-303-217-9043, FAX: +1-303-217-9020 e-mail: pete.caviness@lefthandnetworks.com
Write a technical report Present your results Write a workshop/conference paper (optional) Could be a real system, simulation and/or theoretical
 Could be a real system, simulation and/or theoretical") Identify a problem Review approaches to the problem Propose a novel approach to the problem Define, design, prototype an implementation to evaluate your approach Could be a real system, simulation and/or
Identify a problem Review approaches to the problem Propose a novel approach to the problem Define, design, prototype an implementation to evaluate your approach Could be a real system, simulation and/or
High-Performance Lustre with Maximum Data Assurance
 High-Performance Lustre with Maximum Data Assurance Silicon Graphics International Corp. 900 North McCarthy Blvd. Milpitas, CA 95035 Disclaimer and Copyright Notice The information presented here is meant
High-Performance Lustre with Maximum Data Assurance Silicon Graphics International Corp. 900 North McCarthy Blvd. Milpitas, CA 95035 Disclaimer and Copyright Notice The information presented here is meant
Distributed Systems 16. Distributed File Systems II
 Distributed Systems 16. Distributed File Systems II Paul Krzyzanowski pxk@cs.rutgers.edu 1 Review NFS RPC-based access AFS Long-term caching CODA Read/write replication & disconnected operation DFS AFS
Distributed Systems 16. Distributed File Systems II Paul Krzyzanowski pxk@cs.rutgers.edu 1 Review NFS RPC-based access AFS Long-term caching CODA Read/write replication & disconnected operation DFS AFS
Massive Data Processing on the Acxiom Cluster Testbed
 Clemson University TigerPrints Presentations School of Computing 8-2001 Massive Data Processing on the Acxiom Cluster Testbed Amy Apon Clemson University, aapon@clemson.edu Pawel Wolinski University of
Clemson University TigerPrints Presentations School of Computing 8-2001 Massive Data Processing on the Acxiom Cluster Testbed Amy Apon Clemson University, aapon@clemson.edu Pawel Wolinski University of
LS-DYNA Best-Practices: Networking, MPI and Parallel File System Effect on LS-DYNA Performance
 11 th International LS-DYNA Users Conference Computing Technology LS-DYNA Best-Practices: Networking, MPI and Parallel File System Effect on LS-DYNA Performance Gilad Shainer 1, Tong Liu 2, Jeff Layton
11 th International LS-DYNA Users Conference Computing Technology LS-DYNA Best-Practices: Networking, MPI and Parallel File System Effect on LS-DYNA Performance Gilad Shainer 1, Tong Liu 2, Jeff Layton
Cluster Setup and Distributed File System
 Cluster Setup and Distributed File System R&D Storage for the R&D Storage Group People Involved Gaetano Capasso - INFN-Naples Domenico Del Prete INFN-Naples Diacono Domenico INFN-Bari Donvito Giacinto
Cluster Setup and Distributed File System R&D Storage for the R&D Storage Group People Involved Gaetano Capasso - INFN-Naples Domenico Del Prete INFN-Naples Diacono Domenico INFN-Bari Donvito Giacinto
CSE 124: Networked Services Lecture-17
 Fall 2010 CSE 124: Networked Services Lecture-17 Instructor: B. S. Manoj, Ph.D http://cseweb.ucsd.edu/classes/fa10/cse124 11/30/2010 CSE 124 Networked Services Fall 2010 1 Updates PlanetLab experiments
Fall 2010 CSE 124: Networked Services Lecture-17 Instructor: B. S. Manoj, Ph.D http://cseweb.ucsd.edu/classes/fa10/cse124 11/30/2010 CSE 124 Networked Services Fall 2010 1 Updates PlanetLab experiments
Flat Datacenter Storage. Edmund B. Nightingale, Jeremy Elson, et al. 6.S897
 Flat Datacenter Storage Edmund B. Nightingale, Jeremy Elson, et al. 6.S897 Motivation Imagine a world with flat data storage Simple, Centralized, and easy to program Unfortunately, datacenter networks
Flat Datacenter Storage Edmund B. Nightingale, Jeremy Elson, et al. 6.S897 Motivation Imagine a world with flat data storage Simple, Centralized, and easy to program Unfortunately, datacenter networks
朱义普. Resolving High Performance Computing and Big Data Application Bottlenecks with Application-Defined Flash Acceleration. Director, North Asia, HPC
 October 28, 2013 Resolving High Performance Computing and Big Data Application Bottlenecks with Application-Defined Flash Acceleration 朱义普 Director, North Asia, HPC DDN Storage Vendor for HPC & Big Data
October 28, 2013 Resolving High Performance Computing and Big Data Application Bottlenecks with Application-Defined Flash Acceleration 朱义普 Director, North Asia, HPC DDN Storage Vendor for HPC & Big Data
EsgynDB Enterprise 2.0 Platform Reference Architecture
 EsgynDB Enterprise 2.0 Platform Reference Architecture This document outlines a Platform Reference Architecture for EsgynDB Enterprise, built on Apache Trafodion (Incubating) implementation with licensed
EsgynDB Enterprise 2.0 Platform Reference Architecture This document outlines a Platform Reference Architecture for EsgynDB Enterprise, built on Apache Trafodion (Incubating) implementation with licensed
W H I T E P A P E R. Comparison of Storage Protocol Performance in VMware vsphere 4
 W H I T E P A P E R Comparison of Storage Protocol Performance in VMware vsphere 4 Table of Contents Introduction................................................................... 3 Executive Summary............................................................
W H I T E P A P E R Comparison of Storage Protocol Performance in VMware vsphere 4 Table of Contents Introduction................................................................... 3 Executive Summary............................................................
BigData and Map Reduce VITMAC03
 BigData and Map Reduce VITMAC03 1 Motivation Process lots of data Google processed about 24 petabytes of data per day in 2009. A single machine cannot serve all the data You need a distributed system to
BigData and Map Reduce VITMAC03 1 Motivation Process lots of data Google processed about 24 petabytes of data per day in 2009. A single machine cannot serve all the data You need a distributed system to
Performance Optimizations via Connect-IB and Dynamically Connected Transport Service for Maximum Performance on LS-DYNA
 Performance Optimizations via Connect-IB and Dynamically Connected Transport Service for Maximum Performance on LS-DYNA Pak Lui, Gilad Shainer, Brian Klaff Mellanox Technologies Abstract From concept to
Performance Optimizations via Connect-IB and Dynamically Connected Transport Service for Maximum Performance on LS-DYNA Pak Lui, Gilad Shainer, Brian Klaff Mellanox Technologies Abstract From concept to
Efficiency Evaluation of the Input/Output System on Computer Clusters
 Efficiency Evaluation of the Input/Output System on Computer Clusters Sandra Méndez, Dolores Rexachs and Emilio Luque Computer Architecture and Operating System Department (CAOS) Universitat Autònoma de
Efficiency Evaluation of the Input/Output System on Computer Clusters Sandra Méndez, Dolores Rexachs and Emilio Luque Computer Architecture and Operating System Department (CAOS) Universitat Autònoma de
System that permanently stores data Usually layered on top of a lower-level physical storage medium Divided into logical units called files
 System that permanently stores data Usually layered on top of a lower-level physical storage medium Divided into logical units called files Addressable by a filename ( foo.txt ) Usually supports hierarchical
System that permanently stores data Usually layered on top of a lower-level physical storage medium Divided into logical units called files Addressable by a filename ( foo.txt ) Usually supports hierarchical
Next-Generation Cloud Platform
 Next-Generation Cloud Platform Jangwoo Kim Jun 24, 2013 E-mail: jangwoo@postech.ac.kr High Performance Computing Lab Department of Computer Science & Engineering Pohang University of Science and Technology
Next-Generation Cloud Platform Jangwoo Kim Jun 24, 2013 E-mail: jangwoo@postech.ac.kr High Performance Computing Lab Department of Computer Science & Engineering Pohang University of Science and Technology
System Requirements. PREEvision. System requirements and deployment scenarios Version 7.0 English
 System Requirements PREEvision System and deployment scenarios Version 7.0 English Imprint Vector Informatik GmbH Ingersheimer Straße 24 70499 Stuttgart, Germany Vector reserves the right to modify any
System Requirements PREEvision System and deployment scenarios Version 7.0 English Imprint Vector Informatik GmbH Ingersheimer Straße 24 70499 Stuttgart, Germany Vector reserves the right to modify any
What is the maximum file size you have dealt so far? Movies/Files/Streaming video that you have used? What have you observed?
 Simple to start What is the maximum file size you have dealt so far? Movies/Files/Streaming video that you have used? What have you observed? What is the maximum download speed you get? Simple computation
Simple to start What is the maximum file size you have dealt so far? Movies/Files/Streaming video that you have used? What have you observed? What is the maximum download speed you get? Simple computation
CSE 124: Networked Services Lecture-16
 Fall 2010 CSE 124: Networked Services Lecture-16 Instructor: B. S. Manoj, Ph.D http://cseweb.ucsd.edu/classes/fa10/cse124 11/23/2010 CSE 124 Networked Services Fall 2010 1 Updates PlanetLab experiments
Fall 2010 CSE 124: Networked Services Lecture-16 Instructor: B. S. Manoj, Ph.D http://cseweb.ucsd.edu/classes/fa10/cse124 11/23/2010 CSE 124 Networked Services Fall 2010 1 Updates PlanetLab experiments
The Google File System. Alexandru Costan
 1 The Google File System Alexandru Costan Actions on Big Data 2 Storage Analysis Acquisition Handling the data stream Data structured unstructured semi-structured Results Transactions Outline File systems
1 The Google File System Alexandru Costan Actions on Big Data 2 Storage Analysis Acquisition Handling the data stream Data structured unstructured semi-structured Results Transactions Outline File systems
PREEvision System Requirements. Version 9.0 English
 PREEvision System Requirements Version 9.0 English Imprint Vector Informatik GmbH Ingersheimer Straße 24 70499 Stuttgart, Germany Vector reserves the right to modify any information and/or data in this
PREEvision System Requirements Version 9.0 English Imprint Vector Informatik GmbH Ingersheimer Straße 24 70499 Stuttgart, Germany Vector reserves the right to modify any information and/or data in this
Datura The new HPC-Plant at Albert Einstein Institute
 Datura The new HPC-Plant at Albert Einstein Institute Nico Budewitz Max Planck Institue for Gravitational Physics, Germany Cluster Day, 2011 Outline 1 History HPC-Plants at AEI -2009 Peyote, Lagavulin,
Datura The new HPC-Plant at Albert Einstein Institute Nico Budewitz Max Planck Institue for Gravitational Physics, Germany Cluster Day, 2011 Outline 1 History HPC-Plants at AEI -2009 Peyote, Lagavulin,
WHITEPAPER. Improve Hadoop Performance with Memblaze PBlaze SSD
 Improve Hadoop Performance with Memblaze PBlaze SSD Improve Hadoop Performance with Memblaze PBlaze SSD Exclusive Summary We live in the data age. It s not easy to measure the total volume of data stored
Improve Hadoop Performance with Memblaze PBlaze SSD Improve Hadoop Performance with Memblaze PBlaze SSD Exclusive Summary We live in the data age. It s not easy to measure the total volume of data stored
SMCCSE: PaaS Platform for processing large amounts of social media
 KSII The first International Conference on Internet (ICONI) 2011, December 2011 1 Copyright c 2011 KSII SMCCSE: PaaS Platform for processing large amounts of social media Myoungjin Kim 1, Hanku Lee 2 and
KSII The first International Conference on Internet (ICONI) 2011, December 2011 1 Copyright c 2011 KSII SMCCSE: PaaS Platform for processing large amounts of social media Myoungjin Kim 1, Hanku Lee 2 and
Bigtable. A Distributed Storage System for Structured Data. Presenter: Yunming Zhang Conglong Li. Saturday, September 21, 13
 Bigtable A Distributed Storage System for Structured Data Presenter: Yunming Zhang Conglong Li References SOCC 2010 Key Note Slides Jeff Dean Google Introduction to Distributed Computing, Winter 2008 University
Bigtable A Distributed Storage System for Structured Data Presenter: Yunming Zhang Conglong Li References SOCC 2010 Key Note Slides Jeff Dean Google Introduction to Distributed Computing, Winter 2008 University
Google File System. Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung Google fall DIP Heerak lim, Donghun Koo
 Google File System Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung Google 2017 fall DIP Heerak lim, Donghun Koo 1 Agenda Introduction Design overview Systems interactions Master operation Fault tolerance
Google File System Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung Google 2017 fall DIP Heerak lim, Donghun Koo 1 Agenda Introduction Design overview Systems interactions Master operation Fault tolerance
A GPFS Primer October 2005
 A Primer October 2005 Overview This paper describes (General Parallel File System) Version 2, Release 3 for AIX 5L and Linux. It provides an overview of key concepts which should be understood by those
A Primer October 2005 Overview This paper describes (General Parallel File System) Version 2, Release 3 for AIX 5L and Linux. It provides an overview of key concepts which should be understood by those
Enabling Active Storage on Parallel I/O Software Stacks. Seung Woo Son Mathematics and Computer Science Division
 Enabling Active Storage on Parallel I/O Software Stacks Seung Woo Son sson@mcs.anl.gov Mathematics and Computer Science Division MSST 2010, Incline Village, NV May 7, 2010 Performing analysis on large
Enabling Active Storage on Parallel I/O Software Stacks Seung Woo Son sson@mcs.anl.gov Mathematics and Computer Science Division MSST 2010, Incline Village, NV May 7, 2010 Performing analysis on large
BIG DATA AND HADOOP ON THE ZFS STORAGE APPLIANCE
 BIG DATA AND HADOOP ON THE ZFS STORAGE APPLIANCE BRETT WENINGER, MANAGING DIRECTOR 10/21/2014 ADURANT APPROACH TO BIG DATA Align to Un/Semi-structured Data Instead of Big Scale out will become Big Greatest
BIG DATA AND HADOOP ON THE ZFS STORAGE APPLIANCE BRETT WENINGER, MANAGING DIRECTOR 10/21/2014 ADURANT APPROACH TO BIG DATA Align to Un/Semi-structured Data Instead of Big Scale out will become Big Greatest
Big Table. Google s Storage Choice for Structured Data. Presented by Group E - Dawei Yang - Grace Ramamoorthy - Patrick O Sullivan - Rohan Singla
 Big Table Google s Storage Choice for Structured Data Presented by Group E - Dawei Yang - Grace Ramamoorthy - Patrick O Sullivan - Rohan Singla Bigtable: Introduction Resembles a database. Does not support
Big Table Google s Storage Choice for Structured Data Presented by Group E - Dawei Yang - Grace Ramamoorthy - Patrick O Sullivan - Rohan Singla Bigtable: Introduction Resembles a database. Does not support
System Requirements. PREEvision. System requirements and deployment scenarios Version 7.0 English
 System Requirements PREEvision System and deployment scenarios Version 7.0 English Imprint Vector Informatik GmbH Ingersheimer Straße 24 70499 Stuttgart, Germany Vector reserves the right to modify any
System Requirements PREEvision System and deployment scenarios Version 7.0 English Imprint Vector Informatik GmbH Ingersheimer Straße 24 70499 Stuttgart, Germany Vector reserves the right to modify any
CSE 124: Networked Services Fall 2009 Lecture-19
 CSE 124: Networked Services Fall 2009 Lecture-19 Instructor: B. S. Manoj, Ph.D http://cseweb.ucsd.edu/classes/fa09/cse124 Some of these slides are adapted from various sources/individuals including but
CSE 124: Networked Services Fall 2009 Lecture-19 Instructor: B. S. Manoj, Ph.D http://cseweb.ucsd.edu/classes/fa09/cse124 Some of these slides are adapted from various sources/individuals including but
Evaluating Algorithms for Shared File Pointer Operations in MPI I/O
 Evaluating Algorithms for Shared File Pointer Operations in MPI I/O Ketan Kulkarni and Edgar Gabriel Parallel Software Technologies Laboratory, Department of Computer Science, University of Houston {knkulkarni,gabriel}@cs.uh.edu
Evaluating Algorithms for Shared File Pointer Operations in MPI I/O Ketan Kulkarni and Edgar Gabriel Parallel Software Technologies Laboratory, Department of Computer Science, University of Houston {knkulkarni,gabriel}@cs.uh.edu
Cloud Programming. Programming Environment Oct 29, 2015 Osamu Tatebe
 Cloud Programming Programming Environment Oct 29, 2015 Osamu Tatebe Cloud Computing Only required amount of CPU and storage can be used anytime from anywhere via network Availability, throughput, reliability
Cloud Programming Programming Environment Oct 29, 2015 Osamu Tatebe Cloud Computing Only required amount of CPU and storage can be used anytime from anywhere via network Availability, throughput, reliability
NAMD Performance Benchmark and Profiling. January 2015
 NAMD Performance Benchmark and Profiling January 2015 2 Note The following research was performed under the HPC Advisory Council activities Participating vendors: Intel, Dell, Mellanox Compute resource
NAMD Performance Benchmark and Profiling January 2015 2 Note The following research was performed under the HPC Advisory Council activities Participating vendors: Intel, Dell, Mellanox Compute resource
Data Management. Parallel Filesystems. Dr David Henty HPC Training and Support
 Data Management Dr David Henty HPC Training and Support d.henty@epcc.ed.ac.uk +44 131 650 5960 Overview Lecture will cover Why is IO difficult Why is parallel IO even worse Lustre GPFS Performance on ARCHER
Data Management Dr David Henty HPC Training and Support d.henty@epcc.ed.ac.uk +44 131 650 5960 Overview Lecture will cover Why is IO difficult Why is parallel IO even worse Lustre GPFS Performance on ARCHER
Introduction to Hadoop and MapReduce
 Introduction to Hadoop and MapReduce Antonino Virgillito THE CONTRACTOR IS ACTING UNDER A FRAMEWORK CONTRACT CONCLUDED WITH THE COMMISSION Large-scale Computation Traditional solutions for computing large
Introduction to Hadoop and MapReduce Antonino Virgillito THE CONTRACTOR IS ACTING UNDER A FRAMEWORK CONTRACT CONCLUDED WITH THE COMMISSION Large-scale Computation Traditional solutions for computing large
ViewBox. Integrating Local File Systems with Cloud Storage Services. Yupu Zhang +, Chris Dragga + *, Andrea Arpaci-Dusseau +, Remzi Arpaci-Dusseau +
 ViewBox Integrating Local File Systems with Cloud Storage Services Yupu Zhang +, Chris Dragga + *, Andrea Arpaci-Dusseau +, Remzi Arpaci-Dusseau + + University of Wisconsin Madison *NetApp, Inc. 5/16/2014
ViewBox Integrating Local File Systems with Cloud Storage Services Yupu Zhang +, Chris Dragga + *, Andrea Arpaci-Dusseau +, Remzi Arpaci-Dusseau + + University of Wisconsin Madison *NetApp, Inc. 5/16/2014
Divide & Recombine with Tessera: Analyzing Larger and More Complex Data. tessera.io
 1 Divide & Recombine with Tessera: Analyzing Larger and More Complex Data tessera.io The D&R Framework Computationally, this is a very simple. 2 Division a division method specified by the analyst divides
1 Divide & Recombine with Tessera: Analyzing Larger and More Complex Data tessera.io The D&R Framework Computationally, this is a very simple. 2 Division a division method specified by the analyst divides
Deploy a High-Performance Database Solution: Cisco UCS B420 M4 Blade Server with Fusion iomemory PX600 Using Oracle Database 12c
 White Paper Deploy a High-Performance Database Solution: Cisco UCS B420 M4 Blade Server with Fusion iomemory PX600 Using Oracle Database 12c What You Will Learn This document demonstrates the benefits
White Paper Deploy a High-Performance Database Solution: Cisco UCS B420 M4 Blade Server with Fusion iomemory PX600 Using Oracle Database 12c What You Will Learn This document demonstrates the benefits
CS / Cloud Computing. Recitation 3 September 9 th & 11 th, 2014
 CS15-319 / 15-619 Cloud Computing Recitation 3 September 9 th & 11 th, 2014 Overview Last Week s Reflection --Project 1.1, Quiz 1, Unit 1 This Week s Schedule --Unit2 (module 3 & 4), Project 1.2 Questions
CS15-319 / 15-619 Cloud Computing Recitation 3 September 9 th & 11 th, 2014 Overview Last Week s Reflection --Project 1.1, Quiz 1, Unit 1 This Week s Schedule --Unit2 (module 3 & 4), Project 1.2 Questions
IBM InfoSphere Streams v4.0 Performance Best Practices
 Henry May IBM InfoSphere Streams v4.0 Performance Best Practices Abstract Streams v4.0 introduces powerful high availability features. Leveraging these requires careful consideration of performance related
Henry May IBM InfoSphere Streams v4.0 Performance Best Practices Abstract Streams v4.0 introduces powerful high availability features. Leveraging these requires careful consideration of performance related
EMC SYMMETRIX VMAX 40K SYSTEM
 EMC SYMMETRIX VMAX 40K SYSTEM The EMC Symmetrix VMAX 40K storage system delivers unmatched scalability and high availability for the enterprise while providing market-leading functionality to accelerate
EMC SYMMETRIX VMAX 40K SYSTEM The EMC Symmetrix VMAX 40K storage system delivers unmatched scalability and high availability for the enterprise while providing market-leading functionality to accelerate
Benchmark of a Cubieboard cluster
 Benchmark of a Cubieboard cluster M J Schnepf, D Gudu, B Rische, M Fischer, C Jung and M Hardt Steinbuch Centre for Computing, Karlsruhe Institute of Technology, Karlsruhe, Germany E-mail: matthias.schnepf@student.kit.edu,
Benchmark of a Cubieboard cluster M J Schnepf, D Gudu, B Rische, M Fischer, C Jung and M Hardt Steinbuch Centre for Computing, Karlsruhe Institute of Technology, Karlsruhe, Germany E-mail: matthias.schnepf@student.kit.edu,
Dell Reference Configuration for Large Oracle Database Deployments on Dell EqualLogic Storage
 Dell Reference Configuration for Large Oracle Database Deployments on Dell EqualLogic Storage Database Solutions Engineering By Raghunatha M, Ravi Ramappa Dell Product Group October 2009 Executive Summary
Dell Reference Configuration for Large Oracle Database Deployments on Dell EqualLogic Storage Database Solutions Engineering By Raghunatha M, Ravi Ramappa Dell Product Group October 2009 Executive Summary
HPC Storage Use Cases & Future Trends
 Oct, 2014 HPC Storage Use Cases & Future Trends Massively-Scalable Platforms and Solutions Engineered for the Big Data and Cloud Era Atul Vidwansa Email: atul@ DDN About Us DDN is a Leader in Massively
Oct, 2014 HPC Storage Use Cases & Future Trends Massively-Scalable Platforms and Solutions Engineered for the Big Data and Cloud Era Atul Vidwansa Email: atul@ DDN About Us DDN is a Leader in Massively
Aziz Gulbeden Dell HPC Engineering Team
 DELL PowerVault MD1200 Performance as a Network File System (NFS) Backend Storage Solution Aziz Gulbeden Dell HPC Engineering Team THIS WHITE PAPER IS FOR INFORMATIONAL PURPOSES ONLY, AND MAY CONTAIN TYPOGRAPHICAL
DELL PowerVault MD1200 Performance as a Network File System (NFS) Backend Storage Solution Aziz Gulbeden Dell HPC Engineering Team THIS WHITE PAPER IS FOR INFORMATIONAL PURPOSES ONLY, AND MAY CONTAIN TYPOGRAPHICAL
Emerging Technologies for HPC Storage
 Emerging Technologies for HPC Storage Dr. Wolfgang Mertz CTO EMEA Unstructured Data Solutions June 2018 The very definition of HPC is expanding Blazing Fast Speed Accessibility and flexibility 2 Traditional
Emerging Technologies for HPC Storage Dr. Wolfgang Mertz CTO EMEA Unstructured Data Solutions June 2018 The very definition of HPC is expanding Blazing Fast Speed Accessibility and flexibility 2 Traditional
PREEvision. System Requirements. Version 7.5 English
 PREEvision System Requirements Version 7.5 English Imprint Vector Informatik GmbH Ingersheimer Straße 24 70499 Stuttgart, Germany Vector reserves the right to modify any information and/or data in this
PREEvision System Requirements Version 7.5 English Imprint Vector Informatik GmbH Ingersheimer Straße 24 70499 Stuttgart, Germany Vector reserves the right to modify any information and/or data in this
STAR-CCM+ Performance Benchmark and Profiling. July 2014
 STAR-CCM+ Performance Benchmark and Profiling July 2014 Note The following research was performed under the HPC Advisory Council activities Participating vendors: CD-adapco, Intel, Dell, Mellanox Compute
STAR-CCM+ Performance Benchmark and Profiling July 2014 Note The following research was performed under the HPC Advisory Council activities Participating vendors: CD-adapco, Intel, Dell, Mellanox Compute
pnfs and Linux: Working Towards a Heterogeneous Future
 CITI Technical Report 06-06 pnfs and Linux: Working Towards a Heterogeneous Future Dean Hildebrand dhildebz@umich.edu Peter Honeyman honey@umich.edu ABSTRACT Anticipating terascale and petascale HPC demands,
CITI Technical Report 06-06 pnfs and Linux: Working Towards a Heterogeneous Future Dean Hildebrand dhildebz@umich.edu Peter Honeyman honey@umich.edu ABSTRACT Anticipating terascale and petascale HPC demands,
Quobyte The Data Center File System QUOBYTE INC.
 Quobyte The Data Center File System QUOBYTE INC. The Quobyte Data Center File System All Workloads Consolidate all application silos into a unified highperformance file, block, and object storage (POSIX
Quobyte The Data Center File System QUOBYTE INC. The Quobyte Data Center File System All Workloads Consolidate all application silos into a unified highperformance file, block, and object storage (POSIX
Energy Management of MapReduce Clusters. Jan Pohland
 Energy Management of MapReduce Clusters Jan Pohland 2518099 1 [maps.google.com] installed solar panels on headquarters 1.6 MW (1,000 homes) invested $38.8 million North Dakota wind farms 169.5 MW (55,000
Energy Management of MapReduce Clusters Jan Pohland 2518099 1 [maps.google.com] installed solar panels on headquarters 1.6 MW (1,000 homes) invested $38.8 million North Dakota wind farms 169.5 MW (55,000
Yuval Carmel Tel-Aviv University "Advanced Topics in Storage Systems" - Spring 2013
 Yuval Carmel Tel-Aviv University "Advanced Topics in About & Keywords Motivation & Purpose Assumptions Architecture overview & Comparison Measurements How does it fit in? The Future 2 About & Keywords
Yuval Carmel Tel-Aviv University "Advanced Topics in About & Keywords Motivation & Purpose Assumptions Architecture overview & Comparison Measurements How does it fit in? The Future 2 About & Keywords