Neural Network based Energy-Efficient Fault Tolerant Architect
|
|
|
- Christopher Summers
- 5 years ago
- Views:
Transcription
1 Neural Network based Energy-Efficient Fault Tolerant Architectures and Accelerators University of Rochester February 7, 2013
2
3 References Flexible Error Protection for Energy Efficient Reliable Architectures T. Miller, N. Surapaneni, R. Teodorescu, Ohio State Univ., SBAC-PAD 10 BenchNN: On the Broad Potential Applications Scope of Hardware NN Accelerators T. Chen et.al., Univ. of Wisconsin, IISWC 12 A Defect-Tolerant Accelerator for Emerging High Performance Applications Olivier Temam, INRIA France, ISCA 12 Neural Acceleration for General-Purpose Approximate Programs H. Esmaeilzadeh et.al., U. of Washington & Microsoft, MICRO 12
4 Introduction and Motivation Technology scaling has a detrimental effect on reliability Dark silicon jeopardizes many-cores and massive on-chip parallelism One way to tackle dark silicon and energy issue is to do specialization through heterogeneous multi-cores In conventional architectures A single transistor breakdown can potentially prove fatal Artificial neural network based system Inherently more tolerant to defects and noise More energy efficient compared to conventional architectures Interest in ANN died because they were beaten by SVM Due to emergence of RMS (Recognition, Mining and Synthesis) workload ANN are being looked again
5 Neural Network based Architectures and Solutions 1. A multi-core architecture which achieves energy efficiency for user specified reliability (FIT) target by controlling the replications and supply voltages using hill-climbing algorithm.
6 Neural Network based Architectures and Solutions 1. A multi-core architecture which achieves energy efficiency for user specified reliability (FIT) target by controlling the replications and supply voltages using hill-climbing algorithm. 2. Set of neural network based computational kernels which are alternatives to many PARSEC (i.e. blackscholes etc.) benchmarks and achieve at par or better performance.
7 Neural Network based Architectures and Solutions 1. A multi-core architecture which achieves energy efficiency for user specified reliability (FIT) target by controlling the replications and supply voltages using hill-climbing algorithm. 2. Set of neural network based computational kernels which are alternatives to many PARSEC (i.e. blackscholes etc.) benchmarks and achieve at par or better performance. 3. A neural network based multi-purpose hardware accelerator which can tolerate multiple defects, implements computational kernels of emerging RMS workloads and like custom circuits can achieve 2 order of energy efficiency.
8 Neural Network based Architectures and Solutions 1. A multi-core architecture which achieves energy efficiency for user specified reliability (FIT) target by controlling the replications and supply voltages using hill-climbing algorithm. 2. Set of neural network based computational kernels which are alternatives to many PARSEC (i.e. blackscholes etc.) benchmarks and achieve at par or better performance. 3. A neural network based multi-purpose hardware accelerator which can tolerate multiple defects, implements computational kernels of emerging RMS workloads and like custom circuits can achieve 2 order of energy efficiency. 4. A neural network based program transformation technique which targets the approximable code regions in general purpose programs and offloads it to neural processing unit.
9 Machine Learning based Adaptive Multicore Architecture Presents a reliable, energy efficient and adaptive multicore architecture Each core consists of a pair of pipelines They can run independently (running separate thread) or in concert (running same threads and verifying results) The idea is to adopt the characteristics of individual cores and applications to provide the acceptable reliability with minimum energy On-line control based on hill-climbing dynamically adjusts multiple parameters to minimize the energy consumption Dynamic adaptation of voltage and redundancy can reduce the energy delay product of a CMP by 30-60% compared to static dual modular redundancy (DMR)
10 Architecture and Error Detection Shadow register replication mode Only timing errors can be detected and results are restored from delayed shadow registers Shadow pipeline replication mode Timing and soft errors both can be detected Re-execution would fix soft errors For timing errors instructions are marked, re-executed and if the error re-occurs the result is restored from shadow registers
11 Support for Timing Speculation If a FU is not fully replicated then selectively enable the pipeline registers which has delayed clock more like RAZOR.
12 Neural Networks for Power and Error Prediction Primary Power ANN: predicts power of primary pipelines based on voltage, utilization, and temperature Shadow Power ANN: predicts power of shadow pipelines based on voltage, utilization, replication, and temperature Error Probability ANN: predicts raw probability of an error on each cycle based on voltage and temperature ANNs are trained online by comparing predictions against measurement and weights are adjusted
13 Hill-climbing Search for Optimal Voltage Energy optimization for a given FIT at regular intervals Start with maximum voltages for all FUs and lower them one step at a time, checking for errors, and computing ED Voltages are lowered until minimum ED is found
 yields: Average power saving: 50% ; Replications: 3 FUs/app For very low FIT rate of 1.1-1.")
14 Results and Analysis Area overhead: 4%; impact on cycle time: 10% A FIT target of 11.4 (MTBF=10 5 years) yields: Average power saving: 50% ; Replications: 3 FUs/app For very low FIT rate of , ED savings are around 30%
15 BenchNN: Potential of Neural Network Accelerator After being hyped up in the 1990s, the ANN faded away Now there is surge of interest because of their Energy efficiency and fault-tolerance properties, and Applicability to emerging high-performance applications
16 ANN alternative: blackscholes Function: Predicts the price at a certain date in future based on today s inputs through solving partial differential equations ANN alternative: 6-input multi layer perceptron with 1 output layer; Hidden layers are explored during the training phase Accuracy: PARSEC version - 1e-5; ANN version - 3e-5 Slowdown: NN software version over PARSEC version is 3.6x
17 ANN alternative: canneal Function: Optimization benchmark which uses simulated annealing to minimize the routing cost of a chip design ANN alternative: For optimization Hopfield Neural Network has been used to solve problems including layout, placement Accuracy: Average wire length calculated by HNN are at par or better than PARSEC version Slowdown: For 100K cells slowdown is significant; Hierarchical approach can be used to break the problem into smaller size


18 ANN alternative: ferret Function: Content similarity; Finding one or several objects matching an input object; Stationary image similarity; biased towards color moments, bounding boxes and segment sizes ANN alternative: Object data is converted into feature vectors and compressed into compact vectors (the sketch); Feature extraction is performed using a set of 2160 Gabor filters. Accuracy: PARSEC version - 88%; ANN version - 93% Slowdown: 2x compared to PARSEC version
19 ANN alternative: streamcluster Function: Online clustering program which classifies the input data into several groups so each group shares similar features ANN alternative: Most time-consuming task of reducing the data dimensionality (89%) can be done efficiently using Self-Organizing Maps (SOM) Accuracy: Comparable or better than PARSEC version Slowdown: Software version of ANN is sequential whereas PARSEC version is parallel and divides the data into chunks
20 ANN alternative: dedup Function: Data compression application which combines data-deduplication with Ziv-Lempel to achieve high compression ratios ANN alternative: 4 out of 5 stages are replaced by neural network - fragmentation, hashing, building the global database and compression Accuracy: Except for small files CR is always better Slowdown: Slowdown is so significant that even a hardware based accelerator may not be competitive
21 BenchNN: Summary 5 PARSEC benchmarks, considered here, are representative of emerging high-performance benchmarks For these applications it is possible to substitute the core computational task with a neural network algorithm Neural networks can achieve slightly worse, comparable or sometime even better solutions Software versions are significantly slower which advocate the need of hardware accelerator for these computational kernels These kind of accelerators would be very useful for embedded system applications which achieve very good accuracy but not always state-of-the-art accuracy.
22 Neural Network based Hardware Accelerator From BenchNN study, it is clear that there is a need to build neural network based hardware accelerator Neural networks are inherently tolerant to errors and defects so when a hardware is built using them it would be naturally tolerant to defects such as transistor short or open defects This study proposes a hardware based ANN accelerator Inputs and attributes to modern high-performance algorithm are rather limited (< 100) so hardware based neural network is conceivable Emerging algorithms category including PARSEC and RMS: Classification, clustering, statistical optimization, approximation Competitive ANN based algorithm exist for most of these
23 Time-Multiplexed vs. Spatially Expanded ANN Downside of time-multiplexed ANN Incurs extra memory latency; consumes more power and energy Control logic is vulnerable to defects; less scalable
24 Accelerator Implementation Only scaled down version is shown here; actual network contains 90 inputs, 10 hidden neurons and 10 outputs Input/Output: Fetch rows, write weights during training Fixed-Point computations: 16-bit Fixed point achieves same as floating-point design for most of the applications Activation function, partial time-multiplexing
25 Gate-level vs Transistor-level Defects Logic gate-level hardware fault (stuck at) can exhibit a significantly different behavior than transistor-level hardware faults
26 Impact of Defects on 4-bit Adder and Multiplier
27 Injection and Impact of Transistor-Level Defects
28 Comparison: Accelerator vs CPU versions Biggest advantage is the energy consumption by accelerator This is possible due to massive parallel multiplications/ additions and circuit-level parallelism
29 Evaluations Accelerator can tolerate upto 12 defects; most applications are not significantly affected by upto 20 defects Accuracy is fairly sensitive to errors at the output layers or defect occurring just before or at the activation function
30 Neural Acceleration for Approximate Programs Tolerance to approximation is one of the program characteristic which is growing increasingly important. Modern day applications image rendering, signal processing, augmented reality, data mining, robotics, speech recognition, face recognition etc. Key idea is to learn how and original region of approximable code behaves and replace the original code with and efficient computation of the learned model. Compiler replaces the original code with an invocation of a low-power accelerator called a neural processing unit (NPU) which is tightly coupled to the processor pipeline. NPU provides speedup of 2.3x and energy saving of 3.0x on average with quality loss of at most 9.6%
31 Parrot* Transformation at a Glance Programming: Programmer explicitly marks functions, amenable to approximate execution, to be transformed Compilation: Compiler selects and trains a suitable neural network and replaces the original code with a NN invocations Code observation (input-output probes), Neural network selection and training, binary generation Execution: Main core configures NPU and invokes to perform neural network evaluation
32 Transformation Stages of Edge Detection Algorithm Edge detection: Sobel filter, a 3x3 matrix convolution that approximates the image s intensity gradient Executed many times, so the convolution is a hot function

33 Neural Processing Unit Architecture and Organization Multi-layer perceptrons (MLP) are used due to their broad applicability; compiler uses the back-propagation algorithm to train the neural network
34 ISA and Architectural Support for NPU Acceleration NPU is a variable delay, tightly-coupled accelerator that communicates with the rest of the core via FIFO queues Config FIFO: sending and retrieving the configuration Input FIFO: sending the inputs of approximable functions Output FIFO: retrieving the neural network s outputs ISA extn: enq.c %r, deq.c %r, enq.d %r, deq.d %r deq.c %r is used during the contexts switches All NPU instructions are not reordered treated as dependent
")
35 Benchmarks Transformed in this Study Only those functions for which compiler can find a suitable competitive ANN based algorithm should be replaced Select the best topology by 70%(training) 30%(testing)


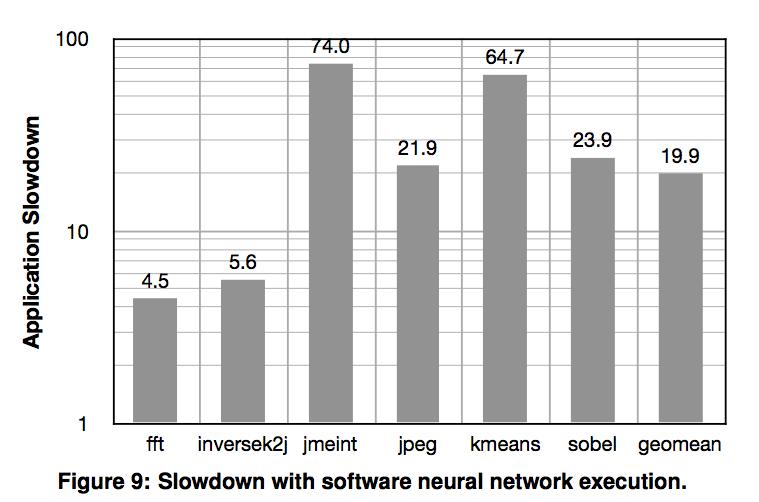
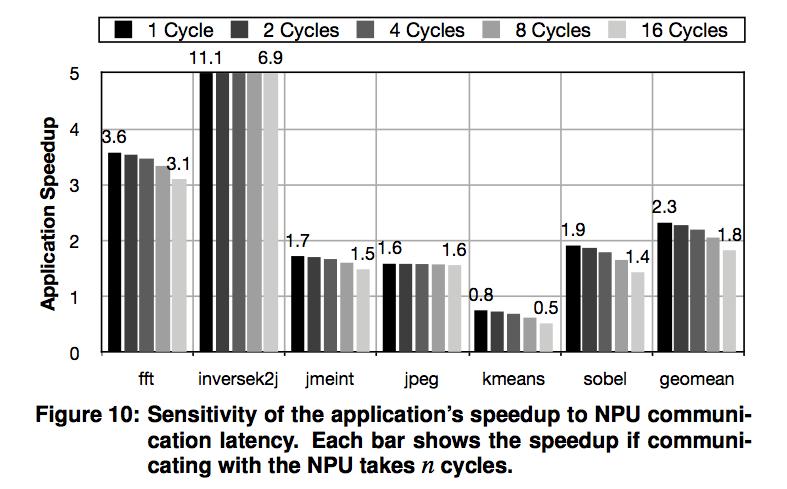
36 Speedup and Energy Improvement Ideal NPU: zero cycle Speedup: 0.8x 11.1x Avg NPU acceleration: 2.3x Avg energy reduction: 3.0x Optimal # of PEs in NPU: 8

37 Other Results Outline
38 Key Findings and Insights Different applications require different neural network topologies, so the NPU structure must be reconfigurable The majority (80% to 100%) of each transformed application s output elements have error less than 10% Parrot transformation and NPU acceleration provided an average 2.3x speedup and 3.0x energy reduction Proposed technique requires efficient neural network execution, such as hardware acceleration, to be beneficial For some applications, with simple neural network topologies, a tightly- coupled, low-latency NPU-CPU integrated design is highly beneficial
39 Neural network based accelerator are more flexible compared to an ASIC based accelerators and can easily adapt to many high performance applications ANN are inherently fault tolerant so an accelerator built using them naturally possess those qualities Typical hardware based ANNs show two order of energy efficiency compared to conventional systems Can play a major role in heterogeneous multi-core chips to solve some of the energy and dark silicon issues
Neural Acceleration for General-Purpose Approximate Programs
 2012 IEEE/ACM 45th Annual International Symposium on Microarchitecture Neural Acceleration for General-Purpose Approximate Programs Hadi Esmaeilzadeh Adrian Sampson Luis Ceze Doug Burger University of
2012 IEEE/ACM 45th Annual International Symposium on Microarchitecture Neural Acceleration for General-Purpose Approximate Programs Hadi Esmaeilzadeh Adrian Sampson Luis Ceze Doug Burger University of
Exploiting Hidden Layer Modular Redundancy for Fault-Tolerance in Neural Network Accelerators
 Exploiting Hidden Layer Modular Redundancy for Fault-Tolerance in Neural Network Accelerators Schuyler Eldridge Ajay Joshi Department of Electrical and Computer Engineering, Boston University schuye@bu.edu
Exploiting Hidden Layer Modular Redundancy for Fault-Tolerance in Neural Network Accelerators Schuyler Eldridge Ajay Joshi Department of Electrical and Computer Engineering, Boston University schuye@bu.edu
Fundamentals of Quantitative Design and Analysis
 Fundamentals of Quantitative Design and Analysis Dr. Jiang Li Adapted from the slides provided by the authors Computer Technology Performance improvements: Improvements in semiconductor technology Feature
Fundamentals of Quantitative Design and Analysis Dr. Jiang Li Adapted from the slides provided by the authors Computer Technology Performance improvements: Improvements in semiconductor technology Feature
Deep Learning Accelerators
 Deep Learning Accelerators Abhishek Srivastava (as29) Samarth Kulshreshtha (samarth5) University of Illinois, Urbana-Champaign Submitted as a requirement for CS 433 graduate student project Outline Introduction
Deep Learning Accelerators Abhishek Srivastava (as29) Samarth Kulshreshtha (samarth5) University of Illinois, Urbana-Champaign Submitted as a requirement for CS 433 graduate student project Outline Introduction
Neural Computer Architectures
 Neural Computer Architectures 5kk73 Embedded Computer Architecture By: Maurice Peemen Date: Convergence of different domains Neurobiology Applications 1 Constraints Machine Learning Technology Innovations
Neural Computer Architectures 5kk73 Embedded Computer Architecture By: Maurice Peemen Date: Convergence of different domains Neurobiology Applications 1 Constraints Machine Learning Technology Innovations
Computer Architecture: Multi-Core Processors: Why? Prof. Onur Mutlu Carnegie Mellon University
 Computer Architecture: Multi-Core Processors: Why? Prof. Onur Mutlu Carnegie Mellon University Moore s Law Moore, Cramming more components onto integrated circuits, Electronics, 1965. 2 3 Multi-Core Idea:
Computer Architecture: Multi-Core Processors: Why? Prof. Onur Mutlu Carnegie Mellon University Moore s Law Moore, Cramming more components onto integrated circuits, Electronics, 1965. 2 3 Multi-Core Idea:
Copyright 2012, Elsevier Inc. All rights reserved.
 Computer Architecture A Quantitative Approach, Fifth Edition Chapter 1 Fundamentals of Quantitative Design and Analysis 1 Computer Technology Performance improvements: Improvements in semiconductor technology
Computer Architecture A Quantitative Approach, Fifth Edition Chapter 1 Fundamentals of Quantitative Design and Analysis 1 Computer Technology Performance improvements: Improvements in semiconductor technology
Index. Springer Nature Switzerland AG 2019 B. Moons et al., Embedded Deep Learning,
 Index A Algorithmic noise tolerance (ANT), 93 94 Application specific instruction set processors (ASIPs), 115 116 Approximate computing application level, 95 circuits-levels, 93 94 DAS and DVAS, 107 110
Index A Algorithmic noise tolerance (ANT), 93 94 Application specific instruction set processors (ASIPs), 115 116 Approximate computing application level, 95 circuits-levels, 93 94 DAS and DVAS, 107 110
Hardware Design Environments. Dr. Mahdi Abbasi Computer Engineering Department Bu-Ali Sina University
 Hardware Design Environments Dr. Mahdi Abbasi Computer Engineering Department Bu-Ali Sina University Outline Welcome to COE 405 Digital System Design Design Domains and Levels of Abstractions Synthesis
Hardware Design Environments Dr. Mahdi Abbasi Computer Engineering Department Bu-Ali Sina University Outline Welcome to COE 405 Digital System Design Design Domains and Levels of Abstractions Synthesis
Computer Architecture: Multi-Core Processors: Why? Onur Mutlu & Seth Copen Goldstein Carnegie Mellon University 9/11/13
 Computer Architecture: Multi-Core Processors: Why? Onur Mutlu & Seth Copen Goldstein Carnegie Mellon University 9/11/13 Moore s Law Moore, Cramming more components onto integrated circuits, Electronics,
Computer Architecture: Multi-Core Processors: Why? Onur Mutlu & Seth Copen Goldstein Carnegie Mellon University 9/11/13 Moore s Law Moore, Cramming more components onto integrated circuits, Electronics,
Bridging Analog Neuromorphic and Digital von Neumann Computing
 Bridging Analog Neuromorphic and Digital von Neumann Computing Amir Yazdanbakhsh, Bradley Thwaites Advisors: Hadi Esmaeilzadeh and Doug Burger Qualcomm Mentors: Manu Rastogiand Girish Varatkar Alternative
Bridging Analog Neuromorphic and Digital von Neumann Computing Amir Yazdanbakhsh, Bradley Thwaites Advisors: Hadi Esmaeilzadeh and Doug Burger Qualcomm Mentors: Manu Rastogiand Girish Varatkar Alternative
Power dissipation! The VLSI Interconnect Challenge. Interconnect is the crux of the problem. Interconnect is the crux of the problem.
 The VLSI Interconnect Challenge Avinoam Kolodny Electrical Engineering Department Technion Israel Institute of Technology VLSI Challenges System complexity Performance Tolerance to digital noise and faults
The VLSI Interconnect Challenge Avinoam Kolodny Electrical Engineering Department Technion Israel Institute of Technology VLSI Challenges System complexity Performance Tolerance to digital noise and faults
COE 561 Digital System Design & Synthesis Introduction
 1 COE 561 Digital System Design & Synthesis Introduction Dr. Aiman H. El-Maleh Computer Engineering Department King Fahd University of Petroleum & Minerals Outline Course Topics Microelectronics Design
1 COE 561 Digital System Design & Synthesis Introduction Dr. Aiman H. El-Maleh Computer Engineering Department King Fahd University of Petroleum & Minerals Outline Course Topics Microelectronics Design
Memory Systems IRAM. Principle of IRAM
 Memory Systems 165 other devices of the module will be in the Standby state (which is the primary state of all RDRAM devices) or another state with low-power consumption. The RDRAM devices provide several
Memory Systems 165 other devices of the module will be in the Standby state (which is the primary state of all RDRAM devices) or another state with low-power consumption. The RDRAM devices provide several
AR-SMT: A Microarchitectural Approach to Fault Tolerance in Microprocessors
 AR-SMT: A Microarchitectural Approach to Fault Tolerance in Microprocessors Computer Sciences Department University of Wisconsin Madison http://www.cs.wisc.edu/~ericro/ericro.html ericro@cs.wisc.edu High-Performance
AR-SMT: A Microarchitectural Approach to Fault Tolerance in Microprocessors Computer Sciences Department University of Wisconsin Madison http://www.cs.wisc.edu/~ericro/ericro.html ericro@cs.wisc.edu High-Performance
Lecture 1: Introduction
 Contemporary Computer Architecture Instruction set architecture Lecture 1: Introduction CprE 581 Computer Systems Architecture, Fall 2016 Reading: Textbook, Ch. 1.1-1.7 Microarchitecture; examples: Pipeline
Contemporary Computer Architecture Instruction set architecture Lecture 1: Introduction CprE 581 Computer Systems Architecture, Fall 2016 Reading: Textbook, Ch. 1.1-1.7 Microarchitecture; examples: Pipeline
Computer Architecture A Quantitative Approach, Fifth Edition. Chapter 1. Copyright 2012, Elsevier Inc. All rights reserved. Computer Technology
 Computer Architecture A Quantitative Approach, Fifth Edition Chapter 1 Fundamentals of Quantitative Design and Analysis 1 Computer Technology Performance improvements: Improvements in semiconductor technology
Computer Architecture A Quantitative Approach, Fifth Edition Chapter 1 Fundamentals of Quantitative Design and Analysis 1 Computer Technology Performance improvements: Improvements in semiconductor technology
Using FPGAs as Microservices
 Using FPGAs as Microservices David Ojika, Ann Gordon-Ross, Herman Lam, Bhavesh Patel, Gaurav Kaul, Jayson Strayer (University of Florida, DELL EMC, Intel Corporation) The 9 th Workshop on Big Data Benchmarks,
Using FPGAs as Microservices David Ojika, Ann Gordon-Ross, Herman Lam, Bhavesh Patel, Gaurav Kaul, Jayson Strayer (University of Florida, DELL EMC, Intel Corporation) The 9 th Workshop on Big Data Benchmarks,
Fault Tolerant and Secure Architectures for On Chip Networks With Emerging Interconnect Technologies. Mohsin Y Ahmed Conlan Wesson
 Fault Tolerant and Secure Architectures for On Chip Networks With Emerging Interconnect Technologies Mohsin Y Ahmed Conlan Wesson Overview NoC: Future generation of many core processor on a single chip
Fault Tolerant and Secure Architectures for On Chip Networks With Emerging Interconnect Technologies Mohsin Y Ahmed Conlan Wesson Overview NoC: Future generation of many core processor on a single chip
Chapter 2 Parallel Hardware
 Chapter 2 Parallel Hardware Part I. Preliminaries Chapter 1. What Is Parallel Computing? Chapter 2. Parallel Hardware Chapter 3. Parallel Software Chapter 4. Parallel Applications Chapter 5. Supercomputers
Chapter 2 Parallel Hardware Part I. Preliminaries Chapter 1. What Is Parallel Computing? Chapter 2. Parallel Hardware Chapter 3. Parallel Software Chapter 4. Parallel Applications Chapter 5. Supercomputers
PARSEC vs. SPLASH-2: A Quantitative Comparison of Two Multithreaded Benchmark Suites
 PARSEC vs. SPLASH-2: A Quantitative Comparison of Two Multithreaded Benchmark Suites Christian Bienia (Princeton University), Sanjeev Kumar (Intel), Kai Li (Princeton University) Outline Overview What
PARSEC vs. SPLASH-2: A Quantitative Comparison of Two Multithreaded Benchmark Suites Christian Bienia (Princeton University), Sanjeev Kumar (Intel), Kai Li (Princeton University) Outline Overview What
Stochastic Processors (or processors that do not always compute correctly by design)
") Stochastic Processors (or processors that do not always compute correctly by design) Rakesh Kumar Department of Electrical and Computer Engineering University of Illinois, Urbana-Champaign Insisting on
Stochastic Processors (or processors that do not always compute correctly by design) Rakesh Kumar Department of Electrical and Computer Engineering University of Illinois, Urbana-Champaign Insisting on
Architecture as Interface
 Architecture as Interface André DeHon Friday, June 21, 2002 Previously How do we build efficient, programmable machines How we mix Computational complexity W/ physical landscape
Architecture as Interface André DeHon Friday, June 21, 2002 Previously How do we build efficient, programmable machines How we mix Computational complexity W/ physical landscape
Outline. Parity-based ECC and Mechanism for Detecting and Correcting Soft Errors in On-Chip Communication. Outline
 Parity-based ECC and Mechanism for Detecting and Correcting Soft Errors in On-Chip Communication Khanh N. Dang and Xuan-Tu Tran Email: khanh.n.dang@vnu.edu.vn VNU Key Laboratory for Smart Integrated Systems
Parity-based ECC and Mechanism for Detecting and Correcting Soft Errors in On-Chip Communication Khanh N. Dang and Xuan-Tu Tran Email: khanh.n.dang@vnu.edu.vn VNU Key Laboratory for Smart Integrated Systems
High Performance Computing Hiroki Kanezashi Tokyo Institute of Technology Dept. of mathematical and computing sciences Matsuoka Lab.
 High Performance Computing 2015 Hiroki Kanezashi Tokyo Institute of Technology Dept. of mathematical and computing sciences Matsuoka Lab. 1 Reviewed Paper 1 DaDianNao: A Machine- Learning Supercomputer
High Performance Computing 2015 Hiroki Kanezashi Tokyo Institute of Technology Dept. of mathematical and computing sciences Matsuoka Lab. 1 Reviewed Paper 1 DaDianNao: A Machine- Learning Supercomputer
EECS4201 Computer Architecture
 Computer Architecture A Quantitative Approach, Fifth Edition Chapter 1 Fundamentals of Quantitative Design and Analysis These slides are based on the slides provided by the publisher. The slides will be
Computer Architecture A Quantitative Approach, Fifth Edition Chapter 1 Fundamentals of Quantitative Design and Analysis These slides are based on the slides provided by the publisher. The slides will be
Runtime Adaptation of Application Execution under Thermal and Power Constraints in Massively Parallel Processor Arrays
 Runtime Adaptation of Application Execution under Thermal and Power Constraints in Massively Parallel Processor Arrays Éricles Sousa 1, Frank Hannig 1, Jürgen Teich 1, Qingqing Chen 2, and Ulf Schlichtmann
Runtime Adaptation of Application Execution under Thermal and Power Constraints in Massively Parallel Processor Arrays Éricles Sousa 1, Frank Hannig 1, Jürgen Teich 1, Qingqing Chen 2, and Ulf Schlichtmann
Neural Networks. CE-725: Statistical Pattern Recognition Sharif University of Technology Spring Soleymani
 Neural Networks CE-725: Statistical Pattern Recognition Sharif University of Technology Spring 2013 Soleymani Outline Biological and artificial neural networks Feed-forward neural networks Single layer
Neural Networks CE-725: Statistical Pattern Recognition Sharif University of Technology Spring 2013 Soleymani Outline Biological and artificial neural networks Feed-forward neural networks Single layer
Hardware Implementation of a Fault-Tolerant Hopfield Neural Network on FPGAs
 Hardware Implementation of a Fault-Tolerant Hopfield Neural Network on FPGAs Juan Antonio Clemente a, Wassim Mansour b, Rafic Ayoubi c, Felipe Serrano a, Hortensia Mecha a, Haissam Ziade d, Wassim El Falou
Hardware Implementation of a Fault-Tolerant Hopfield Neural Network on FPGAs Juan Antonio Clemente a, Wassim Mansour b, Rafic Ayoubi c, Felipe Serrano a, Hortensia Mecha a, Haissam Ziade d, Wassim El Falou
Massively Parallel Computing on Silicon: SIMD Implementations. V.M.. Brea Univ. of Santiago de Compostela Spain
 Massively Parallel Computing on Silicon: SIMD Implementations V.M.. Brea Univ. of Santiago de Compostela Spain GOAL Give an overview on the state-of of-the- art of Digital on-chip CMOS SIMD Solutions,
Massively Parallel Computing on Silicon: SIMD Implementations V.M.. Brea Univ. of Santiago de Compostela Spain GOAL Give an overview on the state-of of-the- art of Digital on-chip CMOS SIMD Solutions,
Outline Marquette University
 COEN-4710 Computer Hardware Lecture 1 Computer Abstractions and Technology (Ch.1) Cristinel Ababei Department of Electrical and Computer Engineering Credits: Slides adapted primarily from presentations
COEN-4710 Computer Hardware Lecture 1 Computer Abstractions and Technology (Ch.1) Cristinel Ababei Department of Electrical and Computer Engineering Credits: Slides adapted primarily from presentations
Lecture 2: Performance
 Lecture 2: Performance Today s topics: Technology wrap-up Performance trends and equations Reminders: YouTube videos, canvas, and class webpage: http://www.cs.utah.edu/~rajeev/cs3810/ 1 Important Trends
Lecture 2: Performance Today s topics: Technology wrap-up Performance trends and equations Reminders: YouTube videos, canvas, and class webpage: http://www.cs.utah.edu/~rajeev/cs3810/ 1 Important Trends
Commercial Real-time Operating Systems An Introduction. Swaminathan Sivasubramanian Dependable Computing & Networking Laboratory
 Commercial Real-time Operating Systems An Introduction Swaminathan Sivasubramanian Dependable Computing & Networking Laboratory swamis@iastate.edu Outline Introduction RTOS Issues and functionalities LynxOS
Commercial Real-time Operating Systems An Introduction Swaminathan Sivasubramanian Dependable Computing & Networking Laboratory swamis@iastate.edu Outline Introduction RTOS Issues and functionalities LynxOS
Machine Learning 13. week
 Machine Learning 13. week Deep Learning Convolutional Neural Network Recurrent Neural Network 1 Why Deep Learning is so Popular? 1. Increase in the amount of data Thanks to the Internet, huge amount of
Machine Learning 13. week Deep Learning Convolutional Neural Network Recurrent Neural Network 1 Why Deep Learning is so Popular? 1. Increase in the amount of data Thanks to the Internet, huge amount of
Computer Architecture
 Computer Architecture Slide Sets WS 2013/2014 Prof. Dr. Uwe Brinkschulte M.Sc. Benjamin Betting Part 10 Thread and Task Level Parallelism Computer Architecture Part 10 page 1 of 36 Prof. Dr. Uwe Brinkschulte,
Computer Architecture Slide Sets WS 2013/2014 Prof. Dr. Uwe Brinkschulte M.Sc. Benjamin Betting Part 10 Thread and Task Level Parallelism Computer Architecture Part 10 page 1 of 36 Prof. Dr. Uwe Brinkschulte,
Virtual Machines. 2 Disco: Running Commodity Operating Systems on Scalable Multiprocessors([1])
![Virtual Machines. 2 Disco: Running Commodity Operating Systems on Scalable Multiprocessors([1])](/thumbs/77/75166382.jpg "Virtual Machines. 2 Disco: Running Commodity Operating Systems on Scalable Multiprocessors([1])") EE392C: Advanced Topics in Computer Architecture Lecture #10 Polymorphic Processors Stanford University Thursday, 8 May 2003 Virtual Machines Lecture #10: Thursday, 1 May 2003 Lecturer: Jayanth Gummaraju,
EE392C: Advanced Topics in Computer Architecture Lecture #10 Polymorphic Processors Stanford University Thursday, 8 May 2003 Virtual Machines Lecture #10: Thursday, 1 May 2003 Lecturer: Jayanth Gummaraju,
Implementation of FPGA-Based General Purpose Artificial Neural Network
 Implementation of FPGA-Based General Purpose Artificial Neural Network Chandrashekhar Kalbande & Anil Bavaskar Dept of Electronics Engineering, Priyadarshini College of Nagpur, Maharashtra India E-mail
Implementation of FPGA-Based General Purpose Artificial Neural Network Chandrashekhar Kalbande & Anil Bavaskar Dept of Electronics Engineering, Priyadarshini College of Nagpur, Maharashtra India E-mail
TETRIS: Scalable and Efficient Neural Network Acceleration with 3D Memory
 TETRIS: Scalable and Efficient Neural Network Acceleration with 3D Memory Mingyu Gao, Jing Pu, Xuan Yang, Mark Horowitz, Christos Kozyrakis Stanford University Platform Lab Review Feb 2017 Deep Neural
TETRIS: Scalable and Efficient Neural Network Acceleration with 3D Memory Mingyu Gao, Jing Pu, Xuan Yang, Mark Horowitz, Christos Kozyrakis Stanford University Platform Lab Review Feb 2017 Deep Neural
Research Article Dynamic Reconfigurable Computing: The Alternative to Homogeneous Multicores under Massive Defect Rates
 International Journal of Reconfigurable Computing Volume 2, Article ID 452589, 7 pages doi:.55/2/452589 Research Article Dynamic Reconfigurable Computing: The Alternative to Homogeneous Multicores under
International Journal of Reconfigurable Computing Volume 2, Article ID 452589, 7 pages doi:.55/2/452589 Research Article Dynamic Reconfigurable Computing: The Alternative to Homogeneous Multicores under
Lecture 7: Parallel Processing
 Lecture 7: Parallel Processing Introduction and motivation Architecture classification Performance evaluation Interconnection network Zebo Peng, IDA, LiTH 1 Performance Improvement Reduction of instruction
Lecture 7: Parallel Processing Introduction and motivation Architecture classification Performance evaluation Interconnection network Zebo Peng, IDA, LiTH 1 Performance Improvement Reduction of instruction
Higher Level Programming Abstractions for FPGAs using OpenCL
 Higher Level Programming Abstractions for FPGAs using OpenCL Desh Singh Supervising Principal Engineer Altera Corporation Toronto Technology Center ! Technology scaling favors programmability CPUs."#/0$*12'$-*
Higher Level Programming Abstractions for FPGAs using OpenCL Desh Singh Supervising Principal Engineer Altera Corporation Toronto Technology Center ! Technology scaling favors programmability CPUs."#/0$*12'$-*
OVERHEADS ENHANCEMENT IN MUTIPLE PROCESSING SYSTEMS BY ANURAG REDDY GANKAT KARTHIK REDDY AKKATI
 CMPE 655- MULTIPLE PROCESSOR SYSTEMS OVERHEADS ENHANCEMENT IN MUTIPLE PROCESSING SYSTEMS BY ANURAG REDDY GANKAT KARTHIK REDDY AKKATI What is MULTI PROCESSING?? Multiprocessing is the coordinated processing
CMPE 655- MULTIPLE PROCESSOR SYSTEMS OVERHEADS ENHANCEMENT IN MUTIPLE PROCESSING SYSTEMS BY ANURAG REDDY GANKAT KARTHIK REDDY AKKATI What is MULTI PROCESSING?? Multiprocessing is the coordinated processing
Trends in the Infrastructure of Computing
 Trends in the Infrastructure of Computing CSCE 9: Computing in the Modern World Dr. Jason D. Bakos My Questions How do computer processors work? Why do computer processors get faster over time? How much
Trends in the Infrastructure of Computing CSCE 9: Computing in the Modern World Dr. Jason D. Bakos My Questions How do computer processors work? Why do computer processors get faster over time? How much
MULTIPROCESSORS AND THREAD-LEVEL. B649 Parallel Architectures and Programming
 MULTIPROCESSORS AND THREAD-LEVEL PARALLELISM B649 Parallel Architectures and Programming Motivation behind Multiprocessors Limitations of ILP (as already discussed) Growing interest in servers and server-performance
MULTIPROCESSORS AND THREAD-LEVEL PARALLELISM B649 Parallel Architectures and Programming Motivation behind Multiprocessors Limitations of ILP (as already discussed) Growing interest in servers and server-performance
Dataflow: The Road Less Complex
 Dataflow: The Road Less Complex Steven Swanson Ken Michelson Andrew Schwerin Mark Oskin University of Washington Sponsored by NSF and Intel Things to keep you up at night (~2016) Opportunities 8 billion
Dataflow: The Road Less Complex Steven Swanson Ken Michelson Andrew Schwerin Mark Oskin University of Washington Sponsored by NSF and Intel Things to keep you up at night (~2016) Opportunities 8 billion
Achieving Lightweight Multicast in Asynchronous Networks-on-Chip Using Local Speculation
 Achieving Lightweight Multicast in Asynchronous Networks-on-Chip Using Local Speculation Kshitij Bhardwaj Dept. of Computer Science Columbia University Steven M. Nowick 2016 ACM/IEEE Design Automation
Achieving Lightweight Multicast in Asynchronous Networks-on-Chip Using Local Speculation Kshitij Bhardwaj Dept. of Computer Science Columbia University Steven M. Nowick 2016 ACM/IEEE Design Automation
Introduction to Parallel and Distributed Computing. Linh B. Ngo CPSC 3620
 Introduction to Parallel and Distributed Computing Linh B. Ngo CPSC 3620 Overview: What is Parallel Computing To be run using multiple processors A problem is broken into discrete parts that can be solved
Introduction to Parallel and Distributed Computing Linh B. Ngo CPSC 3620 Overview: What is Parallel Computing To be run using multiple processors A problem is broken into discrete parts that can be solved
MULTIPROCESSORS AND THREAD-LEVEL PARALLELISM. B649 Parallel Architectures and Programming
 MULTIPROCESSORS AND THREAD-LEVEL PARALLELISM B649 Parallel Architectures and Programming Motivation behind Multiprocessors Limitations of ILP (as already discussed) Growing interest in servers and server-performance
MULTIPROCESSORS AND THREAD-LEVEL PARALLELISM B649 Parallel Architectures and Programming Motivation behind Multiprocessors Limitations of ILP (as already discussed) Growing interest in servers and server-performance
Checker Processors. Smruti R. Sarangi. Department of Computer Science Indian Institute of Technology New Delhi, India
 Advanced Department of Computer Science Indian Institute of Technology New Delhi, India Outline Introduction Advanced 1 Introduction 2 Checker Pipeline Checking Mechanism 3 Advanced Core Checker L1 Failure
Advanced Department of Computer Science Indian Institute of Technology New Delhi, India Outline Introduction Advanced 1 Introduction 2 Checker Pipeline Checking Mechanism 3 Advanced Core Checker L1 Failure
MOST PROGRESS MADE ALGORITHM: COMBATING SYNCHRONIZATION INDUCED PERFORMANCE LOSS ON SALVAGED CHIP MULTI-PROCESSORS
 MOST PROGRESS MADE ALGORITHM: COMBATING SYNCHRONIZATION INDUCED PERFORMANCE LOSS ON SALVAGED CHIP MULTI-PROCESSORS by Jacob J. Dutson A thesis submitted in partial fulfillment of the requirements for the
MOST PROGRESS MADE ALGORITHM: COMBATING SYNCHRONIZATION INDUCED PERFORMANCE LOSS ON SALVAGED CHIP MULTI-PROCESSORS by Jacob J. Dutson A thesis submitted in partial fulfillment of the requirements for the
XPU A Programmable FPGA Accelerator for Diverse Workloads
 XPU A Programmable FPGA Accelerator for Diverse Workloads Jian Ouyang, 1 (ouyangjian@baidu.com) Ephrem Wu, 2 Jing Wang, 1 Yupeng Li, 1 Hanlin Xie 1 1 Baidu, Inc. 2 Xilinx Outlines Background - FPGA for
XPU A Programmable FPGA Accelerator for Diverse Workloads Jian Ouyang, 1 (ouyangjian@baidu.com) Ephrem Wu, 2 Jing Wang, 1 Yupeng Li, 1 Hanlin Xie 1 1 Baidu, Inc. 2 Xilinx Outlines Background - FPGA for
CMU Lecture 18: Deep learning and Vision: Convolutional neural networks. Teacher: Gianni A. Di Caro
 CMU 15-781 Lecture 18: Deep learning and Vision: Convolutional neural networks Teacher: Gianni A. Di Caro DEEP, SHALLOW, CONNECTED, SPARSE? Fully connected multi-layer feed-forward perceptrons: More powerful
CMU 15-781 Lecture 18: Deep learning and Vision: Convolutional neural networks Teacher: Gianni A. Di Caro DEEP, SHALLOW, CONNECTED, SPARSE? Fully connected multi-layer feed-forward perceptrons: More powerful
Chapter 03. Authors: John Hennessy & David Patterson. Copyright 2011, Elsevier Inc. All rights Reserved. 1
 Chapter 03 Authors: John Hennessy & David Patterson Copyright 2011, Elsevier Inc. All rights Reserved. 1 Figure 3.3 Comparison of 2-bit predictors. A noncorrelating predictor for 4096 bits is first, followed
Chapter 03 Authors: John Hennessy & David Patterson Copyright 2011, Elsevier Inc. All rights Reserved. 1 Figure 3.3 Comparison of 2-bit predictors. A noncorrelating predictor for 4096 bits is first, followed
Transistors and Wires
 Computer Architecture A Quantitative Approach, Fifth Edition Chapter 1 Fundamentals of Quantitative Design and Analysis Part II These slides are based on the slides provided by the publisher. The slides
Computer Architecture A Quantitative Approach, Fifth Edition Chapter 1 Fundamentals of Quantitative Design and Analysis Part II These slides are based on the slides provided by the publisher. The slides
Co-synthesis and Accelerator based Embedded System Design
 Co-synthesis and Accelerator based Embedded System Design COE838: Embedded Computer System http://www.ee.ryerson.ca/~courses/coe838/ Dr. Gul N. Khan http://www.ee.ryerson.ca/~gnkhan Electrical and Computer
Co-synthesis and Accelerator based Embedded System Design COE838: Embedded Computer System http://www.ee.ryerson.ca/~courses/coe838/ Dr. Gul N. Khan http://www.ee.ryerson.ca/~gnkhan Electrical and Computer
IMPROVING ENERGY EFFICIENCY THROUGH PARALLELIZATION AND VECTORIZATION ON INTEL R CORE TM
 IMPROVING ENERGY EFFICIENCY THROUGH PARALLELIZATION AND VECTORIZATION ON INTEL R CORE TM I5 AND I7 PROCESSORS Juan M. Cebrián 1 Lasse Natvig 1 Jan Christian Meyer 2 1 Depart. of Computer and Information
IMPROVING ENERGY EFFICIENCY THROUGH PARALLELIZATION AND VECTORIZATION ON INTEL R CORE TM I5 AND I7 PROCESSORS Juan M. Cebrián 1 Lasse Natvig 1 Jan Christian Meyer 2 1 Depart. of Computer and Information
Scalable and Dynamically Updatable Lookup Engine for Decision-trees on FPGA
 Scalable and Dynamically Updatable Lookup Engine for Decision-trees on FPGA Yun R. Qu, Viktor K. Prasanna Ming Hsieh Dept. of Electrical Engineering University of Southern California Los Angeles, CA 90089
Scalable and Dynamically Updatable Lookup Engine for Decision-trees on FPGA Yun R. Qu, Viktor K. Prasanna Ming Hsieh Dept. of Electrical Engineering University of Southern California Los Angeles, CA 90089
A 3-D CPU-FPGA-DRAM Hybrid Architecture for Low-Power Computation
 A 3-D CPU-FPGA-DRAM Hybrid Architecture for Low-Power Computation Abstract: The power budget is expected to limit the portion of the chip that we can power ON at the upcoming technology nodes. This problem,
A 3-D CPU-FPGA-DRAM Hybrid Architecture for Low-Power Computation Abstract: The power budget is expected to limit the portion of the chip that we can power ON at the upcoming technology nodes. This problem,
PRIME: A Novel Processing-in-memory Architecture for Neural Network Computation in ReRAM-based Main Memory
 Scalable and Energy-Efficient Architecture Lab (SEAL) PRIME: A Novel Processing-in-memory Architecture for Neural Network Computation in -based Main Memory Ping Chi *, Shuangchen Li *, Tao Zhang, Cong
Scalable and Energy-Efficient Architecture Lab (SEAL) PRIME: A Novel Processing-in-memory Architecture for Neural Network Computation in -based Main Memory Ping Chi *, Shuangchen Li *, Tao Zhang, Cong
Efficient Data Movement in Modern SoC Designs Why It Matters
 WHITE PAPER Efficient Data Movement in Modern SoC Designs Why It Matters COPROCESSORS OFFLOAD AND ACCELERATE SPECIFIC WORKLOADS, HOWEVER DATA MOVEMENT EFFICIENCY ACROSS THE PROCESSING CORES AND MEMORY
WHITE PAPER Efficient Data Movement in Modern SoC Designs Why It Matters COPROCESSORS OFFLOAD AND ACCELERATE SPECIFIC WORKLOADS, HOWEVER DATA MOVEMENT EFFICIENCY ACROSS THE PROCESSING CORES AND MEMORY
Reconfigurable Multicore Server Processors for Low Power Operation
 Reconfigurable Multicore Server Processors for Low Power Operation Ronald G. Dreslinski, David Fick, David Blaauw, Dennis Sylvester, Trevor Mudge University of Michigan, Advanced Computer Architecture
Reconfigurable Multicore Server Processors for Low Power Operation Ronald G. Dreslinski, David Fick, David Blaauw, Dennis Sylvester, Trevor Mudge University of Michigan, Advanced Computer Architecture
IBM Cell Processor. Gilbert Hendry Mark Kretschmann
 IBM Cell Processor Gilbert Hendry Mark Kretschmann Architectural components Architectural security Programming Models Compiler Applications Performance Power and Cost Conclusion Outline Cell Architecture:
IBM Cell Processor Gilbert Hendry Mark Kretschmann Architectural components Architectural security Programming Models Compiler Applications Performance Power and Cost Conclusion Outline Cell Architecture:
Speeding Up Crossbar Resistive Memory by Exploiting In-memory Data Patterns
 March 12, 2018 Speeding Up Crossbar Resistive Memory by Exploiting In-memory Data Patterns Wen Wen Lei Zhao, Youtao Zhang, Jun Yang Executive Summary Problems: performance and reliability of write operations
March 12, 2018 Speeding Up Crossbar Resistive Memory by Exploiting In-memory Data Patterns Wen Wen Lei Zhao, Youtao Zhang, Jun Yang Executive Summary Problems: performance and reliability of write operations
High performance 2D Discrete Fourier Transform on Heterogeneous Platforms. Shrenik Lad, IIIT Hyderabad Advisor : Dr. Kishore Kothapalli
 High performance 2D Discrete Fourier Transform on Heterogeneous Platforms Shrenik Lad, IIIT Hyderabad Advisor : Dr. Kishore Kothapalli Motivation Fourier Transform widely used in Physics, Astronomy, Engineering
High performance 2D Discrete Fourier Transform on Heterogeneous Platforms Shrenik Lad, IIIT Hyderabad Advisor : Dr. Kishore Kothapalli Motivation Fourier Transform widely used in Physics, Astronomy, Engineering
Motivation for Parallelism. Motivation for Parallelism. ILP Example: Loop Unrolling. Types of Parallelism
 Motivation for Parallelism Motivation for Parallelism The speed of an application is determined by more than just processor speed. speed Disk speed Network speed... Multiprocessors typically improve the
Motivation for Parallelism Motivation for Parallelism The speed of an application is determined by more than just processor speed. speed Disk speed Network speed... Multiprocessors typically improve the
Tutorial 11. Final Exam Review
 Tutorial 11 Final Exam Review Introduction Instruction Set Architecture: contract between programmer and designers (e.g.: IA-32, IA-64, X86-64) Computer organization: describe the functional units, cache
Tutorial 11 Final Exam Review Introduction Instruction Set Architecture: contract between programmer and designers (e.g.: IA-32, IA-64, X86-64) Computer organization: describe the functional units, cache
CS6303 Computer Architecture Regulation 2013 BE-Computer Science and Engineering III semester 2 MARKS
 CS6303 Computer Architecture Regulation 2013 BE-Computer Science and Engineering III semester 2 MARKS UNIT-I OVERVIEW & INSTRUCTIONS 1. What are the eight great ideas in computer architecture? The eight
CS6303 Computer Architecture Regulation 2013 BE-Computer Science and Engineering III semester 2 MARKS UNIT-I OVERVIEW & INSTRUCTIONS 1. What are the eight great ideas in computer architecture? The eight
Chapter 5. Introduction ARM Cortex series
 Chapter 5 Introduction ARM Cortex series 5.1 ARM Cortex series variants 5.2 ARM Cortex A series 5.3 ARM Cortex R series 5.4 ARM Cortex M series 5.5 Comparison of Cortex M series with 8/16 bit MCUs 51 5.1
Chapter 5 Introduction ARM Cortex series 5.1 ARM Cortex series variants 5.2 ARM Cortex A series 5.3 ARM Cortex R series 5.4 ARM Cortex M series 5.5 Comparison of Cortex M series with 8/16 bit MCUs 51 5.1
Imaging Solutions by Mercury Computer Systems
 Imaging Solutions by Mercury Computer Systems Presented By Raj Parihar Computer Architecture Reading Group, UofR Mercury Computer Systems Boston based; designs and builds embedded multi computers Loosely
Imaging Solutions by Mercury Computer Systems Presented By Raj Parihar Computer Architecture Reading Group, UofR Mercury Computer Systems Boston based; designs and builds embedded multi computers Loosely
Indian Silicon Technologies 2013
 SI.No Topics IEEE YEAR 1. An RFID Based Solution for Real-Time Patient Surveillance and data Processing Bio- Metric System using FPGA 2. Real-time Binary Shape Matching System Based on FPGA 3. An Optimized
SI.No Topics IEEE YEAR 1. An RFID Based Solution for Real-Time Patient Surveillance and data Processing Bio- Metric System using FPGA 2. Real-time Binary Shape Matching System Based on FPGA 3. An Optimized
Efficient Hardware Acceleration on SoC- FPGA using OpenCL
 Efficient Hardware Acceleration on SoC- FPGA using OpenCL Advisor : Dr. Benjamin Carrion Schafer Susmitha Gogineni 30 th August 17 Presentation Overview 1.Objective & Motivation 2.Configurable SoC -FPGA
Efficient Hardware Acceleration on SoC- FPGA using OpenCL Advisor : Dr. Benjamin Carrion Schafer Susmitha Gogineni 30 th August 17 Presentation Overview 1.Objective & Motivation 2.Configurable SoC -FPGA
PARALLEL TRAINING OF NEURAL NETWORKS FOR SPEECH RECOGNITION
 PARALLEL TRAINING OF NEURAL NETWORKS FOR SPEECH RECOGNITION Stanislav Kontár Speech@FIT, Dept. of Computer Graphics and Multimedia, FIT, BUT, Brno, Czech Republic E-mail: xkonta00@stud.fit.vutbr.cz In
PARALLEL TRAINING OF NEURAL NETWORKS FOR SPEECH RECOGNITION Stanislav Kontár Speech@FIT, Dept. of Computer Graphics and Multimedia, FIT, BUT, Brno, Czech Republic E-mail: xkonta00@stud.fit.vutbr.cz In
Overview. CSE372 Digital Systems Organization and Design Lab. Hardware CAD. Two Types of Chips
 Overview CSE372 Digital Systems Organization and Design Lab Prof. Milo Martin Unit 5: Hardware Synthesis CAD (Computer Aided Design) Use computers to design computers Virtuous cycle Architectural-level,
Overview CSE372 Digital Systems Organization and Design Lab Prof. Milo Martin Unit 5: Hardware Synthesis CAD (Computer Aided Design) Use computers to design computers Virtuous cycle Architectural-level,
Module 5 Introduction to Parallel Processing Systems
 Module 5 Introduction to Parallel Processing Systems 1. What is the difference between pipelining and parallelism? In general, parallelism is simply multiple operations being done at the same time.this
Module 5 Introduction to Parallel Processing Systems 1. What is the difference between pipelining and parallelism? In general, parallelism is simply multiple operations being done at the same time.this
Performance of Multicore LUP Decomposition
 Performance of Multicore LUP Decomposition Nathan Beckmann Silas Boyd-Wickizer May 3, 00 ABSTRACT This paper evaluates the performance of four parallel LUP decomposition implementations. The implementations
Performance of Multicore LUP Decomposition Nathan Beckmann Silas Boyd-Wickizer May 3, 00 ABSTRACT This paper evaluates the performance of four parallel LUP decomposition implementations. The implementations
Embedded Systems: Hardware Components (part I) Todor Stefanov
 Todor Stefanov") Embedded Systems: Hardware Components (part I) Todor Stefanov Leiden Embedded Research Center Leiden Institute of Advanced Computer Science Leiden University, The Netherlands Outline Generic Embedded System
Embedded Systems: Hardware Components (part I) Todor Stefanov Leiden Embedded Research Center Leiden Institute of Advanced Computer Science Leiden University, The Netherlands Outline Generic Embedded System
The Use of Cloud Computing Resources in an HPC Environment
 The Use of Cloud Computing Resources in an HPC Environment Bill, Labate, UCLA Office of Information Technology Prakashan Korambath, UCLA Institute for Digital Research & Education Cloud computing becomes
The Use of Cloud Computing Resources in an HPC Environment Bill, Labate, UCLA Office of Information Technology Prakashan Korambath, UCLA Institute for Digital Research & Education Cloud computing becomes
Computer and Information Sciences College / Computer Science Department CS 207 D. Computer Architecture
 Computer and Information Sciences College / Computer Science Department CS 207 D Computer Architecture The Computer Revolution Progress in computer technology Underpinned by Moore s Law Makes novel applications
Computer and Information Sciences College / Computer Science Department CS 207 D Computer Architecture The Computer Revolution Progress in computer technology Underpinned by Moore s Law Makes novel applications
Understanding Sources of Inefficiency in General-Purpose Chips
 Understanding Sources of Inefficiency in General-Purpose Chips Rehan Hameed Wajahat Qadeer Megan Wachs Omid Azizi Alex Solomatnikov Benjamin Lee Stephen Richardson Christos Kozyrakis Mark Horowitz GP Processors
Understanding Sources of Inefficiency in General-Purpose Chips Rehan Hameed Wajahat Qadeer Megan Wachs Omid Azizi Alex Solomatnikov Benjamin Lee Stephen Richardson Christos Kozyrakis Mark Horowitz GP Processors
Computer Architectures for Deep Learning. Ethan Dell and Daniyal Iqbal
 Computer Architectures for Deep Learning Ethan Dell and Daniyal Iqbal Agenda Introduction to Deep Learning Challenges Architectural Solutions Hardware Architectures CPUs GPUs Accelerators FPGAs SOCs ASICs
Computer Architectures for Deep Learning Ethan Dell and Daniyal Iqbal Agenda Introduction to Deep Learning Challenges Architectural Solutions Hardware Architectures CPUs GPUs Accelerators FPGAs SOCs ASICs
TENSORFLOW: LARGE-SCALE MACHINE LEARNING ON HETEROGENEOUS DISTRIBUTED SYSTEMS. by Google Research. presented by Weichen Wang
 TENSORFLOW: LARGE-SCALE MACHINE LEARNING ON HETEROGENEOUS DISTRIBUTED SYSTEMS by Google Research presented by Weichen Wang 2016.11.28 OUTLINE Introduction The Programming Model The Implementation Single
TENSORFLOW: LARGE-SCALE MACHINE LEARNING ON HETEROGENEOUS DISTRIBUTED SYSTEMS by Google Research presented by Weichen Wang 2016.11.28 OUTLINE Introduction The Programming Model The Implementation Single
Dual-Core Execution: Building A Highly Scalable Single-Thread Instruction Window
 Dual-Core Execution: Building A Highly Scalable Single-Thread Instruction Window Huiyang Zhou School of Computer Science University of Central Florida New Challenges in Billion-Transistor Processor Era
Dual-Core Execution: Building A Highly Scalable Single-Thread Instruction Window Huiyang Zhou School of Computer Science University of Central Florida New Challenges in Billion-Transistor Processor Era
Course web site: teaching/courses/car. Piazza discussion forum:
 Announcements Course web site: http://www.inf.ed.ac.uk/ teaching/courses/car Lecture slides Tutorial problems Courseworks Piazza discussion forum: http://piazza.com/ed.ac.uk/spring2018/car Tutorials start
Announcements Course web site: http://www.inf.ed.ac.uk/ teaching/courses/car Lecture slides Tutorial problems Courseworks Piazza discussion forum: http://piazza.com/ed.ac.uk/spring2018/car Tutorials start
System-on-Chip Architecture for Mobile Applications. Sabyasachi Dey
 System-on-Chip Architecture for Mobile Applications Sabyasachi Dey Email: sabyasachi.dey@gmail.com Agenda What is Mobile Application Platform Challenges Key Architecture Focus Areas Conclusion Mobile Revolution
System-on-Chip Architecture for Mobile Applications Sabyasachi Dey Email: sabyasachi.dey@gmail.com Agenda What is Mobile Application Platform Challenges Key Architecture Focus Areas Conclusion Mobile Revolution
Microprocessor Trends and Implications for the Future
 Microprocessor Trends and Implications for the Future John Mellor-Crummey Department of Computer Science Rice University johnmc@rice.edu COMP 522 Lecture 4 1 September 2016 Context Last two classes: from
Microprocessor Trends and Implications for the Future John Mellor-Crummey Department of Computer Science Rice University johnmc@rice.edu COMP 522 Lecture 4 1 September 2016 Context Last two classes: from
Compilation and Hardware Support for Approximate Acceleration
 Compilation and Hardware Support for Approximate Acceleration Thierry Moreau Adrian Sampson Andre Baixo Mark Wyse Ben Ransford Jacob Nelson Luis Ceze Mark Oskin University of Washington Abstract Approximate
Compilation and Hardware Support for Approximate Acceleration Thierry Moreau Adrian Sampson Andre Baixo Mark Wyse Ben Ransford Jacob Nelson Luis Ceze Mark Oskin University of Washington Abstract Approximate
Parallelizing Inline Data Reduction Operations for Primary Storage Systems
 Parallelizing Inline Data Reduction Operations for Primary Storage Systems Jeonghyeon Ma ( ) and Chanik Park Department of Computer Science and Engineering, POSTECH, Pohang, South Korea {doitnow0415,cipark}@postech.ac.kr
Parallelizing Inline Data Reduction Operations for Primary Storage Systems Jeonghyeon Ma ( ) and Chanik Park Department of Computer Science and Engineering, POSTECH, Pohang, South Korea {doitnow0415,cipark}@postech.ac.kr
On Supporting Adaptive Fault Tolerant at Run-Time with Virtual FPGAs
 On Supporting Adaptive Fault Tolerant at Run-Time with Virtual FPAs K. Siozios 1, D. Soudris 1 and M. Hüebner 2 1 School of ECE, National Technical University of Athens reece Email: {ksiop, dsoudris}@microlab.ntua.gr
On Supporting Adaptive Fault Tolerant at Run-Time with Virtual FPAs K. Siozios 1, D. Soudris 1 and M. Hüebner 2 1 School of ECE, National Technical University of Athens reece Email: {ksiop, dsoudris}@microlab.ntua.gr
ElasticFlow: A Complexity-Effective Approach for Pipelining Irregular Loop Nests
 ElasticFlow: A Complexity-Effective Approach for Pipelining Irregular Loop Nests Mingxing Tan 1 2, Gai Liu 1, Ritchie Zhao 1, Steve Dai 1, Zhiru Zhang 1 1 Computer Systems Laboratory, Electrical and Computer
ElasticFlow: A Complexity-Effective Approach for Pipelining Irregular Loop Nests Mingxing Tan 1 2, Gai Liu 1, Ritchie Zhao 1, Steve Dai 1, Zhiru Zhang 1 1 Computer Systems Laboratory, Electrical and Computer
PowerVR Hardware. Architecture Overview for Developers
 Public Imagination Technologies PowerVR Hardware Public. This publication contains proprietary information which is subject to change without notice and is supplied 'as is' without warranty of any kind.
Public Imagination Technologies PowerVR Hardware Public. This publication contains proprietary information which is subject to change without notice and is supplied 'as is' without warranty of any kind.
Outline of Presentation Field Programmable Gate Arrays (FPGAs(
 FPGA Architectures and Operation for Tolerating SEUs Chuck Stroud Electrical and Computer Engineering Auburn University Outline of Presentation Field Programmable Gate Arrays (FPGAs( FPGAs) How Programmable
FPGA Architectures and Operation for Tolerating SEUs Chuck Stroud Electrical and Computer Engineering Auburn University Outline of Presentation Field Programmable Gate Arrays (FPGAs( FPGAs) How Programmable
Computer Systems Research in the Post-Dennard Scaling Era. Emilio G. Cota Candidacy Exam April 30, 2013
 Computer Systems Research in the Post-Dennard Scaling Era Emilio G. Cota Candidacy Exam April 30, 2013 Intel 4004, 1971 1 core, no cache 23K 10um transistors Intel Nehalem EX, 2009 8c, 24MB cache 2.3B
Computer Systems Research in the Post-Dennard Scaling Era Emilio G. Cota Candidacy Exam April 30, 2013 Intel 4004, 1971 1 core, no cache 23K 10um transistors Intel Nehalem EX, 2009 8c, 24MB cache 2.3B
A Neural Network Model Of Insurance Customer Ratings
 A Neural Network Model Of Insurance Customer Ratings Jan Jantzen 1 Abstract Given a set of data on customers the engineering problem in this study is to model the data and classify customers
A Neural Network Model Of Insurance Customer Ratings Jan Jantzen 1 Abstract Given a set of data on customers the engineering problem in this study is to model the data and classify customers
Memory Systems and Compiler Support for MPSoC Architectures. Mahmut Kandemir and Nikil Dutt. Cap. 9
 Memory Systems and Compiler Support for MPSoC Architectures Mahmut Kandemir and Nikil Dutt Cap. 9 Fernando Moraes 28/maio/2013 1 MPSoC - Vantagens MPSoC architecture has several advantages over a conventional
Memory Systems and Compiler Support for MPSoC Architectures Mahmut Kandemir and Nikil Dutt Cap. 9 Fernando Moraes 28/maio/2013 1 MPSoC - Vantagens MPSoC architecture has several advantages over a conventional
Linux multi-core scalability
 Linux multi-core scalability Oct 2009 Andi Kleen Intel Corporation andi@firstfloor.org Overview Scalability theory Linux history Some common scalability trouble-spots Application workarounds Motivation
Linux multi-core scalability Oct 2009 Andi Kleen Intel Corporation andi@firstfloor.org Overview Scalability theory Linux history Some common scalability trouble-spots Application workarounds Motivation
Biologically-Inspired Massively-Parallel Architectures - computing beyond a million processors
 Biologically-Inspired Massively-Parallel Architectures - computing beyond a million processors Dave Lester The University of Manchester d.lester@manchester.ac.uk NeuroML March 2011 1 Outline 60 years of
Biologically-Inspired Massively-Parallel Architectures - computing beyond a million processors Dave Lester The University of Manchester d.lester@manchester.ac.uk NeuroML March 2011 1 Outline 60 years of
Design Tradeoffs for Data Deduplication Performance in Backup Workloads
 Design Tradeoffs for Data Deduplication Performance in Backup Workloads Min Fu,DanFeng,YuHua,XubinHe, Zuoning Chen *, Wen Xia,YuchengZhang,YujuanTan Huazhong University of Science and Technology Virginia
Design Tradeoffs for Data Deduplication Performance in Backup Workloads Min Fu,DanFeng,YuHua,XubinHe, Zuoning Chen *, Wen Xia,YuchengZhang,YujuanTan Huazhong University of Science and Technology Virginia
Concurrent/Parallel Processing
 Concurrent/Parallel Processing David May: April 9, 2014 Introduction The idea of using a collection of interconnected processing devices is not new. Before the emergence of the modern stored program computer,
Concurrent/Parallel Processing David May: April 9, 2014 Introduction The idea of using a collection of interconnected processing devices is not new. Before the emergence of the modern stored program computer,
A Scalable Speech Recognizer with Deep-Neural-Network Acoustic Models
 A Scalable Speech Recognizer with Deep-Neural-Network Acoustic Models and Voice-Activated Power Gating Michael Price*, James Glass, Anantha Chandrakasan MIT, Cambridge, MA * now at Analog Devices, Cambridge,
A Scalable Speech Recognizer with Deep-Neural-Network Acoustic Models and Voice-Activated Power Gating Michael Price*, James Glass, Anantha Chandrakasan MIT, Cambridge, MA * now at Analog Devices, Cambridge,
Computer Architecture A Quantitative Approach, Fifth Edition. Chapter 2. Memory Hierarchy Design. Copyright 2012, Elsevier Inc. All rights reserved.
 Computer Architecture A Quantitative Approach, Fifth Edition Chapter 2 Memory Hierarchy Design 1 Introduction Programmers want unlimited amounts of memory with low latency Fast memory technology is more
Computer Architecture A Quantitative Approach, Fifth Edition Chapter 2 Memory Hierarchy Design 1 Introduction Programmers want unlimited amounts of memory with low latency Fast memory technology is more