Elaborazione dati real-time su architetture embedded many-core e FPGA
|
|
|
- Basil Atkins
- 5 years ago
- Views:
Transcription

1 Elaborazione dati real-time su architetture embedded many-core e FPGA DAVIDE ROSSI A L E S S A N D R O C A P O T O N D I G I U S E P P E T A G L I A V I N I A N D R E A M A R O N G I U C I R I - I C T U n i v e r s i t à D i B o l o g n a
2 Heterogeneous Many-Core Architectures



")

 Targeting PARALLELISM: massively")
.")

3 Heterogeneous Many-Core Architectures Various design schemes are available: Targeting ADAPTIVITY: heterogeneity and specialization for efficient computing. Es. ARM Big.Little Embedded systems need to be capable to process workloads usually tailored for workstations or HPC. Multi-Processor Systems-on-Chip (MPSoCs) computing units embedded in the same die designed to deliver high performance at low power consumption = high energy efficiency (GOPS/Watt) Targeting PARALLELISM: massively parallel many-core accelerators, to maximize GOPS/Watt (i.e. GPUs, GPGPUs, PMCA). Nvidia Tegra-K1 Two levels of heterogeneity: Host Processor (4 powerful cores + 1 energy efficient core) Parallel many-core co-processor (192 cores accelerator: NvidiaKeplerGPU)
: NVIDIA Kepler GPU with 192 SM (326 GFLOPS) NVIDIA \"4-Plus-1\" 2.")

4 Nvidia K1 (jetson) Hardware Features Dimensions: 5" x 5" (127mm x 127mm) board Tegra K1 SOC (1 to 5 Watts): NVIDIA Kepler GPU with 192 SM (326 GFLOPS) NVIDIA "4-Plus-1" 2.32GHz ARM quad-core Cortex-A15 DRAM: 2GB DDR3L 933MHz IO Features mini-pcie SD/MMC card USB 3.0/2.0 HDMI RS232 Gigabit Ethernet SATA JTAG UART 3x I2C 7 x GPIo Software Features CUDA 6.0 OpenGL 4.4 OpenMAX IL multimedia codec including H.264 OpenCV4Tegra
 Quad-core ARM Cortex-A57 MPCore Processor 4 GB LPDDR4 Memory")

5 Nvidia TX1 Hardware Features Dimensions: 8" x 8 board Tegra TX1 SOC (15 Watts): NVIDIA Maxwell GPU with 256 NVIDIA CUDA Cores(1 TFLOP/s) Quad-core ARM Cortex-A57 MPCore Processor 4 GB LPDDR4 Memory IO Features PCI-E x4 5MP CSI SD/MMC card USB 3.0/2.0 HDMI RS232 Gigabit Ethernet SATA JTAG UART 3x I2C 7 x GPIo Software Features CUDA 6.0 OpenGL 4.4 OpenMAX IL multimedia codec including H.264 OpenCV4Tegra


6 TI Keystone II Hardware Features Dimensions: 8" x 8 board TI 66AK2H12 SOC (14 Watts): 8x C6600 DSP 1.2 GHz (304 GMACs) Quad-core ARM Cortex-A15 MPCore Up to 4 GB DDR3 Memory IO Features PCI-E SD/MMC card USB 3.0/2.0 2x Gigabit Ethernet SATA JTAG UART 3x I2C 38 x GPIo Hyperlink SRIO 20x 64bit Timers Security Accelerators Software Features OpenMP OpenCL

7 MPPA Kalray

8 Xilinx Zynq All Programmable SoC Hardware Features Optimized for quickly prototyping embedded applications using Zynq-7000 SoCs Hardware, design tools, IP, and pre-verified reference designs Demonstrates a embedded design, targeting video pipeline Advanced memory interface with 1GB DDR3 Component Memory 1GB DDR3 SODIM Memory Connectivity Features Enabling serial connectivity with PCIe Gen2x4, SFP+ and SMA Pairs, USB OTG, UART, IIC Supports embedded processing with Dual ARM Cortex-A9 core processors Develop networking applications with Mbps Ethernet (RGMII) Implement Video display applications with HDMI out Expand I/O with the FPGA Mezzanine Card (FMC) interface Programming Features C/C++ VHDL/Verilog SDSoC / OpenCL flows






9 Heterogeneous SoCs Memory Model Strong push for unified memory model in heterogeneous SoCs Shared DRAM Good for programmability Optimized to reduce performance loss How about predictability?

10 Maxwell GPGPU Architecture (Tegra X1) MEMORY HIERARCHY On-Chip Shared Memory Explicitly managed data accesses No interference between host and accelerator Intruction/Data Cache Refill on System Memory Can cause interference between host and accelerator

11 How large can the interference in execution time among the two subsystems be? NVIDIA Tegra X1 3x GPU execution A mix of synthetic workload and real bechmarks Polybench 4x CPU execution Synthetic workload to model high-interference slowdown VS GPU execution in isolation
12 How large can the interference in execution time among the two subsystems be? euler3d sc_gpu lud_cuda srad_v1 srad_v2 heartwall leukocyte needle backprop kmeans particlefilter_float pathfinder lavamd HOW ABOUT REAL WORKLOADS? Rodinia benchmarks executing on both the GPU and the CPU (on all 4 A57, one is observed) Up to 2.5x slower execution under mutual interference CPU/GPU NVIDIA Tegra X1 srad_v1 1,7 1,5 1,2 1,4 1,4 1,2 1,2 1,2 1,4 1,6 1,2 1,2 1,2 srad_v2 1,2 1,4 1,1 1,3 1,2 1,1 1,1 1,1 1,3 1,5 1,1 1,2 1,1 needle 1,6 2,0 1,3 1,9 1,9 1,3 1,3 1,3 1,9 2,5 1,3 1,7 1,3 euler3d_cpu 1,2 1,4 1,1 1,1 1,3 1,1 1,1 1,1 1,3 1,5 1,1 1,2 1,1 streamcluster 1,5 1,9 1,3 1,3 1,8 1,3 1,3 1,3 2,0 2,0 1,3 1,4 1,3 lud_omp 1,1 1,3 1,0 1,2 1,2 1,1 1,0 1,0 1,2 1,4 1,0 1,1 1,0 heartwall 1,0 1,0 1,0 1,0 1,0 1,0 1,0 1,0 1,0 1,0 1,0 1,1 1,0 particle_filter 1,2 1,2 1,2 1,3 1,1 1,1 1,2 1,1 1,1 1,1 1,1 1,3 1,1 mummergpu 1,6 2,1 1,3 1,4 1,9 1,4 1,4 1,3 2,0 2,5 1,4 1,7 1,4 bfs 2,1 1,7 1,6 1,9 1,8 1,7 1,5 1,7 1,6 1,6 1,5 1,8 1,7 backprop 1,9 2,4 1,8 2,0 2,4 1,5 1,6 1,5 2,3 2,5 1,7 2,0 1,6 nn 1,2 1,2 1,2 1,2 1,2 1,2 1,2 1,2 1,2 1,2 1,2 1,2 1,2 hotspot 1,5 1,5 1,5 1,5 1,7 1,5 1,7 1,7 1,5 1,8 1,6 1,5 1,5 hotspot3d 1,5 2,0 1,5 1,6 1,9 1,4 1,5 1,9 2,4 1,9 1,6 1,8 1,6 kmeans 1,1 1,1 1,1 1,1 1,1 1,1 1,1 1,1 1,1 1,1 1,1 1,1 1,0 lavamd 1,0 1,0 1,0 1,0 1,0 1,0 1,0 1,0 1,0 1,0 1,0 1,0 1,0 myocyte.out 1,1 1,1 1,0 1,1 1,1 1,0 1,1 1,0 1,1 1,2 1,1 1,1 1,1 pathfinder 1,1 1,1 1,1 1,1 1,1 1,1 1,1 1,1 1,1 1,1 1,1 1,1 1,1 b+tree 1,0 1,1 1,0 1,1 1,1 1,0 1,0 1,0 1,1 1,1 1,0 1,1 1,0 leukocyte 1,1 1,1 1,1 1,1 1,1 1,1 1,1 1,1 1,1 1,1 1,1 1,1 1,1 hotspot 1,7 1,6 1,6 1,6 1,6 1,7 1,6 1,7 1,6 1,6 1,7 1,5 1,7
13 srad_v1 srad_v2 needle euler3d_cpu sc_omp lud_omp heartwall particle_filter mummergpu bfs backprop filelist_512k hotspot 3D kmeans_serial lavamd myocyte.out pathfinder b+tree.out leukocyte hotspot classification How large can the interference in execution time among the two subsystems be? HOW ABOUT REAL WORKLOADS? Rodinia benchmarks executing on both the GPU (observed values) and the CPU (on all 4 A57) Up to 33x slower execution under mutual interference NVIDIA Tegra X1 GPU / CPU euler3d 1,2 1,2 1,3 1,1 1,2 1,2 1,0 1,0 1,2 1,1 1,4 1,0 1,0 1,1 1,1 1,0 1,1 1,1 1,0 1,0 1,0 1,2 lud_cuda 1,5 1,5 1,3 1,1 1,2 1,1 1,0 1,0 2,2 1,1 1,6 1,0 1,0 1,2 1,1 1,0 1,2 1,1 1,0 1,0 1,0 2,4 srad_v1 1,2 5,2 1,3 1,3 1,4 1,2 1,1 1,3 1,4 1,6 1,5 1,2 1,2 1,2 1,2 1,1 1,1 1,2 1,1 1,1 1,1 3,1 srad_v2 1,4 8,9 1,5 1,1 1,1 1,9 1,0 6,5 1,3 3,6 5,6 1,2 1,8 1,1 1,1 1,0 1,2 1,5 1,3 1,0 2,9 3,6 heartwall 1,1 1,4 1,2 1,0 1,1 1,1 1,0 1,1 1,8 1,0 1,4 1,0 1,0 1,1 1,0 1,0 1,2 1,1 1,1 1,0 1,1 1,2 leukocyte 1,4 1,5 1,6 1,0 1,0 1,0 1,0 1,6 2,6 1,2 1,6 1,3 1,2 1,1 1,0 1,1 1,3 1,1 1,1 1,0 1,4 2,3 needle 2,8 4,5 2,9 2,6 2,7 2,4 1,7 13,0 4,6 5,2 2,9 3,8 6,4 2,6 2,4 2,4 3,2 2,6 2,5 1,9 4,1 14,2 backprop 3,6 32,7 2,6 2,6 2,6 16,3 2,0 3,6 9,2 2,1 3,8 7,7 2,0 2,2 2,6 2,0 3,6 2,2 2,1 2,0 2,1 2,5 kmeans 19,3 21,0 14,4 1,2 2,2 4,4 1,0 29,8 4,2 28,9 22,7 9,5 19,9 2,9 4,4 1,0 1,9 15,7 5,4 1,2 8,3 3,8 particlefilter_float 1,2 1,3 1,3 1,1 1,1 1,1 1,0 1,3 1,8 1,1 1,2 1,1 1,5 1,1 1,1 1,0 1,2 1,1 1,0 1,1 1,0 1,1 pathfinder 8,0 19,3 8,2 1,1 7,5 10,5 6,4 9,3 4,1 27,2 9,2 12,1 5,4 9,6 3,4 1,6 7,4 10,8 7,8 1,1 8,2 27,7 lavamd 1,0 1,0 1,0 1,0 1,0 1,0 1,0 1,0 1,2 1,0 1,0 1,0 1,0 1,0 1,0 1,0 1,0 1,0 1,0 1,0 1,0 1,2



14 The predictable execution model (PREM) Predictable interval Memory prefetching in the first phase No cache misses in the execution phase Non-preemptive execution Requires compiler support for code re-structuring Originally proposed for (multi-core) CPU. We study the applicability of this idea to heterogeneous SoCs



15 The predictable execution model (PREM) System-wide co-scheduling of memory phases from multiple actors Requires runtime techniques for global memory arbitration Originally proposed for (multi-core) CPU. We study the applicability of this idea to heterogeneous SoCs



16 A heterogeneous variant of PREM Current focus on GPU behavior (way more severely affected by interference than CPU) SPM as a predictable, local memory Implement PREM phases within a single offload Arbitration of main memory accesses via timed interrupts+shmem
 GPU inactivity forced via active polling on the on-chip shared memory")
17 CPU/GPU synchronization Basic mechanism in place to control GPU execution CPU inactivity forced via the throttle thread approach (MEMguard) GPU inactivity forced via active polling on the on-chip shared memory (GPUguard)
18 OpenMP offloading annotations #pragma omp target teams distribute parallel for for (i = LB; i < UB; i++) C[i] = A[i] + B[i] The annotated loop is to be offloaded to the accelerator Divide the iteration space over the available execution groups (SMs in CUDA) Execute loop iterations in parallel over the available threads

19 Loops Apply tiling to reorganize loops so as to operate in stripes of the original data structures whose footprint can be accommodated in the SPM Can leverage well-established techniques to prepare loops to expose the most suitable access pattern for SPM reorganization So far the main transformation applied

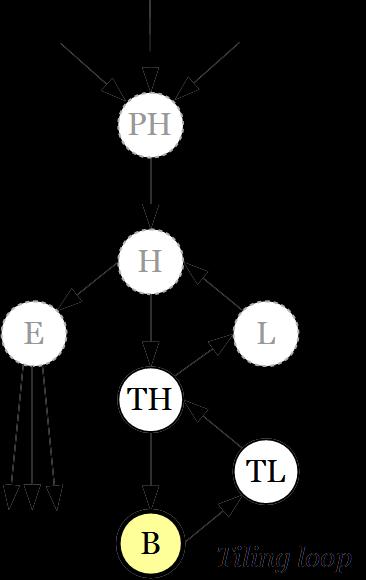
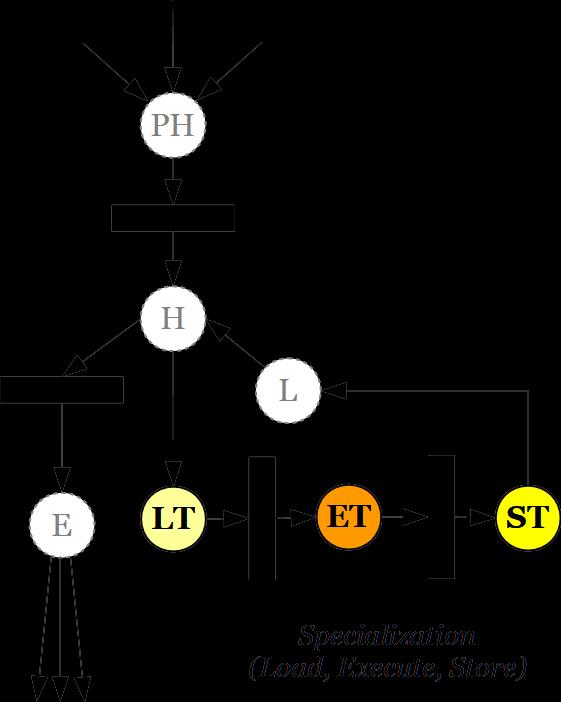
20 Clang OpenMP Compilation Loop tiling Loop outlining Separation Specialization
21 EVALUATION PREDICTABILITY (PolyBench) 1. Near-zero variance when sizing PREM periods for the worst case 2. Up to 70x variance reduction w.r.t. baseline!!! 3. What s the performance drop? 70x Execution time with interference/execution time with no interference
 1.")


22 EVALUATION PREDICTABILITY vs PERFORMANCE (PolyBench) 1. Up to 6x slowdown wrt unmodified program w/o interference 2. Up to 11x improvement wrt unmodified program w interference 11x 6x Execution Time normalized w.r.t. unmodified baseline execution w/o iterference
 1. GPU idleness")
23 EVALUATION OVERHEADS (1) 1. Code refactoring 2. Synchronization OVERHEADS (2) 1. GPU idleness
24 EVALUATION PATH PLANNER APPLICATION WCET Near zero variance 3X reduction in WCET Increased instruction count for specialization and/or tiling Compiler optimizations possible Overhead due to GPU idleness Synchronization scheme Property of the workload Björn Forsberg, Daniele Palossi, Andrea Marongiu, Luca Benini: GPU-Accelerated Real-Time Path Planning and the Predictable Execution Model. ICCS 2017
25 WORK IN PROGRESS Understanding key functionality/performance issues Extensively characterizing performance and overheads on real benchmarks PREMization of CPU code Extend scope of analysis to more control-oriented codes Extend the metodology to All Programmable SoC (CPU + FPGA)

26 END!
Elaborazione di dati ad elevate prestazioni e bassa potenza su architetture embedded many-core e FPGA
 Elaborazione di dati ad elevate prestazioni e bassa potenza su architetture embedded many-core e FPGA Dott. Alessandro Capotondi alessandro.capotondi@unibo.it Prof. Davide Rossi davide.rossi@unibo.it Agenda
Elaborazione di dati ad elevate prestazioni e bassa potenza su architetture embedded many-core e FPGA Dott. Alessandro Capotondi alessandro.capotondi@unibo.it Prof. Davide Rossi davide.rossi@unibo.it Agenda
UNLOCKING BANDWIDTH FOR GPUS IN CC-NUMA SYSTEMS
 UNLOCKING BANDWIDTH FOR GPUS IN CC-NUMA SYSTEMS Neha Agarwal* David Nellans Mike O Connor Stephen W. Keckler Thomas F. Wenisch* NVIDIA University of Michigan* (Major part of this work was done when Neha
UNLOCKING BANDWIDTH FOR GPUS IN CC-NUMA SYSTEMS Neha Agarwal* David Nellans Mike O Connor Stephen W. Keckler Thomas F. Wenisch* NVIDIA University of Michigan* (Major part of this work was done when Neha
Embedded Computing without Compromise. Evolution of the Rugged GPGPU Computer Session: SIL7127 Dan Mor PLM -Aitech Systems GTC Israel 2017
 Evolution of the Rugged GPGPU Computer Session: SIL7127 Dan Mor PLM - Systems GTC Israel 2017 Agenda Current GPGPU systems NVIDIA Jetson TX1 and TX2 evaluation Conclusions New Products 2 GPGPU Product
Evolution of the Rugged GPGPU Computer Session: SIL7127 Dan Mor PLM - Systems GTC Israel 2017 Agenda Current GPGPU systems NVIDIA Jetson TX1 and TX2 evaluation Conclusions New Products 2 GPGPU Product
Manycore and GPU Channelisers. Seth Hall High Performance Computing Lab, AUT
 Manycore and GPU Channelisers Seth Hall High Performance Computing Lab, AUT GPU Accelerated Computing GPU-accelerated computing is the use of a graphics processing unit (GPU) together with a CPU to accelerate
Manycore and GPU Channelisers Seth Hall High Performance Computing Lab, AUT GPU Accelerated Computing GPU-accelerated computing is the use of a graphics processing unit (GPU) together with a CPU to accelerate
A176 Cyclone. GPGPU Fanless Small FF RediBuilt Supercomputer. IT and Instrumentation for industry. Aitech I/O
 The A176 Cyclone is the smallest and most powerful Rugged-GPGPU, ideally suited for distributed systems. Its 256 CUDA cores reach 1 TFLOPS, and it consumes less than 17W at full load (8-10W at typical
The A176 Cyclone is the smallest and most powerful Rugged-GPGPU, ideally suited for distributed systems. Its 256 CUDA cores reach 1 TFLOPS, and it consumes less than 17W at full load (8-10W at typical
A176 C clone. GPGPU Fanless Small FF RediBuilt Supercomputer. Aitech
 The A176 Cyclone is the smallest and most powerful Rugged-GPGPU, ideally suited for distributed systems. Its 256 CUDA cores reach 1 TFLOPS at a remarkable level of energy efficiency, providing all the
The A176 Cyclone is the smallest and most powerful Rugged-GPGPU, ideally suited for distributed systems. Its 256 CUDA cores reach 1 TFLOPS at a remarkable level of energy efficiency, providing all the
PAGE PLACEMENT STRATEGIES FOR GPUS WITHIN HETEROGENEOUS MEMORY SYSTEMS
 PAGE PLACEMENT STRATEGIES FOR GPUS WITHIN HETEROGENEOUS MEMORY SYSTEMS Neha Agarwal* David Nellans Mark Stephenson Mike O Connor Stephen W. Keckler NVIDIA University of Michigan* ASPLOS 2015 EVOLVING GPU
PAGE PLACEMENT STRATEGIES FOR GPUS WITHIN HETEROGENEOUS MEMORY SYSTEMS Neha Agarwal* David Nellans Mark Stephenson Mike O Connor Stephen W. Keckler NVIDIA University of Michigan* ASPLOS 2015 EVOLVING GPU
THE LEADER IN VISUAL COMPUTING
 MOBILE EMBEDDED THE LEADER IN VISUAL COMPUTING 2 TAKING OUR VISION TO REALITY HPC DESIGN and VISUALIZATION AUTO GAMING 3 BEST DEVELOPER EXPERIENCE Tools for Fast Development Debug and Performance Tuning
MOBILE EMBEDDED THE LEADER IN VISUAL COMPUTING 2 TAKING OUR VISION TO REALITY HPC DESIGN and VISUALIZATION AUTO GAMING 3 BEST DEVELOPER EXPERIENCE Tools for Fast Development Debug and Performance Tuning
gem5-gpu Extending gem5 for GPGPUs Jason Power, Marc Orr, Joel Hestness, Mark Hill, David Wood
 gem5-gpu Extending gem5 for GPGPUs Jason Power, Marc Orr, Joel Hestness, Mark Hill, David Wood (powerjg/morr)@cs.wisc.edu UW-Madison Computer Sciences 2012 gem5-gpu gem5 + GPGPU-Sim (v3.0.1) Flexible memory
gem5-gpu Extending gem5 for GPGPUs Jason Power, Marc Orr, Joel Hestness, Mark Hill, David Wood (powerjg/morr)@cs.wisc.edu UW-Madison Computer Sciences 2012 gem5-gpu gem5 + GPGPU-Sim (v3.0.1) Flexible memory
Integrating DMA capabilities into BLIS for on-chip data movement. Devangi Parikh Ilya Polkovnichenko Francisco Igual Peña Murtaza Ali
 Integrating DMA capabilities into BLIS for on-chip data movement Devangi Parikh Ilya Polkovnichenko Francisco Igual Peña Murtaza Ali 5 Generations of TI Multicore Processors Keystone architecture Lowers
Integrating DMA capabilities into BLIS for on-chip data movement Devangi Parikh Ilya Polkovnichenko Francisco Igual Peña Murtaza Ali 5 Generations of TI Multicore Processors Keystone architecture Lowers
Nvidia Jetson TX2 and its Software Toolset. João Fernandes 2017/2018
 Nvidia Jetson TX2 and its Software Toolset João Fernandes 2017/2018 In this presentation Nvidia Jetson TX2: Hardware Nvidia Jetson TX2: Software Machine Learning: Neural Networks Convolutional Neural Networks
Nvidia Jetson TX2 and its Software Toolset João Fernandes 2017/2018 In this presentation Nvidia Jetson TX2: Hardware Nvidia Jetson TX2: Software Machine Learning: Neural Networks Convolutional Neural Networks
Carlos Reaño, Javier Prades and Federico Silla Technical University of Valencia (Spain)
") Carlos Reaño, Javier Prades and Federico Silla Technical University of Valencia (Spain) 4th IEEE International Workshop of High-Performance Interconnection Networks in the Exascale and Big-Data Era (HiPINEB
Carlos Reaño, Javier Prades and Federico Silla Technical University of Valencia (Spain) 4th IEEE International Workshop of High-Performance Interconnection Networks in the Exascale and Big-Data Era (HiPINEB
MYC-C7Z010/20 CPU Module
 MYC-C7Z010/20 CPU Module - 667MHz Xilinx XC7Z010/20 Dual-core ARM Cortex-A9 Processor with Xilinx 7-series FPGA logic - 1GB DDR3 SDRAM (2 x 512MB, 32-bit), 4GB emmc, 32MB QSPI Flash - On-board Gigabit
MYC-C7Z010/20 CPU Module - 667MHz Xilinx XC7Z010/20 Dual-core ARM Cortex-A9 Processor with Xilinx 7-series FPGA logic - 1GB DDR3 SDRAM (2 x 512MB, 32-bit), 4GB emmc, 32MB QSPI Flash - On-board Gigabit
MYD-C7Z010/20 Development Board
 MYD-C7Z010/20 Development Board MYC-C7Z010/20 CPU Module as Controller Board Two 0.8mm pitch 140-pin Connectors for Board-to-Board Connections 667MHz Xilinx XC7Z010/20 Dual-core ARM Cortex-A9 Processor
MYD-C7Z010/20 Development Board MYC-C7Z010/20 CPU Module as Controller Board Two 0.8mm pitch 140-pin Connectors for Board-to-Board Connections 667MHz Xilinx XC7Z010/20 Dual-core ARM Cortex-A9 Processor
LoGA: Low-overhead GPU accounting using events
 : Low-overhead GPU accounting using events Jens Kehne Stanislav Spassov Marius Hillenbrand Marc Rittinghaus Frank Bellosa Karlsruhe Institute of Technology (KIT) Operating Systems Group os@itec.kit.edu
: Low-overhead GPU accounting using events Jens Kehne Stanislav Spassov Marius Hillenbrand Marc Rittinghaus Frank Bellosa Karlsruhe Institute of Technology (KIT) Operating Systems Group os@itec.kit.edu
Copyright 2017 Xilinx.
 All Programmable Automotive SoC Comparison XA Zynq UltraScale+ MPSoC ZU2/3EG, ZU4/5EV Devices XA Zynq -7000 SoC Z-7010/7020/7030 Devices Application Processor Real-Time Processor Quad-core ARM Cortex -A53
All Programmable Automotive SoC Comparison XA Zynq UltraScale+ MPSoC ZU2/3EG, ZU4/5EV Devices XA Zynq -7000 SoC Z-7010/7020/7030 Devices Application Processor Real-Time Processor Quad-core ARM Cortex -A53
GPUs and Emerging Architectures
 GPUs and Emerging Architectures Mike Giles mike.giles@maths.ox.ac.uk Mathematical Institute, Oxford University e-infrastructure South Consortium Oxford e-research Centre Emerging Architectures p. 1 CPUs
GPUs and Emerging Architectures Mike Giles mike.giles@maths.ox.ac.uk Mathematical Institute, Oxford University e-infrastructure South Consortium Oxford e-research Centre Emerging Architectures p. 1 CPUs
. SMARC 2.0 Compliant
 MSC SM2S-IMX8 NXP i.mx8 ARM Cortex -A72/A53 Description The new MSC SM2S-IMX8 module offers a quantum leap in terms of computing and graphics performance. It integrates the currently most powerful i.mx8
MSC SM2S-IMX8 NXP i.mx8 ARM Cortex -A72/A53 Description The new MSC SM2S-IMX8 module offers a quantum leap in terms of computing and graphics performance. It integrates the currently most powerful i.mx8
Energy Efficient K-Means Clustering for an Intel Hybrid Multi-Chip Package
 High Performance Machine Learning Workshop Energy Efficient K-Means Clustering for an Intel Hybrid Multi-Chip Package Matheus Souza, Lucas Maciel, Pedro Penna, Henrique Freitas 24/09/2018 Agenda Introduction
High Performance Machine Learning Workshop Energy Efficient K-Means Clustering for an Intel Hybrid Multi-Chip Package Matheus Souza, Lucas Maciel, Pedro Penna, Henrique Freitas 24/09/2018 Agenda Introduction
CUDA on ARM Update. Developing Accelerated Applications on ARM. Bas Aarts and Donald Becker
 CUDA on ARM Update Developing Accelerated Applications on ARM Bas Aarts and Donald Becker CUDA on ARM: a forward-looking development platform for high performance, energy efficient hybrid computing It
CUDA on ARM Update Developing Accelerated Applications on ARM Bas Aarts and Donald Becker CUDA on ARM: a forward-looking development platform for high performance, energy efficient hybrid computing It
Zynq-7000 All Programmable SoC Product Overview
 Zynq-7000 All Programmable SoC Product Overview The SW, HW and IO Programmable Platform August 2012 Copyright 2012 2009 Xilinx Introducing the Zynq -7000 All Programmable SoC Breakthrough Processing Platform
Zynq-7000 All Programmable SoC Product Overview The SW, HW and IO Programmable Platform August 2012 Copyright 2012 2009 Xilinx Introducing the Zynq -7000 All Programmable SoC Breakthrough Processing Platform
FiPS and M2DC: Novel Architectures for Reconfigurable Hyperscale Servers
 FiPS and M2DC: Novel Architectures for Reconfigurable Hyperscale Servers Rene Griessl, Meysam Peykanu, Lennart Tigges, Jens Hagemeyer, Mario Porrmann Center of Excellence Cognitive Interaction Technology
FiPS and M2DC: Novel Architectures for Reconfigurable Hyperscale Servers Rene Griessl, Meysam Peykanu, Lennart Tigges, Jens Hagemeyer, Mario Porrmann Center of Excellence Cognitive Interaction Technology
An Investigation of Unified Memory Access Performance in CUDA
 An Investigation of Unified Memory Access Performance in CUDA Raphael Landaverde, Tiansheng Zhang, Ayse K. Coskun and Martin Herbordt Electrical and Computer Engineering Department, Boston University,
An Investigation of Unified Memory Access Performance in CUDA Raphael Landaverde, Tiansheng Zhang, Ayse K. Coskun and Martin Herbordt Electrical and Computer Engineering Department, Boston University,
NVIDIA Think about Computing as Heterogeneous One Leo Liao, 1/29/2106, NTU
 NVIDIA Think about Computing as Heterogeneous One Leo Liao, 1/29/2106, NTU GPGPU opens the door for co-design HPC, moreover middleware-support embedded system designs to harness the power of GPUaccelerated
NVIDIA Think about Computing as Heterogeneous One Leo Liao, 1/29/2106, NTU GPGPU opens the door for co-design HPC, moreover middleware-support embedded system designs to harness the power of GPUaccelerated
Experiences Using Tegra K1 and X1 for Highly Energy Efficient Computing
 Experiences Using Tegra K1 and X1 for Highly Energy Efficient Computing Gaurav Mitra Andrew Haigh Luke Angove Anish Varghese Eric McCreath Alistair P. Rendell Research School of Computer Science Australian
Experiences Using Tegra K1 and X1 for Highly Energy Efficient Computing Gaurav Mitra Andrew Haigh Luke Angove Anish Varghese Eric McCreath Alistair P. Rendell Research School of Computer Science Australian
XMC-ZU1. XMC Module Xilinx Zynq UltraScale+ MPSoC. Overview. Key Features. Typical Applications
 XMC-ZU1 XMC Module Xilinx Zynq UltraScale+ MPSoC Overview PanaTeQ s XMC-ZU1 is a XMC module based on the Zynq UltraScale+ MultiProcessor SoC device from Xilinx. The Zynq UltraScale+ integrates a Quad-core
XMC-ZU1 XMC Module Xilinx Zynq UltraScale+ MPSoC Overview PanaTeQ s XMC-ZU1 is a XMC module based on the Zynq UltraScale+ MultiProcessor SoC device from Xilinx. The Zynq UltraScale+ integrates a Quad-core
Exploring Task Parallelism for Heterogeneous Systems Using Multicore Task Management API
 EuroPAR 2016 ROME Workshop Exploring Task Parallelism for Heterogeneous Systems Using Multicore Task Management API Suyang Zhu 1, Sunita Chandrasekaran 2, Peng Sun 1, Barbara Chapman 1, Marcus Winter 3,
EuroPAR 2016 ROME Workshop Exploring Task Parallelism for Heterogeneous Systems Using Multicore Task Management API Suyang Zhu 1, Sunita Chandrasekaran 2, Peng Sun 1, Barbara Chapman 1, Marcus Winter 3,
. Micro SD Card Socket. SMARC 2.0 Compliant
 MSC SM2S-IMX6 NXP i.mx6 ARM Cortex -A9 Description The design of the MSC SM2S-IMX6 module is based on NXP s i.mx 6 processors offering quad-, dual- and single-core ARM Cortex -A9 compute performance at
MSC SM2S-IMX6 NXP i.mx6 ARM Cortex -A9 Description The design of the MSC SM2S-IMX6 module is based on NXP s i.mx 6 processors offering quad-, dual- and single-core ARM Cortex -A9 compute performance at
Embedded Linux Conference San Diego 2016
 Embedded Linux Conference San Diego 2016 Linux Power Management Optimization on the Nvidia Jetson Platform Merlin Friesen merlin@gg-research.com About You Target Audience - The presentation is introductory
Embedded Linux Conference San Diego 2016 Linux Power Management Optimization on the Nvidia Jetson Platform Merlin Friesen merlin@gg-research.com About You Target Audience - The presentation is introductory
E4-ARKA: ARM64+GPU+IB is Now Here Piero Altoè. ARM64 and GPGPU
 E4-ARKA: ARM64+GPU+IB is Now Here Piero Altoè ARM64 and GPGPU 1 E4 Computer Engineering Company E4 Computer Engineering S.p.A. specializes in the manufacturing of high performance IT systems of medium
E4-ARKA: ARM64+GPU+IB is Now Here Piero Altoè ARM64 and GPGPU 1 E4 Computer Engineering Company E4 Computer Engineering S.p.A. specializes in the manufacturing of high performance IT systems of medium
Multimedia SoC System Solutions
 Multimedia SoC System Solutions Presented By Yashu Gosain & Forrest Picket: System Software & SoC Solutions Marketing Girish Malipeddi: IP Subsystems Marketing Agenda Zynq Ultrascale+ MPSoC and Multimedia
Multimedia SoC System Solutions Presented By Yashu Gosain & Forrest Picket: System Software & SoC Solutions Marketing Girish Malipeddi: IP Subsystems Marketing Agenda Zynq Ultrascale+ MPSoC and Multimedia
Kalray MPPA Manycore Challenges for the Next Generation of Professional Applications Benoît Dupont de Dinechin MPSoC 2013
 Kalray MPPA Manycore Challenges for the Next Generation of Professional Applications Benoît Dupont de Dinechin MPSoC 2013 The End of Dennard MOSFET Scaling Theory 2013 Kalray SA All Rights Reserved MPSoC
Kalray MPPA Manycore Challenges for the Next Generation of Professional Applications Benoît Dupont de Dinechin MPSoC 2013 The End of Dennard MOSFET Scaling Theory 2013 Kalray SA All Rights Reserved MPSoC
TOOLS FOR IMPROVING CROSS-PLATFORM SOFTWARE DEVELOPMENT
 TOOLS FOR IMPROVING CROSS-PLATFORM SOFTWARE DEVELOPMENT Eric Kelmelis 28 March 2018 OVERVIEW BACKGROUND Evolution of processing hardware CROSS-PLATFORM KERNEL DEVELOPMENT Write once, target multiple hardware
TOOLS FOR IMPROVING CROSS-PLATFORM SOFTWARE DEVELOPMENT Eric Kelmelis 28 March 2018 OVERVIEW BACKGROUND Evolution of processing hardware CROSS-PLATFORM KERNEL DEVELOPMENT Write once, target multiple hardware
EyeCheck Smart Cameras
 EyeCheck Smart Cameras 2 3 EyeCheck 9xx & 1xxx series Technical data Memory: DDR RAM 128 MB FLASH 128 MB Interfaces: Ethernet (LAN) RS422, RS232 (not EC900, EC910, EC1000, EC1010) EtherNet / IP PROFINET
EyeCheck Smart Cameras 2 3 EyeCheck 9xx & 1xxx series Technical data Memory: DDR RAM 128 MB FLASH 128 MB Interfaces: Ethernet (LAN) RS422, RS232 (not EC900, EC910, EC1000, EC1010) EtherNet / IP PROFINET
A Closer Look at the Epiphany IV 28nm 64 core Coprocessor. Andreas Olofsson PEGPUM 2013
 A Closer Look at the Epiphany IV 28nm 64 core Coprocessor Andreas Olofsson PEGPUM 2013 1 Adapteva Achieves 3 World Firsts 1. First processor company to reach 50 GFLOPS/W 3. First semiconductor company
A Closer Look at the Epiphany IV 28nm 64 core Coprocessor Andreas Olofsson PEGPUM 2013 1 Adapteva Achieves 3 World Firsts 1. First processor company to reach 50 GFLOPS/W 3. First semiconductor company
VPX3-ZU1. 3U OpenVPX Module Xilinx Zynq UltraScale+ MPSoC with FMC HPC Site. Overview. Key Features. Typical Applications
 VPX3-ZU1 3U OpenVPX Module Xilinx Zynq UltraScale+ MPSoC with FMC HPC Site Overview PanaTeQ s VPX3-ZU1 is a 3U OpenVPX module based on the Zynq UltraScale+ MultiProcessor SoC device from Xilinx. The Zynq
VPX3-ZU1 3U OpenVPX Module Xilinx Zynq UltraScale+ MPSoC with FMC HPC Site Overview PanaTeQ s VPX3-ZU1 is a 3U OpenVPX module based on the Zynq UltraScale+ MultiProcessor SoC device from Xilinx. The Zynq
S2C K7 Prodigy Logic Module Series
 S2C K7 Prodigy Logic Module Series Low-Cost Fifth Generation Rapid FPGA-based Prototyping Hardware The S2C K7 Prodigy Logic Module is equipped with one Xilinx Kintex-7 XC7K410T or XC7K325T FPGA device
S2C K7 Prodigy Logic Module Series Low-Cost Fifth Generation Rapid FPGA-based Prototyping Hardware The S2C K7 Prodigy Logic Module is equipped with one Xilinx Kintex-7 XC7K410T or XC7K325T FPGA device
XMC-RFSOC-A. XMC Module Xilinx Zynq UltraScale+ RFSOC. Overview. Key Features. Typical Applications. Advanced Information Subject To Change
 Advanced Information Subject To Change XMC-RFSOC-A XMC Module Xilinx Zynq UltraScale+ RFSOC Overview PanaTeQ s XMC-RFSOC-A is a XMC module based on the Zynq UltraScale+ RFSoC device from Xilinx. The Zynq
Advanced Information Subject To Change XMC-RFSOC-A XMC Module Xilinx Zynq UltraScale+ RFSOC Overview PanaTeQ s XMC-RFSOC-A is a XMC module based on the Zynq UltraScale+ RFSoC device from Xilinx. The Zynq
GaaS Workload Characterization under NUMA Architecture for Virtualized GPU
 GaaS Workload Characterization under NUMA Architecture for Virtualized GPU Huixiang Chen, Meng Wang, Yang Hu, Mingcong Song, Tao Li Presented by Huixiang Chen ISPASS 2017 April 24, 2017, Santa Rosa, California
GaaS Workload Characterization under NUMA Architecture for Virtualized GPU Huixiang Chen, Meng Wang, Yang Hu, Mingcong Song, Tao Li Presented by Huixiang Chen ISPASS 2017 April 24, 2017, Santa Rosa, California
VPX3-ZU1. 3U OpenVPX Module Xilinx Zynq UltraScale+ MPSoC with FMC HPC Site. Overview. Key Features. Typical Applications
 VPX3-ZU1 3U OpenVPX Module Xilinx Zynq UltraScale+ MPSoC with FMC HPC Site Overview PanaTeQ s VPX3-ZU1 is a 3U OpenVPX module based on the Zynq UltraScale+ MultiProcessor SoC device from Xilinx. The Zynq
VPX3-ZU1 3U OpenVPX Module Xilinx Zynq UltraScale+ MPSoC with FMC HPC Site Overview PanaTeQ s VPX3-ZU1 is a 3U OpenVPX module based on the Zynq UltraScale+ MultiProcessor SoC device from Xilinx. The Zynq
XMC-SDR-A. XMC Zynq MPSoC + Dual ADRV9009 module. Preliminary Information Subject To Change. Overview. Key Features. Typical Applications
 Preliminary Information Subject To Change XMC-SDR-A XMC Zynq MPSoC + Dual ADRV9009 module Overview PanaTeQ s XMC-SDR-A is a XMC module based on the Zynq UltraScale+ MultiProcessor SoC device from Xilinx
Preliminary Information Subject To Change XMC-SDR-A XMC Zynq MPSoC + Dual ADRV9009 module Overview PanaTeQ s XMC-SDR-A is a XMC module based on the Zynq UltraScale+ MultiProcessor SoC device from Xilinx
Simplify System Complexity
 Simplify System Complexity With the new high-performance CompactRIO controller Fanie Coetzer Field Sales Engineer Northern South Africa 2 3 New control system CompactPCI MMI/Sequencing/Logging FieldPoint
Simplify System Complexity With the new high-performance CompactRIO controller Fanie Coetzer Field Sales Engineer Northern South Africa 2 3 New control system CompactPCI MMI/Sequencing/Logging FieldPoint
Performance Characterization, Prediction, and Optimization for Heterogeneous Systems with Multi-Level Memory Interference
 The 2017 IEEE International Symposium on Workload Characterization Performance Characterization, Prediction, and Optimization for Heterogeneous Systems with Multi-Level Memory Interference Shin-Ying Lee
The 2017 IEEE International Symposium on Workload Characterization Performance Characterization, Prediction, and Optimization for Heterogeneous Systems with Multi-Level Memory Interference Shin-Ying Lee
Position Paper: OpenMP scheduling on ARM big.little architecture
 Position Paper: OpenMP scheduling on ARM big.little architecture Anastasiia Butko, Louisa Bessad, David Novo, Florent Bruguier, Abdoulaye Gamatié, Gilles Sassatelli, Lionel Torres, and Michel Robert LIRMM
Position Paper: OpenMP scheduling on ARM big.little architecture Anastasiia Butko, Louisa Bessad, David Novo, Florent Bruguier, Abdoulaye Gamatié, Gilles Sassatelli, Lionel Torres, and Michel Robert LIRMM
CPU-GPU Heterogeneous Computing
 CPU-GPU Heterogeneous Computing Advanced Seminar "Computer Engineering Winter-Term 2015/16 Steffen Lammel 1 Content Introduction Motivation Characteristics of CPUs and GPUs Heterogeneous Computing Systems
CPU-GPU Heterogeneous Computing Advanced Seminar "Computer Engineering Winter-Term 2015/16 Steffen Lammel 1 Content Introduction Motivation Characteristics of CPUs and GPUs Heterogeneous Computing Systems
Hugo Cunha. Senior Firmware Developer Globaltronics
 Hugo Cunha Senior Firmware Developer Globaltronics NB-IoT Product Acceleration Platforms 2018 Speaker Hugo Cunha Project Developper Agenda About us NB IoT Platforms The WIIPIIDO The Gateway FE 1 About
Hugo Cunha Senior Firmware Developer Globaltronics NB-IoT Product Acceleration Platforms 2018 Speaker Hugo Cunha Project Developper Agenda About us NB IoT Platforms The WIIPIIDO The Gateway FE 1 About
Exercise: OpenMP Programming
 Exercise: OpenMP Programming Multicore programming with OpenMP 19.04.2016 A. Marongiu - amarongiu@iis.ee.ethz.ch D. Palossi dpalossi@iis.ee.ethz.ch ETH zürich Odroid Board Board Specs Exynos5 Octa Cortex
Exercise: OpenMP Programming Multicore programming with OpenMP 19.04.2016 A. Marongiu - amarongiu@iis.ee.ethz.ch D. Palossi dpalossi@iis.ee.ethz.ch ETH zürich Odroid Board Board Specs Exynos5 Octa Cortex
SoC Platforms and CPU Cores
 SoC Platforms and CPU Cores COE838: Systems on Chip Design http://www.ee.ryerson.ca/~courses/coe838/ Dr. Gul N. Khan http://www.ee.ryerson.ca/~gnkhan Electrical and Computer Engineering Ryerson University
SoC Platforms and CPU Cores COE838: Systems on Chip Design http://www.ee.ryerson.ca/~courses/coe838/ Dr. Gul N. Khan http://www.ee.ryerson.ca/~gnkhan Electrical and Computer Engineering Ryerson University
The rcuda middleware and applications
 The rcuda middleware and applications Will my application work with rcuda? rcuda currently provides binary compatibility with CUDA 5.0, virtualizing the entire Runtime API except for the graphics functions,
The rcuda middleware and applications Will my application work with rcuda? rcuda currently provides binary compatibility with CUDA 5.0, virtualizing the entire Runtime API except for the graphics functions,
ARM and x86 on Qseven & COM Express Mini. Zeljko Loncaric, Marketing Engineer, congatec AG
 ARM and x86 on Qseven & COM Express Mini Zeljko Loncaric, Marketing Engineer, congatec AG Content COM Computer-On-Module Concept Qseven Key Points The Right ARM Integration with Freescale i.mx6 Qseven
ARM and x86 on Qseven & COM Express Mini Zeljko Loncaric, Marketing Engineer, congatec AG Content COM Computer-On-Module Concept Qseven Key Points The Right ARM Integration with Freescale i.mx6 Qseven
OpenMP Device Offloading to FPGA Accelerators. Lukas Sommer, Jens Korinth, Andreas Koch
 OpenMP Device Offloading to FPGA Accelerators Lukas Sommer, Jens Korinth, Andreas Koch Motivation Increasing use of heterogeneous systems to overcome CPU power limitations 2017-07-12 OpenMP FPGA Device
OpenMP Device Offloading to FPGA Accelerators Lukas Sommer, Jens Korinth, Andreas Koch Motivation Increasing use of heterogeneous systems to overcome CPU power limitations 2017-07-12 OpenMP FPGA Device
TR An Overview of NVIDIA Tegra K1 Architecture. Ang Li, Radu Serban, Dan Negrut
 TR-2014-17 An Overview of NVIDIA Tegra K1 Architecture Ang Li, Radu Serban, Dan Negrut November 20, 2014 Abstract This paperwork gives an overview of NVIDIA s Jetson TK1 Development Kit and its Tegra K1
TR-2014-17 An Overview of NVIDIA Tegra K1 Architecture Ang Li, Radu Serban, Dan Negrut November 20, 2014 Abstract This paperwork gives an overview of NVIDIA s Jetson TK1 Development Kit and its Tegra K1
Simplify System Complexity
 1 2 Simplify System Complexity With the new high-performance CompactRIO controller Arun Veeramani Senior Program Manager National Instruments NI CompactRIO The Worlds Only Software Designed Controller
1 2 Simplify System Complexity With the new high-performance CompactRIO controller Arun Veeramani Senior Program Manager National Instruments NI CompactRIO The Worlds Only Software Designed Controller
Intelligent Video Analytics for Urban Management
 Smart-I Gabriele Randelli Founder & CTO Intelligent Video Analytics for Urban Management Gabriele Randelli Founder & CTO gabriele@smart-interaction.com 1 Gabriele Randelli Founder & CTO Smart- Feel Interactive
Smart-I Gabriele Randelli Founder & CTO Intelligent Video Analytics for Urban Management Gabriele Randelli Founder & CTO gabriele@smart-interaction.com 1 Gabriele Randelli Founder & CTO Smart- Feel Interactive
Design Choices for FPGA-based SoCs When Adding a SATA Storage }
 U4 U7 U7 Q D U5 Q D Design Choices for FPGA-based SoCs When Adding a SATA Storage } Lorenz Kolb & Endric Schubert, Missing Link Electronics Rudolf Usselmann, ASICS World Services Motivation for SATA Storage
U4 U7 U7 Q D U5 Q D Design Choices for FPGA-based SoCs When Adding a SATA Storage } Lorenz Kolb & Endric Schubert, Missing Link Electronics Rudolf Usselmann, ASICS World Services Motivation for SATA Storage
VT988. Key Features. Benefits. High speed 16 ADC at 3 GSPS with Synchronous Capture VT ADC for synchronous capture
 Key Features VT988 High speed 16 ADC at 3 GSPS with Synchronous Capture 16 ADC for synchronous capture Xilinx Virtex-7 XC7VX485T FPGA NVidia Jetson TX2 System on Module TI ADC08B3000 8-bit @ 3 GSPS Managed
Key Features VT988 High speed 16 ADC at 3 GSPS with Synchronous Capture 16 ADC for synchronous capture Xilinx Virtex-7 XC7VX485T FPGA NVidia Jetson TX2 System on Module TI ADC08B3000 8-bit @ 3 GSPS Managed
Embedded platforms for nextgeneration autonomous driving systems
 Embedded platforms for nextgeneration autonomous driving systems PAOLO BURGIO U N I V E R S I T Y O F M O D E N A A N D R E G G I O E M I L I A P A O L O. B U R G I O @ U N I M O R E. I T This Project
Embedded platforms for nextgeneration autonomous driving systems PAOLO BURGIO U N I V E R S I T Y O F M O D E N A A N D R E G G I O E M I L I A P A O L O. B U R G I O @ U N I M O R E. I T This Project
What is GPU? CS 590: High Performance Computing. GPU Architectures and CUDA Concepts/Terms
 CS 590: High Performance Computing GPU Architectures and CUDA Concepts/Terms Fengguang Song Department of Computer & Information Science IUPUI What is GPU? Conventional GPUs are used to generate 2D, 3D
CS 590: High Performance Computing GPU Architectures and CUDA Concepts/Terms Fengguang Song Department of Computer & Information Science IUPUI What is GPU? Conventional GPUs are used to generate 2D, 3D
Mapping applications into MPSoC
 Mapping applications into MPSoC concurrency & communication Jos van Eijndhoven jos@vectorfabrics.com March 12, 2011 MPSoC mapping: exploiting concurrency 2 March 12, 2012 Computation on general purpose
Mapping applications into MPSoC concurrency & communication Jos van Eijndhoven jos@vectorfabrics.com March 12, 2011 MPSoC mapping: exploiting concurrency 2 March 12, 2012 Computation on general purpose
There s STILL plenty of room at the bottom! Andreas Olofsson
 There s STILL plenty of room at the bottom! Andreas Olofsson 1 Richard Feynman s Lecture (1959) There's Plenty of Room at the Bottom An Invitation to Enter a New Field of Physics Why cannot we write the
There s STILL plenty of room at the bottom! Andreas Olofsson 1 Richard Feynman s Lecture (1959) There's Plenty of Room at the Bottom An Invitation to Enter a New Field of Physics Why cannot we write the
F28HS Hardware-Software Interface: Systems Programming
 F28HS Hardware-Software Interface: Systems Programming Hans-Wolfgang Loidl School of Mathematical and Computer Sciences, Heriot-Watt University, Edinburgh Semester 2 2017/18 0 No proprietary software has
F28HS Hardware-Software Interface: Systems Programming Hans-Wolfgang Loidl School of Mathematical and Computer Sciences, Heriot-Watt University, Edinburgh Semester 2 2017/18 0 No proprietary software has
Compact form factor. High speed MXM edge connector. Processor. Max Cores 4. Max Thread 4. Memory. Graphics. Video Interfaces.
 QSEVEN STANDARD ADVANTAGES Rel. 2.1 with the Intel Atom X Series, Intel Celeron J / N Series and Intel Pentium N Series (formerly Apollo Lake) s High graphics performance and extreme temperature for low
QSEVEN STANDARD ADVANTAGES Rel. 2.1 with the Intel Atom X Series, Intel Celeron J / N Series and Intel Pentium N Series (formerly Apollo Lake) s High graphics performance and extreme temperature for low
Parallel Computing. Hwansoo Han (SKKU)
") Parallel Computing Hwansoo Han (SKKU) Unicore Limitations Performance scaling stopped due to Power consumption Wire delay DRAM latency Limitation in ILP 10000 SPEC CINT2000 2 cores/chip Xeon 3.0GHz Core2duo
Parallel Computing Hwansoo Han (SKKU) Unicore Limitations Performance scaling stopped due to Power consumption Wire delay DRAM latency Limitation in ILP 10000 SPEC CINT2000 2 cores/chip Xeon 3.0GHz Core2duo
Real-Time Support for GPU. GPU Management Heechul Yun
 Real-Time Support for GPU GPU Management Heechul Yun 1 This Week Topic: Real-Time Support for General Purpose Graphic Processing Unit (GPGPU) Today Background Challenges Real-Time GPU Management Frameworks
Real-Time Support for GPU GPU Management Heechul Yun 1 This Week Topic: Real-Time Support for General Purpose Graphic Processing Unit (GPGPU) Today Background Challenges Real-Time GPU Management Frameworks
CS GPU and GPGPU Programming Lecture 8+9: GPU Architecture 7+8. Markus Hadwiger, KAUST
 CS 380 - GPU and GPGPU Programming Lecture 8+9: GPU Architecture 7+8 Markus Hadwiger, KAUST Reading Assignment #5 (until March 12) Read (required): Programming Massively Parallel Processors book, Chapter
CS 380 - GPU and GPGPU Programming Lecture 8+9: GPU Architecture 7+8 Markus Hadwiger, KAUST Reading Assignment #5 (until March 12) Read (required): Programming Massively Parallel Processors book, Chapter
Benchmarking Real-World In-Vehicle Applications
 Benchmarking Real-World In-Vehicle Applications NVIDIA GTC 2015-03-18 m y c a b l e GmbH Michael Carstens-Behrens Gartenstraße 10 24534 Neumuenster, Germany +49 4321 559 56-55 +49 4321 559 56-10 mcb@mycable.de
Benchmarking Real-World In-Vehicle Applications NVIDIA GTC 2015-03-18 m y c a b l e GmbH Michael Carstens-Behrens Gartenstraße 10 24534 Neumuenster, Germany +49 4321 559 56-55 +49 4321 559 56-10 mcb@mycable.de
TEGRA K1 AND THE AUTOMOTIVE INDUSTRY. Gernot Ziegler, Timo Stich
 TEGRA K1 AND THE AUTOMOTIVE INDUSTRY Gernot Ziegler, Timo Stich Previously: Tegra in Automotive Infotainment / Navigation Digital Instrument Cluster Passenger Entertainment TEGRA K1 with Kepler GPU GPU:
TEGRA K1 AND THE AUTOMOTIVE INDUSTRY Gernot Ziegler, Timo Stich Previously: Tegra in Automotive Infotainment / Navigation Digital Instrument Cluster Passenger Entertainment TEGRA K1 with Kepler GPU GPU:
FPGA-based Supercomputing: New Opportunities and Challenges
 FPGA-based Supercomputing: New Opportunities and Challenges Naoya Maruyama (RIKEN AICS)* 5 th ADAC Workshop Feb 15, 2018 * Current Main affiliation is Lawrence Livermore National Laboratory SIAM PP18:
FPGA-based Supercomputing: New Opportunities and Challenges Naoya Maruyama (RIKEN AICS)* 5 th ADAC Workshop Feb 15, 2018 * Current Main affiliation is Lawrence Livermore National Laboratory SIAM PP18:
Hi3536 H.265 Decoder Processor. Brief Data Sheet. Issue 03. Date
 Hi3536 H.265 Decoder Processor Brief Data Sheet Issue 03 Date 2015-04-19 . 2014. All rights reserved. No part of this document may be reproduced or transmitted in any form or by any means without prior
Hi3536 H.265 Decoder Processor Brief Data Sheet Issue 03 Date 2015-04-19 . 2014. All rights reserved. No part of this document may be reproduced or transmitted in any form or by any means without prior
Use ZCU102 TRD to Accelerate Development of ZYNQ UltraScale+ MPSoC
 Use ZCU102 TRD to Accelerate Development of ZYNQ UltraScale+ MPSoC Topics Hardware advantages of ZYNQ UltraScale+ MPSoC Software stacks of MPSoC Target reference design introduction Details about one Design
Use ZCU102 TRD to Accelerate Development of ZYNQ UltraScale+ MPSoC Topics Hardware advantages of ZYNQ UltraScale+ MPSoC Software stacks of MPSoC Target reference design introduction Details about one Design
SoC FPGAs. Your User-Customizable System on Chip Altera Corporation Public
 SoC FPGAs Your User-Customizable System on Chip Embedded Developers Needs Low High Increase system performance Reduce system power Reduce board size Reduce system cost 2 Providing the Best of Both Worlds
SoC FPGAs Your User-Customizable System on Chip Embedded Developers Needs Low High Increase system performance Reduce system power Reduce board size Reduce system cost 2 Providing the Best of Both Worlds
INTEGRATING COMPUTER VISION SENSOR INNOVATIONS INTO MOBILE DEVICES. Eli Savransky Principal Architect - CTO Office Mobile BU NVIDIA corp.
 INTEGRATING COMPUTER VISION SENSOR INNOVATIONS INTO MOBILE DEVICES Eli Savransky Principal Architect - CTO Office Mobile BU NVIDIA corp. Computer Vision in Mobile Tegra K1 It s time! AGENDA Use cases categories
INTEGRATING COMPUTER VISION SENSOR INNOVATIONS INTO MOBILE DEVICES Eli Savransky Principal Architect - CTO Office Mobile BU NVIDIA corp. Computer Vision in Mobile Tegra K1 It s time! AGENDA Use cases categories
Designing a Multi-Processor based system with FPGAs
 Designing a Multi-Processor based system with FPGAs BRINGING BRINGING YOU YOU THE THE NEXT NEXT LEVEL LEVEL IN IN EMBEDDED EMBEDDED DEVELOPMENT DEVELOPMENT Frank de Bont Trainer / Consultant Cereslaan
Designing a Multi-Processor based system with FPGAs BRINGING BRINGING YOU YOU THE THE NEXT NEXT LEVEL LEVEL IN IN EMBEDDED EMBEDDED DEVELOPMENT DEVELOPMENT Frank de Bont Trainer / Consultant Cereslaan
CUDA on ARM Update. Developing Accelerated Applications on ARM. Bas Aarts and Donald Becker
 CUDA on ARM Update Developing Accelerated Applications on ARM Bas Aarts and Donald Becker CUDA on ARM: a forward-looking development platform for high performance, energy efficient hybrid computing It
CUDA on ARM Update Developing Accelerated Applications on ARM Bas Aarts and Donald Becker CUDA on ARM: a forward-looking development platform for high performance, energy efficient hybrid computing It
SOM PRODUCTS BRIEF. S y s t e m o n M o d u l e. Engicam. SOMProducts ver
 SOM S y s t e m o n M o d u l e PRODUCTS BRIEF GEA M6425IB ARM9 TM Low cost solution Reduced Time to Market Very small form factor Low cost multimedia solutions Industrial Automotive Consumer Single power
SOM S y s t e m o n M o d u l e PRODUCTS BRIEF GEA M6425IB ARM9 TM Low cost solution Reduced Time to Market Very small form factor Low cost multimedia solutions Industrial Automotive Consumer Single power
CSCI 402: Computer Architectures. Parallel Processors (2) Fengguang Song Department of Computer & Information Science IUPUI.
 Fengguang Song Department of Computer & Information Science IUPUI.") CSCI 402: Computer Architectures Parallel Processors (2) Fengguang Song Department of Computer & Information Science IUPUI 6.6 - End Today s Contents GPU Cluster and its network topology The Roofline performance
CSCI 402: Computer Architectures Parallel Processors (2) Fengguang Song Department of Computer & Information Science IUPUI 6.6 - End Today s Contents GPU Cluster and its network topology The Roofline performance
Building supercomputers from embedded technologies
 http://www.montblanc-project.eu Building supercomputers from embedded technologies Alex Ramirez Barcelona Supercomputing Center Technical Coordinator This project and the research leading to these results
http://www.montblanc-project.eu Building supercomputers from embedded technologies Alex Ramirez Barcelona Supercomputing Center Technical Coordinator This project and the research leading to these results
8/28/12. CSE 820 Graduate Computer Architecture. Richard Enbody. Dr. Enbody. 1 st Day 2
 CSE 820 Graduate Computer Architecture Richard Enbody Dr. Enbody 1 st Day 2 1 Why Computer Architecture? Improve coding. Knowledge to make architectural choices. Ability to understand articles about architecture.
CSE 820 Graduate Computer Architecture Richard Enbody Dr. Enbody 1 st Day 2 1 Why Computer Architecture? Improve coding. Knowledge to make architectural choices. Ability to understand articles about architecture.
Introduction to GPGPU and GPU-architectures
 Introduction to GPGPU and GPU-architectures Henk Corporaal Gert-Jan van den Braak http://www.es.ele.tue.nl/ Contents 1. What is a GPU 2. Programming a GPU 3. GPU thread scheduling 4. GPU performance bottlenecks
Introduction to GPGPU and GPU-architectures Henk Corporaal Gert-Jan van den Braak http://www.es.ele.tue.nl/ Contents 1. What is a GPU 2. Programming a GPU 3. GPU thread scheduling 4. GPU performance bottlenecks
Introduction to the Tegra SoC Family and the ARM Architecture. Kristoffer Robin Stokke, PhD FLIR UAS
 Introduction to the Tegra SoC Family and the ARM Architecture Kristoffer Robin Stokke, PhD FLIR UAS Goals of Lecture To give you something concrete to start on Simple introduction to ARMv8 NEON programming
Introduction to the Tegra SoC Family and the ARM Architecture Kristoffer Robin Stokke, PhD FLIR UAS Goals of Lecture To give you something concrete to start on Simple introduction to ARMv8 NEON programming
Embedded Systems: Architecture
 Embedded Systems: Architecture Jinkyu Jeong (Jinkyu@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu ICE3028: Embedded Systems Design, Fall 2018, Jinkyu Jeong (jinkyu@skku.edu)
Embedded Systems: Architecture Jinkyu Jeong (Jinkyu@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu ICE3028: Embedded Systems Design, Fall 2018, Jinkyu Jeong (jinkyu@skku.edu)
Antonio R. Miele Marco D. Santambrogio
 Advanced Topics on Heterogeneous System Architectures GPU Politecnico di Milano Seminar Room A. Alario 18 November, 2015 Antonio R. Miele Marco D. Santambrogio Politecnico di Milano 2 Introduction First
Advanced Topics on Heterogeneous System Architectures GPU Politecnico di Milano Seminar Room A. Alario 18 November, 2015 Antonio R. Miele Marco D. Santambrogio Politecnico di Milano 2 Introduction First
On-chip Networks Enable the Dark Silicon Advantage. Drew Wingard CTO & Co-founder Sonics, Inc.
 On-chip Networks Enable the Dark Silicon Advantage Drew Wingard CTO & Co-founder Sonics, Inc. Agenda Sonics history and corporate summary Power challenges in advanced SoCs General power management techniques
On-chip Networks Enable the Dark Silicon Advantage Drew Wingard CTO & Co-founder Sonics, Inc. Agenda Sonics history and corporate summary Power challenges in advanced SoCs General power management techniques
Transparent Offloading and Mapping (TOM) Enabling Programmer-Transparent Near-Data Processing in GPU Systems Kevin Hsieh
 Enabling Programmer-Transparent Near-Data Processing in GPU Systems Kevin Hsieh") Transparent Offloading and Mapping () Enabling Programmer-Transparent Near-Data Processing in GPU Systems Kevin Hsieh Eiman Ebrahimi, Gwangsun Kim, Niladrish Chatterjee, Mike O Connor, Nandita Vijaykumar,
Transparent Offloading and Mapping () Enabling Programmer-Transparent Near-Data Processing in GPU Systems Kevin Hsieh Eiman Ebrahimi, Gwangsun Kim, Niladrish Chatterjee, Mike O Connor, Nandita Vijaykumar,
An Evaluation of Unified Memory Technology on NVIDIA GPUs
 An Evaluation of Unified Memory Technology on NVIDIA GPUs Wenqiang Li 1, Guanghao Jin 2, Xuewen Cui 1, Simon See 1,3 Center for High Performance Computing, Shanghai Jiao Tong University, China 1 Tokyo
An Evaluation of Unified Memory Technology on NVIDIA GPUs Wenqiang Li 1, Guanghao Jin 2, Xuewen Cui 1, Simon See 1,3 Center for High Performance Computing, Shanghai Jiao Tong University, China 1 Tokyo
General Purpose GPU Computing in Partial Wave Analysis
 JLAB at 12 GeV - INT General Purpose GPU Computing in Partial Wave Analysis Hrayr Matevosyan - NTC, Indiana University November 18/2009 COmputationAL Challenges IN PWA Rapid Increase in Available Data
JLAB at 12 GeV - INT General Purpose GPU Computing in Partial Wave Analysis Hrayr Matevosyan - NTC, Indiana University November 18/2009 COmputationAL Challenges IN PWA Rapid Increase in Available Data
OpenMP Accelerator Model for TI s Keystone DSP+ARM Devices. SC13, Denver, CO Eric Stotzer Ajay Jayaraj
 OpenMP Accelerator Model for TI s Keystone DSP+ Devices SC13, Denver, CO Eric Stotzer Ajay Jayaraj 1 High Performance Embedded Computing 2 C Core Architecture 8-way VLIW processor 8 functional units in
OpenMP Accelerator Model for TI s Keystone DSP+ Devices SC13, Denver, CO Eric Stotzer Ajay Jayaraj 1 High Performance Embedded Computing 2 C Core Architecture 8-way VLIW processor 8 functional units in
Finite Element Integration and Assembly on Modern Multi and Many-core Processors
 Finite Element Integration and Assembly on Modern Multi and Many-core Processors Krzysztof Banaś, Jan Bielański, Kazimierz Chłoń AGH University of Science and Technology, Mickiewicza 30, 30-059 Kraków,
Finite Element Integration and Assembly on Modern Multi and Many-core Processors Krzysztof Banaś, Jan Bielański, Kazimierz Chłoń AGH University of Science and Technology, Mickiewicza 30, 30-059 Kraków,
Profiling and Debugging OpenCL Applications with ARM Development Tools. October 2014
 Profiling and Debugging OpenCL Applications with ARM Development Tools October 2014 1 Agenda 1. Introduction to GPU Compute 2. ARM Development Solutions 3. Mali GPU Architecture 4. Using ARM DS-5 Streamline
Profiling and Debugging OpenCL Applications with ARM Development Tools October 2014 1 Agenda 1. Introduction to GPU Compute 2. ARM Development Solutions 3. Mali GPU Architecture 4. Using ARM DS-5 Streamline
NVIDIA Jetson Platform Characterization
 NVIDIA Jetson Platform Characterization Hassan Halawa, Hazem A. Abdelhafez, Andrew Boktor, Matei Ripeanu The University of British Columbia {hhalawa, hazem, boktor, matei}@ece.ubc.ca Abstract. This study
NVIDIA Jetson Platform Characterization Hassan Halawa, Hazem A. Abdelhafez, Andrew Boktor, Matei Ripeanu The University of British Columbia {hhalawa, hazem, boktor, matei}@ece.ubc.ca Abstract. This study
Ten (or so) Small Computers
 Small Computers") Ten (or so) Small Computers by Jon "maddog" Hall Executive Director Linux International and President, Project Cauã 1 of 50 Who Am I? Half Electrical Engineer, Half Business, Half Computer Software In
Ten (or so) Small Computers by Jon "maddog" Hall Executive Director Linux International and President, Project Cauã 1 of 50 Who Am I? Half Electrical Engineer, Half Business, Half Computer Software In
Pedraforca: a First ARM + GPU Cluster for HPC
 www.bsc.es Pedraforca: a First ARM + GPU Cluster for HPC Nikola Puzovic, Alex Ramirez We ve hit the power wall ALL computers are limited by power consumption Energy-efficient approaches Multi-core Fujitsu
www.bsc.es Pedraforca: a First ARM + GPU Cluster for HPC Nikola Puzovic, Alex Ramirez We ve hit the power wall ALL computers are limited by power consumption Energy-efficient approaches Multi-core Fujitsu
Efficient Video Processing on Embedded GPU
 Efficient Video Processing on Embedded GPU Tobias Kammacher Armin Weiss Matthias Frei Institute of Embedded Systems High Performance Multimedia Research Group Zurich University of Applied Sciences (ZHAW)
Efficient Video Processing on Embedded GPU Tobias Kammacher Armin Weiss Matthias Frei Institute of Embedded Systems High Performance Multimedia Research Group Zurich University of Applied Sciences (ZHAW)
Profiling-Based L1 Data Cache Bypassing to Improve GPU Performance and Energy Efficiency
 Profiling-Based L1 Data Cache Bypassing to Improve GPU Performance and Energy Efficiency Yijie Huangfu and Wei Zhang Department of Electrical and Computer Engineering Virginia Commonwealth University {huangfuy2,wzhang4}@vcu.edu
Profiling-Based L1 Data Cache Bypassing to Improve GPU Performance and Energy Efficiency Yijie Huangfu and Wei Zhang Department of Electrical and Computer Engineering Virginia Commonwealth University {huangfuy2,wzhang4}@vcu.edu
Copyright 2016 Xilinx
 Zynq Architecture Zynq Vivado 2015.4 Version This material exempt per Department of Commerce license exception TSU Objectives After completing this module, you will be able to: Identify the basic building
Zynq Architecture Zynq Vivado 2015.4 Version This material exempt per Department of Commerce license exception TSU Objectives After completing this module, you will be able to: Identify the basic building
Freescale i.mx6 Architecture
 Freescale i.mx6 Architecture Course Description Freescale i.mx6 architecture is a 3 days Freescale official course. The course goes into great depth and provides all necessary know-how to develop software
Freescale i.mx6 Architecture Course Description Freescale i.mx6 architecture is a 3 days Freescale official course. The course goes into great depth and provides all necessary know-how to develop software
IMPROVING ENERGY EFFICIENCY THROUGH PARALLELIZATION AND VECTORIZATION ON INTEL R CORE TM
 IMPROVING ENERGY EFFICIENCY THROUGH PARALLELIZATION AND VECTORIZATION ON INTEL R CORE TM I5 AND I7 PROCESSORS Juan M. Cebrián 1 Lasse Natvig 1 Jan Christian Meyer 2 1 Depart. of Computer and Information
IMPROVING ENERGY EFFICIENCY THROUGH PARALLELIZATION AND VECTORIZATION ON INTEL R CORE TM I5 AND I7 PROCESSORS Juan M. Cebrián 1 Lasse Natvig 1 Jan Christian Meyer 2 1 Depart. of Computer and Information
INTELLIGENCE AT THE EDGE -HIGH PERFORMANCE EMBEDDED COMPUTING TRENDS (HPEC)
") INTELLIGENCE AT THE EDGE -HIGH PERFORMANCE EMBEDDED COMPUTING TRENDS (HPEC) Sida 1 Patrik Björklund-Director of sales Tritech Solutions WE ARE TRITECH Sida 2 Embedded products, solutions and engineering
INTELLIGENCE AT THE EDGE -HIGH PERFORMANCE EMBEDDED COMPUTING TRENDS (HPEC) Sida 1 Patrik Björklund-Director of sales Tritech Solutions WE ARE TRITECH Sida 2 Embedded products, solutions and engineering
Yafit Snir Arindam Guha Cadence Design Systems, Inc. Accelerating System level Verification of SOC Designs with MIPI Interfaces
 Yafit Snir Arindam Guha, Inc. Accelerating System level Verification of SOC Designs with MIPI Interfaces Agenda Overview: MIPI Verification approaches and challenges Acceleration methodology overview and
Yafit Snir Arindam Guha, Inc. Accelerating System level Verification of SOC Designs with MIPI Interfaces Agenda Overview: MIPI Verification approaches and challenges Acceleration methodology overview and
NXP-Freescale i.mx6 MicroSoM i4pro. Quad Core SoM (System-On-Module) Rev 1.3
 Rev 1.3") NXP-Freescale i.mx6 MicroSoM i4pro Quad Core SoM (System-On-Module) Rev 1.3 Simple. Robust. Computing Solutions SolidRun Ltd. 3 Dolev st., 3rd floor, P.O. Box 75 Migdal Tefen 2495900, Israel. www.solid-run.com
NXP-Freescale i.mx6 MicroSoM i4pro Quad Core SoM (System-On-Module) Rev 1.3 Simple. Robust. Computing Solutions SolidRun Ltd. 3 Dolev st., 3rd floor, P.O. Box 75 Migdal Tefen 2495900, Israel. www.solid-run.com