Mixing and matching virtual and physical HPC clusters. Paolo Anedda
|
|
|
- Silvia Lang
- 5 years ago
- Views:
Transcription

1 Mixing and matching virtual and physical HPC clusters Paolo Anedda HPC Cetraro 22/06/2010 1
2 Outline Introduction Scalability Issues System architecture Conclusions & Future Works 2
3 Introduction Scalability Issues System architecture Conclusions & Future Works 3
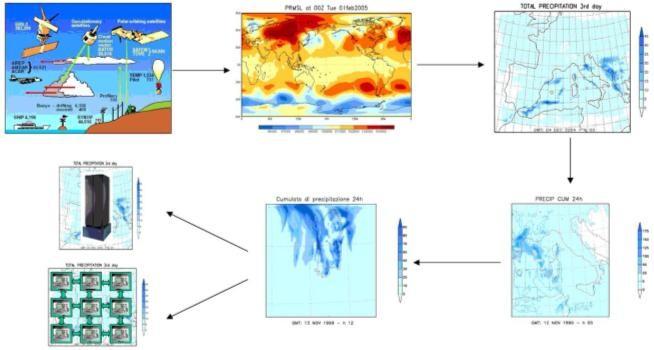



4 Supporting High Data Producing Applications
5 HPC: The Traditional Way Based on a (almost) fixed hardware/software platform. Good for standard production environments. Unsuitable for research and development enviroments. It lacks flexibility. 5
6 What if... We need to support multiple computational paradigms at the same time? We need to deploy transient experimental clusters? We need to deploy multiple development environment? We need to experiment new solutions?
7 Why Virtual Clusters? Virtualization is a consitent technology. Support for Multiple Computational Paradigms. Virtual Cluster makes the management of HPC environments flexible. The loss of performances can be acceptable (~5%). Support for hardware accelerator. Virtual Clusters can be saved for later use.
8 But... Virtual clusters operations can lead to scalability problems. Managing virtual clusters can be very difficult with traditional tools. Some users still want to run their code on traditional systems.
9 HPC: ANewWay Build Smarter Management Tools: Enable dynamic and flexible computational environments. Very different computational approaches can coexist on the same physical facility: Map-reduce. Standard parallel jobs. Virtual HPC Clusters. 9
10 Introduction Scalability Issues System architecture Conclusions & Future Works 10
11 Virtual Clusters Virtual cluster are collections of virtual machines deployed and managed as a single entity (Foster et al. 2006). HPC virtual cluster are atomic objects I.e., macro-computing task subdivided between the VC nodes. HPC virtual clusters are big objects E.g., 128 nodes (3GB disk + 8GB memory) ~ 1.5TB. 11
12 Three BasicOperations on VMImages Repository Repository Get: one -> many save: many -> many Repository restore: many -> many
13 NFS based image transfer
14 VCOperations VM Disk images are, as far as the repository is concerned, WORM (Write Once Read Many) objects. Get, save and restore are all simple I/O operations: only one client writes and writes sequentially; when a file is closed is closed, no appends needed;suitable for applications that have large data sets. It appears that HDFS (KFS, GFS ) should be ok.
15 HDFS Distributed File System designed to run on commodity hardware. Suitable for applications that have large data sets. Highly Fault-Tolerant.
16 Measurement Procedure S := # of physical cluster nodes N := # of virtual cluster nodes R := block replication Blocksize := 64MB Procedure Allocate a cluster with S nodes and install HDFS Save reference image in HDFS (from a node NOT in the cluster) Randomly select groups of N=2,4,8,16,32,,S nodes from the cluster Use dsh for concurrent get, save and restore requests.
17 Transfer Time
18 Effective Bandwidth
19 Introduction Scalability Issues System architecture Conclusions & Future Works 19
20 Requirements Flexibility. Scalability. Support for Multiple Computational Paradigms. Encapsulation. Reliability and Security. High Performances. 20


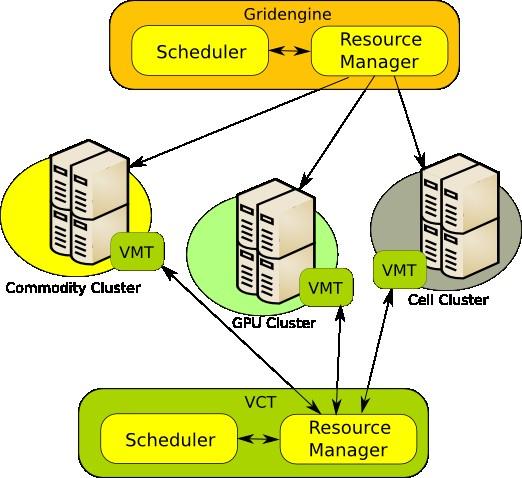
21 Architecture VIDA: Allocate the Virtual Clusters. Manages all the Virtual Clusters operations. Gridengine Allocate the physical resources. Support different computational environment. HDFS: A parallel filesystem. HaDeS: A physical images deployment tool.
22 Gridengine An open source batch-queuing system. Supports advance reservation. Supports multiple computational paradigms. Integration with Hadoop.
23 VIDA: Why another tool? Traditional tools: Virtual Machines Oriented. Management operations are carried on using a polling approach. Aren't very reliable. VIDA: Virtual Cluster Oriented. Management based on a heartbeat approach. Very reliable.
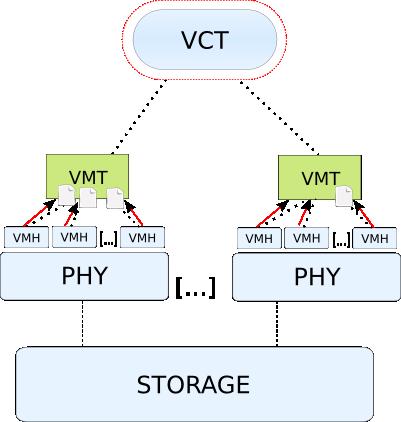
24 VIDAArchitecture Virtual Cluster Tracker (VCT): Manages all the clusters operations, coordinates the creation of each single virtual machine, collect and mantain all the status informations coming from the VMs on each node. 24
25 VIDAArchitecture Virtual Machine Tracker (VMT): Coordinates the operations on a specific node, reports the status of the physical resources available on the host to the VCT, creates and manages the virtual machines according to the directives received from the VCT. Virtual Machine Handler (VMH): Control and administer a single virtual machine. 25


26 VCT Service Interface Heartbeat Service FSManager Resources Scheduler

27 VIDA-GE Integration 27


28 Virtual Bubble Cluster
29 VIDAScalability Deploy Time vs Virtual Nodes Number. Average Data Transfer vs Virtual Nodes Number. Settings: Core number: Replication Factor: Average Data Transfert Image size: 4.39 GB Nodes Number
30 Introduction Virtualization and Cloud Computing Virtual Clusters System architecture Conclusions & Future Works 30
31 Conclusions Virtual Clusters simplify the management of HPC environments making them more flexible. Gridengine+VIDA = A very flexible architecture for the deployment and management of Virtual Clusters. Gridengine+VIDA+HDFS = A scalable architecture for the deployment and management of Virtual Clusters.
32 Future Works Support for encrypted filesystems. VMs commissioning and decomissioning. Integration with the Haizea Scheduler. Release VIDA on Sourceforge.
33 THANK YOU! 33
34 WORMData Need Specialized Filesystems datanode Block 1 mapper worker 1 datanode mapper worker n namenode Block N HDFS master
35 Virtual map-reduce cluster datanode worker-1 reducer mapper mapper Task tracker namenode JobTracker HDFS master datanode worker-n reducer mapper mapper Task tracker MapReduce master

36 HDFS Distributed File System designed to run on commodity hardware. Suitable for applications that have large data sets. Highly Fault-Tolerant.
37 Hadoop datanode worker-1 reducer mapper mapper Task tracker namenode JobTracker HDFS master datanode worker-n reducer mapper mapper Task tracker MapReduce master

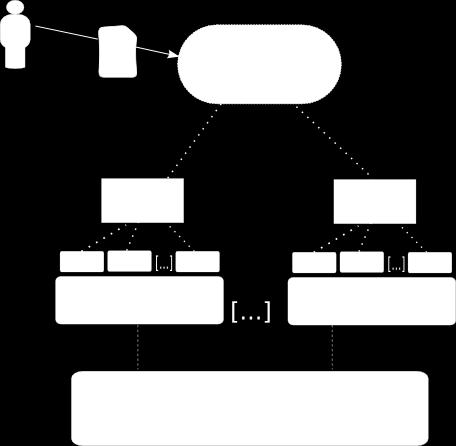
38 The Heartbeat Mechanism

39 The Heartbeat Mechanism
40 The Heartbeat Mechanism
41 The Heartbeat Mechanism
42
43 The Heartbeat Mechanism
MapReduce. U of Toronto, 2014
 MapReduce U of Toronto, 2014 http://www.google.org/flutrends/ca/ (2012) Average Searches Per Day: 5,134,000,000 2 Motivation Process lots of data Google processed about 24 petabytes of data per day in
MapReduce U of Toronto, 2014 http://www.google.org/flutrends/ca/ (2012) Average Searches Per Day: 5,134,000,000 2 Motivation Process lots of data Google processed about 24 petabytes of data per day in
Lecture 11 Hadoop & Spark
 Lecture 11 Hadoop & Spark Dr. Wilson Rivera ICOM 6025: High Performance Computing Electrical and Computer Engineering Department University of Puerto Rico Outline Distributed File Systems Hadoop Ecosystem
Lecture 11 Hadoop & Spark Dr. Wilson Rivera ICOM 6025: High Performance Computing Electrical and Computer Engineering Department University of Puerto Rico Outline Distributed File Systems Hadoop Ecosystem
Cloud Computing and Hadoop Distributed File System. UCSB CS170, Spring 2018
 Cloud Computing and Hadoop Distributed File System UCSB CS70, Spring 08 Cluster Computing Motivations Large-scale data processing on clusters Scan 000 TB on node @ 00 MB/s = days Scan on 000-node cluster
Cloud Computing and Hadoop Distributed File System UCSB CS70, Spring 08 Cluster Computing Motivations Large-scale data processing on clusters Scan 000 TB on node @ 00 MB/s = days Scan on 000-node cluster
BigData and Map Reduce VITMAC03
 BigData and Map Reduce VITMAC03 1 Motivation Process lots of data Google processed about 24 petabytes of data per day in 2009. A single machine cannot serve all the data You need a distributed system to
BigData and Map Reduce VITMAC03 1 Motivation Process lots of data Google processed about 24 petabytes of data per day in 2009. A single machine cannot serve all the data You need a distributed system to
Hadoop/MapReduce Computing Paradigm
 Hadoop/Reduce Computing Paradigm 1 Large-Scale Data Analytics Reduce computing paradigm (E.g., Hadoop) vs. Traditional database systems vs. Database Many enterprises are turning to Hadoop Especially applications
Hadoop/Reduce Computing Paradigm 1 Large-Scale Data Analytics Reduce computing paradigm (E.g., Hadoop) vs. Traditional database systems vs. Database Many enterprises are turning to Hadoop Especially applications
MI-PDB, MIE-PDB: Advanced Database Systems
 MI-PDB, MIE-PDB: Advanced Database Systems http://www.ksi.mff.cuni.cz/~svoboda/courses/2015-2-mie-pdb/ Lecture 10: MapReduce, Hadoop 26. 4. 2016 Lecturer: Martin Svoboda svoboda@ksi.mff.cuni.cz Author:
MI-PDB, MIE-PDB: Advanced Database Systems http://www.ksi.mff.cuni.cz/~svoboda/courses/2015-2-mie-pdb/ Lecture 10: MapReduce, Hadoop 26. 4. 2016 Lecturer: Martin Svoboda svoboda@ksi.mff.cuni.cz Author:
April Final Quiz COSC MapReduce Programming a) Explain briefly the main ideas and components of the MapReduce programming model.
 Explain briefly the main ideas and components of the MapReduce programming model.") 1. MapReduce Programming a) Explain briefly the main ideas and components of the MapReduce programming model. MapReduce is a framework for processing big data which processes data in two phases, a Map
1. MapReduce Programming a) Explain briefly the main ideas and components of the MapReduce programming model. MapReduce is a framework for processing big data which processes data in two phases, a Map
Big Data for Engineers Spring Resource Management
 Ghislain Fourny Big Data for Engineers Spring 2018 7. Resource Management artjazz / 123RF Stock Photo Data Technology Stack User interfaces Querying Data stores Indexing Processing Validation Data models
Ghislain Fourny Big Data for Engineers Spring 2018 7. Resource Management artjazz / 123RF Stock Photo Data Technology Stack User interfaces Querying Data stores Indexing Processing Validation Data models
TITLE: PRE-REQUISITE THEORY. 1. Introduction to Hadoop. 2. Cluster. Implement sort algorithm and run it using HADOOP
 TITLE: Implement sort algorithm and run it using HADOOP PRE-REQUISITE Preliminary knowledge of clusters and overview of Hadoop and its basic functionality. THEORY 1. Introduction to Hadoop The Apache Hadoop
TITLE: Implement sort algorithm and run it using HADOOP PRE-REQUISITE Preliminary knowledge of clusters and overview of Hadoop and its basic functionality. THEORY 1. Introduction to Hadoop The Apache Hadoop
A brief history on Hadoop
 Hadoop Basics A brief history on Hadoop 2003 - Google launches project Nutch to handle billions of searches and indexing millions of web pages. Oct 2003 - Google releases papers with GFS (Google File System)
Hadoop Basics A brief history on Hadoop 2003 - Google launches project Nutch to handle billions of searches and indexing millions of web pages. Oct 2003 - Google releases papers with GFS (Google File System)
CS60021: Scalable Data Mining. Sourangshu Bhattacharya
 CS60021: Scalable Data Mining Sourangshu Bhattacharya In this Lecture: Outline: HDFS Motivation HDFS User commands HDFS System architecture HDFS Implementation details Sourangshu Bhattacharya Computer
CS60021: Scalable Data Mining Sourangshu Bhattacharya In this Lecture: Outline: HDFS Motivation HDFS User commands HDFS System architecture HDFS Implementation details Sourangshu Bhattacharya Computer
Distributed Systems 16. Distributed File Systems II
 Distributed Systems 16. Distributed File Systems II Paul Krzyzanowski pxk@cs.rutgers.edu 1 Review NFS RPC-based access AFS Long-term caching CODA Read/write replication & disconnected operation DFS AFS
Distributed Systems 16. Distributed File Systems II Paul Krzyzanowski pxk@cs.rutgers.edu 1 Review NFS RPC-based access AFS Long-term caching CODA Read/write replication & disconnected operation DFS AFS
Overview. Why MapReduce? What is MapReduce? The Hadoop Distributed File System Cloudera, Inc.
 MapReduce and HDFS This presentation includes course content University of Washington Redistributed under the Creative Commons Attribution 3.0 license. All other contents: Overview Why MapReduce? What
MapReduce and HDFS This presentation includes course content University of Washington Redistributed under the Creative Commons Attribution 3.0 license. All other contents: Overview Why MapReduce? What
Hadoop and HDFS Overview. Madhu Ankam
 Hadoop and HDFS Overview Madhu Ankam Why Hadoop We are gathering more data than ever Examples of data : Server logs Web logs Financial transactions Analytics Emails and text messages Social media like
Hadoop and HDFS Overview Madhu Ankam Why Hadoop We are gathering more data than ever Examples of data : Server logs Web logs Financial transactions Analytics Emails and text messages Social media like
Big Data 7. Resource Management
 Ghislain Fourny Big Data 7. Resource Management artjazz / 123RF Stock Photo Data Technology Stack User interfaces Querying Data stores Indexing Processing Validation Data models Syntax Encoding Storage
Ghislain Fourny Big Data 7. Resource Management artjazz / 123RF Stock Photo Data Technology Stack User interfaces Querying Data stores Indexing Processing Validation Data models Syntax Encoding Storage
CA485 Ray Walshe Google File System
 Google File System Overview Google File System is scalable, distributed file system on inexpensive commodity hardware that provides: Fault Tolerance File system runs on hundreds or thousands of storage
Google File System Overview Google File System is scalable, distributed file system on inexpensive commodity hardware that provides: Fault Tolerance File system runs on hundreds or thousands of storage
CPSC 426/526. Cloud Computing. Ennan Zhai. Computer Science Department Yale University
 CPSC 426/526 Cloud Computing Ennan Zhai Computer Science Department Yale University Recall: Lec-7 In the lec-7, I talked about: - P2P vs Enterprise control - Firewall - NATs - Software defined network
CPSC 426/526 Cloud Computing Ennan Zhai Computer Science Department Yale University Recall: Lec-7 In the lec-7, I talked about: - P2P vs Enterprise control - Firewall - NATs - Software defined network
Distributed File Systems II
 Distributed File Systems II To do q Very-large scale: Google FS, Hadoop FS, BigTable q Next time: Naming things GFS A radically new environment NFS, etc. Independence Small Scale Variety of workloads Cooperation
Distributed File Systems II To do q Very-large scale: Google FS, Hadoop FS, BigTable q Next time: Naming things GFS A radically new environment NFS, etc. Independence Small Scale Variety of workloads Cooperation
Distributed Systems CS6421
 Distributed Systems CS6421 Intro to Distributed Systems and the Cloud Prof. Tim Wood v I teach: Software Engineering, Operating Systems, Sr. Design I like: distributed systems, networks, building cool
Distributed Systems CS6421 Intro to Distributed Systems and the Cloud Prof. Tim Wood v I teach: Software Engineering, Operating Systems, Sr. Design I like: distributed systems, networks, building cool
18-hdfs-gfs.txt Thu Oct 27 10:05: Notes on Parallel File Systems: HDFS & GFS , Fall 2011 Carnegie Mellon University Randal E.
 18-hdfs-gfs.txt Thu Oct 27 10:05:07 2011 1 Notes on Parallel File Systems: HDFS & GFS 15-440, Fall 2011 Carnegie Mellon University Randal E. Bryant References: Ghemawat, Gobioff, Leung, "The Google File
18-hdfs-gfs.txt Thu Oct 27 10:05:07 2011 1 Notes on Parallel File Systems: HDFS & GFS 15-440, Fall 2011 Carnegie Mellon University Randal E. Bryant References: Ghemawat, Gobioff, Leung, "The Google File
Google File System (GFS) and Hadoop Distributed File System (HDFS)
 and Hadoop Distributed File System (HDFS)") Google File System (GFS) and Hadoop Distributed File System (HDFS) 1 Hadoop: Architectural Design Principles Linear scalability More nodes can do more work within the same time Linear on data size, linear
Google File System (GFS) and Hadoop Distributed File System (HDFS) 1 Hadoop: Architectural Design Principles Linear scalability More nodes can do more work within the same time Linear on data size, linear
Hadoop File System S L I D E S M O D I F I E D F R O M P R E S E N T A T I O N B Y B. R A M A M U R T H Y 11/15/2017
 Hadoop File System 1 S L I D E S M O D I F I E D F R O M P R E S E N T A T I O N B Y B. R A M A M U R T H Y Moving Computation is Cheaper than Moving Data Motivation: Big Data! What is BigData? - Google
Hadoop File System 1 S L I D E S M O D I F I E D F R O M P R E S E N T A T I O N B Y B. R A M A M U R T H Y Moving Computation is Cheaper than Moving Data Motivation: Big Data! What is BigData? - Google
Hadoop-PR Hortonworks Certified Apache Hadoop 2.0 Developer (Pig and Hive Developer)
") Hortonworks Hadoop-PR000007 Hortonworks Certified Apache Hadoop 2.0 Developer (Pig and Hive Developer) http://killexams.com/pass4sure/exam-detail/hadoop-pr000007 QUESTION: 99 Which one of the following
Hortonworks Hadoop-PR000007 Hortonworks Certified Apache Hadoop 2.0 Developer (Pig and Hive Developer) http://killexams.com/pass4sure/exam-detail/hadoop-pr000007 QUESTION: 99 Which one of the following
Big Data Analytics. Izabela Moise, Evangelos Pournaras, Dirk Helbing
 Big Data Analytics Izabela Moise, Evangelos Pournaras, Dirk Helbing Izabela Moise, Evangelos Pournaras, Dirk Helbing 1 Big Data "The world is crazy. But at least it s getting regular analysis." Izabela
Big Data Analytics Izabela Moise, Evangelos Pournaras, Dirk Helbing Izabela Moise, Evangelos Pournaras, Dirk Helbing 1 Big Data "The world is crazy. But at least it s getting regular analysis." Izabela
CCA-410. Cloudera. Cloudera Certified Administrator for Apache Hadoop (CCAH)
") Cloudera CCA-410 Cloudera Certified Administrator for Apache Hadoop (CCAH) Download Full Version : http://killexams.com/pass4sure/exam-detail/cca-410 Reference: CONFIGURATION PARAMETERS DFS.BLOCK.SIZE
Cloudera CCA-410 Cloudera Certified Administrator for Apache Hadoop (CCAH) Download Full Version : http://killexams.com/pass4sure/exam-detail/cca-410 Reference: CONFIGURATION PARAMETERS DFS.BLOCK.SIZE
Distributed Filesystem
 Distributed Filesystem 1 How do we get data to the workers? NAS Compute Nodes SAN 2 Distributing Code! Don t move data to workers move workers to the data! - Store data on the local disks of nodes in the
Distributed Filesystem 1 How do we get data to the workers? NAS Compute Nodes SAN 2 Distributing Code! Don t move data to workers move workers to the data! - Store data on the local disks of nodes in the
International Journal of Advance Engineering and Research Development. A Study: Hadoop Framework
 Scientific Journal of Impact Factor (SJIF): e-issn (O): 2348- International Journal of Advance Engineering and Research Development Volume 3, Issue 2, February -2016 A Study: Hadoop Framework Devateja
Scientific Journal of Impact Factor (SJIF): e-issn (O): 2348- International Journal of Advance Engineering and Research Development Volume 3, Issue 2, February -2016 A Study: Hadoop Framework Devateja
Enhanced Hadoop with Search and MapReduce Concurrency Optimization
 Volume 114 No. 12 2017, 323-331 ISSN: 1311-8080 (printed version); ISSN: 1314-3395 (on-line version) url: http://www.ijpam.eu ijpam.eu Enhanced Hadoop with Search and MapReduce Concurrency Optimization
Volume 114 No. 12 2017, 323-331 ISSN: 1311-8080 (printed version); ISSN: 1314-3395 (on-line version) url: http://www.ijpam.eu ijpam.eu Enhanced Hadoop with Search and MapReduce Concurrency Optimization
Data Clustering on the Parallel Hadoop MapReduce Model. Dimitrios Verraros
 Data Clustering on the Parallel Hadoop MapReduce Model Dimitrios Verraros Overview The purpose of this thesis is to implement and benchmark the performance of a parallel K- means clustering algorithm on
Data Clustering on the Parallel Hadoop MapReduce Model Dimitrios Verraros Overview The purpose of this thesis is to implement and benchmark the performance of a parallel K- means clustering algorithm on
Yuval Carmel Tel-Aviv University "Advanced Topics in Storage Systems" - Spring 2013
 Yuval Carmel Tel-Aviv University "Advanced Topics in About & Keywords Motivation & Purpose Assumptions Architecture overview & Comparison Measurements How does it fit in? The Future 2 About & Keywords
Yuval Carmel Tel-Aviv University "Advanced Topics in About & Keywords Motivation & Purpose Assumptions Architecture overview & Comparison Measurements How does it fit in? The Future 2 About & Keywords
HADOOP 3.0 is here! Dr. Sandeep Deshmukh Sadepach Labs Pvt. Ltd. - Let us grow together!
 HADOOP 3.0 is here! Dr. Sandeep Deshmukh sandeep@sadepach.com Sadepach Labs Pvt. Ltd. - Let us grow together! About me BE from VNIT Nagpur, MTech+PhD from IIT Bombay Worked with Persistent Systems - Life
HADOOP 3.0 is here! Dr. Sandeep Deshmukh sandeep@sadepach.com Sadepach Labs Pvt. Ltd. - Let us grow together! About me BE from VNIT Nagpur, MTech+PhD from IIT Bombay Worked with Persistent Systems - Life
The Google File System. Alexandru Costan
 1 The Google File System Alexandru Costan Actions on Big Data 2 Storage Analysis Acquisition Handling the data stream Data structured unstructured semi-structured Results Transactions Outline File systems
1 The Google File System Alexandru Costan Actions on Big Data 2 Storage Analysis Acquisition Handling the data stream Data structured unstructured semi-structured Results Transactions Outline File systems
HADOOP FRAMEWORK FOR BIG DATA
 HADOOP FRAMEWORK FOR BIG DATA Mr K. Srinivas Babu 1,Dr K. Rameshwaraiah 2 1 Research Scholar S V University, Tirupathi 2 Professor and Head NNRESGI, Hyderabad Abstract - Data has to be stored for further
HADOOP FRAMEWORK FOR BIG DATA Mr K. Srinivas Babu 1,Dr K. Rameshwaraiah 2 1 Research Scholar S V University, Tirupathi 2 Professor and Head NNRESGI, Hyderabad Abstract - Data has to be stored for further
CLIENT DATA NODE NAME NODE
 Volume 6, Issue 12, December 2016 ISSN: 2277 128X International Journal of Advanced Research in Computer Science and Software Engineering Research Paper Available online at: www.ijarcsse.com Efficiency
Volume 6, Issue 12, December 2016 ISSN: 2277 128X International Journal of Advanced Research in Computer Science and Software Engineering Research Paper Available online at: www.ijarcsse.com Efficiency
HDFS: Hadoop Distributed File System. CIS 612 Sunnie Chung
 HDFS: Hadoop Distributed File System CIS 612 Sunnie Chung What is Big Data?? Bulk Amount Unstructured Introduction Lots of Applications which need to handle huge amount of data (in terms of 500+ TB per
HDFS: Hadoop Distributed File System CIS 612 Sunnie Chung What is Big Data?? Bulk Amount Unstructured Introduction Lots of Applications which need to handle huge amount of data (in terms of 500+ TB per
Systems Infrastructure for Data Science. Web Science Group Uni Freiburg WS 2012/13
 Systems Infrastructure for Data Science Web Science Group Uni Freiburg WS 2012/13 MapReduce & Hadoop The new world of Big Data (programming model) Overview of this Lecture Module Background Google MapReduce
Systems Infrastructure for Data Science Web Science Group Uni Freiburg WS 2012/13 MapReduce & Hadoop The new world of Big Data (programming model) Overview of this Lecture Module Background Google MapReduce
Introduction to Hadoop and MapReduce
 Introduction to Hadoop and MapReduce Antonino Virgillito THE CONTRACTOR IS ACTING UNDER A FRAMEWORK CONTRACT CONCLUDED WITH THE COMMISSION Large-scale Computation Traditional solutions for computing large
Introduction to Hadoop and MapReduce Antonino Virgillito THE CONTRACTOR IS ACTING UNDER A FRAMEWORK CONTRACT CONCLUDED WITH THE COMMISSION Large-scale Computation Traditional solutions for computing large
18-hdfs-gfs.txt Thu Nov 01 09:53: Notes on Parallel File Systems: HDFS & GFS , Fall 2012 Carnegie Mellon University Randal E.
 18-hdfs-gfs.txt Thu Nov 01 09:53:32 2012 1 Notes on Parallel File Systems: HDFS & GFS 15-440, Fall 2012 Carnegie Mellon University Randal E. Bryant References: Ghemawat, Gobioff, Leung, "The Google File
18-hdfs-gfs.txt Thu Nov 01 09:53:32 2012 1 Notes on Parallel File Systems: HDFS & GFS 15-440, Fall 2012 Carnegie Mellon University Randal E. Bryant References: Ghemawat, Gobioff, Leung, "The Google File
Evaluation of Apache Hadoop for parallel data analysis with ROOT
 Evaluation of Apache Hadoop for parallel data analysis with ROOT S Lehrack, G Duckeck, J Ebke Ludwigs-Maximilians-University Munich, Chair of elementary particle physics, Am Coulombwall 1, D-85748 Garching,
Evaluation of Apache Hadoop for parallel data analysis with ROOT S Lehrack, G Duckeck, J Ebke Ludwigs-Maximilians-University Munich, Chair of elementary particle physics, Am Coulombwall 1, D-85748 Garching,
Analytics in the cloud
 Analytics in the cloud Dow we really need to reinvent the storage stack? R. Ananthanarayanan, Karan Gupta, Prashant Pandey, Himabindu Pucha, Prasenjit Sarkar, Mansi Shah, Renu Tewari Image courtesy NASA
Analytics in the cloud Dow we really need to reinvent the storage stack? R. Ananthanarayanan, Karan Gupta, Prashant Pandey, Himabindu Pucha, Prasenjit Sarkar, Mansi Shah, Renu Tewari Image courtesy NASA
Systems Infrastructure for Data Science. Web Science Group Uni Freiburg WS 2013/14
 Systems Infrastructure for Data Science Web Science Group Uni Freiburg WS 2013/14 MapReduce & Hadoop The new world of Big Data (programming model) Overview of this Lecture Module Background Cluster File
Systems Infrastructure for Data Science Web Science Group Uni Freiburg WS 2013/14 MapReduce & Hadoop The new world of Big Data (programming model) Overview of this Lecture Module Background Cluster File
Introduction to MapReduce
 Basics of Cloud Computing Lecture 4 Introduction to MapReduce Satish Srirama Some material adapted from slides by Jimmy Lin, Christophe Bisciglia, Aaron Kimball, & Sierra Michels-Slettvet, Google Distributed
Basics of Cloud Computing Lecture 4 Introduction to MapReduce Satish Srirama Some material adapted from slides by Jimmy Lin, Christophe Bisciglia, Aaron Kimball, & Sierra Michels-Slettvet, Google Distributed
Spark Over RDMA: Accelerate Big Data SC Asia 2018 Ido Shamay Mellanox Technologies
 Spark Over RDMA: Accelerate Big Data SC Asia 2018 Ido Shamay 1 Apache Spark - Intro Spark within the Big Data ecosystem Data Sources Data Acquisition / ETL Data Storage Data Analysis / ML Serving 3 Apache
Spark Over RDMA: Accelerate Big Data SC Asia 2018 Ido Shamay 1 Apache Spark - Intro Spark within the Big Data ecosystem Data Sources Data Acquisition / ETL Data Storage Data Analysis / ML Serving 3 Apache
Cloud Computing. Hwajung Lee. Key Reference: Prof. Jong-Moon Chung s Lecture Notes at Yonsei University
 Cloud Computing Hwajung Lee Key Reference: Prof. Jong-Moon Chung s Lecture Notes at Yonsei University Cloud Computing Cloud Introduction Cloud Service Model Big Data Hadoop MapReduce HDFS (Hadoop Distributed
Cloud Computing Hwajung Lee Key Reference: Prof. Jong-Moon Chung s Lecture Notes at Yonsei University Cloud Computing Cloud Introduction Cloud Service Model Big Data Hadoop MapReduce HDFS (Hadoop Distributed
Facilitating Consistency Check between Specification & Implementation with MapReduce Framework
 Facilitating Consistency Check between Specification & Implementation with MapReduce Framework Shigeru KUSAKABE, Yoichi OMORI, Keijiro ARAKI Kyushu University, Japan 2 Our expectation Light-weight formal
Facilitating Consistency Check between Specification & Implementation with MapReduce Framework Shigeru KUSAKABE, Yoichi OMORI, Keijiro ARAKI Kyushu University, Japan 2 Our expectation Light-weight formal
Hadoop. copyright 2011 Trainologic LTD
 Hadoop Hadoop is a framework for processing large amounts of data in a distributed manner. It can scale up to thousands of machines. It provides high-availability. Provides map-reduce functionality. Hides
Hadoop Hadoop is a framework for processing large amounts of data in a distributed manner. It can scale up to thousands of machines. It provides high-availability. Provides map-reduce functionality. Hides
Distributed Systems. CS422/522 Lecture17 17 November 2014
 Distributed Systems CS422/522 Lecture17 17 November 2014 Lecture Outline Introduction Hadoop Chord What s a distributed system? What s a distributed system? A distributed system is a collection of loosely
Distributed Systems CS422/522 Lecture17 17 November 2014 Lecture Outline Introduction Hadoop Chord What s a distributed system? What s a distributed system? A distributed system is a collection of loosely
HDFS Architecture. Gregory Kesden, CSE-291 (Storage Systems) Fall 2017
 Fall 2017") HDFS Architecture Gregory Kesden, CSE-291 (Storage Systems) Fall 2017 Based Upon: http://hadoop.apache.org/docs/r3.0.0-alpha1/hadoopproject-dist/hadoop-hdfs/hdfsdesign.html Assumptions At scale, hardware
HDFS Architecture Gregory Kesden, CSE-291 (Storage Systems) Fall 2017 Based Upon: http://hadoop.apache.org/docs/r3.0.0-alpha1/hadoopproject-dist/hadoop-hdfs/hdfsdesign.html Assumptions At scale, hardware
August Li Qiang, Huang Qiulan, Sun Gongxing IHEP-CC. Supported by the National Natural Science Fund
 August 15 2016 Li Qiang, Huang Qiulan, Sun Gongxing IHEP-CC Supported by the National Natural Science Fund The Current Computing System What is Hadoop? Why Hadoop? The New Computing System with Hadoop
August 15 2016 Li Qiang, Huang Qiulan, Sun Gongxing IHEP-CC Supported by the National Natural Science Fund The Current Computing System What is Hadoop? Why Hadoop? The New Computing System with Hadoop
Chapter 5. The MapReduce Programming Model and Implementation
 Chapter 5. The MapReduce Programming Model and Implementation - Traditional computing: data-to-computing (send data to computing) * Data stored in separate repository * Data brought into system for computing
Chapter 5. The MapReduce Programming Model and Implementation - Traditional computing: data-to-computing (send data to computing) * Data stored in separate repository * Data brought into system for computing
The Analysis Research of Hierarchical Storage System Based on Hadoop Framework Yan LIU 1, a, Tianjian ZHENG 1, Mingjiang LI 1, Jinpeng YUAN 1
 International Conference on Intelligent Systems Research and Mechatronics Engineering (ISRME 2015) The Analysis Research of Hierarchical Storage System Based on Hadoop Framework Yan LIU 1, a, Tianjian
International Conference on Intelligent Systems Research and Mechatronics Engineering (ISRME 2015) The Analysis Research of Hierarchical Storage System Based on Hadoop Framework Yan LIU 1, a, Tianjian
Vendor: Cloudera. Exam Code: CCA-505. Exam Name: Cloudera Certified Administrator for Apache Hadoop (CCAH) CDH5 Upgrade Exam.
 CDH5 Upgrade Exam.") Vendor: Cloudera Exam Code: CCA-505 Exam Name: Cloudera Certified Administrator for Apache Hadoop (CCAH) CDH5 Upgrade Exam Version: Demo QUESTION 1 You have installed a cluster running HDFS and MapReduce
Vendor: Cloudera Exam Code: CCA-505 Exam Name: Cloudera Certified Administrator for Apache Hadoop (CCAH) CDH5 Upgrade Exam Version: Demo QUESTION 1 You have installed a cluster running HDFS and MapReduce
CLOUD-SCALE FILE SYSTEMS
 Data Management in the Cloud CLOUD-SCALE FILE SYSTEMS 92 Google File System (GFS) Designing a file system for the Cloud design assumptions design choices Architecture GFS Master GFS Chunkservers GFS Clients
Data Management in the Cloud CLOUD-SCALE FILE SYSTEMS 92 Google File System (GFS) Designing a file system for the Cloud design assumptions design choices Architecture GFS Master GFS Chunkservers GFS Clients
Hadoop MapReduce Framework
 Hadoop MapReduce Framework Contents Hadoop MapReduce Framework Architecture Interaction Diagram of MapReduce Framework (Hadoop 1.0) Interaction Diagram of MapReduce Framework (Hadoop 2.0) Hadoop MapReduce
Hadoop MapReduce Framework Contents Hadoop MapReduce Framework Architecture Interaction Diagram of MapReduce Framework (Hadoop 1.0) Interaction Diagram of MapReduce Framework (Hadoop 2.0) Hadoop MapReduce
A Multilevel Secure MapReduce Framework for Cross-Domain Information Sharing in the Cloud
 Calhoun: The NPS Institutional Archive Faculty and Researcher Publications Faculty and Researcher Publications 2013-03 A Multilevel Secure MapReduce Framework for Cross-Domain Information Sharing in the
Calhoun: The NPS Institutional Archive Faculty and Researcher Publications Faculty and Researcher Publications 2013-03 A Multilevel Secure MapReduce Framework for Cross-Domain Information Sharing in the
Distributed Computing.
 Distributed Computing at Hai.Thai@rackspace.com About: Me ME About: Me ME 09 Tech grad B.S. Computer Engineering 4 years at rackspace About: Rackspace About: Rackspace Managed + Cloud hosting Cloud Applications:
Distributed Computing at Hai.Thai@rackspace.com About: Me ME About: Me ME 09 Tech grad B.S. Computer Engineering 4 years at rackspace About: Rackspace About: Rackspace Managed + Cloud hosting Cloud Applications:
Parallel Programming Principle and Practice. Lecture 10 Big Data Processing with MapReduce
 Parallel Programming Principle and Practice Lecture 10 Big Data Processing with MapReduce Outline MapReduce Programming Model MapReduce Examples Hadoop 2 Incredible Things That Happen Every Minute On The
Parallel Programming Principle and Practice Lecture 10 Big Data Processing with MapReduce Outline MapReduce Programming Model MapReduce Examples Hadoop 2 Incredible Things That Happen Every Minute On The
goals monitoring, fault tolerance, auto-recovery (thousands of low-cost machines) handle appends efficiently (no random writes & sequential reads)
 handle appends efficiently (no random writes & sequential reads)") Google File System goals monitoring, fault tolerance, auto-recovery (thousands of low-cost machines) focus on multi-gb files handle appends efficiently (no random writes & sequential reads) co-design GFS
Google File System goals monitoring, fault tolerance, auto-recovery (thousands of low-cost machines) focus on multi-gb files handle appends efficiently (no random writes & sequential reads) co-design GFS
Flat Datacenter Storage. Edmund B. Nightingale, Jeremy Elson, et al. 6.S897
 Flat Datacenter Storage Edmund B. Nightingale, Jeremy Elson, et al. 6.S897 Motivation Imagine a world with flat data storage Simple, Centralized, and easy to program Unfortunately, datacenter networks
Flat Datacenter Storage Edmund B. Nightingale, Jeremy Elson, et al. 6.S897 Motivation Imagine a world with flat data storage Simple, Centralized, and easy to program Unfortunately, datacenter networks
Distributed Systems. 15. Distributed File Systems. Paul Krzyzanowski. Rutgers University. Fall 2017
 Distributed Systems 15. Distributed File Systems Paul Krzyzanowski Rutgers University Fall 2017 1 Google Chubby ( Apache Zookeeper) 2 Chubby Distributed lock service + simple fault-tolerant file system
Distributed Systems 15. Distributed File Systems Paul Krzyzanowski Rutgers University Fall 2017 1 Google Chubby ( Apache Zookeeper) 2 Chubby Distributed lock service + simple fault-tolerant file system
Hadoop Virtualization Extensions on VMware vsphere 5 T E C H N I C A L W H I T E P A P E R
 Hadoop Virtualization Extensions on VMware vsphere 5 T E C H N I C A L W H I T E P A P E R Table of Contents Introduction... 3 Topology Awareness in Hadoop... 3 Virtual Hadoop... 4 HVE Solution... 5 Architecture...
Hadoop Virtualization Extensions on VMware vsphere 5 T E C H N I C A L W H I T E P A P E R Table of Contents Introduction... 3 Topology Awareness in Hadoop... 3 Virtual Hadoop... 4 HVE Solution... 5 Architecture...
BIG DATA AND HADOOP ON THE ZFS STORAGE APPLIANCE
 BIG DATA AND HADOOP ON THE ZFS STORAGE APPLIANCE BRETT WENINGER, MANAGING DIRECTOR 10/21/2014 ADURANT APPROACH TO BIG DATA Align to Un/Semi-structured Data Instead of Big Scale out will become Big Greatest
BIG DATA AND HADOOP ON THE ZFS STORAGE APPLIANCE BRETT WENINGER, MANAGING DIRECTOR 10/21/2014 ADURANT APPROACH TO BIG DATA Align to Un/Semi-structured Data Instead of Big Scale out will become Big Greatest
CSE 124: Networked Services Lecture-16
 Fall 2010 CSE 124: Networked Services Lecture-16 Instructor: B. S. Manoj, Ph.D http://cseweb.ucsd.edu/classes/fa10/cse124 11/23/2010 CSE 124 Networked Services Fall 2010 1 Updates PlanetLab experiments
Fall 2010 CSE 124: Networked Services Lecture-16 Instructor: B. S. Manoj, Ph.D http://cseweb.ucsd.edu/classes/fa10/cse124 11/23/2010 CSE 124 Networked Services Fall 2010 1 Updates PlanetLab experiments
Database Applications (15-415)
") Database Applications (15-415) Hadoop Lecture 24, April 23, 2014 Mohammad Hammoud Today Last Session: NoSQL databases Today s Session: Hadoop = HDFS + MapReduce Announcements: Final Exam is on Sunday April
Database Applications (15-415) Hadoop Lecture 24, April 23, 2014 Mohammad Hammoud Today Last Session: NoSQL databases Today s Session: Hadoop = HDFS + MapReduce Announcements: Final Exam is on Sunday April
Where We Are. Review: Parallel DBMS. Parallel DBMS. Introduction to Data Management CSE 344
 Where We Are Introduction to Data Management CSE 344 Lecture 22: MapReduce We are talking about parallel query processing There exist two main types of engines: Parallel DBMSs (last lecture + quick review)
Where We Are Introduction to Data Management CSE 344 Lecture 22: MapReduce We are talking about parallel query processing There exist two main types of engines: Parallel DBMSs (last lecture + quick review)
Hadoop 2.x Core: YARN, Tez, and Spark. Hortonworks Inc All Rights Reserved
 Hadoop 2.x Core: YARN, Tez, and Spark YARN Hadoop Machine Types top-of-rack switches core switch client machines have client-side software used to access a cluster to process data master nodes run Hadoop
Hadoop 2.x Core: YARN, Tez, and Spark YARN Hadoop Machine Types top-of-rack switches core switch client machines have client-side software used to access a cluster to process data master nodes run Hadoop
Modeling and Optimization of Resource Allocation in Cloud
 PhD Thesis Progress First Report Thesis Advisor: Asst. Prof. Dr. Tolga Ovatman Istanbul Technical University Department of Computer Engineering January 8, 2015 Outline 1 Introduction 2 Studies Time Plan
PhD Thesis Progress First Report Thesis Advisor: Asst. Prof. Dr. Tolga Ovatman Istanbul Technical University Department of Computer Engineering January 8, 2015 Outline 1 Introduction 2 Studies Time Plan
MixApart: Decoupled Analytics for Shared Storage Systems. Madalin Mihailescu, Gokul Soundararajan, Cristiana Amza University of Toronto and NetApp
 MixApart: Decoupled Analytics for Shared Storage Systems Madalin Mihailescu, Gokul Soundararajan, Cristiana Amza University of Toronto and NetApp Hadoop Pig, Hive Hadoop + Enterprise storage?! Shared storage
MixApart: Decoupled Analytics for Shared Storage Systems Madalin Mihailescu, Gokul Soundararajan, Cristiana Amza University of Toronto and NetApp Hadoop Pig, Hive Hadoop + Enterprise storage?! Shared storage
CS370 Operating Systems
 CS370 Operating Systems Colorado State University Yashwant K Malaiya Fall 2017 Lecture 26 File Systems Slides based on Text by Silberschatz, Galvin, Gagne Various sources 1 1 FAQ Cylinders: all the platters?
CS370 Operating Systems Colorado State University Yashwant K Malaiya Fall 2017 Lecture 26 File Systems Slides based on Text by Silberschatz, Galvin, Gagne Various sources 1 1 FAQ Cylinders: all the platters?
3. Monitoring Scenarios
 3. Monitoring Scenarios This section describes the following: Navigation Alerts Interval Rules Navigation Ambari SCOM Use the Ambari SCOM main navigation tree to browse cluster, HDFS and MapReduce performance
3. Monitoring Scenarios This section describes the following: Navigation Alerts Interval Rules Navigation Ambari SCOM Use the Ambari SCOM main navigation tree to browse cluster, HDFS and MapReduce performance
CloudBATCH: A Batch Job Queuing System on Clouds with Hadoop and HBase. Chen Zhang Hans De Sterck University of Waterloo
 CloudBATCH: A Batch Job Queuing System on Clouds with Hadoop and HBase Chen Zhang Hans De Sterck University of Waterloo Outline Introduction Motivation Related Work System Design Future Work Introduction
CloudBATCH: A Batch Job Queuing System on Clouds with Hadoop and HBase Chen Zhang Hans De Sterck University of Waterloo Outline Introduction Motivation Related Work System Design Future Work Introduction
CSE 124: Networked Services Fall 2009 Lecture-19
 CSE 124: Networked Services Fall 2009 Lecture-19 Instructor: B. S. Manoj, Ph.D http://cseweb.ucsd.edu/classes/fa09/cse124 Some of these slides are adapted from various sources/individuals including but
CSE 124: Networked Services Fall 2009 Lecture-19 Instructor: B. S. Manoj, Ph.D http://cseweb.ucsd.edu/classes/fa09/cse124 Some of these slides are adapted from various sources/individuals including but
Topics. Big Data Analytics What is and Why Hadoop? Comparison to other technologies Hadoop architecture Hadoop ecosystem Hadoop usage examples
 Hadoop Introduction 1 Topics Big Data Analytics What is and Why Hadoop? Comparison to other technologies Hadoop architecture Hadoop ecosystem Hadoop usage examples 2 Big Data Analytics What is Big Data?
Hadoop Introduction 1 Topics Big Data Analytics What is and Why Hadoop? Comparison to other technologies Hadoop architecture Hadoop ecosystem Hadoop usage examples 2 Big Data Analytics What is Big Data?
Abstract. 1. Introduction. 2. Design and Implementation Master Chunkserver
 Abstract GFS from Scratch Ge Bian, Niket Agarwal, Wenli Looi https://github.com/looi/cs244b Dec 2017 GFS from Scratch is our partial re-implementation of GFS, the Google File System. Like GFS, our system
Abstract GFS from Scratch Ge Bian, Niket Agarwal, Wenli Looi https://github.com/looi/cs244b Dec 2017 GFS from Scratch is our partial re-implementation of GFS, the Google File System. Like GFS, our system
PaaS and Hadoop. Dr. Laiping Zhao ( 赵来平 ) School of Computer Software, Tianjin University
 School of Computer Software, Tianjin University") PaaS and Hadoop Dr. Laiping Zhao ( 赵来平 ) School of Computer Software, Tianjin University laiping@tju.edu.cn 1 Outline PaaS Hadoop: HDFS and Mapreduce YARN Single-Processor Scheduling Hadoop Scheduling
PaaS and Hadoop Dr. Laiping Zhao ( 赵来平 ) School of Computer Software, Tianjin University laiping@tju.edu.cn 1 Outline PaaS Hadoop: HDFS and Mapreduce YARN Single-Processor Scheduling Hadoop Scheduling
Distributed System. Gang Wu. Spring,2018
 Distributed System Gang Wu Spring,2018 Lecture7:DFS What is DFS? A method of storing and accessing files base in a client/server architecture. A distributed file system is a client/server-based application
Distributed System Gang Wu Spring,2018 Lecture7:DFS What is DFS? A method of storing and accessing files base in a client/server architecture. A distributed file system is a client/server-based application
TP1-2: Analyzing Hadoop Logs
 TP1-2: Analyzing Hadoop Logs Shadi Ibrahim January 26th, 2017 MapReduce has emerged as a leading programming model for data-intensive computing. It was originally proposed by Google to simplify development
TP1-2: Analyzing Hadoop Logs Shadi Ibrahim January 26th, 2017 MapReduce has emerged as a leading programming model for data-intensive computing. It was originally proposed by Google to simplify development
Google File System 2
 Google File System 2 goals monitoring, fault tolerance, auto-recovery (thousands of low-cost machines) focus on multi-gb files handle appends efficiently (no random writes & sequential reads) co-design
Google File System 2 goals monitoring, fault tolerance, auto-recovery (thousands of low-cost machines) focus on multi-gb files handle appends efficiently (no random writes & sequential reads) co-design
Batch Inherence of Map Reduce Framework
 Available Online at www.ijcsmc.com International Journal of Computer Science and Mobile Computing A Monthly Journal of Computer Science and Information Technology IJCSMC, Vol. 4, Issue. 6, June 2015, pg.287
Available Online at www.ijcsmc.com International Journal of Computer Science and Mobile Computing A Monthly Journal of Computer Science and Information Technology IJCSMC, Vol. 4, Issue. 6, June 2015, pg.287
L5-6:Runtime Platforms Hadoop and HDFS
 Indian Institute of Science Bangalore, India भ रत य व ज ञ न स स थ न ब गल र, भ रत Department of Computational and Data Sciences SE256:Jan16 (2:1) L5-6:Runtime Platforms Hadoop and HDFS Yogesh Simmhan 03/
Indian Institute of Science Bangalore, India भ रत य व ज ञ न स स थ न ब गल र, भ रत Department of Computational and Data Sciences SE256:Jan16 (2:1) L5-6:Runtime Platforms Hadoop and HDFS Yogesh Simmhan 03/
VIAF: Verification-based Integrity Assurance Framework for MapReduce. YongzhiWang, JinpengWei
 VIAF: Verification-based Integrity Assurance Framework for MapReduce YongzhiWang, JinpengWei MapReduce in Brief Satisfying the demand for large scale data processing It is a parallel programming model
VIAF: Verification-based Integrity Assurance Framework for MapReduce YongzhiWang, JinpengWei MapReduce in Brief Satisfying the demand for large scale data processing It is a parallel programming model
Konstantin Shvachko, Hairong Kuang, Sanjay Radia, Robert Chansler Yahoo! Sunnyvale, California USA {Shv, Hairong, SRadia,
 Konstantin Shvachko, Hairong Kuang, Sanjay Radia, Robert Chansler Yahoo! Sunnyvale, California USA {Shv, Hairong, SRadia, Chansler}@Yahoo-Inc.com Presenter: Alex Hu } Introduction } Architecture } File
Konstantin Shvachko, Hairong Kuang, Sanjay Radia, Robert Chansler Yahoo! Sunnyvale, California USA {Shv, Hairong, SRadia, Chansler}@Yahoo-Inc.com Presenter: Alex Hu } Introduction } Architecture } File
! Design constraints. " Component failures are the norm. " Files are huge by traditional standards. ! POSIX-like
 Cloud background Google File System! Warehouse scale systems " 10K-100K nodes " 50MW (1 MW = 1,000 houses) " Power efficient! Located near cheap power! Passive cooling! Power Usage Effectiveness = Total
Cloud background Google File System! Warehouse scale systems " 10K-100K nodes " 50MW (1 MW = 1,000 houses) " Power efficient! Located near cheap power! Passive cooling! Power Usage Effectiveness = Total
Can Parallel Replication Benefit Hadoop Distributed File System for High Performance Interconnects?
 Can Parallel Replication Benefit Hadoop Distributed File System for High Performance Interconnects? N. S. Islam, X. Lu, M. W. Rahman, and D. K. Panda Network- Based Compu2ng Laboratory Department of Computer
Can Parallel Replication Benefit Hadoop Distributed File System for High Performance Interconnects? N. S. Islam, X. Lu, M. W. Rahman, and D. K. Panda Network- Based Compu2ng Laboratory Department of Computer
CS /30/17. Paul Krzyzanowski 1. Google Chubby ( Apache Zookeeper) Distributed Systems. Chubby. Chubby Deployment.
 Distributed Systems. Chubby. Chubby Deployment.") Distributed Systems 15. Distributed File Systems Google ( Apache Zookeeper) Paul Krzyzanowski Rutgers University Fall 2017 1 2 Distributed lock service + simple fault-tolerant file system Deployment Client
Distributed Systems 15. Distributed File Systems Google ( Apache Zookeeper) Paul Krzyzanowski Rutgers University Fall 2017 1 2 Distributed lock service + simple fault-tolerant file system Deployment Client
Certified Big Data Hadoop and Spark Scala Course Curriculum
 Certified Big Data Hadoop and Spark Scala Course Curriculum The Certified Big Data Hadoop and Spark Scala course by DataFlair is a perfect blend of indepth theoretical knowledge and strong practical skills
Certified Big Data Hadoop and Spark Scala Course Curriculum The Certified Big Data Hadoop and Spark Scala course by DataFlair is a perfect blend of indepth theoretical knowledge and strong practical skills
HDFS Federation. Sanjay Radia Founder and Hortonworks. Page 1
 HDFS Federation Sanjay Radia Founder and Architect @ Hortonworks Page 1 About Me Apache Hadoop Committer and Member of Hadoop PMC Architect of core-hadoop @ Yahoo - Focusing on HDFS, MapReduce scheduler,
HDFS Federation Sanjay Radia Founder and Architect @ Hortonworks Page 1 About Me Apache Hadoop Committer and Member of Hadoop PMC Architect of core-hadoop @ Yahoo - Focusing on HDFS, MapReduce scheduler,
2/26/2017. For instance, consider running Word Count across 20 splits
 Based on the slides of prof. Pietro Michiardi Hadoop Internals https://github.com/michiard/disc-cloud-course/raw/master/hadoop/hadoop.pdf Job: execution of a MapReduce application across a data set Task:
Based on the slides of prof. Pietro Michiardi Hadoop Internals https://github.com/michiard/disc-cloud-course/raw/master/hadoop/hadoop.pdf Job: execution of a MapReduce application across a data set Task:
MapReduce-style data processing
 MapReduce-style data processing Software Languages Team University of Koblenz-Landau Ralf Lämmel and Andrei Varanovich Related meanings of MapReduce Functional programming with map & reduce An algorithmic
MapReduce-style data processing Software Languages Team University of Koblenz-Landau Ralf Lämmel and Andrei Varanovich Related meanings of MapReduce Functional programming with map & reduce An algorithmic
Introduction to MapReduce. Instructor: Dr. Weikuan Yu Computer Sci. & Software Eng.
 Introduction to MapReduce Instructor: Dr. Weikuan Yu Computer Sci. & Software Eng. Before MapReduce Large scale data processing was difficult! Managing hundreds or thousands of processors Managing parallelization
Introduction to MapReduce Instructor: Dr. Weikuan Yu Computer Sci. & Software Eng. Before MapReduce Large scale data processing was difficult! Managing hundreds or thousands of processors Managing parallelization
Programming Systems for Big Data
 Programming Systems for Big Data CS315B Lecture 17 Including material from Kunle Olukotun Prof. Aiken CS 315B Lecture 17 1 Big Data We ve focused on parallel programming for computational science There
Programming Systems for Big Data CS315B Lecture 17 Including material from Kunle Olukotun Prof. Aiken CS 315B Lecture 17 1 Big Data We ve focused on parallel programming for computational science There
Mounica B, Aditya Srivastava, Md. Faisal Alam
 International Journal of Scientific Research in Computer Science, Engineering and Information Technology 2017 IJSRCSEIT Volume 2 Issue 3 ISSN : 2456-3307 Clustering of large datasets using Hadoop Ecosystem
International Journal of Scientific Research in Computer Science, Engineering and Information Technology 2017 IJSRCSEIT Volume 2 Issue 3 ISSN : 2456-3307 Clustering of large datasets using Hadoop Ecosystem
MapReduce Simplified Data Processing on Large Clusters
 MapReduce Simplified Data Processing on Large Clusters Amir H. Payberah amir@sics.se Amirkabir University of Technology (Tehran Polytechnic) Amir H. Payberah (Tehran Polytechnic) MapReduce 1393/8/5 1 /
MapReduce Simplified Data Processing on Large Clusters Amir H. Payberah amir@sics.se Amirkabir University of Technology (Tehran Polytechnic) Amir H. Payberah (Tehran Polytechnic) MapReduce 1393/8/5 1 /
Georgia Institute of Technology ECE6102 4/20/2009 David Colvin, Jimmy Vuong
 Georgia Institute of Technology ECE6102 4/20/2009 David Colvin, Jimmy Vuong Relatively recent; still applicable today GFS: Google s storage platform for the generation and processing of data used by services
Georgia Institute of Technology ECE6102 4/20/2009 David Colvin, Jimmy Vuong Relatively recent; still applicable today GFS: Google s storage platform for the generation and processing of data used by services
GFS Overview. Design goals/priorities Design for big-data workloads Huge files, mostly appends, concurrency, huge bandwidth Design for failures
 GFS Overview Design goals/priorities Design for big-data workloads Huge files, mostly appends, concurrency, huge bandwidth Design for failures Interface: non-posix New op: record appends (atomicity matters,
GFS Overview Design goals/priorities Design for big-data workloads Huge files, mostly appends, concurrency, huge bandwidth Design for failures Interface: non-posix New op: record appends (atomicity matters,
Google File System. Arun Sundaram Operating Systems
 Arun Sundaram Operating Systems 1 Assumptions GFS built with commodity hardware GFS stores a modest number of large files A few million files, each typically 100MB or larger (Multi-GB files are common)
Arun Sundaram Operating Systems 1 Assumptions GFS built with commodity hardware GFS stores a modest number of large files A few million files, each typically 100MB or larger (Multi-GB files are common)
Dept. Of Computer Science, Colorado State University
 CS 455: INTRODUCTION TO DISTRIBUTED SYSTEMS [HADOOP/HDFS] Trying to have your cake and eat it too Each phase pines for tasks with locality and their numbers on a tether Alas within a phase, you get one,
CS 455: INTRODUCTION TO DISTRIBUTED SYSTEMS [HADOOP/HDFS] Trying to have your cake and eat it too Each phase pines for tasks with locality and their numbers on a tether Alas within a phase, you get one,
Hadoop محبوبه دادخواه کارگاه ساالنه آزمایشگاه فناوری وب زمستان 1391
 Hadoop محبوبه دادخواه کارگاه ساالنه آزمایشگاه فناوری وب زمستان 1391 Outline Big Data Big Data Examples Challenges with traditional storage NoSQL Hadoop HDFS MapReduce Architecture 2 Big Data In information
Hadoop محبوبه دادخواه کارگاه ساالنه آزمایشگاه فناوری وب زمستان 1391 Outline Big Data Big Data Examples Challenges with traditional storage NoSQL Hadoop HDFS MapReduce Architecture 2 Big Data In information
Certified Big Data and Hadoop Course Curriculum
 Certified Big Data and Hadoop Course Curriculum The Certified Big Data and Hadoop course by DataFlair is a perfect blend of in-depth theoretical knowledge and strong practical skills via implementation
Certified Big Data and Hadoop Course Curriculum The Certified Big Data and Hadoop course by DataFlair is a perfect blend of in-depth theoretical knowledge and strong practical skills via implementation
Informa)on Retrieval and Map- Reduce Implementa)ons. Mohammad Amir Sharif PhD Student Center for Advanced Computer Studies
on Retrieval and Map- Reduce Implementa)ons. Mohammad Amir Sharif PhD Student Center for Advanced Computer Studies") Informa)on Retrieval and Map- Reduce Implementa)ons Mohammad Amir Sharif PhD Student Center for Advanced Computer Studies mas4108@louisiana.edu Map-Reduce: Why? Need to process 100TB datasets On 1 node:
Informa)on Retrieval and Map- Reduce Implementa)ons Mohammad Amir Sharif PhD Student Center for Advanced Computer Studies mas4108@louisiana.edu Map-Reduce: Why? Need to process 100TB datasets On 1 node: