Intel Xeon Phi Coprocessors
|
|
|
- Vivien McDowell
- 6 years ago
- Views:
Transcription

1 Intel Xeon Phi Coprocessors Reference: Parallel Programming and Optimization with Intel Xeon Phi Coprocessors, by A. Vladimirov and V. Karpusenko, 2013

2 Ring Bus on Intel Xeon Phi Example with 8 cores
3 Xeon Phi Card Coprocessor connected via PCIe Gen 2 (6 GB/s) 6-8 GB memory on card
4 Intel Xeon Phi Coprocessors Many Integrated Core (MIC) architecture, with cores on a chip Processors connected via a ring bus Peak approx 1 Tflop/s double precision Simple x86 cores at approx 1 GHz clock speed Enhances code portability In-order processor Each core supports 4-way hyperthreading; each hyperthread issues instructions every other cycle Cores have 512-bit SIMD units
5
6 Memory characteristics L1D: 32 KB, L1I: 32 KB (per core) L2: 512 KB (per core) unified Memory BW: 350 GB/s peak; 200 GB/s attainable
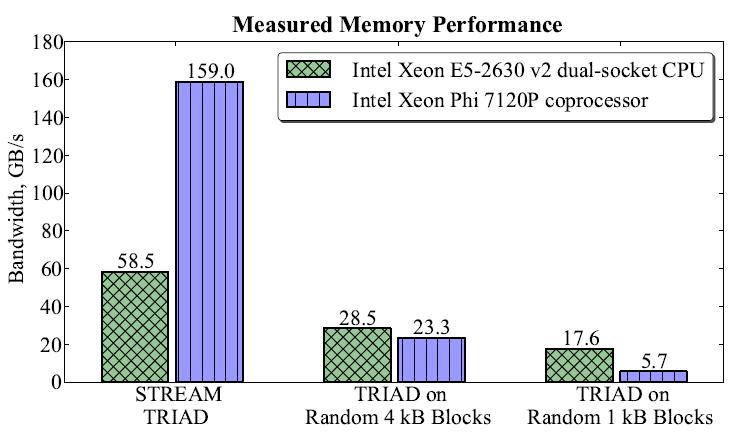
7
8 Programming Modes Offload Program executes on host and offloads work to coprocessors Native (coprocessor runs Linux uos) Could run several MPI processes Symmetric (MPI between hosts and coprocessors)
9 Where s the disk? File system is stored on a virtual file system (stored in DRAM on the card) When the coprocessors are rebooted, home directories are reset and necessary libraries must be copied to the file system Or, an actual disk file system can be mounted on the coprocessor, but access would be slow (across PCIe)
10 Offloading vs. Native/Symmetric Mode Offloading is good when Application is not highly parallel throughout and not all cores of the coprocessor can always be used (few fast cores vs. many slow cores) Application has high memory requirements where offloaded portions can use less memory (coprocessor limited to 8 GB in native mode) Offloading is bad when Overhead of data transfer is high compared to offload computation
11 Offloading Common offload procedure: #pragma offload target(mic) inout(data: length(size)) This is performed automatically: allocate memory on coprocessor transfer data to coprocessor perform offload calculation transfer data to host deallocate memory on coprocessor Fall back to host if no coprocessor available Code still works if directives are disabled
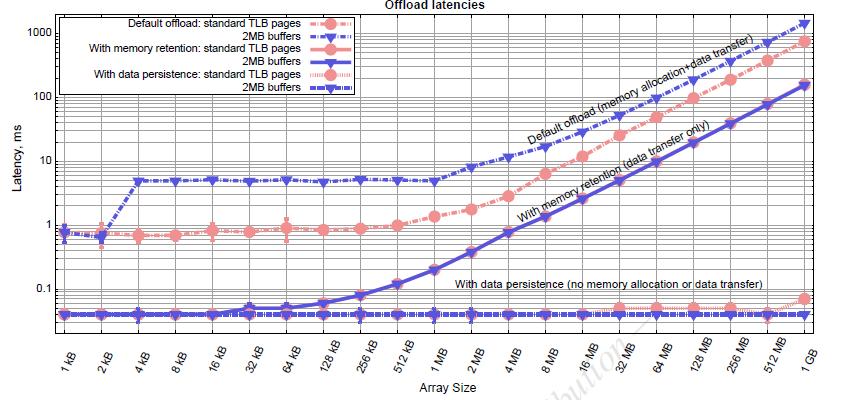
12 Persistent data in offloads Data allocation and transfer are expensive Can reuse memory space allocated on the coprocessor (alloc_if, free_if) Can control when data transfer occurs between host and coprocessor in, out, inout nocopy to avoid transfering statically allocated variables length(0) to avoid transfering data referenced by pointers

13 What does this code do?
14

15 Asynchronous Offloading Host program blocks until the offload completes (default) For non-blocking offload, use signal clause Works for asynchronous data transfer as well
16 Offloading on Intel Xeon Phi Two methods pragma offload (fast, managed data allocation and transfer) shared virtual memory model (convenient but slower due to software managing coherency) Compare to GPU offloading CUDA approach: launch kernels from the host; explicit function calls to allocate data on GPU and to transfer data between host and GPU OpenACC: pragmas Other options OpenMP (pragmas for offloading) OpenCL (explicit function calls), more suitable for GPUs
17 Virtual Shared Memory for Offloading Logically shared memory between host and coprocessor Programmer marks variables that are shared Runtime maintains coherence at the beginning and end of offload statements (only modified data is copied) _Cilk_shared keyword to mark shared variables/data shared variables have the same addresses on host and coprocessor, to simply offloading of complex data structures shared variables are allocated dynamically (not on the stack) _Cilk_offload keyword to mark offloaded functions Dynamically allocated memory can also be shared: _Offload_shared_malloc, _Offload_shared_free

18 Multiple coprocessors Use OpenMP threads; one thread offloads to one coprocessor. On coprocessor, use OpenMP to parallelize across cores.

19 Native/Symmetric MPI vs. MPI+Offload
Introduction to Intel Xeon Phi programming techniques. Fabio Affinito Vittorio Ruggiero
 Introduction to Intel Xeon Phi programming techniques Fabio Affinito Vittorio Ruggiero Outline High level overview of the Intel Xeon Phi hardware and software stack Intel Xeon Phi programming paradigms:
Introduction to Intel Xeon Phi programming techniques Fabio Affinito Vittorio Ruggiero Outline High level overview of the Intel Xeon Phi hardware and software stack Intel Xeon Phi programming paradigms:
PORTING CP2K TO THE INTEL XEON PHI. ARCHER Technical Forum, Wed 30 th July Iain Bethune
 PORTING CP2K TO THE INTEL XEON PHI ARCHER Technical Forum, Wed 30 th July Iain Bethune (ibethune@epcc.ed.ac.uk) Outline Xeon Phi Overview Porting CP2K to Xeon Phi Performance Results Lessons Learned Further
PORTING CP2K TO THE INTEL XEON PHI ARCHER Technical Forum, Wed 30 th July Iain Bethune (ibethune@epcc.ed.ac.uk) Outline Xeon Phi Overview Porting CP2K to Xeon Phi Performance Results Lessons Learned Further
Intel Xeon Phi Coprocessor
 Intel Xeon Phi Coprocessor A guide to using it on the Cray XC40 Terminology Warning: may also be referred to as MIC or KNC in what follows! What are Intel Xeon Phi Coprocessors? Hardware designed to accelerate
Intel Xeon Phi Coprocessor A guide to using it on the Cray XC40 Terminology Warning: may also be referred to as MIC or KNC in what follows! What are Intel Xeon Phi Coprocessors? Hardware designed to accelerate
Introduction to Xeon Phi. Bill Barth January 11, 2013
 Introduction to Xeon Phi Bill Barth January 11, 2013 What is it? Co-processor PCI Express card Stripped down Linux operating system Dense, simplified processor Many power-hungry operations removed Wider
Introduction to Xeon Phi Bill Barth January 11, 2013 What is it? Co-processor PCI Express card Stripped down Linux operating system Dense, simplified processor Many power-hungry operations removed Wider
6/14/2017. The Intel Xeon Phi. Setup. Xeon Phi Internals. Fused Multiply-Add. Getting to rabbit and setting up your account. Xeon Phi Peak Performance
 The Intel Xeon Phi 1 Setup 2 Xeon system Mike Bailey mjb@cs.oregonstate.edu rabbit.engr.oregonstate.edu 2 E5-2630 Xeon Processors 8 Cores 64 GB of memory 2 TB of disk NVIDIA Titan Black 15 SMs 2880 CUDA
The Intel Xeon Phi 1 Setup 2 Xeon system Mike Bailey mjb@cs.oregonstate.edu rabbit.engr.oregonstate.edu 2 E5-2630 Xeon Processors 8 Cores 64 GB of memory 2 TB of disk NVIDIA Titan Black 15 SMs 2880 CUDA
Introduction to the Xeon Phi programming model. Fabio AFFINITO, CINECA
 Introduction to the Xeon Phi programming model Fabio AFFINITO, CINECA What is a Xeon Phi? MIC = Many Integrated Core architecture by Intel Other names: KNF, KNC, Xeon Phi... Not a CPU (but somewhat similar
Introduction to the Xeon Phi programming model Fabio AFFINITO, CINECA What is a Xeon Phi? MIC = Many Integrated Core architecture by Intel Other names: KNF, KNC, Xeon Phi... Not a CPU (but somewhat similar
Intel Xeon Phi Coprocessor Offloading Computation
 Intel Xeon Phi Coprocessor Offloading Computation Legal Disclaimer INFORMATION IN THIS DOCUMENT IS PROVIDED IN CONNECTION WITH INTEL PRODUCTS. NO LICENSE, EXPRESS OR IMPLIED, BY ESTOPPEL OR OTHERWISE,
Intel Xeon Phi Coprocessor Offloading Computation Legal Disclaimer INFORMATION IN THIS DOCUMENT IS PROVIDED IN CONNECTION WITH INTEL PRODUCTS. NO LICENSE, EXPRESS OR IMPLIED, BY ESTOPPEL OR OTHERWISE,
Evaluation of Asynchronous Offloading Capabilities of Accelerator Programming Models for Multiple Devices
 Evaluation of Asynchronous Offloading Capabilities of Accelerator Programming Models for Multiple Devices Jonas Hahnfeld 1, Christian Terboven 1, James Price 2, Hans Joachim Pflug 1, Matthias S. Müller
Evaluation of Asynchronous Offloading Capabilities of Accelerator Programming Models for Multiple Devices Jonas Hahnfeld 1, Christian Terboven 1, James Price 2, Hans Joachim Pflug 1, Matthias S. Müller
Parallel Systems. Project topics
 Parallel Systems Project topics 2016-2017 1. Scheduling Scheduling is a common problem which however is NP-complete, so that we are never sure about the optimality of the solution. Parallelisation is a
Parallel Systems Project topics 2016-2017 1. Scheduling Scheduling is a common problem which however is NP-complete, so that we are never sure about the optimality of the solution. Parallelisation is a
Overview of Intel Xeon Phi Coprocessor
 Overview of Intel Xeon Phi Coprocessor Sept 20, 2013 Ritu Arora Texas Advanced Computing Center Email: rauta@tacc.utexas.edu This talk is only a trailer A comprehensive training on running and optimizing
Overview of Intel Xeon Phi Coprocessor Sept 20, 2013 Ritu Arora Texas Advanced Computing Center Email: rauta@tacc.utexas.edu This talk is only a trailer A comprehensive training on running and optimizing
Tutorial. Preparing for Stampede: Programming Heterogeneous Many-Core Supercomputers
 Tutorial Preparing for Stampede: Programming Heterogeneous Many-Core Supercomputers Dan Stanzione, Lars Koesterke, Bill Barth, Kent Milfeld dan/lars/bbarth/milfeld@tacc.utexas.edu XSEDE 12 July 16, 2012
Tutorial Preparing for Stampede: Programming Heterogeneous Many-Core Supercomputers Dan Stanzione, Lars Koesterke, Bill Barth, Kent Milfeld dan/lars/bbarth/milfeld@tacc.utexas.edu XSEDE 12 July 16, 2012
Intel Many Integrated Core (MIC) Matt Kelly & Ryan Rawlins
 Matt Kelly & Ryan Rawlins") Intel Many Integrated Core (MIC) Matt Kelly & Ryan Rawlins Outline History & Motivation Architecture Core architecture Network Topology Memory hierarchy Brief comparison to GPU & Tilera Programming Applications
Intel Many Integrated Core (MIC) Matt Kelly & Ryan Rawlins Outline History & Motivation Architecture Core architecture Network Topology Memory hierarchy Brief comparison to GPU & Tilera Programming Applications
Reusing this material
 XEON PHI BASICS Reusing this material This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike 4.0 International License. http://creativecommons.org/licenses/by-nc-sa/4.0/deed.en_us
XEON PHI BASICS Reusing this material This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike 4.0 International License. http://creativecommons.org/licenses/by-nc-sa/4.0/deed.en_us
Intel MIC Programming Workshop, Hardware Overview & Native Execution. IT4Innovations, Ostrava,
 , Hardware Overview & Native Execution IT4Innovations, Ostrava, 3.2.- 4.2.2016 1 Agenda Intro @ accelerators on HPC Architecture overview of the Intel Xeon Phi (MIC) Programming models Native mode programming
, Hardware Overview & Native Execution IT4Innovations, Ostrava, 3.2.- 4.2.2016 1 Agenda Intro @ accelerators on HPC Architecture overview of the Intel Xeon Phi (MIC) Programming models Native mode programming
Accelerator Programming Lecture 1
 Accelerator Programming Lecture 1 Manfred Liebmann Technische Universität München Chair of Optimal Control Center for Mathematical Sciences, M17 manfred.liebmann@tum.de January 11, 2016 Accelerator Programming
Accelerator Programming Lecture 1 Manfred Liebmann Technische Universität München Chair of Optimal Control Center for Mathematical Sciences, M17 manfred.liebmann@tum.de January 11, 2016 Accelerator Programming
Programming Intel R Xeon Phi TM
 Programming Intel R Xeon Phi TM An Overview Anup Zope Mississippi State University 20 March 2018 Anup Zope (Mississippi State University) Programming Intel R Xeon Phi TM 20 March 2018 1 / 46 Outline 1
Programming Intel R Xeon Phi TM An Overview Anup Zope Mississippi State University 20 March 2018 Anup Zope (Mississippi State University) Programming Intel R Xeon Phi TM 20 March 2018 1 / 46 Outline 1
A case study of performance portability with OpenMP 4.5
 A case study of performance portability with OpenMP 4.5 Rahul Gayatri, Charlene Yang, Thorsten Kurth, Jack Deslippe NERSC pre-print copy 1 Outline General Plasmon Pole (GPP) application from BerkeleyGW
A case study of performance portability with OpenMP 4.5 Rahul Gayatri, Charlene Yang, Thorsten Kurth, Jack Deslippe NERSC pre-print copy 1 Outline General Plasmon Pole (GPP) application from BerkeleyGW
INTRODUCTION TO THE ARCHER KNIGHTS LANDING CLUSTER. Adrian
 INTRODUCTION TO THE ARCHER KNIGHTS LANDING CLUSTER Adrian Jackson a.jackson@epcc.ed.ac.uk @adrianjhpc Processors The power used by a CPU core is proportional to Clock Frequency x Voltage 2 In the past,
INTRODUCTION TO THE ARCHER KNIGHTS LANDING CLUSTER Adrian Jackson a.jackson@epcc.ed.ac.uk @adrianjhpc Processors The power used by a CPU core is proportional to Clock Frequency x Voltage 2 In the past,
the Intel Xeon Phi coprocessor
 the Intel Xeon Phi coprocessor 1 Introduction about the Intel Xeon Phi coprocessor comparing Phi with CUDA the Intel Many Integrated Core architecture 2 Programming the Intel Xeon Phi Coprocessor with
the Intel Xeon Phi coprocessor 1 Introduction about the Intel Xeon Phi coprocessor comparing Phi with CUDA the Intel Many Integrated Core architecture 2 Programming the Intel Xeon Phi Coprocessor with
Intel Many Integrated Core (MIC) Programming Intel Xeon Phi
 Programming Intel Xeon Phi") Intel Many Integrated Core (MIC) Programming Intel Xeon Phi Dmitry Petunin Intel Technical Consultant 1 Legal Disclaimer & INFORMATION IN THIS DOCUMENT IS PROVIDED AS IS. NO LICENSE, EXPRESS OR IMPLIED,
Intel Many Integrated Core (MIC) Programming Intel Xeon Phi Dmitry Petunin Intel Technical Consultant 1 Legal Disclaimer & INFORMATION IN THIS DOCUMENT IS PROVIDED AS IS. NO LICENSE, EXPRESS OR IMPLIED,
Parallel Accelerators
 Parallel Accelerators Přemysl Šůcha ``Parallel algorithms'', 2017/2018 CTU/FEL 1 Topic Overview Graphical Processing Units (GPU) and CUDA Vector addition on CUDA Intel Xeon Phi Matrix equations on Xeon
Parallel Accelerators Přemysl Šůcha ``Parallel algorithms'', 2017/2018 CTU/FEL 1 Topic Overview Graphical Processing Units (GPU) and CUDA Vector addition on CUDA Intel Xeon Phi Matrix equations on Xeon
Intel MIC Programming Workshop, Hardware Overview & Native Execution LRZ,
 Intel MIC Programming Workshop, Hardware Overview & Native Execution LRZ, 27.6.- 29.6.2016 1 Agenda Intro @ accelerators on HPC Architecture overview of the Intel Xeon Phi Products Programming models Native
Intel MIC Programming Workshop, Hardware Overview & Native Execution LRZ, 27.6.- 29.6.2016 1 Agenda Intro @ accelerators on HPC Architecture overview of the Intel Xeon Phi Products Programming models Native
INTRODUCTION TO THE ARCHER KNIGHTS LANDING CLUSTER. Adrian
 INTRODUCTION TO THE ARCHER KNIGHTS LANDING CLUSTER Adrian Jackson adrianj@epcc.ed.ac.uk @adrianjhpc Processors The power used by a CPU core is proportional to Clock Frequency x Voltage 2 In the past, computers
INTRODUCTION TO THE ARCHER KNIGHTS LANDING CLUSTER Adrian Jackson adrianj@epcc.ed.ac.uk @adrianjhpc Processors The power used by a CPU core is proportional to Clock Frequency x Voltage 2 In the past, computers
A Unified Approach to Heterogeneous Architectures Using the Uintah Framework
 DOE for funding the CSAFE project (97-10), DOE NETL, DOE NNSA NSF for funding via SDCI and PetaApps A Unified Approach to Heterogeneous Architectures Using the Uintah Framework Qingyu Meng, Alan Humphrey
DOE for funding the CSAFE project (97-10), DOE NETL, DOE NNSA NSF for funding via SDCI and PetaApps A Unified Approach to Heterogeneous Architectures Using the Uintah Framework Qingyu Meng, Alan Humphrey
Finite Element Integration and Assembly on Modern Multi and Many-core Processors
 Finite Element Integration and Assembly on Modern Multi and Many-core Processors Krzysztof Banaś, Jan Bielański, Kazimierz Chłoń AGH University of Science and Technology, Mickiewicza 30, 30-059 Kraków,
Finite Element Integration and Assembly on Modern Multi and Many-core Processors Krzysztof Banaś, Jan Bielański, Kazimierz Chłoń AGH University of Science and Technology, Mickiewicza 30, 30-059 Kraków,
PROGRAMOVÁNÍ V C++ CVIČENÍ. Michal Brabec
 PROGRAMOVÁNÍ V C++ CVIČENÍ Michal Brabec PARALLELISM CATEGORIES CPU? SSE Multiprocessor SIMT - GPU 2 / 17 PARALLELISM V C++ Weak support in the language itself, powerful libraries Many different parallelization
PROGRAMOVÁNÍ V C++ CVIČENÍ Michal Brabec PARALLELISM CATEGORIES CPU? SSE Multiprocessor SIMT - GPU 2 / 17 PARALLELISM V C++ Weak support in the language itself, powerful libraries Many different parallelization
Parallel Programming on Ranger and Stampede
 Parallel Programming on Ranger and Stampede Steve Lantz Senior Research Associate Cornell CAC Parallel Computing at TACC: Ranger to Stampede Transition December 11, 2012 What is Stampede? NSF-funded XSEDE
Parallel Programming on Ranger and Stampede Steve Lantz Senior Research Associate Cornell CAC Parallel Computing at TACC: Ranger to Stampede Transition December 11, 2012 What is Stampede? NSF-funded XSEDE
Parallel Accelerators
 Parallel Accelerators Přemysl Šůcha ``Parallel algorithms'', 2017/2018 CTU/FEL 1 Topic Overview Graphical Processing Units (GPU) and CUDA Vector addition on CUDA Intel Xeon Phi Matrix equations on Xeon
Parallel Accelerators Přemysl Šůcha ``Parallel algorithms'', 2017/2018 CTU/FEL 1 Topic Overview Graphical Processing Units (GPU) and CUDA Vector addition on CUDA Intel Xeon Phi Matrix equations on Xeon
Scientific Computing with Intel Xeon Phi Coprocessors
 Scientific Computing with Intel Xeon Phi Coprocessors Andrey Vladimirov Colfax International HPC Advisory Council Stanford Conference 2015 Compututing with Xeon Phi Welcome Colfax International, 2014 Contents
Scientific Computing with Intel Xeon Phi Coprocessors Andrey Vladimirov Colfax International HPC Advisory Council Stanford Conference 2015 Compututing with Xeon Phi Welcome Colfax International, 2014 Contents
n N c CIni.o ewsrg.au
 @NCInews NCI and Raijin National Computational Infrastructure 2 Our Partners General purpose, highly parallel processors High FLOPs/watt and FLOPs/$ Unit of execution Kernel Separate memory subsystem GPGPU
@NCInews NCI and Raijin National Computational Infrastructure 2 Our Partners General purpose, highly parallel processors High FLOPs/watt and FLOPs/$ Unit of execution Kernel Separate memory subsystem GPGPU
OpenACC 2.6 Proposed Features
 OpenACC 2.6 Proposed Features OpenACC.org June, 2017 1 Introduction This document summarizes features and changes being proposed for the next version of the OpenACC Application Programming Interface, tentatively
OpenACC 2.6 Proposed Features OpenACC.org June, 2017 1 Introduction This document summarizes features and changes being proposed for the next version of the OpenACC Application Programming Interface, tentatively
CSCI 402: Computer Architectures. Parallel Processors (2) Fengguang Song Department of Computer & Information Science IUPUI.
 Fengguang Song Department of Computer & Information Science IUPUI.") CSCI 402: Computer Architectures Parallel Processors (2) Fengguang Song Department of Computer & Information Science IUPUI 6.6 - End Today s Contents GPU Cluster and its network topology The Roofline performance
CSCI 402: Computer Architectures Parallel Processors (2) Fengguang Song Department of Computer & Information Science IUPUI 6.6 - End Today s Contents GPU Cluster and its network topology The Roofline performance
Bring your application to a new era:
 Bring your application to a new era: learning by example how to parallelize and optimize for Intel Xeon processor and Intel Xeon Phi TM coprocessor Manel Fernández, Roger Philp, Richard Paul Bayncore Ltd.
Bring your application to a new era: learning by example how to parallelize and optimize for Intel Xeon processor and Intel Xeon Phi TM coprocessor Manel Fernández, Roger Philp, Richard Paul Bayncore Ltd.
THE FUTURE OF GPU DATA MANAGEMENT. Michael Wolfe, May 9, 2017
 THE FUTURE OF GPU DATA MANAGEMENT Michael Wolfe, May 9, 2017 CPU CACHE Hardware managed What data to cache? Where to store the cached data? What data to evict when the cache fills up? When to store data
THE FUTURE OF GPU DATA MANAGEMENT Michael Wolfe, May 9, 2017 CPU CACHE Hardware managed What data to cache? Where to store the cached data? What data to evict when the cache fills up? When to store data
Accelerating Leukocyte Tracking Using CUDA: A Case Study in Leveraging Manycore Coprocessors
 Accelerating Leukocyte Tracking Using CUDA: A Case Study in Leveraging Manycore Coprocessors Michael Boyer, David Tarjan, Scott T. Acton, and Kevin Skadron University of Virginia IPDPS 2009 Outline Leukocyte
Accelerating Leukocyte Tracking Using CUDA: A Case Study in Leveraging Manycore Coprocessors Michael Boyer, David Tarjan, Scott T. Acton, and Kevin Skadron University of Virginia IPDPS 2009 Outline Leukocyte
Lecture 13. Shared memory: Architecture and programming
 Lecture 13 Shared memory: Architecture and programming Announcements Special guest lecture on Parallel Programming Language Uniform Parallel C Thursday 11/2, 2:00 to 3:20 PM EBU3B 1202 See www.cse.ucsd.edu/classes/fa06/cse260/lectures/lec13
Lecture 13 Shared memory: Architecture and programming Announcements Special guest lecture on Parallel Programming Language Uniform Parallel C Thursday 11/2, 2:00 to 3:20 PM EBU3B 1202 See www.cse.ucsd.edu/classes/fa06/cse260/lectures/lec13
Debugging Intel Xeon Phi KNC Tutorial
 Debugging Intel Xeon Phi KNC Tutorial Last revised on: 10/7/16 07:37 Overview: The Intel Xeon Phi Coprocessor 2 Debug Library Requirements 2 Debugging Host-Side Applications that Use the Intel Offload
Debugging Intel Xeon Phi KNC Tutorial Last revised on: 10/7/16 07:37 Overview: The Intel Xeon Phi Coprocessor 2 Debug Library Requirements 2 Debugging Host-Side Applications that Use the Intel Offload
Native Computing and Optimization. Hang Liu December 4 th, 2013
 Native Computing and Optimization Hang Liu December 4 th, 2013 Overview Why run native? What is a native application? Building a native application Running a native application Setting affinity and pinning
Native Computing and Optimization Hang Liu December 4 th, 2013 Overview Why run native? What is a native application? Building a native application Running a native application Setting affinity and pinning
CME 213 S PRING Eric Darve
 CME 213 S PRING 2017 Eric Darve Summary of previous lectures Pthreads: low-level multi-threaded programming OpenMP: simplified interface based on #pragma, adapted to scientific computing OpenMP for and
CME 213 S PRING 2017 Eric Darve Summary of previous lectures Pthreads: low-level multi-threaded programming OpenMP: simplified interface based on #pragma, adapted to scientific computing OpenMP for and
Heterogeneous Computing and OpenCL
 Heterogeneous Computing and OpenCL Hongsuk Yi (hsyi@kisti.re.kr) (Korea Institute of Science and Technology Information) Contents Overview of the Heterogeneous Computing Introduction to Intel Xeon Phi
Heterogeneous Computing and OpenCL Hongsuk Yi (hsyi@kisti.re.kr) (Korea Institute of Science and Technology Information) Contents Overview of the Heterogeneous Computing Introduction to Intel Xeon Phi
Addressing the Increasing Challenges of Debugging on Accelerated HPC Systems. Ed Hinkel Senior Sales Engineer
 Addressing the Increasing Challenges of Debugging on Accelerated HPC Systems Ed Hinkel Senior Sales Engineer Agenda Overview - Rogue Wave & TotalView GPU Debugging with TotalView Nvdia CUDA Intel Phi 2
Addressing the Increasing Challenges of Debugging on Accelerated HPC Systems Ed Hinkel Senior Sales Engineer Agenda Overview - Rogue Wave & TotalView GPU Debugging with TotalView Nvdia CUDA Intel Phi 2
COSC 6385 Computer Architecture - Data Level Parallelism (III) The Intel Larrabee, Intel Xeon Phi and IBM Cell processors
 The Intel Larrabee, Intel Xeon Phi and IBM Cell processors") COSC 6385 Computer Architecture - Data Level Parallelism (III) The Intel Larrabee, Intel Xeon Phi and IBM Cell processors Edgar Gabriel Fall 2018 References Intel Larrabee: [1] L. Seiler, D. Carmean, E.
COSC 6385 Computer Architecture - Data Level Parallelism (III) The Intel Larrabee, Intel Xeon Phi and IBM Cell processors Edgar Gabriel Fall 2018 References Intel Larrabee: [1] L. Seiler, D. Carmean, E.
Preparing for Highly Parallel, Heterogeneous Coprocessing
 Preparing for Highly Parallel, Heterogeneous Coprocessing Steve Lantz Senior Research Associate Cornell CAC Workshop: Parallel Computing on Ranger and Lonestar May 17, 2012 What Are We Talking About Here?
Preparing for Highly Parallel, Heterogeneous Coprocessing Steve Lantz Senior Research Associate Cornell CAC Workshop: Parallel Computing on Ranger and Lonestar May 17, 2012 What Are We Talking About Here?
Introduction: Modern computer architecture. The stored program computer and its inherent bottlenecks Multi- and manycore chips and nodes
 Introduction: Modern computer architecture The stored program computer and its inherent bottlenecks Multi- and manycore chips and nodes Motivation: Multi-Cores where and why Introduction: Moore s law Intel
Introduction: Modern computer architecture The stored program computer and its inherent bottlenecks Multi- and manycore chips and nodes Motivation: Multi-Cores where and why Introduction: Moore s law Intel
Accelerator cards are typically PCIx cards that supplement a host processor, which they require to operate Today, the most common accelerators include
 3.1 Overview Accelerator cards are typically PCIx cards that supplement a host processor, which they require to operate Today, the most common accelerators include GPUs (Graphics Processing Units) AMD/ATI
3.1 Overview Accelerator cards are typically PCIx cards that supplement a host processor, which they require to operate Today, the most common accelerators include GPUs (Graphics Processing Units) AMD/ATI
Klaus-Dieter Oertel, May 28 th 2013 Software and Services Group Intel Corporation
 S c i c o m P 2 0 1 3 T u t o r i a l Intel Xeon Phi Product Family Programming Tools Klaus-Dieter Oertel, May 28 th 2013 Software and Services Group Intel Corporation Agenda Intel Parallel Studio XE 2013
S c i c o m P 2 0 1 3 T u t o r i a l Intel Xeon Phi Product Family Programming Tools Klaus-Dieter Oertel, May 28 th 2013 Software and Services Group Intel Corporation Agenda Intel Parallel Studio XE 2013
Introduc)on to Xeon Phi
on to Xeon Phi") Introduc)on to Xeon Phi ACES Aus)n, TX Dec. 04 2013 Kent Milfeld, Luke Wilson, John McCalpin, Lars Koesterke TACC What is it? Co- processor PCI Express card Stripped down Linux opera)ng system Dense, simplified
Introduc)on to Xeon Phi ACES Aus)n, TX Dec. 04 2013 Kent Milfeld, Luke Wilson, John McCalpin, Lars Koesterke TACC What is it? Co- processor PCI Express card Stripped down Linux opera)ng system Dense, simplified
arxiv: v1 [physics.comp-ph] 4 Nov 2013
![arxiv: v1 [physics.comp-ph] 4 Nov 2013](/thumbs/74/70979601.jpg "arxiv: v1 [physics.comp-ph] 4 Nov 2013") arxiv:1311.0590v1 [physics.comp-ph] 4 Nov 2013 Performance of Kepler GTX Titan GPUs and Xeon Phi System, Weonjong Lee, and Jeonghwan Pak Lattice Gauge Theory Research Center, CTP, and FPRD, Department
arxiv:1311.0590v1 [physics.comp-ph] 4 Nov 2013 Performance of Kepler GTX Titan GPUs and Xeon Phi System, Weonjong Lee, and Jeonghwan Pak Lattice Gauge Theory Research Center, CTP, and FPRD, Department
GpuWrapper: A Portable API for Heterogeneous Programming at CGG
 GpuWrapper: A Portable API for Heterogeneous Programming at CGG Victor Arslan, Jean-Yves Blanc, Gina Sitaraman, Marc Tchiboukdjian, Guillaume Thomas-Collignon March 2 nd, 2016 GpuWrapper: Objectives &
GpuWrapper: A Portable API for Heterogeneous Programming at CGG Victor Arslan, Jean-Yves Blanc, Gina Sitaraman, Marc Tchiboukdjian, Guillaume Thomas-Collignon March 2 nd, 2016 GpuWrapper: Objectives &
EXASCALE COMPUTING ROADMAP IMPACT ON LEGACY CODES MARCH 17 TH, MIC Workshop PAGE 1. MIC workshop Guillaume Colin de Verdière
 EXASCALE COMPUTING ROADMAP IMPACT ON LEGACY CODES MIC workshop Guillaume Colin de Verdière MARCH 17 TH, 2015 MIC Workshop PAGE 1 CEA, DAM, DIF, F-91297 Arpajon, France March 17th, 2015 Overview Context
EXASCALE COMPUTING ROADMAP IMPACT ON LEGACY CODES MIC workshop Guillaume Colin de Verdière MARCH 17 TH, 2015 MIC Workshop PAGE 1 CEA, DAM, DIF, F-91297 Arpajon, France March 17th, 2015 Overview Context
IBM CORAL HPC System Solution
 IBM CORAL HPC System Solution HPC and HPDA towards Cognitive, AI and Deep Learning Deep Learning AI / Deep Learning Strategy for Power Power AI Platform High Performance Data Analytics Big Data Strategy
IBM CORAL HPC System Solution HPC and HPDA towards Cognitive, AI and Deep Learning Deep Learning AI / Deep Learning Strategy for Power Power AI Platform High Performance Data Analytics Big Data Strategy
Architecture, Programming and Performance of MIC Phi Coprocessor
 Architecture, Programming and Performance of MIC Phi Coprocessor JanuszKowalik, Piotr Arłukowicz Professor (ret), The Boeing Company, Washington, USA Assistant professor, Faculty of Mathematics, Physics
Architecture, Programming and Performance of MIC Phi Coprocessor JanuszKowalik, Piotr Arłukowicz Professor (ret), The Boeing Company, Washington, USA Assistant professor, Faculty of Mathematics, Physics
Double Rewards of Porting Scientific Applications to the Intel MIC Architecture
 Double Rewards of Porting Scientific Applications to the Intel MIC Architecture Troy A. Porter Hansen Experimental Physics Laboratory and Kavli Institute for Particle Astrophysics and Cosmology Stanford
Double Rewards of Porting Scientific Applications to the Intel MIC Architecture Troy A. Porter Hansen Experimental Physics Laboratory and Kavli Institute for Particle Astrophysics and Cosmology Stanford
The Intel Xeon Phi Coprocessor. Dr-Ing. Michael Klemm Software and Services Group Intel Corporation
 The Intel Xeon Phi Coprocessor Dr-Ing. Michael Klemm Software and Services Group Intel Corporation (michael.klemm@intel.com) Legal Disclaimer & Optimization Notice INFORMATION IN THIS DOCUMENT IS PROVIDED
The Intel Xeon Phi Coprocessor Dr-Ing. Michael Klemm Software and Services Group Intel Corporation (michael.klemm@intel.com) Legal Disclaimer & Optimization Notice INFORMATION IN THIS DOCUMENT IS PROVIDED
An Evaluation of Unified Memory Technology on NVIDIA GPUs
 An Evaluation of Unified Memory Technology on NVIDIA GPUs Wenqiang Li 1, Guanghao Jin 2, Xuewen Cui 1, Simon See 1,3 Center for High Performance Computing, Shanghai Jiao Tong University, China 1 Tokyo
An Evaluation of Unified Memory Technology on NVIDIA GPUs Wenqiang Li 1, Guanghao Jin 2, Xuewen Cui 1, Simon See 1,3 Center for High Performance Computing, Shanghai Jiao Tong University, China 1 Tokyo
Vincent C. Betro, Ph.D. NICS March 6, 2014
 Vincent C. Betro, Ph.D. NICS March 6, 2014 NSF Acknowledgement This material is based upon work supported by the National Science Foundation under Grant Number 1137097 Any opinions, findings, and conclusions
Vincent C. Betro, Ph.D. NICS March 6, 2014 NSF Acknowledgement This material is based upon work supported by the National Science Foundation under Grant Number 1137097 Any opinions, findings, and conclusions
OpenACC Course. Office Hour #2 Q&A
 OpenACC Course Office Hour #2 Q&A Q1: How many threads does each GPU core have? A: GPU cores execute arithmetic instructions. Each core can execute one single precision floating point instruction per cycle
OpenACC Course Office Hour #2 Q&A Q1: How many threads does each GPU core have? A: GPU cores execute arithmetic instructions. Each core can execute one single precision floating point instruction per cycle
Can Accelerators Really Accelerate Harmonie?
 Can Accelerators Really Accelerate Harmonie? Enda O Brien, Adam Ralph Irish Centre for High-End Computing Motivation There is constant demand for more performance Conventional compute cores not getting
Can Accelerators Really Accelerate Harmonie? Enda O Brien, Adam Ralph Irish Centre for High-End Computing Motivation There is constant demand for more performance Conventional compute cores not getting
Introduction to the Intel Xeon Phi on Stampede
 June 10, 2014 Introduction to the Intel Xeon Phi on Stampede John Cazes Texas Advanced Computing Center Stampede - High Level Overview Base Cluster (Dell/Intel/Mellanox): Intel Sandy Bridge processors
June 10, 2014 Introduction to the Intel Xeon Phi on Stampede John Cazes Texas Advanced Computing Center Stampede - High Level Overview Base Cluster (Dell/Intel/Mellanox): Intel Sandy Bridge processors
E, F. Best-known methods (BKMs), 153 Boot strap processor (BSP),
, 153 Boot strap processor (BSP),") Index A Accelerated Strategic Computing Initiative (ASCI), 3 Address generation interlock (AGI), 55 Algorithm and data structures, 171. See also General matrix-matrix multiplication (GEMM) design rules,
Index A Accelerated Strategic Computing Initiative (ASCI), 3 Address generation interlock (AGI), 55 Algorithm and data structures, 171. See also General matrix-matrix multiplication (GEMM) design rules,
Accelerator programming with OpenACC
 ..... Accelerator programming with OpenACC Colaboratorio Nacional de Computación Avanzada Jorge Castro jcastro@cenat.ac.cr 2018. Agenda 1 Introduction 2 OpenACC life cycle 3 Hands on session Profiling
..... Accelerator programming with OpenACC Colaboratorio Nacional de Computación Avanzada Jorge Castro jcastro@cenat.ac.cr 2018. Agenda 1 Introduction 2 OpenACC life cycle 3 Hands on session Profiling
Offloading. Kent Milfeld Stampede Training, January 11, 2013
 Kent Milfeld milfeld@tacc.utexas.edu Stampede Training, January 11, 2013 1 MIC Information Stampede User Guide: http://www.tacc.utexas.edu/user-services/user-guides/stampede-user-guide TACC Advanced Offloading:
Kent Milfeld milfeld@tacc.utexas.edu Stampede Training, January 11, 2013 1 MIC Information Stampede User Guide: http://www.tacc.utexas.edu/user-services/user-guides/stampede-user-guide TACC Advanced Offloading:
rabbit.engr.oregonstate.edu What is rabbit?
 1 rabbit.engr.oregonstate.edu Mike Bailey mjb@cs.oregonstate.edu rabbit.pptx What is rabbit? 2 NVIDIA Titan Black PCIe Bus 15 SMs 2880 CUDA cores 6 GB of memory OpenGL support OpenCL support Xeon system
1 rabbit.engr.oregonstate.edu Mike Bailey mjb@cs.oregonstate.edu rabbit.pptx What is rabbit? 2 NVIDIA Titan Black PCIe Bus 15 SMs 2880 CUDA cores 6 GB of memory OpenGL support OpenCL support Xeon system
The Era of Heterogeneous Computing
 The Era of Heterogeneous Computing EU-US Summer School on High Performance Computing New York, NY, USA June 28, 2013 Lars Koesterke: Research Staff @ TACC Nomenclature Architecture Model -------------------------------------------------------
The Era of Heterogeneous Computing EU-US Summer School on High Performance Computing New York, NY, USA June 28, 2013 Lars Koesterke: Research Staff @ TACC Nomenclature Architecture Model -------------------------------------------------------
Native Computing and Optimization on the Intel Xeon Phi Coprocessor. John D. McCalpin
 Native Computing and Optimization on the Intel Xeon Phi Coprocessor John D. McCalpin mccalpin@tacc.utexas.edu Intro (very brief) Outline Compiling & Running Native Apps Controlling Execution Tuning Vectorization
Native Computing and Optimization on the Intel Xeon Phi Coprocessor John D. McCalpin mccalpin@tacc.utexas.edu Intro (very brief) Outline Compiling & Running Native Apps Controlling Execution Tuning Vectorization
Memory Footprint of Locality Information On Many-Core Platforms Brice Goglin Inria Bordeaux Sud-Ouest France 2018/05/25
 ROME Workshop @ IPDPS Vancouver Memory Footprint of Locality Information On Many- Platforms Brice Goglin Inria Bordeaux Sud-Ouest France 2018/05/25 Locality Matters to HPC Applications Locality Matters
ROME Workshop @ IPDPS Vancouver Memory Footprint of Locality Information On Many- Platforms Brice Goglin Inria Bordeaux Sud-Ouest France 2018/05/25 Locality Matters to HPC Applications Locality Matters
Efficient CPU GPU data transfers CUDA 6.0 Unified Virtual Memory
 Institute of Computational Science Efficient CPU GPU data transfers CUDA 6.0 Unified Virtual Memory Juraj Kardoš (University of Lugano) July 9, 2014 Juraj Kardoš Efficient GPU data transfers July 9, 2014
Institute of Computational Science Efficient CPU GPU data transfers CUDA 6.0 Unified Virtual Memory Juraj Kardoš (University of Lugano) July 9, 2014 Juraj Kardoš Efficient GPU data transfers July 9, 2014
COMPUTING ELEMENT EVOLUTION AND ITS IMPACT ON SIMULATION CODES
 COMPUTING ELEMENT EVOLUTION AND ITS IMPACT ON SIMULATION CODES P(ND) 2-2 2014 Guillaume Colin de Verdière OCTOBER 14TH, 2014 P(ND)^2-2 PAGE 1 CEA, DAM, DIF, F-91297 Arpajon, France October 14th, 2014 Abstract:
COMPUTING ELEMENT EVOLUTION AND ITS IMPACT ON SIMULATION CODES P(ND) 2-2 2014 Guillaume Colin de Verdière OCTOBER 14TH, 2014 P(ND)^2-2 PAGE 1 CEA, DAM, DIF, F-91297 Arpajon, France October 14th, 2014 Abstract:
Big Data Analytics Performance for Large Out-Of- Core Matrix Solvers on Advanced Hybrid Architectures
 Procedia Computer Science Volume 51, 2015, Pages 2774 2778 ICCS 2015 International Conference On Computational Science Big Data Analytics Performance for Large Out-Of- Core Matrix Solvers on Advanced Hybrid
Procedia Computer Science Volume 51, 2015, Pages 2774 2778 ICCS 2015 International Conference On Computational Science Big Data Analytics Performance for Large Out-Of- Core Matrix Solvers on Advanced Hybrid
GPU Architecture. Alan Gray EPCC The University of Edinburgh
 GPU Architecture Alan Gray EPCC The University of Edinburgh Outline Why do we want/need accelerators such as GPUs? Architectural reasons for accelerator performance advantages Latest GPU Products From
GPU Architecture Alan Gray EPCC The University of Edinburgh Outline Why do we want/need accelerators such as GPUs? Architectural reasons for accelerator performance advantages Latest GPU Products From
Designing Optimized MPI Broadcast and Allreduce for Many Integrated Core (MIC) InfiniBand Clusters
 InfiniBand Clusters") Designing Optimized MPI Broadcast and Allreduce for Many Integrated Core (MIC) InfiniBand Clusters K. Kandalla, A. Venkatesh, K. Hamidouche, S. Potluri, D. Bureddy and D. K. Panda Presented by Dr. Xiaoyi
Designing Optimized MPI Broadcast and Allreduce for Many Integrated Core (MIC) InfiniBand Clusters K. Kandalla, A. Venkatesh, K. Hamidouche, S. Potluri, D. Bureddy and D. K. Panda Presented by Dr. Xiaoyi
Parallel Computing. November 20, W.Homberg
 Mitglied der Helmholtz-Gemeinschaft Parallel Computing November 20, 2017 W.Homberg Why go parallel? Problem too large for single node Job requires more memory Shorter time to solution essential Better
Mitglied der Helmholtz-Gemeinschaft Parallel Computing November 20, 2017 W.Homberg Why go parallel? Problem too large for single node Job requires more memory Shorter time to solution essential Better
Intel Parallel Studio XE 2015
 2015 Create faster code faster with this comprehensive parallel software development suite. Faster code: Boost applications performance that scales on today s and next-gen processors Create code faster:
2015 Create faster code faster with this comprehensive parallel software development suite. Faster code: Boost applications performance that scales on today s and next-gen processors Create code faster:
Intel Xeon Phi Coprocessor
 Intel Xeon Phi Coprocessor 1 Agenda Introduction Intel Xeon Phi Architecture Programming Models Outlook Summary 2 Intel Multicore Architecture Intel Many Integrated Core Architecture (Intel MIC) Foundation
Intel Xeon Phi Coprocessor 1 Agenda Introduction Intel Xeon Phi Architecture Programming Models Outlook Summary 2 Intel Multicore Architecture Intel Many Integrated Core Architecture (Intel MIC) Foundation
Many-core Processor Programming for beginners. Hongsuk Yi ( 李泓錫 ) KISTI (Korea Institute of Science and Technology Information)
 KISTI (Korea Institute of Science and Technology Information)") Many-core Processor Programming for beginners Hongsuk Yi ( 李泓錫 ) (hsyi@kisti.re.kr) KISTI (Korea Institute of Science and Technology Information) Contents Overview of the Heterogeneous Computing Introduction
Many-core Processor Programming for beginners Hongsuk Yi ( 李泓錫 ) (hsyi@kisti.re.kr) KISTI (Korea Institute of Science and Technology Information) Contents Overview of the Heterogeneous Computing Introduction
Modernizing OpenMP for an Accelerated World
 Modernizing OpenMP for an Accelerated World Tom Scogland Bronis de Supinski This work was performed under the auspices of the U.S. Department of Energy by Lawrence Livermore National Laboratory under Contract
Modernizing OpenMP for an Accelerated World Tom Scogland Bronis de Supinski This work was performed under the auspices of the U.S. Department of Energy by Lawrence Livermore National Laboratory under Contract
Accelerating Implicit LS-DYNA with GPU
 Accelerating Implicit LS-DYNA with GPU Yih-Yih Lin Hewlett-Packard Company Abstract A major hindrance to the widespread use of Implicit LS-DYNA is its high compute cost. This paper will show modern GPU,
Accelerating Implicit LS-DYNA with GPU Yih-Yih Lin Hewlett-Packard Company Abstract A major hindrance to the widespread use of Implicit LS-DYNA is its high compute cost. This paper will show modern GPU,
Martin Dubois, ing. Contents
 Martin Dubois, ing Contents Without OpenNet vs With OpenNet Technical information Possible applications Artificial Intelligence Deep Packet Inspection Image and Video processing Network equipment development
Martin Dubois, ing Contents Without OpenNet vs With OpenNet Technical information Possible applications Artificial Intelligence Deep Packet Inspection Image and Video processing Network equipment development
Parallel Programming. Libraries and Implementations
 Parallel Programming Libraries and Implementations Reusing this material This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike 4.0 International License. http://creativecommons.org/licenses/by-nc-sa/4.0/deed.en_us
Parallel Programming Libraries and Implementations Reusing this material This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike 4.0 International License. http://creativecommons.org/licenses/by-nc-sa/4.0/deed.en_us
Native Computing and Optimization on the Intel Xeon Phi Coprocessor. John D. McCalpin
 Native Computing and Optimization on the Intel Xeon Phi Coprocessor John D. McCalpin mccalpin@tacc.utexas.edu Outline Overview What is a native application? Why run native? Getting Started: Building a
Native Computing and Optimization on the Intel Xeon Phi Coprocessor John D. McCalpin mccalpin@tacc.utexas.edu Outline Overview What is a native application? Why run native? Getting Started: Building a
A GPU based brute force de-dispersion algorithm for LOFAR
 A GPU based brute force de-dispersion algorithm for LOFAR W. Armour, M. Giles, A. Karastergiou and C. Williams. University of Oxford. 8 th May 2012 1 GPUs Why use GPUs? Latest Kepler/Fermi based cards
A GPU based brute force de-dispersion algorithm for LOFAR W. Armour, M. Giles, A. Karastergiou and C. Williams. University of Oxford. 8 th May 2012 1 GPUs Why use GPUs? Latest Kepler/Fermi based cards
Running HARMONIE on Xeon Phi Coprocessors
 Running HARMONIE on Xeon Phi Coprocessors Enda O Brien Irish Centre for High-End Computing Disclosure Intel is funding ICHEC to port & optimize some applications, including HARMONIE, to Xeon Phi coprocessors.
Running HARMONIE on Xeon Phi Coprocessors Enda O Brien Irish Centre for High-End Computing Disclosure Intel is funding ICHEC to port & optimize some applications, including HARMONIE, to Xeon Phi coprocessors.
Introduction to CELL B.E. and GPU Programming. Agenda
 Introduction to CELL B.E. and GPU Programming Department of Electrical & Computer Engineering Rutgers University Agenda Background CELL B.E. Architecture Overview CELL B.E. Programming Environment GPU
Introduction to CELL B.E. and GPU Programming Department of Electrical & Computer Engineering Rutgers University Agenda Background CELL B.E. Architecture Overview CELL B.E. Programming Environment GPU
Technology for a better society. hetcomp.com
 Technology for a better society hetcomp.com 1 J. Seland, C. Dyken, T. R. Hagen, A. R. Brodtkorb, J. Hjelmervik,E Bjønnes GPU Computing USIT Course Week 16th November 2011 hetcomp.com 2 9:30 10:15 Introduction
Technology for a better society hetcomp.com 1 J. Seland, C. Dyken, T. R. Hagen, A. R. Brodtkorb, J. Hjelmervik,E Bjønnes GPU Computing USIT Course Week 16th November 2011 hetcomp.com 2 9:30 10:15 Introduction
Parallel Programming Libraries and implementations
 Parallel Programming Libraries and implementations Partners Funding Reusing this material This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike 4.0 International License.
Parallel Programming Libraries and implementations Partners Funding Reusing this material This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike 4.0 International License.
Resources Current and Future Systems. Timothy H. Kaiser, Ph.D.
 Resources Current and Future Systems Timothy H. Kaiser, Ph.D. tkaiser@mines.edu 1 Most likely talk to be out of date History of Top 500 Issues with building bigger machines Current and near future academic
Resources Current and Future Systems Timothy H. Kaiser, Ph.D. tkaiser@mines.edu 1 Most likely talk to be out of date History of Top 500 Issues with building bigger machines Current and near future academic
Introduction to CUDA Programming
 Introduction to CUDA Programming Steve Lantz Cornell University Center for Advanced Computing October 30, 2013 Based on materials developed by CAC and TACC Outline Motivation for GPUs and CUDA Overview
Introduction to CUDA Programming Steve Lantz Cornell University Center for Advanced Computing October 30, 2013 Based on materials developed by CAC and TACC Outline Motivation for GPUs and CUDA Overview
The Stampede is Coming: A New Petascale Resource for the Open Science Community
 The Stampede is Coming: A New Petascale Resource for the Open Science Community Jay Boisseau Texas Advanced Computing Center boisseau@tacc.utexas.edu Stampede: Solicitation US National Science Foundation
The Stampede is Coming: A New Petascale Resource for the Open Science Community Jay Boisseau Texas Advanced Computing Center boisseau@tacc.utexas.edu Stampede: Solicitation US National Science Foundation
COMP Parallel Computing. Programming Accelerators using Directives
 COMP 633 - Parallel Computing Lecture 15 October 30, 2018 Programming Accelerators using Directives Credits: Introduction to OpenACC and toolkit Jeff Larkin, Nvidia COMP 633 - Prins Directives for Accelerator
COMP 633 - Parallel Computing Lecture 15 October 30, 2018 Programming Accelerators using Directives Credits: Introduction to OpenACC and toolkit Jeff Larkin, Nvidia COMP 633 - Prins Directives for Accelerator
Vincent C. Betro, R. Glenn Brook, & Ryan C. Hulguin XSEDE Xtreme Scaling Workshop Chicago, IL July 15-16, 2012
 Vincent C. Betro, R. Glenn Brook, & Ryan C. Hulguin XSEDE Xtreme Scaling Workshop Chicago, IL July 15-16, 2012 Outline NICS and AACE Architecture Overview Resources Native Mode Boltzmann BGK Solver Native/Offload
Vincent C. Betro, R. Glenn Brook, & Ryan C. Hulguin XSEDE Xtreme Scaling Workshop Chicago, IL July 15-16, 2012 Outline NICS and AACE Architecture Overview Resources Native Mode Boltzmann BGK Solver Native/Offload
Approaches to acceleration: GPUs vs Intel MIC. Fabio AFFINITO SCAI department
 Approaches to acceleration: GPUs vs Intel MIC Fabio AFFINITO SCAI department Single core Multi core Many core GPU Intel MIC 61 cores 512bit-SIMD units from http://www.karlrupp.net/ from http://www.karlrupp.net/
Approaches to acceleration: GPUs vs Intel MIC Fabio AFFINITO SCAI department Single core Multi core Many core GPU Intel MIC 61 cores 512bit-SIMD units from http://www.karlrupp.net/ from http://www.karlrupp.net/
An Extension of the StarSs Programming Model for Platforms with Multiple GPUs
 An Extension of the StarSs Programming Model for Platforms with Multiple GPUs Eduard Ayguadé 2 Rosa M. Badia 2 Francisco Igual 1 Jesús Labarta 2 Rafael Mayo 1 Enrique S. Quintana-Ortí 1 1 Departamento
An Extension of the StarSs Programming Model for Platforms with Multiple GPUs Eduard Ayguadé 2 Rosa M. Badia 2 Francisco Igual 1 Jesús Labarta 2 Rafael Mayo 1 Enrique S. Quintana-Ortí 1 1 Departamento
High Performance Computing. Leopold Grinberg T. J. Watson IBM Research Center, USA
 High Performance Computing Leopold Grinberg T. J. Watson IBM Research Center, USA High Performance Computing Why do we need HPC? High Performance Computing Amazon can ship products within hours would it
High Performance Computing Leopold Grinberg T. J. Watson IBM Research Center, USA High Performance Computing Why do we need HPC? High Performance Computing Amazon can ship products within hours would it
Debugging CUDA Applications with Allinea DDT. Ian Lumb Sr. Systems Engineer, Allinea Software Inc.
 Debugging CUDA Applications with Allinea DDT Ian Lumb Sr. Systems Engineer, Allinea Software Inc. ilumb@allinea.com GTC 2013, San Jose, March 20, 2013 Embracing GPUs GPUs a rival to traditional processors
Debugging CUDA Applications with Allinea DDT Ian Lumb Sr. Systems Engineer, Allinea Software Inc. ilumb@allinea.com GTC 2013, San Jose, March 20, 2013 Embracing GPUs GPUs a rival to traditional processors
Computer Architecture and Structured Parallel Programming James Reinders, Intel
 Computer Architecture and Structured Parallel Programming James Reinders, Intel Parallel Computing CIS 410/510 Department of Computer and Information Science Lecture 17 Manycore Computing and GPUs Computer
Computer Architecture and Structured Parallel Programming James Reinders, Intel Parallel Computing CIS 410/510 Department of Computer and Information Science Lecture 17 Manycore Computing and GPUs Computer
Native Computing and Optimization on the Intel Xeon Phi Coprocessor. Lars Koesterke John D. McCalpin
 Native Computing and Optimization on the Intel Xeon Phi Coprocessor Lars Koesterke John D. McCalpin lars@tacc.utexas.edu mccalpin@tacc.utexas.edu Intro (very brief) Outline Compiling & Running Native Apps
Native Computing and Optimization on the Intel Xeon Phi Coprocessor Lars Koesterke John D. McCalpin lars@tacc.utexas.edu mccalpin@tacc.utexas.edu Intro (very brief) Outline Compiling & Running Native Apps
Ryan Hulguin
 Ryan Hulguin ryan-hulguin@tennessee.edu Outline Beacon The Beacon project The Beacon cluster TOP500 ranking System specs Xeon Phi Coprocessor Technical specs Many core trend Programming models Applications
Ryan Hulguin ryan-hulguin@tennessee.edu Outline Beacon The Beacon project The Beacon cluster TOP500 ranking System specs Xeon Phi Coprocessor Technical specs Many core trend Programming models Applications
LUNAR TEMPERATURE CALCULATIONS ON A GPU
 LUNAR TEMPERATURE CALCULATIONS ON A GPU Kyle M. Berney Department of Information & Computer Sciences Department of Mathematics University of Hawai i at Mānoa Honolulu, HI 96822 ABSTRACT Lunar surface temperature
LUNAR TEMPERATURE CALCULATIONS ON A GPU Kyle M. Berney Department of Information & Computer Sciences Department of Mathematics University of Hawai i at Mānoa Honolulu, HI 96822 ABSTRACT Lunar surface temperature
TACC s Stampede Project: Intel MIC for Simulation and Data-Intensive Computing
 TACC s Stampede Project: Intel MIC for Simulation and Data-Intensive Computing Jay Boisseau, Director April 17, 2012 TACC Vision & Strategy Provide the most powerful, capable computing technologies and
TACC s Stampede Project: Intel MIC for Simulation and Data-Intensive Computing Jay Boisseau, Director April 17, 2012 TACC Vision & Strategy Provide the most powerful, capable computing technologies and
PRACE PATC Course: Intel MIC Programming Workshop, MKL. Ostrava,
 PRACE PATC Course: Intel MIC Programming Workshop, MKL Ostrava, 7-8.2.2017 1 Agenda A quick overview of Intel MKL Usage of MKL on Xeon Phi Compiler Assisted Offload Automatic Offload Native Execution Hands-on
PRACE PATC Course: Intel MIC Programming Workshop, MKL Ostrava, 7-8.2.2017 1 Agenda A quick overview of Intel MKL Usage of MKL on Xeon Phi Compiler Assisted Offload Automatic Offload Native Execution Hands-on