DNN ENGINE: A 16nm Sub-uJ DNN Inference Accelerator for the Embedded Masses
|
|
|
- Milo Welch
- 6 years ago
- Views:
Transcription


1 DNN ENGINE: A 16nm Sub-uJ DNN Inference Accelerator for the Embedded Masses Paul N. Whatmough 1,2 S. K. Lee 2, N. Mulholland 2, P. Hansen 2, S. Kodali 3, D. Brooks 2, G.-Y. Wei 2 1 ARM Research, Boston, MA 2 Harvard University, Cambridge, MA 3 Princeton University, NJ






2 The age of deep learning Deeper Nets More Compute Bigger Data



3 The embedded masses Interpret noisy real-world data from sensor-rich systems Keep inference at the edge: always-on sensing Large memory footprint and compute load 3


4 DNN inference at the edge Trained weights Raw Data Pre-Processing Norm. Data Feature Extraction Features Classifier Classes Normalize mean=0, variance=1 FFT, MFCC, Sobel, HOG, etc Fully-connected Deep neural network (DNN)
5 DNN classifier design flow Data - Training, validation, test [Reagen et al., ISCA 2016] Training - Optimize hyper-parameters - Minimize size and test error Quantization - Fixed-point 8-bit / 16-bit Inference - CPU, DSP, GPU, Accelerator 5
6 DNN ENGINE accelerator architecture Inputs DNN ENGINE Outputs Sensor Data + DNN Topology + Weights Input Vector Weight Neuron Hidden Layers Output Classes Argmax Classification Parallelism and data reuse Sparse data and small data types Algorithmic resilience
7 Outline Background and motivation DNN ENGINE - Parallelism and data reuse - Sparse data and small data types - Algorithmic resilience Measurement Results Summary 7
8 Fully-connected DNN graph Input Vector Output Classes Input Layer Output Layer Hidden Layers 8
9 Fully-connected DNN graph Weight Neuron Input Vector Output Classes 9
10 Fully-connected DNN graph SIMD Window Input Vector Output Classes Process a group of neurons in parallel 10
11 Fully-connected DNN graph Weights Input Vector Output Classes Re-use of activation data across neurons 11
12 Fully-connected DNN graph Input Vector Output Classes 12
13 Fully-connected DNN graph Input Vector Output Classes 13
14 Fully-connected DNN graph Input Vector Output Classes 14
15 Fully-connected DNN graph Input Vector Output Classes Add bias and apply activation function 15
16 Fully-connected DNN graph Input Vector Output Classes 16
17 Fully-connected DNN graph Input Vector Output Classes 17
18 Fully-connected DNN graph Input Vector Output Classes 18
19 Fully-connected DNN graph Input Vector Output Classes 19
20 Balancing efficiency and bandwidth No Data Reuse Parallelism increases throughput and data reuse 20
21 Balancing efficiency and bandwidth No Data Reuse Bandwidth too high Parallelism increases throughput and data reuse - But also increases Memory Bandwidth demands 21
22 Balancing efficiency and bandwidth No Data Reuse 128b/cycle Bandwidth too high Parallelism increases throughput and data reuse - But also increases Memory Bandwidth demands 8-Way SIMD is efficient at reasonable memory BW - 10x Activation reuse, with 128b AXI channel 22
23 DNN ENGINE micro-architecture Host Processor Data In CFG Data Out Data Read IPBUF XBUF Writeback NBUF W-MEM DMA Weight Load MAC Datapath Activation 8-Way SIMD accelerator architecture 23
24 DNN ENGINE micro-architecture Host Processor Data In CFG Data Out Data Read IPBUF XBUF Writeback NBUF W-MEM DMA Weight Load MAC Datapath Activation Host Processor loads configuration and input data 24
25 DNN ENGINE micro-architecture Host Processor Data In CFG Data Out Data Read IPBUF XBUF Writeback NBUF W-MEM DMA Weight Load MAC Datapath Activation Accumulate products of Activation and Weights 25
26 DNN ENGINE micro-architecture Host Processor Data In CFG Data Out Data Read IPBUF XBUF Writeback NBUF W-MEM DMA Weight Load MAC Datapath Activation Add bias, apply ReLU activation and writeback 26
27 DNN ENGINE micro-architecture Host Processor Data In CFG Data Out Data Read IPBUF XBUF Writeback NBUF W-MEM DMA Weight Load MAC Datapath Activation IRQ to host, which retrieves output data 27
28 Outline Background and motivation DNN ENGINE - Parallelism and data reuse - Sparse data and small data types - Algorithmic resilience Measurement Results Summary 28
29 Exploiting sparse data Input Vector Output Classes 29
30 Exploiting sparse data Input Vector Output Classes Discard small activation data 30
31 Exploiting sparse data Input Vector Output Classes Dynamically prune graph connectivity 31
32 Exploiting sparse data Input Vector Output Classes 32
33 Exploiting sparse data Input Vector Output Classes 33
34 Exploiting sparse data Input Vector Output Classes 34
35 Exploiting sparse data Input Vector Output Classes Discard small activation data 35
36 Exploiting sparse data Input Vector Output Classes Dynamically prune graph connectivity 36
37 Exploiting sparse data Input Vector Output Classes 37
38 Exploiting sparse data Input Vector Output Classes 38
39 Exploiting sparse data Input Vector Output Classes 39
40 Exploiting sparse data Input Vector Output Classes 40
41 DNN ENGINE micro-architecture Host Processor Data In CFG Data Out Data Read IPBUF XBUF Writeback NBUF W-MEM DMA Weight Load MAC Datapath Activation 41
42 DNN ENGINE micro-architecture Host Processor Data In CFG Data Out Data Read IPBUF XBUF Writeback NBUF W-MEM SKIP Index DMA Weight Load MAC Datapath Activation 42
43 DNN ENGINE micro-architecture Host Processor Data In CFG Data Out Data Read IPBUF XBUF Writeback NBUF W-MEM SKIP Index DMA Weight Load MAC Datapath Activation W-MEM supports 8b or 16b data types 43
44 Outline Background and motivation DNN ENGINE - Parallelism and data reuse - Sparse data and small data types - Algorithmic resilience Measurement Results Summary 44
45 DNN ENGINE micro-architecture Host Processor Data In CFG Data Out Data Read IPBUF XBUF RZ Writeback NBUF W-MEM RZ SKIP Index DMA Weight Load MAC Datapath Activation [Whatmough et al., ISSCC 17] 45
46 Timing error tolerance Timing Violation Rate % Accuracy Memory Datapath Combined > 1,000,000 X TC SM BM TC SM TB TC ALL [Whatmough et al., ISSCC 17] 46
47 Outline Background and motivation DNN ENGINE - Parallelism and data reuse - Sparse data and small data types - Algorithmic resilience Measurement Results Summary 47

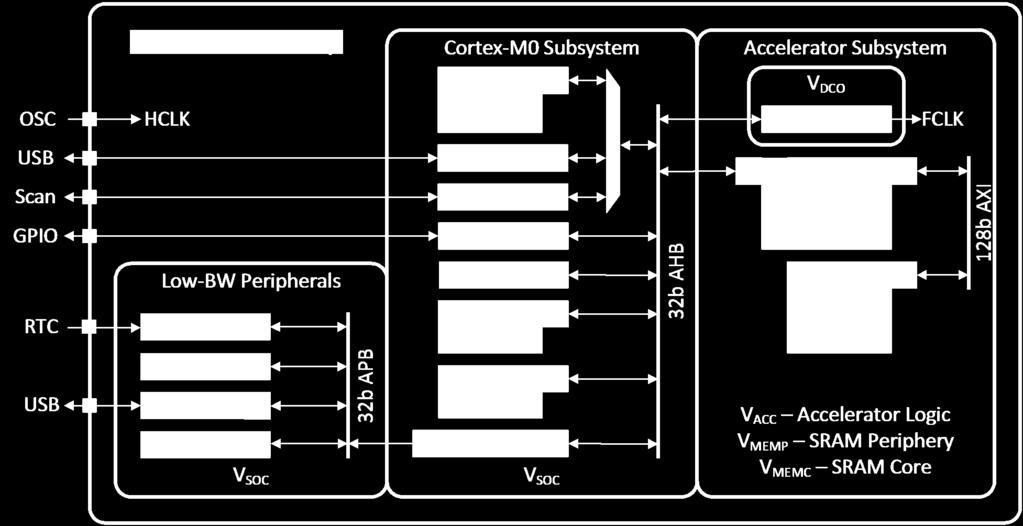
48 16nm SoC for always-on applications 48


49 16nm SoC for always-on applications 49

50 Measured energy for always-on applications Nominal Vdd / signoff Fmax 667MHz / 0.8V Energy varies with application Exponential with accuracy 2.5x energy 0.3% accuracy On-chip memory critical A few KBs from DRAM >1uJ Constrains model size 50
51 Measured energy improvement Joint architecture and circuit optimizations Typical silicon at room temp 667MHz / 0.8V 667MHz / 0.67V 10x Measurements demonstrate 10x energy reduction 4x throughput increase 51

52 State of the art classifiers Dedicated NN accelerators Different performance points Different technologies Accuracy critical metric Linear classifier 88% Exponential cost The next 10x improvement Algorithm innovations? 52
53 Summary Inference moving from cloud to the device: always-on sensing DNN ENGINE architecture optimizations - Parallelism and data reuse - Sparse data and small data types - Algorithmic resilience 16nm test chip measurements - Critical to store the model in on-chip memory - 10x energy and 4x throughput improvement - 1uJ per prediction for always-on applications We are grateful for support from DARPA CRAFT and PERFECT projects 53
A Scalable Speech Recognizer with Deep-Neural-Network Acoustic Models
 A Scalable Speech Recognizer with Deep-Neural-Network Acoustic Models and Voice-Activated Power Gating Michael Price*, James Glass, Anantha Chandrakasan MIT, Cambridge, MA * now at Analog Devices, Cambridge,
A Scalable Speech Recognizer with Deep-Neural-Network Acoustic Models and Voice-Activated Power Gating Michael Price*, James Glass, Anantha Chandrakasan MIT, Cambridge, MA * now at Analog Devices, Cambridge,
How to Estimate the Energy Consumption of Deep Neural Networks
 How to Estimate the Energy Consumption of Deep Neural Networks Tien-Ju Yang, Yu-Hsin Chen, Joel Emer, Vivienne Sze MIT 1 Problem of DNNs Recognition Smart Drone AI Computation DNN 15k 300k OP/Px DPM 0.1k
How to Estimate the Energy Consumption of Deep Neural Networks Tien-Ju Yang, Yu-Hsin Chen, Joel Emer, Vivienne Sze MIT 1 Problem of DNNs Recognition Smart Drone AI Computation DNN 15k 300k OP/Px DPM 0.1k
Hello Edge: Keyword Spotting on Microcontrollers
 Hello Edge: Keyword Spotting on Microcontrollers Yundong Zhang, Naveen Suda, Liangzhen Lai and Vikas Chandra ARM Research, Stanford University arxiv.org, 2017 Presented by Mohammad Mofrad University of
Hello Edge: Keyword Spotting on Microcontrollers Yundong Zhang, Naveen Suda, Liangzhen Lai and Vikas Chandra ARM Research, Stanford University arxiv.org, 2017 Presented by Mohammad Mofrad University of
DNNBuilder: an Automated Tool for Building High-Performance DNN Hardware Accelerators for FPGAs
 IBM Research AI Systems Day DNNBuilder: an Automated Tool for Building High-Performance DNN Hardware Accelerators for FPGAs Xiaofan Zhang 1, Junsong Wang 2, Chao Zhu 2, Yonghua Lin 2, Jinjun Xiong 3, Wen-mei
IBM Research AI Systems Day DNNBuilder: an Automated Tool for Building High-Performance DNN Hardware Accelerators for FPGAs Xiaofan Zhang 1, Junsong Wang 2, Chao Zhu 2, Yonghua Lin 2, Jinjun Xiong 3, Wen-mei
Index. Springer Nature Switzerland AG 2019 B. Moons et al., Embedded Deep Learning,
 Index A Algorithmic noise tolerance (ANT), 93 94 Application specific instruction set processors (ASIPs), 115 116 Approximate computing application level, 95 circuits-levels, 93 94 DAS and DVAS, 107 110
Index A Algorithmic noise tolerance (ANT), 93 94 Application specific instruction set processors (ASIPs), 115 116 Approximate computing application level, 95 circuits-levels, 93 94 DAS and DVAS, 107 110
Arm s First-Generation Machine Learning Processor
 Arm s First-Generation Machine Learning Processor Ian Bratt 2018 Arm Limited Introducing the Arm Machine Learning (ML) Processor Optimized ground-up architecture for machine learning processing Massive
Arm s First-Generation Machine Learning Processor Ian Bratt 2018 Arm Limited Introducing the Arm Machine Learning (ML) Processor Optimized ground-up architecture for machine learning processing Massive
Research Faculty Summit Systems Fueling future disruptions
 Research Faculty Summit 2018 Systems Fueling future disruptions Efficient Edge Computing for Deep Neural Networks and Beyond Vivienne Sze In collaboration with Yu-Hsin Chen, Joel Emer, Tien-Ju Yang, Sertac
Research Faculty Summit 2018 Systems Fueling future disruptions Efficient Edge Computing for Deep Neural Networks and Beyond Vivienne Sze In collaboration with Yu-Hsin Chen, Joel Emer, Tien-Ju Yang, Sertac
Computer Architectures for Deep Learning. Ethan Dell and Daniyal Iqbal
 Computer Architectures for Deep Learning Ethan Dell and Daniyal Iqbal Agenda Introduction to Deep Learning Challenges Architectural Solutions Hardware Architectures CPUs GPUs Accelerators FPGAs SOCs ASICs
Computer Architectures for Deep Learning Ethan Dell and Daniyal Iqbal Agenda Introduction to Deep Learning Challenges Architectural Solutions Hardware Architectures CPUs GPUs Accelerators FPGAs SOCs ASICs
Versal: AI Engine & Programming Environment
 Engineering Director, Xilinx Silicon Architecture Group Versal: Engine & Programming Environment Presented By Ambrose Finnerty Xilinx DSP Technical Marketing Manager October 16, 2018 MEMORY MEMORY MEMORY
Engineering Director, Xilinx Silicon Architecture Group Versal: Engine & Programming Environment Presented By Ambrose Finnerty Xilinx DSP Technical Marketing Manager October 16, 2018 MEMORY MEMORY MEMORY
Deep Learning on Arm Cortex-M Microcontrollers. Rod Crawford Director Software Technologies, Arm
 Deep Learning on Arm Cortex-M Microcontrollers Rod Crawford Director Software Technologies, Arm What is Machine Learning (ML)? Artificial Intelligence Machine Learning Deep Learning Neural Networks Additional
Deep Learning on Arm Cortex-M Microcontrollers Rod Crawford Director Software Technologies, Arm What is Machine Learning (ML)? Artificial Intelligence Machine Learning Deep Learning Neural Networks Additional
Towards a Uniform Template-based Architecture for Accelerating 2D and 3D CNNs on FPGA
 Towards a Uniform Template-based Architecture for Accelerating 2D and 3D CNNs on FPGA Junzhong Shen, You Huang, Zelong Wang, Yuran Qiao, Mei Wen, Chunyuan Zhang National University of Defense Technology,
Towards a Uniform Template-based Architecture for Accelerating 2D and 3D CNNs on FPGA Junzhong Shen, You Huang, Zelong Wang, Yuran Qiao, Mei Wen, Chunyuan Zhang National University of Defense Technology,
Maximizing Server Efficiency from μarch to ML accelerators. Michael Ferdman
 Maximizing Server Efficiency from μarch to ML accelerators Michael Ferdman Maximizing Server Efficiency from μarch to ML accelerators Michael Ferdman Maximizing Server Efficiency with ML accelerators Michael
Maximizing Server Efficiency from μarch to ML accelerators Michael Ferdman Maximizing Server Efficiency from μarch to ML accelerators Michael Ferdman Maximizing Server Efficiency with ML accelerators Michael
Throughput-Optimized OpenCL-based FPGA Accelerator for Large-Scale Convolutional Neural Networks
 Throughput-Optimized OpenCL-based FPGA Accelerator for Large-Scale Convolutional Neural Networks Naveen Suda, Vikas Chandra *, Ganesh Dasika *, Abinash Mohanty, Yufei Ma, Sarma Vrudhula, Jae-sun Seo, Yu
Throughput-Optimized OpenCL-based FPGA Accelerator for Large-Scale Convolutional Neural Networks Naveen Suda, Vikas Chandra *, Ganesh Dasika *, Abinash Mohanty, Yufei Ma, Sarma Vrudhula, Jae-sun Seo, Yu
Exploiting Hidden Layer Modular Redundancy for Fault-Tolerance in Neural Network Accelerators
 Exploiting Hidden Layer Modular Redundancy for Fault-Tolerance in Neural Network Accelerators Schuyler Eldridge Ajay Joshi Department of Electrical and Computer Engineering, Boston University schuye@bu.edu
Exploiting Hidden Layer Modular Redundancy for Fault-Tolerance in Neural Network Accelerators Schuyler Eldridge Ajay Joshi Department of Electrical and Computer Engineering, Boston University schuye@bu.edu
TETRIS: Scalable and Efficient Neural Network Acceleration with 3D Memory
 TETRIS: Scalable and Efficient Neural Network Acceleration with 3D Memory Mingyu Gao, Jing Pu, Xuan Yang, Mark Horowitz, Christos Kozyrakis Stanford University Platform Lab Review Feb 2017 Deep Neural
TETRIS: Scalable and Efficient Neural Network Acceleration with 3D Memory Mingyu Gao, Jing Pu, Xuan Yang, Mark Horowitz, Christos Kozyrakis Stanford University Platform Lab Review Feb 2017 Deep Neural
Session 14 Overview: Deep-Learning Processors
 ISSCC 2017 / SESSION 14 / DEEP-LEARNING PROCESSORS / OVERVIEW Session 14 Overview: Deep-Learning Processors DIGITAL ARCHITECTURE AND SYSTEMS SUBCOMMITTEE Session Chair: Takashi Hashimoto, Panasonic, Osaka,
ISSCC 2017 / SESSION 14 / DEEP-LEARNING PROCESSORS / OVERVIEW Session 14 Overview: Deep-Learning Processors DIGITAL ARCHITECTURE AND SYSTEMS SUBCOMMITTEE Session Chair: Takashi Hashimoto, Panasonic, Osaka,
Bandwidth-Centric Deep Learning Processing through Software-Hardware Co-Design
 Bandwidth-Centric Deep Learning Processing through Software-Hardware Co-Design Song Yao 姚颂 Founder & CEO DeePhi Tech 深鉴科技 song.yao@deephi.tech Outline - About DeePhi Tech - Background - Bandwidth Matters
Bandwidth-Centric Deep Learning Processing through Software-Hardware Co-Design Song Yao 姚颂 Founder & CEO DeePhi Tech 深鉴科技 song.yao@deephi.tech Outline - About DeePhi Tech - Background - Bandwidth Matters
FINN: A Framework for Fast, Scalable Binarized Neural Network Inference
 FINN: A Framework for Fast, Scalable Binarized Neural Network Inference Yaman Umuroglu (XIR & NTNU), Nick Fraser (XIR & USydney), Giulio Gambardella (XIR), Michaela Blott (XIR), Philip Leong (USydney),
FINN: A Framework for Fast, Scalable Binarized Neural Network Inference Yaman Umuroglu (XIR & NTNU), Nick Fraser (XIR & USydney), Giulio Gambardella (XIR), Michaela Blott (XIR), Philip Leong (USydney),
Brainchip OCTOBER
 Brainchip OCTOBER 2017 1 Agenda Neuromorphic computing background Akida Neuromorphic System-on-Chip (NSoC) Brainchip OCTOBER 2017 2 Neuromorphic Computing Background Brainchip OCTOBER 2017 3 A Brief History
Brainchip OCTOBER 2017 1 Agenda Neuromorphic computing background Akida Neuromorphic System-on-Chip (NSoC) Brainchip OCTOBER 2017 2 Neuromorphic Computing Background Brainchip OCTOBER 2017 3 A Brief History
Accelerating Binarized Convolutional Neural Networks with Software-Programmable FPGAs
 Accelerating Binarized Convolutional Neural Networks with Software-Programmable FPGAs Ritchie Zhao 1, Weinan Song 2, Wentao Zhang 2, Tianwei Xing 3, Jeng-Hau Lin 4, Mani Srivastava 3, Rajesh Gupta 4, Zhiru
Accelerating Binarized Convolutional Neural Networks with Software-Programmable FPGAs Ritchie Zhao 1, Weinan Song 2, Wentao Zhang 2, Tianwei Xing 3, Jeng-Hau Lin 4, Mani Srivastava 3, Rajesh Gupta 4, Zhiru
Scalable and Modularized RTL Compilation of Convolutional Neural Networks onto FPGA
 Scalable and Modularized RTL Compilation of Convolutional Neural Networks onto FPGA Yufei Ma, Naveen Suda, Yu Cao, Jae-sun Seo, Sarma Vrudhula School of Electrical, Computer and Energy Engineering School
Scalable and Modularized RTL Compilation of Convolutional Neural Networks onto FPGA Yufei Ma, Naveen Suda, Yu Cao, Jae-sun Seo, Sarma Vrudhula School of Electrical, Computer and Energy Engineering School
ComPEND: Computation Pruning through Early Negative Detection for ReLU in a Deep Neural Network Accelerator
 ICS 28 ComPEND: Computation Pruning through Early Negative Detection for ReLU in a Deep Neural Network Accelerator June 3, 28 Dongwoo Lee, Sungbum Kang, Kiyoung Choi Neural Processing Research Center (NPRC)
ICS 28 ComPEND: Computation Pruning through Early Negative Detection for ReLU in a Deep Neural Network Accelerator June 3, 28 Dongwoo Lee, Sungbum Kang, Kiyoung Choi Neural Processing Research Center (NPRC)
Implementing Long-term Recurrent Convolutional Network Using HLS on POWER System
 Implementing Long-term Recurrent Convolutional Network Using HLS on POWER System Xiaofan Zhang1, Mohamed El Hadedy1, Wen-mei Hwu1, Nam Sung Kim1, Jinjun Xiong2, Deming Chen1 1 University of Illinois Urbana-Champaign
Implementing Long-term Recurrent Convolutional Network Using HLS on POWER System Xiaofan Zhang1, Mohamed El Hadedy1, Wen-mei Hwu1, Nam Sung Kim1, Jinjun Xiong2, Deming Chen1 1 University of Illinois Urbana-Champaign
A 167-processor Computational Array for Highly-Efficient DSP and Embedded Application Processing
 A 167-processor Computational Array for Highly-Efficient DSP and Embedded Application Processing Dean Truong, Wayne Cheng, Tinoosh Mohsenin, Zhiyi Yu, Toney Jacobson, Gouri Landge, Michael Meeuwsen, Christine
A 167-processor Computational Array for Highly-Efficient DSP and Embedded Application Processing Dean Truong, Wayne Cheng, Tinoosh Mohsenin, Zhiyi Yu, Toney Jacobson, Gouri Landge, Michael Meeuwsen, Christine
Versal: The New Xilinx Adaptive Compute Acceleration Platform (ACAP) in 7nm
 in 7nm") Engineering Director, Xilinx Silicon Architecture Group Versal: The New Xilinx Adaptive Compute Acceleration Platform (ACAP) in 7nm Presented By Kees Vissers Fellow February 25, FPGA 2019 Technology scaling
Engineering Director, Xilinx Silicon Architecture Group Versal: The New Xilinx Adaptive Compute Acceleration Platform (ACAP) in 7nm Presented By Kees Vissers Fellow February 25, FPGA 2019 Technology scaling
High Performance Computing
 High Performance Computing 9th Lecture 2016/10/28 YUKI ITO 1 Selected Paper: vdnn: Virtualized Deep Neural Networks for Scalable, MemoryEfficient Neural Network Design Minsoo Rhu, Natalia Gimelshein, Jason
High Performance Computing 9th Lecture 2016/10/28 YUKI ITO 1 Selected Paper: vdnn: Virtualized Deep Neural Networks for Scalable, MemoryEfficient Neural Network Design Minsoo Rhu, Natalia Gimelshein, Jason
Deep Learning Accelerators
 Deep Learning Accelerators Abhishek Srivastava (as29) Samarth Kulshreshtha (samarth5) University of Illinois, Urbana-Champaign Submitted as a requirement for CS 433 graduate student project Outline Introduction
Deep Learning Accelerators Abhishek Srivastava (as29) Samarth Kulshreshtha (samarth5) University of Illinois, Urbana-Champaign Submitted as a requirement for CS 433 graduate student project Outline Introduction
Can FPGAs beat GPUs in accelerating next-generation Deep Neural Networks? Discussion of the FPGA 17 paper by Intel Corp. (Nurvitadhi et al.
 Can FPGAs beat GPUs in accelerating next-generation Deep Neural Networks? Discussion of the FPGA 17 paper by Intel Corp. (Nurvitadhi et al.) Andreas Kurth 2017-12-05 1 In short: The situation Image credit:
Can FPGAs beat GPUs in accelerating next-generation Deep Neural Networks? Discussion of the FPGA 17 paper by Intel Corp. (Nurvitadhi et al.) Andreas Kurth 2017-12-05 1 In short: The situation Image credit:
High Capacity and High Performance 20nm FPGAs. Steve Young, Dinesh Gaitonde August Copyright 2014 Xilinx
 High Capacity and High Performance 20nm FPGAs Steve Young, Dinesh Gaitonde August 2014 Not a Complete Product Overview Page 2 Outline Page 3 Petabytes per month Increasing Bandwidth Global IP Traffic Growth
High Capacity and High Performance 20nm FPGAs Steve Young, Dinesh Gaitonde August 2014 Not a Complete Product Overview Page 2 Outline Page 3 Petabytes per month Increasing Bandwidth Global IP Traffic Growth
Xilinx DNN Processor An Inference Engine, Network Compiler + Runtime for Xilinx FPGAs
 ilinx DNN Proceor An Inference Engine, Network Compiler Runtime for ilinx FPGA Rahul Nimaiyar, Brian Sun, Victor Wu, Thoma Branca, Yi Wang, Jutin Oo, Elliott Delaye, Aaron Ng, Paolo D'Alberto, Sean Settle,
ilinx DNN Proceor An Inference Engine, Network Compiler Runtime for ilinx FPGA Rahul Nimaiyar, Brian Sun, Victor Wu, Thoma Branca, Yi Wang, Jutin Oo, Elliott Delaye, Aaron Ng, Paolo D'Alberto, Sean Settle,
Tutorial Outline. 9:00 am 10:00 am Pre-RTL Simulation Framework: Aladdin. 8:30 am 9:00 am! Introduction! 10:00 am 10:30 am! Break!
 Tutorial Outline Time Topic! 8:30 am 9:00 am! Introduction! 9:00 am 10:00 am Pre-RTL Simulation Framework: Aladdin 10:00 am 10:30 am! Break! 10:30 am 11:00 am! Workload Characterization Tool: WIICA! 11:00
Tutorial Outline Time Topic! 8:30 am 9:00 am! Introduction! 9:00 am 10:00 am Pre-RTL Simulation Framework: Aladdin 10:00 am 10:30 am! Break! 10:30 am 11:00 am! Workload Characterization Tool: WIICA! 11:00
Processor Architectures At A Glance: M.I.T. Raw vs. UC Davis AsAP
 Processor Architectures At A Glance: M.I.T. Raw vs. UC Davis AsAP Presenter: Course: EEC 289Q: Reconfigurable Computing Course Instructor: Professor Soheil Ghiasi Outline Overview of M.I.T. Raw processor
Processor Architectures At A Glance: M.I.T. Raw vs. UC Davis AsAP Presenter: Course: EEC 289Q: Reconfigurable Computing Course Instructor: Professor Soheil Ghiasi Outline Overview of M.I.T. Raw processor
Frequency Domain Acceleration of Convolutional Neural Networks on CPU-FPGA Shared Memory System
 Frequency Domain Acceleration of Convolutional Neural Networks on CPU-FPGA Shared Memory System Chi Zhang, Viktor K Prasanna University of Southern California {zhan527, prasanna}@usc.edu fpga.usc.edu ACM
Frequency Domain Acceleration of Convolutional Neural Networks on CPU-FPGA Shared Memory System Chi Zhang, Viktor K Prasanna University of Southern California {zhan527, prasanna}@usc.edu fpga.usc.edu ACM
Xilinx ML Suite Overview
 Xilinx ML Suite Overview Yao Fu System Architect Data Center Acceleration Xilinx Accelerated Computing Workloads Machine Learning Inference Image classification and object detection Video Streaming Frame
Xilinx ML Suite Overview Yao Fu System Architect Data Center Acceleration Xilinx Accelerated Computing Workloads Machine Learning Inference Image classification and object detection Video Streaming Frame
SDA: Software-Defined Accelerator for Large- Scale DNN Systems
 SDA: Software-Defined Accelerator for Large- Scale DNN Systems Jian Ouyang, 1 Shiding Lin, 1 Wei Qi, Yong Wang, Bo Yu, Song Jiang, 2 1 Baidu, Inc. 2 Wayne State University Introduction of Baidu A dominant
SDA: Software-Defined Accelerator for Large- Scale DNN Systems Jian Ouyang, 1 Shiding Lin, 1 Wei Qi, Yong Wang, Bo Yu, Song Jiang, 2 1 Baidu, Inc. 2 Wayne State University Introduction of Baidu A dominant
Deep Learning with Intel DAAL
 Deep Learning with Intel DAAL on Knights Landing Processor David Ojika dave.n.ojika@cern.ch March 22, 2017 Outline Introduction and Motivation Intel Knights Landing Processor Intel Data Analytics and Acceleration
Deep Learning with Intel DAAL on Knights Landing Processor David Ojika dave.n.ojika@cern.ch March 22, 2017 Outline Introduction and Motivation Intel Knights Landing Processor Intel Data Analytics and Acceleration
Deep ST, Ultra Low Power Artificial Neural Network SOC in 28 FD-SOI. Nitin Chawla,
 Deep learning @ ST, Ultra Low Power Artificial Neural Network SOC in 28 FD-SOI Nitin Chawla, Senior Principal Engineer and Senior Member of Technical Staff at STMicroelectronics Outline Introduction Chip
Deep learning @ ST, Ultra Low Power Artificial Neural Network SOC in 28 FD-SOI Nitin Chawla, Senior Principal Engineer and Senior Member of Technical Staff at STMicroelectronics Outline Introduction Chip
arxiv: v1 [cs.cv] 11 Feb 2018
![arxiv: v1 [cs.cv] 11 Feb 2018](/thumbs/79/79222664.jpg "arxiv: v1 [cs.cv] 11 Feb 2018") arxiv:8.8v [cs.cv] Feb 8 - Partitioning of Deep Neural Networks with Feature Space Encoding for Resource-Constrained Internet-of-Things Platforms ABSTRACT Jong Hwan Ko, Taesik Na, Mohammad Faisal Amir,
arxiv:8.8v [cs.cv] Feb 8 - Partitioning of Deep Neural Networks with Feature Space Encoding for Resource-Constrained Internet-of-Things Platforms ABSTRACT Jong Hwan Ko, Taesik Na, Mohammad Faisal Amir,
Two FPGA-DNN Projects: 1. Low Latency Multi-Layer Perceptrons using FPGAs 2. Acceleration of CNN Training on FPGA-based Clusters
 Two FPGA-DNN Projects: 1. Low Latency Multi-Layer Perceptrons using FPGAs 2. Acceleration of CNN Training on FPGA-based Clusters *Argonne National Lab +BU & USTC Presented by Martin Herbordt Work by Ahmed
Two FPGA-DNN Projects: 1. Low Latency Multi-Layer Perceptrons using FPGAs 2. Acceleration of CNN Training on FPGA-based Clusters *Argonne National Lab +BU & USTC Presented by Martin Herbordt Work by Ahmed
Small is the New Big: Data Analytics on the Edge
 Small is the New Big: Data Analytics on the Edge An overview of processors and algorithms for deep learning techniques on the edge Dr. Abhay Samant VP Engineering, Hiller Measurements Adjunct Faculty,
Small is the New Big: Data Analytics on the Edge An overview of processors and algorithms for deep learning techniques on the edge Dr. Abhay Samant VP Engineering, Hiller Measurements Adjunct Faculty,
SDA: Software-Defined Accelerator for Large- Scale DNN Systems
 SDA: Software-Defined Accelerator for Large- Scale DNN Systems Jian Ouyang, 1 Shiding Lin, 1 Wei Qi, 1 Yong Wang, 1 Bo Yu, 1 Song Jiang, 2 1 Baidu, Inc. 2 Wayne State University Introduction of Baidu A
SDA: Software-Defined Accelerator for Large- Scale DNN Systems Jian Ouyang, 1 Shiding Lin, 1 Wei Qi, 1 Yong Wang, 1 Bo Yu, 1 Song Jiang, 2 1 Baidu, Inc. 2 Wayne State University Introduction of Baidu A
Deep Learning Hardware Acceleration
 * Deep Learning Hardware Acceleration Jorge Albericio + Alberto Delmas Lascorz Patrick Judd Sayeh Sharify Tayler Hetherington* Natalie Enright Jerger Tor Aamodt* + now at NVIDIA Andreas Moshovos Disclaimer
* Deep Learning Hardware Acceleration Jorge Albericio + Alberto Delmas Lascorz Patrick Judd Sayeh Sharify Tayler Hetherington* Natalie Enright Jerger Tor Aamodt* + now at NVIDIA Andreas Moshovos Disclaimer
New STM32 F7 Series. World s 1 st to market, ARM Cortex -M7 based 32-bit MCU
 New STM32 F7 Series World s 1 st to market, ARM Cortex -M7 based 32-bit MCU 7 Keys of STM32 F7 series 2 1 2 3 4 5 6 7 First. ST is first to sample a fully functional Cortex-M7 based 32-bit MCU : STM32
New STM32 F7 Series World s 1 st to market, ARM Cortex -M7 based 32-bit MCU 7 Keys of STM32 F7 series 2 1 2 3 4 5 6 7 First. ST is first to sample a fully functional Cortex-M7 based 32-bit MCU : STM32
Multimedia in Mobile Phones. Architectures and Trends Lund
 Multimedia in Mobile Phones Architectures and Trends Lund 091124 Presentation Henrik Ohlsson Contact: henrik.h.ohlsson@stericsson.com Working with multimedia hardware (graphics and displays) at ST- Ericsson
Multimedia in Mobile Phones Architectures and Trends Lund 091124 Presentation Henrik Ohlsson Contact: henrik.h.ohlsson@stericsson.com Working with multimedia hardware (graphics and displays) at ST- Ericsson
Neural Computer Architectures
 Neural Computer Architectures 5kk73 Embedded Computer Architecture By: Maurice Peemen Date: Convergence of different domains Neurobiology Applications 1 Constraints Machine Learning Technology Innovations
Neural Computer Architectures 5kk73 Embedded Computer Architecture By: Maurice Peemen Date: Convergence of different domains Neurobiology Applications 1 Constraints Machine Learning Technology Innovations
Gables: A Roofline Model for Mobile SoCs
 Gables: A Roofline Model for Mobile SoCs Mark D. Hill, Wisconsin & Former Google Intern Vijay Janapa Reddi, Harvard & Former Google Intern HPCA, Feb 2019 Outline Motivation Gables Model Example Balanced
Gables: A Roofline Model for Mobile SoCs Mark D. Hill, Wisconsin & Former Google Intern Vijay Janapa Reddi, Harvard & Former Google Intern HPCA, Feb 2019 Outline Motivation Gables Model Example Balanced
Eyeriss: A Spatial Architecture for Energy-Efficient Dataflow for Convolutional Neural Networks
 Eyeriss: A Spatial Architecture for Energy-Efficient Dataflow for Convolutional Neural Networks Yu-Hsin Chen 1, Joel Emer 1, 2, Vivienne Sze 1 1 MIT 2 NVIDIA 1 Contributions of This Work A novel energy-efficient
Eyeriss: A Spatial Architecture for Energy-Efficient Dataflow for Convolutional Neural Networks Yu-Hsin Chen 1, Joel Emer 1, 2, Vivienne Sze 1 1 MIT 2 NVIDIA 1 Contributions of This Work A novel energy-efficient
arxiv: v1 [cs.ne] 20 Nov 2017
![arxiv: v1 [cs.ne] 20 Nov 2017](/thumbs/83/87871407.jpg "arxiv: v1 [cs.ne] 20 Nov 2017") E-PUR: An Energy-Efficient Processing Unit for Recurrent Neural Networks arxiv:1711.748v1 [cs.ne] 2 Nov 217 ABSTRACT Franyell Silfa, Gem Dot, Jose-Maria Arnau, Antonio Gonzalez Computer Architecture Deparment,
E-PUR: An Energy-Efficient Processing Unit for Recurrent Neural Networks arxiv:1711.748v1 [cs.ne] 2 Nov 217 ABSTRACT Franyell Silfa, Gem Dot, Jose-Maria Arnau, Antonio Gonzalez Computer Architecture Deparment,
M.Tech Student, Department of ECE, S.V. College of Engineering, Tirupati, India
 International Journal of Scientific Research in Computer Science, Engineering and Information Technology 2018 IJSRCSEIT Volume 3 Issue 5 ISSN : 2456-3307 High Performance Scalable Deep Learning Accelerator
International Journal of Scientific Research in Computer Science, Engineering and Information Technology 2018 IJSRCSEIT Volume 3 Issue 5 ISSN : 2456-3307 High Performance Scalable Deep Learning Accelerator
Intelligent Hybrid Flash Management
 Intelligent Hybrid Flash Management Jérôme Gaysse Senior Technology&Market Analyst jerome.gaysse@silinnov-consulting.com Flash Memory Summit 2018 Santa Clara, CA 1 Research context Analysis of system &
Intelligent Hybrid Flash Management Jérôme Gaysse Senior Technology&Market Analyst jerome.gaysse@silinnov-consulting.com Flash Memory Summit 2018 Santa Clara, CA 1 Research context Analysis of system &
Low-Power Neural Processor for Embedded Human and Face detection
 Low-Power Neural Processor for Embedded Human and Face detection Olivier Brousse 1, Olivier Boisard 1, Michel Paindavoine 1,2, Jean-Marc Philippe, Alexandre Carbon (1) GlobalSensing Technologies (GST)
Low-Power Neural Processor for Embedded Human and Face detection Olivier Brousse 1, Olivier Boisard 1, Michel Paindavoine 1,2, Jean-Marc Philippe, Alexandre Carbon (1) GlobalSensing Technologies (GST)
Adaptable Intelligence The Next Computing Era
 Adaptable Intelligence The Next Computing Era Hot Chips, August 21, 2018 Victor Peng, CEO, Xilinx Pervasive Intelligence from Cloud to Edge to Endpoints >> 1 Exponential Growth and Opportunities Data Explosion
Adaptable Intelligence The Next Computing Era Hot Chips, August 21, 2018 Victor Peng, CEO, Xilinx Pervasive Intelligence from Cloud to Edge to Endpoints >> 1 Exponential Growth and Opportunities Data Explosion
Chapter 5. Introduction ARM Cortex series
 Chapter 5 Introduction ARM Cortex series 5.1 ARM Cortex series variants 5.2 ARM Cortex A series 5.3 ARM Cortex R series 5.4 ARM Cortex M series 5.5 Comparison of Cortex M series with 8/16 bit MCUs 51 5.1
Chapter 5 Introduction ARM Cortex series 5.1 ARM Cortex series variants 5.2 ARM Cortex A series 5.3 ARM Cortex R series 5.4 ARM Cortex M series 5.5 Comparison of Cortex M series with 8/16 bit MCUs 51 5.1
Scalpel: Customizing DNN Pruning to the Underlying Hardware Parallelism
 Scalpel: Customizing DNN Pruning to the Underlying Hardware Parallelism Jiecao Yu 1, Andrew Lukefahr 1, David Palframan 2, Ganesh Dasika 2, Reetuparna Das 1, Scott Mahlke 1 1 University of Michigan 2 ARM
Scalpel: Customizing DNN Pruning to the Underlying Hardware Parallelism Jiecao Yu 1, Andrew Lukefahr 1, David Palframan 2, Ganesh Dasika 2, Reetuparna Das 1, Scott Mahlke 1 1 University of Michigan 2 ARM
The Memory Hierarchy & Cache Review of Memory Hierarchy & Cache Basics (from 350):
:") The Memory Hierarchy & Cache Review of Memory Hierarchy & Cache Basics (from 350): Motivation for The Memory Hierarchy: { CPU/Memory Performance Gap The Principle Of Locality Cache $$$$$ Cache Basics:
The Memory Hierarchy & Cache Review of Memory Hierarchy & Cache Basics (from 350): Motivation for The Memory Hierarchy: { CPU/Memory Performance Gap The Principle Of Locality Cache $$$$$ Cache Basics:
Scaling Convolutional Neural Networks on Reconfigurable Logic Michaela Blott, Principal Engineer, Xilinx Research
 Scaling Convolutional Neural Networks on Reconfigurable Logic Michaela Blott, Principal Engineer, Xilinx Research Nick Fraser (Xilinx & USydney) Yaman Umuroglu (Xilinx & NTNU) Giulio Gambardella (Xilinx)
Scaling Convolutional Neural Networks on Reconfigurable Logic Michaela Blott, Principal Engineer, Xilinx Research Nick Fraser (Xilinx & USydney) Yaman Umuroglu (Xilinx & NTNU) Giulio Gambardella (Xilinx)
An introduction to Machine Learning silicon
 An introduction to Machine Learning silicon November 28 2017 Insight for Technology Investors AI/ML terminology Artificial Intelligence Machine Learning Deep Learning Algorithms: CNNs, RNNs, etc. Additional
An introduction to Machine Learning silicon November 28 2017 Insight for Technology Investors AI/ML terminology Artificial Intelligence Machine Learning Deep Learning Algorithms: CNNs, RNNs, etc. Additional
BHNN: a Memory-Efficient Accelerator for Compressing Deep Neural Network with Blocked Hashing Techniques
 BHNN: a Memory-Efficient Accelerator for Compressing Deep Neural Network with Blocked Hashing Techniques Jingyang Zhu 1, Zhiliang Qian 2*, and Chi-Ying Tsui 1 1 The Hong Kong University of Science and
BHNN: a Memory-Efficient Accelerator for Compressing Deep Neural Network with Blocked Hashing Techniques Jingyang Zhu 1, Zhiliang Qian 2*, and Chi-Ying Tsui 1 1 The Hong Kong University of Science and
Outline Marquette University
 COEN-4710 Computer Hardware Lecture 1 Computer Abstractions and Technology (Ch.1) Cristinel Ababei Department of Electrical and Computer Engineering Credits: Slides adapted primarily from presentations
COEN-4710 Computer Hardware Lecture 1 Computer Abstractions and Technology (Ch.1) Cristinel Ababei Department of Electrical and Computer Engineering Credits: Slides adapted primarily from presentations
Introduction to Neural Networks
 ECE 5775 (Fall 17) High-Level Digital Design Automation Introduction to Neural Networks Ritchie Zhao, Zhiru Zhang School of Electrical and Computer Engineering Rise of the Machines Neural networks have
ECE 5775 (Fall 17) High-Level Digital Design Automation Introduction to Neural Networks Ritchie Zhao, Zhiru Zhang School of Electrical and Computer Engineering Rise of the Machines Neural networks have
KiloCore: A 32 nm 1000-Processor Array
 KiloCore: A 32 nm 1000-Processor Array Brent Bohnenstiehl, Aaron Stillmaker, Jon Pimentel, Timothy Andreas, Bin Liu, Anh Tran, Emmanuel Adeagbo, Bevan Baas University of California, Davis VLSI Computation
KiloCore: A 32 nm 1000-Processor Array Brent Bohnenstiehl, Aaron Stillmaker, Jon Pimentel, Timothy Andreas, Bin Liu, Anh Tran, Emmanuel Adeagbo, Bevan Baas University of California, Davis VLSI Computation
The Explosion in Neural Network Hardware
 1 The Explosion in Neural Network Hardware Arm Summit, Cambridge, September 17 th, 2018 Trevor Mudge Bredt Family Professor of Computer Science and Engineering The, Ann Arbor 1 What Just Happened? 2 For
1 The Explosion in Neural Network Hardware Arm Summit, Cambridge, September 17 th, 2018 Trevor Mudge Bredt Family Professor of Computer Science and Engineering The, Ann Arbor 1 What Just Happened? 2 For
FINN: A Framework for Fast, Scalable Binarized Neural Network Inference
 FINN: A Framework for Fast, Scalable Binarized Neural Network Inference Yaman Umuroglu (NTNU & Xilinx Research Labs Ireland) in collaboration with N Fraser, G Gambardella, M Blott, P Leong, M Jahre and
FINN: A Framework for Fast, Scalable Binarized Neural Network Inference Yaman Umuroglu (NTNU & Xilinx Research Labs Ireland) in collaboration with N Fraser, G Gambardella, M Blott, P Leong, M Jahre and
DEEP LEARNING ACCELERATOR UNIT WITH HIGH EFFICIENCY ON FPGA
 DEEP LEARNING ACCELERATOR UNIT WITH HIGH EFFICIENCY ON FPGA J.Jayalakshmi 1, S.Ali Asgar 2, V.Thrimurthulu 3 1 M.tech Student, Department of ECE, Chadalawada Ramanamma Engineering College, Tirupati Email
DEEP LEARNING ACCELERATOR UNIT WITH HIGH EFFICIENCY ON FPGA J.Jayalakshmi 1, S.Ali Asgar 2, V.Thrimurthulu 3 1 M.tech Student, Department of ECE, Chadalawada Ramanamma Engineering College, Tirupati Email
Lab 4: Convolutional Neural Networks Due Friday, November 3, 2017, 11:59pm
 ECE5775 High-Level Digital Design Automation, Fall 2017 School of Electrical Computer Engineering, Cornell University Lab 4: Convolutional Neural Networks Due Friday, November 3, 2017, 11:59pm 1 Introduction
ECE5775 High-Level Digital Design Automation, Fall 2017 School of Electrical Computer Engineering, Cornell University Lab 4: Convolutional Neural Networks Due Friday, November 3, 2017, 11:59pm 1 Introduction
DNN Accelerator Architectures
 DNN Accelerator Architectures ISCA Tutorial (2017) Website: http://eyeriss.mit.edu/tutorial.html Joel Emer, Vivienne Sze, Yu-Hsin Chen 1 2 Highly-Parallel Compute Paradigms Temporal Architecture (SIMD/SIMT)
DNN Accelerator Architectures ISCA Tutorial (2017) Website: http://eyeriss.mit.edu/tutorial.html Joel Emer, Vivienne Sze, Yu-Hsin Chen 1 2 Highly-Parallel Compute Paradigms Temporal Architecture (SIMD/SIMT)
Implementation of Deep Convolutional Neural Net on a Digital Signal Processor
 Implementation of Deep Convolutional Neural Net on a Digital Signal Processor Elaina Chai December 12, 2014 1. Abstract In this paper I will discuss the feasibility of an implementation of an algorithm
Implementation of Deep Convolutional Neural Net on a Digital Signal Processor Elaina Chai December 12, 2014 1. Abstract In this paper I will discuss the feasibility of an implementation of an algorithm
Deep Learning on Modern Architectures. Keren Zhou 4/17/2017
 Deep Learning on Modern Architectures Keren Zhou 4/17/2017 HPC Software Stack Application Algorithm Data Layout CPU GPU MIC Others HPC Software Stack Deep Learning Algorithm Data Layout CPU GPU MIC Others
Deep Learning on Modern Architectures Keren Zhou 4/17/2017 HPC Software Stack Application Algorithm Data Layout CPU GPU MIC Others HPC Software Stack Deep Learning Algorithm Data Layout CPU GPU MIC Others
Multi-dimensional Parallel Training of Winograd Layer on Memory-Centric Architecture
 The 51st Annual IEEE/ACM International Symposium on Microarchitecture Multi-dimensional Parallel Training of Winograd Layer on Memory-Centric Architecture Byungchul Hong Yeonju Ro John Kim FuriosaAI Samsung
The 51st Annual IEEE/ACM International Symposium on Microarchitecture Multi-dimensional Parallel Training of Winograd Layer on Memory-Centric Architecture Byungchul Hong Yeonju Ro John Kim FuriosaAI Samsung
A Lightweight YOLOv2:
 FPGA2018 @Monterey A Lightweight YOLOv2: A Binarized CNN with a Parallel Support Vector Regression for an FPGA Hiroki Nakahara, Haruyoshi Yonekawa, Tomoya Fujii, Shimpei Sato Tokyo Institute of Technology,
FPGA2018 @Monterey A Lightweight YOLOv2: A Binarized CNN with a Parallel Support Vector Regression for an FPGA Hiroki Nakahara, Haruyoshi Yonekawa, Tomoya Fujii, Shimpei Sato Tokyo Institute of Technology,
Exploiting the OpenPOWER Platform for Big Data Analytics and Cognitive. Rajesh Bordawekar and Ruchir Puri IBM T. J. Watson Research Center
 Exploiting the OpenPOWER Platform for Big Data Analytics and Cognitive Rajesh Bordawekar and Ruchir Puri IBM T. J. Watson Research Center 3/17/2015 2014 IBM Corporation Outline IBM OpenPower Platform Accelerating
Exploiting the OpenPOWER Platform for Big Data Analytics and Cognitive Rajesh Bordawekar and Ruchir Puri IBM T. J. Watson Research Center 3/17/2015 2014 IBM Corporation Outline IBM OpenPower Platform Accelerating
Accelerating Convolutional Neural Nets. Yunming Zhang
 Accelerating Convolutional Neural Nets Yunming Zhang Focus Convolutional Neural Nets is the state of the art in classifying the images The models take days to train Difficult for the programmers to tune
Accelerating Convolutional Neural Nets Yunming Zhang Focus Convolutional Neural Nets is the state of the art in classifying the images The models take days to train Difficult for the programmers to tune
XPU A Programmable FPGA Accelerator for Diverse Workloads
 XPU A Programmable FPGA Accelerator for Diverse Workloads Jian Ouyang, 1 (ouyangjian@baidu.com) Ephrem Wu, 2 Jing Wang, 1 Yupeng Li, 1 Hanlin Xie 1 1 Baidu, Inc. 2 Xilinx Outlines Background - FPGA for
XPU A Programmable FPGA Accelerator for Diverse Workloads Jian Ouyang, 1 (ouyangjian@baidu.com) Ephrem Wu, 2 Jing Wang, 1 Yupeng Li, 1 Hanlin Xie 1 1 Baidu, Inc. 2 Xilinx Outlines Background - FPGA for
Embedded Binarized Neural Networks
 Embedded Binarized Neural Networks Bradley McDanel Harvard University mcdanel@fasharvardedu Surat Teerapittayanon Harvard University steerapi@seasharvardedu HT Kung Harvard University kung@harvardedu Abstract
Embedded Binarized Neural Networks Bradley McDanel Harvard University mcdanel@fasharvardedu Surat Teerapittayanon Harvard University steerapi@seasharvardedu HT Kung Harvard University kung@harvardedu Abstract
Comprehensive Arm Solutions for Innovative Machine Learning (ML) and Computer Vision (CV) Applications
 and Computer Vision (CV) Applications") Comprehensive Arm Solutions for Innovative Machine Learning (ML) and Computer Vision (CV) Applications Helena Zheng ML Group, Arm Arm Technical Symposia 2017, Taipei Machine Learning is a Subset of Artificial
Comprehensive Arm Solutions for Innovative Machine Learning (ML) and Computer Vision (CV) Applications Helena Zheng ML Group, Arm Arm Technical Symposia 2017, Taipei Machine Learning is a Subset of Artificial
The Nios II Family of Configurable Soft-core Processors
 The Nios II Family of Configurable Soft-core Processors James Ball August 16, 2005 2005 Altera Corporation Agenda Nios II Introduction Configuring your CPU FPGA vs. ASIC CPU Design Instruction Set Architecture
The Nios II Family of Configurable Soft-core Processors James Ball August 16, 2005 2005 Altera Corporation Agenda Nios II Introduction Configuring your CPU FPGA vs. ASIC CPU Design Instruction Set Architecture
Gigascale Integration Design Challenges & Opportunities. Shekhar Borkar Circuit Research, Intel Labs October 24, 2004
 Gigascale Integration Design Challenges & Opportunities Shekhar Borkar Circuit Research, Intel Labs October 24, 2004 Outline CMOS technology challenges Technology, circuit and μarchitecture solutions Integration
Gigascale Integration Design Challenges & Opportunities Shekhar Borkar Circuit Research, Intel Labs October 24, 2004 Outline CMOS technology challenges Technology, circuit and μarchitecture solutions Integration
Xilinx Machine Learning Strategies For Edge
 Xilinx Machine Learning Strategies For Edge Presented By Alvin Clark, Sr. FAE, Northwest The Hottest Research: AI / Machine Learning Nick s ML Model Nick s ML Framework copyright sources: Gospel Coalition
Xilinx Machine Learning Strategies For Edge Presented By Alvin Clark, Sr. FAE, Northwest The Hottest Research: AI / Machine Learning Nick s ML Model Nick s ML Framework copyright sources: Gospel Coalition
NVIDIA FOR DEEP LEARNING. Bill Veenhuis
 NVIDIA FOR DEEP LEARNING Bill Veenhuis bveenhuis@nvidia.com Nvidia is the world s leading ai platform ONE ARCHITECTURE CUDA 2 GPU: Perfect Companion for Accelerating Apps & A.I. CPU GPU 3 Intro to AI AGENDA
NVIDIA FOR DEEP LEARNING Bill Veenhuis bveenhuis@nvidia.com Nvidia is the world s leading ai platform ONE ARCHITECTURE CUDA 2 GPU: Perfect Companion for Accelerating Apps & A.I. CPU GPU 3 Intro to AI AGENDA
CS6220: DATA MINING TECHNIQUES
 CS6220: DATA MINING TECHNIQUES Image Data: Classification via Neural Networks Instructor: Yizhou Sun yzsun@ccs.neu.edu November 19, 2015 Methods to Learn Classification Clustering Frequent Pattern Mining
CS6220: DATA MINING TECHNIQUES Image Data: Classification via Neural Networks Instructor: Yizhou Sun yzsun@ccs.neu.edu November 19, 2015 Methods to Learn Classification Clustering Frequent Pattern Mining
LSTM: An Image Classification Model Based on Fashion-MNIST Dataset
 LSTM: An Image Classification Model Based on Fashion-MNIST Dataset Kexin Zhang, Research School of Computer Science, Australian National University Kexin Zhang, U6342657@anu.edu.au Abstract. The application
LSTM: An Image Classification Model Based on Fashion-MNIST Dataset Kexin Zhang, Research School of Computer Science, Australian National University Kexin Zhang, U6342657@anu.edu.au Abstract. The application
HRL: Efficient and Flexible Reconfigurable Logic for Near-Data Processing
 HRL: Efficient and Flexible Reconfigurable Logic for Near-Data Processing Mingyu Gao and Christos Kozyrakis Stanford University http://mast.stanford.edu HPCA March 14, 2016 PIM is Coming Back End of Dennard
HRL: Efficient and Flexible Reconfigurable Logic for Near-Data Processing Mingyu Gao and Christos Kozyrakis Stanford University http://mast.stanford.edu HPCA March 14, 2016 PIM is Coming Back End of Dennard
Deep Learning Inference in Facebook Data Centers: Characterization, Performance Optimizations, and Hardware Implications
 Deep Learning Inference in Facebook Data Centers: Characterization, Performance Optimizations, and Hardware Implications Jongsoo Park Facebook AI System SW/HW Co-design Team Sep-21 2018 Team Introduction
Deep Learning Inference in Facebook Data Centers: Characterization, Performance Optimizations, and Hardware Implications Jongsoo Park Facebook AI System SW/HW Co-design Team Sep-21 2018 Team Introduction
THE NVIDIA DEEP LEARNING ACCELERATOR
 THE NVIDIA DEEP LEARNING ACCELERATOR INTRODUCTION NVDLA NVIDIA Deep Learning Accelerator Developed as part of Xavier NVIDIA s SOC for autonomous driving applications Optimized for Convolutional Neural
THE NVIDIA DEEP LEARNING ACCELERATOR INTRODUCTION NVDLA NVIDIA Deep Learning Accelerator Developed as part of Xavier NVIDIA s SOC for autonomous driving applications Optimized for Convolutional Neural
A Method to Estimate the Energy Consumption of Deep Neural Networks
 A Method to Estimate the Consumption of Deep Neural Networks Tien-Ju Yang, Yu-Hsin Chen, Joel Emer, Vivienne Sze Massachusetts Institute of Technology, Cambridge, MA, USA {tjy, yhchen, jsemer, sze}@mit.edu
A Method to Estimate the Consumption of Deep Neural Networks Tien-Ju Yang, Yu-Hsin Chen, Joel Emer, Vivienne Sze Massachusetts Institute of Technology, Cambridge, MA, USA {tjy, yhchen, jsemer, sze}@mit.edu
Software Defined Hardware
 Software Defined Hardware For data intensive computation Wade Shen DARPA I2O September 19, 2017 1 Goal Statement Build runtime reconfigurable hardware and software that enables near ASIC performance (within
Software Defined Hardware For data intensive computation Wade Shen DARPA I2O September 19, 2017 1 Goal Statement Build runtime reconfigurable hardware and software that enables near ASIC performance (within
A Reconfigurable Crossbar Switch with Adaptive Bandwidth Control for Networks-on
 A Reconfigurable Crossbar Switch with Adaptive Bandwidth Control for Networks-on on-chip Donghyun Kim, Kangmin Lee, Se-joong Lee and Hoi-Jun Yoo Semiconductor System Laboratory, Dept. of EECS, Korea Advanced
A Reconfigurable Crossbar Switch with Adaptive Bandwidth Control for Networks-on on-chip Donghyun Kim, Kangmin Lee, Se-joong Lee and Hoi-Jun Yoo Semiconductor System Laboratory, Dept. of EECS, Korea Advanced
An Evaluation of an Energy Efficient Many-Core SoC with Parallelized Face Detection
 An Evaluation of an Energy Efficient Many-Core SoC with Parallelized Face Detection Hiroyuki Usui, Jun Tanabe, Toru Sano, Hui Xu, and Takashi Miyamori Toshiba Corporation, Kawasaki, Japan Copyright 2013,
An Evaluation of an Energy Efficient Many-Core SoC with Parallelized Face Detection Hiroyuki Usui, Jun Tanabe, Toru Sano, Hui Xu, and Takashi Miyamori Toshiba Corporation, Kawasaki, Japan Copyright 2013,
Smart Ultra-Low Power Visual Sensing
 Smart Ultra-Low Power Visual Sensing Manuele Rusci*, Francesco Conti * manuele.rusci@unibo.it f.conti@unibo.it Energy-Efficient Embedded Systems Laboratory Dipartimento di Ingegneria dell Energia Elettrica
Smart Ultra-Low Power Visual Sensing Manuele Rusci*, Francesco Conti * manuele.rusci@unibo.it f.conti@unibo.it Energy-Efficient Embedded Systems Laboratory Dipartimento di Ingegneria dell Energia Elettrica
Bridging Analog Neuromorphic and Digital von Neumann Computing
 Bridging Analog Neuromorphic and Digital von Neumann Computing Amir Yazdanbakhsh, Bradley Thwaites Advisors: Hadi Esmaeilzadeh and Doug Burger Qualcomm Mentors: Manu Rastogiand Girish Varatkar Alternative
Bridging Analog Neuromorphic and Digital von Neumann Computing Amir Yazdanbakhsh, Bradley Thwaites Advisors: Hadi Esmaeilzadeh and Doug Burger Qualcomm Mentors: Manu Rastogiand Girish Varatkar Alternative
Revolutionizing the Datacenter
 Power-Efficient Machine Learning using FPGAs on POWER Systems Ralph Wittig, Distinguished Engineer Office of the CTO, Xilinx Revolutionizing the Datacenter Join the Conversation #OpenPOWERSummit Top-5
Power-Efficient Machine Learning using FPGAs on POWER Systems Ralph Wittig, Distinguished Engineer Office of the CTO, Xilinx Revolutionizing the Datacenter Join the Conversation #OpenPOWERSummit Top-5
Edge Computing and the Next Generation of IoT Sensors. Alex Raimondi
 Edge Computing and the Next Generation of IoT Sensors Alex Raimondi Who I am? Background: o Studied Electrical Engineering at ETH Zurich o Over 20 years of experience in embedded design o Co-founder of
Edge Computing and the Next Generation of IoT Sensors Alex Raimondi Who I am? Background: o Studied Electrical Engineering at ETH Zurich o Over 20 years of experience in embedded design o Co-founder of
PageForge: A Near-Memory Content- Aware Page-Merging Architecture
 PageForge: A Near-Memory Content- Aware Page-Merging Architecture Dimitrios Skarlatos, Nam Sung Kim, and Josep Torrellas University of Illinois at Urbana-Champaign MICRO-50 @ Boston Motivation: Server
PageForge: A Near-Memory Content- Aware Page-Merging Architecture Dimitrios Skarlatos, Nam Sung Kim, and Josep Torrellas University of Illinois at Urbana-Champaign MICRO-50 @ Boston Motivation: Server
The Path to Embedded Vision & AI using a Low Power Vision DSP. Yair Siegel, Director of Segment Marketing Hotchips August 2016
 The Path to Embedded Vision & AI using a Low Power Vision DSP Yair Siegel, Director of Segment Marketing Hotchips August 2016 Presentation Outline Introduction The Need for Embedded Vision & AI Vision
The Path to Embedded Vision & AI using a Low Power Vision DSP Yair Siegel, Director of Segment Marketing Hotchips August 2016 Presentation Outline Introduction The Need for Embedded Vision & AI Vision
Computer Architecture Dr. Charles Kim Howard University
 EECE416 Microcomputer Fundamentals Computer Architecture Dr. Charles Kim Howard University 1 Computer Architecture Computer Architecture Art of selecting and interconnecting hardware components to create
EECE416 Microcomputer Fundamentals Computer Architecture Dr. Charles Kim Howard University 1 Computer Architecture Computer Architecture Art of selecting and interconnecting hardware components to create
A Deep Learning primer
 A Deep Learning primer Riccardo Zanella r.zanella@cineca.it SuperComputing Applications and Innovation Department 1/21 Table of Contents Deep Learning: a review Representation Learning methods DL Applications
A Deep Learning primer Riccardo Zanella r.zanella@cineca.it SuperComputing Applications and Innovation Department 1/21 Table of Contents Deep Learning: a review Representation Learning methods DL Applications
Computer Engineering Mekelweg 4, 2628 CD Delft The Netherlands MSc THESIS. Exploring Convolutional Neural Networks on the
 Computer Engineering Mekelweg 4, 2628 CD Delft The Netherlands http://ce.et.tudelft.nl/ 2018 MSc THESIS Exploring Convolutional Neural Networks on the ρ-vex architecture Jonathan Tetteroo Abstract As machine
Computer Engineering Mekelweg 4, 2628 CD Delft The Netherlands http://ce.et.tudelft.nl/ 2018 MSc THESIS Exploring Convolutional Neural Networks on the ρ-vex architecture Jonathan Tetteroo Abstract As machine
A 19.4 nj/decision 364K Decisions/s In-Memory Random Forest Classifier in 6T SRAM Array. Mingu Kang, Sujan Gonugondla, Naresh Shanbhag
 A 19.4 nj/decision 364K Decisions/s In-Memory Random Forest Classifier in 6T SRAM Array Mingu Kang, Sujan Gonugondla, Naresh Shanbhag University of Illinois at Urbana Champaign Machine Learning under Resource
A 19.4 nj/decision 364K Decisions/s In-Memory Random Forest Classifier in 6T SRAM Array Mingu Kang, Sujan Gonugondla, Naresh Shanbhag University of Illinois at Urbana Champaign Machine Learning under Resource
TEXAS INSTRUMENTS DEEP LEARNING (TIDL) GOES HERE FOR SITARA PROCESSORS GOES HERE
 GOES HERE FOR SITARA PROCESSORS GOES HERE") YOUR TEXAS INSTRUMENTS VIDEO TITLE DEEP LEARNING (TIDL) GOES HERE FOR SITARA PROCESSORS OVERVIEW THE SUBTITLE GOES HERE Texas Instruments Deep Learning (TIDL) for Sitara Processors Overview Texas Instruments
YOUR TEXAS INSTRUMENTS VIDEO TITLE DEEP LEARNING (TIDL) GOES HERE FOR SITARA PROCESSORS OVERVIEW THE SUBTITLE GOES HERE Texas Instruments Deep Learning (TIDL) for Sitara Processors Overview Texas Instruments
PULP: an open source hardware-software platform for near-sensor analytics. Luca Benini IIS-ETHZ & DEI-UNIBO
 PULP: an open source hardware-software platform for near-sensor analytics Luca Benini IIS-ETHZ & DEI-UNIBO An IoT System View Sense MEMS IMU MEMS Microphone ULP Imager Analyze µcontroller L2 Memory e.g.
PULP: an open source hardware-software platform for near-sensor analytics Luca Benini IIS-ETHZ & DEI-UNIBO An IoT System View Sense MEMS IMU MEMS Microphone ULP Imager Analyze µcontroller L2 Memory e.g.