Department of Computer Science University of Cyprus EPL646 Advanced Topics in Databases. Lecture 14
|
|
|
- Anna Foster
- 5 years ago
- Views:
Transcription
1 Department of Computer Science University of Cyprus EPL646 Advanced Topics in Databases Lecture 14 Big Data Management IV: Big-data Infrastructures (Background, IO, From NFS to HFDS) Chapter 14-15: Abideboul et. Al. Demetris Zeinalipour
2 Lecture Outline Introduction to Cloud Computing Typical Datacenters, Cloud Stack and Buzzwords, Public / Private Clouds, Utility Computing, Killer Apps, Economic Model Distributed System Basics I/O Performance Replication Strategies The Hadoop Project (Core, HDFS, Map-Reduce, HBase, HIVE) The Hadoop Distributed File System (HDFS) HDFS vs. NFS (Network File System) HDFS Example Deployments (Yahoo, Facebook) 14-2


3 Cloud Computing αγαθά Google's Datacenter in Oregon Microsoft Azure in Chicago 14-3
")
4 Cloud Computing (Datacenters) Datacenter 14-4
")
5 Cloud Computing (Cloud Stack) 14-5
6 Cloud Computing (Public vs. Private) Based on: Above the Clouds: A Berkeley View of Cloud Computing, RAD Lab, UC Berkeley 14-7
 NewSQL-as-a-Service To Amazon RDS* (Relational Database Service) 963$ / year 27,165 $ / year")
7 Cloud Computing (Utility Computing Yπ. Ωφελείας) NewSQL-as-a-Service To Amazon RDS* (Relational Database Service) 963$ / year 27,165 $ / year (*essentially MySQL running on Amazon EC2 Elastic Computing Cloud) 14-8
8 Cloud Computing (Utility Computing Yπ. Ωφελείας) 14-9
9 Cloud Computing (Virtualization - Tεχνολογία εικονικών συστημάτων) 14-10

10 Our IaaS Private Cloud Demo 14-11
11 Cloud Computing (Economic Model) 14-12
12 Cloud Computing (Killer Apps: OLTP/OLAP) 14-13
13 Cloud Computing (Killer Apps: escience) 14-14
 Each")
 3.")

14 Distributed Systems Basics (I/O Performance) Each Disk: 2TB 7,200 rpm 6Gb SAS (Serial Attach. SCSI) 3.5" HDD In RAID-5 configuration [10Gbps FCoE also available] 14-15
15 Distributed Systems Basics (I/O Performance) (throughput) 14-16
")
16 Distributed Systems Basics (I/O Performance) (Similar to Parallel but more scalable) 14-17
17 Distributed Systems Basics (I/O Performance) 14-18
18 Distributed Systems Basics (Replication Strategies) NOSQL DBMSs SQL RDBMSs 14-19
 (Recall conflict resolution in")
19 Distributed Systems Basics (Replication Strategies) (Recall conflict resolution in CouchDB) 14-20

20 Terminology (MR => HADOOP => HBASE) Map-Reduce: a programming model for processing large data sets. Invented by Google! "MapReduce: Simplified Data Processing on Large Clusters, Jeffrey Dean and Sanjay Ghemawat, OSDI'04: Sixth Symposium on Operating System Design and Implementation,San Francisco, CA, December, 2004." Can be implemented in any language (recall javascript Map- Reduce we used in the context of CouchDB). Hadoop: Apache's open-source software framework that supports data-intensive distributed applications Derived from Google's MapReduce + Google File System (GFS) papers. Enables applications to work with thousands of computationindependent computers and petabytes of data. Download:
21 Terminology (MR => HADOOP => HBASE) Hadoop Project Modules: Hadoop Common: The common utilities that support the other Hadoop modules. Hadoop Distributed File System (HDFS ): A distributed file system that provides highthroughput access to application data. Hadoop YARN (Yet Another Resource Negotiator): A framework for job scheduling and cluster resource management. Hadoop MapReduce (MapReduce v2.0): A YARN-based system for parallel processing of large data sets. (Next Lectures) Other Hadoop-related projects at Apache include: Ambari: Dashboard management system for Hadoop. Avro : A data serialization system. Cassandra : A scalable multi-master database with no single points of failure. Chukwa : A data collection system for managing large distributed systems. HBase (Hadoop Database): A scalable, distributed database that supports structured data storage for large tables. (Next Lectures) Hive : A data warehouse infrastructure that provides data summarization and ad hoc querying. Mahout : A Scalable machine learning and data mining library. Pig : A high-level data-flow language and execution framework for parallel computation. (Next Lectures) ZooKeeper : A high-performance coordination service for distributed applications
22 Large-Scale File Systems (GFS => HDFS) Problem: if nodes can fail, how can we store data persistently? Answer: Distributed File System (global file namespace) The Google File System, Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung, 19th ACM Symposium on Operating Systems Principles, Lake George, NY, October,
23 Network File Systems (NFS=>GFS=>HDFS) UNIX NFS (Network File System): nfsd (deamon) mounts remote folders to a UNIX host (/etc/fstab)


24 NFS uses a Client/Server Architecture that is a single point of failure by default. Network File Systems (NFS=>GFS=>HDFS) 14-26

, 1 (single), 2 (double), και 3 (triple) 2KB block <24ΚΒ <1ΜΒ <512ΜB < max supported")
25 inode Δομές στο UNIX (Επανάληψη) Τι γίνεται εάν ένα αρχείο έχει πολλά blocks; Υπάρχει αρκετός χώρος για να αποθηκευτούν όλα τα i-nodes των blocks που συσχετίζονται με το αρχείο; Το Υποσύστημα Αρχείων χρησιμοποιεί ένα ιεραρχικό σχήμα το οποίο αποτελείται από δένδρα δεικτών βάθους 0 (direct, αυτό το οποίο είδαμε ήδη), 1 (single), 2 (double), και 3 (triple) 2KB block <24ΚΒ <1ΜΒ <512ΜB < max supported file size 14-27
26 Large-Scale File Systems (Hadoop File System - HDFS) Chuck (Block) Size: 4KB-32KB NFS File Size Limit = 2GB Default Chunk Size: 64 MB Unlimited File Size (21PB by Facebook) 3x replicas per chunk 14-28
")


27 Large-Scale File Systems (Hadoop File System - HDFS) HDFS scalability: the limits to growth
28 Large-Scale File Systems (Hadoop File System - HDFS) Namespace lookup are fast (1 Master enough!) [ 1GB Metadata = 1PB Data ] In NFS Metadata + Transfers going through same server => Not Scalable HDFS designed for unreliable hardware (2-3 failures / 1000 nodes / day) New Hardware: 3x more unreliable!!! 14-30
")
29 Large-Scale File Systems (Hadoop File System - HDFS) 14-31
30 User Interface API Java API C language wrapper (libhdfs) for the Java API is also avaiable POSIX like command hadoop dfs -mkdir /foodir hadoop dfs -cat /foodir/myfile.txt hadoop dfs -rm /foodir myfile.txt HDFS Admin bin/hadoop dfsadmin safemode bin/hadoop dfsadmin report bin/hadoop dfsadmin -refreshnodes Web Interface Ex:

31 Web Interface (

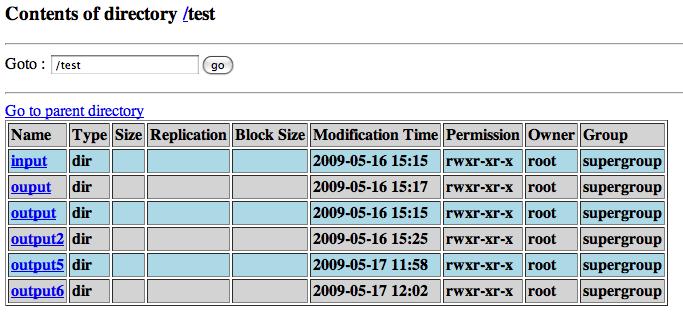
32 Web Interface ( Browse the file system 14-34

33 POSIX Like command 14-35
34 Latest API Java API
CS370 Operating Systems
 CS370 Operating Systems Colorado State University Yashwant K Malaiya Fall 2017 Lecture 26 File Systems Slides based on Text by Silberschatz, Galvin, Gagne Various sources 1 1 FAQ Cylinders: all the platters?
CS370 Operating Systems Colorado State University Yashwant K Malaiya Fall 2017 Lecture 26 File Systems Slides based on Text by Silberschatz, Galvin, Gagne Various sources 1 1 FAQ Cylinders: all the platters?
Chase Wu New Jersey Institute of Technology
 CS 644: Introduction to Big Data Chapter 4. Big Data Analytics Platforms Chase Wu New Jersey Institute of Technology Some of the slides were provided through the courtesy of Dr. Ching-Yung Lin at Columbia
CS 644: Introduction to Big Data Chapter 4. Big Data Analytics Platforms Chase Wu New Jersey Institute of Technology Some of the slides were provided through the courtesy of Dr. Ching-Yung Lin at Columbia
Distributed Systems 16. Distributed File Systems II
 Distributed Systems 16. Distributed File Systems II Paul Krzyzanowski pxk@cs.rutgers.edu 1 Review NFS RPC-based access AFS Long-term caching CODA Read/write replication & disconnected operation DFS AFS
Distributed Systems 16. Distributed File Systems II Paul Krzyzanowski pxk@cs.rutgers.edu 1 Review NFS RPC-based access AFS Long-term caching CODA Read/write replication & disconnected operation DFS AFS
The Google File System. Alexandru Costan
 1 The Google File System Alexandru Costan Actions on Big Data 2 Storage Analysis Acquisition Handling the data stream Data structured unstructured semi-structured Results Transactions Outline File systems
1 The Google File System Alexandru Costan Actions on Big Data 2 Storage Analysis Acquisition Handling the data stream Data structured unstructured semi-structured Results Transactions Outline File systems
Hadoop An Overview. - Socrates CCDH
 Hadoop An Overview - Socrates CCDH What is Big Data? Volume Not Gigabyte. Terabyte, Petabyte, Exabyte, Zettabyte - Due to handheld gadgets,and HD format images and videos - In total data, 90% of them collected
Hadoop An Overview - Socrates CCDH What is Big Data? Volume Not Gigabyte. Terabyte, Petabyte, Exabyte, Zettabyte - Due to handheld gadgets,and HD format images and videos - In total data, 90% of them collected
Topics. Big Data Analytics What is and Why Hadoop? Comparison to other technologies Hadoop architecture Hadoop ecosystem Hadoop usage examples
 Hadoop Introduction 1 Topics Big Data Analytics What is and Why Hadoop? Comparison to other technologies Hadoop architecture Hadoop ecosystem Hadoop usage examples 2 Big Data Analytics What is Big Data?
Hadoop Introduction 1 Topics Big Data Analytics What is and Why Hadoop? Comparison to other technologies Hadoop architecture Hadoop ecosystem Hadoop usage examples 2 Big Data Analytics What is Big Data?
Parallel Programming Principle and Practice. Lecture 10 Big Data Processing with MapReduce
 Parallel Programming Principle and Practice Lecture 10 Big Data Processing with MapReduce Outline MapReduce Programming Model MapReduce Examples Hadoop 2 Incredible Things That Happen Every Minute On The
Parallel Programming Principle and Practice Lecture 10 Big Data Processing with MapReduce Outline MapReduce Programming Model MapReduce Examples Hadoop 2 Incredible Things That Happen Every Minute On The
Microsoft Big Data and Hadoop
 Microsoft Big Data and Hadoop Lara Rubbelke @sqlgal Cindy Gross @sqlcindy 2 The world of data is changing The 4Vs of Big Data http://nosql.mypopescu.com/post/9621746531/a-definition-of-big-data 3 Common
Microsoft Big Data and Hadoop Lara Rubbelke @sqlgal Cindy Gross @sqlcindy 2 The world of data is changing The 4Vs of Big Data http://nosql.mypopescu.com/post/9621746531/a-definition-of-big-data 3 Common
Hadoop File System S L I D E S M O D I F I E D F R O M P R E S E N T A T I O N B Y B. R A M A M U R T H Y 11/15/2017
 Hadoop File System 1 S L I D E S M O D I F I E D F R O M P R E S E N T A T I O N B Y B. R A M A M U R T H Y Moving Computation is Cheaper than Moving Data Motivation: Big Data! What is BigData? - Google
Hadoop File System 1 S L I D E S M O D I F I E D F R O M P R E S E N T A T I O N B Y B. R A M A M U R T H Y Moving Computation is Cheaper than Moving Data Motivation: Big Data! What is BigData? - Google
PLATFORM AND SOFTWARE AS A SERVICE THE MAPREDUCE PROGRAMMING MODEL AND IMPLEMENTATIONS
 PLATFORM AND SOFTWARE AS A SERVICE THE MAPREDUCE PROGRAMMING MODEL AND IMPLEMENTATIONS By HAI JIN, SHADI IBRAHIM, LI QI, HAIJUN CAO, SONG WU and XUANHUA SHI Prepared by: Dr. Faramarz Safi Islamic Azad
PLATFORM AND SOFTWARE AS A SERVICE THE MAPREDUCE PROGRAMMING MODEL AND IMPLEMENTATIONS By HAI JIN, SHADI IBRAHIM, LI QI, HAIJUN CAO, SONG WU and XUANHUA SHI Prepared by: Dr. Faramarz Safi Islamic Azad
CPSC 426/526. Cloud Computing. Ennan Zhai. Computer Science Department Yale University
 CPSC 426/526 Cloud Computing Ennan Zhai Computer Science Department Yale University Recall: Lec-7 In the lec-7, I talked about: - P2P vs Enterprise control - Firewall - NATs - Software defined network
CPSC 426/526 Cloud Computing Ennan Zhai Computer Science Department Yale University Recall: Lec-7 In the lec-7, I talked about: - P2P vs Enterprise control - Firewall - NATs - Software defined network
The Hadoop Ecosystem. EECS 4415 Big Data Systems. Tilemachos Pechlivanoglou
 The Hadoop Ecosystem EECS 4415 Big Data Systems Tilemachos Pechlivanoglou tipech@eecs.yorku.ca A lot of tools designed to work with Hadoop 2 HDFS, MapReduce Hadoop Distributed File System Core Hadoop component
The Hadoop Ecosystem EECS 4415 Big Data Systems Tilemachos Pechlivanoglou tipech@eecs.yorku.ca A lot of tools designed to work with Hadoop 2 HDFS, MapReduce Hadoop Distributed File System Core Hadoop component
Systems Infrastructure for Data Science. Web Science Group Uni Freiburg WS 2013/14
 Systems Infrastructure for Data Science Web Science Group Uni Freiburg WS 2013/14 MapReduce & Hadoop The new world of Big Data (programming model) Overview of this Lecture Module Background Cluster File
Systems Infrastructure for Data Science Web Science Group Uni Freiburg WS 2013/14 MapReduce & Hadoop The new world of Big Data (programming model) Overview of this Lecture Module Background Cluster File
ΕΠΛ 602:Foundations of Internet Technologies. Cloud Computing
 ΕΠΛ 602:Foundations of Internet Technologies Cloud Computing 1 Outline Bigtable(data component of cloud) Web search basedonch13of thewebdatabook 2 What is Cloud Computing? ACloudis an infrastructure, transparent
ΕΠΛ 602:Foundations of Internet Technologies Cloud Computing 1 Outline Bigtable(data component of cloud) Web search basedonch13of thewebdatabook 2 What is Cloud Computing? ACloudis an infrastructure, transparent
CS 345A Data Mining. MapReduce
 CS 345A Data Mining MapReduce Single-node architecture CPU Machine Learning, Statistics Memory Classical Data Mining Disk Commodity Clusters Web data sets can be very large Tens to hundreds of terabytes
CS 345A Data Mining MapReduce Single-node architecture CPU Machine Learning, Statistics Memory Classical Data Mining Disk Commodity Clusters Web data sets can be very large Tens to hundreds of terabytes
Hadoop. Introduction / Overview
 Hadoop Introduction / Overview Preface We will use these PowerPoint slides to guide us through our topic. Expect 15 minute segments of lecture Expect 1-4 hour lab segments Expect minimal pretty pictures
Hadoop Introduction / Overview Preface We will use these PowerPoint slides to guide us through our topic. Expect 15 minute segments of lecture Expect 1-4 hour lab segments Expect minimal pretty pictures
Cloud Computing and Hadoop Distributed File System. UCSB CS170, Spring 2018
 Cloud Computing and Hadoop Distributed File System UCSB CS70, Spring 08 Cluster Computing Motivations Large-scale data processing on clusters Scan 000 TB on node @ 00 MB/s = days Scan on 000-node cluster
Cloud Computing and Hadoop Distributed File System UCSB CS70, Spring 08 Cluster Computing Motivations Large-scale data processing on clusters Scan 000 TB on node @ 00 MB/s = days Scan on 000-node cluster
CISC 7610 Lecture 2b The beginnings of NoSQL
 CISC 7610 Lecture 2b The beginnings of NoSQL Topics: Big Data Google s infrastructure Hadoop: open google infrastructure Scaling through sharding CAP theorem Amazon s Dynamo 5 V s of big data Everyone
CISC 7610 Lecture 2b The beginnings of NoSQL Topics: Big Data Google s infrastructure Hadoop: open google infrastructure Scaling through sharding CAP theorem Amazon s Dynamo 5 V s of big data Everyone
Big Data with Hadoop Ecosystem
 Diógenes Pires Big Data with Hadoop Ecosystem Hands-on (HBase, MySql and Hive + Power BI) Internet Live http://www.internetlivestats.com/ Introduction Business Intelligence Business Intelligence Process
Diógenes Pires Big Data with Hadoop Ecosystem Hands-on (HBase, MySql and Hive + Power BI) Internet Live http://www.internetlivestats.com/ Introduction Business Intelligence Business Intelligence Process
Big Data Hadoop Stack
 Big Data Hadoop Stack Lecture #1 Hadoop Beginnings What is Hadoop? Apache Hadoop is an open source software framework for storage and large scale processing of data-sets on clusters of commodity hardware
Big Data Hadoop Stack Lecture #1 Hadoop Beginnings What is Hadoop? Apache Hadoop is an open source software framework for storage and large scale processing of data-sets on clusters of commodity hardware
HDInsight > Hadoop. October 12, 2017
 HDInsight > Hadoop October 12, 2017 2 Introduction Mark Hudson >20 years mixing technology with data >10 years with CapTech Microsoft Certified IT Professional Business Intelligence Member of the Richmond
HDInsight > Hadoop October 12, 2017 2 Introduction Mark Hudson >20 years mixing technology with data >10 years with CapTech Microsoft Certified IT Professional Business Intelligence Member of the Richmond
HDFS: Hadoop Distributed File System. CIS 612 Sunnie Chung
 HDFS: Hadoop Distributed File System CIS 612 Sunnie Chung What is Big Data?? Bulk Amount Unstructured Introduction Lots of Applications which need to handle huge amount of data (in terms of 500+ TB per
HDFS: Hadoop Distributed File System CIS 612 Sunnie Chung What is Big Data?? Bulk Amount Unstructured Introduction Lots of Applications which need to handle huge amount of data (in terms of 500+ TB per
Where We Are. Review: Parallel DBMS. Parallel DBMS. Introduction to Data Management CSE 344
 Where We Are Introduction to Data Management CSE 344 Lecture 22: MapReduce We are talking about parallel query processing There exist two main types of engines: Parallel DBMSs (last lecture + quick review)
Where We Are Introduction to Data Management CSE 344 Lecture 22: MapReduce We are talking about parallel query processing There exist two main types of engines: Parallel DBMSs (last lecture + quick review)
A New HadoopBased Network Management System with Policy Approach
 Computer Engineering and Applications Vol. 3, No. 3, September 2014 A New HadoopBased Network Management System with Policy Approach Department of Computer Engineering and IT, Shiraz University of Technology,
Computer Engineering and Applications Vol. 3, No. 3, September 2014 A New HadoopBased Network Management System with Policy Approach Department of Computer Engineering and IT, Shiraz University of Technology,
Data Clustering on the Parallel Hadoop MapReduce Model. Dimitrios Verraros
 Data Clustering on the Parallel Hadoop MapReduce Model Dimitrios Verraros Overview The purpose of this thesis is to implement and benchmark the performance of a parallel K- means clustering algorithm on
Data Clustering on the Parallel Hadoop MapReduce Model Dimitrios Verraros Overview The purpose of this thesis is to implement and benchmark the performance of a parallel K- means clustering algorithm on
MapR Enterprise Hadoop
 2014 MapR Technologies 2014 MapR Technologies 1 MapR Enterprise Hadoop Top Ranked Cloud Leaders 500+ Customers 2014 MapR Technologies 2 Key MapR Advantage Partners Business Services APPLICATIONS & OS ANALYTICS
2014 MapR Technologies 2014 MapR Technologies 1 MapR Enterprise Hadoop Top Ranked Cloud Leaders 500+ Customers 2014 MapR Technologies 2 Key MapR Advantage Partners Business Services APPLICATIONS & OS ANALYTICS
Systems Infrastructure for Data Science. Web Science Group Uni Freiburg WS 2012/13
 Systems Infrastructure for Data Science Web Science Group Uni Freiburg WS 2012/13 MapReduce & Hadoop The new world of Big Data (programming model) Overview of this Lecture Module Background Google MapReduce
Systems Infrastructure for Data Science Web Science Group Uni Freiburg WS 2012/13 MapReduce & Hadoop The new world of Big Data (programming model) Overview of this Lecture Module Background Google MapReduce
Yuval Carmel Tel-Aviv University "Advanced Topics in Storage Systems" - Spring 2013
 Yuval Carmel Tel-Aviv University "Advanced Topics in About & Keywords Motivation & Purpose Assumptions Architecture overview & Comparison Measurements How does it fit in? The Future 2 About & Keywords
Yuval Carmel Tel-Aviv University "Advanced Topics in About & Keywords Motivation & Purpose Assumptions Architecture overview & Comparison Measurements How does it fit in? The Future 2 About & Keywords
Distributed Systems. 15. Distributed File Systems. Paul Krzyzanowski. Rutgers University. Fall 2016
 Distributed Systems 15. Distributed File Systems Paul Krzyzanowski Rutgers University Fall 2016 1 Google Chubby 2 Chubby Distributed lock service + simple fault-tolerant file system Interfaces File access
Distributed Systems 15. Distributed File Systems Paul Krzyzanowski Rutgers University Fall 2016 1 Google Chubby 2 Chubby Distributed lock service + simple fault-tolerant file system Interfaces File access
Chapter 5. The MapReduce Programming Model and Implementation
 Chapter 5. The MapReduce Programming Model and Implementation - Traditional computing: data-to-computing (send data to computing) * Data stored in separate repository * Data brought into system for computing
Chapter 5. The MapReduce Programming Model and Implementation - Traditional computing: data-to-computing (send data to computing) * Data stored in separate repository * Data brought into system for computing
Distributed Systems. 15. Distributed File Systems. Paul Krzyzanowski. Rutgers University. Fall 2017
 Distributed Systems 15. Distributed File Systems Paul Krzyzanowski Rutgers University Fall 2017 1 Google Chubby ( Apache Zookeeper) 2 Chubby Distributed lock service + simple fault-tolerant file system
Distributed Systems 15. Distributed File Systems Paul Krzyzanowski Rutgers University Fall 2017 1 Google Chubby ( Apache Zookeeper) 2 Chubby Distributed lock service + simple fault-tolerant file system
CS /30/17. Paul Krzyzanowski 1. Google Chubby ( Apache Zookeeper) Distributed Systems. Chubby. Chubby Deployment.
 Distributed Systems. Chubby. Chubby Deployment.") Distributed Systems 15. Distributed File Systems Google ( Apache Zookeeper) Paul Krzyzanowski Rutgers University Fall 2017 1 2 Distributed lock service + simple fault-tolerant file system Deployment Client
Distributed Systems 15. Distributed File Systems Google ( Apache Zookeeper) Paul Krzyzanowski Rutgers University Fall 2017 1 2 Distributed lock service + simple fault-tolerant file system Deployment Client
The Hadoop Distributed File System Konstantin Shvachko Hairong Kuang Sanjay Radia Robert Chansler
 The Hadoop Distributed File System Konstantin Shvachko Hairong Kuang Sanjay Radia Robert Chansler MSST 10 Hadoop in Perspective Hadoop scales computation capacity, storage capacity, and I/O bandwidth by
The Hadoop Distributed File System Konstantin Shvachko Hairong Kuang Sanjay Radia Robert Chansler MSST 10 Hadoop in Perspective Hadoop scales computation capacity, storage capacity, and I/O bandwidth by
Big Trend in Business Intelligence: Data Mining over Big Data Web Transaction Data. Fall 2012
 Big Trend in Business Intelligence: Data Mining over Big Data Web Transaction Data Fall 2012 Data Warehousing and OLAP Introduction Decision Support Technology On Line Analytical Processing Star Schema
Big Trend in Business Intelligence: Data Mining over Big Data Web Transaction Data Fall 2012 Data Warehousing and OLAP Introduction Decision Support Technology On Line Analytical Processing Star Schema
Scalable Web Programming. CS193S - Jan Jannink - 2/25/10
 Scalable Web Programming CS193S - Jan Jannink - 2/25/10 Weekly Syllabus 1.Scalability: (Jan.) 2.Agile Practices 3.Ecology/Mashups 4.Browser/Client 7.Analytics 8.Cloud/Map-Reduce 9.Published APIs: (Mar.)*
Scalable Web Programming CS193S - Jan Jannink - 2/25/10 Weekly Syllabus 1.Scalability: (Jan.) 2.Agile Practices 3.Ecology/Mashups 4.Browser/Client 7.Analytics 8.Cloud/Map-Reduce 9.Published APIs: (Mar.)*
Stages of Data Processing
 Data processing can be understood as the conversion of raw data into a meaningful and desired form. Basically, producing information that can be understood by the end user. So then, the question arises,
Data processing can be understood as the conversion of raw data into a meaningful and desired form. Basically, producing information that can be understood by the end user. So then, the question arises,
The amount of data increases every day Some numbers ( 2012):
:") 1 The amount of data increases every day Some numbers ( 2012): Data processed by Google every day: 100+ PB Data processed by Facebook every day: 10+ PB To analyze them, systems that scale with respect
1 The amount of data increases every day Some numbers ( 2012): Data processed by Google every day: 100+ PB Data processed by Facebook every day: 10+ PB To analyze them, systems that scale with respect
2/26/2017. The amount of data increases every day Some numbers ( 2012):
:") The amount of data increases every day Some numbers ( 2012): Data processed by Google every day: 100+ PB Data processed by Facebook every day: 10+ PB To analyze them, systems that scale with respect to
The amount of data increases every day Some numbers ( 2012): Data processed by Google every day: 100+ PB Data processed by Facebook every day: 10+ PB To analyze them, systems that scale with respect to
Big Data landscape Lecture #2
 Big Data landscape Lecture #2 Contents 1 1 CORE Technologies 2 3 MapReduce YARN 4 SparK 5 Cassandra Contents 2 16 HBase 72 83 Accumulo memcached 94 Blur 10 5 Sqoop/Flume Contents 3 111 MongoDB 12 2 13
Big Data landscape Lecture #2 Contents 1 1 CORE Technologies 2 3 MapReduce YARN 4 SparK 5 Cassandra Contents 2 16 HBase 72 83 Accumulo memcached 94 Blur 10 5 Sqoop/Flume Contents 3 111 MongoDB 12 2 13
Big Data Hadoop Developer Course Content. Big Data Hadoop Developer - The Complete Course Course Duration: 45 Hours
 Big Data Hadoop Developer Course Content Who is the target audience? Big Data Hadoop Developer - The Complete Course Course Duration: 45 Hours Complete beginners who want to learn Big Data Hadoop Professionals
Big Data Hadoop Developer Course Content Who is the target audience? Big Data Hadoop Developer - The Complete Course Course Duration: 45 Hours Complete beginners who want to learn Big Data Hadoop Professionals
DATA SCIENCE USING SPARK: AN INTRODUCTION
 DATA SCIENCE USING SPARK: AN INTRODUCTION TOPICS COVERED Introduction to Spark Getting Started with Spark Programming in Spark Data Science with Spark What next? 2 DATA SCIENCE PROCESS Exploratory Data
DATA SCIENCE USING SPARK: AN INTRODUCTION TOPICS COVERED Introduction to Spark Getting Started with Spark Programming in Spark Data Science with Spark What next? 2 DATA SCIENCE PROCESS Exploratory Data
Principles of Data Management. Lecture #16 (MapReduce & DFS for Big Data)
") Principles of Data Management Lecture #16 (MapReduce & DFS for Big Data) Instructor: Mike Carey mjcarey@ics.uci.edu Database Management Systems 3ed, R. Ramakrishnan and J. Gehrke 1 Today s News Bulletin
Principles of Data Management Lecture #16 (MapReduce & DFS for Big Data) Instructor: Mike Carey mjcarey@ics.uci.edu Database Management Systems 3ed, R. Ramakrishnan and J. Gehrke 1 Today s News Bulletin
Distributed File Systems II
 Distributed File Systems II To do q Very-large scale: Google FS, Hadoop FS, BigTable q Next time: Naming things GFS A radically new environment NFS, etc. Independence Small Scale Variety of workloads Cooperation
Distributed File Systems II To do q Very-large scale: Google FS, Hadoop FS, BigTable q Next time: Naming things GFS A radically new environment NFS, etc. Independence Small Scale Variety of workloads Cooperation
Big Data com Hadoop. VIII Sessão - SQL Bahia. Impala, Hive e Spark. Diógenes Pires 03/03/2018
 Big Data com Hadoop Impala, Hive e Spark VIII Sessão - SQL Bahia 03/03/2018 Diógenes Pires Connect with PASS Sign up for a free membership today at: pass.org #sqlpass Internet Live http://www.internetlivestats.com/
Big Data com Hadoop Impala, Hive e Spark VIII Sessão - SQL Bahia 03/03/2018 Diógenes Pires Connect with PASS Sign up for a free membership today at: pass.org #sqlpass Internet Live http://www.internetlivestats.com/
Big Data Architect.
 Big Data Architect www.austech.edu.au WHAT IS BIG DATA ARCHITECT? A big data architecture is designed to handle the ingestion, processing, and analysis of data that is too large or complex for traditional
Big Data Architect www.austech.edu.au WHAT IS BIG DATA ARCHITECT? A big data architecture is designed to handle the ingestion, processing, and analysis of data that is too large or complex for traditional
Big Data Programming: an Introduction. Spring 2015, X. Zhang Fordham Univ.
 Big Data Programming: an Introduction Spring 2015, X. Zhang Fordham Univ. Outline What the course is about? scope Introduction to big data programming Opportunity and challenge of big data Origin of Hadoop
Big Data Programming: an Introduction Spring 2015, X. Zhang Fordham Univ. Outline What the course is about? scope Introduction to big data programming Opportunity and challenge of big data Origin of Hadoop
CS 345A Data Mining. MapReduce
 CS 345A Data Mining MapReduce Single-node architecture CPU Machine Learning, Statistics Memory Classical Data Mining Dis Commodity Clusters Web data sets can be ery large Tens to hundreds of terabytes
CS 345A Data Mining MapReduce Single-node architecture CPU Machine Learning, Statistics Memory Classical Data Mining Dis Commodity Clusters Web data sets can be ery large Tens to hundreds of terabytes
Windows Azure Overview
 Windows Azure Overview Christine Collet, Genoveva Vargas-Solar Grenoble INP, France MS Azure Educator Grant Packaged Software Infrastructure (as a Service) Platform (as a Service) Software (as a Service)
Windows Azure Overview Christine Collet, Genoveva Vargas-Solar Grenoble INP, France MS Azure Educator Grant Packaged Software Infrastructure (as a Service) Platform (as a Service) Software (as a Service)
Innovatus Technologies
 HADOOP 2.X BIGDATA ANALYTICS 1. Java Overview of Java Classes and Objects Garbage Collection and Modifiers Inheritance, Aggregation, Polymorphism Command line argument Abstract class and Interfaces String
HADOOP 2.X BIGDATA ANALYTICS 1. Java Overview of Java Classes and Objects Garbage Collection and Modifiers Inheritance, Aggregation, Polymorphism Command line argument Abstract class and Interfaces String
Things Every Oracle DBA Needs to Know about the Hadoop Ecosystem. Zohar Elkayam
 Things Every Oracle DBA Needs to Know about the Hadoop Ecosystem Zohar Elkayam www.realdbamagic.com Twitter: @realmgic Who am I? Zohar Elkayam, CTO at Brillix Programmer, DBA, team leader, database trainer,
Things Every Oracle DBA Needs to Know about the Hadoop Ecosystem Zohar Elkayam www.realdbamagic.com Twitter: @realmgic Who am I? Zohar Elkayam, CTO at Brillix Programmer, DBA, team leader, database trainer,
Challenges for Data Driven Systems
 Challenges for Data Driven Systems Eiko Yoneki University of Cambridge Computer Laboratory Data Centric Systems and Networking Emergence of Big Data Shift of Communication Paradigm From end-to-end to data
Challenges for Data Driven Systems Eiko Yoneki University of Cambridge Computer Laboratory Data Centric Systems and Networking Emergence of Big Data Shift of Communication Paradigm From end-to-end to data
Gain Insights From Unstructured Data Using Pivotal HD. Copyright 2013 EMC Corporation. All rights reserved.
 Gain Insights From Unstructured Data Using Pivotal HD 1 Traditional Enterprise Analytics Process 2 The Fundamental Paradigm Shift Internet age and exploding data growth Enterprises leverage new data sources
Gain Insights From Unstructured Data Using Pivotal HD 1 Traditional Enterprise Analytics Process 2 The Fundamental Paradigm Shift Internet age and exploding data growth Enterprises leverage new data sources
Introduction to Hadoop. Owen O Malley Yahoo!, Grid Team
 Introduction to Hadoop Owen O Malley Yahoo!, Grid Team owen@yahoo-inc.com Who Am I? Yahoo! Architect on Hadoop Map/Reduce Design, review, and implement features in Hadoop Working on Hadoop full time since
Introduction to Hadoop Owen O Malley Yahoo!, Grid Team owen@yahoo-inc.com Who Am I? Yahoo! Architect on Hadoop Map/Reduce Design, review, and implement features in Hadoop Working on Hadoop full time since
HDFS Architecture Guide
 by Dhruba Borthakur Table of contents 1 Introduction...3 2 Assumptions and Goals...3 2.1 Hardware Failure... 3 2.2 Streaming Data Access...3 2.3 Large Data Sets...3 2.4 Simple Coherency Model... 4 2.5
by Dhruba Borthakur Table of contents 1 Introduction...3 2 Assumptions and Goals...3 2.1 Hardware Failure... 3 2.2 Streaming Data Access...3 2.3 Large Data Sets...3 2.4 Simple Coherency Model... 4 2.5
Lecture 12 DATA ANALYTICS ON WEB SCALE
 Lecture 12 DATA ANALYTICS ON WEB SCALE Source: The Economist, February 25, 2010 The Data Deluge EIGHTEEN months ago, Li & Fung, a firm that manages supply chains for retailers, saw 100 gigabytes of information
Lecture 12 DATA ANALYTICS ON WEB SCALE Source: The Economist, February 25, 2010 The Data Deluge EIGHTEEN months ago, Li & Fung, a firm that manages supply chains for retailers, saw 100 gigabytes of information
Introduction to MapReduce
 Basics of Cloud Computing Lecture 4 Introduction to MapReduce Satish Srirama Some material adapted from slides by Jimmy Lin, Christophe Bisciglia, Aaron Kimball, & Sierra Michels-Slettvet, Google Distributed
Basics of Cloud Computing Lecture 4 Introduction to MapReduce Satish Srirama Some material adapted from slides by Jimmy Lin, Christophe Bisciglia, Aaron Kimball, & Sierra Michels-Slettvet, Google Distributed
HADOOP FRAMEWORK FOR BIG DATA
 HADOOP FRAMEWORK FOR BIG DATA Mr K. Srinivas Babu 1,Dr K. Rameshwaraiah 2 1 Research Scholar S V University, Tirupathi 2 Professor and Head NNRESGI, Hyderabad Abstract - Data has to be stored for further
HADOOP FRAMEWORK FOR BIG DATA Mr K. Srinivas Babu 1,Dr K. Rameshwaraiah 2 1 Research Scholar S V University, Tirupathi 2 Professor and Head NNRESGI, Hyderabad Abstract - Data has to be stored for further
Introduction into Big Data analytics Lecture 3 Hadoop ecosystem. Janusz Szwabiński
 Introduction into Big Data analytics Lecture 3 Hadoop ecosystem Janusz Szwabiński Outlook of today s talk Apache Hadoop Project Common use cases Getting started with Hadoop Single node cluster Further
Introduction into Big Data analytics Lecture 3 Hadoop ecosystem Janusz Szwabiński Outlook of today s talk Apache Hadoop Project Common use cases Getting started with Hadoop Single node cluster Further
A BigData Tour HDFS, Ceph and MapReduce
 A BigData Tour HDFS, Ceph and MapReduce These slides are possible thanks to these sources Jonathan Drusi - SCInet Toronto Hadoop Tutorial, Amir Payberah - Course in Data Intensive Computing SICS; Yahoo!
A BigData Tour HDFS, Ceph and MapReduce These slides are possible thanks to these sources Jonathan Drusi - SCInet Toronto Hadoop Tutorial, Amir Payberah - Course in Data Intensive Computing SICS; Yahoo!
CSE-E5430 Scalable Cloud Computing Lecture 9
 CSE-E5430 Scalable Cloud Computing Lecture 9 Keijo Heljanko Department of Computer Science School of Science Aalto University keijo.heljanko@aalto.fi 15.11-2015 1/24 BigTable Described in the paper: Fay
CSE-E5430 Scalable Cloud Computing Lecture 9 Keijo Heljanko Department of Computer Science School of Science Aalto University keijo.heljanko@aalto.fi 15.11-2015 1/24 BigTable Described in the paper: Fay
Google File System (GFS) and Hadoop Distributed File System (HDFS)
 and Hadoop Distributed File System (HDFS)") Google File System (GFS) and Hadoop Distributed File System (HDFS) 1 Hadoop: Architectural Design Principles Linear scalability More nodes can do more work within the same time Linear on data size, linear
Google File System (GFS) and Hadoop Distributed File System (HDFS) 1 Hadoop: Architectural Design Principles Linear scalability More nodes can do more work within the same time Linear on data size, linear
The Google File System
 The Google File System Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung Google SOSP 03, October 19 22, 2003, New York, USA Hyeon-Gyu Lee, and Yeong-Jae Woo Memory & Storage Architecture Lab. School
The Google File System Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung Google SOSP 03, October 19 22, 2003, New York, USA Hyeon-Gyu Lee, and Yeong-Jae Woo Memory & Storage Architecture Lab. School
The Datacenter Needs an Operating System
 UC BERKELEY The Datacenter Needs an Operating System Anthony D. Joseph LASER Summer School September 2013 My Talks at LASER 2013 1. AMP Lab introduction 2. The Datacenter Needs an Operating System 3. Mesos,
UC BERKELEY The Datacenter Needs an Operating System Anthony D. Joseph LASER Summer School September 2013 My Talks at LASER 2013 1. AMP Lab introduction 2. The Datacenter Needs an Operating System 3. Mesos,
Big Data Fundamentals
 Big Data Fundamentals. Raj Jain Washington University in Saint Louis Saint Louis, MO 63130 Jain@cse.wustl.edu These slides and audio/video recordings of this class lecture are at: 18-1 Overview 1. Why
Big Data Fundamentals. Raj Jain Washington University in Saint Louis Saint Louis, MO 63130 Jain@cse.wustl.edu These slides and audio/video recordings of this class lecture are at: 18-1 Overview 1. Why
Next-Generation Cloud Platform
 Next-Generation Cloud Platform Jangwoo Kim Jun 24, 2013 E-mail: jangwoo@postech.ac.kr High Performance Computing Lab Department of Computer Science & Engineering Pohang University of Science and Technology
Next-Generation Cloud Platform Jangwoo Kim Jun 24, 2013 E-mail: jangwoo@postech.ac.kr High Performance Computing Lab Department of Computer Science & Engineering Pohang University of Science and Technology
EsgynDB Enterprise 2.0 Platform Reference Architecture
 EsgynDB Enterprise 2.0 Platform Reference Architecture This document outlines a Platform Reference Architecture for EsgynDB Enterprise, built on Apache Trafodion (Incubating) implementation with licensed
EsgynDB Enterprise 2.0 Platform Reference Architecture This document outlines a Platform Reference Architecture for EsgynDB Enterprise, built on Apache Trafodion (Incubating) implementation with licensed
Introduction to Big Data. Hadoop. Instituto Politécnico de Tomar. Ricardo Campos
 Instituto Politécnico de Tomar Introduction to Big Data Hadoop Ricardo Campos Mestrado EI-IC Análise e Processamento de Grandes Volumes de Dados Tomar, Portugal, 2016 Part of the slides used in this presentation
Instituto Politécnico de Tomar Introduction to Big Data Hadoop Ricardo Campos Mestrado EI-IC Análise e Processamento de Grandes Volumes de Dados Tomar, Portugal, 2016 Part of the slides used in this presentation
We are ready to serve Latest Testing Trends, Are you ready to learn?? New Batches Info
 We are ready to serve Latest Testing Trends, Are you ready to learn?? New Batches Info START DATE : TIMINGS : DURATION : TYPE OF BATCH : FEE : FACULTY NAME : LAB TIMINGS : PH NO: 9963799240, 040-40025423
We are ready to serve Latest Testing Trends, Are you ready to learn?? New Batches Info START DATE : TIMINGS : DURATION : TYPE OF BATCH : FEE : FACULTY NAME : LAB TIMINGS : PH NO: 9963799240, 040-40025423
CS370 Operating Systems
 CS370 Operating Systems Colorado State University Yashwant K Malaiya Spring 2018 Lecture 24 Mass Storage, HDFS/Hadoop Slides based on Text by Silberschatz, Galvin, Gagne Various sources 1 1 FAQ What 2
CS370 Operating Systems Colorado State University Yashwant K Malaiya Spring 2018 Lecture 24 Mass Storage, HDFS/Hadoop Slides based on Text by Silberschatz, Galvin, Gagne Various sources 1 1 FAQ What 2
CSE 444: Database Internals. Lecture 23 Spark
 CSE 444: Database Internals Lecture 23 Spark References Spark is an open source system from Berkeley Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster Computing. Matei
CSE 444: Database Internals Lecture 23 Spark References Spark is an open source system from Berkeley Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster Computing. Matei
Hadoop & Big Data Analytics Complete Practical & Real-time Training
 An ISO Certified Training Institute A Unit of Sequelgate Innovative Technologies Pvt. Ltd. www.sqlschool.com Hadoop & Big Data Analytics Complete Practical & Real-time Training Mode : Instructor Led LIVE
An ISO Certified Training Institute A Unit of Sequelgate Innovative Technologies Pvt. Ltd. www.sqlschool.com Hadoop & Big Data Analytics Complete Practical & Real-time Training Mode : Instructor Led LIVE
A Review Paper on Big data & Hadoop
 A Review Paper on Big data & Hadoop Rupali Jagadale MCA Department, Modern College of Engg. Modern College of Engginering Pune,India rupalijagadale02@gmail.com Pratibha Adkar MCA Department, Modern College
A Review Paper on Big data & Hadoop Rupali Jagadale MCA Department, Modern College of Engg. Modern College of Engginering Pune,India rupalijagadale02@gmail.com Pratibha Adkar MCA Department, Modern College
Column Stores and HBase. Rui LIU, Maksim Hrytsenia
 Column Stores and HBase Rui LIU, Maksim Hrytsenia December 2017 Contents 1 Hadoop 2 1.1 Creation................................ 2 2 HBase 3 2.1 Column Store Database....................... 3 2.2 HBase
Column Stores and HBase Rui LIU, Maksim Hrytsenia December 2017 Contents 1 Hadoop 2 1.1 Creation................................ 2 2 HBase 3 2.1 Column Store Database....................... 3 2.2 HBase
How Apache Hadoop Complements Existing BI Systems. Dr. Amr Awadallah Founder, CTO Cloudera,
 How Apache Hadoop Complements Existing BI Systems Dr. Amr Awadallah Founder, CTO Cloudera, Inc. Twitter: @awadallah, @cloudera 2 The Problems with Current Data Systems BI Reports + Interactive Apps RDBMS
How Apache Hadoop Complements Existing BI Systems Dr. Amr Awadallah Founder, CTO Cloudera, Inc. Twitter: @awadallah, @cloudera 2 The Problems with Current Data Systems BI Reports + Interactive Apps RDBMS
NoSQL Databases MongoDB vs Cassandra. Kenny Huynh, Andre Chik, Kevin Vu
 NoSQL Databases MongoDB vs Cassandra Kenny Huynh, Andre Chik, Kevin Vu Introduction - Relational database model - Concept developed in 1970 - Inefficient - NoSQL - Concept introduced in 1980 - Related
NoSQL Databases MongoDB vs Cassandra Kenny Huynh, Andre Chik, Kevin Vu Introduction - Relational database model - Concept developed in 1970 - Inefficient - NoSQL - Concept introduced in 1980 - Related
18-hdfs-gfs.txt Thu Oct 27 10:05: Notes on Parallel File Systems: HDFS & GFS , Fall 2011 Carnegie Mellon University Randal E.
 18-hdfs-gfs.txt Thu Oct 27 10:05:07 2011 1 Notes on Parallel File Systems: HDFS & GFS 15-440, Fall 2011 Carnegie Mellon University Randal E. Bryant References: Ghemawat, Gobioff, Leung, "The Google File
18-hdfs-gfs.txt Thu Oct 27 10:05:07 2011 1 Notes on Parallel File Systems: HDFS & GFS 15-440, Fall 2011 Carnegie Mellon University Randal E. Bryant References: Ghemawat, Gobioff, Leung, "The Google File
Staggeringly Large File Systems. Presented by Haoyan Geng
 Staggeringly Large File Systems Presented by Haoyan Geng Large-scale File Systems How Large? Google s file system in 2009 (Jeff Dean, LADIS 09) - 200+ clusters - Thousands of machines per cluster - Pools
Staggeringly Large File Systems Presented by Haoyan Geng Large-scale File Systems How Large? Google s file system in 2009 (Jeff Dean, LADIS 09) - 200+ clusters - Thousands of machines per cluster - Pools
The Evolving Apache Hadoop Ecosystem What it means for Storage Industry
 The Evolving Apache Hadoop Ecosystem What it means for Storage Industry Sanjay Radia Architect/Founder, Hortonworks Inc. All Rights Reserved Page 1 Outline Hadoop (HDFS) and Storage Data platform drivers
The Evolving Apache Hadoop Ecosystem What it means for Storage Industry Sanjay Radia Architect/Founder, Hortonworks Inc. All Rights Reserved Page 1 Outline Hadoop (HDFS) and Storage Data platform drivers
The Google File System
 The Google File System Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung December 2003 ACM symposium on Operating systems principles Publisher: ACM Nov. 26, 2008 OUTLINE INTRODUCTION DESIGN OVERVIEW
The Google File System Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung December 2003 ACM symposium on Operating systems principles Publisher: ACM Nov. 26, 2008 OUTLINE INTRODUCTION DESIGN OVERVIEW
Data Storage Infrastructure at Facebook
 Data Storage Infrastructure at Facebook Spring 2018 Cleveland State University CIS 601 Presentation Yi Dong Instructor: Dr. Chung Outline Strategy of data storage, processing, and log collection Data flow
Data Storage Infrastructure at Facebook Spring 2018 Cleveland State University CIS 601 Presentation Yi Dong Instructor: Dr. Chung Outline Strategy of data storage, processing, and log collection Data flow
Big Data and Cloud Computing
 Big Data and Cloud Computing Presented at Faculty of Computer Science University of Murcia Presenter: Muhammad Fahim, PhD Department of Computer Eng. Istanbul S. Zaim University, Istanbul, Turkey About
Big Data and Cloud Computing Presented at Faculty of Computer Science University of Murcia Presenter: Muhammad Fahim, PhD Department of Computer Eng. Istanbul S. Zaim University, Istanbul, Turkey About
Data Centers and Cloud Computing
 Data Centers and Cloud Computing CS677 Guest Lecture Tim Wood 1 Data Centers Large server and storage farms 1000s of servers Many TBs or PBs of data Used by Enterprises for server applications Internet
Data Centers and Cloud Computing CS677 Guest Lecture Tim Wood 1 Data Centers Large server and storage farms 1000s of servers Many TBs or PBs of data Used by Enterprises for server applications Internet
MapReduce and Friends
 MapReduce and Friends Craig C. Douglas University of Wyoming with thanks to Mookwon Seo Why was it invented? MapReduce is a mergesort for large distributed memory computers. It was the basis for a web
MapReduce and Friends Craig C. Douglas University of Wyoming with thanks to Mookwon Seo Why was it invented? MapReduce is a mergesort for large distributed memory computers. It was the basis for a web
EXTRACT DATA IN LARGE DATABASE WITH HADOOP
 International Journal of Advances in Engineering & Scientific Research (IJAESR) ISSN: 2349 3607 (Online), ISSN: 2349 4824 (Print) Download Full paper from : http://www.arseam.com/content/volume-1-issue-7-nov-2014-0
International Journal of Advances in Engineering & Scientific Research (IJAESR) ISSN: 2349 3607 (Online), ISSN: 2349 4824 (Print) Download Full paper from : http://www.arseam.com/content/volume-1-issue-7-nov-2014-0
Data Storage in the Cloud
 Data Storage in the Cloud KHALID ELGAZZAR GOODWIN 531 ELGAZZAR@CS.QUEENSU.CA Outline 1. Distributed File Systems 1.1. Google File System (GFS) 2. NoSQL Data Store 2.1. BigTable Elgazzar - CISC 886 - Fall
Data Storage in the Cloud KHALID ELGAZZAR GOODWIN 531 ELGAZZAR@CS.QUEENSU.CA Outline 1. Distributed File Systems 1.1. Google File System (GFS) 2. NoSQL Data Store 2.1. BigTable Elgazzar - CISC 886 - Fall
Accelerating Big Data: Using SanDisk SSDs for Apache HBase Workloads
 WHITE PAPER Accelerating Big Data: Using SanDisk SSDs for Apache HBase Workloads December 2014 Western Digital Technologies, Inc. 951 SanDisk Drive, Milpitas, CA 95035 www.sandisk.com Table of Contents
WHITE PAPER Accelerating Big Data: Using SanDisk SSDs for Apache HBase Workloads December 2014 Western Digital Technologies, Inc. 951 SanDisk Drive, Milpitas, CA 95035 www.sandisk.com Table of Contents
CSE6331: Cloud Computing
 CSE6331: Cloud Computing Leonidas Fegaras University of Texas at Arlington c 2019 by Leonidas Fegaras Cloud Computing Fundamentals Based on: J. Freire s class notes on Big Data http://vgc.poly.edu/~juliana/courses/bigdata2016/
CSE6331: Cloud Computing Leonidas Fegaras University of Texas at Arlington c 2019 by Leonidas Fegaras Cloud Computing Fundamentals Based on: J. Freire s class notes on Big Data http://vgc.poly.edu/~juliana/courses/bigdata2016/
Page 1. Goals for Today" Background of Cloud Computing" Sources Driving Big Data" CS162 Operating Systems and Systems Programming Lecture 24
 Goals for Today" CS162 Operating Systems and Systems Programming Lecture 24 Capstone: Cloud Computing" Distributed systems Cloud Computing programming paradigms Cloud Computing OS December 2, 2013 Anthony
Goals for Today" CS162 Operating Systems and Systems Programming Lecture 24 Capstone: Cloud Computing" Distributed systems Cloud Computing programming paradigms Cloud Computing OS December 2, 2013 Anthony
On the Varieties of Clouds for Data Intensive Computing
 On the Varieties of Clouds for Data Intensive Computing Robert L. Grossman University of Illinois at Chicago and Open Data Group Yunhong Gu University of Illinois at Chicago Abstract By a cloud we mean
On the Varieties of Clouds for Data Intensive Computing Robert L. Grossman University of Illinois at Chicago and Open Data Group Yunhong Gu University of Illinois at Chicago Abstract By a cloud we mean
Big Data Processing Technologies. Chentao Wu Associate Professor Dept. of Computer Science and Engineering
 Big Data Processing Technologies Chentao Wu Associate Professor Dept. of Computer Science and Engineering wuct@cs.sjtu.edu.cn Schedule (1) Storage system part (first eight weeks) lec1: Introduction on
Big Data Processing Technologies Chentao Wu Associate Professor Dept. of Computer Science and Engineering wuct@cs.sjtu.edu.cn Schedule (1) Storage system part (first eight weeks) lec1: Introduction on
Hadoop 2.x Core: YARN, Tez, and Spark. Hortonworks Inc All Rights Reserved
 Hadoop 2.x Core: YARN, Tez, and Spark YARN Hadoop Machine Types top-of-rack switches core switch client machines have client-side software used to access a cluster to process data master nodes run Hadoop
Hadoop 2.x Core: YARN, Tez, and Spark YARN Hadoop Machine Types top-of-rack switches core switch client machines have client-side software used to access a cluster to process data master nodes run Hadoop
Kinetic drive. Bingzhe Li
 Kinetic drive Bingzhe Li Consumption has changed It s an object storage world, unprecedented growth and scale In total, a complete redefinition of the storage stack https://www.openstack.org/summit/openstack-summit-atlanta-2014/session-videos/presentation/casestudy-seagate-kinetic-platform-in-action
Kinetic drive Bingzhe Li Consumption has changed It s an object storage world, unprecedented growth and scale In total, a complete redefinition of the storage stack https://www.openstack.org/summit/openstack-summit-atlanta-2014/session-videos/presentation/casestudy-seagate-kinetic-platform-in-action
The Google File System
 The Google File System Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung Google* 정학수, 최주영 1 Outline Introduction Design Overview System Interactions Master Operation Fault Tolerance and Diagnosis Conclusions
The Google File System Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung Google* 정학수, 최주영 1 Outline Introduction Design Overview System Interactions Master Operation Fault Tolerance and Diagnosis Conclusions
SURVEY ON BIG DATA TECHNOLOGIES
 SURVEY ON BIG DATA TECHNOLOGIES Prof. Kannadasan R. Assistant Professor Vit University, Vellore India kannadasan.r@vit.ac.in ABSTRACT Rahis Shaikh M.Tech CSE - 13MCS0045 VIT University, Vellore rais137123@gmail.com
SURVEY ON BIG DATA TECHNOLOGIES Prof. Kannadasan R. Assistant Professor Vit University, Vellore India kannadasan.r@vit.ac.in ABSTRACT Rahis Shaikh M.Tech CSE - 13MCS0045 VIT University, Vellore rais137123@gmail.com
Databases 2 (VU) ( / )
 ( / )") Databases 2 (VU) (706.711 / 707.030) MapReduce (Part 3) Mark Kröll ISDS, TU Graz Nov. 27, 2017 Mark Kröll (ISDS, TU Graz) MapReduce Nov. 27, 2017 1 / 42 Outline 1 Problems Suited for Map-Reduce 2 MapReduce:
Databases 2 (VU) (706.711 / 707.030) MapReduce (Part 3) Mark Kröll ISDS, TU Graz Nov. 27, 2017 Mark Kröll (ISDS, TU Graz) MapReduce Nov. 27, 2017 1 / 42 Outline 1 Problems Suited for Map-Reduce 2 MapReduce:
Timeline Dec 2004: Dean/Ghemawat (Google) MapReduce paper 2005: Doug Cutting and Mike Cafarella (Yahoo) create Hadoop, at first only to extend Nutch (
 MapReduce paper 2005: Doug Cutting and Mike Cafarella (Yahoo) create Hadoop, at first only to extend Nutch (") HADOOP Lecture 5 Timeline Dec 2004: Dean/Ghemawat (Google) MapReduce paper 2005: Doug Cutting and Mike Cafarella (Yahoo) create Hadoop, at first only to extend Nutch (the name is derived from Doug s son
HADOOP Lecture 5 Timeline Dec 2004: Dean/Ghemawat (Google) MapReduce paper 2005: Doug Cutting and Mike Cafarella (Yahoo) create Hadoop, at first only to extend Nutch (the name is derived from Doug s son
50 Must Read Hadoop Interview Questions & Answers
 50 Must Read Hadoop Interview Questions & Answers Whizlabs Dec 29th, 2017 Big Data Are you planning to land a job with big data and data analytics? Are you worried about cracking the Hadoop job interview?
50 Must Read Hadoop Interview Questions & Answers Whizlabs Dec 29th, 2017 Big Data Are you planning to land a job with big data and data analytics? Are you worried about cracking the Hadoop job interview?
INTERNATIONAL JOURNAL OF PURE AND APPLIED RESEARCH IN ENGINEERING AND TECHNOLOGY
 INTERNATIONAL JOURNAL OF PURE AND APPLIED RESEARCH IN ENGINEERING AND TECHNOLOGY A PATH FOR HORIZING YOUR INNOVATIVE WORK BIG DATA ANALYSIS ISSUES AND EVOLUTION OF HADOOP SURAJIT DAS, DR. DINESH GOPALANI
INTERNATIONAL JOURNAL OF PURE AND APPLIED RESEARCH IN ENGINEERING AND TECHNOLOGY A PATH FOR HORIZING YOUR INNOVATIVE WORK BIG DATA ANALYSIS ISSUES AND EVOLUTION OF HADOOP SURAJIT DAS, DR. DINESH GOPALANI
CLOUD-SCALE FILE SYSTEMS
 Data Management in the Cloud CLOUD-SCALE FILE SYSTEMS 92 Google File System (GFS) Designing a file system for the Cloud design assumptions design choices Architecture GFS Master GFS Chunkservers GFS Clients
Data Management in the Cloud CLOUD-SCALE FILE SYSTEMS 92 Google File System (GFS) Designing a file system for the Cloud design assumptions design choices Architecture GFS Master GFS Chunkservers GFS Clients
Big Data Syllabus. Understanding big data and Hadoop. Limitations and Solutions of existing Data Analytics Architecture
 Big Data Syllabus Hadoop YARN Setup Programming in YARN framework j Understanding big data and Hadoop Big Data Limitations and Solutions of existing Data Analytics Architecture Hadoop Features Hadoop Ecosystem
Big Data Syllabus Hadoop YARN Setup Programming in YARN framework j Understanding big data and Hadoop Big Data Limitations and Solutions of existing Data Analytics Architecture Hadoop Features Hadoop Ecosystem