Konstantin Shvachko, Hairong Kuang, Sanjay Radia, Robert Chansler Yahoo! Sunnyvale, California USA {Shv, Hairong, SRadia,
|
|
|
- Coleen Simon
- 5 years ago
- Views:
Transcription


1 Konstantin Shvachko, Hairong Kuang, Sanjay Radia, Robert Chansler Yahoo! Sunnyvale, California USA {Shv, Hairong, SRadia, Presenter: Alex Hu

2 } Introduction } Architecture } File I/O Operations and Replica Management } Practice at YAHOO! } Future Work } Critiques and Discussion
3 } What is Hadoop? Provide a distributed file system and a framework Analysis and transformation of very large data set MapReduce
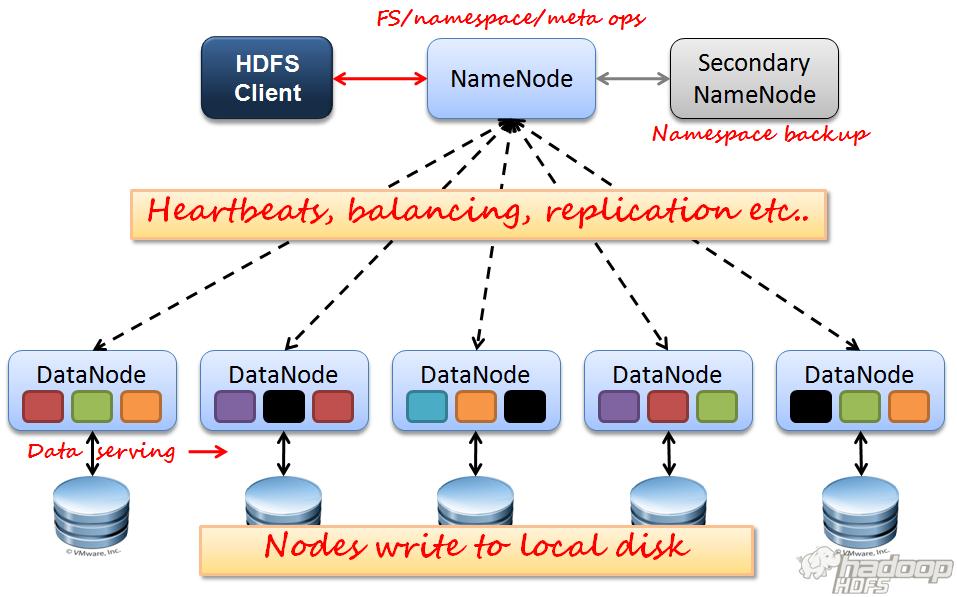
4 } What is Hadoop Distributed File System (HDFS)? File system component of Hadoop Store metadata on a dedicated server NameNode Store application data on other servers DataNode TCP-based protocols Replication for reliability Multiply data transfer bandwidth for durability
5 } NameNode } DataNodes } HDFS Client } Image Journal } CheckpointNode } BackupNode } Upgrade, File System Snapshots
6
7 } Maintain The HDFS namespace, a hierarchy of files and directories represented by inodes } Maintain the mapping of file blocks to DataNodes Read: ask NameNode for the location Write: ask NameNode to nominate DataNodes } Image and Journal } Checkpoint: native files store persistent record of images (no location)

8 } Two files to represent a block replica on DN The data itself length flexible Checksums and generation stamp } Handshake when connect to the NameNode Verify namespace ID and software version New DN can get one namespace ID when join } Register with NameNode Storage ID is assigned and never changes Storage ID is a unique internal identifier
9 } Block report: identify block replicas Block ID, the generation stamp, and the length Send first when register and then send per hour } Heartbeats: message to indicate availability Default interval is three seconds DN is considered dead if not received in 10 mins Contains Information for space allocation and load balancing Storage capacity Fraction of storage in use Number of data transfers currently in progress NN replies with instructions to the DN Keep frequent. Scalability

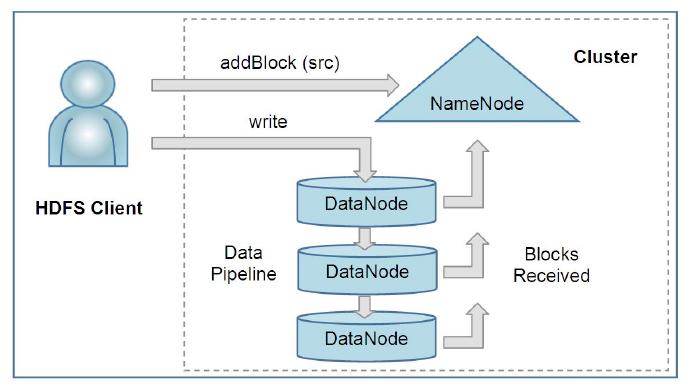
10 } A code library exports HDFS interface } Read a file Ask for a list of DN host replicas of the blocks Contact a DN directly and request transfer } Write a file Ask NN to choose DNs to host replicas of the first block of the file Organize a pipeline and send the data Iteration } Delete a file and create/delete directory } Various APIs Schedule tasks to where the data are located Set replication factor (number of replicas)
11
12 } Image: metadata describe organization Persistent record is called checkpoint Checkpoint is never changed, and can be replaced } Journal: log for persistence changes Flushed and synched before change is committed } Store in multiple places to prevent missing NN shut down if no place is available } Bottleneck: threads wait for flush-and-sync Solution: batch
13 } CheckpointNode is NameNode } Runs on different host } Create new checkpoint Download current checkpoint and journal Merge Create new and return to NameNode NameNode truncate the tail of the journal } Challenge: large journal makes restart slow Solution: create a daily checkpoint

14 } Recent feature } Similar to CheckpointNode } Maintain an in memory, up-to-date image Create checkpoint without downloading } Journal store } Read-only NameNode All metadata information except block locations No modification

15 } Minimize damage to data during upgrade } Only one can exist } NameNode Merge current checkpoint and journal in memory Create new checkpoint and journal in a new place Instruct DataNodes to create a local snapshot } DataNode Create a copy of storage directory Hard link existing block files
16 } NameNode recovers the checkpoint } DataNode resotres directory and delete replicas after snapshot is created } The layout version stored on both NN and DN Identify the data representation formats Prevent inconsistent format } Snapshot creation is all-cluster effort Prevent data loss

17 } File Read and Write } Block Placement and Replication management } Other features
18 } Checksum Read by the HDFS client to detect any corruption DataNode store checksum in a separate place Ship to client when perform HDFS read Clients verify checksum } Choose the closet replica to read } Read fail due to Unavailable DataNode A replica of the block is no longer hosted Replica is corrupted } Read while writing: ask for the latest length
19 } New data can only be appended } Single-writer, multiple-reader } Lease Who open a file for writing is granted a lease Renewed by heartbeats and revoked when closed Soft limit and hard limit Many readers are allowed to read } Optimized for sequential reads and writes Can be improved Scribe: provide real-time data streaming Hbase: provide random, real-time access to large tables

20 Unique block ID Perform write operation new change is not guaranteed to be visible The hflush hflush

21 } Not practical to connect all nodes } Spread across multiple racks Communication has to go through multiple switches Inter-rack and intra-rack Shorter distance, greater bandwidth } NameNode decides the rack of a DataNode Configure script
22 } Improve data reliability, availability and network bandwidth utilization } Minimize write cost } Reduce inter-rack and inter-node write } Rule1: No Datanode contains more than one replica of any block } Rule2: No rack contains more than two replicas of the same block, provided there are sufficient racks on the cluster
23 } Detected by NameNode } Under-replicated Priority queue (node with one replica has the highest) Similar to replication replacement policy } Over-replicated Remove the old replica Not reduce the number of racks
24 } Balancer Balance disk space usage Bandwidth consuming control } Block Scanner Verification of the replica Corrupted replica is not deleted immediately } Decommissioning Include and exclude lists Re-evaluate lists Remove decommissioning DataNode only if all blocks on it are replicated } Inter-Cluster Data Copy DistCp MapReduce job

25 } 3500 nodes and 9.8PB of storage available } Durability of Data Uncorrelated node failures Chance of losing a block during one year: <.5% Chance of node fail each month:.8% Correlated node failures Failure of rack or switch Loss of electrical power } Caring for the commons Permissions modeled on UNIX Total space available



26 DFSIO benchmark } } DFSIO Read: 66MB/s per node DFISO Write: 40MB/s per node Production cluster } } Busy Cluster Read: 1.02MB/s per node Busy Cluster Write: 1.09MB/s per node Sort benchmark Operation Benchmark
27 } Automated failover solution Zookeeper } Scalability Multiple namespaces to share physical storage Advantage Isolate namespaces Improve overall availability Generalizes the block storage abstraction Drawback Cost of management Job-centric namespaces rather than cluster centric
28 } Pros Architecture: NameNode, DataNode, and powerful features to provide kinds of operations, detect corrupted replica, balance disk space usage and provide consistency. HDFS is easy to use: users don t have to worry about different servers. It can be used as local file system to provide various operations Benchmarks are sufficient. They use real data with large number of nodes and storage to provide kinds of experiments. } Cons Fault tolerance is not very sophisticated. All the recoveries introduced are based on the assumption that NameNode is alive. No proper solution currently in this paper handles the failure of NameNode Scalability, especially the handling of replying heartbeats with instructions. If there are too many messages come in, the performance of NameNode is not proper measured in this paper The test of correlated failure is not provided. We can t get any information of the performance of HDFS after correlated failure is encountered.
29 } Thank you very much
The Hadoop Distributed File System Konstantin Shvachko Hairong Kuang Sanjay Radia Robert Chansler
 The Hadoop Distributed File System Konstantin Shvachko Hairong Kuang Sanjay Radia Robert Chansler MSST 10 Hadoop in Perspective Hadoop scales computation capacity, storage capacity, and I/O bandwidth by
The Hadoop Distributed File System Konstantin Shvachko Hairong Kuang Sanjay Radia Robert Chansler MSST 10 Hadoop in Perspective Hadoop scales computation capacity, storage capacity, and I/O bandwidth by
CLOUD-SCALE FILE SYSTEMS
 Data Management in the Cloud CLOUD-SCALE FILE SYSTEMS 92 Google File System (GFS) Designing a file system for the Cloud design assumptions design choices Architecture GFS Master GFS Chunkservers GFS Clients
Data Management in the Cloud CLOUD-SCALE FILE SYSTEMS 92 Google File System (GFS) Designing a file system for the Cloud design assumptions design choices Architecture GFS Master GFS Chunkservers GFS Clients
Google File System (GFS) and Hadoop Distributed File System (HDFS)
 and Hadoop Distributed File System (HDFS)") Google File System (GFS) and Hadoop Distributed File System (HDFS) 1 Hadoop: Architectural Design Principles Linear scalability More nodes can do more work within the same time Linear on data size, linear
Google File System (GFS) and Hadoop Distributed File System (HDFS) 1 Hadoop: Architectural Design Principles Linear scalability More nodes can do more work within the same time Linear on data size, linear
Yuval Carmel Tel-Aviv University "Advanced Topics in Storage Systems" - Spring 2013
 Yuval Carmel Tel-Aviv University "Advanced Topics in About & Keywords Motivation & Purpose Assumptions Architecture overview & Comparison Measurements How does it fit in? The Future 2 About & Keywords
Yuval Carmel Tel-Aviv University "Advanced Topics in About & Keywords Motivation & Purpose Assumptions Architecture overview & Comparison Measurements How does it fit in? The Future 2 About & Keywords
HDFS Design Principles
 HDFS Design Principles The Scale-out-Ability of Distributed Storage SVForum Software Architecture & Platform SIG Konstantin V. Shvachko May 23, 2012 Big Data Computations that need the power of many computers
HDFS Design Principles The Scale-out-Ability of Distributed Storage SVForum Software Architecture & Platform SIG Konstantin V. Shvachko May 23, 2012 Big Data Computations that need the power of many computers
The Google File System. Alexandru Costan
 1 The Google File System Alexandru Costan Actions on Big Data 2 Storage Analysis Acquisition Handling the data stream Data structured unstructured semi-structured Results Transactions Outline File systems
1 The Google File System Alexandru Costan Actions on Big Data 2 Storage Analysis Acquisition Handling the data stream Data structured unstructured semi-structured Results Transactions Outline File systems
18-hdfs-gfs.txt Thu Oct 27 10:05: Notes on Parallel File Systems: HDFS & GFS , Fall 2011 Carnegie Mellon University Randal E.
 18-hdfs-gfs.txt Thu Oct 27 10:05:07 2011 1 Notes on Parallel File Systems: HDFS & GFS 15-440, Fall 2011 Carnegie Mellon University Randal E. Bryant References: Ghemawat, Gobioff, Leung, "The Google File
18-hdfs-gfs.txt Thu Oct 27 10:05:07 2011 1 Notes on Parallel File Systems: HDFS & GFS 15-440, Fall 2011 Carnegie Mellon University Randal E. Bryant References: Ghemawat, Gobioff, Leung, "The Google File
18-hdfs-gfs.txt Thu Nov 01 09:53: Notes on Parallel File Systems: HDFS & GFS , Fall 2012 Carnegie Mellon University Randal E.
 18-hdfs-gfs.txt Thu Nov 01 09:53:32 2012 1 Notes on Parallel File Systems: HDFS & GFS 15-440, Fall 2012 Carnegie Mellon University Randal E. Bryant References: Ghemawat, Gobioff, Leung, "The Google File
18-hdfs-gfs.txt Thu Nov 01 09:53:32 2012 1 Notes on Parallel File Systems: HDFS & GFS 15-440, Fall 2012 Carnegie Mellon University Randal E. Bryant References: Ghemawat, Gobioff, Leung, "The Google File
HDFS Architecture. Gregory Kesden, CSE-291 (Storage Systems) Fall 2017
 Fall 2017") HDFS Architecture Gregory Kesden, CSE-291 (Storage Systems) Fall 2017 Based Upon: http://hadoop.apache.org/docs/r3.0.0-alpha1/hadoopproject-dist/hadoop-hdfs/hdfsdesign.html Assumptions At scale, hardware
HDFS Architecture Gregory Kesden, CSE-291 (Storage Systems) Fall 2017 Based Upon: http://hadoop.apache.org/docs/r3.0.0-alpha1/hadoopproject-dist/hadoop-hdfs/hdfsdesign.html Assumptions At scale, hardware
The Google File System
 October 13, 2010 Based on: S. Ghemawat, H. Gobioff, and S.-T. Leung: The Google file system, in Proceedings ACM SOSP 2003, Lake George, NY, USA, October 2003. 1 Assumptions Interface Architecture Single
October 13, 2010 Based on: S. Ghemawat, H. Gobioff, and S.-T. Leung: The Google file system, in Proceedings ACM SOSP 2003, Lake George, NY, USA, October 2003. 1 Assumptions Interface Architecture Single
HDFS Architecture Guide
 by Dhruba Borthakur Table of contents 1 Introduction...3 2 Assumptions and Goals...3 2.1 Hardware Failure... 3 2.2 Streaming Data Access...3 2.3 Large Data Sets...3 2.4 Simple Coherency Model... 4 2.5
by Dhruba Borthakur Table of contents 1 Introduction...3 2 Assumptions and Goals...3 2.1 Hardware Failure... 3 2.2 Streaming Data Access...3 2.3 Large Data Sets...3 2.4 Simple Coherency Model... 4 2.5
The Google File System
 The Google File System Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung Google* 정학수, 최주영 1 Outline Introduction Design Overview System Interactions Master Operation Fault Tolerance and Diagnosis Conclusions
The Google File System Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung Google* 정학수, 최주영 1 Outline Introduction Design Overview System Interactions Master Operation Fault Tolerance and Diagnosis Conclusions
Distributed Filesystem
 Distributed Filesystem 1 How do we get data to the workers? NAS Compute Nodes SAN 2 Distributing Code! Don t move data to workers move workers to the data! - Store data on the local disks of nodes in the
Distributed Filesystem 1 How do we get data to the workers? NAS Compute Nodes SAN 2 Distributing Code! Don t move data to workers move workers to the data! - Store data on the local disks of nodes in the
Automatic-Hot HA for HDFS NameNode Konstantin V Shvachko Ari Flink Timothy Coulter EBay Cisco Aisle Five. November 11, 2011
 Automatic-Hot HA for HDFS NameNode Konstantin V Shvachko Ari Flink Timothy Coulter EBay Cisco Aisle Five November 11, 2011 About Authors Konstantin Shvachko Hadoop Architect, ebay; Hadoop Committer Ari
Automatic-Hot HA for HDFS NameNode Konstantin V Shvachko Ari Flink Timothy Coulter EBay Cisco Aisle Five November 11, 2011 About Authors Konstantin Shvachko Hadoop Architect, ebay; Hadoop Committer Ari
Hadoop and HDFS Overview. Madhu Ankam
 Hadoop and HDFS Overview Madhu Ankam Why Hadoop We are gathering more data than ever Examples of data : Server logs Web logs Financial transactions Analytics Emails and text messages Social media like
Hadoop and HDFS Overview Madhu Ankam Why Hadoop We are gathering more data than ever Examples of data : Server logs Web logs Financial transactions Analytics Emails and text messages Social media like
GFS: The Google File System. Dr. Yingwu Zhu
 GFS: The Google File System Dr. Yingwu Zhu Motivating Application: Google Crawl the whole web Store it all on one big disk Process users searches on one big CPU More storage, CPU required than one PC can
GFS: The Google File System Dr. Yingwu Zhu Motivating Application: Google Crawl the whole web Store it all on one big disk Process users searches on one big CPU More storage, CPU required than one PC can
Distributed System. Gang Wu. Spring,2018
 Distributed System Gang Wu Spring,2018 Lecture7:DFS What is DFS? A method of storing and accessing files base in a client/server architecture. A distributed file system is a client/server-based application
Distributed System Gang Wu Spring,2018 Lecture7:DFS What is DFS? A method of storing and accessing files base in a client/server architecture. A distributed file system is a client/server-based application
Distributed Systems 16. Distributed File Systems II
 Distributed Systems 16. Distributed File Systems II Paul Krzyzanowski pxk@cs.rutgers.edu 1 Review NFS RPC-based access AFS Long-term caching CODA Read/write replication & disconnected operation DFS AFS
Distributed Systems 16. Distributed File Systems II Paul Krzyzanowski pxk@cs.rutgers.edu 1 Review NFS RPC-based access AFS Long-term caching CODA Read/write replication & disconnected operation DFS AFS
MapReduce. U of Toronto, 2014
 MapReduce U of Toronto, 2014 http://www.google.org/flutrends/ca/ (2012) Average Searches Per Day: 5,134,000,000 2 Motivation Process lots of data Google processed about 24 petabytes of data per day in
MapReduce U of Toronto, 2014 http://www.google.org/flutrends/ca/ (2012) Average Searches Per Day: 5,134,000,000 2 Motivation Process lots of data Google processed about 24 petabytes of data per day in
BigData and Map Reduce VITMAC03
 BigData and Map Reduce VITMAC03 1 Motivation Process lots of data Google processed about 24 petabytes of data per day in 2009. A single machine cannot serve all the data You need a distributed system to
BigData and Map Reduce VITMAC03 1 Motivation Process lots of data Google processed about 24 petabytes of data per day in 2009. A single machine cannot serve all the data You need a distributed system to
L1:Google File System Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung ACM SOSP, 2003
 Indian Institute of Science Bangalore, India भ रत य व ज ञ न स स थ न ब गल र, भ रत Department of Computational and Data Sciences DS256:Jan18 (3:1) L1:Google File System Sanjay Ghemawat, Howard Gobioff, and
Indian Institute of Science Bangalore, India भ रत य व ज ञ न स स थ न ब गल र, भ रत Department of Computational and Data Sciences DS256:Jan18 (3:1) L1:Google File System Sanjay Ghemawat, Howard Gobioff, and
Hadoop File System S L I D E S M O D I F I E D F R O M P R E S E N T A T I O N B Y B. R A M A M U R T H Y 11/15/2017
 Hadoop File System 1 S L I D E S M O D I F I E D F R O M P R E S E N T A T I O N B Y B. R A M A M U R T H Y Moving Computation is Cheaper than Moving Data Motivation: Big Data! What is BigData? - Google
Hadoop File System 1 S L I D E S M O D I F I E D F R O M P R E S E N T A T I O N B Y B. R A M A M U R T H Y Moving Computation is Cheaper than Moving Data Motivation: Big Data! What is BigData? - Google
Google File System. By Dinesh Amatya
 Google File System By Dinesh Amatya Google File System (GFS) Sanjay Ghemawat, Howard Gobioff, Shun-Tak Leung designed and implemented to meet rapidly growing demand of Google's data processing need a scalable
Google File System By Dinesh Amatya Google File System (GFS) Sanjay Ghemawat, Howard Gobioff, Shun-Tak Leung designed and implemented to meet rapidly growing demand of Google's data processing need a scalable
Google File System. Arun Sundaram Operating Systems
 Arun Sundaram Operating Systems 1 Assumptions GFS built with commodity hardware GFS stores a modest number of large files A few million files, each typically 100MB or larger (Multi-GB files are common)
Arun Sundaram Operating Systems 1 Assumptions GFS built with commodity hardware GFS stores a modest number of large files A few million files, each typically 100MB or larger (Multi-GB files are common)
The Google File System (GFS)
") 1 The Google File System (GFS) CS60002: Distributed Systems Antonio Bruto da Costa Ph.D. Student, Formal Methods Lab, Dept. of Computer Sc. & Engg., Indian Institute of Technology Kharagpur 2 Design constraints
1 The Google File System (GFS) CS60002: Distributed Systems Antonio Bruto da Costa Ph.D. Student, Formal Methods Lab, Dept. of Computer Sc. & Engg., Indian Institute of Technology Kharagpur 2 Design constraints
The Google File System
 The Google File System Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung December 2003 ACM symposium on Operating systems principles Publisher: ACM Nov. 26, 2008 OUTLINE INTRODUCTION DESIGN OVERVIEW
The Google File System Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung December 2003 ACM symposium on Operating systems principles Publisher: ACM Nov. 26, 2008 OUTLINE INTRODUCTION DESIGN OVERVIEW
Distributed File Systems II
 Distributed File Systems II To do q Very-large scale: Google FS, Hadoop FS, BigTable q Next time: Naming things GFS A radically new environment NFS, etc. Independence Small Scale Variety of workloads Cooperation
Distributed File Systems II To do q Very-large scale: Google FS, Hadoop FS, BigTable q Next time: Naming things GFS A radically new environment NFS, etc. Independence Small Scale Variety of workloads Cooperation
A BigData Tour HDFS, Ceph and MapReduce
 A BigData Tour HDFS, Ceph and MapReduce These slides are possible thanks to these sources Jonathan Drusi - SCInet Toronto Hadoop Tutorial, Amir Payberah - Course in Data Intensive Computing SICS; Yahoo!
A BigData Tour HDFS, Ceph and MapReduce These slides are possible thanks to these sources Jonathan Drusi - SCInet Toronto Hadoop Tutorial, Amir Payberah - Course in Data Intensive Computing SICS; Yahoo!
! Design constraints. " Component failures are the norm. " Files are huge by traditional standards. ! POSIX-like
 Cloud background Google File System! Warehouse scale systems " 10K-100K nodes " 50MW (1 MW = 1,000 houses) " Power efficient! Located near cheap power! Passive cooling! Power Usage Effectiveness = Total
Cloud background Google File System! Warehouse scale systems " 10K-100K nodes " 50MW (1 MW = 1,000 houses) " Power efficient! Located near cheap power! Passive cooling! Power Usage Effectiveness = Total
Namenode HA. Sanjay Radia - Hortonworks
 Namenode HA Sanjay Radia - Hortonworks Sanjay Radia - Background Working on Hadoop for the last 4 years Part of the original team at Yahoo Primarily worked on HDFS, MR Capacity scheduler wire protocols,
Namenode HA Sanjay Radia - Hortonworks Sanjay Radia - Background Working on Hadoop for the last 4 years Part of the original team at Yahoo Primarily worked on HDFS, MR Capacity scheduler wire protocols,
GFS: The Google File System
 GFS: The Google File System Brad Karp UCL Computer Science CS GZ03 / M030 24 th October 2014 Motivating Application: Google Crawl the whole web Store it all on one big disk Process users searches on one
GFS: The Google File System Brad Karp UCL Computer Science CS GZ03 / M030 24 th October 2014 Motivating Application: Google Crawl the whole web Store it all on one big disk Process users searches on one
The Google File System
 The Google File System Sanjay Ghemawat, Howard Gobioff and Shun Tak Leung Google* Shivesh Kumar Sharma fl4164@wayne.edu Fall 2015 004395771 Overview Google file system is a scalable distributed file system
The Google File System Sanjay Ghemawat, Howard Gobioff and Shun Tak Leung Google* Shivesh Kumar Sharma fl4164@wayne.edu Fall 2015 004395771 Overview Google file system is a scalable distributed file system
Distributed Systems. 15. Distributed File Systems. Paul Krzyzanowski. Rutgers University. Fall 2017
 Distributed Systems 15. Distributed File Systems Paul Krzyzanowski Rutgers University Fall 2017 1 Google Chubby ( Apache Zookeeper) 2 Chubby Distributed lock service + simple fault-tolerant file system
Distributed Systems 15. Distributed File Systems Paul Krzyzanowski Rutgers University Fall 2017 1 Google Chubby ( Apache Zookeeper) 2 Chubby Distributed lock service + simple fault-tolerant file system
The Google File System
 The Google File System Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung Google SOSP 03, October 19 22, 2003, New York, USA Hyeon-Gyu Lee, and Yeong-Jae Woo Memory & Storage Architecture Lab. School
The Google File System Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung Google SOSP 03, October 19 22, 2003, New York, USA Hyeon-Gyu Lee, and Yeong-Jae Woo Memory & Storage Architecture Lab. School
Authors : Sanjay Ghemawat, Howard Gobioff, Shun-Tak Leung Presentation by: Vijay Kumar Chalasani
 The Authors : Sanjay Ghemawat, Howard Gobioff, Shun-Tak Leung Presentation by: Vijay Kumar Chalasani CS5204 Operating Systems 1 Introduction GFS is a scalable distributed file system for large data intensive
The Authors : Sanjay Ghemawat, Howard Gobioff, Shun-Tak Leung Presentation by: Vijay Kumar Chalasani CS5204 Operating Systems 1 Introduction GFS is a scalable distributed file system for large data intensive
Google File System. Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung Google fall DIP Heerak lim, Donghun Koo
 Google File System Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung Google 2017 fall DIP Heerak lim, Donghun Koo 1 Agenda Introduction Design overview Systems interactions Master operation Fault tolerance
Google File System Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung Google 2017 fall DIP Heerak lim, Donghun Koo 1 Agenda Introduction Design overview Systems interactions Master operation Fault tolerance
CS /30/17. Paul Krzyzanowski 1. Google Chubby ( Apache Zookeeper) Distributed Systems. Chubby. Chubby Deployment.
 Distributed Systems. Chubby. Chubby Deployment.") Distributed Systems 15. Distributed File Systems Google ( Apache Zookeeper) Paul Krzyzanowski Rutgers University Fall 2017 1 2 Distributed lock service + simple fault-tolerant file system Deployment Client
Distributed Systems 15. Distributed File Systems Google ( Apache Zookeeper) Paul Krzyzanowski Rutgers University Fall 2017 1 2 Distributed lock service + simple fault-tolerant file system Deployment Client
UNIT-IV HDFS. Ms. Selva Mary. G
 UNIT-IV HDFS HDFS ARCHITECTURE Dataset partition across a number of separate machines Hadoop Distributed File system The Design of HDFS HDFS is a file system designed for storing very large files with
UNIT-IV HDFS HDFS ARCHITECTURE Dataset partition across a number of separate machines Hadoop Distributed File system The Design of HDFS HDFS is a file system designed for storing very large files with
ECE 7650 Scalable and Secure Internet Services and Architecture ---- A Systems Perspective
 ECE 7650 Scalable and Secure Internet Services and Architecture ---- A Systems Perspective Part II: Data Center Software Architecture: Topic 1: Distributed File Systems GFS (The Google File System) 1 Filesystems
ECE 7650 Scalable and Secure Internet Services and Architecture ---- A Systems Perspective Part II: Data Center Software Architecture: Topic 1: Distributed File Systems GFS (The Google File System) 1 Filesystems
The Google File System
 The Google File System Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung SOSP 2003 presented by Kun Suo Outline GFS Background, Concepts and Key words Example of GFS Operations Some optimizations in
The Google File System Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung SOSP 2003 presented by Kun Suo Outline GFS Background, Concepts and Key words Example of GFS Operations Some optimizations in
Distributed Systems. 15. Distributed File Systems. Paul Krzyzanowski. Rutgers University. Fall 2016
 Distributed Systems 15. Distributed File Systems Paul Krzyzanowski Rutgers University Fall 2016 1 Google Chubby 2 Chubby Distributed lock service + simple fault-tolerant file system Interfaces File access
Distributed Systems 15. Distributed File Systems Paul Krzyzanowski Rutgers University Fall 2016 1 Google Chubby 2 Chubby Distributed lock service + simple fault-tolerant file system Interfaces File access
CSE 124: Networked Services Fall 2009 Lecture-19
 CSE 124: Networked Services Fall 2009 Lecture-19 Instructor: B. S. Manoj, Ph.D http://cseweb.ucsd.edu/classes/fa09/cse124 Some of these slides are adapted from various sources/individuals including but
CSE 124: Networked Services Fall 2009 Lecture-19 Instructor: B. S. Manoj, Ph.D http://cseweb.ucsd.edu/classes/fa09/cse124 Some of these slides are adapted from various sources/individuals including but
CSE 124: Networked Services Lecture-16
 Fall 2010 CSE 124: Networked Services Lecture-16 Instructor: B. S. Manoj, Ph.D http://cseweb.ucsd.edu/classes/fa10/cse124 11/23/2010 CSE 124 Networked Services Fall 2010 1 Updates PlanetLab experiments
Fall 2010 CSE 124: Networked Services Lecture-16 Instructor: B. S. Manoj, Ph.D http://cseweb.ucsd.edu/classes/fa10/cse124 11/23/2010 CSE 124 Networked Services Fall 2010 1 Updates PlanetLab experiments
TI2736-B Big Data Processing. Claudia Hauff
 TI2736-B Big Data Processing Claudia Hauff ti2736b-ewi@tudelft.nl Intro Streams Streams Map Reduce HDFS Pig Pig Design Pattern Hadoop Mix Graphs Giraph Spark Zoo Keeper Spark But first Partitioner & Combiner
TI2736-B Big Data Processing Claudia Hauff ti2736b-ewi@tudelft.nl Intro Streams Streams Map Reduce HDFS Pig Pig Design Pattern Hadoop Mix Graphs Giraph Spark Zoo Keeper Spark But first Partitioner & Combiner
CS435 Introduction to Big Data FALL 2018 Colorado State University. 11/7/2018 Week 12-B Sangmi Lee Pallickara. FAQs
 11/7/2018 CS435 Introduction to Big Data - FALL 2018 W12.B.0.0 CS435 Introduction to Big Data 11/7/2018 CS435 Introduction to Big Data - FALL 2018 W12.B.1 FAQs Deadline of the Programming Assignment 3
11/7/2018 CS435 Introduction to Big Data - FALL 2018 W12.B.0.0 CS435 Introduction to Big Data 11/7/2018 CS435 Introduction to Big Data - FALL 2018 W12.B.1 FAQs Deadline of the Programming Assignment 3
HDFS Federation. Sanjay Radia Founder and Hortonworks. Page 1
 HDFS Federation Sanjay Radia Founder and Architect @ Hortonworks Page 1 About Me Apache Hadoop Committer and Member of Hadoop PMC Architect of core-hadoop @ Yahoo - Focusing on HDFS, MapReduce scheduler,
HDFS Federation Sanjay Radia Founder and Architect @ Hortonworks Page 1 About Me Apache Hadoop Committer and Member of Hadoop PMC Architect of core-hadoop @ Yahoo - Focusing on HDFS, MapReduce scheduler,
The Google File System
 The Google File System By Ghemawat, Gobioff and Leung Outline Overview Assumption Design of GFS System Interactions Master Operations Fault Tolerance Measurements Overview GFS: Scalable distributed file
The Google File System By Ghemawat, Gobioff and Leung Outline Overview Assumption Design of GFS System Interactions Master Operations Fault Tolerance Measurements Overview GFS: Scalable distributed file
Georgia Institute of Technology ECE6102 4/20/2009 David Colvin, Jimmy Vuong
 Georgia Institute of Technology ECE6102 4/20/2009 David Colvin, Jimmy Vuong Relatively recent; still applicable today GFS: Google s storage platform for the generation and processing of data used by services
Georgia Institute of Technology ECE6102 4/20/2009 David Colvin, Jimmy Vuong Relatively recent; still applicable today GFS: Google s storage platform for the generation and processing of data used by services
CS60021: Scalable Data Mining. Sourangshu Bhattacharya
 CS60021: Scalable Data Mining Sourangshu Bhattacharya In this Lecture: Outline: HDFS Motivation HDFS User commands HDFS System architecture HDFS Implementation details Sourangshu Bhattacharya Computer
CS60021: Scalable Data Mining Sourangshu Bhattacharya In this Lecture: Outline: HDFS Motivation HDFS User commands HDFS System architecture HDFS Implementation details Sourangshu Bhattacharya Computer
Lecture 11 Hadoop & Spark
 Lecture 11 Hadoop & Spark Dr. Wilson Rivera ICOM 6025: High Performance Computing Electrical and Computer Engineering Department University of Puerto Rico Outline Distributed File Systems Hadoop Ecosystem
Lecture 11 Hadoop & Spark Dr. Wilson Rivera ICOM 6025: High Performance Computing Electrical and Computer Engineering Department University of Puerto Rico Outline Distributed File Systems Hadoop Ecosystem
4/9/2018 Week 13-A Sangmi Lee Pallickara. CS435 Introduction to Big Data Spring 2018 Colorado State University. FAQs. Architecture of GFS
 W13.A.0.0 CS435 Introduction to Big Data W13.A.1 FAQs Programming Assignment 3 has been posted PART 2. LARGE SCALE DATA STORAGE SYSTEMS DISTRIBUTED FILE SYSTEMS Recitations Apache Spark tutorial 1 and
W13.A.0.0 CS435 Introduction to Big Data W13.A.1 FAQs Programming Assignment 3 has been posted PART 2. LARGE SCALE DATA STORAGE SYSTEMS DISTRIBUTED FILE SYSTEMS Recitations Apache Spark tutorial 1 and
7680: Distributed Systems
 Cristina Nita-Rotaru 7680: Distributed Systems GFS. HDFS Required Reading } Google File System. S, Ghemawat, H. Gobioff and S.-T. Leung. SOSP 2003. } http://hadoop.apache.org } A Novel Approach to Improving
Cristina Nita-Rotaru 7680: Distributed Systems GFS. HDFS Required Reading } Google File System. S, Ghemawat, H. Gobioff and S.-T. Leung. SOSP 2003. } http://hadoop.apache.org } A Novel Approach to Improving
CPSC 426/526. Cloud Computing. Ennan Zhai. Computer Science Department Yale University
 CPSC 426/526 Cloud Computing Ennan Zhai Computer Science Department Yale University Recall: Lec-7 In the lec-7, I talked about: - P2P vs Enterprise control - Firewall - NATs - Software defined network
CPSC 426/526 Cloud Computing Ennan Zhai Computer Science Department Yale University Recall: Lec-7 In the lec-7, I talked about: - P2P vs Enterprise control - Firewall - NATs - Software defined network
Distributed Systems. GFS / HDFS / Spanner
 15-440 Distributed Systems GFS / HDFS / Spanner Agenda Google File System (GFS) Hadoop Distributed File System (HDFS) Distributed File Systems Replication Spanner Distributed Database System Paxos Replication
15-440 Distributed Systems GFS / HDFS / Spanner Agenda Google File System (GFS) Hadoop Distributed File System (HDFS) Distributed File Systems Replication Spanner Distributed Database System Paxos Replication
NPTEL Course Jan K. Gopinath Indian Institute of Science
 Storage Systems NPTEL Course Jan 2012 (Lecture 39) K. Gopinath Indian Institute of Science Google File System Non-Posix scalable distr file system for large distr dataintensive applications performance,
Storage Systems NPTEL Course Jan 2012 (Lecture 39) K. Gopinath Indian Institute of Science Google File System Non-Posix scalable distr file system for large distr dataintensive applications performance,
NPTEL Course Jan K. Gopinath Indian Institute of Science
 Storage Systems NPTEL Course Jan 2012 (Lecture 41) K. Gopinath Indian Institute of Science Lease Mgmt designed to minimize mgmt overhead at master a lease initially times out at 60 secs. primary can request
Storage Systems NPTEL Course Jan 2012 (Lecture 41) K. Gopinath Indian Institute of Science Lease Mgmt designed to minimize mgmt overhead at master a lease initially times out at 60 secs. primary can request
HDFS What is New and Futures
 HDFS What is New and Futures Sanjay Radia, Founder, Architect Suresh Srinivas, Founder, Architect Hortonworks Inc. Page 1 About me Founder, Architect, Hortonworks Part of the Hadoop team at Yahoo! since
HDFS What is New and Futures Sanjay Radia, Founder, Architect Suresh Srinivas, Founder, Architect Hortonworks Inc. Page 1 About me Founder, Architect, Hortonworks Part of the Hadoop team at Yahoo! since
Cloudera Exam CCA-410 Cloudera Certified Administrator for Apache Hadoop (CCAH) Version: 7.5 [ Total Questions: 97 ]
![Cloudera Exam CCA-410 Cloudera Certified Administrator for Apache Hadoop (CCAH) Version: 7.5 [ Total Questions: 97 ]](/thumbs/96/126854374.jpg "Cloudera Exam CCA-410 Cloudera Certified Administrator for Apache Hadoop (CCAH) Version: 7.5 [ Total Questions: 97 ]") s@lm@n Cloudera Exam CCA-410 Cloudera Certified Administrator for Apache Hadoop (CCAH) Version: 7.5 [ Total Questions: 97 ] Question No : 1 Which two updates occur when a client application opens a stream
s@lm@n Cloudera Exam CCA-410 Cloudera Certified Administrator for Apache Hadoop (CCAH) Version: 7.5 [ Total Questions: 97 ] Question No : 1 Which two updates occur when a client application opens a stream
The Google File System
 The Google File System Sanjay Ghemawat, Howard Gobioff, Shun-Tak Leung ACM SIGOPS 2003 {Google Research} Vaibhav Bajpai NDS Seminar 2011 Looking Back time Classics Sun NFS (1985) CMU Andrew FS (1988) Fault
The Google File System Sanjay Ghemawat, Howard Gobioff, Shun-Tak Leung ACM SIGOPS 2003 {Google Research} Vaibhav Bajpai NDS Seminar 2011 Looking Back time Classics Sun NFS (1985) CMU Andrew FS (1988) Fault
TITLE: PRE-REQUISITE THEORY. 1. Introduction to Hadoop. 2. Cluster. Implement sort algorithm and run it using HADOOP
 TITLE: Implement sort algorithm and run it using HADOOP PRE-REQUISITE Preliminary knowledge of clusters and overview of Hadoop and its basic functionality. THEORY 1. Introduction to Hadoop The Apache Hadoop
TITLE: Implement sort algorithm and run it using HADOOP PRE-REQUISITE Preliminary knowledge of clusters and overview of Hadoop and its basic functionality. THEORY 1. Introduction to Hadoop The Apache Hadoop
Cloud Computing and Hadoop Distributed File System. UCSB CS170, Spring 2018
 Cloud Computing and Hadoop Distributed File System UCSB CS70, Spring 08 Cluster Computing Motivations Large-scale data processing on clusters Scan 000 TB on node @ 00 MB/s = days Scan on 000-node cluster
Cloud Computing and Hadoop Distributed File System UCSB CS70, Spring 08 Cluster Computing Motivations Large-scale data processing on clusters Scan 000 TB on node @ 00 MB/s = days Scan on 000-node cluster
GFS Overview. Design goals/priorities Design for big-data workloads Huge files, mostly appends, concurrency, huge bandwidth Design for failures
 GFS Overview Design goals/priorities Design for big-data workloads Huge files, mostly appends, concurrency, huge bandwidth Design for failures Interface: non-posix New op: record appends (atomicity matters,
GFS Overview Design goals/priorities Design for big-data workloads Huge files, mostly appends, concurrency, huge bandwidth Design for failures Interface: non-posix New op: record appends (atomicity matters,
CA485 Ray Walshe Google File System
 Google File System Overview Google File System is scalable, distributed file system on inexpensive commodity hardware that provides: Fault Tolerance File system runs on hundreds or thousands of storage
Google File System Overview Google File System is scalable, distributed file system on inexpensive commodity hardware that provides: Fault Tolerance File system runs on hundreds or thousands of storage
Dept. Of Computer Science, Colorado State University
 CS 455: INTRODUCTION TO DISTRIBUTED SYSTEMS [HADOOP/HDFS] Trying to have your cake and eat it too Each phase pines for tasks with locality and their numbers on a tether Alas within a phase, you get one,
CS 455: INTRODUCTION TO DISTRIBUTED SYSTEMS [HADOOP/HDFS] Trying to have your cake and eat it too Each phase pines for tasks with locality and their numbers on a tether Alas within a phase, you get one,
Introduction to Hadoop. Owen O Malley Yahoo!, Grid Team
 Introduction to Hadoop Owen O Malley Yahoo!, Grid Team owen@yahoo-inc.com Who Am I? Yahoo! Architect on Hadoop Map/Reduce Design, review, and implement features in Hadoop Working on Hadoop full time since
Introduction to Hadoop Owen O Malley Yahoo!, Grid Team owen@yahoo-inc.com Who Am I? Yahoo! Architect on Hadoop Map/Reduce Design, review, and implement features in Hadoop Working on Hadoop full time since
FLAT DATACENTER STORAGE CHANDNI MODI (FN8692)
") FLAT DATACENTER STORAGE CHANDNI MODI (FN8692) OUTLINE Flat datacenter storage Deterministic data placement in fds Metadata properties of fds Per-blob metadata in fds Dynamic Work Allocation in fds Replication
FLAT DATACENTER STORAGE CHANDNI MODI (FN8692) OUTLINE Flat datacenter storage Deterministic data placement in fds Metadata properties of fds Per-blob metadata in fds Dynamic Work Allocation in fds Replication
11/5/2018 Week 12-A Sangmi Lee Pallickara. CS435 Introduction to Big Data FALL 2018 Colorado State University
 11/5/2018 CS435 Introduction to Big Data - FALL 2018 W12.A.0.0 CS435 Introduction to Big Data 11/5/2018 CS435 Introduction to Big Data - FALL 2018 W12.A.1 Consider a Graduate Degree in Computer Science
11/5/2018 CS435 Introduction to Big Data - FALL 2018 W12.A.0.0 CS435 Introduction to Big Data 11/5/2018 CS435 Introduction to Big Data - FALL 2018 W12.A.1 Consider a Graduate Degree in Computer Science
9/26/2017 Sangmi Lee Pallickara Week 6- A. CS535 Big Data Fall 2017 Colorado State University
 CS535 Big Data - Fall 2017 Week 6-A-1 CS535 BIG DATA FAQs PA1: Use only one word query Deadends {{Dead end}} Hub value will be?? PART 1. BATCH COMPUTING MODEL FOR BIG DATA ANALYTICS 4. GOOGLE FILE SYSTEM
CS535 Big Data - Fall 2017 Week 6-A-1 CS535 BIG DATA FAQs PA1: Use only one word query Deadends {{Dead end}} Hub value will be?? PART 1. BATCH COMPUTING MODEL FOR BIG DATA ANALYTICS 4. GOOGLE FILE SYSTEM
Hadoop Distributed File System(HDFS)
") Hadoop Distributed File System(HDFS) Bu eğitim sunumları İstanbul Kalkınma Ajansı nın 2016 yılı Yenilikçi ve Yaratıcı İstanbul Mali Destek Programı kapsamında yürütülmekte olan TR10/16/YNY/0036 no lu İstanbul
Hadoop Distributed File System(HDFS) Bu eğitim sunumları İstanbul Kalkınma Ajansı nın 2016 yılı Yenilikçi ve Yaratıcı İstanbul Mali Destek Programı kapsamında yürütülmekte olan TR10/16/YNY/0036 no lu İstanbul
HARDFS: Hardening HDFS with Selective and Lightweight Versioning
 HARDFS: Hardening HDFS with Selective and Lightweight Versioning Thanh Do, Tyler Harter, Yingchao Liu, Andrea C. Arpaci-Dusseau, and Remzi H. Arpaci-Dusseau Haryadi S. Gunawi 1 Cloud Reliability q Cloud
HARDFS: Hardening HDFS with Selective and Lightweight Versioning Thanh Do, Tyler Harter, Yingchao Liu, Andrea C. Arpaci-Dusseau, and Remzi H. Arpaci-Dusseau Haryadi S. Gunawi 1 Cloud Reliability q Cloud
The Google File System GFS
 The Google File System GFS Common Goals of GFS and most Distributed File Systems Performance Reliability Scalability Availability Other GFS Concepts Component failures are the norm rather than the exception.
The Google File System GFS Common Goals of GFS and most Distributed File Systems Performance Reliability Scalability Availability Other GFS Concepts Component failures are the norm rather than the exception.
The Evolving Apache Hadoop Ecosystem What it means for Storage Industry
 The Evolving Apache Hadoop Ecosystem What it means for Storage Industry Sanjay Radia Architect/Founder, Hortonworks Inc. All Rights Reserved Page 1 Outline Hadoop (HDFS) and Storage Data platform drivers
The Evolving Apache Hadoop Ecosystem What it means for Storage Industry Sanjay Radia Architect/Founder, Hortonworks Inc. All Rights Reserved Page 1 Outline Hadoop (HDFS) and Storage Data platform drivers
Hadoop File Management System
 Volume-6, Issue-5, September-October 2016 International Journal of Engineering and Management Research Page Number: 281-286 Hadoop File Management System Swaraj Pritam Padhy 1, Sashi Bhusan Maharana 2
Volume-6, Issue-5, September-October 2016 International Journal of Engineering and Management Research Page Number: 281-286 Hadoop File Management System Swaraj Pritam Padhy 1, Sashi Bhusan Maharana 2
HADOOP FRAMEWORK FOR BIG DATA
 HADOOP FRAMEWORK FOR BIG DATA Mr K. Srinivas Babu 1,Dr K. Rameshwaraiah 2 1 Research Scholar S V University, Tirupathi 2 Professor and Head NNRESGI, Hyderabad Abstract - Data has to be stored for further
HADOOP FRAMEWORK FOR BIG DATA Mr K. Srinivas Babu 1,Dr K. Rameshwaraiah 2 1 Research Scholar S V University, Tirupathi 2 Professor and Head NNRESGI, Hyderabad Abstract - Data has to be stored for further
Flat Datacenter Storage. Edmund B. Nightingale, Jeremy Elson, et al. 6.S897
 Flat Datacenter Storage Edmund B. Nightingale, Jeremy Elson, et al. 6.S897 Motivation Imagine a world with flat data storage Simple, Centralized, and easy to program Unfortunately, datacenter networks
Flat Datacenter Storage Edmund B. Nightingale, Jeremy Elson, et al. 6.S897 Motivation Imagine a world with flat data storage Simple, Centralized, and easy to program Unfortunately, datacenter networks
Distributed Systems. Tutorial 9 Windows Azure Storage
 Distributed Systems Tutorial 9 Windows Azure Storage written by Alex Libov Based on SOSP 2011 presentation winter semester, 2011-2012 Windows Azure Storage (WAS) A scalable cloud storage system In production
Distributed Systems Tutorial 9 Windows Azure Storage written by Alex Libov Based on SOSP 2011 presentation winter semester, 2011-2012 Windows Azure Storage (WAS) A scalable cloud storage system In production
Outline. INF3190:Distributed Systems - Examples. Last week: Definitions Transparencies Challenges&pitfalls Architecturalstyles
 INF3190:Distributed Systems - Examples Thomas Plagemann & Roman Vitenberg Outline Last week: Definitions Transparencies Challenges&pitfalls Architecturalstyles Today: Examples Googel File System (Thomas)
INF3190:Distributed Systems - Examples Thomas Plagemann & Roman Vitenberg Outline Last week: Definitions Transparencies Challenges&pitfalls Architecturalstyles Today: Examples Googel File System (Thomas)
Batch Inherence of Map Reduce Framework
 Available Online at www.ijcsmc.com International Journal of Computer Science and Mobile Computing A Monthly Journal of Computer Science and Information Technology IJCSMC, Vol. 4, Issue. 6, June 2015, pg.287
Available Online at www.ijcsmc.com International Journal of Computer Science and Mobile Computing A Monthly Journal of Computer Science and Information Technology IJCSMC, Vol. 4, Issue. 6, June 2015, pg.287
Google File System and BigTable. and tiny bits of HDFS (Hadoop File System) and Chubby. Not in textbook; additional information
 and Chubby. Not in textbook; additional information") Subject 10 Fall 2015 Google File System and BigTable and tiny bits of HDFS (Hadoop File System) and Chubby Not in textbook; additional information Disclaimer: These abbreviated notes DO NOT substitute
Subject 10 Fall 2015 Google File System and BigTable and tiny bits of HDFS (Hadoop File System) and Chubby Not in textbook; additional information Disclaimer: These abbreviated notes DO NOT substitute
CS370 Operating Systems
 CS370 Operating Systems Colorado State University Yashwant K Malaiya Fall 2017 Lecture 26 File Systems Slides based on Text by Silberschatz, Galvin, Gagne Various sources 1 1 FAQ Cylinders: all the platters?
CS370 Operating Systems Colorado State University Yashwant K Malaiya Fall 2017 Lecture 26 File Systems Slides based on Text by Silberschatz, Galvin, Gagne Various sources 1 1 FAQ Cylinders: all the platters?
Google File System 2
 Google File System 2 goals monitoring, fault tolerance, auto-recovery (thousands of low-cost machines) focus on multi-gb files handle appends efficiently (no random writes & sequential reads) co-design
Google File System 2 goals monitoring, fault tolerance, auto-recovery (thousands of low-cost machines) focus on multi-gb files handle appends efficiently (no random writes & sequential reads) co-design
Google Disk Farm. Early days
 Google Disk Farm Early days today CS 5204 Fall, 2007 2 Design Design factors Failures are common (built from inexpensive commodity components) Files large (multi-gb) mutation principally via appending
Google Disk Farm Early days today CS 5204 Fall, 2007 2 Design Design factors Failures are common (built from inexpensive commodity components) Files large (multi-gb) mutation principally via appending
Yves Goeleven. Solution Architect - Particular Software. Shipping software since Azure MVP since Co-founder & board member AZUG
 Storage Services Yves Goeleven Solution Architect - Particular Software Shipping software since 2001 Azure MVP since 2010 Co-founder & board member AZUG NServiceBus & MessageHandler Used azure storage?
Storage Services Yves Goeleven Solution Architect - Particular Software Shipping software since 2001 Azure MVP since 2010 Co-founder & board member AZUG NServiceBus & MessageHandler Used azure storage?
Abstract. 1. Introduction. 2. Design and Implementation Master Chunkserver
 Abstract GFS from Scratch Ge Bian, Niket Agarwal, Wenli Looi https://github.com/looi/cs244b Dec 2017 GFS from Scratch is our partial re-implementation of GFS, the Google File System. Like GFS, our system
Abstract GFS from Scratch Ge Bian, Niket Agarwal, Wenli Looi https://github.com/looi/cs244b Dec 2017 GFS from Scratch is our partial re-implementation of GFS, the Google File System. Like GFS, our system
MI-PDB, MIE-PDB: Advanced Database Systems
 MI-PDB, MIE-PDB: Advanced Database Systems http://www.ksi.mff.cuni.cz/~svoboda/courses/2015-2-mie-pdb/ Lecture 10: MapReduce, Hadoop 26. 4. 2016 Lecturer: Martin Svoboda svoboda@ksi.mff.cuni.cz Author:
MI-PDB, MIE-PDB: Advanced Database Systems http://www.ksi.mff.cuni.cz/~svoboda/courses/2015-2-mie-pdb/ Lecture 10: MapReduce, Hadoop 26. 4. 2016 Lecturer: Martin Svoboda svoboda@ksi.mff.cuni.cz Author:
Map-Reduce. Marco Mura 2010 March, 31th
 Map-Reduce Marco Mura (mura@di.unipi.it) 2010 March, 31th This paper is a note from the 2009-2010 course Strumenti di programmazione per sistemi paralleli e distribuiti and it s based by the lessons of
Map-Reduce Marco Mura (mura@di.unipi.it) 2010 March, 31th This paper is a note from the 2009-2010 course Strumenti di programmazione per sistemi paralleli e distribuiti and it s based by the lessons of
A Distributed Namespace for a Distributed File System
 A Distributed Namespace for a Distributed File System Wasif Riaz Malik wasif@kth.se Master of Science Thesis Examiner: Dr. Jim Dowling, KTH/SICS Berlin, Aug 7, 2012 TRITA-ICT-EX-2012:173 Abstract Due
A Distributed Namespace for a Distributed File System Wasif Riaz Malik wasif@kth.se Master of Science Thesis Examiner: Dr. Jim Dowling, KTH/SICS Berlin, Aug 7, 2012 TRITA-ICT-EX-2012:173 Abstract Due
Systems Infrastructure for Data Science. Web Science Group Uni Freiburg WS 2013/14
 Systems Infrastructure for Data Science Web Science Group Uni Freiburg WS 2013/14 MapReduce & Hadoop The new world of Big Data (programming model) Overview of this Lecture Module Background Cluster File
Systems Infrastructure for Data Science Web Science Group Uni Freiburg WS 2013/14 MapReduce & Hadoop The new world of Big Data (programming model) Overview of this Lecture Module Background Cluster File
Programming Models MapReduce
 Programming Models MapReduce Majd Sakr, Garth Gibson, Greg Ganger, Raja Sambasivan 15-719/18-847b Advanced Cloud Computing Fall 2013 Sep 23, 2013 1 MapReduce In a Nutshell MapReduce incorporates two phases
Programming Models MapReduce Majd Sakr, Garth Gibson, Greg Ganger, Raja Sambasivan 15-719/18-847b Advanced Cloud Computing Fall 2013 Sep 23, 2013 1 MapReduce In a Nutshell MapReduce incorporates two phases
A brief history on Hadoop
 Hadoop Basics A brief history on Hadoop 2003 - Google launches project Nutch to handle billions of searches and indexing millions of web pages. Oct 2003 - Google releases papers with GFS (Google File System)
Hadoop Basics A brief history on Hadoop 2003 - Google launches project Nutch to handle billions of searches and indexing millions of web pages. Oct 2003 - Google releases papers with GFS (Google File System)
CS 138: Google. CS 138 XVI 1 Copyright 2017 Thomas W. Doeppner. All rights reserved.
 CS 138: Google CS 138 XVI 1 Copyright 2017 Thomas W. Doeppner. All rights reserved. Google Environment Lots (tens of thousands) of computers all more-or-less equal - processor, disk, memory, network interface
CS 138: Google CS 138 XVI 1 Copyright 2017 Thomas W. Doeppner. All rights reserved. Google Environment Lots (tens of thousands) of computers all more-or-less equal - processor, disk, memory, network interface
Introduction to Cloud Computing
 Introduction to Cloud Computing Distributed File Systems 15 319, spring 2010 12 th Lecture, Feb 18 th Majd F. Sakr Lecture Motivation Quick Refresher on Files and File Systems Understand the importance
Introduction to Cloud Computing Distributed File Systems 15 319, spring 2010 12 th Lecture, Feb 18 th Majd F. Sakr Lecture Motivation Quick Refresher on Files and File Systems Understand the importance
Intra-cluster Replication for Apache Kafka. Jun Rao
 Intra-cluster Replication for Apache Kafka Jun Rao About myself Engineer at LinkedIn since 2010 Worked on Apache Kafka and Cassandra Database researcher at IBM Outline Overview of Kafka Kafka architecture
Intra-cluster Replication for Apache Kafka Jun Rao About myself Engineer at LinkedIn since 2010 Worked on Apache Kafka and Cassandra Database researcher at IBM Outline Overview of Kafka Kafka architecture
Distributed Systems. Lec 10: Distributed File Systems GFS. Slide acks: Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung
 Distributed Systems Lec 10: Distributed File Systems GFS Slide acks: Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung 1 Distributed File Systems NFS AFS GFS Some themes in these classes: Workload-oriented
Distributed Systems Lec 10: Distributed File Systems GFS Slide acks: Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung 1 Distributed File Systems NFS AFS GFS Some themes in these classes: Workload-oriented
How Apache Hadoop Complements Existing BI Systems. Dr. Amr Awadallah Founder, CTO Cloudera,
 How Apache Hadoop Complements Existing BI Systems Dr. Amr Awadallah Founder, CTO Cloudera, Inc. Twitter: @awadallah, @cloudera 2 The Problems with Current Data Systems BI Reports + Interactive Apps RDBMS
How Apache Hadoop Complements Existing BI Systems Dr. Amr Awadallah Founder, CTO Cloudera, Inc. Twitter: @awadallah, @cloudera 2 The Problems with Current Data Systems BI Reports + Interactive Apps RDBMS
*Prof.Komal Shringare
 results by the use of table boundaries detection techniques and the use of text post-processing techniques to detect the noise and to correct bad-recognized words. Appendix OCR:- Optical character recognition,
results by the use of table boundaries detection techniques and the use of text post-processing techniques to detect the noise and to correct bad-recognized words. Appendix OCR:- Optical character recognition,
What Is Datacenter (Warehouse) Computing. Distributed and Parallel Technology. Datacenter Computing Architecture
 Computing. Distributed and Parallel Technology. Datacenter Computing Architecture") What Is Datacenter (Warehouse) Computing Distributed and Parallel Technology Datacenter, Warehouse and Cloud Computing Hans-Wolfgang Loidl School of Mathematical and Computer Sciences Heriot-Watt University,
What Is Datacenter (Warehouse) Computing Distributed and Parallel Technology Datacenter, Warehouse and Cloud Computing Hans-Wolfgang Loidl School of Mathematical and Computer Sciences Heriot-Watt University,
Installing and configuring Apache Kafka
 3 Installing and configuring Date of Publish: 2018-08-13 http://docs.hortonworks.com Contents Installing Kafka...3 Prerequisites... 3 Installing Kafka Using Ambari... 3... 9 Preparing the Environment...9
3 Installing and configuring Date of Publish: 2018-08-13 http://docs.hortonworks.com Contents Installing Kafka...3 Prerequisites... 3 Installing Kafka Using Ambari... 3... 9 Preparing the Environment...9
Big Data Processing Technologies. Chentao Wu Associate Professor Dept. of Computer Science and Engineering
 Big Data Processing Technologies Chentao Wu Associate Professor Dept. of Computer Science and Engineering wuct@cs.sjtu.edu.cn Schedule (1) Storage system part (first eight weeks) lec1: Introduction on
Big Data Processing Technologies Chentao Wu Associate Professor Dept. of Computer Science and Engineering wuct@cs.sjtu.edu.cn Schedule (1) Storage system part (first eight weeks) lec1: Introduction on
Optimistic Concurrency Control in a Distributed NameNode Architecture for Hadoop Distributed File System
 Optimistic Concurrency Control in a Distributed NameNode Architecture for Hadoop Distributed File System Qi Qi Instituto Superior Técnico - IST (Portugal) Royal Institute of Technology - KTH (Sweden) Abstract.
Optimistic Concurrency Control in a Distributed NameNode Architecture for Hadoop Distributed File System Qi Qi Instituto Superior Técnico - IST (Portugal) Royal Institute of Technology - KTH (Sweden) Abstract.