SIMULATED ANALYSIS OF EFFICIENT ALGORITHMS FOR MINING TOP-K HIGH UTILITY ITEMSETS
|
|
|
- Sandra Walton
- 5 years ago
- Views:
Transcription
1 3 rd International Conference on Emerging Technologies in Engineering, Biomedical, Management and Science SIMULATED ANALYSIS OF EFFICIENT ALGORITHMS FOR MINING TOP-K HIGH UTILITY ITEMSETS Surbhi Choudhary 1, Devendra Nagal 2, Swati Sharma 3 1 PhD Research Scholar, Dept. of Computer Applications, JNU Jodhpur 2,3 Faculty, Dept. of Electrical Engineering, JNU Jodhpur Abstract High utility sequential pattern mining is an emerging topic in the data mining community. Compared to the classic frequent sequence mining, the utility framework provides more informative and actionable knowledge since the utility of a sequence indicates business value and impact. However, the introduction of utility makes the problem fundamentally different from the frequency-based pattern mining framework and brings about dramatic challenges. Although the existing high utility sequential pattern mining algorithms can discover all the patterns satisfying a given minimum utility, it is often difficult for users to set a proper minimum utility. A too small value may produce thousands of patterns, whereas a too big one may lead to no findings. In this paper, we propose a novel framework called top-k high utility sequential pattern mining to tackle this critical problem. Accordingly, an efficient algorithm, Top-k high Utility Sequence (TUS for short) mining, is designed to identify top-k high utility sequential patterns without minimum utility. In addition, three effective features are introduced to handle the efficiency problem, including two strategies for raising the threshold and one pruning for filtering unpromising items. Our experiments are conducted on both synthetic and real datasets.. F I. INTRODUCTION REQUENT sequential pattern mining [1], as one of thefundamental research topics in data mining, discovers frequent subsequences in sequence databases. It is very usefulfor handling order-based business problems, and has beensuccessfully adopted to various domains and applicationssuch as complex behaviour analysis [1] and gene sequenceanalysis [2], [3], [4]. In the frequency-based framework fortypical sequence analysis, the downward closure property(also known as Apriori property) [1] plays a fundamentalrole in identifying frequent sequential patterns.however, taking the frequency to measure pattern in-terestingness may be insufficient for selecting actionablesequences associated with expected quality and businessimpact, because the patterns identified under the frequency(support) framework do not disclose the business valueand impact. To solve the above problems, the conceptutility is introduced into sequential pattern mining to select sequences of high utility by considering the quality and value (such as profit) of itemsets. This leads to anemerging area, high utility pattern mining [1], [2], [3], [8],[9] and high utility sequential pattern mining, which selects interesting patterns / sequentialpatterns based on minimum utility rather than minimumsupport. The utilitybased patterns are proven to be moreinformative and actionable for decision-making than the frequency-based ones [2]. For instance, in [4], [5], the authors discuss the extraction of profitable behaviours fromthe mobile commerce environments. [4] Proposes methodsto mine high utility sequences from web logs by assigningeach page an impact/significance. In [6], a US pan algorithmis built for utility-based sequential pattern mining satisfyinga predefined minimum utility.although algorithms such as USpan can obtain high utilitysequences based on a given minimum utility, it is verydifficult for users to specify an appropriate minimum utilitythreshold and to directly obtain the most valuable patterns.this is because the complexity of utility-based sequencedatabases (which may be different from the classic itemsets),determining multiple factors including the distribution of theitems and utilities, density of the database, lengths of thesequences, and so on. Consequently, it is not surprising that,with a same minimum utility threshold, some datasets mayproduce millions of patterns while others may contributenothing. The challenge here is that it may not be doableto tune the threshold to capture the expected number ofpatterns. This is because the sensitivity of the thresholdmakes it hard to tune for a variety of databases. It maybe very costly and time consuming to achieve the properthreshold for the desired patterns.in fact, the classic frequency/support based pattern miningalso faces the same challenge. Accordingly, the concept ofextracting top-k patterns has been proposed in [2], [4], [7],[8] to select the patterns with the highest frequency. Inthe top-k frequent pattern mining, instead of letting a userspecify a threshold, the top-k pattern selection algorithmsallow a user to set the number of top-k high frequencypatterns to be discovered. This makes it much easier andmore intuitive and practical than determining a minimumsupport; also the determination of k by a user is morestraightforward than considering data characteristics, whichare often invisible to users, for choosing a proper threshold. The easiness for users to determine k does not indicatethe simplicity of developing an efficient algorithm for selecting top-k high utility sequential patterns. In the utilityframework, TKU is the only method for mining top-k high utility itemsets, to the best of our knowledge. Nowork is reported on mining top-k high utility sequences. There is significant difference between top-k utility itemsetmining and top-k utility sequence mining in which the orderbetween itemsets is considered. In fact, the problem of top-khigh utility sequence mining is much more challenging thanmining top-k high utility itemsets. First, as 15

![Second, compared to top-k highutility itemset mining [8], utility-based sequence analysisfaces the critical combinational explosion and](/docs-images/88/115550403/images/2-1.jpg "computationalcomplexity caused by sequencing between itemsets.")
![Thismeans that the techniques in [9] cannot be directly transferred to top-k high utility sequential pattern mining either.](/docs-images/88/115550403/images/2-2.jpg "third, since the minimum utility is not given in advance, thealgorithm essentially starts the searching from 0 minimumsupports.")
2 with high utilityitemset mining, the downward closure property does not holdin the utility-based sequence mining. This means that the existing top-k frequent sequential pattern mining algorithms [7]cannot be directly applied. Second, compared to top-k highutility itemset mining [8], utility-based sequence analysisfaces the critical combinational explosion and computationalcomplexity caused by sequencing between itemsets. Thismeans that the techniques in [9] cannot be directly transferred to top-k high utility sequential pattern mining either.third, since the minimum utility is not given in advance, thealgorithm essentially starts the searching from 0 minimumsupports. This not only incurs very high computational costs,but also the challenge of how to raise the minimum thresholdwithout missing any top-k high utility sequences. II. SIMULATION RESULTS 16
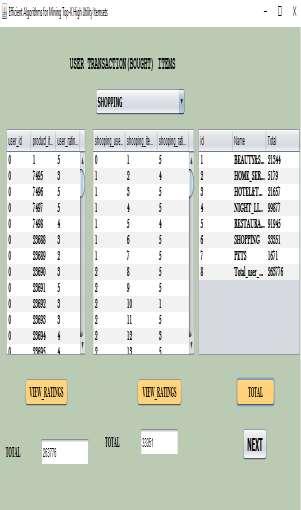
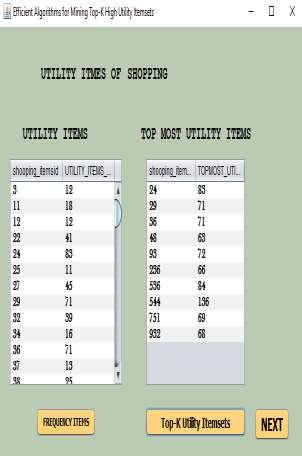
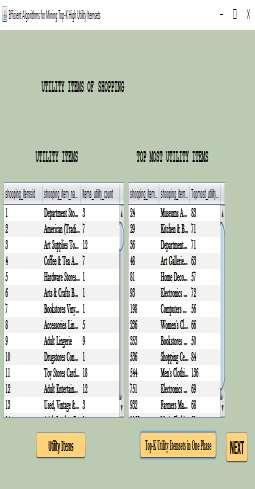
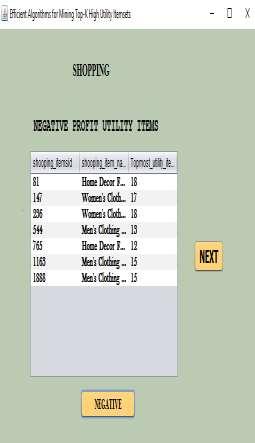
3 17
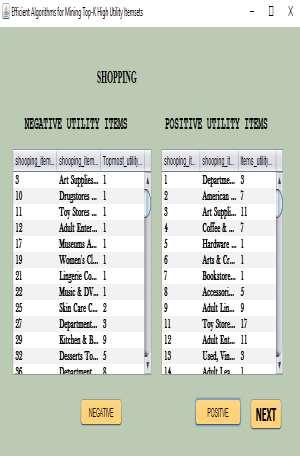
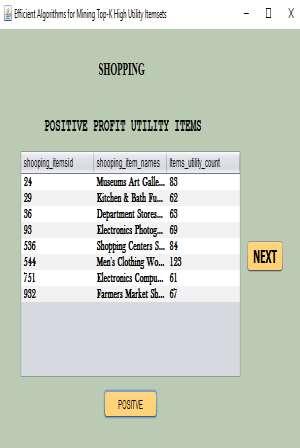
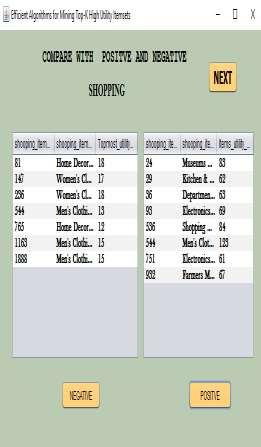
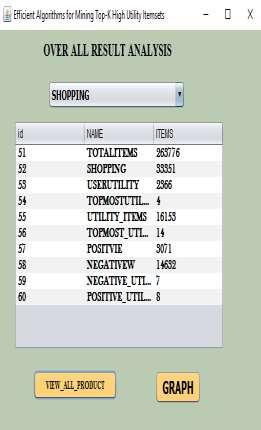
4 18
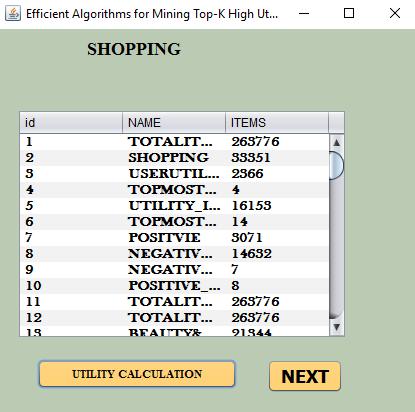
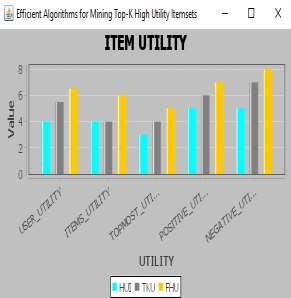
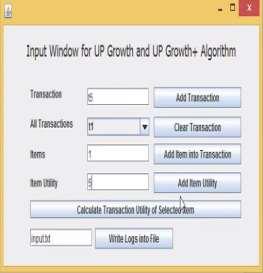
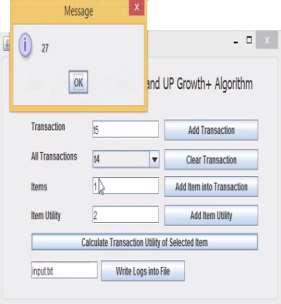
5 19
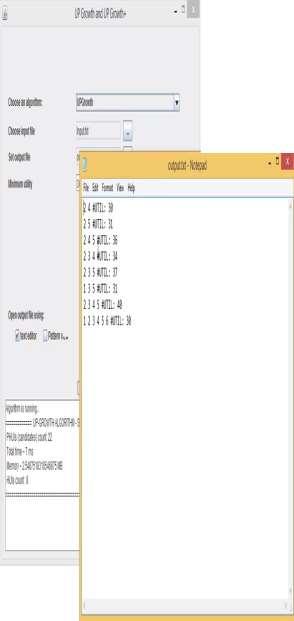
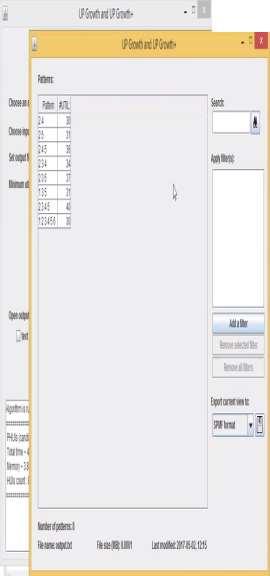
6 20


7 transactions and generate fewer number of candidates than FP-Growth. Two important problems are always in consideration first is how minimize number no of candidates and another is how to remove space and time complexity. Also, choosing an appropriate minimum utility threshold is a difficult task for application users: if the threshold is high, there might be no HUI; if the threshold is low, there might result too many HUIs, and the mining performance might be severely affected, even leading to memory overflow. It would also be a time-consuming task if one tries to determine the threshold value through various testing calculations. To address this issue, Wu [10] proposes top-k algorithm, mining the top k itemsets with the highest utility values without presetting the minimum threshold. IV. CONCLUSION In this paper, we have studied the problem of top-k high utility item sets mining, where k is the desired number of high utility item sets to be mined. Two efficient algorithms TKU (mining Top-K Utility item sets) and TKO (mining Top-K utility item sets in One phase) are proposed for mining such item sets without setting minimum utility thresholds. TKU is the first two-phase algorithm for mining top-k high utility item sets, which incorporates five strategies PE, NU, MD, MC and SE to effectively raise the border minimum utility thresholds and further prune the search space. On the other hand, TKO is the first one-phase algorithm developed for top-k HUI mining, which integrates the novel strategies RUC, RUZ and EPB to greatly improve its performance. Empirical evaluations on different types of real and synthetic datasets show that the proposed algorithms have good scalability on large datasets and the performance of the proposed algorithms is close to the optimal case of the state-of-theart two-phase and one-phase utility mining algorithms. Although we have proposed a new framework for top-k HUI mining, it has not yet been incorporated with other utility mining tasks to discover different types of top-k high utility patterns such as top-k high utility episodes, top-k closed high utility item sets, topk high utility web access patterns and top-k mobile high utility sequential patterns. These leave wide rooms for exploration as future work. III. COMPARISON WITH UPGROWTH AND UPGROWTH+ ALGORITHM In this project, two algorithms utility pattern growth (UP- Growth) and UP-Growth+, for mining high utility itemsets are used to compare. Performance of UP-Growth and UP- Growth+ become more efficient since database contain long REFERENCES [1] R. Agrawal and R. Srikant, Fast algorithms for mining association rules, in Proc. Int. Conf. Very Large Data Bases, 1994, pp [2] C. Ahmed, S. Tanbeer, B. Jeong, and Y. Lee, Efficient tree structures for high-utility pattern mining in incremental databases, IEEE Trans. Knowl. Data Eng., vol. 21, no. 12, pp , Dec [3] K. Chuang, J. Huang, and M. Chen, Mining top-k frequent patterns in the presence of the memory constraint, VLDB J., vol. 17, pp , [4] R. Chan, Q. Yang, and Y. Shen, Mining high-utility itemsets, in Proc. IEEE Int. Conf. Data Mining, 2003, pp [5] P. Fournier-Viger and V. S. Tseng, Mining top-k sequential rules, in Proc. Int. Conf. Adv. Data Mining Appl., 2011, pp
8 [6] P. Fournier-Viger, C.Wu, and V. S. Tseng, Mining top-k association rules, in Proc. Int. Conf. Can. Conf. Adv. Artif. Intell., 2012, pp [7] P. Fournier-Viger, C. Wu, and V. S. Tseng, Novel concise representations of high utility item sets using generator patterns, in Proc. Int. Conf. Adv. Data Mining Appl. Lecture Notes Comput. Sci., 2014, vol. 8933, pp [8] J. Han, J. Pei, and Y. Yin, Mining frequent patterns without candidate generation, in Proc. ACM SIGMOD Int. Conf. Manag. Data, 2000, pp [9] J. Han, J. Wang, Y. Lu, and P. Tzvetkov, Mining top-k frequent closed patterns without minimum support, in Proc. IEEE Int. Conf. Data Mining, 2002, pp [10] S. Krishnamoorthy, Pruning strategies for mining high utility itemsets, Expert Syst. Appl., vol. 42, no. 5, pp , [11] C. Lin, T. Hong, G. Lan, J. Wong, and W. Lin, Efficient updating of discovered high-utility itemsets for transaction deletion in dynamic databases, Adv. Eng. Informat., vol. 29, no. 1, pp , [12] G. Lan, T. Hong, V. S. Tseng, and S. Wang, Applying the maximum utility measure in high utility sequential pattern mining, Expert Syst. Appl., vol. 41, no. 11, pp , [13] Y. Liu, W. Liao, and A. Choudhary, A fast high utility itemsets mining algorithm, in Proc. Utility-Based Data Mining Workshop, 2005, pp [14] M. Liu and J. Qu, Mining high utility itemsets without candidate generation, in Proc. ACM Int. Conf. Inf. Knowl. Manag., 2012, pp
Generation of Potential High Utility Itemsets from Transactional Databases
 Generation of Potential High Utility Itemsets from Transactional Databases Rajmohan.C Priya.G Niveditha.C Pragathi.R Asst.Prof/IT, Dept of IT Dept of IT Dept of IT SREC, Coimbatore,INDIA,SREC,Coimbatore,.INDIA
Generation of Potential High Utility Itemsets from Transactional Databases Rajmohan.C Priya.G Niveditha.C Pragathi.R Asst.Prof/IT, Dept of IT Dept of IT Dept of IT SREC, Coimbatore,INDIA,SREC,Coimbatore,.INDIA
Keywords: Frequent itemset, closed high utility itemset, utility mining, data mining, traverse path. I. INTRODUCTION
 ISSN: 2321-7782 (Online) Impact Factor: 6.047 Volume 4, Issue 11, November 2016 International Journal of Advance Research in Computer Science and Management Studies Research Article / Survey Paper / Case
ISSN: 2321-7782 (Online) Impact Factor: 6.047 Volume 4, Issue 11, November 2016 International Journal of Advance Research in Computer Science and Management Studies Research Article / Survey Paper / Case
Design of Search Engine considering top k High Utility Item set (HUI) Mining
 Mining") Design of Search Engine considering top k High Utility Item set (HUI) Mining Sanjana S. Shirsat, Prof. S. A. Joshi Department of Computer Network, Sinhgad College of Engineering, Pune, Savitribai Phule
Design of Search Engine considering top k High Utility Item set (HUI) Mining Sanjana S. Shirsat, Prof. S. A. Joshi Department of Computer Network, Sinhgad College of Engineering, Pune, Savitribai Phule
Implementation of CHUD based on Association Matrix
 Implementation of CHUD based on Association Matrix Abhijit P. Ingale 1, Kailash Patidar 2, Megha Jain 3 1 apingale83@gmail.com, 2 kailashpatidar123@gmail.com, 3 06meghajain@gmail.com, Sri Satya Sai Institute
Implementation of CHUD based on Association Matrix Abhijit P. Ingale 1, Kailash Patidar 2, Megha Jain 3 1 apingale83@gmail.com, 2 kailashpatidar123@gmail.com, 3 06meghajain@gmail.com, Sri Satya Sai Institute
RHUIET : Discovery of Rare High Utility Itemsets using Enumeration Tree
 International Journal for Research in Engineering Application & Management (IJREAM) ISSN : 2454-915 Vol-4, Issue-3, June 218 RHUIET : Discovery of Rare High Utility Itemsets using Enumeration Tree Mrs.
International Journal for Research in Engineering Application & Management (IJREAM) ISSN : 2454-915 Vol-4, Issue-3, June 218 RHUIET : Discovery of Rare High Utility Itemsets using Enumeration Tree Mrs.
FHM: Faster High-Utility Itemset Mining using Estimated Utility Co-occurrence Pruning
 FHM: Faster High-Utility Itemset Mining using Estimated Utility Co-occurrence Pruning Philippe Fournier-Viger 1, Cheng-Wei Wu 2, Souleymane Zida 1, Vincent S. Tseng 2 1 Dept. of Computer Science, University
FHM: Faster High-Utility Itemset Mining using Estimated Utility Co-occurrence Pruning Philippe Fournier-Viger 1, Cheng-Wei Wu 2, Souleymane Zida 1, Vincent S. Tseng 2 1 Dept. of Computer Science, University
A Survey on Efficient Algorithms for Mining HUI and Closed Item sets
 A Survey on Efficient Algorithms for Mining HUI and Closed Item sets Mr. Mahendra M. Kapadnis 1, Mr. Prashant B. Koli 2 1 PG Student, Kalyani Charitable Trust s Late G.N. Sapkal College of Engineering,
A Survey on Efficient Algorithms for Mining HUI and Closed Item sets Mr. Mahendra M. Kapadnis 1, Mr. Prashant B. Koli 2 1 PG Student, Kalyani Charitable Trust s Late G.N. Sapkal College of Engineering,
CHUIs-Concise and Lossless representation of High Utility Itemsets
 CHUIs-Concise and Lossless representation of High Utility Itemsets Vandana K V 1, Dr Y.C Kiran 2 P.G. Student, Department of Computer Science & Engineering, BNMIT, Bengaluru, India 1 Associate Professor,
CHUIs-Concise and Lossless representation of High Utility Itemsets Vandana K V 1, Dr Y.C Kiran 2 P.G. Student, Department of Computer Science & Engineering, BNMIT, Bengaluru, India 1 Associate Professor,
JOURNAL OF APPLIED SCIENCES RESEARCH
 Copyright 2015, American-Eurasian Network for Scientific Information publisher JOURNAL OF APPLIED SCIENCES RESEARCH ISSN: 1819-544X EISSN: 1816-157X JOURNAL home page: http://www.aensiweb.com/jasr 2015
Copyright 2015, American-Eurasian Network for Scientific Information publisher JOURNAL OF APPLIED SCIENCES RESEARCH ISSN: 1819-544X EISSN: 1816-157X JOURNAL home page: http://www.aensiweb.com/jasr 2015
Utility Mining: An Enhanced UP Growth Algorithm for Finding Maximal High Utility Itemsets
 Utility Mining: An Enhanced UP Growth Algorithm for Finding Maximal High Utility Itemsets C. Sivamathi 1, Dr. S. Vijayarani 2 1 Ph.D Research Scholar, 2 Assistant Professor, Department of CSE, Bharathiar
Utility Mining: An Enhanced UP Growth Algorithm for Finding Maximal High Utility Itemsets C. Sivamathi 1, Dr. S. Vijayarani 2 1 Ph.D Research Scholar, 2 Assistant Professor, Department of CSE, Bharathiar
An Efficient Generation of Potential High Utility Itemsets from Transactional Databases
 An Efficient Generation of Potential High Utility Itemsets from Transactional Databases Velpula Koteswara Rao, Ch. Satyananda Reddy Department of CS & SE, Andhra University Visakhapatnam, Andhra Pradesh,
An Efficient Generation of Potential High Utility Itemsets from Transactional Databases Velpula Koteswara Rao, Ch. Satyananda Reddy Department of CS & SE, Andhra University Visakhapatnam, Andhra Pradesh,
AN EFFICIENT GRADUAL PRUNING TECHNIQUE FOR UTILITY MINING. Received April 2011; revised October 2011
 International Journal of Innovative Computing, Information and Control ICIC International c 2012 ISSN 1349-4198 Volume 8, Number 7(B), July 2012 pp. 5165 5178 AN EFFICIENT GRADUAL PRUNING TECHNIQUE FOR
International Journal of Innovative Computing, Information and Control ICIC International c 2012 ISSN 1349-4198 Volume 8, Number 7(B), July 2012 pp. 5165 5178 AN EFFICIENT GRADUAL PRUNING TECHNIQUE FOR
Infrequent Weighted Item Set Mining Using Frequent Pattern Growth
 Infrequent Weighted Item Set Mining Using Frequent Pattern Growth Sahu Smita Rani Assistant Professor, & HOD, Dept of CSE, Sri Vaishnavi College of Engineering. D.Vikram Lakshmikanth Assistant Professor,
Infrequent Weighted Item Set Mining Using Frequent Pattern Growth Sahu Smita Rani Assistant Professor, & HOD, Dept of CSE, Sri Vaishnavi College of Engineering. D.Vikram Lakshmikanth Assistant Professor,
An Efficient Algorithm for finding high utility itemsets from online sell
 An Efficient Algorithm for finding high utility itemsets from online sell Sarode Nutan S, Kothavle Suhas R 1 Department of Computer Engineering, ICOER, Maharashtra, India 2 Department of Computer Engineering,
An Efficient Algorithm for finding high utility itemsets from online sell Sarode Nutan S, Kothavle Suhas R 1 Department of Computer Engineering, ICOER, Maharashtra, India 2 Department of Computer Engineering,
Mining High Average-Utility Itemsets
 Proceedings of the 2009 IEEE International Conference on Systems, Man, and Cybernetics San Antonio, TX, USA - October 2009 Mining High Itemsets Tzung-Pei Hong Dept of Computer Science and Information Engineering
Proceedings of the 2009 IEEE International Conference on Systems, Man, and Cybernetics San Antonio, TX, USA - October 2009 Mining High Itemsets Tzung-Pei Hong Dept of Computer Science and Information Engineering
Utility Mining Algorithm for High Utility Item sets from Transactional Databases
 IOSR Journal of Computer Engineering (IOSR-JCE) e-issn: 2278-0661, p- ISSN: 2278-8727Volume 16, Issue 2, Ver. V (Mar-Apr. 2014), PP 34-40 Utility Mining Algorithm for High Utility Item sets from Transactional
IOSR Journal of Computer Engineering (IOSR-JCE) e-issn: 2278-0661, p- ISSN: 2278-8727Volume 16, Issue 2, Ver. V (Mar-Apr. 2014), PP 34-40 Utility Mining Algorithm for High Utility Item sets from Transactional
A Review on High Utility Mining to Improve Discovery of Utility Item set
 A Review on High Utility Mining to Improve Discovery of Utility Item set Vishakha R. Jaware 1, Madhuri I. Patil 2, Diksha D. Neve 3 Ghrushmarani L. Gayakwad 4, Venus S. Dixit 5, Prof. R. P. Chaudhari 6
A Review on High Utility Mining to Improve Discovery of Utility Item set Vishakha R. Jaware 1, Madhuri I. Patil 2, Diksha D. Neve 3 Ghrushmarani L. Gayakwad 4, Venus S. Dixit 5, Prof. R. P. Chaudhari 6
Minig Top-K High Utility Itemsets - Report
 Minig Top-K High Utility Itemsets - Report Daniel Yu, yuda@student.ethz.ch Computer Science Bsc., ETH Zurich, Switzerland May 29, 2015 The report is written as a overview about the main aspects in mining
Minig Top-K High Utility Itemsets - Report Daniel Yu, yuda@student.ethz.ch Computer Science Bsc., ETH Zurich, Switzerland May 29, 2015 The report is written as a overview about the main aspects in mining
 Mining Top-K Association Rules Philippe Fournier-Viger 1, Cheng-Wei Wu 2 and Vincent S. Tseng 2 1 Dept. of Computer Science, University of Moncton, Canada philippe.fv@gmail.com 2 Dept. of Computer Science
Mining Top-K Association Rules Philippe Fournier-Viger 1, Cheng-Wei Wu 2 and Vincent S. Tseng 2 1 Dept. of Computer Science, University of Moncton, Canada philippe.fv@gmail.com 2 Dept. of Computer Science
Appropriate Item Partition for Improving the Mining Performance
 Appropriate Item Partition for Improving the Mining Performance Tzung-Pei Hong 1,2, Jheng-Nan Huang 1, Kawuu W. Lin 3 and Wen-Yang Lin 1 1 Department of Computer Science and Information Engineering National
Appropriate Item Partition for Improving the Mining Performance Tzung-Pei Hong 1,2, Jheng-Nan Huang 1, Kawuu W. Lin 3 and Wen-Yang Lin 1 1 Department of Computer Science and Information Engineering National
A New Method for Mining High Average Utility Itemsets
 A New Method for Mining High Average Utility Itemsets Tien Lu 1, Bay Vo 2,3, Hien T. Nguyen 3, and Tzung-Pei Hong 4 1 University of Sciences, Ho Chi Minh, Vietnam 2 Divison of Data Science, Ton Duc Thang
A New Method for Mining High Average Utility Itemsets Tien Lu 1, Bay Vo 2,3, Hien T. Nguyen 3, and Tzung-Pei Hong 4 1 University of Sciences, Ho Chi Minh, Vietnam 2 Divison of Data Science, Ton Duc Thang
Mining Frequent Itemsets Along with Rare Itemsets Based on Categorical Multiple Minimum Support
 IOSR Journal of Computer Engineering (IOSR-JCE) e-issn: 2278-0661,p-ISSN: 2278-8727, Volume 18, Issue 6, Ver. IV (Nov.-Dec. 2016), PP 109-114 www.iosrjournals.org Mining Frequent Itemsets Along with Rare
IOSR Journal of Computer Engineering (IOSR-JCE) e-issn: 2278-0661,p-ISSN: 2278-8727, Volume 18, Issue 6, Ver. IV (Nov.-Dec. 2016), PP 109-114 www.iosrjournals.org Mining Frequent Itemsets Along with Rare
UAPRIORI: AN ALGORITHM FOR FINDING SEQUENTIAL PATTERNS IN PROBABILISTIC DATA
 UAPRIORI: AN ALGORITHM FOR FINDING SEQUENTIAL PATTERNS IN PROBABILISTIC DATA METANAT HOOSHSADAT, SAMANEH BAYAT, PARISA NAEIMI, MAHDIEH S. MIRIAN, OSMAR R. ZAÏANE Computing Science Department, University
UAPRIORI: AN ALGORITHM FOR FINDING SEQUENTIAL PATTERNS IN PROBABILISTIC DATA METANAT HOOSHSADAT, SAMANEH BAYAT, PARISA NAEIMI, MAHDIEH S. MIRIAN, OSMAR R. ZAÏANE Computing Science Department, University
AN EFFECTIVE WAY OF MINING HIGH UTILITY ITEMSETS FROM LARGE TRANSACTIONAL DATABASES
 AN EFFECTIVE WAY OF MINING HIGH UTILITY ITEMSETS FROM LARGE TRANSACTIONAL DATABASES 1Chadaram Prasad, 2 Dr. K..Amarendra 1M.Tech student, Dept of CSE, 2 Professor & Vice Principal, DADI INSTITUTE OF INFORMATION
AN EFFECTIVE WAY OF MINING HIGH UTILITY ITEMSETS FROM LARGE TRANSACTIONAL DATABASES 1Chadaram Prasad, 2 Dr. K..Amarendra 1M.Tech student, Dept of CSE, 2 Professor & Vice Principal, DADI INSTITUTE OF INFORMATION
Mining High Utility Itemsets in Big Data
 Mining High Utility Itemsets in Big Data Ying Chun Lin 1( ), Cheng-Wei Wu 2, and Vincent S. Tseng 2 1 Department of Computer Science and Information Engineering, National Cheng Kung University, Tainan,
Mining High Utility Itemsets in Big Data Ying Chun Lin 1( ), Cheng-Wei Wu 2, and Vincent S. Tseng 2 1 Department of Computer Science and Information Engineering, National Cheng Kung University, Tainan,
A Survey on Frequent Itemset Mining using Differential Private with Transaction Splitting
 A Survey on Frequent Itemset Mining using Differential Private with Transaction Splitting Bhagyashree R. Vhatkar 1,Prof. (Dr. ). S. A. Itkar 2 1 Computer Department, P.E.S. Modern College of Engineering
A Survey on Frequent Itemset Mining using Differential Private with Transaction Splitting Bhagyashree R. Vhatkar 1,Prof. (Dr. ). S. A. Itkar 2 1 Computer Department, P.E.S. Modern College of Engineering
A Review on Mining Top-K High Utility Itemsets without Generating Candidates
 A Review on Mining Top-K High Utility Itemsets without Generating Candidates Lekha I. Surana, Professor Vijay B. More Lekha I. Surana, Dept of Computer Engineering, MET s Institute of Engineering Nashik,
A Review on Mining Top-K High Utility Itemsets without Generating Candidates Lekha I. Surana, Professor Vijay B. More Lekha I. Surana, Dept of Computer Engineering, MET s Institute of Engineering Nashik,
FOSHU: Faster On-Shelf High Utility Itemset Mining with or without Negative Unit Profit
 : Faster On-Shelf High Utility Itemset Mining with or without Negative Unit Profit ABSTRACT Philippe Fournier-Viger University of Moncton 18 Antonine-Maillet Ave Moncton, NB, Canada philippe.fournier-viger@umoncton.ca
: Faster On-Shelf High Utility Itemset Mining with or without Negative Unit Profit ABSTRACT Philippe Fournier-Viger University of Moncton 18 Antonine-Maillet Ave Moncton, NB, Canada philippe.fournier-viger@umoncton.ca
Enhanced SWASP Algorithm for Mining Associated Patterns from Wireless Sensor Networks Dataset
 IJIRST International Journal for Innovative Research in Science & Technology Volume 3 Issue 02 July 2016 ISSN (online): 2349-6010 Enhanced SWASP Algorithm for Mining Associated Patterns from Wireless Sensor
IJIRST International Journal for Innovative Research in Science & Technology Volume 3 Issue 02 July 2016 ISSN (online): 2349-6010 Enhanced SWASP Algorithm for Mining Associated Patterns from Wireless Sensor
FUFM-High Utility Itemsets in Transactional Database
 Available Online at www.ijcsmc.com International Journal of Computer Science and Mobile Computing A Monthly Journal of Computer Science and Information Technology IJCSMC, Vol. 3, Issue. 3, March 2014,
Available Online at www.ijcsmc.com International Journal of Computer Science and Mobile Computing A Monthly Journal of Computer Science and Information Technology IJCSMC, Vol. 3, Issue. 3, March 2014,
Improved UP Growth Algorithm for Mining of High Utility Itemsets from Transactional Databases Based on Mapreduce Framework on Hadoop.
 Improved UP Growth Algorithm for Mining of High Utility Itemsets from Transactional Databases Based on Mapreduce Framework on Hadoop. Vivek Jethe Computer Department MGM College of Engineering and Technology
Improved UP Growth Algorithm for Mining of High Utility Itemsets from Transactional Databases Based on Mapreduce Framework on Hadoop. Vivek Jethe Computer Department MGM College of Engineering and Technology
Implementation of Efficient Algorithm for Mining High Utility Itemsets in Distributed and Dynamic Database
 International Journal of Engineering and Technology Volume 4 No. 3, March, 2014 Implementation of Efficient Algorithm for Mining High Utility Itemsets in Distributed and Dynamic Database G. Saranya 1,
International Journal of Engineering and Technology Volume 4 No. 3, March, 2014 Implementation of Efficient Algorithm for Mining High Utility Itemsets in Distributed and Dynamic Database G. Saranya 1,
WIP: mining Weighted Interesting Patterns with a strong weight and/or support affinity
 WIP: mining Weighted Interesting Patterns with a strong weight and/or support affinity Unil Yun and John J. Leggett Department of Computer Science Texas A&M University College Station, Texas 7783, USA
WIP: mining Weighted Interesting Patterns with a strong weight and/or support affinity Unil Yun and John J. Leggett Department of Computer Science Texas A&M University College Station, Texas 7783, USA
A Survey on Moving Towards Frequent Pattern Growth for Infrequent Weighted Itemset Mining
 A Survey on Moving Towards Frequent Pattern Growth for Infrequent Weighted Itemset Mining Miss. Rituja M. Zagade Computer Engineering Department,JSPM,NTC RSSOER,Savitribai Phule Pune University Pune,India
A Survey on Moving Towards Frequent Pattern Growth for Infrequent Weighted Itemset Mining Miss. Rituja M. Zagade Computer Engineering Department,JSPM,NTC RSSOER,Savitribai Phule Pune University Pune,India
A New Method for Mining High Average Utility Itemsets
 A New Method for Mining High Average Utility Itemsets Tien Lu, Bay Vo, Hien Nguyen, Tzung-Pei Hong To cite this version: Tien Lu, Bay Vo, Hien Nguyen, Tzung-Pei Hong. A New Method for Mining High Average
A New Method for Mining High Average Utility Itemsets Tien Lu, Bay Vo, Hien Nguyen, Tzung-Pei Hong To cite this version: Tien Lu, Bay Vo, Hien Nguyen, Tzung-Pei Hong. A New Method for Mining High Average
Utility Pattern Mining: A Concise and Lossless Representation using Up Growth+
 Utility Pattern Mining: A Concise and Lossless Representation using Up Growth+ Anusmitha.A 1, Renjana Ramachandran 2 M. Tech PG Scholar, Department of CSE, Mangalam College of Engineering, Kottayam, India
Utility Pattern Mining: A Concise and Lossless Representation using Up Growth+ Anusmitha.A 1, Renjana Ramachandran 2 M. Tech PG Scholar, Department of CSE, Mangalam College of Engineering, Kottayam, India
PTclose: A novel algorithm for generation of closed frequent itemsets from dense and sparse datasets
 : A novel algorithm for generation of closed frequent itemsets from dense and sparse datasets J. Tahmores Nezhad ℵ, M.H.Sadreddini Abstract In recent years, various algorithms for mining closed frequent
: A novel algorithm for generation of closed frequent itemsets from dense and sparse datasets J. Tahmores Nezhad ℵ, M.H.Sadreddini Abstract In recent years, various algorithms for mining closed frequent
An Emphasized Apriori Algorithm for Huge Sequence of Datasets
 An Emphasized Apriori Algorithm for Huge Sequence of Datasets Ravi Kumar.V Associate Professor, Department of IT, TKRCET. Abstract: In this paper, an Emphasized Apriori algorithm is proposed based on the
An Emphasized Apriori Algorithm for Huge Sequence of Datasets Ravi Kumar.V Associate Professor, Department of IT, TKRCET. Abstract: In this paper, an Emphasized Apriori algorithm is proposed based on the
Mining Top-K High Utility Itemsets
 Mining Top- High Utility Itemsets Cheng Wei Wu 1, Bai-En Shie 1, Philip S. Yu 2, Vincent S. Tseng 1 1 Department of Computer Science and Information Engineering, National Cheng ung University, Taiwan,
Mining Top- High Utility Itemsets Cheng Wei Wu 1, Bai-En Shie 1, Philip S. Yu 2, Vincent S. Tseng 1 1 Department of Computer Science and Information Engineering, National Cheng ung University, Taiwan,
Efficient Mining of High-Utility Sequential Rules
 Efficient Mining of High-Utility Sequential Rules Souleymane Zida 1, Philippe Fournier-Viger 1, Cheng-Wei Wu 2, Jerry Chun-Wei Lin 3, Vincent S. Tseng 2 1 Dept. of Computer Science, University of Moncton,
Efficient Mining of High-Utility Sequential Rules Souleymane Zida 1, Philippe Fournier-Viger 1, Cheng-Wei Wu 2, Jerry Chun-Wei Lin 3, Vincent S. Tseng 2 1 Dept. of Computer Science, University of Moncton,
Discovering High Utility Change Points in Customer Transaction Data
 Discovering High Utility Change Points in Customer Transaction Data Philippe Fournier-Viger 1, Yimin Zhang 2, Jerry Chun-Wei Lin 3, and Yun Sing Koh 4 1 School of Natural Sciences and Humanities, Harbin
Discovering High Utility Change Points in Customer Transaction Data Philippe Fournier-Viger 1, Yimin Zhang 2, Jerry Chun-Wei Lin 3, and Yun Sing Koh 4 1 School of Natural Sciences and Humanities, Harbin
An Efficient Tree-based Fuzzy Data Mining Approach
 150 International Journal of Fuzzy Systems, Vol. 12, No. 2, June 2010 An Efficient Tree-based Fuzzy Data Mining Approach Chun-Wei Lin, Tzung-Pei Hong, and Wen-Hsiang Lu Abstract 1 In the past, many algorithms
150 International Journal of Fuzzy Systems, Vol. 12, No. 2, June 2010 An Efficient Tree-based Fuzzy Data Mining Approach Chun-Wei Lin, Tzung-Pei Hong, and Wen-Hsiang Lu Abstract 1 In the past, many algorithms
A NOVEL ALGORITHM FOR MINING CLOSED SEQUENTIAL PATTERNS
 A NOVEL ALGORITHM FOR MINING CLOSED SEQUENTIAL PATTERNS ABSTRACT V. Purushothama Raju 1 and G.P. Saradhi Varma 2 1 Research Scholar, Dept. of CSE, Acharya Nagarjuna University, Guntur, A.P., India 2 Department
A NOVEL ALGORITHM FOR MINING CLOSED SEQUENTIAL PATTERNS ABSTRACT V. Purushothama Raju 1 and G.P. Saradhi Varma 2 1 Research Scholar, Dept. of CSE, Acharya Nagarjuna University, Guntur, A.P., India 2 Department
Infrequent Weighted Itemset Mining Using SVM Classifier in Transaction Dataset
 Infrequent Weighted Itemset Mining Using SVM Classifier in Transaction Dataset M.Hamsathvani 1, D.Rajeswari 2 M.E, R.Kalaiselvi 3 1 PG Scholar(M.E), Angel College of Engineering and Technology, Tiruppur,
Infrequent Weighted Itemset Mining Using SVM Classifier in Transaction Dataset M.Hamsathvani 1, D.Rajeswari 2 M.E, R.Kalaiselvi 3 1 PG Scholar(M.E), Angel College of Engineering and Technology, Tiruppur,
Association Rule Mining. Introduction 46. Study core 46
 Learning Unit 7 Association Rule Mining Introduction 46 Study core 46 1 Association Rule Mining: Motivation and Main Concepts 46 2 Apriori Algorithm 47 3 FP-Growth Algorithm 47 4 Assignment Bundle: Frequent
Learning Unit 7 Association Rule Mining Introduction 46 Study core 46 1 Association Rule Mining: Motivation and Main Concepts 46 2 Apriori Algorithm 47 3 FP-Growth Algorithm 47 4 Assignment Bundle: Frequent
Incrementally mining high utility patterns based on pre-large concept
 Appl Intell (2014) 40:343 357 DOI 10.1007/s10489-013-0467-z Incrementally mining high utility patterns based on pre-large concept Chun-Wei Lin Tzung-Pei Hong Guo-Cheng Lan Jia-Wei Wong Wen-Yang Lin Published
Appl Intell (2014) 40:343 357 DOI 10.1007/s10489-013-0467-z Incrementally mining high utility patterns based on pre-large concept Chun-Wei Lin Tzung-Pei Hong Guo-Cheng Lan Jia-Wei Wong Wen-Yang Lin Published
Mining Top-K Association Rules. Philippe Fournier-Viger 1 Cheng-Wei Wu 2 Vincent Shin-Mu Tseng 2. University of Moncton, Canada
 Mining Top-K Association Rules Philippe Fournier-Viger 1 Cheng-Wei Wu 2 Vincent Shin-Mu Tseng 2 1 University of Moncton, Canada 2 National Cheng Kung University, Taiwan AI 2012 28 May 2012 Introduction
Mining Top-K Association Rules Philippe Fournier-Viger 1 Cheng-Wei Wu 2 Vincent Shin-Mu Tseng 2 1 University of Moncton, Canada 2 National Cheng Kung University, Taiwan AI 2012 28 May 2012 Introduction
AN ENHNACED HIGH UTILITY PATTERN APPROACH FOR MINING ITEMSETS
 International Journal of Advanced Research in Computer Engineering & Technology (IJARCET) AN ENHNACED HIGH UTILITY PATTERN APPROACH FOR MINING ITEMSETS P.Sharmila 1, Dr. S.Meenakshi 2 1 Research Scholar,
International Journal of Advanced Research in Computer Engineering & Technology (IJARCET) AN ENHNACED HIGH UTILITY PATTERN APPROACH FOR MINING ITEMSETS P.Sharmila 1, Dr. S.Meenakshi 2 1 Research Scholar,
Efficient Algorithm for Mining High Utility Itemsets from Large Datasets Using Vertical Approach
 IOSR Journal of Computer Engineering (IOSR-JCE) e-issn: 2278-0661,p-ISSN: 2278-8727, Volume 18, Issue 4, Ver. VI (Jul.-Aug. 2016), PP 68-74 www.iosrjournals.org Efficient Algorithm for Mining High Utility
IOSR Journal of Computer Engineering (IOSR-JCE) e-issn: 2278-0661,p-ISSN: 2278-8727, Volume 18, Issue 4, Ver. VI (Jul.-Aug. 2016), PP 68-74 www.iosrjournals.org Efficient Algorithm for Mining High Utility
Enhancing the Performance of Mining High Utility Itemsets Based On Pattern Algorithm
 Enhancing the Performance of Mining High Utility Itemsets Based On Pattern Algorithm Ranjith Kumar. M 1, kalaivani. A 2, Dr. Sankar Ram. N 3 Assistant Professor, Dept. of CSE., R.M. K College of Engineering
Enhancing the Performance of Mining High Utility Itemsets Based On Pattern Algorithm Ranjith Kumar. M 1, kalaivani. A 2, Dr. Sankar Ram. N 3 Assistant Professor, Dept. of CSE., R.M. K College of Engineering
High Utility Web Access Patterns Mining from Distributed Databases
 High Utility Web Access Patterns Mining from Distributed Databases Md.Azam Hosssain 1, Md.Mamunur Rashid 1, Byeong-Soo Jeong 1, Ho-Jin Choi 2 1 Database Lab, Department of Computer Engineering, Kyung Hee
High Utility Web Access Patterns Mining from Distributed Databases Md.Azam Hosssain 1, Md.Mamunur Rashid 1, Byeong-Soo Jeong 1, Ho-Jin Choi 2 1 Database Lab, Department of Computer Engineering, Kyung Hee
USING FREQUENT PATTERN MINING ALGORITHMS IN TEXT ANALYSIS
 INFORMATION SYSTEMS IN MANAGEMENT Information Systems in Management (2017) Vol. 6 (3) 213 222 USING FREQUENT PATTERN MINING ALGORITHMS IN TEXT ANALYSIS PIOTR OŻDŻYŃSKI, DANUTA ZAKRZEWSKA Institute of Information
INFORMATION SYSTEMS IN MANAGEMENT Information Systems in Management (2017) Vol. 6 (3) 213 222 USING FREQUENT PATTERN MINING ALGORITHMS IN TEXT ANALYSIS PIOTR OŻDŻYŃSKI, DANUTA ZAKRZEWSKA Institute of Information
Efficient Mining of Generalized Negative Association Rules
 2010 IEEE International Conference on Granular Computing Efficient Mining of Generalized egative Association Rules Li-Min Tsai, Shu-Jing Lin, and Don-Lin Yang Dept. of Information Engineering and Computer
2010 IEEE International Conference on Granular Computing Efficient Mining of Generalized egative Association Rules Li-Min Tsai, Shu-Jing Lin, and Don-Lin Yang Dept. of Information Engineering and Computer
Maintenance of the Prelarge Trees for Record Deletion
 12th WSEAS Int. Conf. on APPLIED MATHEMATICS, Cairo, Egypt, December 29-31, 2007 105 Maintenance of the Prelarge Trees for Record Deletion Chun-Wei Lin, Tzung-Pei Hong, and Wen-Hsiang Lu Department of
12th WSEAS Int. Conf. on APPLIED MATHEMATICS, Cairo, Egypt, December 29-31, 2007 105 Maintenance of the Prelarge Trees for Record Deletion Chun-Wei Lin, Tzung-Pei Hong, and Wen-Hsiang Lu Department of
EFIM: A Highly Efficient Algorithm for High-Utility Itemset Mining
 EFIM: A Highly Efficient Algorithm for High-Utility Itemset Mining Souleymane Zida 1, Philippe Fournier-Viger 1, Jerry Chun-Wei Lin 2, Cheng-Wei Wu 3, Vincent S. Tseng 3 1 Dept. of Computer Science, University
EFIM: A Highly Efficient Algorithm for High-Utility Itemset Mining Souleymane Zida 1, Philippe Fournier-Viger 1, Jerry Chun-Wei Lin 2, Cheng-Wei Wu 3, Vincent S. Tseng 3 1 Dept. of Computer Science, University
Mining Rare Periodic-Frequent Patterns Using Multiple Minimum Supports
 Mining Rare Periodic-Frequent Patterns Using Multiple Minimum Supports R. Uday Kiran P. Krishna Reddy Center for Data Engineering International Institute of Information Technology-Hyderabad Hyderabad,
Mining Rare Periodic-Frequent Patterns Using Multiple Minimum Supports R. Uday Kiran P. Krishna Reddy Center for Data Engineering International Institute of Information Technology-Hyderabad Hyderabad,
An Efficient Algorithm for Finding the Support Count of Frequent 1-Itemsets in Frequent Pattern Mining
 An Efficient Algorithm for Finding the Support Count of Frequent 1-Itemsets in Frequent Pattern Mining P.Subhashini 1, Dr.G.Gunasekaran 2 Research Scholar, Dept. of Information Technology, St.Peter s University,
An Efficient Algorithm for Finding the Support Count of Frequent 1-Itemsets in Frequent Pattern Mining P.Subhashini 1, Dr.G.Gunasekaran 2 Research Scholar, Dept. of Information Technology, St.Peter s University,
ANALYSIS OF DENSE AND SPARSE PATTERNS TO IMPROVE MINING EFFICIENCY
 ANALYSIS OF DENSE AND SPARSE PATTERNS TO IMPROVE MINING EFFICIENCY A. Veeramuthu Department of Information Technology, Sathyabama University, Chennai India E-Mail: aveeramuthu@gmail.com ABSTRACT Generally,
ANALYSIS OF DENSE AND SPARSE PATTERNS TO IMPROVE MINING EFFICIENCY A. Veeramuthu Department of Information Technology, Sathyabama University, Chennai India E-Mail: aveeramuthu@gmail.com ABSTRACT Generally,
A Two-Phase Algorithm for Fast Discovery of High Utility Itemsets
 A Two-Phase Algorithm for Fast Discovery of High Utility temsets Ying Liu, Wei-keng Liao, and Alok Choudhary Electrical and Computer Engineering Department, Northwestern University, Evanston, L, USA 60208
A Two-Phase Algorithm for Fast Discovery of High Utility temsets Ying Liu, Wei-keng Liao, and Alok Choudhary Electrical and Computer Engineering Department, Northwestern University, Evanston, L, USA 60208
Mining Quantitative Maximal Hyperclique Patterns: A Summary of Results
 Mining Quantitative Maximal Hyperclique Patterns: A Summary of Results Yaochun Huang, Hui Xiong, Weili Wu, and Sam Y. Sung 3 Computer Science Department, University of Texas - Dallas, USA, {yxh03800,wxw0000}@utdallas.edu
Mining Quantitative Maximal Hyperclique Patterns: A Summary of Results Yaochun Huang, Hui Xiong, Weili Wu, and Sam Y. Sung 3 Computer Science Department, University of Texas - Dallas, USA, {yxh03800,wxw0000}@utdallas.edu
DMSA TECHNIQUE FOR FINDING SIGNIFICANT PATTERNS IN LARGE DATABASE
 DMSA TECHNIQUE FOR FINDING SIGNIFICANT PATTERNS IN LARGE DATABASE Saravanan.Suba Assistant Professor of Computer Science Kamarajar Government Art & Science College Surandai, TN, India-627859 Email:saravanansuba@rediffmail.com
DMSA TECHNIQUE FOR FINDING SIGNIFICANT PATTERNS IN LARGE DATABASE Saravanan.Suba Assistant Professor of Computer Science Kamarajar Government Art & Science College Surandai, TN, India-627859 Email:saravanansuba@rediffmail.com
Item Set Extraction of Mining Association Rule
 Item Set Extraction of Mining Association Rule Shabana Yasmeen, Prof. P.Pradeep Kumar, A.Ranjith Kumar Department CSE, Vivekananda Institute of Technology and Science, Karimnagar, A.P, India Abstract:
Item Set Extraction of Mining Association Rule Shabana Yasmeen, Prof. P.Pradeep Kumar, A.Ranjith Kumar Department CSE, Vivekananda Institute of Technology and Science, Karimnagar, A.P, India Abstract:
To Enhance Projection Scalability of Item Transactions by Parallel and Partition Projection using Dynamic Data Set
 To Enhance Scalability of Item Transactions by Parallel and Partition using Dynamic Data Set Priyanka Soni, Research Scholar (CSE), MTRI, Bhopal, priyanka.soni379@gmail.com Dhirendra Kumar Jha, MTRI, Bhopal,
To Enhance Scalability of Item Transactions by Parallel and Partition using Dynamic Data Set Priyanka Soni, Research Scholar (CSE), MTRI, Bhopal, priyanka.soni379@gmail.com Dhirendra Kumar Jha, MTRI, Bhopal,
Mining Frequent Itemsets for data streams over Weighted Sliding Windows
 Mining Frequent Itemsets for data streams over Weighted Sliding Windows Pauray S.M. Tsai Yao-Ming Chen Department of Computer Science and Information Engineering Minghsin University of Science and Technology
Mining Frequent Itemsets for data streams over Weighted Sliding Windows Pauray S.M. Tsai Yao-Ming Chen Department of Computer Science and Information Engineering Minghsin University of Science and Technology
INTERNATIONAL JOURNAL OF COMPUTER ENGINEERING & TECHNOLOGY (IJCET)
") INTERNATIONAL JOURNAL OF COMPUTER ENGINEERING & TECHNOLOGY (IJCET) International Journal of Computer Engineering and Technology (IJCET), ISSN 0976-6367(Print), ISSN 0976 6367(Print) ISSN 0976 6375(Online)
INTERNATIONAL JOURNAL OF COMPUTER ENGINEERING & TECHNOLOGY (IJCET) International Journal of Computer Engineering and Technology (IJCET), ISSN 0976-6367(Print), ISSN 0976 6367(Print) ISSN 0976 6375(Online)
Associating Terms with Text Categories
 Associating Terms with Text Categories Osmar R. Zaïane Department of Computing Science University of Alberta Edmonton, AB, Canada zaiane@cs.ualberta.ca Maria-Luiza Antonie Department of Computing Science
Associating Terms with Text Categories Osmar R. Zaïane Department of Computing Science University of Alberta Edmonton, AB, Canada zaiane@cs.ualberta.ca Maria-Luiza Antonie Department of Computing Science
Efficient Remining of Generalized Multi-supported Association Rules under Support Update
 Efficient Remining of Generalized Multi-supported Association Rules under Support Update WEN-YANG LIN 1 and MING-CHENG TSENG 1 Dept. of Information Management, Institute of Information Engineering I-Shou
Efficient Remining of Generalized Multi-supported Association Rules under Support Update WEN-YANG LIN 1 and MING-CHENG TSENG 1 Dept. of Information Management, Institute of Information Engineering I-Shou
A Hierarchical Document Clustering Approach with Frequent Itemsets
 A Hierarchical Document Clustering Approach with Frequent Itemsets Cheng-Jhe Lee, Chiun-Chieh Hsu, and Da-Ren Chen Abstract In order to effectively retrieve required information from the large amount of
A Hierarchical Document Clustering Approach with Frequent Itemsets Cheng-Jhe Lee, Chiun-Chieh Hsu, and Da-Ren Chen Abstract In order to effectively retrieve required information from the large amount of
ETP-Mine: An Efficient Method for Mining Transitional Patterns
 ETP-Mine: An Efficient Method for Mining Transitional Patterns B. Kiran Kumar 1 and A. Bhaskar 2 1 Department of M.C.A., Kakatiya Institute of Technology & Science, A.P. INDIA. kirankumar.bejjanki@gmail.com
ETP-Mine: An Efficient Method for Mining Transitional Patterns B. Kiran Kumar 1 and A. Bhaskar 2 1 Department of M.C.A., Kakatiya Institute of Technology & Science, A.P. INDIA. kirankumar.bejjanki@gmail.com
A Decremental Algorithm for Maintaining Frequent Itemsets in Dynamic Databases *
 A Decremental Algorithm for Maintaining Frequent Itemsets in Dynamic Databases * Shichao Zhang 1, Xindong Wu 2, Jilian Zhang 3, and Chengqi Zhang 1 1 Faculty of Information Technology, University of Technology
A Decremental Algorithm for Maintaining Frequent Itemsets in Dynamic Databases * Shichao Zhang 1, Xindong Wu 2, Jilian Zhang 3, and Chengqi Zhang 1 1 Faculty of Information Technology, University of Technology
UP-Hist Tree: An Efficient Data Structure for Mining High Utility Patterns from Transaction Databases
 UP-Hist Tree: n fficient Data Structure for Mining High Utility Patterns from Transaction Databases Siddharth Dawar Indraprastha Institute of Information Technology Delhi, India siddharthd@iiitd.ac.in
UP-Hist Tree: n fficient Data Structure for Mining High Utility Patterns from Transaction Databases Siddharth Dawar Indraprastha Institute of Information Technology Delhi, India siddharthd@iiitd.ac.in
Mining Top-K Strongly Correlated Item Pairs Without Minimum Correlation Threshold
 Mining Top-K Strongly Correlated Item Pairs Without Minimum Correlation Threshold Zengyou He, Xiaofei Xu, Shengchun Deng Department of Computer Science and Engineering, Harbin Institute of Technology,
Mining Top-K Strongly Correlated Item Pairs Without Minimum Correlation Threshold Zengyou He, Xiaofei Xu, Shengchun Deng Department of Computer Science and Engineering, Harbin Institute of Technology,
An Evolutionary Algorithm for Mining Association Rules Using Boolean Approach
 An Evolutionary Algorithm for Mining Association Rules Using Boolean Approach ABSTRACT G.Ravi Kumar 1 Dr.G.A. Ramachandra 2 G.Sunitha 3 1. Research Scholar, Department of Computer Science &Technology,
An Evolutionary Algorithm for Mining Association Rules Using Boolean Approach ABSTRACT G.Ravi Kumar 1 Dr.G.A. Ramachandra 2 G.Sunitha 3 1. Research Scholar, Department of Computer Science &Technology,
DISCOVERING ACTIVE AND PROFITABLE PATTERNS WITH RFM (RECENCY, FREQUENCY AND MONETARY) SEQUENTIAL PATTERN MINING A CONSTRAINT BASED APPROACH
 SEQUENTIAL PATTERN MINING A CONSTRAINT BASED APPROACH") International Journal of Information Technology and Knowledge Management January-June 2011, Volume 4, No. 1, pp. 27-32 DISCOVERING ACTIVE AND PROFITABLE PATTERNS WITH RFM (RECENCY, FREQUENCY AND MONETARY)
International Journal of Information Technology and Knowledge Management January-June 2011, Volume 4, No. 1, pp. 27-32 DISCOVERING ACTIVE AND PROFITABLE PATTERNS WITH RFM (RECENCY, FREQUENCY AND MONETARY)
Implementation of object oriented approach to Index Support for Item Set Mining (IMine)
") Implementation of object oriented approach to Index Support for Item Set Mining (IMine) R.SRIKANTH, 2/2 M.TECH CSE, DEPARTMENT OF COMPUTER SCIENCE AND ENGINEERING, ADITYA INSTITUTE OF TECHNOLOGY AND MANAGEMENT,
Implementation of object oriented approach to Index Support for Item Set Mining (IMine) R.SRIKANTH, 2/2 M.TECH CSE, DEPARTMENT OF COMPUTER SCIENCE AND ENGINEERING, ADITYA INSTITUTE OF TECHNOLOGY AND MANAGEMENT,
Improved Frequent Pattern Mining Algorithm with Indexing
 IOSR Journal of Computer Engineering (IOSR-JCE) e-issn: 2278-0661,p-ISSN: 2278-8727, Volume 16, Issue 6, Ver. VII (Nov Dec. 2014), PP 73-78 Improved Frequent Pattern Mining Algorithm with Indexing Prof.
IOSR Journal of Computer Engineering (IOSR-JCE) e-issn: 2278-0661,p-ISSN: 2278-8727, Volume 16, Issue 6, Ver. VII (Nov Dec. 2014), PP 73-78 Improved Frequent Pattern Mining Algorithm with Indexing Prof.
Efficient Tree Based Structure for Mining Frequent Pattern from Transactional Databases
 International Journal of Computational Engineering Research Vol, 03 Issue, 6 Efficient Tree Based Structure for Mining Frequent Pattern from Transactional Databases Hitul Patel 1, Prof. Mehul Barot 2,
International Journal of Computational Engineering Research Vol, 03 Issue, 6 Efficient Tree Based Structure for Mining Frequent Pattern from Transactional Databases Hitul Patel 1, Prof. Mehul Barot 2,
Efficient Mining of High Average-Utility Itemsets with Multiple Minimum Thresholds
 Efficient Mining of High Average-Utility Itemsets with Multiple Minimum Thresholds Jerry Chun-Wei Lin 1(B), Ting Li 1, Philippe Fournier-Viger 2, Tzung-Pei Hong 3,4, and Ja-Hwung Su 5 1 School of Computer
Efficient Mining of High Average-Utility Itemsets with Multiple Minimum Thresholds Jerry Chun-Wei Lin 1(B), Ting Li 1, Philippe Fournier-Viger 2, Tzung-Pei Hong 3,4, and Ja-Hwung Su 5 1 School of Computer
Keshavamurthy B.N., Mitesh Sharma and Durga Toshniwal
 Keshavamurthy B.N., Mitesh Sharma and Durga Toshniwal Department of Electronics and Computer Engineering, Indian Institute of Technology, Roorkee, Uttarkhand, India. bnkeshav123@gmail.com, mitusuec@iitr.ernet.in,
Keshavamurthy B.N., Mitesh Sharma and Durga Toshniwal Department of Electronics and Computer Engineering, Indian Institute of Technology, Roorkee, Uttarkhand, India. bnkeshav123@gmail.com, mitusuec@iitr.ernet.in,
STUDY ON FREQUENT PATTEREN GROWTH ALGORITHM WITHOUT CANDIDATE KEY GENERATION IN DATABASES
 STUDY ON FREQUENT PATTEREN GROWTH ALGORITHM WITHOUT CANDIDATE KEY GENERATION IN DATABASES Prof. Ambarish S. Durani 1 and Mrs. Rashmi B. Sune 2 1 Assistant Professor, Datta Meghe Institute of Engineering,
STUDY ON FREQUENT PATTEREN GROWTH ALGORITHM WITHOUT CANDIDATE KEY GENERATION IN DATABASES Prof. Ambarish S. Durani 1 and Mrs. Rashmi B. Sune 2 1 Assistant Professor, Datta Meghe Institute of Engineering,
Mining High Utility Itemsets from Large Transactions using Efficient Tree Structure
 Mining High Utility Itemsets from Large Transactions using Efficient Tree Structure T.Vinothini Department of Computer Science and Engineering, Knowledge Institute of Technology, Salem. V.V.Ramya Shree
Mining High Utility Itemsets from Large Transactions using Efficient Tree Structure T.Vinothini Department of Computer Science and Engineering, Knowledge Institute of Technology, Salem. V.V.Ramya Shree
Efficient Mining of Uncertain Data for High-Utility Itemsets
 Efficient Mining of Uncertain Data for High-Utility Itemsets Jerry Chun-Wei Lin 1(B), Wensheng Gan 1, Philippe Fournier-Viger 2, Tzung-Pei Hong 3,4, and Vincent S. Tseng 5 1 School of Computer Science
Efficient Mining of Uncertain Data for High-Utility Itemsets Jerry Chun-Wei Lin 1(B), Wensheng Gan 1, Philippe Fournier-Viger 2, Tzung-Pei Hong 3,4, and Vincent S. Tseng 5 1 School of Computer Science
Kavitha V et al., International Journal of Advanced Engineering Technology E-ISSN
 Research Paper HIGH UTILITY ITEMSET MINING WITH INFLUENTIAL CROSS SELLING ITEMS FROM TRANSACTIONAL DATABASE Kavitha V 1, Dr.Geetha B G 2 Address for Correspondence 1.Assistant Professor(Sl.Gr), Department
Research Paper HIGH UTILITY ITEMSET MINING WITH INFLUENTIAL CROSS SELLING ITEMS FROM TRANSACTIONAL DATABASE Kavitha V 1, Dr.Geetha B G 2 Address for Correspondence 1.Assistant Professor(Sl.Gr), Department
[Shingarwade, 6(2): February 2019] ISSN DOI /zenodo Impact Factor
![[Shingarwade, 6(2): February 2019] ISSN DOI /zenodo Impact Factor](/thumbs/94/118515711.jpg "[Shingarwade, 6(2): February 2019] ISSN DOI /zenodo Impact Factor") GLOBAL JOURNAL OF ENGINEERING SCIENCE AND RESEARCHES DEVELOPMENT OF TOP K RULES FOR ASSOCIATION RULE MINING ON E- COMMERCE DATASET A. K. Shingarwade *1 & Dr. P. N. Mulkalwar 2 *1 Department of Computer
GLOBAL JOURNAL OF ENGINEERING SCIENCE AND RESEARCHES DEVELOPMENT OF TOP K RULES FOR ASSOCIATION RULE MINING ON E- COMMERCE DATASET A. K. Shingarwade *1 & Dr. P. N. Mulkalwar 2 *1 Department of Computer
Fast Algorithm for Mining Association Rules
 Fast Algorithm for Mining Association Rules M.H.Margahny and A.A.Mitwaly Dept. of Computer Science, Faculty of Computers and Information, Assuit University, Egypt, Email: marghny@acc.aun.edu.eg. Abstract
Fast Algorithm for Mining Association Rules M.H.Margahny and A.A.Mitwaly Dept. of Computer Science, Faculty of Computers and Information, Assuit University, Egypt, Email: marghny@acc.aun.edu.eg. Abstract
Study on Mining Weighted Infrequent Itemsets Using FP Growth
 www.ijecs.in International Journal Of Engineering And Computer Science ISSN:2319-7242 Volume 4 Issue 6 June 2015, Page No. 12719-12723 Study on Mining Weighted Infrequent Itemsets Using FP Growth K.Hemanthakumar
www.ijecs.in International Journal Of Engineering And Computer Science ISSN:2319-7242 Volume 4 Issue 6 June 2015, Page No. 12719-12723 Study on Mining Weighted Infrequent Itemsets Using FP Growth K.Hemanthakumar
Discovery of Multi-level Association Rules from Primitive Level Frequent Patterns Tree
 Discovery of Multi-level Association Rules from Primitive Level Frequent Patterns Tree Virendra Kumar Shrivastava 1, Parveen Kumar 2, K. R. Pardasani 3 1 Department of Computer Science & Engineering, Singhania
Discovery of Multi-level Association Rules from Primitive Level Frequent Patterns Tree Virendra Kumar Shrivastava 1, Parveen Kumar 2, K. R. Pardasani 3 1 Department of Computer Science & Engineering, Singhania
Pattern Mining. Knowledge Discovery and Data Mining 1. Roman Kern KTI, TU Graz. Roman Kern (KTI, TU Graz) Pattern Mining / 42
 Pattern Mining / 42") Pattern Mining Knowledge Discovery and Data Mining 1 Roman Kern KTI, TU Graz 2016-01-14 Roman Kern (KTI, TU Graz) Pattern Mining 2016-01-14 1 / 42 Outline 1 Introduction 2 Apriori Algorithm 3 FP-Growth
Pattern Mining Knowledge Discovery and Data Mining 1 Roman Kern KTI, TU Graz 2016-01-14 Roman Kern (KTI, TU Graz) Pattern Mining 2016-01-14 1 / 42 Outline 1 Introduction 2 Apriori Algorithm 3 FP-Growth
An Improved Apriori Algorithm for Association Rules
 Research article An Improved Apriori Algorithm for Association Rules Hassan M. Najadat 1, Mohammed Al-Maolegi 2, Bassam Arkok 3 Computer Science, Jordan University of Science and Technology, Irbid, Jordan
Research article An Improved Apriori Algorithm for Association Rules Hassan M. Najadat 1, Mohammed Al-Maolegi 2, Bassam Arkok 3 Computer Science, Jordan University of Science and Technology, Irbid, Jordan
Closest Keywords Search on Spatial Databases
 Closest Keywords Search on Spatial Databases 1 A. YOJANA, 2 Dr. A. SHARADA 1 M. Tech Student, Department of CSE, G.Narayanamma Institute of Technology & Science, Telangana, India. 2 Associate Professor,
Closest Keywords Search on Spatial Databases 1 A. YOJANA, 2 Dr. A. SHARADA 1 M. Tech Student, Department of CSE, G.Narayanamma Institute of Technology & Science, Telangana, India. 2 Associate Professor,
ISSN: ISO 9001:2008 Certified International Journal of Engineering Science and Innovative Technology (IJESIT) Volume 2, Issue 2, March 2013
 Volume 2, Issue 2, March 2013") A Novel Approach to Mine Frequent Item sets Of Process Models for Cloud Computing Using Association Rule Mining Roshani Parate M.TECH. Computer Science. NRI Institute of Technology, Bhopal (M.P.) Sitendra
A Novel Approach to Mine Frequent Item sets Of Process Models for Cloud Computing Using Association Rule Mining Roshani Parate M.TECH. Computer Science. NRI Institute of Technology, Bhopal (M.P.) Sitendra
A Modified Apriori Algorithm for Fast and Accurate Generation of Frequent Item Sets
 INTERNATIONAL JOURNAL OF SCIENTIFIC & TECHNOLOGY RESEARCH VOLUME 6, ISSUE 08, AUGUST 2017 ISSN 2277-8616 A Modified Apriori Algorithm for Fast and Accurate Generation of Frequent Item Sets K.A.Baffour,
INTERNATIONAL JOURNAL OF SCIENTIFIC & TECHNOLOGY RESEARCH VOLUME 6, ISSUE 08, AUGUST 2017 ISSN 2277-8616 A Modified Apriori Algorithm for Fast and Accurate Generation of Frequent Item Sets K.A.Baffour,
H-Mine: Hyper-Structure Mining of Frequent Patterns in Large Databases. Paper s goals. H-mine characteristics. Why a new algorithm?
 H-Mine: Hyper-Structure Mining of Frequent Patterns in Large Databases Paper s goals Introduce a new data structure: H-struct J. Pei, J. Han, H. Lu, S. Nishio, S. Tang, and D. Yang Int. Conf. on Data Mining
H-Mine: Hyper-Structure Mining of Frequent Patterns in Large Databases Paper s goals Introduce a new data structure: H-struct J. Pei, J. Han, H. Lu, S. Nishio, S. Tang, and D. Yang Int. Conf. on Data Mining
Log Information Mining Using Association Rules Technique: A Case Study Of Utusan Education Portal
 Log Information Mining Using Association Rules Technique: A Case Study Of Utusan Education Portal Mohd Helmy Ab Wahab 1, Azizul Azhar Ramli 2, Nureize Arbaiy 3, Zurinah Suradi 4 1 Faculty of Electrical
Log Information Mining Using Association Rules Technique: A Case Study Of Utusan Education Portal Mohd Helmy Ab Wahab 1, Azizul Azhar Ramli 2, Nureize Arbaiy 3, Zurinah Suradi 4 1 Faculty of Electrical
Improved Algorithm for Frequent Item sets Mining Based on Apriori and FP-Tree
 Global Journal of Computer Science and Technology Software & Data Engineering Volume 13 Issue 2 Version 1.0 Year 2013 Type: Double Blind Peer Reviewed International Research Journal Publisher: Global Journals
Global Journal of Computer Science and Technology Software & Data Engineering Volume 13 Issue 2 Version 1.0 Year 2013 Type: Double Blind Peer Reviewed International Research Journal Publisher: Global Journals
AC-Close: Efficiently Mining Approximate Closed Itemsets by Core Pattern Recovery
 : Efficiently Mining Approximate Closed Itemsets by Core Pattern Recovery Hong Cheng Philip S. Yu Jiawei Han University of Illinois at Urbana-Champaign IBM T. J. Watson Research Center {hcheng3, hanj}@cs.uiuc.edu,
: Efficiently Mining Approximate Closed Itemsets by Core Pattern Recovery Hong Cheng Philip S. Yu Jiawei Han University of Illinois at Urbana-Champaign IBM T. J. Watson Research Center {hcheng3, hanj}@cs.uiuc.edu,
FREQUENT ITEMSET MINING USING PFP-GROWTH VIA SMART SPLITTING
 FREQUENT ITEMSET MINING USING PFP-GROWTH VIA SMART SPLITTING Neha V. Sonparote, Professor Vijay B. More. Neha V. Sonparote, Dept. of computer Engineering, MET s Institute of Engineering Nashik, Maharashtra,
FREQUENT ITEMSET MINING USING PFP-GROWTH VIA SMART SPLITTING Neha V. Sonparote, Professor Vijay B. More. Neha V. Sonparote, Dept. of computer Engineering, MET s Institute of Engineering Nashik, Maharashtra,
Web page recommendation using a stochastic process model
 Data Mining VII: Data, Text and Web Mining and their Business Applications 233 Web page recommendation using a stochastic process model B. J. Park 1, W. Choi 1 & S. H. Noh 2 1 Computer Science Department,
Data Mining VII: Data, Text and Web Mining and their Business Applications 233 Web page recommendation using a stochastic process model B. J. Park 1, W. Choi 1 & S. H. Noh 2 1 Computer Science Department,
CMRULES: An Efficient Algorithm for Mining Sequential Rules Common to Several Sequences
 CMRULES: An Efficient Algorithm for Mining Sequential Rules Common to Several Sequences Philippe Fournier-Viger 1, Usef Faghihi 1, Roger Nkambou 1, Engelbert Mephu Nguifo 2 1 Department of Computer Sciences,
CMRULES: An Efficient Algorithm for Mining Sequential Rules Common to Several Sequences Philippe Fournier-Viger 1, Usef Faghihi 1, Roger Nkambou 1, Engelbert Mephu Nguifo 2 1 Department of Computer Sciences,
Mining of Web Server Logs using Extended Apriori Algorithm
 International Association of Scientific Innovation and Research (IASIR) (An Association Unifying the Sciences, Engineering, and Applied Research) International Journal of Emerging Technologies in Computational
International Association of Scientific Innovation and Research (IASIR) (An Association Unifying the Sciences, Engineering, and Applied Research) International Journal of Emerging Technologies in Computational