FLAT DATACENTER STORAGE. Paper-3 Presenter-Pratik Bhatt fx6568
|
|
|
- Jodie Robbins
- 5 years ago
- Views:
Transcription
1 FLAT DATACENTER STORAGE Paper-3 Presenter-Pratik Bhatt fx6568
2 FDS Main discussion points A cluster storage system Stores giant "blobs" bit ID, multi-megabyte content Clients and servers connected by network with high bisection bandwidth For big-data processing (like MapReduce) Cluster of 1000s of computers processing data in parallel Compute and storage are logically separate Metadata management Networks Read and write performance Failure recovery Application performance
3 FDS
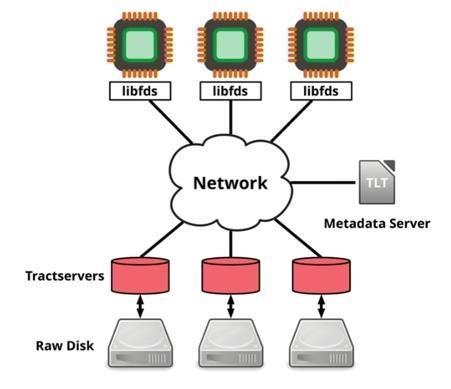
4 FDS the storage system is pretty simple. It's a straight-up blob store, where blobs are arbitrarily large, but are read and written in 8MB chunks called tracts. Blobs are identified with a 128-bit GUID, and tracts are 8MB offsets into the blob. Choosing 8MB means that the disks get essentially full sequential write bandwidth, since seek times are amortized over these long reads. It provides asynchronous APIs for read and write operations; pretty necessary for doing high-performance parallel I/O. Data is placed on storage nodes (aka tractservers) through a simple hashing scheme. There's no Name node like in Hadoop. Instead, clients cache a tract locator table (TLT) which lists all of the tractservers in immutable order. Lookups for a tract in a blob are done by hashing the blob GUID, adding the tract number, and then moduling to index into the TLT. Client access through the TLT is normally going to be sequential, since clients will mostly be sequentially scanning through the tracts of a blob. To find the TLT index, the blob ID is hashed, but the tract number is just added. This is countered by taking 20 copies of the list of tractservers, shuffling each copy, and then concatenating them together. This super-list prevents auto-synchronizing lockstep, and also does a good job of balancing data distribution across tractservers.
 Partition")

5 High-level design Lots of clients Lots of storage servers ("tractservers") Partition the data Master ("metadata server") controls partitioning Replica groups for reliability
6 Why is this high-level design useful? 1000s of disks of space Store giant blobs or many big blobs 1000s of servers/disks/arms of parallel throughput Can expand over time - reconfiguration Large pool of storage servers for instant replacement after failure Recreate lost copies from replicas.
7 Data Placement How do they place blobs on machines? Break each blob into 8 MB tracts "TLT" maintained by metadata server for blob g tract i and TLT size n, slot = (hash(g) + i) mod n TLT[slot] contains list of tractservers w/ copy of the tract Clients and servers all have copies of the latest TLT table
8 Metadata Properties Metadata server is in critical path only when a client process starts. So tract size can be kept arbitrarily small. TLT can be cached since it changes only on cluster configuration(not each read & write), eliminate all traffic to metadata server in system under normal conditions. The metadata server stores metadata only about the hardware configuration, not about blobs. Because blob traffic is low, its implementation is simple and lightweight. Since the TLT contains random permutations of the list of tractservers, sequential reads and writes by independent clients are highly likely to utilize all tractservers uniformly and are unlikely to organize into synchronized convoys.
9 Pre-blob metadata Each blob has metadata such as its length and it is stored it in each blob s special metadata tract ( tract 1 ). Clients find a blob s metadata on a tractserver using the same TLT used to find regular data. When a blob is created, the tractserver responsible for its metadata tract and creates that tract on disk and initializes the blob s size to 0. When a blob is deleted, that tractserver deletes the metadata. Newly created blobs have a length of 0 tracts. Applications must extend a blob before writing past the end of it. The extend operation is atomic and is safe to execute concurrently with other clients, and returns the new size of the blob as a result of the client s call. A separate API tells the client the blob s current size. Extend operations for a blob are sent to the tractserver that owns that blob s metadata tract. The tractserver serializes it, atomically updates the metadata, and returns the new size to each caller. If all writers follow this pattern, the extend operation provides a range of tracts and the caller may write without risk of conflict
10 Dynamic work allocation In any system if a node falls behind, the only options for recovery is restarting its computation elsewhere. So here straggler period can represent a great loss in efficiency if most resources are idle while waiting for a slow task to complete. In FDS, since storage and compute are no longer co-located, the assignment of work to worker can be done dynamically, at fine granularity, during task execution. The best practice for FDS applications is to centrally give small units of work to each worker as it nears completion of its previous unit. This self-clocking system ensures that the maximum dispersion in completion times across the cluster is only the time required for the slowest worker to complete a single unit.
11 REPLICATION IN FDS To improve durability and availability, FDS supports higher levels of replication. When a disk fails, redundant copies of the lost data are used to restore the data to full replication. What happen to replicas when application writes and reads? When an application writes a tract, the client library finds the appropriate row of the TLT and sends the write to every tractserver it contains. Applications are notified that their writes have completed only after the client library receives write acknowledgments from all replicas. Reads select a single tractserver at random. Applications are notified that their writes have completed only after the client library receives write acknowledgments from all replicas. Replication also requires changes to CreateBlob, ExtendBlobSize, and DeleteBlob. When a tractserver receives one of these operations, it executes a two-phase commit with the other replicas. The primary replica does not commit the change until all other replicas have completed successfully. FDS also supports per-blob variable replication.

12 Comparison with hadoop In FDS, data is only read and written to disk once. Hadoop's intermediate data is sorted and spilled to disk by the mapper, while FDS keeps this entirely in memory. FDS also streams and sorts data during the read phase, while Hadoop has a barrier between its map and reduce phases. Hadoop can do some preaggregation in the mapper with a combiner, but not as flexibly as in FDS, not on the reduce side, and not without hogging an entire task slot. FDS has better task scheduling, with a dynamic work queue and dynamic work item sizes. FDS uses a single process for both the read and write phases, so the JVM startup cost is gone, and there's no unnecessary movement of data between address spaces.
13 Questions and Answers 1. Consider a centralized file server in a small computer science department. Data stored by any computer can be retrieved by any other. This conceptual simplicity makes it easy to use: computation can happen on any computer, even in parallel, without regard to first putting data in the right place. Is GFS a centralized file system? To achieve good performance for an I/O-intensive program running on GFS, how does the data placement affect its performance? [Hint: consider the case where processes of the program run on the chunk servers.] Ans. The GFS is a centralized file system. In order to -simplify the design,increase its reliability flexibility. The GFS got a simple centralized management system. As the system has centralized data storage system. But general GFS is a distributed file system. In GFS the data is distributed as chucks. Master does not store all the useful data on a single chunk rather it distributes it to balance load and disk space on chunk server. So in the scenario of the question the GFS can be viewed as centralized file system but generally the GFS is a distributed file system. - In particular, a centralized master makes it much easier to implement sophisticated chunk placement and replication policies since the master already has most of the relevant information and controls how it changes. The fault tolerance by keeping the master state small and fully replicated on other machines. Scalability and high availability (for reads) are currently provided by our shadow master mechanism.
14 2. The root of this cascade of consequences was the locality constraint, itself rooted in the datacenter bandwidth shortage. Show example consequences of relying on locality in program s execution. Why does a sufficient I/O bandwidth help remove the constraint? Ans. Stragglers is one example. Locality constraints can sometimes even hinder efficient resource utilization. One example is stragglers: if data is singly replicated, a single unexpectedly slow machine can preclude an entire job s timely completion even while most of the resources are idle. The preference for local disks also serves as a barrier to quickly re-tasking nodes: since a CPU is only useful for processing the data resident there, re-tasking requires expensive data movement. If we consider the network is not oversubscribed then we could provide full bisectional bandwidth between the disks. So that there would be no distinction between local and remote disks. So constraints like re-tasking doesn t require expensive data movement
15 3. In FDS, data is logically stored in blobs.... Reads from and writes to a blob are done in units called tracts. What are blob and tracts? Are they of constant sizes? Ans. Data is stored in logical blobs Byte sequences with a 128-bit Global Unique Identifiers (GUID) Blob can be any length up to system s storage capacity. Divided into constant sized units called tracts Tracts are sized so random and sequential accesses have same throughput Both tracts and blobs are mutable Disk is managed by a tractserver process Read/write to disk directly without filesystem; tract data cached in memory
16 4. In our cluster, tracts are 8MB. Why is a tract in FDS sized this large? Ans. Tracts are sized such that random and sequential access achieves nearly the same throughput. In our cluster, tracts are 8MB The tract size is set when the cluster is created based upon cluster hardware. For example, if flash were used instead of disks, the tract size could be made far smaller (e.g., 64kB).Every disk is managed by a process called a tract server. 1) If the tract size is small, the client need to write number of times for a large blob. The process would be slow. If the tract size is large, the number of writes will reduce. 2) The researches say that they have done several experiments on rpm disks. The experiments results that the throughput of the disk is good when the tract size is 8MB.
17 5. Tractservers do not use a file system. Explain this design choice. The FDS is storage system. It is not a file system. The tractservers are just raw disks, there will be no file system on them. They will just take all the blobs on the disks, divide them into sequential tracts and use those sequential tracks number them sequentially. The client just communicate with the FDS through an API that abstracts some of the complexity around the messaging layer. Tractservers and their network protocol are not exposed directly to FDS applications. Instead, these details are hidden in a client library with a narrow and straightforward interface.

18 6. Figure 1: FDS API. Read the API. Does FDS support file operations? Is a blob similar to a file in a (distributed) file system? Blob is not similar to a file. Blobs are typically images, audio or other multimedia objects, though sometimes binary executable code is stored as a blob similar as a file. FDS support several file operations as create blob, delete blob, open blob and close blob. We can also do several operations like writing and reading the tract etc.

19 7. FDS uses a metadata server, but its role during normal operations is simple and limited: What are drawbacks of using a centralized metadata server? How does FDS address the issue? Metadata server s role during normal operations is simple and limited. When the system is initialized, tractservers locally store their position in the TLT. This means the metadata server does not need to store durable state. So it will simplify its implementation. So, in case of a metadata server failure, the TLT is reconstructed by collecting the table assignments from each tractserver. So we will not lose all our data in case of metadata server failure. It collects a list of system s active tract server and distribute it to TLT with k-replicaton, each entry has k tractservers. To read or write tract number i from a blob with GUID g, Eq:- Tract_Locator = (Hash(g)+i) mod TLT_Length (uses eq to replace big size table)
20 8.How does FDS locate the track server that stores a particular tract of a given blob? Why does FDS first identify a tract locator (an index to an entry of tract locator table) and then in the entry to find the track server, rather than directly identifying a trackserver using a hash function without having such a table? Tract_Locator= (Hash(g) + i) mod TLT_Length If no hash then, i,g equati on A B C i,g equati on E F G If we do not have such table then we do not have any space to put the replicated data. So, in case where we do not have such table, we have just one(original) copy of the data and if something wrong happened to that data or disk then we cannot able to recover that lost data.
21 9. To be clear, the TLT does not contain complete information about the location of individual tracts in the system. and in the GFS paper The master maintains less than 64 bytes of metadata for each 64 MB chunk. Compare the TLT table with GFS s use of a full chunk-chunkserver mapping table in the context of efficiency, scalability, and flexibility. [Hint: It is not modified by tract reads and writes. Its size in a singlereplicated system is proportional to the number of tractservers in the system.] In GFS, chunk is large. So, once you ask some data location from master second time you do not need to ask location for other data in this system. This makes data excess very flexible. But single master in a system can still become potential bottleneck. In FDS, it uses a metadata server, but its role during normal operations is simple and limited i.e. it collects a list of the system s active tractservers and distribute it to clients and this list is called tract locator table, or TLT. And when the system is initialized, tractservers locally store their position in the TLT. In case of a metadata server failure, the TLT is reconstructed by collecting the table assignments from each tractserver. So here scalability and efficiency is very good.
22 10. In our 1,000 disk cluster, FDS recovers 92GB lost from a failed disk in 6.2 seconds. What is normal throughput of a hard disk? What s the throughput of this recovery? How can this be possible? [Hint: Describe the procedure of recovering from a dead tract server to answer this question. See Figure 2 and read Section 3.3] Normal throughput of HD MB/S. Approximately 15 GB/S, very high. Possible because of large number of replication
FLAT DATACENTER STORAGE CHANDNI MODI (FN8692)
") FLAT DATACENTER STORAGE CHANDNI MODI (FN8692) OUTLINE Flat datacenter storage Deterministic data placement in fds Metadata properties of fds Per-blob metadata in fds Dynamic Work Allocation in fds Replication
FLAT DATACENTER STORAGE CHANDNI MODI (FN8692) OUTLINE Flat datacenter storage Deterministic data placement in fds Metadata properties of fds Per-blob metadata in fds Dynamic Work Allocation in fds Replication
Flat Datacenter Storage. Edmund B. Nightingale, Jeremy Elson, et al. 6.S897
 Flat Datacenter Storage Edmund B. Nightingale, Jeremy Elson, et al. 6.S897 Motivation Imagine a world with flat data storage Simple, Centralized, and easy to program Unfortunately, datacenter networks
Flat Datacenter Storage Edmund B. Nightingale, Jeremy Elson, et al. 6.S897 Motivation Imagine a world with flat data storage Simple, Centralized, and easy to program Unfortunately, datacenter networks
Distributed Filesystem
 Distributed Filesystem 1 How do we get data to the workers? NAS Compute Nodes SAN 2 Distributing Code! Don t move data to workers move workers to the data! - Store data on the local disks of nodes in the
Distributed Filesystem 1 How do we get data to the workers? NAS Compute Nodes SAN 2 Distributing Code! Don t move data to workers move workers to the data! - Store data on the local disks of nodes in the
GFS Overview. Design goals/priorities Design for big-data workloads Huge files, mostly appends, concurrency, huge bandwidth Design for failures
 GFS Overview Design goals/priorities Design for big-data workloads Huge files, mostly appends, concurrency, huge bandwidth Design for failures Interface: non-posix New op: record appends (atomicity matters,
GFS Overview Design goals/priorities Design for big-data workloads Huge files, mostly appends, concurrency, huge bandwidth Design for failures Interface: non-posix New op: record appends (atomicity matters,
BigData and Map Reduce VITMAC03
 BigData and Map Reduce VITMAC03 1 Motivation Process lots of data Google processed about 24 petabytes of data per day in 2009. A single machine cannot serve all the data You need a distributed system to
BigData and Map Reduce VITMAC03 1 Motivation Process lots of data Google processed about 24 petabytes of data per day in 2009. A single machine cannot serve all the data You need a distributed system to
MapReduce. U of Toronto, 2014
 MapReduce U of Toronto, 2014 http://www.google.org/flutrends/ca/ (2012) Average Searches Per Day: 5,134,000,000 2 Motivation Process lots of data Google processed about 24 petabytes of data per day in
MapReduce U of Toronto, 2014 http://www.google.org/flutrends/ca/ (2012) Average Searches Per Day: 5,134,000,000 2 Motivation Process lots of data Google processed about 24 petabytes of data per day in
CA485 Ray Walshe Google File System
 Google File System Overview Google File System is scalable, distributed file system on inexpensive commodity hardware that provides: Fault Tolerance File system runs on hundreds or thousands of storage
Google File System Overview Google File System is scalable, distributed file system on inexpensive commodity hardware that provides: Fault Tolerance File system runs on hundreds or thousands of storage
CS 138: Google. CS 138 XVII 1 Copyright 2016 Thomas W. Doeppner. All rights reserved.
 CS 138: Google CS 138 XVII 1 Copyright 2016 Thomas W. Doeppner. All rights reserved. Google Environment Lots (tens of thousands) of computers all more-or-less equal - processor, disk, memory, network interface
CS 138: Google CS 138 XVII 1 Copyright 2016 Thomas W. Doeppner. All rights reserved. Google Environment Lots (tens of thousands) of computers all more-or-less equal - processor, disk, memory, network interface
The Google File System
 October 13, 2010 Based on: S. Ghemawat, H. Gobioff, and S.-T. Leung: The Google file system, in Proceedings ACM SOSP 2003, Lake George, NY, USA, October 2003. 1 Assumptions Interface Architecture Single
October 13, 2010 Based on: S. Ghemawat, H. Gobioff, and S.-T. Leung: The Google file system, in Proceedings ACM SOSP 2003, Lake George, NY, USA, October 2003. 1 Assumptions Interface Architecture Single
CLOUD-SCALE FILE SYSTEMS
 Data Management in the Cloud CLOUD-SCALE FILE SYSTEMS 92 Google File System (GFS) Designing a file system for the Cloud design assumptions design choices Architecture GFS Master GFS Chunkservers GFS Clients
Data Management in the Cloud CLOUD-SCALE FILE SYSTEMS 92 Google File System (GFS) Designing a file system for the Cloud design assumptions design choices Architecture GFS Master GFS Chunkservers GFS Clients
Map-Reduce. Marco Mura 2010 March, 31th
 Map-Reduce Marco Mura (mura@di.unipi.it) 2010 March, 31th This paper is a note from the 2009-2010 course Strumenti di programmazione per sistemi paralleli e distribuiti and it s based by the lessons of
Map-Reduce Marco Mura (mura@di.unipi.it) 2010 March, 31th This paper is a note from the 2009-2010 course Strumenti di programmazione per sistemi paralleli e distribuiti and it s based by the lessons of
Distributed File Systems II
 Distributed File Systems II To do q Very-large scale: Google FS, Hadoop FS, BigTable q Next time: Naming things GFS A radically new environment NFS, etc. Independence Small Scale Variety of workloads Cooperation
Distributed File Systems II To do q Very-large scale: Google FS, Hadoop FS, BigTable q Next time: Naming things GFS A radically new environment NFS, etc. Independence Small Scale Variety of workloads Cooperation
GFS: The Google File System. Dr. Yingwu Zhu
 GFS: The Google File System Dr. Yingwu Zhu Motivating Application: Google Crawl the whole web Store it all on one big disk Process users searches on one big CPU More storage, CPU required than one PC can
GFS: The Google File System Dr. Yingwu Zhu Motivating Application: Google Crawl the whole web Store it all on one big disk Process users searches on one big CPU More storage, CPU required than one PC can
! Design constraints. " Component failures are the norm. " Files are huge by traditional standards. ! POSIX-like
 Cloud background Google File System! Warehouse scale systems " 10K-100K nodes " 50MW (1 MW = 1,000 houses) " Power efficient! Located near cheap power! Passive cooling! Power Usage Effectiveness = Total
Cloud background Google File System! Warehouse scale systems " 10K-100K nodes " 50MW (1 MW = 1,000 houses) " Power efficient! Located near cheap power! Passive cooling! Power Usage Effectiveness = Total
CS 138: Google. CS 138 XVI 1 Copyright 2017 Thomas W. Doeppner. All rights reserved.
 CS 138: Google CS 138 XVI 1 Copyright 2017 Thomas W. Doeppner. All rights reserved. Google Environment Lots (tens of thousands) of computers all more-or-less equal - processor, disk, memory, network interface
CS 138: Google CS 138 XVI 1 Copyright 2017 Thomas W. Doeppner. All rights reserved. Google Environment Lots (tens of thousands) of computers all more-or-less equal - processor, disk, memory, network interface
GFS: The Google File System
 GFS: The Google File System Brad Karp UCL Computer Science CS GZ03 / M030 24 th October 2014 Motivating Application: Google Crawl the whole web Store it all on one big disk Process users searches on one
GFS: The Google File System Brad Karp UCL Computer Science CS GZ03 / M030 24 th October 2014 Motivating Application: Google Crawl the whole web Store it all on one big disk Process users searches on one
Distributed Systems. Lec 10: Distributed File Systems GFS. Slide acks: Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung
 Distributed Systems Lec 10: Distributed File Systems GFS Slide acks: Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung 1 Distributed File Systems NFS AFS GFS Some themes in these classes: Workload-oriented
Distributed Systems Lec 10: Distributed File Systems GFS Slide acks: Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung 1 Distributed File Systems NFS AFS GFS Some themes in these classes: Workload-oriented
Thank you, and welcome to OSDI! My name is Jeremy Elson and I m going to be talking about a project called flat datacenter storage, or FDS.
 Thank you, and welcome to OSDI! My name is Jeremy Elson and I m going to be talking about a project called flat datacenter storage, or FDS. I want to start with a little thought experiment. This session
Thank you, and welcome to OSDI! My name is Jeremy Elson and I m going to be talking about a project called flat datacenter storage, or FDS. I want to start with a little thought experiment. This session
The Google File System
 The Google File System Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung SOSP 2003 presented by Kun Suo Outline GFS Background, Concepts and Key words Example of GFS Operations Some optimizations in
The Google File System Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung SOSP 2003 presented by Kun Suo Outline GFS Background, Concepts and Key words Example of GFS Operations Some optimizations in
Programming Models MapReduce
 Programming Models MapReduce Majd Sakr, Garth Gibson, Greg Ganger, Raja Sambasivan 15-719/18-847b Advanced Cloud Computing Fall 2013 Sep 23, 2013 1 MapReduce In a Nutshell MapReduce incorporates two phases
Programming Models MapReduce Majd Sakr, Garth Gibson, Greg Ganger, Raja Sambasivan 15-719/18-847b Advanced Cloud Computing Fall 2013 Sep 23, 2013 1 MapReduce In a Nutshell MapReduce incorporates two phases
CS6030 Cloud Computing. Acknowledgements. Today s Topics. Intro to Cloud Computing 10/20/15. Ajay Gupta, WMU-CS. WiSe Lab
 CS6030 Cloud Computing Ajay Gupta B239, CEAS Computer Science Department Western Michigan University ajay.gupta@wmich.edu 276-3104 1 Acknowledgements I have liberally borrowed these slides and material
CS6030 Cloud Computing Ajay Gupta B239, CEAS Computer Science Department Western Michigan University ajay.gupta@wmich.edu 276-3104 1 Acknowledgements I have liberally borrowed these slides and material
ECE 7650 Scalable and Secure Internet Services and Architecture ---- A Systems Perspective
 ECE 7650 Scalable and Secure Internet Services and Architecture ---- A Systems Perspective Part II: Data Center Software Architecture: Topic 1: Distributed File Systems GFS (The Google File System) 1 Filesystems
ECE 7650 Scalable and Secure Internet Services and Architecture ---- A Systems Perspective Part II: Data Center Software Architecture: Topic 1: Distributed File Systems GFS (The Google File System) 1 Filesystems
MI-PDB, MIE-PDB: Advanced Database Systems
 MI-PDB, MIE-PDB: Advanced Database Systems http://www.ksi.mff.cuni.cz/~svoboda/courses/2015-2-mie-pdb/ Lecture 10: MapReduce, Hadoop 26. 4. 2016 Lecturer: Martin Svoboda svoboda@ksi.mff.cuni.cz Author:
MI-PDB, MIE-PDB: Advanced Database Systems http://www.ksi.mff.cuni.cz/~svoboda/courses/2015-2-mie-pdb/ Lecture 10: MapReduce, Hadoop 26. 4. 2016 Lecturer: Martin Svoboda svoboda@ksi.mff.cuni.cz Author:
The Google File System
 The Google File System Sanjay Ghemawat, Howard Gobioff and Shun Tak Leung Google* Shivesh Kumar Sharma fl4164@wayne.edu Fall 2015 004395771 Overview Google file system is a scalable distributed file system
The Google File System Sanjay Ghemawat, Howard Gobioff and Shun Tak Leung Google* Shivesh Kumar Sharma fl4164@wayne.edu Fall 2015 004395771 Overview Google file system is a scalable distributed file system
The Google File System
 The Google File System Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung Google* 정학수, 최주영 1 Outline Introduction Design Overview System Interactions Master Operation Fault Tolerance and Diagnosis Conclusions
The Google File System Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung Google* 정학수, 최주영 1 Outline Introduction Design Overview System Interactions Master Operation Fault Tolerance and Diagnosis Conclusions
The Google File System (GFS)
") 1 The Google File System (GFS) CS60002: Distributed Systems Antonio Bruto da Costa Ph.D. Student, Formal Methods Lab, Dept. of Computer Sc. & Engg., Indian Institute of Technology Kharagpur 2 Design constraints
1 The Google File System (GFS) CS60002: Distributed Systems Antonio Bruto da Costa Ph.D. Student, Formal Methods Lab, Dept. of Computer Sc. & Engg., Indian Institute of Technology Kharagpur 2 Design constraints
ECE 7650 Scalable and Secure Internet Services and Architecture ---- A Systems Perspective
 ECE 7650 Scalable and Secure Internet Services and Architecture ---- A Systems Perspective Part II: Software Infrastructure in Data Centers: Distributed File Systems 1 Permanently stores data Filesystems
ECE 7650 Scalable and Secure Internet Services and Architecture ---- A Systems Perspective Part II: Software Infrastructure in Data Centers: Distributed File Systems 1 Permanently stores data Filesystems
NPTEL Course Jan K. Gopinath Indian Institute of Science
 Storage Systems NPTEL Course Jan 2012 (Lecture 39) K. Gopinath Indian Institute of Science Google File System Non-Posix scalable distr file system for large distr dataintensive applications performance,
Storage Systems NPTEL Course Jan 2012 (Lecture 39) K. Gopinath Indian Institute of Science Google File System Non-Posix scalable distr file system for large distr dataintensive applications performance,
Dept. Of Computer Science, Colorado State University
 CS 455: INTRODUCTION TO DISTRIBUTED SYSTEMS [HADOOP/HDFS] Trying to have your cake and eat it too Each phase pines for tasks with locality and their numbers on a tether Alas within a phase, you get one,
CS 455: INTRODUCTION TO DISTRIBUTED SYSTEMS [HADOOP/HDFS] Trying to have your cake and eat it too Each phase pines for tasks with locality and their numbers on a tether Alas within a phase, you get one,
Google File System. Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung Google fall DIP Heerak lim, Donghun Koo
 Google File System Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung Google 2017 fall DIP Heerak lim, Donghun Koo 1 Agenda Introduction Design overview Systems interactions Master operation Fault tolerance
Google File System Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung Google 2017 fall DIP Heerak lim, Donghun Koo 1 Agenda Introduction Design overview Systems interactions Master operation Fault tolerance
CSE 124: Networked Services Lecture-16
 Fall 2010 CSE 124: Networked Services Lecture-16 Instructor: B. S. Manoj, Ph.D http://cseweb.ucsd.edu/classes/fa10/cse124 11/23/2010 CSE 124 Networked Services Fall 2010 1 Updates PlanetLab experiments
Fall 2010 CSE 124: Networked Services Lecture-16 Instructor: B. S. Manoj, Ph.D http://cseweb.ucsd.edu/classes/fa10/cse124 11/23/2010 CSE 124 Networked Services Fall 2010 1 Updates PlanetLab experiments
Google File System (GFS) and Hadoop Distributed File System (HDFS)
 and Hadoop Distributed File System (HDFS)") Google File System (GFS) and Hadoop Distributed File System (HDFS) 1 Hadoop: Architectural Design Principles Linear scalability More nodes can do more work within the same time Linear on data size, linear
Google File System (GFS) and Hadoop Distributed File System (HDFS) 1 Hadoop: Architectural Design Principles Linear scalability More nodes can do more work within the same time Linear on data size, linear
18-hdfs-gfs.txt Thu Oct 27 10:05: Notes on Parallel File Systems: HDFS & GFS , Fall 2011 Carnegie Mellon University Randal E.
 18-hdfs-gfs.txt Thu Oct 27 10:05:07 2011 1 Notes on Parallel File Systems: HDFS & GFS 15-440, Fall 2011 Carnegie Mellon University Randal E. Bryant References: Ghemawat, Gobioff, Leung, "The Google File
18-hdfs-gfs.txt Thu Oct 27 10:05:07 2011 1 Notes on Parallel File Systems: HDFS & GFS 15-440, Fall 2011 Carnegie Mellon University Randal E. Bryant References: Ghemawat, Gobioff, Leung, "The Google File
Bigtable. A Distributed Storage System for Structured Data. Presenter: Yunming Zhang Conglong Li. Saturday, September 21, 13
 Bigtable A Distributed Storage System for Structured Data Presenter: Yunming Zhang Conglong Li References SOCC 2010 Key Note Slides Jeff Dean Google Introduction to Distributed Computing, Winter 2008 University
Bigtable A Distributed Storage System for Structured Data Presenter: Yunming Zhang Conglong Li References SOCC 2010 Key Note Slides Jeff Dean Google Introduction to Distributed Computing, Winter 2008 University
Cluster-Level Google How we use Colossus to improve storage efficiency
 Cluster-Level Storage @ Google How we use Colossus to improve storage efficiency Denis Serenyi Senior Staff Software Engineer dserenyi@google.com November 13, 2017 Keynote at the 2nd Joint International
Cluster-Level Storage @ Google How we use Colossus to improve storage efficiency Denis Serenyi Senior Staff Software Engineer dserenyi@google.com November 13, 2017 Keynote at the 2nd Joint International
The Google File System
 The Google File System By Ghemawat, Gobioff and Leung Outline Overview Assumption Design of GFS System Interactions Master Operations Fault Tolerance Measurements Overview GFS: Scalable distributed file
The Google File System By Ghemawat, Gobioff and Leung Outline Overview Assumption Design of GFS System Interactions Master Operations Fault Tolerance Measurements Overview GFS: Scalable distributed file
Systems Infrastructure for Data Science. Web Science Group Uni Freiburg WS 2013/14
 Systems Infrastructure for Data Science Web Science Group Uni Freiburg WS 2013/14 MapReduce & Hadoop The new world of Big Data (programming model) Overview of this Lecture Module Background Cluster File
Systems Infrastructure for Data Science Web Science Group Uni Freiburg WS 2013/14 MapReduce & Hadoop The new world of Big Data (programming model) Overview of this Lecture Module Background Cluster File
CSE 124: Networked Services Fall 2009 Lecture-19
 CSE 124: Networked Services Fall 2009 Lecture-19 Instructor: B. S. Manoj, Ph.D http://cseweb.ucsd.edu/classes/fa09/cse124 Some of these slides are adapted from various sources/individuals including but
CSE 124: Networked Services Fall 2009 Lecture-19 Instructor: B. S. Manoj, Ph.D http://cseweb.ucsd.edu/classes/fa09/cse124 Some of these slides are adapted from various sources/individuals including but
Replication. Feb 10, 2016 CPSC 416
 Replication Feb 10, 2016 CPSC 416 How d we get here? Failures & single systems; fault tolerance techniques added redundancy (ECC memory, RAID, etc.) Conceptually, ECC & RAID both put a master in front
Replication Feb 10, 2016 CPSC 416 How d we get here? Failures & single systems; fault tolerance techniques added redundancy (ECC memory, RAID, etc.) Conceptually, ECC & RAID both put a master in front
The Google File System
 The Google File System Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung December 2003 ACM symposium on Operating systems principles Publisher: ACM Nov. 26, 2008 OUTLINE INTRODUCTION DESIGN OVERVIEW
The Google File System Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung December 2003 ACM symposium on Operating systems principles Publisher: ACM Nov. 26, 2008 OUTLINE INTRODUCTION DESIGN OVERVIEW
ECE 7650 Scalable and Secure Internet Services and Architecture ---- A Systems Perspective
 ECE 7650 Scalable and Secure Internet Services and Architecture ---- A Systems Perspective Part II: Data Center Software Architecture: Topic 3: Programming Models Piccolo: Building Fast, Distributed Programs
ECE 7650 Scalable and Secure Internet Services and Architecture ---- A Systems Perspective Part II: Data Center Software Architecture: Topic 3: Programming Models Piccolo: Building Fast, Distributed Programs
Cloud Computing CS
 Cloud Computing CS 15-319 Programming Models- Part III Lecture 6, Feb 1, 2012 Majd F. Sakr and Mohammad Hammoud 1 Today Last session Programming Models- Part II Today s session Programming Models Part
Cloud Computing CS 15-319 Programming Models- Part III Lecture 6, Feb 1, 2012 Majd F. Sakr and Mohammad Hammoud 1 Today Last session Programming Models- Part II Today s session Programming Models Part
Today CSCI Coda. Naming: Volumes. Coda GFS PAST. Instructor: Abhishek Chandra. Main Goals: Volume is a subtree in the naming space
 Today CSCI 5105 Coda GFS PAST Instructor: Abhishek Chandra 2 Coda Main Goals: Availability: Work in the presence of disconnection Scalability: Support large number of users Successor of Andrew File System
Today CSCI 5105 Coda GFS PAST Instructor: Abhishek Chandra 2 Coda Main Goals: Availability: Work in the presence of disconnection Scalability: Support large number of users Successor of Andrew File System
Map Reduce. Yerevan.
 Map Reduce Erasmus+ @ Yerevan dacosta@irit.fr Divide and conquer at PaaS 100 % // Typical problem Iterate over a large number of records Extract something of interest from each Shuffle and sort intermediate
Map Reduce Erasmus+ @ Yerevan dacosta@irit.fr Divide and conquer at PaaS 100 % // Typical problem Iterate over a large number of records Extract something of interest from each Shuffle and sort intermediate
Chapter 11: File System Implementation. Objectives
 Chapter 11: File System Implementation Objectives To describe the details of implementing local file systems and directory structures To describe the implementation of remote file systems To discuss block
Chapter 11: File System Implementation Objectives To describe the details of implementing local file systems and directory structures To describe the implementation of remote file systems To discuss block
Bigtable: A Distributed Storage System for Structured Data By Fay Chang, et al. OSDI Presented by Xiang Gao
 Bigtable: A Distributed Storage System for Structured Data By Fay Chang, et al. OSDI 2006 Presented by Xiang Gao 2014-11-05 Outline Motivation Data Model APIs Building Blocks Implementation Refinement
Bigtable: A Distributed Storage System for Structured Data By Fay Chang, et al. OSDI 2006 Presented by Xiang Gao 2014-11-05 Outline Motivation Data Model APIs Building Blocks Implementation Refinement
Introduction to MapReduce
 Basics of Cloud Computing Lecture 4 Introduction to MapReduce Satish Srirama Some material adapted from slides by Jimmy Lin, Christophe Bisciglia, Aaron Kimball, & Sierra Michels-Slettvet, Google Distributed
Basics of Cloud Computing Lecture 4 Introduction to MapReduce Satish Srirama Some material adapted from slides by Jimmy Lin, Christophe Bisciglia, Aaron Kimball, & Sierra Michels-Slettvet, Google Distributed
MapReduce & Resilient Distributed Datasets. Yiqing Hua, Mengqi(Mandy) Xia
 Xia") MapReduce & Resilient Distributed Datasets Yiqing Hua, Mengqi(Mandy) Xia Outline - MapReduce: - - Resilient Distributed Datasets (RDD) - - Motivation Examples The Design and How it Works Performance Motivation
MapReduce & Resilient Distributed Datasets Yiqing Hua, Mengqi(Mandy) Xia Outline - MapReduce: - - Resilient Distributed Datasets (RDD) - - Motivation Examples The Design and How it Works Performance Motivation
The Google File System
 The Google File System Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung Google SOSP 03, October 19 22, 2003, New York, USA Hyeon-Gyu Lee, and Yeong-Jae Woo Memory & Storage Architecture Lab. School
The Google File System Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung Google SOSP 03, October 19 22, 2003, New York, USA Hyeon-Gyu Lee, and Yeong-Jae Woo Memory & Storage Architecture Lab. School
TITLE: PRE-REQUISITE THEORY. 1. Introduction to Hadoop. 2. Cluster. Implement sort algorithm and run it using HADOOP
 TITLE: Implement sort algorithm and run it using HADOOP PRE-REQUISITE Preliminary knowledge of clusters and overview of Hadoop and its basic functionality. THEORY 1. Introduction to Hadoop The Apache Hadoop
TITLE: Implement sort algorithm and run it using HADOOP PRE-REQUISITE Preliminary knowledge of clusters and overview of Hadoop and its basic functionality. THEORY 1. Introduction to Hadoop The Apache Hadoop
Clustering Lecture 8: MapReduce
 Clustering Lecture 8: MapReduce Jing Gao SUNY Buffalo 1 Divide and Conquer Work Partition w 1 w 2 w 3 worker worker worker r 1 r 2 r 3 Result Combine 4 Distributed Grep Very big data Split data Split data
Clustering Lecture 8: MapReduce Jing Gao SUNY Buffalo 1 Divide and Conquer Work Partition w 1 w 2 w 3 worker worker worker r 1 r 2 r 3 Result Combine 4 Distributed Grep Very big data Split data Split data
MapReduce & HyperDex. Kathleen Durant PhD Lecture 21 CS 3200 Northeastern University
 MapReduce & HyperDex Kathleen Durant PhD Lecture 21 CS 3200 Northeastern University 1 Distributing Processing Mantra Scale out, not up. Assume failures are common. Move processing to the data. Process
MapReduce & HyperDex Kathleen Durant PhD Lecture 21 CS 3200 Northeastern University 1 Distributing Processing Mantra Scale out, not up. Assume failures are common. Move processing to the data. Process
Georgia Institute of Technology ECE6102 4/20/2009 David Colvin, Jimmy Vuong
 Georgia Institute of Technology ECE6102 4/20/2009 David Colvin, Jimmy Vuong Relatively recent; still applicable today GFS: Google s storage platform for the generation and processing of data used by services
Georgia Institute of Technology ECE6102 4/20/2009 David Colvin, Jimmy Vuong Relatively recent; still applicable today GFS: Google s storage platform for the generation and processing of data used by services
Motivation. Map in Lisp (Scheme) Map/Reduce. MapReduce: Simplified Data Processing on Large Clusters
 Map/Reduce. MapReduce: Simplified Data Processing on Large Clusters") Motivation MapReduce: Simplified Data Processing on Large Clusters These are slides from Dan Weld s class at U. Washington (who in turn made his slides based on those by Jeff Dean, Sanjay Ghemawat, Google,
Motivation MapReduce: Simplified Data Processing on Large Clusters These are slides from Dan Weld s class at U. Washington (who in turn made his slides based on those by Jeff Dean, Sanjay Ghemawat, Google,
Abstract. 1. Introduction. 2. Design and Implementation Master Chunkserver
 Abstract GFS from Scratch Ge Bian, Niket Agarwal, Wenli Looi https://github.com/looi/cs244b Dec 2017 GFS from Scratch is our partial re-implementation of GFS, the Google File System. Like GFS, our system
Abstract GFS from Scratch Ge Bian, Niket Agarwal, Wenli Looi https://github.com/looi/cs244b Dec 2017 GFS from Scratch is our partial re-implementation of GFS, the Google File System. Like GFS, our system
Distributed System. Gang Wu. Spring,2018
 Distributed System Gang Wu Spring,2018 Lecture7:DFS What is DFS? A method of storing and accessing files base in a client/server architecture. A distributed file system is a client/server-based application
Distributed System Gang Wu Spring,2018 Lecture7:DFS What is DFS? A method of storing and accessing files base in a client/server architecture. A distributed file system is a client/server-based application
BigTable. CSE-291 (Cloud Computing) Fall 2016
 Fall 2016") BigTable CSE-291 (Cloud Computing) Fall 2016 Data Model Sparse, distributed persistent, multi-dimensional sorted map Indexed by a row key, column key, and timestamp Values are uninterpreted arrays of bytes
BigTable CSE-291 (Cloud Computing) Fall 2016 Data Model Sparse, distributed persistent, multi-dimensional sorted map Indexed by a row key, column key, and timestamp Values are uninterpreted arrays of bytes
Introduction to MapReduce
 732A54 Big Data Analytics Introduction to MapReduce Christoph Kessler IDA, Linköping University Towards Parallel Processing of Big-Data Big Data too large to be read+processed in reasonable time by 1 server
732A54 Big Data Analytics Introduction to MapReduce Christoph Kessler IDA, Linköping University Towards Parallel Processing of Big-Data Big Data too large to be read+processed in reasonable time by 1 server
CS3600 SYSTEMS AND NETWORKS
 CS3600 SYSTEMS AND NETWORKS NORTHEASTERN UNIVERSITY Lecture 11: File System Implementation Prof. Alan Mislove (amislove@ccs.neu.edu) File-System Structure File structure Logical storage unit Collection
CS3600 SYSTEMS AND NETWORKS NORTHEASTERN UNIVERSITY Lecture 11: File System Implementation Prof. Alan Mislove (amislove@ccs.neu.edu) File-System Structure File structure Logical storage unit Collection
18-hdfs-gfs.txt Thu Nov 01 09:53: Notes on Parallel File Systems: HDFS & GFS , Fall 2012 Carnegie Mellon University Randal E.
 18-hdfs-gfs.txt Thu Nov 01 09:53:32 2012 1 Notes on Parallel File Systems: HDFS & GFS 15-440, Fall 2012 Carnegie Mellon University Randal E. Bryant References: Ghemawat, Gobioff, Leung, "The Google File
18-hdfs-gfs.txt Thu Nov 01 09:53:32 2012 1 Notes on Parallel File Systems: HDFS & GFS 15-440, Fall 2012 Carnegie Mellon University Randal E. Bryant References: Ghemawat, Gobioff, Leung, "The Google File
Introduction to Map Reduce
 Introduction to Map Reduce 1 Map Reduce: Motivation We realized that most of our computations involved applying a map operation to each logical record in our input in order to compute a set of intermediate
Introduction to Map Reduce 1 Map Reduce: Motivation We realized that most of our computations involved applying a map operation to each logical record in our input in order to compute a set of intermediate
GFS. CS6450: Distributed Systems Lecture 5. Ryan Stutsman
 GFS CS6450: Distributed Systems Lecture 5 Ryan Stutsman Some material taken/derived from Princeton COS-418 materials created by Michael Freedman and Kyle Jamieson at Princeton University. Licensed for
GFS CS6450: Distributed Systems Lecture 5 Ryan Stutsman Some material taken/derived from Princeton COS-418 materials created by Michael Freedman and Kyle Jamieson at Princeton University. Licensed for
The Google File System. Alexandru Costan
 1 The Google File System Alexandru Costan Actions on Big Data 2 Storage Analysis Acquisition Handling the data stream Data structured unstructured semi-structured Results Transactions Outline File systems
1 The Google File System Alexandru Costan Actions on Big Data 2 Storage Analysis Acquisition Handling the data stream Data structured unstructured semi-structured Results Transactions Outline File systems
Google File System, Replication. Amin Vahdat CSE 123b May 23, 2006
 Google File System, Replication Amin Vahdat CSE 123b May 23, 2006 Annoucements Third assignment available today Due date June 9, 5 pm Final exam, June 14, 11:30-2:30 Google File System (thanks to Mahesh
Google File System, Replication Amin Vahdat CSE 123b May 23, 2006 Annoucements Third assignment available today Due date June 9, 5 pm Final exam, June 14, 11:30-2:30 Google File System (thanks to Mahesh
CS /15/16. Paul Krzyzanowski 1. Question 1. Distributed Systems 2016 Exam 2 Review. Question 3. Question 2. Question 5.
 Question 1 What makes a message unstable? How does an unstable message become stable? Distributed Systems 2016 Exam 2 Review Paul Krzyzanowski Rutgers University Fall 2016 In virtual sychrony, a message
Question 1 What makes a message unstable? How does an unstable message become stable? Distributed Systems 2016 Exam 2 Review Paul Krzyzanowski Rutgers University Fall 2016 In virtual sychrony, a message
Distributed computing: index building and use
 Distributed computing: index building and use Distributed computing Goals Distributing computation across several machines to Do one computation faster - latency Do more computations in given time - throughput
Distributed computing: index building and use Distributed computing Goals Distributing computation across several machines to Do one computation faster - latency Do more computations in given time - throughput
Database Architectures
 Database Architectures CPS352: Database Systems Simon Miner Gordon College Last Revised: 11/15/12 Agenda Check-in Centralized and Client-Server Models Parallelism Distributed Databases Homework 6 Check-in
Database Architectures CPS352: Database Systems Simon Miner Gordon College Last Revised: 11/15/12 Agenda Check-in Centralized and Client-Server Models Parallelism Distributed Databases Homework 6 Check-in
Staggeringly Large Filesystems
 Staggeringly Large Filesystems Evan Danaher CS 6410 - October 27, 2009 Outline 1 Large Filesystems 2 GFS 3 Pond Outline 1 Large Filesystems 2 GFS 3 Pond Internet Scale Web 2.0 GFS Thousands of machines
Staggeringly Large Filesystems Evan Danaher CS 6410 - October 27, 2009 Outline 1 Large Filesystems 2 GFS 3 Pond Outline 1 Large Filesystems 2 GFS 3 Pond Internet Scale Web 2.0 GFS Thousands of machines
Programming Systems for Big Data
 Programming Systems for Big Data CS315B Lecture 17 Including material from Kunle Olukotun Prof. Aiken CS 315B Lecture 17 1 Big Data We ve focused on parallel programming for computational science There
Programming Systems for Big Data CS315B Lecture 17 Including material from Kunle Olukotun Prof. Aiken CS 315B Lecture 17 1 Big Data We ve focused on parallel programming for computational science There
Google File System. By Dinesh Amatya
 Google File System By Dinesh Amatya Google File System (GFS) Sanjay Ghemawat, Howard Gobioff, Shun-Tak Leung designed and implemented to meet rapidly growing demand of Google's data processing need a scalable
Google File System By Dinesh Amatya Google File System (GFS) Sanjay Ghemawat, Howard Gobioff, Shun-Tak Leung designed and implemented to meet rapidly growing demand of Google's data processing need a scalable
CS 345A Data Mining. MapReduce
 CS 345A Data Mining MapReduce Single-node architecture CPU Machine Learning, Statistics Memory Classical Data Mining Disk Commodity Clusters Web data sets can be very large Tens to hundreds of terabytes
CS 345A Data Mining MapReduce Single-node architecture CPU Machine Learning, Statistics Memory Classical Data Mining Disk Commodity Clusters Web data sets can be very large Tens to hundreds of terabytes
File Structures and Indexing
 File Structures and Indexing CPS352: Database Systems Simon Miner Gordon College Last Revised: 10/11/12 Agenda Check-in Database File Structures Indexing Database Design Tips Check-in Database File Structures
File Structures and Indexing CPS352: Database Systems Simon Miner Gordon College Last Revised: 10/11/12 Agenda Check-in Database File Structures Indexing Database Design Tips Check-in Database File Structures
Distributed Computation Models
 Distributed Computation Models SWE 622, Spring 2017 Distributed Software Engineering Some slides ack: Jeff Dean HW4 Recap https://b.socrative.com/ Class: SWE622 2 Review Replicating state machines Case
Distributed Computation Models SWE 622, Spring 2017 Distributed Software Engineering Some slides ack: Jeff Dean HW4 Recap https://b.socrative.com/ Class: SWE622 2 Review Replicating state machines Case
CSE Lecture 11: Map/Reduce 7 October Nate Nystrom UTA
 CSE 3302 Lecture 11: Map/Reduce 7 October 2010 Nate Nystrom UTA 378,000 results in 0.17 seconds including images and video communicates with 1000s of machines web server index servers document servers
CSE 3302 Lecture 11: Map/Reduce 7 October 2010 Nate Nystrom UTA 378,000 results in 0.17 seconds including images and video communicates with 1000s of machines web server index servers document servers
Operating Systems. Lecture File system implementation. Master of Computer Science PUF - Hồ Chí Minh 2016/2017
 Operating Systems Lecture 7.2 - File system implementation Adrien Krähenbühl Master of Computer Science PUF - Hồ Chí Minh 2016/2017 Design FAT or indexed allocation? UFS, FFS & Ext2 Journaling with Ext3
Operating Systems Lecture 7.2 - File system implementation Adrien Krähenbühl Master of Computer Science PUF - Hồ Chí Minh 2016/2017 Design FAT or indexed allocation? UFS, FFS & Ext2 Journaling with Ext3
Ext3/4 file systems. Don Porter CSE 506
 Ext3/4 file systems Don Porter CSE 506 Logical Diagram Binary Formats Memory Allocators System Calls Threads User Today s Lecture Kernel RCU File System Networking Sync Memory Management Device Drivers
Ext3/4 file systems Don Porter CSE 506 Logical Diagram Binary Formats Memory Allocators System Calls Threads User Today s Lecture Kernel RCU File System Networking Sync Memory Management Device Drivers
Introduction to Distributed Data Systems
 Introduction to Distributed Data Systems Serge Abiteboul Ioana Manolescu Philippe Rigaux Marie-Christine Rousset Pierre Senellart Web Data Management and Distribution http://webdam.inria.fr/textbook January
Introduction to Distributed Data Systems Serge Abiteboul Ioana Manolescu Philippe Rigaux Marie-Christine Rousset Pierre Senellart Web Data Management and Distribution http://webdam.inria.fr/textbook January
Distributed computing: index building and use
 Distributed computing: index building and use Distributed computing Goals Distributing computation across several machines to Do one computation faster - latency Do more computations in given time - throughput
Distributed computing: index building and use Distributed computing Goals Distributing computation across several machines to Do one computation faster - latency Do more computations in given time - throughput
Google File System. Arun Sundaram Operating Systems
 Arun Sundaram Operating Systems 1 Assumptions GFS built with commodity hardware GFS stores a modest number of large files A few million files, each typically 100MB or larger (Multi-GB files are common)
Arun Sundaram Operating Systems 1 Assumptions GFS built with commodity hardware GFS stores a modest number of large files A few million files, each typically 100MB or larger (Multi-GB files are common)
goals monitoring, fault tolerance, auto-recovery (thousands of low-cost machines) handle appends efficiently (no random writes & sequential reads)
 handle appends efficiently (no random writes & sequential reads)") Google File System goals monitoring, fault tolerance, auto-recovery (thousands of low-cost machines) focus on multi-gb files handle appends efficiently (no random writes & sequential reads) co-design GFS
Google File System goals monitoring, fault tolerance, auto-recovery (thousands of low-cost machines) focus on multi-gb files handle appends efficiently (no random writes & sequential reads) co-design GFS
MapReduce Spark. Some slides are adapted from those of Jeff Dean and Matei Zaharia
 MapReduce Spark Some slides are adapted from those of Jeff Dean and Matei Zaharia What have we learnt so far? Distributed storage systems consistency semantics protocols for fault tolerance Paxos, Raft,
MapReduce Spark Some slides are adapted from those of Jeff Dean and Matei Zaharia What have we learnt so far? Distributed storage systems consistency semantics protocols for fault tolerance Paxos, Raft,
ΕΠΛ 602:Foundations of Internet Technologies. Cloud Computing
 ΕΠΛ 602:Foundations of Internet Technologies Cloud Computing 1 Outline Bigtable(data component of cloud) Web search basedonch13of thewebdatabook 2 What is Cloud Computing? ACloudis an infrastructure, transparent
ΕΠΛ 602:Foundations of Internet Technologies Cloud Computing 1 Outline Bigtable(data component of cloud) Web search basedonch13of thewebdatabook 2 What is Cloud Computing? ACloudis an infrastructure, transparent
MapReduce: Recap. Juliana Freire & Cláudio Silva. Some slides borrowed from Jimmy Lin, Jeff Ullman, Jerome Simeon, and Jure Leskovec
 MapReduce: Recap Some slides borrowed from Jimmy Lin, Jeff Ullman, Jerome Simeon, and Jure Leskovec MapReduce: Recap Sequentially read a lot of data Why? Map: extract something we care about map (k, v)
MapReduce: Recap Some slides borrowed from Jimmy Lin, Jeff Ullman, Jerome Simeon, and Jure Leskovec MapReduce: Recap Sequentially read a lot of data Why? Map: extract something we care about map (k, v)
MapReduce. Stony Brook University CSE545, Fall 2016
 MapReduce Stony Brook University CSE545, Fall 2016 Classical Data Mining CPU Memory Disk Classical Data Mining CPU Memory (64 GB) Disk Classical Data Mining CPU Memory (64 GB) Disk Classical Data Mining
MapReduce Stony Brook University CSE545, Fall 2016 Classical Data Mining CPU Memory Disk Classical Data Mining CPU Memory (64 GB) Disk Classical Data Mining CPU Memory (64 GB) Disk Classical Data Mining
Google File System 2
 Google File System 2 goals monitoring, fault tolerance, auto-recovery (thousands of low-cost machines) focus on multi-gb files handle appends efficiently (no random writes & sequential reads) co-design
Google File System 2 goals monitoring, fault tolerance, auto-recovery (thousands of low-cost machines) focus on multi-gb files handle appends efficiently (no random writes & sequential reads) co-design
Parallel Computing: MapReduce Jin, Hai
 Parallel Computing: MapReduce Jin, Hai School of Computer Science and Technology Huazhong University of Science and Technology ! MapReduce is a distributed/parallel computing framework introduced by Google
Parallel Computing: MapReduce Jin, Hai School of Computer Science and Technology Huazhong University of Science and Technology ! MapReduce is a distributed/parallel computing framework introduced by Google
Lecture 21: Reliable, High Performance Storage. CSC 469H1F Fall 2006 Angela Demke Brown
 Lecture 21: Reliable, High Performance Storage CSC 469H1F Fall 2006 Angela Demke Brown 1 Review We ve looked at fault tolerance via server replication Continue operating with up to f failures Recovery
Lecture 21: Reliable, High Performance Storage CSC 469H1F Fall 2006 Angela Demke Brown 1 Review We ve looked at fault tolerance via server replication Continue operating with up to f failures Recovery
Parallel Programming Principle and Practice. Lecture 10 Big Data Processing with MapReduce
 Parallel Programming Principle and Practice Lecture 10 Big Data Processing with MapReduce Outline MapReduce Programming Model MapReduce Examples Hadoop 2 Incredible Things That Happen Every Minute On The
Parallel Programming Principle and Practice Lecture 10 Big Data Processing with MapReduce Outline MapReduce Programming Model MapReduce Examples Hadoop 2 Incredible Things That Happen Every Minute On The
Hadoop File System S L I D E S M O D I F I E D F R O M P R E S E N T A T I O N B Y B. R A M A M U R T H Y 11/15/2017
 Hadoop File System 1 S L I D E S M O D I F I E D F R O M P R E S E N T A T I O N B Y B. R A M A M U R T H Y Moving Computation is Cheaper than Moving Data Motivation: Big Data! What is BigData? - Google
Hadoop File System 1 S L I D E S M O D I F I E D F R O M P R E S E N T A T I O N B Y B. R A M A M U R T H Y Moving Computation is Cheaper than Moving Data Motivation: Big Data! What is BigData? - Google
CS435 Introduction to Big Data FALL 2018 Colorado State University. 11/7/2018 Week 12-B Sangmi Lee Pallickara. FAQs
 11/7/2018 CS435 Introduction to Big Data - FALL 2018 W12.B.0.0 CS435 Introduction to Big Data 11/7/2018 CS435 Introduction to Big Data - FALL 2018 W12.B.1 FAQs Deadline of the Programming Assignment 3
11/7/2018 CS435 Introduction to Big Data - FALL 2018 W12.B.0.0 CS435 Introduction to Big Data 11/7/2018 CS435 Introduction to Big Data - FALL 2018 W12.B.1 FAQs Deadline of the Programming Assignment 3
ò Very reliable, best-of-breed traditional file system design ò Much like the JOS file system you are building now
 Ext2 review Very reliable, best-of-breed traditional file system design Ext3/4 file systems Don Porter CSE 506 Much like the JOS file system you are building now Fixed location super blocks A few direct
Ext2 review Very reliable, best-of-breed traditional file system design Ext3/4 file systems Don Porter CSE 506 Much like the JOS file system you are building now Fixed location super blocks A few direct
Bigtable: A Distributed Storage System for Structured Data. Andrew Hon, Phyllis Lau, Justin Ng
 Bigtable: A Distributed Storage System for Structured Data Andrew Hon, Phyllis Lau, Justin Ng What is Bigtable? - A storage system for managing structured data - Used in 60+ Google services - Motivation:
Bigtable: A Distributed Storage System for Structured Data Andrew Hon, Phyllis Lau, Justin Ng What is Bigtable? - A storage system for managing structured data - Used in 60+ Google services - Motivation:
Google is Really Different.
 COMP 790-088 -- Distributed File Systems Google File System 7 Google is Really Different. Huge Datacenters in 5+ Worldwide Locations Datacenters house multiple server clusters Coming soon to Lenior, NC
COMP 790-088 -- Distributed File Systems Google File System 7 Google is Really Different. Huge Datacenters in 5+ Worldwide Locations Datacenters house multiple server clusters Coming soon to Lenior, NC
Distributed Systems 16. Distributed File Systems II
 Distributed Systems 16. Distributed File Systems II Paul Krzyzanowski pxk@cs.rutgers.edu 1 Review NFS RPC-based access AFS Long-term caching CODA Read/write replication & disconnected operation DFS AFS
Distributed Systems 16. Distributed File Systems II Paul Krzyzanowski pxk@cs.rutgers.edu 1 Review NFS RPC-based access AFS Long-term caching CODA Read/write replication & disconnected operation DFS AFS
Bigtable. Presenter: Yijun Hou, Yixiao Peng
 Bigtable Fay Chang, Jeffrey Dean, Sanjay Ghemawat, Wilson C. Hsieh, Deborah A. Wallach Mike Burrows, Tushar Chandra, Andrew Fikes, Robert E. Gruber Google, Inc. OSDI 06 Presenter: Yijun Hou, Yixiao Peng
Bigtable Fay Chang, Jeffrey Dean, Sanjay Ghemawat, Wilson C. Hsieh, Deborah A. Wallach Mike Burrows, Tushar Chandra, Andrew Fikes, Robert E. Gruber Google, Inc. OSDI 06 Presenter: Yijun Hou, Yixiao Peng
Authors : Sanjay Ghemawat, Howard Gobioff, Shun-Tak Leung Presentation by: Vijay Kumar Chalasani
 The Authors : Sanjay Ghemawat, Howard Gobioff, Shun-Tak Leung Presentation by: Vijay Kumar Chalasani CS5204 Operating Systems 1 Introduction GFS is a scalable distributed file system for large data intensive
The Authors : Sanjay Ghemawat, Howard Gobioff, Shun-Tak Leung Presentation by: Vijay Kumar Chalasani CS5204 Operating Systems 1 Introduction GFS is a scalable distributed file system for large data intensive
OPERATING SYSTEM. Chapter 12: File System Implementation
 OPERATING SYSTEM Chapter 12: File System Implementation Chapter 12: File System Implementation File-System Structure File-System Implementation Directory Implementation Allocation Methods Free-Space Management
OPERATING SYSTEM Chapter 12: File System Implementation Chapter 12: File System Implementation File-System Structure File-System Implementation Directory Implementation Allocation Methods Free-Space Management
15-440/15-640: Homework 3 Due: November 8, :59pm
 Name: 15-440/15-640: Homework 3 Due: November 8, 2018 11:59pm Andrew ID: 1 GFS FTW (25 points) Part A (10 points) The Google File System (GFS) is an extremely popular filesystem used by Google for a lot
Name: 15-440/15-640: Homework 3 Due: November 8, 2018 11:59pm Andrew ID: 1 GFS FTW (25 points) Part A (10 points) The Google File System (GFS) is an extremely popular filesystem used by Google for a lot
Distributed Computations MapReduce. adapted from Jeff Dean s slides
 Distributed Computations MapReduce adapted from Jeff Dean s slides What we ve learnt so far Basic distributed systems concepts Consistency (sequential, eventual) Fault tolerance (recoverability, availability)
Distributed Computations MapReduce adapted from Jeff Dean s slides What we ve learnt so far Basic distributed systems concepts Consistency (sequential, eventual) Fault tolerance (recoverability, availability)
9/26/2017 Sangmi Lee Pallickara Week 6- A. CS535 Big Data Fall 2017 Colorado State University
 CS535 Big Data - Fall 2017 Week 6-A-1 CS535 BIG DATA FAQs PA1: Use only one word query Deadends {{Dead end}} Hub value will be?? PART 1. BATCH COMPUTING MODEL FOR BIG DATA ANALYTICS 4. GOOGLE FILE SYSTEM
CS535 Big Data - Fall 2017 Week 6-A-1 CS535 BIG DATA FAQs PA1: Use only one word query Deadends {{Dead end}} Hub value will be?? PART 1. BATCH COMPUTING MODEL FOR BIG DATA ANALYTICS 4. GOOGLE FILE SYSTEM