Information Retrieval
|
|
|
- Evan Baldwin
- 5 years ago
- Views:
Transcription



1 Information Retrieval Venkatesh Vinayakarao Term: Aug Dec, 2018 Indian Institute of Information Technology, Sri City So much of life, it seems to me, is determined by pure randomness. Sidney Poitier. Love Tarun Venkatesh Vinayakarao (Vv)
2 Big Data Hadoop, Map Reduce and Pig
3 Near Duplicates How to detect near duplicate documents?
4 Near Duplicates How to detect near duplicate documents? Document d1 Tendulkar hits a century. k-shingles {Tendulkar hits, hits a, a century } Document d2 Tendulkar hits a fantastic century. k-shingles {Tendulkar hits, hits a, a fantastic, fantastic century} Apply Jaccard Similarity

5 3Vs of Big Data 5

6 An Example of Distributed Platforms 6

7 HDP: Hortonworks Data Platform 7
8 8 Hadoop Installation

9 Virtualbox Installation 9

10 Cloudera VM installation 10
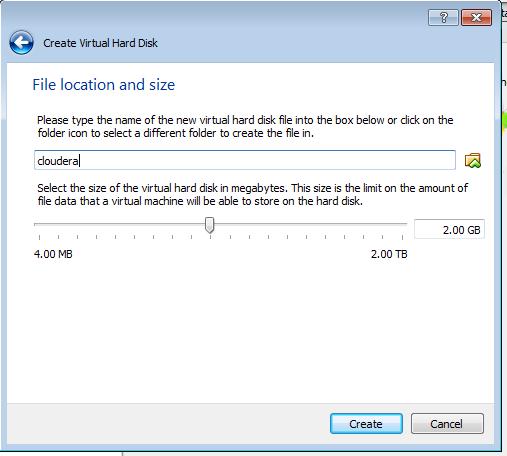
11 Virtualbox setup 11

12 Adding cloudera vm 12


13 Installation Video h?v=p7ucyffwl-c h?v=l0lppc5qeyu 13
14 Advanced Map Reduce: Job Chaining How to find top k words? Write one MR job for word count. Write another MR job to process the output to find top k. Sometimes, the output of job 1 is not so big. You do not need MR job to do the task. You may just use shell script or manually do it. For example, hadoop fs -cat /output/of/wordcount/part* sort -n -k2 -r head -n20 14
15 Reduce - Optimization How to do top k? Have each reducer only output k results. If you have only one reducer, this problem is already solved. 15
16 Example ns/blob/master/mrdp/src/main/java/mrdp/ch3/to ptendriver.java 16

17 MR Design Patterns Taxonomy of Patterns 1. Summarization 1. Average 2. Median 2. Filtering 1. Top k 2. Distinct 3. Joins 1. Cartesian Product 4. Meta patters 1. Job Chaining 5. Data Organization 1. Partitioning 2. Bin ning 6. External I/O 17
18 Pig A scripting language to simplify processing on Hadoop. More information at 18
19 Benefits & Limitations Benefits 10 lines of Pig Latin (approx.) = 200 lines in Java 15 minutes in Pig Latin (approx.) = 3 hours in Java Simple Easy Quick to Code Limitations Slower than Map-Reduce 19
20 Word Count Lines=LOAD input/hadoop.log AS (line: chararray); Words = FOREACH Lines GENERATE FLATTEN(TOKENIZE(line)) AS word; Groups = GROUP Words BY word; Counts = FOREACH Groups GENERATE group, COUNT(Words); Results = ORDER Words BY Counts DESC; Top5 = LIMIT Results 5; STORE Top5 INTO /output/top5words; 20
21 Pig in Real-World Yahoo used it extensively (>70% of jobs) Facebook Process Logs Twitter Process Logs ebay Data processing for intelligence 21
22 UDF in Pig -- myscript.pig REGISTER myudfs.jar; A = LOAD 'student_data' AS (name: chararray, age: int, gpa: float); B = FOREACH A GENERATE myudfs.upper(name); DUMP B; 22
23 Simple UDF 6 public class UPPER extends EvalFunc<String> 7 { 8 public String exec(tuple input) throws IOException { 9 if (input == null input.size() == 0) 10 return null; 11 try{ 12 String str = (String)input.get(0); 13 return str.touppercase(); 14 }catch(exception e){ 15 throw new IOException("Caught exception processing input row ", e); 16 } 17 } 18 } Source: 23
24 Creating the Jar Javac -cp /..path../pig.jar UPPER.java jar -cf exampleudf.jar exampleudf Know where have you placed this jar. In Pig Script: REGISTER path to jar ; DEFINE SIMPLEUPPER exampleudf.upper(); now you can use this method. 24
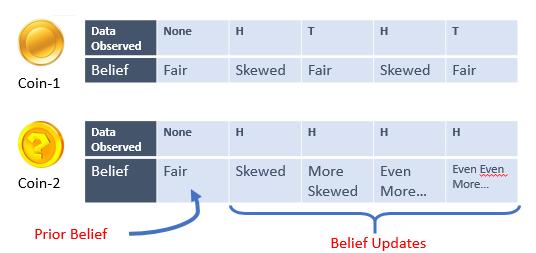
25 Information Retrieval Venkatesh Vinayakarao Term: Aug Dec, 2018 Indian Institute of Information Technology, Sri City So much of life, it seems to me, is determined by pure randomness. Sidney Poitier. Love Tarun Venkatesh Vinayakarao (Vv)
26 The Intuition Which bucket is most likely to lead to a Black Ball? OR OR 26
27 The Intuition Which bucket is most likely to lead to a Black Ball? OR OR 27

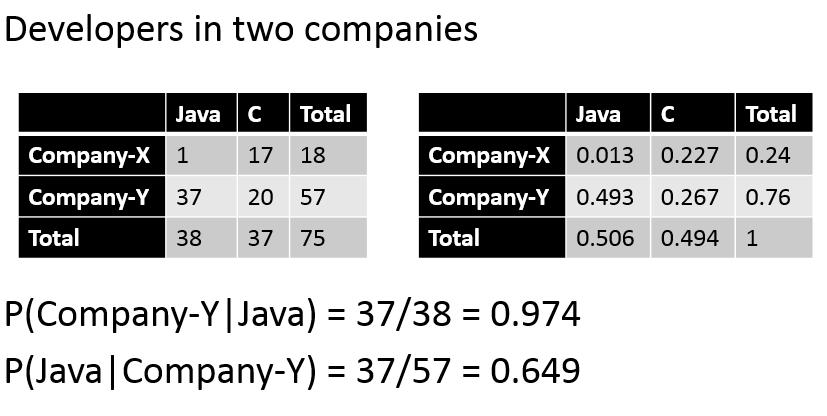
28 The Intuition Which document is most likely to lead to a query? query terms OR OR Document 1 Document 2 Document 3 Can be modeled using a discriminative model (P(D R=1,Q)) or a generative model (P(Q R=1,D)). 28
29 A good query Words that are most likely to appear in a relevant document 29
30 Another Way to Rank Rank documents based on the probability of the model generating the query: P(q M d ) M d is the model of the document which generates the query 30
31 A Model to Generate a String What strings can this model generate? This is a Finite Automaton that can generate: I wish I wish I wish I wish I wish I wish 31
32 Key Idea Document Generative Model Words with probability 32
33 Example P(STOP t) = 0.2 i.e., probability that our automaton stops after encountering any word is 0.2. You are given with the probabilities of words appearing in the query. What is probability of frog said that toad likes frog being the query? Answer: (0.01 x 0.03 x 0.04 x 0.01 x 0.02 x 0.01) x (0.8^5 x 0.2) = Word Probability the 0.2 a 0.1 frog 0.01 toad 0.01 said 0.03 likes 0.02 that 0.04 Uday: It is much easier to take log and add instead of multiplying these numbers. 33
34 Comparing Models Say we have two models: Model 1 seems to have higher probability of generating the string. Model 1 will match a document containing these terms better to this query. 34
35 A Simple Language Model Simple Model Even simpler The Unigram Language Model The Bigram Model 35
36 Document as a Bag of Words We rank documents based on the probability of that document to generate the given query. If documents are bag of words, Assume p(d) is uniform. Hence can be dropped. P(q) and K q does not affect ranking. Hence can be dropped. 36
37 Missing Terms What happens to P(d q) if a query term does not appear in the document? Clue: We approximate P(d q) to document ranking by computing 37
38 Missing Terms & Smoothening Instead of zero, use P(t M c ) M c is the model over the entire collection. Smoothen: We can also mix document and collection probabilities using a linear interpolation co-efficient λ. 38
39 Wake Up Quiz Is the following same as the document length? True or False? tf(ti, d) 1 i M M is the term vocabulary size. Function tf(t,d) is term frequency of a term in a document. 39
40 Example Suppose: d1: Tada is a city between Chennai and Tirupati d2: Tada has few restaurants but no good malls Use the smoothened MLE unigram language model to rank these documents for the query Tada City. Assume λ =
41 Example Suppose: d1: Tada is a city between Chennai and Tirupati d2: Tada has few restaurants but no good malls Use the smoothened MLE unigram language model to rank these documents for the query Tada City. Assume λ = 0.5. P(q d1) = [(1/8 + 2/16)/2] [(1/8 + 1/16)/2] = 1/8 3/32 = 3/256 P(q d2) = [(1/8 + 2/16)/2] [(0/8 + 1/16)/2] = 1/8 1/32 = 1/256 Ranking: d1 > d2 41
42 Summary Probabilistic Retrieval 42
43 Summary Odds of Relevance 43

44 Summary 44
45 Summary Smoothening 45
46 Thank You 46
Apache Pig. Craig Douglas and Mookwon Seo University of Wyoming
 Apache Pig Craig Douglas and Mookwon Seo University of Wyoming Why were they invented? Apache Pig Latin and Sandia OINK are scripting languages that interface to HADOOP and MR- MPI, respectively. http://pig.apache.org
Apache Pig Craig Douglas and Mookwon Seo University of Wyoming Why were they invented? Apache Pig Latin and Sandia OINK are scripting languages that interface to HADOOP and MR- MPI, respectively. http://pig.apache.org
The Pig Experience. A. Gates et al., VLDB 2009
 The Pig Experience A. Gates et al., VLDB 2009 Why not Map-Reduce? Does not directly support complex N-Step dataflows All operations have to be expressed using MR primitives Lacks explicit support for processing
The Pig Experience A. Gates et al., VLDB 2009 Why not Map-Reduce? Does not directly support complex N-Step dataflows All operations have to be expressed using MR primitives Lacks explicit support for processing
Hadoop is supplemented by an ecosystem of open source projects IBM Corporation. How to Analyze Large Data Sets in Hadoop
 Hadoop Open Source Projects Hadoop is supplemented by an ecosystem of open source projects Oozie 25 How to Analyze Large Data Sets in Hadoop Although the Hadoop framework is implemented in Java, MapReduce
Hadoop Open Source Projects Hadoop is supplemented by an ecosystem of open source projects Oozie 25 How to Analyze Large Data Sets in Hadoop Although the Hadoop framework is implemented in Java, MapReduce
Apache Pig. Big Data 2015
 Apache Pig Big Data 2015 Pig Configuration Download a release of apache pig: pig-0.14.0.tar.gz Pig Configuration In the bash_profile export all needed environment variables Pig Running Running Pig: $:~pig-*/bin/pig
Apache Pig Big Data 2015 Pig Configuration Download a release of apache pig: pig-0.14.0.tar.gz Pig Configuration In the bash_profile export all needed environment variables Pig Running Running Pig: $:~pig-*/bin/pig
Pig A language for data processing in Hadoop
 Pig A language for data processing in Hadoop Antonino Virgillito THE CONTRACTOR IS ACTING UNDER A FRAMEWORK CONTRACT CONCLUDED WITH THE COMMISSION Apache Pig: Introduction Tool for querying data on Hadoop
Pig A language for data processing in Hadoop Antonino Virgillito THE CONTRACTOR IS ACTING UNDER A FRAMEWORK CONTRACT CONCLUDED WITH THE COMMISSION Apache Pig: Introduction Tool for querying data on Hadoop
Pig Latin Reference Manual 1
 Table of contents 1 Overview.2 2 Pig Latin Statements. 2 3 Multi-Query Execution 5 4 Specialized Joins..10 5 Optimization Rules. 13 6 Memory Management15 7 Zebra Integration..15 1. Overview Use this manual
Table of contents 1 Overview.2 2 Pig Latin Statements. 2 3 Multi-Query Execution 5 4 Specialized Joins..10 5 Optimization Rules. 13 6 Memory Management15 7 Zebra Integration..15 1. Overview Use this manual
Hadoop. Course Duration: 25 days (60 hours duration). Bigdata Fundamentals. Day1: (2hours)
. Bigdata Fundamentals. Day1: (2hours)") Bigdata Fundamentals Day1: (2hours) 1. Understanding BigData. a. What is Big Data? b. Big-Data characteristics. c. Challenges with the traditional Data Base Systems and Distributed Systems. 2. Distributions:
Bigdata Fundamentals Day1: (2hours) 1. Understanding BigData. a. What is Big Data? b. Big-Data characteristics. c. Challenges with the traditional Data Base Systems and Distributed Systems. 2. Distributions:
Scaling Up Pig. Duen Horng (Polo) Chau Assistant Professor Associate Director, MS Analytics Georgia Tech. CSE6242 / CX4242: Data & Visual Analytics
 Chau Assistant Professor Associate Director, MS Analytics Georgia Tech. CSE6242 / CX4242: Data & Visual Analytics") http://poloclub.gatech.edu/cse6242 CSE6242 / CX4242: Data & Visual Analytics Scaling Up Pig Duen Horng (Polo) Chau Assistant Professor Associate Director, MS Analytics Georgia Tech Partly based on materials
http://poloclub.gatech.edu/cse6242 CSE6242 / CX4242: Data & Visual Analytics Scaling Up Pig Duen Horng (Polo) Chau Assistant Professor Associate Director, MS Analytics Georgia Tech Partly based on materials
Distributed Data Management Summer Semester 2013 TU Kaiserslautern
 Distributed Data Management Summer Semester 2013 TU Kaiserslautern Dr.- Ing. Sebas4an Michel smichel@mmci.uni- saarland.de Distributed Data Management, SoSe 2013, S. Michel 1 Lecture 4 PIG/HIVE Distributed
Distributed Data Management Summer Semester 2013 TU Kaiserslautern Dr.- Ing. Sebas4an Michel smichel@mmci.uni- saarland.de Distributed Data Management, SoSe 2013, S. Michel 1 Lecture 4 PIG/HIVE Distributed
PigUnit - Pig script testing simplified.
 Table of contents 1 Overview...2 2 PigUnit Example...2 3 Running PigUnit... 3 4 Building PigUnit... 4 5 Troubleshooting Tips... 4 6 Future Enhancements...5 1. Overview PigUnit is a simple xunit framework
Table of contents 1 Overview...2 2 PigUnit Example...2 3 Running PigUnit... 3 4 Building PigUnit... 4 5 Troubleshooting Tips... 4 6 Future Enhancements...5 1. Overview PigUnit is a simple xunit framework
Big Data Hadoop Developer Course Content. Big Data Hadoop Developer - The Complete Course Course Duration: 45 Hours
 Big Data Hadoop Developer Course Content Who is the target audience? Big Data Hadoop Developer - The Complete Course Course Duration: 45 Hours Complete beginners who want to learn Big Data Hadoop Professionals
Big Data Hadoop Developer Course Content Who is the target audience? Big Data Hadoop Developer - The Complete Course Course Duration: 45 Hours Complete beginners who want to learn Big Data Hadoop Professionals
Introduction to HDFS and MapReduce
 Introduction to HDFS and MapReduce Who Am I - Ryan Tabora - Data Developer at Think Big Analytics - Big Data Consulting - Experience working with Hadoop, HBase, Hive, Solr, Cassandra, etc. 2 Who Am I -
Introduction to HDFS and MapReduce Who Am I - Ryan Tabora - Data Developer at Think Big Analytics - Big Data Consulting - Experience working with Hadoop, HBase, Hive, Solr, Cassandra, etc. 2 Who Am I -
Introduction to Apache Pig ja Hive
 Introduction to Apache Pig ja Hive Pelle Jakovits 30 September, 2014, Tartu Outline Why Pig or Hive instead of MapReduce Apache Pig Pig Latin language Examples Architecture Hive Hive Query Language Examples
Introduction to Apache Pig ja Hive Pelle Jakovits 30 September, 2014, Tartu Outline Why Pig or Hive instead of MapReduce Apache Pig Pig Latin language Examples Architecture Hive Hive Query Language Examples
Techno Expert Solutions An institute for specialized studies!
 Course Content of Big Data Hadoop( Intermediate+ Advance) Pre-requistes: knowledge of Core Java/ Oracle: Basic of Unix S.no Topics Date Status Introduction to Big Data & Hadoop Importance of Data& Data
Course Content of Big Data Hadoop( Intermediate+ Advance) Pre-requistes: knowledge of Core Java/ Oracle: Basic of Unix S.no Topics Date Status Introduction to Big Data & Hadoop Importance of Data& Data
Hadoop ecosystem. Nikos Parlavantzas
 1 Hadoop ecosystem Nikos Parlavantzas Lecture overview 2 Objective Provide an overview of a selection of technologies in the Hadoop ecosystem Hadoop ecosystem 3 Hadoop ecosystem 4 Outline 5 HBase Hive
1 Hadoop ecosystem Nikos Parlavantzas Lecture overview 2 Objective Provide an overview of a selection of technologies in the Hadoop ecosystem Hadoop ecosystem 3 Hadoop ecosystem 4 Outline 5 HBase Hive
Beyond Hive Pig and Python
 Beyond Hive Pig and Python What is Pig? Pig performs a series of transformations to data relations based on Pig Latin statements Relations are loaded using schema on read semantics to project table structure
Beyond Hive Pig and Python What is Pig? Pig performs a series of transformations to data relations based on Pig Latin statements Relations are loaded using schema on read semantics to project table structure
Information Retrieval
 https://vvtesh.sarahah.com/ Information Retrieval Venkatesh Vinayakarao Term: Aug Dec, 2018 Indian Institute of Information Technology, Sri City My whole life, I ve been a seeker, searching for something.
https://vvtesh.sarahah.com/ Information Retrieval Venkatesh Vinayakarao Term: Aug Dec, 2018 Indian Institute of Information Technology, Sri City My whole life, I ve been a seeker, searching for something.
Hortonworks Certified Developer (HDPCD Exam) Training Program
 Training Program") Hortonworks Certified Developer (HDPCD Exam) Training Program Having this badge on your resume can be your chance of standing out from the crowd. The HDP Certified Developer (HDPCD) exam is designed for
Hortonworks Certified Developer (HDPCD Exam) Training Program Having this badge on your resume can be your chance of standing out from the crowd. The HDP Certified Developer (HDPCD) exam is designed for
Introduction to BigData, Hadoop:-
 Introduction to BigData, Hadoop:- Big Data Introduction: Hadoop Introduction What is Hadoop? Why Hadoop? Hadoop History. Different types of Components in Hadoop? HDFS, MapReduce, PIG, Hive, SQOOP, HBASE,
Introduction to BigData, Hadoop:- Big Data Introduction: Hadoop Introduction What is Hadoop? Why Hadoop? Hadoop History. Different types of Components in Hadoop? HDFS, MapReduce, PIG, Hive, SQOOP, HBASE,
Big Data Hadoop Course Content
 Big Data Hadoop Course Content Topics covered in the training Introduction to Linux and Big Data Virtual Machine ( VM) Introduction/ Installation of VirtualBox and the Big Data VM Introduction to Linux
Big Data Hadoop Course Content Topics covered in the training Introduction to Linux and Big Data Virtual Machine ( VM) Introduction/ Installation of VirtualBox and the Big Data VM Introduction to Linux
Scaling Up Pig. Duen Horng (Polo) Chau Assistant Professor Associate Director, MS Analytics Georgia Tech. CSE6242 / CX4242: Data & Visual Analytics
 Chau Assistant Professor Associate Director, MS Analytics Georgia Tech. CSE6242 / CX4242: Data & Visual Analytics") http://poloclub.gatech.edu/cse6242 CSE6242 / CX4242: Data & Visual Analytics Scaling Up Pig Duen Horng (Polo) Chau Assistant Professor Associate Director, MS Analytics Georgia Tech Partly based on materials
http://poloclub.gatech.edu/cse6242 CSE6242 / CX4242: Data & Visual Analytics Scaling Up Pig Duen Horng (Polo) Chau Assistant Professor Associate Director, MS Analytics Georgia Tech Partly based on materials
Scaling Up 1 CSE 6242 / CX Duen Horng (Polo) Chau Georgia Tech. Hadoop, Pig
 Chau Georgia Tech. Hadoop, Pig") CSE 6242 / CX 4242 Scaling Up 1 Hadoop, Pig Duen Horng (Polo) Chau Georgia Tech Some lectures are partly based on materials by Professors Guy Lebanon, Jeffrey Heer, John Stasko, Christos Faloutsos, Le
CSE 6242 / CX 4242 Scaling Up 1 Hadoop, Pig Duen Horng (Polo) Chau Georgia Tech Some lectures are partly based on materials by Professors Guy Lebanon, Jeffrey Heer, John Stasko, Christos Faloutsos, Le
Introduction to Hadoop. High Availability Scaling Advantages and Challenges. Introduction to Big Data
 Introduction to Hadoop High Availability Scaling Advantages and Challenges Introduction to Big Data What is Big data Big Data opportunities Big Data Challenges Characteristics of Big data Introduction
Introduction to Hadoop High Availability Scaling Advantages and Challenges Introduction to Big Data What is Big data Big Data opportunities Big Data Challenges Characteristics of Big data Introduction
Delving Deep into Hadoop Course Contents Introduction to Hadoop and Architecture
 Delving Deep into Hadoop Course Contents Introduction to Hadoop and Architecture Hadoop 1.0 Architecture Introduction to Hadoop & Big Data Hadoop Evolution Hadoop Architecture Networking Concepts Use cases
Delving Deep into Hadoop Course Contents Introduction to Hadoop and Architecture Hadoop 1.0 Architecture Introduction to Hadoop & Big Data Hadoop Evolution Hadoop Architecture Networking Concepts Use cases
CC PROCESAMIENTO MASIVO DE DATOS OTOÑO 2018
 CC5212-1 PROCESAMIENTO MASIVO DE DATOS OTOÑO 2018 Lecture 4: Apache Pig Aidan Hogan aidhog@gmail.com HADOOP: WRAPPING UP 0. Reading/Writing to HDFS Creates a file system for default configuration Check
CC5212-1 PROCESAMIENTO MASIVO DE DATOS OTOÑO 2018 Lecture 4: Apache Pig Aidan Hogan aidhog@gmail.com HADOOP: WRAPPING UP 0. Reading/Writing to HDFS Creates a file system for default configuration Check
Shell and Utility Commands
 Table of contents 1 Shell Commands... 2 2 Utility Commands...3 1. Shell Commands 1.1. fs Invokes any FsShell command from within a Pig script or the Grunt shell. 1.1.1. Syntax fs subcommand subcommand_parameters
Table of contents 1 Shell Commands... 2 2 Utility Commands...3 1. Shell Commands 1.1. fs Invokes any FsShell command from within a Pig script or the Grunt shell. 1.1.1. Syntax fs subcommand subcommand_parameters
Click Stream Data Analysis Using Hadoop
 Governors State University OPUS Open Portal to University Scholarship All Capstone Projects Student Capstone Projects Spring 2015 Click Stream Data Analysis Using Hadoop Krishna Chand Reddy Gaddam Governors
Governors State University OPUS Open Portal to University Scholarship All Capstone Projects Student Capstone Projects Spring 2015 Click Stream Data Analysis Using Hadoop Krishna Chand Reddy Gaddam Governors
Hadoop Online Training
 Hadoop Online Training IQ training facility offers Hadoop Online Training. Our Hadoop trainers come with vast work experience and teaching skills. Our Hadoop training online is regarded as the one of the
Hadoop Online Training IQ training facility offers Hadoop Online Training. Our Hadoop trainers come with vast work experience and teaching skills. Our Hadoop training online is regarded as the one of the
COSC 6339 Big Data Analytics. Hadoop MapReduce Infrastructure: Pig, Hive, and Mahout. Edgar Gabriel Fall Pig
 COSC 6339 Big Data Analytics Hadoop MapReduce Infrastructure: Pig, Hive, and Mahout Edgar Gabriel Fall 2018 Pig Pig is a platform for analyzing large data sets abstraction on top of Hadoop Provides high
COSC 6339 Big Data Analytics Hadoop MapReduce Infrastructure: Pig, Hive, and Mahout Edgar Gabriel Fall 2018 Pig Pig is a platform for analyzing large data sets abstraction on top of Hadoop Provides high
Joe Hummel, PhD. Visiting Researcher: U. of California, Irvine Adjunct Professor: U. of Illinois, Chicago & Loyola U., Chicago
 Joe Hummel, PhD Visiting Researcher: U. of California, Irvine Adjunct Professor: U. of Illinois, Chicago & Loyola U., Chicago Materials: http://www.joehummel.net/downloads.html Email: joe@joehummel.net
Joe Hummel, PhD Visiting Researcher: U. of California, Irvine Adjunct Professor: U. of Illinois, Chicago & Loyola U., Chicago Materials: http://www.joehummel.net/downloads.html Email: joe@joehummel.net
Outline. MapReduce Data Model. MapReduce. Step 2: the REDUCE Phase. Step 1: the MAP Phase 11/29/11. Introduction to Data Management CSE 344
 Outline Introduction to Data Management CSE 344 Review of MapReduce Introduction to Pig System Pig Latin tutorial Lecture 23: Pig Latin Some slides are courtesy of Alan Gates, Yahoo!Research 1 2 MapReduce
Outline Introduction to Data Management CSE 344 Review of MapReduce Introduction to Pig System Pig Latin tutorial Lecture 23: Pig Latin Some slides are courtesy of Alan Gates, Yahoo!Research 1 2 MapReduce
MAP-REDUCE ABSTRACTIONS
 MAP-REDUCE ABSTRACTIONS 1 Abstractions On Top Of Hadoop We ve decomposed some algorithms into a map- reduce work9low (series of map- reduce steps) naive Bayes training naïve Bayes testing phrase scoring
MAP-REDUCE ABSTRACTIONS 1 Abstractions On Top Of Hadoop We ve decomposed some algorithms into a map- reduce work9low (series of map- reduce steps) naive Bayes training naïve Bayes testing phrase scoring
ExamTorrent. Best exam torrent, excellent test torrent, valid exam dumps are here waiting for you
 ExamTorrent http://www.examtorrent.com Best exam torrent, excellent test torrent, valid exam dumps are here waiting for you Exam : Apache-Hadoop-Developer Title : Hadoop 2.0 Certification exam for Pig
ExamTorrent http://www.examtorrent.com Best exam torrent, excellent test torrent, valid exam dumps are here waiting for you Exam : Apache-Hadoop-Developer Title : Hadoop 2.0 Certification exam for Pig
Apache DataFu (incubating)
") Apache DataFu (incubating) William Vaughan Staff Software Engineer, LinkedIn www.linkedin.com/in/williamgvaughan Apache DataFu Apache DataFu is a collection of libraries for working with large-scale data
Apache DataFu (incubating) William Vaughan Staff Software Engineer, LinkedIn www.linkedin.com/in/williamgvaughan Apache DataFu Apache DataFu is a collection of libraries for working with large-scale data
Processing Big Data with Hadoop in Azure HDInsight
 Processing Big Data with Hadoop in Azure HDInsight Lab 3B Using Python Overview In this lab, you will use Python to create custom user-defined functions (UDFs), and call them from Hive and Pig. Hive provides
Processing Big Data with Hadoop in Azure HDInsight Lab 3B Using Python Overview In this lab, you will use Python to create custom user-defined functions (UDFs), and call them from Hive and Pig. Hive provides
Shell and Utility Commands
 Table of contents 1 Shell Commands... 2 2 Utility Commands... 3 1 Shell Commands 1.1 fs Invokes any FsShell command from within a Pig script or the Grunt shell. 1.1.1 Syntax fs subcommand subcommand_parameters
Table of contents 1 Shell Commands... 2 2 Utility Commands... 3 1 Shell Commands 1.1 fs Invokes any FsShell command from within a Pig script or the Grunt shell. 1.1.1 Syntax fs subcommand subcommand_parameters
Innovatus Technologies
 HADOOP 2.X BIGDATA ANALYTICS 1. Java Overview of Java Classes and Objects Garbage Collection and Modifiers Inheritance, Aggregation, Polymorphism Command line argument Abstract class and Interfaces String
HADOOP 2.X BIGDATA ANALYTICS 1. Java Overview of Java Classes and Objects Garbage Collection and Modifiers Inheritance, Aggregation, Polymorphism Command line argument Abstract class and Interfaces String
Aims. Background. This exercise aims to get you to:
 Aims This exercise aims to get you to: Import data into HBase using bulk load Read MapReduce input from HBase and write MapReduce output to HBase Manage data using Hive Manage data using Pig Background
Aims This exercise aims to get you to: Import data into HBase using bulk load Read MapReduce input from HBase and write MapReduce output to HBase Manage data using Hive Manage data using Pig Background
International Journal of Computer Engineering and Applications, BIG DATA ANALYTICS USING APACHE PIG Prabhjot Kaur
 Prabhjot Kaur Department of Computer Engineering ME CSE(BIG DATA ANALYTICS)-CHANDIGARH UNIVERSITY,GHARUAN kaurprabhjot770@gmail.com ABSTRACT: In today world, as we know data is expanding along with the
Prabhjot Kaur Department of Computer Engineering ME CSE(BIG DATA ANALYTICS)-CHANDIGARH UNIVERSITY,GHARUAN kaurprabhjot770@gmail.com ABSTRACT: In today world, as we know data is expanding along with the
IN ACTION. Chuck Lam SAMPLE CHAPTER MANNING
 IN ACTION Chuck Lam SAMPLE CHAPTER MANNING Hadoop in Action by Chuck Lam Chapter 10 Copyright 2010 Manning Publications brief contents PART I HADOOP A DISTRIBUTED PROGRAMMING FRAMEWORK... 1 1 Introducing
IN ACTION Chuck Lam SAMPLE CHAPTER MANNING Hadoop in Action by Chuck Lam Chapter 10 Copyright 2010 Manning Publications brief contents PART I HADOOP A DISTRIBUTED PROGRAMMING FRAMEWORK... 1 1 Introducing
this is so cumbersome!
 Pig Arend Hintze this is so cumbersome! Instead of programming everything in java MapReduce or streaming: wouldn t it we wonderful to have a simpler interface? Problem: break down complex MapReduce tasks
Pig Arend Hintze this is so cumbersome! Instead of programming everything in java MapReduce or streaming: wouldn t it we wonderful to have a simpler interface? Problem: break down complex MapReduce tasks
Templates for Supporting Sequenced Temporal Semantics in Pig Latin
 Utah State University DigitalCommons@USU All Graduate Plan B and other Reports Graduate Studies 5-2011 Templates for Supporting Sequenced Temporal Semantics in Pig Latin Dhaval Deshpande Utah State University
Utah State University DigitalCommons@USU All Graduate Plan B and other Reports Graduate Studies 5-2011 Templates for Supporting Sequenced Temporal Semantics in Pig Latin Dhaval Deshpande Utah State University
Big Data Syllabus. Understanding big data and Hadoop. Limitations and Solutions of existing Data Analytics Architecture
 Big Data Syllabus Hadoop YARN Setup Programming in YARN framework j Understanding big data and Hadoop Big Data Limitations and Solutions of existing Data Analytics Architecture Hadoop Features Hadoop Ecosystem
Big Data Syllabus Hadoop YARN Setup Programming in YARN framework j Understanding big data and Hadoop Big Data Limitations and Solutions of existing Data Analytics Architecture Hadoop Features Hadoop Ecosystem
Introduction to Hive Cloudera, Inc.
 Introduction to Hive Outline Motivation Overview Data Model Working with Hive Wrap up & Conclusions Background Started at Facebook Data was collected by nightly cron jobs into Oracle DB ETL via hand-coded
Introduction to Hive Outline Motivation Overview Data Model Working with Hive Wrap up & Conclusions Background Started at Facebook Data was collected by nightly cron jobs into Oracle DB ETL via hand-coded
Hadoop Development Introduction
 Hadoop Development Introduction What is Bigdata? Evolution of Bigdata Types of Data and their Significance Need for Bigdata Analytics Why Bigdata with Hadoop? History of Hadoop Why Hadoop is in demand
Hadoop Development Introduction What is Bigdata? Evolution of Bigdata Types of Data and their Significance Need for Bigdata Analytics Why Bigdata with Hadoop? History of Hadoop Why Hadoop is in demand
Overview. : Cloudera Data Analyst Training. Course Outline :: Cloudera Data Analyst Training::
 Module Title Duration : Cloudera Data Analyst Training : 4 days Overview Take your knowledge to the next level Cloudera University s four-day data analyst training course will teach you to apply traditional
Module Title Duration : Cloudera Data Analyst Training : 4 days Overview Take your knowledge to the next level Cloudera University s four-day data analyst training course will teach you to apply traditional
On behalf of ASE crew, I welcome you onboard. We will cover this journey in roughly 50 minutes.
 On behalf of ASE crew, I welcome you onboard. We will cover this journey in roughly 50 minutes. We will fly over the basics of Object Oriented Analysis and Design. We may encounter some turbulence at times.
On behalf of ASE crew, I welcome you onboard. We will cover this journey in roughly 50 minutes. We will fly over the basics of Object Oriented Analysis and Design. We may encounter some turbulence at times.
Getting Started. Table of contents. 1 Pig Setup Running Pig Pig Latin Statements Pig Properties Pig Tutorial...
 Table of contents 1 Pig Setup... 2 2 Running Pig... 3 3 Pig Latin Statements... 6 4 Pig Properties... 8 5 Pig Tutorial... 9 1. Pig Setup 1.1. Requirements Mandatory Unix and Windows users need the following:
Table of contents 1 Pig Setup... 2 2 Running Pig... 3 3 Pig Latin Statements... 6 4 Pig Properties... 8 5 Pig Tutorial... 9 1. Pig Setup 1.1. Requirements Mandatory Unix and Windows users need the following:
Dr. Chuck Cartledge. 18 Feb. 2015
 CS-495/595 Pig Lecture #6 Dr. Chuck Cartledge 18 Feb. 2015 1/18 Table of contents I 1 Miscellanea 2 The Book 3 Chapter 11 4 Conclusion 5 References 2/18 Corrections and additions since last lecture. Completed
CS-495/595 Pig Lecture #6 Dr. Chuck Cartledge 18 Feb. 2015 1/18 Table of contents I 1 Miscellanea 2 The Book 3 Chapter 11 4 Conclusion 5 References 2/18 Corrections and additions since last lecture. Completed
Hadoop & Big Data Analytics Complete Practical & Real-time Training
 An ISO Certified Training Institute A Unit of Sequelgate Innovative Technologies Pvt. Ltd. www.sqlschool.com Hadoop & Big Data Analytics Complete Practical & Real-time Training Mode : Instructor Led LIVE
An ISO Certified Training Institute A Unit of Sequelgate Innovative Technologies Pvt. Ltd. www.sqlschool.com Hadoop & Big Data Analytics Complete Practical & Real-time Training Mode : Instructor Led LIVE
Blended Learning Outline: Cloudera Data Analyst Training (171219a)
") Blended Learning Outline: Cloudera Data Analyst Training (171219a) Cloudera Univeristy s data analyst training course will teach you to apply traditional data analytics and business intelligence skills
Blended Learning Outline: Cloudera Data Analyst Training (171219a) Cloudera Univeristy s data analyst training course will teach you to apply traditional data analytics and business intelligence skills
Big Data Analytics using Apache Hadoop and Spark with Scala
 Big Data Analytics using Apache Hadoop and Spark with Scala Training Highlights : 80% of the training is with Practical Demo (On Custom Cloudera and Ubuntu Machines) 20% Theory Portion will be important
Big Data Analytics using Apache Hadoop and Spark with Scala Training Highlights : 80% of the training is with Practical Demo (On Custom Cloudera and Ubuntu Machines) 20% Theory Portion will be important
HIVE INTERVIEW QUESTIONS
 HIVE INTERVIEW QUESTIONS http://www.tutorialspoint.com/hive/hive_interview_questions.htm Copyright tutorialspoint.com Dear readers, these Hive Interview Questions have been designed specially to get you
HIVE INTERVIEW QUESTIONS http://www.tutorialspoint.com/hive/hive_interview_questions.htm Copyright tutorialspoint.com Dear readers, these Hive Interview Questions have been designed specially to get you
Big Data Hadoop Stack
 Big Data Hadoop Stack Lecture #1 Hadoop Beginnings What is Hadoop? Apache Hadoop is an open source software framework for storage and large scale processing of data-sets on clusters of commodity hardware
Big Data Hadoop Stack Lecture #1 Hadoop Beginnings What is Hadoop? Apache Hadoop is an open source software framework for storage and large scale processing of data-sets on clusters of commodity hardware
SET DEFINITION 1 elements members
 SETS SET DEFINITION 1 Unordered collection of objects, called elements or members of the set. Said to contain its elements. We write a A to denote that a is an element of the set A. The notation a A denotes
SETS SET DEFINITION 1 Unordered collection of objects, called elements or members of the set. Said to contain its elements. We write a A to denote that a is an element of the set A. The notation a A denotes
Hashing and sketching
 Hashing and sketching 1 The age of big data An age of big data is upon us, brought on by a combination of: Pervasive sensing: so much of what goes on in our lives and in the world at large is now digitally
Hashing and sketching 1 The age of big data An age of big data is upon us, brought on by a combination of: Pervasive sensing: so much of what goes on in our lives and in the world at large is now digitally
HBase vs Neo4j. Technical overview. Name: Vladan Jovičić CR09 Advanced Scalable Data (Fall, 2017) Ecolé Normale Superiuere de Lyon
 Ecolé Normale Superiuere de Lyon") HBase vs Neo4j Technical overview Name: Vladan Jovičić CR09 Advanced Scalable Data (Fall, 2017) Ecolé Normale Superiuere de Lyon 12th October 2017 1 Contents 1 Introduction 3 2 Overview of HBase and Neo4j
HBase vs Neo4j Technical overview Name: Vladan Jovičić CR09 Advanced Scalable Data (Fall, 2017) Ecolé Normale Superiuere de Lyon 12th October 2017 1 Contents 1 Introduction 3 2 Overview of HBase and Neo4j
User Defined Functions
 Table of contents 1 Introduction... 2 2 Writing Java UDFs... 2 3 Writing Jython UDFs...35 4 Writing JavaScript UDFs... 38 5 Writing Ruby UDFs...40 6 Writing Groovy UDFs... 42 7 Writing Python UDFs... 46
Table of contents 1 Introduction... 2 2 Writing Java UDFs... 2 3 Writing Jython UDFs...35 4 Writing JavaScript UDFs... 38 5 Writing Ruby UDFs...40 6 Writing Groovy UDFs... 42 7 Writing Python UDFs... 46
Certified Big Data and Hadoop Course Curriculum
 Certified Big Data and Hadoop Course Curriculum The Certified Big Data and Hadoop course by DataFlair is a perfect blend of in-depth theoretical knowledge and strong practical skills via implementation
Certified Big Data and Hadoop Course Curriculum The Certified Big Data and Hadoop course by DataFlair is a perfect blend of in-depth theoretical knowledge and strong practical skills via implementation
Shark: Hive (SQL) on Spark
 on Spark") Shark: Hive (SQL) on Spark Reynold Xin UC Berkeley AMP Camp Aug 21, 2012 UC BERKELEY SELECT page_name, SUM(page_views) views FROM wikistats GROUP BY page_name ORDER BY views DESC LIMIT 10; Stage 0: Map-Shuffle-Reduce
Shark: Hive (SQL) on Spark Reynold Xin UC Berkeley AMP Camp Aug 21, 2012 UC BERKELEY SELECT page_name, SUM(page_views) views FROM wikistats GROUP BY page_name ORDER BY views DESC LIMIT 10; Stage 0: Map-Shuffle-Reduce
Faster ETL Workflows using Apache Pig & Spark. - Praveen Rachabattuni,
 Faster ETL Workflows using Apache Pig & Spark - Praveen Rachabattuni, Sigmoid @praveenr019 About me Apache Pig committer and Pig on Spark project lead. OUR CUSTOMERS Why pig on spark? Spark shell (scala),
Faster ETL Workflows using Apache Pig & Spark - Praveen Rachabattuni, Sigmoid @praveenr019 About me Apache Pig committer and Pig on Spark project lead. OUR CUSTOMERS Why pig on spark? Spark shell (scala),
Index. Symbols A B C D E F G H I J K L M N O P Q R S T U V W X Y Z
 Symbols A B C D E F G H I J K L M N O P Q R S T U V W X Y Z Symbols + addition operator?: bincond operator /* */ comments - multi-line -- comments - single-line # deference operator (map). deference operator
Symbols A B C D E F G H I J K L M N O P Q R S T U V W X Y Z Symbols + addition operator?: bincond operator /* */ comments - multi-line -- comments - single-line # deference operator (map). deference operator
Big Data and Hadoop. Course Curriculum: Your 10 Module Learning Plan. About Edureka
 Course Curriculum: Your 10 Module Learning Plan Big Data and Hadoop About Edureka Edureka is a leading e-learning platform providing live instructor-led interactive online training. We cater to professionals
Course Curriculum: Your 10 Module Learning Plan Big Data and Hadoop About Edureka Edureka is a leading e-learning platform providing live instructor-led interactive online training. We cater to professionals
Typing Massive JSON Datasets
 Typing Massive JSON Datasets Dario Colazzo Université Paris Sud - INRIA Giorgio Ghelli Università di Pisa Carlo Sartiani Università della Basilicata Outline Introduction & Motivation Data model & Type
Typing Massive JSON Datasets Dario Colazzo Université Paris Sud - INRIA Giorgio Ghelli Università di Pisa Carlo Sartiani Università della Basilicata Outline Introduction & Motivation Data model & Type
OKC MySQL Users Group
 OKC MySQL Users Group OKC MySQL Discuss topics about MySQL and related open source RDBMS Discuss complementary topics (big data, NoSQL, etc) Help to grow the local ecosystem through meetups and events
OKC MySQL Users Group OKC MySQL Discuss topics about MySQL and related open source RDBMS Discuss complementary topics (big data, NoSQL, etc) Help to grow the local ecosystem through meetups and events
CSCI 599: Applications of Natural Language Processing Information Retrieval Retrieval Models (Part 3)"
") CSCI 599: Applications of Natural Language Processing Information Retrieval Retrieval Models (Part 3)" All slides Addison Wesley, Donald Metzler, and Anton Leuski, 2008, 2012! Language Model" Unigram language
CSCI 599: Applications of Natural Language Processing Information Retrieval Retrieval Models (Part 3)" All slides Addison Wesley, Donald Metzler, and Anton Leuski, 2008, 2012! Language Model" Unigram language
Processing Big Data with Hadoop in Azure HDInsight
 Processing Big Data with Hadoop in Azure HDInsight Lab 3A Using Pig Overview In this lab, you will use Pig to process data. You will run Pig Latin statements and create Pig Latin scripts that cleanse,
Processing Big Data with Hadoop in Azure HDInsight Lab 3A Using Pig Overview In this lab, you will use Pig to process data. You will run Pig Latin statements and create Pig Latin scripts that cleanse,
Importing and Exporting Data Between Hadoop and MySQL
 Importing and Exporting Data Between Hadoop and MySQL + 1 About me Sarah Sproehnle Former MySQL instructor Joined Cloudera in March 2010 sarah@cloudera.com 2 What is Hadoop? An open-source framework for
Importing and Exporting Data Between Hadoop and MySQL + 1 About me Sarah Sproehnle Former MySQL instructor Joined Cloudera in March 2010 sarah@cloudera.com 2 What is Hadoop? An open-source framework for
Models for Document & Query Representation. Ziawasch Abedjan
 Models for Document & Query Representation Ziawasch Abedjan Overview Introduction & Definition Boolean retrieval Vector Space Model Probabilistic Information Retrieval Language Model Approach Summary Overview
Models for Document & Query Representation Ziawasch Abedjan Overview Introduction & Definition Boolean retrieval Vector Space Model Probabilistic Information Retrieval Language Model Approach Summary Overview
Prototyping Data Intensive Apps: TrendingTopics.org
 Prototyping Data Intensive Apps: TrendingTopics.org Pete Skomoroch Research Scientist at LinkedIn Consultant at Data Wrangling @peteskomoroch 09/29/09 1 Talk Outline TrendingTopics Overview Wikipedia Page
Prototyping Data Intensive Apps: TrendingTopics.org Pete Skomoroch Research Scientist at LinkedIn Consultant at Data Wrangling @peteskomoroch 09/29/09 1 Talk Outline TrendingTopics Overview Wikipedia Page
Hive SQL over Hadoop
 Hive SQL over Hadoop Antonino Virgillito THE CONTRACTOR IS ACTING UNDER A FRAMEWORK CONTRACT CONCLUDED WITH THE COMMISSION Introduction Apache Hive is a high-level abstraction on top of MapReduce Uses
Hive SQL over Hadoop Antonino Virgillito THE CONTRACTOR IS ACTING UNDER A FRAMEWORK CONTRACT CONCLUDED WITH THE COMMISSION Introduction Apache Hive is a high-level abstraction on top of MapReduce Uses
Certified Big Data Hadoop and Spark Scala Course Curriculum
 Certified Big Data Hadoop and Spark Scala Course Curriculum The Certified Big Data Hadoop and Spark Scala course by DataFlair is a perfect blend of indepth theoretical knowledge and strong practical skills
Certified Big Data Hadoop and Spark Scala Course Curriculum The Certified Big Data Hadoop and Spark Scala course by DataFlair is a perfect blend of indepth theoretical knowledge and strong practical skills
Lecture 16. Reading: Weiss Ch. 5 CSE 100, UCSD: LEC 16. Page 1 of 40
 Lecture 16 Hashing Hash table and hash function design Hash functions for integers and strings Collision resolution strategies: linear probing, double hashing, random hashing, separate chaining Hash table
Lecture 16 Hashing Hash table and hash function design Hash functions for integers and strings Collision resolution strategies: linear probing, double hashing, random hashing, separate chaining Hash table
Systems Infrastructure for Data Science. Web Science Group Uni Freiburg WS 2014/15
 Systems Infrastructure for Data Science Web Science Group Uni Freiburg WS 2014/15 Hadoop Evolution and Ecosystem Hadoop Map/Reduce has been an incredible success, but not everybody is happy with it 3 DB
Systems Infrastructure for Data Science Web Science Group Uni Freiburg WS 2014/15 Hadoop Evolution and Ecosystem Hadoop Map/Reduce has been an incredible success, but not everybody is happy with it 3 DB
DHANALAKSHMI COLLEGE OF ENGINEERING, CHENNAI
 DHANALAKSHMI COLLEGE OF ENGINEERING, CHENNAI Department of Information Technology IT6701 - INFORMATION MANAGEMENT Anna University 2 & 16 Mark Questions & Answers Year / Semester: IV / VII Regulation: 2013
DHANALAKSHMI COLLEGE OF ENGINEERING, CHENNAI Department of Information Technology IT6701 - INFORMATION MANAGEMENT Anna University 2 & 16 Mark Questions & Answers Year / Semester: IV / VII Regulation: 2013
Topics covered in this lecture
 9/5/2018 CS435 Introduction to Big Data - FALL 2018 W3.B.0 CS435 Introduction to Big Data 9/5/2018 CS435 Introduction to Big Data - FALL 2018 W3.B.1 FAQs How does Hadoop mapreduce run the map instance?
9/5/2018 CS435 Introduction to Big Data - FALL 2018 W3.B.0 CS435 Introduction to Big Data 9/5/2018 CS435 Introduction to Big Data - FALL 2018 W3.B.1 FAQs How does Hadoop mapreduce run the map instance?
CSE 190D Spring 2017 Final Exam Answers
 CSE 190D Spring 2017 Final Exam Answers Q 1. [20pts] For the following questions, clearly circle True or False. 1. The hash join algorithm always has fewer page I/Os compared to the block nested loop join
CSE 190D Spring 2017 Final Exam Answers Q 1. [20pts] For the following questions, clearly circle True or False. 1. The hash join algorithm always has fewer page I/Os compared to the block nested loop join
Big Data and Scripting map reduce in Hadoop
 Big Data and Scripting map reduce in Hadoop 1, 2, connecting to last session set up a local map reduce distribution enable execution of map reduce implementations using local file system only all tasks
Big Data and Scripting map reduce in Hadoop 1, 2, connecting to last session set up a local map reduce distribution enable execution of map reduce implementations using local file system only all tasks
Talend Open Studio for Big Data. Getting Started Guide 5.3.2
 Talend Open Studio for Big Data Getting Started Guide 5.3.2 Talend Open Studio for Big Data Adapted for v5.3.2. Supersedes previous Getting Started Guide releases. Publication date: January 24, 2014 Copyleft
Talend Open Studio for Big Data Getting Started Guide 5.3.2 Talend Open Studio for Big Data Adapted for v5.3.2. Supersedes previous Getting Started Guide releases. Publication date: January 24, 2014 Copyleft
Talend Open Studio for Big Data. Getting Started Guide 5.4.0
 Talend Open Studio for Big Data Getting Started Guide 5.4.0 Talend Open Studio for Big Data Adapted for v5.4.0. Supersedes previous Getting Started Guide releases. Publication date: October 28, 2013 Copyleft
Talend Open Studio for Big Data Getting Started Guide 5.4.0 Talend Open Studio for Big Data Adapted for v5.4.0. Supersedes previous Getting Started Guide releases. Publication date: October 28, 2013 Copyleft
User Defined Functions
 Table of contents 1 Introduction...2 2 Writing Java UDFs...2 3 Writing Python UDFs... 33 4 Writing JavaScript UDFs...36 5 Writing Ruby UDFs...38 6 Piggy Bank...41 1. Introduction Pig provides extensive
Table of contents 1 Introduction...2 2 Writing Java UDFs...2 3 Writing Python UDFs... 33 4 Writing JavaScript UDFs...36 5 Writing Ruby UDFs...38 6 Piggy Bank...41 1. Introduction Pig provides extensive
Database Usage (and Construction)
") Lecture 7 Database Usage (and Construction) More SQL Queries and Relational Algebra Previously Capacity per campus? name capacity campus HB2 186 Johanneberg HC1 105 Johanneberg HC2 115 Johanneberg Jupiter44
Lecture 7 Database Usage (and Construction) More SQL Queries and Relational Algebra Previously Capacity per campus? name capacity campus HB2 186 Johanneberg HC1 105 Johanneberg HC2 115 Johanneberg Jupiter44
GLADE: A Scalable Framework for Efficient Analytics. Florin Rusu (University of California, Merced) Alin Dobra (University of Florida)
 Alin Dobra (University of Florida)") DE: A Scalable Framework for Efficient Analytics Florin Rusu (University of California, Merced) Alin Dobra (University of Florida) Big Data Analytics Big Data Storage is cheap ($100 for 1TB disk) Everything
DE: A Scalable Framework for Efficient Analytics Florin Rusu (University of California, Merced) Alin Dobra (University of Florida) Big Data Analytics Big Data Storage is cheap ($100 for 1TB disk) Everything
Talend Open Studio for Big Data. Getting Started Guide 5.4.2
 Talend Open Studio for Big Data Getting Started Guide 5.4.2 Talend Open Studio for Big Data Adapted for v5.4.2. Supersedes previous releases. Publication date: May 13, 2014 Copyleft This documentation
Talend Open Studio for Big Data Getting Started Guide 5.4.2 Talend Open Studio for Big Data Adapted for v5.4.2. Supersedes previous releases. Publication date: May 13, 2014 Copyleft This documentation
Hortonworks Data Platform
 Hortonworks Data Platform Workflow Management (August 31, 2017) docs.hortonworks.com Hortonworks Data Platform: Workflow Management Copyright 2012-2017 Hortonworks, Inc. Some rights reserved. The Hortonworks
Hortonworks Data Platform Workflow Management (August 31, 2017) docs.hortonworks.com Hortonworks Data Platform: Workflow Management Copyright 2012-2017 Hortonworks, Inc. Some rights reserved. The Hortonworks
Higher level data processing in Apache Spark
 Higher level data processing in Apache Spark Pelle Jakovits 12 October, 2016, Tartu Outline Recall Apache Spark Spark DataFrames Introduction Creating and storing DataFrames DataFrame API functions SQL
Higher level data processing in Apache Spark Pelle Jakovits 12 October, 2016, Tartu Outline Recall Apache Spark Spark DataFrames Introduction Creating and storing DataFrames DataFrame API functions SQL
CS 186/286 Spring 2018 Midterm 1
 CS 186/286 Spring 2018 Midterm 1 Do not turn this page until instructed to start the exam. You should receive 1 single-sided answer sheet and a 13-page exam packet. All answers should be written on the
CS 186/286 Spring 2018 Midterm 1 Do not turn this page until instructed to start the exam. You should receive 1 single-sided answer sheet and a 13-page exam packet. All answers should be written on the
Introduction to Hive. Feng Li School of Statistics and Mathematics Central University of Finance and Economics
 Introduction to Hive Feng Li feng.li@cufe.edu.cn School of Statistics and Mathematics Central University of Finance and Economics Revised on December 14, 2017 Today we are going to learn... 1 Introduction
Introduction to Hive Feng Li feng.li@cufe.edu.cn School of Statistics and Mathematics Central University of Finance and Economics Revised on December 14, 2017 Today we are going to learn... 1 Introduction
Big Data Infrastructure CS 489/698 Big Data Infrastructure (Winter 2016)
") Big Data Infrastructure CS 489/698 Big Data Infrastructure (Winter 2016) Week 9: Data Mining (3/4) March 8, 2016 Jimmy Lin David R. Cheriton School of Computer Science University of Waterloo These slides
Big Data Infrastructure CS 489/698 Big Data Infrastructure (Winter 2016) Week 9: Data Mining (3/4) March 8, 2016 Jimmy Lin David R. Cheriton School of Computer Science University of Waterloo These slides
Where We Are. Review: Parallel DBMS. Parallel DBMS. Introduction to Data Management CSE 344
 Where We Are Introduction to Data Management CSE 344 Lecture 22: MapReduce We are talking about parallel query processing There exist two main types of engines: Parallel DBMSs (last lecture + quick review)
Where We Are Introduction to Data Management CSE 344 Lecture 22: MapReduce We are talking about parallel query processing There exist two main types of engines: Parallel DBMSs (last lecture + quick review)
Hadoop. Introduction to BIGDATA and HADOOP
 Hadoop Introduction to BIGDATA and HADOOP What is Big Data? What is Hadoop? Relation between Big Data and Hadoop What is the need of going ahead with Hadoop? Scenarios to apt Hadoop Technology in REAL
Hadoop Introduction to BIGDATA and HADOOP What is Big Data? What is Hadoop? Relation between Big Data and Hadoop What is the need of going ahead with Hadoop? Scenarios to apt Hadoop Technology in REAL
Data-intensive computing systems
 Data-intensive computing systems High-Level Languages University of Verona Computer Science Department Damiano Carra Acknowledgements! Credits Part of the course material is based on slides provided by
Data-intensive computing systems High-Level Languages University of Verona Computer Science Department Damiano Carra Acknowledgements! Credits Part of the course material is based on slides provided by
Pig Latin: A Not-So-Foreign Language for Data Processing
 Pig Latin: A Not-So-Foreign Language for Data Processing Christopher Olston, Benjamin Reed, Utkarsh Srivastava, Ravi Kumar, Andrew Tomkins (Yahoo! Research) Presented by Aaron Moss (University of Waterloo)
Pig Latin: A Not-So-Foreign Language for Data Processing Christopher Olston, Benjamin Reed, Utkarsh Srivastava, Ravi Kumar, Andrew Tomkins (Yahoo! Research) Presented by Aaron Moss (University of Waterloo)
Getting Started. Table of contents. 1 Pig Setup Running Pig Pig Latin Statements Pig Properties Pig Tutorial...
 Table of contents 1 Pig Setup... 2 2 Running Pig... 3 3 Pig Latin Statements... 6 4 Pig Properties... 8 5 Pig Tutorial... 9 1 Pig Setup 1.1 Requirements Mandatory Unix and Windows users need the following:
Table of contents 1 Pig Setup... 2 2 Running Pig... 3 3 Pig Latin Statements... 6 4 Pig Properties... 8 5 Pig Tutorial... 9 1 Pig Setup 1.1 Requirements Mandatory Unix and Windows users need the following:
????? An Exercise. Suppose that we have written a class named Play that has a String instance variable named filename.
 An Exercise Suppose that we have written a class named Play that has a String instance variable named filename. A Plays respond to a startswith( char initial ) message by returning the number of Strings
An Exercise Suppose that we have written a class named Play that has a String instance variable named filename. A Plays respond to a startswith( char initial ) message by returning the number of Strings
Apache Pig coreservlets.com and Dima May coreservlets.com and Dima May
 2012 coreservlets.com and Dima May Apache Pig Originals of slides and source code for examples: http://www.coreservlets.com/hadoop-tutorial/ Also see the customized Hadoop training courses (onsite or at
2012 coreservlets.com and Dima May Apache Pig Originals of slides and source code for examples: http://www.coreservlets.com/hadoop-tutorial/ Also see the customized Hadoop training courses (onsite or at
Hadoop-PR Hortonworks Certified Apache Hadoop 2.0 Developer (Pig and Hive Developer)
") Hortonworks Hadoop-PR000007 Hortonworks Certified Apache Hadoop 2.0 Developer (Pig and Hive Developer) http://killexams.com/pass4sure/exam-detail/hadoop-pr000007 QUESTION: 99 Which one of the following
Hortonworks Hadoop-PR000007 Hortonworks Certified Apache Hadoop 2.0 Developer (Pig and Hive Developer) http://killexams.com/pass4sure/exam-detail/hadoop-pr000007 QUESTION: 99 Which one of the following
An Information Retrieval Approach for Source Code Plagiarism Detection
 -2014: An Information Retrieval Approach for Source Code Plagiarism Detection Debasis Ganguly, Gareth J. F. Jones CNGL: Centre for Global Intelligent Content School of Computing, Dublin City University
-2014: An Information Retrieval Approach for Source Code Plagiarism Detection Debasis Ganguly, Gareth J. F. Jones CNGL: Centre for Global Intelligent Content School of Computing, Dublin City University
SQT03 Big Data and Hadoop with Azure HDInsight Andrew Brust. Senior Director, Technical Product Marketing and Evangelism
 Big Data and Hadoop with Azure HDInsight Andrew Brust Senior Director, Technical Product Marketing and Evangelism Datameer Level: Intermediate Meet Andrew Senior Director, Technical Product Marketing and
Big Data and Hadoop with Azure HDInsight Andrew Brust Senior Director, Technical Product Marketing and Evangelism Datameer Level: Intermediate Meet Andrew Senior Director, Technical Product Marketing and
CS115 - Module 4 - Compound data: structures
 Fall 2017 Reminder: if you have not already, ensure you: Read How to Design Programs, sections 6-7, omitting 6.2, 6.6, 6.7, and 7.4. Compound data It often comes up that we wish to join several pieces
Fall 2017 Reminder: if you have not already, ensure you: Read How to Design Programs, sections 6-7, omitting 6.2, 6.6, 6.7, and 7.4. Compound data It often comes up that we wish to join several pieces