Cloud Computing & Visualization
|
|
|
- Darren Willis
- 5 years ago
- Views:
Transcription
1 Cloud Computing & Visualization Workflows Distributed Computation with Spark Data Warehousing with Redshift Visualization with Tableau #FIUSCIS School of Computing & Information Sciences, Florida International University, Miami
2 Introduction Distributed Computation -Elastic Map Reduce -Spark -Ganglia Data Warehousing -Redshift -RDS Visualization - Tableau Desktop - Tabeau Prep 2 2
3 Distributed Computation Spark is a computing platform designed to be fast and general-purpose. 3 3
4 Data Warehousing Amazon Redshift is a fully managed, petabyte-scale data warehouse service in the cloud. 4 4

5 Visualization Tableau is a Business Intelligence tool for visually analyzing data. 5 5


6 Cloud Computing Cloud computing is shared pools of configurable computer system resources and higher-level services that can be rapidly provisioned with minimal management effort, often over the Internet. Third-party cloud providers enable organizations to focus on core tasks instead of expending resources on computer infrastructure and maintenance. aws.amazon.com 6 6
7 aws.amazon.com 7 7
8 8 8
9 Analytics -EMR Database -Redshift -RDS 9 9

10
11 Distributed Computation with Spark 11 11
12 Apache Spark Spark is a Big Data Processing Engine a Fast, General- Purpose, Cluster-computing Platform. Handles the Scheduling, Distribution, and Monitoring of applications spanning many worker machines. Has a Rich API to distribute data across the cluster, and process it in parallel. Supports a variety of workloads such as Machine Learning (MLlib), Streaming, interactive queries, graph programming and SQL. Execution Frameworks have language support for Python, R, Java, and Scala
13 Spark Unified Stack The Spark project contains multiple high-level specialized components (MLlib, Streaming, etc.). Spark s main programming abstraction are Resilient Distributed Datasets (RDDs), a data structure distributed across nodes that can be worked on in parallel. Spark s multiple components operate on RDDs, which allows for close interoperability and tight integration. Applications that use multiple processing models can be written without high maintenance and development costs
14 Spark Main Benefits Solve problems faster, and on a much larger scale -Ease of Use Rich, high level APIs -Speed Fast parallel execution -General Engine Combine processing models -Open Source Freely Available Makes developing General Purpose Distributed programs easier, less painful. Reduces the management burden of maintaining separate tools. Allows the close Interoperability of high-level components 14 14
, which are Spark s main programming abstraction.")
15 Spark Core Spark Core contains the basic functionality of Spark, including components for task scheduling, memory management, fault recovery, interacting with storage systems, and more. Spark Core is also home to the API that defines resilient distributed datasets (RDDs), which are Spark s main programming abstraction. RDDs represent a collection of items distributed across many compute nodes that can be manipulated in parallel
16 Spark Data Processing Spark provides a simple way to parallelize applications across clusters, and hides the complexity of distributed systems programming, network communication, and fault tolerance. The system gives control to monitor, inspect, and tune applications while allowing implementation of common tasks quickly. The modular nature of the API (based on passing distributed collections of objects) makes it easy to factor work into reusable libraries and test it locally
.")
. It s important to remember that Spark does not require Hadoop.")
17 Storage Layers for Spark Spark can create resilient distributed datasets, RDDs, from any file stored in the Hadoop distributed filesystem (HDFS). Spark also support other storage systems supported by the Hadoop APIs (including your local filesystem, Amazon S3, Cassandra, Hive, HBase, etc.). It s important to remember that Spark does not require Hadoop. It simply has support for storage systems implementing the Hadoop APIs
18 Spark REPL Spark can be used from Python, R, Java, or Scala. Spark itself is written in Scala, and runs on the Java Virtual Machine (JVM). To run Spark on either your laptop or a cluster, all you need is an installation of Java 6 or newer. If you wish to use the Python API you will also need a Python interpreter (version 2.6 or newer). You don t need to have Hadoop. Spark comes with interactive shells that enable ad hoc data analysis. Spark s shells will feel familiar if you have used other shells such as those in R, Python, and Scala, 18 18
19 pyspark Python version of the Spark Shell
20 pyspark In Spark, we express our computation through operations on distributed collections that are automatically parallelized across the cluster. These collections are called resilient distributed datasets, or RDDs. RDDs are Spark s fundamental abstraction for distributed data and computation
21 RDDs An RDD is simply a distributed collection of elements. In Spark all work is expressed as either creating new RDDs, transforming existing RDDs, or calling operations on RDDs to compute a result. Spark automatically distributes the data contained in RDDs across your cluster and parallelizes the operations you perform on them. An RDD in Spark is simply an immutable distributed collection of objects. Each RDD is split into multiple partitions, which may be computed on different nodes of the cluster. RDDs can contain any type of Python, Java, or Scala objects, including userdefined classes. Once created, RDDs offer two types of operations: transformations and actions
22 RDDs Transformations construct a new RDD from a previous one. Actions compute a result based on an RDD, and either return it to the driver program or save it to an external storage system. Although you can define new RDDs any time, Spark computes them only in a lazy fashion that is, the first time they are used in an action. Spark provides two ways to create RDDs -loading an external dataset. -Parallelizing a collection in your driver program

23 Spark Cluster Every Spark application consists of a driver program that launches various parallel operations on a cluster. The driver program contains your application s main function and defines distributed datasets on the cluster, then applies operations to them. The driver communicates with a potentially large number of distributed workers called executors. A driver and its executors are together termed a Spark application
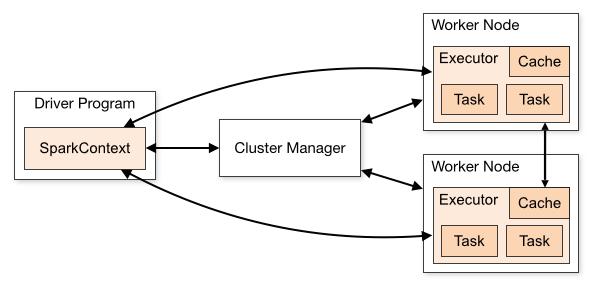
24
25 Solve problems faster, and on a Much Larger Scale 25 25

26 Data Warehousing with Redshift 26 26
27 Data Warehouse A system used for reporting and data analysis. Central repositories of integrated data from one or more disparate sources. A data warehouse can store current and historical data in a single place. Subject-oriented, integrated, time-variant and non-volatile collection of data in support of a decision making process. The data stored in the warehouse is uploaded from different operational systems systems used to pre-process the data in some way. Data sources can also come from clusters such as Spark and Hadoop

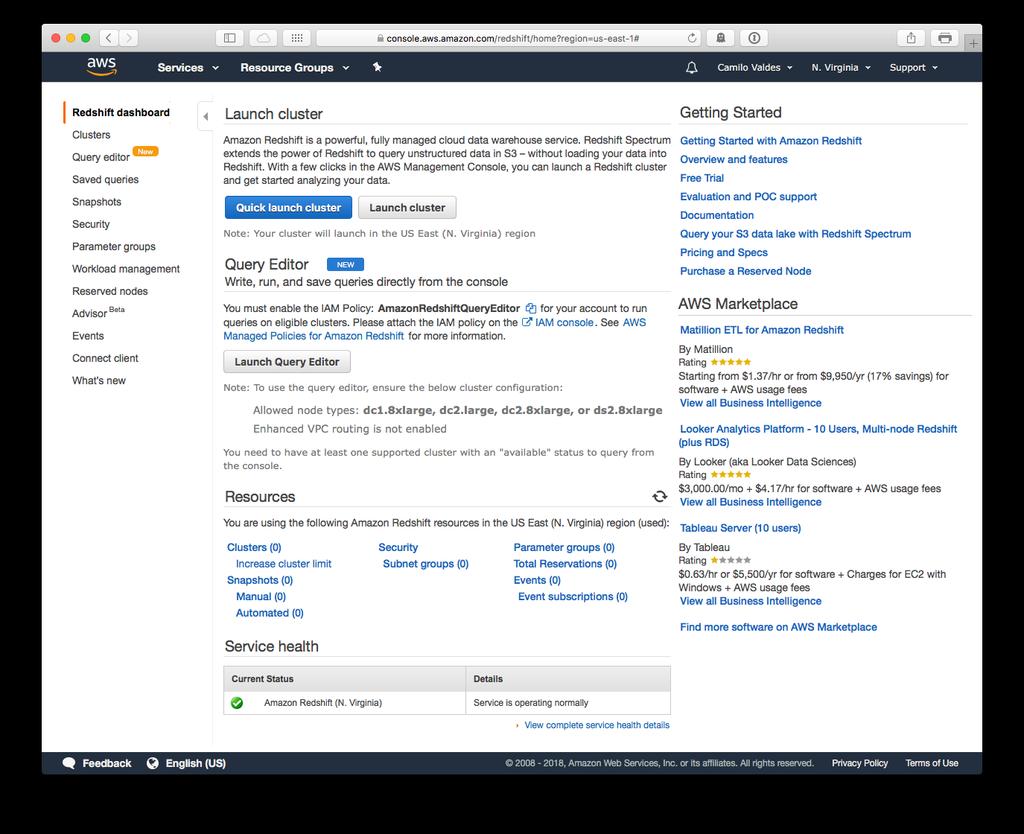
28 Redshift Amazon Redshift is a fully managed, petabyte-scale data warehouse service in the cloud. An Amazon Redshift data warehouse is a collection of computing resources called nodes, which are organized into a group called a cluster. Each cluster runs an Amazon Redshift engine and contains one or more databases. Redshift differs from Amazon's other hosted database offering, Amazon RDS, in its ability to handle analytics workloads on big data datasets. Redshift allows you to analyze data using Business Intelligence (BI) tools such as Spotfire and Tableau

29 Redshift Redshift is based on PostgreSQL. An Amazon Redshift data warehouse is an enterprise-class, relational database query and management system. Amazon Redshift is built around industry-standard SQL, with added functionality to manage very large datasets and support high-performance analysis and reporting of that data. Amazon Redshift achieves efficient storage and optimum query performance through a combination of massively parallel processing, columnar data storage, and very efficient, targeted data compression encoding schemes
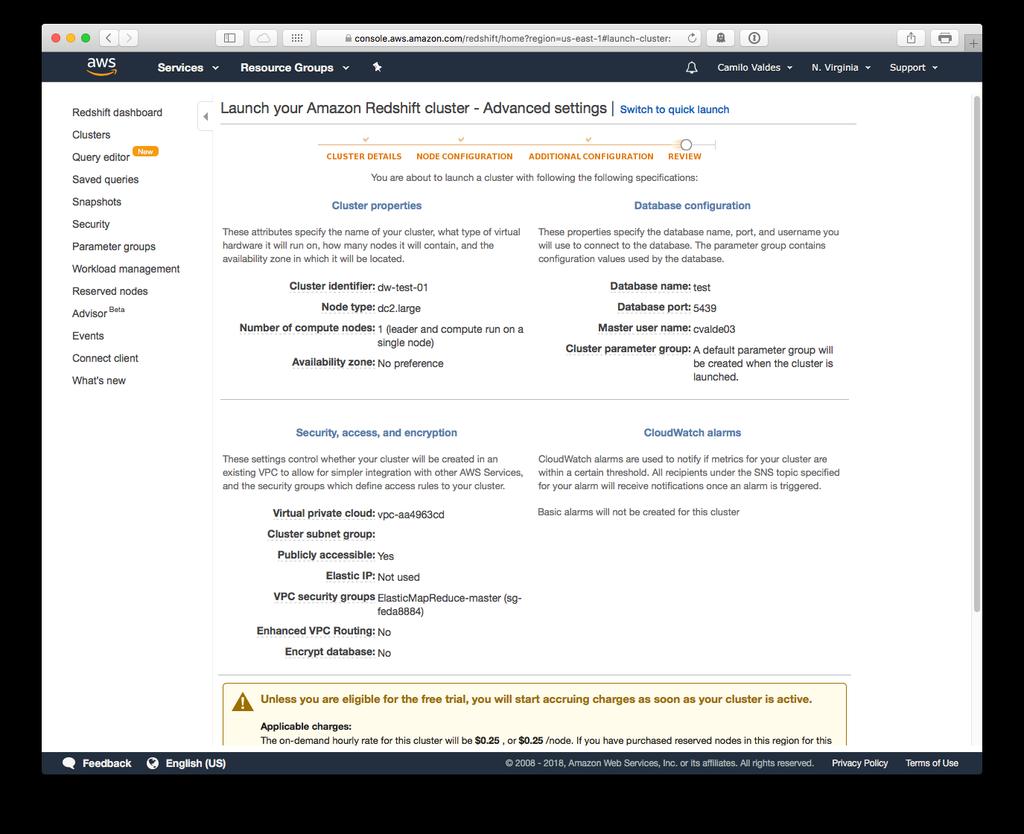
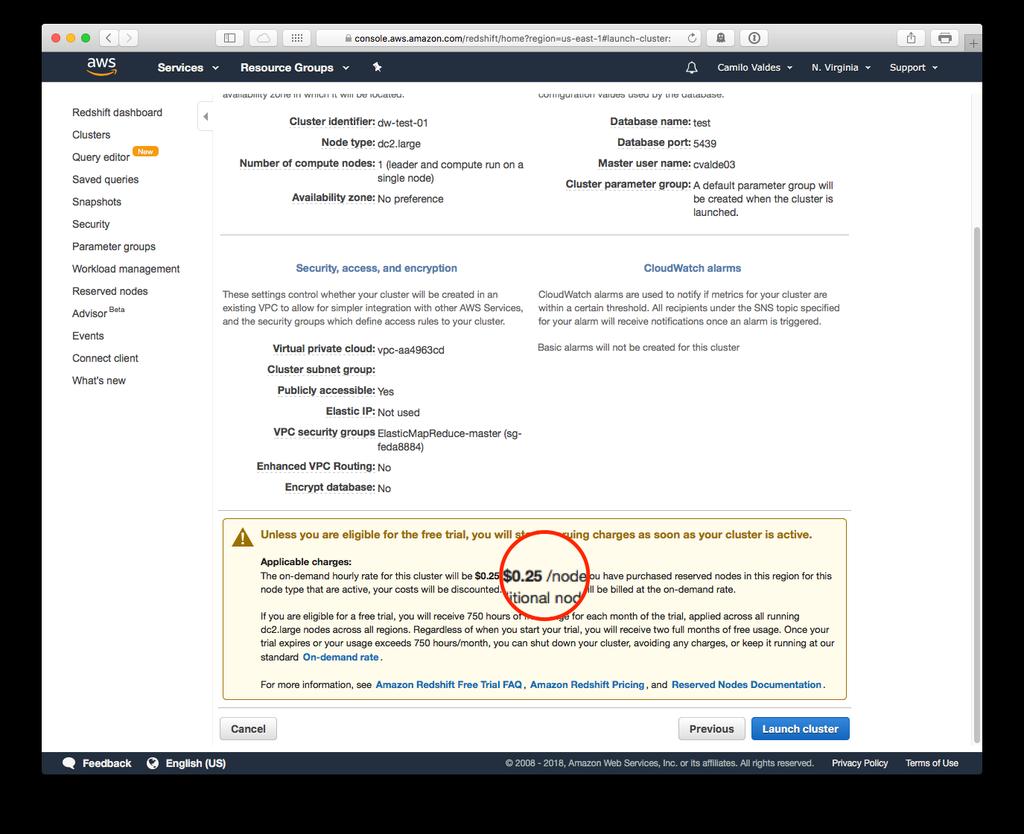
30 Redshift Redshift is based on industry-standard PostgreSQL, so most existing SQL client applications will work with only minimal changes. A cluster is composed of one or more compute nodes. If a cluster is provisioned with two or more compute nodes, an additional leader node coordinates the compute nodes and handles external communication. Your client application interacts directly only with the leader node. Compute nodes are transparent to external applications
31 31 31
32 Redshift Cluster Composed of three (3) main elements -Leader Node -Compute Node -Node Slices 32 32
33 Leader Node The leader node manages communications with client programs and all communication with compute nodes. It parses and develops execution plans to carry out database operations, in particular, the series of steps necessary to obtain results for complex queries. Based on the execution plan, the leader node compiles code, distributes the compiled code to the compute nodes, and assigns a portion of the data to each compute node. The leader node distributes SQL statements to the compute nodes only when a query references tables that are stored on the compute nodes. All other queries run exclusively on the leader node
34 Compute Nodes The leader node compiles code for individual elements of the execution plan and assigns the code to individual compute nodes. The compute nodes execute the compiled code and send intermediate results back to the leader node for final aggregation. Each compute node has its own dedicated CPU, memory, and attached disk storage, which are determined by the node type. As your workload grows, you can increase the compute capacity and storage capacity of a cluster by increasing the number of nodes, upgrading the node type, or both. You can start with a single 160 GB node and scale up to multiple 16 TB nodes to support a petabyte of data or more 34 34
35 Node Slices A compute node is partitioned into slices. Each slice is allocated a portion of the node's memory and disk space, where it processes a portion of the workload assigned to the node. The leader node manages distributing data to the slices and apportions the workload for any queries or other database operations to the slices. The slices then work in parallel to complete the operation. The number of slices per node is determined by the node size of the cluster
36 Redshift Databases User data is stored on the compute nodes. SQL clients communicate with the leader node, which in turn coordinates query execution with the compute nodes. Amazon Redshift is a relational database management system (RDBMS), so it is compatible with other RDBMS applications. Although it provides the same functionality as a typical RDBMS, Amazon Redshift is optimized for high-performance analysis and reporting of very large datasets. Amazon Redshift is based on PostgreSQL Redshift and PostgreSQL have a number of very important differences that you need to take into account as you design and develop your data warehouse applications
37 37 37
38 38 38
39 39 39
40 40 40
41 41 41
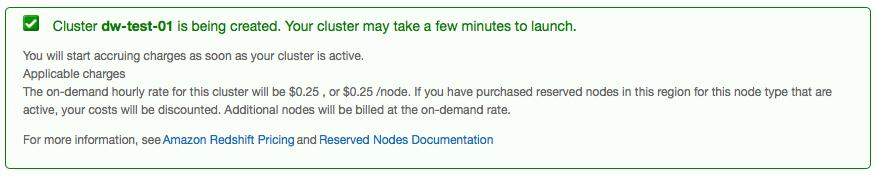
42 42 42
43 43 43
44 44 44
45 Persist large amounts of data

46 Visualization with Tableau 46 46
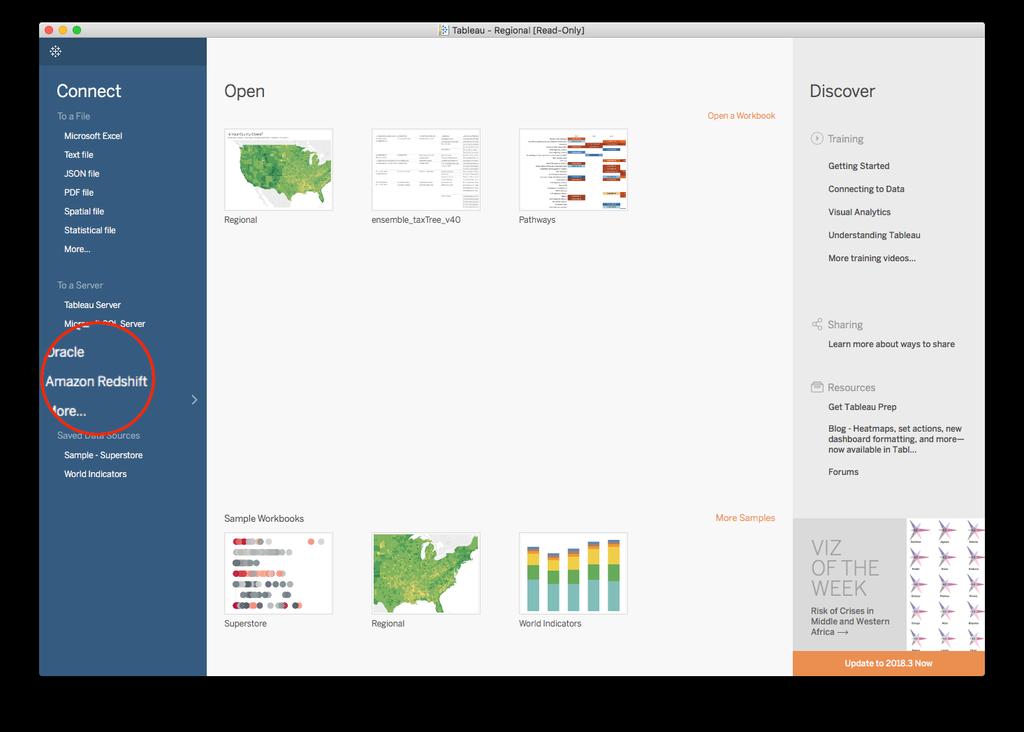
47 47 47
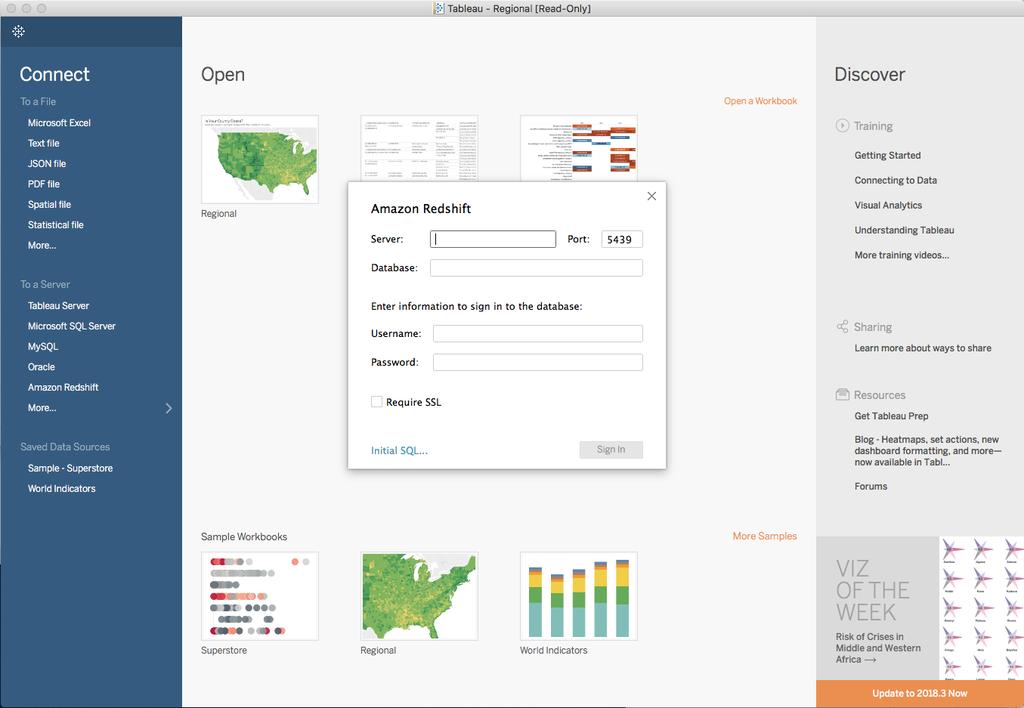
48 48 48

49 AWS Educate
50 50 50
DATA SCIENCE USING SPARK: AN INTRODUCTION
 DATA SCIENCE USING SPARK: AN INTRODUCTION TOPICS COVERED Introduction to Spark Getting Started with Spark Programming in Spark Data Science with Spark What next? 2 DATA SCIENCE PROCESS Exploratory Data
DATA SCIENCE USING SPARK: AN INTRODUCTION TOPICS COVERED Introduction to Spark Getting Started with Spark Programming in Spark Data Science with Spark What next? 2 DATA SCIENCE PROCESS Exploratory Data
Overview. Prerequisites. Course Outline. Course Outline :: Apache Spark Development::
 Title Duration : Apache Spark Development : 4 days Overview Spark is a fast and general cluster computing system for Big Data. It provides high-level APIs in Scala, Java, Python, and R, and an optimized
Title Duration : Apache Spark Development : 4 days Overview Spark is a fast and general cluster computing system for Big Data. It provides high-level APIs in Scala, Java, Python, and R, and an optimized
Cloud Computing 3. CSCI 4850/5850 High-Performance Computing Spring 2018
 Cloud Computing 3 CSCI 4850/5850 High-Performance Computing Spring 2018 Tae-Hyuk (Ted) Ahn Department of Computer Science Program of Bioinformatics and Computational Biology Saint Louis University Learning
Cloud Computing 3 CSCI 4850/5850 High-Performance Computing Spring 2018 Tae-Hyuk (Ted) Ahn Department of Computer Science Program of Bioinformatics and Computational Biology Saint Louis University Learning
Processing of big data with Apache Spark
 Processing of big data with Apache Spark JavaSkop 18 Aleksandar Donevski AGENDA What is Apache Spark? Spark vs Hadoop MapReduce Application Requirements Example Architecture Application Challenges 2 WHAT
Processing of big data with Apache Spark JavaSkop 18 Aleksandar Donevski AGENDA What is Apache Spark? Spark vs Hadoop MapReduce Application Requirements Example Architecture Application Challenges 2 WHAT
CSE 444: Database Internals. Lecture 23 Spark
 CSE 444: Database Internals Lecture 23 Spark References Spark is an open source system from Berkeley Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster Computing. Matei
CSE 444: Database Internals Lecture 23 Spark References Spark is an open source system from Berkeley Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster Computing. Matei
Apache Spark is a fast and general-purpose engine for large-scale data processing Spark aims at achieving the following goals in the Big data context
 1 Apache Spark is a fast and general-purpose engine for large-scale data processing Spark aims at achieving the following goals in the Big data context Generality: diverse workloads, operators, job sizes
1 Apache Spark is a fast and general-purpose engine for large-scale data processing Spark aims at achieving the following goals in the Big data context Generality: diverse workloads, operators, job sizes
A Tutorial on Apache Spark
 A Tutorial on Apache Spark A Practical Perspective By Harold Mitchell The Goal Learning Outcomes The Goal Learning Outcomes NOTE: The setup, installation, and examples assume Windows user Learn the following:
A Tutorial on Apache Spark A Practical Perspective By Harold Mitchell The Goal Learning Outcomes The Goal Learning Outcomes NOTE: The setup, installation, and examples assume Windows user Learn the following:
Lambda Architecture for Batch and Real- Time Processing on AWS with Spark Streaming and Spark SQL. May 2015
 Lambda Architecture for Batch and Real- Time Processing on AWS with Spark Streaming and Spark SQL May 2015 2015, Amazon Web Services, Inc. or its affiliates. All rights reserved. Notices This document
Lambda Architecture for Batch and Real- Time Processing on AWS with Spark Streaming and Spark SQL May 2015 2015, Amazon Web Services, Inc. or its affiliates. All rights reserved. Notices This document
Spark Overview. Professor Sasu Tarkoma.
 Spark Overview 2015 Professor Sasu Tarkoma www.cs.helsinki.fi Apache Spark Spark is a general-purpose computing framework for iterative tasks API is provided for Java, Scala and Python The model is based
Spark Overview 2015 Professor Sasu Tarkoma www.cs.helsinki.fi Apache Spark Spark is a general-purpose computing framework for iterative tasks API is provided for Java, Scala and Python The model is based
IBM Data Science Experience White paper. SparkR. Transforming R into a tool for big data analytics
 IBM Data Science Experience White paper R Transforming R into a tool for big data analytics 2 R Executive summary This white paper introduces R, a package for the R statistical programming language that
IBM Data Science Experience White paper R Transforming R into a tool for big data analytics 2 R Executive summary This white paper introduces R, a package for the R statistical programming language that
Cloud Computing 2. CSCI 4850/5850 High-Performance Computing Spring 2018
 Cloud Computing 2 CSCI 4850/5850 High-Performance Computing Spring 2018 Tae-Hyuk (Ted) Ahn Department of Computer Science Program of Bioinformatics and Computational Biology Saint Louis University Learning
Cloud Computing 2 CSCI 4850/5850 High-Performance Computing Spring 2018 Tae-Hyuk (Ted) Ahn Department of Computer Science Program of Bioinformatics and Computational Biology Saint Louis University Learning
Analytic Cloud with. Shelly Garion. IBM Research -- Haifa IBM Corporation
 Analytic Cloud with Shelly Garion IBM Research -- Haifa 2014 IBM Corporation Why Spark? Apache Spark is a fast and general open-source cluster computing engine for big data processing Speed: Spark is capable
Analytic Cloud with Shelly Garion IBM Research -- Haifa 2014 IBM Corporation Why Spark? Apache Spark is a fast and general open-source cluster computing engine for big data processing Speed: Spark is capable
COSC 6339 Big Data Analytics. Introduction to Spark. Edgar Gabriel Fall What is SPARK?
 COSC 6339 Big Data Analytics Introduction to Spark Edgar Gabriel Fall 2018 What is SPARK? In-Memory Cluster Computing for Big Data Applications Fixes the weaknesses of MapReduce Iterative applications
COSC 6339 Big Data Analytics Introduction to Spark Edgar Gabriel Fall 2018 What is SPARK? In-Memory Cluster Computing for Big Data Applications Fixes the weaknesses of MapReduce Iterative applications
Blended Learning Outline: Developer Training for Apache Spark and Hadoop (180404a)
") Blended Learning Outline: Developer Training for Apache Spark and Hadoop (180404a) Cloudera s Developer Training for Apache Spark and Hadoop delivers the key concepts and expertise need to develop high-performance
Blended Learning Outline: Developer Training for Apache Spark and Hadoop (180404a) Cloudera s Developer Training for Apache Spark and Hadoop delivers the key concepts and expertise need to develop high-performance
QLIK INTEGRATION WITH AMAZON REDSHIFT
 QLIK INTEGRATION WITH AMAZON REDSHIFT Qlik Partner Engineering Created August 2016, last updated March 2017 Contents Introduction... 2 About Amazon Web Services (AWS)... 2 About Amazon Redshift... 2 Qlik
QLIK INTEGRATION WITH AMAZON REDSHIFT Qlik Partner Engineering Created August 2016, last updated March 2017 Contents Introduction... 2 About Amazon Web Services (AWS)... 2 About Amazon Redshift... 2 Qlik
An Introduction to Apache Spark
 An Introduction to Apache Spark 1 History Developed in 2009 at UC Berkeley AMPLab. Open sourced in 2010. Spark becomes one of the largest big-data projects with more 400 contributors in 50+ organizations
An Introduction to Apache Spark 1 History Developed in 2009 at UC Berkeley AMPLab. Open sourced in 2010. Spark becomes one of the largest big-data projects with more 400 contributors in 50+ organizations
Big Data. Big Data Analyst. Big Data Engineer. Big Data Architect
 Big Data Big Data Analyst INTRODUCTION TO BIG DATA ANALYTICS ANALYTICS PROCESSING TECHNIQUES DATA TRANSFORMATION & BATCH PROCESSING REAL TIME (STREAM) DATA PROCESSING Big Data Engineer BIG DATA FOUNDATION
Big Data Big Data Analyst INTRODUCTION TO BIG DATA ANALYTICS ANALYTICS PROCESSING TECHNIQUES DATA TRANSFORMATION & BATCH PROCESSING REAL TIME (STREAM) DATA PROCESSING Big Data Engineer BIG DATA FOUNDATION
Hadoop 2.x Core: YARN, Tez, and Spark. Hortonworks Inc All Rights Reserved
 Hadoop 2.x Core: YARN, Tez, and Spark YARN Hadoop Machine Types top-of-rack switches core switch client machines have client-side software used to access a cluster to process data master nodes run Hadoop
Hadoop 2.x Core: YARN, Tez, and Spark YARN Hadoop Machine Types top-of-rack switches core switch client machines have client-side software used to access a cluster to process data master nodes run Hadoop
Cloud, Big Data & Linear Algebra
 Cloud, Big Data & Linear Algebra Shelly Garion IBM Research -- Haifa 2014 IBM Corporation What is Big Data? 2 Global Data Volume in Exabytes What is Big Data? 2005 2012 2017 3 Global Data Volume in Exabytes
Cloud, Big Data & Linear Algebra Shelly Garion IBM Research -- Haifa 2014 IBM Corporation What is Big Data? 2 Global Data Volume in Exabytes What is Big Data? 2005 2012 2017 3 Global Data Volume in Exabytes
Agenda. AWS Database Services Traditional vs AWS Data services model Amazon RDS Redshift DynamoDB ElastiCache
 Databases on AWS 2017 Amazon Web Services, Inc. and its affiliates. All rights served. May not be copied, modified, or distributed in whole or in part without the express consent of Amazon Web Services,
Databases on AWS 2017 Amazon Web Services, Inc. and its affiliates. All rights served. May not be copied, modified, or distributed in whole or in part without the express consent of Amazon Web Services,
Hadoop Development Introduction
 Hadoop Development Introduction What is Bigdata? Evolution of Bigdata Types of Data and their Significance Need for Bigdata Analytics Why Bigdata with Hadoop? History of Hadoop Why Hadoop is in demand
Hadoop Development Introduction What is Bigdata? Evolution of Bigdata Types of Data and their Significance Need for Bigdata Analytics Why Bigdata with Hadoop? History of Hadoop Why Hadoop is in demand
MapReduce, Hadoop and Spark. Bompotas Agorakis
 MapReduce, Hadoop and Spark Bompotas Agorakis Big Data Processing Most of the computations are conceptually straightforward on a single machine but the volume of data is HUGE Need to use many (1.000s)
MapReduce, Hadoop and Spark Bompotas Agorakis Big Data Processing Most of the computations are conceptually straightforward on a single machine but the volume of data is HUGE Need to use many (1.000s)
2/26/2017. Originally developed at the University of California - Berkeley's AMPLab
 Apache is a fast and general engine for large-scale data processing aims at achieving the following goals in the Big data context Generality: diverse workloads, operators, job sizes Low latency: sub-second
Apache is a fast and general engine for large-scale data processing aims at achieving the following goals in the Big data context Generality: diverse workloads, operators, job sizes Low latency: sub-second
Big Data Infrastructures & Technologies
 Big Data Infrastructures & Technologies Spark and MLLIB OVERVIEW OF SPARK What is Spark? Fast and expressive cluster computing system interoperable with Apache Hadoop Improves efficiency through: In-memory
Big Data Infrastructures & Technologies Spark and MLLIB OVERVIEW OF SPARK What is Spark? Fast and expressive cluster computing system interoperable with Apache Hadoop Improves efficiency through: In-memory
Intro to Big Data on AWS Igor Roiter Big Data Cloud Solution Architect
 Intro to Big Data on AWS Igor Roiter Big Data Cloud Solution Architect Igor Roiter Big Data Cloud Solution Architect Working as a Data Specialist for the last 11 years 9 of them as a Consultant specializing
Intro to Big Data on AWS Igor Roiter Big Data Cloud Solution Architect Igor Roiter Big Data Cloud Solution Architect Working as a Data Specialist for the last 11 years 9 of them as a Consultant specializing
Big data systems 12/8/17
 Big data systems 12/8/17 Today Basic architecture Two levels of scheduling Spark overview Basic architecture Cluster Manager Cluster Cluster Manager 64GB RAM 32 cores 64GB RAM 32 cores 64GB RAM 32 cores
Big data systems 12/8/17 Today Basic architecture Two levels of scheduling Spark overview Basic architecture Cluster Manager Cluster Cluster Manager 64GB RAM 32 cores 64GB RAM 32 cores 64GB RAM 32 cores
Topics. Big Data Analytics What is and Why Hadoop? Comparison to other technologies Hadoop architecture Hadoop ecosystem Hadoop usage examples
 Hadoop Introduction 1 Topics Big Data Analytics What is and Why Hadoop? Comparison to other technologies Hadoop architecture Hadoop ecosystem Hadoop usage examples 2 Big Data Analytics What is Big Data?
Hadoop Introduction 1 Topics Big Data Analytics What is and Why Hadoop? Comparison to other technologies Hadoop architecture Hadoop ecosystem Hadoop usage examples 2 Big Data Analytics What is Big Data?
Spark, Shark and Spark Streaming Introduction
 Spark, Shark and Spark Streaming Introduction Tushar Kale tusharkale@in.ibm.com June 2015 This Talk Introduction to Shark, Spark and Spark Streaming Architecture Deployment Methodology Performance References
Spark, Shark and Spark Streaming Introduction Tushar Kale tusharkale@in.ibm.com June 2015 This Talk Introduction to Shark, Spark and Spark Streaming Architecture Deployment Methodology Performance References
Scalable Tools - Part I Introduction to Scalable Tools
 Scalable Tools - Part I Introduction to Scalable Tools Adisak Sukul, Ph.D., Lecturer, Department of Computer Science, adisak@iastate.edu http://web.cs.iastate.edu/~adisak/mbds2018/ Scalable Tools session
Scalable Tools - Part I Introduction to Scalable Tools Adisak Sukul, Ph.D., Lecturer, Department of Computer Science, adisak@iastate.edu http://web.cs.iastate.edu/~adisak/mbds2018/ Scalable Tools session
Accelerating Spark Workloads using GPUs
 Accelerating Spark Workloads using GPUs Rajesh Bordawekar, Minsik Cho, Wei Tan, Benjamin Herta, Vladimir Zolotov, Alexei Lvov, Liana Fong, and David Kung IBM T. J. Watson Research Center 1 Outline Spark
Accelerating Spark Workloads using GPUs Rajesh Bordawekar, Minsik Cho, Wei Tan, Benjamin Herta, Vladimir Zolotov, Alexei Lvov, Liana Fong, and David Kung IBM T. J. Watson Research Center 1 Outline Spark
Principal Software Engineer Red Hat Emerging Technology June 24, 2015
 USING APACHE SPARK FOR ANALYTICS IN THE CLOUD William C. Benton Principal Software Engineer Red Hat Emerging Technology June 24, 2015 ABOUT ME Distributed systems and data science in Red Hat's Emerging
USING APACHE SPARK FOR ANALYTICS IN THE CLOUD William C. Benton Principal Software Engineer Red Hat Emerging Technology June 24, 2015 ABOUT ME Distributed systems and data science in Red Hat's Emerging
Hadoop. Introduction / Overview
 Hadoop Introduction / Overview Preface We will use these PowerPoint slides to guide us through our topic. Expect 15 minute segments of lecture Expect 1-4 hour lab segments Expect minimal pretty pictures
Hadoop Introduction / Overview Preface We will use these PowerPoint slides to guide us through our topic. Expect 15 minute segments of lecture Expect 1-4 hour lab segments Expect minimal pretty pictures
Big Data Analytics using Apache Hadoop and Spark with Scala
 Big Data Analytics using Apache Hadoop and Spark with Scala Training Highlights : 80% of the training is with Practical Demo (On Custom Cloudera and Ubuntu Machines) 20% Theory Portion will be important
Big Data Analytics using Apache Hadoop and Spark with Scala Training Highlights : 80% of the training is with Practical Demo (On Custom Cloudera and Ubuntu Machines) 20% Theory Portion will be important
Asanka Padmakumara. ETL 2.0: Data Engineering with Azure Databricks
 Asanka Padmakumara ETL 2.0: Data Engineering with Azure Databricks Who am I? Asanka Padmakumara Business Intelligence Consultant, More than 8 years in BI and Data Warehousing A regular speaker in data
Asanka Padmakumara ETL 2.0: Data Engineering with Azure Databricks Who am I? Asanka Padmakumara Business Intelligence Consultant, More than 8 years in BI and Data Warehousing A regular speaker in data
Agenda. Spark Platform Spark Core Spark Extensions Using Apache Spark
 Agenda Spark Platform Spark Core Spark Extensions Using Apache Spark About me Vitalii Bondarenko Data Platform Competency Manager Eleks www.eleks.com 20 years in software development 9+ years of developing
Agenda Spark Platform Spark Core Spark Extensions Using Apache Spark About me Vitalii Bondarenko Data Platform Competency Manager Eleks www.eleks.com 20 years in software development 9+ years of developing
Big Data Hadoop Developer Course Content. Big Data Hadoop Developer - The Complete Course Course Duration: 45 Hours
 Big Data Hadoop Developer Course Content Who is the target audience? Big Data Hadoop Developer - The Complete Course Course Duration: 45 Hours Complete beginners who want to learn Big Data Hadoop Professionals
Big Data Hadoop Developer Course Content Who is the target audience? Big Data Hadoop Developer - The Complete Course Course Duration: 45 Hours Complete beginners who want to learn Big Data Hadoop Professionals
Best Practices and Performance Tuning on Amazon Elastic MapReduce
 Best Practices and Performance Tuning on Amazon Elastic MapReduce Michael Hanisch Solutions Architect Amo Abeyaratne Big Data and Analytics Consultant ANZ 12.04.2016 2016, Amazon Web Services, Inc. or
Best Practices and Performance Tuning on Amazon Elastic MapReduce Michael Hanisch Solutions Architect Amo Abeyaratne Big Data and Analytics Consultant ANZ 12.04.2016 2016, Amazon Web Services, Inc. or
Introduction to Database Services
 Introduction to Database Services Shaun Pearce AWS Solutions Architect 2015, Amazon Web Services, Inc. or its affiliates. All rights reserved Today s agenda Why managed database services? A non-relational
Introduction to Database Services Shaun Pearce AWS Solutions Architect 2015, Amazon Web Services, Inc. or its affiliates. All rights reserved Today s agenda Why managed database services? A non-relational
Pervasive DataRush TM
 Pervasive DataRush TM Parallel Data Analysis with KNIME www.pervasivedatarush.com Company Overview Global Software Company Tens of thousands of users across the globe Americas, EMEA, Asia ~230 employees
Pervasive DataRush TM Parallel Data Analysis with KNIME www.pervasivedatarush.com Company Overview Global Software Company Tens of thousands of users across the globe Americas, EMEA, Asia ~230 employees
CSC 261/461 Database Systems Lecture 24. Spring 2017 MW 3:25 pm 4:40 pm January 18 May 3 Dewey 1101
 CSC 261/461 Database Systems Lecture 24 Spring 2017 MW 3:25 pm 4:40 pm January 18 May 3 Dewey 1101 Announcements Term Paper due on April 20 April 23 Project 1 Milestone 4 is out Due on 05/03 But I would
CSC 261/461 Database Systems Lecture 24 Spring 2017 MW 3:25 pm 4:40 pm January 18 May 3 Dewey 1101 Announcements Term Paper due on April 20 April 23 Project 1 Milestone 4 is out Due on 05/03 But I would
Distributed Systems. 22. Spark. Paul Krzyzanowski. Rutgers University. Fall 2016
 Distributed Systems 22. Spark Paul Krzyzanowski Rutgers University Fall 2016 November 26, 2016 2015-2016 Paul Krzyzanowski 1 Apache Spark Goal: generalize MapReduce Similar shard-and-gather approach to
Distributed Systems 22. Spark Paul Krzyzanowski Rutgers University Fall 2016 November 26, 2016 2015-2016 Paul Krzyzanowski 1 Apache Spark Goal: generalize MapReduce Similar shard-and-gather approach to
Big Data Architect.
 Big Data Architect www.austech.edu.au WHAT IS BIG DATA ARCHITECT? A big data architecture is designed to handle the ingestion, processing, and analysis of data that is too large or complex for traditional
Big Data Architect www.austech.edu.au WHAT IS BIG DATA ARCHITECT? A big data architecture is designed to handle the ingestion, processing, and analysis of data that is too large or complex for traditional
Cloud Analytics and Business Intelligence on AWS
 Cloud Analytics and Business Intelligence on AWS Enterprise Applications Virtual Desktops Sharing & Collaboration Platform Services Analytics Hadoop Real-time Streaming Data Machine Learning Data Warehouse
Cloud Analytics and Business Intelligence on AWS Enterprise Applications Virtual Desktops Sharing & Collaboration Platform Services Analytics Hadoop Real-time Streaming Data Machine Learning Data Warehouse
Things Every Oracle DBA Needs to Know about the Hadoop Ecosystem. Zohar Elkayam
 Things Every Oracle DBA Needs to Know about the Hadoop Ecosystem Zohar Elkayam www.realdbamagic.com Twitter: @realmgic Who am I? Zohar Elkayam, CTO at Brillix Programmer, DBA, team leader, database trainer,
Things Every Oracle DBA Needs to Know about the Hadoop Ecosystem Zohar Elkayam www.realdbamagic.com Twitter: @realmgic Who am I? Zohar Elkayam, CTO at Brillix Programmer, DBA, team leader, database trainer,
Accelerate Big Data Insights
 Accelerate Big Data Insights Executive Summary An abundance of information isn t always helpful when time is of the essence. In the world of big data, the ability to accelerate time-to-insight can not
Accelerate Big Data Insights Executive Summary An abundance of information isn t always helpful when time is of the essence. In the world of big data, the ability to accelerate time-to-insight can not
Outline. CS-562 Introduction to data analysis using Apache Spark
 Outline Data flow vs. traditional network programming What is Apache Spark? Core things of Apache Spark RDD CS-562 Introduction to data analysis using Apache Spark Instructor: Vassilis Christophides T.A.:
Outline Data flow vs. traditional network programming What is Apache Spark? Core things of Apache Spark RDD CS-562 Introduction to data analysis using Apache Spark Instructor: Vassilis Christophides T.A.:
Part 1: Indexes for Big Data
 JethroData Making Interactive BI for Big Data a Reality Technical White Paper This white paper explains how JethroData can help you achieve a truly interactive interactive response time for BI on big data,
JethroData Making Interactive BI for Big Data a Reality Technical White Paper This white paper explains how JethroData can help you achieve a truly interactive interactive response time for BI on big data,
Khadija Souissi. Auf z Systems November IBM z Systems Mainframe Event 2016
 Khadija Souissi Auf z Systems 07. 08. November 2016 @ IBM z Systems Mainframe Event 2016 Acknowledgements Apache Spark, Spark, Apache, and the Spark logo are trademarks of The Apache Software Foundation.
Khadija Souissi Auf z Systems 07. 08. November 2016 @ IBM z Systems Mainframe Event 2016 Acknowledgements Apache Spark, Spark, Apache, and the Spark logo are trademarks of The Apache Software Foundation.
Delving Deep into Hadoop Course Contents Introduction to Hadoop and Architecture
 Delving Deep into Hadoop Course Contents Introduction to Hadoop and Architecture Hadoop 1.0 Architecture Introduction to Hadoop & Big Data Hadoop Evolution Hadoop Architecture Networking Concepts Use cases
Delving Deep into Hadoop Course Contents Introduction to Hadoop and Architecture Hadoop 1.0 Architecture Introduction to Hadoop & Big Data Hadoop Evolution Hadoop Architecture Networking Concepts Use cases
Oracle Big Data Fundamentals Ed 2
 Oracle University Contact Us: 1.800.529.0165 Oracle Big Data Fundamentals Ed 2 Duration: 5 Days What you will learn In the Oracle Big Data Fundamentals course, you learn about big data, the technologies
Oracle University Contact Us: 1.800.529.0165 Oracle Big Data Fundamentals Ed 2 Duration: 5 Days What you will learn In the Oracle Big Data Fundamentals course, you learn about big data, the technologies
Certified Big Data Hadoop and Spark Scala Course Curriculum
 Certified Big Data Hadoop and Spark Scala Course Curriculum The Certified Big Data Hadoop and Spark Scala course by DataFlair is a perfect blend of indepth theoretical knowledge and strong practical skills
Certified Big Data Hadoop and Spark Scala Course Curriculum The Certified Big Data Hadoop and Spark Scala course by DataFlair is a perfect blend of indepth theoretical knowledge and strong practical skills
microsoft
 70-775.microsoft Number: 70-775 Passing Score: 800 Time Limit: 120 min Exam A QUESTION 1 Note: This question is part of a series of questions that present the same scenario. Each question in the series
70-775.microsoft Number: 70-775 Passing Score: 800 Time Limit: 120 min Exam A QUESTION 1 Note: This question is part of a series of questions that present the same scenario. Each question in the series
Shark: SQL and Rich Analytics at Scale. Michael Xueyuan Han Ronny Hajoon Ko
 Shark: SQL and Rich Analytics at Scale Michael Xueyuan Han Ronny Hajoon Ko What Are The Problems? Data volumes are expanding dramatically Why Is It Hard? Needs to scale out Managing hundreds of machines
Shark: SQL and Rich Analytics at Scale Michael Xueyuan Han Ronny Hajoon Ko What Are The Problems? Data volumes are expanding dramatically Why Is It Hard? Needs to scale out Managing hundreds of machines
Apache Spark and Scala Certification Training
 About Intellipaat Intellipaat is a fast-growing professional training provider that is offering training in over 150 most sought-after tools and technologies. We have a learner base of 600,000 in over
About Intellipaat Intellipaat is a fast-growing professional training provider that is offering training in over 150 most sought-after tools and technologies. We have a learner base of 600,000 in over
Lecture 11 Hadoop & Spark
 Lecture 11 Hadoop & Spark Dr. Wilson Rivera ICOM 6025: High Performance Computing Electrical and Computer Engineering Department University of Puerto Rico Outline Distributed File Systems Hadoop Ecosystem
Lecture 11 Hadoop & Spark Dr. Wilson Rivera ICOM 6025: High Performance Computing Electrical and Computer Engineering Department University of Puerto Rico Outline Distributed File Systems Hadoop Ecosystem
Oracle Big Data Connectors
 Oracle Big Data Connectors Oracle Big Data Connectors is a software suite that integrates processing in Apache Hadoop distributions with operations in Oracle Database. It enables the use of Hadoop to process
Oracle Big Data Connectors Oracle Big Data Connectors is a software suite that integrates processing in Apache Hadoop distributions with operations in Oracle Database. It enables the use of Hadoop to process
Flash Storage Complementing a Data Lake for Real-Time Insight
 Flash Storage Complementing a Data Lake for Real-Time Insight Dr. Sanhita Sarkar Global Director, Analytics Software Development August 7, 2018 Agenda 1 2 3 4 5 Delivering insight along the entire spectrum
Flash Storage Complementing a Data Lake for Real-Time Insight Dr. Sanhita Sarkar Global Director, Analytics Software Development August 7, 2018 Agenda 1 2 3 4 5 Delivering insight along the entire spectrum
DURATION : 03 DAYS. same along with BI tools.
 AWS REDSHIFT TRAINING MILDAIN DURATION : 03 DAYS To benefit from this Amazon Redshift Training course from mildain, you will need to have basic IT application development and deployment concepts, and good
AWS REDSHIFT TRAINING MILDAIN DURATION : 03 DAYS To benefit from this Amazon Redshift Training course from mildain, you will need to have basic IT application development and deployment concepts, and good
WHITEPAPER. MemSQL Enterprise Feature List
 WHITEPAPER MemSQL Enterprise Feature List 2017 MemSQL Enterprise Feature List DEPLOYMENT Provision and deploy MemSQL anywhere according to your desired cluster configuration. On-Premises: Maximize infrastructure
WHITEPAPER MemSQL Enterprise Feature List 2017 MemSQL Enterprise Feature List DEPLOYMENT Provision and deploy MemSQL anywhere according to your desired cluster configuration. On-Premises: Maximize infrastructure
An exceedingly high-level overview of ambient noise processing with Spark and Hadoop
 IRIS: USArray Short Course in Bloomington, Indian Special focus: Oklahoma Wavefields An exceedingly high-level overview of ambient noise processing with Spark and Hadoop Presented by Rob Mellors but based
IRIS: USArray Short Course in Bloomington, Indian Special focus: Oklahoma Wavefields An exceedingly high-level overview of ambient noise processing with Spark and Hadoop Presented by Rob Mellors but based
Microsoft Big Data and Hadoop
 Microsoft Big Data and Hadoop Lara Rubbelke @sqlgal Cindy Gross @sqlcindy 2 The world of data is changing The 4Vs of Big Data http://nosql.mypopescu.com/post/9621746531/a-definition-of-big-data 3 Common
Microsoft Big Data and Hadoop Lara Rubbelke @sqlgal Cindy Gross @sqlcindy 2 The world of data is changing The 4Vs of Big Data http://nosql.mypopescu.com/post/9621746531/a-definition-of-big-data 3 Common
BIG DATA COURSE CONTENT
 BIG DATA COURSE CONTENT [I] Get Started with Big Data Microsoft Professional Orientation: Big Data Duration: 12 hrs Course Content: Introduction Course Introduction Data Fundamentals Introduction to Data
BIG DATA COURSE CONTENT [I] Get Started with Big Data Microsoft Professional Orientation: Big Data Duration: 12 hrs Course Content: Introduction Course Introduction Data Fundamentals Introduction to Data
In-memory data pipeline and warehouse at scale using Spark, Spark SQL, Tachyon and Parquet
 In-memory data pipeline and warehouse at scale using Spark, Spark SQL, Tachyon and Parquet Ema Iancuta iorhian@gmail.com Radu Chilom radu.chilom@gmail.com Big data analytics / machine learning 6+ years
In-memory data pipeline and warehouse at scale using Spark, Spark SQL, Tachyon and Parquet Ema Iancuta iorhian@gmail.com Radu Chilom radu.chilom@gmail.com Big data analytics / machine learning 6+ years
MODERN BIG DATA DESIGN PATTERNS CASE DRIVEN DESINGS
 MODERN BIG DATA DESIGN PATTERNS CASE DRIVEN DESINGS SUJEE MANIYAM FOUNDER / PRINCIPAL @ ELEPHANT SCALE www.elephantscale.com sujee@elephantscale.com HI, I M SUJEE MANIYAM Founder / Principal @ ElephantScale
MODERN BIG DATA DESIGN PATTERNS CASE DRIVEN DESINGS SUJEE MANIYAM FOUNDER / PRINCIPAL @ ELEPHANT SCALE www.elephantscale.com sujee@elephantscale.com HI, I M SUJEE MANIYAM Founder / Principal @ ElephantScale
The Hadoop Ecosystem. EECS 4415 Big Data Systems. Tilemachos Pechlivanoglou
 The Hadoop Ecosystem EECS 4415 Big Data Systems Tilemachos Pechlivanoglou tipech@eecs.yorku.ca A lot of tools designed to work with Hadoop 2 HDFS, MapReduce Hadoop Distributed File System Core Hadoop component
The Hadoop Ecosystem EECS 4415 Big Data Systems Tilemachos Pechlivanoglou tipech@eecs.yorku.ca A lot of tools designed to work with Hadoop 2 HDFS, MapReduce Hadoop Distributed File System Core Hadoop component
CloudExpo November 2017 Tomer Levi
 CloudExpo November 2017 Tomer Levi About me Full Stack Engineer @ Intel s Advanced Analytics group. Artificial Intelligence unit at Intel. Responsible for (1) Radical improvement of critical processes
CloudExpo November 2017 Tomer Levi About me Full Stack Engineer @ Intel s Advanced Analytics group. Artificial Intelligence unit at Intel. Responsible for (1) Radical improvement of critical processes
We are ready to serve Latest Testing Trends, Are you ready to learn?? New Batches Info
 We are ready to serve Latest Testing Trends, Are you ready to learn?? New Batches Info START DATE : TIMINGS : DURATION : TYPE OF BATCH : FEE : FACULTY NAME : LAB TIMINGS : PH NO: 9963799240, 040-40025423
We are ready to serve Latest Testing Trends, Are you ready to learn?? New Batches Info START DATE : TIMINGS : DURATION : TYPE OF BATCH : FEE : FACULTY NAME : LAB TIMINGS : PH NO: 9963799240, 040-40025423
An Introduction to Apache Spark
 An Introduction to Apache Spark Anastasios Skarlatidis @anskarl Software Engineer/Researcher IIT, NCSR "Demokritos" Outline Part I: Getting to know Spark Part II: Basic programming Part III: Spark under
An Introduction to Apache Spark Anastasios Skarlatidis @anskarl Software Engineer/Researcher IIT, NCSR "Demokritos" Outline Part I: Getting to know Spark Part II: Basic programming Part III: Spark under
Microsoft Azure Databricks for data engineering. Building production data pipelines with Apache Spark in the cloud
 Microsoft Azure Databricks for data engineering Building production data pipelines with Apache Spark in the cloud Azure Databricks As companies continue to set their sights on making data-driven decisions
Microsoft Azure Databricks for data engineering Building production data pipelines with Apache Spark in the cloud Azure Databricks As companies continue to set their sights on making data-driven decisions
Chapter 4: Apache Spark
 Chapter 4: Apache Spark Lecture Notes Winter semester 2016 / 2017 Ludwig-Maximilians-University Munich PD Dr. Matthias Renz 2015, Based on lectures by Donald Kossmann (ETH Zürich), as well as Jure Leskovec,
Chapter 4: Apache Spark Lecture Notes Winter semester 2016 / 2017 Ludwig-Maximilians-University Munich PD Dr. Matthias Renz 2015, Based on lectures by Donald Kossmann (ETH Zürich), as well as Jure Leskovec,
Configuring and Deploying Hadoop Cluster Deployment Templates
 Configuring and Deploying Hadoop Cluster Deployment Templates This chapter contains the following sections: Hadoop Cluster Profile Templates, on page 1 Creating a Hadoop Cluster Profile Template, on page
Configuring and Deploying Hadoop Cluster Deployment Templates This chapter contains the following sections: Hadoop Cluster Profile Templates, on page 1 Creating a Hadoop Cluster Profile Template, on page
Overview of Data Services and Streaming Data Solution with Azure
 Overview of Data Services and Streaming Data Solution with Azure Tara Mason Senior Consultant tmason@impactmakers.com Platform as a Service Offerings SQL Server On Premises vs. Azure SQL Server SQL Server
Overview of Data Services and Streaming Data Solution with Azure Tara Mason Senior Consultant tmason@impactmakers.com Platform as a Service Offerings SQL Server On Premises vs. Azure SQL Server SQL Server
Big Data Hadoop Course Content
 Big Data Hadoop Course Content Topics covered in the training Introduction to Linux and Big Data Virtual Machine ( VM) Introduction/ Installation of VirtualBox and the Big Data VM Introduction to Linux
Big Data Hadoop Course Content Topics covered in the training Introduction to Linux and Big Data Virtual Machine ( VM) Introduction/ Installation of VirtualBox and the Big Data VM Introduction to Linux
An Introduction to Apache Spark Big Data Madison: 29 July William Red Hat, Inc.
 An Introduction to Apache Spark Big Data Madison: 29 July 2014 William Benton @willb Red Hat, Inc. About me At Red Hat for almost 6 years, working on distributed computing Currently contributing to Spark,
An Introduction to Apache Spark Big Data Madison: 29 July 2014 William Benton @willb Red Hat, Inc. About me At Red Hat for almost 6 years, working on distributed computing Currently contributing to Spark,
Analytics in Spark. Yanlei Diao Tim Hunter. Slides Courtesy of Ion Stoica, Matei Zaharia and Brooke Wenig
 Analytics in Spark Yanlei Diao Tim Hunter Slides Courtesy of Ion Stoica, Matei Zaharia and Brooke Wenig Outline 1. A brief history of Big Data and Spark 2. Technical summary of Spark 3. Unified analytics
Analytics in Spark Yanlei Diao Tim Hunter Slides Courtesy of Ion Stoica, Matei Zaharia and Brooke Wenig Outline 1. A brief history of Big Data and Spark 2. Technical summary of Spark 3. Unified analytics
 About Codefrux While the current trends around the world are based on the internet, mobile and its applications, we try to make the most out of it. As for us, we are a well established IT professionals
About Codefrux While the current trends around the world are based on the internet, mobile and its applications, we try to make the most out of it. As for us, we are a well established IT professionals
Department of Digital Systems. Digital Communications and Networks. Master Thesis
 Department of Digital Systems Digital Communications and Networks Master Thesis Study of technologies/research systems for big scientific data analytics Surname/Name: Petsas Konstantinos Registration Number:
Department of Digital Systems Digital Communications and Networks Master Thesis Study of technologies/research systems for big scientific data analytics Surname/Name: Petsas Konstantinos Registration Number:
Oracle GoldenGate for Big Data
 Oracle GoldenGate for Big Data The Oracle GoldenGate for Big Data 12c product streams transactional data into big data systems in real time, without impacting the performance of source systems. It streamlines
Oracle GoldenGate for Big Data The Oracle GoldenGate for Big Data 12c product streams transactional data into big data systems in real time, without impacting the performance of source systems. It streamlines
08/04/2018. RDDs. RDDs are the primary abstraction in Spark RDDs are distributed collections of objects spread across the nodes of a clusters
 are the primary abstraction in Spark are distributed collections of objects spread across the nodes of a clusters They are split in partitions Each node of the cluster that is running an application contains
are the primary abstraction in Spark are distributed collections of objects spread across the nodes of a clusters They are split in partitions Each node of the cluster that is running an application contains
Gabriel Villa. Architecting an Analytics Solution on AWS
 Gabriel Villa Architecting an Analytics Solution on AWS Cloud and Data Architect Skilled leader, solution architect, and technical expert focusing primarily on Microsoft technologies and AWS. Passionate
Gabriel Villa Architecting an Analytics Solution on AWS Cloud and Data Architect Skilled leader, solution architect, and technical expert focusing primarily on Microsoft technologies and AWS. Passionate
Introduction to Big-Data
 Introduction to Big-Data Ms.N.D.Sonwane 1, Mr.S.P.Taley 2 1 Assistant Professor, Computer Science & Engineering, DBACER, Maharashtra, India 2 Assistant Professor, Information Technology, DBACER, Maharashtra,
Introduction to Big-Data Ms.N.D.Sonwane 1, Mr.S.P.Taley 2 1 Assistant Professor, Computer Science & Engineering, DBACER, Maharashtra, India 2 Assistant Professor, Information Technology, DBACER, Maharashtra,
Massive Online Analysis - Storm,Spark
 Massive Online Analysis - Storm,Spark presentation by R. Kishore Kumar Research Scholar Department of Computer Science & Engineering Indian Institute of Technology, Kharagpur Kharagpur-721302, India (R
Massive Online Analysis - Storm,Spark presentation by R. Kishore Kumar Research Scholar Department of Computer Science & Engineering Indian Institute of Technology, Kharagpur Kharagpur-721302, India (R
Unifying Big Data Workloads in Apache Spark
 Unifying Big Data Workloads in Apache Spark Hossein Falaki @mhfalaki Outline What s Apache Spark Why Unification Evolution of Unification Apache Spark + Databricks Q & A What s Apache Spark What is Apache
Unifying Big Data Workloads in Apache Spark Hossein Falaki @mhfalaki Outline What s Apache Spark Why Unification Evolution of Unification Apache Spark + Databricks Q & A What s Apache Spark What is Apache
Index. Raul Estrada and Isaac Ruiz 2016 R. Estrada and I. Ruiz, Big Data SMACK, DOI /
 Index A ACID, 251 Actor model Akka installation, 44 Akka logos, 41 OOP vs. actors, 42 43 thread-based concurrency, 42 Agents server, 140, 251 Aggregation techniques materialized views, 216 probabilistic
Index A ACID, 251 Actor model Akka installation, 44 Akka logos, 41 OOP vs. actors, 42 43 thread-based concurrency, 42 Agents server, 140, 251 Aggregation techniques materialized views, 216 probabilistic
MapReduce: Simplified Data Processing on Large Clusters 유연일민철기
 MapReduce: Simplified Data Processing on Large Clusters 유연일민철기 Introduction MapReduce is a programming model and an associated implementation for processing and generating large data set with parallel,
MapReduce: Simplified Data Processing on Large Clusters 유연일민철기 Introduction MapReduce is a programming model and an associated implementation for processing and generating large data set with parallel,
The age of Big Data Big Data for Oracle Database Professionals
 The age of Big Data Big Data for Oracle Database Professionals Oracle OpenWorld 2017 #OOW17 SessionID: SUN5698 Tom S. Reddy tom.reddy@datareddy.com About the Speaker COLLABORATE & OpenWorld Speaker IOUG
The age of Big Data Big Data for Oracle Database Professionals Oracle OpenWorld 2017 #OOW17 SessionID: SUN5698 Tom S. Reddy tom.reddy@datareddy.com About the Speaker COLLABORATE & OpenWorld Speaker IOUG
Big Data Hadoop Stack
 Big Data Hadoop Stack Lecture #1 Hadoop Beginnings What is Hadoop? Apache Hadoop is an open source software framework for storage and large scale processing of data-sets on clusters of commodity hardware
Big Data Hadoop Stack Lecture #1 Hadoop Beginnings What is Hadoop? Apache Hadoop is an open source software framework for storage and large scale processing of data-sets on clusters of commodity hardware
Amazon AWS-Solution-Architect-Associate Exam
 Volume: 858 Questions Question: 1 You are trying to launch an EC2 instance, however the instance seems to go into a terminated status immediately. What would probably not be a reason that this is happening?
Volume: 858 Questions Question: 1 You are trying to launch an EC2 instance, however the instance seems to go into a terminated status immediately. What would probably not be a reason that this is happening?
Turning Relational Database Tables into Spark Data Sources
 Turning Relational Database Tables into Spark Data Sources Kuassi Mensah Jean de Lavarene Director Product Mgmt Director Development Server Technologies October 04, 2017 3 Safe Harbor Statement The following
Turning Relational Database Tables into Spark Data Sources Kuassi Mensah Jean de Lavarene Director Product Mgmt Director Development Server Technologies October 04, 2017 3 Safe Harbor Statement The following
Shark. Hive on Spark. Cliff Engle, Antonio Lupher, Reynold Xin, Matei Zaharia, Michael Franklin, Ion Stoica, Scott Shenker
 Shark Hive on Spark Cliff Engle, Antonio Lupher, Reynold Xin, Matei Zaharia, Michael Franklin, Ion Stoica, Scott Shenker Agenda Intro to Spark Apache Hive Shark Shark s Improvements over Hive Demo Alpha
Shark Hive on Spark Cliff Engle, Antonio Lupher, Reynold Xin, Matei Zaharia, Michael Franklin, Ion Stoica, Scott Shenker Agenda Intro to Spark Apache Hive Shark Shark s Improvements over Hive Demo Alpha
AWS 101. Patrick Pierson, IonChannel
 AWS 101 Patrick Pierson, IonChannel What is AWS? Amazon Web Services (AWS) is a secure cloud services platform, offering compute power, database storage, content delivery and other functionality to help
AWS 101 Patrick Pierson, IonChannel What is AWS? Amazon Web Services (AWS) is a secure cloud services platform, offering compute power, database storage, content delivery and other functionality to help
Gain Insights From Unstructured Data Using Pivotal HD. Copyright 2013 EMC Corporation. All rights reserved.
 Gain Insights From Unstructured Data Using Pivotal HD 1 Traditional Enterprise Analytics Process 2 The Fundamental Paradigm Shift Internet age and exploding data growth Enterprises leverage new data sources
Gain Insights From Unstructured Data Using Pivotal HD 1 Traditional Enterprise Analytics Process 2 The Fundamental Paradigm Shift Internet age and exploding data growth Enterprises leverage new data sources
EXTRACT DATA IN LARGE DATABASE WITH HADOOP
 International Journal of Advances in Engineering & Scientific Research (IJAESR) ISSN: 2349 3607 (Online), ISSN: 2349 4824 (Print) Download Full paper from : http://www.arseam.com/content/volume-1-issue-7-nov-2014-0
International Journal of Advances in Engineering & Scientific Research (IJAESR) ISSN: 2349 3607 (Online), ISSN: 2349 4824 (Print) Download Full paper from : http://www.arseam.com/content/volume-1-issue-7-nov-2014-0
Shark: SQL and Rich Analytics at Scale. Yash Thakkar ( ) Deeksha Singh ( )
 Deeksha Singh ( )") Shark: SQL and Rich Analytics at Scale Yash Thakkar (2642764) Deeksha Singh (2641679) RDDs as foundation for relational processing in Shark: Resilient Distributed Datasets (RDDs): RDDs can be written at
Shark: SQL and Rich Analytics at Scale Yash Thakkar (2642764) Deeksha Singh (2641679) RDDs as foundation for relational processing in Shark: Resilient Distributed Datasets (RDDs): RDDs can be written at
Webinar Series TMIP VISION
 Webinar Series TMIP VISION TMIP provides technical support and promotes knowledge and information exchange in the transportation planning and modeling community. Today s Goals To Consider: Parallel Processing
Webinar Series TMIP VISION TMIP provides technical support and promotes knowledge and information exchange in the transportation planning and modeling community. Today s Goals To Consider: Parallel Processing
Applied Spark. From Concepts to Bitcoin Analytics. Andrew F.
 Applied Spark From Concepts to Bitcoin Analytics Andrew F. Hart ahart@apache.org @andrewfhart My Day Job CTO, Pogoseat Upgrade technology for live events 3/28/16 QCON-SP Andrew Hart 2 Additionally Member,
Applied Spark From Concepts to Bitcoin Analytics Andrew F. Hart ahart@apache.org @andrewfhart My Day Job CTO, Pogoseat Upgrade technology for live events 3/28/16 QCON-SP Andrew Hart 2 Additionally Member,
Big Data Infrastructure at Spotify
 Big Data Infrastructure at Spotify Wouter de Bie Team Lead Data Infrastructure September 26, 2013 2 Who am I? According to ZDNet: "The work they have done to improve the Apache Hive data warehouse system
Big Data Infrastructure at Spotify Wouter de Bie Team Lead Data Infrastructure September 26, 2013 2 Who am I? According to ZDNet: "The work they have done to improve the Apache Hive data warehouse system
HDFS: Hadoop Distributed File System. CIS 612 Sunnie Chung
 HDFS: Hadoop Distributed File System CIS 612 Sunnie Chung What is Big Data?? Bulk Amount Unstructured Introduction Lots of Applications which need to handle huge amount of data (in terms of 500+ TB per
HDFS: Hadoop Distributed File System CIS 612 Sunnie Chung What is Big Data?? Bulk Amount Unstructured Introduction Lots of Applications which need to handle huge amount of data (in terms of 500+ TB per
Report on The Infrastructure for Implementing the Mobile Technologies for Data Collection in Egypt
 Report on The Infrastructure for Implementing the Mobile Technologies for Data Collection in Egypt Date: 10 Sep, 2017 Draft v 4.0 Table of Contents 1. Introduction... 3 2. Infrastructure Reference Architecture...
Report on The Infrastructure for Implementing the Mobile Technologies for Data Collection in Egypt Date: 10 Sep, 2017 Draft v 4.0 Table of Contents 1. Introduction... 3 2. Infrastructure Reference Architecture...
MapR Enterprise Hadoop
 2014 MapR Technologies 2014 MapR Technologies 1 MapR Enterprise Hadoop Top Ranked Cloud Leaders 500+ Customers 2014 MapR Technologies 2 Key MapR Advantage Partners Business Services APPLICATIONS & OS ANALYTICS
2014 MapR Technologies 2014 MapR Technologies 1 MapR Enterprise Hadoop Top Ranked Cloud Leaders 500+ Customers 2014 MapR Technologies 2 Key MapR Advantage Partners Business Services APPLICATIONS & OS ANALYTICS