CS60021: Scalable Data Mining. Sourangshu Bhattacharya
|
|
|
- Scott Hampton
- 5 years ago
- Views:
Transcription
1 CS60021: Scalable Data Mining Sourangshu Bhattacharya
2 In this Lecture: Outline: HDFS Motivation HDFS User commands HDFS System architecture HDFS Implementation details Sourangshu Bhattacharya Computer Science and Engg.
3 Hadoop Map Reduce q Provides: q Automatic parallelization and Distribution q Fault Tolerance q Methods for interfacing with HDFS for colocation of computation and storage of output. q Status and Monitoring tools q API in Java q Ability to define the mapper and reducer in many languages through Hadoop streaming.
4 What is Hadoop? q A scalable fault-tolerant distributed system for data storage and processing. q Core Hadoop: q Hadoop Distributed File System (HDFS) q Hadoop YARN: Job Scheduling and Cluster Resource Management q Hadoop Map Reduce: Framework for distributed data processing. q Open Source system with large community support.
5 HDFS
6 6 What s HDFS HDFS is a distributed file system that is fault tolerant, scalable and extremely easy to expand. HDFS is the primary distributed storage for Hadoop applications. HDFS provides interfaces for applications to move themselves closer to data. HDFS is designed to just work, however a working knowledge helps in diagnostics and improvements.
7 HDFS q Design Assumptions q Hardware failure is the norm. q Streaming data access. q Write once, read many times. q High throughput, not low latency. q Large datasets. q Characteristics: q Performs best with modest number of large files q Optimized for streaming reads q Layer on top of native file system.
8 HDFS q Data is organized into file and directories. q Files are divided into blocks and distributed to nodes. q Block placement is known at the time of read q Computation moved to same node. q Replication is used for: q Speed q Fault tolerance q Self healing.
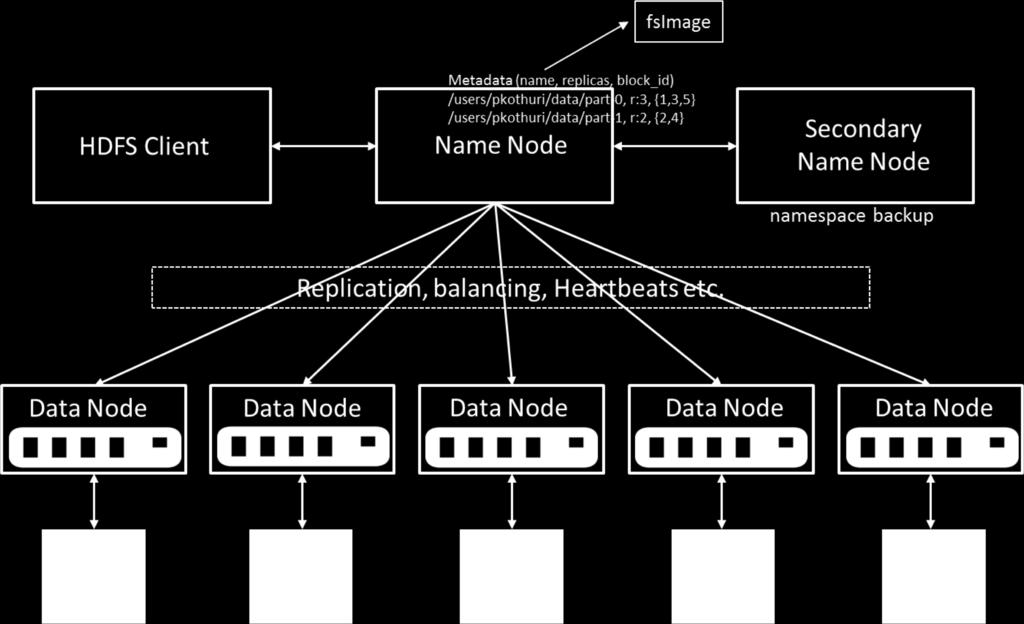
9 Components of HDFS There are two (and a half) types of machines in a HDFS cluster NameNode : is the heart of an HDFS filesystem, it maintains and manages the file system metadata. E.g; what blocks make up a file, and on which datanodes those blocks are stored. DataNode :- where HDFS stores the actual data, there are usually quite a few of these.
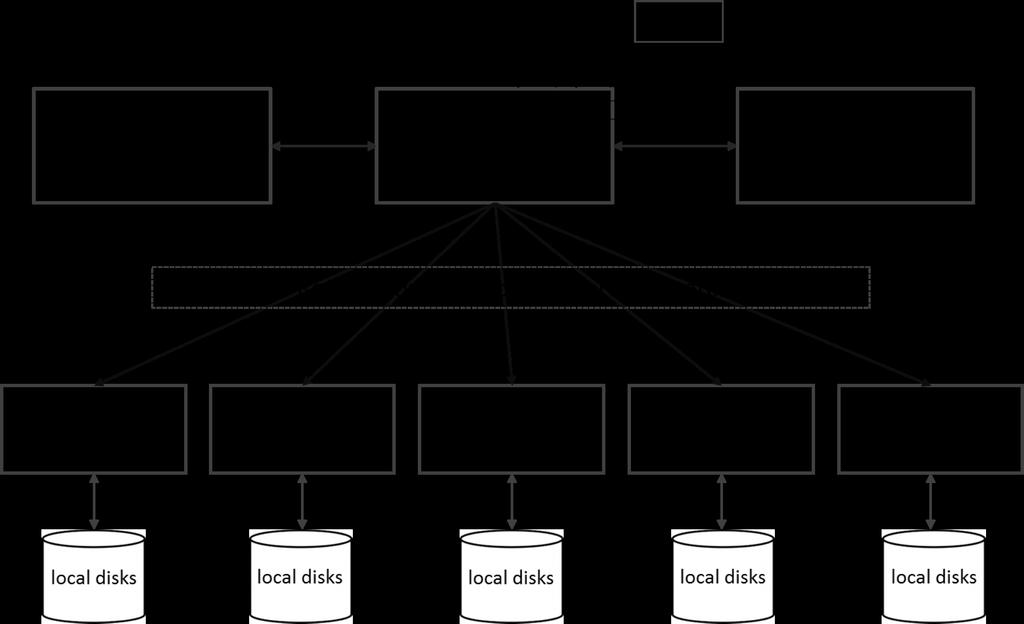
10 HDFS Architecture
11 HDFS User Commands (dfs) List directory contents hdfs dfs ls hdfs dfs -ls / hdfs dfs -ls -R /var Display the disk space used by files hdfs dfs -du /hbase/data/hbase/namespace/ hdfs dfs -du -h /hbase/data/hbase/namespace/ hdfs dfs -du -s /hbase/data/hbase/namespace/
12 HDFS User Commands (dfs) Copy data to HDFS hdfs dfs -mkdir tdata hdfs dfs -ls hdfs dfs -copyfromlocal tutorials/data/geneva.csv tdata hdfs dfs -ls R Copy the file back to local filesystem cd tutorials/data/ hdfs dfs copytolocal tdata/geneva.csv geneva.csv.hdfs md5sum geneva.csv geneva.csv.hdfs
13 HDFS User Commands (acls) List acl for a file hdfs dfs -getfacl tdata/geneva.csv List the file statistics (%r replication factor) hdfs dfs -stat "%r" tdata/geneva.csv Write to hdfs reading from stdin echo "blah blah blah" hdfs dfs -put - tdataset/tfile.txt hdfs dfs -ls R hdfs dfs -cat tdataset/tfile.txt
14 Goals of HDFS Very Large Distributed File System 10K nodes, 100 million files, 10 PB Assumes Commodity Hardware Files are replicated to handle hardware failure Detect failures and recovers from them Optimized for Batch Processing Data locations exposed so that computations can move to where data resides Provides very high aggregate bandwidth User Space, runs on heterogeneous OS
15 Distributed File System Single Namespace for entire cluster Data Coherency Write-once-read-many access model Client can only append to existing files Files are broken up into blocks Typically 128 MB block size Each block replicated on multiple DataNodes Intelligent Client Client can find location of blocks Client accesses data directly from DataNode
16 NameNode Metadata Meta-data in Memory The entire metadata is in main memory No demand paging of meta-data Types of Metadata List of files List of Blocks for each file List of DataNodes for each block File attributes, e.g creation time, replication factor A Transaction Log Records file creations, file deletions. etc
17 DataNode A Block Server Stores data in the local file system (e.g. ext3) Stores meta-data of a block (e.g. CRC) Serves data and meta-data to Clients Block Report Periodically sends a report of all existing blocks to the NameNode Facilitates Pipelining of Data Forwards data to other specified DataNodes
18
19 HDFS read client Source: Hadoop: The Definitive Guide

20 HDFS write Client Source: Hadoop: The Definitive Guide
21 Block Placement Current Strategy -- One replica on local node -- Second replica on a remote rack -- Third replica on same remote rack -- Additional replicas are randomly placed Clients read from nearest replica Would like to make this policy pluggable
22 NameNode Failure A single point of failure Transaction Log stored in multiple directories A directory on the local file system A directory on a remote file system (NFS/CIFS) Need to develop a real HA solution
23 Data Pipelining Client retrieves a list of DataNodes on which to place replicas of a block Client writes block to the first DataNode The first DataNode forwards the data to the next DataNode in the Pipeline When all replicas are written, the Client moves on to write the next block in file
24 Conclusion: We have seen: The structure of HDFS. The shell commands. The architecture of HDFS system. Internal functioning of HDFS. Sourangshu Bhattacharya Computer Science and Engg. 24
25 References: Jure Leskovec, Anand Rajaraman, Jeff Ullman. Mining of Massive Datasets. 2 nd edition. - Cambridge University Press. Tom White. Hadoop: The definitive Guide. Oreilly Press. Sourangshu Bhattacharya Computer Science and Engg. 25
Cloud Computing and Hadoop Distributed File System. UCSB CS170, Spring 2018
 Cloud Computing and Hadoop Distributed File System UCSB CS70, Spring 08 Cluster Computing Motivations Large-scale data processing on clusters Scan 000 TB on node @ 00 MB/s = days Scan on 000-node cluster
Cloud Computing and Hadoop Distributed File System UCSB CS70, Spring 08 Cluster Computing Motivations Large-scale data processing on clusters Scan 000 TB on node @ 00 MB/s = days Scan on 000-node cluster
CS November 2017
 Distributed Systems 09r. Map-Reduce Programming on AWS/EMR (Part I) Setting Up AWS/EMR Paul Krzyzanowski TA: Long Zhao Rutgers University Fall 2017 November 21, 2017 2017 Paul Krzyzanowski 1 November 21,
Distributed Systems 09r. Map-Reduce Programming on AWS/EMR (Part I) Setting Up AWS/EMR Paul Krzyzanowski TA: Long Zhao Rutgers University Fall 2017 November 21, 2017 2017 Paul Krzyzanowski 1 November 21,
Distributed Systems. 09r. Map-Reduce Programming on AWS/EMR (Part I) 2017 Paul Krzyzanowski. TA: Long Zhao Rutgers University Fall 2017
 2017 Paul Krzyzanowski. TA: Long Zhao Rutgers University Fall 2017") Distributed Systems 09r. Map-Reduce Programming on AWS/EMR (Part I) Paul Krzyzanowski TA: Long Zhao Rutgers University Fall 2017 November 21, 2017 2017 Paul Krzyzanowski 1 Setting Up AWS/EMR November 21,
Distributed Systems 09r. Map-Reduce Programming on AWS/EMR (Part I) Paul Krzyzanowski TA: Long Zhao Rutgers University Fall 2017 November 21, 2017 2017 Paul Krzyzanowski 1 Setting Up AWS/EMR November 21,
Hadoop File System S L I D E S M O D I F I E D F R O M P R E S E N T A T I O N B Y B. R A M A M U R T H Y 11/15/2017
 Hadoop File System 1 S L I D E S M O D I F I E D F R O M P R E S E N T A T I O N B Y B. R A M A M U R T H Y Moving Computation is Cheaper than Moving Data Motivation: Big Data! What is BigData? - Google
Hadoop File System 1 S L I D E S M O D I F I E D F R O M P R E S E N T A T I O N B Y B. R A M A M U R T H Y Moving Computation is Cheaper than Moving Data Motivation: Big Data! What is BigData? - Google
UNIT-IV HDFS. Ms. Selva Mary. G
 UNIT-IV HDFS HDFS ARCHITECTURE Dataset partition across a number of separate machines Hadoop Distributed File system The Design of HDFS HDFS is a file system designed for storing very large files with
UNIT-IV HDFS HDFS ARCHITECTURE Dataset partition across a number of separate machines Hadoop Distributed File system The Design of HDFS HDFS is a file system designed for storing very large files with
HDFS Architecture. Gregory Kesden, CSE-291 (Storage Systems) Fall 2017
 Fall 2017") HDFS Architecture Gregory Kesden, CSE-291 (Storage Systems) Fall 2017 Based Upon: http://hadoop.apache.org/docs/r3.0.0-alpha1/hadoopproject-dist/hadoop-hdfs/hdfsdesign.html Assumptions At scale, hardware
HDFS Architecture Gregory Kesden, CSE-291 (Storage Systems) Fall 2017 Based Upon: http://hadoop.apache.org/docs/r3.0.0-alpha1/hadoopproject-dist/hadoop-hdfs/hdfsdesign.html Assumptions At scale, hardware
CA485 Ray Walshe Google File System
 Google File System Overview Google File System is scalable, distributed file system on inexpensive commodity hardware that provides: Fault Tolerance File system runs on hundreds or thousands of storage
Google File System Overview Google File System is scalable, distributed file system on inexpensive commodity hardware that provides: Fault Tolerance File system runs on hundreds or thousands of storage
HDFS Architecture Guide
 by Dhruba Borthakur Table of contents 1 Introduction...3 2 Assumptions and Goals...3 2.1 Hardware Failure... 3 2.2 Streaming Data Access...3 2.3 Large Data Sets...3 2.4 Simple Coherency Model... 4 2.5
by Dhruba Borthakur Table of contents 1 Introduction...3 2 Assumptions and Goals...3 2.1 Hardware Failure... 3 2.2 Streaming Data Access...3 2.3 Large Data Sets...3 2.4 Simple Coherency Model... 4 2.5
Distributed Systems 16. Distributed File Systems II
 Distributed Systems 16. Distributed File Systems II Paul Krzyzanowski pxk@cs.rutgers.edu 1 Review NFS RPC-based access AFS Long-term caching CODA Read/write replication & disconnected operation DFS AFS
Distributed Systems 16. Distributed File Systems II Paul Krzyzanowski pxk@cs.rutgers.edu 1 Review NFS RPC-based access AFS Long-term caching CODA Read/write replication & disconnected operation DFS AFS
Distributed Filesystem
 Distributed Filesystem 1 How do we get data to the workers? NAS Compute Nodes SAN 2 Distributing Code! Don t move data to workers move workers to the data! - Store data on the local disks of nodes in the
Distributed Filesystem 1 How do we get data to the workers? NAS Compute Nodes SAN 2 Distributing Code! Don t move data to workers move workers to the data! - Store data on the local disks of nodes in the
Hadoop and HDFS Overview. Madhu Ankam
 Hadoop and HDFS Overview Madhu Ankam Why Hadoop We are gathering more data than ever Examples of data : Server logs Web logs Financial transactions Analytics Emails and text messages Social media like
Hadoop and HDFS Overview Madhu Ankam Why Hadoop We are gathering more data than ever Examples of data : Server logs Web logs Financial transactions Analytics Emails and text messages Social media like
The Google File System. Alexandru Costan
 1 The Google File System Alexandru Costan Actions on Big Data 2 Storage Analysis Acquisition Handling the data stream Data structured unstructured semi-structured Results Transactions Outline File systems
1 The Google File System Alexandru Costan Actions on Big Data 2 Storage Analysis Acquisition Handling the data stream Data structured unstructured semi-structured Results Transactions Outline File systems
Hadoop Distributed File System(HDFS)
") Hadoop Distributed File System(HDFS) Bu eğitim sunumları İstanbul Kalkınma Ajansı nın 2016 yılı Yenilikçi ve Yaratıcı İstanbul Mali Destek Programı kapsamında yürütülmekte olan TR10/16/YNY/0036 no lu İstanbul
Hadoop Distributed File System(HDFS) Bu eğitim sunumları İstanbul Kalkınma Ajansı nın 2016 yılı Yenilikçi ve Yaratıcı İstanbul Mali Destek Programı kapsamında yürütülmekte olan TR10/16/YNY/0036 no lu İstanbul
MI-PDB, MIE-PDB: Advanced Database Systems
 MI-PDB, MIE-PDB: Advanced Database Systems http://www.ksi.mff.cuni.cz/~svoboda/courses/2015-2-mie-pdb/ Lecture 10: MapReduce, Hadoop 26. 4. 2016 Lecturer: Martin Svoboda svoboda@ksi.mff.cuni.cz Author:
MI-PDB, MIE-PDB: Advanced Database Systems http://www.ksi.mff.cuni.cz/~svoboda/courses/2015-2-mie-pdb/ Lecture 10: MapReduce, Hadoop 26. 4. 2016 Lecturer: Martin Svoboda svoboda@ksi.mff.cuni.cz Author:
CS370 Operating Systems
 CS370 Operating Systems Colorado State University Yashwant K Malaiya Fall 2017 Lecture 26 File Systems Slides based on Text by Silberschatz, Galvin, Gagne Various sources 1 1 FAQ Cylinders: all the platters?
CS370 Operating Systems Colorado State University Yashwant K Malaiya Fall 2017 Lecture 26 File Systems Slides based on Text by Silberschatz, Galvin, Gagne Various sources 1 1 FAQ Cylinders: all the platters?
A BigData Tour HDFS, Ceph and MapReduce
 A BigData Tour HDFS, Ceph and MapReduce These slides are possible thanks to these sources Jonathan Drusi - SCInet Toronto Hadoop Tutorial, Amir Payberah - Course in Data Intensive Computing SICS; Yahoo!
A BigData Tour HDFS, Ceph and MapReduce These slides are possible thanks to these sources Jonathan Drusi - SCInet Toronto Hadoop Tutorial, Amir Payberah - Course in Data Intensive Computing SICS; Yahoo!
MapReduce. U of Toronto, 2014
 MapReduce U of Toronto, 2014 http://www.google.org/flutrends/ca/ (2012) Average Searches Per Day: 5,134,000,000 2 Motivation Process lots of data Google processed about 24 petabytes of data per day in
MapReduce U of Toronto, 2014 http://www.google.org/flutrends/ca/ (2012) Average Searches Per Day: 5,134,000,000 2 Motivation Process lots of data Google processed about 24 petabytes of data per day in
Overview. Why MapReduce? What is MapReduce? The Hadoop Distributed File System Cloudera, Inc.
 MapReduce and HDFS This presentation includes course content University of Washington Redistributed under the Creative Commons Attribution 3.0 license. All other contents: Overview Why MapReduce? What
MapReduce and HDFS This presentation includes course content University of Washington Redistributed under the Creative Commons Attribution 3.0 license. All other contents: Overview Why MapReduce? What
Introduction to MapReduce
 Basics of Cloud Computing Lecture 4 Introduction to MapReduce Satish Srirama Some material adapted from slides by Jimmy Lin, Christophe Bisciglia, Aaron Kimball, & Sierra Michels-Slettvet, Google Distributed
Basics of Cloud Computing Lecture 4 Introduction to MapReduce Satish Srirama Some material adapted from slides by Jimmy Lin, Christophe Bisciglia, Aaron Kimball, & Sierra Michels-Slettvet, Google Distributed
Konstantin Shvachko, Hairong Kuang, Sanjay Radia, Robert Chansler Yahoo! Sunnyvale, California USA {Shv, Hairong, SRadia,
 Konstantin Shvachko, Hairong Kuang, Sanjay Radia, Robert Chansler Yahoo! Sunnyvale, California USA {Shv, Hairong, SRadia, Chansler}@Yahoo-Inc.com Presenter: Alex Hu } Introduction } Architecture } File
Konstantin Shvachko, Hairong Kuang, Sanjay Radia, Robert Chansler Yahoo! Sunnyvale, California USA {Shv, Hairong, SRadia, Chansler}@Yahoo-Inc.com Presenter: Alex Hu } Introduction } Architecture } File
Dept. Of Computer Science, Colorado State University
 CS 455: INTRODUCTION TO DISTRIBUTED SYSTEMS [HADOOP/HDFS] Trying to have your cake and eat it too Each phase pines for tasks with locality and their numbers on a tether Alas within a phase, you get one,
CS 455: INTRODUCTION TO DISTRIBUTED SYSTEMS [HADOOP/HDFS] Trying to have your cake and eat it too Each phase pines for tasks with locality and their numbers on a tether Alas within a phase, you get one,
A brief history on Hadoop
 Hadoop Basics A brief history on Hadoop 2003 - Google launches project Nutch to handle billions of searches and indexing millions of web pages. Oct 2003 - Google releases papers with GFS (Google File System)
Hadoop Basics A brief history on Hadoop 2003 - Google launches project Nutch to handle billions of searches and indexing millions of web pages. Oct 2003 - Google releases papers with GFS (Google File System)
BigData and Map Reduce VITMAC03
 BigData and Map Reduce VITMAC03 1 Motivation Process lots of data Google processed about 24 petabytes of data per day in 2009. A single machine cannot serve all the data You need a distributed system to
BigData and Map Reduce VITMAC03 1 Motivation Process lots of data Google processed about 24 petabytes of data per day in 2009. A single machine cannot serve all the data You need a distributed system to
Distributed Systems. CS422/522 Lecture17 17 November 2014
 Distributed Systems CS422/522 Lecture17 17 November 2014 Lecture Outline Introduction Hadoop Chord What s a distributed system? What s a distributed system? A distributed system is a collection of loosely
Distributed Systems CS422/522 Lecture17 17 November 2014 Lecture Outline Introduction Hadoop Chord What s a distributed system? What s a distributed system? A distributed system is a collection of loosely
Introduction to MapReduce. Instructor: Dr. Weikuan Yu Computer Sci. & Software Eng.
 Introduction to MapReduce Instructor: Dr. Weikuan Yu Computer Sci. & Software Eng. Before MapReduce Large scale data processing was difficult! Managing hundreds or thousands of processors Managing parallelization
Introduction to MapReduce Instructor: Dr. Weikuan Yu Computer Sci. & Software Eng. Before MapReduce Large scale data processing was difficult! Managing hundreds or thousands of processors Managing parallelization
Google File System (GFS) and Hadoop Distributed File System (HDFS)
 and Hadoop Distributed File System (HDFS)") Google File System (GFS) and Hadoop Distributed File System (HDFS) 1 Hadoop: Architectural Design Principles Linear scalability More nodes can do more work within the same time Linear on data size, linear
Google File System (GFS) and Hadoop Distributed File System (HDFS) 1 Hadoop: Architectural Design Principles Linear scalability More nodes can do more work within the same time Linear on data size, linear
Lecture 11 Hadoop & Spark
 Lecture 11 Hadoop & Spark Dr. Wilson Rivera ICOM 6025: High Performance Computing Electrical and Computer Engineering Department University of Puerto Rico Outline Distributed File Systems Hadoop Ecosystem
Lecture 11 Hadoop & Spark Dr. Wilson Rivera ICOM 6025: High Performance Computing Electrical and Computer Engineering Department University of Puerto Rico Outline Distributed File Systems Hadoop Ecosystem
CSE 124: Networked Services Lecture-16
 Fall 2010 CSE 124: Networked Services Lecture-16 Instructor: B. S. Manoj, Ph.D http://cseweb.ucsd.edu/classes/fa10/cse124 11/23/2010 CSE 124 Networked Services Fall 2010 1 Updates PlanetLab experiments
Fall 2010 CSE 124: Networked Services Lecture-16 Instructor: B. S. Manoj, Ph.D http://cseweb.ucsd.edu/classes/fa10/cse124 11/23/2010 CSE 124 Networked Services Fall 2010 1 Updates PlanetLab experiments
CS370 Operating Systems
 CS370 Operating Systems Colorado State University Yashwant K Malaiya Spring 2018 Lecture 24 Mass Storage, HDFS/Hadoop Slides based on Text by Silberschatz, Galvin, Gagne Various sources 1 1 FAQ What 2
CS370 Operating Systems Colorado State University Yashwant K Malaiya Spring 2018 Lecture 24 Mass Storage, HDFS/Hadoop Slides based on Text by Silberschatz, Galvin, Gagne Various sources 1 1 FAQ What 2
Big Data Analytics. Izabela Moise, Evangelos Pournaras, Dirk Helbing
 Big Data Analytics Izabela Moise, Evangelos Pournaras, Dirk Helbing Izabela Moise, Evangelos Pournaras, Dirk Helbing 1 Big Data "The world is crazy. But at least it s getting regular analysis." Izabela
Big Data Analytics Izabela Moise, Evangelos Pournaras, Dirk Helbing Izabela Moise, Evangelos Pournaras, Dirk Helbing 1 Big Data "The world is crazy. But at least it s getting regular analysis." Izabela
Big Data Programming: an Introduction. Spring 2015, X. Zhang Fordham Univ.
 Big Data Programming: an Introduction Spring 2015, X. Zhang Fordham Univ. Outline What the course is about? scope Introduction to big data programming Opportunity and challenge of big data Origin of Hadoop
Big Data Programming: an Introduction Spring 2015, X. Zhang Fordham Univ. Outline What the course is about? scope Introduction to big data programming Opportunity and challenge of big data Origin of Hadoop
CLOUD-SCALE FILE SYSTEMS
 Data Management in the Cloud CLOUD-SCALE FILE SYSTEMS 92 Google File System (GFS) Designing a file system for the Cloud design assumptions design choices Architecture GFS Master GFS Chunkservers GFS Clients
Data Management in the Cloud CLOUD-SCALE FILE SYSTEMS 92 Google File System (GFS) Designing a file system for the Cloud design assumptions design choices Architecture GFS Master GFS Chunkservers GFS Clients
HDFS: Hadoop Distributed File System. Sector: Distributed Storage System
 GFS: Google File System Google C/C++ HDFS: Hadoop Distributed File System Yahoo Java, Open Source Sector: Distributed Storage System University of Illinois at Chicago C++, Open Source 2 System that permanently
GFS: Google File System Google C/C++ HDFS: Hadoop Distributed File System Yahoo Java, Open Source Sector: Distributed Storage System University of Illinois at Chicago C++, Open Source 2 System that permanently
Introduction to Cloud Computing
 Introduction to Cloud Computing Distributed File Systems 15 319, spring 2010 12 th Lecture, Feb 18 th Majd F. Sakr Lecture Motivation Quick Refresher on Files and File Systems Understand the importance
Introduction to Cloud Computing Distributed File Systems 15 319, spring 2010 12 th Lecture, Feb 18 th Majd F. Sakr Lecture Motivation Quick Refresher on Files and File Systems Understand the importance
CSE 124: Networked Services Fall 2009 Lecture-19
 CSE 124: Networked Services Fall 2009 Lecture-19 Instructor: B. S. Manoj, Ph.D http://cseweb.ucsd.edu/classes/fa09/cse124 Some of these slides are adapted from various sources/individuals including but
CSE 124: Networked Services Fall 2009 Lecture-19 Instructor: B. S. Manoj, Ph.D http://cseweb.ucsd.edu/classes/fa09/cse124 Some of these slides are adapted from various sources/individuals including but
COSC 6397 Big Data Analytics. Distributed File Systems (II) Edgar Gabriel Spring HDFS Basics
 Edgar Gabriel Spring HDFS Basics") COSC 6397 Big Data Analytics Distributed File Systems (II) Edgar Gabriel Spring 2017 HDFS Basics An open-source implementation of Google File System Assume that node failure rate is high Assumes a small
COSC 6397 Big Data Analytics Distributed File Systems (II) Edgar Gabriel Spring 2017 HDFS Basics An open-source implementation of Google File System Assume that node failure rate is high Assumes a small
International Journal of Advance Engineering and Research Development. A Study: Hadoop Framework
 Scientific Journal of Impact Factor (SJIF): e-issn (O): 2348- International Journal of Advance Engineering and Research Development Volume 3, Issue 2, February -2016 A Study: Hadoop Framework Devateja
Scientific Journal of Impact Factor (SJIF): e-issn (O): 2348- International Journal of Advance Engineering and Research Development Volume 3, Issue 2, February -2016 A Study: Hadoop Framework Devateja
HADOOP FRAMEWORK FOR BIG DATA
 HADOOP FRAMEWORK FOR BIG DATA Mr K. Srinivas Babu 1,Dr K. Rameshwaraiah 2 1 Research Scholar S V University, Tirupathi 2 Professor and Head NNRESGI, Hyderabad Abstract - Data has to be stored for further
HADOOP FRAMEWORK FOR BIG DATA Mr K. Srinivas Babu 1,Dr K. Rameshwaraiah 2 1 Research Scholar S V University, Tirupathi 2 Professor and Head NNRESGI, Hyderabad Abstract - Data has to be stored for further
Distributed Systems. 15. Distributed File Systems. Paul Krzyzanowski. Rutgers University. Fall 2017
 Distributed Systems 15. Distributed File Systems Paul Krzyzanowski Rutgers University Fall 2017 1 Google Chubby ( Apache Zookeeper) 2 Chubby Distributed lock service + simple fault-tolerant file system
Distributed Systems 15. Distributed File Systems Paul Krzyzanowski Rutgers University Fall 2017 1 Google Chubby ( Apache Zookeeper) 2 Chubby Distributed lock service + simple fault-tolerant file system
CPSC 426/526. Cloud Computing. Ennan Zhai. Computer Science Department Yale University
 CPSC 426/526 Cloud Computing Ennan Zhai Computer Science Department Yale University Recall: Lec-7 In the lec-7, I talked about: - P2P vs Enterprise control - Firewall - NATs - Software defined network
CPSC 426/526 Cloud Computing Ennan Zhai Computer Science Department Yale University Recall: Lec-7 In the lec-7, I talked about: - P2P vs Enterprise control - Firewall - NATs - Software defined network
Data Storage Infrastructure at Facebook
 Data Storage Infrastructure at Facebook Spring 2018 Cleveland State University CIS 601 Presentation Yi Dong Instructor: Dr. Chung Outline Strategy of data storage, processing, and log collection Data flow
Data Storage Infrastructure at Facebook Spring 2018 Cleveland State University CIS 601 Presentation Yi Dong Instructor: Dr. Chung Outline Strategy of data storage, processing, and log collection Data flow
COSC 6397 Big Data Analytics. Distributed File Systems (II) Edgar Gabriel Fall HDFS Basics
 Edgar Gabriel Fall HDFS Basics") COSC 6397 Big Data Analytics Distributed File Systems (II) Edgar Gabriel Fall 2018 HDFS Basics An open-source implementation of Google File System Assume that node failure rate is high Assumes a small
COSC 6397 Big Data Analytics Distributed File Systems (II) Edgar Gabriel Fall 2018 HDFS Basics An open-source implementation of Google File System Assume that node failure rate is high Assumes a small
Distributed File Systems II
 Distributed File Systems II To do q Very-large scale: Google FS, Hadoop FS, BigTable q Next time: Naming things GFS A radically new environment NFS, etc. Independence Small Scale Variety of workloads Cooperation
Distributed File Systems II To do q Very-large scale: Google FS, Hadoop FS, BigTable q Next time: Naming things GFS A radically new environment NFS, etc. Independence Small Scale Variety of workloads Cooperation
Cloud Computing. Hwajung Lee. Key Reference: Prof. Jong-Moon Chung s Lecture Notes at Yonsei University
 Cloud Computing Hwajung Lee Key Reference: Prof. Jong-Moon Chung s Lecture Notes at Yonsei University Cloud Computing Cloud Introduction Cloud Service Model Big Data Hadoop MapReduce HDFS (Hadoop Distributed
Cloud Computing Hwajung Lee Key Reference: Prof. Jong-Moon Chung s Lecture Notes at Yonsei University Cloud Computing Cloud Introduction Cloud Service Model Big Data Hadoop MapReduce HDFS (Hadoop Distributed
The Google File System
 The Google File System Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung Google SOSP 03, October 19 22, 2003, New York, USA Hyeon-Gyu Lee, and Yeong-Jae Woo Memory & Storage Architecture Lab. School
The Google File System Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung Google SOSP 03, October 19 22, 2003, New York, USA Hyeon-Gyu Lee, and Yeong-Jae Woo Memory & Storage Architecture Lab. School
Chase Wu New Jersey Institute of Technology
 CS 644: Introduction to Big Data Chapter 4. Big Data Analytics Platforms Chase Wu New Jersey Institute of Technology Some of the slides were provided through the courtesy of Dr. Ching-Yung Lin at Columbia
CS 644: Introduction to Big Data Chapter 4. Big Data Analytics Platforms Chase Wu New Jersey Institute of Technology Some of the slides were provided through the courtesy of Dr. Ching-Yung Lin at Columbia
Where We Are. Review: Parallel DBMS. Parallel DBMS. Introduction to Data Management CSE 344
 Where We Are Introduction to Data Management CSE 344 Lecture 22: MapReduce We are talking about parallel query processing There exist two main types of engines: Parallel DBMSs (last lecture + quick review)
Where We Are Introduction to Data Management CSE 344 Lecture 22: MapReduce We are talking about parallel query processing There exist two main types of engines: Parallel DBMSs (last lecture + quick review)
18-hdfs-gfs.txt Thu Oct 27 10:05: Notes on Parallel File Systems: HDFS & GFS , Fall 2011 Carnegie Mellon University Randal E.
 18-hdfs-gfs.txt Thu Oct 27 10:05:07 2011 1 Notes on Parallel File Systems: HDFS & GFS 15-440, Fall 2011 Carnegie Mellon University Randal E. Bryant References: Ghemawat, Gobioff, Leung, "The Google File
18-hdfs-gfs.txt Thu Oct 27 10:05:07 2011 1 Notes on Parallel File Systems: HDFS & GFS 15-440, Fall 2011 Carnegie Mellon University Randal E. Bryant References: Ghemawat, Gobioff, Leung, "The Google File
Enhanced Hadoop with Search and MapReduce Concurrency Optimization
 Volume 114 No. 12 2017, 323-331 ISSN: 1311-8080 (printed version); ISSN: 1314-3395 (on-line version) url: http://www.ijpam.eu ijpam.eu Enhanced Hadoop with Search and MapReduce Concurrency Optimization
Volume 114 No. 12 2017, 323-331 ISSN: 1311-8080 (printed version); ISSN: 1314-3395 (on-line version) url: http://www.ijpam.eu ijpam.eu Enhanced Hadoop with Search and MapReduce Concurrency Optimization
CS /30/17. Paul Krzyzanowski 1. Google Chubby ( Apache Zookeeper) Distributed Systems. Chubby. Chubby Deployment.
 Distributed Systems. Chubby. Chubby Deployment.") Distributed Systems 15. Distributed File Systems Google ( Apache Zookeeper) Paul Krzyzanowski Rutgers University Fall 2017 1 2 Distributed lock service + simple fault-tolerant file system Deployment Client
Distributed Systems 15. Distributed File Systems Google ( Apache Zookeeper) Paul Krzyzanowski Rutgers University Fall 2017 1 2 Distributed lock service + simple fault-tolerant file system Deployment Client
Distributed Systems. 15. Distributed File Systems. Paul Krzyzanowski. Rutgers University. Fall 2016
 Distributed Systems 15. Distributed File Systems Paul Krzyzanowski Rutgers University Fall 2016 1 Google Chubby 2 Chubby Distributed lock service + simple fault-tolerant file system Interfaces File access
Distributed Systems 15. Distributed File Systems Paul Krzyzanowski Rutgers University Fall 2016 1 Google Chubby 2 Chubby Distributed lock service + simple fault-tolerant file system Interfaces File access
Yuval Carmel Tel-Aviv University "Advanced Topics in Storage Systems" - Spring 2013
 Yuval Carmel Tel-Aviv University "Advanced Topics in About & Keywords Motivation & Purpose Assumptions Architecture overview & Comparison Measurements How does it fit in? The Future 2 About & Keywords
Yuval Carmel Tel-Aviv University "Advanced Topics in About & Keywords Motivation & Purpose Assumptions Architecture overview & Comparison Measurements How does it fit in? The Future 2 About & Keywords
ECE 7650 Scalable and Secure Internet Services and Architecture ---- A Systems Perspective
 ECE 7650 Scalable and Secure Internet Services and Architecture ---- A Systems Perspective Part II: Data Center Software Architecture: Topic 1: Distributed File Systems GFS (The Google File System) 1 Filesystems
ECE 7650 Scalable and Secure Internet Services and Architecture ---- A Systems Perspective Part II: Data Center Software Architecture: Topic 1: Distributed File Systems GFS (The Google File System) 1 Filesystems
Introduction to Hadoop. Owen O Malley Yahoo!, Grid Team
 Introduction to Hadoop Owen O Malley Yahoo!, Grid Team owen@yahoo-inc.com Who Am I? Yahoo! Architect on Hadoop Map/Reduce Design, review, and implement features in Hadoop Working on Hadoop full time since
Introduction to Hadoop Owen O Malley Yahoo!, Grid Team owen@yahoo-inc.com Who Am I? Yahoo! Architect on Hadoop Map/Reduce Design, review, and implement features in Hadoop Working on Hadoop full time since
Service and Cloud Computing Lecture 10: DFS2 Prof. George Baciu PQ838
 COMP4442 Service and Cloud Computing Lecture 10: DFS2 www.comp.polyu.edu.hk/~csgeorge/comp4442 Prof. George Baciu PQ838 csgeorge@comp.polyu.edu.hk 1 Preamble 2 Recall the Cloud Stack Model A B Application
COMP4442 Service and Cloud Computing Lecture 10: DFS2 www.comp.polyu.edu.hk/~csgeorge/comp4442 Prof. George Baciu PQ838 csgeorge@comp.polyu.edu.hk 1 Preamble 2 Recall the Cloud Stack Model A B Application
Mixing and matching virtual and physical HPC clusters. Paolo Anedda
 Mixing and matching virtual and physical HPC clusters Paolo Anedda paolo.anedda@crs4.it HPC 2010 - Cetraro 22/06/2010 1 Outline Introduction Scalability Issues System architecture Conclusions & Future
Mixing and matching virtual and physical HPC clusters Paolo Anedda paolo.anedda@crs4.it HPC 2010 - Cetraro 22/06/2010 1 Outline Introduction Scalability Issues System architecture Conclusions & Future
Programming Systems for Big Data
 Programming Systems for Big Data CS315B Lecture 17 Including material from Kunle Olukotun Prof. Aiken CS 315B Lecture 17 1 Big Data We ve focused on parallel programming for computational science There
Programming Systems for Big Data CS315B Lecture 17 Including material from Kunle Olukotun Prof. Aiken CS 315B Lecture 17 1 Big Data We ve focused on parallel programming for computational science There
Authors : Sanjay Ghemawat, Howard Gobioff, Shun-Tak Leung Presentation by: Vijay Kumar Chalasani
 The Authors : Sanjay Ghemawat, Howard Gobioff, Shun-Tak Leung Presentation by: Vijay Kumar Chalasani CS5204 Operating Systems 1 Introduction GFS is a scalable distributed file system for large data intensive
The Authors : Sanjay Ghemawat, Howard Gobioff, Shun-Tak Leung Presentation by: Vijay Kumar Chalasani CS5204 Operating Systems 1 Introduction GFS is a scalable distributed file system for large data intensive
CS370 Operating Systems
 CS370 Operating Systems Colorado State University Yashwant K Malaiya Spring 2018 Lecture 25 RAIDs, HDFS/Hadoop Slides based on Text by Silberschatz, Galvin, Gagne (not) Various sources 1 1 FAQ Striping:
CS370 Operating Systems Colorado State University Yashwant K Malaiya Spring 2018 Lecture 25 RAIDs, HDFS/Hadoop Slides based on Text by Silberschatz, Galvin, Gagne (not) Various sources 1 1 FAQ Striping:
CS455: Introduction to Distributed Systems [Spring 2018] Dept. Of Computer Science, Colorado State University
![CS455: Introduction to Distributed Systems [Spring 2018] Dept. Of Computer Science, Colorado State University](/thumbs/87/96390739.jpg "CS455: Introduction to Distributed Systems [Spring 2018] Dept. Of Computer Science, Colorado State University") CS 455: INTRODUCTION TO DISTRIBUTED SYSTEMS [HDFS] Circumventing The Perils of Doing Too Much Protect the namenode, you must, from failure What s not an option? Playing it by ear Given the volumes, be
CS 455: INTRODUCTION TO DISTRIBUTED SYSTEMS [HDFS] Circumventing The Perils of Doing Too Much Protect the namenode, you must, from failure What s not an option? Playing it by ear Given the volumes, be
Parallel Data Processing with Hadoop/MapReduce. CS140 Tao Yang, 2014
 Parallel Data Processing with Hadoop/MapReduce CS140 Tao Yang, 2014 Overview What is MapReduce? Example with word counting Parallel data processing with MapReduce Hadoop file system More application example
Parallel Data Processing with Hadoop/MapReduce CS140 Tao Yang, 2014 Overview What is MapReduce? Example with word counting Parallel data processing with MapReduce Hadoop file system More application example
Dept. Of Computer Science, Colorado State University
 CS 455: INTRODUCTION TO DISTRIBUTED SYSTEMS [HDFS] Circumventing The Perils of Doing Too Much Protect the namenode, you must, from failure What s not an option? Playing it by ear Given the volumes, be
CS 455: INTRODUCTION TO DISTRIBUTED SYSTEMS [HDFS] Circumventing The Perils of Doing Too Much Protect the namenode, you must, from failure What s not an option? Playing it by ear Given the volumes, be
Chuck Cartledge, PhD. 24 September 2017
 Introduction Basics Hands-on Q&A Conclusion References Files Big Data: Data Analysis Boot Camp Hadoop and R Chuck Cartledge, PhD 24 September 2017 1/26 Table of contents (1 of 1) 1 Introduction 2 Basics
Introduction Basics Hands-on Q&A Conclusion References Files Big Data: Data Analysis Boot Camp Hadoop and R Chuck Cartledge, PhD 24 September 2017 1/26 Table of contents (1 of 1) 1 Introduction 2 Basics
Introduction to Hadoop and MapReduce
 Introduction to Hadoop and MapReduce Antonino Virgillito THE CONTRACTOR IS ACTING UNDER A FRAMEWORK CONTRACT CONCLUDED WITH THE COMMISSION Large-scale Computation Traditional solutions for computing large
Introduction to Hadoop and MapReduce Antonino Virgillito THE CONTRACTOR IS ACTING UNDER A FRAMEWORK CONTRACT CONCLUDED WITH THE COMMISSION Large-scale Computation Traditional solutions for computing large
The Analysis Research of Hierarchical Storage System Based on Hadoop Framework Yan LIU 1, a, Tianjian ZHENG 1, Mingjiang LI 1, Jinpeng YUAN 1
 International Conference on Intelligent Systems Research and Mechatronics Engineering (ISRME 2015) The Analysis Research of Hierarchical Storage System Based on Hadoop Framework Yan LIU 1, a, Tianjian
International Conference on Intelligent Systems Research and Mechatronics Engineering (ISRME 2015) The Analysis Research of Hierarchical Storage System Based on Hadoop Framework Yan LIU 1, a, Tianjian
The Google File System
 The Google File System Sanjay Ghemawat, Howard Gobioff and Shun Tak Leung Google* Shivesh Kumar Sharma fl4164@wayne.edu Fall 2015 004395771 Overview Google file system is a scalable distributed file system
The Google File System Sanjay Ghemawat, Howard Gobioff and Shun Tak Leung Google* Shivesh Kumar Sharma fl4164@wayne.edu Fall 2015 004395771 Overview Google file system is a scalable distributed file system
Systems Infrastructure for Data Science. Web Science Group Uni Freiburg WS 2013/14
 Systems Infrastructure for Data Science Web Science Group Uni Freiburg WS 2013/14 MapReduce & Hadoop The new world of Big Data (programming model) Overview of this Lecture Module Background Cluster File
Systems Infrastructure for Data Science Web Science Group Uni Freiburg WS 2013/14 MapReduce & Hadoop The new world of Big Data (programming model) Overview of this Lecture Module Background Cluster File
50 Must Read Hadoop Interview Questions & Answers
 50 Must Read Hadoop Interview Questions & Answers Whizlabs Dec 29th, 2017 Big Data Are you planning to land a job with big data and data analytics? Are you worried about cracking the Hadoop job interview?
50 Must Read Hadoop Interview Questions & Answers Whizlabs Dec 29th, 2017 Big Data Are you planning to land a job with big data and data analytics? Are you worried about cracking the Hadoop job interview?
Hadoop/MapReduce Computing Paradigm
 Hadoop/Reduce Computing Paradigm 1 Large-Scale Data Analytics Reduce computing paradigm (E.g., Hadoop) vs. Traditional database systems vs. Database Many enterprises are turning to Hadoop Especially applications
Hadoop/Reduce Computing Paradigm 1 Large-Scale Data Analytics Reduce computing paradigm (E.g., Hadoop) vs. Traditional database systems vs. Database Many enterprises are turning to Hadoop Especially applications
Hadoop Lab 2 Exploring the Hadoop Environment
 Programming for Big Data Hadoop Lab 2 Exploring the Hadoop Environment Video A short video guide for some of what is covered in this lab. Link for this video is on my module webpage 1 Open a Terminal window
Programming for Big Data Hadoop Lab 2 Exploring the Hadoop Environment Video A short video guide for some of what is covered in this lab. Link for this video is on my module webpage 1 Open a Terminal window
Data Management. Parallel Filesystems. Dr David Henty HPC Training and Support
 Data Management Dr David Henty HPC Training and Support d.henty@epcc.ed.ac.uk +44 131 650 5960 Overview Lecture will cover Why is IO difficult Why is parallel IO even worse Lustre GPFS Performance on ARCHER
Data Management Dr David Henty HPC Training and Support d.henty@epcc.ed.ac.uk +44 131 650 5960 Overview Lecture will cover Why is IO difficult Why is parallel IO even worse Lustre GPFS Performance on ARCHER
Analytics in the cloud
 Analytics in the cloud Dow we really need to reinvent the storage stack? R. Ananthanarayanan, Karan Gupta, Prashant Pandey, Himabindu Pucha, Prasenjit Sarkar, Mansi Shah, Renu Tewari Image courtesy NASA
Analytics in the cloud Dow we really need to reinvent the storage stack? R. Ananthanarayanan, Karan Gupta, Prashant Pandey, Himabindu Pucha, Prasenjit Sarkar, Mansi Shah, Renu Tewari Image courtesy NASA
TITLE: PRE-REQUISITE THEORY. 1. Introduction to Hadoop. 2. Cluster. Implement sort algorithm and run it using HADOOP
 TITLE: Implement sort algorithm and run it using HADOOP PRE-REQUISITE Preliminary knowledge of clusters and overview of Hadoop and its basic functionality. THEORY 1. Introduction to Hadoop The Apache Hadoop
TITLE: Implement sort algorithm and run it using HADOOP PRE-REQUISITE Preliminary knowledge of clusters and overview of Hadoop and its basic functionality. THEORY 1. Introduction to Hadoop The Apache Hadoop
Lecture 12 DATA ANALYTICS ON WEB SCALE
 Lecture 12 DATA ANALYTICS ON WEB SCALE Source: The Economist, February 25, 2010 The Data Deluge EIGHTEEN months ago, Li & Fung, a firm that manages supply chains for retailers, saw 100 gigabytes of information
Lecture 12 DATA ANALYTICS ON WEB SCALE Source: The Economist, February 25, 2010 The Data Deluge EIGHTEEN months ago, Li & Fung, a firm that manages supply chains for retailers, saw 100 gigabytes of information
Chapter 4: Apache Spark
 Chapter 4: Apache Spark Lecture Notes Winter semester 2016 / 2017 Ludwig-Maximilians-University Munich PD Dr. Matthias Renz 2015, Based on lectures by Donald Kossmann (ETH Zürich), as well as Jure Leskovec,
Chapter 4: Apache Spark Lecture Notes Winter semester 2016 / 2017 Ludwig-Maximilians-University Munich PD Dr. Matthias Renz 2015, Based on lectures by Donald Kossmann (ETH Zürich), as well as Jure Leskovec,
The Google File System (GFS)
") 1 The Google File System (GFS) CS60002: Distributed Systems Antonio Bruto da Costa Ph.D. Student, Formal Methods Lab, Dept. of Computer Sc. & Engg., Indian Institute of Technology Kharagpur 2 Design constraints
1 The Google File System (GFS) CS60002: Distributed Systems Antonio Bruto da Costa Ph.D. Student, Formal Methods Lab, Dept. of Computer Sc. & Engg., Indian Institute of Technology Kharagpur 2 Design constraints
Google File System and BigTable. and tiny bits of HDFS (Hadoop File System) and Chubby. Not in textbook; additional information
 and Chubby. Not in textbook; additional information") Subject 10 Fall 2015 Google File System and BigTable and tiny bits of HDFS (Hadoop File System) and Chubby Not in textbook; additional information Disclaimer: These abbreviated notes DO NOT substitute
Subject 10 Fall 2015 Google File System and BigTable and tiny bits of HDFS (Hadoop File System) and Chubby Not in textbook; additional information Disclaimer: These abbreviated notes DO NOT substitute
Getting Started with Hadoop
 Getting Started with Hadoop May 28, 2018 Michael Völske, Shahbaz Syed Web Technology & Information Systems Bauhaus-Universität Weimar 1 webis 2018 What is Hadoop Started in 2004 by Yahoo Open-Source implementation
Getting Started with Hadoop May 28, 2018 Michael Völske, Shahbaz Syed Web Technology & Information Systems Bauhaus-Universität Weimar 1 webis 2018 What is Hadoop Started in 2004 by Yahoo Open-Source implementation
Google File System. Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung Google fall DIP Heerak lim, Donghun Koo
 Google File System Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung Google 2017 fall DIP Heerak lim, Donghun Koo 1 Agenda Introduction Design overview Systems interactions Master operation Fault tolerance
Google File System Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung Google 2017 fall DIP Heerak lim, Donghun Koo 1 Agenda Introduction Design overview Systems interactions Master operation Fault tolerance
Mounica B, Aditya Srivastava, Md. Faisal Alam
 International Journal of Scientific Research in Computer Science, Engineering and Information Technology 2017 IJSRCSEIT Volume 2 Issue 3 ISSN : 2456-3307 Clustering of large datasets using Hadoop Ecosystem
International Journal of Scientific Research in Computer Science, Engineering and Information Technology 2017 IJSRCSEIT Volume 2 Issue 3 ISSN : 2456-3307 Clustering of large datasets using Hadoop Ecosystem
NPTEL Course Jan K. Gopinath Indian Institute of Science
 Storage Systems NPTEL Course Jan 2012 (Lecture 39) K. Gopinath Indian Institute of Science Google File System Non-Posix scalable distr file system for large distr dataintensive applications performance,
Storage Systems NPTEL Course Jan 2012 (Lecture 39) K. Gopinath Indian Institute of Science Google File System Non-Posix scalable distr file system for large distr dataintensive applications performance,
The Google File System
 The Google File System Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung December 2003 ACM symposium on Operating systems principles Publisher: ACM Nov. 26, 2008 OUTLINE INTRODUCTION DESIGN OVERVIEW
The Google File System Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung December 2003 ACM symposium on Operating systems principles Publisher: ACM Nov. 26, 2008 OUTLINE INTRODUCTION DESIGN OVERVIEW
18-hdfs-gfs.txt Thu Nov 01 09:53: Notes on Parallel File Systems: HDFS & GFS , Fall 2012 Carnegie Mellon University Randal E.
 18-hdfs-gfs.txt Thu Nov 01 09:53:32 2012 1 Notes on Parallel File Systems: HDFS & GFS 15-440, Fall 2012 Carnegie Mellon University Randal E. Bryant References: Ghemawat, Gobioff, Leung, "The Google File
18-hdfs-gfs.txt Thu Nov 01 09:53:32 2012 1 Notes on Parallel File Systems: HDFS & GFS 15-440, Fall 2012 Carnegie Mellon University Randal E. Bryant References: Ghemawat, Gobioff, Leung, "The Google File
Performance Enhancement of Data Processing using Multiple Intelligent Cache in Hadoop
 Performance Enhancement of Data Processing using Multiple Intelligent Cache in Hadoop K. Senthilkumar PG Scholar Department of Computer Science and Engineering SRM University, Chennai, Tamilnadu, India
Performance Enhancement of Data Processing using Multiple Intelligent Cache in Hadoop K. Senthilkumar PG Scholar Department of Computer Science and Engineering SRM University, Chennai, Tamilnadu, India
Introduction to MapReduce
 Introduction to MapReduce Some slides borrowed from Jimmy Lin, Jeff Ullman, Jerome Simeon, and Jure Leskovec Single-node architecture CPU Memory Data Analysis, Machine Learning, Statistics Disk How much
Introduction to MapReduce Some slides borrowed from Jimmy Lin, Jeff Ullman, Jerome Simeon, and Jure Leskovec Single-node architecture CPU Memory Data Analysis, Machine Learning, Statistics Disk How much
Hadoop An Overview. - Socrates CCDH
 Hadoop An Overview - Socrates CCDH What is Big Data? Volume Not Gigabyte. Terabyte, Petabyte, Exabyte, Zettabyte - Due to handheld gadgets,and HD format images and videos - In total data, 90% of them collected
Hadoop An Overview - Socrates CCDH What is Big Data? Volume Not Gigabyte. Terabyte, Petabyte, Exabyte, Zettabyte - Due to handheld gadgets,and HD format images and videos - In total data, 90% of them collected
Voldemort. Smruti R. Sarangi. Department of Computer Science Indian Institute of Technology New Delhi, India. Overview Design Evaluation
 Voldemort Smruti R. Sarangi Department of Computer Science Indian Institute of Technology New Delhi, India Smruti R. Sarangi Leader Election 1/29 Outline 1 2 3 Smruti R. Sarangi Leader Election 2/29 Data
Voldemort Smruti R. Sarangi Department of Computer Science Indian Institute of Technology New Delhi, India Smruti R. Sarangi Leader Election 1/29 Outline 1 2 3 Smruti R. Sarangi Leader Election 2/29 Data
Cloud Computing 2. CSCI 4850/5850 High-Performance Computing Spring 2018
 Cloud Computing 2 CSCI 4850/5850 High-Performance Computing Spring 2018 Tae-Hyuk (Ted) Ahn Department of Computer Science Program of Bioinformatics and Computational Biology Saint Louis University Learning
Cloud Computing 2 CSCI 4850/5850 High-Performance Computing Spring 2018 Tae-Hyuk (Ted) Ahn Department of Computer Science Program of Bioinformatics and Computational Biology Saint Louis University Learning
Hadoop 2.x Core: YARN, Tez, and Spark. Hortonworks Inc All Rights Reserved
 Hadoop 2.x Core: YARN, Tez, and Spark YARN Hadoop Machine Types top-of-rack switches core switch client machines have client-side software used to access a cluster to process data master nodes run Hadoop
Hadoop 2.x Core: YARN, Tez, and Spark YARN Hadoop Machine Types top-of-rack switches core switch client machines have client-side software used to access a cluster to process data master nodes run Hadoop
The Google File System
 The Google File System Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung SOSP 2003 presented by Kun Suo Outline GFS Background, Concepts and Key words Example of GFS Operations Some optimizations in
The Google File System Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung SOSP 2003 presented by Kun Suo Outline GFS Background, Concepts and Key words Example of GFS Operations Some optimizations in
Google File System. By Dinesh Amatya
 Google File System By Dinesh Amatya Google File System (GFS) Sanjay Ghemawat, Howard Gobioff, Shun-Tak Leung designed and implemented to meet rapidly growing demand of Google's data processing need a scalable
Google File System By Dinesh Amatya Google File System (GFS) Sanjay Ghemawat, Howard Gobioff, Shun-Tak Leung designed and implemented to meet rapidly growing demand of Google's data processing need a scalable
Introduction to MapReduce
 Basics of Cloud Computing Lecture 4 Introduction to MapReduce Satish Srirama Some material adapted from slides by Jimmy Lin, Christophe Bisciglia, Aaron Kimball, & Sierra Michels-Slettvet, Google Distributed
Basics of Cloud Computing Lecture 4 Introduction to MapReduce Satish Srirama Some material adapted from slides by Jimmy Lin, Christophe Bisciglia, Aaron Kimball, & Sierra Michels-Slettvet, Google Distributed
Distributed System. Gang Wu. Spring,2018
 Distributed System Gang Wu Spring,2018 Lecture7:DFS What is DFS? A method of storing and accessing files base in a client/server architecture. A distributed file system is a client/server-based application
Distributed System Gang Wu Spring,2018 Lecture7:DFS What is DFS? A method of storing and accessing files base in a client/server architecture. A distributed file system is a client/server-based application
A Review Approach for Big Data and Hadoop Technology
 International Journal of Modern Trends in Engineering and Research www.ijmter.com e-issn No.:2349-9745, Date: 2-4 July, 2015 A Review Approach for Big Data and Hadoop Technology Prof. Ghanshyam Dhomse
International Journal of Modern Trends in Engineering and Research www.ijmter.com e-issn No.:2349-9745, Date: 2-4 July, 2015 A Review Approach for Big Data and Hadoop Technology Prof. Ghanshyam Dhomse
Parallel Programming Principle and Practice. Lecture 10 Big Data Processing with MapReduce
 Parallel Programming Principle and Practice Lecture 10 Big Data Processing with MapReduce Outline MapReduce Programming Model MapReduce Examples Hadoop 2 Incredible Things That Happen Every Minute On The
Parallel Programming Principle and Practice Lecture 10 Big Data Processing with MapReduce Outline MapReduce Programming Model MapReduce Examples Hadoop 2 Incredible Things That Happen Every Minute On The
Informa)on Retrieval and Map- Reduce Implementa)ons. Mohammad Amir Sharif PhD Student Center for Advanced Computer Studies
on Retrieval and Map- Reduce Implementa)ons. Mohammad Amir Sharif PhD Student Center for Advanced Computer Studies") Informa)on Retrieval and Map- Reduce Implementa)ons Mohammad Amir Sharif PhD Student Center for Advanced Computer Studies mas4108@louisiana.edu Map-Reduce: Why? Need to process 100TB datasets On 1 node:
Informa)on Retrieval and Map- Reduce Implementa)ons Mohammad Amir Sharif PhD Student Center for Advanced Computer Studies mas4108@louisiana.edu Map-Reduce: Why? Need to process 100TB datasets On 1 node:
The Google File System
 The Google File System Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung Google* 정학수, 최주영 1 Outline Introduction Design Overview System Interactions Master Operation Fault Tolerance and Diagnosis Conclusions
The Google File System Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung Google* 정학수, 최주영 1 Outline Introduction Design Overview System Interactions Master Operation Fault Tolerance and Diagnosis Conclusions
CS435 Introduction to Big Data FALL 2018 Colorado State University. 11/7/2018 Week 12-B Sangmi Lee Pallickara. FAQs
 11/7/2018 CS435 Introduction to Big Data - FALL 2018 W12.B.0.0 CS435 Introduction to Big Data 11/7/2018 CS435 Introduction to Big Data - FALL 2018 W12.B.1 FAQs Deadline of the Programming Assignment 3
11/7/2018 CS435 Introduction to Big Data - FALL 2018 W12.B.0.0 CS435 Introduction to Big Data 11/7/2018 CS435 Introduction to Big Data - FALL 2018 W12.B.1 FAQs Deadline of the Programming Assignment 3
How Apache Hadoop Complements Existing BI Systems. Dr. Amr Awadallah Founder, CTO Cloudera,
 How Apache Hadoop Complements Existing BI Systems Dr. Amr Awadallah Founder, CTO Cloudera, Inc. Twitter: @awadallah, @cloudera 2 The Problems with Current Data Systems BI Reports + Interactive Apps RDBMS
How Apache Hadoop Complements Existing BI Systems Dr. Amr Awadallah Founder, CTO Cloudera, Inc. Twitter: @awadallah, @cloudera 2 The Problems with Current Data Systems BI Reports + Interactive Apps RDBMS
Map-Reduce. Marco Mura 2010 March, 31th
 Map-Reduce Marco Mura (mura@di.unipi.it) 2010 March, 31th This paper is a note from the 2009-2010 course Strumenti di programmazione per sistemi paralleli e distribuiti and it s based by the lessons of
Map-Reduce Marco Mura (mura@di.unipi.it) 2010 March, 31th This paper is a note from the 2009-2010 course Strumenti di programmazione per sistemi paralleli e distribuiti and it s based by the lessons of