Introduction & Motivation Problem Statement Proposed Work Evaluation Conclusions Future Work
|
|
|
- Lauren Norris
- 6 years ago
- Views:
Transcription



1
2 Introduction & Motivation Problem Statement Proposed Work Evaluation Conclusions Future Work
3 Introduction & Motivation Problem Statement Proposed Work Evaluation Conclusions Future Work

4
: Exascale Computing 1000PFlops 1Billion cores http://s.top500.")

5 Today (2014): PetaScale Computing 34PFlops 3Million cores Near Future (~2020): Exascale Computing 1000PFlops 1Billion cores
6 Manages resources compute storage network Job scheduling/management resource allocation job launch Data management data movement caching

7
.")
. Many-Task Computing (MTC) applications Production Runs in Drug Design 1990s State-of-the-art Brute force code Resource breaking (EFF Managers DES cracker).")
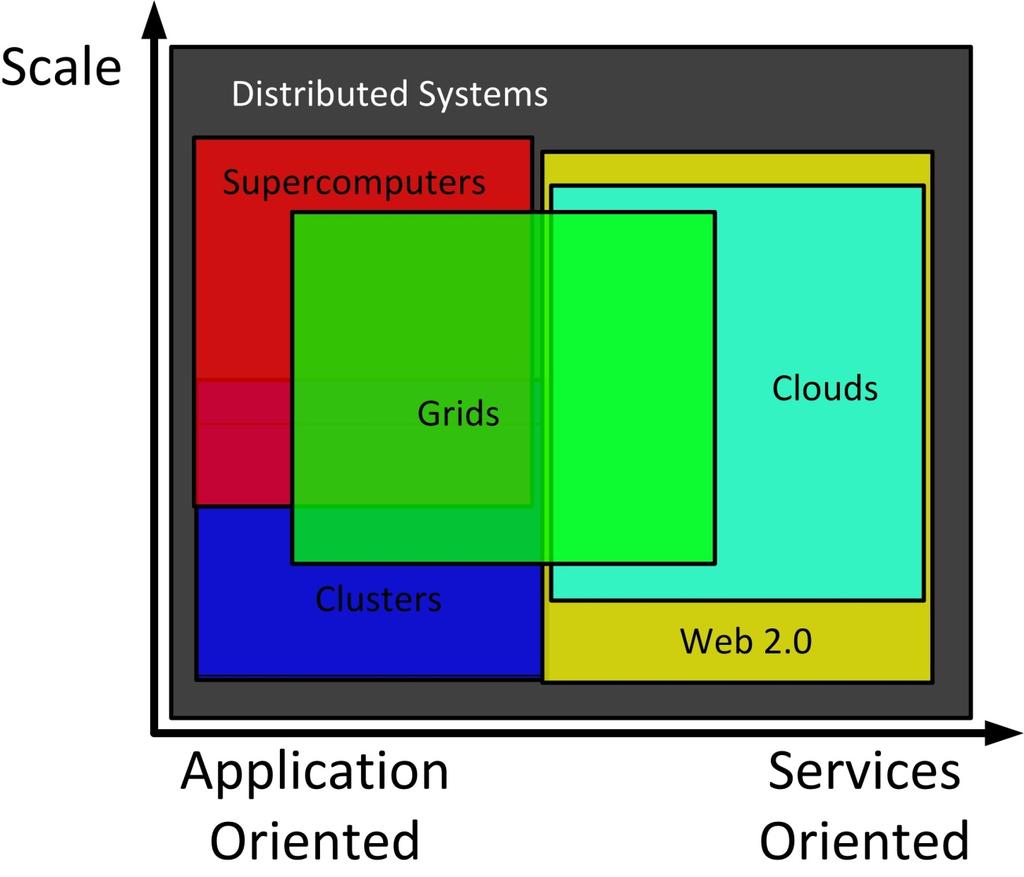
8 Medical PetaScale Image Processing: à Exascale Functional Uses (10^18 and computer Magnetic Flops, involved Resonance 1B cores) Workload Diversity Decade 1970s Weather forecasting, aerodynamic research (Cray-1). Chemistry Traditional Domain: large-scale MolDyn High Performance Computing (HPC) jobs HPC ensemble runs 1980s Molecular Probabilistic Dynamics: analysis, DOCK radiation shielding modeling (CDC Cyber). Many-Task Computing (MTC) applications Production Runs in Drug Design 1990s State-of-the-art Brute force code Resource breaking (EFF Managers DES cracker). Economic Centralized Modeling: paradigm: MARS job scheduling Large-scale HPC 3D nuclear Astronomy resource test managers: simulations Application SLURM, as a substitute PBS, for Moab, legal Torque, conduct Cobalt 2000s Evaluation HTC Nuclear resource Non-Proliferation manager: Condor, Treaty (ASCI Falkon, Q). Mesos, YARN Next-generation Resource Managers Astronomy Domain: Montage 2010s Molecular Dynamics Simulation (Tianhe-1A) Distributed paradigm Data Analytics: Sort and WordCount Scalable, efficient, reliable
9 Introduction & Motivation Problem Statement Proposed Work Evaluation Conclusions Future Work
10 Scalability System scale is increasing Workload size is increasing Processing capacity needs to increase Efficiency Allocating resources fast Making fast enough scheduling decisions Maintaining a high system utilization Reliability Still functioning well under failures
11 Introduction & Motivation Problem Statement Proposed Work Evaluation Conclusions Future Work

12 Client Client Client MTC Centralized Scheduling Falkon Scheduler Scheduler MTC Distributed communication Scheduling Executor Executor KVS server KVS server MATRIX Compute Node Fully-Connected Compute Node HPC Centralized Scheduling Slurm Controller and KVS server Client Client Client HPC Distributed Scheduling Fully-Connected Slurm++ Controller and KVS Server Controller and KVS Server cd cd cd cd cd cd cd cd cd
13 T1 T2 T3 T4 P1 Local Ready Queue P2 Client Client Client Task 1 Wait Queue Task 2 Complete Queue Scheduler Executor KVS server communication Scheduler Executor KVS server Task 1 Task 2 Task 3 Task 6 Work-Stealing Ready Queue Task 1 Task 2 Task 3 Compute Node Fully-Connected Compute Node Task 4 Task 5 Task 3 Task 4 Task 4 Task 5 Task 6 Task 5 Task 6 Scheduler Specification
14 Client Client Client Scheduler communication Scheduler Executor KVS server Executor KVS server Compute Node Fully-Connected Compute Node

15 Fine-grained Workloads Load Balancing Data-Aware Scheduling
 17-month period on IBM BG/P machine Minimum length: 0 sec Maximum length: 1470 sec Medium length: 30 sec Average length: 95 sec Direct Acyclic Graphs (DAG)")
16 100% MTC application trace MTC application DAGs 90% 80% 70% Percentage 60% 50% 40% 30% 20% 10% 0% Task Execution Time (s) 17-month period on IBM BG/P machine Minimum length: 0 sec Maximum length: 1470 sec Medium length: 30 sec Average length: 95 sec Direct Acyclic Graphs (DAG) Vertices are discrete events Edges are data-flows Task can have parents Task can have children

17 Load balancing Steal tasks Steal tasks Distribute workloads as evenly as possible Scheduler Difficult 1 because Scheduler of local 2 view Scheduler 3 Scheduler 4 Dynamic change Task 1 Task 9 Task 10 Task 4 Task 2 Task 7 Task 11 Popular in shared-memory Task Task 5 send tasks machine at thread level Task 3 Task 8 Task 12 Starved processors Task Task 6 steal tasks from overloaded ones Task 4 Apply it at the node level in distributed environment Task 5 Task 4 Various parameters Send tasks Task 6 Task 5 Work stealing: distributed load balancing technique number of tasks to steal Task 7 number of neighbors Task 6 Task 8 static vs dynamic neighbors (dynamic multi-random neighbor selection) polling interval (exponential back-off)
18 Big-data era data-intensive applications Data-flow driven programming models (MTC) Workflow, task execution framework Work Stealing Original work stealing is data locality-oblivious Migrating tasks randomly comprise data-locality Propose a Data-aware Work Stealing technique
19 Steal tasks Steal tasks Scheduler 1 Scheduler 2 Scheduler 3 Scheduler 4 Task 1 Task 2 Task 3 Task 4 Task 5 Task 6 Task 7 Task 8 Task 9 Task 10 Task 4 Task 7 Task 11 Task Task 5 send tasks Task 8 Task 12 Task Task 6 Task 4 Send tasks Task 5 Task 6 Task length 1ms 1ms 1ms 1ms 1ms 1ms 1ms 1ms Data size 5GB 20KB 1MB 20GB 30KB 0B 20KB 1MB
20 typedef TaskMetaData Wait Queue (WaitQ): holds tasks that T1 T2 T3 T4 { are waiting for parents to complete Dedicated Local Ready Queue int num_wait_parent; // number (LReadyQ): of holds waiting ready tasks that can parents only be executed on local node P1 P2 Local vector<string> parent_list; // schedulers that run each parent task Ready Queue Shared Work-Stealing Ready Queue vector<string> data_object; // data object name produced by each parent (SReadyQ): holds ready tasks that can be shared through work stealing Task 1 vector<long> data_size; // data object size (byte) produced by each parent Complete Queue (CompleteQ): holds Complete Wait Queue Task 2 tasks that are completed Queue long all_data_size; // all data object size (byte) produced by all parents Task 1 Task 6 Task 1 P1: a program that checks if a is vector<string> children; // children of this ready to run, and moves ready tasks to Task 2 Task 2 either ready queue according to the Work-Stealing } TMD; decision making algorithm Task 3 Ready Queue Task 3 P2: a program that updates the task metadata for each child of a completed task Task 4 Task 5 Task 3 Task 4 Task 4 Task 5 T1 to T4: executor has 4 (configurable) executing threads that executes tasks in the ready queues and move a task to complete queue when it is done Task 6 Task 5 Task 6
21 MLB Maximized Load Balancing MDL Maximized Data-Locality RLDS Rigid Load balancing and Data-locality Segregation FLDS Flexible Load balancing and Data-locality Segregation
22 A discrete event simulator Simulates MTC task execution framework 1M nodes, 1B cores, 100B tasks Explore the scalability fully distributed MTC-architecture work stealing technique data-aware work stealing technique
23 Efficiency Efficiency 100% 90% 80% 70% 60% 50% 40% 30% 20% 10% 0% 100% 90% 80% 70% 60% 50% 40% 30% 20% 10% 0% nb_1 nb_2 nb_log 8 nb_sqrt % steal_1 80% steal_2 nb_2 70% steal_log nb_log 60% steal_sqrt nb_sqrt 50% steal_half nb_eighth 40% nb_quar No. of Task to Steal 30% nb_half 20% 10% The conclusion drawn about the simulation-based 0% optimal parameters for the adaptive work stealing is Scale (No. of Nodes) Scale (No. of Nodes) to steal half the number of tasks from their neighbors, and to use the square root number of dynamic random neighbors. The data-aware work stealing technique is scalable at extreme-scales No. of Dynamic Neighbors Scale (No. of Nodes) Efficiency 100% No. of Static neighbors Dataaware Work Stealing

24 Simulations have shown that the distributed architecture and the work stealing technique are scalable, now we can do real implementations
25 MATRIX components Client (submit tasks, monitoring execution progress) Scheduler (scheduling tasks for execution) Executor (execute tasks) MATRIX code ( 5K lines of C++ code 8K lines of ZHT code 1K lines of auto-generated code from Google protocol buffer MATRIX goal Scalable distributed scheduling system for MTC applications The prototype has been finished working on running real applications Testbeds: IBM Blue Gene/P/Q supercomputers (4K cores) Probe Kodiak cluster (200 cores) Executor Scheduler KVS server Compute Node Amazon EC2 (256 cores) Client Client Client communication Fully-Connected Executor Scheduler KVS server Compute Node
26 Introduction & Motivation Problem Statement Proposed Work Evaluation Conclusions Future Work
27 For sub-second tasks (64ms), MATRIX achieves efficiency as high as 85%+ at scales of 1024 nodes (4096 cores), meaning throughput as high as 13K tasks/sec
28 100% 90% 80% 70% Efficiency 60% 50% 40% 30% 20% 10% sleep 1 (Falkon) sleep 2 (Falkon) sleep 4 (Falkon) sleep 8 (Falkon) sleep 1 (MATRIX) sleep 2 (MATRIX) sleep 4 (MATRIX) sleep 8 (MATRIX) 0% Scale (No. of Cores)
29




30 f 0 f 1 f 2 f 3 f m f 0,0 f 0,1 f 1,0 f 1,1 t 0 t 1 t 2 t 3 t 4 t n t end Astroportal: Image Stacking t 0 t 1 t 2 t 3 Biometrics: All-pairs
31 Efficiency 100% 80% 60% 40% 20% 0% MATRIX efficiency Average task length 99% 99% 69% 57% YARN efficiency 94% 91% 91% 55% 40% 30% Scale (No. of cores) Average Task Length (sec) Bio-Informatics Application Protein-ligand Clustering 5 P h a s e s o f MapReduce Jobs 256MB data per node First phase has the majority of tasks
32 Introduction & Motivation Problem Statement Proposed Work Evaluation Conclusions Future Work
33 System scale is approaching exascale Applications are becoming fine-grained Next-generation resource management systems need to be highly scalable, efficient and available Fully distributed architectures are scalable Data-aware work stealing technique is scalable
34 Introduction & Motivation Problem Statement Proposed Work Evaluation Conclusions Future Work

35 Hadoop Integration of MATRIX Hadoop scheduler is centralized Replace the Hadoop scheduler with MATRIX Workflow integration of MATRIX Swift workflow system Will enable the execution of real scientific applications File System integration of MATRX FusionFS distributed file system Take care of the data storage and management Expose the data to MATRIX
36 More information: Contact: Questions?
Introduction & Motivation Problem Statement Proposed Work Evaluation Conclusions Future Work
 Introduction & Motivation Problem Statement Proposed Work Evaluation Conclusions Future Work Introduction & Motivation Problem Statement Proposed Work Evaluation Conclusions Future Work Today (2014):
Introduction & Motivation Problem Statement Proposed Work Evaluation Conclusions Future Work Introduction & Motivation Problem Statement Proposed Work Evaluation Conclusions Future Work Today (2014):
Optimizing Load Balancing and Data-Locality with Data-aware Scheduling
 Optimizing Load Balancing and Data-Locality with Data-aware Scheduling Ke Wang *, Xiaobing Zhou, Tonglin Li *, Dongfang Zhao *, Michael Lang, Ioan Raicu * * Illinois Institute of Technology, Hortonworks
Optimizing Load Balancing and Data-Locality with Data-aware Scheduling Ke Wang *, Xiaobing Zhou, Tonglin Li *, Dongfang Zhao *, Michael Lang, Ioan Raicu * * Illinois Institute of Technology, Hortonworks
Load-balanced and locality-aware scheduling for dataintensive workloads at extreme scales
 CONCURRENCY AND COMPUTATION: PRACTICE AND EXPERIENCE Concurrency Computat.: Pract. Exper. 2015; 00:1-29 Load-balanced and locality-aware scheduling for dataintensive workloads at extreme scales Ke Wang
CONCURRENCY AND COMPUTATION: PRACTICE AND EXPERIENCE Concurrency Computat.: Pract. Exper. 2015; 00:1-29 Load-balanced and locality-aware scheduling for dataintensive workloads at extreme scales Ke Wang
Towards Next Generation Resource Management at Extreme-Scales
 Towards Next Generation Resource Management at Extreme-Scales Ke Wang Department of Computer Science Illinois Institute of Technology kwang22@hawk.iit.edu Fall 2014 Committee Members: Ioan Raicu: Research
Towards Next Generation Resource Management at Extreme-Scales Ke Wang Department of Computer Science Illinois Institute of Technology kwang22@hawk.iit.edu Fall 2014 Committee Members: Ioan Raicu: Research
MOHA: Many-Task Computing Framework on Hadoop
 Apache: Big Data North America 2017 @ Miami MOHA: Many-Task Computing Framework on Hadoop Soonwook Hwang Korea Institute of Science and Technology Information May 18, 2017 Table of Contents Introduction
Apache: Big Data North America 2017 @ Miami MOHA: Many-Task Computing Framework on Hadoop Soonwook Hwang Korea Institute of Science and Technology Information May 18, 2017 Table of Contents Introduction
The Fusion Distributed File System
 Slide 1 / 44 The Fusion Distributed File System Dongfang Zhao February 2015 Slide 2 / 44 Outline Introduction FusionFS System Architecture Metadata Management Data Movement Implementation Details Unique
Slide 1 / 44 The Fusion Distributed File System Dongfang Zhao February 2015 Slide 2 / 44 Outline Introduction FusionFS System Architecture Metadata Management Data Movement Implementation Details Unique
Synonymous with supercomputing Tightly-coupled applications Implemented using Message Passing Interface (MPI) Large of amounts of computing for short
 Large of amounts of computing for short") Synonymous with supercomputing Tightly-coupled applications Implemented using Message Passing Interface (MPI) Large of amounts of computing for short periods of time Usually requires low latency interconnects
Synonymous with supercomputing Tightly-coupled applications Implemented using Message Passing Interface (MPI) Large of amounts of computing for short periods of time Usually requires low latency interconnects
NFS, GPFS, PVFS, Lustre Batch-scheduled systems: Clusters, Grids, and Supercomputers Programming paradigm: HPC, MTC, and HTC
 Segregated storage and compute NFS, GPFS, PVFS, Lustre Batch-scheduled systems: Clusters, Grids, and Supercomputers Programming paradigm: HPC, MTC, and HTC Co-located storage and compute HDFS, GFS Data
Segregated storage and compute NFS, GPFS, PVFS, Lustre Batch-scheduled systems: Clusters, Grids, and Supercomputers Programming paradigm: HPC, MTC, and HTC Co-located storage and compute HDFS, GFS Data
MATRIX:DJLSYS EXPLORING RESOURCE ALLOCATION TECHNIQUES FOR DISTRIBUTED JOB LAUNCH UNDER HIGH SYSTEM UTILIZATION
 MATRIX:DJLSYS EXPLORING RESOURCE ALLOCATION TECHNIQUES FOR DISTRIBUTED JOB LAUNCH UNDER HIGH SYSTEM UTILIZATION XIAOBING ZHOU(xzhou40@hawk.iit.edu) HAO CHEN (hchen71@hawk.iit.edu) Contents Introduction
MATRIX:DJLSYS EXPLORING RESOURCE ALLOCATION TECHNIQUES FOR DISTRIBUTED JOB LAUNCH UNDER HIGH SYSTEM UTILIZATION XIAOBING ZHOU(xzhou40@hawk.iit.edu) HAO CHEN (hchen71@hawk.iit.edu) Contents Introduction
Typically applied in clusters and grids Loosely-coupled applications with sequential jobs Large amounts of computing for long periods of times
 Typically applied in clusters and grids Loosely-coupled applications with sequential jobs Large amounts of computing for long periods of times Measured in operations per month or years 2 Bridge the gap
Typically applied in clusters and grids Loosely-coupled applications with sequential jobs Large amounts of computing for long periods of times Measured in operations per month or years 2 Bridge the gap
Ioan Raicu Distributed Systems Laboratory Computer Science Department University of Chicago
 Falkon, a Fast and Light-weight task execution framework for Clusters, Grids, and Supercomputers Ioan Raicu Distributed Systems Laboratory Computer Science Department University of Chicago In Collaboration
Falkon, a Fast and Light-weight task execution framework for Clusters, Grids, and Supercomputers Ioan Raicu Distributed Systems Laboratory Computer Science Department University of Chicago In Collaboration
SimMatrix: SIMulator for MAny-Task computing execution fabric at exascales
 SimMatrix: SIMulator for MAny-Task computing execution fabric at exascales Ke Wang 1, Ioan Raicu 1,2 kwang22@hawk.iit.edu, iraicu@cs.iit.edu 1 Department of Computer Science, Illinois Institute of Technology,
SimMatrix: SIMulator for MAny-Task computing execution fabric at exascales Ke Wang 1, Ioan Raicu 1,2 kwang22@hawk.iit.edu, iraicu@cs.iit.edu 1 Department of Computer Science, Illinois Institute of Technology,
Ioan Raicu Distributed Systems Laboratory Computer Science Department University of Chicago
 Running 1 Million Jobs in 10 Minutes via the Falkon Fast and Light-weight Ioan Raicu Distributed Systems Laboratory Computer Science Department University of Chicago In Collaboration with: Ian Foster,
Running 1 Million Jobs in 10 Minutes via the Falkon Fast and Light-weight Ioan Raicu Distributed Systems Laboratory Computer Science Department University of Chicago In Collaboration with: Ian Foster,
NFS, GPFS, PVFS, Lustre Batch-scheduled systems: Clusters, Grids, and Supercomputers Programming paradigm: HPC, MTC, and HTC
 Segregated storage and compute NFS, GPFS, PVFS, Lustre Batch-scheduled systems: Clusters, Grids, and Supercomputers Programming paradigm: HPC, MTC, and HTC Co-located storage and compute HDFS, GFS Data
Segregated storage and compute NFS, GPFS, PVFS, Lustre Batch-scheduled systems: Clusters, Grids, and Supercomputers Programming paradigm: HPC, MTC, and HTC Co-located storage and compute HDFS, GFS Data
A Data Diffusion Approach to Large Scale Scientific Exploration
 A Data Diffusion Approach to Large Scale Scientific Exploration Ioan Raicu Distributed Systems Laboratory Computer Science Department University of Chicago Joint work with: Yong Zhao: Microsoft Ian Foster:
A Data Diffusion Approach to Large Scale Scientific Exploration Ioan Raicu Distributed Systems Laboratory Computer Science Department University of Chicago Joint work with: Yong Zhao: Microsoft Ian Foster:
Managing and Executing Loosely-Coupled Large-Scale Applications on Clusters, Grids, and Supercomputers
 Managing and Executing Loosely-Coupled Large-Scale Applications on Clusters, Grids, and Supercomputers Ioan Raicu Distributed Systems Laboratory Computer Science Department University of Chicago Collaborators:
Managing and Executing Loosely-Coupled Large-Scale Applications on Clusters, Grids, and Supercomputers Ioan Raicu Distributed Systems Laboratory Computer Science Department University of Chicago Collaborators:
Overview Past Work Future Work. Motivation Proposal. Work-in-Progress
 Overview Past Work Future Work Motivation Proposal Work-in-Progress 2 HPC: High-Performance Computing Synonymous with supercomputing Tightly-coupled applications Implemented using Message Passing Interface
Overview Past Work Future Work Motivation Proposal Work-in-Progress 2 HPC: High-Performance Computing Synonymous with supercomputing Tightly-coupled applications Implemented using Message Passing Interface
Overcoming Hadoop Scaling Limitations through Distributed Task Execution
 Overcoming Hadoop Scaling Limitations through Distributed Task Execution Ke Wang *, Ning Liu *, Iman Sadooghi *, Xi Yang *, Xiaobing Zhou, Tonglin Li *, Michael Lang, Xian-He Sun *, Ioan Raicu * * Illinois
Overcoming Hadoop Scaling Limitations through Distributed Task Execution Ke Wang *, Ning Liu *, Iman Sadooghi *, Xi Yang *, Xiaobing Zhou, Tonglin Li *, Michael Lang, Xian-He Sun *, Ioan Raicu * * Illinois
Ian Foster, An Overview of Distributed Systems
 The advent of computation can be compared, in terms of the breadth and depth of its impact on research and scholarship, to the invention of writing and the development of modern mathematics. Ian Foster,
The advent of computation can be compared, in terms of the breadth and depth of its impact on research and scholarship, to the invention of writing and the development of modern mathematics. Ian Foster,
MATE-EC2: A Middleware for Processing Data with Amazon Web Services
 MATE-EC2: A Middleware for Processing Data with Amazon Web Services Tekin Bicer David Chiu* and Gagan Agrawal Department of Compute Science and Engineering Ohio State University * School of Engineering
MATE-EC2: A Middleware for Processing Data with Amazon Web Services Tekin Bicer David Chiu* and Gagan Agrawal Department of Compute Science and Engineering Ohio State University * School of Engineering
Supercomputers. Alex Reid & James O'Donoghue
 Supercomputers Alex Reid & James O'Donoghue The Need for Supercomputers Supercomputers allow large amounts of processing to be dedicated to calculation-heavy problems Supercomputers are centralized in
Supercomputers Alex Reid & James O'Donoghue The Need for Supercomputers Supercomputers allow large amounts of processing to be dedicated to calculation-heavy problems Supercomputers are centralized in
Crossing the Chasm: Sneaking a parallel file system into Hadoop
 Crossing the Chasm: Sneaking a parallel file system into Hadoop Wittawat Tantisiriroj Swapnil Patil, Garth Gibson PARALLEL DATA LABORATORY Carnegie Mellon University In this work Compare and contrast large
Crossing the Chasm: Sneaking a parallel file system into Hadoop Wittawat Tantisiriroj Swapnil Patil, Garth Gibson PARALLEL DATA LABORATORY Carnegie Mellon University In this work Compare and contrast large
Executing dynamic heterogeneous workloads on Blue Waters with RADICAL-Pilot
 Executing dynamic heterogeneous workloads on Blue Waters with RADICAL-Pilot Research in Advanced DIstributed Cyberinfrastructure & Applications Laboratory (RADICAL) Rutgers University http://radical.rutgers.edu
Executing dynamic heterogeneous workloads on Blue Waters with RADICAL-Pilot Research in Advanced DIstributed Cyberinfrastructure & Applications Laboratory (RADICAL) Rutgers University http://radical.rutgers.edu
Distributed NoSQL Storage for Extreme-scale System Services
 Distributed NoSQL Storage for Extreme-scale System Services Short Bio 6 th year PhD student from DataSys Lab, CS Department, Illinois Institute oftechnology,chicago Academic advisor: Dr. Ioan Raicu Research
Distributed NoSQL Storage for Extreme-scale System Services Short Bio 6 th year PhD student from DataSys Lab, CS Department, Illinois Institute oftechnology,chicago Academic advisor: Dr. Ioan Raicu Research
High Performance Data Analytics for Numerical Simulations. Bruno Raffin DataMove
 High Performance Data Analytics for Numerical Simulations Bruno Raffin DataMove bruno.raffin@inria.fr April 2016 About this Talk HPC for analyzing the results of large scale parallel numerical simulations
High Performance Data Analytics for Numerical Simulations Bruno Raffin DataMove bruno.raffin@inria.fr April 2016 About this Talk HPC for analyzing the results of large scale parallel numerical simulations
Arguably one of the most fundamental discipline that touches all other disciplines and people
 The scientific and mathematical approach in information technology and computing Started in the 1960s from Mathematics or Electrical Engineering Today: Arguably one of the most fundamental discipline that
The scientific and mathematical approach in information technology and computing Started in the 1960s from Mathematics or Electrical Engineering Today: Arguably one of the most fundamental discipline that
Co-existence: Can Big Data and Big Computation Co-exist on the Same Systems?
 Co-existence: Can Big Data and Big Computation Co-exist on the Same Systems? Dr. William Kramer National Center for Supercomputing Applications, University of Illinois Where these views come from Large
Co-existence: Can Big Data and Big Computation Co-exist on the Same Systems? Dr. William Kramer National Center for Supercomputing Applications, University of Illinois Where these views come from Large
YCSB++ benchmarking tool Performance debugging advanced features of scalable table stores
 YCSB++ benchmarking tool Performance debugging advanced features of scalable table stores Swapnil Patil M. Polte, W. Tantisiriroj, K. Ren, L.Xiao, J. Lopez, G.Gibson, A. Fuchs *, B. Rinaldi * Carnegie
YCSB++ benchmarking tool Performance debugging advanced features of scalable table stores Swapnil Patil M. Polte, W. Tantisiriroj, K. Ren, L.Xiao, J. Lopez, G.Gibson, A. Fuchs *, B. Rinaldi * Carnegie
Challenges in large-scale graph processing on HPC platforms and the Graph500 benchmark. by Nkemdirim Dockery
 Challenges in large-scale graph processing on HPC platforms and the Graph500 benchmark by Nkemdirim Dockery High Performance Computing Workloads Core-memory sized Floating point intensive Well-structured
Challenges in large-scale graph processing on HPC platforms and the Graph500 benchmark by Nkemdirim Dockery High Performance Computing Workloads Core-memory sized Floating point intensive Well-structured
Crossing the Chasm: Sneaking a parallel file system into Hadoop
 Crossing the Chasm: Sneaking a parallel file system into Hadoop Wittawat Tantisiriroj Swapnil Patil, Garth Gibson PARALLEL DATA LABORATORY Carnegie Mellon University In this work Compare and contrast large
Crossing the Chasm: Sneaking a parallel file system into Hadoop Wittawat Tantisiriroj Swapnil Patil, Garth Gibson PARALLEL DATA LABORATORY Carnegie Mellon University In this work Compare and contrast large
Write a technical report Present your results Write a workshop/conference paper (optional) Could be a real system, simulation and/or theoretical
 Could be a real system, simulation and/or theoretical") Identify a problem Review approaches to the problem Propose a novel approach to the problem Define, design, prototype an implementation to evaluate your approach Could be a real system, simulation and/or
Identify a problem Review approaches to the problem Propose a novel approach to the problem Define, design, prototype an implementation to evaluate your approach Could be a real system, simulation and/or
Using Alluxio to Improve the Performance and Consistency of HDFS Clusters
 ARTICLE Using Alluxio to Improve the Performance and Consistency of HDFS Clusters Calvin Jia Software Engineer at Alluxio Learn how Alluxio is used in clusters with co-located compute and storage to improve
ARTICLE Using Alluxio to Improve the Performance and Consistency of HDFS Clusters Calvin Jia Software Engineer at Alluxio Learn how Alluxio is used in clusters with co-located compute and storage to improve
PART I - Fundamentals of Parallel Computing
 PART I - Fundamentals of Parallel Computing Objectives What is scientific computing? The need for more computing power The need for parallel computing and parallel programs 1 What is scientific computing?
PART I - Fundamentals of Parallel Computing Objectives What is scientific computing? The need for more computing power The need for parallel computing and parallel programs 1 What is scientific computing?
NERSC Site Update. National Energy Research Scientific Computing Center Lawrence Berkeley National Laboratory. Richard Gerber
 NERSC Site Update National Energy Research Scientific Computing Center Lawrence Berkeley National Laboratory Richard Gerber NERSC Senior Science Advisor High Performance Computing Department Head Cori
NERSC Site Update National Energy Research Scientific Computing Center Lawrence Berkeley National Laboratory Richard Gerber NERSC Senior Science Advisor High Performance Computing Department Head Cori
Practical Considerations for Multi- Level Schedulers. Benjamin
 Practical Considerations for Multi- Level Schedulers Benjamin Hindman @benh agenda 1 multi- level scheduling (scheduler activations) 2 intra- process multi- level scheduling (Lithe) 3 distributed multi-
Practical Considerations for Multi- Level Schedulers Benjamin Hindman @benh agenda 1 multi- level scheduling (scheduler activations) 2 intra- process multi- level scheduling (Lithe) 3 distributed multi-
Leveraging Software-Defined Storage to Meet Today and Tomorrow s Infrastructure Demands
 Leveraging Software-Defined Storage to Meet Today and Tomorrow s Infrastructure Demands Unleash Your Data Center s Hidden Power September 16, 2014 Molly Rector CMO, EVP Product Management & WW Marketing
Leveraging Software-Defined Storage to Meet Today and Tomorrow s Infrastructure Demands Unleash Your Data Center s Hidden Power September 16, 2014 Molly Rector CMO, EVP Product Management & WW Marketing
Requirement and Dependencies
 Requirement and Dependencies Linux GCC Google Protocol Buffer Version 2.4.1: https://protobuf.googlecode.com/files/protobuf- 2.4.1.tar.gz Google Protocol Buffer C-bindings Version 0.15: https://code.google.com/p/protobufc/downloads/detail?name=protobuf-c-0.15.tar.gz
Requirement and Dependencies Linux GCC Google Protocol Buffer Version 2.4.1: https://protobuf.googlecode.com/files/protobuf- 2.4.1.tar.gz Google Protocol Buffer C-bindings Version 0.15: https://code.google.com/p/protobufc/downloads/detail?name=protobuf-c-0.15.tar.gz
Cloud Computing Paradigms for Pleasingly Parallel Biomedical Applications
 Cloud Computing Paradigms for Pleasingly Parallel Biomedical Applications Thilina Gunarathne, Tak-Lon Wu Judy Qiu, Geoffrey Fox School of Informatics, Pervasive Technology Institute Indiana University
Cloud Computing Paradigms for Pleasingly Parallel Biomedical Applications Thilina Gunarathne, Tak-Lon Wu Judy Qiu, Geoffrey Fox School of Informatics, Pervasive Technology Institute Indiana University
Real-time Scheduling of Skewed MapReduce Jobs in Heterogeneous Environments
 Real-time Scheduling of Skewed MapReduce Jobs in Heterogeneous Environments Nikos Zacheilas, Vana Kalogeraki Department of Informatics Athens University of Economics and Business 1 Big Data era has arrived!
Real-time Scheduling of Skewed MapReduce Jobs in Heterogeneous Environments Nikos Zacheilas, Vana Kalogeraki Department of Informatics Athens University of Economics and Business 1 Big Data era has arrived!
Data Movement & Tiering with DMF 7
 Data Movement & Tiering with DMF 7 Kirill Malkin Director of Engineering April 2019 Why Move or Tier Data? We wish we could keep everything in DRAM, but It s volatile It s expensive Data in Memory 2 Why
Data Movement & Tiering with DMF 7 Kirill Malkin Director of Engineering April 2019 Why Move or Tier Data? We wish we could keep everything in DRAM, but It s volatile It s expensive Data in Memory 2 Why
HPC Technology Trends
 HPC Technology Trends High Performance Embedded Computing Conference September 18, 2007 David S Scott, Ph.D. Petascale Product Line Architect Digital Enterprise Group Risk Factors Today s s presentations
HPC Technology Trends High Performance Embedded Computing Conference September 18, 2007 David S Scott, Ph.D. Petascale Product Line Architect Digital Enterprise Group Risk Factors Today s s presentations
Applying DDN to Machine Learning
 Applying DDN to Machine Learning Jean-Thomas Acquaviva jacquaviva@ddn.com Learning from What? Multivariate data Image data Facial recognition Action recognition Object detection and recognition Handwriting
Applying DDN to Machine Learning Jean-Thomas Acquaviva jacquaviva@ddn.com Learning from What? Multivariate data Image data Facial recognition Action recognition Object detection and recognition Handwriting
Data Clustering on the Parallel Hadoop MapReduce Model. Dimitrios Verraros
 Data Clustering on the Parallel Hadoop MapReduce Model Dimitrios Verraros Overview The purpose of this thesis is to implement and benchmark the performance of a parallel K- means clustering algorithm on
Data Clustering on the Parallel Hadoop MapReduce Model Dimitrios Verraros Overview The purpose of this thesis is to implement and benchmark the performance of a parallel K- means clustering algorithm on
IBM Spectrum NAS, IBM Spectrum Scale and IBM Cloud Object Storage
 IBM Spectrum NAS, IBM Spectrum Scale and IBM Cloud Object Storage Silverton Consulting, Inc. StorInt Briefing 2017 SILVERTON CONSULTING, INC. ALL RIGHTS RESERVED Page 2 Introduction Unstructured data has
IBM Spectrum NAS, IBM Spectrum Scale and IBM Cloud Object Storage Silverton Consulting, Inc. StorInt Briefing 2017 SILVERTON CONSULTING, INC. ALL RIGHTS RESERVED Page 2 Introduction Unstructured data has
Predictable Time-Sharing for DryadLINQ Cluster. Sang-Min Park and Marty Humphrey Dept. of Computer Science University of Virginia
 Predictable Time-Sharing for DryadLINQ Cluster Sang-Min Park and Marty Humphrey Dept. of Computer Science University of Virginia 1 DryadLINQ What is DryadLINQ? LINQ: Data processing language and run-time
Predictable Time-Sharing for DryadLINQ Cluster Sang-Min Park and Marty Humphrey Dept. of Computer Science University of Virginia 1 DryadLINQ What is DryadLINQ? LINQ: Data processing language and run-time
NERSC. National Energy Research Scientific Computing Center
 NERSC National Energy Research Scientific Computing Center Established 1974, first unclassified supercomputer center Original mission: to enable computational science as a complement to magnetically controlled
NERSC National Energy Research Scientific Computing Center Established 1974, first unclassified supercomputer center Original mission: to enable computational science as a complement to magnetically controlled
Storage and Compute Resource Management via DYRE, 3DcacheGrid, and CompuStore Ioan Raicu, Ian Foster
 Storage and Compute Resource Management via DYRE, 3DcacheGrid, and CompuStore Ioan Raicu, Ian Foster. Overview Both the industry and academia have an increase demand for good policies and mechanisms to
Storage and Compute Resource Management via DYRE, 3DcacheGrid, and CompuStore Ioan Raicu, Ian Foster. Overview Both the industry and academia have an increase demand for good policies and mechanisms to
Aim High. Intel Technical Update Teratec 07 Symposium. June 20, Stephen R. Wheat, Ph.D. Director, HPC Digital Enterprise Group
 Aim High Intel Technical Update Teratec 07 Symposium June 20, 2007 Stephen R. Wheat, Ph.D. Director, HPC Digital Enterprise Group Risk Factors Today s s presentations contain forward-looking statements.
Aim High Intel Technical Update Teratec 07 Symposium June 20, 2007 Stephen R. Wheat, Ph.D. Director, HPC Digital Enterprise Group Risk Factors Today s s presentations contain forward-looking statements.
Automating Real-time Seismic Analysis
 Automating Real-time Seismic Analysis Through Streaming and High Throughput Workflows Rafael Ferreira da Silva, Ph.D. http://pegasus.isi.edu Do we need seismic analysis? Pegasus http://pegasus.isi.edu
Automating Real-time Seismic Analysis Through Streaming and High Throughput Workflows Rafael Ferreira da Silva, Ph.D. http://pegasus.isi.edu Do we need seismic analysis? Pegasus http://pegasus.isi.edu
Directions in Workload Management
 Directions in Workload Management Alex Sanchez and Morris Jette SchedMD LLC HPC Knowledge Meeting 2016 Areas of Focus Scalability Large Node and Core Counts Power Management Failure Management Federated
Directions in Workload Management Alex Sanchez and Morris Jette SchedMD LLC HPC Knowledge Meeting 2016 Areas of Focus Scalability Large Node and Core Counts Power Management Failure Management Federated
Ioan Raicu. Everyone else. More information at: Background? What do you want to get out of this course?
 Ioan Raicu More information at: http://www.cs.iit.edu/~iraicu/ Everyone else Background? What do you want to get out of this course? 2 Data Intensive Computing is critical to advancing modern science Applies
Ioan Raicu More information at: http://www.cs.iit.edu/~iraicu/ Everyone else Background? What do you want to get out of this course? 2 Data Intensive Computing is critical to advancing modern science Applies
Enosis: Bridging the Semantic Gap between
 Enosis: Bridging the Semantic Gap between File-based and Object-based Data Models Anthony Kougkas - akougkas@hawk.iit.edu, Hariharan Devarajan, Xian-He Sun Outline Introduction Background Approach Evaluation
Enosis: Bridging the Semantic Gap between File-based and Object-based Data Models Anthony Kougkas - akougkas@hawk.iit.edu, Hariharan Devarajan, Xian-He Sun Outline Introduction Background Approach Evaluation
Advances of parallel computing. Kirill Bogachev May 2016
 Advances of parallel computing Kirill Bogachev May 2016 Demands in Simulations Field development relies more and more on static and dynamic modeling of the reservoirs that has come a long way from being
Advances of parallel computing Kirill Bogachev May 2016 Demands in Simulations Field development relies more and more on static and dynamic modeling of the reservoirs that has come a long way from being
Bigtable. A Distributed Storage System for Structured Data. Presenter: Yunming Zhang Conglong Li. Saturday, September 21, 13
 Bigtable A Distributed Storage System for Structured Data Presenter: Yunming Zhang Conglong Li References SOCC 2010 Key Note Slides Jeff Dean Google Introduction to Distributed Computing, Winter 2008 University
Bigtable A Distributed Storage System for Structured Data Presenter: Yunming Zhang Conglong Li References SOCC 2010 Key Note Slides Jeff Dean Google Introduction to Distributed Computing, Winter 2008 University
System Software for Big Data and Post Petascale Computing
 The Japanese Extreme Big Data Workshop February 26, 2014 System Software for Big Data and Post Petascale Computing Osamu Tatebe University of Tsukuba I/O performance requirement for exascale applications
The Japanese Extreme Big Data Workshop February 26, 2014 System Software for Big Data and Post Petascale Computing Osamu Tatebe University of Tsukuba I/O performance requirement for exascale applications
Big Data Programming: an Introduction. Spring 2015, X. Zhang Fordham Univ.
 Big Data Programming: an Introduction Spring 2015, X. Zhang Fordham Univ. Outline What the course is about? scope Introduction to big data programming Opportunity and challenge of big data Origin of Hadoop
Big Data Programming: an Introduction Spring 2015, X. Zhang Fordham Univ. Outline What the course is about? scope Introduction to big data programming Opportunity and challenge of big data Origin of Hadoop
Spark, Shark and Spark Streaming Introduction
 Spark, Shark and Spark Streaming Introduction Tushar Kale tusharkale@in.ibm.com June 2015 This Talk Introduction to Shark, Spark and Spark Streaming Architecture Deployment Methodology Performance References
Spark, Shark and Spark Streaming Introduction Tushar Kale tusharkale@in.ibm.com June 2015 This Talk Introduction to Shark, Spark and Spark Streaming Architecture Deployment Methodology Performance References
Pocket: Elastic Ephemeral Storage for Serverless Analytics
 Pocket: Elastic Ephemeral Storage for Serverless Analytics Ana Klimovic*, Yawen Wang*, Patrick Stuedi +, Animesh Trivedi +, Jonas Pfefferle +, Christos Kozyrakis* *Stanford University, + IBM Research 1
Pocket: Elastic Ephemeral Storage for Serverless Analytics Ana Klimovic*, Yawen Wang*, Patrick Stuedi +, Animesh Trivedi +, Jonas Pfefferle +, Christos Kozyrakis* *Stanford University, + IBM Research 1
ECE 7650 Scalable and Secure Internet Services and Architecture ---- A Systems Perspective
 ECE 7650 Scalable and Secure Internet Services and Architecture ---- A Systems Perspective Part II: Data Center Software Architecture: Topic 3: Programming Models CIEL: A Universal Execution Engine for
ECE 7650 Scalable and Secure Internet Services and Architecture ---- A Systems Perspective Part II: Data Center Software Architecture: Topic 3: Programming Models CIEL: A Universal Execution Engine for
Chapter 5. The MapReduce Programming Model and Implementation
 Chapter 5. The MapReduce Programming Model and Implementation - Traditional computing: data-to-computing (send data to computing) * Data stored in separate repository * Data brought into system for computing
Chapter 5. The MapReduce Programming Model and Implementation - Traditional computing: data-to-computing (send data to computing) * Data stored in separate repository * Data brought into system for computing
Tuning I/O Performance for Data Intensive Computing. Nicholas J. Wright. lbl.gov
 Tuning I/O Performance for Data Intensive Computing. Nicholas J. Wright njwright @ lbl.gov NERSC- National Energy Research Scientific Computing Center Mission: Accelerate the pace of scientific discovery
Tuning I/O Performance for Data Intensive Computing. Nicholas J. Wright njwright @ lbl.gov NERSC- National Energy Research Scientific Computing Center Mission: Accelerate the pace of scientific discovery
Case Studies in Storage Access by Loosely Coupled Petascale Applications
 Case Studies in Storage Access by Loosely Coupled Petascale Applications Justin M Wozniak and Michael Wilde Petascale Data Storage Workshop at SC 09 Portland, Oregon November 15, 2009 Outline Scripted
Case Studies in Storage Access by Loosely Coupled Petascale Applications Justin M Wozniak and Michael Wilde Petascale Data Storage Workshop at SC 09 Portland, Oregon November 15, 2009 Outline Scripted
Accelerating Large Scale Scientific Exploration through Data Diffusion
 Accelerating Large Scale Scientific Exploration through Data Diffusion Ioan Raicu *, Yong Zhao *, Ian Foster #*+, Alex Szalay - {iraicu,yongzh }@cs.uchicago.edu, foster@mcs.anl.gov, szalay@jhu.edu * Department
Accelerating Large Scale Scientific Exploration through Data Diffusion Ioan Raicu *, Yong Zhao *, Ian Foster #*+, Alex Szalay - {iraicu,yongzh }@cs.uchicago.edu, foster@mcs.anl.gov, szalay@jhu.edu * Department
HPC over Cloud. July 16 th, SCENT HPC Summer GIST. SCENT (Super Computing CENTer) GIST (Gwangju Institute of Science & Technology)
 GIST (Gwangju Institute of Science & Technology)") HPC over Cloud July 16 th, 2014 2014 HPC Summer School @ GIST (Super Computing CENTer) GIST (Gwangju Institute of Science & Technology) Dr. JongWon Kim jongwon@nm.gist.ac.kr Interplay between Theory, Simulation,
HPC over Cloud July 16 th, 2014 2014 HPC Summer School @ GIST (Super Computing CENTer) GIST (Gwangju Institute of Science & Technology) Dr. JongWon Kim jongwon@nm.gist.ac.kr Interplay between Theory, Simulation,
FUSION PROCESSORS AND HPC
 FUSION PROCESSORS AND HPC Chuck Moore AMD Corporate Fellow & Technology Group CTO June 14, 2011 Fusion Processors and HPC Today: Multi-socket x86 CMPs + optional dgpu + high BW memory Fusion APUs (SPFP)
FUSION PROCESSORS AND HPC Chuck Moore AMD Corporate Fellow & Technology Group CTO June 14, 2011 Fusion Processors and HPC Today: Multi-socket x86 CMPs + optional dgpu + high BW memory Fusion APUs (SPFP)
SCALABLE RESOURCE MANAGEMENT IN CLOUD COMPUTING IMAN SADOOGHI DEPARTMENT OF COMPUTER SCIENCE
 SCALABLE RESOURCE MANAGEMENT IN CLOUD COMPUTING BY IMAN SADOOGHI DEPARTMENT OF COMPUTER SCIENCE Submitted in partial fulfillment of the requirements for the degree of Doctor of Philosophy in Computer Science
SCALABLE RESOURCE MANAGEMENT IN CLOUD COMPUTING BY IMAN SADOOGHI DEPARTMENT OF COMPUTER SCIENCE Submitted in partial fulfillment of the requirements for the degree of Doctor of Philosophy in Computer Science
ZHT A Fast, Reliable and Scalable Zero- hop Distributed Hash Table
 ZHT A Fast, Reliable and Scalable Zero- hop Distributed Hash Table 1 What is KVS? Why to use? Why not to use? Who s using it? Design issues A storage system A distributed hash table Spread simple structured
ZHT A Fast, Reliable and Scalable Zero- hop Distributed Hash Table 1 What is KVS? Why to use? Why not to use? Who s using it? Design issues A storage system A distributed hash table Spread simple structured
Motivation Goal Idea Proposition for users Study
 Exploring Tradeoffs Between Power and Performance for a Scientific Visualization Algorithm Stephanie Labasan Computer and Information Science University of Oregon 23 November 2015 Overview Motivation:
Exploring Tradeoffs Between Power and Performance for a Scientific Visualization Algorithm Stephanie Labasan Computer and Information Science University of Oregon 23 November 2015 Overview Motivation:
IME (Infinite Memory Engine) Extreme Application Acceleration & Highly Efficient I/O Provisioning
 Extreme Application Acceleration & Highly Efficient I/O Provisioning") IME (Infinite Memory Engine) Extreme Application Acceleration & Highly Efficient I/O Provisioning September 22 nd 2015 Tommaso Cecchi 2 What is IME? This breakthrough, software defined storage application
IME (Infinite Memory Engine) Extreme Application Acceleration & Highly Efficient I/O Provisioning September 22 nd 2015 Tommaso Cecchi 2 What is IME? This breakthrough, software defined storage application
HADOOP 3.0 is here! Dr. Sandeep Deshmukh Sadepach Labs Pvt. Ltd. - Let us grow together!
 HADOOP 3.0 is here! Dr. Sandeep Deshmukh sandeep@sadepach.com Sadepach Labs Pvt. Ltd. - Let us grow together! About me BE from VNIT Nagpur, MTech+PhD from IIT Bombay Worked with Persistent Systems - Life
HADOOP 3.0 is here! Dr. Sandeep Deshmukh sandeep@sadepach.com Sadepach Labs Pvt. Ltd. - Let us grow together! About me BE from VNIT Nagpur, MTech+PhD from IIT Bombay Worked with Persistent Systems - Life
Big Data Analytics at OSC
 Big Data Analytics at OSC 04/05/2018 SUG Shameema Oottikkal Data Application Engineer Ohio SuperComputer Center email:soottikkal@osc.edu 1 Data Analytics at OSC Introduction: Data Analytical nodes OSC
Big Data Analytics at OSC 04/05/2018 SUG Shameema Oottikkal Data Application Engineer Ohio SuperComputer Center email:soottikkal@osc.edu 1 Data Analytics at OSC Introduction: Data Analytical nodes OSC
Big data systems 12/8/17
 Big data systems 12/8/17 Today Basic architecture Two levels of scheduling Spark overview Basic architecture Cluster Manager Cluster Cluster Manager 64GB RAM 32 cores 64GB RAM 32 cores 64GB RAM 32 cores
Big data systems 12/8/17 Today Basic architecture Two levels of scheduling Spark overview Basic architecture Cluster Manager Cluster Cluster Manager 64GB RAM 32 cores 64GB RAM 32 cores 64GB RAM 32 cores
CS435 Introduction to Big Data FALL 2018 Colorado State University. 10/24/2018 Week 10-B Sangmi Lee Pallickara
 10/24/2018 CS435 Introduction to Big Data - FALL 2018 W10B00 CS435 Introduction to Big Data 10/24/2018 CS435 Introduction to Big Data - FALL 2018 W10B1 FAQs Programming Assignment 3 has been posted Recitations
10/24/2018 CS435 Introduction to Big Data - FALL 2018 W10B00 CS435 Introduction to Big Data 10/24/2018 CS435 Introduction to Big Data - FALL 2018 W10B1 FAQs Programming Assignment 3 has been posted Recitations
PBS PROFESSIONAL VS. MICROSOFT HPC PACK
 PBS PROFESSIONAL VS. MICROSOFT HPC PACK On the Microsoft Windows Platform PBS Professional offers many features which are not supported by Microsoft HPC Pack. SOME OF THE IMPORTANT ADVANTAGES OF PBS PROFESSIONAL
PBS PROFESSIONAL VS. MICROSOFT HPC PACK On the Microsoft Windows Platform PBS Professional offers many features which are not supported by Microsoft HPC Pack. SOME OF THE IMPORTANT ADVANTAGES OF PBS PROFESSIONAL
CSD3 The Cambridge Service for Data Driven Discovery. A New National HPC Service for Data Intensive science
 CSD3 The Cambridge Service for Data Driven Discovery A New National HPC Service for Data Intensive science Dr Paul Calleja Director of Research Computing University of Cambridge Problem statement Today
CSD3 The Cambridge Service for Data Driven Discovery A New National HPC Service for Data Intensive science Dr Paul Calleja Director of Research Computing University of Cambridge Problem statement Today
Storage and Compute Resource Management via DYRE, 3DcacheGrid, and CompuStore
 Storage and Compute Resource Management via DYRE, 3DcacheGrid, and CompuStore Ioan Raicu Distributed Systems Laboratory Computer Science Department University of Chicago DSL Seminar November st, 006 Analysis
Storage and Compute Resource Management via DYRE, 3DcacheGrid, and CompuStore Ioan Raicu Distributed Systems Laboratory Computer Science Department University of Chicago DSL Seminar November st, 006 Analysis
Automatic Identification of Application I/O Signatures from Noisy Server-Side Traces. Yang Liu Raghul Gunasekaran Xiaosong Ma Sudharshan S.
 Automatic Identification of Application I/O Signatures from Noisy Server-Side Traces Yang Liu Raghul Gunasekaran Xiaosong Ma Sudharshan S. Vazhkudai Instance of Large-Scale HPC Systems ORNL s TITAN (World
Automatic Identification of Application I/O Signatures from Noisy Server-Side Traces Yang Liu Raghul Gunasekaran Xiaosong Ma Sudharshan S. Vazhkudai Instance of Large-Scale HPC Systems ORNL s TITAN (World
MapReduce. U of Toronto, 2014
 MapReduce U of Toronto, 2014 http://www.google.org/flutrends/ca/ (2012) Average Searches Per Day: 5,134,000,000 2 Motivation Process lots of data Google processed about 24 petabytes of data per day in
MapReduce U of Toronto, 2014 http://www.google.org/flutrends/ca/ (2012) Average Searches Per Day: 5,134,000,000 2 Motivation Process lots of data Google processed about 24 petabytes of data per day in
Topics. Big Data Analytics What is and Why Hadoop? Comparison to other technologies Hadoop architecture Hadoop ecosystem Hadoop usage examples
 Hadoop Introduction 1 Topics Big Data Analytics What is and Why Hadoop? Comparison to other technologies Hadoop architecture Hadoop ecosystem Hadoop usage examples 2 Big Data Analytics What is Big Data?
Hadoop Introduction 1 Topics Big Data Analytics What is and Why Hadoop? Comparison to other technologies Hadoop architecture Hadoop ecosystem Hadoop usage examples 2 Big Data Analytics What is Big Data?
PLATFORM AND SOFTWARE AS A SERVICE THE MAPREDUCE PROGRAMMING MODEL AND IMPLEMENTATIONS
 PLATFORM AND SOFTWARE AS A SERVICE THE MAPREDUCE PROGRAMMING MODEL AND IMPLEMENTATIONS By HAI JIN, SHADI IBRAHIM, LI QI, HAIJUN CAO, SONG WU and XUANHUA SHI Prepared by: Dr. Faramarz Safi Islamic Azad
PLATFORM AND SOFTWARE AS A SERVICE THE MAPREDUCE PROGRAMMING MODEL AND IMPLEMENTATIONS By HAI JIN, SHADI IBRAHIM, LI QI, HAIJUN CAO, SONG WU and XUANHUA SHI Prepared by: Dr. Faramarz Safi Islamic Azad
Resource and Performance Distribution Prediction for Large Scale Analytics Queries
 Resource and Performance Distribution Prediction for Large Scale Analytics Queries Prof. Rajiv Ranjan, SMIEEE School of Computing Science, Newcastle University, UK Visiting Scientist, Data61, CSIRO, Australia
Resource and Performance Distribution Prediction for Large Scale Analytics Queries Prof. Rajiv Ranjan, SMIEEE School of Computing Science, Newcastle University, UK Visiting Scientist, Data61, CSIRO, Australia
Green Supercomputing
 Green Supercomputing On the Energy Consumption of Modern E-Science Prof. Dr. Thomas Ludwig German Climate Computing Centre Hamburg, Germany ludwig@dkrz.de Outline DKRZ 2013 and Climate Science The Exascale
Green Supercomputing On the Energy Consumption of Modern E-Science Prof. Dr. Thomas Ludwig German Climate Computing Centre Hamburg, Germany ludwig@dkrz.de Outline DKRZ 2013 and Climate Science The Exascale
HPC in Cloud. Presenter: Naresh K. Sehgal Contributors: Billy Cox, John M. Acken, Sohum Sohoni
 HPC in Cloud Presenter: Naresh K. Sehgal Contributors: Billy Cox, John M. Acken, Sohum Sohoni 2 Agenda What is HPC? Problem Statement(s) Cloud Workload Characterization Translation from High Level Issues
HPC in Cloud Presenter: Naresh K. Sehgal Contributors: Billy Cox, John M. Acken, Sohum Sohoni 2 Agenda What is HPC? Problem Statement(s) Cloud Workload Characterization Translation from High Level Issues
The MOSIX Scalable Cluster Computing for Linux. mosix.org
 The MOSIX Scalable Cluster Computing for Linux Prof. Amnon Barak Computer Science Hebrew University http://www. mosix.org 1 Presentation overview Part I : Why computing clusters (slide 3-7) Part II : What
The MOSIX Scalable Cluster Computing for Linux Prof. Amnon Barak Computer Science Hebrew University http://www. mosix.org 1 Presentation overview Part I : Why computing clusters (slide 3-7) Part II : What
Embedded Technosolutions
 Hadoop Big Data An Important technology in IT Sector Hadoop - Big Data Oerie 90% of the worlds data was generated in the last few years. Due to the advent of new technologies, devices, and communication
Hadoop Big Data An Important technology in IT Sector Hadoop - Big Data Oerie 90% of the worlds data was generated in the last few years. Due to the advent of new technologies, devices, and communication
Leveraging Flash in HPC Systems
 Leveraging Flash in HPC Systems IEEE MSST June 3, 2015 This work was performed under the auspices of the U.S. Department of Energy by under Contract DE-AC52-07NA27344. Lawrence Livermore National Security,
Leveraging Flash in HPC Systems IEEE MSST June 3, 2015 This work was performed under the auspices of the U.S. Department of Energy by under Contract DE-AC52-07NA27344. Lawrence Livermore National Security,
YCSB++ Benchmarking Tool Performance Debugging Advanced Features of Scalable Table Stores
 YCSB++ Benchmarking Tool Performance Debugging Advanced Features of Scalable Table Stores Swapnil Patil Milo Polte, Wittawat Tantisiriroj, Kai Ren, Lin Xiao, Julio Lopez, Garth Gibson, Adam Fuchs *, Billie
YCSB++ Benchmarking Tool Performance Debugging Advanced Features of Scalable Table Stores Swapnil Patil Milo Polte, Wittawat Tantisiriroj, Kai Ren, Lin Xiao, Julio Lopez, Garth Gibson, Adam Fuchs *, Billie
Let s say I give you a homework assignment today with 100 problems. Each problem takes 2 hours to solve. The homework is due tomorrow.
 Let s say I give you a homework assignment today with 100 problems. Each problem takes 2 hours to solve. The homework is due tomorrow. Big problems and Very Big problems in Science How do we live Protein
Let s say I give you a homework assignment today with 100 problems. Each problem takes 2 hours to solve. The homework is due tomorrow. Big problems and Very Big problems in Science How do we live Protein
CSE 451: Operating Systems Spring Module 12 Secondary Storage
 CSE 451: Operating Systems Spring 2017 Module 12 Secondary Storage John Zahorjan 1 Secondary storage Secondary storage typically: is anything that is outside of primary memory does not permit direct execution
CSE 451: Operating Systems Spring 2017 Module 12 Secondary Storage John Zahorjan 1 Secondary storage Secondary storage typically: is anything that is outside of primary memory does not permit direct execution
MDHIM: A Parallel Key/Value Store Framework for HPC
 MDHIM: A Parallel Key/Value Store Framework for HPC Hugh Greenberg 7/6/2015 LA-UR-15-25039 HPC Clusters Managed by a job scheduler (e.g., Slurm, Moab) Designed for running user jobs Difficult to run system
MDHIM: A Parallel Key/Value Store Framework for HPC Hugh Greenberg 7/6/2015 LA-UR-15-25039 HPC Clusters Managed by a job scheduler (e.g., Slurm, Moab) Designed for running user jobs Difficult to run system
Page 1. Goals for Today" Background of Cloud Computing" Sources Driving Big Data" CS162 Operating Systems and Systems Programming Lecture 24
 Goals for Today" CS162 Operating Systems and Systems Programming Lecture 24 Capstone: Cloud Computing" Distributed systems Cloud Computing programming paradigms Cloud Computing OS December 2, 2013 Anthony
Goals for Today" CS162 Operating Systems and Systems Programming Lecture 24 Capstone: Cloud Computing" Distributed systems Cloud Computing programming paradigms Cloud Computing OS December 2, 2013 Anthony
On the Role of Burst Buffers in Leadership- Class Storage Systems
 On the Role of Burst Buffers in Leadership- Class Storage Systems Ning Liu, Jason Cope, Philip Carns, Christopher Carothers, Robert Ross, Gary Grider, Adam Crume, Carlos Maltzahn Contact: liun2@cs.rpi.edu,
On the Role of Burst Buffers in Leadership- Class Storage Systems Ning Liu, Jason Cope, Philip Carns, Christopher Carothers, Robert Ross, Gary Grider, Adam Crume, Carlos Maltzahn Contact: liun2@cs.rpi.edu,
High Performance Computing on MapReduce Programming Framework
 International Journal of Private Cloud Computing Environment and Management Vol. 2, No. 1, (2015), pp. 27-32 http://dx.doi.org/10.21742/ijpccem.2015.2.1.04 High Performance Computing on MapReduce Programming
International Journal of Private Cloud Computing Environment and Management Vol. 2, No. 1, (2015), pp. 27-32 http://dx.doi.org/10.21742/ijpccem.2015.2.1.04 High Performance Computing on MapReduce Programming
Key Technologies for 100 PFLOPS. Copyright 2014 FUJITSU LIMITED
 Key Technologies for 100 PFLOPS How to keep the HPC-tree growing Molecular dynamics Computational materials Drug discovery Life-science Quantum chemistry Eigenvalue problem FFT Subatomic particle phys.
Key Technologies for 100 PFLOPS How to keep the HPC-tree growing Molecular dynamics Computational materials Drug discovery Life-science Quantum chemistry Eigenvalue problem FFT Subatomic particle phys.
Scientific Workflows and Cloud Computing. Gideon Juve USC Information Sciences Institute
 Scientific Workflows and Cloud Computing Gideon Juve USC Information Sciences Institute gideon@isi.edu Scientific Workflows Loosely-coupled parallel applications Expressed as directed acyclic graphs (DAGs)
Scientific Workflows and Cloud Computing Gideon Juve USC Information Sciences Institute gideon@isi.edu Scientific Workflows Loosely-coupled parallel applications Expressed as directed acyclic graphs (DAGs)
Cray XC Scalability and the Aries Network Tony Ford
 Cray XC Scalability and the Aries Network Tony Ford June 29, 2017 Exascale Scalability Which scalability metrics are important for Exascale? Performance (obviously!) What are the contributing factors?
Cray XC Scalability and the Aries Network Tony Ford June 29, 2017 Exascale Scalability Which scalability metrics are important for Exascale? Performance (obviously!) What are the contributing factors?
Consolidating Complementary VMs with Spatial/Temporalawareness
 Consolidating Complementary VMs with Spatial/Temporalawareness in Cloud Datacenters Liuhua Chen and Haiying Shen Dept. of Electrical and Computer Engineering Clemson University, SC, USA 1 Outline Introduction
Consolidating Complementary VMs with Spatial/Temporalawareness in Cloud Datacenters Liuhua Chen and Haiying Shen Dept. of Electrical and Computer Engineering Clemson University, SC, USA 1 Outline Introduction
CSE 451: Operating Systems Spring Module 12 Secondary Storage. Steve Gribble
 CSE 451: Operating Systems Spring 2009 Module 12 Secondary Storage Steve Gribble Secondary storage Secondary storage typically: is anything that is outside of primary memory does not permit direct execution
CSE 451: Operating Systems Spring 2009 Module 12 Secondary Storage Steve Gribble Secondary storage Secondary storage typically: is anything that is outside of primary memory does not permit direct execution
Towards Exascale Programming Models HPC Summit, Prague Erwin Laure, KTH
 Towards Exascale Programming Models HPC Summit, Prague Erwin Laure, KTH 1 Exascale Programming Models With the evolution of HPC architecture towards exascale, new approaches for programming these machines
Towards Exascale Programming Models HPC Summit, Prague Erwin Laure, KTH 1 Exascale Programming Models With the evolution of HPC architecture towards exascale, new approaches for programming these machines
Hadoop Virtualization Extensions on VMware vsphere 5 T E C H N I C A L W H I T E P A P E R
 Hadoop Virtualization Extensions on VMware vsphere 5 T E C H N I C A L W H I T E P A P E R Table of Contents Introduction... 3 Topology Awareness in Hadoop... 3 Virtual Hadoop... 4 HVE Solution... 5 Architecture...
Hadoop Virtualization Extensions on VMware vsphere 5 T E C H N I C A L W H I T E P A P E R Table of Contents Introduction... 3 Topology Awareness in Hadoop... 3 Virtual Hadoop... 4 HVE Solution... 5 Architecture...