Advanced Database Technologies NoSQL: Not only SQL
|
|
|
- Joan Potter
- 6 years ago
- Views:
Transcription
1 Advanced Database Technologies NoSQL: Not only SQL Christian Grün Database & Information Systems Group
2 NoSQL Introduction 30, 40 years history of well-established database technology all in vain? Not at all! But both setups and demands have drastically changed: main memory and CPU speed have exploded, compared to the time when System R (the mother of all RDBMS) was developed at the same time, huge amounts of data are now handled in real-time both data and use cases are getting more and more dynamic social networks (relying on graph data) have gained impressive momentum full-texts have always been treated shabbily by relational DBMS 2
3 NoSQL: Facebook Statistics royal.pingdom.com/2010/06/18/the-software-behind-facebook 500 million users 570 billion page views per month 3 billion photos uploaded per month 1.2 million photos served per second 25 billion pieces of content (updates, comments) shared every month 50 million server-side operations per second 2008: 10,000 servers; 2009: 30,000, One RDBMS may not be enough to keep this going on! 3


4 NoSQL: Facebook Architecture Memcached distributed memory caching system caching layer between web and database servers based on a distributed hash table (DHT) HipHop for PHP developed by Facebook to improve scalability compiles PHP to C++ code, which can be better optimized PHP runtime system was reimplemented 4
 Hadoop/Hive implementation of Google s MapReduce framework performs data-intensive calculations (initially) used by Facebook for data")
5 NoSQL: Facebook Architecture Cassandra developed by Facebook for inbox searching data is automatically replicated to multiple nodes no single point of failure (all nodes are equal) Hadoop/Hive implementation of Google s MapReduce framework performs data-intensive calculations (initially) used by Facebook for data analysis 5
 Scribe aggregates log data from")
6 NoSQL: Facebook Architecture Varnish HTTP accelerator, speeds up dynamic web sites Haystack object store, used for storing and retrieving photos BigPipe web page serving system; serves parts of the page (chat, news feed, ) Scribe aggregates log data from different servers 6
7 NoSQL: Facebook Architecture: Hadoop Cluster hadoopblog.blogspot.com/2010/05/facebook-has-worlds-largest-hadoop.html 21 PB in Data Warehouse cluster, spread across 2000 machines: 1200 machines with 8 cores, 800 machines with 16 cores 12 TB disk space per machine, 32 GB RAM per machine 15 map-reduce tasks per machine Workload daily: 12 TB of compressed data, and 800 TB of scanned data 25,000 map-reduce jobs and 65 million files per day 7

8 NoSQL: Facebook Architecture Conclusion HBase Hadoop database, used for s, IM and SMS has recently replaced MySQL, Cassandra and few others built on Google s BigTable model...to be continued classical database solutions have turned out to be completely insufficient heterogeneous software architecture is needed to match all requirements 8
9 NoSQL: Not only SQL do we need a Facebook-like architecture for conventional tasks? Thoughts Depends on problems to be solved: RDBMS are still a great solution for centralized, tabular data sets NoSQL gets interesting if data is heterogeneous and/or too large most NoSQL projects are open source and have open communities code bases are up-to-date (no 30 years old, closed legacy code) they are subject to rapid development and change cannot offer general-purpose solutions yet, as claimed by RDBMS 9
10 NoSQL: Not only SQL 10 Things: Five Advantages Elastic Scaling Economics scaling out: distributing data based on cheap commodity servers instead of buying bigger servers less costs per transaction/second Big Data Flexible Data Models opens new dimensions that non-existing/relaxed data schema cannot be handled with RDBMS structural changes cause no Goodbye DBAs (see you later?) overhead automatic repair, distribution, tuning, 10
11 NoSQL: Not only SQL 10 Things: Five Challengees Maturity Analytics and Business Intelligence still in pre-production phase, key focused on web apps scenarios features yet to be implemented limited ad-hoc querying Support Expertise mostly open source, start-ups, few number of NoSQL experts limited resources or credibility available in the market Administration require lot of skill to install and effort to maintain 11
12 Definition nosql-database.org Next Generation Databases mostly addressing some of the points: being non-relational, distributed, opensource and horizontally scalable. The original intention has been modern web-scale databases. The movement began early 2009 and is growing rapidly. Often more characteristics apply as: schema-free, easy replication support, simple API, eventually consistent/base (not ACID), a huge data amount, and more. History Stefan Edlich 1998 term was coined by NoSQL RDBMS, developed by Carlo Strozzi 2009 reintroduced on a meetup for open source, distributed, non relational databases, organized by last.fm developer Johan Oskarsson 12
13 Scalability System can handle growing amounts of data without losing performance. Vertical Scalability (scale up) add resources (more CPUs, more memory) to a single node using more threads to handle a local problem Horizontal Scalability (scale out) add nodes (more computers, servers) to a distributed system gets more and more popular due to low costs for commodity hardware often surpasses scalability of vertical approach 13
14 CAP Theorem: Consistency, Availability, Partition Tolerance Brewer [2000]: Towards Robust Distributed Systems Consistency after an update, all readers in a distributed system see the same data all nodes are supposed to contain the same data at all times Example single database instance will always be consistent if multiple instances exist, all writes must be duplicated before write operation is completed 14
15 CAP Theorem: Consistency, Availability, Partition Tolerance Brewer [2000]: Towards Robust Distributed Systems Availability all requests will be answered, regardless of crashes or downtimes Example a single instance has an availability of 100% or 0% two servers may be available 100%, 50%, or 0% Partition Tolerance system continues to operate, even if two sets of servers get isolated Example system gets partitioned if connection between server clusters fails failed connection won t cause troubles if system is tolerant 15
![CAP Theorem: Consistency, Availability, Partition Tolerance Brewer [2000]: Towards Robust Distributed Systems Theorem (proven 2002): only 2 of the 3 guarantees can be given in a shared-data system](/docs-images/72/66255852/images/16-3.jpg "(Positive) consequence: we can concentrate on two challenges ACID properties needed to guarantee consistency and availability BASE properties come into play if availability and partition tolerance is")
16 CAP Theorem: Consistency, Availability, Partition Tolerance Brewer [2000]: Towards Robust Distributed Systems Theorem (proven 2002): only 2 of the 3 guarantees can be given in a shared-data system (Positive) consequence: we can concentrate on two challenges ACID properties needed to guarantee consistency and availability BASE properties come into play if availability and partition tolerance is favored 16
17 ACID: Atomicity, Consistency, Isolation, Durability Härder & Reuter [1983]: Principles of Transaction-Oriented Database Recovery Atomicity all operations in the transaction will complete, or none will Consistency before and after transactions, database will be in a consistent state Isolation operations cannot access data that is currently modified Durability data will not be lost upon completion of a transaction 17
18 BASE: Basically Available, Soft State, Eventual Consistency Fox et al. [1997]: Cluster-Based Scalable Network Services Basically Available an application works basically all the time (despite partial failures) Soft State is in flux and non-deterministic (changes all the time) Eventual Consistency will be in some consistent state (at some time in future) Why is BASE a reasonable paradigm for e.g. web search? 18
19 MapReduce Framework Dean & Ghemawat [2004]: MapReduce: Simplified Data Processing on Large Clusters developed by Google to replace old, centralized index structure supports distributed, parallel computing on large data sets inspired by ( not equal to ) the map and fold functions in functional programming: no side effects, deadlocks, race conditions divide-and-conquer paradigm: Map recursively breaks down a problem into sub-problems and distributes it to worker nodes; Reduce receives and combines the sub-answers to solve the problem 19
20 Map/Fold in XQuery 3.0 map() function: let $func:=function($a){$a*$a} return map($func,1 to 4) Result: fold-left() function: let $func:=function($a,$b){$a*$b} return fold-left($func,1,1 to 4) Same as: ((((1*1)*2)*3)*4) Result: 24 applies a function to all items of a sequence iterates a function over a sequence and builds up a single item 20
21 MapReduce: Functions Input & Output: each a set of key/value pairs. Programmer specifies two functions: map(in_key, in_value) list(out_key, intermed_value): processes input key/value pair, produces set of intermediate pairs reduce(out_key, list(intermed_value)) list(out_value): combines all intermediate values for a particular key, produces a set of merged output values (usually just one) 21
22 MapReduce: Example All-time favorite: count word occurrence map(string input_key, String input_value): # input_key: document name # input_value: document contents for each word w in input_value: EmitIntermediate(w, "1") reduce(string output_key, Iterator intermed_values): # output_key: a word # output_values: a list of counts int result = 0 for each v in intermed_values: result += ParseInt(v) Emit(AsString(result)) programmer can focus on map/reduce code framework cares about parallelization, fault tolerance, scheduling, 22
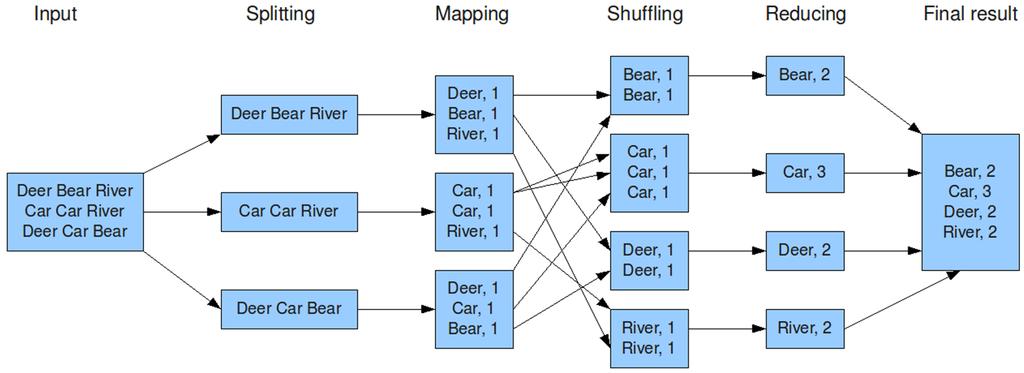
23 23 MapReduce: Example blog.jteam.nl/2009/08/04/introduction-to-hadoop
24 MapReduce: Execution Dean & Ghemawat [2004] input files are stored on map worker disks master assigns tasks to workers map workers write on local disk reduce workers retrieve data and write result ( may be recursively repeated) 24
25 MapReduce: File System often based on a custom file system, which is optimized for distributed access (Google: GFS, Hadoop: HDFS) uses few large files, as data throughput >> access time Summary MapReduce framework can be written for different environments: shared memory, distributed networks, used in a wide range of scenarios: distributed search (grep), creation of word indexes, sorting distributed data, count page links, 25
TDDD43 HT2014: Advanced databases and data models Theme 4: NoSQL, Distributed File System, Map-Reduce
 TDDD43 HT2014: Advanced databases and data models Theme 4: NoSQL, Distributed File System, Map-Reduce Valentina Ivanova ADIT, IDA, Linköping University Slides based on slides by Fang Wei-Kleiner DFS, Map-Reduce
TDDD43 HT2014: Advanced databases and data models Theme 4: NoSQL, Distributed File System, Map-Reduce Valentina Ivanova ADIT, IDA, Linköping University Slides based on slides by Fang Wei-Kleiner DFS, Map-Reduce
Modern Database Concepts
 Modern Database Concepts Introduction to the world of Big Data Doc. RNDr. Irena Holubova, Ph.D. holubova@ksi.mff.cuni.cz What is Big Data? buzzword? bubble? gold rush? revolution? Big data is like teenage
Modern Database Concepts Introduction to the world of Big Data Doc. RNDr. Irena Holubova, Ph.D. holubova@ksi.mff.cuni.cz What is Big Data? buzzword? bubble? gold rush? revolution? Big data is like teenage
Parallel Programming Principle and Practice. Lecture 10 Big Data Processing with MapReduce
 Parallel Programming Principle and Practice Lecture 10 Big Data Processing with MapReduce Outline MapReduce Programming Model MapReduce Examples Hadoop 2 Incredible Things That Happen Every Minute On The
Parallel Programming Principle and Practice Lecture 10 Big Data Processing with MapReduce Outline MapReduce Programming Model MapReduce Examples Hadoop 2 Incredible Things That Happen Every Minute On The
TDDD43 HT2015: Advanced databases and data models Theme 4: NoSQL, Distributed File System, Map-Reduce
 TDDD43 HT2015: Advanced databases and data models Theme 4: NoSQL, Distributed File System, Map-Reduce Valentina Ivanova ADIT, IDA, Linköping University Slides based on slides by Fang Wei-Kleiner DFS, Map-Reduce
TDDD43 HT2015: Advanced databases and data models Theme 4: NoSQL, Distributed File System, Map-Reduce Valentina Ivanova ADIT, IDA, Linköping University Slides based on slides by Fang Wei-Kleiner DFS, Map-Reduce
CIB Session 12th NoSQL Databases Structures
 CIB Session 12th NoSQL Databases Structures By: Shahab Safaee & Morteza Zahedi Software Engineering PhD Email: safaee.shx@gmail.com, morteza.zahedi.a@gmail.com cibtrc.ir cibtrc cibtrc 2 Agenda What is
CIB Session 12th NoSQL Databases Structures By: Shahab Safaee & Morteza Zahedi Software Engineering PhD Email: safaee.shx@gmail.com, morteza.zahedi.a@gmail.com cibtrc.ir cibtrc cibtrc 2 Agenda What is
The NoSQL Movement. FlockDB. CSCI 470: Web Science Keith Vertanen
 The NoSQL Movement FlockDB CSCI 470: Web Science Keith Vertanen 2 3 h2p://techcrunch.com/2012/10/27/big- data- right- now- five- trendy- open- source- technologies/ 4 h2p://blog.beany.co.kr/archives/275
The NoSQL Movement FlockDB CSCI 470: Web Science Keith Vertanen 2 3 h2p://techcrunch.com/2012/10/27/big- data- right- now- five- trendy- open- source- technologies/ 4 h2p://blog.beany.co.kr/archives/275
Topics. Big Data Analytics What is and Why Hadoop? Comparison to other technologies Hadoop architecture Hadoop ecosystem Hadoop usage examples
 Hadoop Introduction 1 Topics Big Data Analytics What is and Why Hadoop? Comparison to other technologies Hadoop architecture Hadoop ecosystem Hadoop usage examples 2 Big Data Analytics What is Big Data?
Hadoop Introduction 1 Topics Big Data Analytics What is and Why Hadoop? Comparison to other technologies Hadoop architecture Hadoop ecosystem Hadoop usage examples 2 Big Data Analytics What is Big Data?
Overview. Why MapReduce? What is MapReduce? The Hadoop Distributed File System Cloudera, Inc.
 MapReduce and HDFS This presentation includes course content University of Washington Redistributed under the Creative Commons Attribution 3.0 license. All other contents: Overview Why MapReduce? What
MapReduce and HDFS This presentation includes course content University of Washington Redistributed under the Creative Commons Attribution 3.0 license. All other contents: Overview Why MapReduce? What
CS 61C: Great Ideas in Computer Architecture. MapReduce
 CS 61C: Great Ideas in Computer Architecture MapReduce Guest Lecturer: Justin Hsia 3/06/2013 Spring 2013 Lecture #18 1 Review of Last Lecture Performance latency and throughput Warehouse Scale Computing
CS 61C: Great Ideas in Computer Architecture MapReduce Guest Lecturer: Justin Hsia 3/06/2013 Spring 2013 Lecture #18 1 Review of Last Lecture Performance latency and throughput Warehouse Scale Computing
MapReduce: Simplified Data Processing on Large Clusters
 MapReduce: Simplified Data Processing on Large Clusters Jeffrey Dean and Sanjay Ghemawat OSDI 2004 Presented by Zachary Bischof Winter '10 EECS 345 Distributed Systems 1 Motivation Summary Example Implementation
MapReduce: Simplified Data Processing on Large Clusters Jeffrey Dean and Sanjay Ghemawat OSDI 2004 Presented by Zachary Bischof Winter '10 EECS 345 Distributed Systems 1 Motivation Summary Example Implementation
The MapReduce Abstraction
 The MapReduce Abstraction Parallel Computing at Google Leverages multiple technologies to simplify large-scale parallel computations Proprietary computing clusters Map/Reduce software library Lots of other
The MapReduce Abstraction Parallel Computing at Google Leverages multiple technologies to simplify large-scale parallel computations Proprietary computing clusters Map/Reduce software library Lots of other
Practice and Applications of Data Management CMPSCI 345. Lecture 18: Big Data, Hadoop, and MapReduce
 Practice and Applications of Data Management CMPSCI 345 Lecture 18: Big Data, Hadoop, and MapReduce Why Big Data, Hadoop, M-R? } What is the connec,on with the things we learned? } What about SQL? } What
Practice and Applications of Data Management CMPSCI 345 Lecture 18: Big Data, Hadoop, and MapReduce Why Big Data, Hadoop, M-R? } What is the connec,on with the things we learned? } What about SQL? } What
Introduction to MapReduce. Adapted from Jimmy Lin (U. Maryland, USA)
") Introduction to MapReduce Adapted from Jimmy Lin (U. Maryland, USA) Motivation Overview Need for handling big data New programming paradigm Review of functional programming mapreduce uses this abstraction
Introduction to MapReduce Adapted from Jimmy Lin (U. Maryland, USA) Motivation Overview Need for handling big data New programming paradigm Review of functional programming mapreduce uses this abstraction
CISC 7610 Lecture 2b The beginnings of NoSQL
 CISC 7610 Lecture 2b The beginnings of NoSQL Topics: Big Data Google s infrastructure Hadoop: open google infrastructure Scaling through sharding CAP theorem Amazon s Dynamo 5 V s of big data Everyone
CISC 7610 Lecture 2b The beginnings of NoSQL Topics: Big Data Google s infrastructure Hadoop: open google infrastructure Scaling through sharding CAP theorem Amazon s Dynamo 5 V s of big data Everyone
Distributed Computations MapReduce. adapted from Jeff Dean s slides
 Distributed Computations MapReduce adapted from Jeff Dean s slides What we ve learnt so far Basic distributed systems concepts Consistency (sequential, eventual) Fault tolerance (recoverability, availability)
Distributed Computations MapReduce adapted from Jeff Dean s slides What we ve learnt so far Basic distributed systems concepts Consistency (sequential, eventual) Fault tolerance (recoverability, availability)
Where We Are. Review: Parallel DBMS. Parallel DBMS. Introduction to Data Management CSE 344
 Where We Are Introduction to Data Management CSE 344 Lecture 22: MapReduce We are talking about parallel query processing There exist two main types of engines: Parallel DBMSs (last lecture + quick review)
Where We Are Introduction to Data Management CSE 344 Lecture 22: MapReduce We are talking about parallel query processing There exist two main types of engines: Parallel DBMSs (last lecture + quick review)
Database System Architectures Parallel DBs, MapReduce, ColumnStores
 Database System Architectures Parallel DBs, MapReduce, ColumnStores CMPSCI 445 Fall 2010 Some slides courtesy of Yanlei Diao, Christophe Bisciglia, Aaron Kimball, & Sierra Michels- Slettvet Motivation:
Database System Architectures Parallel DBs, MapReduce, ColumnStores CMPSCI 445 Fall 2010 Some slides courtesy of Yanlei Diao, Christophe Bisciglia, Aaron Kimball, & Sierra Michels- Slettvet Motivation:
The MapReduce Framework
 The MapReduce Framework In Partial fulfilment of the requirements for course CMPT 816 Presented by: Ahmed Abdel Moamen Agents Lab Overview MapReduce was firstly introduced by Google on 2004. MapReduce
The MapReduce Framework In Partial fulfilment of the requirements for course CMPT 816 Presented by: Ahmed Abdel Moamen Agents Lab Overview MapReduce was firstly introduced by Google on 2004. MapReduce
Introduction to Data Management CSE 344
 Introduction to Data Management CSE 344 Lecture 24: MapReduce CSE 344 - Fall 2016 1 HW8 is out Last assignment! Get Amazon credits now (see instructions) Spark with Hadoop Due next wed CSE 344 - Fall 2016
Introduction to Data Management CSE 344 Lecture 24: MapReduce CSE 344 - Fall 2016 1 HW8 is out Last assignment! Get Amazon credits now (see instructions) Spark with Hadoop Due next wed CSE 344 - Fall 2016
MapReduce Spark. Some slides are adapted from those of Jeff Dean and Matei Zaharia
 MapReduce Spark Some slides are adapted from those of Jeff Dean and Matei Zaharia What have we learnt so far? Distributed storage systems consistency semantics protocols for fault tolerance Paxos, Raft,
MapReduce Spark Some slides are adapted from those of Jeff Dean and Matei Zaharia What have we learnt so far? Distributed storage systems consistency semantics protocols for fault tolerance Paxos, Raft,
MapReduce, Hadoop and Spark. Bompotas Agorakis
 MapReduce, Hadoop and Spark Bompotas Agorakis Big Data Processing Most of the computations are conceptually straightforward on a single machine but the volume of data is HUGE Need to use many (1.000s)
MapReduce, Hadoop and Spark Bompotas Agorakis Big Data Processing Most of the computations are conceptually straightforward on a single machine but the volume of data is HUGE Need to use many (1.000s)
Big Data Management and NoSQL Databases
 NDBI040 Big Data Management and NoSQL Databases Lecture 2. MapReduce Doc. RNDr. Irena Holubova, Ph.D. holubova@ksi.mff.cuni.cz http://www.ksi.mff.cuni.cz/~holubova/ndbi040/ Framework A programming model
NDBI040 Big Data Management and NoSQL Databases Lecture 2. MapReduce Doc. RNDr. Irena Holubova, Ph.D. holubova@ksi.mff.cuni.cz http://www.ksi.mff.cuni.cz/~holubova/ndbi040/ Framework A programming model
Big Data Management and NoSQL Databases
 NDBI040 Big Data Management and NoSQL Databases Lecture 1. Introduction Doc. RNDr. Irena Holubova, Ph.D. holubova@ksi.mff.cuni.cz http://www.ksi.mff.cuni.cz/~holubova/ndbi040/ What is Big Data? buzzword?
NDBI040 Big Data Management and NoSQL Databases Lecture 1. Introduction Doc. RNDr. Irena Holubova, Ph.D. holubova@ksi.mff.cuni.cz http://www.ksi.mff.cuni.cz/~holubova/ndbi040/ What is Big Data? buzzword?
Parallel Computing: MapReduce Jin, Hai
 Parallel Computing: MapReduce Jin, Hai School of Computer Science and Technology Huazhong University of Science and Technology ! MapReduce is a distributed/parallel computing framework introduced by Google
Parallel Computing: MapReduce Jin, Hai School of Computer Science and Technology Huazhong University of Science and Technology ! MapReduce is a distributed/parallel computing framework introduced by Google
Announcements. Parallel Data Processing in the 20 th Century. Parallel Join Illustration. Introduction to Database Systems CSE 414
 Introduction to Database Systems CSE 414 Lecture 17: MapReduce and Spark Announcements Midterm this Friday in class! Review session tonight See course website for OHs Includes everything up to Monday s
Introduction to Database Systems CSE 414 Lecture 17: MapReduce and Spark Announcements Midterm this Friday in class! Review session tonight See course website for OHs Includes everything up to Monday s
CS6030 Cloud Computing. Acknowledgements. Today s Topics. Intro to Cloud Computing 10/20/15. Ajay Gupta, WMU-CS. WiSe Lab
 CS6030 Cloud Computing Ajay Gupta B239, CEAS Computer Science Department Western Michigan University ajay.gupta@wmich.edu 276-3104 1 Acknowledgements I have liberally borrowed these slides and material
CS6030 Cloud Computing Ajay Gupta B239, CEAS Computer Science Department Western Michigan University ajay.gupta@wmich.edu 276-3104 1 Acknowledgements I have liberally borrowed these slides and material
PROFESSIONAL. NoSQL. Shashank Tiwari WILEY. John Wiley & Sons, Inc.
 PROFESSIONAL NoSQL Shashank Tiwari WILEY John Wiley & Sons, Inc. Examining CONTENTS INTRODUCTION xvil CHAPTER 1: NOSQL: WHAT IT IS AND WHY YOU NEED IT 3 Definition and Introduction 4 Context and a Bit
PROFESSIONAL NoSQL Shashank Tiwari WILEY John Wiley & Sons, Inc. Examining CONTENTS INTRODUCTION xvil CHAPTER 1: NOSQL: WHAT IT IS AND WHY YOU NEED IT 3 Definition and Introduction 4 Context and a Bit
Cassandra, MongoDB, and HBase. Cassandra, MongoDB, and HBase. I have chosen these three due to their recent
 Tanton Jeppson CS 401R Lab 3 Cassandra, MongoDB, and HBase Introduction For my report I have chosen to take a deeper look at 3 NoSQL database systems: Cassandra, MongoDB, and HBase. I have chosen these
Tanton Jeppson CS 401R Lab 3 Cassandra, MongoDB, and HBase Introduction For my report I have chosen to take a deeper look at 3 NoSQL database systems: Cassandra, MongoDB, and HBase. I have chosen these
Cloud Programming. Programming Environment Oct 29, 2015 Osamu Tatebe
 Cloud Programming Programming Environment Oct 29, 2015 Osamu Tatebe Cloud Computing Only required amount of CPU and storage can be used anytime from anywhere via network Availability, throughput, reliability
Cloud Programming Programming Environment Oct 29, 2015 Osamu Tatebe Cloud Computing Only required amount of CPU and storage can be used anytime from anywhere via network Availability, throughput, reliability
CSE 344 MAY 2 ND MAP/REDUCE
 CSE 344 MAY 2 ND MAP/REDUCE ADMINISTRIVIA HW5 Due Tonight Practice midterm Section tomorrow Exam review PERFORMANCE METRICS FOR PARALLEL DBMSS Nodes = processors, computers Speedup: More nodes, same data
CSE 344 MAY 2 ND MAP/REDUCE ADMINISTRIVIA HW5 Due Tonight Practice midterm Section tomorrow Exam review PERFORMANCE METRICS FOR PARALLEL DBMSS Nodes = processors, computers Speedup: More nodes, same data
Introduction to Data Management CSE 344
 Introduction to Data Management CSE 344 Lecture 26: Parallel Databases and MapReduce CSE 344 - Winter 2013 1 HW8 MapReduce (Hadoop) w/ declarative language (Pig) Cluster will run in Amazon s cloud (AWS)
Introduction to Data Management CSE 344 Lecture 26: Parallel Databases and MapReduce CSE 344 - Winter 2013 1 HW8 MapReduce (Hadoop) w/ declarative language (Pig) Cluster will run in Amazon s cloud (AWS)
Modern Database Concepts
 Modern Database Concepts Basic Principles Doc. RNDr. Irena Holubova, Ph.D. holubova@ksi.mff.cuni.cz NoSQL Overview Main objective: to implement a distributed state Different objects stored on different
Modern Database Concepts Basic Principles Doc. RNDr. Irena Holubova, Ph.D. holubova@ksi.mff.cuni.cz NoSQL Overview Main objective: to implement a distributed state Different objects stored on different
NoSQL Databases. Amir H. Payberah. Swedish Institute of Computer Science. April 10, 2014
 NoSQL Databases Amir H. Payberah Swedish Institute of Computer Science amir@sics.se April 10, 2014 Amir H. Payberah (SICS) NoSQL Databases April 10, 2014 1 / 67 Database and Database Management System
NoSQL Databases Amir H. Payberah Swedish Institute of Computer Science amir@sics.se April 10, 2014 Amir H. Payberah (SICS) NoSQL Databases April 10, 2014 1 / 67 Database and Database Management System
Agenda. Request- Level Parallelism. Agenda. Anatomy of a Web Search. Google Query- Serving Architecture 9/20/10
 Agenda CS 61C: Great Ideas in Computer Architecture (Machine Structures) Instructors: Randy H. Katz David A. PaHerson hhp://inst.eecs.berkeley.edu/~cs61c/fa10 Request and Data Level Parallelism Administrivia
Agenda CS 61C: Great Ideas in Computer Architecture (Machine Structures) Instructors: Randy H. Katz David A. PaHerson hhp://inst.eecs.berkeley.edu/~cs61c/fa10 Request and Data Level Parallelism Administrivia
Parallel Programming Concepts
 Parallel Programming Concepts MapReduce Frank Feinbube Source: MapReduce: Simplied Data Processing on Large Clusters; Dean et. Al. Examples for Parallel Programming Support 2 MapReduce 3 Programming model
Parallel Programming Concepts MapReduce Frank Feinbube Source: MapReduce: Simplied Data Processing on Large Clusters; Dean et. Al. Examples for Parallel Programming Support 2 MapReduce 3 Programming model
MI-PDB, MIE-PDB: Advanced Database Systems
 MI-PDB, MIE-PDB: Advanced Database Systems http://www.ksi.mff.cuni.cz/~svoboda/courses/2015-2-mie-pdb/ Lecture 10: MapReduce, Hadoop 26. 4. 2016 Lecturer: Martin Svoboda svoboda@ksi.mff.cuni.cz Author:
MI-PDB, MIE-PDB: Advanced Database Systems http://www.ksi.mff.cuni.cz/~svoboda/courses/2015-2-mie-pdb/ Lecture 10: MapReduce, Hadoop 26. 4. 2016 Lecturer: Martin Svoboda svoboda@ksi.mff.cuni.cz Author:
CS 655 Advanced Topics in Distributed Systems
 Presented by : Walid Budgaga CS 655 Advanced Topics in Distributed Systems Computer Science Department Colorado State University 1 Outline Problem Solution Approaches Comparison Conclusion 2 Problem 3
Presented by : Walid Budgaga CS 655 Advanced Topics in Distributed Systems Computer Science Department Colorado State University 1 Outline Problem Solution Approaches Comparison Conclusion 2 Problem 3
Map Reduce. Yerevan.
 Map Reduce Erasmus+ @ Yerevan dacosta@irit.fr Divide and conquer at PaaS 100 % // Typical problem Iterate over a large number of records Extract something of interest from each Shuffle and sort intermediate
Map Reduce Erasmus+ @ Yerevan dacosta@irit.fr Divide and conquer at PaaS 100 % // Typical problem Iterate over a large number of records Extract something of interest from each Shuffle and sort intermediate
Hadoop محبوبه دادخواه کارگاه ساالنه آزمایشگاه فناوری وب زمستان 1391
 Hadoop محبوبه دادخواه کارگاه ساالنه آزمایشگاه فناوری وب زمستان 1391 Outline Big Data Big Data Examples Challenges with traditional storage NoSQL Hadoop HDFS MapReduce Architecture 2 Big Data In information
Hadoop محبوبه دادخواه کارگاه ساالنه آزمایشگاه فناوری وب زمستان 1391 Outline Big Data Big Data Examples Challenges with traditional storage NoSQL Hadoop HDFS MapReduce Architecture 2 Big Data In information
NoSQL Concepts, Techniques & Systems Part 1. Valentina Ivanova IDA, Linköping University
 NoSQL Concepts, Techniques & Systems Part 1 Valentina Ivanova IDA, Linköping University 2017-03-20 2 Outline Today Part 1 RDBMS NoSQL NewSQL DBMS OLAP vs OLTP NoSQL Concepts and Techniques Horizontal scalability
NoSQL Concepts, Techniques & Systems Part 1 Valentina Ivanova IDA, Linköping University 2017-03-20 2 Outline Today Part 1 RDBMS NoSQL NewSQL DBMS OLAP vs OLTP NoSQL Concepts and Techniques Horizontal scalability
MapReduce: A Programming Model for Large-Scale Distributed Computation
 CSC 258/458 MapReduce: A Programming Model for Large-Scale Distributed Computation University of Rochester Department of Computer Science Shantonu Hossain April 18, 2011 Outline Motivation MapReduce Overview
CSC 258/458 MapReduce: A Programming Model for Large-Scale Distributed Computation University of Rochester Department of Computer Science Shantonu Hossain April 18, 2011 Outline Motivation MapReduce Overview
CSE 544 Principles of Database Management Systems. Alvin Cheung Fall 2015 Lecture 10 Parallel Programming Models: Map Reduce and Spark
 CSE 544 Principles of Database Management Systems Alvin Cheung Fall 2015 Lecture 10 Parallel Programming Models: Map Reduce and Spark Announcements HW2 due this Thursday AWS accounts Any success? Feel
CSE 544 Principles of Database Management Systems Alvin Cheung Fall 2015 Lecture 10 Parallel Programming Models: Map Reduce and Spark Announcements HW2 due this Thursday AWS accounts Any success? Feel
Bioinforma)cs Resources - NoSQL -
cs Resources - NoSQL -") Bioinforma)cs Resources - NoSQL - Lecture & Exercises Prof. B. Rost, Dr. L. Richter, J. Reeb Ins)tut für Informa)k I12 Short SQL Recap schema typed data tables defined layout space consump)on is computable
Bioinforma)cs Resources - NoSQL - Lecture & Exercises Prof. B. Rost, Dr. L. Richter, J. Reeb Ins)tut für Informa)k I12 Short SQL Recap schema typed data tables defined layout space consump)on is computable
Database Systems CSE 414
 Database Systems CSE 414 Lecture 19: MapReduce (Ch. 20.2) CSE 414 - Fall 2017 1 Announcements HW5 is due tomorrow 11pm HW6 is posted and due Nov. 27 11pm Section Thursday on setting up Spark on AWS Create
Database Systems CSE 414 Lecture 19: MapReduce (Ch. 20.2) CSE 414 - Fall 2017 1 Announcements HW5 is due tomorrow 11pm HW6 is posted and due Nov. 27 11pm Section Thursday on setting up Spark on AWS Create
Announcements. Optional Reading. Distributed File System (DFS) MapReduce Process. MapReduce. Database Systems CSE 414. HW5 is due tomorrow 11pm
 MapReduce Process. MapReduce. Database Systems CSE 414. HW5 is due tomorrow 11pm") Announcements HW5 is due tomorrow 11pm Database Systems CSE 414 Lecture 19: MapReduce (Ch. 20.2) HW6 is posted and due Nov. 27 11pm Section Thursday on setting up Spark on AWS Create your AWS account before
Announcements HW5 is due tomorrow 11pm Database Systems CSE 414 Lecture 19: MapReduce (Ch. 20.2) HW6 is posted and due Nov. 27 11pm Section Thursday on setting up Spark on AWS Create your AWS account before
L22: SC Report, Map Reduce
 L22: SC Report, Map Reduce November 23, 2010 Map Reduce What is MapReduce? Example computing environment How it works Fault Tolerance Debugging Performance Google version = Map Reduce; Hadoop = Open source
L22: SC Report, Map Reduce November 23, 2010 Map Reduce What is MapReduce? Example computing environment How it works Fault Tolerance Debugging Performance Google version = Map Reduce; Hadoop = Open source
Clustering Lecture 8: MapReduce
 Clustering Lecture 8: MapReduce Jing Gao SUNY Buffalo 1 Divide and Conquer Work Partition w 1 w 2 w 3 worker worker worker r 1 r 2 r 3 Result Combine 4 Distributed Grep Very big data Split data Split data
Clustering Lecture 8: MapReduce Jing Gao SUNY Buffalo 1 Divide and Conquer Work Partition w 1 w 2 w 3 worker worker worker r 1 r 2 r 3 Result Combine 4 Distributed Grep Very big data Split data Split data
CS555: Distributed Systems [Fall 2017] Dept. Of Computer Science, Colorado State University
![CS555: Distributed Systems [Fall 2017] Dept. Of Computer Science, Colorado State University](/thumbs/90/104368640.jpg "CS555: Distributed Systems [Fall 2017] Dept. Of Computer Science, Colorado State University") CS 555: DISTRIBUTED SYSTEMS [MAPREDUCE] Shrideep Pallickara Computer Science Colorado State University Frequently asked questions from the previous class survey Bit Torrent What is the right chunk/piece
CS 555: DISTRIBUTED SYSTEMS [MAPREDUCE] Shrideep Pallickara Computer Science Colorado State University Frequently asked questions from the previous class survey Bit Torrent What is the right chunk/piece
Distributed Data Store
 Distributed Data Store Large-Scale Distributed le system Q: What if we have too much data to store in a single machine? Q: How can we create one big filesystem over a cluster of machines, whose data is
Distributed Data Store Large-Scale Distributed le system Q: What if we have too much data to store in a single machine? Q: How can we create one big filesystem over a cluster of machines, whose data is
Large-Scale GPU programming
 Large-Scale GPU programming Tim Kaldewey Research Staff Member Database Technologies IBM Almaden Research Center tkaldew@us.ibm.com Assistant Adjunct Professor Computer and Information Science Dept. University
Large-Scale GPU programming Tim Kaldewey Research Staff Member Database Technologies IBM Almaden Research Center tkaldew@us.ibm.com Assistant Adjunct Professor Computer and Information Science Dept. University
Apache Hadoop Goes Realtime at Facebook. Himanshu Sharma
 Apache Hadoop Goes Realtime at Facebook Guide - Dr. Sunny S. Chung Presented By- Anand K Singh Himanshu Sharma Index Problem with Current Stack Apache Hadoop and Hbase Zookeeper Applications of HBase at
Apache Hadoop Goes Realtime at Facebook Guide - Dr. Sunny S. Chung Presented By- Anand K Singh Himanshu Sharma Index Problem with Current Stack Apache Hadoop and Hbase Zookeeper Applications of HBase at
Jargons, Concepts, Scope and Systems. Key Value Stores, Document Stores, Extensible Record Stores. Overview of different scalable relational systems
 Jargons, Concepts, Scope and Systems Key Value Stores, Document Stores, Extensible Record Stores Overview of different scalable relational systems Examples of different Data stores Predictions, Comparisons
Jargons, Concepts, Scope and Systems Key Value Stores, Document Stores, Extensible Record Stores Overview of different scalable relational systems Examples of different Data stores Predictions, Comparisons
L22: NoSQL. CS3200 Database design (sp18 s2) 4/5/2018 Several slides courtesy of Benny Kimelfeld
 4/5/2018 Several slides courtesy of Benny Kimelfeld") L22: NoSQL CS3200 Database design (sp18 s2) https://course.ccs.neu.edu/cs3200sp18s2/ 4/5/2018 Several slides courtesy of Benny Kimelfeld 2 Outline 3 Introduction Transaction Consistency 4 main data models
L22: NoSQL CS3200 Database design (sp18 s2) https://course.ccs.neu.edu/cs3200sp18s2/ 4/5/2018 Several slides courtesy of Benny Kimelfeld 2 Outline 3 Introduction Transaction Consistency 4 main data models
HDFS: Hadoop Distributed File System. CIS 612 Sunnie Chung
 HDFS: Hadoop Distributed File System CIS 612 Sunnie Chung What is Big Data?? Bulk Amount Unstructured Introduction Lots of Applications which need to handle huge amount of data (in terms of 500+ TB per
HDFS: Hadoop Distributed File System CIS 612 Sunnie Chung What is Big Data?? Bulk Amount Unstructured Introduction Lots of Applications which need to handle huge amount of data (in terms of 500+ TB per
CS-580K/480K Advanced Topics in Cloud Computing. NoSQL Database
 CS-580K/480K dvanced Topics in Cloud Computing NoSQL Database 1 1 Where are we? Cloud latforms 2 VM1 VM2 VM3 3 Operating System 4 1 2 3 Operating System 4 1 2 Virtualization Layer 3 Operating System 4
CS-580K/480K dvanced Topics in Cloud Computing NoSQL Database 1 1 Where are we? Cloud latforms 2 VM1 VM2 VM3 3 Operating System 4 1 2 3 Operating System 4 1 2 Virtualization Layer 3 Operating System 4
MapReduce-style data processing
 MapReduce-style data processing Software Languages Team University of Koblenz-Landau Ralf Lämmel and Andrei Varanovich Related meanings of MapReduce Functional programming with map & reduce An algorithmic
MapReduce-style data processing Software Languages Team University of Koblenz-Landau Ralf Lämmel and Andrei Varanovich Related meanings of MapReduce Functional programming with map & reduce An algorithmic
Next-Generation Cloud Platform
 Next-Generation Cloud Platform Jangwoo Kim Jun 24, 2013 E-mail: jangwoo@postech.ac.kr High Performance Computing Lab Department of Computer Science & Engineering Pohang University of Science and Technology
Next-Generation Cloud Platform Jangwoo Kim Jun 24, 2013 E-mail: jangwoo@postech.ac.kr High Performance Computing Lab Department of Computer Science & Engineering Pohang University of Science and Technology
Typical size of data you deal with on a daily basis
 Typical size of data you deal with on a daily basis Processes More than 161 Petabytes of raw data a day https://aci.info/2014/07/12/the-dataexplosion-in-2014-minute-by-minuteinfographic/ On average, 1MB-2MB
Typical size of data you deal with on a daily basis Processes More than 161 Petabytes of raw data a day https://aci.info/2014/07/12/the-dataexplosion-in-2014-minute-by-minuteinfographic/ On average, 1MB-2MB
The amount of data increases every day Some numbers ( 2012):
:") 1 The amount of data increases every day Some numbers ( 2012): Data processed by Google every day: 100+ PB Data processed by Facebook every day: 10+ PB To analyze them, systems that scale with respect
1 The amount of data increases every day Some numbers ( 2012): Data processed by Google every day: 100+ PB Data processed by Facebook every day: 10+ PB To analyze them, systems that scale with respect
2/26/2017. The amount of data increases every day Some numbers ( 2012):
:") The amount of data increases every day Some numbers ( 2012): Data processed by Google every day: 100+ PB Data processed by Facebook every day: 10+ PB To analyze them, systems that scale with respect to
The amount of data increases every day Some numbers ( 2012): Data processed by Google every day: 100+ PB Data processed by Facebook every day: 10+ PB To analyze them, systems that scale with respect to
Data Storage Infrastructure at Facebook
 Data Storage Infrastructure at Facebook Spring 2018 Cleveland State University CIS 601 Presentation Yi Dong Instructor: Dr. Chung Outline Strategy of data storage, processing, and log collection Data flow
Data Storage Infrastructure at Facebook Spring 2018 Cleveland State University CIS 601 Presentation Yi Dong Instructor: Dr. Chung Outline Strategy of data storage, processing, and log collection Data flow
In the news. Request- Level Parallelism (RLP) Agenda 10/7/11
 Agenda 10/7/11") In the news "The cloud isn't this big fluffy area up in the sky," said Rich Miller, who edits Data Center Knowledge, a publicaeon that follows the data center industry. "It's buildings filled with servers
In the news "The cloud isn't this big fluffy area up in the sky," said Rich Miller, who edits Data Center Knowledge, a publicaeon that follows the data center industry. "It's buildings filled with servers
Big Data Analytics. Izabela Moise, Evangelos Pournaras, Dirk Helbing
 Big Data Analytics Izabela Moise, Evangelos Pournaras, Dirk Helbing Izabela Moise, Evangelos Pournaras, Dirk Helbing 1 Big Data "The world is crazy. But at least it s getting regular analysis." Izabela
Big Data Analytics Izabela Moise, Evangelos Pournaras, Dirk Helbing Izabela Moise, Evangelos Pournaras, Dirk Helbing 1 Big Data "The world is crazy. But at least it s getting regular analysis." Izabela
Hadoop/MapReduce Computing Paradigm
 Hadoop/Reduce Computing Paradigm 1 Large-Scale Data Analytics Reduce computing paradigm (E.g., Hadoop) vs. Traditional database systems vs. Database Many enterprises are turning to Hadoop Especially applications
Hadoop/Reduce Computing Paradigm 1 Large-Scale Data Analytics Reduce computing paradigm (E.g., Hadoop) vs. Traditional database systems vs. Database Many enterprises are turning to Hadoop Especially applications
Introduction to Data Management CSE 344
 Introduction to Data Management CSE 344 Lecture 24: MapReduce CSE 344 - Winter 215 1 HW8 MapReduce (Hadoop) w/ declarative language (Pig) Due next Thursday evening Will send out reimbursement codes later
Introduction to Data Management CSE 344 Lecture 24: MapReduce CSE 344 - Winter 215 1 HW8 MapReduce (Hadoop) w/ declarative language (Pig) Due next Thursday evening Will send out reimbursement codes later
MapReduce. Simplified Data Processing on Large Clusters (Without the Agonizing Pain) Presented by Aaron Nathan
 Presented by Aaron Nathan") MapReduce Simplified Data Processing on Large Clusters (Without the Agonizing Pain) Presented by Aaron Nathan The Problem Massive amounts of data >100TB (the internet) Needs simple processing Computers
MapReduce Simplified Data Processing on Large Clusters (Without the Agonizing Pain) Presented by Aaron Nathan The Problem Massive amounts of data >100TB (the internet) Needs simple processing Computers
Parallel Nested Loops
 Parallel Nested Loops For each tuple s i in S For each tuple t j in T If s i =t j, then add (s i,t j ) to output Create partitions S 1, S 2, T 1, and T 2 Have processors work on (S 1,T 1 ), (S 1,T 2 ),
Parallel Nested Loops For each tuple s i in S For each tuple t j in T If s i =t j, then add (s i,t j ) to output Create partitions S 1, S 2, T 1, and T 2 Have processors work on (S 1,T 1 ), (S 1,T 2 ),
Parallel Partition-Based. Parallel Nested Loops. Median. More Join Thoughts. Parallel Office Tools 9/15/2011
 Parallel Nested Loops Parallel Partition-Based For each tuple s i in S For each tuple t j in T If s i =t j, then add (s i,t j ) to output Create partitions S 1, S 2, T 1, and T 2 Have processors work on
Parallel Nested Loops Parallel Partition-Based For each tuple s i in S For each tuple t j in T If s i =t j, then add (s i,t j ) to output Create partitions S 1, S 2, T 1, and T 2 Have processors work on
PLATFORM AND SOFTWARE AS A SERVICE THE MAPREDUCE PROGRAMMING MODEL AND IMPLEMENTATIONS
 PLATFORM AND SOFTWARE AS A SERVICE THE MAPREDUCE PROGRAMMING MODEL AND IMPLEMENTATIONS By HAI JIN, SHADI IBRAHIM, LI QI, HAIJUN CAO, SONG WU and XUANHUA SHI Prepared by: Dr. Faramarz Safi Islamic Azad
PLATFORM AND SOFTWARE AS A SERVICE THE MAPREDUCE PROGRAMMING MODEL AND IMPLEMENTATIONS By HAI JIN, SHADI IBRAHIM, LI QI, HAIJUN CAO, SONG WU and XUANHUA SHI Prepared by: Dr. Faramarz Safi Islamic Azad
CPSC 426/526. Cloud Computing. Ennan Zhai. Computer Science Department Yale University
 CPSC 426/526 Cloud Computing Ennan Zhai Computer Science Department Yale University Recall: Lec-7 In the lec-7, I talked about: - P2P vs Enterprise control - Firewall - NATs - Software defined network
CPSC 426/526 Cloud Computing Ennan Zhai Computer Science Department Yale University Recall: Lec-7 In the lec-7, I talked about: - P2P vs Enterprise control - Firewall - NATs - Software defined network
Introduction to Map Reduce
 Introduction to Map Reduce 1 Map Reduce: Motivation We realized that most of our computations involved applying a map operation to each logical record in our input in order to compute a set of intermediate
Introduction to Map Reduce 1 Map Reduce: Motivation We realized that most of our computations involved applying a map operation to each logical record in our input in order to compute a set of intermediate
CA485 Ray Walshe NoSQL
 NoSQL BASE vs ACID Summary Traditional relational database management systems (RDBMS) do not scale because they adhere to ACID. A strong movement within cloud computing is to utilize non-traditional data
NoSQL BASE vs ACID Summary Traditional relational database management systems (RDBMS) do not scale because they adhere to ACID. A strong movement within cloud computing is to utilize non-traditional data
Introduction to Hadoop and MapReduce
 Introduction to Hadoop and MapReduce Antonino Virgillito THE CONTRACTOR IS ACTING UNDER A FRAMEWORK CONTRACT CONCLUDED WITH THE COMMISSION Large-scale Computation Traditional solutions for computing large
Introduction to Hadoop and MapReduce Antonino Virgillito THE CONTRACTOR IS ACTING UNDER A FRAMEWORK CONTRACT CONCLUDED WITH THE COMMISSION Large-scale Computation Traditional solutions for computing large
Big Data Programming: an Introduction. Spring 2015, X. Zhang Fordham Univ.
 Big Data Programming: an Introduction Spring 2015, X. Zhang Fordham Univ. Outline What the course is about? scope Introduction to big data programming Opportunity and challenge of big data Origin of Hadoop
Big Data Programming: an Introduction Spring 2015, X. Zhang Fordham Univ. Outline What the course is about? scope Introduction to big data programming Opportunity and challenge of big data Origin of Hadoop
CS 102. Big Data. Spring Big Data Platforms
 CS 102 Big Data Spring 2016 Big Data Platforms How Big is Big? The Data Data Sets 1000 2 (5.3 MB) Complete works of Shakespeare (text) 1000 3 (~5-500 GB) Your data 1000 4 (10 TB) Library of Congress (text)
CS 102 Big Data Spring 2016 Big Data Platforms How Big is Big? The Data Data Sets 1000 2 (5.3 MB) Complete works of Shakespeare (text) 1000 3 (~5-500 GB) Your data 1000 4 (10 TB) Library of Congress (text)
Data Informatics. Seon Ho Kim, Ph.D.
 Data Informatics Seon Ho Kim, Ph.D. seonkim@usc.edu NoSQL and Big Data Processing Database Relational Databases mainstay of business Web-based applications caused spikes Especially true for public-facing
Data Informatics Seon Ho Kim, Ph.D. seonkim@usc.edu NoSQL and Big Data Processing Database Relational Databases mainstay of business Web-based applications caused spikes Especially true for public-facing
CompSci 516 Database Systems
 CompSci 516 Database Systems Lecture 20 NoSQL and Column Store Instructor: Sudeepa Roy Duke CS, Fall 2018 CompSci 516: Database Systems 1 Reading Material NOSQL: Scalable SQL and NoSQL Data Stores Rick
CompSci 516 Database Systems Lecture 20 NoSQL and Column Store Instructor: Sudeepa Roy Duke CS, Fall 2018 CompSci 516: Database Systems 1 Reading Material NOSQL: Scalable SQL and NoSQL Data Stores Rick
Introduction to MapReduce. Adapted from Jimmy Lin (U. Maryland, USA)
") Introduction to MapReduce Adapted from Jimmy Lin (U. Maryland, USA) Motivation Overview Need for handling big data New programming paradigm Review of functional programming mapreduce uses this abstraction
Introduction to MapReduce Adapted from Jimmy Lin (U. Maryland, USA) Motivation Overview Need for handling big data New programming paradigm Review of functional programming mapreduce uses this abstraction
6.830 Lecture Spark 11/15/2017
 6.830 Lecture 19 -- Spark 11/15/2017 Recap / finish dynamo Sloppy Quorum (healthy N) Dynamo authors don't think quorums are sufficient, for 2 reasons: - Decreased durability (want to write all data at
6.830 Lecture 19 -- Spark 11/15/2017 Recap / finish dynamo Sloppy Quorum (healthy N) Dynamo authors don't think quorums are sufficient, for 2 reasons: - Decreased durability (want to write all data at
Introduction to MapReduce
 Basics of Cloud Computing Lecture 4 Introduction to MapReduce Satish Srirama Some material adapted from slides by Jimmy Lin, Christophe Bisciglia, Aaron Kimball, & Sierra Michels-Slettvet, Google Distributed
Basics of Cloud Computing Lecture 4 Introduction to MapReduce Satish Srirama Some material adapted from slides by Jimmy Lin, Christophe Bisciglia, Aaron Kimball, & Sierra Michels-Slettvet, Google Distributed
Distributed File Systems II
 Distributed File Systems II To do q Very-large scale: Google FS, Hadoop FS, BigTable q Next time: Naming things GFS A radically new environment NFS, etc. Independence Small Scale Variety of workloads Cooperation
Distributed File Systems II To do q Very-large scale: Google FS, Hadoop FS, BigTable q Next time: Naming things GFS A radically new environment NFS, etc. Independence Small Scale Variety of workloads Cooperation
A Review Paper on Big data & Hadoop
 A Review Paper on Big data & Hadoop Rupali Jagadale MCA Department, Modern College of Engg. Modern College of Engginering Pune,India rupalijagadale02@gmail.com Pratibha Adkar MCA Department, Modern College
A Review Paper on Big data & Hadoop Rupali Jagadale MCA Department, Modern College of Engg. Modern College of Engginering Pune,India rupalijagadale02@gmail.com Pratibha Adkar MCA Department, Modern College
CSE 530A. Non-Relational Databases. Washington University Fall 2013
 CSE 530A Non-Relational Databases Washington University Fall 2013 NoSQL "NoSQL" was originally the name of a specific RDBMS project that did not use a SQL interface Was co-opted years later to refer to
CSE 530A Non-Relational Databases Washington University Fall 2013 NoSQL "NoSQL" was originally the name of a specific RDBMS project that did not use a SQL interface Was co-opted years later to refer to
CISC 7610 Lecture 5 Distributed multimedia databases. Topics: Scaling up vs out Replication Partitioning CAP Theorem NoSQL NewSQL
 CISC 7610 Lecture 5 Distributed multimedia databases Topics: Scaling up vs out Replication Partitioning CAP Theorem NoSQL NewSQL Motivation YouTube receives 400 hours of video per minute That is 200M hours
CISC 7610 Lecture 5 Distributed multimedia databases Topics: Scaling up vs out Replication Partitioning CAP Theorem NoSQL NewSQL Motivation YouTube receives 400 hours of video per minute That is 200M hours
10 Million Smart Meter Data with Apache HBase
 10 Million Smart Meter Data with Apache HBase 5/31/2017 OSS Solution Center Hitachi, Ltd. Masahiro Ito OSS Summit Japan 2017 Who am I? Masahiro Ito ( 伊藤雅博 ) Software Engineer at Hitachi, Ltd. Focus on
10 Million Smart Meter Data with Apache HBase 5/31/2017 OSS Solution Center Hitachi, Ltd. Masahiro Ito OSS Summit Japan 2017 Who am I? Masahiro Ito ( 伊藤雅博 ) Software Engineer at Hitachi, Ltd. Focus on
THE ATLAS DISTRIBUTED DATA MANAGEMENT SYSTEM & DATABASES
 1 THE ATLAS DISTRIBUTED DATA MANAGEMENT SYSTEM & DATABASES Vincent Garonne, Mario Lassnig, Martin Barisits, Thomas Beermann, Ralph Vigne, Cedric Serfon Vincent.Garonne@cern.ch ph-adp-ddm-lab@cern.ch XLDB
1 THE ATLAS DISTRIBUTED DATA MANAGEMENT SYSTEM & DATABASES Vincent Garonne, Mario Lassnig, Martin Barisits, Thomas Beermann, Ralph Vigne, Cedric Serfon Vincent.Garonne@cern.ch ph-adp-ddm-lab@cern.ch XLDB
Goal of the presentation is to give an introduction of NoSQL databases, why they are there.
 1 Goal of the presentation is to give an introduction of NoSQL databases, why they are there. We want to present "Why?" first to explain the need of something like "NoSQL" and then in "What?" we go in
1 Goal of the presentation is to give an introduction of NoSQL databases, why they are there. We want to present "Why?" first to explain the need of something like "NoSQL" and then in "What?" we go in
MapReduce. Kiril Valev LMU Kiril Valev (LMU) MapReduce / 35
 MapReduce / 35") MapReduce Kiril Valev LMU valevk@cip.ifi.lmu.de 23.11.2013 Kiril Valev (LMU) MapReduce 23.11.2013 1 / 35 Agenda 1 MapReduce Motivation Definition Example Why MapReduce? Distributed Environment Fault Tolerance
MapReduce Kiril Valev LMU valevk@cip.ifi.lmu.de 23.11.2013 Kiril Valev (LMU) MapReduce 23.11.2013 1 / 35 Agenda 1 MapReduce Motivation Definition Example Why MapReduce? Distributed Environment Fault Tolerance
Distributed Databases: SQL vs NoSQL
 Distributed Databases: SQL vs NoSQL Seda Unal, Yuchen Zheng April 23, 2017 1 Introduction Distributed databases have become increasingly popular in the era of big data because of their advantages over
Distributed Databases: SQL vs NoSQL Seda Unal, Yuchen Zheng April 23, 2017 1 Introduction Distributed databases have become increasingly popular in the era of big data because of their advantages over
1. Introduction to MapReduce
 Processing of massive data: MapReduce 1. Introduction to MapReduce 1 Origins: the Problem Google faced the problem of analyzing huge sets of data (order of petabytes) E.g. pagerank, web access logs, etc.
Processing of massive data: MapReduce 1. Introduction to MapReduce 1 Origins: the Problem Google faced the problem of analyzing huge sets of data (order of petabytes) E.g. pagerank, web access logs, etc.
Scalability of web applications
 Scalability of web applications CSCI 470: Web Science Keith Vertanen Copyright 2014 Scalability questions Overview What's important in order to build scalable web sites? High availability vs. load balancing
Scalability of web applications CSCI 470: Web Science Keith Vertanen Copyright 2014 Scalability questions Overview What's important in order to build scalable web sites? High availability vs. load balancing
Scalable Web Programming. CS193S - Jan Jannink - 2/25/10
 Scalable Web Programming CS193S - Jan Jannink - 2/25/10 Weekly Syllabus 1.Scalability: (Jan.) 2.Agile Practices 3.Ecology/Mashups 4.Browser/Client 7.Analytics 8.Cloud/Map-Reduce 9.Published APIs: (Mar.)*
Scalable Web Programming CS193S - Jan Jannink - 2/25/10 Weekly Syllabus 1.Scalability: (Jan.) 2.Agile Practices 3.Ecology/Mashups 4.Browser/Client 7.Analytics 8.Cloud/Map-Reduce 9.Published APIs: (Mar.)*
Study of NoSQL Database Along With Security Comparison
 Study of NoSQL Database Along With Security Comparison Ankita A. Mall [1], Jwalant B. Baria [2] [1] Student, Computer Engineering Department, Government Engineering College, Modasa, Gujarat, India ank.fetr@gmail.com
Study of NoSQL Database Along With Security Comparison Ankita A. Mall [1], Jwalant B. Baria [2] [1] Student, Computer Engineering Department, Government Engineering College, Modasa, Gujarat, India ank.fetr@gmail.com
CSE-E5430 Scalable Cloud Computing Lecture 9
 CSE-E5430 Scalable Cloud Computing Lecture 9 Keijo Heljanko Department of Computer Science School of Science Aalto University keijo.heljanko@aalto.fi 15.11-2015 1/24 BigTable Described in the paper: Fay
CSE-E5430 Scalable Cloud Computing Lecture 9 Keijo Heljanko Department of Computer Science School of Science Aalto University keijo.heljanko@aalto.fi 15.11-2015 1/24 BigTable Described in the paper: Fay
ECE5610/CSC6220 Introduction to Parallel and Distribution Computing. Lecture 6: MapReduce in Parallel Computing
 ECE5610/CSC6220 Introduction to Parallel and Distribution Computing Lecture 6: MapReduce in Parallel Computing 1 MapReduce: Simplified Data Processing Motivation Large-Scale Data Processing on Large Clusters
ECE5610/CSC6220 Introduction to Parallel and Distribution Computing Lecture 6: MapReduce in Parallel Computing 1 MapReduce: Simplified Data Processing Motivation Large-Scale Data Processing on Large Clusters
HBase Solutions at Facebook
 HBase Solutions at Facebook Nicolas Spiegelberg Software Engineer, Facebook QCon Hangzhou, October 28 th, 2012 Outline HBase Overview Single Tenant: Messages Selection Criteria Multi-tenant Solutions
HBase Solutions at Facebook Nicolas Spiegelberg Software Engineer, Facebook QCon Hangzhou, October 28 th, 2012 Outline HBase Overview Single Tenant: Messages Selection Criteria Multi-tenant Solutions
NOSQL EGCO321 DATABASE SYSTEMS KANAT POOLSAWASD DEPARTMENT OF COMPUTER ENGINEERING MAHIDOL UNIVERSITY
 NOSQL EGCO321 DATABASE SYSTEMS KANAT POOLSAWASD DEPARTMENT OF COMPUTER ENGINEERING MAHIDOL UNIVERSITY WHAT IS NOSQL? Stands for No-SQL or Not Only SQL. Class of non-relational data storage systems E.g.
NOSQL EGCO321 DATABASE SYSTEMS KANAT POOLSAWASD DEPARTMENT OF COMPUTER ENGINEERING MAHIDOL UNIVERSITY WHAT IS NOSQL? Stands for No-SQL or Not Only SQL. Class of non-relational data storage systems E.g.
Massive Online Analysis - Storm,Spark
 Massive Online Analysis - Storm,Spark presentation by R. Kishore Kumar Research Scholar Department of Computer Science & Engineering Indian Institute of Technology, Kharagpur Kharagpur-721302, India (R
Massive Online Analysis - Storm,Spark presentation by R. Kishore Kumar Research Scholar Department of Computer Science & Engineering Indian Institute of Technology, Kharagpur Kharagpur-721302, India (R
A Fast and High Throughput SQL Query System for Big Data
 A Fast and High Throughput SQL Query System for Big Data Feng Zhu, Jie Liu, and Lijie Xu Technology Center of Software Engineering, Institute of Software, Chinese Academy of Sciences, Beijing, China 100190
A Fast and High Throughput SQL Query System for Big Data Feng Zhu, Jie Liu, and Lijie Xu Technology Center of Software Engineering, Institute of Software, Chinese Academy of Sciences, Beijing, China 100190
Comparing SQL and NOSQL databases
 COSC 6397 Big Data Analytics Data Formats (II) HBase Edgar Gabriel Spring 2014 Comparing SQL and NOSQL databases Types Development History Data Storage Model SQL One type (SQL database) with minor variations
COSC 6397 Big Data Analytics Data Formats (II) HBase Edgar Gabriel Spring 2014 Comparing SQL and NOSQL databases Types Development History Data Storage Model SQL One type (SQL database) with minor variations