App Engine MapReduce. Mike Aizatsky 11 May Hashtags: #io2011 #AppEngine Feedback:
|
|
|
- Jayson Barber
- 6 years ago
- Views:
Transcription

1

2 App Engine MapReduce Mike Aizatsky 11 May 2011 Hashtags: #io2011 #AppEngine Feedback:
3 Agenda MapReduce Computational Model Mapper library Announcement Technical bits: Files API User-space shuffling MapReduce & Pipeline API Examples and Demos
4 MapReduce Computational Model
5 MapReduce A model to do efficient distributed computing over large data sets. Used at Google for years Every project uses MapReduce!

6 MapReduce Computational Model
 pairs User code")
7 Map Input: user data Output: (key, value) pairs User code

 pairs No")
8 Shuffle Collates value with the same key Input: (key, value) pairs Output: (key, [value]) pairs No user code
")

9 Reduce Input: (key, [value]) pairs Output: user data User code
10 MapReduce Computational Model
11 Common App Engine Approach Take what works for us at Google Give it to people
12 App Engine & Google's MapReduce Additional scaling dimension: Lots and lots of applications Many of them will run MapReduce at the same time Isolation: application shouldn't influence performance of the other
13 App Engine & Google's MapReduce Rate limiting: you don't want to burn all day's resources in 15min and kill your online traffic Very slow execution: free apps want to go really slow, staying under their resource limint Protection: from malicious App Engine users
14 Mapper
15 Mapper Library Released at Google I/O 2010 Heavily used by developers outside and inside Google (admin console, new indexer pipeline, etc.) Has seen lots of improvements since
16 Mapper Library Improvements Control API - start your jobs programmatically (and transactionally) Custom mutation pools - batch work between map function calls Namespaces support - iterate over data in different namespaces or over namespaces themselves Better sharding with scatter indices And more!
17 Mapper => MapReduce? Storage system for intermediate data: Files API, released in (March 2011) Shuffler Lots of glue code
18 Launching Shuffler Functionality In-memory, user-space, task-driven shuffle for small (100Mb) datasets. Trusted testers access to big shuffler. All the integration pieces needed to run your own mapreduce jobs are part of Mapper library. Mapper library => Mapreduce library! Python today, Java soon.
19 Examples
20 Example 1: Word Count # Map def map(line): for w in clean(line).split(): yield (w, '') Zed's dead, baby, Zed's dead! ('zed's', ''), ('dead', ''), ('baby', ''), ('zed's', ''), ('dead', '') # Reduce def reduce(key, values): yield (key, len(values)) ('zed's', ['', '']), ('dead', ['', '']), ('baby', ['']) ('zed's', 2), ('dead', 2'), ('baby', 1)
21 Demo
22 Example 2: Inverse Index # Map def map(line, filename): for w in clean(line).split(): yield (w, filename) # Reduce def reduce(key, values): yield (key, list(set(values)))
23 Demo
24 MapReduce: Technical Bits
25 Technical Bits Files API: solution to MapReduce storage problem User-space shuffler
26 Files API
27 Mapreduce Storage Mapreduce jobs generate lots of intermediate data. Datastore: expensive, 1MB entity limit Blobstore: read-only Memcache: small, volatile
28 Files API Familiar, files-like interface to various virtual file systems. Released in 1.4.3, integrated with Mapper library. Considered to be a low-level API.
29 Files API Files have two states: writable and readable. Start in writable. Moved to readable by "finalization". Can't read writable, can't write to readable. Write is append-only, atomic and fully serializable between concurrent clients. Concrete filesystems might have their own reliability constraints and/or additional APIs.
30 Blobstore Filesystem Write directly to blobstore. Files can be >2G. Finalized files are durable. Writable files are not (just restart your MapReduce) Can fetch a blob key for finalized files and use blobstore api.
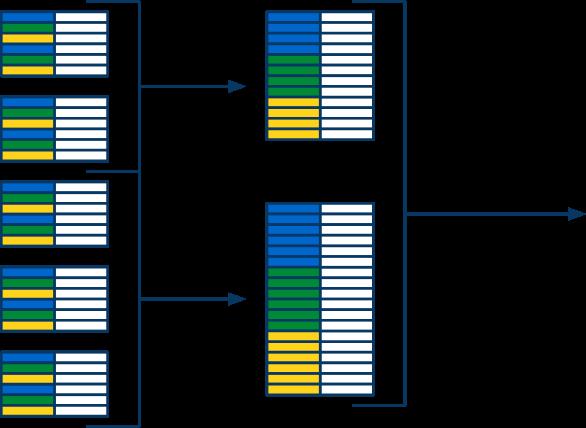
31 Blobstore Filesystem Python Example from google.appengine.api import files from future import with_statement # Create the file. file_name = files.blobstore.create() # Open the file for append. with files.open(file_name, 'a') as f: f.write('data') # All data is in. Finalize the file. files.finalize(file_name)
32 Blobstore Filesystem Python Example # Open the file for read. with files.open(file_name, 'r') as f: data = f.read(4) # Fetch blobkey for blobstore api. blob_key = files.blobstore.get_blob_key(file_name)
33 Mapper Integration # mapreduce.yaml... mapper: output_writer: mapreduce.output_writers. BlobstoreOutputWriters # Handler function def map(entity): yield entity.to_csv_line() + '\n'
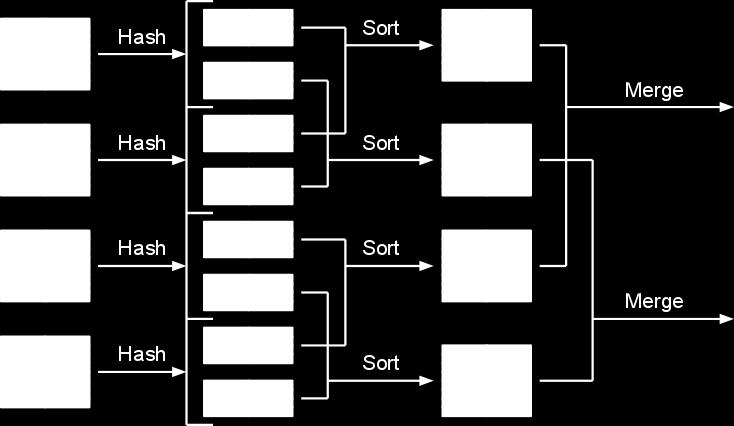
34 Low-level Features Exclusive locks: files can be opened exclusively by a single client only. Sequence keys: each write can have a "sequence key" attached. Our backends make sure that they only increase.
35 Future Plans "Tempfile" file system: much faster, much cheaper, but not durable, several days of storage only (geared specifically towards MapReduce) Integrations with other Google storage technologies and other reliability guarantees
36 User-Space Shuffler
37 User-Space Shuffler Consolidates values for the same key together. [(key, value)] => [(key, [value])] Should be reasonably fast, scalable and efficient. User-space: full source code, no new AppEngine components.
38 Take 1 Load all data into memory Sort Read sorted array
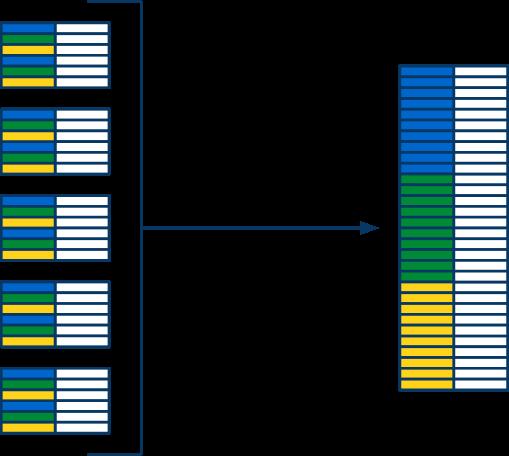
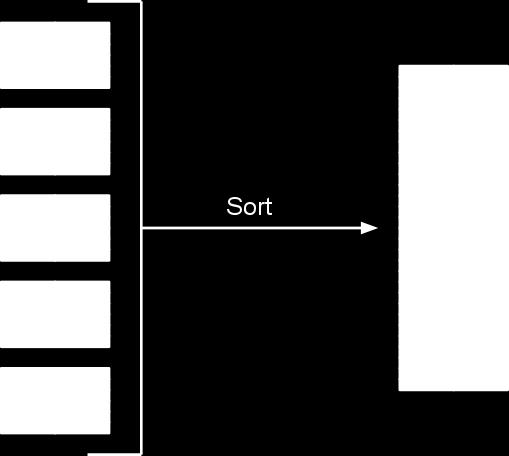
39 Take 1
40 Take 1 Properties Memory-bound No parallelism
41 Take 2 Sort chunks of data and store them back to Files API Merge-sort all chunks (or merge-read)
42 Take 2
43 Take 2 Properties No longer memory-bound Sorting is parallel Merge phase is not parallel Difficult (and slow) to read from too many files
44 Take 3 Shard mapper output by key hash code Sort each shard into chunks Merge-read each shard
45 Take 3
46 Take 3 Properties No longer memory-bound Sorting is parallel Merge phase is now parallel This is the shuffler we release today.
47 MapReduce & Pipeline
48 Pipeline API New API to chain complex work together. A glue which holds Mapper + Shuffler + Reducer together. MapReduce library is fully integrated with Pipeline. For in-depth look visit "Large-scale Data Analysis Using the App Engine Pipeline API" talk later today.
49 More Complex Example
50 Example 3: Distinguishing Phrases # Map def map(text, filename): for words in ngrams(text): yield (words, filename) # Reduce def reduce(key, values): if len(values) < 10: return for filename, count in count_occurences(values): if count > len(values) / 2: yield (key, filename)
51 Demo
52 Summary Small & Medium MapReduce jobs can be run by anyone today! Contact us for getting access to Large MapReduce jobs.
53 Questions? Hashtags: #io2011 #AppEngine Feedback:
54
Optimizing Your App Engine App
 Optimizing Your App Engine App Marzia Niccolai Spender of GBucks Greg Darke Byte Herder Troy Trimble Professional Expert Agenda Overview Writing applications efficiently Datastore Tips Caching, Caching,
Optimizing Your App Engine App Marzia Niccolai Spender of GBucks Greg Darke Byte Herder Troy Trimble Professional Expert Agenda Overview Writing applications efficiently Datastore Tips Caching, Caching,
App Engine: Datastore Introduction
 App Engine: Datastore Introduction Part 1 Another very useful course: https://www.udacity.com/course/developing-scalableapps-in-java--ud859 1 Topics cover in this lesson What is Datastore? Datastore and
App Engine: Datastore Introduction Part 1 Another very useful course: https://www.udacity.com/course/developing-scalableapps-in-java--ud859 1 Topics cover in this lesson What is Datastore? Datastore and
Building Scalable Web Apps with Google App Engine. Brett Slatkin June 14, 2008
 Building Scalable Web Apps with Google App Engine Brett Slatkin June 14, 2008 Agenda Using the Python runtime effectively Numbers everyone should know Tools for storing and scaling large data sets Example:
Building Scalable Web Apps with Google App Engine Brett Slatkin June 14, 2008 Agenda Using the Python runtime effectively Numbers everyone should know Tools for storing and scaling large data sets Example:
Developing Solutions for Google Cloud Platform (CPD200) Course Agenda
 Course Agenda") Developing Solutions for Google Cloud Platform (CPD200) Course Agenda Module 1: Developing Solutions for Google Cloud Platform Identify the advantages of Google Cloud Platform for solution development
Developing Solutions for Google Cloud Platform (CPD200) Course Agenda Module 1: Developing Solutions for Google Cloud Platform Identify the advantages of Google Cloud Platform for solution development
61A Lecture 36. Wednesday, November 30
 61A Lecture 36 Wednesday, November 30 Project 4 Contest Gallery Prizes will be awarded for the winning entry in each of the following categories. Featherweight. At most 128 words of Logo, not including
61A Lecture 36 Wednesday, November 30 Project 4 Contest Gallery Prizes will be awarded for the winning entry in each of the following categories. Featherweight. At most 128 words of Logo, not including
GFS Overview. Design goals/priorities Design for big-data workloads Huge files, mostly appends, concurrency, huge bandwidth Design for failures
 GFS Overview Design goals/priorities Design for big-data workloads Huge files, mostly appends, concurrency, huge bandwidth Design for failures Interface: non-posix New op: record appends (atomicity matters,
GFS Overview Design goals/priorities Design for big-data workloads Huge files, mostly appends, concurrency, huge bandwidth Design for failures Interface: non-posix New op: record appends (atomicity matters,
Dept. Of Computer Science, Colorado State University
 CS 455: INTRODUCTION TO DISTRIBUTED SYSTEMS [HADOOP/HDFS] Trying to have your cake and eat it too Each phase pines for tasks with locality and their numbers on a tether Alas within a phase, you get one,
CS 455: INTRODUCTION TO DISTRIBUTED SYSTEMS [HADOOP/HDFS] Trying to have your cake and eat it too Each phase pines for tasks with locality and their numbers on a tether Alas within a phase, you get one,
HDFS: Hadoop Distributed File System. CIS 612 Sunnie Chung
 HDFS: Hadoop Distributed File System CIS 612 Sunnie Chung What is Big Data?? Bulk Amount Unstructured Introduction Lots of Applications which need to handle huge amount of data (in terms of 500+ TB per
HDFS: Hadoop Distributed File System CIS 612 Sunnie Chung What is Big Data?? Bulk Amount Unstructured Introduction Lots of Applications which need to handle huge amount of data (in terms of 500+ TB per
Getting the most out of Spring and App Engine!!
 Getting the most out of Spring and App Engine!! Chris Ramsdale Product Manager, App Engine Google 2011 SpringOne 2GX 2011. All rights reserved. Do not distribute without permission. Whatʼs on tap today?
Getting the most out of Spring and App Engine!! Chris Ramsdale Product Manager, App Engine Google 2011 SpringOne 2GX 2011. All rights reserved. Do not distribute without permission. Whatʼs on tap today?
Batch Processing Basic architecture
 Batch Processing Basic architecture in big data systems COS 518: Distributed Systems Lecture 10 Andrew Or, Mike Freedman 2 1 2 64GB RAM 32 cores 64GB RAM 32 cores 64GB RAM 32 cores 64GB RAM 32 cores 3
Batch Processing Basic architecture in big data systems COS 518: Distributed Systems Lecture 10 Andrew Or, Mike Freedman 2 1 2 64GB RAM 32 cores 64GB RAM 32 cores 64GB RAM 32 cores 64GB RAM 32 cores 3
ECE 7650 Scalable and Secure Internet Services and Architecture ---- A Systems Perspective
 ECE 7650 Scalable and Secure Internet Services and Architecture ---- A Systems Perspective Part II: Data Center Software Architecture: Topic 1: Distributed File Systems GFS (The Google File System) 1 Filesystems
ECE 7650 Scalable and Secure Internet Services and Architecture ---- A Systems Perspective Part II: Data Center Software Architecture: Topic 1: Distributed File Systems GFS (The Google File System) 1 Filesystems
Clustering Lecture 8: MapReduce
 Clustering Lecture 8: MapReduce Jing Gao SUNY Buffalo 1 Divide and Conquer Work Partition w 1 w 2 w 3 worker worker worker r 1 r 2 r 3 Result Combine 4 Distributed Grep Very big data Split data Split data
Clustering Lecture 8: MapReduce Jing Gao SUNY Buffalo 1 Divide and Conquer Work Partition w 1 w 2 w 3 worker worker worker r 1 r 2 r 3 Result Combine 4 Distributed Grep Very big data Split data Split data
ML from Large Datasets
 10-605 ML from Large Datasets 1 Announcements HW1b is going out today You should now be on autolab have a an account on stoat a locally-administered Hadoop cluster shortly receive a coupon for Amazon Web
10-605 ML from Large Datasets 1 Announcements HW1b is going out today You should now be on autolab have a an account on stoat a locally-administered Hadoop cluster shortly receive a coupon for Amazon Web
Map Reduce. Yerevan.
 Map Reduce Erasmus+ @ Yerevan dacosta@irit.fr Divide and conquer at PaaS 100 % // Typical problem Iterate over a large number of records Extract something of interest from each Shuffle and sort intermediate
Map Reduce Erasmus+ @ Yerevan dacosta@irit.fr Divide and conquer at PaaS 100 % // Typical problem Iterate over a large number of records Extract something of interest from each Shuffle and sort intermediate
FLAT DATACENTER STORAGE. Paper-3 Presenter-Pratik Bhatt fx6568
 FLAT DATACENTER STORAGE Paper-3 Presenter-Pratik Bhatt fx6568 FDS Main discussion points A cluster storage system Stores giant "blobs" - 128-bit ID, multi-megabyte content Clients and servers connected
FLAT DATACENTER STORAGE Paper-3 Presenter-Pratik Bhatt fx6568 FDS Main discussion points A cluster storage system Stores giant "blobs" - 128-bit ID, multi-megabyte content Clients and servers connected
Distributed Systems. Lec 10: Distributed File Systems GFS. Slide acks: Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung
 Distributed Systems Lec 10: Distributed File Systems GFS Slide acks: Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung 1 Distributed File Systems NFS AFS GFS Some themes in these classes: Workload-oriented
Distributed Systems Lec 10: Distributed File Systems GFS Slide acks: Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung 1 Distributed File Systems NFS AFS GFS Some themes in these classes: Workload-oriented
Informa)on Retrieval and Map- Reduce Implementa)ons. Mohammad Amir Sharif PhD Student Center for Advanced Computer Studies
on Retrieval and Map- Reduce Implementa)ons. Mohammad Amir Sharif PhD Student Center for Advanced Computer Studies") Informa)on Retrieval and Map- Reduce Implementa)ons Mohammad Amir Sharif PhD Student Center for Advanced Computer Studies mas4108@louisiana.edu Map-Reduce: Why? Need to process 100TB datasets On 1 node:
Informa)on Retrieval and Map- Reduce Implementa)ons Mohammad Amir Sharif PhD Student Center for Advanced Computer Studies mas4108@louisiana.edu Map-Reduce: Why? Need to process 100TB datasets On 1 node:
Designing for the Cloud
 Design Page 1 Designing for the Cloud 3:47 PM Designing for the Cloud So far, I've given you the "solution" and asked you to "program a piece of it". This is a short-term problem! In fact, 90% of the real
Design Page 1 Designing for the Cloud 3:47 PM Designing for the Cloud So far, I've given you the "solution" and asked you to "program a piece of it". This is a short-term problem! In fact, 90% of the real
Database Applications (15-415)
") Database Applications (15-415) Hadoop Lecture 24, April 23, 2014 Mohammad Hammoud Today Last Session: NoSQL databases Today s Session: Hadoop = HDFS + MapReduce Announcements: Final Exam is on Sunday April
Database Applications (15-415) Hadoop Lecture 24, April 23, 2014 Mohammad Hammoud Today Last Session: NoSQL databases Today s Session: Hadoop = HDFS + MapReduce Announcements: Final Exam is on Sunday April
Programming Models MapReduce
 Programming Models MapReduce Majd Sakr, Garth Gibson, Greg Ganger, Raja Sambasivan 15-719/18-847b Advanced Cloud Computing Fall 2013 Sep 23, 2013 1 MapReduce In a Nutshell MapReduce incorporates two phases
Programming Models MapReduce Majd Sakr, Garth Gibson, Greg Ganger, Raja Sambasivan 15-719/18-847b Advanced Cloud Computing Fall 2013 Sep 23, 2013 1 MapReduce In a Nutshell MapReduce incorporates two phases
MapReduce. Stony Brook University CSE545, Fall 2016
 MapReduce Stony Brook University CSE545, Fall 2016 Classical Data Mining CPU Memory Disk Classical Data Mining CPU Memory (64 GB) Disk Classical Data Mining CPU Memory (64 GB) Disk Classical Data Mining
MapReduce Stony Brook University CSE545, Fall 2016 Classical Data Mining CPU Memory Disk Classical Data Mining CPU Memory (64 GB) Disk Classical Data Mining CPU Memory (64 GB) Disk Classical Data Mining
The Google File System. Alexandru Costan
 1 The Google File System Alexandru Costan Actions on Big Data 2 Storage Analysis Acquisition Handling the data stream Data structured unstructured semi-structured Results Transactions Outline File systems
1 The Google File System Alexandru Costan Actions on Big Data 2 Storage Analysis Acquisition Handling the data stream Data structured unstructured semi-structured Results Transactions Outline File systems
Developing MapReduce Programs
 Cloud Computing Developing MapReduce Programs Dell Zhang Birkbeck, University of London 2017/18 MapReduce Algorithm Design MapReduce: Recap Programmers must specify two functions: map (k, v) * Takes
Cloud Computing Developing MapReduce Programs Dell Zhang Birkbeck, University of London 2017/18 MapReduce Algorithm Design MapReduce: Recap Programmers must specify two functions: map (k, v) * Takes
Scaling App Engine Applications. Justin Haugh, Guido van Rossum May 10, 2011
 Scaling App Engine Applications Justin Haugh, Guido van Rossum May 10, 2011 First things first Justin Haugh Software Engineer Systems Infrastructure jhaugh@google.com Guido Van Rossum Software Engineer
Scaling App Engine Applications Justin Haugh, Guido van Rossum May 10, 2011 First things first Justin Haugh Software Engineer Systems Infrastructure jhaugh@google.com Guido Van Rossum Software Engineer
Map-Reduce. Marco Mura 2010 March, 31th
 Map-Reduce Marco Mura (mura@di.unipi.it) 2010 March, 31th This paper is a note from the 2009-2010 course Strumenti di programmazione per sistemi paralleli e distribuiti and it s based by the lessons of
Map-Reduce Marco Mura (mura@di.unipi.it) 2010 March, 31th This paper is a note from the 2009-2010 course Strumenti di programmazione per sistemi paralleli e distribuiti and it s based by the lessons of
PaaS Cloud mit Java. Eberhard Wolff, Principal Technologist, SpringSource A division of VMware VMware Inc. All rights reserved
 PaaS Cloud mit Java Eberhard Wolff, Principal Technologist, SpringSource A division of VMware 2009 VMware Inc. All rights reserved Agenda! A Few Words About Cloud! PaaS Platform as a Service! Google App
PaaS Cloud mit Java Eberhard Wolff, Principal Technologist, SpringSource A division of VMware 2009 VMware Inc. All rights reserved Agenda! A Few Words About Cloud! PaaS Platform as a Service! Google App
Building Scalable Web Apps with Python and Google Cloud Platform. Dan Sanderson, April 2015
 Building Scalable Web Apps with Python and Google Cloud Platform Dan Sanderson, April 2015 June 2015 pre-order now Agenda Introducing GCP & GAE Starting a project with gcloud and Cloud Console Understanding
Building Scalable Web Apps with Python and Google Cloud Platform Dan Sanderson, April 2015 June 2015 pre-order now Agenda Introducing GCP & GAE Starting a project with gcloud and Cloud Console Understanding
Lecture 12. Lecture 12: The IO Model & External Sorting
 Lecture 12 Lecture 12: The IO Model & External Sorting Announcements Announcements 1. Thank you for the great feedback (post coming soon)! 2. Educational goals: 1. Tech changes, principles change more
Lecture 12 Lecture 12: The IO Model & External Sorting Announcements Announcements 1. Thank you for the great feedback (post coming soon)! 2. Educational goals: 1. Tech changes, principles change more
Large-Scale Web Applications
 Large-Scale Web Applications Mendel Rosenblum Web Application Architecture Web Browser Web Server / Application server Storage System HTTP Internet CS142 Lecture Notes - Intro LAN 2 Large-Scale: Scale-Out
Large-Scale Web Applications Mendel Rosenblum Web Application Architecture Web Browser Web Server / Application server Storage System HTTP Internet CS142 Lecture Notes - Intro LAN 2 Large-Scale: Scale-Out
Apache Spark is a fast and general-purpose engine for large-scale data processing Spark aims at achieving the following goals in the Big data context
 1 Apache Spark is a fast and general-purpose engine for large-scale data processing Spark aims at achieving the following goals in the Big data context Generality: diverse workloads, operators, job sizes
1 Apache Spark is a fast and general-purpose engine for large-scale data processing Spark aims at achieving the following goals in the Big data context Generality: diverse workloads, operators, job sizes
Distributed File Systems II
 Distributed File Systems II To do q Very-large scale: Google FS, Hadoop FS, BigTable q Next time: Naming things GFS A radically new environment NFS, etc. Independence Small Scale Variety of workloads Cooperation
Distributed File Systems II To do q Very-large scale: Google FS, Hadoop FS, BigTable q Next time: Naming things GFS A radically new environment NFS, etc. Independence Small Scale Variety of workloads Cooperation
Vendor: Hortonworks. Exam Code: HDPCD. Exam Name: Hortonworks Data Platform Certified Developer. Version: Demo
 Vendor: Hortonworks Exam Code: HDPCD Exam Name: Hortonworks Data Platform Certified Developer Version: Demo QUESTION 1 Workflows expressed in Oozie can contain: A. Sequences of MapReduce and Pig. These
Vendor: Hortonworks Exam Code: HDPCD Exam Name: Hortonworks Data Platform Certified Developer Version: Demo QUESTION 1 Workflows expressed in Oozie can contain: A. Sequences of MapReduce and Pig. These
Developing with Google App Engine
 Developing with Google App Engine Dan Morrill, Developer Advocate Dan Morrill Google App Engine Slide 1 Developing with Google App Engine Introduction Dan Morrill Google App Engine Slide 2 Google App Engine
Developing with Google App Engine Dan Morrill, Developer Advocate Dan Morrill Google App Engine Slide 1 Developing with Google App Engine Introduction Dan Morrill Google App Engine Slide 2 Google App Engine
Big Data Infrastructure CS 489/698 Big Data Infrastructure (Winter 2017)
") Big Data Infrastructure CS 489/698 Big Data Infrastructure (Winter 2017) Week 2: MapReduce Algorithm Design (2/2) January 12, 2017 Jimmy Lin David R. Cheriton School of Computer Science University of Waterloo
Big Data Infrastructure CS 489/698 Big Data Infrastructure (Winter 2017) Week 2: MapReduce Algorithm Design (2/2) January 12, 2017 Jimmy Lin David R. Cheriton School of Computer Science University of Waterloo
CSE 544 Principles of Database Management Systems. Alvin Cheung Fall 2015 Lecture 10 Parallel Programming Models: Map Reduce and Spark
 CSE 544 Principles of Database Management Systems Alvin Cheung Fall 2015 Lecture 10 Parallel Programming Models: Map Reduce and Spark Announcements HW2 due this Thursday AWS accounts Any success? Feel
CSE 544 Principles of Database Management Systems Alvin Cheung Fall 2015 Lecture 10 Parallel Programming Models: Map Reduce and Spark Announcements HW2 due this Thursday AWS accounts Any success? Feel
A brief history on Hadoop
 Hadoop Basics A brief history on Hadoop 2003 - Google launches project Nutch to handle billions of searches and indexing millions of web pages. Oct 2003 - Google releases papers with GFS (Google File System)
Hadoop Basics A brief history on Hadoop 2003 - Google launches project Nutch to handle billions of searches and indexing millions of web pages. Oct 2003 - Google releases papers with GFS (Google File System)
Extract API: Build sophisticated data models with the Extract API
 Welcome # T C 1 8 Extract API: Build sophisticated data models with the Extract API Justin Craycraft Senior Sales Consultant Tableau / Customer Consulting My Office Photo Used with permission Agenda 1)
Welcome # T C 1 8 Extract API: Build sophisticated data models with the Extract API Justin Craycraft Senior Sales Consultant Tableau / Customer Consulting My Office Photo Used with permission Agenda 1)
CPSC 426/526. Cloud Computing. Ennan Zhai. Computer Science Department Yale University
 CPSC 426/526 Cloud Computing Ennan Zhai Computer Science Department Yale University Recall: Lec-7 In the lec-7, I talked about: - P2P vs Enterprise control - Firewall - NATs - Software defined network
CPSC 426/526 Cloud Computing Ennan Zhai Computer Science Department Yale University Recall: Lec-7 In the lec-7, I talked about: - P2P vs Enterprise control - Firewall - NATs - Software defined network
Distributed Data Store
 Distributed Data Store Large-Scale Distributed le system Q: What if we have too much data to store in a single machine? Q: How can we create one big filesystem over a cluster of machines, whose data is
Distributed Data Store Large-Scale Distributed le system Q: What if we have too much data to store in a single machine? Q: How can we create one big filesystem over a cluster of machines, whose data is
CSE Lecture 11: Map/Reduce 7 October Nate Nystrom UTA
 CSE 3302 Lecture 11: Map/Reduce 7 October 2010 Nate Nystrom UTA 378,000 results in 0.17 seconds including images and video communicates with 1000s of machines web server index servers document servers
CSE 3302 Lecture 11: Map/Reduce 7 October 2010 Nate Nystrom UTA 378,000 results in 0.17 seconds including images and video communicates with 1000s of machines web server index servers document servers
GFS-python: A Simplified GFS Implementation in Python
 GFS-python: A Simplified GFS Implementation in Python Andy Strohman ABSTRACT GFS-python is distributed network filesystem written entirely in python. There are no dependencies other than Python s standard
GFS-python: A Simplified GFS Implementation in Python Andy Strohman ABSTRACT GFS-python is distributed network filesystem written entirely in python. There are no dependencies other than Python s standard
Distributed Systems CS6421
 Distributed Systems CS6421 Intro to Distributed Systems and the Cloud Prof. Tim Wood v I teach: Software Engineering, Operating Systems, Sr. Design I like: distributed systems, networks, building cool
Distributed Systems CS6421 Intro to Distributed Systems and the Cloud Prof. Tim Wood v I teach: Software Engineering, Operating Systems, Sr. Design I like: distributed systems, networks, building cool
TITLE: PRE-REQUISITE THEORY. 1. Introduction to Hadoop. 2. Cluster. Implement sort algorithm and run it using HADOOP
 TITLE: Implement sort algorithm and run it using HADOOP PRE-REQUISITE Preliminary knowledge of clusters and overview of Hadoop and its basic functionality. THEORY 1. Introduction to Hadoop The Apache Hadoop
TITLE: Implement sort algorithm and run it using HADOOP PRE-REQUISITE Preliminary knowledge of clusters and overview of Hadoop and its basic functionality. THEORY 1. Introduction to Hadoop The Apache Hadoop
Announcements. Optional Reading. Distributed File System (DFS) MapReduce Process. MapReduce. Database Systems CSE 414. HW5 is due tomorrow 11pm
 MapReduce Process. MapReduce. Database Systems CSE 414. HW5 is due tomorrow 11pm") Announcements HW5 is due tomorrow 11pm Database Systems CSE 414 Lecture 19: MapReduce (Ch. 20.2) HW6 is posted and due Nov. 27 11pm Section Thursday on setting up Spark on AWS Create your AWS account before
Announcements HW5 is due tomorrow 11pm Database Systems CSE 414 Lecture 19: MapReduce (Ch. 20.2) HW6 is posted and due Nov. 27 11pm Section Thursday on setting up Spark on AWS Create your AWS account before
Introduction to Concurrent Software Systems. CSCI 5828: Foundations of Software Engineering Lecture 08 09/17/2015
 Introduction to Concurrent Software Systems CSCI 5828: Foundations of Software Engineering Lecture 08 09/17/2015 1 Goals Present an overview of concurrency in software systems Review the benefits and challenges
Introduction to Concurrent Software Systems CSCI 5828: Foundations of Software Engineering Lecture 08 09/17/2015 1 Goals Present an overview of concurrency in software systems Review the benefits and challenges
9/26/2017 Sangmi Lee Pallickara Week 6- A. CS535 Big Data Fall 2017 Colorado State University
 CS535 Big Data - Fall 2017 Week 6-A-1 CS535 BIG DATA FAQs PA1: Use only one word query Deadends {{Dead end}} Hub value will be?? PART 1. BATCH COMPUTING MODEL FOR BIG DATA ANALYTICS 4. GOOGLE FILE SYSTEM
CS535 Big Data - Fall 2017 Week 6-A-1 CS535 BIG DATA FAQs PA1: Use only one word query Deadends {{Dead end}} Hub value will be?? PART 1. BATCH COMPUTING MODEL FOR BIG DATA ANALYTICS 4. GOOGLE FILE SYSTEM
ΕΠΛ 602:Foundations of Internet Technologies. Cloud Computing
 ΕΠΛ 602:Foundations of Internet Technologies Cloud Computing 1 Outline Bigtable(data component of cloud) Web search basedonch13of thewebdatabook 2 What is Cloud Computing? ACloudis an infrastructure, transparent
ΕΠΛ 602:Foundations of Internet Technologies Cloud Computing 1 Outline Bigtable(data component of cloud) Web search basedonch13of thewebdatabook 2 What is Cloud Computing? ACloudis an infrastructure, transparent
HDFS: Hadoop Distributed File System. Sector: Distributed Storage System
 GFS: Google File System Google C/C++ HDFS: Hadoop Distributed File System Yahoo Java, Open Source Sector: Distributed Storage System University of Illinois at Chicago C++, Open Source 2 System that permanently
GFS: Google File System Google C/C++ HDFS: Hadoop Distributed File System Yahoo Java, Open Source Sector: Distributed Storage System University of Illinois at Chicago C++, Open Source 2 System that permanently
CS 138: Google. CS 138 XVI 1 Copyright 2017 Thomas W. Doeppner. All rights reserved.
 CS 138: Google CS 138 XVI 1 Copyright 2017 Thomas W. Doeppner. All rights reserved. Google Environment Lots (tens of thousands) of computers all more-or-less equal - processor, disk, memory, network interface
CS 138: Google CS 138 XVI 1 Copyright 2017 Thomas W. Doeppner. All rights reserved. Google Environment Lots (tens of thousands) of computers all more-or-less equal - processor, disk, memory, network interface
Big Data Infrastructure CS 489/698 Big Data Infrastructure (Winter 2016)
") Big Data Infrastructure CS 489/698 Big Data Infrastructure (Winter 2016) Week 2: MapReduce Algorithm Design (2/2) January 14, 2016 Jimmy Lin David R. Cheriton School of Computer Science University of Waterloo
Big Data Infrastructure CS 489/698 Big Data Infrastructure (Winter 2016) Week 2: MapReduce Algorithm Design (2/2) January 14, 2016 Jimmy Lin David R. Cheriton School of Computer Science University of Waterloo
Introduction to MapReduce
 Basics of Cloud Computing Lecture 4 Introduction to MapReduce Satish Srirama Some material adapted from slides by Jimmy Lin, Christophe Bisciglia, Aaron Kimball, & Sierra Michels-Slettvet, Google Distributed
Basics of Cloud Computing Lecture 4 Introduction to MapReduce Satish Srirama Some material adapted from slides by Jimmy Lin, Christophe Bisciglia, Aaron Kimball, & Sierra Michels-Slettvet, Google Distributed
Database Systems CSE 414
 Database Systems CSE 414 Lecture 19: MapReduce (Ch. 20.2) CSE 414 - Fall 2017 1 Announcements HW5 is due tomorrow 11pm HW6 is posted and due Nov. 27 11pm Section Thursday on setting up Spark on AWS Create
Database Systems CSE 414 Lecture 19: MapReduce (Ch. 20.2) CSE 414 - Fall 2017 1 Announcements HW5 is due tomorrow 11pm HW6 is posted and due Nov. 27 11pm Section Thursday on setting up Spark on AWS Create
Big Data Infrastructure CS 489/698 Big Data Infrastructure (Winter 2017)
") Big Data Infrastructure CS 489/698 Big Data Infrastructure (Winter 2017) Week 10: Mutable State (1/2) March 14, 2017 Jimmy Lin David R. Cheriton School of Computer Science University of Waterloo These
Big Data Infrastructure CS 489/698 Big Data Infrastructure (Winter 2017) Week 10: Mutable State (1/2) March 14, 2017 Jimmy Lin David R. Cheriton School of Computer Science University of Waterloo These
Introduction to Concurrent Software Systems. CSCI 5828: Foundations of Software Engineering Lecture 12 09/29/2016
 Introduction to Concurrent Software Systems CSCI 5828: Foundations of Software Engineering Lecture 12 09/29/2016 1 Goals Present an overview of concurrency in software systems Review the benefits and challenges
Introduction to Concurrent Software Systems CSCI 5828: Foundations of Software Engineering Lecture 12 09/29/2016 1 Goals Present an overview of concurrency in software systems Review the benefits and challenges
Batch Inherence of Map Reduce Framework
 Available Online at www.ijcsmc.com International Journal of Computer Science and Mobile Computing A Monthly Journal of Computer Science and Information Technology IJCSMC, Vol. 4, Issue. 6, June 2015, pg.287
Available Online at www.ijcsmc.com International Journal of Computer Science and Mobile Computing A Monthly Journal of Computer Science and Information Technology IJCSMC, Vol. 4, Issue. 6, June 2015, pg.287
Announcements. Parallel Data Processing in the 20 th Century. Parallel Join Illustration. Introduction to Database Systems CSE 414
 Introduction to Database Systems CSE 414 Lecture 17: MapReduce and Spark Announcements Midterm this Friday in class! Review session tonight See course website for OHs Includes everything up to Monday s
Introduction to Database Systems CSE 414 Lecture 17: MapReduce and Spark Announcements Midterm this Friday in class! Review session tonight See course website for OHs Includes everything up to Monday s
HADOOP FRAMEWORK FOR BIG DATA
 HADOOP FRAMEWORK FOR BIG DATA Mr K. Srinivas Babu 1,Dr K. Rameshwaraiah 2 1 Research Scholar S V University, Tirupathi 2 Professor and Head NNRESGI, Hyderabad Abstract - Data has to be stored for further
HADOOP FRAMEWORK FOR BIG DATA Mr K. Srinivas Babu 1,Dr K. Rameshwaraiah 2 1 Research Scholar S V University, Tirupathi 2 Professor and Head NNRESGI, Hyderabad Abstract - Data has to be stored for further
CS MapReduce. Vitaly Shmatikov
 CS 5450 MapReduce Vitaly Shmatikov BackRub (Google), 1997 slide 2 NEC Earth Simulator, 2002 slide 3 Conventional HPC Machine ucompute nodes High-end processors Lots of RAM unetwork Specialized Very high
CS 5450 MapReduce Vitaly Shmatikov BackRub (Google), 1997 slide 2 NEC Earth Simulator, 2002 slide 3 Conventional HPC Machine ucompute nodes High-end processors Lots of RAM unetwork Specialized Very high
Introduction to MapReduce (cont.)
") Introduction to MapReduce (cont.) Rafael Ferreira da Silva rafsilva@isi.edu http://rafaelsilva.com USC INF 553 Foundations and Applications of Data Mining (Fall 2018) 2 MapReduce: Summary USC INF 553 Foundations
Introduction to MapReduce (cont.) Rafael Ferreira da Silva rafsilva@isi.edu http://rafaelsilva.com USC INF 553 Foundations and Applications of Data Mining (Fall 2018) 2 MapReduce: Summary USC INF 553 Foundations
GFS: The Google File System
 GFS: The Google File System Brad Karp UCL Computer Science CS GZ03 / M030 24 th October 2014 Motivating Application: Google Crawl the whole web Store it all on one big disk Process users searches on one
GFS: The Google File System Brad Karp UCL Computer Science CS GZ03 / M030 24 th October 2014 Motivating Application: Google Crawl the whole web Store it all on one big disk Process users searches on one
Introduction to Data Management CSE 344
 Introduction to Data Management CSE 344 Lecture 24: MapReduce CSE 344 - Winter 215 1 HW8 MapReduce (Hadoop) w/ declarative language (Pig) Due next Thursday evening Will send out reimbursement codes later
Introduction to Data Management CSE 344 Lecture 24: MapReduce CSE 344 - Winter 215 1 HW8 MapReduce (Hadoop) w/ declarative language (Pig) Due next Thursday evening Will send out reimbursement codes later
Extreme Computing. NoSQL.
 Extreme Computing NoSQL PREVIOUSLY: BATCH Query most/all data Results Eventually NOW: ON DEMAND Single Data Points Latency Matters One problem, three ideas We want to keep track of mutable state in a scalable
Extreme Computing NoSQL PREVIOUSLY: BATCH Query most/all data Results Eventually NOW: ON DEMAND Single Data Points Latency Matters One problem, three ideas We want to keep track of mutable state in a scalable
Introduction to MapReduce. Adapted from Jimmy Lin (U. Maryland, USA)
") Introduction to MapReduce Adapted from Jimmy Lin (U. Maryland, USA) Motivation Overview Need for handling big data New programming paradigm Review of functional programming mapreduce uses this abstraction
Introduction to MapReduce Adapted from Jimmy Lin (U. Maryland, USA) Motivation Overview Need for handling big data New programming paradigm Review of functional programming mapreduce uses this abstraction
Distributed Computation Models
 Distributed Computation Models SWE 622, Spring 2017 Distributed Software Engineering Some slides ack: Jeff Dean HW4 Recap https://b.socrative.com/ Class: SWE622 2 Review Replicating state machines Case
Distributed Computation Models SWE 622, Spring 2017 Distributed Software Engineering Some slides ack: Jeff Dean HW4 Recap https://b.socrative.com/ Class: SWE622 2 Review Replicating state machines Case
Introduction to MapReduce
 732A54 Big Data Analytics Introduction to MapReduce Christoph Kessler IDA, Linköping University Towards Parallel Processing of Big-Data Big Data too large to be read+processed in reasonable time by 1 server
732A54 Big Data Analytics Introduction to MapReduce Christoph Kessler IDA, Linköping University Towards Parallel Processing of Big-Data Big Data too large to be read+processed in reasonable time by 1 server
CSE 444: Database Internals. Lecture 23 Spark
 CSE 444: Database Internals Lecture 23 Spark References Spark is an open source system from Berkeley Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster Computing. Matei
CSE 444: Database Internals Lecture 23 Spark References Spark is an open source system from Berkeley Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster Computing. Matei
CSE 544: Principles of Database Systems
 CSE 544: Principles of Database Systems Anatomy of a DBMS, Parallel Databases 1 Announcements Lecture on Thursday, May 2nd: Moved to 9am-10:30am, CSE 403 Paper reviews: Anatomy paper was due yesterday;
CSE 544: Principles of Database Systems Anatomy of a DBMS, Parallel Databases 1 Announcements Lecture on Thursday, May 2nd: Moved to 9am-10:30am, CSE 403 Paper reviews: Anatomy paper was due yesterday;
CS 61C: Great Ideas in Computer Architecture. MapReduce
 CS 61C: Great Ideas in Computer Architecture MapReduce Guest Lecturer: Justin Hsia 3/06/2013 Spring 2013 Lecture #18 1 Review of Last Lecture Performance latency and throughput Warehouse Scale Computing
CS 61C: Great Ideas in Computer Architecture MapReduce Guest Lecturer: Justin Hsia 3/06/2013 Spring 2013 Lecture #18 1 Review of Last Lecture Performance latency and throughput Warehouse Scale Computing
Google GCP-Solution Architects Exam
 Volume: 90 Questions Question: 1 Regarding memcache which of the options is an ideal use case? A. Caching data that isn't accessed often B. Caching data that is written more than it's read C. Caching important
Volume: 90 Questions Question: 1 Regarding memcache which of the options is an ideal use case? A. Caching data that isn't accessed often B. Caching data that is written more than it's read C. Caching important
CS 138: Google. CS 138 XVII 1 Copyright 2016 Thomas W. Doeppner. All rights reserved.
 CS 138: Google CS 138 XVII 1 Copyright 2016 Thomas W. Doeppner. All rights reserved. Google Environment Lots (tens of thousands) of computers all more-or-less equal - processor, disk, memory, network interface
CS 138: Google CS 138 XVII 1 Copyright 2016 Thomas W. Doeppner. All rights reserved. Google Environment Lots (tens of thousands) of computers all more-or-less equal - processor, disk, memory, network interface
Scalability. ! Load Balancing. ! Provisioning/auto scaling. ! State Caching Commonly used items of the database are kept in memory. !
 Scalability! Load Balancing Recommended Text: Scalability! Provisioning/auto scaling! State Caching Commonly used items of the database are kept in memory. Replication Logical items of the database (e.g.,
Scalability! Load Balancing Recommended Text: Scalability! Provisioning/auto scaling! State Caching Commonly used items of the database are kept in memory. Replication Logical items of the database (e.g.,
Data-Intensive Distributed Computing
 Data-Intensive Distributed Computing CS 451/651 431/631 (Winter 2018) Part 1: MapReduce Algorithm Design (4/4) January 16, 2018 Jimmy Lin David R. Cheriton School of Computer Science University of Waterloo
Data-Intensive Distributed Computing CS 451/651 431/631 (Winter 2018) Part 1: MapReduce Algorithm Design (4/4) January 16, 2018 Jimmy Lin David R. Cheriton School of Computer Science University of Waterloo
Megastore: Providing Scalable, Highly Available Storage for Interactive Services & Spanner: Google s Globally- Distributed Database.
 Megastore: Providing Scalable, Highly Available Storage for Interactive Services & Spanner: Google s Globally- Distributed Database. Presented by Kewei Li The Problem db nosql complex legacy tuning expensive
Megastore: Providing Scalable, Highly Available Storage for Interactive Services & Spanner: Google s Globally- Distributed Database. Presented by Kewei Li The Problem db nosql complex legacy tuning expensive
Parallel Computing: MapReduce Jin, Hai
 Parallel Computing: MapReduce Jin, Hai School of Computer Science and Technology Huazhong University of Science and Technology ! MapReduce is a distributed/parallel computing framework introduced by Google
Parallel Computing: MapReduce Jin, Hai School of Computer Science and Technology Huazhong University of Science and Technology ! MapReduce is a distributed/parallel computing framework introduced by Google
The Evolution of a Data Project
 The Evolution of a Data Project The Evolution of a Data Project Python script The Evolution of a Data Project Python script SQL on live DB The Evolution of a Data Project Python script SQL on live DB SQL
The Evolution of a Data Project The Evolution of a Data Project Python script The Evolution of a Data Project Python script SQL on live DB The Evolution of a Data Project Python script SQL on live DB SQL
Algorithms for MapReduce. Combiners Partition and Sort Pairs vs Stripes
 Algorithms for MapReduce 1 Assignment 1 released Due 16:00 on 20 October Correctness is not enough! Most marks are for efficiency. 2 Combining, Sorting, and Partitioning... and algorithms exploiting these
Algorithms for MapReduce 1 Assignment 1 released Due 16:00 on 20 October Correctness is not enough! Most marks are for efficiency. 2 Combining, Sorting, and Partitioning... and algorithms exploiting these
Research challenges in data-intensive computing The Stratosphere Project Apache Flink
 Research challenges in data-intensive computing The Stratosphere Project Apache Flink Seif Haridi KTH/SICS haridi@kth.se e2e-clouds.org Presented by: Seif Haridi May 2014 Research Areas Data-intensive
Research challenges in data-intensive computing The Stratosphere Project Apache Flink Seif Haridi KTH/SICS haridi@kth.se e2e-clouds.org Presented by: Seif Haridi May 2014 Research Areas Data-intensive
Principles of Data Management. Lecture #16 (MapReduce & DFS for Big Data)
") Principles of Data Management Lecture #16 (MapReduce & DFS for Big Data) Instructor: Mike Carey mjcarey@ics.uci.edu Database Management Systems 3ed, R. Ramakrishnan and J. Gehrke 1 Today s News Bulletin
Principles of Data Management Lecture #16 (MapReduce & DFS for Big Data) Instructor: Mike Carey mjcarey@ics.uci.edu Database Management Systems 3ed, R. Ramakrishnan and J. Gehrke 1 Today s News Bulletin
GFS: The Google File System. Dr. Yingwu Zhu
 GFS: The Google File System Dr. Yingwu Zhu Motivating Application: Google Crawl the whole web Store it all on one big disk Process users searches on one big CPU More storage, CPU required than one PC can
GFS: The Google File System Dr. Yingwu Zhu Motivating Application: Google Crawl the whole web Store it all on one big disk Process users searches on one big CPU More storage, CPU required than one PC can
Where We Are. Review: Parallel DBMS. Parallel DBMS. Introduction to Data Management CSE 344
 Where We Are Introduction to Data Management CSE 344 Lecture 22: MapReduce We are talking about parallel query processing There exist two main types of engines: Parallel DBMSs (last lecture + quick review)
Where We Are Introduction to Data Management CSE 344 Lecture 22: MapReduce We are talking about parallel query processing There exist two main types of engines: Parallel DBMSs (last lecture + quick review)
Hadoop File System S L I D E S M O D I F I E D F R O M P R E S E N T A T I O N B Y B. R A M A M U R T H Y 11/15/2017
 Hadoop File System 1 S L I D E S M O D I F I E D F R O M P R E S E N T A T I O N B Y B. R A M A M U R T H Y Moving Computation is Cheaper than Moving Data Motivation: Big Data! What is BigData? - Google
Hadoop File System 1 S L I D E S M O D I F I E D F R O M P R E S E N T A T I O N B Y B. R A M A M U R T H Y Moving Computation is Cheaper than Moving Data Motivation: Big Data! What is BigData? - Google
Google File System (GFS) and Hadoop Distributed File System (HDFS)
 and Hadoop Distributed File System (HDFS)") Google File System (GFS) and Hadoop Distributed File System (HDFS) 1 Hadoop: Architectural Design Principles Linear scalability More nodes can do more work within the same time Linear on data size, linear
Google File System (GFS) and Hadoop Distributed File System (HDFS) 1 Hadoop: Architectural Design Principles Linear scalability More nodes can do more work within the same time Linear on data size, linear
MapReduce: Recap. Juliana Freire & Cláudio Silva. Some slides borrowed from Jimmy Lin, Jeff Ullman, Jerome Simeon, and Jure Leskovec
 MapReduce: Recap Some slides borrowed from Jimmy Lin, Jeff Ullman, Jerome Simeon, and Jure Leskovec MapReduce: Recap Sequentially read a lot of data Why? Map: extract something we care about map (k, v)
MapReduce: Recap Some slides borrowed from Jimmy Lin, Jeff Ullman, Jerome Simeon, and Jure Leskovec MapReduce: Recap Sequentially read a lot of data Why? Map: extract something we care about map (k, v)
Data Processing with Apache Beam (incubating) and Google Cloud Dataflow
 and Google Cloud Dataflow") Data Processing with Apache Beam (incubating) and Google Cloud Dataflow Jelena Pjesivac-Grbovic Staff software engineer Cloud Big Data In collaboration with Frances Perry, Tayler Akidau, and Dataflow team
Data Processing with Apache Beam (incubating) and Google Cloud Dataflow Jelena Pjesivac-Grbovic Staff software engineer Cloud Big Data In collaboration with Frances Perry, Tayler Akidau, and Dataflow team
Distributed Filesystem
 Distributed Filesystem 1 How do we get data to the workers? NAS Compute Nodes SAN 2 Distributing Code! Don t move data to workers move workers to the data! - Store data on the local disks of nodes in the
Distributed Filesystem 1 How do we get data to the workers? NAS Compute Nodes SAN 2 Distributing Code! Don t move data to workers move workers to the data! - Store data on the local disks of nodes in the
Big data systems 12/8/17
 Big data systems 12/8/17 Today Basic architecture Two levels of scheduling Spark overview Basic architecture Cluster Manager Cluster Cluster Manager 64GB RAM 32 cores 64GB RAM 32 cores 64GB RAM 32 cores
Big data systems 12/8/17 Today Basic architecture Two levels of scheduling Spark overview Basic architecture Cluster Manager Cluster Cluster Manager 64GB RAM 32 cores 64GB RAM 32 cores 64GB RAM 32 cores
Making Immutable Infrastructure simpler with LinuxKit. Justin Cormack
 Making Immutable Infrastructure simpler with LinuxKit Justin Cormack Who am I? Engineer at Docker in Cambridge, UK. Work on security, operating systems, LinuxKit, containers @justincormack 3 Some history
Making Immutable Infrastructure simpler with LinuxKit Justin Cormack Who am I? Engineer at Docker in Cambridge, UK. Work on security, operating systems, LinuxKit, containers @justincormack 3 Some history
Balanced Trees Part One
 Balanced Trees Part One Balanced Trees Balanced search trees are among the most useful and versatile data structures. Many programming languages ship with a balanced tree library. C++: std::map / std::set
Balanced Trees Part One Balanced Trees Balanced search trees are among the most useful and versatile data structures. Many programming languages ship with a balanced tree library. C++: std::map / std::set
2/26/2017. For instance, consider running Word Count across 20 splits
 Based on the slides of prof. Pietro Michiardi Hadoop Internals https://github.com/michiard/disc-cloud-course/raw/master/hadoop/hadoop.pdf Job: execution of a MapReduce application across a data set Task:
Based on the slides of prof. Pietro Michiardi Hadoop Internals https://github.com/michiard/disc-cloud-course/raw/master/hadoop/hadoop.pdf Job: execution of a MapReduce application across a data set Task:
Hadoop and Map-reduce computing
 Hadoop and Map-reduce computing 1 Introduction This activity contains a great deal of background information and detailed instructions so that you can refer to it later for further activities and homework.
Hadoop and Map-reduce computing 1 Introduction This activity contains a great deal of background information and detailed instructions so that you can refer to it later for further activities and homework.
KillTest *KIJGT 3WCNKV[ $GVVGT 5GTXKEG Q&A NZZV ]]] QORRZKYZ IUS =K ULLKX LXKK [VJGZK YKX\OIK LUX UTK _KGX
![KillTest *KIJGT 3WCNKV[ $GVVGT 5GTXKEG Q&A NZZV ]]] QORRZKYZ IUS =K ULLKX LXKK [VJGZK YKX\OIK LUX UTK _KGX](/thumbs/87/96360053.jpg "KillTest *KIJGT 3WCNKV[ $GVVGT 5GTXKEG Q&A NZZV ]]] QORRZKYZ IUS =K ULLKX LXKK [VJGZK YKX\OIK LUX UTK _KGX") KillTest Q&A Exam : CCD-410 Title : Cloudera Certified Developer for Apache Hadoop (CCDH) Version : DEMO 1 / 4 1.When is the earliest point at which the reduce method of a given Reducer can be called?
KillTest Q&A Exam : CCD-410 Title : Cloudera Certified Developer for Apache Hadoop (CCDH) Version : DEMO 1 / 4 1.When is the earliest point at which the reduce method of a given Reducer can be called?
April Final Quiz COSC MapReduce Programming a) Explain briefly the main ideas and components of the MapReduce programming model.
 Explain briefly the main ideas and components of the MapReduce programming model.") 1. MapReduce Programming a) Explain briefly the main ideas and components of the MapReduce programming model. MapReduce is a framework for processing big data which processes data in two phases, a Map
1. MapReduce Programming a) Explain briefly the main ideas and components of the MapReduce programming model. MapReduce is a framework for processing big data which processes data in two phases, a Map
/ Cloud Computing. Recitation 3 Sep 13 & 15, 2016
 15-319 / 15-619 Cloud Computing Recitation 3 Sep 13 & 15, 2016 1 Overview Administrative Issues Last Week s Reflection Project 1.1, OLI Unit 1, Quiz 1 This Week s Schedule Project1.2, OLI Unit 2, Module
15-319 / 15-619 Cloud Computing Recitation 3 Sep 13 & 15, 2016 1 Overview Administrative Issues Last Week s Reflection Project 1.1, OLI Unit 1, Quiz 1 This Week s Schedule Project1.2, OLI Unit 2, Module
2/26/2017. Originally developed at the University of California - Berkeley's AMPLab
 Apache is a fast and general engine for large-scale data processing aims at achieving the following goals in the Big data context Generality: diverse workloads, operators, job sizes Low latency: sub-second
Apache is a fast and general engine for large-scale data processing aims at achieving the following goals in the Big data context Generality: diverse workloads, operators, job sizes Low latency: sub-second
CS6030 Cloud Computing. Acknowledgements. Today s Topics. Intro to Cloud Computing 10/20/15. Ajay Gupta, WMU-CS. WiSe Lab
 CS6030 Cloud Computing Ajay Gupta B239, CEAS Computer Science Department Western Michigan University ajay.gupta@wmich.edu 276-3104 1 Acknowledgements I have liberally borrowed these slides and material
CS6030 Cloud Computing Ajay Gupta B239, CEAS Computer Science Department Western Michigan University ajay.gupta@wmich.edu 276-3104 1 Acknowledgements I have liberally borrowed these slides and material
Hadoop MapReduce Framework
 Hadoop MapReduce Framework Contents Hadoop MapReduce Framework Architecture Interaction Diagram of MapReduce Framework (Hadoop 1.0) Interaction Diagram of MapReduce Framework (Hadoop 2.0) Hadoop MapReduce
Hadoop MapReduce Framework Contents Hadoop MapReduce Framework Architecture Interaction Diagram of MapReduce Framework (Hadoop 1.0) Interaction Diagram of MapReduce Framework (Hadoop 2.0) Hadoop MapReduce
CS /29/18. Paul Krzyzanowski 1. Question 1 (Bigtable) Distributed Systems 2018 Pre-exam 3 review Selected questions from past exams
 Distributed Systems 2018 Pre-exam 3 review Selected questions from past exams") Question 1 (Bigtable) What is an SSTable in Bigtable? Distributed Systems 2018 Pre-exam 3 review Selected questions from past exams It is the internal file format used to store Bigtable data. It maps keys
Question 1 (Bigtable) What is an SSTable in Bigtable? Distributed Systems 2018 Pre-exam 3 review Selected questions from past exams It is the internal file format used to store Bigtable data. It maps keys
Lecture 18: Reliable Storage
 CS 422/522 Design & Implementation of Operating Systems Lecture 18: Reliable Storage Zhong Shao Dept. of Computer Science Yale University Acknowledgement: some slides are taken from previous versions of
CS 422/522 Design & Implementation of Operating Systems Lecture 18: Reliable Storage Zhong Shao Dept. of Computer Science Yale University Acknowledgement: some slides are taken from previous versions of
EVCache: Lowering Costs for a Low Latency Cache with RocksDB. Scott Mansfield Vu Nguyen EVCache
 EVCache: Lowering Costs for a Low Latency Cache with RocksDB Scott Mansfield Vu Nguyen EVCache 90 seconds What do caches touch? Signing up* Logging in Choosing a profile Picking liked videos
EVCache: Lowering Costs for a Low Latency Cache with RocksDB Scott Mansfield Vu Nguyen EVCache 90 seconds What do caches touch? Signing up* Logging in Choosing a profile Picking liked videos
Programming model and implementation for processing and. Programs can be automatically parallelized and executed on a large cluster of machines
 A programming model in Cloud: MapReduce Programming model and implementation for processing and generating large data sets Users specify a map function to generate a set of intermediate key/value pairs
A programming model in Cloud: MapReduce Programming model and implementation for processing and generating large data sets Users specify a map function to generate a set of intermediate key/value pairs