A Vision on the Status and Evolution of HEP Physics Software Tools
|
|
|
- Dennis Harrell
- 6 years ago
- Views:
Transcription
1 26 Jun 2013 A Vision on the Status and Evolution of HEP Physics Software Tools P. Canal, D. Elvira, R. Hatcher, S.Y. Jun, S. Mrenna arxiv: v1 [hep-ex] 29 Jul 2013 Fermilab, Batavia, IL 60510, USA
2 1 Introduction This paper represents the vision of the members of the Fermilab Scientific Computing Division s Computational Physics Department (SCD-CPD) on the status and the evolution of various HEP software tools such as the Geant4 detector simulation toolkit, the Pythia and GENIE physics generators, and the ROOT data analysis framework. We do not intend to present here a complete and balanced overview of current development, planned or potential R&D activities associated with the HEP software tools, since we would need to get many individuals and institutions around the world involved in the process for the summary to be representative of the thinking of the whole HEP community. Instead, we present a vision that expresses opinions and interests of the members of the SCD-CPD at Fermilab. The goal of this paper is therefore to contribute ideas to the Snowmass 2013 process toward the composition of a unified document on the current status and potential evolution of the physics software tools which are essential to HEP. 2
3 2 Generator 2.1 Introduction Monte Carlo event generators have long been an essential tool in high-energy physics. They are applied at almost every stage of an experimental program: for design, for collecting data, and for interpreting data. An example of their impact is the fact that the manual for the PYTHIA event generator was the most highly-cited publication in high-energy physics for A primary goal of particle physics is to determine the Lagrangian which describes particle interactions at short distances. Since the effects of long-distance physics cannot be calculated from first principles, the event generator must invoke models and parametrization in the translation from short- to long-distance physics. In developing an experimental program, event generators are often important for determining what kind of accelerator (beam types and energy) is necessary for answering a particular theoretical question. Enough was known about the Z boson to determine that a high-energy hadron collider was the best machine for discovery and a lepton collider tuned to the measured mass was the best machine for measuring its detailed properties. However, the case for how to understand electro-weak symmetry breaking is not as clear. The fact that many viable proposals for physics beyond the Standard Model involve weakly-interacting particles further complicates the issue. Event generators allow physicists to run toy experiments and make judgments on the most promising experimental program. Event generators also play a part in detector design, especially when extrapolations must be made to unexplored energies. Educated guesses must be made regarding the production of charged and neutral energy in time and space. For example, the occupancy of a silicon detector must be known to determine an optimal distance from the beam pipe. When running an experimental program, decisions must be made on how to collect data. Event generators give estimates of the production of event topologies that can be used as trigger signatures and evaluation of alternative schemes. Most detectors have limited angular and energy coverage. Particles can be lost because they are produced particular directions, or at too low of an energy or because of detector inefficiencies. Event generators are used to estimate these acceptance effects. 2.2 Software Event generators are integrated into the computational framework of an experiment so that their predictions can be treated on an equal footing with data. This means that the software should act as a library. For some given configuration data, which specify the parameters of the physics model, the event generator returns a list of particles (including information about the particle type, momentum, production vertex, etc.) that can be used as an input for a detector simulation. In the past, event generators were mainly written in FORTRAN. Currently, C++ versions of the major event generators exist, though they are used interchangeably with some of the older FORTRAN codes. The main reason for this is that the FORTRAN codes have been validated and tuned to data to provide reliable predictions. Thus, despite the computational advantages of using programs written in a modern language, the physics content of the program is an important consideration. The codes produce theoretical (or Monte Carlo truth) event records of the underlying interactions, a combinations of the incoming particles, intermediate states and the long lived final state particles leaving the interaction. Usually a number of events are generated and then propagated through a detector simulation. The output of the detector simulation is a record that is mostly indistinguishable from the recorded data. The event generator can operate in such a fashion because many of the physics processes can be simply coded and sampled using Monte Carlo techniques. However, this structure has become less attractive as more advanced and detailed calculations are required. In some instances it is sufficient to generate lots of events and use more crude smearing, rather than detailed detector simulations, to explore the potential for discovery in various physics scenarios. In such cases it is important that the generator be efficient. In some experimental setups, such as neutrino experiments, the interaction region is diffuse and not a central crossing point; in such cases the generator is needed to determine where the neutrino probe interacts with the target nucleon within the detector apparatus. Most of the recent advancements in predicting Standard Model processes has come at the stage of the event de- 3
4 velopment where fixed-order, perturbation theory can be applied. This piece is know as the hard interaction, and the predictions coded into the event generators are typically those at the lowest order of perturbation theory. The higher-order, more-accurate predictions are computationally intensive and often require specialized code. The other pieces of event generation, such as the parton shower, multi-parton interactions, hadronization, nuclear breakup and decays must also be handled by the event generator models. For generators used by collider experiments much work has gone into interfacing the calculation of the hard interaction beyond the lowest order with the event generators. Mostly, this is accomplished by passing the output of the the higher-order calculation into the event generator through files. This adds the complication that the hard-interaction files must be coordinated with the running of the event generator. Alternatively, software can be rewritten to perform both the calculation of the hard interaction and the other aspects of event generation. This has certain practical limitations. One is that executable must increase in size as the calculations become more extensive. This can become an issue on computing platforms with limited memory. A second is that many of the codes to calculate hard interactions are not engineered to fit easily into this model. Examples of event generators used by HEP physics programs are PYTHIA and GENIE. The PYTHIA code is widely used in the collider programs both past and present and is continually being updated to supply users with desired simulations of numerous extensions to the physics models. The GENIE code was developed to consolidate a number of competing neutrino event generators and provide a framework for adding extensions and modeling of more complex or rare processes. 2.3 Future As more detailed calculations are required to better understand the theoretical implications of HEP data, the event generators will face the problem of complexity and timing. Timing is usually not considered an important issue, because detector simulations are usually orders-of-magnitude slower. However, there are several reasons why the execution speed of the event generators matter. First, code can be developed and validated in proportion to execution speed. Second, the tuning process when the parameters of the event generator are varied to match data is facilitated by speed. Thirdly, the calculation of systematic uncertainties for an analysis typically requires running the event generators several times, each with different configurations. The problem of complexity may be solved by optimizing code design. Currently, the theorists who develop code do not coordinate with computing or experimental experts. We should promote communication between these different communities. Improvements in timing can arise from the intelligent application of multi-core processors or GPU s. Already, GPU s have been successfully employed in calculating many-parton Feynman diagrams, and we should look for other, practical uses. The possibility of performing multi-core calculations does not currently look fruitful, because the event generator codes are structured serially typically one step of a calculation must be completed before the next. However, this could be the result of the code design. A successful merging of the theory and computing communities may find avenues for improving the design of event generator codes. 4
5 3 Root 3.1 Introduction ROOT [1] is an object-oriented C++ framework that is designed to store huge amounts of data in an efficient way optimized for very fast data analysis. Any instance of a C++ class can be stored, in a machine independent compressed binary format, into a ROOT file. The ROOT TTree object container is optimized for statistical data analysis over very large data sets by using vertical data storage techniques. The TTree containers can span a large number of files. These files may be on local disks, on the web or on a number of different shared file systems. The users have access to a very wide set of mathematical and statistical functions, including linear algebra, numerical integration and minimization. For example the RooFit library allows the user to choose the desired minimization engine. In addition, the RooStat library provides abstractions for most used statistical entities, supporting all their operations and manipulations. ROOT also provides 1D, 2D and 3D histograms that support any kind of operation and can be displayed and modified in real-time using either a interactive C++ interpreter, other interactive language like python or a graphical user interface. The final result can be saved in high-quality graphical formats like PostScript and PDF or in bitmap formats like JPG that are easier to include into a web page. The result can also be stored into ROOT macros that can be used to fully recreate and rework the graphics. Users typically create their analysis macros step by step, making use of the interactive C++ interpreter, by running over small data samples. Once the development is finished, they can then run these macros, at full compiled speed, over large data sets by either using ACLiC (the automatic compiler interface) to build a shared library that is then automatically loaded and executed, or by creating a stand-alone batch program. Finally, if processing farms are available, the user can make full use of the inherent event parallelism by running their macros using PROOF, that will take care of distributing the analysis over all available CPUs and disks in a transparent way. ROOT is at the heart of almost all HEP experiments world wide. From simulation to data acquisition, from event processing to data analysis, from detector monitoring to event displays, it provides essential components and building block for the experiments to assemble their framework. In particular all the experiment s data is stored in ROOT files. At the time of writing there were already more than 177 PBs of data for just the Large Hadron Colliders experiments. The use of ROOT extend beyond HEP to many sciences, including nuclear physics, biology, astronomy and even in the private sector where many finance firms use ROOT in their own data analysis and market trend prediction software tools. 3.2 Root for the Future Building on years of success, ROOT is in the mist of a significant migration to future proof its architecture and code base. ROOT is replacing its existing home-grown C++ interpreter (CINT) [2]. CINT has been since its inception in the early 1990s, the premier solution for C++ interactivity, offering access to most of the features of the C standard while providing a very simple and portable to use solution to access any compiled code from the interpreter session. Upgrading CINT to support the large number of extensions in the 2011 C++ standard would have required a very large efforts. In addition CINT architecture was not designed to support heavily multi-tasking processing. To address CINT s limitations, ROOT is leveraging the rise of a very flexible and very programmable compiler framework, LLVM [3], which includes a fully C standard compliant compiler (clang). Clang and LLVM have become industry standard tools supported and relied upon by a large set of commercial companies including Apple, Google, Nvidia, etc. Using clang and its versatile libraries, ROOT is developing a new C++ interpreter (cling) to replace CINT. Migrating to the new interpreter will open up a host of new opportunities. Since it is based on a flexible and expandable compiler framework, cling can easily be extended to support additional languages, including objective C or NVidia s CUDA programming language. Rather than a classical interpreter, Cling s implementation is closer to an interactive compiler. Once processed, any code input on the command line is slightly transformed and then compiled in memory using the Clang compiler, the same compiler currently used to build all of MacOS components. The seamless availability of just-in-time compilation of C++ code enables a large set of possible optimizations, including boosting I/O performance by optimizing specific uses cases of the currently running application, improving the minimization s algorithm s performance by customizing and recompiling the hot-spots of the current search. In addition, the migration will enable the library and the users to start using the many performance and code improvements allowed by the new 2011 C++ standard. In conjunction with this major migration, ROOT is also preparing for the newest set of hardware platforms. Several 5
6 efforts are in place to leverage general graphical processor units, in particular to speed up minimization algorithms. The internal mathematical libraries are being upgraded to take advantage of vectorized processing units, including incorporating and using the VC (Vector Classes) library [4]. ROOT has been recently ported to both the ARM and Xeon Phi architectures which should both benefit from the on-going vectorization efforts. As the number of individual cores offered in each processing unit is increasing rapidly, the need for multi-threading and multi-processing solutions is becoming greater. ROOT is planning on offering multiple alternative for parallelizing the Input and Output. One medium term alternative is to provide for fast merging of files produced in parallel. In this scenario rather than write the files locally and wait until all producers are finished to start the merging process, the merging process is started as soon as the producers have created a medium size chunks of data (dozens of megabytes). Once the merging process has started, rather than writing the data to local disk, the data is send directly to the server to be written into the final file and then to disk, avoiding many unnecessary reads. Longer term solutions include upgrading the infrastructure to support the seamless writing from multiple producing stream within the same process into a single file. Solutions will be developed in close collaboration with the main users in order to ease their transition to the many-cores era. 3.3 Conclusions ROOT is at the core of HEP software as well many other science and industry frameworks. Its migration into the many-core era is an essential stepping stone to enable the eco-system that has been built upon its libraries to flourish and benefit from the newest hardware generations. Many of its features, including a unique customizable framework to efficiently store and retrieve extremely large data back and forth between persistent storage and live representation in C++ while supporting significant schema evolution, are fundamental to many currently running and upcoming experiments and any improvements in ROOT libraries will greatly benefit them. Upgrading ROOT infrastructure is a challenging balancing act of enabling new technologies while supporting existing use patterns to avoid disruption to running experiments. However any investment and progress towards using, enabling and promulgating modern, multitasking coding patterns will flow through all software layers involved in the experiments. Both framework developers and individual researchers will benefit from the examples and leads that ROOT can provide. 6
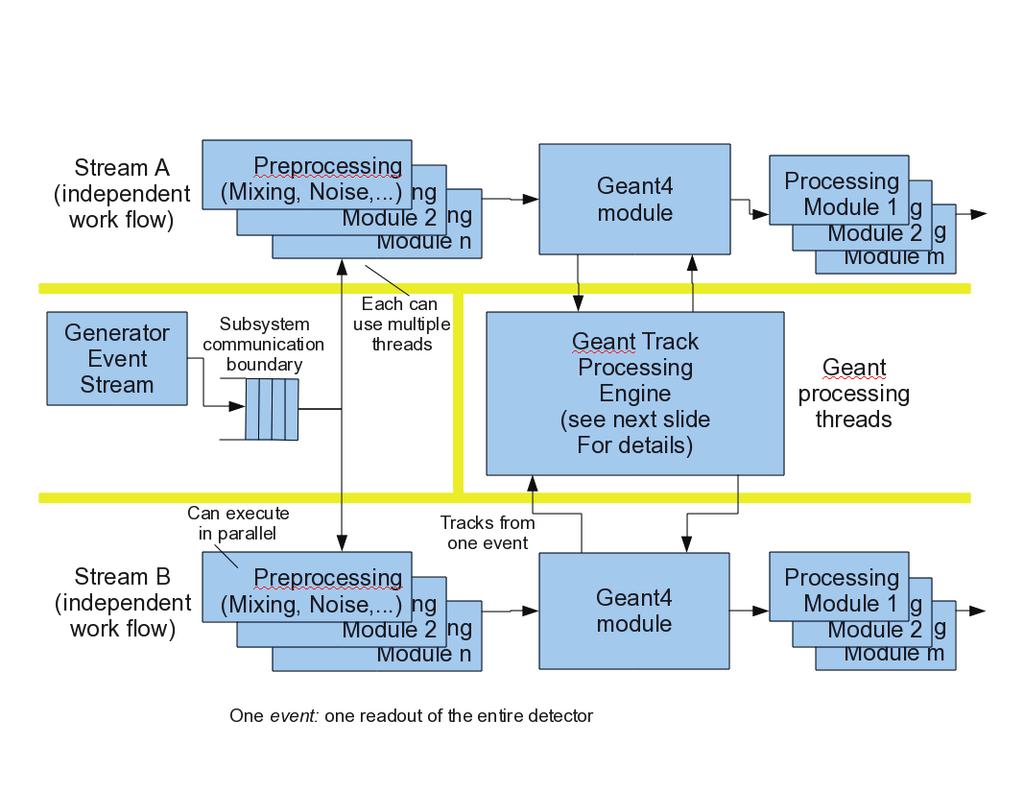
7 4 Geant4 R&D 4.1 Introduction Precise modeling of particle interactions with matter in systems with complex geometries is essential in experimental high-energy physics (HEP) and certain accelerator and astrophysics applications. Because of the impact of this type of simulation, it is imperative that the HEP community has access to computational tools that provide state-of-the art physical and numerical algorithms and run efficiently on modern computing hardware. Geant4 [5] is a toolkit for the simulation of particle-matter interactions that has been developed for almost twenty years by an international collaboration of physicists and computer scientists. The most commonly used simulation tool in experimental HEP, Geant4 incorporates physics knowledge from modern HEP and nuclear physics experiments and theory. The computing landscape continues to evolve as technologies improve. Modern-day computers used to support High Energy Physics (HEP) experiments now have upwards of 32 processors on a single chip, and that trend will only continue. Furthermore, new generations of computing hardware such as Graphics Processing Units (GPUs) are emerging for markets like the enhancement of end-user experience in gaming and entertainment. Their highly parallel structure makes them often more effective than general-purpose central processing units (CPUs) for compute-bound algorithms, where processing of data is done in highly parallel manner. This technology has great potential for the high-energy physics community. The current implementation of Geant4 contains many features that hinder our ability to make use of modern parallel architectures since Geant4 relies heavily on the object-oriented features of C++ for developing class hierarchies. Of particular significance is the use of global resources and the complexity they introduce into the management of program and processing state. Such an arrangement makes parallelism through threading difficult. Other contributing factors are its heavy reliance on C++ inheritance, abstract interfaces, and organization of of data structures. The diversity among these forthcoming machines presents a number of challenges to porting scientific software such as Geant4 and achieving good performance. Extrapolating to the situation over the next several years, we anticipate more cores per chip, and these will likely be a heterogeneous mix of processors, with a few optimized to maximize single thread throughput, while most are designed to maximize energy efficiency with wide SIMD data paths. The Advanced Micro Devices (AMD) Fusion family of Accelerated Processing Units (APU), blending Opteron CPUs and Radeon GPUs, is just the beginning. This trend will not only exacerbate performance optimization challenges,but also simultaneously promote the issues of energy consumption and resilience to the forefront. Moreover, as new memory technologies (e.g., phase change, resistive, spin-transfer torque) begin to appear, computational scientists will need to learn to exploit the resultant asymmetric read/write bandwidths and latencies. 4.2 Geant4 Research and Development for the Future To address both the scientific and the computing challenges facing Geant4, it will be essential to bring together expertise in physics simulation and modeling with specialists in software systems engineering, performance analysis and tuning, and algorithm analysis and development. The overall goal is to move Geant4 into the era of multi-core and many-core computing, effectively utilizing existing and future large-scale heterogeneous high-performance computing resources for both core science simulation data-set generation and also data-set storage, retrieval, and end-user validation and analysis. Significant exploration and study is needed in order to move the Geant4 toolkit toward the long term goal of being able to utilize large-scale, heterogeneous computing systems, as it was designed for much simpler platforms. Thus the need for complete studies and work towards a re-engineering of the underlying system software framework that retains connections to crucial existing applications and physics libraries while permitting migration and transition to a new improved construction. An extensive reorganization of the underlying coordination framework will allow for more diverse processing options (e.g., GPUs) and allow for greater flexibility as computing resources evolve. While exploring concurrency, part of the focus should be on abstracting the overall structure of the Geant4-based codes in terms of computational flows, algorithms and models. This analysis can be used to enable the development of code generation schemes and execution strategies targeting future high-performance architectures. To enable the use of multiple concurrent and heterogeneous execution units, Geant4 needs to be re-engineered to have at its core a concurrent particle propagation engine. Integration of the equations of motion and determination of particle interaction has very different structures and computational requirements. Thus a smart dispatcher is 7

8 required that can dynamically adapt to its run-time environment, scheduling bundles of work for resources best suited for the operation to be performed. The coordination framework must also permit asynchronous interactions amongst the internal components and with the surrounding application software infrastructure necessary for event processing. Such an arrangement allows for more rare and complex particle interactions to not interfere with more common, less resource-intensive ones. Figure 1 depicts a possible structure for such a concurrent particle propagation engine. A track bundle is a set of tracks that can be conveniently and efficiently scheduled to go through the same set of processes which could potentially include propagation. The role of the track dispatcher is to assemble the tracks in bundles in such a way as to maximize the efficiency of the processes that run on them. The dispatcher also selects which processor or group of processors or cores, for example a GPU enhanced PC cluster, to schedule the execution of the processes for a specific track bundle. In order to leverage the on-chip and on-core caches of general purpose CPUs, the dispatcher might decide to associate a set of geometrical elements with a specific processor/core and to send to this processor/core only the bundle of tracks that are traversing these geometrical elements. It might also gather together tracks that need to go through processes that have been optimized for GPUs and send them to one of the graphics cards. Once the tracks are done going through the simulation, they are added to another stack, which can also be handled in parallel, to run processes that require all the finished tracks for a given simulation event, for example to digitize the energy deposit on the detector elements. Figure 1: Simplified view of Geant4 re-engineered processing entities. Real-world Geant4 program traces can be used to drive prototype propagation components. A fundamental change in strategy will be required, removing the event-by-event and particle-by-particle processing ensconced in the current framework. A new strategy will remove these boundaries and allow large particle vectors to be assembled across event boundaries where this would enhance processing efficiency on the target hardware architecture. A key aspect of this work is adherence to science constraints. Two important ones are validation of the physics and reproducibility. Validation tells us that the modules we are working with give answers that are in statistical agreement with experimental measurements, or at least in agreement with answers from the previously validated code. Reproducibility means that results can be regenerated within a tolerance defined by the scientific community of users a bit-for-bit agreement where possible. Both validation and reproducibility are likely to be affected by parallelism and non-deterministic processing characteristics. Reproducibility will need to be precisely defined by working with the physics collaborations. One area of difficulty will be in random-number stream management. A strategy could be defined to prevent bottlenecks where random numbers are used and to record necessary seeds to allow replication of results. Deviations in results, including measurement uncertainties should be studied. Geant4 would also benefit from research required to optimize I/O in heavily multi-threaded systems. In particular, it is important to understand what data-organization tasks can be achieved by the simulation itself and what tasks would be more efficiently performed by separate IO run-time services focused on data collection and organization. 8
9 4.3 Conclusions Geant4 is an important software tool for the HEP community as well as many other communities. As experiments evolve, the demands on both the amount of simulated data as well as precision of the simulations will grow. Geant4 must evolve in order to both take advantage of the emerging computing technologies and to be able to meet the future simulation demands in a cost effective way. Furthermore, this evolution of Geant4 will enable HEP experimental scientists to take advantage of current leadership class computing that is available but not utilized by this community. Transforming Geant4 will require research to overcome a broad range of challenges of which categories include systematically improving the sequential performance of Geant4; re-factoring the code for emerging, highly parallel computing systems; improving data access, management, and analysis; exploring novel new programming abstractions, and reducing the human effort required to handle the upcoming, Exabyte-scale, globally distributed, data sets generated by Geant4. There appear to be opportunities for near-term performance enhancement on individual processors, as well as more profound, long-term changes that would lead to a new Geant4 that effectively exploits a variety of future multicore systems. Taking Geant4 to the next level in terms of parallelization is paramount for HEP scientists. The next generation of experiments will demand it and the current ones would profit greatly. 9
10 References [1] Rene Brun and Fons Rademakers, ROOT - An Object Oriented Data Analysis Framework, Proceedings AI- HENP 96 Workshop, Lausanne, Sep. 1996, Nucl. Inst. & Meth. in Phys. Res. A 389 (1997) See also [2] See [3] See [4] See [5] 10
11
GPU Programming Using NVIDIA CUDA
 GPU Programming Using NVIDIA CUDA Siddhante Nangla 1, Professor Chetna Achar 2 1, 2 MET s Institute of Computer Science, Bandra Mumbai University Abstract: GPGPU or General-Purpose Computing on Graphics
GPU Programming Using NVIDIA CUDA Siddhante Nangla 1, Professor Chetna Achar 2 1, 2 MET s Institute of Computer Science, Bandra Mumbai University Abstract: GPGPU or General-Purpose Computing on Graphics
ASYNCHRONOUS SHADERS WHITE PAPER 0
 ASYNCHRONOUS SHADERS WHITE PAPER 0 INTRODUCTION GPU technology is constantly evolving to deliver more performance with lower cost and lower power consumption. Transistor scaling and Moore s Law have helped
ASYNCHRONOUS SHADERS WHITE PAPER 0 INTRODUCTION GPU technology is constantly evolving to deliver more performance with lower cost and lower power consumption. Transistor scaling and Moore s Law have helped
Introduction to Geant4
 Introduction to Geant4 Release 10.4 Geant4 Collaboration Rev1.0: Dec 8th, 2017 CONTENTS: 1 Geant4 Scope of Application 3 2 History of Geant4 5 3 Overview of Geant4 Functionality 7 4 Geant4 User Support
Introduction to Geant4 Release 10.4 Geant4 Collaboration Rev1.0: Dec 8th, 2017 CONTENTS: 1 Geant4 Scope of Application 3 2 History of Geant4 5 3 Overview of Geant4 Functionality 7 4 Geant4 User Support
Geant4 Computing Performance Benchmarking and Monitoring
 Journal of Physics: Conference Series PAPER OPEN ACCESS Geant4 Computing Performance Benchmarking and Monitoring To cite this article: Andrea Dotti et al 2015 J. Phys.: Conf. Ser. 664 062021 View the article
Journal of Physics: Conference Series PAPER OPEN ACCESS Geant4 Computing Performance Benchmarking and Monitoring To cite this article: Andrea Dotti et al 2015 J. Phys.: Conf. Ser. 664 062021 View the article
ATLAS NOTE. December 4, ATLAS offline reconstruction timing improvements for run-2. The ATLAS Collaboration. Abstract
 ATLAS NOTE December 4, 2014 ATLAS offline reconstruction timing improvements for run-2 The ATLAS Collaboration Abstract ATL-SOFT-PUB-2014-004 04/12/2014 From 2013 to 2014 the LHC underwent an upgrade to
ATLAS NOTE December 4, 2014 ATLAS offline reconstruction timing improvements for run-2 The ATLAS Collaboration Abstract ATL-SOFT-PUB-2014-004 04/12/2014 From 2013 to 2014 the LHC underwent an upgrade to
CSE 591: GPU Programming. Introduction. Entertainment Graphics: Virtual Realism for the Masses. Computer games need to have: Klaus Mueller
 Entertainment Graphics: Virtual Realism for the Masses CSE 591: GPU Programming Introduction Computer games need to have: realistic appearance of characters and objects believable and creative shading,
Entertainment Graphics: Virtual Realism for the Masses CSE 591: GPU Programming Introduction Computer games need to have: realistic appearance of characters and objects believable and creative shading,
Stitched Together: Transitioning CMS to a Hierarchical Threaded Framework
 Stitched Together: Transitioning CMS to a Hierarchical Threaded Framework CD Jones and E Sexton-Kennedy Fermilab, P.O.Box 500, Batavia, IL 60510-5011, USA E-mail: cdj@fnal.gov, sexton@fnal.gov Abstract.
Stitched Together: Transitioning CMS to a Hierarchical Threaded Framework CD Jones and E Sexton-Kennedy Fermilab, P.O.Box 500, Batavia, IL 60510-5011, USA E-mail: cdj@fnal.gov, sexton@fnal.gov Abstract.
Copyright Khronos Group Page 1. Vulkan Overview. June 2015
 Copyright Khronos Group 2015 - Page 1 Vulkan Overview June 2015 Copyright Khronos Group 2015 - Page 2 Khronos Connects Software to Silicon Open Consortium creating OPEN STANDARD APIs for hardware acceleration
Copyright Khronos Group 2015 - Page 1 Vulkan Overview June 2015 Copyright Khronos Group 2015 - Page 2 Khronos Connects Software to Silicon Open Consortium creating OPEN STANDARD APIs for hardware acceleration
SNiPER: an offline software framework for non-collider physics experiments
 SNiPER: an offline software framework for non-collider physics experiments J. H. Zou 1, X. T. Huang 2, W. D. Li 1, T. Lin 1, T. Li 2, K. Zhang 1, Z. Y. Deng 1, G. F. Cao 1 1 Institute of High Energy Physics,
SNiPER: an offline software framework for non-collider physics experiments J. H. Zou 1, X. T. Huang 2, W. D. Li 1, T. Lin 1, T. Li 2, K. Zhang 1, Z. Y. Deng 1, G. F. Cao 1 1 Institute of High Energy Physics,
Fundamentals of STEP Implementation
 Fundamentals of STEP Implementation David Loffredo loffredo@steptools.com STEP Tools, Inc., Rensselaer Technology Park, Troy, New York 12180 A) Introduction The STEP standard documents contain such a large
Fundamentals of STEP Implementation David Loffredo loffredo@steptools.com STEP Tools, Inc., Rensselaer Technology Park, Troy, New York 12180 A) Introduction The STEP standard documents contain such a large
Monte Carlo programs
 Monte Carlo programs Alexander Khanov PHYS6260: Experimental Methods is HEP Oklahoma State University November 15, 2017 Simulation steps: event generator Input = data cards (program options) this is the
Monte Carlo programs Alexander Khanov PHYS6260: Experimental Methods is HEP Oklahoma State University November 15, 2017 Simulation steps: event generator Input = data cards (program options) this is the
Massive Data Analysis
 Professor, Department of Electrical and Computer Engineering Tennessee Technological University February 25, 2015 Big Data This talk is based on the report [1]. The growth of big data is changing that
Professor, Department of Electrical and Computer Engineering Tennessee Technological University February 25, 2015 Big Data This talk is based on the report [1]. The growth of big data is changing that
Machine Learning for (fast) simulation
 simulation") Machine Learning for (fast) simulation Sofia Vallecorsa for the GeantV team CERN, April 2017 1 Monte Carlo Simulation: Why Detailed simulation of subatomic particles is essential for data analysis, detector
Machine Learning for (fast) simulation Sofia Vallecorsa for the GeantV team CERN, April 2017 1 Monte Carlo Simulation: Why Detailed simulation of subatomic particles is essential for data analysis, detector
Multicore Computing and Scientific Discovery
 scientific infrastructure Multicore Computing and Scientific Discovery James Larus Dennis Gannon Microsoft Research In the past half century, parallel computers, parallel computation, and scientific research
scientific infrastructure Multicore Computing and Scientific Discovery James Larus Dennis Gannon Microsoft Research In the past half century, parallel computers, parallel computation, and scientific research
CSE 591/392: GPU Programming. Introduction. Klaus Mueller. Computer Science Department Stony Brook University
 CSE 591/392: GPU Programming Introduction Klaus Mueller Computer Science Department Stony Brook University First: A Big Word of Thanks! to the millions of computer game enthusiasts worldwide Who demand
CSE 591/392: GPU Programming Introduction Klaus Mueller Computer Science Department Stony Brook University First: A Big Word of Thanks! to the millions of computer game enthusiasts worldwide Who demand
Generators at the LHC
 High Performance Computing for Event Generators at the LHC A Multi-Threaded Version of MCFM, J.M. Campbell, R.K. Ellis, W. Giele, 2015. Higgs boson production in association with a jet at NNLO using jettiness
High Performance Computing for Event Generators at the LHC A Multi-Threaded Version of MCFM, J.M. Campbell, R.K. Ellis, W. Giele, 2015. Higgs boson production in association with a jet at NNLO using jettiness
ECE 8823: GPU Architectures. Objectives
 ECE 8823: GPU Architectures Introduction 1 Objectives Distinguishing features of GPUs vs. CPUs Major drivers in the evolution of general purpose GPUs (GPGPUs) 2 1 Chapter 1 Chapter 2: 2.2, 2.3 Reading
ECE 8823: GPU Architectures Introduction 1 Objectives Distinguishing features of GPUs vs. CPUs Major drivers in the evolution of general purpose GPUs (GPGPUs) 2 1 Chapter 1 Chapter 2: 2.2, 2.3 Reading
IEPSAS-Kosice: experiences in running LCG site
 IEPSAS-Kosice: experiences in running LCG site Marian Babik 1, Dusan Bruncko 2, Tomas Daranyi 1, Ladislav Hluchy 1 and Pavol Strizenec 2 1 Department of Parallel and Distributed Computing, Institute of
IEPSAS-Kosice: experiences in running LCG site Marian Babik 1, Dusan Bruncko 2, Tomas Daranyi 1, Ladislav Hluchy 1 and Pavol Strizenec 2 1 Department of Parallel and Distributed Computing, Institute of
Accelerating Applications. the art of maximum performance computing James Spooner Maxeler VP of Acceleration
 Accelerating Applications the art of maximum performance computing James Spooner Maxeler VP of Acceleration Introduction The Process The Tools Case Studies Summary What do we mean by acceleration? How
Accelerating Applications the art of maximum performance computing James Spooner Maxeler VP of Acceleration Introduction The Process The Tools Case Studies Summary What do we mean by acceleration? How
The GAP project: GPU applications for High Level Trigger and Medical Imaging
 The GAP project: GPU applications for High Level Trigger and Medical Imaging Matteo Bauce 1,2, Andrea Messina 1,2,3, Marco Rescigno 3, Stefano Giagu 1,3, Gianluca Lamanna 4,6, Massimiliano Fiorini 5 1
The GAP project: GPU applications for High Level Trigger and Medical Imaging Matteo Bauce 1,2, Andrea Messina 1,2,3, Marco Rescigno 3, Stefano Giagu 1,3, Gianluca Lamanna 4,6, Massimiliano Fiorini 5 1
Benchmarking AMD64 and EMT64
 Benchmarking AMD64 and EMT64 Hans Wenzel, Oliver Gutsche, FNAL, Batavia, IL 60510, USA Mako Furukawa, University of Nebraska, Lincoln, USA Abstract We have benchmarked various single and dual core 64 Bit
Benchmarking AMD64 and EMT64 Hans Wenzel, Oliver Gutsche, FNAL, Batavia, IL 60510, USA Mako Furukawa, University of Nebraska, Lincoln, USA Abstract We have benchmarked various single and dual core 64 Bit
Software Development for Linear Accelerator Data Acquisition Systems
 Software Development for Linear Accelerator Data Acquisition Systems Jackson DeBuhr Department of Physics, Applied Physics, and Astronomy, Rensselaer Polytechnic Institute, Troy, NY, 12180 (Dated: August
Software Development for Linear Accelerator Data Acquisition Systems Jackson DeBuhr Department of Physics, Applied Physics, and Astronomy, Rensselaer Polytechnic Institute, Troy, NY, 12180 (Dated: August
Trends in HPC (hardware complexity and software challenges)
") Trends in HPC (hardware complexity and software challenges) Mike Giles Oxford e-research Centre Mathematical Institute MIT seminar March 13th, 2013 Mike Giles (Oxford) HPC Trends March 13th, 2013 1 / 18
Trends in HPC (hardware complexity and software challenges) Mike Giles Oxford e-research Centre Mathematical Institute MIT seminar March 13th, 2013 Mike Giles (Oxford) HPC Trends March 13th, 2013 1 / 18
OpenCL Base Course Ing. Marco Stefano Scroppo, PhD Student at University of Catania
 OpenCL Base Course Ing. Marco Stefano Scroppo, PhD Student at University of Catania Course Overview This OpenCL base course is structured as follows: Introduction to GPGPU programming, parallel programming
OpenCL Base Course Ing. Marco Stefano Scroppo, PhD Student at University of Catania Course Overview This OpenCL base course is structured as follows: Introduction to GPGPU programming, parallel programming
ATLAS Tracking Detector Upgrade studies using the Fast Simulation Engine
 Journal of Physics: Conference Series PAPER OPEN ACCESS ATLAS Tracking Detector Upgrade studies using the Fast Simulation Engine To cite this article: Noemi Calace et al 2015 J. Phys.: Conf. Ser. 664 072005
Journal of Physics: Conference Series PAPER OPEN ACCESS ATLAS Tracking Detector Upgrade studies using the Fast Simulation Engine To cite this article: Noemi Calace et al 2015 J. Phys.: Conf. Ser. 664 072005
Memory Bound Computing
 Memory Bound Computing Francesc Alted Freelance Consultant & Trainer http://www.blosc.org/professional-services.html Advanced Scientific Programming in Python Reading, UK September, 2016 Goals Recognize
Memory Bound Computing Francesc Alted Freelance Consultant & Trainer http://www.blosc.org/professional-services.html Advanced Scientific Programming in Python Reading, UK September, 2016 Goals Recognize
NVIDIA DGX SYSTEMS PURPOSE-BUILT FOR AI
 NVIDIA DGX SYSTEMS PURPOSE-BUILT FOR AI Overview Unparalleled Value Product Portfolio Software Platform From Desk to Data Center to Cloud Summary AI researchers depend on computing performance to gain
NVIDIA DGX SYSTEMS PURPOSE-BUILT FOR AI Overview Unparalleled Value Product Portfolio Software Platform From Desk to Data Center to Cloud Summary AI researchers depend on computing performance to gain
COMPARISON OF PYTHON 3 SINGLE-GPU PARALLELIZATION TECHNOLOGIES ON THE EXAMPLE OF A CHARGED PARTICLES DYNAMICS SIMULATION PROBLEM
 COMPARISON OF PYTHON 3 SINGLE-GPU PARALLELIZATION TECHNOLOGIES ON THE EXAMPLE OF A CHARGED PARTICLES DYNAMICS SIMULATION PROBLEM A. Boytsov 1,a, I. Kadochnikov 1,4,b, M. Zuev 1,c, A. Bulychev 2,d, Ya.
COMPARISON OF PYTHON 3 SINGLE-GPU PARALLELIZATION TECHNOLOGIES ON THE EXAMPLE OF A CHARGED PARTICLES DYNAMICS SIMULATION PROBLEM A. Boytsov 1,a, I. Kadochnikov 1,4,b, M. Zuev 1,c, A. Bulychev 2,d, Ya.
Ultra-Low Latency Down to Microseconds SSDs Make It. Possible
 Ultra-Low Latency Down to Microseconds SSDs Make It Possible DAL is a large ocean shipping company that covers ocean and land transportation, storage, cargo handling, and ship management. Every day, its
Ultra-Low Latency Down to Microseconds SSDs Make It Possible DAL is a large ocean shipping company that covers ocean and land transportation, storage, cargo handling, and ship management. Every day, its
Benefits of Programming Graphically in NI LabVIEW
 Benefits of Programming Graphically in NI LabVIEW Publish Date: Jun 14, 2013 0 Ratings 0.00 out of 5 Overview For more than 20 years, NI LabVIEW has been used by millions of engineers and scientists to
Benefits of Programming Graphically in NI LabVIEW Publish Date: Jun 14, 2013 0 Ratings 0.00 out of 5 Overview For more than 20 years, NI LabVIEW has been used by millions of engineers and scientists to
Benefits of Programming Graphically in NI LabVIEW
 1 of 8 12/24/2013 2:22 PM Benefits of Programming Graphically in NI LabVIEW Publish Date: Jun 14, 2013 0 Ratings 0.00 out of 5 Overview For more than 20 years, NI LabVIEW has been used by millions of engineers
1 of 8 12/24/2013 2:22 PM Benefits of Programming Graphically in NI LabVIEW Publish Date: Jun 14, 2013 0 Ratings 0.00 out of 5 Overview For more than 20 years, NI LabVIEW has been used by millions of engineers
GPU Architecture. Alan Gray EPCC The University of Edinburgh
 GPU Architecture Alan Gray EPCC The University of Edinburgh Outline Why do we want/need accelerators such as GPUs? Architectural reasons for accelerator performance advantages Latest GPU Products From
GPU Architecture Alan Gray EPCC The University of Edinburgh Outline Why do we want/need accelerators such as GPUs? Architectural reasons for accelerator performance advantages Latest GPU Products From
MONTE CARLO SIMULATION FOR RADIOTHERAPY IN A DISTRIBUTED COMPUTING ENVIRONMENT
 The Monte Carlo Method: Versatility Unbounded in a Dynamic Computing World Chattanooga, Tennessee, April 17-21, 2005, on CD-ROM, American Nuclear Society, LaGrange Park, IL (2005) MONTE CARLO SIMULATION
The Monte Carlo Method: Versatility Unbounded in a Dynamic Computing World Chattanooga, Tennessee, April 17-21, 2005, on CD-ROM, American Nuclear Society, LaGrange Park, IL (2005) MONTE CARLO SIMULATION
Early Experiences Writing Performance Portable OpenMP 4 Codes
 Early Experiences Writing Performance Portable OpenMP 4 Codes Verónica G. Vergara Larrea Wayne Joubert M. Graham Lopez Oscar Hernandez Oak Ridge National Laboratory Problem statement APU FPGA neuromorphic
Early Experiences Writing Performance Portable OpenMP 4 Codes Verónica G. Vergara Larrea Wayne Joubert M. Graham Lopez Oscar Hernandez Oak Ridge National Laboratory Problem statement APU FPGA neuromorphic
PART I - Fundamentals of Parallel Computing
 PART I - Fundamentals of Parallel Computing Objectives What is scientific computing? The need for more computing power The need for parallel computing and parallel programs 1 What is scientific computing?
PART I - Fundamentals of Parallel Computing Objectives What is scientific computing? The need for more computing power The need for parallel computing and parallel programs 1 What is scientific computing?
Merging Enterprise Applications with Docker* Container Technology
 Solution Brief NetApp Docker Volume Plugin* Intel Xeon Processors Intel Ethernet Converged Network Adapters Merging Enterprise Applications with Docker* Container Technology Enabling Scale-out Solutions
Solution Brief NetApp Docker Volume Plugin* Intel Xeon Processors Intel Ethernet Converged Network Adapters Merging Enterprise Applications with Docker* Container Technology Enabling Scale-out Solutions
PARALLEL FRAMEWORK FOR PARTIAL WAVE ANALYSIS AT BES-III EXPERIMENT
 PARALLEL FRAMEWORK FOR PARTIAL WAVE ANALYSIS AT BES-III EXPERIMENT V.A. Tokareva a, I.I. Denisenko Laboratory of Nuclear Problems, Joint Institute for Nuclear Research, 6 Joliot-Curie, Dubna, Moscow region,
PARALLEL FRAMEWORK FOR PARTIAL WAVE ANALYSIS AT BES-III EXPERIMENT V.A. Tokareva a, I.I. Denisenko Laboratory of Nuclear Problems, Joint Institute for Nuclear Research, 6 Joliot-Curie, Dubna, Moscow region,
Clustering and Reclustering HEP Data in Object Databases
 Clustering and Reclustering HEP Data in Object Databases Koen Holtman CERN EP division CH - Geneva 3, Switzerland We formulate principles for the clustering of data, applicable to both sequential HEP applications
Clustering and Reclustering HEP Data in Object Databases Koen Holtman CERN EP division CH - Geneva 3, Switzerland We formulate principles for the clustering of data, applicable to both sequential HEP applications
When Milliseconds Matter. The Definitive Buying Guide to Network Services for Healthcare Organizations
 When Milliseconds Matter The Definitive Buying Guide to Network Services for Healthcare Organizations The Changing Landscape of Healthcare IT Pick any of the top trends in healthcare and you ll find both
When Milliseconds Matter The Definitive Buying Guide to Network Services for Healthcare Organizations The Changing Landscape of Healthcare IT Pick any of the top trends in healthcare and you ll find both
CUDA GPGPU Workshop 2012
 CUDA GPGPU Workshop 2012 Parallel Programming: C thread, Open MP, and Open MPI Presenter: Nasrin Sultana Wichita State University 07/10/2012 Parallel Programming: Open MP, MPI, Open MPI & CUDA Outline
CUDA GPGPU Workshop 2012 Parallel Programming: C thread, Open MP, and Open MPI Presenter: Nasrin Sultana Wichita State University 07/10/2012 Parallel Programming: Open MP, MPI, Open MPI & CUDA Outline
Benefits of Multi-Node Scale-out Clusters running NetApp Clustered Data ONTAP. Silverton Consulting, Inc. StorInt Briefing
 Benefits of Multi-Node Scale-out Clusters running NetApp Clustered Data ONTAP Silverton Consulting, Inc. StorInt Briefing BENEFITS OF MULTI- NODE SCALE- OUT CLUSTERS RUNNING NETAPP CDOT PAGE 2 OF 7 Introduction
Benefits of Multi-Node Scale-out Clusters running NetApp Clustered Data ONTAP Silverton Consulting, Inc. StorInt Briefing BENEFITS OF MULTI- NODE SCALE- OUT CLUSTERS RUNNING NETAPP CDOT PAGE 2 OF 7 Introduction
WHY PARALLEL PROCESSING? (CE-401)
") PARALLEL PROCESSING (CE-401) COURSE INFORMATION 2 + 1 credits (60 marks theory, 40 marks lab) Labs introduced for second time in PP history of SSUET Theory marks breakup: Midterm Exam: 15 marks Assignment:
PARALLEL PROCESSING (CE-401) COURSE INFORMATION 2 + 1 credits (60 marks theory, 40 marks lab) Labs introduced for second time in PP history of SSUET Theory marks breakup: Midterm Exam: 15 marks Assignment:
A unified multicore programming model
 A unified multicore programming model Simplifying multicore migration By Sven Brehmer Abstract There are a number of different multicore architectures and programming models available, making it challenging
A unified multicore programming model Simplifying multicore migration By Sven Brehmer Abstract There are a number of different multicore architectures and programming models available, making it challenging
CMS Simulation Software
 CMS Simulation Software Dmitry Onoprienko Kansas State University on behalf of the CMS collaboration 10th Topical Seminar on Innovative Particle and Radiation Detectors 1-5 October 2006. Siena, Italy Simulation
CMS Simulation Software Dmitry Onoprienko Kansas State University on behalf of the CMS collaboration 10th Topical Seminar on Innovative Particle and Radiation Detectors 1-5 October 2006. Siena, Italy Simulation
Users and utilization of CERIT-SC infrastructure
 Users and utilization of CERIT-SC infrastructure Equipment CERIT-SC is an integral part of the national e-infrastructure operated by CESNET, and it leverages many of its services (e.g. management of user
Users and utilization of CERIT-SC infrastructure Equipment CERIT-SC is an integral part of the national e-infrastructure operated by CESNET, and it leverages many of its services (e.g. management of user
GRIDS INTRODUCTION TO GRID INFRASTRUCTURES. Fabrizio Gagliardi
 GRIDS INTRODUCTION TO GRID INFRASTRUCTURES Fabrizio Gagliardi Dr. Fabrizio Gagliardi is the leader of the EU DataGrid project and designated director of the proposed EGEE (Enabling Grids for E-science
GRIDS INTRODUCTION TO GRID INFRASTRUCTURES Fabrizio Gagliardi Dr. Fabrizio Gagliardi is the leader of the EU DataGrid project and designated director of the proposed EGEE (Enabling Grids for E-science
JULIA ENABLED COMPUTATION OF MOLECULAR LIBRARY COMPLEXITY IN DNA SEQUENCING
 JULIA ENABLED COMPUTATION OF MOLECULAR LIBRARY COMPLEXITY IN DNA SEQUENCING Larson Hogstrom, Mukarram Tahir, Andres Hasfura Massachusetts Institute of Technology, Cambridge, Massachusetts, USA 18.337/6.338
JULIA ENABLED COMPUTATION OF MOLECULAR LIBRARY COMPLEXITY IN DNA SEQUENCING Larson Hogstrom, Mukarram Tahir, Andres Hasfura Massachusetts Institute of Technology, Cambridge, Massachusetts, USA 18.337/6.338
Use of ROOT in the DØ Online Event Monitoring System
 Use of ROOT in the DØ Online Event Monitoring System J. Snow 1, P. Canal 2, J. Kowalkowski 2,J.Yu 2 1 Langston University, Langston, Oklahoma 73050, USA 2 Fermi National Accelerator Laboratory, P.O. Box
Use of ROOT in the DØ Online Event Monitoring System J. Snow 1, P. Canal 2, J. Kowalkowski 2,J.Yu 2 1 Langston University, Langston, Oklahoma 73050, USA 2 Fermi National Accelerator Laboratory, P.O. Box
Computer Architecture
 Computer Architecture Slide Sets WS 2013/2014 Prof. Dr. Uwe Brinkschulte M.Sc. Benjamin Betting Part 10 Thread and Task Level Parallelism Computer Architecture Part 10 page 1 of 36 Prof. Dr. Uwe Brinkschulte,
Computer Architecture Slide Sets WS 2013/2014 Prof. Dr. Uwe Brinkschulte M.Sc. Benjamin Betting Part 10 Thread and Task Level Parallelism Computer Architecture Part 10 page 1 of 36 Prof. Dr. Uwe Brinkschulte,
Version 11
 The Big Challenges Networked and Electronic Media European Technology Platform The birth of a new sector www.nem-initiative.org Version 11 1. NEM IN THE WORLD The main objective of the Networked and Electronic
The Big Challenges Networked and Electronic Media European Technology Platform The birth of a new sector www.nem-initiative.org Version 11 1. NEM IN THE WORLD The main objective of the Networked and Electronic
Reconfigurable Multicore Server Processors for Low Power Operation
 Reconfigurable Multicore Server Processors for Low Power Operation Ronald G. Dreslinski, David Fick, David Blaauw, Dennis Sylvester, Trevor Mudge University of Michigan, Advanced Computer Architecture
Reconfigurable Multicore Server Processors for Low Power Operation Ronald G. Dreslinski, David Fick, David Blaauw, Dennis Sylvester, Trevor Mudge University of Michigan, Advanced Computer Architecture
Commentary. EMC VPLEX Launches the Virtual Storage Era
 Mesabi Group Commentary May 10, 2010 EMC VPLEX Launches the Virtual Storage Era Magicians make objects appear, disappear, or change appearance. EMC is doing the same thing with information and long-held
Mesabi Group Commentary May 10, 2010 EMC VPLEX Launches the Virtual Storage Era Magicians make objects appear, disappear, or change appearance. EMC is doing the same thing with information and long-held
TOOLS FOR IMPROVING CROSS-PLATFORM SOFTWARE DEVELOPMENT
 TOOLS FOR IMPROVING CROSS-PLATFORM SOFTWARE DEVELOPMENT Eric Kelmelis 28 March 2018 OVERVIEW BACKGROUND Evolution of processing hardware CROSS-PLATFORM KERNEL DEVELOPMENT Write once, target multiple hardware
TOOLS FOR IMPROVING CROSS-PLATFORM SOFTWARE DEVELOPMENT Eric Kelmelis 28 March 2018 OVERVIEW BACKGROUND Evolution of processing hardware CROSS-PLATFORM KERNEL DEVELOPMENT Write once, target multiple hardware
A Geometrical Modeller for HEP
 A Geometrical Modeller for HEP R. Brun, A. Gheata CERN, CH 1211, Geneva 23, Switzerland M. Gheata ISS, RO 76900, Bucharest MG23, Romania For ALICE off-line collaboration Geometrical modelling generally
A Geometrical Modeller for HEP R. Brun, A. Gheata CERN, CH 1211, Geneva 23, Switzerland M. Gheata ISS, RO 76900, Bucharest MG23, Romania For ALICE off-line collaboration Geometrical modelling generally
The Future of High Performance Computing
 The Future of High Performance Computing Randal E. Bryant Carnegie Mellon University http://www.cs.cmu.edu/~bryant Comparing Two Large-Scale Systems Oakridge Titan Google Data Center 2 Monolithic supercomputer
The Future of High Performance Computing Randal E. Bryant Carnegie Mellon University http://www.cs.cmu.edu/~bryant Comparing Two Large-Scale Systems Oakridge Titan Google Data Center 2 Monolithic supercomputer
ComPWA: A common amplitude analysis framework for PANDA
 Journal of Physics: Conference Series OPEN ACCESS ComPWA: A common amplitude analysis framework for PANDA To cite this article: M Michel et al 2014 J. Phys.: Conf. Ser. 513 022025 Related content - Partial
Journal of Physics: Conference Series OPEN ACCESS ComPWA: A common amplitude analysis framework for PANDA To cite this article: M Michel et al 2014 J. Phys.: Conf. Ser. 513 022025 Related content - Partial
Monitoring of Computing Resource Use of Active Software Releases at ATLAS
 1 2 3 4 5 6 Monitoring of Computing Resource Use of Active Software Releases at ATLAS Antonio Limosani on behalf of the ATLAS Collaboration CERN CH-1211 Geneva 23 Switzerland and University of Sydney,
1 2 3 4 5 6 Monitoring of Computing Resource Use of Active Software Releases at ATLAS Antonio Limosani on behalf of the ATLAS Collaboration CERN CH-1211 Geneva 23 Switzerland and University of Sydney,
GPU > CPU. FOR HIGH PERFORMANCE COMPUTING PRESENTATION BY - SADIQ PASHA CHETHANA DILIP
 GPU > CPU. FOR HIGH PERFORMANCE COMPUTING PRESENTATION BY - SADIQ PASHA CHETHANA DILIP INTRODUCTION or With the exponential increase in computational power of todays hardware, the complexity of the problem
GPU > CPU. FOR HIGH PERFORMANCE COMPUTING PRESENTATION BY - SADIQ PASHA CHETHANA DILIP INTRODUCTION or With the exponential increase in computational power of todays hardware, the complexity of the problem
Introduction to CUDA Algoritmi e Calcolo Parallelo. Daniele Loiacono
 Introduction to CUDA Algoritmi e Calcolo Parallelo References q This set of slides is mainly based on: " CUDA Technical Training, Dr. Antonino Tumeo, Pacific Northwest National Laboratory " Slide of Applied
Introduction to CUDA Algoritmi e Calcolo Parallelo References q This set of slides is mainly based on: " CUDA Technical Training, Dr. Antonino Tumeo, Pacific Northwest National Laboratory " Slide of Applied
GPGPUs in HPC. VILLE TIMONEN Åbo Akademi University CSC
 GPGPUs in HPC VILLE TIMONEN Åbo Akademi University 2.11.2010 @ CSC Content Background How do GPUs pull off higher throughput Typical architecture Current situation & the future GPGPU languages A tale of
GPGPUs in HPC VILLE TIMONEN Åbo Akademi University 2.11.2010 @ CSC Content Background How do GPUs pull off higher throughput Typical architecture Current situation & the future GPGPU languages A tale of
ClearSpeed Visual Profiler
 ClearSpeed Visual Profiler Copyright 2007 ClearSpeed Technology plc. All rights reserved. 12 November 2007 www.clearspeed.com 1 Profiling Application Code Why use a profiler? Program analysis tools are
ClearSpeed Visual Profiler Copyright 2007 ClearSpeed Technology plc. All rights reserved. 12 November 2007 www.clearspeed.com 1 Profiling Application Code Why use a profiler? Program analysis tools are
Parallel Computing: Parallel Architectures Jin, Hai
 Parallel Computing: Parallel Architectures Jin, Hai School of Computer Science and Technology Huazhong University of Science and Technology Peripherals Computer Central Processing Unit Main Memory Computer
Parallel Computing: Parallel Architectures Jin, Hai School of Computer Science and Technology Huazhong University of Science and Technology Peripherals Computer Central Processing Unit Main Memory Computer
Concurrent/Parallel Processing
 Concurrent/Parallel Processing David May: April 9, 2014 Introduction The idea of using a collection of interconnected processing devices is not new. Before the emergence of the modern stored program computer,
Concurrent/Parallel Processing David May: April 9, 2014 Introduction The idea of using a collection of interconnected processing devices is not new. Before the emergence of the modern stored program computer,
Monte Carlo Production on the Grid by the H1 Collaboration
 Journal of Physics: Conference Series Monte Carlo Production on the Grid by the H1 Collaboration To cite this article: E Bystritskaya et al 2012 J. Phys.: Conf. Ser. 396 032067 Recent citations - Monitoring
Journal of Physics: Conference Series Monte Carlo Production on the Grid by the H1 Collaboration To cite this article: E Bystritskaya et al 2012 J. Phys.: Conf. Ser. 396 032067 Recent citations - Monitoring
Particle-in-Cell Simulations on Modern Computing Platforms. Viktor K. Decyk and Tajendra V. Singh UCLA
 Particle-in-Cell Simulations on Modern Computing Platforms Viktor K. Decyk and Tajendra V. Singh UCLA Outline of Presentation Abstraction of future computer hardware PIC on GPUs OpenCL and Cuda Fortran
Particle-in-Cell Simulations on Modern Computing Platforms Viktor K. Decyk and Tajendra V. Singh UCLA Outline of Presentation Abstraction of future computer hardware PIC on GPUs OpenCL and Cuda Fortran
CUDA PROGRAMMING MODEL Chaithanya Gadiyam Swapnil S Jadhav
 CUDA PROGRAMMING MODEL Chaithanya Gadiyam Swapnil S Jadhav CMPE655 - Multiple Processor Systems Fall 2015 Rochester Institute of Technology Contents What is GPGPU? What s the need? CUDA-Capable GPU Architecture
CUDA PROGRAMMING MODEL Chaithanya Gadiyam Swapnil S Jadhav CMPE655 - Multiple Processor Systems Fall 2015 Rochester Institute of Technology Contents What is GPGPU? What s the need? CUDA-Capable GPU Architecture
8.882 LHC Physics. Track Reconstruction and Fitting. [Lecture 8, March 2, 2009] Experimental Methods and Measurements
![8.882 LHC Physics. Track Reconstruction and Fitting. [Lecture 8, March 2, 2009] Experimental Methods and Measurements](/thumbs/84/91007011.jpg "8.882 LHC Physics. Track Reconstruction and Fitting. [Lecture 8, March 2, 2009] Experimental Methods and Measurements") 8.882 LHC Physics Experimental Methods and Measurements Track Reconstruction and Fitting [Lecture 8, March 2, 2009] Organizational Issues Due days for the documented analyses project 1 is due March 12
8.882 LHC Physics Experimental Methods and Measurements Track Reconstruction and Fitting [Lecture 8, March 2, 2009] Organizational Issues Due days for the documented analyses project 1 is due March 12
Performance impact of dynamic parallelism on different clustering algorithms
 Performance impact of dynamic parallelism on different clustering algorithms Jeffrey DiMarco and Michela Taufer Computer and Information Sciences, University of Delaware E-mail: jdimarco@udel.edu, taufer@udel.edu
Performance impact of dynamic parallelism on different clustering algorithms Jeffrey DiMarco and Michela Taufer Computer and Information Sciences, University of Delaware E-mail: jdimarco@udel.edu, taufer@udel.edu
HETEROGENEOUS SYSTEM ARCHITECTURE: PLATFORM FOR THE FUTURE
 HETEROGENEOUS SYSTEM ARCHITECTURE: PLATFORM FOR THE FUTURE Haibo Xie, Ph.D. Chief HSA Evangelist AMD China OUTLINE: The Challenges with Computing Today Introducing Heterogeneous System Architecture (HSA)
HETEROGENEOUS SYSTEM ARCHITECTURE: PLATFORM FOR THE FUTURE Haibo Xie, Ph.D. Chief HSA Evangelist AMD China OUTLINE: The Challenges with Computing Today Introducing Heterogeneous System Architecture (HSA)
Track pattern-recognition on GPGPUs in the LHCb experiment
 Track pattern-recognition on GPGPUs in the LHCb experiment Stefano Gallorini 1,2 1 University and INFN Padova, Via Marzolo 8, 35131, Padova, Italy 2 CERN, 1211 Geneve 23, Switzerland DOI: http://dx.doi.org/10.3204/desy-proc-2014-05/7
Track pattern-recognition on GPGPUs in the LHCb experiment Stefano Gallorini 1,2 1 University and INFN Padova, Via Marzolo 8, 35131, Padova, Italy 2 CERN, 1211 Geneve 23, Switzerland DOI: http://dx.doi.org/10.3204/desy-proc-2014-05/7
Conference The Data Challenges of the LHC. Reda Tafirout, TRIUMF
 Conference 2017 The Data Challenges of the LHC Reda Tafirout, TRIUMF Outline LHC Science goals, tools and data Worldwide LHC Computing Grid Collaboration & Scale Key challenges Networking ATLAS experiment
Conference 2017 The Data Challenges of the LHC Reda Tafirout, TRIUMF Outline LHC Science goals, tools and data Worldwide LHC Computing Grid Collaboration & Scale Key challenges Networking ATLAS experiment
Introduction to Computing and Systems Architecture
 Introduction to Computing and Systems Architecture 1. Computability A task is computable if a sequence of instructions can be described which, when followed, will complete such a task. This says little
Introduction to Computing and Systems Architecture 1. Computability A task is computable if a sequence of instructions can be described which, when followed, will complete such a task. This says little
PyROOT: Seamless Melting of C++ and Python. Pere MATO, Danilo PIPARO on behalf of the ROOT Team
 PyROOT: Seamless Melting of C++ and Python Pere MATO, Danilo PIPARO on behalf of the ROOT Team ROOT At the root of the experiments, project started in 1995 Open Source project (LGPL2) mainly written in
PyROOT: Seamless Melting of C++ and Python Pere MATO, Danilo PIPARO on behalf of the ROOT Team ROOT At the root of the experiments, project started in 1995 Open Source project (LGPL2) mainly written in
GPUs and GPGPUs. Greg Blanton John T. Lubia
 GPUs and GPGPUs Greg Blanton John T. Lubia PROCESSOR ARCHITECTURAL ROADMAP Design CPU Optimized for sequential performance ILP increasingly difficult to extract from instruction stream Control hardware
GPUs and GPGPUs Greg Blanton John T. Lubia PROCESSOR ARCHITECTURAL ROADMAP Design CPU Optimized for sequential performance ILP increasingly difficult to extract from instruction stream Control hardware
SDACCEL DEVELOPMENT ENVIRONMENT. The Xilinx SDAccel Development Environment. Bringing The Best Performance/Watt to the Data Center
 SDAccel Environment The Xilinx SDAccel Development Environment Bringing The Best Performance/Watt to the Data Center Introduction Data center operators constantly seek more server performance. Currently
SDAccel Environment The Xilinx SDAccel Development Environment Bringing The Best Performance/Watt to the Data Center Introduction Data center operators constantly seek more server performance. Currently
Oracle Exadata Statement of Direction NOVEMBER 2017
 Oracle Exadata Statement of Direction NOVEMBER 2017 Disclaimer The following is intended to outline our general product direction. It is intended for information purposes only, and may not be incorporated
Oracle Exadata Statement of Direction NOVEMBER 2017 Disclaimer The following is intended to outline our general product direction. It is intended for information purposes only, and may not be incorporated
Chapter 1: Introduction
 Chapter 1: Introduction Silberschatz, Galvin and Gagne 2009 Chapter 1: Introduction What Operating Systems Do Computer-System Organization Computer-System Architecture Operating-System Structure Operating-System
Chapter 1: Introduction Silberschatz, Galvin and Gagne 2009 Chapter 1: Introduction What Operating Systems Do Computer-System Organization Computer-System Architecture Operating-System Structure Operating-System
Chapter 1: Introduction
 Chapter 1: Introduction Chapter 1: Introduction What Operating Systems Do Computer-System Organization Computer-System Architecture Operating-System Structure Operating-System Operations Process Management
Chapter 1: Introduction Chapter 1: Introduction What Operating Systems Do Computer-System Organization Computer-System Architecture Operating-System Structure Operating-System Operations Process Management
MediaTek CorePilot 2.0. Delivering extreme compute performance with maximum power efficiency
 MediaTek CorePilot 2.0 Heterogeneous Computing Technology Delivering extreme compute performance with maximum power efficiency In July 2013, MediaTek delivered the industry s first mobile system on a chip
MediaTek CorePilot 2.0 Heterogeneous Computing Technology Delivering extreme compute performance with maximum power efficiency In July 2013, MediaTek delivered the industry s first mobile system on a chip
High-Performance and Parallel Computing
 9 High-Performance and Parallel Computing 9.1 Code optimization To use resources efficiently, the time saved through optimizing code has to be weighed against the human resources required to implement
9 High-Performance and Parallel Computing 9.1 Code optimization To use resources efficiently, the time saved through optimizing code has to be weighed against the human resources required to implement
W H I T E P A P E R U n l o c k i n g t h e P o w e r o f F l a s h w i t h t h e M C x - E n a b l e d N e x t - G e n e r a t i o n V N X
 Global Headquarters: 5 Speen Street Framingham, MA 01701 USA P.508.872.8200 F.508.935.4015 www.idc.com W H I T E P A P E R U n l o c k i n g t h e P o w e r o f F l a s h w i t h t h e M C x - E n a b
Global Headquarters: 5 Speen Street Framingham, MA 01701 USA P.508.872.8200 F.508.935.4015 www.idc.com W H I T E P A P E R U n l o c k i n g t h e P o w e r o f F l a s h w i t h t h e M C x - E n a b
The Accelerator Toolbox (AT) is a heavily matured collection of tools and scripts
 is a heavily matured collection of tools and scripts") 1. Abstract The Accelerator Toolbox (AT) is a heavily matured collection of tools and scripts specifically oriented toward solving problems dealing with computational accelerator physics. It is integrated
1. Abstract The Accelerator Toolbox (AT) is a heavily matured collection of tools and scripts specifically oriented toward solving problems dealing with computational accelerator physics. It is integrated
Data handling with SAM and art at the NOνA experiment
 Data handling with SAM and art at the NOνA experiment A Aurisano 1, C Backhouse 2, G S Davies 3, R Illingworth 4, N Mayer 5, M Mengel 4, A Norman 4, D Rocco 6 and J Zirnstein 6 1 University of Cincinnati,
Data handling with SAM and art at the NOνA experiment A Aurisano 1, C Backhouse 2, G S Davies 3, R Illingworth 4, N Mayer 5, M Mengel 4, A Norman 4, D Rocco 6 and J Zirnstein 6 1 University of Cincinnati,
arxiv: v1 [physics.ins-det] 11 Jul 2015
![arxiv: v1 [physics.ins-det] 11 Jul 2015](/thumbs/90/102656934.jpg "arxiv: v1 [physics.ins-det] 11 Jul 2015") GPGPU for track finding in High Energy Physics arxiv:7.374v [physics.ins-det] Jul 5 L Rinaldi, M Belgiovine, R Di Sipio, A Gabrielli, M Negrini, F Semeria, A Sidoti, S A Tupputi 3, M Villa Bologna University
GPGPU for track finding in High Energy Physics arxiv:7.374v [physics.ins-det] Jul 5 L Rinaldi, M Belgiovine, R Di Sipio, A Gabrielli, M Negrini, F Semeria, A Sidoti, S A Tupputi 3, M Villa Bologna University
Next Generation OpenGL Neil Trevett Khronos President NVIDIA VP Mobile Copyright Khronos Group Page 1
 Next Generation OpenGL Neil Trevett Khronos President NVIDIA VP Mobile Ecosystem @neilt3d Copyright Khronos Group 2015 - Page 1 Copyright Khronos Group 2015 - Page 2 Khronos Connects Software to Silicon
Next Generation OpenGL Neil Trevett Khronos President NVIDIA VP Mobile Ecosystem @neilt3d Copyright Khronos Group 2015 - Page 1 Copyright Khronos Group 2015 - Page 2 Khronos Connects Software to Silicon
Challenges for GPU Architecture. Michael Doggett Graphics Architecture Group April 2, 2008
 Michael Doggett Graphics Architecture Group April 2, 2008 Graphics Processing Unit Architecture CPUs vsgpus AMD s ATI RADEON 2900 Programming Brook+, CAL, ShaderAnalyzer Architecture Challenges Accelerated
Michael Doggett Graphics Architecture Group April 2, 2008 Graphics Processing Unit Architecture CPUs vsgpus AMD s ATI RADEON 2900 Programming Brook+, CAL, ShaderAnalyzer Architecture Challenges Accelerated
ASSEMBLY LANGUAGE MACHINE ORGANIZATION
 ASSEMBLY LANGUAGE MACHINE ORGANIZATION CHAPTER 3 1 Sub-topics The topic will cover: Microprocessor architecture CPU processing methods Pipelining Superscalar RISC Multiprocessing Instruction Cycle Instruction
ASSEMBLY LANGUAGE MACHINE ORGANIZATION CHAPTER 3 1 Sub-topics The topic will cover: Microprocessor architecture CPU processing methods Pipelining Superscalar RISC Multiprocessing Instruction Cycle Instruction
Upgraded Swimmer for Computationally Efficient Particle Tracking for Jefferson Lab s CLAS12 Spectrometer
 Upgraded Swimmer for Computationally Efficient Particle Tracking for Jefferson Lab s CLAS12 Spectrometer Lydia Lorenti Advisor: David Heddle April 29, 2018 Abstract The CLAS12 spectrometer at Jefferson
Upgraded Swimmer for Computationally Efficient Particle Tracking for Jefferson Lab s CLAS12 Spectrometer Lydia Lorenti Advisor: David Heddle April 29, 2018 Abstract The CLAS12 spectrometer at Jefferson
Evaluation Report: Improving SQL Server Database Performance with Dot Hill AssuredSAN 4824 Flash Upgrades
 Evaluation Report: Improving SQL Server Database Performance with Dot Hill AssuredSAN 4824 Flash Upgrades Evaluation report prepared under contract with Dot Hill August 2015 Executive Summary Solid state
Evaluation Report: Improving SQL Server Database Performance with Dot Hill AssuredSAN 4824 Flash Upgrades Evaluation report prepared under contract with Dot Hill August 2015 Executive Summary Solid state
PoS(High-pT physics09)036
036") Triggering on Jets and D 0 in HLT at ALICE 1 University of Bergen Allegaten 55, 5007 Bergen, Norway E-mail: st05886@alf.uib.no The High Level Trigger (HLT) of the ALICE experiment is designed to perform
Triggering on Jets and D 0 in HLT at ALICE 1 University of Bergen Allegaten 55, 5007 Bergen, Norway E-mail: st05886@alf.uib.no The High Level Trigger (HLT) of the ALICE experiment is designed to perform
WHAT IS SOFTWARE ARCHITECTURE?
 WHAT IS SOFTWARE ARCHITECTURE? Chapter Outline What Software Architecture Is and What It Isn t Architectural Structures and Views Architectural Patterns What Makes a Good Architecture? Summary 1 What is
WHAT IS SOFTWARE ARCHITECTURE? Chapter Outline What Software Architecture Is and What It Isn t Architectural Structures and Views Architectural Patterns What Makes a Good Architecture? Summary 1 What is
Gen-Z Overview. 1. Introduction. 2. Background. 3. A better way to access data. 4. Why a memory-semantic fabric
 Gen-Z Overview 1. Introduction Gen-Z is a new data access technology that will allow business and technology leaders, to overcome current challenges with the existing computer architecture and provide
Gen-Z Overview 1. Introduction Gen-Z is a new data access technology that will allow business and technology leaders, to overcome current challenges with the existing computer architecture and provide
CERN openlab II. CERN openlab and. Sverre Jarp CERN openlab CTO 16 September 2008
 CERN openlab II CERN openlab and Intel: Today and Tomorrow Sverre Jarp CERN openlab CTO 16 September 2008 Overview of CERN 2 CERN is the world's largest particle physics centre What is CERN? Particle physics
CERN openlab II CERN openlab and Intel: Today and Tomorrow Sverre Jarp CERN openlab CTO 16 September 2008 Overview of CERN 2 CERN is the world's largest particle physics centre What is CERN? Particle physics
Best Practices for Setting BIOS Parameters for Performance
 White Paper Best Practices for Setting BIOS Parameters for Performance Cisco UCS E5-based M3 Servers May 2013 2014 Cisco and/or its affiliates. All rights reserved. This document is Cisco Public. Page
White Paper Best Practices for Setting BIOS Parameters for Performance Cisco UCS E5-based M3 Servers May 2013 2014 Cisco and/or its affiliates. All rights reserved. This document is Cisco Public. Page
Technical Brief. AGP 8X Evolving the Graphics Interface
 Technical Brief AGP 8X Evolving the Graphics Interface Increasing Graphics Bandwidth No one needs to be convinced that the overall PC experience is increasingly dependent on the efficient processing of
Technical Brief AGP 8X Evolving the Graphics Interface Increasing Graphics Bandwidth No one needs to be convinced that the overall PC experience is increasingly dependent on the efficient processing of
Profiling-Based L1 Data Cache Bypassing to Improve GPU Performance and Energy Efficiency
 Profiling-Based L1 Data Cache Bypassing to Improve GPU Performance and Energy Efficiency Yijie Huangfu and Wei Zhang Department of Electrical and Computer Engineering Virginia Commonwealth University {huangfuy2,wzhang4}@vcu.edu
Profiling-Based L1 Data Cache Bypassing to Improve GPU Performance and Energy Efficiency Yijie Huangfu and Wei Zhang Department of Electrical and Computer Engineering Virginia Commonwealth University {huangfuy2,wzhang4}@vcu.edu
An Oracle White Paper October Minimizing Planned Downtime of SAP Systems with the Virtualization Technologies in Oracle Solaris 10
 An Oracle White Paper October 2010 Minimizing Planned Downtime of SAP Systems with the Virtualization Technologies in Oracle Solaris 10 Introduction When business-critical systems are down for a variety
An Oracle White Paper October 2010 Minimizing Planned Downtime of SAP Systems with the Virtualization Technologies in Oracle Solaris 10 Introduction When business-critical systems are down for a variety
Computer Systems Architecture
 Computer Systems Architecture Lecture 24 Mahadevan Gomathisankaran April 29, 2010 04/29/2010 Lecture 24 CSCE 4610/5610 1 Reminder ABET Feedback: http://www.cse.unt.edu/exitsurvey.cgi?csce+4610+001 Student
Computer Systems Architecture Lecture 24 Mahadevan Gomathisankaran April 29, 2010 04/29/2010 Lecture 24 CSCE 4610/5610 1 Reminder ABET Feedback: http://www.cse.unt.edu/exitsurvey.cgi?csce+4610+001 Student
Computer Architecture: Multi-Core Processors: Why? Onur Mutlu & Seth Copen Goldstein Carnegie Mellon University 9/11/13
 Computer Architecture: Multi-Core Processors: Why? Onur Mutlu & Seth Copen Goldstein Carnegie Mellon University 9/11/13 Moore s Law Moore, Cramming more components onto integrated circuits, Electronics,
Computer Architecture: Multi-Core Processors: Why? Onur Mutlu & Seth Copen Goldstein Carnegie Mellon University 9/11/13 Moore s Law Moore, Cramming more components onto integrated circuits, Electronics,
Joe Wingbermuehle, (A paper written under the guidance of Prof. Raj Jain)
") 1 of 11 5/4/2011 4:49 PM Joe Wingbermuehle, wingbej@wustl.edu (A paper written under the guidance of Prof. Raj Jain) Download The Auto-Pipe system allows one to evaluate various resource mappings and topologies
1 of 11 5/4/2011 4:49 PM Joe Wingbermuehle, wingbej@wustl.edu (A paper written under the guidance of Prof. Raj Jain) Download The Auto-Pipe system allows one to evaluate various resource mappings and topologies