Google: A Computer Scientist s Playground
|
|
|
- Isabella Parrish
- 6 years ago
- Views:
Transcription
1 Google: A Computer Scientist s Playground Jochen Hollmann Google Zürich und Trondheim joho@google.com Outline Mission, data, and scaling Systems infrastructure Parallel programming model: MapReduce Googles work environment 1
2 Google s Mission To organize the world s information and make it universally accessible and useful A sense of scale Example: The Web 20+ billion web pages x 20KB = 400+ terabytes One computer can read MB/sec from disk ~four month to read the web ~1,000 hard drives just to store the web Even more to do something with the data 2
3 Dealing with Scale Hardware, networking Building a basic computing platform with low cost Distributed systems Building reliable systems out of many individual computers Algorithms, data structures Processing data efficiently, and in new and interesting ways Machine learning, information retrieval Improving quality of search results by analyzing (lots of) data User interfaces Designing effective interfaces for search and other products Many others Why Use Commodity PCs? Single high-end 8-way Intel server: IBM eserver xseries GHz Xeon, 64 GB RAM, 8 TB of disk $758,000 Commodity machines: Rack of 88 machines GHz Xeons, 176 GB RAM, ~7 TB of disk $278,000 1/3X price, 22X CPU, 3X RAM, 1X disk Sources: racksaver.com, TPC-C performance results, both from late

 google.")
4 7/2/07 google.stanford.edu (circa 1997) google.com (1999) 4
 google.")
5 7/2/07 Google Data Center (circa 2000) google.com (new data center 2001) 5
 Implications of our Computing Environment Single-thread performance doesn t matter We have large problems and total throughput/$ more")

6 7/2/07 google.com (3 days later) Implications of our Computing Environment Single-thread performance doesn t matter We have large problems and total throughput/$ more important than peak performance Stuff Breaks If you have one server, it may stay up three years (1,000 days) If you have 10,000 servers, expect to lose ten a day Ultra-reliable hardware doesn t really help At large scales, super-fancy reliable hardware still fails, albeit less often software still needs to be fault-tolerant commodity machines without fancy hardware give better perf/$ Fault-tolerant software makes cheap hardware practical 6
7 An Example: The Index Similar to index in the back of a book (but big!) Building takes several days on hundreds of machines More than 4 billion web documents Images: 880M images File types: More than 35M non-html documents (PDF, Microsoft Word, etc.) Usenet: 800M messages from >35K newsgroups Structuring the Index Too large for one machine, so... Use PageRank as a total order Split it into pieces, called shards, small enough to have several per machine Replicate the shards, making more replicas of high PageRank shards Do the same for the documents Then: replicate this whole structure within and across data centers 7
8 Google Query Serving Infrastructure query Google Web Server Misc. servers Spell checker Ad Server Index servers Doc servers Replicas I 0 I 1 I 2 I N I 0 I 1 I 2 I N Replicas D 0 D 1 D M D 0 D 1 D M I 0 I 1 I 2 I N D 0 D 1 D M Index shards Doc shards Elapsed time: 0.25s, machines involved: Reliable Building Blocks Need to store data reliably Need to run jobs on pools of machines Need to make it easy to apply lots of computational resources to problems In-house solutions: Storage: Google File System (GFS) Job scheduling: Global Work Queue (GWQ) MapReduce: simplified large-scale data processing 8
9 Google File System (GFS) Masters Replicas GFS Master GFS Master Misc. servers Client Client C 0 C 1 C 5 C 2 C 5 C 1 C 3 C 0 C 5 C 2 Chunkserver 1 Chunkserver 2 Chunkserver N Master manages metadata Data transfers happen directly between clients/chunkservers Files broken into chunks (typically 64 MB) Chunks triplicated across three machines for safety GFS Usage at Google 30+ Clusters Clusters as large as chunkservers Petabyte-sized filesystems MB/s sustained read/write load All in the presence of HW failures More information can be found in SOSP, 03 9
10 MapReduce: Easy-to-use Cycles A simple programming model that applies to many large-scale computing problems Hide messy details in MapReduce runtime library: automatic parallelization load balancing network and disk transfer optimization handling of machine failures robustness improvements to core library benefit all users of library! Typical problem solved by MapReduce Read a lot of data Map: extract something you care about from each record Shuffle and Sort Reduce: aggregate, summarize, filter, or transform Write the results Outline stays the same, map and reduce change to fit the problem 10
11 More specifically Programmer specifies two primary methods: map(k, v) <k', v'>* reduce(k', <v'>*) <k', v''>* All v' with same k' are reduced together, in order. Usually also specify: partition(k, total partitions) -> partition for k often a simple hash of the key allows reduce operations for different k to be parallelized Example: Word Frequencies in Web Pages A typical exercise for a new engineer in his or her first week Input is files with one document per record Specify a map function that takes a key/value pair key = document URL value = document contents Output of map function is (potentially many) key/value pairs. In our case, output (word, 1 ) once per word in the document document1, to be or not to be to, 1 be, 1 or, 1 11
12 Example continued: word frequencies in web pages MapReduce library gathers together all pairs with the same key (shuffle/sort) The reduce function combines the values for a key In our case, compute the sum key = be values = 1, 1 2 key = not values = 1 1 key = or values = 1 1 key = to values = 1, 1 2 Output of reduce (usually 0 or 1 value) paired with key and saved be, 2 not, 1 or, 1 to, 2 Example: Pseudo-code Map(String input_key, String input_value): // input_key: document name // input_value: document contents for each word w in input_values: EmitIntermediate(w, "1"); Reduce(String key, Iterator intermediate_values): // key: a word, same for input and output // intermediate_values: a list of counts int result = 0; for each v in intermediate_values: result += ParseInt(v); Emit(AsString(result)); Total 80 lines of C++ code including comments, main() 12



13 Widely applicable at Google Implemented as a C++ library linked to user programs Can read and write many different data types Example uses: distributed grep distributed sort term-vector per host document clustering machine learning... web access log stats web link-graph reversal inverted index construction statistical machine translation Query Frequency Over Time Queries containing eclipse Queries containing world series Queries containing full moon Queries containing summer olympics Queries containing watermelon Queries containing opteron 13
14 Example: Generating Language Model Statistics Used in our statistical machine translation system need to count # of times every 5-word sequence occurs in large corpus of documents (and keep all those where count >= 4) Easy with MapReduce: map: extract 5-word sequences => count from document reduce: combine counts, and keep if count large enough Example: Joining with Other Data Example: generate per-doc summary, but include perhost information (e.g. # of pages on host, important terms on host) per-host information might be in per-process data structure, or might involve RPC to a set of machines containing data for all sites map: extract host name from URL, lookup per-host info, combine with per-doc data and emit reduce: identity function (just emit key/value directly) 14


15 MapReduce Programs in Google s Source Tree New MapReduce Programs Per Month Summer intern effect 15
 Reduce phase partitioned into R reduce tasks Tasks are assigned to workers")

 Worker produces R local files containing intermediate k/v pairs Master assigns each")

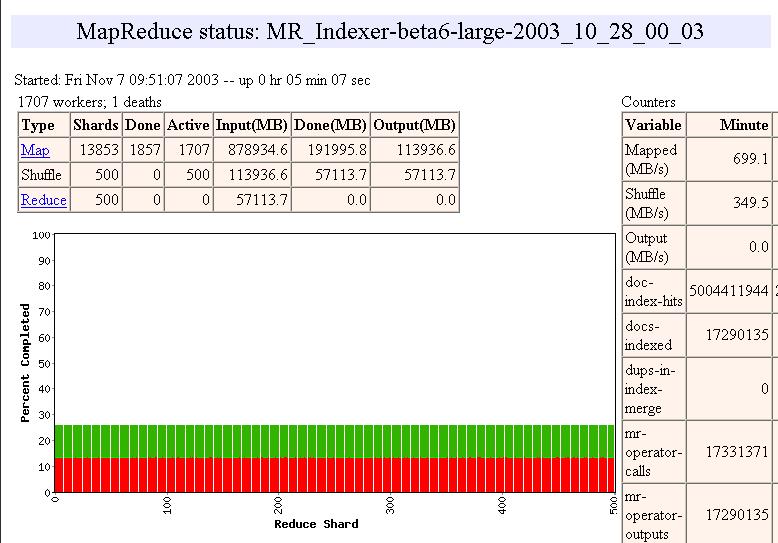
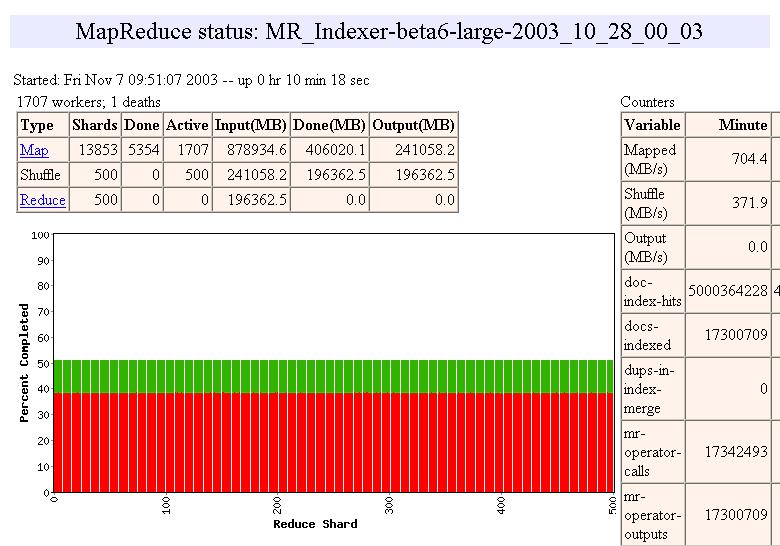
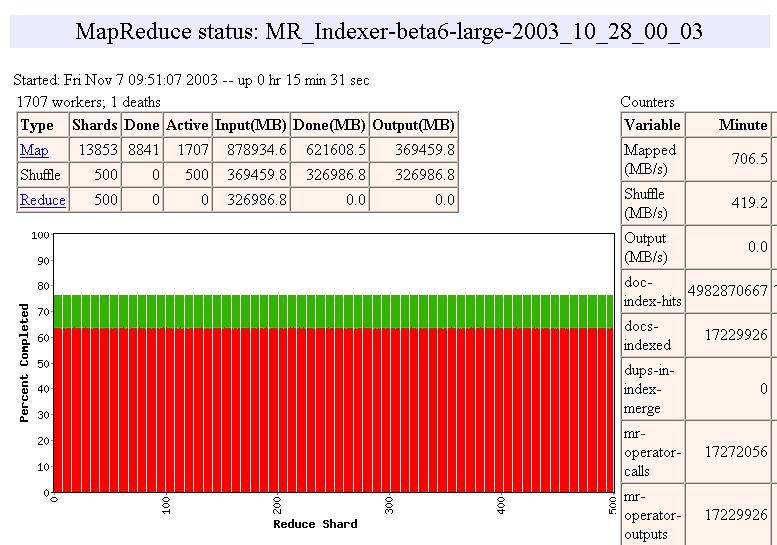
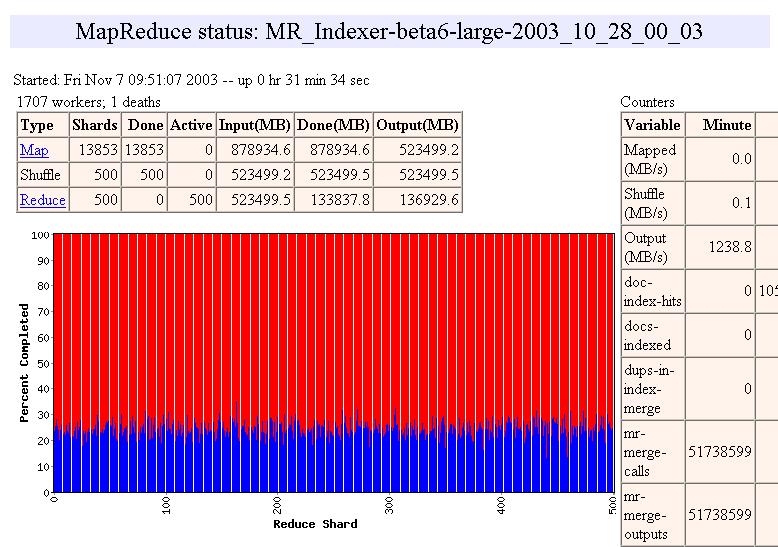
16 MapReduce: Scheduling One master, many workers Input data split into M map tasks (typically 64 MB in size) Reduce phase partitioned into R reduce tasks Tasks are assigned to workers dynamically Often: M=200000; R=4000; workers=2000 Master assigns each map task to a free worker Considers locality of data to worker when assigning task Worker reads task input (often from local disk!) Worker produces R local files containing intermediate k/v pairs Master assigns each reduce task to a free worker Worker reads intermediate k/v pairs from map workers Worker sorts & applies user s Reduce op to produce the output Parallel MapReduce Input data Map Map Map Map Master Shuffle Shuffle Shuffle Reduce Reduce Reduce Partitioned output 16


17 Task Granularity and Pipelining Fine granularity tasks: many more map tasks than machines Minimizes time for fault recovery Can pipeline shuffling with map execution Better dynamic load balancing Often use 200,000 map/5000 reduce tasks w/ 2000 machines 17
18 18
19 19
20 20
21 21
22 22
23 Fault tolerance: Handled via re-execution On worker failure: Detect failure via periodic heartbeats Re-execute completed and in-progress map tasks Re-execute in progress reduce tasks Task completion committed through master On master failure: State is checkpointed to GFS: new master recovers & continues Very Robust: lost 1600 of 1800 machines once, but finished fine Refinement: Backup Tasks Slow workers significantly lengthen completion time Other jobs consuming resources on machine Bad disks with soft errors transfer data very slowly Weird things: processor caches disabled (!!) Solution: Near end of phase, spawn backup copies of tasks Whichever one finishes first "wins" Effect: Dramatically shortens job completion time 23
24 MR_Sort Refinement: Locality Optimization Master scheduling policy: Asks GFS for locations of replicas of input file blocks Map tasks typically split into 64MB (== GFS block size) Map tasks scheduled so GFS input block replica are on same machine or same rack Effect: Thousands of machines read input at local disk speed Without this, rack switches limit read rate 24
25 Refinement: Skipping Bad Records Map/Reduce functions sometimes fail for particular inputs Best solution is to debug & fix, but not always possible On seg fault: Send UDP packet to master from signal handler Include sequence number of record being processed If master sees K failures for same record (typically K set to 2 or 3) : Next worker is told to skip the record Effect: Can work around bugs in third-party libraries Other Refinements Optional secondary keys for ordering Compression of intermediate data Combiner: useful for saving network bandwidth Local execution for debugging/testing User-defined counters 25
26 Performance Results & Experience Using 1,800 machines: MR_Grep scanned 1 terabyte in 100 seconds MR_Sort sorted 1 terabyte of 100 byte records in 14 minutes Rewrote Google's production indexing system a sequence of 7, 10, 14, 17, 21, 24 MapReductions simpler more robust faster more scalable Implications for Multi-core Processors Multi-core processors require parallelism, but many programmers are uncomfortable writing parallel programs MapReduce provides an easy-to-understand programming model for a very diverse set of computing problems users don t need to be parallel programming experts system automatically adapts to number of cores & machines available Optimizations useful even in single machine, multicore environment locality, load balancing, status monitoring, robustness, 26





27 Data + CPUs = Playground Substantial fraction of internet available for processing Easy-to-use teraflops/petabytes Cool problems, great colleagues Google Product Suite Google Web Search World s most used web search AdSense for Search Monetizing search results pages AdSense for Content Monetize content pages Blogger Post your thoughts to the web Froogle: Product Search 20 M+ products from 150k+ sites Gmail Web-based with 1GB storage Google Deskbar Search from the desktop at any time Google Search Appliance Corporate search solution Google Toolbar Search from browser, block popups, etc 27
 on problems that matter with freedom to explore their ideas 20% rule, access to computational resources It s not just search: Google has")
28 Who Does All This? Talented, motivated people working in small teams (3-5 people) on problems that matter with freedom to explore their ideas 20% rule, access to computational resources It s not just search: Google has experts in Hardware, networking, distributed systems, fault tolerance, data structures, algorithms, machine learning, information retrieval, AI, user interfaces, compilers, programming languages, statistics, product design, mechanical eng., Work philosophy: Let people work on exciting problems Work on things that matter Affect everyone in the world Solve problems with algorithms if at all possible Hire bright people and give them lots of freedom Don t be afraid to try new things Number 1 work place in the US and TOP 10 in Ireland 28


29 7/2/07 Work Environment Work Environment 29


30 7/2/07 Work Environment Work Environment 30

31 We re Hiring! If this sounds like fun, we have engineering positions in: Trondheim, Zürich, Munich, London, Dublin And around the globe!
32 The End Thanks to Jeff Dean for compiling most of the slides 32
Google: A Computer Scientist s Playground
 Outline Mission, data, and scaling Google: A Computer Scientist s Playground Jochen Hollmann Google Zürich und Trondheim joho@google.com Systems infrastructure Parallel programming model: MapReduce Googles
Outline Mission, data, and scaling Google: A Computer Scientist s Playground Jochen Hollmann Google Zürich und Trondheim joho@google.com Systems infrastructure Parallel programming model: MapReduce Googles
Distributed Computations MapReduce. adapted from Jeff Dean s slides
 Distributed Computations MapReduce adapted from Jeff Dean s slides What we ve learnt so far Basic distributed systems concepts Consistency (sequential, eventual) Fault tolerance (recoverability, availability)
Distributed Computations MapReduce adapted from Jeff Dean s slides What we ve learnt so far Basic distributed systems concepts Consistency (sequential, eventual) Fault tolerance (recoverability, availability)
The MapReduce Abstraction
 The MapReduce Abstraction Parallel Computing at Google Leverages multiple technologies to simplify large-scale parallel computations Proprietary computing clusters Map/Reduce software library Lots of other
The MapReduce Abstraction Parallel Computing at Google Leverages multiple technologies to simplify large-scale parallel computations Proprietary computing clusters Map/Reduce software library Lots of other
Motivation. Map in Lisp (Scheme) Map/Reduce. MapReduce: Simplified Data Processing on Large Clusters
 Map/Reduce. MapReduce: Simplified Data Processing on Large Clusters") Motivation MapReduce: Simplified Data Processing on Large Clusters These are slides from Dan Weld s class at U. Washington (who in turn made his slides based on those by Jeff Dean, Sanjay Ghemawat, Google,
Motivation MapReduce: Simplified Data Processing on Large Clusters These are slides from Dan Weld s class at U. Washington (who in turn made his slides based on those by Jeff Dean, Sanjay Ghemawat, Google,
MapReduce Spark. Some slides are adapted from those of Jeff Dean and Matei Zaharia
 MapReduce Spark Some slides are adapted from those of Jeff Dean and Matei Zaharia What have we learnt so far? Distributed storage systems consistency semantics protocols for fault tolerance Paxos, Raft,
MapReduce Spark Some slides are adapted from those of Jeff Dean and Matei Zaharia What have we learnt so far? Distributed storage systems consistency semantics protocols for fault tolerance Paxos, Raft,
Parallel Computing: MapReduce Jin, Hai
 Parallel Computing: MapReduce Jin, Hai School of Computer Science and Technology Huazhong University of Science and Technology ! MapReduce is a distributed/parallel computing framework introduced by Google
Parallel Computing: MapReduce Jin, Hai School of Computer Science and Technology Huazhong University of Science and Technology ! MapReduce is a distributed/parallel computing framework introduced by Google
CS 61C: Great Ideas in Computer Architecture. MapReduce
 CS 61C: Great Ideas in Computer Architecture MapReduce Guest Lecturer: Justin Hsia 3/06/2013 Spring 2013 Lecture #18 1 Review of Last Lecture Performance latency and throughput Warehouse Scale Computing
CS 61C: Great Ideas in Computer Architecture MapReduce Guest Lecturer: Justin Hsia 3/06/2013 Spring 2013 Lecture #18 1 Review of Last Lecture Performance latency and throughput Warehouse Scale Computing
MapReduce: Simplified Data Processing on Large Clusters
 MapReduce: Simplified Data Processing on Large Clusters Jeffrey Dean and Sanjay Ghemawat OSDI 2004 Presented by Zachary Bischof Winter '10 EECS 345 Distributed Systems 1 Motivation Summary Example Implementation
MapReduce: Simplified Data Processing on Large Clusters Jeffrey Dean and Sanjay Ghemawat OSDI 2004 Presented by Zachary Bischof Winter '10 EECS 345 Distributed Systems 1 Motivation Summary Example Implementation
CSE Lecture 11: Map/Reduce 7 October Nate Nystrom UTA
 CSE 3302 Lecture 11: Map/Reduce 7 October 2010 Nate Nystrom UTA 378,000 results in 0.17 seconds including images and video communicates with 1000s of machines web server index servers document servers
CSE 3302 Lecture 11: Map/Reduce 7 October 2010 Nate Nystrom UTA 378,000 results in 0.17 seconds including images and video communicates with 1000s of machines web server index servers document servers
Parallel Programming Principle and Practice. Lecture 10 Big Data Processing with MapReduce
 Parallel Programming Principle and Practice Lecture 10 Big Data Processing with MapReduce Outline MapReduce Programming Model MapReduce Examples Hadoop 2 Incredible Things That Happen Every Minute On The
Parallel Programming Principle and Practice Lecture 10 Big Data Processing with MapReduce Outline MapReduce Programming Model MapReduce Examples Hadoop 2 Incredible Things That Happen Every Minute On The
Agenda. Request- Level Parallelism. Agenda. Anatomy of a Web Search. Google Query- Serving Architecture 9/20/10
 Agenda CS 61C: Great Ideas in Computer Architecture (Machine Structures) Instructors: Randy H. Katz David A. PaHerson hhp://inst.eecs.berkeley.edu/~cs61c/fa10 Request and Data Level Parallelism Administrivia
Agenda CS 61C: Great Ideas in Computer Architecture (Machine Structures) Instructors: Randy H. Katz David A. PaHerson hhp://inst.eecs.berkeley.edu/~cs61c/fa10 Request and Data Level Parallelism Administrivia
Cloud Programming. Programming Environment Oct 29, 2015 Osamu Tatebe
 Cloud Programming Programming Environment Oct 29, 2015 Osamu Tatebe Cloud Computing Only required amount of CPU and storage can be used anytime from anywhere via network Availability, throughput, reliability
Cloud Programming Programming Environment Oct 29, 2015 Osamu Tatebe Cloud Computing Only required amount of CPU and storage can be used anytime from anywhere via network Availability, throughput, reliability
CS427 Multicore Architecture and Parallel Computing
 CS427 Multicore Architecture and Parallel Computing Lecture 9 MapReduce Prof. Li Jiang 2014/11/19 1 What is MapReduce Origin from Google, [OSDI 04] A simple programming model Functional model For large-scale
CS427 Multicore Architecture and Parallel Computing Lecture 9 MapReduce Prof. Li Jiang 2014/11/19 1 What is MapReduce Origin from Google, [OSDI 04] A simple programming model Functional model For large-scale
Introduction to Map Reduce
 Introduction to Map Reduce 1 Map Reduce: Motivation We realized that most of our computations involved applying a map operation to each logical record in our input in order to compute a set of intermediate
Introduction to Map Reduce 1 Map Reduce: Motivation We realized that most of our computations involved applying a map operation to each logical record in our input in order to compute a set of intermediate
Lessons Learned While Building Infrastructure Software at Google
 Lessons Learned While Building Infrastructure Software at Google Jeff Dean jeff@google.com Google Circa 1997 (google.stanford.edu) Corkboards (1999) Google Data Center (2000) Google Data Center (2000)
Lessons Learned While Building Infrastructure Software at Google Jeff Dean jeff@google.com Google Circa 1997 (google.stanford.edu) Corkboards (1999) Google Data Center (2000) Google Data Center (2000)
Parallel Programming Concepts
 Parallel Programming Concepts MapReduce Frank Feinbube Source: MapReduce: Simplied Data Processing on Large Clusters; Dean et. Al. Examples for Parallel Programming Support 2 MapReduce 3 Programming model
Parallel Programming Concepts MapReduce Frank Feinbube Source: MapReduce: Simplied Data Processing on Large Clusters; Dean et. Al. Examples for Parallel Programming Support 2 MapReduce 3 Programming model
Big Data Management and NoSQL Databases
 NDBI040 Big Data Management and NoSQL Databases Lecture 2. MapReduce Doc. RNDr. Irena Holubova, Ph.D. holubova@ksi.mff.cuni.cz http://www.ksi.mff.cuni.cz/~holubova/ndbi040/ Framework A programming model
NDBI040 Big Data Management and NoSQL Databases Lecture 2. MapReduce Doc. RNDr. Irena Holubova, Ph.D. holubova@ksi.mff.cuni.cz http://www.ksi.mff.cuni.cz/~holubova/ndbi040/ Framework A programming model
CS6030 Cloud Computing. Acknowledgements. Today s Topics. Intro to Cloud Computing 10/20/15. Ajay Gupta, WMU-CS. WiSe Lab
 CS6030 Cloud Computing Ajay Gupta B239, CEAS Computer Science Department Western Michigan University ajay.gupta@wmich.edu 276-3104 1 Acknowledgements I have liberally borrowed these slides and material
CS6030 Cloud Computing Ajay Gupta B239, CEAS Computer Science Department Western Michigan University ajay.gupta@wmich.edu 276-3104 1 Acknowledgements I have liberally borrowed these slides and material
ECE5610/CSC6220 Introduction to Parallel and Distribution Computing. Lecture 6: MapReduce in Parallel Computing
 ECE5610/CSC6220 Introduction to Parallel and Distribution Computing Lecture 6: MapReduce in Parallel Computing 1 MapReduce: Simplified Data Processing Motivation Large-Scale Data Processing on Large Clusters
ECE5610/CSC6220 Introduction to Parallel and Distribution Computing Lecture 6: MapReduce in Parallel Computing 1 MapReduce: Simplified Data Processing Motivation Large-Scale Data Processing on Large Clusters
Distributed Systems. 05r. Case study: Google Cluster Architecture. Paul Krzyzanowski. Rutgers University. Fall 2016
 Distributed Systems 05r. Case study: Google Cluster Architecture Paul Krzyzanowski Rutgers University Fall 2016 1 A note about relevancy This describes the Google search cluster architecture in the mid
Distributed Systems 05r. Case study: Google Cluster Architecture Paul Krzyzanowski Rutgers University Fall 2016 1 A note about relevancy This describes the Google search cluster architecture in the mid
MapReduce & Resilient Distributed Datasets. Yiqing Hua, Mengqi(Mandy) Xia
 Xia") MapReduce & Resilient Distributed Datasets Yiqing Hua, Mengqi(Mandy) Xia Outline - MapReduce: - - Resilient Distributed Datasets (RDD) - - Motivation Examples The Design and How it Works Performance Motivation
MapReduce & Resilient Distributed Datasets Yiqing Hua, Mengqi(Mandy) Xia Outline - MapReduce: - - Resilient Distributed Datasets (RDD) - - Motivation Examples The Design and How it Works Performance Motivation
Systems Infrastructure for Data Science. Web Science Group Uni Freiburg WS 2013/14
 Systems Infrastructure for Data Science Web Science Group Uni Freiburg WS 2013/14 MapReduce & Hadoop The new world of Big Data (programming model) Overview of this Lecture Module Background Cluster File
Systems Infrastructure for Data Science Web Science Group Uni Freiburg WS 2013/14 MapReduce & Hadoop The new world of Big Data (programming model) Overview of this Lecture Module Background Cluster File
Where We Are. Review: Parallel DBMS. Parallel DBMS. Introduction to Data Management CSE 344
 Where We Are Introduction to Data Management CSE 344 Lecture 22: MapReduce We are talking about parallel query processing There exist two main types of engines: Parallel DBMSs (last lecture + quick review)
Where We Are Introduction to Data Management CSE 344 Lecture 22: MapReduce We are talking about parallel query processing There exist two main types of engines: Parallel DBMSs (last lecture + quick review)
CS 138: Google. CS 138 XVII 1 Copyright 2016 Thomas W. Doeppner. All rights reserved.
 CS 138: Google CS 138 XVII 1 Copyright 2016 Thomas W. Doeppner. All rights reserved. Google Environment Lots (tens of thousands) of computers all more-or-less equal - processor, disk, memory, network interface
CS 138: Google CS 138 XVII 1 Copyright 2016 Thomas W. Doeppner. All rights reserved. Google Environment Lots (tens of thousands) of computers all more-or-less equal - processor, disk, memory, network interface
CS 138: Google. CS 138 XVI 1 Copyright 2017 Thomas W. Doeppner. All rights reserved.
 CS 138: Google CS 138 XVI 1 Copyright 2017 Thomas W. Doeppner. All rights reserved. Google Environment Lots (tens of thousands) of computers all more-or-less equal - processor, disk, memory, network interface
CS 138: Google CS 138 XVI 1 Copyright 2017 Thomas W. Doeppner. All rights reserved. Google Environment Lots (tens of thousands) of computers all more-or-less equal - processor, disk, memory, network interface
CS555: Distributed Systems [Fall 2017] Dept. Of Computer Science, Colorado State University
![CS555: Distributed Systems [Fall 2017] Dept. Of Computer Science, Colorado State University](/thumbs/90/104368640.jpg "CS555: Distributed Systems [Fall 2017] Dept. Of Computer Science, Colorado State University") CS 555: DISTRIBUTED SYSTEMS [MAPREDUCE] Shrideep Pallickara Computer Science Colorado State University Frequently asked questions from the previous class survey Bit Torrent What is the right chunk/piece
CS 555: DISTRIBUTED SYSTEMS [MAPREDUCE] Shrideep Pallickara Computer Science Colorado State University Frequently asked questions from the previous class survey Bit Torrent What is the right chunk/piece
MapReduce: A Programming Model for Large-Scale Distributed Computation
 CSC 258/458 MapReduce: A Programming Model for Large-Scale Distributed Computation University of Rochester Department of Computer Science Shantonu Hossain April 18, 2011 Outline Motivation MapReduce Overview
CSC 258/458 MapReduce: A Programming Model for Large-Scale Distributed Computation University of Rochester Department of Computer Science Shantonu Hossain April 18, 2011 Outline Motivation MapReduce Overview
Introduction to MapReduce. Adapted from Jimmy Lin (U. Maryland, USA)
") Introduction to MapReduce Adapted from Jimmy Lin (U. Maryland, USA) Motivation Overview Need for handling big data New programming paradigm Review of functional programming mapreduce uses this abstraction
Introduction to MapReduce Adapted from Jimmy Lin (U. Maryland, USA) Motivation Overview Need for handling big data New programming paradigm Review of functional programming mapreduce uses this abstraction
In the news. Request- Level Parallelism (RLP) Agenda 10/7/11
 Agenda 10/7/11") In the news "The cloud isn't this big fluffy area up in the sky," said Rich Miller, who edits Data Center Knowledge, a publicaeon that follows the data center industry. "It's buildings filled with servers
In the news "The cloud isn't this big fluffy area up in the sky," said Rich Miller, who edits Data Center Knowledge, a publicaeon that follows the data center industry. "It's buildings filled with servers
Principles of Data Management. Lecture #16 (MapReduce & DFS for Big Data)
") Principles of Data Management Lecture #16 (MapReduce & DFS for Big Data) Instructor: Mike Carey mjcarey@ics.uci.edu Database Management Systems 3ed, R. Ramakrishnan and J. Gehrke 1 Today s News Bulletin
Principles of Data Management Lecture #16 (MapReduce & DFS for Big Data) Instructor: Mike Carey mjcarey@ics.uci.edu Database Management Systems 3ed, R. Ramakrishnan and J. Gehrke 1 Today s News Bulletin
CSE 544 Principles of Database Management Systems. Alvin Cheung Fall 2015 Lecture 10 Parallel Programming Models: Map Reduce and Spark
 CSE 544 Principles of Database Management Systems Alvin Cheung Fall 2015 Lecture 10 Parallel Programming Models: Map Reduce and Spark Announcements HW2 due this Thursday AWS accounts Any success? Feel
CSE 544 Principles of Database Management Systems Alvin Cheung Fall 2015 Lecture 10 Parallel Programming Models: Map Reduce and Spark Announcements HW2 due this Thursday AWS accounts Any success? Feel
MI-PDB, MIE-PDB: Advanced Database Systems
 MI-PDB, MIE-PDB: Advanced Database Systems http://www.ksi.mff.cuni.cz/~svoboda/courses/2015-2-mie-pdb/ Lecture 10: MapReduce, Hadoop 26. 4. 2016 Lecturer: Martin Svoboda svoboda@ksi.mff.cuni.cz Author:
MI-PDB, MIE-PDB: Advanced Database Systems http://www.ksi.mff.cuni.cz/~svoboda/courses/2015-2-mie-pdb/ Lecture 10: MapReduce, Hadoop 26. 4. 2016 Lecturer: Martin Svoboda svoboda@ksi.mff.cuni.cz Author:
MapReduce: Simplified Data Processing on Large Clusters 유연일민철기
 MapReduce: Simplified Data Processing on Large Clusters 유연일민철기 Introduction MapReduce is a programming model and an associated implementation for processing and generating large data set with parallel,
MapReduce: Simplified Data Processing on Large Clusters 유연일민철기 Introduction MapReduce is a programming model and an associated implementation for processing and generating large data set with parallel,
CS 345A Data Mining. MapReduce
 CS 345A Data Mining MapReduce Single-node architecture CPU Machine Learning, Statistics Memory Classical Data Mining Disk Commodity Clusters Web data sets can be very large Tens to hundreds of terabytes
CS 345A Data Mining MapReduce Single-node architecture CPU Machine Learning, Statistics Memory Classical Data Mining Disk Commodity Clusters Web data sets can be very large Tens to hundreds of terabytes
Database Systems CSE 414
 Database Systems CSE 414 Lecture 19: MapReduce (Ch. 20.2) CSE 414 - Fall 2017 1 Announcements HW5 is due tomorrow 11pm HW6 is posted and due Nov. 27 11pm Section Thursday on setting up Spark on AWS Create
Database Systems CSE 414 Lecture 19: MapReduce (Ch. 20.2) CSE 414 - Fall 2017 1 Announcements HW5 is due tomorrow 11pm HW6 is posted and due Nov. 27 11pm Section Thursday on setting up Spark on AWS Create
Announcements. Optional Reading. Distributed File System (DFS) MapReduce Process. MapReduce. Database Systems CSE 414. HW5 is due tomorrow 11pm
 MapReduce Process. MapReduce. Database Systems CSE 414. HW5 is due tomorrow 11pm") Announcements HW5 is due tomorrow 11pm Database Systems CSE 414 Lecture 19: MapReduce (Ch. 20.2) HW6 is posted and due Nov. 27 11pm Section Thursday on setting up Spark on AWS Create your AWS account before
Announcements HW5 is due tomorrow 11pm Database Systems CSE 414 Lecture 19: MapReduce (Ch. 20.2) HW6 is posted and due Nov. 27 11pm Section Thursday on setting up Spark on AWS Create your AWS account before
Introduction to Hadoop. Owen O Malley Yahoo!, Grid Team
 Introduction to Hadoop Owen O Malley Yahoo!, Grid Team owen@yahoo-inc.com Who Am I? Yahoo! Architect on Hadoop Map/Reduce Design, review, and implement features in Hadoop Working on Hadoop full time since
Introduction to Hadoop Owen O Malley Yahoo!, Grid Team owen@yahoo-inc.com Who Am I? Yahoo! Architect on Hadoop Map/Reduce Design, review, and implement features in Hadoop Working on Hadoop full time since
Clustering Lecture 8: MapReduce
 Clustering Lecture 8: MapReduce Jing Gao SUNY Buffalo 1 Divide and Conquer Work Partition w 1 w 2 w 3 worker worker worker r 1 r 2 r 3 Result Combine 4 Distributed Grep Very big data Split data Split data
Clustering Lecture 8: MapReduce Jing Gao SUNY Buffalo 1 Divide and Conquer Work Partition w 1 w 2 w 3 worker worker worker r 1 r 2 r 3 Result Combine 4 Distributed Grep Very big data Split data Split data
The MapReduce Framework
 The MapReduce Framework In Partial fulfilment of the requirements for course CMPT 816 Presented by: Ahmed Abdel Moamen Agents Lab Overview MapReduce was firstly introduced by Google on 2004. MapReduce
The MapReduce Framework In Partial fulfilment of the requirements for course CMPT 816 Presented by: Ahmed Abdel Moamen Agents Lab Overview MapReduce was firstly introduced by Google on 2004. MapReduce
Announcements. Parallel Data Processing in the 20 th Century. Parallel Join Illustration. Introduction to Database Systems CSE 414
 Introduction to Database Systems CSE 414 Lecture 17: MapReduce and Spark Announcements Midterm this Friday in class! Review session tonight See course website for OHs Includes everything up to Monday s
Introduction to Database Systems CSE 414 Lecture 17: MapReduce and Spark Announcements Midterm this Friday in class! Review session tonight See course website for OHs Includes everything up to Monday s
Systems Infrastructure for Data Science. Web Science Group Uni Freiburg WS 2012/13
 Systems Infrastructure for Data Science Web Science Group Uni Freiburg WS 2012/13 MapReduce & Hadoop The new world of Big Data (programming model) Overview of this Lecture Module Background Google MapReduce
Systems Infrastructure for Data Science Web Science Group Uni Freiburg WS 2012/13 MapReduce & Hadoop The new world of Big Data (programming model) Overview of this Lecture Module Background Google MapReduce
Today s Lecture. CS 61C: Great Ideas in Computer Architecture (Machine Structures) Map Reduce
 Map Reduce") CS 61C: Great Ideas in Computer Architecture (Machine Structures) Map Reduce 8/29/12 Instructors Krste Asanovic, Randy H. Katz hgp://inst.eecs.berkeley.edu/~cs61c/fa12 Fall 2012 - - Lecture #3 1 Today
CS 61C: Great Ideas in Computer Architecture (Machine Structures) Map Reduce 8/29/12 Instructors Krste Asanovic, Randy H. Katz hgp://inst.eecs.berkeley.edu/~cs61c/fa12 Fall 2012 - - Lecture #3 1 Today
Bigtable: A Distributed Storage System for Structured Data By Fay Chang, et al. OSDI Presented by Xiang Gao
 Bigtable: A Distributed Storage System for Structured Data By Fay Chang, et al. OSDI 2006 Presented by Xiang Gao 2014-11-05 Outline Motivation Data Model APIs Building Blocks Implementation Refinement
Bigtable: A Distributed Storage System for Structured Data By Fay Chang, et al. OSDI 2006 Presented by Xiang Gao 2014-11-05 Outline Motivation Data Model APIs Building Blocks Implementation Refinement
Introduction to MapReduce. Instructor: Dr. Weikuan Yu Computer Sci. & Software Eng.
 Introduction to MapReduce Instructor: Dr. Weikuan Yu Computer Sci. & Software Eng. Before MapReduce Large scale data processing was difficult! Managing hundreds or thousands of processors Managing parallelization
Introduction to MapReduce Instructor: Dr. Weikuan Yu Computer Sci. & Software Eng. Before MapReduce Large scale data processing was difficult! Managing hundreds or thousands of processors Managing parallelization
Introduction to Data Management CSE 344
 Introduction to Data Management CSE 344 Lecture 24: MapReduce CSE 344 - Winter 215 1 HW8 MapReduce (Hadoop) w/ declarative language (Pig) Due next Thursday evening Will send out reimbursement codes later
Introduction to Data Management CSE 344 Lecture 24: MapReduce CSE 344 - Winter 215 1 HW8 MapReduce (Hadoop) w/ declarative language (Pig) Due next Thursday evening Will send out reimbursement codes later
L22: SC Report, Map Reduce
 L22: SC Report, Map Reduce November 23, 2010 Map Reduce What is MapReduce? Example computing environment How it works Fault Tolerance Debugging Performance Google version = Map Reduce; Hadoop = Open source
L22: SC Report, Map Reduce November 23, 2010 Map Reduce What is MapReduce? Example computing environment How it works Fault Tolerance Debugging Performance Google version = Map Reduce; Hadoop = Open source
Introduction to Data Management CSE 344
 Introduction to Data Management CSE 344 Lecture 26: Parallel Databases and MapReduce CSE 344 - Winter 2013 1 HW8 MapReduce (Hadoop) w/ declarative language (Pig) Cluster will run in Amazon s cloud (AWS)
Introduction to Data Management CSE 344 Lecture 26: Parallel Databases and MapReduce CSE 344 - Winter 2013 1 HW8 MapReduce (Hadoop) w/ declarative language (Pig) Cluster will run in Amazon s cloud (AWS)
MapReduce. Kiril Valev LMU Kiril Valev (LMU) MapReduce / 35
 MapReduce / 35") MapReduce Kiril Valev LMU valevk@cip.ifi.lmu.de 23.11.2013 Kiril Valev (LMU) MapReduce 23.11.2013 1 / 35 Agenda 1 MapReduce Motivation Definition Example Why MapReduce? Distributed Environment Fault Tolerance
MapReduce Kiril Valev LMU valevk@cip.ifi.lmu.de 23.11.2013 Kiril Valev (LMU) MapReduce 23.11.2013 1 / 35 Agenda 1 MapReduce Motivation Definition Example Why MapReduce? Distributed Environment Fault Tolerance
Introduction to Data Management CSE 344
 Introduction to Data Management CSE 344 Lecture 24: MapReduce CSE 344 - Fall 2016 1 HW8 is out Last assignment! Get Amazon credits now (see instructions) Spark with Hadoop Due next wed CSE 344 - Fall 2016
Introduction to Data Management CSE 344 Lecture 24: MapReduce CSE 344 - Fall 2016 1 HW8 is out Last assignment! Get Amazon credits now (see instructions) Spark with Hadoop Due next wed CSE 344 - Fall 2016
Plumbing the Web. Narayanan Shivakumar. Google Distinguished Entrepreneur & Director
 Plumbing the Web Narayanan Shivakumar Google Distinguished Entrepreneur & Director Google Developer Day 2007 powered by 3 Copyright 2007, Google Inc Developers and Google AJAX Search API Google Code Project
Plumbing the Web Narayanan Shivakumar Google Distinguished Entrepreneur & Director Google Developer Day 2007 powered by 3 Copyright 2007, Google Inc Developers and Google AJAX Search API Google Code Project
Map Reduce Group Meeting
 Map Reduce Group Meeting Yasmine Badr 10/07/2014 A lot of material in this presenta0on has been adopted from the original MapReduce paper in OSDI 2004 What is Map Reduce? Programming paradigm/model for
Map Reduce Group Meeting Yasmine Badr 10/07/2014 A lot of material in this presenta0on has been adopted from the original MapReduce paper in OSDI 2004 What is Map Reduce? Programming paradigm/model for
Introduction to MapReduce (cont.)
") Introduction to MapReduce (cont.) Rafael Ferreira da Silva rafsilva@isi.edu http://rafaelsilva.com USC INF 553 Foundations and Applications of Data Mining (Fall 2018) 2 MapReduce: Summary USC INF 553 Foundations
Introduction to MapReduce (cont.) Rafael Ferreira da Silva rafsilva@isi.edu http://rafaelsilva.com USC INF 553 Foundations and Applications of Data Mining (Fall 2018) 2 MapReduce: Summary USC INF 553 Foundations
Flat Datacenter Storage. Edmund B. Nightingale, Jeremy Elson, et al. 6.S897
 Flat Datacenter Storage Edmund B. Nightingale, Jeremy Elson, et al. 6.S897 Motivation Imagine a world with flat data storage Simple, Centralized, and easy to program Unfortunately, datacenter networks
Flat Datacenter Storage Edmund B. Nightingale, Jeremy Elson, et al. 6.S897 Motivation Imagine a world with flat data storage Simple, Centralized, and easy to program Unfortunately, datacenter networks
Introduction to MapReduce
 732A54 Big Data Analytics Introduction to MapReduce Christoph Kessler IDA, Linköping University Towards Parallel Processing of Big-Data Big Data too large to be read+processed in reasonable time by 1 server
732A54 Big Data Analytics Introduction to MapReduce Christoph Kessler IDA, Linköping University Towards Parallel Processing of Big-Data Big Data too large to be read+processed in reasonable time by 1 server
FLAT DATACENTER STORAGE. Paper-3 Presenter-Pratik Bhatt fx6568
 FLAT DATACENTER STORAGE Paper-3 Presenter-Pratik Bhatt fx6568 FDS Main discussion points A cluster storage system Stores giant "blobs" - 128-bit ID, multi-megabyte content Clients and servers connected
FLAT DATACENTER STORAGE Paper-3 Presenter-Pratik Bhatt fx6568 FDS Main discussion points A cluster storage system Stores giant "blobs" - 128-bit ID, multi-megabyte content Clients and servers connected
Introduction to MapReduce
 Basics of Cloud Computing Lecture 4 Introduction to MapReduce Satish Srirama Some material adapted from slides by Jimmy Lin, Christophe Bisciglia, Aaron Kimball, & Sierra Michels-Slettvet, Google Distributed
Basics of Cloud Computing Lecture 4 Introduction to MapReduce Satish Srirama Some material adapted from slides by Jimmy Lin, Christophe Bisciglia, Aaron Kimball, & Sierra Michels-Slettvet, Google Distributed
Overview. Why MapReduce? What is MapReduce? The Hadoop Distributed File System Cloudera, Inc.
 MapReduce and HDFS This presentation includes course content University of Washington Redistributed under the Creative Commons Attribution 3.0 license. All other contents: Overview Why MapReduce? What
MapReduce and HDFS This presentation includes course content University of Washington Redistributed under the Creative Commons Attribution 3.0 license. All other contents: Overview Why MapReduce? What
MapReduce. U of Toronto, 2014
 MapReduce U of Toronto, 2014 http://www.google.org/flutrends/ca/ (2012) Average Searches Per Day: 5,134,000,000 2 Motivation Process lots of data Google processed about 24 petabytes of data per day in
MapReduce U of Toronto, 2014 http://www.google.org/flutrends/ca/ (2012) Average Searches Per Day: 5,134,000,000 2 Motivation Process lots of data Google processed about 24 petabytes of data per day in
Distributed Computation Models
 Distributed Computation Models SWE 622, Spring 2017 Distributed Software Engineering Some slides ack: Jeff Dean HW4 Recap https://b.socrative.com/ Class: SWE622 2 Review Replicating state machines Case
Distributed Computation Models SWE 622, Spring 2017 Distributed Software Engineering Some slides ack: Jeff Dean HW4 Recap https://b.socrative.com/ Class: SWE622 2 Review Replicating state machines Case
Distributed Systems. 18. MapReduce. Paul Krzyzanowski. Rutgers University. Fall 2015
 Distributed Systems 18. MapReduce Paul Krzyzanowski Rutgers University Fall 2015 November 21, 2016 2014-2016 Paul Krzyzanowski 1 Credit Much of this information is from Google: Google Code University [no
Distributed Systems 18. MapReduce Paul Krzyzanowski Rutgers University Fall 2015 November 21, 2016 2014-2016 Paul Krzyzanowski 1 Credit Much of this information is from Google: Google Code University [no
Map Reduce. Yerevan.
 Map Reduce Erasmus+ @ Yerevan dacosta@irit.fr Divide and conquer at PaaS 100 % // Typical problem Iterate over a large number of records Extract something of interest from each Shuffle and sort intermediate
Map Reduce Erasmus+ @ Yerevan dacosta@irit.fr Divide and conquer at PaaS 100 % // Typical problem Iterate over a large number of records Extract something of interest from each Shuffle and sort intermediate
Distributed computing: index building and use
 Distributed computing: index building and use Distributed computing Goals Distributing computation across several machines to Do one computation faster - latency Do more computations in given time - throughput
Distributed computing: index building and use Distributed computing Goals Distributing computation across several machines to Do one computation faster - latency Do more computations in given time - throughput
Parallel Nested Loops
 Parallel Nested Loops For each tuple s i in S For each tuple t j in T If s i =t j, then add (s i,t j ) to output Create partitions S 1, S 2, T 1, and T 2 Have processors work on (S 1,T 1 ), (S 1,T 2 ),
Parallel Nested Loops For each tuple s i in S For each tuple t j in T If s i =t j, then add (s i,t j ) to output Create partitions S 1, S 2, T 1, and T 2 Have processors work on (S 1,T 1 ), (S 1,T 2 ),
Parallel Partition-Based. Parallel Nested Loops. Median. More Join Thoughts. Parallel Office Tools 9/15/2011
 Parallel Nested Loops Parallel Partition-Based For each tuple s i in S For each tuple t j in T If s i =t j, then add (s i,t j ) to output Create partitions S 1, S 2, T 1, and T 2 Have processors work on
Parallel Nested Loops Parallel Partition-Based For each tuple s i in S For each tuple t j in T If s i =t j, then add (s i,t j ) to output Create partitions S 1, S 2, T 1, and T 2 Have processors work on
GFS: The Google File System. Dr. Yingwu Zhu
 GFS: The Google File System Dr. Yingwu Zhu Motivating Application: Google Crawl the whole web Store it all on one big disk Process users searches on one big CPU More storage, CPU required than one PC can
GFS: The Google File System Dr. Yingwu Zhu Motivating Application: Google Crawl the whole web Store it all on one big disk Process users searches on one big CPU More storage, CPU required than one PC can
! Design constraints. " Component failures are the norm. " Files are huge by traditional standards. ! POSIX-like
 Cloud background Google File System! Warehouse scale systems " 10K-100K nodes " 50MW (1 MW = 1,000 houses) " Power efficient! Located near cheap power! Passive cooling! Power Usage Effectiveness = Total
Cloud background Google File System! Warehouse scale systems " 10K-100K nodes " 50MW (1 MW = 1,000 houses) " Power efficient! Located near cheap power! Passive cooling! Power Usage Effectiveness = Total
MapReduce-style data processing
 MapReduce-style data processing Software Languages Team University of Koblenz-Landau Ralf Lämmel and Andrei Varanovich Related meanings of MapReduce Functional programming with map & reduce An algorithmic
MapReduce-style data processing Software Languages Team University of Koblenz-Landau Ralf Lämmel and Andrei Varanovich Related meanings of MapReduce Functional programming with map & reduce An algorithmic
MapReduce: Recap. Juliana Freire & Cláudio Silva. Some slides borrowed from Jimmy Lin, Jeff Ullman, Jerome Simeon, and Jure Leskovec
 MapReduce: Recap Some slides borrowed from Jimmy Lin, Jeff Ullman, Jerome Simeon, and Jure Leskovec MapReduce: Recap Sequentially read a lot of data Why? Map: extract something we care about map (k, v)
MapReduce: Recap Some slides borrowed from Jimmy Lin, Jeff Ullman, Jerome Simeon, and Jure Leskovec MapReduce: Recap Sequentially read a lot of data Why? Map: extract something we care about map (k, v)
Map-Reduce. Marco Mura 2010 March, 31th
 Map-Reduce Marco Mura (mura@di.unipi.it) 2010 March, 31th This paper is a note from the 2009-2010 course Strumenti di programmazione per sistemi paralleli e distribuiti and it s based by the lessons of
Map-Reduce Marco Mura (mura@di.unipi.it) 2010 March, 31th This paper is a note from the 2009-2010 course Strumenti di programmazione per sistemi paralleli e distribuiti and it s based by the lessons of
BigTable: A Distributed Storage System for Structured Data (2006) Slides adapted by Tyler Davis
 Slides adapted by Tyler Davis") BigTable: A Distributed Storage System for Structured Data (2006) Slides adapted by Tyler Davis Motivation Lots of (semi-)structured data at Google URLs: Contents, crawl metadata, links, anchors, pagerank,
BigTable: A Distributed Storage System for Structured Data (2006) Slides adapted by Tyler Davis Motivation Lots of (semi-)structured data at Google URLs: Contents, crawl metadata, links, anchors, pagerank,
BigData and Map Reduce VITMAC03
 BigData and Map Reduce VITMAC03 1 Motivation Process lots of data Google processed about 24 petabytes of data per day in 2009. A single machine cannot serve all the data You need a distributed system to
BigData and Map Reduce VITMAC03 1 Motivation Process lots of data Google processed about 24 petabytes of data per day in 2009. A single machine cannot serve all the data You need a distributed system to
NPTEL Course Jan K. Gopinath Indian Institute of Science
 Storage Systems NPTEL Course Jan 2012 (Lecture 39) K. Gopinath Indian Institute of Science Google File System Non-Posix scalable distr file system for large distr dataintensive applications performance,
Storage Systems NPTEL Course Jan 2012 (Lecture 39) K. Gopinath Indian Institute of Science Google File System Non-Posix scalable distr file system for large distr dataintensive applications performance,
MapReduce. Simplified Data Processing on Large Clusters (Without the Agonizing Pain) Presented by Aaron Nathan
 Presented by Aaron Nathan") MapReduce Simplified Data Processing on Large Clusters (Without the Agonizing Pain) Presented by Aaron Nathan The Problem Massive amounts of data >100TB (the internet) Needs simple processing Computers
MapReduce Simplified Data Processing on Large Clusters (Without the Agonizing Pain) Presented by Aaron Nathan The Problem Massive amounts of data >100TB (the internet) Needs simple processing Computers
Outline. Distributed File System Map-Reduce The Computational Model Map-Reduce Algorithm Evaluation Computing Joins
 MapReduce 1 Outline Distributed File System Map-Reduce The Computational Model Map-Reduce Algorithm Evaluation Computing Joins 2 Outline Distributed File System Map-Reduce The Computational Model Map-Reduce
MapReduce 1 Outline Distributed File System Map-Reduce The Computational Model Map-Reduce Algorithm Evaluation Computing Joins 2 Outline Distributed File System Map-Reduce The Computational Model Map-Reduce
Distributed computing: index building and use
 Distributed computing: index building and use Distributed computing Goals Distributing computation across several machines to Do one computation faster - latency Do more computations in given time - throughput
Distributed computing: index building and use Distributed computing Goals Distributing computation across several machines to Do one computation faster - latency Do more computations in given time - throughput
CA485 Ray Walshe Google File System
 Google File System Overview Google File System is scalable, distributed file system on inexpensive commodity hardware that provides: Fault Tolerance File system runs on hundreds or thousands of storage
Google File System Overview Google File System is scalable, distributed file system on inexpensive commodity hardware that provides: Fault Tolerance File system runs on hundreds or thousands of storage
CS /5/18. Paul Krzyzanowski 1. Credit. Distributed Systems 18. MapReduce. Simplest environment for parallel processing. Background.
 Credit Much of this information is from Google: Google Code University [no longer supported] http://code.google.com/edu/parallel/mapreduce-tutorial.html Distributed Systems 18. : The programming model
Credit Much of this information is from Google: Google Code University [no longer supported] http://code.google.com/edu/parallel/mapreduce-tutorial.html Distributed Systems 18. : The programming model
Database System Architectures Parallel DBs, MapReduce, ColumnStores
 Database System Architectures Parallel DBs, MapReduce, ColumnStores CMPSCI 445 Fall 2010 Some slides courtesy of Yanlei Diao, Christophe Bisciglia, Aaron Kimball, & Sierra Michels- Slettvet Motivation:
Database System Architectures Parallel DBs, MapReduce, ColumnStores CMPSCI 445 Fall 2010 Some slides courtesy of Yanlei Diao, Christophe Bisciglia, Aaron Kimball, & Sierra Michels- Slettvet Motivation:
MapReduce & BigTable
 CPSC 426/526 MapReduce & BigTable Ennan Zhai Computer Science Department Yale University Lecture Roadmap Cloud Computing Overview Challenges in the Clouds Distributed File Systems: GFS Data Process & Analysis:
CPSC 426/526 MapReduce & BigTable Ennan Zhai Computer Science Department Yale University Lecture Roadmap Cloud Computing Overview Challenges in the Clouds Distributed File Systems: GFS Data Process & Analysis:
Concurrency for data-intensive applications
 Concurrency for data-intensive applications Dennis Kafura CS5204 Operating Systems 1 Jeff Dean Sanjay Ghemawat Dennis Kafura CS5204 Operating Systems 2 Motivation Application characteristics Large/massive
Concurrency for data-intensive applications Dennis Kafura CS5204 Operating Systems 1 Jeff Dean Sanjay Ghemawat Dennis Kafura CS5204 Operating Systems 2 Motivation Application characteristics Large/massive
Big Data Programming: an Introduction. Spring 2015, X. Zhang Fordham Univ.
 Big Data Programming: an Introduction Spring 2015, X. Zhang Fordham Univ. Outline What the course is about? scope Introduction to big data programming Opportunity and challenge of big data Origin of Hadoop
Big Data Programming: an Introduction Spring 2015, X. Zhang Fordham Univ. Outline What the course is about? scope Introduction to big data programming Opportunity and challenge of big data Origin of Hadoop
Distributed Filesystem
 Distributed Filesystem 1 How do we get data to the workers? NAS Compute Nodes SAN 2 Distributing Code! Don t move data to workers move workers to the data! - Store data on the local disks of nodes in the
Distributed Filesystem 1 How do we get data to the workers? NAS Compute Nodes SAN 2 Distributing Code! Don t move data to workers move workers to the data! - Store data on the local disks of nodes in the
Distributed File Systems II
 Distributed File Systems II To do q Very-large scale: Google FS, Hadoop FS, BigTable q Next time: Naming things GFS A radically new environment NFS, etc. Independence Small Scale Variety of workloads Cooperation
Distributed File Systems II To do q Very-large scale: Google FS, Hadoop FS, BigTable q Next time: Naming things GFS A radically new environment NFS, etc. Independence Small Scale Variety of workloads Cooperation
Lecture 11 Hadoop & Spark
 Lecture 11 Hadoop & Spark Dr. Wilson Rivera ICOM 6025: High Performance Computing Electrical and Computer Engineering Department University of Puerto Rico Outline Distributed File Systems Hadoop Ecosystem
Lecture 11 Hadoop & Spark Dr. Wilson Rivera ICOM 6025: High Performance Computing Electrical and Computer Engineering Department University of Puerto Rico Outline Distributed File Systems Hadoop Ecosystem
GFS: The Google File System
 GFS: The Google File System Brad Karp UCL Computer Science CS GZ03 / M030 24 th October 2014 Motivating Application: Google Crawl the whole web Store it all on one big disk Process users searches on one
GFS: The Google File System Brad Karp UCL Computer Science CS GZ03 / M030 24 th October 2014 Motivating Application: Google Crawl the whole web Store it all on one big disk Process users searches on one
CSE 124: Networked Services Fall 2009 Lecture-19
 CSE 124: Networked Services Fall 2009 Lecture-19 Instructor: B. S. Manoj, Ph.D http://cseweb.ucsd.edu/classes/fa09/cse124 Some of these slides are adapted from various sources/individuals including but
CSE 124: Networked Services Fall 2009 Lecture-19 Instructor: B. S. Manoj, Ph.D http://cseweb.ucsd.edu/classes/fa09/cse124 Some of these slides are adapted from various sources/individuals including but
Advanced Database Technologies NoSQL: Not only SQL
 Advanced Database Technologies NoSQL: Not only SQL Christian Grün Database & Information Systems Group NoSQL Introduction 30, 40 years history of well-established database technology all in vain? Not at
Advanced Database Technologies NoSQL: Not only SQL Christian Grün Database & Information Systems Group NoSQL Introduction 30, 40 years history of well-established database technology all in vain? Not at
MapReduce. Cloud Computing COMP / ECPE 293A
 Cloud Computing COMP / ECPE 293A MapReduce Jeffrey Dean and Sanjay Ghemawat, MapReduce: simplified data processing on large clusters, In Proceedings of the 6th conference on Symposium on Opera7ng Systems
Cloud Computing COMP / ECPE 293A MapReduce Jeffrey Dean and Sanjay Ghemawat, MapReduce: simplified data processing on large clusters, In Proceedings of the 6th conference on Symposium on Opera7ng Systems
CSE 124: Networked Services Lecture-16
 Fall 2010 CSE 124: Networked Services Lecture-16 Instructor: B. S. Manoj, Ph.D http://cseweb.ucsd.edu/classes/fa10/cse124 11/23/2010 CSE 124 Networked Services Fall 2010 1 Updates PlanetLab experiments
Fall 2010 CSE 124: Networked Services Lecture-16 Instructor: B. S. Manoj, Ph.D http://cseweb.ucsd.edu/classes/fa10/cse124 11/23/2010 CSE 124 Networked Services Fall 2010 1 Updates PlanetLab experiments
The Google File System
 The Google File System Sanjay Ghemawat, Howard Gobioff and Shun Tak Leung Google* Shivesh Kumar Sharma fl4164@wayne.edu Fall 2015 004395771 Overview Google file system is a scalable distributed file system
The Google File System Sanjay Ghemawat, Howard Gobioff and Shun Tak Leung Google* Shivesh Kumar Sharma fl4164@wayne.edu Fall 2015 004395771 Overview Google file system is a scalable distributed file system
CSE 344 MAY 2 ND MAP/REDUCE
 CSE 344 MAY 2 ND MAP/REDUCE ADMINISTRIVIA HW5 Due Tonight Practice midterm Section tomorrow Exam review PERFORMANCE METRICS FOR PARALLEL DBMSS Nodes = processors, computers Speedup: More nodes, same data
CSE 344 MAY 2 ND MAP/REDUCE ADMINISTRIVIA HW5 Due Tonight Practice midterm Section tomorrow Exam review PERFORMANCE METRICS FOR PARALLEL DBMSS Nodes = processors, computers Speedup: More nodes, same data
PLATFORM AND SOFTWARE AS A SERVICE THE MAPREDUCE PROGRAMMING MODEL AND IMPLEMENTATIONS
 PLATFORM AND SOFTWARE AS A SERVICE THE MAPREDUCE PROGRAMMING MODEL AND IMPLEMENTATIONS By HAI JIN, SHADI IBRAHIM, LI QI, HAIJUN CAO, SONG WU and XUANHUA SHI Prepared by: Dr. Faramarz Safi Islamic Azad
PLATFORM AND SOFTWARE AS A SERVICE THE MAPREDUCE PROGRAMMING MODEL AND IMPLEMENTATIONS By HAI JIN, SHADI IBRAHIM, LI QI, HAIJUN CAO, SONG WU and XUANHUA SHI Prepared by: Dr. Faramarz Safi Islamic Azad
Georgia Institute of Technology ECE6102 4/20/2009 David Colvin, Jimmy Vuong
 Georgia Institute of Technology ECE6102 4/20/2009 David Colvin, Jimmy Vuong Relatively recent; still applicable today GFS: Google s storage platform for the generation and processing of data used by services
Georgia Institute of Technology ECE6102 4/20/2009 David Colvin, Jimmy Vuong Relatively recent; still applicable today GFS: Google s storage platform for the generation and processing of data used by services
TITLE: PRE-REQUISITE THEORY. 1. Introduction to Hadoop. 2. Cluster. Implement sort algorithm and run it using HADOOP
 TITLE: Implement sort algorithm and run it using HADOOP PRE-REQUISITE Preliminary knowledge of clusters and overview of Hadoop and its basic functionality. THEORY 1. Introduction to Hadoop The Apache Hadoop
TITLE: Implement sort algorithm and run it using HADOOP PRE-REQUISITE Preliminary knowledge of clusters and overview of Hadoop and its basic functionality. THEORY 1. Introduction to Hadoop The Apache Hadoop
The Google File System (GFS)
") 1 The Google File System (GFS) CS60002: Distributed Systems Antonio Bruto da Costa Ph.D. Student, Formal Methods Lab, Dept. of Computer Sc. & Engg., Indian Institute of Technology Kharagpur 2 Design constraints
1 The Google File System (GFS) CS60002: Distributed Systems Antonio Bruto da Costa Ph.D. Student, Formal Methods Lab, Dept. of Computer Sc. & Engg., Indian Institute of Technology Kharagpur 2 Design constraints
Course Staff Intro. Distributed Systems Intro. Logistics. Course Goals. Instructor: David Andersen TAs: Alex Katkova.
 Distributed Systems Intro Instructor: David Andersen TAs: Alex Katkova Course Staff Intro Jonathan Harbuck Administrative: Angela Miller Logistics Course Policies see web page... http://www.cs.cmu.edu/~dga/15-440/f10
Distributed Systems Intro Instructor: David Andersen TAs: Alex Katkova Course Staff Intro Jonathan Harbuck Administrative: Angela Miller Logistics Course Policies see web page... http://www.cs.cmu.edu/~dga/15-440/f10
MapReduce, Hadoop and Spark. Bompotas Agorakis
 MapReduce, Hadoop and Spark Bompotas Agorakis Big Data Processing Most of the computations are conceptually straightforward on a single machine but the volume of data is HUGE Need to use many (1.000s)
MapReduce, Hadoop and Spark Bompotas Agorakis Big Data Processing Most of the computations are conceptually straightforward on a single machine but the volume of data is HUGE Need to use many (1.000s)
CIS 601 Graduate Seminar Presentation Introduction to MapReduce --Mechanism and Applicatoin. Presented by: Suhua Wei Yong Yu
 CIS 601 Graduate Seminar Presentation Introduction to MapReduce --Mechanism and Applicatoin Presented by: Suhua Wei Yong Yu Papers: MapReduce: Simplified Data Processing on Large Clusters 1 --Jeffrey Dean
CIS 601 Graduate Seminar Presentation Introduction to MapReduce --Mechanism and Applicatoin Presented by: Suhua Wei Yong Yu Papers: MapReduce: Simplified Data Processing on Large Clusters 1 --Jeffrey Dean
Distributed Data Infrastructures, Fall 2017, Chapter 2. Jussi Kangasharju
 Distributed Data Infrastructures, Fall 2017, Chapter 2 Jussi Kangasharju Chapter Outline Warehouse-scale computing overview Workloads and software infrastructure Failures and repairs Note: Term Warehouse-scale
Distributed Data Infrastructures, Fall 2017, Chapter 2 Jussi Kangasharju Chapter Outline Warehouse-scale computing overview Workloads and software infrastructure Failures and repairs Note: Term Warehouse-scale
Hadoop File System S L I D E S M O D I F I E D F R O M P R E S E N T A T I O N B Y B. R A M A M U R T H Y 11/15/2017
 Hadoop File System 1 S L I D E S M O D I F I E D F R O M P R E S E N T A T I O N B Y B. R A M A M U R T H Y Moving Computation is Cheaper than Moving Data Motivation: Big Data! What is BigData? - Google
Hadoop File System 1 S L I D E S M O D I F I E D F R O M P R E S E N T A T I O N B Y B. R A M A M U R T H Y Moving Computation is Cheaper than Moving Data Motivation: Big Data! What is BigData? - Google