MapReduce: Algorithm Design for Relational Operations
|
|
|
- Holly Gregory
- 6 years ago
- Views:
Transcription
1 MapReduce: Algorithm Design for Relational Operations Some slides borrowed from Jimmy Lin, Jeff Ullman, Jerome Simeon, and Jure Leskovec
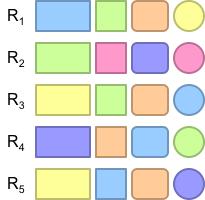
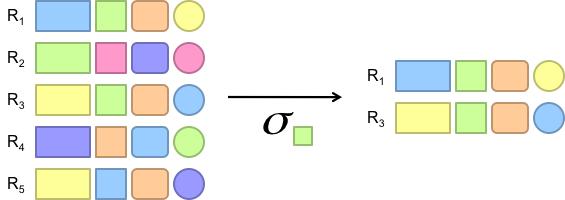
2 Projection π
3 Projection in MapReduce Easy Map over tuples, emit new tuples with appropriate attributes No reducers, unless for regrouping or re-sorting tuples Alternative: do projection in reducer, after some other processing Limited by HDFS streaming speeds Speed of encoding/decoding tuples becomes important Semi-structured (XML) data? No problem!
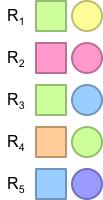
4 Selection
5 Selection in MapReduce Easy Map over tuples, emit new tuples with appropriate attributes No reducers, unless for regrouping or re-sorting tuples Alternative: do projection in reducer, after some other processing Limited by HDFS streaming speeds Speed of encoding/decoding tuples becomes important Semi-structured (XML) data? No problem!
6 Aggregation in MapReduce Example Log analysis: What is the average time spent per URL? In SQL: SELECT url, AVG(time) FROM visits GROUP BY url In MapReduce: Map over tuples, emit time, keyed by url Framework automatically groups values by keys Compute average in reducer How can you make this more efficient?
7 Relational Joins
8 Running Example Two tables: S: User demographics (user_id, gender, age, income, etc.) R: User page visits (user_id, URL, time spent, etc.) Analyses we might want to perform: Statistics on demographic characteristics Statistics on page visits Statistics on page visits by URL Statistics on page visits by demographic characteristic Need to join S and R!
9 Reduce-side join Map-side join In-memory join Join Algorithms in MapReduce
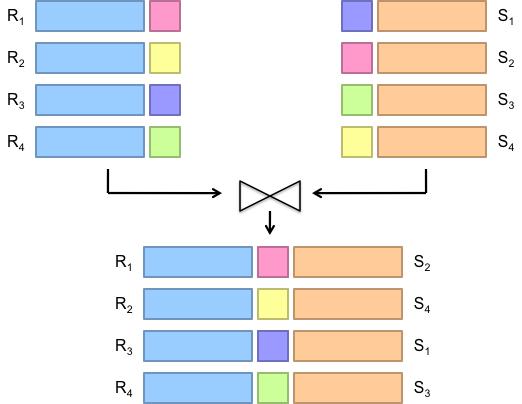
10 Reduce-Side Join Basic idea: group by join key Map over both sets of tuples Emit tuple as value with join key as the intermediate key Execution framework brings together tuples sharing the same key Perform actual join in reducer Similar to a sort-merge join in database terminology Two variants 1-to-1 joins 1-to-many and many-to-many joins
11 Reduce-Side Join: 1-to-1 Map keys values R 4 R 4 S 2 S 2 Reduce keys values S 2 R 4 Note: no guarantee if R is going to come first or S
12 Reduce-Side Join: 1-to-1 At most one tuple from R and one tuple from S share the same join key Reducer will receive keys in the following format k23 [(r64,r 64 ),(s84,s 84 )] k37 [(r68, R 68 )] k59 [(s97,s 97 ),(r81,r 81 )] k61 [(s99, S 99 )] S i à other attr of S R i à other attr of R si,rià tuple id If there are two values associated with a key, one must be from R and the other from S What should the reduced do for k 37?
13 Map Reduce-Side Join: 1-to-many keys values S 2 S 2 S 9 S 9 Reduce keys values S 2 What s the problem? R is the one side, S is the many!
14 Reduce-Side Join: 1-to-many Reducer will receive keys in the following format k23 [(r64,r 64 ),(s84,s 84 ),(r65, R 65 )] k37 [(r68, R 68 )] k59 [(s97,s 97 ),(s98,s 98 ), (s99,s 99 ), k61 [(s99, S 99 )] (s100,s 100 ), (r81,r 81 )] S i à other attr of S R i à other attr of R si,rià tuple id There can be many values from S for a given key, we do not know when the value for R will be encountered
15 Reduce-Side Join: 1-to-many! Map keys values S 2 S 9 Buffer all values in memory, S 2 pick out the tuple from R, and then cross it with every tuple from S 9 S to perform the join Reduce keys values S 2 What s the problem? R is the one side, S is the many!
16 Reduce-Side Join: 1-to-many! Map keys values S 2 S 9 Buffer all values in memory, S 2 pick out the tuple from R, and then cross it with every tuple from S 9 S to perform the join Reduce keys values S 2 What s the problem? R is the one side, S is the many!
17 Sorting: Use Values Value-to-key conversion design pattern: form composite intermediate key, (k, v 1 ) Let execution framework do the sorting: Sort by join attribute, then sort all tuple ids from R before S Before k (s97,s 97 ),(s98,s 98 ), (s99,s 99 ), (s100,s 100 ), (r81,r 81 ) Values arrive in arbitrary order After (k, r81) (r81, R 81 ) (k, s97) (s97, S 97 ) (k, s98) (s98, S 98 ) (k, s99) (s99, S 99 ) Values arrive in sorted order of tuple id Process by preserving state across multiple keys Remember to partition correctly!
18 Reduce-Side Join: Value-to-Key Conversion In reducer keys values S 2 New key encountered: hold in memory Cross with records from other set S 9 R 4 New key encountered: hold in memory Cross with records from other set S 7
19 Reduce-Side Join Many-to-Many In reducer keys values R 5 Hold in memory R 8 S 2 Cross with records from other set S 9 What s the problem? R is the smaller dataset!
20 Reduce-Side Join Many-to-Many In reducer keys values R 5 Hold in memory R 8 S 2 Cross with records from other set S 9 What s the problem? R is the smaller dataset!
21 Reduce-Side Join What are the limitations? Both datasets are transferred over the network!
22 Map-Side Join: Basic Idea Assume two datasets are sorted by the join key: S 2 R 2 S 4 R 4 R 3 S 1 A sequential scan through both datasets to join (called a merge join in database terminology)
23 Map-Side Join: Parallel Scans If datasets are sorted by join key, join can be accomplished by a scan over both datasets How can we accomplish this in parallel? Partition and sort both datasets in the same manner In MapReduce: Map over one dataset, read from other corresponding partition No reducers necessary (unless to repartition or resort) Consistently partitioned datasets: realistic to expect? Depends on the workflow For ad hoc data analysis, reduce-side are more general, although less efficient
24 References Data Intensive Text Processing with MapReduce, Lin and Dyer (Chapter 3) Mining of Massive Data Sets, Rajaraman et al. (Chapter 2) Hadoop tutorial: module4.html Jeffrey Dean and Sanjay Ghemawat, MapReduce: Simplified Data Processing on Large Clusters Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung, The Google File System
MapReduce: Recap. Juliana Freire & Cláudio Silva. Some slides borrowed from Jimmy Lin, Jeff Ullman, Jerome Simeon, and Jure Leskovec
 MapReduce: Recap Some slides borrowed from Jimmy Lin, Jeff Ullman, Jerome Simeon, and Jure Leskovec MapReduce: Recap Sequentially read a lot of data Why? Map: extract something we care about map (k, v)
MapReduce: Recap Some slides borrowed from Jimmy Lin, Jeff Ullman, Jerome Simeon, and Jure Leskovec MapReduce: Recap Sequentially read a lot of data Why? Map: extract something we care about map (k, v)
Anurag Sharma (IIT Bombay) 1 / 13
 1 / 13") 0 Map Reduce Algorithm Design Anurag Sharma (IIT Bombay) 1 / 13 Relational Joins Anurag Sharma Fundamental Research Group IIT Bombay Anurag Sharma (IIT Bombay) 1 / 13 Secondary Sorting Required if we need
0 Map Reduce Algorithm Design Anurag Sharma (IIT Bombay) 1 / 13 Relational Joins Anurag Sharma Fundamental Research Group IIT Bombay Anurag Sharma (IIT Bombay) 1 / 13 Secondary Sorting Required if we need
University of Maryland. Tuesday, March 23, 2010
 Data-Intensive Information Processing Applications Session #7 MapReduce and databases Jimmy Lin University of Maryland Tuesday, March 23, 2010 This work is licensed under a Creative Commons Attribution-Noncommercial-Share
Data-Intensive Information Processing Applications Session #7 MapReduce and databases Jimmy Lin University of Maryland Tuesday, March 23, 2010 This work is licensed under a Creative Commons Attribution-Noncommercial-Share
MapReduce Design Patterns
 MapReduce Design Patterns MapReduce Restrictions Any algorithm that needs to be implemented using MapReduce must be expressed in terms of a small number of rigidly defined components that must fit together
MapReduce Design Patterns MapReduce Restrictions Any algorithm that needs to be implemented using MapReduce must be expressed in terms of a small number of rigidly defined components that must fit together
1. Introduction to MapReduce
 Processing of massive data: MapReduce 1. Introduction to MapReduce 1 Origins: the Problem Google faced the problem of analyzing huge sets of data (order of petabytes) E.g. pagerank, web access logs, etc.
Processing of massive data: MapReduce 1. Introduction to MapReduce 1 Origins: the Problem Google faced the problem of analyzing huge sets of data (order of petabytes) E.g. pagerank, web access logs, etc.
TI2736-B Big Data Processing. Claudia Hauff
 TI2736-B Big Data Processing Claudia Hauff ti2736b-ewi@tudelft.nl Intro Streams Streams Map Reduce HDFS Pig Pig Design Patterns Hadoop Ctd. Graphs Giraph Spark Zoo Keeper Spark Learning objectives Implement
TI2736-B Big Data Processing Claudia Hauff ti2736b-ewi@tudelft.nl Intro Streams Streams Map Reduce HDFS Pig Pig Design Patterns Hadoop Ctd. Graphs Giraph Spark Zoo Keeper Spark Learning objectives Implement
Lecture 7: MapReduce design patterns! Claudia Hauff (Web Information Systems)!
!") Big Data Processing, 2014/15 Lecture 7: MapReduce design patterns!! Claudia Hauff (Web Information Systems)! ti2736b-ewi@tudelft.nl 1 Course content Introduction Data streams 1 & 2 The MapReduce paradigm
Big Data Processing, 2014/15 Lecture 7: MapReduce design patterns!! Claudia Hauff (Web Information Systems)! ti2736b-ewi@tudelft.nl 1 Course content Introduction Data streams 1 & 2 The MapReduce paradigm
CompSci 516: Database Systems
 CompSci 516 Database Systems Lecture 12 Map-Reduce and Spark Instructor: Sudeepa Roy Duke CS, Fall 2017 CompSci 516: Database Systems 1 Announcements Practice midterm posted on sakai First prepare and
CompSci 516 Database Systems Lecture 12 Map-Reduce and Spark Instructor: Sudeepa Roy Duke CS, Fall 2017 CompSci 516: Database Systems 1 Announcements Practice midterm posted on sakai First prepare and
Where We Are. Review: Parallel DBMS. Parallel DBMS. Introduction to Data Management CSE 344
 Where We Are Introduction to Data Management CSE 344 Lecture 22: MapReduce We are talking about parallel query processing There exist two main types of engines: Parallel DBMSs (last lecture + quick review)
Where We Are Introduction to Data Management CSE 344 Lecture 22: MapReduce We are talking about parallel query processing There exist two main types of engines: Parallel DBMSs (last lecture + quick review)
CS 345A Data Mining. MapReduce
 CS 345A Data Mining MapReduce Single-node architecture CPU Machine Learning, Statistics Memory Classical Data Mining Disk Commodity Clusters Web data sets can be very large Tens to hundreds of terabytes
CS 345A Data Mining MapReduce Single-node architecture CPU Machine Learning, Statistics Memory Classical Data Mining Disk Commodity Clusters Web data sets can be very large Tens to hundreds of terabytes
Principles of Data Management. Lecture #16 (MapReduce & DFS for Big Data)
") Principles of Data Management Lecture #16 (MapReduce & DFS for Big Data) Instructor: Mike Carey mjcarey@ics.uci.edu Database Management Systems 3ed, R. Ramakrishnan and J. Gehrke 1 Today s News Bulletin
Principles of Data Management Lecture #16 (MapReduce & DFS for Big Data) Instructor: Mike Carey mjcarey@ics.uci.edu Database Management Systems 3ed, R. Ramakrishnan and J. Gehrke 1 Today s News Bulletin
Epilog: Further Topics
 Ludwig-Maximilians-Universität München Institut für Informatik Lehr- und Forschungseinheit für Datenbanksysteme Knowledge Discovery in Databases SS 2016 Epilog: Further Topics Lecture: Prof. Dr. Thomas
Ludwig-Maximilians-Universität München Institut für Informatik Lehr- und Forschungseinheit für Datenbanksysteme Knowledge Discovery in Databases SS 2016 Epilog: Further Topics Lecture: Prof. Dr. Thomas
Announcements. Parallel Data Processing in the 20 th Century. Parallel Join Illustration. Introduction to Database Systems CSE 414
 Introduction to Database Systems CSE 414 Lecture 17: MapReduce and Spark Announcements Midterm this Friday in class! Review session tonight See course website for OHs Includes everything up to Monday s
Introduction to Database Systems CSE 414 Lecture 17: MapReduce and Spark Announcements Midterm this Friday in class! Review session tonight See course website for OHs Includes everything up to Monday s
MapReduce for Data Warehouses 1/25
 MapReduce for Data Warehouses 1/25 Data Warehouses: Hadoop and Relational Databases In an enterprise setting, a data warehouse serves as a vast repository of data, holding everything from sales transactions
MapReduce for Data Warehouses 1/25 Data Warehouses: Hadoop and Relational Databases In an enterprise setting, a data warehouse serves as a vast repository of data, holding everything from sales transactions
PSON: A Parallelized SON Algorithm with MapReduce for Mining Frequent Sets
 2011 Fourth International Symposium on Parallel Architectures, Algorithms and Programming PSON: A Parallelized SON Algorithm with MapReduce for Mining Frequent Sets Tao Xiao Chunfeng Yuan Yihua Huang Department
2011 Fourth International Symposium on Parallel Architectures, Algorithms and Programming PSON: A Parallelized SON Algorithm with MapReduce for Mining Frequent Sets Tao Xiao Chunfeng Yuan Yihua Huang Department
Introduction to Data Management CSE 344
 Introduction to Data Management CSE 344 Lecture 26: Parallel Databases and MapReduce CSE 344 - Winter 2013 1 HW8 MapReduce (Hadoop) w/ declarative language (Pig) Cluster will run in Amazon s cloud (AWS)
Introduction to Data Management CSE 344 Lecture 26: Parallel Databases and MapReduce CSE 344 - Winter 2013 1 HW8 MapReduce (Hadoop) w/ declarative language (Pig) Cluster will run in Amazon s cloud (AWS)
Databases 2 (VU) ( / )
 ( / )") Databases 2 (VU) (706.711 / 707.030) MapReduce (Part 3) Mark Kröll ISDS, TU Graz Nov. 27, 2017 Mark Kröll (ISDS, TU Graz) MapReduce Nov. 27, 2017 1 / 42 Outline 1 Problems Suited for Map-Reduce 2 MapReduce:
Databases 2 (VU) (706.711 / 707.030) MapReduce (Part 3) Mark Kröll ISDS, TU Graz Nov. 27, 2017 Mark Kröll (ISDS, TU Graz) MapReduce Nov. 27, 2017 1 / 42 Outline 1 Problems Suited for Map-Reduce 2 MapReduce:
CS 345A Data Mining. MapReduce
 CS 345A Data Mining MapReduce Single-node architecture CPU Machine Learning, Statistics Memory Classical Data Mining Dis Commodity Clusters Web data sets can be ery large Tens to hundreds of terabytes
CS 345A Data Mining MapReduce Single-node architecture CPU Machine Learning, Statistics Memory Classical Data Mining Dis Commodity Clusters Web data sets can be ery large Tens to hundreds of terabytes
Announcements. Optional Reading. Distributed File System (DFS) MapReduce Process. MapReduce. Database Systems CSE 414. HW5 is due tomorrow 11pm
 MapReduce Process. MapReduce. Database Systems CSE 414. HW5 is due tomorrow 11pm") Announcements HW5 is due tomorrow 11pm Database Systems CSE 414 Lecture 19: MapReduce (Ch. 20.2) HW6 is posted and due Nov. 27 11pm Section Thursday on setting up Spark on AWS Create your AWS account before
Announcements HW5 is due tomorrow 11pm Database Systems CSE 414 Lecture 19: MapReduce (Ch. 20.2) HW6 is posted and due Nov. 27 11pm Section Thursday on setting up Spark on AWS Create your AWS account before
Database Systems CSE 414
 Database Systems CSE 414 Lecture 19: MapReduce (Ch. 20.2) CSE 414 - Fall 2017 1 Announcements HW5 is due tomorrow 11pm HW6 is posted and due Nov. 27 11pm Section Thursday on setting up Spark on AWS Create
Database Systems CSE 414 Lecture 19: MapReduce (Ch. 20.2) CSE 414 - Fall 2017 1 Announcements HW5 is due tomorrow 11pm HW6 is posted and due Nov. 27 11pm Section Thursday on setting up Spark on AWS Create
Announcements. Reading Material. Map Reduce. The Map-Reduce Framework 10/3/17. Big Data. CompSci 516: Database Systems
 Announcements CompSci 516 Database Systems Lecture 12 - and Spark Practice midterm posted on sakai First prepare and then attempt! Midterm next Wednesday 10/11 in class Closed book/notes, no electronic
Announcements CompSci 516 Database Systems Lecture 12 - and Spark Practice midterm posted on sakai First prepare and then attempt! Midterm next Wednesday 10/11 in class Closed book/notes, no electronic
Introduction to Data Management CSE 344
 Introduction to Data Management CSE 344 Lecture 24: MapReduce CSE 344 - Fall 2016 1 HW8 is out Last assignment! Get Amazon credits now (see instructions) Spark with Hadoop Due next wed CSE 344 - Fall 2016
Introduction to Data Management CSE 344 Lecture 24: MapReduce CSE 344 - Fall 2016 1 HW8 is out Last assignment! Get Amazon credits now (see instructions) Spark with Hadoop Due next wed CSE 344 - Fall 2016
Introduction to MapReduce
 Introduction to MapReduce Based on slides by Juliana Freire Some slides borrowed from Jimmy Lin, Jeff Ullman, Jerome Simeon, and Jure Leskovec Required Reading! Data-Intensive Text Processing with MapReduce,
Introduction to MapReduce Based on slides by Juliana Freire Some slides borrowed from Jimmy Lin, Jeff Ullman, Jerome Simeon, and Jure Leskovec Required Reading! Data-Intensive Text Processing with MapReduce,
CompSci 516: Database Systems. Lecture 20. Parallel DBMS. Instructor: Sudeepa Roy
 CompSci 516 Database Systems Lecture 20 Parallel DBMS Instructor: Sudeepa Roy Duke CS, Fall 2017 CompSci 516: Database Systems 1 Announcements HW3 due on Monday, Nov 20, 11:55 pm (in 2 weeks) See some
CompSci 516 Database Systems Lecture 20 Parallel DBMS Instructor: Sudeepa Roy Duke CS, Fall 2017 CompSci 516: Database Systems 1 Announcements HW3 due on Monday, Nov 20, 11:55 pm (in 2 weeks) See some
Relational Data Processing on MapReduce
 Relational Data Processing on MapReduce data every day V. CHRISTOPHIDES vassilis.christophides@inria.fr https://who.rocq.inria.fr/vassilis.christophides/big/ Ecole CentraleSupélec 1 Peta-scale Data Analysis
Relational Data Processing on MapReduce data every day V. CHRISTOPHIDES vassilis.christophides@inria.fr https://who.rocq.inria.fr/vassilis.christophides/big/ Ecole CentraleSupélec 1 Peta-scale Data Analysis
Introduction to MapReduce
 Basics of Cloud Computing Lecture 4 Introduction to MapReduce Satish Srirama Some material adapted from slides by Jimmy Lin, Christophe Bisciglia, Aaron Kimball, & Sierra Michels-Slettvet, Google Distributed
Basics of Cloud Computing Lecture 4 Introduction to MapReduce Satish Srirama Some material adapted from slides by Jimmy Lin, Christophe Bisciglia, Aaron Kimball, & Sierra Michels-Slettvet, Google Distributed
Introduction to Data Management CSE 344
 Introduction to Data Management CSE 344 Lecture 24: MapReduce CSE 344 - Winter 215 1 HW8 MapReduce (Hadoop) w/ declarative language (Pig) Due next Thursday evening Will send out reimbursement codes later
Introduction to Data Management CSE 344 Lecture 24: MapReduce CSE 344 - Winter 215 1 HW8 MapReduce (Hadoop) w/ declarative language (Pig) Due next Thursday evening Will send out reimbursement codes later
MapReduce Algorithms
 Large-scale data processing on the Cloud Lecture 3 MapReduce Algorithms Satish Srirama Some material adapted from slides by Jimmy Lin, 2008 (licensed under Creation Commons Attribution 3.0 License) Outline
Large-scale data processing on the Cloud Lecture 3 MapReduce Algorithms Satish Srirama Some material adapted from slides by Jimmy Lin, 2008 (licensed under Creation Commons Attribution 3.0 License) Outline
Google File System (GFS) and Hadoop Distributed File System (HDFS)
 and Hadoop Distributed File System (HDFS)") Google File System (GFS) and Hadoop Distributed File System (HDFS) 1 Hadoop: Architectural Design Principles Linear scalability More nodes can do more work within the same time Linear on data size, linear
Google File System (GFS) and Hadoop Distributed File System (HDFS) 1 Hadoop: Architectural Design Principles Linear scalability More nodes can do more work within the same time Linear on data size, linear
Distributed computing: index building and use
 Distributed computing: index building and use Distributed computing Goals Distributing computation across several machines to Do one computation faster - latency Do more computations in given time - throughput
Distributed computing: index building and use Distributed computing Goals Distributing computation across several machines to Do one computation faster - latency Do more computations in given time - throughput
CIS 601 Graduate Seminar Presentation Introduction to MapReduce --Mechanism and Applicatoin. Presented by: Suhua Wei Yong Yu
 CIS 601 Graduate Seminar Presentation Introduction to MapReduce --Mechanism and Applicatoin Presented by: Suhua Wei Yong Yu Papers: MapReduce: Simplified Data Processing on Large Clusters 1 --Jeffrey Dean
CIS 601 Graduate Seminar Presentation Introduction to MapReduce --Mechanism and Applicatoin Presented by: Suhua Wei Yong Yu Papers: MapReduce: Simplified Data Processing on Large Clusters 1 --Jeffrey Dean
L22: SC Report, Map Reduce
 L22: SC Report, Map Reduce November 23, 2010 Map Reduce What is MapReduce? Example computing environment How it works Fault Tolerance Debugging Performance Google version = Map Reduce; Hadoop = Open source
L22: SC Report, Map Reduce November 23, 2010 Map Reduce What is MapReduce? Example computing environment How it works Fault Tolerance Debugging Performance Google version = Map Reduce; Hadoop = Open source
"Big Data" Open Source Systems. CS347: Map-Reduce & Pig. Motivation for Map-Reduce. Building Text Index - Part II. Building Text Index - Part I
 "Big Data" Open Source Systems CS347: Map-Reduce & Pig Hector Garcia-Molina Stanford University Infrastructure for distributed data computations Map-Reduce, S4, Hyracks, Pregel [Storm, Mupet] Components
"Big Data" Open Source Systems CS347: Map-Reduce & Pig Hector Garcia-Molina Stanford University Infrastructure for distributed data computations Map-Reduce, S4, Hyracks, Pregel [Storm, Mupet] Components
HADOOP FRAMEWORK FOR BIG DATA
 HADOOP FRAMEWORK FOR BIG DATA Mr K. Srinivas Babu 1,Dr K. Rameshwaraiah 2 1 Research Scholar S V University, Tirupathi 2 Professor and Head NNRESGI, Hyderabad Abstract - Data has to be stored for further
HADOOP FRAMEWORK FOR BIG DATA Mr K. Srinivas Babu 1,Dr K. Rameshwaraiah 2 1 Research Scholar S V University, Tirupathi 2 Professor and Head NNRESGI, Hyderabad Abstract - Data has to be stored for further
CS246: Mining Massive Datasets Jure Leskovec, Stanford University
 CS246: Mining Massive Datasets Jure Leskovec, Stanford University http://cs246.stanford.edu 1/6/2015 Jure Leskovec, Stanford CS246: Mining Massive Datasets, http://cs246.stanford.edu 3 1/6/2015 Jure Leskovec,
CS246: Mining Massive Datasets Jure Leskovec, Stanford University http://cs246.stanford.edu 1/6/2015 Jure Leskovec, Stanford CS246: Mining Massive Datasets, http://cs246.stanford.edu 3 1/6/2015 Jure Leskovec,
Data Partitioning and MapReduce
 Data Partitioning and MapReduce Krzysztof Dembczyński Intelligent Decision Support Systems Laboratory (IDSS) Poznań University of Technology, Poland Intelligent Decision Support Systems Master studies,
Data Partitioning and MapReduce Krzysztof Dembczyński Intelligent Decision Support Systems Laboratory (IDSS) Poznań University of Technology, Poland Intelligent Decision Support Systems Master studies,
Big Data Management and NoSQL Databases
 NDBI040 Big Data Management and NoSQL Databases Lecture 2. MapReduce Doc. RNDr. Irena Holubova, Ph.D. holubova@ksi.mff.cuni.cz http://www.ksi.mff.cuni.cz/~holubova/ndbi040/ Framework A programming model
NDBI040 Big Data Management and NoSQL Databases Lecture 2. MapReduce Doc. RNDr. Irena Holubova, Ph.D. holubova@ksi.mff.cuni.cz http://www.ksi.mff.cuni.cz/~holubova/ndbi040/ Framework A programming model
Developing MapReduce Programs
 Cloud Computing Developing MapReduce Programs Dell Zhang Birkbeck, University of London 2017/18 MapReduce Algorithm Design MapReduce: Recap Programmers must specify two functions: map (k, v) * Takes
Cloud Computing Developing MapReduce Programs Dell Zhang Birkbeck, University of London 2017/18 MapReduce Algorithm Design MapReduce: Recap Programmers must specify two functions: map (k, v) * Takes
Parallel Computing: MapReduce Jin, Hai
 Parallel Computing: MapReduce Jin, Hai School of Computer Science and Technology Huazhong University of Science and Technology ! MapReduce is a distributed/parallel computing framework introduced by Google
Parallel Computing: MapReduce Jin, Hai School of Computer Science and Technology Huazhong University of Science and Technology ! MapReduce is a distributed/parallel computing framework introduced by Google
Distributed computing: index building and use
 Distributed computing: index building and use Distributed computing Goals Distributing computation across several machines to Do one computation faster - latency Do more computations in given time - throughput
Distributed computing: index building and use Distributed computing Goals Distributing computation across several machines to Do one computation faster - latency Do more computations in given time - throughput
CS-2510 COMPUTER OPERATING SYSTEMS
 CS-2510 COMPUTER OPERATING SYSTEMS Cloud Computing MAPREDUCE Dr. Taieb Znati Computer Science Department University of Pittsburgh MAPREDUCE Programming Model Scaling Data Intensive Application Functional
CS-2510 COMPUTER OPERATING SYSTEMS Cloud Computing MAPREDUCE Dr. Taieb Znati Computer Science Department University of Pittsburgh MAPREDUCE Programming Model Scaling Data Intensive Application Functional
Big Data Infrastructure CS 489/698 Big Data Infrastructure (Winter 2016)
") Big Data Infrastructure CS 489/698 Big Data Infrastructure (Winter 2016) Week 2: MapReduce Algorithm Design (2/2) January 14, 2016 Jimmy Lin David R. Cheriton School of Computer Science University of Waterloo
Big Data Infrastructure CS 489/698 Big Data Infrastructure (Winter 2016) Week 2: MapReduce Algorithm Design (2/2) January 14, 2016 Jimmy Lin David R. Cheriton School of Computer Science University of Waterloo
Introduction to MapReduce
 Introduction to MapReduce Based on slides by Jimmy Lin, Jeff Ullman, Jerome Simeon, and Jure Leskovec How much data? Google processes 20 PB a day (2008) Internet Archive Wayback Machine has 3 PB + 100
Introduction to MapReduce Based on slides by Jimmy Lin, Jeff Ullman, Jerome Simeon, and Jure Leskovec How much data? Google processes 20 PB a day (2008) Internet Archive Wayback Machine has 3 PB + 100
Map Reduce Group Meeting
 Map Reduce Group Meeting Yasmine Badr 10/07/2014 A lot of material in this presenta0on has been adopted from the original MapReduce paper in OSDI 2004 What is Map Reduce? Programming paradigm/model for
Map Reduce Group Meeting Yasmine Badr 10/07/2014 A lot of material in this presenta0on has been adopted from the original MapReduce paper in OSDI 2004 What is Map Reduce? Programming paradigm/model for
CS555: Distributed Systems [Fall 2017] Dept. Of Computer Science, Colorado State University
![CS555: Distributed Systems [Fall 2017] Dept. Of Computer Science, Colorado State University](/thumbs/90/104368640.jpg "CS555: Distributed Systems [Fall 2017] Dept. Of Computer Science, Colorado State University") CS 555: DISTRIBUTED SYSTEMS [MAPREDUCE] Shrideep Pallickara Computer Science Colorado State University Frequently asked questions from the previous class survey Bit Torrent What is the right chunk/piece
CS 555: DISTRIBUTED SYSTEMS [MAPREDUCE] Shrideep Pallickara Computer Science Colorado State University Frequently asked questions from the previous class survey Bit Torrent What is the right chunk/piece
CS60021: Scalable Data Mining. Sourangshu Bhattacharya
 CS60021: Scalable Data Mining Sourangshu Bhattacharya In this Lecture: Outline: HDFS Motivation HDFS User commands HDFS System architecture HDFS Implementation details Sourangshu Bhattacharya Computer
CS60021: Scalable Data Mining Sourangshu Bhattacharya In this Lecture: Outline: HDFS Motivation HDFS User commands HDFS System architecture HDFS Implementation details Sourangshu Bhattacharya Computer
Introduction to MapReduce Algorithms and Analysis
 Introduction to MapReduce Algorithms and Analysis Jeff M. Phillips October 25, 2013 Trade-Offs Massive parallelism that is very easy to program. Cheaper than HPC style (uses top of the line everything)
Introduction to MapReduce Algorithms and Analysis Jeff M. Phillips October 25, 2013 Trade-Offs Massive parallelism that is very easy to program. Cheaper than HPC style (uses top of the line everything)
Parallel Nested Loops
 Parallel Nested Loops For each tuple s i in S For each tuple t j in T If s i =t j, then add (s i,t j ) to output Create partitions S 1, S 2, T 1, and T 2 Have processors work on (S 1,T 1 ), (S 1,T 2 ),
Parallel Nested Loops For each tuple s i in S For each tuple t j in T If s i =t j, then add (s i,t j ) to output Create partitions S 1, S 2, T 1, and T 2 Have processors work on (S 1,T 1 ), (S 1,T 2 ),
Parallel Partition-Based. Parallel Nested Loops. Median. More Join Thoughts. Parallel Office Tools 9/15/2011
 Parallel Nested Loops Parallel Partition-Based For each tuple s i in S For each tuple t j in T If s i =t j, then add (s i,t j ) to output Create partitions S 1, S 2, T 1, and T 2 Have processors work on
Parallel Nested Loops Parallel Partition-Based For each tuple s i in S For each tuple t j in T If s i =t j, then add (s i,t j ) to output Create partitions S 1, S 2, T 1, and T 2 Have processors work on
MapReduce: Simplified Data Processing on Large Clusters 유연일민철기
 MapReduce: Simplified Data Processing on Large Clusters 유연일민철기 Introduction MapReduce is a programming model and an associated implementation for processing and generating large data set with parallel,
MapReduce: Simplified Data Processing on Large Clusters 유연일민철기 Introduction MapReduce is a programming model and an associated implementation for processing and generating large data set with parallel,
What happens. 376a. Database Design. Execution strategy. Query conversion. Next. Two types of techniques
 376a. Database Design Dept. of Computer Science Vassar College http://www.cs.vassar.edu/~cs376 Class 16 Query optimization What happens Database is given a query Query is scanned - scanner creates a list
376a. Database Design Dept. of Computer Science Vassar College http://www.cs.vassar.edu/~cs376 Class 16 Query optimization What happens Database is given a query Query is scanned - scanner creates a list
On the Varieties of Clouds for Data Intensive Computing
 On the Varieties of Clouds for Data Intensive Computing Robert L. Grossman University of Illinois at Chicago and Open Data Group Yunhong Gu University of Illinois at Chicago Abstract By a cloud we mean
On the Varieties of Clouds for Data Intensive Computing Robert L. Grossman University of Illinois at Chicago and Open Data Group Yunhong Gu University of Illinois at Chicago Abstract By a cloud we mean
Streaming Algorithms. Stony Brook University CSE545, Fall 2016
 Streaming Algorithms Stony Brook University CSE545, Fall 2016 Big Data Analytics -- The Class We will learn: to analyze different types of data: high dimensional graphs infinite/never-ending labeled to
Streaming Algorithms Stony Brook University CSE545, Fall 2016 Big Data Analytics -- The Class We will learn: to analyze different types of data: high dimensional graphs infinite/never-ending labeled to
Introduction to MapReduce
 Basics of Cloud Computing Lecture 4 Introduction to MapReduce Satish Srirama Some material adapted from slides by Jimmy Lin, Christophe Bisciglia, Aaron Kimball, & Sierra Michels-Slettvet, Google Distributed
Basics of Cloud Computing Lecture 4 Introduction to MapReduce Satish Srirama Some material adapted from slides by Jimmy Lin, Christophe Bisciglia, Aaron Kimball, & Sierra Michels-Slettvet, Google Distributed
Parallel DBMS. Lecture 20. Reading Material. Instructor: Sudeepa Roy. Reading Material. Parallel vs. Distributed DBMS. Parallel DBMS 11/15/18
 Reading aterial CompSci 516 atabase Systems Lecture 20 Parallel BS Instructor: Sudeepa Roy [RG] Parallel BS: Chapter 22.1-22.5 [GUW] Parallel BS and map-reduce: Chapter 20.1-20.2 Acknowledgement: The following
Reading aterial CompSci 516 atabase Systems Lecture 20 Parallel BS Instructor: Sudeepa Roy [RG] Parallel BS: Chapter 22.1-22.5 [GUW] Parallel BS and map-reduce: Chapter 20.1-20.2 Acknowledgement: The following
Big Data Infrastructure CS 489/698 Big Data Infrastructure (Winter 2017)
") Big Data Infrastructure CS 489/698 Big Data Infrastructure (Winter 2017) Week 2: MapReduce Algorithm Design (2/2) January 12, 2017 Jimmy Lin David R. Cheriton School of Computer Science University of Waterloo
Big Data Infrastructure CS 489/698 Big Data Infrastructure (Winter 2017) Week 2: MapReduce Algorithm Design (2/2) January 12, 2017 Jimmy Lin David R. Cheriton School of Computer Science University of Waterloo
How to Implement MapReduce Using. Presented By Jamie Pitts
 How to Implement MapReduce Using Presented By Jamie Pitts A Problem Seeking A Solution Given a corpus of html-stripped financial filings: Identify and count unique subjects. Possible Solutions: 1. Use
How to Implement MapReduce Using Presented By Jamie Pitts A Problem Seeking A Solution Given a corpus of html-stripped financial filings: Identify and count unique subjects. Possible Solutions: 1. Use
Chapter 4: Apache Spark
 Chapter 4: Apache Spark Lecture Notes Winter semester 2016 / 2017 Ludwig-Maximilians-University Munich PD Dr. Matthias Renz 2015, Based on lectures by Donald Kossmann (ETH Zürich), as well as Jure Leskovec,
Chapter 4: Apache Spark Lecture Notes Winter semester 2016 / 2017 Ludwig-Maximilians-University Munich PD Dr. Matthias Renz 2015, Based on lectures by Donald Kossmann (ETH Zürich), as well as Jure Leskovec,
Graphs (Part II) Shannon Quinn
 Shannon Quinn") Graphs (Part II) Shannon Quinn (with thanks to William Cohen and Aapo Kyrola of CMU, and J. Leskovec, A. Rajaraman, and J. Ullman of Stanford University) Parallel Graph Computation Distributed computation
Graphs (Part II) Shannon Quinn (with thanks to William Cohen and Aapo Kyrola of CMU, and J. Leskovec, A. Rajaraman, and J. Ullman of Stanford University) Parallel Graph Computation Distributed computation
TI2736-B Big Data Processing. Claudia Hauff
 TI2736-B Big Data Processing Claudia Hauff ti2736b-ewi@tudelft.nl Software Virtual machine-based: Cloudera CDH 5.8, based on CentOS Saves us from a manual Hadoop installation (especially difficult on Windows)
TI2736-B Big Data Processing Claudia Hauff ti2736b-ewi@tudelft.nl Software Virtual machine-based: Cloudera CDH 5.8, based on CentOS Saves us from a manual Hadoop installation (especially difficult on Windows)
MapReduce for Graph Algorithms
 Seminar: Massive-Scale Graph Analysis Summer Semester 2015 MapReduce for Graph Algorithms Modeling & Approach Ankur Sharma ankur@stud.uni-saarland.de May 8, 2015 Agenda 1 Map-Reduce Framework Big Data
Seminar: Massive-Scale Graph Analysis Summer Semester 2015 MapReduce for Graph Algorithms Modeling & Approach Ankur Sharma ankur@stud.uni-saarland.de May 8, 2015 Agenda 1 Map-Reduce Framework Big Data
Big Trend in Business Intelligence: Data Mining over Big Data Web Transaction Data. Fall 2012
 Big Trend in Business Intelligence: Data Mining over Big Data Web Transaction Data Fall 2012 Data Warehousing and OLAP Introduction Decision Support Technology On Line Analytical Processing Star Schema
Big Trend in Business Intelligence: Data Mining over Big Data Web Transaction Data Fall 2012 Data Warehousing and OLAP Introduction Decision Support Technology On Line Analytical Processing Star Schema
MapReduce and Hadoop. Debapriyo Majumdar Indian Statistical Institute Kolkata
 MapReduce and Hadoop Debapriyo Majumdar Indian Statistical Institute Kolkata debapriyo@isical.ac.in Let s keep the intro short Modern data mining: process immense amount of data quickly Exploit parallelism
MapReduce and Hadoop Debapriyo Majumdar Indian Statistical Institute Kolkata debapriyo@isical.ac.in Let s keep the intro short Modern data mining: process immense amount of data quickly Exploit parallelism
Parallel Programming Principle and Practice. Lecture 10 Big Data Processing with MapReduce
 Parallel Programming Principle and Practice Lecture 10 Big Data Processing with MapReduce Outline MapReduce Programming Model MapReduce Examples Hadoop 2 Incredible Things That Happen Every Minute On The
Parallel Programming Principle and Practice Lecture 10 Big Data Processing with MapReduce Outline MapReduce Programming Model MapReduce Examples Hadoop 2 Incredible Things That Happen Every Minute On The
Introduction to MapReduce
 Introduction to MapReduce Some slides borrowed from Jimmy Lin, Jeff Ullman, Jerome Simeon, and Jure Leskovec Single-node architecture CPU Memory Data Analysis, Machine Learning, Statistics Disk How much
Introduction to MapReduce Some slides borrowed from Jimmy Lin, Jeff Ullman, Jerome Simeon, and Jure Leskovec Single-node architecture CPU Memory Data Analysis, Machine Learning, Statistics Disk How much
Instructor: Dr. Mehmet Aktaş. Mining of Massive Datasets Jure Leskovec, Anand Rajaraman, Jeff Ullman Stanford University
 Instructor: Dr. Mehmet Aktaş Mining of Massive Datasets Jure Leskovec, Anand Rajaraman, Jeff Ullman Stanford University J. Leskovec, A. Rajaraman, J. Ullman: Mining of Massive Datasets, http://www.mmds.org
Instructor: Dr. Mehmet Aktaş Mining of Massive Datasets Jure Leskovec, Anand Rajaraman, Jeff Ullman Stanford University J. Leskovec, A. Rajaraman, J. Ullman: Mining of Massive Datasets, http://www.mmds.org
The MapReduce Abstraction
 The MapReduce Abstraction Parallel Computing at Google Leverages multiple technologies to simplify large-scale parallel computations Proprietary computing clusters Map/Reduce software library Lots of other
The MapReduce Abstraction Parallel Computing at Google Leverages multiple technologies to simplify large-scale parallel computations Proprietary computing clusters Map/Reduce software library Lots of other
CS370 Operating Systems
 CS370 Operating Systems Colorado State University Yashwant K Malaiya Fall 2017 Lecture 26 File Systems Slides based on Text by Silberschatz, Galvin, Gagne Various sources 1 1 FAQ Cylinders: all the platters?
CS370 Operating Systems Colorado State University Yashwant K Malaiya Fall 2017 Lecture 26 File Systems Slides based on Text by Silberschatz, Galvin, Gagne Various sources 1 1 FAQ Cylinders: all the platters?
CS246: Mining Massive Datasets Jure Leskovec, Stanford University
 CS246: Mining Massive Datasets Jure Leskovec, Stanford University http://cs246.stanford.edu 3/6/2012 Jure Leskovec, Stanford CS246: Mining Massive Datasets, http://cs246.stanford.edu 2 In many data mining
CS246: Mining Massive Datasets Jure Leskovec, Stanford University http://cs246.stanford.edu 3/6/2012 Jure Leskovec, Stanford CS246: Mining Massive Datasets, http://cs246.stanford.edu 2 In many data mining
PLATFORM AND SOFTWARE AS A SERVICE THE MAPREDUCE PROGRAMMING MODEL AND IMPLEMENTATIONS
 PLATFORM AND SOFTWARE AS A SERVICE THE MAPREDUCE PROGRAMMING MODEL AND IMPLEMENTATIONS By HAI JIN, SHADI IBRAHIM, LI QI, HAIJUN CAO, SONG WU and XUANHUA SHI Prepared by: Dr. Faramarz Safi Islamic Azad
PLATFORM AND SOFTWARE AS A SERVICE THE MAPREDUCE PROGRAMMING MODEL AND IMPLEMENTATIONS By HAI JIN, SHADI IBRAHIM, LI QI, HAIJUN CAO, SONG WU and XUANHUA SHI Prepared by: Dr. Faramarz Safi Islamic Azad
Parallel data processing with MapReduce
 Parallel data processing with MapReduce Tomi Aarnio Helsinki University of Technology tomi.aarnio@hut.fi Abstract MapReduce is a parallel programming model and an associated implementation introduced by
Parallel data processing with MapReduce Tomi Aarnio Helsinki University of Technology tomi.aarnio@hut.fi Abstract MapReduce is a parallel programming model and an associated implementation introduced by
Clustering websites using a MapReduce programming model
 Clustering websites using a MapReduce programming model Shafi Ahmed, Peiyuan Pan, Shanyu Tang* London Metropolitan University, UK Abstract In this paper, we describe an effective method of using Self-Organizing
Clustering websites using a MapReduce programming model Shafi Ahmed, Peiyuan Pan, Shanyu Tang* London Metropolitan University, UK Abstract In this paper, we describe an effective method of using Self-Organizing
BIG DATA & HADOOP: A Survey
 Available Online at www.ijcsmc.com International Journal of Computer Science and Mobile Computing A Monthly Journal of Computer Science and Information Technology ISSN 2320 088X IMPACT FACTOR: 6.017 IJCSMC,
Available Online at www.ijcsmc.com International Journal of Computer Science and Mobile Computing A Monthly Journal of Computer Science and Information Technology ISSN 2320 088X IMPACT FACTOR: 6.017 IJCSMC,
Map Reduce. Yerevan.
 Map Reduce Erasmus+ @ Yerevan dacosta@irit.fr Divide and conquer at PaaS 100 % // Typical problem Iterate over a large number of records Extract something of interest from each Shuffle and sort intermediate
Map Reduce Erasmus+ @ Yerevan dacosta@irit.fr Divide and conquer at PaaS 100 % // Typical problem Iterate over a large number of records Extract something of interest from each Shuffle and sort intermediate
CS246: Mining Massive Datasets Jure Leskovec, Stanford University
 CS246: Mining Massive Datasets Jure Leskovec, Stanford University http://cs246.stanford.edu 2/25/2013 Jure Leskovec, Stanford CS246: Mining Massive Datasets, http://cs246.stanford.edu 3 In many data mining
CS246: Mining Massive Datasets Jure Leskovec, Stanford University http://cs246.stanford.edu 2/25/2013 Jure Leskovec, Stanford CS246: Mining Massive Datasets, http://cs246.stanford.edu 3 In many data mining
APPLICATION OF HADOOP MAPREDUCE TECHNIQUE TOVIRTUAL DATABASE SYSTEM DESIGN. Neha Tiwari Rahul Pandita Nisha Chhatwani Divyakalpa Patil Prof. N.B.
 APPLICATION OF HADOOP MAPREDUCE TECHNIQUE TOVIRTUAL DATABASE SYSTEM DESIGN. Neha Tiwari Rahul Pandita Nisha Chhatwani Divyakalpa Patil Prof. N.B.Kadu PREC, Loni, India. ABSTRACT- Today in the world of
APPLICATION OF HADOOP MAPREDUCE TECHNIQUE TOVIRTUAL DATABASE SYSTEM DESIGN. Neha Tiwari Rahul Pandita Nisha Chhatwani Divyakalpa Patil Prof. N.B.Kadu PREC, Loni, India. ABSTRACT- Today in the world of
The MapReduce Framework
 The MapReduce Framework In Partial fulfilment of the requirements for course CMPT 816 Presented by: Ahmed Abdel Moamen Agents Lab Overview MapReduce was firstly introduced by Google on 2004. MapReduce
The MapReduce Framework In Partial fulfilment of the requirements for course CMPT 816 Presented by: Ahmed Abdel Moamen Agents Lab Overview MapReduce was firstly introduced by Google on 2004. MapReduce
Clustering Lecture 8: MapReduce
 Clustering Lecture 8: MapReduce Jing Gao SUNY Buffalo 1 Divide and Conquer Work Partition w 1 w 2 w 3 worker worker worker r 1 r 2 r 3 Result Combine 4 Distributed Grep Very big data Split data Split data
Clustering Lecture 8: MapReduce Jing Gao SUNY Buffalo 1 Divide and Conquer Work Partition w 1 w 2 w 3 worker worker worker r 1 r 2 r 3 Result Combine 4 Distributed Grep Very big data Split data Split data
This material is covered in the textbook in Chapter 21.
 This material is covered in the textbook in Chapter 21. The Google File System paper, by S Ghemawat, H Gobioff, and S-T Leung, was published in the proceedings of the ACM Symposium on Operating Systems
This material is covered in the textbook in Chapter 21. The Google File System paper, by S Ghemawat, H Gobioff, and S-T Leung, was published in the proceedings of the ACM Symposium on Operating Systems
Outline. MapReduce Data Model. MapReduce. Step 2: the REDUCE Phase. Step 1: the MAP Phase 11/29/11. Introduction to Data Management CSE 344
 Outline Introduction to Data Management CSE 344 Review of MapReduce Introduction to Pig System Pig Latin tutorial Lecture 23: Pig Latin Some slides are courtesy of Alan Gates, Yahoo!Research 1 2 MapReduce
Outline Introduction to Data Management CSE 344 Review of MapReduce Introduction to Pig System Pig Latin tutorial Lecture 23: Pig Latin Some slides are courtesy of Alan Gates, Yahoo!Research 1 2 MapReduce
CHAPTER 4 ROUND ROBIN PARTITIONING
 79 CHAPTER 4 ROUND ROBIN PARTITIONING 4.1 INTRODUCTION The Hadoop Distributed File System (HDFS) is constructed to store immensely colossal data sets accurately and to send those data sets at huge bandwidth
79 CHAPTER 4 ROUND ROBIN PARTITIONING 4.1 INTRODUCTION The Hadoop Distributed File System (HDFS) is constructed to store immensely colossal data sets accurately and to send those data sets at huge bandwidth
Outline. What is Big Data? Hadoop HDFS MapReduce Twitter Analytics and Hadoop
 Intro To Hadoop Bill Graham - @billgraham Data Systems Engineer, Analytics Infrastructure Info 290 - Analyzing Big Data With Twitter UC Berkeley Information School September 2012 This work is licensed
Intro To Hadoop Bill Graham - @billgraham Data Systems Engineer, Analytics Infrastructure Info 290 - Analyzing Big Data With Twitter UC Berkeley Information School September 2012 This work is licensed
Data-Intensive Distributed Computing
 Data-Intensive Distributed Computing CS 451/651 431/631 (Winter 2018) Part 5: Analyzing Relational Data (1/3) February 8, 2018 Jimmy Lin David R. Cheriton School of Computer Science University of Waterloo
Data-Intensive Distributed Computing CS 451/651 431/631 (Winter 2018) Part 5: Analyzing Relational Data (1/3) February 8, 2018 Jimmy Lin David R. Cheriton School of Computer Science University of Waterloo
Distributed Systems. 18. MapReduce. Paul Krzyzanowski. Rutgers University. Fall 2015
 Distributed Systems 18. MapReduce Paul Krzyzanowski Rutgers University Fall 2015 November 21, 2016 2014-2016 Paul Krzyzanowski 1 Credit Much of this information is from Google: Google Code University [no
Distributed Systems 18. MapReduce Paul Krzyzanowski Rutgers University Fall 2015 November 21, 2016 2014-2016 Paul Krzyzanowski 1 Credit Much of this information is from Google: Google Code University [no
Bigtable. A Distributed Storage System for Structured Data. Presenter: Yunming Zhang Conglong Li. Saturday, September 21, 13
 Bigtable A Distributed Storage System for Structured Data Presenter: Yunming Zhang Conglong Li References SOCC 2010 Key Note Slides Jeff Dean Google Introduction to Distributed Computing, Winter 2008 University
Bigtable A Distributed Storage System for Structured Data Presenter: Yunming Zhang Conglong Li References SOCC 2010 Key Note Slides Jeff Dean Google Introduction to Distributed Computing, Winter 2008 University
Research on the Application of Bank Transaction Data Stream Storage based on HBase Xiaoguo Wang*, Yuxiang Liu and Lin Zhang
 International Conference on Engineering Management (Iconf-EM 2016) Research on the Application of Bank Transaction Data Stream Storage based on HBase Xiaoguo Wang*, Yuxiang Liu and Lin Zhang School of
International Conference on Engineering Management (Iconf-EM 2016) Research on the Application of Bank Transaction Data Stream Storage based on HBase Xiaoguo Wang*, Yuxiang Liu and Lin Zhang School of
Introduction to streams and stream processing. Mining Data Streams. Florian Rappl. September 4, 2014
 Introduction to streams and stream processing Mining Data Streams Florian Rappl September 4, 2014 Abstract Performing real time evaluation and analysis of big data is challenging. A special case focuses
Introduction to streams and stream processing Mining Data Streams Florian Rappl September 4, 2014 Abstract Performing real time evaluation and analysis of big data is challenging. A special case focuses
Yuval Carmel Tel-Aviv University "Advanced Topics in Storage Systems" - Spring 2013
 Yuval Carmel Tel-Aviv University "Advanced Topics in About & Keywords Motivation & Purpose Assumptions Architecture overview & Comparison Measurements How does it fit in? The Future 2 About & Keywords
Yuval Carmel Tel-Aviv University "Advanced Topics in About & Keywords Motivation & Purpose Assumptions Architecture overview & Comparison Measurements How does it fit in? The Future 2 About & Keywords
FAST DATA RETRIEVAL USING MAP REDUCE: A CASE STUDY
 , pp-01-05 FAST DATA RETRIEVAL USING MAP REDUCE: A CASE STUDY Ravin Ahuja 1, Anindya Lahiri 2, Nitesh Jain 3, Aditya Gabrani 4 1 Corresponding Author PhD scholar with the Department of Computer Engineering,
, pp-01-05 FAST DATA RETRIEVAL USING MAP REDUCE: A CASE STUDY Ravin Ahuja 1, Anindya Lahiri 2, Nitesh Jain 3, Aditya Gabrani 4 1 Corresponding Author PhD scholar with the Department of Computer Engineering,
Introduction to MapReduce
 732A54 Big Data Analytics Introduction to MapReduce Christoph Kessler IDA, Linköping University Towards Parallel Processing of Big-Data Big Data too large to be read+processed in reasonable time by 1 server
732A54 Big Data Analytics Introduction to MapReduce Christoph Kessler IDA, Linköping University Towards Parallel Processing of Big-Data Big Data too large to be read+processed in reasonable time by 1 server
Obtaining Rough Set Approximation using MapReduce Technique in Data Mining
 Obtaining Rough Set Approximation using MapReduce Technique in Data Mining Varda Dhande 1, Dr. B. K. Sarkar 2 1 M.E II yr student, Dept of Computer Engg, P.V.P.I.T Collage of Engineering Pune, Maharashtra,
Obtaining Rough Set Approximation using MapReduce Technique in Data Mining Varda Dhande 1, Dr. B. K. Sarkar 2 1 M.E II yr student, Dept of Computer Engg, P.V.P.I.T Collage of Engineering Pune, Maharashtra,
CS246: Mining Massive Datasets Jure Leskovec, Stanford University
 CS246: Mining Massive Datasets Jure Leskovec, Stanford University http://cs246.stanford.edu 2/24/2014 Jure Leskovec, Stanford CS246: Mining Massive Datasets, http://cs246.stanford.edu 2 High dim. data
CS246: Mining Massive Datasets Jure Leskovec, Stanford University http://cs246.stanford.edu 2/24/2014 Jure Leskovec, Stanford CS246: Mining Massive Datasets, http://cs246.stanford.edu 2 High dim. data
Parallel DBMS. Lecture 20. Reading Material. Instructor: Sudeepa Roy. Reading Material. Parallel vs. Distributed DBMS. Parallel DBMS 11/7/17
 Reading aterial CompSci 516 atabase Systems Lecture 20 Parallel BS Instructor: Sudeepa Roy [RG] Parallel BS: Chapter 22.1-22.5 [GUW] Parallel BS and map-reduce: Chapter 20.1-20.2 Acknowledgement: The following
Reading aterial CompSci 516 atabase Systems Lecture 20 Parallel BS Instructor: Sudeepa Roy [RG] Parallel BS: Chapter 22.1-22.5 [GUW] Parallel BS and map-reduce: Chapter 20.1-20.2 Acknowledgement: The following
MapReduce. Kiril Valev LMU Kiril Valev (LMU) MapReduce / 35
 MapReduce / 35") MapReduce Kiril Valev LMU valevk@cip.ifi.lmu.de 23.11.2013 Kiril Valev (LMU) MapReduce 23.11.2013 1 / 35 Agenda 1 MapReduce Motivation Definition Example Why MapReduce? Distributed Environment Fault Tolerance
MapReduce Kiril Valev LMU valevk@cip.ifi.lmu.de 23.11.2013 Kiril Valev (LMU) MapReduce 23.11.2013 1 / 35 Agenda 1 MapReduce Motivation Definition Example Why MapReduce? Distributed Environment Fault Tolerance
ML from Large Datasets
 10-605 ML from Large Datasets 1 Announcements HW1b is going out today You should now be on autolab have a an account on stoat a locally-administered Hadoop cluster shortly receive a coupon for Amazon Web
10-605 ML from Large Datasets 1 Announcements HW1b is going out today You should now be on autolab have a an account on stoat a locally-administered Hadoop cluster shortly receive a coupon for Amazon Web
MapReduce Algorithm Design
 MapReduce Algorithm Design Bu eğitim sunumları İstanbul Kalkınma Ajansı nın 2016 yılı Yenilikçi ve Yaratıcı İstanbul Mali Destek Programı kapsamında yürütülmekte olan TR10/16/YNY/0036 no lu İstanbul Big
MapReduce Algorithm Design Bu eğitim sunumları İstanbul Kalkınma Ajansı nın 2016 yılı Yenilikçi ve Yaratıcı İstanbul Mali Destek Programı kapsamında yürütülmekte olan TR10/16/YNY/0036 no lu İstanbul Big
Part A: MapReduce. Introduction Model Implementation issues
 Part A: Massive Parallelism li with MapReduce Introduction Model Implementation issues Acknowledgements Map-Reduce The material is largely based on material from the Stanford cources CS246, CS345A and
Part A: Massive Parallelism li with MapReduce Introduction Model Implementation issues Acknowledgements Map-Reduce The material is largely based on material from the Stanford cources CS246, CS345A and
The Google File System
 The Google File System Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung Google* 정학수, 최주영 1 Outline Introduction Design Overview System Interactions Master Operation Fault Tolerance and Diagnosis Conclusions
The Google File System Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung Google* 정학수, 최주영 1 Outline Introduction Design Overview System Interactions Master Operation Fault Tolerance and Diagnosis Conclusions
GOOGLE FILE SYSTEM: MASTER Sanjay Ghemawat, Howard Gobioff and Shun-Tak Leung
 ECE7650 Scalable and Secure Internet Services and Architecture ---- A Systems Perspective (Winter 2015) Presentation Report GOOGLE FILE SYSTEM: MASTER Sanjay Ghemawat, Howard Gobioff and Shun-Tak Leung
ECE7650 Scalable and Secure Internet Services and Architecture ---- A Systems Perspective (Winter 2015) Presentation Report GOOGLE FILE SYSTEM: MASTER Sanjay Ghemawat, Howard Gobioff and Shun-Tak Leung
Parallel HITS Algorithm Implemented Using HADOOP GIRAPH Framework to resolve Big Data Problem
 I J C T A, 9(41) 2016, pp. 1235-1239 International Science Press Parallel HITS Algorithm Implemented Using HADOOP GIRAPH Framework to resolve Big Data Problem Hema Dubey *, Nilay Khare *, Alind Khare **
I J C T A, 9(41) 2016, pp. 1235-1239 International Science Press Parallel HITS Algorithm Implemented Using HADOOP GIRAPH Framework to resolve Big Data Problem Hema Dubey *, Nilay Khare *, Alind Khare **