Benchmarking Distributed Stream Processing Platforms for IoT Applications
|
|
|
- Evangeline Lang
- 6 years ago
- Views:
Transcription

1 DISTRIBUTED RESEARCH ON EMERGING APPLICATIONS & MACHINES dream-lab.in Indian Institute of Science, Bangalore DREAM:Lab Benchmarking Distributed Stream Processing Platforms for IoT Applications Anshu Shukla and Yogesh Simmhan Department of Computational & Data Sciences Indian Institute of Science Eighth TPC Technology Conference on Performance Evaluation & Benchmarking (TPCTC 2016) DREAM:Lab, 2016 This work is licensed under a Creative Commons Attribution 4.0 International License 5-Sep-16

2 Motivation: Internet of Things (IoT) Billions of sensors monitoring physical infrastructure, human beings and virtual entities in realtime, distributed across network Data streams drive realtime processing, analytics & decisions making Streaming applications control feedback on physical structure, notifications to users
 Fast data rates, Weaker message order Distributed execution, fault-tolerant Flexible composition &")
3 Data Platforms for IoT MapReduce/Hadoop Large volume, high latency on distributed hosts Training models over sensor data archives Complex Event Processing Declarative pattern matching over event tuples Detect critical events, changing trends Distributed Stream Processing Systems (DSPS) Fast data rates, Weaker message order Distributed execution, fault-tolerant Flexible composition & responsive coordination of Observe, Orient, Decide, Act (OODA) loop Realtime Processing Mission critical apps, Strong latency guarantees Embedded medical devices, power networks * *Big Data Analytics Platforms for Real-time Applications in IoT, Yogesh Simmhan & Srinath Perera, Big Data Analytics: Methods and Applications, Eds. Saumyadipta Pyne, B.L.S. Prakasa Rao, S.B. Rao, 2016 (to appear)
4 DAG Distributed Stream Processing System [DSPS] Scalable, Distributed and fault-tolerant computations over data streams Composition of streaming applications Directed Acyclic Graph (DAG) of tasks and message streams Unbounded sequence of opaque messages as streams User-define logic blocks as tasks IoT System Task (lat,long) --> Zipcode Actuation Source (lat.,long.,taxiid,status) No.cars in CITY Sink Stream Booking Cancel > 3 times [ 10 mins ]
5 Need for a DSPS Benchmark for IoT Uniformly compare performance of DSPS for IoT applications Helps select DSPS platform for IoT domain Understanding gaps in capabilities of DSPS Composition of meaningful IoT applications Benchmark design goals Categories & platform-independent implementations of» Common IoT tasks» Classes of non-trivial IoT applications Different real-world IoT data streams
6 Gaps in related work IoTAbench: Emphasis on scalable synthetic data generation and not on application logic CityBench: RDF stream processing systems Stream Bench: 7 micro-benchmarks on 4 different synthetic workload suites, does not consider aspects unique to IoT applications and streams Spark Bench: Specific to Apache Spark, goal is to identify spark tuning parameters, not platform-agnostic Yahoo Cloud Serving Benchmark (YCSB): Compares different key-value stores on the Cloud Bigbench: Simulates online retail enterprise data with queries covering velocity, volume and variety of data
7 Contributions 1. Classification of essential tasks & IoT applications, and characteristics of their data sources 2. Propose IoT Benchmark for DSPS a. Micro-benchmark tasks implemented from the above classification b. Reference IoT applications implemented for Pre-processing & statistical summarisation (STATS) Predictive Analytics (PRED) 3. Practical evaluation on Apache Storm DSPS
8 Classification & Metrics IoT characteristics, DSPS capabilities, Performance Metrics 5-Sep-16 Eighth TPC Technology Conference on Performance Evaluation & Benchmarking (TPCTC 2016)
 Decide input")
 Selectivity 1:3 Width 3-Transform Data Parallelism 1-Source")

9 Dataflow Semantics Dataflow patterns determine consumption & routing of messages Selectivity ratio: Number of output messages emitted by a task on consuming a logical unit input message(s) Decide input rate for downstream tasks Number of tasks, Edge Degree, Length/ Width of Dataflow affect performance, scalability Length= critical path (latency) Selectivity 1:3 Width 3-Transform Data Parallelism 1-Source 2-FlatMap 4-Filter 6- Sink No. of Tasks - 6 [estimated number of cores required ] Width - 3 [Max task parallelism in the streaming data-flow] Length - [length of the critical path in terms of latency duration] 5-Aggregate
10 IoT Data stream Characteristics Input Throughput Rate at which messages enter the source tasks of the application dataflow Determines the parallelism of tasks in DSPS, ability to scale and meet latency goals Throughput Distribution Variation of input throughput over time. E.g. High demand for cabs in morning/evenings Dynamic load balancing, elasticity CITY dataset [1]: Environmental sensors at 7 cities across 3 continents; TAXI dataset [2]: Smart transportation messages from 2M trips of New York city taxis Impact of Message size, temporal ordering can also be considered [1] [2]
11 IoT Streaming Application Classes Extract-Transform-Load (ETL) and Archival Pre-processing like data format transformations, normalizing observation units, interpolate missing data items Archive a copy of the data offline Summarization and Visualization Statistical aggregation and analytics to orient the decision Generate visualizations to present it to end-users and decision makers Prediction and Pattern Detection Prediction to determine the future state and decide if any reaction is required Identify the patterns of interest Classification and notification Mapping decisions to specific actions Notifying the entities in IoT system
12 Categories of IoT Tasks Parse - parsing encoded messages from the stream sources [XML, CBOR, JSON, SenML] Filter - filtering on specific attribute values [bloom, range filter] Statistical Analytics - finding outliers, second order moments, distinct count Predictive Analytics - predictions using past and current messages, online model training [WEKA library, R Packages] Pattern Detection - identify patterns across events using CEP engines Visual Analytics - periodic charts for streaming application as part of the dataflow [D3.js, JFreeChart] IO Operations - accessing external storage or messaging services to access data [file/cloud storage, database ops, pub-sub]
13 Evaluation Metrics Metrics to meet performance & scalability needs for IoT applications from DSPS Latency Time between message consumed at source task(s) and their causally dependent messages generated at sink task(s),lesser is better Decides task parallelism for required input rate Peak Rate Aggregated peak output message rate generated from sink task(s),higher is better Estimated resource requirement for required input rate Jitter Variation in observed vs. expected output throughput based on input rate and task selectivity,close to zero is better Stability of task for given rate with sustainable queuing of messages CPU and Memory Utilisation Uniform distribution of load on VMs, hotspots causing bottlenecks Identify which VMs are the potential bottlenecks/under-used, scale-out/in
14 Benchmarks 5-Sep-16 Eighth TPC Technology Conference on Performance Evaluation & Benchmarking (TPCTC 2016)
15 Datasets used CITY: Urban environmental sensing data from 90 sensors at 7 cities, sampled per minute Scaled to 1000x to simulate 90,000 sensors timestamp, source, long, lat, temperature, humidity, light, dust, airquality TAXI: Smart transportation messages from 2M trips from 20K taxis in NYC, one per trip Bi-modal rate distribution [morning & evening commutes]; 1000x scaling for temporal freq. Medallion, Hack_license, Pickup_datetime, Dropoff_datetime, Trip_time, Trip_distance, Pickup_long, Pickup_lat, Dropoff_long, Dropoff_lat, Payment_type, Fare_amount, Surcharge, Mta_tax, Tip_amount, Tolls_amount, Total_amount [1] [2]

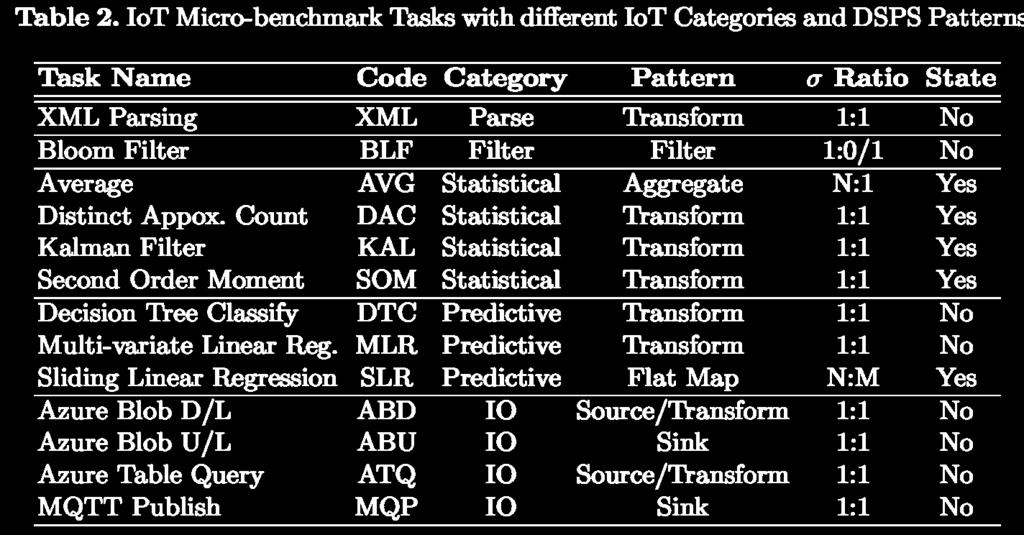
16 Benchmarks available at Micro-benchmark Tasks

17 Benchmarks available at Application Benchmarks [STATS] Streaming statistical analysis and filtering of data Data filtering of outliers on individual observation types using a Bloom filter Statistical analytics on observations from individual sensor/taxi IDs Approximate count of distinct readings for every observation type Publishing the results using MQTT task Different types of patterns, selectivities, task parallelisms» Application uses Hash,filter,Aggregate as dataflow patterns

18 Benchmarks available at Application Benchmarks [PRED] Streaming predictive analysis of data Timer Source and blob read - for reading updated model files using timestamp Decision tree uses trained model to classify messages into classes [good,average or poor air quality ] Multi-Variate Linear regression & Average used for finding the error estimate Group and Viz. - Batch and plot the summarised results for different observations Blob write - Result files are written to Cloud storage for hosting on a portal» Application uses duplicate,join,aggregate as dataflow patterns» Multiple source of Input streams
19 Experiments Apache Storm Sep-16 Eighth TPC Technology Conference on Performance Evaluation & Benchmarking (TPCTC 2016)
20 Experimental setup Apache Storm DSPS Executed on Microsoft Azure Cloud VMs OpenJDK 1.7 and CentOS Micro-Benchmarks Benchmark task runs on one exclusive D1 VM, 1 thread» 1-core Intel Xeon E5@2.2 GHz, 3.5 GiB RAM, 50 GiB SSD» Used to finding peak rate Master services, source & sink tasks run on a D8 VM» 8-core Intel Xeon E5@2.2 GHz, 28 GiB RAM, 400 GiB SSD» Ensures spout is not bottleneck at peak rate Application Benchmarks [STATS & PRED] D8 VMs as per input rate for all tasks of the dataflow Experiments run for 10 mins 1000 scaling 7 days of data for CITY and TAXI Application runtime = 7 days*24 hours*60 mins 1000 * scaling = mins
 and SLA (5 msg/sec) bound Wide variability in")

21 Results: Micro-benchmark Peak rate is 3,000 msg/sec or higher except XML parsing & Azure ops being CPU (310 msg/sec) and SLA (5 msg/sec) bound Wide variability in latency box plots Non-uniform task execution times, slow executions causes input tuples to queue up Higher input rates are more sensitive to even small per-tuple framework overhead





22 Results: Micro-benchmark Jitter: Close to zero values indicates stability of Storm at peak rate without unsustainable queuing CPU and MEM utilization Single-core VM used at 70% or above except Azure tasks being I/O driven High memory utilization for tasks supporting high throughput indicates messages waiting in memory queue

23 Results: Application benchmark PRED: Tall latency box plot due to variability in WEKA task execution times [observed in micro-benchmarks for DTC and MLR] Jitter remains close to zero, indicating sustainable performance

24 Results: Application benchmark TAXI : CPU is wider due to bimodal distribution of input rate X-axis represents the number of VMs required to support the given input distribution
25 Summary & Future Work Classified essential tasks, IoT applications & data stream characteristics Metrics for performance & scalability needs for IoT applications from DSPS Evaluation of Micro and application benchmarks on Apache storm for CITY and TAXI datasets in distributed environment Indicates the viability of Apache Storm for IoT Application Domains Introducing new tasks to the task categories [SenML, CBOR parsing,annotation] Benchmark and comparison of Apache Spark Streaming with Storm Using CEP engine like Siddhi as Tasks in Pattern recognition category
26 DISTRIBUTED RESEARCH ON EMERGING APPLICATIONS & MACHINES DISTRIBUTED RESEARCH ON EMERGING APPLICATIONS & MACHINES dream-lab.in Thank you! Indian Institute of Science Contact : shukla@grads.cds.iisc.ac.in DREAM:Lab, 2014 This work is licensed under a Creative Commons Attribution 4.0 International License
Data Analytics with HPC. Data Streaming
 Data Analytics with HPC Data Streaming Reusing this material This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike 4.0 International License. http://creativecommons.org/licenses/by-nc-sa/4.0/deed.en_us
Data Analytics with HPC Data Streaming Reusing this material This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike 4.0 International License. http://creativecommons.org/licenses/by-nc-sa/4.0/deed.en_us
Sub-millisecond Stateful Stream Querying over Fast-evolving Linked Data
 Sub-millisecond Stateful Stream Querying over Fast-evolving Linked Data Yunhao Zhang, Rong Chen, Haibo Chen Institute of Parallel and Distributed Systems (IPADS) Shanghai Jiao Tong University Stream Query
Sub-millisecond Stateful Stream Querying over Fast-evolving Linked Data Yunhao Zhang, Rong Chen, Haibo Chen Institute of Parallel and Distributed Systems (IPADS) Shanghai Jiao Tong University Stream Query
Tutorial: Apache Storm
 Indian Institute of Science Bangalore, India भ रत य वज ञ न स स थ न ब गल र, भ रत Department of Computational and Data Sciences DS256:Jan17 (3:1) Tutorial: Apache Storm Anshu Shukla 16 Feb, 2017 Yogesh Simmhan
Indian Institute of Science Bangalore, India भ रत य वज ञ न स स थ न ब गल र, भ रत Department of Computational and Data Sciences DS256:Jan17 (3:1) Tutorial: Apache Storm Anshu Shukla 16 Feb, 2017 Yogesh Simmhan
Scalable Streaming Analytics
 Scalable Streaming Analytics KARTHIK RAMASAMY @karthikz TALK OUTLINE BEGIN I! II ( III b Overview Storm Overview Storm Internals IV Z V K Heron Operational Experiences END WHAT IS ANALYTICS? according
Scalable Streaming Analytics KARTHIK RAMASAMY @karthikz TALK OUTLINE BEGIN I! II ( III b Overview Storm Overview Storm Internals IV Z V K Heron Operational Experiences END WHAT IS ANALYTICS? according
REAL-TIME ANALYTICS WITH APACHE STORM
 REAL-TIME ANALYTICS WITH APACHE STORM Mevlut Demir PhD Student IN TODAY S TALK 1- Problem Formulation 2- A Real-Time Framework and Its Components with an existing applications 3- Proposed Framework 4-
REAL-TIME ANALYTICS WITH APACHE STORM Mevlut Demir PhD Student IN TODAY S TALK 1- Problem Formulation 2- A Real-Time Framework and Its Components with an existing applications 3- Proposed Framework 4-
Apache Kafka Your Event Stream Processing Solution
 Apache Kafka Your Event Stream Processing Solution Introduction Data is one among the newer ingredients in the Internet-based systems and includes user-activity events related to logins, page visits, clicks,
Apache Kafka Your Event Stream Processing Solution Introduction Data is one among the newer ingredients in the Internet-based systems and includes user-activity events related to logins, page visits, clicks,
SnailTrail Generalizing Critical Paths for Online Analysis of Distributed Dataflows
 SnailTrail Generalizing Critical Paths for Online Analysis of Distributed Dataflows Moritz Hoffmann, Andrea Lattuada, John Liagouris, Vasiliki Kalavri, Desislava Dimitrova, Sebastian Wicki, Zaheer Chothia,
SnailTrail Generalizing Critical Paths for Online Analysis of Distributed Dataflows Moritz Hoffmann, Andrea Lattuada, John Liagouris, Vasiliki Kalavri, Desislava Dimitrova, Sebastian Wicki, Zaheer Chothia,
New Oracle NoSQL Database APIs that Speed Insertion and Retrieval
 New Oracle NoSQL Database APIs that Speed Insertion and Retrieval O R A C L E W H I T E P A P E R F E B R U A R Y 2 0 1 6 1 NEW ORACLE NoSQL DATABASE APIs that SPEED INSERTION AND RETRIEVAL Introduction
New Oracle NoSQL Database APIs that Speed Insertion and Retrieval O R A C L E W H I T E P A P E R F E B R U A R Y 2 0 1 6 1 NEW ORACLE NoSQL DATABASE APIs that SPEED INSERTION AND RETRIEVAL Introduction
Parallel Patterns for Window-based Stateful Operators on Data Streams: an Algorithmic Skeleton Approach
 Parallel Patterns for Window-based Stateful Operators on Data Streams: an Algorithmic Skeleton Approach Tiziano De Matteis, Gabriele Mencagli University of Pisa Italy INTRODUCTION The recent years have
Parallel Patterns for Window-based Stateful Operators on Data Streams: an Algorithmic Skeleton Approach Tiziano De Matteis, Gabriele Mencagli University of Pisa Italy INTRODUCTION The recent years have
Data Stream Processing in the Cloud
 Department of Computing Data Stream Processing in the Cloud Evangelia Kalyvianaki ekalyv@imperial.ac.uk joint work with Raul Castro Fernandez, Marco Fiscato, Matteo Migliavacca and Peter Pietzuch Peter
Department of Computing Data Stream Processing in the Cloud Evangelia Kalyvianaki ekalyv@imperial.ac.uk joint work with Raul Castro Fernandez, Marco Fiscato, Matteo Migliavacca and Peter Pietzuch Peter
JVM Performance Study Comparing Oracle HotSpot and Azul Zing Using Apache Cassandra
 JVM Performance Study Comparing Oracle HotSpot and Azul Zing Using Apache Cassandra Legal Notices Apache Cassandra, Spark and Solr and their respective logos are trademarks or registered trademarks of
JVM Performance Study Comparing Oracle HotSpot and Azul Zing Using Apache Cassandra Legal Notices Apache Cassandra, Spark and Solr and their respective logos are trademarks or registered trademarks of
arxiv: v1 [cs.dc] 11 Sep 2017
![arxiv: v1 [cs.dc] 11 Sep 2017](/thumbs/95/125832441.jpg "arxiv: v1 [cs.dc] 11 Sep 2017") Collaborative Reuse of Streaming Dataflows in IoT Applications arxiv:179.3332v1 [cs.dc] 11 Sep 217 Shilpa Chaturvedi, Sahil Tyagi and Yogesh Simmhan Department of Computational and Data Sciences Indian
Collaborative Reuse of Streaming Dataflows in IoT Applications arxiv:179.3332v1 [cs.dc] 11 Sep 217 Shilpa Chaturvedi, Sahil Tyagi and Yogesh Simmhan Department of Computational and Data Sciences Indian
TPCX-BB (BigBench) Big Data Analytics Benchmark
 Big Data Analytics Benchmark") TPCX-BB (BigBench) Big Data Analytics Benchmark Bhaskar D Gowda Senior Staff Engineer Analytics & AI Solutions Group Intel Corporation bhaskar.gowda@intel.com 1 Agenda Big Data Analytics & Benchmarks Industry
TPCX-BB (BigBench) Big Data Analytics Benchmark Bhaskar D Gowda Senior Staff Engineer Analytics & AI Solutions Group Intel Corporation bhaskar.gowda@intel.com 1 Agenda Big Data Analytics & Benchmarks Industry
HiTune. Dataflow-Based Performance Analysis for Big Data Cloud
 HiTune Dataflow-Based Performance Analysis for Big Data Cloud Jinquan (Jason) Dai, Jie Huang, Shengsheng Huang, Bo Huang, Yan Liu Intel Asia-Pacific Research and Development Ltd Shanghai, China, 200241
HiTune Dataflow-Based Performance Analysis for Big Data Cloud Jinquan (Jason) Dai, Jie Huang, Shengsheng Huang, Bo Huang, Yan Liu Intel Asia-Pacific Research and Development Ltd Shanghai, China, 200241
Embedded Technosolutions
 Hadoop Big Data An Important technology in IT Sector Hadoop - Big Data Oerie 90% of the worlds data was generated in the last few years. Due to the advent of new technologies, devices, and communication
Hadoop Big Data An Important technology in IT Sector Hadoop - Big Data Oerie 90% of the worlds data was generated in the last few years. Due to the advent of new technologies, devices, and communication
Turbocharge your MySQL analytics with ElasticSearch. Guillaume Lefranc Data & Infrastructure Architect, Productsup GmbH Percona Live Europe 2017
 Turbocharge your MySQL analytics with ElasticSearch Guillaume Lefranc Data & Infrastructure Architect, Productsup GmbH Percona Live Europe 2017 About the Speaker Guillaume Lefranc Data Architect at Productsup
Turbocharge your MySQL analytics with ElasticSearch Guillaume Lefranc Data & Infrastructure Architect, Productsup GmbH Percona Live Europe 2017 About the Speaker Guillaume Lefranc Data Architect at Productsup
Research Faculty Summit Systems Fueling future disruptions
 Research Faculty Summit 2018 Systems Fueling future disruptions Elevating the Edge to be a Peer of the Cloud Kishore Ramachandran Embedded Pervasive Lab, Georgia Tech August 2, 2018 Acknowledgements Enrique
Research Faculty Summit 2018 Systems Fueling future disruptions Elevating the Edge to be a Peer of the Cloud Kishore Ramachandran Embedded Pervasive Lab, Georgia Tech August 2, 2018 Acknowledgements Enrique
High-Performance Event Processing Bridging the Gap between Low Latency and High Throughput Bernhard Seeger University of Marburg
 High-Performance Event Processing Bridging the Gap between Low Latency and High Throughput Bernhard Seeger University of Marburg common work with Nikolaus Glombiewski, Michael Körber, Marc Seidemann 1.
High-Performance Event Processing Bridging the Gap between Low Latency and High Throughput Bernhard Seeger University of Marburg common work with Nikolaus Glombiewski, Michael Körber, Marc Seidemann 1.
Next-Generation Cloud Platform
 Next-Generation Cloud Platform Jangwoo Kim Jun 24, 2013 E-mail: jangwoo@postech.ac.kr High Performance Computing Lab Department of Computer Science & Engineering Pohang University of Science and Technology
Next-Generation Cloud Platform Jangwoo Kim Jun 24, 2013 E-mail: jangwoo@postech.ac.kr High Performance Computing Lab Department of Computer Science & Engineering Pohang University of Science and Technology
WHY AND HOW TO LEVERAGE THE POWER AND SIMPLICITY OF SQL ON APACHE FLINK - FABIAN HUESKE, SOFTWARE ENGINEER
 WHY AND HOW TO LEVERAGE THE POWER AND SIMPLICITY OF SQL ON APACHE FLINK - FABIAN HUESKE, SOFTWARE ENGINEER ABOUT ME Apache Flink PMC member & ASF member Contributing since day 1 at TU Berlin Focusing on
WHY AND HOW TO LEVERAGE THE POWER AND SIMPLICITY OF SQL ON APACHE FLINK - FABIAN HUESKE, SOFTWARE ENGINEER ABOUT ME Apache Flink PMC member & ASF member Contributing since day 1 at TU Berlin Focusing on
Unifying Big Data Workloads in Apache Spark
 Unifying Big Data Workloads in Apache Spark Hossein Falaki @mhfalaki Outline What s Apache Spark Why Unification Evolution of Unification Apache Spark + Databricks Q & A What s Apache Spark What is Apache
Unifying Big Data Workloads in Apache Spark Hossein Falaki @mhfalaki Outline What s Apache Spark Why Unification Evolution of Unification Apache Spark + Databricks Q & A What s Apache Spark What is Apache
VOLTDB + HP VERTICA. page
 VOLTDB + HP VERTICA ARCHITECTURE FOR FAST AND BIG DATA ARCHITECTURE FOR FAST + BIG DATA FAST DATA Fast Serve Analytics BIG DATA BI Reporting Fast Operational Database Streaming Analytics Columnar Analytics
VOLTDB + HP VERTICA ARCHITECTURE FOR FAST AND BIG DATA ARCHITECTURE FOR FAST + BIG DATA FAST DATA Fast Serve Analytics BIG DATA BI Reporting Fast Operational Database Streaming Analytics Columnar Analytics
Overview of Data Services and Streaming Data Solution with Azure
 Overview of Data Services and Streaming Data Solution with Azure Tara Mason Senior Consultant tmason@impactmakers.com Platform as a Service Offerings SQL Server On Premises vs. Azure SQL Server SQL Server
Overview of Data Services and Streaming Data Solution with Azure Tara Mason Senior Consultant tmason@impactmakers.com Platform as a Service Offerings SQL Server On Premises vs. Azure SQL Server SQL Server
Crescando: Predictable Performance for Unpredictable Workloads
 Crescando: Predictable Performance for Unpredictable Workloads G. Alonso, D. Fauser, G. Giannikis, D. Kossmann, J. Meyer, P. Unterbrunner Amadeus S.A. ETH Zurich, Systems Group (Funded by Enterprise Computing
Crescando: Predictable Performance for Unpredictable Workloads G. Alonso, D. Fauser, G. Giannikis, D. Kossmann, J. Meyer, P. Unterbrunner Amadeus S.A. ETH Zurich, Systems Group (Funded by Enterprise Computing
R-Storm: A Resource-Aware Scheduler for STORM. Mohammad Hosseini Boyang Peng Zhihao Hong Reza Farivar Roy Campbell
 R-Storm: A Resource-Aware Scheduler for STORM Mohammad Hosseini Boyang Peng Zhihao Hong Reza Farivar Roy Campbell Introduction STORM is an open source distributed real-time data stream processing system
R-Storm: A Resource-Aware Scheduler for STORM Mohammad Hosseini Boyang Peng Zhihao Hong Reza Farivar Roy Campbell Introduction STORM is an open source distributed real-time data stream processing system
Flash Storage Complementing a Data Lake for Real-Time Insight
 Flash Storage Complementing a Data Lake for Real-Time Insight Dr. Sanhita Sarkar Global Director, Analytics Software Development August 7, 2018 Agenda 1 2 3 4 5 Delivering insight along the entire spectrum
Flash Storage Complementing a Data Lake for Real-Time Insight Dr. Sanhita Sarkar Global Director, Analytics Software Development August 7, 2018 Agenda 1 2 3 4 5 Delivering insight along the entire spectrum
Architectural challenges for building a low latency, scalable multi-tenant data warehouse
 Architectural challenges for building a low latency, scalable multi-tenant data warehouse Mataprasad Agrawal Solutions Architect, Services CTO 2017 Persistent Systems Ltd. All rights reserved. Our analytics
Architectural challenges for building a low latency, scalable multi-tenant data warehouse Mataprasad Agrawal Solutions Architect, Services CTO 2017 Persistent Systems Ltd. All rights reserved. Our analytics
Practical Big Data Processing An Overview of Apache Flink
 Practical Big Data Processing An Overview of Apache Flink Tilmann Rabl Berlin Big Data Center www.dima.tu-berlin.de bbdc.berlin rabl@tu-berlin.de With slides from Volker Markl and data artisans 1 2013
Practical Big Data Processing An Overview of Apache Flink Tilmann Rabl Berlin Big Data Center www.dima.tu-berlin.de bbdc.berlin rabl@tu-berlin.de With slides from Volker Markl and data artisans 1 2013
E-Store: Fine-Grained Elastic Partitioning for Distributed Transaction Processing Systems
 E-Store: Fine-Grained Elastic Partitioning for Distributed Transaction Processing Systems Rebecca Taft, Essam Mansour, Marco Serafini, Jennie Duggan, Aaron J. Elmore, Ashraf Aboulnaga, Andrew Pavlo, Michael
E-Store: Fine-Grained Elastic Partitioning for Distributed Transaction Processing Systems Rebecca Taft, Essam Mansour, Marco Serafini, Jennie Duggan, Aaron J. Elmore, Ashraf Aboulnaga, Andrew Pavlo, Michael
7-8 June 2018 Frankfurt Germany. Improving Business Performance Through Big Data Benchmarking
 7- Frankfurt Germany Improving Business Performance Through Big Data Benchmarking Todor Ivanov (todor@dbis.cs.uni-frankfurt.de) Frankfurt Big Data Lab, Goethe University Benchmarking The Term Benchmark:
7- Frankfurt Germany Improving Business Performance Through Big Data Benchmarking Todor Ivanov (todor@dbis.cs.uni-frankfurt.de) Frankfurt Big Data Lab, Goethe University Benchmarking The Term Benchmark:
Flying Faster with Heron
 Flying Faster with Heron KARTHIK RAMASAMY @KARTHIKZ #TwitterHeron TALK OUTLINE BEGIN I! II ( III b OVERVIEW MOTIVATION HERON IV Z OPERATIONAL EXPERIENCES V K HERON PERFORMANCE END [! OVERVIEW TWITTER IS
Flying Faster with Heron KARTHIK RAMASAMY @KARTHIKZ #TwitterHeron TALK OUTLINE BEGIN I! II ( III b OVERVIEW MOTIVATION HERON IV Z OPERATIONAL EXPERIENCES V K HERON PERFORMANCE END [! OVERVIEW TWITTER IS
microsoft
 70-775.microsoft Number: 70-775 Passing Score: 800 Time Limit: 120 min Exam A QUESTION 1 Note: This question is part of a series of questions that present the same scenario. Each question in the series
70-775.microsoft Number: 70-775 Passing Score: 800 Time Limit: 120 min Exam A QUESTION 1 Note: This question is part of a series of questions that present the same scenario. Each question in the series
Putting it together. Data-Parallel Computation. Ex: Word count using partial aggregation. Big Data Processing. COS 418: Distributed Systems Lecture 21
 Big Processing -Parallel Computation COS 418: Distributed Systems Lecture 21 Michael Freedman 2 Ex: Word count using partial aggregation Putting it together 1. Compute word counts from individual files
Big Processing -Parallel Computation COS 418: Distributed Systems Lecture 21 Michael Freedman 2 Ex: Word count using partial aggregation Putting it together 1. Compute word counts from individual files
Apache Spark is a fast and general-purpose engine for large-scale data processing Spark aims at achieving the following goals in the Big data context
 1 Apache Spark is a fast and general-purpose engine for large-scale data processing Spark aims at achieving the following goals in the Big data context Generality: diverse workloads, operators, job sizes
1 Apache Spark is a fast and general-purpose engine for large-scale data processing Spark aims at achieving the following goals in the Big data context Generality: diverse workloads, operators, job sizes
Remote Health Monitoring for an Embedded System
 July 20, 2012 Remote Health Monitoring for an Embedded System Authors: Puneet Gupta, Kundan Kumar, Vishnu H Prasad 1/22/2014 2 Outline Background Background & Scope Requirements Key Challenges Introduction
July 20, 2012 Remote Health Monitoring for an Embedded System Authors: Puneet Gupta, Kundan Kumar, Vishnu H Prasad 1/22/2014 2 Outline Background Background & Scope Requirements Key Challenges Introduction
Big data streaming: Choices for high availability and disaster recovery on Microsoft Azure. By Arnab Ganguly DataCAT
 : Choices for high availability and disaster recovery on Microsoft Azure By Arnab Ganguly DataCAT March 2019 Contents Overview... 3 The challenge of a single-region architecture... 3 Configuration considerations...
: Choices for high availability and disaster recovery on Microsoft Azure By Arnab Ganguly DataCAT March 2019 Contents Overview... 3 The challenge of a single-region architecture... 3 Configuration considerations...
What's New in MATLAB for Engineering Data Analytics?
 What's New in MATLAB for Engineering Data Analytics? Will Wilson Application Engineer MathWorks, Inc. 2017 The MathWorks, Inc. 1 Agenda Data Types Tall Arrays for Big Data Machine Learning (for Everyone)
What's New in MATLAB for Engineering Data Analytics? Will Wilson Application Engineer MathWorks, Inc. 2017 The MathWorks, Inc. 1 Agenda Data Types Tall Arrays for Big Data Machine Learning (for Everyone)
Creating a Recommender System. An Elasticsearch & Apache Spark approach
 Creating a Recommender System An Elasticsearch & Apache Spark approach My Profile SKILLS Álvaro Santos Andrés Big Data & Analytics Solution Architect in Ericsson with more than 12 years of experience focused
Creating a Recommender System An Elasticsearch & Apache Spark approach My Profile SKILLS Álvaro Santos Andrés Big Data & Analytics Solution Architect in Ericsson with more than 12 years of experience focused
Experiment-Driven Evaluation of Cloud-based Distributed Systems
 Experiment-Driven Evaluation of Cloud-based Distributed Systems Markus Klems,, TU Berlin 11th Symposium and Summer School On Service-Oriented Computing Agenda Introduction Experiments Experiment Automation
Experiment-Driven Evaluation of Cloud-based Distributed Systems Markus Klems,, TU Berlin 11th Symposium and Summer School On Service-Oriented Computing Agenda Introduction Experiments Experiment Automation
Modern Data Warehouse The New Approach to Azure BI
 Modern Data Warehouse The New Approach to Azure BI History On-Premise SQL Server Big Data Solutions Technical Barriers Modern Analytics Platform On-Premise SQL Server Big Data Solutions Modern Analytics
Modern Data Warehouse The New Approach to Azure BI History On-Premise SQL Server Big Data Solutions Technical Barriers Modern Analytics Platform On-Premise SQL Server Big Data Solutions Modern Analytics
Streaming iphone sensor data to SAS Event Stream Processing
 SAS USER FORUM Streaming iphone sensor data to SAS Event Stream Processing Pasi Helenius Senior Advisor SAS Event Stream Processing 3 KEY CHARACTERISTICS Technology Process steams of data events, on the
SAS USER FORUM Streaming iphone sensor data to SAS Event Stream Processing Pasi Helenius Senior Advisor SAS Event Stream Processing 3 KEY CHARACTERISTICS Technology Process steams of data events, on the
Data Acquisition. The reference Big Data stack
 Università degli Studi di Roma Tor Vergata Dipartimento di Ingegneria Civile e Ingegneria Informatica Data Acquisition Corso di Sistemi e Architetture per Big Data A.A. 2016/17 Valeria Cardellini The reference
Università degli Studi di Roma Tor Vergata Dipartimento di Ingegneria Civile e Ingegneria Informatica Data Acquisition Corso di Sistemi e Architetture per Big Data A.A. 2016/17 Valeria Cardellini The reference
System Support for Internet of Things
 System Support for Internet of Things Kishore Ramachandran (Kirak Hong - Google, Dave Lillethun, Dushmanta Mohapatra, Steffen Maas, Enrique Saurez Apuy) Overview Motivation Mobile Fog: A Distributed
System Support for Internet of Things Kishore Ramachandran (Kirak Hong - Google, Dave Lillethun, Dushmanta Mohapatra, Steffen Maas, Enrique Saurez Apuy) Overview Motivation Mobile Fog: A Distributed
Copyright Push Technology Ltd December Diffusion TM 4.4 Performance Benchmarks
 Diffusion TM 4.4 Performance Benchmarks November 2012 Contents 1 Executive Summary...3 2 Introduction...3 3 Environment...4 4 Methodology...5 4.1 Throughput... 5 4.2 Latency... 6 5 Results Summary...7
Diffusion TM 4.4 Performance Benchmarks November 2012 Contents 1 Executive Summary...3 2 Introduction...3 3 Environment...4 4 Methodology...5 4.1 Throughput... 5 4.2 Latency... 6 5 Results Summary...7
(incubating) Introduction. Swapnil Bawaskar.
 Introduction. Swapnil Bawaskar.") (incubating) Introduction William Markito @william_markito Swapnil Bawaskar @sbawaskar Agenda Introduction What? Who? Why? How? DEBS Roadmap Q&A 2 3 Introduction Introduction A distributed, memory-based
(incubating) Introduction William Markito @william_markito Swapnil Bawaskar @sbawaskar Agenda Introduction What? Who? Why? How? DEBS Roadmap Q&A 2 3 Introduction Introduction A distributed, memory-based
TPC-E testing of Microsoft SQL Server 2016 on Dell EMC PowerEdge R830 Server and Dell EMC SC9000 Storage
 TPC-E testing of Microsoft SQL Server 2016 on Dell EMC PowerEdge R830 Server and Dell EMC SC9000 Storage Performance Study of Microsoft SQL Server 2016 Dell Engineering February 2017 Table of contents
TPC-E testing of Microsoft SQL Server 2016 on Dell EMC PowerEdge R830 Server and Dell EMC SC9000 Storage Performance Study of Microsoft SQL Server 2016 Dell Engineering February 2017 Table of contents
Big Data Technology Ecosystem. Mark Burnette Pentaho Director Sales Engineering, Hitachi Vantara
 Big Data Technology Ecosystem Mark Burnette Pentaho Director Sales Engineering, Hitachi Vantara Agenda End-to-End Data Delivery Platform Ecosystem of Data Technologies Mapping an End-to-End Solution Case
Big Data Technology Ecosystem Mark Burnette Pentaho Director Sales Engineering, Hitachi Vantara Agenda End-to-End Data Delivery Platform Ecosystem of Data Technologies Mapping an End-to-End Solution Case
DS504/CS586: Big Data Analytics Data Management Prof. Yanhua Li
 Welcome to DS504/CS586: Big Data Analytics Data Management Prof. Yanhua Li Time: 6:00pm 8:50pm R Location: KH 116 Fall 2017 First Grading for Reading Assignment Weka v 6 weeks v https://weka.waikato.ac.nz/dataminingwithweka/preview
Welcome to DS504/CS586: Big Data Analytics Data Management Prof. Yanhua Li Time: 6:00pm 8:50pm R Location: KH 116 Fall 2017 First Grading for Reading Assignment Weka v 6 weeks v https://weka.waikato.ac.nz/dataminingwithweka/preview
Apache Hadoop 3. Balazs Gaspar Sales Engineer CEE & CIS Cloudera, Inc. All rights reserved.
 Apache Hadoop 3 Balazs Gaspar Sales Engineer CEE & CIS balazs@cloudera.com 1 We believe data can make what is impossible today, possible tomorrow 2 We empower people to transform complex data into clear
Apache Hadoop 3 Balazs Gaspar Sales Engineer CEE & CIS balazs@cloudera.com 1 We believe data can make what is impossible today, possible tomorrow 2 We empower people to transform complex data into clear
Cloud Analytics and Business Intelligence on AWS
 Cloud Analytics and Business Intelligence on AWS Enterprise Applications Virtual Desktops Sharing & Collaboration Platform Services Analytics Hadoop Real-time Streaming Data Machine Learning Data Warehouse
Cloud Analytics and Business Intelligence on AWS Enterprise Applications Virtual Desktops Sharing & Collaboration Platform Services Analytics Hadoop Real-time Streaming Data Machine Learning Data Warehouse
Oracle NoSQL Database and Cisco- Collaboration that produces results. 1 Copyright 2011, Oracle and/or its affiliates. All rights reserved.
 Oracle NoSQL Database and Cisco- Collaboration that produces results 1 Copyright 2011, Oracle and/or its affiliates. All rights reserved. What is Big Data? SOCIAL BLOG SMART METER VOLUME VELOCITY VARIETY
Oracle NoSQL Database and Cisco- Collaboration that produces results 1 Copyright 2011, Oracle and/or its affiliates. All rights reserved. What is Big Data? SOCIAL BLOG SMART METER VOLUME VELOCITY VARIETY
Maximum Sustainable Throughput Prediction for Large-Scale Data Streaming Systems
 JOURNAL OF L A T E X CLASS FILES, VOL. 14, NO. 8, AUGUST 215 1 Maximum Sustainable Throughput Prediction for Large-Scale Data Streaming Systems Abstract In cloud-based stream processing services, the maximum
JOURNAL OF L A T E X CLASS FILES, VOL. 14, NO. 8, AUGUST 215 1 Maximum Sustainable Throughput Prediction for Large-Scale Data Streaming Systems Abstract In cloud-based stream processing services, the maximum
SparkBench: A Comprehensive Spark Benchmarking Suite Characterizing In-memory Data Analytics
 SparkBench: A Comprehensive Spark Benchmarking Suite Characterizing In-memory Data Analytics Min LI,, Jian Tan, Yandong Wang, Li Zhang, Valentina Salapura, Alan Bivens IBM TJ Watson Research Center * A
SparkBench: A Comprehensive Spark Benchmarking Suite Characterizing In-memory Data Analytics Min LI,, Jian Tan, Yandong Wang, Li Zhang, Valentina Salapura, Alan Bivens IBM TJ Watson Research Center * A
Accelerating Big Data: Using SanDisk SSDs for Apache HBase Workloads
 WHITE PAPER Accelerating Big Data: Using SanDisk SSDs for Apache HBase Workloads December 2014 Western Digital Technologies, Inc. 951 SanDisk Drive, Milpitas, CA 95035 www.sandisk.com Table of Contents
WHITE PAPER Accelerating Big Data: Using SanDisk SSDs for Apache HBase Workloads December 2014 Western Digital Technologies, Inc. 951 SanDisk Drive, Milpitas, CA 95035 www.sandisk.com Table of Contents
Sparrow. Distributed Low-Latency Spark Scheduling. Kay Ousterhout, Patrick Wendell, Matei Zaharia, Ion Stoica
 Sparrow Distributed Low-Latency Spark Scheduling Kay Ousterhout, Patrick Wendell, Matei Zaharia, Ion Stoica Outline The Spark scheduling bottleneck Sparrow s fully distributed, fault-tolerant technique
Sparrow Distributed Low-Latency Spark Scheduling Kay Ousterhout, Patrick Wendell, Matei Zaharia, Ion Stoica Outline The Spark scheduling bottleneck Sparrow s fully distributed, fault-tolerant technique
Randy Pagels Sr. Developer Technology Specialist DX US Team AZURE PRIMED
 Randy Pagels Sr. Developer Technology Specialist DX US Team rpagels@microsoft.com AZURE PRIMED 2016.04.11 Interactive Data Analytics Discover the root cause of any app performance behavior almost instantaneously
Randy Pagels Sr. Developer Technology Specialist DX US Team rpagels@microsoft.com AZURE PRIMED 2016.04.11 Interactive Data Analytics Discover the root cause of any app performance behavior almost instantaneously
Correlative Analytic Methods in Large Scale Network Infrastructure Hariharan Krishnaswamy Senior Principal Engineer Dell EMC
 Correlative Analytic Methods in Large Scale Network Infrastructure Hariharan Krishnaswamy Senior Principal Engineer Dell EMC 2018 Storage Developer Conference. Dell EMC. All Rights Reserved. 1 Data Center
Correlative Analytic Methods in Large Scale Network Infrastructure Hariharan Krishnaswamy Senior Principal Engineer Dell EMC 2018 Storage Developer Conference. Dell EMC. All Rights Reserved. 1 Data Center
Predicting impact of changes in application on SLAs: ETL application performance model
 Predicting impact of changes in application on SLAs: ETL application performance model Dr. Abhijit S. Ranjekar Infosys Abstract Service Level Agreements (SLAs) are an integral part of application performance.
Predicting impact of changes in application on SLAs: ETL application performance model Dr. Abhijit S. Ranjekar Infosys Abstract Service Level Agreements (SLAs) are an integral part of application performance.
Apache Flink. Alessandro Margara
 Apache Flink Alessandro Margara alessandro.margara@polimi.it http://home.deib.polimi.it/margara Recap: scenario Big Data Volume and velocity Process large volumes of data possibly produced at high rate
Apache Flink Alessandro Margara alessandro.margara@polimi.it http://home.deib.polimi.it/margara Recap: scenario Big Data Volume and velocity Process large volumes of data possibly produced at high rate
Performance and Scalability with Griddable.io
 Performance and Scalability with Griddable.io Executive summary Griddable.io is an industry-leading timeline-consistent synchronized data integration grid across a range of source and target data systems.
Performance and Scalability with Griddable.io Executive summary Griddable.io is an industry-leading timeline-consistent synchronized data integration grid across a range of source and target data systems.
Understanding the latent value in all content
 Understanding the latent value in all content John F. Kennedy (JFK) November 22, 1963 INGEST ENRICH EXPLORE Cognitive skills Data in any format, any Azure store Search Annotations Data Cloud Intelligence
Understanding the latent value in all content John F. Kennedy (JFK) November 22, 1963 INGEST ENRICH EXPLORE Cognitive skills Data in any format, any Azure store Search Annotations Data Cloud Intelligence
Fit for Purpose Platform Positioning and Performance Architecture
 Fit for Purpose Platform Positioning and Performance Architecture Joe Temple IBM Monday, February 4, 11AM-12PM Session Number 12927 Insert Custom Session QR if Desired. Fit for Purpose Categorized Workload
Fit for Purpose Platform Positioning and Performance Architecture Joe Temple IBM Monday, February 4, 11AM-12PM Session Number 12927 Insert Custom Session QR if Desired. Fit for Purpose Categorized Workload
TrafficDB: HERE s High Performance Shared-Memory Data Store Ricardo Fernandes, Piotr Zaczkowski, Bernd Göttler, Conor Ettinoffe, and Anis Moussa
 TrafficDB: HERE s High Performance Shared-Memory Data Store Ricardo Fernandes, Piotr Zaczkowski, Bernd Göttler, Conor Ettinoffe, and Anis Moussa EPL646: Advanced Topics in Databases Christos Hadjistyllis
TrafficDB: HERE s High Performance Shared-Memory Data Store Ricardo Fernandes, Piotr Zaczkowski, Bernd Göttler, Conor Ettinoffe, and Anis Moussa EPL646: Advanced Topics in Databases Christos Hadjistyllis
8/24/2017 Week 1-B Instructor: Sangmi Lee Pallickara
 Week 1-B-0 Week 1-B-1 CS535 BIG DATA FAQs Slides are available on the course web Wait list Term project topics PART 0. INTRODUCTION 2. DATA PROCESSING PARADIGMS FOR BIG DATA Sangmi Lee Pallickara Computer
Week 1-B-0 Week 1-B-1 CS535 BIG DATA FAQs Slides are available on the course web Wait list Term project topics PART 0. INTRODUCTION 2. DATA PROCESSING PARADIGMS FOR BIG DATA Sangmi Lee Pallickara Computer
Streaming Auto-Scaling in Google Cloud Dataflow
 Streaming Auto-Scaling in Google Cloud Dataflow Manuel Fahndrich Software Engineer Google Addictive Mobile Game https://commons.wikimedia.org/wiki/file:globe_centered_in_the_atlantic_ocean_(green_and_grey_globe_scheme).svg
Streaming Auto-Scaling in Google Cloud Dataflow Manuel Fahndrich Software Engineer Google Addictive Mobile Game https://commons.wikimedia.org/wiki/file:globe_centered_in_the_atlantic_ocean_(green_and_grey_globe_scheme).svg
Benchmarking Spark ML using BigBench. Sweta Singh TPCTC 2016
 Benchmarking Spark ML using BigBench Sweta Singh singhswe@us.ibm.com TPCTC 2016 Motivation Study the performance of Machine Learning use cases on large data warehouses in context of assessing Alternate
Benchmarking Spark ML using BigBench Sweta Singh singhswe@us.ibm.com TPCTC 2016 Motivation Study the performance of Machine Learning use cases on large data warehouses in context of assessing Alternate
Hortonworks and The Internet of Things
 Hortonworks and The Internet of Things Dr. Bernhard Walter Solutions Engineer About Hortonworks Customer Momentum ~700 customers (as of November 4, 2015) 152 customers added in Q3 2015 Publicly traded
Hortonworks and The Internet of Things Dr. Bernhard Walter Solutions Engineer About Hortonworks Customer Momentum ~700 customers (as of November 4, 2015) 152 customers added in Q3 2015 Publicly traded
An Oracle White Paper September Oracle Utilities Meter Data Management Demonstrates Extreme Performance on Oracle Exadata/Exalogic
 An Oracle White Paper September 2011 Oracle Utilities Meter Data Management 2.0.1 Demonstrates Extreme Performance on Oracle Exadata/Exalogic Introduction New utilities technologies are bringing with them
An Oracle White Paper September 2011 Oracle Utilities Meter Data Management 2.0.1 Demonstrates Extreme Performance on Oracle Exadata/Exalogic Introduction New utilities technologies are bringing with them
exam. Microsoft Perform Data Engineering on Microsoft Azure HDInsight. Version 1.0
 70-775.exam Number: 70-775 Passing Score: 800 Time Limit: 120 min File Version: 1.0 Microsoft 70-775 Perform Data Engineering on Microsoft Azure HDInsight Version 1.0 Exam A QUESTION 1 You use YARN to
70-775.exam Number: 70-775 Passing Score: 800 Time Limit: 120 min File Version: 1.0 Microsoft 70-775 Perform Data Engineering on Microsoft Azure HDInsight Version 1.0 Exam A QUESTION 1 You use YARN to
Dynamics 365. for Finance and Operations, Enterprise edition (onpremises) system requirements
 system requirements") Dynamics 365 ignite for Finance and Operations, Enterprise edition (onpremises) system requirements This document describes the various system requirements for Microsoft Dynamics 365 for Finance and Operations,
Dynamics 365 ignite for Finance and Operations, Enterprise edition (onpremises) system requirements This document describes the various system requirements for Microsoft Dynamics 365 for Finance and Operations,
Grand Challenge: Scalable Stateful Stream Processing for Smart Grids
 Grand Challenge: Scalable Stateful Stream Processing for Smart Grids Raul Castro Fernandez, Matthias Weidlich, Peter Pietzuch Imperial College London {rc311, m.weidlich, prp}@imperial.ac.uk Avigdor Gal
Grand Challenge: Scalable Stateful Stream Processing for Smart Grids Raul Castro Fernandez, Matthias Weidlich, Peter Pietzuch Imperial College London {rc311, m.weidlich, prp}@imperial.ac.uk Avigdor Gal
Overview. Prerequisites. Course Outline. Course Outline :: Apache Spark Development::
 Title Duration : Apache Spark Development : 4 days Overview Spark is a fast and general cluster computing system for Big Data. It provides high-level APIs in Scala, Java, Python, and R, and an optimized
Title Duration : Apache Spark Development : 4 days Overview Spark is a fast and general cluster computing system for Big Data. It provides high-level APIs in Scala, Java, Python, and R, and an optimized
Using Apache Beam for Batch, Streaming, and Everything in Between. Dan Halperin Apache Beam PMC Senior Software Engineer, Google
 Abstract Apache Beam is a unified programming model capable of expressing a wide variety of both traditional batch and complex streaming use cases. By neatly separating properties of the data from run-time
Abstract Apache Beam is a unified programming model capable of expressing a wide variety of both traditional batch and complex streaming use cases. By neatly separating properties of the data from run-time
Viper: Communication-Layer Determinism and Scaling in Low-Latency Stream Processing
 Viper: Communication-Layer Determinism and Scaling in Low-Latency Stream Processing Ivan Walulya, Yiannis Nikolakopoulos, Vincenzo Gulisano Marina Papatriantafilou and Philippas Tsigas Auto-DaSP 2017 Chalmers
Viper: Communication-Layer Determinism and Scaling in Low-Latency Stream Processing Ivan Walulya, Yiannis Nikolakopoulos, Vincenzo Gulisano Marina Papatriantafilou and Philippas Tsigas Auto-DaSP 2017 Chalmers
Oracle Exadata: Strategy and Roadmap
 Oracle Exadata: Strategy and Roadmap - New Technologies, Cloud, and On-Premises Juan Loaiza Senior Vice President, Database Systems Technologies, Oracle Safe Harbor Statement The following is intended
Oracle Exadata: Strategy and Roadmap - New Technologies, Cloud, and On-Premises Juan Loaiza Senior Vice President, Database Systems Technologies, Oracle Safe Harbor Statement The following is intended
Nowcasting. D B M G Data Base and Data Mining Group of Politecnico di Torino. Big Data: Hype or Hallelujah? Big data hype?
 Big data hype? Big Data: Hype or Hallelujah? Data Base and Data Mining Group of 2 Google Flu trends On the Internet February 2010 detected flu outbreak two weeks ahead of CDC data Nowcasting http://www.internetlivestats.com/
Big data hype? Big Data: Hype or Hallelujah? Data Base and Data Mining Group of 2 Google Flu trends On the Internet February 2010 detected flu outbreak two weeks ahead of CDC data Nowcasting http://www.internetlivestats.com/
A Generic Microservice Architecture for Environmental Data Management
 A Generic Microservice Architecture for Environmental Data Management Clemens Düpmeier, Eric Braun, Thorsten Schlachter, Karl-Uwe Stucky, Wolfgang Suess KIT The Research University in the Helmholtz Association
A Generic Microservice Architecture for Environmental Data Management Clemens Düpmeier, Eric Braun, Thorsten Schlachter, Karl-Uwe Stucky, Wolfgang Suess KIT The Research University in the Helmholtz Association
vsan 6.6 Performance Improvements First Published On: Last Updated On:
 vsan 6.6 Performance Improvements First Published On: 07-24-2017 Last Updated On: 07-28-2017 1 Table of Contents 1. Overview 1.1.Executive Summary 1.2.Introduction 2. vsan Testing Configuration and Conditions
vsan 6.6 Performance Improvements First Published On: 07-24-2017 Last Updated On: 07-28-2017 1 Table of Contents 1. Overview 1.1.Executive Summary 1.2.Introduction 2. vsan Testing Configuration and Conditions
Challenges for Data Driven Systems
 Challenges for Data Driven Systems Eiko Yoneki University of Cambridge Computer Laboratory Data Centric Systems and Networking Emergence of Big Data Shift of Communication Paradigm From end-to-end to data
Challenges for Data Driven Systems Eiko Yoneki University of Cambridge Computer Laboratory Data Centric Systems and Networking Emergence of Big Data Shift of Communication Paradigm From end-to-end to data
Making the Most of Hadoop with Optimized Data Compression (and Boost Performance) Mark Cusack. Chief Architect RainStor
 Mark Cusack. Chief Architect RainStor") Making the Most of Hadoop with Optimized Data Compression (and Boost Performance) Mark Cusack Chief Architect RainStor Agenda Importance of Hadoop + data compression Data compression techniques Compression,
Making the Most of Hadoop with Optimized Data Compression (and Boost Performance) Mark Cusack Chief Architect RainStor Agenda Importance of Hadoop + data compression Data compression techniques Compression,
Stanislav Harvan Internet of Things
 Stanislav Harvan v-sharva@microsoft.com Internet of Things IoT v číslach Gartner: V roku 2020 bude na Internet pripojených viac ako 25mld zariadení: 1,5mld smart TV 2,5mld pc 5mld smart phone 16mld dedicated
Stanislav Harvan v-sharva@microsoft.com Internet of Things IoT v číslach Gartner: V roku 2020 bude na Internet pripojených viac ako 25mld zariadení: 1,5mld smart TV 2,5mld pc 5mld smart phone 16mld dedicated
Distributed systems for stream processing
 Distributed systems for stream processing Apache Kafka and Spark Structured Streaming Alena Hall Alena Hall Large-scale data processing Distributed Systems Functional Programming Data Science & Machine
Distributed systems for stream processing Apache Kafka and Spark Structured Streaming Alena Hall Alena Hall Large-scale data processing Distributed Systems Functional Programming Data Science & Machine
MOHA: Many-Task Computing Framework on Hadoop
 Apache: Big Data North America 2017 @ Miami MOHA: Many-Task Computing Framework on Hadoop Soonwook Hwang Korea Institute of Science and Technology Information May 18, 2017 Table of Contents Introduction
Apache: Big Data North America 2017 @ Miami MOHA: Many-Task Computing Framework on Hadoop Soonwook Hwang Korea Institute of Science and Technology Information May 18, 2017 Table of Contents Introduction
17/05/2017. What we ll cover. Who is Greg? Why PaaS and SaaS? What we re not discussing: IaaS
 What are all those Azure* and Power* services and why do I want them? Dr Greg Low SQL Down Under greg@sqldownunder.com Who is Greg? CEO and Principal Mentor at SDU Data Platform MVP Microsoft Regional
What are all those Azure* and Power* services and why do I want them? Dr Greg Low SQL Down Under greg@sqldownunder.com Who is Greg? CEO and Principal Mentor at SDU Data Platform MVP Microsoft Regional
Big Data. Big Data Analyst. Big Data Engineer. Big Data Architect
 Big Data Big Data Analyst INTRODUCTION TO BIG DATA ANALYTICS ANALYTICS PROCESSING TECHNIQUES DATA TRANSFORMATION & BATCH PROCESSING REAL TIME (STREAM) DATA PROCESSING Big Data Engineer BIG DATA FOUNDATION
Big Data Big Data Analyst INTRODUCTION TO BIG DATA ANALYTICS ANALYTICS PROCESSING TECHNIQUES DATA TRANSFORMATION & BATCH PROCESSING REAL TIME (STREAM) DATA PROCESSING Big Data Engineer BIG DATA FOUNDATION
A Preliminary Approach for Modeling Energy Efficiency for K-Means Clustering Applications in Data Centers
 A Preliminary Approach for Modeling Energy Efficiency for K-Means Clustering Applications in Data Centers Da Qi Ren, Jianhuan Wen and Zhenya Li Futurewei Technologies 2330 Central Expressway, Santa Clara,
A Preliminary Approach for Modeling Energy Efficiency for K-Means Clustering Applications in Data Centers Da Qi Ren, Jianhuan Wen and Zhenya Li Futurewei Technologies 2330 Central Expressway, Santa Clara,
10 Million Smart Meter Data with Apache HBase
 10 Million Smart Meter Data with Apache HBase 5/31/2017 OSS Solution Center Hitachi, Ltd. Masahiro Ito OSS Summit Japan 2017 Who am I? Masahiro Ito ( 伊藤雅博 ) Software Engineer at Hitachi, Ltd. Focus on
10 Million Smart Meter Data with Apache HBase 5/31/2017 OSS Solution Center Hitachi, Ltd. Masahiro Ito OSS Summit Japan 2017 Who am I? Masahiro Ito ( 伊藤雅博 ) Software Engineer at Hitachi, Ltd. Focus on
Grand Challenge: Scalable Stateful Stream Processing for Smart Grids
 Grand Challenge: Scalable Stateful Stream Processing for Smart Grids Raul Castro Fernandez, Matthias Weidlich, Peter Pietzuch Imperial College London {rc311, m.weidlich, prp}@imperial.ac.uk Avigdor Gal
Grand Challenge: Scalable Stateful Stream Processing for Smart Grids Raul Castro Fernandez, Matthias Weidlich, Peter Pietzuch Imperial College London {rc311, m.weidlich, prp}@imperial.ac.uk Avigdor Gal
Empowering People with Knowledge the Next Frontier for Web Search. Wei-Ying Ma Assistant Managing Director Microsoft Research Asia
 Empowering People with Knowledge the Next Frontier for Web Search Wei-Ying Ma Assistant Managing Director Microsoft Research Asia Important Trends for Web Search Organizing all information Addressing user
Empowering People with Knowledge the Next Frontier for Web Search Wei-Ying Ma Assistant Managing Director Microsoft Research Asia Important Trends for Web Search Organizing all information Addressing user
BIG DATA TESTING: A UNIFIED VIEW
 http://core.ecu.edu/strg BIG DATA TESTING: A UNIFIED VIEW BY NAM THAI ECU, Computer Science Department, March 16, 2016 2/30 PRESENTATION CONTENT 1. Overview of Big Data A. 5 V s of Big Data B. Data generation
http://core.ecu.edu/strg BIG DATA TESTING: A UNIFIED VIEW BY NAM THAI ECU, Computer Science Department, March 16, 2016 2/30 PRESENTATION CONTENT 1. Overview of Big Data A. 5 V s of Big Data B. Data generation
Colin Cunningham, Intel Kumaran Siva, Intel Sandeep Mahajan, Oracle 03-Oct :45 p.m. - 5:30 p.m. Moscone West - Room 3020
 Colin Cunningham, Intel Kumaran Siva, Intel Sandeep Mahajan, Oracle 03-Oct-2017 4:45 p.m. - 5:30 p.m. Moscone West - Room 3020 Big Data Talk Exploring New SSD Usage Models to Accelerate Cloud Performance
Colin Cunningham, Intel Kumaran Siva, Intel Sandeep Mahajan, Oracle 03-Oct-2017 4:45 p.m. - 5:30 p.m. Moscone West - Room 3020 Big Data Talk Exploring New SSD Usage Models to Accelerate Cloud Performance
Enable IoT Solutions using Azure
 Internet Of Things A WHITE PAPER SERIES Enable IoT Solutions using Azure 1 2 TABLE OF CONTENTS EXECUTIVE SUMMARY INTERNET OF THINGS GATEWAY EVENT INGESTION EVENT PERSISTENCE EVENT ACTIONS 3 SYNTEL S IoT
Internet Of Things A WHITE PAPER SERIES Enable IoT Solutions using Azure 1 2 TABLE OF CONTENTS EXECUTIVE SUMMARY INTERNET OF THINGS GATEWAY EVENT INGESTION EVENT PERSISTENCE EVENT ACTIONS 3 SYNTEL S IoT
arxiv: v1 [cs.dc] 2 Dec 2017
![arxiv: v1 [cs.dc] 2 Dec 2017](/thumbs/82/85880664.jpg "arxiv: v1 [cs.dc] 2 Dec 2017") Toward Reliable and Rapid Elasticity for Streaming Dataflows on Clouds Anshu Shukla and Yogesh Simmhan Department of Computational and Data Sciences Indian Institute of Science, Bangalore 5612, India Email:
Toward Reliable and Rapid Elasticity for Streaming Dataflows on Clouds Anshu Shukla and Yogesh Simmhan Department of Computational and Data Sciences Indian Institute of Science, Bangalore 5612, India Email:
DRIZZLE: FAST AND Adaptable STREAM PROCESSING AT SCALE
 DRIZZLE: FAST AND Adaptable STREAM PROCESSING AT SCALE Shivaram Venkataraman, Aurojit Panda, Kay Ousterhout, Michael Armbrust, Ali Ghodsi, Michael Franklin, Benjamin Recht, Ion Stoica STREAMING WORKLOADS
DRIZZLE: FAST AND Adaptable STREAM PROCESSING AT SCALE Shivaram Venkataraman, Aurojit Panda, Kay Ousterhout, Michael Armbrust, Ali Ghodsi, Michael Franklin, Benjamin Recht, Ion Stoica STREAMING WORKLOADS
Cloudline Autonomous Driving Solutions. Accelerating insights through a new generation of Data and Analytics October, 2018
 Cloudline Autonomous Driving Solutions Accelerating insights through a new generation of Data and Analytics October, 2018 HPE big data analytics solutions power the data-driven enterprise Secure, workload-optimized
Cloudline Autonomous Driving Solutions Accelerating insights through a new generation of Data and Analytics October, 2018 HPE big data analytics solutions power the data-driven enterprise Secure, workload-optimized
Data Transformation and Migration in Polystores
 Data Transformation and Migration in Polystores Adam Dziedzic, Aaron Elmore & Michael Stonebraker September 15th, 2016 Agenda Data Migration for Polystores: What & Why? How? Acceleration of physical data
Data Transformation and Migration in Polystores Adam Dziedzic, Aaron Elmore & Michael Stonebraker September 15th, 2016 Agenda Data Migration for Polystores: What & Why? How? Acceleration of physical data
ProphetStor DiskProphet Ensures SLA for VMware vsan
 ProphetStor DiskProphet Ensures SLA for VMware vsan 2017 ProphetStor Data Services, Inc. 0 ProphetStor DiskProphet Ensures SLA for VMware vsan Table of Contents Summary... 2 The Challenges... 2 SLA Compliance...
ProphetStor DiskProphet Ensures SLA for VMware vsan 2017 ProphetStor Data Services, Inc. 0 ProphetStor DiskProphet Ensures SLA for VMware vsan Table of Contents Summary... 2 The Challenges... 2 SLA Compliance...
STYX: Stream Processing with Trustworthy Cloud-based Execution
 STYX: Stream Processing with Trustworthy Cloud-based Execution Julian Stephen, Savvas Savvides, Vinaitheerthan Sundaram, Masoud Saeida Ardekani, Patrick Eugster October 6, 2016 Purdue University Table
STYX: Stream Processing with Trustworthy Cloud-based Execution Julian Stephen, Savvas Savvides, Vinaitheerthan Sundaram, Masoud Saeida Ardekani, Patrick Eugster October 6, 2016 Purdue University Table
Fast and Easy Stream Processing with Hazelcast Jet. Gokhan Oner Hazelcast
 Fast and Easy Stream Processing with Hazelcast Jet Gokhan Oner Hazelcast Stream Processing Why should I bother? What is stream processing? Data Processing: Massage the data when moving from place to place.
Fast and Easy Stream Processing with Hazelcast Jet Gokhan Oner Hazelcast Stream Processing Why should I bother? What is stream processing? Data Processing: Massage the data when moving from place to place.
Energy Management with AWS
 Energy Management with AWS Kyle Hart and Nandakumar Sreenivasan Amazon Web Services August [XX], 2017 Tampa Convention Center Tampa, Florida What is Cloud? The NIST Definition Broad Network Access On-Demand
Energy Management with AWS Kyle Hart and Nandakumar Sreenivasan Amazon Web Services August [XX], 2017 Tampa Convention Center Tampa, Florida What is Cloud? The NIST Definition Broad Network Access On-Demand