Spark: A Brief History.
|
|
|
- Daniel Stokes
- 6 years ago
- Views:
Transcription
1 Spark: A Brief History
2 A Brief History: 2004 MapReduce paper 2010 Spark paper Google 2008 Hadoop Summit 2014 Apache Spark top-level 2006 Yahoo!
3 A Brief History: MapReduce circa 1979 Stanford, MIT, CMU, etc. set/list operations in LISP, Prolog, etc., for parallel processing www-formal.stanford.edu/jmc/history/lisp/lisp.htm circa 2004 Google MapReduce: Simplified Data Processing on Large Clusters Jeffrey Dean and Sanjay Ghemawat research.google.com/archive/mapreduce.html circa 2006 Apache Hadoop, originating from the Nutch Project Doug Cutting research.yahoo.com/files/cutting.pdf circa 2008 Yahoo web scale search indexing Hadoop Summit, HUG, etc. developer.yahoo.com/hadoop/ circa 2009 Amazon AWS Elastic MapReduce Hadoop modified for EC2/S3, plus support for Hive, Pig, Cascading, etc. aws.amazon.com/elasticmapreduce/
4 A Brief History: MapReduce MapReduce use cases showed two major limitations: 1. difficultly of programming directly in MR 2. performance bottlenecks, or batch not fitting the use cases In short, MR doesn t compose well for large applications Therefore, people built specialized systems as workarounds
5 A Brief History: MapReduce Pregel Giraph Dremel Drill Tez MapReduce Impala GraphLab Storm S4 General Batch Processing Specialized Systems: iterative, interactive, streaming, graph, etc. The State of Spark, and Where We're Going Next Matei Zaharia Spark Summit (2013) youtu.be/nu6vo2ejab4
6 A Brief History: Spark 2004 MapReduce paper 2010 Spark paper Google 2006 Yahoo! 2008 Hadoop Summit 2014 Apache Spark top-level Spark: Cluster Computing with Working Sets Matei Zaharia, Mosharaf Chowdhury, Michael J. Franklin, Scott Shenker, Ion Stoica USENIX HotCloud (2010) people.csail.mit.edu/matei/papers/2010/hotcloud_spark.pdf! Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster Computing Matei Zaharia, Mosharaf Chowdhury, Tathagata Das, Ankur Dave, Justin Ma, Murphy McCauley, Michael J. Franklin, Scott Shenker, Ion Stoica NSDI (2012) usenix.org/system/files/conference/nsdi12/nsdi12-final138.pdf
7 A Brief History: Spark Unlike the various specialized systems, Spark s goal was to generalize MapReduce to support new apps within same engine Two reasonably small additions are enough to express the previous models: fast data sharing general DAGs This allows for an approach which is more efficient for the engine, and much simpler for the end users
 youtu.")
8 A Brief History: Spark The State of Spark, and Where We're Going Next Matei Zaharia Spark Summit (2013) youtu.be/nu6vo2ejab4 used as libs, instead of specialized systems
9 A Brief History: Spark Some key points about Spark: handles batch, interactive, and real-time within a single framework native integration with Java, Python, Scala programming at a higher level of abstraction more general: map/reduce is just one set of supported constructs
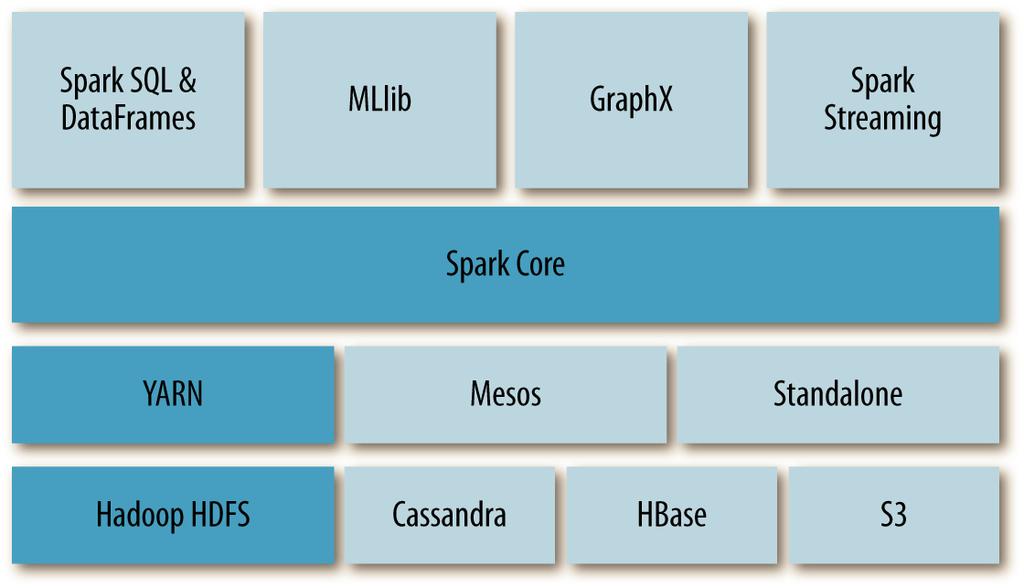
10


11 Resilient Distributed Datasets A Fault- Tolerant Abstraction for In- Memory Cluster Computing Matei Zaharia, Mosharaf Chowdhury, Tathagata Das, Ankur Dave, Justin Ma, Murphy McCauley, Michael Franklin, Scott Shenker, Ion Stoica UC Berkeley UC BERKELEY
12 Motivation MapReduce greatly simplified big data analysis on large, unreliable clusters But as soon as it got popular, users wanted more:» More complex, multi- stage applications (e.g. iterative machine learning & graph processing)» More interactive ad- hoc queries Response: specialized frameworks for some of these apps (e.g. Pregel for graph processing)
13 Motivation Complex apps and interactive queries both need one thing that MapReduce lacks: Efficient primitives for data sharing In MapReduce, the only way to share data across jobs is stable storage slow!

14 Examples HDFS read HDFS write HDFS read HDFS write iter. 1 iter Input HDFS read query 1 query 2 result 1 result 2 Input query 3... result 3 Slow due to replication and disk I/O, but necessary for fault tolerance

15 Goal: In- Memory Data Sharing Input iter. 1 iter one- time processing query 1 query 2 Input query faster than network/disk, but how to get FT?
16 Challenge How to design a distributed memory abstraction that is both fault- tolerant and efficient?
17 Challenge Existing storage abstractions have interfaces based on fine- grained updates to mutable state» RAMCloud, databases, distributed mem, Piccolo Requires replicating data or logs across nodes for fault tolerance» Costly for data- intensive apps» x slower than memory write
18 Solution: Resilient Distributed Datasets (RDDs) Restricted form of distributed shared memory» Immutable, partitioned collections of records» Can only be built through coarse- grained deterministic transformations (map, filter, join, ) Efficient fault recovery using lineage» Log one operation to apply to many elements» Recompute lost partitions on failure» No cost if nothing fails

19 RDD Recovery Input iter. 1 iter one- time processing query 1 query 2 Input query 3...
20 Generality of RDDs Despite their restrictions, RDDs can express surprisingly many parallel algorithms» These naturally apply the same operation to many items Unify many current programming models» Data flow models: MapReduce, Dryad, SQL,» Specialized models for iterative apps: BSP (Pregel), iterative MapReduce (Haloop), bulk incremental, Support new apps that these models don t
21 Tradeoff Space Fine Granularity of Updates K- V stores, databases, RAMCloud HDFS Network bandwidth Best for transactional workloads RDDs Memory bandwidth Best for batch workloads Coarse Low Write Throughput High
22 Spark Programming Interface DryadLINQ- like API in the Scala language Usable interactively from Scala interpreter Provides:» Resilient distributed datasets (RDDs)» Operations on RDDs: transformations (build new RDDs), actions (compute and output results)» Control of each RDD s partitioning (layout across nodes) and persistence (storage in RAM, on disk, etc)
23 Spark Operations Transformations (define a new RDD) map filter sample groupbykey reducebykey sortbykey flatmap union join cogroup cross mapvalues Actions (return a result to driver program) collect reduce count save lookupkey

) messages = errors.map(_.")
).count messages.filter(_.contains( bar )).")
 data)")
24 Example: Log Mining Load error messages from a log into memory, then interactively search for various patterns Base lines = spark.textfile( hdfs://... ) Transformed RDD RDD results errors = lines.filter(_.startswith( ERROR )) messages = errors.map(_.split( \t )(2)) tasks Master messages.persist() Worker Block 1 Msgs. 1 messages.filter(_.contains( foo )).count messages.filter(_.contains( bar )).count Result: scaled full- text to search 1 TB data of Wikipedia in 5-7 sec in <1 (vs sec 170 (vs sec 20 for sec on- disk for on- disk data) data) Action Msgs. 3 Worker Block 3 Worker Block 2 Msgs. 2
25 Task Scheduler Dryad- like DAGs Pipelines functions within a stage Stage 1 A: B: groupby G: Locality & data reuse aware Partitioning- aware to avoid shuffles C: D: map E: Stage 2 F: union join Stage 3 = cached data partition
26
27 What is RDD? Resilient Distributed Dataset - A big collection of data with following properties - Immutable - Distributed - Lazily evaluated - Type inferred - Cacheable
28 Pseudo Monad Wraps iterator + partitions distribution Keeps track of history for fault tolerance Lazily evaluated, chaining of expressions
29 Partitions Logical division of data Derived from Hadoop Map/Reduce All Input,Intermediate and output data will be represented as partitions Partitions are basic unit of parallelism RDD data is just collection of partitions
30 Partition from Input Data RDD Partition 1 Partition 2 Partition 3 Input Format Data in HDFS Chunk 1 Chunk 2 Chunk 3
31 Partition and Immutability All partitions are immutable Every transformation generates new partition Partition immutability driven by underneath storage like HDFS Partition immutability allows for fault recovery
32 Partitions and Distribution Partitions derived from HDFS are distributed by default Partitions also location aware Location awareness of partitions allow for data locality For computed data, using caching we can distribute in memory also
33 Accessing partitions We can access partition together rather single row at a time mapparititons API of RDD allows us that Accessing partition at a time allows us to do some partionwise operation which cannot be done by accessing single row.
34 Partition for transformed Data Partitioning will be different for key/value pairs that are generated by shuffle operation Partitioning is driven by partitioner specified By default HashPartitioner is used You can use your own partitioner also
35 Hash Partitioning Input RDD Partition 1 Partition 2 Partition 3 Hash(key)%no.of.partitions Ouptut RDD Partition 1 Partition 2
36 Custom Partitioner Partition the data according to your data structure Custom partitioning allows control over no of partitions and the distribution of data across when grouping or reducing is done
37 Look up operation Partitioning allows faster lookups Lookup operation allows to look up for a given value by specifying the key Using partitioner, lookup determines which partition look for Then it only need to look in that partition If no partition is specified, it will fallback to filter
38 Parent(Dependency) Each RDD has access to it s parent RDD Nil is the value of parent for first RDD Before computing it s value, it always computes it s parent This chain of running allows for laziness
39 Sub classing Each spark operator, creates an instance of specific sub class of RDD map operator results in MappedRDD, flatmap in FlatMappedRDD etc Subclass allows RDD to remember the operation that is performed in the transformation
40 RDD transformations val datardd = sc.textfile(args (1)) val splitrdd = datardd. flatmap(value => value.split( ) Nil Hadoop RDD datardd : MappedRDD splitrdd: FlatMappedRDD
41 Compute Compute is the function for evaluation of each partition in RDD Compute is an abstract method of RDD Each sub class of RDD like MappedRDD, FilteredRDD have to override this method
42 RDD actions val datardd = sc. textfile(args(1)) val flatmaprdd = datardd.flatmap (value => value.split( ) flatmaprdd.collect() Nil Hadoop RDD compute Mapped RDD compute FlatMap RDD compute runjob
43 runjob API runjob API of RDD is the api to implement actions runjob allows to take each partition and allow you evaluate All spark actions internally use runjob api.
44 Caching cache internally uses persist API persist sets a specific storage level for a given RDD Spark context tracks persistent RDD When first evaluates, partition will be put into memory by block manager
45 Block manager Handles all in memory data in spark Responsible for Cached Data ( BlockRDD) Shuffle Data Broadcast data Partition will be stored in Block with id (RDD. id, partition_index)
46 How caching works? Partition iterator checks the storage level if Storage level is set it calls cachemanager.getorcompute(partition) as iterator is run for each RDD evaluation, its transparent to user
47 A Brief History: Spark The State of Spark, and Where We're Going Next Matei Zaharia Spark Summit (2013) youtu.be/nu6vo2ejab4
 to")
).map(_.")

48 Fault Recovery RDDs track the graph of transformations that built them (their lineage) to rebuild lost data E.g.: messages = textfile(...).filter(_.contains( error )).map(_.split( \t )(2)) HadoopRDD FilteredRDD MappedRDD HadoopRDD FilteredRDD MappedRDD path = hdfs:// func = _.contains(...) func = _.split( )
49 Fault Recovery Results Iteratrion time (s) Failure happens Iteration
Resilient Distributed Datasets
 Resilient Distributed Datasets A Fault- Tolerant Abstraction for In- Memory Cluster Computing Matei Zaharia, Mosharaf Chowdhury, Tathagata Das, Ankur Dave, Justin Ma, Murphy McCauley, Michael Franklin,
Resilient Distributed Datasets A Fault- Tolerant Abstraction for In- Memory Cluster Computing Matei Zaharia, Mosharaf Chowdhury, Tathagata Das, Ankur Dave, Justin Ma, Murphy McCauley, Michael Franklin,
Spark. In- Memory Cluster Computing for Iterative and Interactive Applications
 Spark In- Memory Cluster Computing for Iterative and Interactive Applications Matei Zaharia, Mosharaf Chowdhury, Tathagata Das, Ankur Dave, Justin Ma, Murphy McCauley, Michael Franklin, Scott Shenker,
Spark In- Memory Cluster Computing for Iterative and Interactive Applications Matei Zaharia, Mosharaf Chowdhury, Tathagata Das, Ankur Dave, Justin Ma, Murphy McCauley, Michael Franklin, Scott Shenker,
Spark. In- Memory Cluster Computing for Iterative and Interactive Applications
 Spark In- Memory Cluster Computing for Iterative and Interactive Applications Matei Zaharia, Mosharaf Chowdhury, Tathagata Das, Ankur Dave, Justin Ma, Murphy McCauley, Michael Franklin, Scott Shenker,
Spark In- Memory Cluster Computing for Iterative and Interactive Applications Matei Zaharia, Mosharaf Chowdhury, Tathagata Das, Ankur Dave, Justin Ma, Murphy McCauley, Michael Franklin, Scott Shenker,
Fast, Interactive, Language-Integrated Cluster Computing
 Spark Fast, Interactive, Language-Integrated Cluster Computing Matei Zaharia, Mosharaf Chowdhury, Tathagata Das, Ankur Dave, Justin Ma, Murphy McCauley, Michael Franklin, Scott Shenker, Ion Stoica www.spark-project.org
Spark Fast, Interactive, Language-Integrated Cluster Computing Matei Zaharia, Mosharaf Chowdhury, Tathagata Das, Ankur Dave, Justin Ma, Murphy McCauley, Michael Franklin, Scott Shenker, Ion Stoica www.spark-project.org
Spark. Cluster Computing with Working Sets. Matei Zaharia, Mosharaf Chowdhury, Michael Franklin, Scott Shenker, Ion Stoica.
 Spark Cluster Computing with Working Sets Matei Zaharia, Mosharaf Chowdhury, Michael Franklin, Scott Shenker, Ion Stoica UC Berkeley Background MapReduce and Dryad raised level of abstraction in cluster
Spark Cluster Computing with Working Sets Matei Zaharia, Mosharaf Chowdhury, Michael Franklin, Scott Shenker, Ion Stoica UC Berkeley Background MapReduce and Dryad raised level of abstraction in cluster
RESILIENT DISTRIBUTED DATASETS: A FAULT-TOLERANT ABSTRACTION FOR IN-MEMORY CLUSTER COMPUTING
 RESILIENT DISTRIBUTED DATASETS: A FAULT-TOLERANT ABSTRACTION FOR IN-MEMORY CLUSTER COMPUTING Matei Zaharia, Mosharaf Chowdhury, Tathagata Das, Ankur Dave, Justin Ma, Murphy McCauley, Michael J. Franklin,
RESILIENT DISTRIBUTED DATASETS: A FAULT-TOLERANT ABSTRACTION FOR IN-MEMORY CLUSTER COMPUTING Matei Zaharia, Mosharaf Chowdhury, Tathagata Das, Ankur Dave, Justin Ma, Murphy McCauley, Michael J. Franklin,
CSE 444: Database Internals. Lecture 23 Spark
 CSE 444: Database Internals Lecture 23 Spark References Spark is an open source system from Berkeley Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster Computing. Matei
CSE 444: Database Internals Lecture 23 Spark References Spark is an open source system from Berkeley Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster Computing. Matei
Data-intensive computing systems
 Data-intensive computing systems University of Verona Computer Science Department Damiano Carra Acknowledgements q Credits Part of the course material is based on slides provided by the following authors
Data-intensive computing systems University of Verona Computer Science Department Damiano Carra Acknowledgements q Credits Part of the course material is based on slides provided by the following authors
Massive Online Analysis - Storm,Spark
 Massive Online Analysis - Storm,Spark presentation by R. Kishore Kumar Research Scholar Department of Computer Science & Engineering Indian Institute of Technology, Kharagpur Kharagpur-721302, India (R
Massive Online Analysis - Storm,Spark presentation by R. Kishore Kumar Research Scholar Department of Computer Science & Engineering Indian Institute of Technology, Kharagpur Kharagpur-721302, India (R
Analytics in Spark. Yanlei Diao Tim Hunter. Slides Courtesy of Ion Stoica, Matei Zaharia and Brooke Wenig
 Analytics in Spark Yanlei Diao Tim Hunter Slides Courtesy of Ion Stoica, Matei Zaharia and Brooke Wenig Outline 1. A brief history of Big Data and Spark 2. Technical summary of Spark 3. Unified analytics
Analytics in Spark Yanlei Diao Tim Hunter Slides Courtesy of Ion Stoica, Matei Zaharia and Brooke Wenig Outline 1. A brief history of Big Data and Spark 2. Technical summary of Spark 3. Unified analytics
MapReduce & Resilient Distributed Datasets. Yiqing Hua, Mengqi(Mandy) Xia
 Xia") MapReduce & Resilient Distributed Datasets Yiqing Hua, Mengqi(Mandy) Xia Outline - MapReduce: - - Resilient Distributed Datasets (RDD) - - Motivation Examples The Design and How it Works Performance Motivation
MapReduce & Resilient Distributed Datasets Yiqing Hua, Mengqi(Mandy) Xia Outline - MapReduce: - - Resilient Distributed Datasets (RDD) - - Motivation Examples The Design and How it Works Performance Motivation
CS435 Introduction to Big Data FALL 2018 Colorado State University. 10/22/2018 Week 10-A Sangmi Lee Pallickara. FAQs.
 10/22/2018 - FALL 2018 W10.A.0.0 10/22/2018 - FALL 2018 W10.A.1 FAQs Term project: Proposal 5:00PM October 23, 2018 PART 1. LARGE SCALE DATA ANALYTICS IN-MEMORY CLUSTER COMPUTING Computer Science, Colorado
10/22/2018 - FALL 2018 W10.A.0.0 10/22/2018 - FALL 2018 W10.A.1 FAQs Term project: Proposal 5:00PM October 23, 2018 PART 1. LARGE SCALE DATA ANALYTICS IN-MEMORY CLUSTER COMPUTING Computer Science, Colorado
Today s content. Resilient Distributed Datasets(RDDs) Spark and its data model
 Spark and its data model") Today s content Resilient Distributed Datasets(RDDs) ------ Spark and its data model Resilient Distributed Datasets: A Fault- Tolerant Abstraction for In-Memory Cluster Computing -- Spark By Matei Zaharia,
Today s content Resilient Distributed Datasets(RDDs) ------ Spark and its data model Resilient Distributed Datasets: A Fault- Tolerant Abstraction for In-Memory Cluster Computing -- Spark By Matei Zaharia,
a Spark in the cloud iterative and interactive cluster computing
 a Spark in the cloud iterative and interactive cluster computing Matei Zaharia, Mosharaf Chowdhury, Michael Franklin, Scott Shenker, Ion Stoica UC Berkeley Background MapReduce and Dryad raised level of
a Spark in the cloud iterative and interactive cluster computing Matei Zaharia, Mosharaf Chowdhury, Michael Franklin, Scott Shenker, Ion Stoica UC Berkeley Background MapReduce and Dryad raised level of
CompSci 516: Database Systems
 CompSci 516 Database Systems Lecture 12 Map-Reduce and Spark Instructor: Sudeepa Roy Duke CS, Fall 2017 CompSci 516: Database Systems 1 Announcements Practice midterm posted on sakai First prepare and
CompSci 516 Database Systems Lecture 12 Map-Reduce and Spark Instructor: Sudeepa Roy Duke CS, Fall 2017 CompSci 516: Database Systems 1 Announcements Practice midterm posted on sakai First prepare and
Big Data Infrastructures & Technologies
 Big Data Infrastructures & Technologies Spark and MLLIB OVERVIEW OF SPARK What is Spark? Fast and expressive cluster computing system interoperable with Apache Hadoop Improves efficiency through: In-memory
Big Data Infrastructures & Technologies Spark and MLLIB OVERVIEW OF SPARK What is Spark? Fast and expressive cluster computing system interoperable with Apache Hadoop Improves efficiency through: In-memory
Announcements. Reading Material. Map Reduce. The Map-Reduce Framework 10/3/17. Big Data. CompSci 516: Database Systems
 Announcements CompSci 516 Database Systems Lecture 12 - and Spark Practice midterm posted on sakai First prepare and then attempt! Midterm next Wednesday 10/11 in class Closed book/notes, no electronic
Announcements CompSci 516 Database Systems Lecture 12 - and Spark Practice midterm posted on sakai First prepare and then attempt! Midterm next Wednesday 10/11 in class Closed book/notes, no electronic
Part II: Software Infrastructure in Data Centers: Distributed Execution Engines
 CSE 6350 File and Storage System Infrastructure in Data centers Supporting Internet-wide Services Part II: Software Infrastructure in Data Centers: Distributed Execution Engines 1 MapReduce: Simplified
CSE 6350 File and Storage System Infrastructure in Data centers Supporting Internet-wide Services Part II: Software Infrastructure in Data Centers: Distributed Execution Engines 1 MapReduce: Simplified
2/4/2019 Week 3- A Sangmi Lee Pallickara
 Week 3-A-0 2/4/2019 Colorado State University, Spring 2019 Week 3-A-1 CS535 BIG DATA FAQs PART A. BIG DATA TECHNOLOGY 3. DISTRIBUTED COMPUTING MODELS FOR SCALABLE BATCH COMPUTING SECTION 1: MAPREDUCE PA1
Week 3-A-0 2/4/2019 Colorado State University, Spring 2019 Week 3-A-1 CS535 BIG DATA FAQs PART A. BIG DATA TECHNOLOGY 3. DISTRIBUTED COMPUTING MODELS FOR SCALABLE BATCH COMPUTING SECTION 1: MAPREDUCE PA1
Spark Overview. Professor Sasu Tarkoma.
 Spark Overview 2015 Professor Sasu Tarkoma www.cs.helsinki.fi Apache Spark Spark is a general-purpose computing framework for iterative tasks API is provided for Java, Scala and Python The model is based
Spark Overview 2015 Professor Sasu Tarkoma www.cs.helsinki.fi Apache Spark Spark is a general-purpose computing framework for iterative tasks API is provided for Java, Scala and Python The model is based
L3: Spark & RDD. CDS Department of Computational and Data Sciences. Department of Computational and Data Sciences
 Indian Institute of Science Bangalore, India भ रत य व ज ञ न स स थ न ब गल र, भ रत Department of Computational and Data Sciences L3: Spark & RDD Department of Computational and Data Science, IISc, 2016 This
Indian Institute of Science Bangalore, India भ रत य व ज ञ न स स थ न ब गल र, भ रत Department of Computational and Data Sciences L3: Spark & RDD Department of Computational and Data Science, IISc, 2016 This
Fault Tolerant Distributed Main Memory Systems
 Fault Tolerant Distributed Main Memory Systems CompSci 590.04 Instructor: Ashwin Machanavajjhala Lecture 16 : 590.04 Fall 15 1 Recap: Map Reduce! map!!,!! list!!!!reduce!!, list(!! )!! Map Phase (per record
Fault Tolerant Distributed Main Memory Systems CompSci 590.04 Instructor: Ashwin Machanavajjhala Lecture 16 : 590.04 Fall 15 1 Recap: Map Reduce! map!!,!! list!!!!reduce!!, list(!! )!! Map Phase (per record
Spark & Spark SQL. High- Speed In- Memory Analytics over Hadoop and Hive Data. Instructor: Duen Horng (Polo) Chau
 Chau") CSE 6242 / CX 4242 Data and Visual Analytics Georgia Tech Spark & Spark SQL High- Speed In- Memory Analytics over Hadoop and Hive Data Instructor: Duen Horng (Polo) Chau Slides adopted from Matei Zaharia
CSE 6242 / CX 4242 Data and Visual Analytics Georgia Tech Spark & Spark SQL High- Speed In- Memory Analytics over Hadoop and Hive Data Instructor: Duen Horng (Polo) Chau Slides adopted from Matei Zaharia
MapReduce Spark. Some slides are adapted from those of Jeff Dean and Matei Zaharia
 MapReduce Spark Some slides are adapted from those of Jeff Dean and Matei Zaharia What have we learnt so far? Distributed storage systems consistency semantics protocols for fault tolerance Paxos, Raft,
MapReduce Spark Some slides are adapted from those of Jeff Dean and Matei Zaharia What have we learnt so far? Distributed storage systems consistency semantics protocols for fault tolerance Paxos, Raft,
Dell In-Memory Appliance for Cloudera Enterprise
 Dell In-Memory Appliance for Cloudera Enterprise Spark Technology Overview and Streaming Workload Use Cases Author: Armando Acosta Hadoop Product Manager/Subject Matter Expert Armando_Acosta@Dell.com/
Dell In-Memory Appliance for Cloudera Enterprise Spark Technology Overview and Streaming Workload Use Cases Author: Armando Acosta Hadoop Product Manager/Subject Matter Expert Armando_Acosta@Dell.com/
Spark, Shark and Spark Streaming Introduction
 Spark, Shark and Spark Streaming Introduction Tushar Kale tusharkale@in.ibm.com June 2015 This Talk Introduction to Shark, Spark and Spark Streaming Architecture Deployment Methodology Performance References
Spark, Shark and Spark Streaming Introduction Tushar Kale tusharkale@in.ibm.com June 2015 This Talk Introduction to Shark, Spark and Spark Streaming Architecture Deployment Methodology Performance References
Programming Systems for Big Data
 Programming Systems for Big Data CS315B Lecture 17 Including material from Kunle Olukotun Prof. Aiken CS 315B Lecture 17 1 Big Data We ve focused on parallel programming for computational science There
Programming Systems for Big Data CS315B Lecture 17 Including material from Kunle Olukotun Prof. Aiken CS 315B Lecture 17 1 Big Data We ve focused on parallel programming for computational science There
CS Spark. Slides from Matei Zaharia and Databricks
 CS 5450 Spark Slides from Matei Zaharia and Databricks Goals uextend the MapReduce model to better support two common classes of analytics apps Iterative algorithms (machine learning, graphs) Interactive
CS 5450 Spark Slides from Matei Zaharia and Databricks Goals uextend the MapReduce model to better support two common classes of analytics apps Iterative algorithms (machine learning, graphs) Interactive
Discretized Streams. An Efficient and Fault-Tolerant Model for Stream Processing on Large Clusters
 Discretized Streams An Efficient and Fault-Tolerant Model for Stream Processing on Large Clusters Matei Zaharia, Tathagata Das, Haoyuan Li, Scott Shenker, Ion Stoica UC BERKELEY Motivation Many important
Discretized Streams An Efficient and Fault-Tolerant Model for Stream Processing on Large Clusters Matei Zaharia, Tathagata Das, Haoyuan Li, Scott Shenker, Ion Stoica UC BERKELEY Motivation Many important
Shark. Hive on Spark. Cliff Engle, Antonio Lupher, Reynold Xin, Matei Zaharia, Michael Franklin, Ion Stoica, Scott Shenker
 Shark Hive on Spark Cliff Engle, Antonio Lupher, Reynold Xin, Matei Zaharia, Michael Franklin, Ion Stoica, Scott Shenker Agenda Intro to Spark Apache Hive Shark Shark s Improvements over Hive Demo Alpha
Shark Hive on Spark Cliff Engle, Antonio Lupher, Reynold Xin, Matei Zaharia, Michael Franklin, Ion Stoica, Scott Shenker Agenda Intro to Spark Apache Hive Shark Shark s Improvements over Hive Demo Alpha
Integration of Machine Learning Library in Apache Apex
 Integration of Machine Learning Library in Apache Apex Anurag Wagh, Krushika Tapedia, Harsh Pathak Vishwakarma Institute of Information Technology, Pune, India Abstract- Machine Learning is a type of artificial
Integration of Machine Learning Library in Apache Apex Anurag Wagh, Krushika Tapedia, Harsh Pathak Vishwakarma Institute of Information Technology, Pune, India Abstract- Machine Learning is a type of artificial
Chapter 4: Apache Spark
 Chapter 4: Apache Spark Lecture Notes Winter semester 2016 / 2017 Ludwig-Maximilians-University Munich PD Dr. Matthias Renz 2015, Based on lectures by Donald Kossmann (ETH Zürich), as well as Jure Leskovec,
Chapter 4: Apache Spark Lecture Notes Winter semester 2016 / 2017 Ludwig-Maximilians-University Munich PD Dr. Matthias Renz 2015, Based on lectures by Donald Kossmann (ETH Zürich), as well as Jure Leskovec,
Lecture 11 Hadoop & Spark
 Lecture 11 Hadoop & Spark Dr. Wilson Rivera ICOM 6025: High Performance Computing Electrical and Computer Engineering Department University of Puerto Rico Outline Distributed File Systems Hadoop Ecosystem
Lecture 11 Hadoop & Spark Dr. Wilson Rivera ICOM 6025: High Performance Computing Electrical and Computer Engineering Department University of Puerto Rico Outline Distributed File Systems Hadoop Ecosystem
Shark: Hive on Spark
 Optional Reading (additional material) Shark: Hive on Spark Prajakta Kalmegh Duke University 1 What is Shark? Port of Apache Hive to run on Spark Compatible with existing Hive data, metastores, and queries
Optional Reading (additional material) Shark: Hive on Spark Prajakta Kalmegh Duke University 1 What is Shark? Port of Apache Hive to run on Spark Compatible with existing Hive data, metastores, and queries
Utah Distributed Systems Meetup and Reading Group - Map Reduce and Spark
 Utah Distributed Systems Meetup and Reading Group - Map Reduce and Spark JT Olds Space Monkey Vivint R&D January 19 2016 Outline 1 Map Reduce 2 Spark 3 Conclusion? Map Reduce Outline 1 Map Reduce 2 Spark
Utah Distributed Systems Meetup and Reading Group - Map Reduce and Spark JT Olds Space Monkey Vivint R&D January 19 2016 Outline 1 Map Reduce 2 Spark 3 Conclusion? Map Reduce Outline 1 Map Reduce 2 Spark
MapReduce, Hadoop and Spark. Bompotas Agorakis
 MapReduce, Hadoop and Spark Bompotas Agorakis Big Data Processing Most of the computations are conceptually straightforward on a single machine but the volume of data is HUGE Need to use many (1.000s)
MapReduce, Hadoop and Spark Bompotas Agorakis Big Data Processing Most of the computations are conceptually straightforward on a single machine but the volume of data is HUGE Need to use many (1.000s)
Introduction to MapReduce Algorithms and Analysis
 Introduction to MapReduce Algorithms and Analysis Jeff M. Phillips October 25, 2013 Trade-Offs Massive parallelism that is very easy to program. Cheaper than HPC style (uses top of the line everything)
Introduction to MapReduce Algorithms and Analysis Jeff M. Phillips October 25, 2013 Trade-Offs Massive parallelism that is very easy to program. Cheaper than HPC style (uses top of the line everything)
Apache Spark is a fast and general-purpose engine for large-scale data processing Spark aims at achieving the following goals in the Big data context
 1 Apache Spark is a fast and general-purpose engine for large-scale data processing Spark aims at achieving the following goals in the Big data context Generality: diverse workloads, operators, job sizes
1 Apache Spark is a fast and general-purpose engine for large-scale data processing Spark aims at achieving the following goals in the Big data context Generality: diverse workloads, operators, job sizes
Analytic Cloud with. Shelly Garion. IBM Research -- Haifa IBM Corporation
 Analytic Cloud with Shelly Garion IBM Research -- Haifa 2014 IBM Corporation Why Spark? Apache Spark is a fast and general open-source cluster computing engine for big data processing Speed: Spark is capable
Analytic Cloud with Shelly Garion IBM Research -- Haifa 2014 IBM Corporation Why Spark? Apache Spark is a fast and general open-source cluster computing engine for big data processing Speed: Spark is capable
Unifying Big Data Workloads in Apache Spark
 Unifying Big Data Workloads in Apache Spark Hossein Falaki @mhfalaki Outline What s Apache Spark Why Unification Evolution of Unification Apache Spark + Databricks Q & A What s Apache Spark What is Apache
Unifying Big Data Workloads in Apache Spark Hossein Falaki @mhfalaki Outline What s Apache Spark Why Unification Evolution of Unification Apache Spark + Databricks Q & A What s Apache Spark What is Apache
Cloud, Big Data & Linear Algebra
 Cloud, Big Data & Linear Algebra Shelly Garion IBM Research -- Haifa 2014 IBM Corporation What is Big Data? 2 Global Data Volume in Exabytes What is Big Data? 2005 2012 2017 3 Global Data Volume in Exabytes
Cloud, Big Data & Linear Algebra Shelly Garion IBM Research -- Haifa 2014 IBM Corporation What is Big Data? 2 Global Data Volume in Exabytes What is Big Data? 2005 2012 2017 3 Global Data Volume in Exabytes
Survey on Incremental MapReduce for Data Mining
 Survey on Incremental MapReduce for Data Mining Trupti M. Shinde 1, Prof.S.V.Chobe 2 1 Research Scholar, Computer Engineering Dept., Dr. D. Y. Patil Institute of Engineering &Technology, 2 Associate Professor,
Survey on Incremental MapReduce for Data Mining Trupti M. Shinde 1, Prof.S.V.Chobe 2 1 Research Scholar, Computer Engineering Dept., Dr. D. Y. Patil Institute of Engineering &Technology, 2 Associate Professor,
Intro to Apache Spark
 Intro to Apache Spark Paco Nathan, @pacoid http://databricks.com/ download slides: http://cdn.liber118.com/spark/dbc_bids.pdf Licensed under a Creative Commons Attribution- NonCommercial-NoDerivatives
Intro to Apache Spark Paco Nathan, @pacoid http://databricks.com/ download slides: http://cdn.liber118.com/spark/dbc_bids.pdf Licensed under a Creative Commons Attribution- NonCommercial-NoDerivatives
An Introduction to Apache Spark
 An Introduction to Apache Spark Anastasios Skarlatidis @anskarl Software Engineer/Researcher IIT, NCSR "Demokritos" Outline Part I: Getting to know Spark Part II: Basic programming Part III: Spark under
An Introduction to Apache Spark Anastasios Skarlatidis @anskarl Software Engineer/Researcher IIT, NCSR "Demokritos" Outline Part I: Getting to know Spark Part II: Basic programming Part III: Spark under
Summary of Big Data Frameworks Course 2015 Professor Sasu Tarkoma
 Summary of Big Data Frameworks Course 2015 Professor Sasu Tarkoma www.cs.helsinki.fi Course Schedule Tuesday 10.3. Introduction and the Big Data Challenge Tuesday 17.3. MapReduce and Spark: Overview Tuesday
Summary of Big Data Frameworks Course 2015 Professor Sasu Tarkoma www.cs.helsinki.fi Course Schedule Tuesday 10.3. Introduction and the Big Data Challenge Tuesday 17.3. MapReduce and Spark: Overview Tuesday
Deep Learning Comes of Age. Presenter: 齐琦 海南大学
 Deep Learning Comes of Age Presenter: 齐琦 海南大学 原文引用 Anthes, G. (2013). "Deep learning comes of age." Commun. ACM 56(6): 13-15. AI/Machine learning s new technology deep learning --- multilayer artificial
Deep Learning Comes of Age Presenter: 齐琦 海南大学 原文引用 Anthes, G. (2013). "Deep learning comes of age." Commun. ACM 56(6): 13-15. AI/Machine learning s new technology deep learning --- multilayer artificial
SparkStreaming. Large scale near- realtime stream processing. Tathagata Das (TD) UC Berkeley UC BERKELEY
 UC Berkeley UC BERKELEY") SparkStreaming Large scale near- realtime stream processing Tathagata Das (TD) UC Berkeley UC BERKELEY Motivation Many important applications must process large data streams at second- scale latencies
SparkStreaming Large scale near- realtime stream processing Tathagata Das (TD) UC Berkeley UC BERKELEY Motivation Many important applications must process large data streams at second- scale latencies
Turning Relational Database Tables into Spark Data Sources
 Turning Relational Database Tables into Spark Data Sources Kuassi Mensah Jean de Lavarene Director Product Mgmt Director Development Server Technologies October 04, 2017 3 Safe Harbor Statement The following
Turning Relational Database Tables into Spark Data Sources Kuassi Mensah Jean de Lavarene Director Product Mgmt Director Development Server Technologies October 04, 2017 3 Safe Harbor Statement The following
CDS. André Schaaff1, François-Xavier Pineau1, Gilles Landais1, Laurent Michel2 de Données astronomiques de Strasbourg, 2SSC-XMM-Newton
 Docker @ CDS André Schaaff1, François-Xavier Pineau1, Gilles Landais1, Laurent Michel2 1Centre de Données astronomiques de Strasbourg, 2SSC-XMM-Newton Paul Trehiou Université de technologie de Belfort-Montbéliard
Docker @ CDS André Schaaff1, François-Xavier Pineau1, Gilles Landais1, Laurent Michel2 1Centre de Données astronomiques de Strasbourg, 2SSC-XMM-Newton Paul Trehiou Université de technologie de Belfort-Montbéliard
Research challenges in data-intensive computing The Stratosphere Project Apache Flink
 Research challenges in data-intensive computing The Stratosphere Project Apache Flink Seif Haridi KTH/SICS haridi@kth.se e2e-clouds.org Presented by: Seif Haridi May 2014 Research Areas Data-intensive
Research challenges in data-intensive computing The Stratosphere Project Apache Flink Seif Haridi KTH/SICS haridi@kth.se e2e-clouds.org Presented by: Seif Haridi May 2014 Research Areas Data-intensive
DATA SCIENCE USING SPARK: AN INTRODUCTION
 DATA SCIENCE USING SPARK: AN INTRODUCTION TOPICS COVERED Introduction to Spark Getting Started with Spark Programming in Spark Data Science with Spark What next? 2 DATA SCIENCE PROCESS Exploratory Data
DATA SCIENCE USING SPARK: AN INTRODUCTION TOPICS COVERED Introduction to Spark Getting Started with Spark Programming in Spark Data Science with Spark What next? 2 DATA SCIENCE PROCESS Exploratory Data
2/26/2017. Originally developed at the University of California - Berkeley's AMPLab
 Apache is a fast and general engine for large-scale data processing aims at achieving the following goals in the Big data context Generality: diverse workloads, operators, job sizes Low latency: sub-second
Apache is a fast and general engine for large-scale data processing aims at achieving the following goals in the Big data context Generality: diverse workloads, operators, job sizes Low latency: sub-second
Apache Spark 2.0. Matei
 Apache Spark 2.0 Matei Zaharia @matei_zaharia What is Apache Spark? Open source data processing engine for clusters Generalizes MapReduce model Rich set of APIs and libraries In Scala, Java, Python and
Apache Spark 2.0 Matei Zaharia @matei_zaharia What is Apache Spark? Open source data processing engine for clusters Generalizes MapReduce model Rich set of APIs and libraries In Scala, Java, Python and
An Introduction to Apache Spark Big Data Madison: 29 July William Red Hat, Inc.
 An Introduction to Apache Spark Big Data Madison: 29 July 2014 William Benton @willb Red Hat, Inc. About me At Red Hat for almost 6 years, working on distributed computing Currently contributing to Spark,
An Introduction to Apache Spark Big Data Madison: 29 July 2014 William Benton @willb Red Hat, Inc. About me At Red Hat for almost 6 years, working on distributed computing Currently contributing to Spark,
Processing of big data with Apache Spark
 Processing of big data with Apache Spark JavaSkop 18 Aleksandar Donevski AGENDA What is Apache Spark? Spark vs Hadoop MapReduce Application Requirements Example Architecture Application Challenges 2 WHAT
Processing of big data with Apache Spark JavaSkop 18 Aleksandar Donevski AGENDA What is Apache Spark? Spark vs Hadoop MapReduce Application Requirements Example Architecture Application Challenges 2 WHAT
Spark and distributed data processing
 Stanford CS347 Guest Lecture Spark and distributed data processing Reynold Xin @rxin 2016-05-23 Who am I? Reynold Xin PMC member, Apache Spark Cofounder & Chief Architect, Databricks PhD on leave (ABD),
Stanford CS347 Guest Lecture Spark and distributed data processing Reynold Xin @rxin 2016-05-23 Who am I? Reynold Xin PMC member, Apache Spark Cofounder & Chief Architect, Databricks PhD on leave (ABD),
Big Data Infrastructures & Technologies Hadoop Streaming Revisit.
 Big Data Infrastructures & Technologies Hadoop Streaming Revisit ENRON Mapper ENRON Mapper Output (Excerpt) acomnes@enron.com blake.walker@enron.com edward.snowden@cia.gov alex.berenson@nyt.com ENRON Reducer
Big Data Infrastructures & Technologies Hadoop Streaming Revisit ENRON Mapper ENRON Mapper Output (Excerpt) acomnes@enron.com blake.walker@enron.com edward.snowden@cia.gov alex.berenson@nyt.com ENRON Reducer
Distributed Computing with Spark and MapReduce
 Distributed Computing with Spark and MapReduce Reza Zadeh @Reza_Zadeh http://reza-zadeh.com Traditional Network Programming Message-passing between nodes (e.g. MPI) Very difficult to do at scale:» How
Distributed Computing with Spark and MapReduce Reza Zadeh @Reza_Zadeh http://reza-zadeh.com Traditional Network Programming Message-passing between nodes (e.g. MPI) Very difficult to do at scale:» How
MapReduce review. Spark and distributed data processing. Who am I? Today s Talk. Reynold Xin
 Who am I? Reynold Xin Stanford CS347 Guest Lecture Spark and distributed data processing PMC member, Apache Spark Cofounder & Chief Architect, Databricks PhD on leave (ABD), UC Berkeley AMPLab Reynold
Who am I? Reynold Xin Stanford CS347 Guest Lecture Spark and distributed data processing PMC member, Apache Spark Cofounder & Chief Architect, Databricks PhD on leave (ABD), UC Berkeley AMPLab Reynold
Apache Spark Internals
 Apache Spark Internals Pietro Michiardi Eurecom Pietro Michiardi (Eurecom) Apache Spark Internals 1 / 80 Acknowledgments & Sources Sources Research papers: https://spark.apache.org/research.html Presentations:
Apache Spark Internals Pietro Michiardi Eurecom Pietro Michiardi (Eurecom) Apache Spark Internals 1 / 80 Acknowledgments & Sources Sources Research papers: https://spark.apache.org/research.html Presentations:
15.1 Data flow vs. traditional network programming
 CME 323: Distributed Algorithms and Optimization, Spring 2017 http://stanford.edu/~rezab/dao. Instructor: Reza Zadeh, Matroid and Stanford. Lecture 15, 5/22/2017. Scribed by D. Penner, A. Shoemaker, and
CME 323: Distributed Algorithms and Optimization, Spring 2017 http://stanford.edu/~rezab/dao. Instructor: Reza Zadeh, Matroid and Stanford. Lecture 15, 5/22/2017. Scribed by D. Penner, A. Shoemaker, and
Spark and Spark SQL. Amir H. Payberah. SICS Swedish ICT. Amir H. Payberah (SICS) Spark and Spark SQL June 29, / 71
 Spark and Spark SQL June 29, / 71") Spark and Spark SQL Amir H. Payberah amir@sics.se SICS Swedish ICT Amir H. Payberah (SICS) Spark and Spark SQL June 29, 2016 1 / 71 What is Big Data? Amir H. Payberah (SICS) Spark and Spark SQL June 29,
Spark and Spark SQL Amir H. Payberah amir@sics.se SICS Swedish ICT Amir H. Payberah (SICS) Spark and Spark SQL June 29, 2016 1 / 71 What is Big Data? Amir H. Payberah (SICS) Spark and Spark SQL June 29,
Hadoop 2.x Core: YARN, Tez, and Spark. Hortonworks Inc All Rights Reserved
 Hadoop 2.x Core: YARN, Tez, and Spark YARN Hadoop Machine Types top-of-rack switches core switch client machines have client-side software used to access a cluster to process data master nodes run Hadoop
Hadoop 2.x Core: YARN, Tez, and Spark YARN Hadoop Machine Types top-of-rack switches core switch client machines have client-side software used to access a cluster to process data master nodes run Hadoop
Distributed Computing with Spark
 Distributed Computing with Spark Reza Zadeh Thanks to Matei Zaharia Outline Data flow vs. traditional network programming Limitations of MapReduce Spark computing engine Numerical computing on Spark Ongoing
Distributed Computing with Spark Reza Zadeh Thanks to Matei Zaharia Outline Data flow vs. traditional network programming Limitations of MapReduce Spark computing engine Numerical computing on Spark Ongoing
New Developments in Spark
 New Developments in Spark And Rethinking APIs for Big Data Matei Zaharia and many others What is Spark? Unified computing engine for big data apps > Batch, streaming and interactive Collection of high-level
New Developments in Spark And Rethinking APIs for Big Data Matei Zaharia and many others What is Spark? Unified computing engine for big data apps > Batch, streaming and interactive Collection of high-level
Machine learning library for Apache Flink
 Machine learning library for Apache Flink MTP Mid Term Report submitted to Indian Institute of Technology Mandi for partial fulfillment of the degree of B. Tech. by Devang Bacharwar (B2059) under the guidance
Machine learning library for Apache Flink MTP Mid Term Report submitted to Indian Institute of Technology Mandi for partial fulfillment of the degree of B. Tech. by Devang Bacharwar (B2059) under the guidance
Outline. CS-562 Introduction to data analysis using Apache Spark
 Outline Data flow vs. traditional network programming What is Apache Spark? Core things of Apache Spark RDD CS-562 Introduction to data analysis using Apache Spark Instructor: Vassilis Christophides T.A.:
Outline Data flow vs. traditional network programming What is Apache Spark? Core things of Apache Spark RDD CS-562 Introduction to data analysis using Apache Spark Instructor: Vassilis Christophides T.A.:
Introduction to Apache Spark
 Introduction to Apache Spark Bu eğitim sunumları İstanbul Kalkınma Ajansı nın 2016 yılı Yenilikçi ve Yaratıcı İstanbul Mali Destek Programı kapsamında yürütülmekte olan TR10/16/YNY/0036 no lu İstanbul
Introduction to Apache Spark Bu eğitim sunumları İstanbul Kalkınma Ajansı nın 2016 yılı Yenilikçi ve Yaratıcı İstanbul Mali Destek Programı kapsamında yürütülmekte olan TR10/16/YNY/0036 no lu İstanbul
Lecture 25: Spark. (leveraging bulk-granularity program structure) Parallel Computer Architecture and Programming CMU /15-618, Spring 2015
 Parallel Computer Architecture and Programming CMU /15-618, Spring 2015") Lecture 25: Spark (leveraging bulk-granularity program structure) Parallel Computer Architecture and Programming CMU 15-418/15-618, Spring 2015 Tunes Yeah Yeah Yeahs Sacrilege (Mosquito) In-memory performance
Lecture 25: Spark (leveraging bulk-granularity program structure) Parallel Computer Architecture and Programming CMU 15-418/15-618, Spring 2015 Tunes Yeah Yeah Yeahs Sacrilege (Mosquito) In-memory performance
Spark.jl: Resilient Distributed Datasets in Julia
 Spark.jl: Resilient Distributed Datasets in Julia Dennis Wilson, Martín Martínez Rivera, Nicole Power, Tim Mickel [dennisw, martinmr, npower, tmickel]@mit.edu INTRODUCTION 1 Julia is a new high level,
Spark.jl: Resilient Distributed Datasets in Julia Dennis Wilson, Martín Martínez Rivera, Nicole Power, Tim Mickel [dennisw, martinmr, npower, tmickel]@mit.edu INTRODUCTION 1 Julia is a new high level,
Cloud Computing & Visualization
 Cloud Computing & Visualization Workflows Distributed Computation with Spark Data Warehousing with Redshift Visualization with Tableau #FIUSCIS School of Computing & Information Sciences, Florida International
Cloud Computing & Visualization Workflows Distributed Computation with Spark Data Warehousing with Redshift Visualization with Tableau #FIUSCIS School of Computing & Information Sciences, Florida International
Introduction to Apache Spark. Patrick Wendell - Databricks
 Introduction to Apache Spark Patrick Wendell - Databricks What is Spark? Fast and Expressive Cluster Computing Engine Compatible with Apache Hadoop Efficient General execution graphs In-memory storage
Introduction to Apache Spark Patrick Wendell - Databricks What is Spark? Fast and Expressive Cluster Computing Engine Compatible with Apache Hadoop Efficient General execution graphs In-memory storage
Apache Spark Performance Compared to a Traditional Relational Database using Open Source Big Data Health Software
 PROJECT PAPER FOR CSE8803 BIG DATA ANALYTICS FOR HEALTH CARE, SPRING 2016 1 Apache Spark Performance Compared to a Traditional Relational Database using Open Source Big Data Health Software Joshua Powers
PROJECT PAPER FOR CSE8803 BIG DATA ANALYTICS FOR HEALTH CARE, SPRING 2016 1 Apache Spark Performance Compared to a Traditional Relational Database using Open Source Big Data Health Software Joshua Powers
Applied Spark. From Concepts to Bitcoin Analytics. Andrew F.
 Applied Spark From Concepts to Bitcoin Analytics Andrew F. Hart ahart@apache.org @andrewfhart My Day Job CTO, Pogoseat Upgrade technology for live events 3/28/16 QCON-SP Andrew Hart 2 Additionally Member,
Applied Spark From Concepts to Bitcoin Analytics Andrew F. Hart ahart@apache.org @andrewfhart My Day Job CTO, Pogoseat Upgrade technology for live events 3/28/16 QCON-SP Andrew Hart 2 Additionally Member,
The Datacenter Needs an Operating System
 UC BERKELEY The Datacenter Needs an Operating System Anthony D. Joseph LASER Summer School September 2013 My Talks at LASER 2013 1. AMP Lab introduction 2. The Datacenter Needs an Operating System 3. Mesos,
UC BERKELEY The Datacenter Needs an Operating System Anthony D. Joseph LASER Summer School September 2013 My Talks at LASER 2013 1. AMP Lab introduction 2. The Datacenter Needs an Operating System 3. Mesos,
Evolution From Shark To Spark SQL:
 Evolution From Shark To Spark SQL: Preliminary Analysis and Qualitative Evaluation Xinhui Tian and Xiexuan Zhou Institute of Computing Technology, Chinese Academy of Sciences and University of Chinese
Evolution From Shark To Spark SQL: Preliminary Analysis and Qualitative Evaluation Xinhui Tian and Xiexuan Zhou Institute of Computing Technology, Chinese Academy of Sciences and University of Chinese
Introduction to Spark
 Introduction to Spark Outlines A brief history of Spark Programming with RDDs Transformations Actions A brief history Limitations of MapReduce MapReduce use cases showed two major limitations: Difficulty
Introduction to Spark Outlines A brief history of Spark Programming with RDDs Transformations Actions A brief history Limitations of MapReduce MapReduce use cases showed two major limitations: Difficulty
Principal Software Engineer Red Hat Emerging Technology June 24, 2015
 USING APACHE SPARK FOR ANALYTICS IN THE CLOUD William C. Benton Principal Software Engineer Red Hat Emerging Technology June 24, 2015 ABOUT ME Distributed systems and data science in Red Hat's Emerging
USING APACHE SPARK FOR ANALYTICS IN THE CLOUD William C. Benton Principal Software Engineer Red Hat Emerging Technology June 24, 2015 ABOUT ME Distributed systems and data science in Red Hat's Emerging
An Introduction to Apache Spark
 An Introduction to Apache Spark 1 History Developed in 2009 at UC Berkeley AMPLab. Open sourced in 2010. Spark becomes one of the largest big-data projects with more 400 contributors in 50+ organizations
An Introduction to Apache Spark 1 History Developed in 2009 at UC Berkeley AMPLab. Open sourced in 2010. Spark becomes one of the largest big-data projects with more 400 contributors in 50+ organizations
Data Platforms and Pattern Mining
 Morteza Zihayat Data Platforms and Pattern Mining IBM Corporation About Myself IBM Software Group Big Data Scientist 4Platform Computing, IBM (2014 Now) PhD Candidate (2011 Now) 4Lassonde School of Engineering,
Morteza Zihayat Data Platforms and Pattern Mining IBM Corporation About Myself IBM Software Group Big Data Scientist 4Platform Computing, IBM (2014 Now) PhD Candidate (2011 Now) 4Lassonde School of Engineering,
CS60021: Scalable Data Mining. Sourangshu Bhattacharya
 CS60021: Scalable Data Mining Sourangshu Bhattacharya In this Lecture: Outline: Scala Var and Val Classes and objects Functions and higher order functions Lists SCALA Scala Scala is both functional and
CS60021: Scalable Data Mining Sourangshu Bhattacharya In this Lecture: Outline: Scala Var and Val Classes and objects Functions and higher order functions Lists SCALA Scala Scala is both functional and
Shark: SQL and Rich Analytics at Scale. Michael Xueyuan Han Ronny Hajoon Ko
 Shark: SQL and Rich Analytics at Scale Michael Xueyuan Han Ronny Hajoon Ko What Are The Problems? Data volumes are expanding dramatically Why Is It Hard? Needs to scale out Managing hundreds of machines
Shark: SQL and Rich Analytics at Scale Michael Xueyuan Han Ronny Hajoon Ko What Are The Problems? Data volumes are expanding dramatically Why Is It Hard? Needs to scale out Managing hundreds of machines
Page 1. Goals for Today" Background of Cloud Computing" Sources Driving Big Data" CS162 Operating Systems and Systems Programming Lecture 24
 Goals for Today" CS162 Operating Systems and Systems Programming Lecture 24 Capstone: Cloud Computing" Distributed systems Cloud Computing programming paradigms Cloud Computing OS December 2, 2013 Anthony
Goals for Today" CS162 Operating Systems and Systems Programming Lecture 24 Capstone: Cloud Computing" Distributed systems Cloud Computing programming paradigms Cloud Computing OS December 2, 2013 Anthony
Stream Processing on IoT Devices using Calvin Framework
 Stream Processing on IoT Devices using Calvin Framework by Ameya Nayak A Project Report Submitted in Partial Fulfillment of the Requirements for the Degree of Master of Science in Computer Science Supervised
Stream Processing on IoT Devices using Calvin Framework by Ameya Nayak A Project Report Submitted in Partial Fulfillment of the Requirements for the Degree of Master of Science in Computer Science Supervised
Coflow. Recent Advances and What s Next? Mosharaf Chowdhury. University of Michigan
 Coflow Recent Advances and What s Next? Mosharaf Chowdhury University of Michigan Rack-Scale Computing Datacenter-Scale Computing Geo-Distributed Computing Coflow Networking Open Source Apache Spark Open
Coflow Recent Advances and What s Next? Mosharaf Chowdhury University of Michigan Rack-Scale Computing Datacenter-Scale Computing Geo-Distributed Computing Coflow Networking Open Source Apache Spark Open
Big Data Analytics. C. Distributed Computing Environments / C.2. Resilient Distributed Datasets: Apache Spark. Lars Schmidt-Thieme
 Big Data Analytics C. Distributed Computing Environments / C.2. Resilient Distributed Datasets: Apache Spark Lars Schmidt-Thieme Information Systems and Machine Learning Lab (ISMLL) Institute of Computer
Big Data Analytics C. Distributed Computing Environments / C.2. Resilient Distributed Datasets: Apache Spark Lars Schmidt-Thieme Information Systems and Machine Learning Lab (ISMLL) Institute of Computer
Lambda Architecture with Apache Spark
 Lambda Architecture with Apache Spark Michael Hausenblas, Chief Data Engineer MapR First Galway Data Meetup, 2015-02-03 2015 MapR Technologies 2015 MapR Technologies 1 Polyglot Processing 2015 2014 MapR
Lambda Architecture with Apache Spark Michael Hausenblas, Chief Data Engineer MapR First Galway Data Meetup, 2015-02-03 2015 MapR Technologies 2015 MapR Technologies 1 Polyglot Processing 2015 2014 MapR
CSE 544 Principles of Database Management Systems. Alvin Cheung Fall 2015 Lecture 10 Parallel Programming Models: Map Reduce and Spark
 CSE 544 Principles of Database Management Systems Alvin Cheung Fall 2015 Lecture 10 Parallel Programming Models: Map Reduce and Spark Announcements HW2 due this Thursday AWS accounts Any success? Feel
CSE 544 Principles of Database Management Systems Alvin Cheung Fall 2015 Lecture 10 Parallel Programming Models: Map Reduce and Spark Announcements HW2 due this Thursday AWS accounts Any success? Feel
Shark: SQL and Rich Analytics at Scale. Reynold Xin UC Berkeley
 Shark: SQL and Rich Analytics at Scale Reynold Xin UC Berkeley Challenges in Modern Data Analysis Data volumes expanding. Faults and stragglers complicate parallel database design. Complexity of analysis:
Shark: SQL and Rich Analytics at Scale Reynold Xin UC Berkeley Challenges in Modern Data Analysis Data volumes expanding. Faults and stragglers complicate parallel database design. Complexity of analysis:
I ++ Mapreduce: Incremental Mapreduce for Mining the Big Data
 IOSR Journal of Computer Engineering (IOSR-JCE) e-issn: 2278-0661,p-ISSN: 2278-8727, Volume 18, Issue 3, Ver. IV (May-Jun. 2016), PP 125-129 www.iosrjournals.org I ++ Mapreduce: Incremental Mapreduce for
IOSR Journal of Computer Engineering (IOSR-JCE) e-issn: 2278-0661,p-ISSN: 2278-8727, Volume 18, Issue 3, Ver. IV (May-Jun. 2016), PP 125-129 www.iosrjournals.org I ++ Mapreduce: Incremental Mapreduce for
Distributed Systems. 22. Spark. Paul Krzyzanowski. Rutgers University. Fall 2016
 Distributed Systems 22. Spark Paul Krzyzanowski Rutgers University Fall 2016 November 26, 2016 2015-2016 Paul Krzyzanowski 1 Apache Spark Goal: generalize MapReduce Similar shard-and-gather approach to
Distributed Systems 22. Spark Paul Krzyzanowski Rutgers University Fall 2016 November 26, 2016 2015-2016 Paul Krzyzanowski 1 Apache Spark Goal: generalize MapReduce Similar shard-and-gather approach to
Topics. Big Data Analytics What is and Why Hadoop? Comparison to other technologies Hadoop architecture Hadoop ecosystem Hadoop usage examples
 Hadoop Introduction 1 Topics Big Data Analytics What is and Why Hadoop? Comparison to other technologies Hadoop architecture Hadoop ecosystem Hadoop usage examples 2 Big Data Analytics What is Big Data?
Hadoop Introduction 1 Topics Big Data Analytics What is and Why Hadoop? Comparison to other technologies Hadoop architecture Hadoop ecosystem Hadoop usage examples 2 Big Data Analytics What is Big Data?
An Introduction to Big Data Analysis using Spark
 An Introduction to Big Data Analysis using Spark Mohamad Jaber American University of Beirut - Faculty of Arts & Sciences - Department of Computer Science May 17, 2017 Mohamad Jaber (AUB) Spark May 17,
An Introduction to Big Data Analysis using Spark Mohamad Jaber American University of Beirut - Faculty of Arts & Sciences - Department of Computer Science May 17, 2017 Mohamad Jaber (AUB) Spark May 17,
Batch Processing Basic architecture
 Batch Processing Basic architecture in big data systems COS 518: Distributed Systems Lecture 10 Andrew Or, Mike Freedman 2 1 2 64GB RAM 32 cores 64GB RAM 32 cores 64GB RAM 32 cores 64GB RAM 32 cores 3
Batch Processing Basic architecture in big data systems COS 518: Distributed Systems Lecture 10 Andrew Or, Mike Freedman 2 1 2 64GB RAM 32 cores 64GB RAM 32 cores 64GB RAM 32 cores 64GB RAM 32 cores 3
Backtesting with Spark
 Backtesting with Spark Patrick Angeles, Cloudera Sandy Ryza, Cloudera Rick Carlin, Intel Sheetal Parade, Intel 1 Traditional Grid Shared storage Storage and compute scale independently Bottleneck on I/O
Backtesting with Spark Patrick Angeles, Cloudera Sandy Ryza, Cloudera Rick Carlin, Intel Sheetal Parade, Intel 1 Traditional Grid Shared storage Storage and compute scale independently Bottleneck on I/O
Clash of the Titans: MapReduce vs. Spark for Large Scale Data Analytics
 Clash of the Titans: MapReduce vs. Spark for Large Scale Data Analytics Presented by: Dishant Mittal Authors: Juwei Shi, Yunjie Qiu, Umar Firooq Minhas, Lemei Jiao, Chen Wang, Berthold Reinwald and Fatma
Clash of the Titans: MapReduce vs. Spark for Large Scale Data Analytics Presented by: Dishant Mittal Authors: Juwei Shi, Yunjie Qiu, Umar Firooq Minhas, Lemei Jiao, Chen Wang, Berthold Reinwald and Fatma
Big data systems 12/8/17
 Big data systems 12/8/17 Today Basic architecture Two levels of scheduling Spark overview Basic architecture Cluster Manager Cluster Cluster Manager 64GB RAM 32 cores 64GB RAM 32 cores 64GB RAM 32 cores
Big data systems 12/8/17 Today Basic architecture Two levels of scheduling Spark overview Basic architecture Cluster Manager Cluster Cluster Manager 64GB RAM 32 cores 64GB RAM 32 cores 64GB RAM 32 cores
Spark Streaming. Guido Salvaneschi
 Spark Streaming Guido Salvaneschi 1 Spark Streaming Framework for large scale stream processing Scales to 100s of nodes Can achieve second scale latencies Integrates with Spark s batch and interactive
Spark Streaming Guido Salvaneschi 1 Spark Streaming Framework for large scale stream processing Scales to 100s of nodes Can achieve second scale latencies Integrates with Spark s batch and interactive
Big Data. Big Data Analyst. Big Data Engineer. Big Data Architect
 Big Data Big Data Analyst INTRODUCTION TO BIG DATA ANALYTICS ANALYTICS PROCESSING TECHNIQUES DATA TRANSFORMATION & BATCH PROCESSING REAL TIME (STREAM) DATA PROCESSING Big Data Engineer BIG DATA FOUNDATION
Big Data Big Data Analyst INTRODUCTION TO BIG DATA ANALYTICS ANALYTICS PROCESSING TECHNIQUES DATA TRANSFORMATION & BATCH PROCESSING REAL TIME (STREAM) DATA PROCESSING Big Data Engineer BIG DATA FOUNDATION
Lecture 09. Spark for batch and streaming processing FREDERICK AYALA-GÓMEZ. CS-E4610 Modern Database Systems
 CS-E4610 Modern Database Systems 05.01.2018-05.04.2018 Lecture 09 Spark for batch and streaming processing FREDERICK AYALA-GÓMEZ PHD STUDENT I N COMPUTER SCIENCE, ELT E UNIVERSITY VISITING R ESEA RCHER,
CS-E4610 Modern Database Systems 05.01.2018-05.04.2018 Lecture 09 Spark for batch and streaming processing FREDERICK AYALA-GÓMEZ PHD STUDENT I N COMPUTER SCIENCE, ELT E UNIVERSITY VISITING R ESEA RCHER,