Introduction to Cloud Computing
|
|
|
- Dwight Jennings
- 6 years ago
- Views:
Transcription
1 Introduction to Cloud Computing Distributed File Systems , spring th Lecture, Feb 18 th Majd F. Sakr
2 Lecture Motivation Quick Refresher on Files and File Systems Understand the importance of File Systems in handling data Introduce Distributed File Systems Discuss HDFS
3 Files File in OS? Permanent Storage Sharing information since files can be created with one application and shared with many applications Files have data and attributes File length Creation timestamp Read timestamp Write timestamp Attribute timestamp Reference count Owner File type Access control list Figure 2: File attribute record structure Couloris,Dollimore and Kindberg Distributed Systems: Concepts & Design Edn. 4, Pearson Education 2005
4 File System The OS interface to disk storage Subsystem of the OS Provides an abstraction to storage device and makes it easy to store, organize, name, share, protect and retrieve computer files A typical layered module structure for the implementation of a Non DFS in a typical OS: Directory module: File module: Access control module: File access module: Block module: Device module: relates file names to file IDs relates file IDs to particular files checks permission for operation requested reads or writes file data or attributes accesses and allocates disk blocks disk I/O and buffering Couloris,Dollimore and Kindberg Distributed Systems: Concepts & Design Edn. 4, Pearson Education 2005
5 Great! Now how do you Share Files? 1980s: Sneakernet Copy files onto floppy disks, physically carry it to another computer and copy it again. We still do it today with Flash Disks! Networks emerged Started using FTP Save time of physical movement of storage devices. Two problems: Needed to copy files twice: from source computer onto a server, and from the server onto the destination computer. Users had to know the physical addresses of all computers involved in the file sharing.

6 History of Sharing Computer Files Networks emerged (contd.) Computer companies tried to solve the problems with FTP, new systems with new features were developed. Not as a replacement for the older file systems but represented an additional layer between the disk, FS and user processes. Example: Sun Microsystem's Network File System (NFS).
7 File Sharing (1/7) On a single processor, when a write is followed by a read, the read data is the accurate written one On a distributed system with caching, the read data might not be the most up to date.

8 File Sharing (2/7) How to deal with shared files on a distributed system with caches? There are 4 ways!
9 File Sharing (3/7) UNIX semantics Every file operation is instantly visible to all users. So, any read following a write returns the correct value. A total global order is enforced on all file operations to return the most recent value. In a single physical machines, a shared l Node is used to achieve this control. Files data is a shared data structure among all users. In Distributed file server, same behavior needs to be done! Instant update cause performance implications. Fine grain operations increase overhead.
10 File Sharing (4/7) UNIX semantics Distributed UNIX semantics Could use centralized server that can serialize all file operations. Poor performance under many use patterns. Performance constraints require that the clients cache file blocks, but the system must keep the cached blocks consistent to maintain UNIX semantics. Writes invalidate cached blocks. Read operations on local copies after the write according to a global clock happened before the write. Serializable operations in transaction systems. Global virtual clock orders on all writes, not reads.
11 File Sharing (5/7) Session semantics Changes become visible when the session is finished. When modified by multiple parties, the final file state is determined by who closes last. When two processes modify the same file, session semantics would produce one process changes or the other but not both. Many processes keep files open for long periods. This approach is different from most of programmers experience, so must be used with caution. Good for process whose file modification is transaction oriented (connect, modify, disconnect). Bad for series of open operations.
12 File Sharing (6/7) Immutable Files No updates are possible. Both file sharing and replication are simplified. No way to open a file for writing or appending. Only directory entries may be modified. To replace or change an old file, a new one must be created. Fine for many applications. However, it s different enough that it must be approached with caution. Design Principle: Many applications of distribution involve porting existing nondistributed code along with its assumptions.
13 File Sharing (7/7) Atomic transactions Changes are all or nothing Begin Transaction End Transaction System responsible for enforcing serialization. Ensuring that concurrent transactions produce results consistent with some serial execution. Transaction systems commonly track the read/write component operations. Familiar aid of atomicity provided by transaction model to implementers of distributed systems. Commit and rollback both very useful in simplifying implementation.


14 Distributed File System File System for a physically distributed set of files. Usually within an network of computers. Allows clients to access files on remote hosts as if the client is actually working on the host. Enables maintaining data consistency. Acts as a common data store for distributed applications.
 Keeps track of consistency, backups etc.")
15 Simple Example of a DFS Dropbox Keeps your files synced across many computers. Is a transparent DFS implementation. Transparent to the OS (Windows, Mac, Linux) Keeps track of consistency, backups etc. ACL is not mature personal experiences were near catastrophic.

16 DFS Requirements Most attributes inherited from Distributed Systems Transparency Location Access Scaling Naming Replication Concurrency Concurrent updates Locking Fault Tolerance Scalability Heterogeneity Consistency Efficiency Location Independence Security
. Limited achievement of: concurrency, replication, consistency and security. http://www.cs.uwaterloo.")
17 Network File System (NFS) An industry standard by Sun Microsystems for file sharing on local networks since the 1980s. An open and popular standard with clear and simple interfaces. Supports many of the DFS design requirements (EX: transparency, heterogeneity, efficiency). Limited achievement of: concurrency, replication, consistency and security. 17
18 More on NFS Supports directory and file access via remote procedure calls (RPCs) All UNIX system calls supported other than open & close Open and close are intentionally not supported For a read, client sends lookup message to server Server looks up file and returns handle Unlike open, lookup does not copy info in internal system tables Subsequently, read contains file handle, offset and num bytes Each message is self contained Pros: server is stateless, i.e. no state about open files Cons: Locking is difficult, no concurrency control
19 NFS Tradeoffs NFS Volume is Managed by a Single Server Higher Load on a Single Server Simplified Coherency Protocols Not Fault Tolerant Scalability is a real issue Multiple Points of Failure in large (1000+) systems App Bugs, OS Hardware / Power Failure Network Connectivity Monitor, fault tolerance, auto recovery essential in Cloud Computing.

20 Andrew File System (AFS) Under development since 1983 at CMU. Andrew is highly scalable; the system is targeted to span over 5000 workstations. NFS compatible. Distinguishes between client machines and dedicated server machines. Servers and clients are interconnected by an inter net of LANs.
21 AFS Details Based on the upload/download model Clients download and cache files Server keeps track of clients that cache the file Clients upload files at end of session Whole file caching is central idea behind AFS Later amended to block operations Simple, effective AFS servers are stateful Keep track of clients that have cached files Recall files that have been modified
22 File System (GFS) Google has had issues with existing file systems on their huge distributed systems They created a new file system that matched well with MapReduce (also by Google) They wanted to have : The ability to detect, tolerate, recover, from failures automatically Large Files, >= 100MB in size each Large, streaming reads (each read being >= 1MB in size) Large sequential writes that append Concurrent appends by multiple clients Atomicity for appends without synchronization overhead among clients
23 Architecture of GFS Single master to coordinate access, keep metadata Simple centralized management Fixed size chunks (64MB) Many Chunk Servers ( s) Files stored as chunks Each chunk identified by 64 bit unique id Reliability through replication Each chunk replicated across 3+ chunk servers Many clients accessing same and different files stored on same cluster No data caching Little benefit due to large data sets, streaming reads
24 GFS Architecture (Continued) Figure from The Google File System, Ghemawat et. al., SOSP 2003
25 Master and Chunk Server Responsibilities Master Node Holds all metadata Namespace Current locations of chunks All in RAM for fast access Manages chunk leases to chunk servers Garbage collects orphaned chunks Migrates chunks between chunk servers Polls chunk servers at startup Use heartbeat messages to monitor servers Chunk Servers Simple Stores Chunks as files Chunks are 64MB size Chunks on local disk using standard filesystem Read write requests specify chunk handle and byte range Chunks replicated on configurable chunk servers
26 The Design Tradeoff Can have small number of Large Files Less Metadata, the GFS Masternode can handle it Fewer Chunk Requests to Masternode Best for Streaming Reads Large number of Small Files 1 chunk per file Waste of Space Pressure on Masternode to index all the files
27 How about Clients who need Data? GFS clients Consult master for metadata Access data from chunk servers No caching at clients and chunk servers due to the frequent case of streaming A client typically asks for multiple chunk locations in a single request The master also predicatively provide chunk locations immediately following those requested
28 Differences in the GFS API Not POSIX compliant Cannot mount an HDFS system in Unix directly, no Unix file semantics An API over your existing File System (EXT3, RiserFS etc.) API Operations Open, Close, Create and delete Read and write Record append Snapshot (Quickly create a copy of the file) GFS API POSIX complaint FS (EXT3 etc.) Storage Medium
29 Replication in GFS The Data Chunks on the Chunk Servers are replicated (Typically 3 times) If a Chunk Server Fails Master notices missing heartbeats Master decrements count of replicas for all chunks on dead chunk server Master replicates chunks missing replicas in background Highest priority of chunks missing greatest number of replicas
30 Consistency in GFS Changes to Namespace are atomic Done by Single Master Server Master uses logs to define global total order of namespacechanging operations Data changes are more complicated Consistent: File regions all see as same, regardless of replicas they read from Defined: after data mutation, file region is consistent and all clients see that entire mutation
31 Mutation in GFS Mutation = write or append must be done for all replicas Goal: minimize master involvement Lease mechanism: Master picks one replica as primary; gives it a lease for mutations Primary defines a serial order of mutations All replicas follow this order Data flow decoupled from control flow
32 Hadoop Distributed File System (HDFS) So GFS is super cool. I want it now! Not possible, It s Google s proprietary technology. Good thing they published the technology though. Now you can get the next best thing: HDFS HDFS is open source GFS under Apache Same design goals Similar architecture, API and interfaces Compliments Hadoop MapReduce
33 HDFS Design Files stored as blocks Much larger size than most filesystems (default is 64MB) Reliability through replication Each block replicated across 3+ DataNodes Single master (NameNode) coordinates access, metadata Simple centralized management No data caching Little benefit due to large data sets, streaming reads Familiar interface, but customize the API Simplify the problem; focus on distributed apps
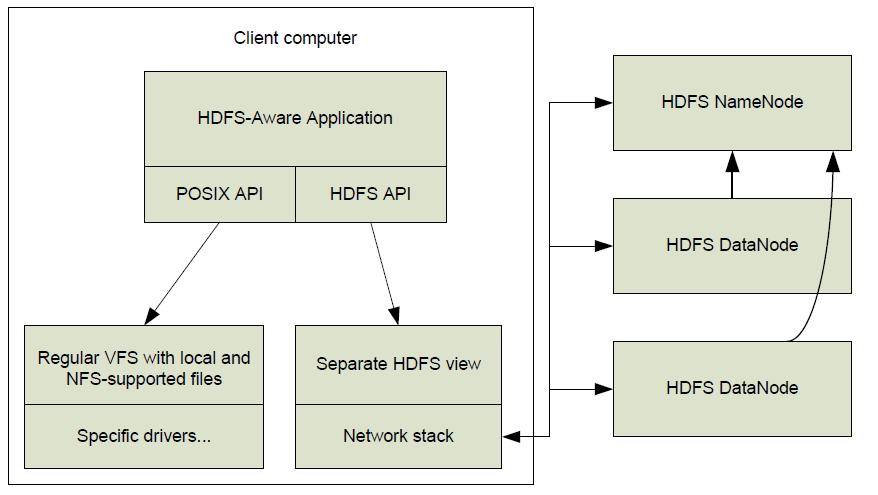
34 HDFS Architecture I
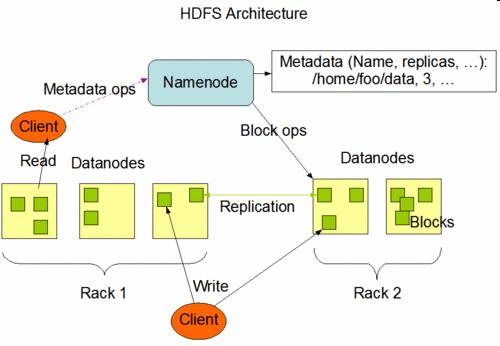
35 HDFS Architecture II
36 How to Talk to HDFS Hadoop and HDFS are written in Java Primary Interface to HDFS is in Java Other Interfaces do exist: C, FUSE,WebDAV, HTTP, FTP (buggy) In Java, we use the FileSystem and DistributedFileSystem classes: Best practice is to use the URI class and hdfs:// Try out the example code in Chapter 3 of Tom White s Hadoop Book.

37 Anatomy of an HDFS File Read A Client Program requests for data from the NameNode using the filename The NameNode returns the block locations on the DataNodes The Client then accesses each block Individually
38 Data Locality and Rack Awareness Bandwidth between two nodes in a Datacenter depends primarily on the distance between the two nodes The Distance can be calculated as follows: Suppose node n1 is on rack r1 in data center d1 (d1/r1/n1) distance( /d1/r1/n1, /d1/r1/n1 ) = 0 (Procceses in the same node) distance( /d1/r1/n1, /d1/r1/n2 ) = 2 (Nodes in the same rack) distance( /d1/r1/n1, /d1/r2/n3 ) = 4 distance( /d1/r1/n1, /d1/r2/n3 ) = 4 (Nodes across racks) distance( /d1/r1/n1, /d2/r3/n4 ) = 6 distance( /d1/r1/n1, /d2/r3/n4 ) = 6 (Nodes across Different DCs) If configured properly with this information, Hadoop will optimize file reads and writes and sends jobs closest to the data.
39 Rack Awareness in HDFS

40 Anatomy of an HDFS File Write The client issues a write request to the NameNode The client then writes individual blocks to the DataNodes and the DataNode pipeline the data for replication. After a block is written, the Data node sends an ACK After the File is written, the Client informs the NameNode
41 Replica Placement Tradeoff between Reliability and Bandwidth Replicas on Same node will be faster but unreliable Replicas across nodes will be reliable but slower Hadoop s Replica Placement Strategy First replica is placed on the same node as client process (or chosen at random if client is outside the cluster) Second replica is placed on different rack from the first (off rack) Third replica is placed on a different node on the same rack as the first.

42 Replica Placement
43 Coherency in HDFS After a File is Created, it will be visible in the FS namespace However writes to HDFS are not guaranteed to be visible, even after a flush(); Path p = new Path("p"); OutputStream out = fs.create(p); out.write("content".getbytes("utf-8")); out.flush(); assertthat(fs.getfilestatus(p).getlen(), is(0l)); File contents are visible only after the stream has been closed in HDFS. Also any file block that is currently being written in HDFS will not be visible MUST sync
44 Current Shortcomings of HDFS Write appends not stable and currently disabled (Hadoop 0.20) Coherency Model is an issue for application developers Handling of Corrupt Data (Sorry for the recent server downtime folks! ) No Authentication for HDFS users You are who you say you are in HDFS Fault Tolerance is still Faulty

45 Applications What does it have to do with cloud computing? Data is at the Heart of Cloud Computing Services Need File Systems that can fit the bill for large, scalable hardware and software GFS/HDFS and similar Distributed File Systems are now part and parcel of Cloud Computing Solutions.
46 References web.cs.wpi.edu/.../week%203%20--%20distributed%20file%20systems.ppt citation.cfm?id= George Coulouris, JeanDollimore and Tim Kindberg. Distributed Systems:Concepts and Design(Edition3 ).Addison-Wesley AndrewS.Tanenbaum,Maartenvan Steen. Distributed Systems:Principles and Paradigms. Prentice-Hall P. K.Sinha, P.K. "Distributed Operating Systems, Concepts and Design", IEEE Press, 1993 Couloris,Dollimore and Kindberg Distributed Systems: Concepts & Design Edn. 4, Pearson Education 2005
GFS: The Google File System
 GFS: The Google File System Brad Karp UCL Computer Science CS GZ03 / M030 24 th October 2014 Motivating Application: Google Crawl the whole web Store it all on one big disk Process users searches on one
GFS: The Google File System Brad Karp UCL Computer Science CS GZ03 / M030 24 th October 2014 Motivating Application: Google Crawl the whole web Store it all on one big disk Process users searches on one
GFS: The Google File System. Dr. Yingwu Zhu
 GFS: The Google File System Dr. Yingwu Zhu Motivating Application: Google Crawl the whole web Store it all on one big disk Process users searches on one big CPU More storage, CPU required than one PC can
GFS: The Google File System Dr. Yingwu Zhu Motivating Application: Google Crawl the whole web Store it all on one big disk Process users searches on one big CPU More storage, CPU required than one PC can
Distributed File Systems. CS 537 Lecture 15. Distributed File Systems. Transfer Model. Naming transparency 3/27/09
 Distributed File Systems CS 537 Lecture 15 Distributed File Systems Michael Swift Goal: view a distributed system as a file system Storage is distributed Web tries to make world a collection of hyperlinked
Distributed File Systems CS 537 Lecture 15 Distributed File Systems Michael Swift Goal: view a distributed system as a file system Storage is distributed Web tries to make world a collection of hyperlinked
Distributed Systems 16. Distributed File Systems II
 Distributed Systems 16. Distributed File Systems II Paul Krzyzanowski pxk@cs.rutgers.edu 1 Review NFS RPC-based access AFS Long-term caching CODA Read/write replication & disconnected operation DFS AFS
Distributed Systems 16. Distributed File Systems II Paul Krzyzanowski pxk@cs.rutgers.edu 1 Review NFS RPC-based access AFS Long-term caching CODA Read/write replication & disconnected operation DFS AFS
Distributed File Systems II
 Distributed File Systems II To do q Very-large scale: Google FS, Hadoop FS, BigTable q Next time: Naming things GFS A radically new environment NFS, etc. Independence Small Scale Variety of workloads Cooperation
Distributed File Systems II To do q Very-large scale: Google FS, Hadoop FS, BigTable q Next time: Naming things GFS A radically new environment NFS, etc. Independence Small Scale Variety of workloads Cooperation
Distributed File Systems. Directory Hierarchy. Transfer Model
 Distributed File Systems Ken Birman Goal: view a distributed system as a file system Storage is distributed Web tries to make world a collection of hyperlinked documents Issues not common to usual file
Distributed File Systems Ken Birman Goal: view a distributed system as a file system Storage is distributed Web tries to make world a collection of hyperlinked documents Issues not common to usual file
Distributed System. Gang Wu. Spring,2018
 Distributed System Gang Wu Spring,2018 Lecture7:DFS What is DFS? A method of storing and accessing files base in a client/server architecture. A distributed file system is a client/server-based application
Distributed System Gang Wu Spring,2018 Lecture7:DFS What is DFS? A method of storing and accessing files base in a client/server architecture. A distributed file system is a client/server-based application
CA485 Ray Walshe Google File System
 Google File System Overview Google File System is scalable, distributed file system on inexpensive commodity hardware that provides: Fault Tolerance File system runs on hundreds or thousands of storage
Google File System Overview Google File System is scalable, distributed file system on inexpensive commodity hardware that provides: Fault Tolerance File system runs on hundreds or thousands of storage
CLOUD-SCALE FILE SYSTEMS
 Data Management in the Cloud CLOUD-SCALE FILE SYSTEMS 92 Google File System (GFS) Designing a file system for the Cloud design assumptions design choices Architecture GFS Master GFS Chunkservers GFS Clients
Data Management in the Cloud CLOUD-SCALE FILE SYSTEMS 92 Google File System (GFS) Designing a file system for the Cloud design assumptions design choices Architecture GFS Master GFS Chunkservers GFS Clients
The Google File System. Alexandru Costan
 1 The Google File System Alexandru Costan Actions on Big Data 2 Storage Analysis Acquisition Handling the data stream Data structured unstructured semi-structured Results Transactions Outline File systems
1 The Google File System Alexandru Costan Actions on Big Data 2 Storage Analysis Acquisition Handling the data stream Data structured unstructured semi-structured Results Transactions Outline File systems
The Google File System (GFS)
") 1 The Google File System (GFS) CS60002: Distributed Systems Antonio Bruto da Costa Ph.D. Student, Formal Methods Lab, Dept. of Computer Sc. & Engg., Indian Institute of Technology Kharagpur 2 Design constraints
1 The Google File System (GFS) CS60002: Distributed Systems Antonio Bruto da Costa Ph.D. Student, Formal Methods Lab, Dept. of Computer Sc. & Engg., Indian Institute of Technology Kharagpur 2 Design constraints
! Design constraints. " Component failures are the norm. " Files are huge by traditional standards. ! POSIX-like
 Cloud background Google File System! Warehouse scale systems " 10K-100K nodes " 50MW (1 MW = 1,000 houses) " Power efficient! Located near cheap power! Passive cooling! Power Usage Effectiveness = Total
Cloud background Google File System! Warehouse scale systems " 10K-100K nodes " 50MW (1 MW = 1,000 houses) " Power efficient! Located near cheap power! Passive cooling! Power Usage Effectiveness = Total
The Google File System
 October 13, 2010 Based on: S. Ghemawat, H. Gobioff, and S.-T. Leung: The Google file system, in Proceedings ACM SOSP 2003, Lake George, NY, USA, October 2003. 1 Assumptions Interface Architecture Single
October 13, 2010 Based on: S. Ghemawat, H. Gobioff, and S.-T. Leung: The Google file system, in Proceedings ACM SOSP 2003, Lake George, NY, USA, October 2003. 1 Assumptions Interface Architecture Single
Distributed Filesystem
 Distributed Filesystem 1 How do we get data to the workers? NAS Compute Nodes SAN 2 Distributing Code! Don t move data to workers move workers to the data! - Store data on the local disks of nodes in the
Distributed Filesystem 1 How do we get data to the workers? NAS Compute Nodes SAN 2 Distributing Code! Don t move data to workers move workers to the data! - Store data on the local disks of nodes in the
Google File System. By Dinesh Amatya
 Google File System By Dinesh Amatya Google File System (GFS) Sanjay Ghemawat, Howard Gobioff, Shun-Tak Leung designed and implemented to meet rapidly growing demand of Google's data processing need a scalable
Google File System By Dinesh Amatya Google File System (GFS) Sanjay Ghemawat, Howard Gobioff, Shun-Tak Leung designed and implemented to meet rapidly growing demand of Google's data processing need a scalable
Distributed File Systems
 Distributed File Systems Today l Basic distributed file systems l Two classical examples Next time l Naming things xkdc Distributed File Systems " A DFS supports network-wide sharing of files and devices
Distributed File Systems Today l Basic distributed file systems l Two classical examples Next time l Naming things xkdc Distributed File Systems " A DFS supports network-wide sharing of files and devices
The Google File System
 The Google File System Sanjay Ghemawat, Howard Gobioff, Shun-Tak Leung ACM SIGOPS 2003 {Google Research} Vaibhav Bajpai NDS Seminar 2011 Looking Back time Classics Sun NFS (1985) CMU Andrew FS (1988) Fault
The Google File System Sanjay Ghemawat, Howard Gobioff, Shun-Tak Leung ACM SIGOPS 2003 {Google Research} Vaibhav Bajpai NDS Seminar 2011 Looking Back time Classics Sun NFS (1985) CMU Andrew FS (1988) Fault
CPSC 426/526. Cloud Computing. Ennan Zhai. Computer Science Department Yale University
 CPSC 426/526 Cloud Computing Ennan Zhai Computer Science Department Yale University Recall: Lec-7 In the lec-7, I talked about: - P2P vs Enterprise control - Firewall - NATs - Software defined network
CPSC 426/526 Cloud Computing Ennan Zhai Computer Science Department Yale University Recall: Lec-7 In the lec-7, I talked about: - P2P vs Enterprise control - Firewall - NATs - Software defined network
18-hdfs-gfs.txt Thu Oct 27 10:05: Notes on Parallel File Systems: HDFS & GFS , Fall 2011 Carnegie Mellon University Randal E.
 18-hdfs-gfs.txt Thu Oct 27 10:05:07 2011 1 Notes on Parallel File Systems: HDFS & GFS 15-440, Fall 2011 Carnegie Mellon University Randal E. Bryant References: Ghemawat, Gobioff, Leung, "The Google File
18-hdfs-gfs.txt Thu Oct 27 10:05:07 2011 1 Notes on Parallel File Systems: HDFS & GFS 15-440, Fall 2011 Carnegie Mellon University Randal E. Bryant References: Ghemawat, Gobioff, Leung, "The Google File
Hadoop File System S L I D E S M O D I F I E D F R O M P R E S E N T A T I O N B Y B. R A M A M U R T H Y 11/15/2017
 Hadoop File System 1 S L I D E S M O D I F I E D F R O M P R E S E N T A T I O N B Y B. R A M A M U R T H Y Moving Computation is Cheaper than Moving Data Motivation: Big Data! What is BigData? - Google
Hadoop File System 1 S L I D E S M O D I F I E D F R O M P R E S E N T A T I O N B Y B. R A M A M U R T H Y Moving Computation is Cheaper than Moving Data Motivation: Big Data! What is BigData? - Google
The Google File System
 The Google File System Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung Google SOSP 03, October 19 22, 2003, New York, USA Hyeon-Gyu Lee, and Yeong-Jae Woo Memory & Storage Architecture Lab. School
The Google File System Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung Google SOSP 03, October 19 22, 2003, New York, USA Hyeon-Gyu Lee, and Yeong-Jae Woo Memory & Storage Architecture Lab. School
Distributed Systems. Lec 10: Distributed File Systems GFS. Slide acks: Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung
 Distributed Systems Lec 10: Distributed File Systems GFS Slide acks: Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung 1 Distributed File Systems NFS AFS GFS Some themes in these classes: Workload-oriented
Distributed Systems Lec 10: Distributed File Systems GFS Slide acks: Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung 1 Distributed File Systems NFS AFS GFS Some themes in these classes: Workload-oriented
Google File System. Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung Google fall DIP Heerak lim, Donghun Koo
 Google File System Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung Google 2017 fall DIP Heerak lim, Donghun Koo 1 Agenda Introduction Design overview Systems interactions Master operation Fault tolerance
Google File System Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung Google 2017 fall DIP Heerak lim, Donghun Koo 1 Agenda Introduction Design overview Systems interactions Master operation Fault tolerance
18-hdfs-gfs.txt Thu Nov 01 09:53: Notes on Parallel File Systems: HDFS & GFS , Fall 2012 Carnegie Mellon University Randal E.
 18-hdfs-gfs.txt Thu Nov 01 09:53:32 2012 1 Notes on Parallel File Systems: HDFS & GFS 15-440, Fall 2012 Carnegie Mellon University Randal E. Bryant References: Ghemawat, Gobioff, Leung, "The Google File
18-hdfs-gfs.txt Thu Nov 01 09:53:32 2012 1 Notes on Parallel File Systems: HDFS & GFS 15-440, Fall 2012 Carnegie Mellon University Randal E. Bryant References: Ghemawat, Gobioff, Leung, "The Google File
NPTEL Course Jan K. Gopinath Indian Institute of Science
 Storage Systems NPTEL Course Jan 2012 (Lecture 39) K. Gopinath Indian Institute of Science Google File System Non-Posix scalable distr file system for large distr dataintensive applications performance,
Storage Systems NPTEL Course Jan 2012 (Lecture 39) K. Gopinath Indian Institute of Science Google File System Non-Posix scalable distr file system for large distr dataintensive applications performance,
The Google File System
 The Google File System Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung December 2003 ACM symposium on Operating systems principles Publisher: ACM Nov. 26, 2008 OUTLINE INTRODUCTION DESIGN OVERVIEW
The Google File System Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung December 2003 ACM symposium on Operating systems principles Publisher: ACM Nov. 26, 2008 OUTLINE INTRODUCTION DESIGN OVERVIEW
Cloud Computing and Hadoop Distributed File System. UCSB CS170, Spring 2018
 Cloud Computing and Hadoop Distributed File System UCSB CS70, Spring 08 Cluster Computing Motivations Large-scale data processing on clusters Scan 000 TB on node @ 00 MB/s = days Scan on 000-node cluster
Cloud Computing and Hadoop Distributed File System UCSB CS70, Spring 08 Cluster Computing Motivations Large-scale data processing on clusters Scan 000 TB on node @ 00 MB/s = days Scan on 000-node cluster
ECE 7650 Scalable and Secure Internet Services and Architecture ---- A Systems Perspective
 ECE 7650 Scalable and Secure Internet Services and Architecture ---- A Systems Perspective Part II: Data Center Software Architecture: Topic 1: Distributed File Systems GFS (The Google File System) 1 Filesystems
ECE 7650 Scalable and Secure Internet Services and Architecture ---- A Systems Perspective Part II: Data Center Software Architecture: Topic 1: Distributed File Systems GFS (The Google File System) 1 Filesystems
DISTRIBUTED SYSTEMS [COMP9243] Lecture 9b: Distributed File Systems INTRODUCTION. Transparency: Flexibility: Slide 1. Slide 3.
![DISTRIBUTED SYSTEMS [COMP9243] Lecture 9b: Distributed File Systems INTRODUCTION. Transparency: Flexibility: Slide 1. Slide 3.](/thumbs/86/93978710.jpg "DISTRIBUTED SYSTEMS [COMP9243] Lecture 9b: Distributed File Systems INTRODUCTION. Transparency: Flexibility: Slide 1. Slide 3.") CHALLENGES Transparency: Slide 1 DISTRIBUTED SYSTEMS [COMP9243] Lecture 9b: Distributed File Systems ➀ Introduction ➁ NFS (Network File System) ➂ AFS (Andrew File System) & Coda ➃ GFS (Google File System)
CHALLENGES Transparency: Slide 1 DISTRIBUTED SYSTEMS [COMP9243] Lecture 9b: Distributed File Systems ➀ Introduction ➁ NFS (Network File System) ➂ AFS (Andrew File System) & Coda ➃ GFS (Google File System)
GFS Overview. Design goals/priorities Design for big-data workloads Huge files, mostly appends, concurrency, huge bandwidth Design for failures
 GFS Overview Design goals/priorities Design for big-data workloads Huge files, mostly appends, concurrency, huge bandwidth Design for failures Interface: non-posix New op: record appends (atomicity matters,
GFS Overview Design goals/priorities Design for big-data workloads Huge files, mostly appends, concurrency, huge bandwidth Design for failures Interface: non-posix New op: record appends (atomicity matters,
Google File System (GFS) and Hadoop Distributed File System (HDFS)
 and Hadoop Distributed File System (HDFS)") Google File System (GFS) and Hadoop Distributed File System (HDFS) 1 Hadoop: Architectural Design Principles Linear scalability More nodes can do more work within the same time Linear on data size, linear
Google File System (GFS) and Hadoop Distributed File System (HDFS) 1 Hadoop: Architectural Design Principles Linear scalability More nodes can do more work within the same time Linear on data size, linear
The Google File System
 The Google File System By Ghemawat, Gobioff and Leung Outline Overview Assumption Design of GFS System Interactions Master Operations Fault Tolerance Measurements Overview GFS: Scalable distributed file
The Google File System By Ghemawat, Gobioff and Leung Outline Overview Assumption Design of GFS System Interactions Master Operations Fault Tolerance Measurements Overview GFS: Scalable distributed file
MapReduce. U of Toronto, 2014
 MapReduce U of Toronto, 2014 http://www.google.org/flutrends/ca/ (2012) Average Searches Per Day: 5,134,000,000 2 Motivation Process lots of data Google processed about 24 petabytes of data per day in
MapReduce U of Toronto, 2014 http://www.google.org/flutrends/ca/ (2012) Average Searches Per Day: 5,134,000,000 2 Motivation Process lots of data Google processed about 24 petabytes of data per day in
Distributed Systems. GFS / HDFS / Spanner
 15-440 Distributed Systems GFS / HDFS / Spanner Agenda Google File System (GFS) Hadoop Distributed File System (HDFS) Distributed File Systems Replication Spanner Distributed Database System Paxos Replication
15-440 Distributed Systems GFS / HDFS / Spanner Agenda Google File System (GFS) Hadoop Distributed File System (HDFS) Distributed File Systems Replication Spanner Distributed Database System Paxos Replication
The Google File System
 The Google File System Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung Google* 정학수, 최주영 1 Outline Introduction Design Overview System Interactions Master Operation Fault Tolerance and Diagnosis Conclusions
The Google File System Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung Google* 정학수, 최주영 1 Outline Introduction Design Overview System Interactions Master Operation Fault Tolerance and Diagnosis Conclusions
Google File System 2
 Google File System 2 goals monitoring, fault tolerance, auto-recovery (thousands of low-cost machines) focus on multi-gb files handle appends efficiently (no random writes & sequential reads) co-design
Google File System 2 goals monitoring, fault tolerance, auto-recovery (thousands of low-cost machines) focus on multi-gb files handle appends efficiently (no random writes & sequential reads) co-design
Distributed File Systems. CS432: Distributed Systems Spring 2017
 Distributed File Systems Reading Chapter 12 (12.1-12.4) [Coulouris 11] Chapter 11 [Tanenbaum 06] Section 4.3, Modern Operating Systems, Fourth Ed., Andrew S. Tanenbaum Section 11.4, Operating Systems Concept,
Distributed File Systems Reading Chapter 12 (12.1-12.4) [Coulouris 11] Chapter 11 [Tanenbaum 06] Section 4.3, Modern Operating Systems, Fourth Ed., Andrew S. Tanenbaum Section 11.4, Operating Systems Concept,
CSE 124: Networked Services Lecture-16
 Fall 2010 CSE 124: Networked Services Lecture-16 Instructor: B. S. Manoj, Ph.D http://cseweb.ucsd.edu/classes/fa10/cse124 11/23/2010 CSE 124 Networked Services Fall 2010 1 Updates PlanetLab experiments
Fall 2010 CSE 124: Networked Services Lecture-16 Instructor: B. S. Manoj, Ph.D http://cseweb.ucsd.edu/classes/fa10/cse124 11/23/2010 CSE 124 Networked Services Fall 2010 1 Updates PlanetLab experiments
Outline. INF3190:Distributed Systems - Examples. Last week: Definitions Transparencies Challenges&pitfalls Architecturalstyles
 INF3190:Distributed Systems - Examples Thomas Plagemann & Roman Vitenberg Outline Last week: Definitions Transparencies Challenges&pitfalls Architecturalstyles Today: Examples Googel File System (Thomas)
INF3190:Distributed Systems - Examples Thomas Plagemann & Roman Vitenberg Outline Last week: Definitions Transparencies Challenges&pitfalls Architecturalstyles Today: Examples Googel File System (Thomas)
CS555: Distributed Systems [Fall 2017] Dept. Of Computer Science, Colorado State University
![CS555: Distributed Systems [Fall 2017] Dept. Of Computer Science, Colorado State University](/thumbs/96/128755699.jpg "CS555: Distributed Systems [Fall 2017] Dept. Of Computer Science, Colorado State University") CS 555: DISTRIBUTED SYSTEMS [DYNAMO & GOOGLE FILE SYSTEM] Frequently asked questions from the previous class survey What s the typical size of an inconsistency window in most production settings? Dynamo?
CS 555: DISTRIBUTED SYSTEMS [DYNAMO & GOOGLE FILE SYSTEM] Frequently asked questions from the previous class survey What s the typical size of an inconsistency window in most production settings? Dynamo?
7680: Distributed Systems
 Cristina Nita-Rotaru 7680: Distributed Systems GFS. HDFS Required Reading } Google File System. S, Ghemawat, H. Gobioff and S.-T. Leung. SOSP 2003. } http://hadoop.apache.org } A Novel Approach to Improving
Cristina Nita-Rotaru 7680: Distributed Systems GFS. HDFS Required Reading } Google File System. S, Ghemawat, H. Gobioff and S.-T. Leung. SOSP 2003. } http://hadoop.apache.org } A Novel Approach to Improving
Distributed Systems. 15. Distributed File Systems. Paul Krzyzanowski. Rutgers University. Fall 2017
 Distributed Systems 15. Distributed File Systems Paul Krzyzanowski Rutgers University Fall 2017 1 Google Chubby ( Apache Zookeeper) 2 Chubby Distributed lock service + simple fault-tolerant file system
Distributed Systems 15. Distributed File Systems Paul Krzyzanowski Rutgers University Fall 2017 1 Google Chubby ( Apache Zookeeper) 2 Chubby Distributed lock service + simple fault-tolerant file system
HDFS Architecture Guide
 by Dhruba Borthakur Table of contents 1 Introduction...3 2 Assumptions and Goals...3 2.1 Hardware Failure... 3 2.2 Streaming Data Access...3 2.3 Large Data Sets...3 2.4 Simple Coherency Model... 4 2.5
by Dhruba Borthakur Table of contents 1 Introduction...3 2 Assumptions and Goals...3 2.1 Hardware Failure... 3 2.2 Streaming Data Access...3 2.3 Large Data Sets...3 2.4 Simple Coherency Model... 4 2.5
CSE 124: Networked Services Fall 2009 Lecture-19
 CSE 124: Networked Services Fall 2009 Lecture-19 Instructor: B. S. Manoj, Ph.D http://cseweb.ucsd.edu/classes/fa09/cse124 Some of these slides are adapted from various sources/individuals including but
CSE 124: Networked Services Fall 2009 Lecture-19 Instructor: B. S. Manoj, Ph.D http://cseweb.ucsd.edu/classes/fa09/cse124 Some of these slides are adapted from various sources/individuals including but
Service and Cloud Computing Lecture 10: DFS2 Prof. George Baciu PQ838
 COMP4442 Service and Cloud Computing Lecture 10: DFS2 www.comp.polyu.edu.hk/~csgeorge/comp4442 Prof. George Baciu PQ838 csgeorge@comp.polyu.edu.hk 1 Preamble 2 Recall the Cloud Stack Model A B Application
COMP4442 Service and Cloud Computing Lecture 10: DFS2 www.comp.polyu.edu.hk/~csgeorge/comp4442 Prof. George Baciu PQ838 csgeorge@comp.polyu.edu.hk 1 Preamble 2 Recall the Cloud Stack Model A B Application
CS /30/17. Paul Krzyzanowski 1. Google Chubby ( Apache Zookeeper) Distributed Systems. Chubby. Chubby Deployment.
 Distributed Systems. Chubby. Chubby Deployment.") Distributed Systems 15. Distributed File Systems Google ( Apache Zookeeper) Paul Krzyzanowski Rutgers University Fall 2017 1 2 Distributed lock service + simple fault-tolerant file system Deployment Client
Distributed Systems 15. Distributed File Systems Google ( Apache Zookeeper) Paul Krzyzanowski Rutgers University Fall 2017 1 2 Distributed lock service + simple fault-tolerant file system Deployment Client
4/9/2018 Week 13-A Sangmi Lee Pallickara. CS435 Introduction to Big Data Spring 2018 Colorado State University. FAQs. Architecture of GFS
 W13.A.0.0 CS435 Introduction to Big Data W13.A.1 FAQs Programming Assignment 3 has been posted PART 2. LARGE SCALE DATA STORAGE SYSTEMS DISTRIBUTED FILE SYSTEMS Recitations Apache Spark tutorial 1 and
W13.A.0.0 CS435 Introduction to Big Data W13.A.1 FAQs Programming Assignment 3 has been posted PART 2. LARGE SCALE DATA STORAGE SYSTEMS DISTRIBUTED FILE SYSTEMS Recitations Apache Spark tutorial 1 and
Distributed Systems. Hajussüsteemid MTAT Distributed File Systems. (slides: adopted from Meelis Roos DS12 course) 1/25
 1/25") Hajussüsteemid MTAT.08.024 Distributed Systems Distributed File Systems (slides: adopted from Meelis Roos DS12 course) 1/25 Examples AFS NFS SMB/CIFS Coda Intermezzo HDFS WebDAV 9P 2/25 Andrew File System
Hajussüsteemid MTAT.08.024 Distributed Systems Distributed File Systems (slides: adopted from Meelis Roos DS12 course) 1/25 Examples AFS NFS SMB/CIFS Coda Intermezzo HDFS WebDAV 9P 2/25 Andrew File System
BigData and Map Reduce VITMAC03
 BigData and Map Reduce VITMAC03 1 Motivation Process lots of data Google processed about 24 petabytes of data per day in 2009. A single machine cannot serve all the data You need a distributed system to
BigData and Map Reduce VITMAC03 1 Motivation Process lots of data Google processed about 24 petabytes of data per day in 2009. A single machine cannot serve all the data You need a distributed system to
Distributed Systems. 15. Distributed File Systems. Paul Krzyzanowski. Rutgers University. Fall 2016
 Distributed Systems 15. Distributed File Systems Paul Krzyzanowski Rutgers University Fall 2016 1 Google Chubby 2 Chubby Distributed lock service + simple fault-tolerant file system Interfaces File access
Distributed Systems 15. Distributed File Systems Paul Krzyzanowski Rutgers University Fall 2016 1 Google Chubby 2 Chubby Distributed lock service + simple fault-tolerant file system Interfaces File access
HDFS Architecture. Gregory Kesden, CSE-291 (Storage Systems) Fall 2017
 Fall 2017") HDFS Architecture Gregory Kesden, CSE-291 (Storage Systems) Fall 2017 Based Upon: http://hadoop.apache.org/docs/r3.0.0-alpha1/hadoopproject-dist/hadoop-hdfs/hdfsdesign.html Assumptions At scale, hardware
HDFS Architecture Gregory Kesden, CSE-291 (Storage Systems) Fall 2017 Based Upon: http://hadoop.apache.org/docs/r3.0.0-alpha1/hadoopproject-dist/hadoop-hdfs/hdfsdesign.html Assumptions At scale, hardware
AN OVERVIEW OF DISTRIBUTED FILE SYSTEM Aditi Khazanchi, Akshay Kanwar, Lovenish Saluja
 www.ijecs.in International Journal Of Engineering And Computer Science ISSN:2319-7242 Volume 2 Issue 10 October, 2013 Page No. 2958-2965 Abstract AN OVERVIEW OF DISTRIBUTED FILE SYSTEM Aditi Khazanchi,
www.ijecs.in International Journal Of Engineering And Computer Science ISSN:2319-7242 Volume 2 Issue 10 October, 2013 Page No. 2958-2965 Abstract AN OVERVIEW OF DISTRIBUTED FILE SYSTEM Aditi Khazanchi,
Today CSCI Coda. Naming: Volumes. Coda GFS PAST. Instructor: Abhishek Chandra. Main Goals: Volume is a subtree in the naming space
 Today CSCI 5105 Coda GFS PAST Instructor: Abhishek Chandra 2 Coda Main Goals: Availability: Work in the presence of disconnection Scalability: Support large number of users Successor of Andrew File System
Today CSCI 5105 Coda GFS PAST Instructor: Abhishek Chandra 2 Coda Main Goals: Availability: Work in the presence of disconnection Scalability: Support large number of users Successor of Andrew File System
The Google File System
 The Google File System Sanjay Ghemawat, Howard Gobioff and Shun Tak Leung Google* Shivesh Kumar Sharma fl4164@wayne.edu Fall 2015 004395771 Overview Google file system is a scalable distributed file system
The Google File System Sanjay Ghemawat, Howard Gobioff and Shun Tak Leung Google* Shivesh Kumar Sharma fl4164@wayne.edu Fall 2015 004395771 Overview Google file system is a scalable distributed file system
Authors : Sanjay Ghemawat, Howard Gobioff, Shun-Tak Leung Presentation by: Vijay Kumar Chalasani
 The Authors : Sanjay Ghemawat, Howard Gobioff, Shun-Tak Leung Presentation by: Vijay Kumar Chalasani CS5204 Operating Systems 1 Introduction GFS is a scalable distributed file system for large data intensive
The Authors : Sanjay Ghemawat, Howard Gobioff, Shun-Tak Leung Presentation by: Vijay Kumar Chalasani CS5204 Operating Systems 1 Introduction GFS is a scalable distributed file system for large data intensive
UNIT-IV HDFS. Ms. Selva Mary. G
 UNIT-IV HDFS HDFS ARCHITECTURE Dataset partition across a number of separate machines Hadoop Distributed File system The Design of HDFS HDFS is a file system designed for storing very large files with
UNIT-IV HDFS HDFS ARCHITECTURE Dataset partition across a number of separate machines Hadoop Distributed File system The Design of HDFS HDFS is a file system designed for storing very large files with
Extreme computing Infrastructure
 Outline Extreme computing School of Informatics University of Edinburgh Replication and fault tolerance Virtualisation Parallelism and parallel/concurrent programming Services So, you want to build a cloud
Outline Extreme computing School of Informatics University of Edinburgh Replication and fault tolerance Virtualisation Parallelism and parallel/concurrent programming Services So, you want to build a cloud
Google File System. Arun Sundaram Operating Systems
 Arun Sundaram Operating Systems 1 Assumptions GFS built with commodity hardware GFS stores a modest number of large files A few million files, each typically 100MB or larger (Multi-GB files are common)
Arun Sundaram Operating Systems 1 Assumptions GFS built with commodity hardware GFS stores a modest number of large files A few million files, each typically 100MB or larger (Multi-GB files are common)
CS435 Introduction to Big Data FALL 2018 Colorado State University. 11/7/2018 Week 12-B Sangmi Lee Pallickara. FAQs
 11/7/2018 CS435 Introduction to Big Data - FALL 2018 W12.B.0.0 CS435 Introduction to Big Data 11/7/2018 CS435 Introduction to Big Data - FALL 2018 W12.B.1 FAQs Deadline of the Programming Assignment 3
11/7/2018 CS435 Introduction to Big Data - FALL 2018 W12.B.0.0 CS435 Introduction to Big Data 11/7/2018 CS435 Introduction to Big Data - FALL 2018 W12.B.1 FAQs Deadline of the Programming Assignment 3
Konstantin Shvachko, Hairong Kuang, Sanjay Radia, Robert Chansler Yahoo! Sunnyvale, California USA {Shv, Hairong, SRadia,
 Konstantin Shvachko, Hairong Kuang, Sanjay Radia, Robert Chansler Yahoo! Sunnyvale, California USA {Shv, Hairong, SRadia, Chansler}@Yahoo-Inc.com Presenter: Alex Hu } Introduction } Architecture } File
Konstantin Shvachko, Hairong Kuang, Sanjay Radia, Robert Chansler Yahoo! Sunnyvale, California USA {Shv, Hairong, SRadia, Chansler}@Yahoo-Inc.com Presenter: Alex Hu } Introduction } Architecture } File
Cloud Computing CS
 Cloud Computing CS 15-319 Distributed File Systems and Cloud Storage Part II Lecture 13, Feb 27, 2012 Majd F. Sakr, Mohammad Hammoud and Suhail Rehman 1 Today Last session Distributed File Systems and
Cloud Computing CS 15-319 Distributed File Systems and Cloud Storage Part II Lecture 13, Feb 27, 2012 Majd F. Sakr, Mohammad Hammoud and Suhail Rehman 1 Today Last session Distributed File Systems and
The Google File System
 The Google File System Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung SOSP 2003 presented by Kun Suo Outline GFS Background, Concepts and Key words Example of GFS Operations Some optimizations in
The Google File System Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung SOSP 2003 presented by Kun Suo Outline GFS Background, Concepts and Key words Example of GFS Operations Some optimizations in
CS60021: Scalable Data Mining. Sourangshu Bhattacharya
 CS60021: Scalable Data Mining Sourangshu Bhattacharya In this Lecture: Outline: HDFS Motivation HDFS User commands HDFS System architecture HDFS Implementation details Sourangshu Bhattacharya Computer
CS60021: Scalable Data Mining Sourangshu Bhattacharya In this Lecture: Outline: HDFS Motivation HDFS User commands HDFS System architecture HDFS Implementation details Sourangshu Bhattacharya Computer
goals monitoring, fault tolerance, auto-recovery (thousands of low-cost machines) handle appends efficiently (no random writes & sequential reads)
 handle appends efficiently (no random writes & sequential reads)") Google File System goals monitoring, fault tolerance, auto-recovery (thousands of low-cost machines) focus on multi-gb files handle appends efficiently (no random writes & sequential reads) co-design GFS
Google File System goals monitoring, fault tolerance, auto-recovery (thousands of low-cost machines) focus on multi-gb files handle appends efficiently (no random writes & sequential reads) co-design GFS
Cloud Computing CS
 Cloud Computing CS 15-319 Distributed File Systems and Cloud Storage Part I Lecture 12, Feb 22, 2012 Majd F. Sakr, Mohammad Hammoud and Suhail Rehman 1 Today Last two sessions Pregel, Dryad and GraphLab
Cloud Computing CS 15-319 Distributed File Systems and Cloud Storage Part I Lecture 12, Feb 22, 2012 Majd F. Sakr, Mohammad Hammoud and Suhail Rehman 1 Today Last two sessions Pregel, Dryad and GraphLab
Hadoop and HDFS Overview. Madhu Ankam
 Hadoop and HDFS Overview Madhu Ankam Why Hadoop We are gathering more data than ever Examples of data : Server logs Web logs Financial transactions Analytics Emails and text messages Social media like
Hadoop and HDFS Overview Madhu Ankam Why Hadoop We are gathering more data than ever Examples of data : Server logs Web logs Financial transactions Analytics Emails and text messages Social media like
Distributed File Systems (Chapter 14, M. Satyanarayanan) CS 249 Kamal Singh
 CS 249 Kamal Singh") Distributed File Systems (Chapter 14, M. Satyanarayanan) CS 249 Kamal Singh Topics Introduction to Distributed File Systems Coda File System overview Communication, Processes, Naming, Synchronization,
Distributed File Systems (Chapter 14, M. Satyanarayanan) CS 249 Kamal Singh Topics Introduction to Distributed File Systems Coda File System overview Communication, Processes, Naming, Synchronization,
System that permanently stores data Usually layered on top of a lower-level physical storage medium Divided into logical units called files
 System that permanently stores data Usually layered on top of a lower-level physical storage medium Divided into logical units called files Addressable by a filename ( foo.txt ) Usually supports hierarchical
System that permanently stores data Usually layered on top of a lower-level physical storage medium Divided into logical units called files Addressable by a filename ( foo.txt ) Usually supports hierarchical
Google Cluster Computing Faculty Training Workshop
 Google Cluster Computing Faculty Training Workshop Module VI: Distributed Filesystems This presentation includes course content University of Washington Some slides designed by Alex Moschuk, University
Google Cluster Computing Faculty Training Workshop Module VI: Distributed Filesystems This presentation includes course content University of Washington Some slides designed by Alex Moschuk, University
Georgia Institute of Technology ECE6102 4/20/2009 David Colvin, Jimmy Vuong
 Georgia Institute of Technology ECE6102 4/20/2009 David Colvin, Jimmy Vuong Relatively recent; still applicable today GFS: Google s storage platform for the generation and processing of data used by services
Georgia Institute of Technology ECE6102 4/20/2009 David Colvin, Jimmy Vuong Relatively recent; still applicable today GFS: Google s storage platform for the generation and processing of data used by services
DISTRIBUTED FILE SYSTEMS & NFS
 DISTRIBUTED FILE SYSTEMS & NFS Dr. Yingwu Zhu File Service Types in Client/Server File service a specification of what the file system offers to clients File server The implementation of a file service
DISTRIBUTED FILE SYSTEMS & NFS Dr. Yingwu Zhu File Service Types in Client/Server File service a specification of what the file system offers to clients File server The implementation of a file service
Hadoop Distributed File System(HDFS)
") Hadoop Distributed File System(HDFS) Bu eğitim sunumları İstanbul Kalkınma Ajansı nın 2016 yılı Yenilikçi ve Yaratıcı İstanbul Mali Destek Programı kapsamında yürütülmekte olan TR10/16/YNY/0036 no lu İstanbul
Hadoop Distributed File System(HDFS) Bu eğitim sunumları İstanbul Kalkınma Ajansı nın 2016 yılı Yenilikçi ve Yaratıcı İstanbul Mali Destek Programı kapsamında yürütülmekte olan TR10/16/YNY/0036 no lu İstanbul
NFS: Naming indirection, abstraction. Abstraction, abstraction, abstraction! Network File Systems: Naming, cache control, consistency
 Abstraction, abstraction, abstraction! Network File Systems: Naming, cache control, consistency Local file systems Disks are terrible abstractions: low-level blocks, etc. Directories, files, links much
Abstraction, abstraction, abstraction! Network File Systems: Naming, cache control, consistency Local file systems Disks are terrible abstractions: low-level blocks, etc. Directories, files, links much
Abstract. 1. Introduction. 2. Design and Implementation Master Chunkserver
 Abstract GFS from Scratch Ge Bian, Niket Agarwal, Wenli Looi https://github.com/looi/cs244b Dec 2017 GFS from Scratch is our partial re-implementation of GFS, the Google File System. Like GFS, our system
Abstract GFS from Scratch Ge Bian, Niket Agarwal, Wenli Looi https://github.com/looi/cs244b Dec 2017 GFS from Scratch is our partial re-implementation of GFS, the Google File System. Like GFS, our system
Yuval Carmel Tel-Aviv University "Advanced Topics in Storage Systems" - Spring 2013
 Yuval Carmel Tel-Aviv University "Advanced Topics in About & Keywords Motivation & Purpose Assumptions Architecture overview & Comparison Measurements How does it fit in? The Future 2 About & Keywords
Yuval Carmel Tel-Aviv University "Advanced Topics in About & Keywords Motivation & Purpose Assumptions Architecture overview & Comparison Measurements How does it fit in? The Future 2 About & Keywords
OPERATING SYSTEM. Chapter 12: File System Implementation
 OPERATING SYSTEM Chapter 12: File System Implementation Chapter 12: File System Implementation File-System Structure File-System Implementation Directory Implementation Allocation Methods Free-Space Management
OPERATING SYSTEM Chapter 12: File System Implementation Chapter 12: File System Implementation File-System Structure File-System Implementation Directory Implementation Allocation Methods Free-Space Management
Dept. Of Computer Science, Colorado State University
 CS 455: INTRODUCTION TO DISTRIBUTED SYSTEMS [HADOOP/HDFS] Trying to have your cake and eat it too Each phase pines for tasks with locality and their numbers on a tether Alas within a phase, you get one,
CS 455: INTRODUCTION TO DISTRIBUTED SYSTEMS [HADOOP/HDFS] Trying to have your cake and eat it too Each phase pines for tasks with locality and their numbers on a tether Alas within a phase, you get one,
Google is Really Different.
 COMP 790-088 -- Distributed File Systems Google File System 7 Google is Really Different. Huge Datacenters in 5+ Worldwide Locations Datacenters house multiple server clusters Coming soon to Lenior, NC
COMP 790-088 -- Distributed File Systems Google File System 7 Google is Really Different. Huge Datacenters in 5+ Worldwide Locations Datacenters house multiple server clusters Coming soon to Lenior, NC
Distributed Systems - III
 CSE 421/521 - Operating Systems Fall 2012 Lecture - XXIV Distributed Systems - III Tevfik Koşar University at Buffalo November 29th, 2012 1 Distributed File Systems Distributed file system (DFS) a distributed
CSE 421/521 - Operating Systems Fall 2012 Lecture - XXIV Distributed Systems - III Tevfik Koşar University at Buffalo November 29th, 2012 1 Distributed File Systems Distributed file system (DFS) a distributed
Staggeringly Large File Systems. Presented by Haoyan Geng
 Staggeringly Large File Systems Presented by Haoyan Geng Large-scale File Systems How Large? Google s file system in 2009 (Jeff Dean, LADIS 09) - 200+ clusters - Thousands of machines per cluster - Pools
Staggeringly Large File Systems Presented by Haoyan Geng Large-scale File Systems How Large? Google s file system in 2009 (Jeff Dean, LADIS 09) - 200+ clusters - Thousands of machines per cluster - Pools
NPTEL Course Jan K. Gopinath Indian Institute of Science
 Storage Systems NPTEL Course Jan 2012 (Lecture 41) K. Gopinath Indian Institute of Science Lease Mgmt designed to minimize mgmt overhead at master a lease initially times out at 60 secs. primary can request
Storage Systems NPTEL Course Jan 2012 (Lecture 41) K. Gopinath Indian Institute of Science Lease Mgmt designed to minimize mgmt overhead at master a lease initially times out at 60 secs. primary can request
Chapter 11: Implementing File Systems
 Chapter 11: Implementing File Systems Operating System Concepts 99h Edition DM510-14 Chapter 11: Implementing File Systems File-System Structure File-System Implementation Directory Implementation Allocation
Chapter 11: Implementing File Systems Operating System Concepts 99h Edition DM510-14 Chapter 11: Implementing File Systems File-System Structure File-System Implementation Directory Implementation Allocation
HDFS: Hadoop Distributed File System. Sector: Distributed Storage System
 GFS: Google File System Google C/C++ HDFS: Hadoop Distributed File System Yahoo Java, Open Source Sector: Distributed Storage System University of Illinois at Chicago C++, Open Source 2 System that permanently
GFS: Google File System Google C/C++ HDFS: Hadoop Distributed File System Yahoo Java, Open Source Sector: Distributed Storage System University of Illinois at Chicago C++, Open Source 2 System that permanently
Operating Systems 2010/2011
 Operating Systems 2010/2011 File Systems part 2 (ch11, ch17) Shudong Chen 1 Recap Tasks, requirements for filesystems Two views: User view File type / attribute / access modes Directory structure OS designers
Operating Systems 2010/2011 File Systems part 2 (ch11, ch17) Shudong Chen 1 Recap Tasks, requirements for filesystems Two views: User view File type / attribute / access modes Directory structure OS designers
Map-Reduce. Marco Mura 2010 March, 31th
 Map-Reduce Marco Mura (mura@di.unipi.it) 2010 March, 31th This paper is a note from the 2009-2010 course Strumenti di programmazione per sistemi paralleli e distribuiti and it s based by the lessons of
Map-Reduce Marco Mura (mura@di.unipi.it) 2010 March, 31th This paper is a note from the 2009-2010 course Strumenti di programmazione per sistemi paralleli e distribuiti and it s based by the lessons of
COSC 6397 Big Data Analytics. Distributed File Systems (II) Edgar Gabriel Spring HDFS Basics
 Edgar Gabriel Spring HDFS Basics") COSC 6397 Big Data Analytics Distributed File Systems (II) Edgar Gabriel Spring 2017 HDFS Basics An open-source implementation of Google File System Assume that node failure rate is high Assumes a small
COSC 6397 Big Data Analytics Distributed File Systems (II) Edgar Gabriel Spring 2017 HDFS Basics An open-source implementation of Google File System Assume that node failure rate is high Assumes a small
DISTRIBUTED FILE SYSTEMS CARSTEN WEINHOLD
 Department of Computer Science Institute of System Architecture, Operating Systems Group DISTRIBUTED FILE SYSTEMS CARSTEN WEINHOLD OUTLINE Classical distributed file systems NFS: Sun Network File System
Department of Computer Science Institute of System Architecture, Operating Systems Group DISTRIBUTED FILE SYSTEMS CARSTEN WEINHOLD OUTLINE Classical distributed file systems NFS: Sun Network File System
11/5/2018 Week 12-A Sangmi Lee Pallickara. CS435 Introduction to Big Data FALL 2018 Colorado State University
 11/5/2018 CS435 Introduction to Big Data - FALL 2018 W12.A.0.0 CS435 Introduction to Big Data 11/5/2018 CS435 Introduction to Big Data - FALL 2018 W12.A.1 Consider a Graduate Degree in Computer Science
11/5/2018 CS435 Introduction to Big Data - FALL 2018 W12.A.0.0 CS435 Introduction to Big Data 11/5/2018 CS435 Introduction to Big Data - FALL 2018 W12.A.1 Consider a Graduate Degree in Computer Science
Google File System, Replication. Amin Vahdat CSE 123b May 23, 2006
 Google File System, Replication Amin Vahdat CSE 123b May 23, 2006 Annoucements Third assignment available today Due date June 9, 5 pm Final exam, June 14, 11:30-2:30 Google File System (thanks to Mahesh
Google File System, Replication Amin Vahdat CSE 123b May 23, 2006 Annoucements Third assignment available today Due date June 9, 5 pm Final exam, June 14, 11:30-2:30 Google File System (thanks to Mahesh
Flat Datacenter Storage. Edmund B. Nightingale, Jeremy Elson, et al. 6.S897
 Flat Datacenter Storage Edmund B. Nightingale, Jeremy Elson, et al. 6.S897 Motivation Imagine a world with flat data storage Simple, Centralized, and easy to program Unfortunately, datacenter networks
Flat Datacenter Storage Edmund B. Nightingale, Jeremy Elson, et al. 6.S897 Motivation Imagine a world with flat data storage Simple, Centralized, and easy to program Unfortunately, datacenter networks
9/26/2017 Sangmi Lee Pallickara Week 6- A. CS535 Big Data Fall 2017 Colorado State University
 CS535 Big Data - Fall 2017 Week 6-A-1 CS535 BIG DATA FAQs PA1: Use only one word query Deadends {{Dead end}} Hub value will be?? PART 1. BATCH COMPUTING MODEL FOR BIG DATA ANALYTICS 4. GOOGLE FILE SYSTEM
CS535 Big Data - Fall 2017 Week 6-A-1 CS535 BIG DATA FAQs PA1: Use only one word query Deadends {{Dead end}} Hub value will be?? PART 1. BATCH COMPUTING MODEL FOR BIG DATA ANALYTICS 4. GOOGLE FILE SYSTEM
What is a file system
 COSC 6397 Big Data Analytics Distributed File Systems Edgar Gabriel Spring 2017 What is a file system A clearly defined method that the OS uses to store, catalog and retrieve files Manage the bits that
COSC 6397 Big Data Analytics Distributed File Systems Edgar Gabriel Spring 2017 What is a file system A clearly defined method that the OS uses to store, catalog and retrieve files Manage the bits that
CS 425 / ECE 428 Distributed Systems Fall Indranil Gupta (Indy) Nov 28, 2017 Lecture 25: Distributed File Systems All slides IG
 Nov 28, 2017 Lecture 25: Distributed File Systems All slides IG") CS 425 / ECE 428 Distributed Systems Fall 2017 Indranil Gupta (Indy) Nov 28, 2017 Lecture 25: Distributed File Systems All slides IG File System Contains files and directories (folders) Higher level of
CS 425 / ECE 428 Distributed Systems Fall 2017 Indranil Gupta (Indy) Nov 28, 2017 Lecture 25: Distributed File Systems All slides IG File System Contains files and directories (folders) Higher level of
Today: Coda, xfs! Brief overview of other file systems. Distributed File System Requirements!
 Today: Coda, xfs! Case Study: Coda File System Brief overview of other file systems xfs Log structured file systems Lecture 21, page 1 Distributed File System Requirements! Transparency Access, location,
Today: Coda, xfs! Case Study: Coda File System Brief overview of other file systems xfs Log structured file systems Lecture 21, page 1 Distributed File System Requirements! Transparency Access, location,
Network File Systems
 Network File Systems CS 240: Computing Systems and Concurrency Lecture 4 Marco Canini Credits: Michael Freedman and Kyle Jamieson developed much of the original material. Abstraction, abstraction, abstraction!
Network File Systems CS 240: Computing Systems and Concurrency Lecture 4 Marco Canini Credits: Michael Freedman and Kyle Jamieson developed much of the original material. Abstraction, abstraction, abstraction!
DISTRIBUTED FILE SYSTEMS CARSTEN WEINHOLD
 Department of Computer Science Institute of System Architecture, Operating Systems Group DISTRIBUTED FILE SYSTEMS CARSTEN WEINHOLD OUTLINE Classical distributed file systems NFS: Sun Network File System
Department of Computer Science Institute of System Architecture, Operating Systems Group DISTRIBUTED FILE SYSTEMS CARSTEN WEINHOLD OUTLINE Classical distributed file systems NFS: Sun Network File System
Chapter 12: File System Implementation
 Chapter 12: File System Implementation Chapter 12: File System Implementation File-System Structure File-System Implementation Directory Implementation Allocation Methods Free-Space Management Efficiency
Chapter 12: File System Implementation Chapter 12: File System Implementation File-System Structure File-System Implementation Directory Implementation Allocation Methods Free-Space Management Efficiency
Introduction to MapReduce
 Basics of Cloud Computing Lecture 4 Introduction to MapReduce Satish Srirama Some material adapted from slides by Jimmy Lin, Christophe Bisciglia, Aaron Kimball, & Sierra Michels-Slettvet, Google Distributed
Basics of Cloud Computing Lecture 4 Introduction to MapReduce Satish Srirama Some material adapted from slides by Jimmy Lin, Christophe Bisciglia, Aaron Kimball, & Sierra Michels-Slettvet, Google Distributed
CS 470 Spring Distributed Web and File Systems. Mike Lam, Professor. Content taken from the following:
 CS 470 Spring 2017 Mike Lam, Professor Distributed Web and File Systems Content taken from the following: "Distributed Systems: Principles and Paradigms" by Andrew S. Tanenbaum and Maarten Van Steen (Chapters
CS 470 Spring 2017 Mike Lam, Professor Distributed Web and File Systems Content taken from the following: "Distributed Systems: Principles and Paradigms" by Andrew S. Tanenbaum and Maarten Van Steen (Chapters
TITLE: PRE-REQUISITE THEORY. 1. Introduction to Hadoop. 2. Cluster. Implement sort algorithm and run it using HADOOP
 TITLE: Implement sort algorithm and run it using HADOOP PRE-REQUISITE Preliminary knowledge of clusters and overview of Hadoop and its basic functionality. THEORY 1. Introduction to Hadoop The Apache Hadoop
TITLE: Implement sort algorithm and run it using HADOOP PRE-REQUISITE Preliminary knowledge of clusters and overview of Hadoop and its basic functionality. THEORY 1. Introduction to Hadoop The Apache Hadoop