Extreme Computing. NoSQL.
|
|
|
- Audra Manning
- 6 years ago
- Views:
Transcription
1 Extreme Computing NoSQL
2 PREVIOUSLY: BATCH Query most/all data Results Eventually NOW: ON DEMAND Single Data Points Latency Matters
3 One problem, three ideas We want to keep track of mutable state in a scalable manner Assumptions: State organized in terms of many records State unlikely to fit on single machine, must be distributed MapReduce won t do! Three core ideas Partitioning (sharding) For scalability For latency Replication For robustness (availability) For throughput Caching For latency Three more problems How do we synchronise partitions? How do we synchronise replicas? What happens to the cache when the underlying data changes?
4 Relational databases to the rescue RDBMSs provide Relational model with schemas Powerful, flexible query language Transactional semantics Rich ecosystem, lots of tool support Great, I m sold! How do they do this? Transactions on a single machine: (relatively) easy! Partition tables to keep transactions on a single machine Example: partition by user What about transactions that require multiple machine? Example: transactions involving multiple users Need a new distributed protocol (but remember two generals) Two-phase commit (2PC)
5 2PC commit coordinator subordinate 1 subordinate 2 subordinate 3 prepare prepare prepare okay commit okay commit okay commit ack ack ack done
6 2PC abort coordinator subordinate 1 subordinate 2 subordinate 3 prepare prepare prepare okay abort okay abort no abort
7 2PC rollback coordinator subordinate 1 subordinate 2 subordinate 3 prepare prepare prepare okay commit okay commit okay commit ack rollback ack rollback rollback timeout
8 2PC: assumptions and limitations Assumptions Persistent storage and write-ahead log (WAL) at every node WAL is never permanently lost Limitations It is blocking and slow What if the coordinator dies? Solution: Paxos! (details beyond scope of this course)
9 Problems with RDBMSs Must design from the beginning Difficult and expensive to evolve True transactions implies two-phase commit Slow! Databases are expensive Distributed databases are even more expensive
10 What do RDBMSs provide? Relational model with schemas Powerful, flexible query language Transactional semantics: ACID Rich ecosystem, lots of tool support Do we need all these? What if we selectively drop some of these assumptions? What if I m willing to give up consistency for scalability? What if I m willing to give up the relational model for something more flexible? What if I just want a cheaper solution? Solution: NoSQL
11 NoSQL 1. Horizontally scale simple operations 2. Replicate/distribute data over many servers 3. Simple call interface 4. Weaker concurrency model than ACID 5. Efficient use of distributed indexes and RAM 6. Flexible schemas The No in NoSQL used to mean No Supposedly now it means Not only Four major types of NoSQL databases Key-value stores Column-oriented databases Document stores Graph databases
12 KEY-VALUE STORES
13 Key-value stores: data model Stores associations between keys and values Keys are usually primitives For example, ints, strings, raw bytes, etc. Values can be primitive or complex: usually opaque to store Primitives: ints, strings, etc. Complex: JSON, HTML fragments, etc.
14 Key-value stores: operations Very simple API: Get fetch value associated with key Put set value associated with key Optional operations: Multi-get Multi-put Range queries Consistency model: Atomic puts (usually) Cross-key operations: who knows?
15 Key-value stores: implementation Non-persistent: Just a big in-memory hash table Persistent Wrapper around a traditional RDBMS But what if data does not fit on a single machine?
16 Dealing with scale Partition the key space across multiple machines Let s say, hash partitioning For n machines, store key k at machine h(k) mod n Okay but: 1. How do we know which physical machine to contact? 2. How do we add a new machine to the cluster? 3. What happens if a machine fails? We need something better Hash the keys Hash the machines Distributed hash tables
17 BIGTABLE
 uninterpreted byte array Supports lookups, inserts, deletes Single row transactions only Image Source: Chang et al.")
18 BigTable: data model A table in Bigtable is a sparse, distributed, persistent multidimensional sorted map Map indexed by a row key, column key, and a timestamp (row:string, column:string, time:int64) uninterpreted byte array Supports lookups, inserts, deletes Single row transactions only Image Source: Chang et al., OSDI 2006
19 Rows and columns Rows maintained in sorted lexicographic order Applications can exploit this property for efficient row scans Row ranges dynamically partitioned into tablets Columns grouped into column families Column key = family:qualifier Column families provide locality hints Unbounded number of columns At the end of the day, it s all key-value pairs!
20 BigTable building blocks GFS Chubby SSTable
21 SSTable Basic building block of BigTable Persistent, ordered immutable map from keys to values Stored in GFS Sequence of blocks on disk plus an index for block lookup Can be completely mapped into memory Supported operations: Look up value associated with key Iterate key/value pairs within a key range SSTable 64KB block 64KB block 64KB block Index
22 Tablets and tables Dynamically partitioned range of rows Built from multiple SSTables Tablet start: aardvark end: apple SSTable SSTable 64KB block 64KB block 64KB block 64KB block 64KB block 64KB block Index Index Multiple tablets make up the table SSTables can be shared Tablet aardvark apple Tablet applepie boat SSTable SSTable SSTable SSTable Source: Graphic from slides by Erik Paulson
23 Notes on the architecture Similar to GFS Single master server, multiple tablet servers BigTable master Assigns tablets to tablet servers Detects addition and expiration of tablet servers Balances tablet server load Handles garbage collection Handles schema evolution Bigtable tablet servers Each tablet server manages a set of tablets Typically between ten to a thousand tablets Each MB by default Handles read and write requests to the tablets Splits tablets when they grow too large
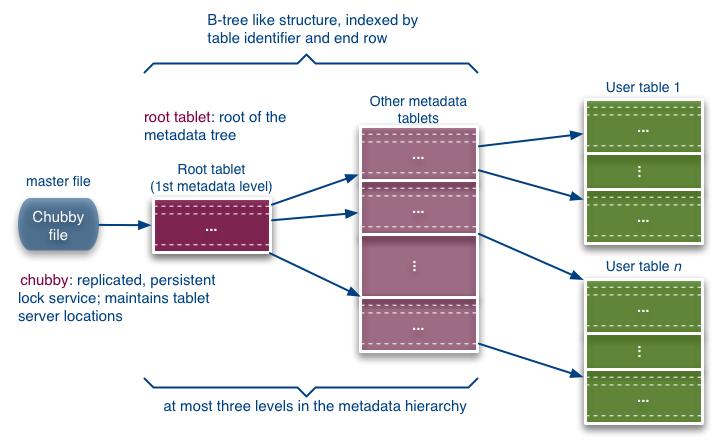
24 Location dereferencing
25 Tablet assignment Master keeps track of Set of live tablet servers Assignment of tablets to tablet servers Unassigned tablets Each tablet is assigned to one tablet server at a time Tablet server maintains an exclusive lock on a file in Chubby Master monitors tablet servers and handles assignment Changes to tablet structure Table creation/deletion (master initiated) Tablet merging (master initiated) Tablet splitting (tablet server initiated)

26 Tablet serving and I/O flow Log Structured Merge Trees Image Source: Chang et al., OSDI 2006
27 Tablet management Minor compaction Converts the memtable into an SSTable Reduces memory usage and log traffic on restart Merging compaction Reads the contents of a few SSTables and the memtable, and writes out a new SSTable Reduces number of SSTables Major compaction Merging compaction that results in only one SSTable No deletion records, only live data
28 DISTRIBUTED HASH TABLES: CHORD
29 h = 2 n 1 h = 0
30 h = 2 n 1 h = 0 Each machine holds pointers to predecessor and successor Send request to any node, gets routed to correct one in O(n) hops Can we do better? Routing: which machine holds the key?
31 h = 2 n 1 h = 0 Each machine holds pointers to predecessor and successor + finger table (+2, +4, +8, ) Send request to any node, gets routed to correct one in O(log n) hops Routing: which machine holds the key?
32 h = 2 n 1 h = 0 How do we rebuild the predecessor, successor, finger tables? New machine joins: what happens?
33 h = 2 n 1 h = 0 Solution: Replication N = 3, replicate +1, 1 Covered! Covered! Machine fails: what happens?
34 CONSISTENCY IN KEY-VALUE STORES
35 Focus on consistency People you do not want seeing your pictures Alice removes mom from list of people who can view photos Alice posts embarrassing pictures from Spring Break Can mom see Alice s photo? Why am I still getting messages? Bob unsubscribes from mailing list Message sent to mailing list right after Does Bob receive the message?
36 Three core ideas Partitioning (sharding) For scalability For latency Replication For robustness (availability) For throughput Caching For latency We ll shift our focus here
37 (Re)CAP CAP stands for Consistency, Availability, Partition tolerance Consistency: all nodes see the same data at the same time Availability: node failures do not prevent system operation Partition tolerance: link failures do not prevent system operation Largely a conjecture attributed to Eric Brewer A distributed system can satisfy any two of these guarantees at the same time, but not all three You can't have a triangle; pick any one side availability consistency partition tolerance
38 CAP Tradeoffs CA = consistency + availability E.g., parallel databases that use 2PC AP = availability + tolerance to partitions E.g., DNS, web caching
39 Replication possibilities Update sent to all replicas at the same time To guarantee consistency you need something like Paxos Update sent to a master Replication is synchronous Replication is asynchronous Combination of both Update sent to an arbitrary replica All these possibilities involve tradeoffs! eventual consistency
40 Three core ideas Partitioning (sharding) For scalability For latency Replication For robustness (availability) For throughput Caching For latency Quick look at this
41 Unit of consistency Single record: Relatively straightforward Complex application logic to handle multi-record transactions Arbitrary transactions: Requires 2PC/Paxos Middle ground: entity groups Groups of entities that share affinity Co-locate entity groups Provide transaction support within entity groups Example: user + user s photos + user s posts etc.
42 Three core ideas Partitioning (sharding) For scalability For latency Replication For robustness (availability) For throughput Caching For latency Quick look at this
43 Facebook architecture memcached MySQL Read path: Look in memcached Look in MySQL Populate in memcached Write path: Write in MySQL Remove in memcached Subsequent read: Look in MySQL Populate in memcached Source:
44 Facebook architecture: multi-dc memcached memcached MySQL Replication lag MySQL California Virginia 1. User updates first name from Jason to Monkey 2. Write Monkey in master DB in CA, delete memcached entry in CA and VA 3. Someone goes to profile in Virginia, read VA slave DB, get Jason 4. Update VA memcache with first name as Jason 5. Replication catches up. Jason stuck in memcached until another write! Source:
45 Three Core Ideas Partitioning (sharding) For scalability For latency Replication For robustness (availability) For throughput Caching For latency Let s go back to this again
46 Yahoo s PNUTS Yahoo s globally distributed/replicated key-value store Provides per-record timeline consistency Guarantees that all replicas provide all updates in same order Different classes of reads: Read-any: may time travel! Read-critical(required version): monotonic reads Read-latest
47 PNUTS: implementation principles Each record has a single master Asynchronous replication across datacenters Allow for synchronous replicate within datacenters All updates routed to master first, updates applied, then propagated Protocols for recognizing master failure and load balancing Tradeoffs Different types of reads have different latencies Availability compromised when master fails and partition failure in protocol for transferring of mastership
48 Google s Spanner Features: Full ACID translations across multiple datacenters, across continents! External consistency: wrt globally-consistent timestamps! How? TrueTime: globally synchronized API using GPSes and atomic clocks Use 2PC but use Paxos to replicate state Tradeoffs?
49 Summary Described the basics of NoSQL stores Discussed the benefits and detriments of RDBMSs Introduced various kinds of non-relational stores Distributed hash tables (Chord) Wide-column stores (BigTable) Introduced caching and replication Addressed some of the associated problems Discussed real-world use cases
Big Data Infrastructure CS 489/698 Big Data Infrastructure (Winter 2017)
") Big Data Infrastructure CS 489/698 Big Data Infrastructure (Winter 2017) Week 10: Mutable State (1/2) March 14, 2017 Jimmy Lin David R. Cheriton School of Computer Science University of Waterloo These
Big Data Infrastructure CS 489/698 Big Data Infrastructure (Winter 2017) Week 10: Mutable State (1/2) March 14, 2017 Jimmy Lin David R. Cheriton School of Computer Science University of Waterloo These
Big Data Infrastructure CS 489/698 Big Data Infrastructure (Winter 2016)
") Big Data Infrastructure CS 489/698 Big Data Infrastructure (Winter 2016) Week 10: Mutable State (1/2) March 15, 2016 Jimmy Lin David R. Cheriton School of Computer Science University of Waterloo These
Big Data Infrastructure CS 489/698 Big Data Infrastructure (Winter 2016) Week 10: Mutable State (1/2) March 15, 2016 Jimmy Lin David R. Cheriton School of Computer Science University of Waterloo These
Big Data Infrastructure CS 489/698 Big Data Infrastructure (Winter 2017)
") Big Data Infrastructure CS 489/698 Big Data Infrastructure (Winter 2017) Week 10: Mutable State (2/2) March 16, 2017 Jimmy Lin David R. Cheriton School of Computer Science University of Waterloo These
Big Data Infrastructure CS 489/698 Big Data Infrastructure (Winter 2017) Week 10: Mutable State (2/2) March 16, 2017 Jimmy Lin David R. Cheriton School of Computer Science University of Waterloo These
Data-Intensive Distributed Computing
 Data-Intensive Distributed Computing CS 451/651 (Fall 2018) Part 7: Mutable State (2/2) November 13, 2018 Jimmy Lin David R. Cheriton School of Computer Science University of Waterloo These slides are
Data-Intensive Distributed Computing CS 451/651 (Fall 2018) Part 7: Mutable State (2/2) November 13, 2018 Jimmy Lin David R. Cheriton School of Computer Science University of Waterloo These slides are
Large-Scale Data Engineering
 Large-Scale Data Engineering nosql: BASE vs ACID THE NEED FOR SOMETHING DIFFERENT One problem, three ideas We want to keep track of mutable state in a scalable manner Assumptions: State organized in terms
Large-Scale Data Engineering nosql: BASE vs ACID THE NEED FOR SOMETHING DIFFERENT One problem, three ideas We want to keep track of mutable state in a scalable manner Assumptions: State organized in terms
BigTable. CSE-291 (Cloud Computing) Fall 2016
 Fall 2016") BigTable CSE-291 (Cloud Computing) Fall 2016 Data Model Sparse, distributed persistent, multi-dimensional sorted map Indexed by a row key, column key, and timestamp Values are uninterpreted arrays of bytes
BigTable CSE-291 (Cloud Computing) Fall 2016 Data Model Sparse, distributed persistent, multi-dimensional sorted map Indexed by a row key, column key, and timestamp Values are uninterpreted arrays of bytes
Big Table. Google s Storage Choice for Structured Data. Presented by Group E - Dawei Yang - Grace Ramamoorthy - Patrick O Sullivan - Rohan Singla
 Big Table Google s Storage Choice for Structured Data Presented by Group E - Dawei Yang - Grace Ramamoorthy - Patrick O Sullivan - Rohan Singla Bigtable: Introduction Resembles a database. Does not support
Big Table Google s Storage Choice for Structured Data Presented by Group E - Dawei Yang - Grace Ramamoorthy - Patrick O Sullivan - Rohan Singla Bigtable: Introduction Resembles a database. Does not support
CSE 444: Database Internals. Lectures 26 NoSQL: Extensible Record Stores
 CSE 444: Database Internals Lectures 26 NoSQL: Extensible Record Stores CSE 444 - Spring 2014 1 References Scalable SQL and NoSQL Data Stores, Rick Cattell, SIGMOD Record, December 2010 (Vol. 39, No. 4)
CSE 444: Database Internals Lectures 26 NoSQL: Extensible Record Stores CSE 444 - Spring 2014 1 References Scalable SQL and NoSQL Data Stores, Rick Cattell, SIGMOD Record, December 2010 (Vol. 39, No. 4)
Bigtable: A Distributed Storage System for Structured Data By Fay Chang, et al. OSDI Presented by Xiang Gao
 Bigtable: A Distributed Storage System for Structured Data By Fay Chang, et al. OSDI 2006 Presented by Xiang Gao 2014-11-05 Outline Motivation Data Model APIs Building Blocks Implementation Refinement
Bigtable: A Distributed Storage System for Structured Data By Fay Chang, et al. OSDI 2006 Presented by Xiang Gao 2014-11-05 Outline Motivation Data Model APIs Building Blocks Implementation Refinement
Distributed File Systems II
 Distributed File Systems II To do q Very-large scale: Google FS, Hadoop FS, BigTable q Next time: Naming things GFS A radically new environment NFS, etc. Independence Small Scale Variety of workloads Cooperation
Distributed File Systems II To do q Very-large scale: Google FS, Hadoop FS, BigTable q Next time: Naming things GFS A radically new environment NFS, etc. Independence Small Scale Variety of workloads Cooperation
References. What is Bigtable? Bigtable Data Model. Outline. Key Features. CSE 444: Database Internals
 References CSE 444: Database Internals Scalable SQL and NoSQL Data Stores, Rick Cattell, SIGMOD Record, December 2010 (Vol 39, No 4) Lectures 26 NoSQL: Extensible Record Stores Bigtable: A Distributed
References CSE 444: Database Internals Scalable SQL and NoSQL Data Stores, Rick Cattell, SIGMOD Record, December 2010 (Vol 39, No 4) Lectures 26 NoSQL: Extensible Record Stores Bigtable: A Distributed
Bigtable: A Distributed Storage System for Structured Data by Google SUNNIE CHUNG CIS 612
 Bigtable: A Distributed Storage System for Structured Data by Google SUNNIE CHUNG CIS 612 Google Bigtable 2 A distributed storage system for managing structured data that is designed to scale to a very
Bigtable: A Distributed Storage System for Structured Data by Google SUNNIE CHUNG CIS 612 Google Bigtable 2 A distributed storage system for managing structured data that is designed to scale to a very
ΕΠΛ 602:Foundations of Internet Technologies. Cloud Computing
 ΕΠΛ 602:Foundations of Internet Technologies Cloud Computing 1 Outline Bigtable(data component of cloud) Web search basedonch13of thewebdatabook 2 What is Cloud Computing? ACloudis an infrastructure, transparent
ΕΠΛ 602:Foundations of Internet Technologies Cloud Computing 1 Outline Bigtable(data component of cloud) Web search basedonch13of thewebdatabook 2 What is Cloud Computing? ACloudis an infrastructure, transparent
CS November 2017
 Bigtable Highly available distributed storage Distributed Systems 18. Bigtable Built with semi-structured data in mind URLs: content, metadata, links, anchors, page rank User data: preferences, account
Bigtable Highly available distributed storage Distributed Systems 18. Bigtable Built with semi-structured data in mind URLs: content, metadata, links, anchors, page rank User data: preferences, account
Bigtable. Presenter: Yijun Hou, Yixiao Peng
 Bigtable Fay Chang, Jeffrey Dean, Sanjay Ghemawat, Wilson C. Hsieh, Deborah A. Wallach Mike Burrows, Tushar Chandra, Andrew Fikes, Robert E. Gruber Google, Inc. OSDI 06 Presenter: Yijun Hou, Yixiao Peng
Bigtable Fay Chang, Jeffrey Dean, Sanjay Ghemawat, Wilson C. Hsieh, Deborah A. Wallach Mike Burrows, Tushar Chandra, Andrew Fikes, Robert E. Gruber Google, Inc. OSDI 06 Presenter: Yijun Hou, Yixiao Peng
CA485 Ray Walshe NoSQL
 NoSQL BASE vs ACID Summary Traditional relational database management systems (RDBMS) do not scale because they adhere to ACID. A strong movement within cloud computing is to utilize non-traditional data
NoSQL BASE vs ACID Summary Traditional relational database management systems (RDBMS) do not scale because they adhere to ACID. A strong movement within cloud computing is to utilize non-traditional data
CSE 544 Principles of Database Management Systems. Magdalena Balazinska Winter 2009 Lecture 12 Google Bigtable
 CSE 544 Principles of Database Management Systems Magdalena Balazinska Winter 2009 Lecture 12 Google Bigtable References Bigtable: A Distributed Storage System for Structured Data. Fay Chang et. al. OSDI
CSE 544 Principles of Database Management Systems Magdalena Balazinska Winter 2009 Lecture 12 Google Bigtable References Bigtable: A Distributed Storage System for Structured Data. Fay Chang et. al. OSDI
BigTable. Chubby. BigTable. Chubby. Why Chubby? How to do consensus as a service
 BigTable BigTable Doug Woos and Tom Anderson In the early 2000s, Google had way more than anybody else did Traditional bases couldn t scale Want something better than a filesystem () BigTable optimized
BigTable BigTable Doug Woos and Tom Anderson In the early 2000s, Google had way more than anybody else did Traditional bases couldn t scale Want something better than a filesystem () BigTable optimized
Bigtable: A Distributed Storage System for Structured Data. Andrew Hon, Phyllis Lau, Justin Ng
 Bigtable: A Distributed Storage System for Structured Data Andrew Hon, Phyllis Lau, Justin Ng What is Bigtable? - A storage system for managing structured data - Used in 60+ Google services - Motivation:
Bigtable: A Distributed Storage System for Structured Data Andrew Hon, Phyllis Lau, Justin Ng What is Bigtable? - A storage system for managing structured data - Used in 60+ Google services - Motivation:
CS November 2018
 Bigtable Highly available distributed storage Distributed Systems 19. Bigtable Built with semi-structured data in mind URLs: content, metadata, links, anchors, page rank User data: preferences, account
Bigtable Highly available distributed storage Distributed Systems 19. Bigtable Built with semi-structured data in mind URLs: content, metadata, links, anchors, page rank User data: preferences, account
BigTable: A Distributed Storage System for Structured Data
 BigTable: A Distributed Storage System for Structured Data Amir H. Payberah amir@sics.se Amirkabir University of Technology (Tehran Polytechnic) Amir H. Payberah (Tehran Polytechnic) BigTable 1393/7/26
BigTable: A Distributed Storage System for Structured Data Amir H. Payberah amir@sics.se Amirkabir University of Technology (Tehran Polytechnic) Amir H. Payberah (Tehran Polytechnic) BigTable 1393/7/26
Distributed Systems [Fall 2012]
![Distributed Systems [Fall 2012]](/thumbs/75/71557798.jpg "Distributed Systems [Fall 2012]") Distributed Systems [Fall 2012] Lec 20: Bigtable (cont ed) Slide acks: Mohsen Taheriyan (http://www-scf.usc.edu/~csci572/2011spring/presentations/taheriyan.pptx) 1 Chubby (Reminder) Lock service with a
Distributed Systems [Fall 2012] Lec 20: Bigtable (cont ed) Slide acks: Mohsen Taheriyan (http://www-scf.usc.edu/~csci572/2011spring/presentations/taheriyan.pptx) 1 Chubby (Reminder) Lock service with a
Bigtable. A Distributed Storage System for Structured Data. Presenter: Yunming Zhang Conglong Li. Saturday, September 21, 13
 Bigtable A Distributed Storage System for Structured Data Presenter: Yunming Zhang Conglong Li References SOCC 2010 Key Note Slides Jeff Dean Google Introduction to Distributed Computing, Winter 2008 University
Bigtable A Distributed Storage System for Structured Data Presenter: Yunming Zhang Conglong Li References SOCC 2010 Key Note Slides Jeff Dean Google Introduction to Distributed Computing, Winter 2008 University
big picture parallel db (one data center) mix of OLTP and batch analysis lots of data, high r/w rates, 1000s of cheap boxes thus many failures
 mix of OLTP and batch analysis lots of data, high r/w rates, 1000s of cheap boxes thus many failures") Lecture 20 -- 11/20/2017 BigTable big picture parallel db (one data center) mix of OLTP and batch analysis lots of data, high r/w rates, 1000s of cheap boxes thus many failures what does paper say Google
Lecture 20 -- 11/20/2017 BigTable big picture parallel db (one data center) mix of OLTP and batch analysis lots of data, high r/w rates, 1000s of cheap boxes thus many failures what does paper say Google
CSE-E5430 Scalable Cloud Computing Lecture 9
 CSE-E5430 Scalable Cloud Computing Lecture 9 Keijo Heljanko Department of Computer Science School of Science Aalto University keijo.heljanko@aalto.fi 15.11-2015 1/24 BigTable Described in the paper: Fay
CSE-E5430 Scalable Cloud Computing Lecture 9 Keijo Heljanko Department of Computer Science School of Science Aalto University keijo.heljanko@aalto.fi 15.11-2015 1/24 BigTable Described in the paper: Fay
BigTable: A Distributed Storage System for Structured Data (2006) Slides adapted by Tyler Davis
 Slides adapted by Tyler Davis") BigTable: A Distributed Storage System for Structured Data (2006) Slides adapted by Tyler Davis Motivation Lots of (semi-)structured data at Google URLs: Contents, crawl metadata, links, anchors, pagerank,
BigTable: A Distributed Storage System for Structured Data (2006) Slides adapted by Tyler Davis Motivation Lots of (semi-)structured data at Google URLs: Contents, crawl metadata, links, anchors, pagerank,
CS 655 Advanced Topics in Distributed Systems
 Presented by : Walid Budgaga CS 655 Advanced Topics in Distributed Systems Computer Science Department Colorado State University 1 Outline Problem Solution Approaches Comparison Conclusion 2 Problem 3
Presented by : Walid Budgaga CS 655 Advanced Topics in Distributed Systems Computer Science Department Colorado State University 1 Outline Problem Solution Approaches Comparison Conclusion 2 Problem 3
CISC 7610 Lecture 2b The beginnings of NoSQL
 CISC 7610 Lecture 2b The beginnings of NoSQL Topics: Big Data Google s infrastructure Hadoop: open google infrastructure Scaling through sharding CAP theorem Amazon s Dynamo 5 V s of big data Everyone
CISC 7610 Lecture 2b The beginnings of NoSQL Topics: Big Data Google s infrastructure Hadoop: open google infrastructure Scaling through sharding CAP theorem Amazon s Dynamo 5 V s of big data Everyone
CS5412: OTHER DATA CENTER SERVICES
 1 CS5412: OTHER DATA CENTER SERVICES Lecture V Ken Birman Tier two and Inner Tiers 2 If tier one faces the user and constructs responses, what lives in tier two? Caching services are very common (many
1 CS5412: OTHER DATA CENTER SERVICES Lecture V Ken Birman Tier two and Inner Tiers 2 If tier one faces the user and constructs responses, what lives in tier two? Caching services are very common (many
CSE 544 Principles of Database Management Systems. Magdalena Balazinska Winter 2015 Lecture 14 NoSQL
 CSE 544 Principles of Database Management Systems Magdalena Balazinska Winter 2015 Lecture 14 NoSQL References Scalable SQL and NoSQL Data Stores, Rick Cattell, SIGMOD Record, December 2010 (Vol. 39, No.
CSE 544 Principles of Database Management Systems Magdalena Balazinska Winter 2015 Lecture 14 NoSQL References Scalable SQL and NoSQL Data Stores, Rick Cattell, SIGMOD Record, December 2010 (Vol. 39, No.
CS5412: DIVING IN: INSIDE THE DATA CENTER
 1 CS5412: DIVING IN: INSIDE THE DATA CENTER Lecture V Ken Birman Data centers 2 Once traffic reaches a data center it tunnels in First passes through a filter that blocks attacks Next, a router that directs
1 CS5412: DIVING IN: INSIDE THE DATA CENTER Lecture V Ken Birman Data centers 2 Once traffic reaches a data center it tunnels in First passes through a filter that blocks attacks Next, a router that directs
Megastore: Providing Scalable, Highly Available Storage for Interactive Services & Spanner: Google s Globally- Distributed Database.
 Megastore: Providing Scalable, Highly Available Storage for Interactive Services & Spanner: Google s Globally- Distributed Database. Presented by Kewei Li The Problem db nosql complex legacy tuning expensive
Megastore: Providing Scalable, Highly Available Storage for Interactive Services & Spanner: Google s Globally- Distributed Database. Presented by Kewei Li The Problem db nosql complex legacy tuning expensive
DIVING IN: INSIDE THE DATA CENTER
 1 DIVING IN: INSIDE THE DATA CENTER Anwar Alhenshiri Data centers 2 Once traffic reaches a data center it tunnels in First passes through a filter that blocks attacks Next, a router that directs it to
1 DIVING IN: INSIDE THE DATA CENTER Anwar Alhenshiri Data centers 2 Once traffic reaches a data center it tunnels in First passes through a filter that blocks attacks Next, a router that directs it to
CISC 7610 Lecture 5 Distributed multimedia databases. Topics: Scaling up vs out Replication Partitioning CAP Theorem NoSQL NewSQL
 CISC 7610 Lecture 5 Distributed multimedia databases Topics: Scaling up vs out Replication Partitioning CAP Theorem NoSQL NewSQL Motivation YouTube receives 400 hours of video per minute That is 200M hours
CISC 7610 Lecture 5 Distributed multimedia databases Topics: Scaling up vs out Replication Partitioning CAP Theorem NoSQL NewSQL Motivation YouTube receives 400 hours of video per minute That is 200M hours
Distributed Data Store
 Distributed Data Store Large-Scale Distributed le system Q: What if we have too much data to store in a single machine? Q: How can we create one big filesystem over a cluster of machines, whose data is
Distributed Data Store Large-Scale Distributed le system Q: What if we have too much data to store in a single machine? Q: How can we create one big filesystem over a cluster of machines, whose data is
Distributed Systems. Fall 2017 Exam 3 Review. Paul Krzyzanowski. Rutgers University. Fall 2017
 Distributed Systems Fall 2017 Exam 3 Review Paul Krzyzanowski Rutgers University Fall 2017 December 11, 2017 CS 417 2017 Paul Krzyzanowski 1 Question 1 The core task of the user s map function within a
Distributed Systems Fall 2017 Exam 3 Review Paul Krzyzanowski Rutgers University Fall 2017 December 11, 2017 CS 417 2017 Paul Krzyzanowski 1 Question 1 The core task of the user s map function within a
Structured Big Data 1: Google Bigtable & HBase Shiow-yang Wu ( 吳秀陽 ) CSIE, NDHU, Taiwan, ROC
 CSIE, NDHU, Taiwan, ROC") Structured Big Data 1: Google Bigtable & HBase Shiow-yang Wu ( 吳秀陽 ) CSIE, NDHU, Taiwan, ROC Lecture material is mostly home-grown, partly taken with permission and courtesy from Professor Shih-Wei Liao
Structured Big Data 1: Google Bigtable & HBase Shiow-yang Wu ( 吳秀陽 ) CSIE, NDHU, Taiwan, ROC Lecture material is mostly home-grown, partly taken with permission and courtesy from Professor Shih-Wei Liao
CS5412: DIVING IN: INSIDE THE DATA CENTER
 1 CS5412: DIVING IN: INSIDE THE DATA CENTER Lecture V Ken Birman We ve seen one cloud service 2 Inside a cloud, Dynamo is an example of a service used to make sure that cloud-hosted applications can scale
1 CS5412: DIVING IN: INSIDE THE DATA CENTER Lecture V Ken Birman We ve seen one cloud service 2 Inside a cloud, Dynamo is an example of a service used to make sure that cloud-hosted applications can scale
Goal of the presentation is to give an introduction of NoSQL databases, why they are there.
 1 Goal of the presentation is to give an introduction of NoSQL databases, why they are there. We want to present "Why?" first to explain the need of something like "NoSQL" and then in "What?" we go in
1 Goal of the presentation is to give an introduction of NoSQL databases, why they are there. We want to present "Why?" first to explain the need of something like "NoSQL" and then in "What?" we go in
NoSQL Databases. Amir H. Payberah. Swedish Institute of Computer Science. April 10, 2014
 NoSQL Databases Amir H. Payberah Swedish Institute of Computer Science amir@sics.se April 10, 2014 Amir H. Payberah (SICS) NoSQL Databases April 10, 2014 1 / 67 Database and Database Management System
NoSQL Databases Amir H. Payberah Swedish Institute of Computer Science amir@sics.se April 10, 2014 Amir H. Payberah (SICS) NoSQL Databases April 10, 2014 1 / 67 Database and Database Management System
PNUTS: Yahoo! s Hosted Data Serving Platform. Reading Review by: Alex Degtiar (adegtiar) /30/2013
 /30/2013") PNUTS: Yahoo! s Hosted Data Serving Platform Reading Review by: Alex Degtiar (adegtiar) 15-799 9/30/2013 What is PNUTS? Yahoo s NoSQL database Motivated by web applications Massively parallel Geographically
PNUTS: Yahoo! s Hosted Data Serving Platform Reading Review by: Alex Degtiar (adegtiar) 15-799 9/30/2013 What is PNUTS? Yahoo s NoSQL database Motivated by web applications Massively parallel Geographically
Cassandra Design Patterns
 Cassandra Design Patterns Sanjay Sharma Chapter No. 1 "An Overview of Architecture and Data Modeling in Cassandra" In this package, you will find: A Biography of the author of the book A preview chapter
Cassandra Design Patterns Sanjay Sharma Chapter No. 1 "An Overview of Architecture and Data Modeling in Cassandra" In this package, you will find: A Biography of the author of the book A preview chapter
NoSQL systems. Lecture 21 (optional) Instructor: Sudeepa Roy. CompSci 516 Data Intensive Computing Systems
 Instructor: Sudeepa Roy. CompSci 516 Data Intensive Computing Systems") CompSci 516 Data Intensive Computing Systems Lecture 21 (optional) NoSQL systems Instructor: Sudeepa Roy Duke CS, Spring 2016 CompSci 516: Data Intensive Computing Systems 1 Key- Value Stores Duke CS,
CompSci 516 Data Intensive Computing Systems Lecture 21 (optional) NoSQL systems Instructor: Sudeepa Roy Duke CS, Spring 2016 CompSci 516: Data Intensive Computing Systems 1 Key- Value Stores Duke CS,
NewSQL Databases. The reference Big Data stack
 Università degli Studi di Roma Tor Vergata Dipartimento di Ingegneria Civile e Ingegneria Informatica NewSQL Databases Corso di Sistemi e Architetture per Big Data A.A. 2017/18 Valeria Cardellini The reference
Università degli Studi di Roma Tor Vergata Dipartimento di Ingegneria Civile e Ingegneria Informatica NewSQL Databases Corso di Sistemi e Architetture per Big Data A.A. 2017/18 Valeria Cardellini The reference
Overview. * Some History. * What is NoSQL? * Why NoSQL? * RDBMS vs NoSQL. * NoSQL Taxonomy. *TowardsNewSQL
 * Some History * What is NoSQL? * Why NoSQL? * RDBMS vs NoSQL * NoSQL Taxonomy * Towards NewSQL Overview * Some History * What is NoSQL? * Why NoSQL? * RDBMS vs NoSQL * NoSQL Taxonomy *TowardsNewSQL NoSQL
* Some History * What is NoSQL? * Why NoSQL? * RDBMS vs NoSQL * NoSQL Taxonomy * Towards NewSQL Overview * Some History * What is NoSQL? * Why NoSQL? * RDBMS vs NoSQL * NoSQL Taxonomy *TowardsNewSQL NoSQL
Introduction Data Model API Building Blocks SSTable Implementation Tablet Location Tablet Assingment Tablet Serving Compactions Refinements
 Fay Chang, Jeffrey Dean, Sanjay Ghemawat, Wilson C. Hsieh, Deborah A. Wallach Mike Burrows, Tushar Chandra, Andrew Fikes, Robert E. Gruber Google, Inc. M. Burak ÖZTÜRK 1 Introduction Data Model API Building
Fay Chang, Jeffrey Dean, Sanjay Ghemawat, Wilson C. Hsieh, Deborah A. Wallach Mike Burrows, Tushar Chandra, Andrew Fikes, Robert E. Gruber Google, Inc. M. Burak ÖZTÜRK 1 Introduction Data Model API Building
CompSci 516 Database Systems
 CompSci 516 Database Systems Lecture 20 NoSQL and Column Store Instructor: Sudeepa Roy Duke CS, Fall 2018 CompSci 516: Database Systems 1 Reading Material NOSQL: Scalable SQL and NoSQL Data Stores Rick
CompSci 516 Database Systems Lecture 20 NoSQL and Column Store Instructor: Sudeepa Roy Duke CS, Fall 2018 CompSci 516: Database Systems 1 Reading Material NOSQL: Scalable SQL and NoSQL Data Stores Rick
7680: Distributed Systems
 Cristina Nita-Rotaru 7680: Distributed Systems BigTable. Hbase.Spanner. 1: BigTable Acknowledgement } Slides based on material from course at UMichigan, U Washington, and the authors of BigTable and Spanner.
Cristina Nita-Rotaru 7680: Distributed Systems BigTable. Hbase.Spanner. 1: BigTable Acknowledgement } Slides based on material from course at UMichigan, U Washington, and the authors of BigTable and Spanner.
Rule 14 Use Databases Appropriately
 Rule 14 Use Databases Appropriately Rule 14: What, When, How, and Why What: Use relational databases when you need ACID properties to maintain relationships between your data. For other data storage needs
Rule 14 Use Databases Appropriately Rule 14: What, When, How, and Why What: Use relational databases when you need ACID properties to maintain relationships between your data. For other data storage needs
Ghislain Fourny. Big Data 5. Wide column stores
 Ghislain Fourny Big Data 5. Wide column stores Data Technology Stack User interfaces Querying Data stores Indexing Processing Validation Data models Syntax Encoding Storage 2 Where we are User interfaces
Ghislain Fourny Big Data 5. Wide column stores Data Technology Stack User interfaces Querying Data stores Indexing Processing Validation Data models Syntax Encoding Storage 2 Where we are User interfaces
Distributed Systems. 19. Spanner. Paul Krzyzanowski. Rutgers University. Fall 2017
 Distributed Systems 19. Spanner Paul Krzyzanowski Rutgers University Fall 2017 November 20, 2017 2014-2017 Paul Krzyzanowski 1 Spanner (Google s successor to Bigtable sort of) 2 Spanner Take Bigtable and
Distributed Systems 19. Spanner Paul Krzyzanowski Rutgers University Fall 2017 November 20, 2017 2014-2017 Paul Krzyzanowski 1 Spanner (Google s successor to Bigtable sort of) 2 Spanner Take Bigtable and
Outline. Spanner Mo/va/on. Tom Anderson
 Spanner Mo/va/on Tom Anderson Outline Last week: Chubby: coordina/on service BigTable: scalable storage of structured data GFS: large- scale storage for bulk data Today/Friday: Lessons from GFS/BigTable
Spanner Mo/va/on Tom Anderson Outline Last week: Chubby: coordina/on service BigTable: scalable storage of structured data GFS: large- scale storage for bulk data Today/Friday: Lessons from GFS/BigTable
CMU SCS CMU SCS Who: What: When: Where: Why: CMU SCS
 Carnegie Mellon Univ. Dept. of Computer Science 15-415/615 - DB s C. Faloutsos A. Pavlo Lecture#23: Distributed Database Systems (R&G ch. 22) Administrivia Final Exam Who: You What: R&G Chapters 15-22
Carnegie Mellon Univ. Dept. of Computer Science 15-415/615 - DB s C. Faloutsos A. Pavlo Lecture#23: Distributed Database Systems (R&G ch. 22) Administrivia Final Exam Who: You What: R&G Chapters 15-22
18-hdfs-gfs.txt Thu Oct 27 10:05: Notes on Parallel File Systems: HDFS & GFS , Fall 2011 Carnegie Mellon University Randal E.
 18-hdfs-gfs.txt Thu Oct 27 10:05:07 2011 1 Notes on Parallel File Systems: HDFS & GFS 15-440, Fall 2011 Carnegie Mellon University Randal E. Bryant References: Ghemawat, Gobioff, Leung, "The Google File
18-hdfs-gfs.txt Thu Oct 27 10:05:07 2011 1 Notes on Parallel File Systems: HDFS & GFS 15-440, Fall 2011 Carnegie Mellon University Randal E. Bryant References: Ghemawat, Gobioff, Leung, "The Google File
Jargons, Concepts, Scope and Systems. Key Value Stores, Document Stores, Extensible Record Stores. Overview of different scalable relational systems
 Jargons, Concepts, Scope and Systems Key Value Stores, Document Stores, Extensible Record Stores Overview of different scalable relational systems Examples of different Data stores Predictions, Comparisons
Jargons, Concepts, Scope and Systems Key Value Stores, Document Stores, Extensible Record Stores Overview of different scalable relational systems Examples of different Data stores Predictions, Comparisons
10. Replication. Motivation
 10. Replication Page 1 10. Replication Motivation Reliable and high-performance computation on a single instance of a data object is prone to failure. Replicate data to overcome single points of failure
10. Replication Page 1 10. Replication Motivation Reliable and high-performance computation on a single instance of a data object is prone to failure. Replicate data to overcome single points of failure
MapReduce & BigTable
 CPSC 426/526 MapReduce & BigTable Ennan Zhai Computer Science Department Yale University Lecture Roadmap Cloud Computing Overview Challenges in the Clouds Distributed File Systems: GFS Data Process & Analysis:
CPSC 426/526 MapReduce & BigTable Ennan Zhai Computer Science Department Yale University Lecture Roadmap Cloud Computing Overview Challenges in the Clouds Distributed File Systems: GFS Data Process & Analysis:
CS /15/16. Paul Krzyzanowski 1. Question 1. Distributed Systems 2016 Exam 2 Review. Question 3. Question 2. Question 5.
 Question 1 What makes a message unstable? How does an unstable message become stable? Distributed Systems 2016 Exam 2 Review Paul Krzyzanowski Rutgers University Fall 2016 In virtual sychrony, a message
Question 1 What makes a message unstable? How does an unstable message become stable? Distributed Systems 2016 Exam 2 Review Paul Krzyzanowski Rutgers University Fall 2016 In virtual sychrony, a message
Spanner: Google's Globally-Distributed Database. Presented by Maciej Swiech
 Spanner: Google's Globally-Distributed Database Presented by Maciej Swiech What is Spanner? "...Google's scalable, multi-version, globallydistributed, and synchronously replicated database." What is Spanner?
Spanner: Google's Globally-Distributed Database Presented by Maciej Swiech What is Spanner? "...Google's scalable, multi-version, globallydistributed, and synchronously replicated database." What is Spanner?
CS /29/18. Paul Krzyzanowski 1. Question 1 (Bigtable) Distributed Systems 2018 Pre-exam 3 review Selected questions from past exams
 Distributed Systems 2018 Pre-exam 3 review Selected questions from past exams") Question 1 (Bigtable) What is an SSTable in Bigtable? Distributed Systems 2018 Pre-exam 3 review Selected questions from past exams It is the internal file format used to store Bigtable data. It maps keys
Question 1 (Bigtable) What is an SSTable in Bigtable? Distributed Systems 2018 Pre-exam 3 review Selected questions from past exams It is the internal file format used to store Bigtable data. It maps keys
Distributed Systems Pre-exam 3 review Selected questions from past exams. David Domingo Paul Krzyzanowski Rutgers University Fall 2018
 Distributed Systems 2018 Pre-exam 3 review Selected questions from past exams David Domingo Paul Krzyzanowski Rutgers University Fall 2018 November 28, 2018 1 Question 1 (Bigtable) What is an SSTable in
Distributed Systems 2018 Pre-exam 3 review Selected questions from past exams David Domingo Paul Krzyzanowski Rutgers University Fall 2018 November 28, 2018 1 Question 1 (Bigtable) What is an SSTable in
Cassandra, MongoDB, and HBase. Cassandra, MongoDB, and HBase. I have chosen these three due to their recent
 Tanton Jeppson CS 401R Lab 3 Cassandra, MongoDB, and HBase Introduction For my report I have chosen to take a deeper look at 3 NoSQL database systems: Cassandra, MongoDB, and HBase. I have chosen these
Tanton Jeppson CS 401R Lab 3 Cassandra, MongoDB, and HBase Introduction For my report I have chosen to take a deeper look at 3 NoSQL database systems: Cassandra, MongoDB, and HBase. I have chosen these
Data Informatics. Seon Ho Kim, Ph.D.
 Data Informatics Seon Ho Kim, Ph.D. seonkim@usc.edu HBase HBase is.. A distributed data store that can scale horizontally to 1,000s of commodity servers and petabytes of indexed storage. Designed to operate
Data Informatics Seon Ho Kim, Ph.D. seonkim@usc.edu HBase HBase is.. A distributed data store that can scale horizontally to 1,000s of commodity servers and petabytes of indexed storage. Designed to operate
CS-580K/480K Advanced Topics in Cloud Computing. NoSQL Database
 CS-580K/480K dvanced Topics in Cloud Computing NoSQL Database 1 1 Where are we? Cloud latforms 2 VM1 VM2 VM3 3 Operating System 4 1 2 3 Operating System 4 1 2 Virtualization Layer 3 Operating System 4
CS-580K/480K dvanced Topics in Cloud Computing NoSQL Database 1 1 Where are we? Cloud latforms 2 VM1 VM2 VM3 3 Operating System 4 1 2 3 Operating System 4 1 2 Virtualization Layer 3 Operating System 4
Bigtable: A Distributed Storage System for Structured Data
 Bigtable: A Distributed Storage System for Structured Data Fay Chang, Jeffrey Dean, Sanjay Ghemawat, Wilson C. Hsieh, Deborah A. Wallach Mike Burrows, Tushar Chandra, Andrew Fikes, Robert E. Gruber {fay,jeff,sanjay,wilsonh,kerr,m3b,tushar,fikes,gruber}@google.com
Bigtable: A Distributed Storage System for Structured Data Fay Chang, Jeffrey Dean, Sanjay Ghemawat, Wilson C. Hsieh, Deborah A. Wallach Mike Burrows, Tushar Chandra, Andrew Fikes, Robert E. Gruber {fay,jeff,sanjay,wilsonh,kerr,m3b,tushar,fikes,gruber}@google.com
EECS 498 Introduction to Distributed Systems
 EECS 498 Introduction to Distributed Systems Fall 2017 Harsha V. Madhyastha Dynamo Recap Consistent hashing 1-hop DHT enabled by gossip Execution of reads and writes Coordinated by first available successor
EECS 498 Introduction to Distributed Systems Fall 2017 Harsha V. Madhyastha Dynamo Recap Consistent hashing 1-hop DHT enabled by gossip Execution of reads and writes Coordinated by first available successor
18-hdfs-gfs.txt Thu Nov 01 09:53: Notes on Parallel File Systems: HDFS & GFS , Fall 2012 Carnegie Mellon University Randal E.
 18-hdfs-gfs.txt Thu Nov 01 09:53:32 2012 1 Notes on Parallel File Systems: HDFS & GFS 15-440, Fall 2012 Carnegie Mellon University Randal E. Bryant References: Ghemawat, Gobioff, Leung, "The Google File
18-hdfs-gfs.txt Thu Nov 01 09:53:32 2012 1 Notes on Parallel File Systems: HDFS & GFS 15-440, Fall 2012 Carnegie Mellon University Randal E. Bryant References: Ghemawat, Gobioff, Leung, "The Google File
Integrity in Distributed Databases
 Integrity in Distributed Databases Andreas Farella Free University of Bozen-Bolzano Table of Contents 1 Introduction................................................... 3 2 Different aspects of integrity.....................................
Integrity in Distributed Databases Andreas Farella Free University of Bozen-Bolzano Table of Contents 1 Introduction................................................... 3 2 Different aspects of integrity.....................................
Bigtable: A Distributed Storage System for Structured Data
 Bigtable: A Distributed Storage System for Structured Data Fay Chang, Jeffrey Dean, Sanjay Ghemawat, Wilson C. Hsieh, Deborah A. Wallach, Mike Burrows, Tushar Chandra, Andrew Fikes, Robert E. Gruber ~Harshvardhan
Bigtable: A Distributed Storage System for Structured Data Fay Chang, Jeffrey Dean, Sanjay Ghemawat, Wilson C. Hsieh, Deborah A. Wallach, Mike Burrows, Tushar Chandra, Andrew Fikes, Robert E. Gruber ~Harshvardhan
MINIMIZING TRANSACTION LATENCY IN GEO-REPLICATED DATA STORES
 MINIMIZING TRANSACTION LATENCY IN GEO-REPLICATED DATA STORES Divy Agrawal Department of Computer Science University of California at Santa Barbara Joint work with: Amr El Abbadi, Hatem Mahmoud, Faisal
MINIMIZING TRANSACTION LATENCY IN GEO-REPLICATED DATA STORES Divy Agrawal Department of Computer Science University of California at Santa Barbara Joint work with: Amr El Abbadi, Hatem Mahmoud, Faisal
Ghislain Fourny. Big Data 5. Column stores
 Ghislain Fourny Big Data 5. Column stores 1 Introduction 2 Relational model 3 Relational model Schema 4 Issues with relational databases (RDBMS) Small scale Single machine 5 Can we fix a RDBMS? Scale up
Ghislain Fourny Big Data 5. Column stores 1 Introduction 2 Relational model 3 Relational model Schema 4 Issues with relational databases (RDBMS) Small scale Single machine 5 Can we fix a RDBMS? Scale up
Exam 2 Review. October 29, Paul Krzyzanowski 1
 Exam 2 Review October 29, 2015 2013 Paul Krzyzanowski 1 Question 1 Why did Dropbox add notification servers to their architecture? To avoid the overhead of clients polling the servers periodically to check
Exam 2 Review October 29, 2015 2013 Paul Krzyzanowski 1 Question 1 Why did Dropbox add notification servers to their architecture? To avoid the overhead of clients polling the servers periodically to check
Distributed Database Case Study on Google s Big Tables
 Distributed Database Case Study on Google s Big Tables Anjali diwakar dwivedi 1, Usha sadanand patil 2 and Vinayak D.Shinde 3 1,2,3 Computer Engineering, Shree l.r.tiwari college of engineering Abstract-
Distributed Database Case Study on Google s Big Tables Anjali diwakar dwivedi 1, Usha sadanand patil 2 and Vinayak D.Shinde 3 1,2,3 Computer Engineering, Shree l.r.tiwari college of engineering Abstract-
Cassandra- A Distributed Database
 Cassandra- A Distributed Database Tulika Gupta Department of Information Technology Poornima Institute of Engineering and Technology Jaipur, Rajasthan, India Abstract- A relational database is a traditional
Cassandra- A Distributed Database Tulika Gupta Department of Information Technology Poornima Institute of Engineering and Technology Jaipur, Rajasthan, India Abstract- A relational database is a traditional
GridGain and Apache Ignite In-Memory Performance with Durability of Disk
 GridGain and Apache Ignite In-Memory Performance with Durability of Disk Dmitriy Setrakyan Apache Ignite PMC GridGain Founder & CPO http://ignite.apache.org #apacheignite Agenda What is GridGain and Ignite
GridGain and Apache Ignite In-Memory Performance with Durability of Disk Dmitriy Setrakyan Apache Ignite PMC GridGain Founder & CPO http://ignite.apache.org #apacheignite Agenda What is GridGain and Ignite
FLAT DATACENTER STORAGE. Paper-3 Presenter-Pratik Bhatt fx6568
 FLAT DATACENTER STORAGE Paper-3 Presenter-Pratik Bhatt fx6568 FDS Main discussion points A cluster storage system Stores giant "blobs" - 128-bit ID, multi-megabyte content Clients and servers connected
FLAT DATACENTER STORAGE Paper-3 Presenter-Pratik Bhatt fx6568 FDS Main discussion points A cluster storage system Stores giant "blobs" - 128-bit ID, multi-megabyte content Clients and servers connected
Chapter 24 NOSQL Databases and Big Data Storage Systems
 Chapter 24 NOSQL Databases and Big Data Storage Systems - Large amounts of data such as social media, Web links, user profiles, marketing and sales, posts and tweets, road maps, spatial data, email - NOSQL
Chapter 24 NOSQL Databases and Big Data Storage Systems - Large amounts of data such as social media, Web links, user profiles, marketing and sales, posts and tweets, road maps, spatial data, email - NOSQL
How do we build TiDB. a Distributed, Consistent, Scalable, SQL Database
 How do we build TiDB a Distributed, Consistent, Scalable, SQL Database About me LiuQi ( 刘奇 ) JD / WandouLabs / PingCAP Co-founder / CEO of PingCAP Open-source hacker / Infrastructure software engineer
How do we build TiDB a Distributed, Consistent, Scalable, SQL Database About me LiuQi ( 刘奇 ) JD / WandouLabs / PingCAP Co-founder / CEO of PingCAP Open-source hacker / Infrastructure software engineer
DISTRIBUTED SYSTEMS [COMP9243] Lecture 9b: Distributed File Systems INTRODUCTION. Transparency: Flexibility: Slide 1. Slide 3.
![DISTRIBUTED SYSTEMS [COMP9243] Lecture 9b: Distributed File Systems INTRODUCTION. Transparency: Flexibility: Slide 1. Slide 3.](/thumbs/86/93978710.jpg "DISTRIBUTED SYSTEMS [COMP9243] Lecture 9b: Distributed File Systems INTRODUCTION. Transparency: Flexibility: Slide 1. Slide 3.") CHALLENGES Transparency: Slide 1 DISTRIBUTED SYSTEMS [COMP9243] Lecture 9b: Distributed File Systems ➀ Introduction ➁ NFS (Network File System) ➂ AFS (Andrew File System) & Coda ➃ GFS (Google File System)
CHALLENGES Transparency: Slide 1 DISTRIBUTED SYSTEMS [COMP9243] Lecture 9b: Distributed File Systems ➀ Introduction ➁ NFS (Network File System) ➂ AFS (Andrew File System) & Coda ➃ GFS (Google File System)
Comparing SQL and NOSQL databases
 COSC 6397 Big Data Analytics Data Formats (II) HBase Edgar Gabriel Spring 2014 Comparing SQL and NOSQL databases Types Development History Data Storage Model SQL One type (SQL database) with minor variations
COSC 6397 Big Data Analytics Data Formats (II) HBase Edgar Gabriel Spring 2014 Comparing SQL and NOSQL databases Types Development History Data Storage Model SQL One type (SQL database) with minor variations
NOSQL EGCO321 DATABASE SYSTEMS KANAT POOLSAWASD DEPARTMENT OF COMPUTER ENGINEERING MAHIDOL UNIVERSITY
 NOSQL EGCO321 DATABASE SYSTEMS KANAT POOLSAWASD DEPARTMENT OF COMPUTER ENGINEERING MAHIDOL UNIVERSITY WHAT IS NOSQL? Stands for No-SQL or Not Only SQL. Class of non-relational data storage systems E.g.
NOSQL EGCO321 DATABASE SYSTEMS KANAT POOLSAWASD DEPARTMENT OF COMPUTER ENGINEERING MAHIDOL UNIVERSITY WHAT IS NOSQL? Stands for No-SQL or Not Only SQL. Class of non-relational data storage systems E.g.
Indexing Large-Scale Data
 Indexing Large-Scale Data Serge Abiteboul Ioana Manolescu Philippe Rigaux Marie-Christine Rousset Pierre Senellart Web Data Management and Distribution http://webdam.inria.fr/textbook November 16, 2010
Indexing Large-Scale Data Serge Abiteboul Ioana Manolescu Philippe Rigaux Marie-Christine Rousset Pierre Senellart Web Data Management and Distribution http://webdam.inria.fr/textbook November 16, 2010
DrRobert N. M. Watson
 Distributed systems Lecture 15: Replication, quorums, consistency, CAP, and Amazon/Google case studies DrRobert N. M. Watson 1 Last time General issue of consensus: How to get processes to agree on something
Distributed systems Lecture 15: Replication, quorums, consistency, CAP, and Amazon/Google case studies DrRobert N. M. Watson 1 Last time General issue of consensus: How to get processes to agree on something
App Engine: Datastore Introduction
 App Engine: Datastore Introduction Part 1 Another very useful course: https://www.udacity.com/course/developing-scalableapps-in-java--ud859 1 Topics cover in this lesson What is Datastore? Datastore and
App Engine: Datastore Introduction Part 1 Another very useful course: https://www.udacity.com/course/developing-scalableapps-in-java--ud859 1 Topics cover in this lesson What is Datastore? Datastore and
Lessons Learned While Building Infrastructure Software at Google
 Lessons Learned While Building Infrastructure Software at Google Jeff Dean jeff@google.com Google Circa 1997 (google.stanford.edu) Corkboards (1999) Google Data Center (2000) Google Data Center (2000)
Lessons Learned While Building Infrastructure Software at Google Jeff Dean jeff@google.com Google Circa 1997 (google.stanford.edu) Corkboards (1999) Google Data Center (2000) Google Data Center (2000)
Map-Reduce. Marco Mura 2010 March, 31th
 Map-Reduce Marco Mura (mura@di.unipi.it) 2010 March, 31th This paper is a note from the 2009-2010 course Strumenti di programmazione per sistemi paralleli e distribuiti and it s based by the lessons of
Map-Reduce Marco Mura (mura@di.unipi.it) 2010 March, 31th This paper is a note from the 2009-2010 course Strumenti di programmazione per sistemi paralleli e distribuiti and it s based by the lessons of
How we build TiDB. Max Liu PingCAP Amsterdam, Netherlands October 5, 2016
 How we build TiDB Max Liu PingCAP Amsterdam, Netherlands October 5, 2016 About me Infrastructure engineer / CEO of PingCAP Working on open source projects: TiDB: https://github.com/pingcap/tidb TiKV: https://github.com/pingcap/tikv
How we build TiDB Max Liu PingCAP Amsterdam, Netherlands October 5, 2016 About me Infrastructure engineer / CEO of PingCAP Working on open source projects: TiDB: https://github.com/pingcap/tidb TiKV: https://github.com/pingcap/tikv
Voldemort. Smruti R. Sarangi. Department of Computer Science Indian Institute of Technology New Delhi, India. Overview Design Evaluation
 Voldemort Smruti R. Sarangi Department of Computer Science Indian Institute of Technology New Delhi, India Smruti R. Sarangi Leader Election 1/29 Outline 1 2 3 Smruti R. Sarangi Leader Election 2/29 Data
Voldemort Smruti R. Sarangi Department of Computer Science Indian Institute of Technology New Delhi, India Smruti R. Sarangi Leader Election 1/29 Outline 1 2 3 Smruti R. Sarangi Leader Election 2/29 Data
Introduction to NoSQL Databases
 Introduction to NoSQL Databases Roman Kern KTI, TU Graz 2017-10-16 Roman Kern (KTI, TU Graz) Dbase2 2017-10-16 1 / 31 Introduction Intro Why NoSQL? Roman Kern (KTI, TU Graz) Dbase2 2017-10-16 2 / 31 Introduction
Introduction to NoSQL Databases Roman Kern KTI, TU Graz 2017-10-16 Roman Kern (KTI, TU Graz) Dbase2 2017-10-16 1 / 31 Introduction Intro Why NoSQL? Roman Kern (KTI, TU Graz) Dbase2 2017-10-16 2 / 31 Introduction
Distributed Computation Models
 Distributed Computation Models SWE 622, Spring 2017 Distributed Software Engineering Some slides ack: Jeff Dean HW4 Recap https://b.socrative.com/ Class: SWE622 2 Review Replicating state machines Case
Distributed Computation Models SWE 622, Spring 2017 Distributed Software Engineering Some slides ack: Jeff Dean HW4 Recap https://b.socrative.com/ Class: SWE622 2 Review Replicating state machines Case
Distributed computing: index building and use
 Distributed computing: index building and use Distributed computing Goals Distributing computation across several machines to Do one computation faster - latency Do more computations in given time - throughput
Distributed computing: index building and use Distributed computing Goals Distributing computation across several machines to Do one computation faster - latency Do more computations in given time - throughput
Transactions and ACID
 Transactions and ACID Kevin Swingler Contents Recap of ACID transactions in RDBMSs Transactions and ACID in MongoDB 1 Concurrency Databases are almost always accessed by multiple users concurrently A user
Transactions and ACID Kevin Swingler Contents Recap of ACID transactions in RDBMSs Transactions and ACID in MongoDB 1 Concurrency Databases are almost always accessed by multiple users concurrently A user
References. NoSQL Motivation. Why NoSQL as the Solution? NoSQL Key Feature Decisions. CSE 444: Database Internals
 References SE 444: atabase Internals Scalable SQL and NoSQL ata Stores, Rick attell, SIGMO Record, ecember 2010 (Vol. 39, No. 4) ynamo: mazon s Highly vailable Key-value Store. y Giuseppe eandia et. al.
References SE 444: atabase Internals Scalable SQL and NoSQL ata Stores, Rick attell, SIGMO Record, ecember 2010 (Vol. 39, No. 4) ynamo: mazon s Highly vailable Key-value Store. y Giuseppe eandia et. al.
Introduction to Distributed Data Systems
 Introduction to Distributed Data Systems Serge Abiteboul Ioana Manolescu Philippe Rigaux Marie-Christine Rousset Pierre Senellart Web Data Management and Distribution http://webdam.inria.fr/textbook January
Introduction to Distributed Data Systems Serge Abiteboul Ioana Manolescu Philippe Rigaux Marie-Christine Rousset Pierre Senellart Web Data Management and Distribution http://webdam.inria.fr/textbook January
Database Architectures
 Database Architectures CPS352: Database Systems Simon Miner Gordon College Last Revised: 4/15/15 Agenda Check-in Parallelism and Distributed Databases Technology Research Project Introduction to NoSQL
Database Architectures CPS352: Database Systems Simon Miner Gordon College Last Revised: 4/15/15 Agenda Check-in Parallelism and Distributed Databases Technology Research Project Introduction to NoSQL
Exam 2 Review. Fall 2011
 Exam 2 Review Fall 2011 Question 1 What is a drawback of the token ring election algorithm? Bad question! Token ring mutex vs. Ring election! Ring election: multiple concurrent elections message size grows
Exam 2 Review Fall 2011 Question 1 What is a drawback of the token ring election algorithm? Bad question! Token ring mutex vs. Ring election! Ring election: multiple concurrent elections message size grows
Asynchronous View Maintenance for VLSD Databases
 Asynchronous View Maintenance for VLSD Databases Parag Agrawal, Adam Silberstein, Brian F. Cooper, Utkarsh Srivastava, Raghu Ramakrishnan SIGMOD 2009 Talk by- Prashant S. Jaiswal Ketan J. Mav Motivation
Asynchronous View Maintenance for VLSD Databases Parag Agrawal, Adam Silberstein, Brian F. Cooper, Utkarsh Srivastava, Raghu Ramakrishnan SIGMOD 2009 Talk by- Prashant S. Jaiswal Ketan J. Mav Motivation
Spanner : Google's Globally-Distributed Database. James Sedgwick and Kayhan Dursun
 Spanner : Google's Globally-Distributed Database James Sedgwick and Kayhan Dursun Spanner - A multi-version, globally-distributed, synchronously-replicated database - First system to - Distribute data
Spanner : Google's Globally-Distributed Database James Sedgwick and Kayhan Dursun Spanner - A multi-version, globally-distributed, synchronously-replicated database - First system to - Distribute data
Intro Cassandra. Adelaide Big Data Meetup.
 Intro Cassandra Adelaide Big Data Meetup instaclustr.com @Instaclustr Who am I and what do I do? Alex Lourie Worked at Red Hat, Datastax and now Instaclustr We currently manage x10s nodes for various customers,
Intro Cassandra Adelaide Big Data Meetup instaclustr.com @Instaclustr Who am I and what do I do? Alex Lourie Worked at Red Hat, Datastax and now Instaclustr We currently manage x10s nodes for various customers,
Using space-filling curves for multidimensional
 Using space-filling curves for multidimensional indexing Dr. Bisztray Dénes Senior Research Engineer 1 Nokia Solutions and Networks 2014 In medias res Performance problems with RDBMS Switch to NoSQL store
Using space-filling curves for multidimensional indexing Dr. Bisztray Dénes Senior Research Engineer 1 Nokia Solutions and Networks 2014 In medias res Performance problems with RDBMS Switch to NoSQL store