The Hadoop Paradigm & the Need for Dataset Management
|
|
|
- Louise Evans
- 6 years ago
- Views:
Transcription
1 The Hadoop Paradigm & the Need for Dataset Management 1. Hadoop Adoption Hadoop is being adopted rapidly by many different types of enterprises and government entities and it is an extraordinarily complex technology that is hard to use and not feature rich yet. Two factors are driving the adoption, price - it is much less expensive that current data processing platforms, and scale, it can process very large sets of data. Much of the data that enterprises own right now in hundreds or thousands of databases, is not used at all to develop advanced analytics, because of the cost. Certainly within a lot of that data, there are very valuable business insights and with this new low cost platform they can now utilize any amount of this data for an advanced analytics purpose. Enterprises will develop many new insights. Once you have those insights your business decision making will have changed radically. Data warehousing has been around for a very long time and it's the standard by which all enterprises manage their data for analytic purposes today. But it is definitely not low cost, is not infinitely scalable, and although it is somewhat fault tolerant it is not nearly to the degree that Hadoop is. Hadoop is offering them a very low cost, almost infinitely scalable and completely fault tolerant data processing platform. They are tending to move a lot of data they otherwise would not have moved into a data warehouse into Hadoop, and once they get it in there, they start figuring out how to process it into a form on which they can perform new kinds of analytics that they could not have afforded to do in the past. Hadoop serves a number of purposes in the analytics pipeline. In order to create high quality analytic, you need data that has been collected, assembled and refined and refined again and
2 again, generally from a number of different systems, which is what Hadoop does well. It is a very powerful, scalable framework that allows you to manipulate these diverse collections of data into a finished dataset suitable for advanced analytics Hadoop itself does not really possess advanced analytic engines, instead it has some more standard data processing engines like Hive and Mapreduce, but in many cases, users want to conduct machine learning or statistical analytics to get different kinds of insights from the data. We have hooked in an open source analytics package called R, into Loom. This means you can get to any of the data in Hadoop, work with it, pull it back into R and perform advanced analytics. The advent of this new data processing paradigm has led directly to the rapid employment of a key new role - the data scientist. This role is a natural evolution of the business analyst role that developed in the 1990 s. Data scientists typically have stronger math skills than do business analysts and in many cases have significant computer science skills. These people are the main users of the new platform, taken together we have a paradigm shift in how data is used to build products and manage the business. 2. Dataset Management in Hadoop Computer based data management systems have been around since the 1960 s. In the beginning you would stick a piece of data in a memory register and have to remember where to find it and write the location in your program, not really a data management system, just data processing. Then data was organized in hierarchies giving structure to the way individual data entities are related and we had the first generation of the database management system. In 1970 E.F. Codd wrote a seminal paper while working at IBM that laid out a new way to organize data so that programs could interact with an abstraction of the data itself and so not have to account for its exact location. Further, the data elements were structured not in hierarchies, but in tables, columns and rows where the relations were understood formally and facilitated processing the abstraction. We define data processing as the computational activities occurring on collections of data elements. We define data management as an abstraction that precisely defines the relationships amongst data elements and amongst collections of data elements. Database Management Systems (DBMS) have both capabilities, data processing and data management. The abstraction layer above the data makes using the data vastly simpler, requiring much less coding and much less time to understand the data. Data processing in relational database management systems (RDBMS) is greatly simplified by understanding how to use the abstraction - tables, columns, row and keys - the management system. Hadoop is not a database management system, just a data processing system. But it is so
3 inexpensive and so scalable and so fault tolerant, that it is used to process many sets of data in the same cluster. The core difference between a RDBMS and Hadoop is that we have one set of data in a DBMS, and in Hadoop we have perhaps hundreds of sets of data. It is not possible to have one abstraction (table-row-column) for each of the sets of data, although Hive tries, so it will be useful to have some other sort of abstraction that simplifies the processing of data in Hadoop. The abstraction will have to be above the level of the schema of the set, although the schema of each collection of data in each data set should be available as a description of each set, it will have to be at the level of the data set and the operations that have affected each data set over time. Hadoop is not used normally as a transactional system where lots of data is being created by an application or a machine as with ERPs or CRMs, it is used to store lots of data that was created in other systems/machines, which is later processed to meet analytic requirements. When we have many sets of data that are processed/transformed and perhaps combined over multiple operations, we have a new kind of problem. How can we efficiently use the sets of data in Hadoop to produce the desired analytics? Studies 1 have confirmed that finding the right collection of data is the first time-consuming step in producing new insights. Then knowing enough about the data once it is found is a second time-consuming step -- what is its structure and other important characteristics. RDBMSs do not need this kind of information associated with the data, as the system itself imposes a structure and findability directly onto the data. But in Hadoop it is otherwise. Finding the right data and understanding it well enough to process it, is an enormous time-consuming effort. Most observers estimate that analysts spend 75% of their time finding and processing the raw data into a form suitable to support analysis. 3. Tracking Data Lineage We have proposed an abstraction to introduce the capabilities of a management system on the core data processing capability of Hadoop. The abstraction consists in a data set, query or transform and job. All data in Hadoop will then be related by being included in a named data set, which can be transformed by a job. In this way we can track all data assets in Hadoop and maintain relations amongst original data sets and all data sets derived for any combination of the original sets. This technique is called tracking data lineage.


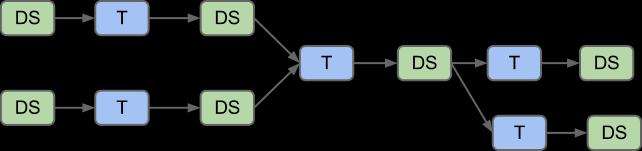
4 Hadoop Information Model Dataset Lineage

5 Further, it is necessary to collect many additional properties about each of the core abstractions (data set, transform, job), things like: SCHEMA Location Number of Columns & Rows Originating System TIme & Date Loaded or Last Transformed More There may be dozens of these properties that are useful in using and processing the data set. Other sorts of properties will be collected for transforms and jobs so that the provenance of a data set can be precisely determined. With this basic abstraction available to organize and MANAGE all data in single Hadoop clusters and across collections of Hadoop clusters, the job of data processing undertaken by the data scientist or developer is greatly simplified and she becomes enormously more productive yielding better insights faster. Above, the Loom Home page displays recent Datasets, Queries and Jobs. Loom s Extensible Registry and the Auto-Scan dataset tracking function represent best practice for Hadoop..

6 Over time this core basic abstraction may grow but probably not by much. We are currently adding the abstraction of cluster soon to keep track of data sets and operations across clusters. Additional roadmap functionality is being driven by active Hadoop-user organizations.
Stages of Data Processing
 Data processing can be understood as the conversion of raw data into a meaningful and desired form. Basically, producing information that can be understood by the end user. So then, the question arises,
Data processing can be understood as the conversion of raw data into a meaningful and desired form. Basically, producing information that can be understood by the end user. So then, the question arises,
Big Data with Hadoop Ecosystem
 Diógenes Pires Big Data with Hadoop Ecosystem Hands-on (HBase, MySql and Hive + Power BI) Internet Live http://www.internetlivestats.com/ Introduction Business Intelligence Business Intelligence Process
Diógenes Pires Big Data with Hadoop Ecosystem Hands-on (HBase, MySql and Hive + Power BI) Internet Live http://www.internetlivestats.com/ Introduction Business Intelligence Business Intelligence Process
Big Data com Hadoop. VIII Sessão - SQL Bahia. Impala, Hive e Spark. Diógenes Pires 03/03/2018
 Big Data com Hadoop Impala, Hive e Spark VIII Sessão - SQL Bahia 03/03/2018 Diógenes Pires Connect with PASS Sign up for a free membership today at: pass.org #sqlpass Internet Live http://www.internetlivestats.com/
Big Data com Hadoop Impala, Hive e Spark VIII Sessão - SQL Bahia 03/03/2018 Diógenes Pires Connect with PASS Sign up for a free membership today at: pass.org #sqlpass Internet Live http://www.internetlivestats.com/
Topics. Big Data Analytics What is and Why Hadoop? Comparison to other technologies Hadoop architecture Hadoop ecosystem Hadoop usage examples
 Hadoop Introduction 1 Topics Big Data Analytics What is and Why Hadoop? Comparison to other technologies Hadoop architecture Hadoop ecosystem Hadoop usage examples 2 Big Data Analytics What is Big Data?
Hadoop Introduction 1 Topics Big Data Analytics What is and Why Hadoop? Comparison to other technologies Hadoop architecture Hadoop ecosystem Hadoop usage examples 2 Big Data Analytics What is Big Data?
International Journal of Advance Engineering and Research Development. A Study: Hadoop Framework
 Scientific Journal of Impact Factor (SJIF): e-issn (O): 2348- International Journal of Advance Engineering and Research Development Volume 3, Issue 2, February -2016 A Study: Hadoop Framework Devateja
Scientific Journal of Impact Factor (SJIF): e-issn (O): 2348- International Journal of Advance Engineering and Research Development Volume 3, Issue 2, February -2016 A Study: Hadoop Framework Devateja
ELTMaestro for Spark: Data integration on clusters
 Introduction Spark represents an important milestone in the effort to make computing on clusters practical and generally available. Hadoop / MapReduce, introduced the early 2000s, allows clusters to be
Introduction Spark represents an important milestone in the effort to make computing on clusters practical and generally available. Hadoop / MapReduce, introduced the early 2000s, allows clusters to be
When, Where & Why to Use NoSQL?
 When, Where & Why to Use NoSQL? 1 Big data is becoming a big challenge for enterprises. Many organizations have built environments for transactional data with Relational Database Management Systems (RDBMS),
When, Where & Why to Use NoSQL? 1 Big data is becoming a big challenge for enterprises. Many organizations have built environments for transactional data with Relational Database Management Systems (RDBMS),
Fundamentals of Design, Implementation, and Management Tenth Edition
 Database Principles: Fundamentals of Design, Implementation, and Management Tenth Edition Chapter 3 Data Models Database Systems, 10th Edition 1 Objectives In this chapter, you will learn: About data modeling
Database Principles: Fundamentals of Design, Implementation, and Management Tenth Edition Chapter 3 Data Models Database Systems, 10th Edition 1 Objectives In this chapter, you will learn: About data modeling
Big Data The end of Data Warehousing?
 Big Data The end of Data Warehousing? Hermann Bär Oracle USA Redwood Shores, CA Schlüsselworte Big data, data warehousing, advanced analytics, Hadoop, unstructured data Introduction If there was an Unwort
Big Data The end of Data Warehousing? Hermann Bär Oracle USA Redwood Shores, CA Schlüsselworte Big data, data warehousing, advanced analytics, Hadoop, unstructured data Introduction If there was an Unwort
Modern Data Warehouse The New Approach to Azure BI
 Modern Data Warehouse The New Approach to Azure BI History On-Premise SQL Server Big Data Solutions Technical Barriers Modern Analytics Platform On-Premise SQL Server Big Data Solutions Modern Analytics
Modern Data Warehouse The New Approach to Azure BI History On-Premise SQL Server Big Data Solutions Technical Barriers Modern Analytics Platform On-Premise SQL Server Big Data Solutions Modern Analytics
EXTRACT DATA IN LARGE DATABASE WITH HADOOP
 International Journal of Advances in Engineering & Scientific Research (IJAESR) ISSN: 2349 3607 (Online), ISSN: 2349 4824 (Print) Download Full paper from : http://www.arseam.com/content/volume-1-issue-7-nov-2014-0
International Journal of Advances in Engineering & Scientific Research (IJAESR) ISSN: 2349 3607 (Online), ISSN: 2349 4824 (Print) Download Full paper from : http://www.arseam.com/content/volume-1-issue-7-nov-2014-0
Embedded Technosolutions
 Hadoop Big Data An Important technology in IT Sector Hadoop - Big Data Oerie 90% of the worlds data was generated in the last few years. Due to the advent of new technologies, devices, and communication
Hadoop Big Data An Important technology in IT Sector Hadoop - Big Data Oerie 90% of the worlds data was generated in the last few years. Due to the advent of new technologies, devices, and communication
Introduction to Big-Data
 Introduction to Big-Data Ms.N.D.Sonwane 1, Mr.S.P.Taley 2 1 Assistant Professor, Computer Science & Engineering, DBACER, Maharashtra, India 2 Assistant Professor, Information Technology, DBACER, Maharashtra,
Introduction to Big-Data Ms.N.D.Sonwane 1, Mr.S.P.Taley 2 1 Assistant Professor, Computer Science & Engineering, DBACER, Maharashtra, India 2 Assistant Professor, Information Technology, DBACER, Maharashtra,
Composite Software Data Virtualization The Five Most Popular Uses of Data Virtualization
 Composite Software Data Virtualization The Five Most Popular Uses of Data Virtualization Composite Software, Inc. June 2011 TABLE OF CONTENTS INTRODUCTION... 3 DATA FEDERATION... 4 PROBLEM DATA CONSOLIDATION
Composite Software Data Virtualization The Five Most Popular Uses of Data Virtualization Composite Software, Inc. June 2011 TABLE OF CONTENTS INTRODUCTION... 3 DATA FEDERATION... 4 PROBLEM DATA CONSOLIDATION
Oracle #1 RDBMS Vendor
 Oracle #1 RDBMS Vendor IBM 20.7% Microsoft 18.1% Other 12.6% Oracle 48.6% Source: Gartner DataQuest July 2008, based on Total Software Revenue Oracle 2 Continuous Innovation Oracle 11g Exadata Storage
Oracle #1 RDBMS Vendor IBM 20.7% Microsoft 18.1% Other 12.6% Oracle 48.6% Source: Gartner DataQuest July 2008, based on Total Software Revenue Oracle 2 Continuous Innovation Oracle 11g Exadata Storage
Evolution of Database Systems
 Evolution of Database Systems Krzysztof Dembczyński Intelligent Decision Support Systems Laboratory (IDSS) Poznań University of Technology, Poland Intelligent Decision Support Systems Master studies, second
Evolution of Database Systems Krzysztof Dembczyński Intelligent Decision Support Systems Laboratory (IDSS) Poznań University of Technology, Poland Intelligent Decision Support Systems Master studies, second
5. Technology Applications
 5. Technology Applications 5.1 What is a Database? 5.2 Types of Databases 5.3 Choosing the Right Database 5.4 Database Programming Tools 5.5 How to Search Your Database 5.6 Data Warehousing and Mining
5. Technology Applications 5.1 What is a Database? 5.2 Types of Databases 5.3 Choosing the Right Database 5.4 Database Programming Tools 5.5 How to Search Your Database 5.6 Data Warehousing and Mining
Partner Presentation Faster and Smarter Data Warehouses with Oracle OLAP 11g
 Partner Presentation Faster and Smarter Data Warehouses with Oracle OLAP 11g Vlamis Software Solutions, Inc. Founded in 1992 in Kansas City, Missouri Oracle Partner and reseller since 1995 Specializes
Partner Presentation Faster and Smarter Data Warehouses with Oracle OLAP 11g Vlamis Software Solutions, Inc. Founded in 1992 in Kansas City, Missouri Oracle Partner and reseller since 1995 Specializes
Gain Insights From Unstructured Data Using Pivotal HD. Copyright 2013 EMC Corporation. All rights reserved.
 Gain Insights From Unstructured Data Using Pivotal HD 1 Traditional Enterprise Analytics Process 2 The Fundamental Paradigm Shift Internet age and exploding data growth Enterprises leverage new data sources
Gain Insights From Unstructured Data Using Pivotal HD 1 Traditional Enterprise Analytics Process 2 The Fundamental Paradigm Shift Internet age and exploding data growth Enterprises leverage new data sources
The Future of Interoperability: Emerging NoSQLs Save Time, Increase Efficiency, Optimize Business Processes, and Maximize Database Value
 The Future of Interoperability: Emerging NoSQLs Save Time, Increase Efficiency, Optimize Business Processes, and Maximize Database Value Author: Tim Dunnington Director of Interoperability, Informatics
The Future of Interoperability: Emerging NoSQLs Save Time, Increase Efficiency, Optimize Business Processes, and Maximize Database Value Author: Tim Dunnington Director of Interoperability, Informatics
Data Governance Overview
 3 Data Governance Overview Date of Publish: 2018-04-01 http://docs.hortonworks.com Contents Apache Atlas Overview...3 Apache Atlas features...3...4 Apache Atlas Overview Apache Atlas Overview Apache Atlas
3 Data Governance Overview Date of Publish: 2018-04-01 http://docs.hortonworks.com Contents Apache Atlas Overview...3 Apache Atlas features...3...4 Apache Atlas Overview Apache Atlas Overview Apache Atlas
COMPARISON WHITEPAPER. Snowplow Insights VS SaaS load-your-data warehouse providers. We do data collection right.
 COMPARISON WHITEPAPER Snowplow Insights VS SaaS load-your-data warehouse providers We do data collection right. Background We were the first company to launch a platform that enabled companies to track
COMPARISON WHITEPAPER Snowplow Insights VS SaaS load-your-data warehouse providers We do data collection right. Background We were the first company to launch a platform that enabled companies to track
Big Data Specialized Studies
 Information Technologies Programs Big Data Specialized Studies Accelerate Your Career extension.uci.edu/bigdata Offered in partnership with University of California, Irvine Extension s professional certificate
Information Technologies Programs Big Data Specialized Studies Accelerate Your Career extension.uci.edu/bigdata Offered in partnership with University of California, Irvine Extension s professional certificate
Overview. : Cloudera Data Analyst Training. Course Outline :: Cloudera Data Analyst Training::
 Module Title Duration : Cloudera Data Analyst Training : 4 days Overview Take your knowledge to the next level Cloudera University s four-day data analyst training course will teach you to apply traditional
Module Title Duration : Cloudera Data Analyst Training : 4 days Overview Take your knowledge to the next level Cloudera University s four-day data analyst training course will teach you to apply traditional
CONSOLIDATING RISK MANAGEMENT AND REGULATORY COMPLIANCE APPLICATIONS USING A UNIFIED DATA PLATFORM
 CONSOLIDATING RISK MANAGEMENT AND REGULATORY COMPLIANCE APPLICATIONS USING A UNIFIED PLATFORM Executive Summary Financial institutions have implemented and continue to implement many disparate applications
CONSOLIDATING RISK MANAGEMENT AND REGULATORY COMPLIANCE APPLICATIONS USING A UNIFIED PLATFORM Executive Summary Financial institutions have implemented and continue to implement many disparate applications
An Introduction to Big Data Formats
 Introduction to Big Data Formats 1 An Introduction to Big Data Formats Understanding Avro, Parquet, and ORC WHITE PAPER Introduction to Big Data Formats 2 TABLE OF TABLE OF CONTENTS CONTENTS INTRODUCTION
Introduction to Big Data Formats 1 An Introduction to Big Data Formats Understanding Avro, Parquet, and ORC WHITE PAPER Introduction to Big Data Formats 2 TABLE OF TABLE OF CONTENTS CONTENTS INTRODUCTION
Hierarchy of knowledge BIG DATA 9/7/2017. Architecture
 BIG DATA Architecture Hierarchy of knowledge Data: Element (fact, figure, etc.) which is basic information that can be to be based on decisions, reasoning, research and which is treated by the human or
BIG DATA Architecture Hierarchy of knowledge Data: Element (fact, figure, etc.) which is basic information that can be to be based on decisions, reasoning, research and which is treated by the human or
Shark: SQL and Rich Analytics at Scale. Michael Xueyuan Han Ronny Hajoon Ko
 Shark: SQL and Rich Analytics at Scale Michael Xueyuan Han Ronny Hajoon Ko What Are The Problems? Data volumes are expanding dramatically Why Is It Hard? Needs to scale out Managing hundreds of machines
Shark: SQL and Rich Analytics at Scale Michael Xueyuan Han Ronny Hajoon Ko What Are The Problems? Data volumes are expanding dramatically Why Is It Hard? Needs to scale out Managing hundreds of machines
Strategic Briefing Paper Big Data
 Strategic Briefing Paper Big Data The promise of Big Data is improved competitiveness, reduced cost and minimized risk by taking better decisions. This requires affordable solution architectures which
Strategic Briefing Paper Big Data The promise of Big Data is improved competitiveness, reduced cost and minimized risk by taking better decisions. This requires affordable solution architectures which
Syncsort DMX-h. Simplifying Big Data Integration. Goals of the Modern Data Architecture SOLUTION SHEET
 SOLUTION SHEET Syncsort DMX-h Simplifying Big Data Integration Goals of the Modern Data Architecture Data warehouses and mainframes are mainstays of traditional data architectures and still play a vital
SOLUTION SHEET Syncsort DMX-h Simplifying Big Data Integration Goals of the Modern Data Architecture Data warehouses and mainframes are mainstays of traditional data architectures and still play a vital
Evolving To The Big Data Warehouse
 Evolving To The Big Data Warehouse Kevin Lancaster 1 Copyright Director, 2012, Oracle and/or its Engineered affiliates. All rights Insert Systems, Information Protection Policy Oracle Classification from
Evolving To The Big Data Warehouse Kevin Lancaster 1 Copyright Director, 2012, Oracle and/or its Engineered affiliates. All rights Insert Systems, Information Protection Policy Oracle Classification from
Microsoft Big Data and Hadoop
 Microsoft Big Data and Hadoop Lara Rubbelke @sqlgal Cindy Gross @sqlcindy 2 The world of data is changing The 4Vs of Big Data http://nosql.mypopescu.com/post/9621746531/a-definition-of-big-data 3 Common
Microsoft Big Data and Hadoop Lara Rubbelke @sqlgal Cindy Gross @sqlcindy 2 The world of data is changing The 4Vs of Big Data http://nosql.mypopescu.com/post/9621746531/a-definition-of-big-data 3 Common
Taming Structured And Unstructured Data With SAP HANA Running On VCE Vblock Systems
 1 Taming Structured And Unstructured Data With SAP HANA Running On VCE Vblock Systems The Defacto Choice For Convergence 2 ABSTRACT & SPEAKER BIO Dealing with enormous data growth is a key challenge for
1 Taming Structured And Unstructured Data With SAP HANA Running On VCE Vblock Systems The Defacto Choice For Convergence 2 ABSTRACT & SPEAKER BIO Dealing with enormous data growth is a key challenge for
Certified Big Data and Hadoop Course Curriculum
 Certified Big Data and Hadoop Course Curriculum The Certified Big Data and Hadoop course by DataFlair is a perfect blend of in-depth theoretical knowledge and strong practical skills via implementation
Certified Big Data and Hadoop Course Curriculum The Certified Big Data and Hadoop course by DataFlair is a perfect blend of in-depth theoretical knowledge and strong practical skills via implementation
Data Storage Infrastructure at Facebook
 Data Storage Infrastructure at Facebook Spring 2018 Cleveland State University CIS 601 Presentation Yi Dong Instructor: Dr. Chung Outline Strategy of data storage, processing, and log collection Data flow
Data Storage Infrastructure at Facebook Spring 2018 Cleveland State University CIS 601 Presentation Yi Dong Instructor: Dr. Chung Outline Strategy of data storage, processing, and log collection Data flow
Big Data Technology Ecosystem. Mark Burnette Pentaho Director Sales Engineering, Hitachi Vantara
 Big Data Technology Ecosystem Mark Burnette Pentaho Director Sales Engineering, Hitachi Vantara Agenda End-to-End Data Delivery Platform Ecosystem of Data Technologies Mapping an End-to-End Solution Case
Big Data Technology Ecosystem Mark Burnette Pentaho Director Sales Engineering, Hitachi Vantara Agenda End-to-End Data Delivery Platform Ecosystem of Data Technologies Mapping an End-to-End Solution Case
Tutorial Outline. Map/Reduce vs. DBMS. MR vs. DBMS [DeWitt and Stonebraker 2008] Acknowledgements. MR is a step backwards in database access
![Tutorial Outline. Map/Reduce vs. DBMS. MR vs. DBMS [DeWitt and Stonebraker 2008] Acknowledgements. MR is a step backwards in database access](/thumbs/92/110435840.jpg "Tutorial Outline. Map/Reduce vs. DBMS. MR vs. DBMS [DeWitt and Stonebraker 2008] Acknowledgements. MR is a step backwards in database access") Map/Reduce vs. DBMS Sharma Chakravarthy Information Technology Laboratory Computer Science and Engineering Department The University of Texas at Arlington, Arlington, TX 76009 Email: sharma@cse.uta.edu
Map/Reduce vs. DBMS Sharma Chakravarthy Information Technology Laboratory Computer Science and Engineering Department The University of Texas at Arlington, Arlington, TX 76009 Email: sharma@cse.uta.edu
Progress DataDirect For Business Intelligence And Analytics Vendors
 Progress DataDirect For Business Intelligence And Analytics Vendors DATA SHEET FEATURES: Direction connection to a variety of SaaS and on-premises data sources via Progress DataDirect Hybrid Data Pipeline
Progress DataDirect For Business Intelligence And Analytics Vendors DATA SHEET FEATURES: Direction connection to a variety of SaaS and on-premises data sources via Progress DataDirect Hybrid Data Pipeline
Spotfire Data Science with Hadoop Using Spotfire Data Science to Operationalize Data Science in the Age of Big Data
 Spotfire Data Science with Hadoop Using Spotfire Data Science to Operationalize Data Science in the Age of Big Data THE RISE OF BIG DATA BIG DATA: A REVOLUTION IN ACCESS Large-scale data sets are nothing
Spotfire Data Science with Hadoop Using Spotfire Data Science to Operationalize Data Science in the Age of Big Data THE RISE OF BIG DATA BIG DATA: A REVOLUTION IN ACCESS Large-scale data sets are nothing
From Silicon Valley to the Test Bed: Bringing Big-Data Technologies into ODS
 AVL List GmbH (Headquarters) From Silicon Valley to the Test Bed: Bringing Big-Data Technologies into ODS ASAM General Assembly 2018 Open Technical Seminar Dr. Sandi Pohorec Agenda Motivation ASAM ODS
AVL List GmbH (Headquarters) From Silicon Valley to the Test Bed: Bringing Big-Data Technologies into ODS ASAM General Assembly 2018 Open Technical Seminar Dr. Sandi Pohorec Agenda Motivation ASAM ODS
The Business Value of Metadata for Data Governance: The Challenge of Integrating Packaged Applications
 The Business Value of Metadata for Data Governance: The Challenge of Integrating Packaged Applications By Donna Burbank Managing Director, Global Data Strategy, Ltd www.globaldatastrategy.com Sponsored
The Business Value of Metadata for Data Governance: The Challenge of Integrating Packaged Applications By Donna Burbank Managing Director, Global Data Strategy, Ltd www.globaldatastrategy.com Sponsored
Unified Governance for Amazon S3 Data Lakes
 WHITEPAPER Unified Governance for Amazon S3 Data Lakes Core Capabilities and Best Practices for Effective Governance Introduction Data governance ensures data quality exists throughout the complete lifecycle
WHITEPAPER Unified Governance for Amazon S3 Data Lakes Core Capabilities and Best Practices for Effective Governance Introduction Data governance ensures data quality exists throughout the complete lifecycle
Five Common Myths About Scaling MySQL
 WHITE PAPER Five Common Myths About Scaling MySQL Five Common Myths About Scaling MySQL In this age of data driven applications, the ability to rapidly store, retrieve and process data is incredibly important.
WHITE PAPER Five Common Myths About Scaling MySQL Five Common Myths About Scaling MySQL In this age of data driven applications, the ability to rapidly store, retrieve and process data is incredibly important.
This tutorial will help computer science graduates to understand the basic-to-advanced concepts related to data warehousing.
 About the Tutorial A data warehouse is constructed by integrating data from multiple heterogeneous sources. It supports analytical reporting, structured and/or ad hoc queries and decision making. This
About the Tutorial A data warehouse is constructed by integrating data from multiple heterogeneous sources. It supports analytical reporting, structured and/or ad hoc queries and decision making. This
White Paper. Low Cost High Availability Clustering for the Enterprise. Jointly published by Winchester Systems Inc. and Red Hat Inc.
 White Paper Low Cost High Availability Clustering for the Enterprise Jointly published by Winchester Systems Inc. and Red Hat Inc. Linux Clustering Moves Into the Enterprise Mention clustering and Linux
White Paper Low Cost High Availability Clustering for the Enterprise Jointly published by Winchester Systems Inc. and Red Hat Inc. Linux Clustering Moves Into the Enterprise Mention clustering and Linux
A Survey on Big Data
 A Survey on Big Data D.Prudhvi 1, D.Jaswitha 2, B. Mounika 3, Monika Bagal 4 1 2 3 4 B.Tech Final Year, CSE, Dadi Institute of Engineering & Technology,Andhra Pradesh,INDIA ---------------------------------------------------------------------***---------------------------------------------------------------------
A Survey on Big Data D.Prudhvi 1, D.Jaswitha 2, B. Mounika 3, Monika Bagal 4 1 2 3 4 B.Tech Final Year, CSE, Dadi Institute of Engineering & Technology,Andhra Pradesh,INDIA ---------------------------------------------------------------------***---------------------------------------------------------------------
Big Data Hadoop Stack
 Big Data Hadoop Stack Lecture #1 Hadoop Beginnings What is Hadoop? Apache Hadoop is an open source software framework for storage and large scale processing of data-sets on clusters of commodity hardware
Big Data Hadoop Stack Lecture #1 Hadoop Beginnings What is Hadoop? Apache Hadoop is an open source software framework for storage and large scale processing of data-sets on clusters of commodity hardware
Minimizing the Risks of OpenStack Adoption
 Minimizing the Risks of OpenStack Adoption White Paper Minimizing the Risks of OpenStack Adoption Introduction Over the last five years, OpenStack has become a solution of choice for enterprise private
Minimizing the Risks of OpenStack Adoption White Paper Minimizing the Risks of OpenStack Adoption Introduction Over the last five years, OpenStack has become a solution of choice for enterprise private
Blended Learning Outline: Cloudera Data Analyst Training (171219a)
") Blended Learning Outline: Cloudera Data Analyst Training (171219a) Cloudera Univeristy s data analyst training course will teach you to apply traditional data analytics and business intelligence skills
Blended Learning Outline: Cloudera Data Analyst Training (171219a) Cloudera Univeristy s data analyst training course will teach you to apply traditional data analytics and business intelligence skills
A SAS/AF Application for Parallel Extraction, Transformation, and Scoring of a Very Large Database
 Paper 11 A SAS/AF Application for Parallel Extraction, Transformation, and Scoring of a Very Large Database Daniel W. Kohn, Ph.D., Torrent Systems Inc., Cambridge, MA David L. Kuhn, Ph.D., Innovative Idea
Paper 11 A SAS/AF Application for Parallel Extraction, Transformation, and Scoring of a Very Large Database Daniel W. Kohn, Ph.D., Torrent Systems Inc., Cambridge, MA David L. Kuhn, Ph.D., Innovative Idea
BIG DATA ANALYTICS USING HADOOP TOOLS APACHE HIVE VS APACHE PIG
 BIG DATA ANALYTICS USING HADOOP TOOLS APACHE HIVE VS APACHE PIG Prof R.Angelin Preethi #1 and Prof J.Elavarasi *2 # Department of Computer Science, Kamban College of Arts and Science for Women, TamilNadu,
BIG DATA ANALYTICS USING HADOOP TOOLS APACHE HIVE VS APACHE PIG Prof R.Angelin Preethi #1 and Prof J.Elavarasi *2 # Department of Computer Science, Kamban College of Arts and Science for Women, TamilNadu,
Shine a Light on Dark Data with Vertica Flex Tables
 White Paper Analytics and Big Data Shine a Light on Dark Data with Vertica Flex Tables Hidden within the dark recesses of your enterprise lurks dark data, information that exists but is forgotten, unused,
White Paper Analytics and Big Data Shine a Light on Dark Data with Vertica Flex Tables Hidden within the dark recesses of your enterprise lurks dark data, information that exists but is forgotten, unused,
FAQ: Database Development and Management
 Question 1: Are normalization rules followed exclusively in the real world? Answer 1: Unfortunately, the answer to this question is no. Database design and development do not have hard and fast rules,
Question 1: Are normalization rules followed exclusively in the real world? Answer 1: Unfortunately, the answer to this question is no. Database design and development do not have hard and fast rules,
SAP IQ Software16, Edge Edition. The Affordable High Performance Analytical Database Engine
 SAP IQ Software16, Edge Edition The Affordable High Performance Analytical Database Engine Agenda Agenda Introduction to Dobler Consulting Today s Data Challenges Overview of SAP IQ 16, Edge Edition SAP
SAP IQ Software16, Edge Edition The Affordable High Performance Analytical Database Engine Agenda Agenda Introduction to Dobler Consulting Today s Data Challenges Overview of SAP IQ 16, Edge Edition SAP
Test bank for accounting information systems 1st edition by richardson chang and smith
 Test bank for accounting information systems 1st edition by richardson chang and smith Chapter 04 Relational Databases and Enterprise Systems True / False Questions 1. Three types of data models used today
Test bank for accounting information systems 1st edition by richardson chang and smith Chapter 04 Relational Databases and Enterprise Systems True / False Questions 1. Three types of data models used today
Data 101 Which DB, When Joe Yong Sr. Program Manager Microsoft Corp.
 17-18 March, 2018 Beijing Data 101 Which DB, When Joe Yong Sr. Program Manager Microsoft Corp. The world is changing AI increased by 300% in 2017 Data will grow to 44 ZB in 2020 Today, 80% of organizations
17-18 March, 2018 Beijing Data 101 Which DB, When Joe Yong Sr. Program Manager Microsoft Corp. The world is changing AI increased by 300% in 2017 Data will grow to 44 ZB in 2020 Today, 80% of organizations
Meaning & Concepts of Databases
 27 th August 2015 Unit 1 Objective Meaning & Concepts of Databases Learning outcome Students will appreciate conceptual development of Databases Section 1: What is a Database & Applications Section 2:
27 th August 2015 Unit 1 Objective Meaning & Concepts of Databases Learning outcome Students will appreciate conceptual development of Databases Section 1: What is a Database & Applications Section 2:
A Glimpse of the Hadoop Echosystem
 A Glimpse of the Hadoop Echosystem 1 Hadoop Echosystem A cluster is shared among several users in an organization Different services HDFS and MapReduce provide the lower layers of the infrastructures Other
A Glimpse of the Hadoop Echosystem 1 Hadoop Echosystem A cluster is shared among several users in an organization Different services HDFS and MapReduce provide the lower layers of the infrastructures Other
Top 7 Data API Headaches (and How to Handle Them) Jeff Reser Data Connectivity & Integration Progress Software
 Jeff Reser Data Connectivity & Integration Progress Software") Top 7 Data API Headaches (and How to Handle Them) Jeff Reser Data Connectivity & Integration Progress Software jreser@progress.com Agenda Data Variety (Cloud and Enterprise) ABL ODBC Bridge Using Progress
Top 7 Data API Headaches (and How to Handle Them) Jeff Reser Data Connectivity & Integration Progress Software jreser@progress.com Agenda Data Variety (Cloud and Enterprise) ABL ODBC Bridge Using Progress
DATABASE MANAGEMENT SYSTEMS. UNIT I Introduction to Database Systems
 DATABASE MANAGEMENT SYSTEMS UNIT I Introduction to Database Systems Terminology Data = known facts that can be recorded Database (DB) = logically coherent collection of related data with some inherent
DATABASE MANAGEMENT SYSTEMS UNIT I Introduction to Database Systems Terminology Data = known facts that can be recorded Database (DB) = logically coherent collection of related data with some inherent
Modernizing Business Intelligence and Analytics
 Modernizing Business Intelligence and Analytics Justin Erickson Senior Director, Product Management 1 Agenda What benefits can I achieve from modernizing my analytic DB? When and how do I migrate from
Modernizing Business Intelligence and Analytics Justin Erickson Senior Director, Product Management 1 Agenda What benefits can I achieve from modernizing my analytic DB? When and how do I migrate from
How to integrate data into Tableau
 1 How to integrate data into Tableau a comparison of 3 approaches: ETL, Tableau self-service and WHITE PAPER WHITE PAPER 2 data How to integrate data into Tableau a comparison of 3 es: ETL, Tableau self-service
1 How to integrate data into Tableau a comparison of 3 approaches: ETL, Tableau self-service and WHITE PAPER WHITE PAPER 2 data How to integrate data into Tableau a comparison of 3 es: ETL, Tableau self-service
The InfoLibrarian Metadata Appliance Automated Cataloging System for your IT infrastructure.
 Metadata Integration Appliance Times have changed and here is modern solution that delivers instant return on your investment. The InfoLibrarian Metadata Appliance Automated Cataloging System for your
Metadata Integration Appliance Times have changed and here is modern solution that delivers instant return on your investment. The InfoLibrarian Metadata Appliance Automated Cataloging System for your
Apache Spark is a fast and general-purpose engine for large-scale data processing Spark aims at achieving the following goals in the Big data context
 1 Apache Spark is a fast and general-purpose engine for large-scale data processing Spark aims at achieving the following goals in the Big data context Generality: diverse workloads, operators, job sizes
1 Apache Spark is a fast and general-purpose engine for large-scale data processing Spark aims at achieving the following goals in the Big data context Generality: diverse workloads, operators, job sizes
THE RISE OF. The Disruptive Data Warehouse
 THE RISE OF The Disruptive Data Warehouse CONTENTS What Is the Disruptive Data Warehouse? 1 Old School Query a single database The data warehouse is for business intelligence The data warehouse is based
THE RISE OF The Disruptive Data Warehouse CONTENTS What Is the Disruptive Data Warehouse? 1 Old School Query a single database The data warehouse is for business intelligence The data warehouse is based
white paper Aster Data ncluster In - database Analytics with R
 white paper Aster Data ncluster In - database Analytics with R Contents Introduction to Aster Data ncluster and SQL-MapReduce... 3 R in Aster Data ncluster... 3 Proprietary Scoring using R without In-database
white paper Aster Data ncluster In - database Analytics with R Contents Introduction to Aster Data ncluster and SQL-MapReduce... 3 R in Aster Data ncluster... 3 Proprietary Scoring using R without In-database
Distributed Virtual Reality Computation
 Jeff Russell 4/15/05 Distributed Virtual Reality Computation Introduction Virtual Reality is generally understood today to mean the combination of digitally generated graphics, sound, and input. The goal
Jeff Russell 4/15/05 Distributed Virtual Reality Computation Introduction Virtual Reality is generally understood today to mean the combination of digitally generated graphics, sound, and input. The goal
Data Management Glossary
 Data Management Glossary A Access path: The route through a system by which data is found, accessed and retrieved Agile methodology: An approach to software development which takes incremental, iterative
Data Management Glossary A Access path: The route through a system by which data is found, accessed and retrieved Agile methodology: An approach to software development which takes incremental, iterative
Fast Innovation requires Fast IT
 Fast Innovation requires Fast IT Cisco Data Virtualization Puneet Kumar Bhugra Business Solutions Manager 1 Challenge In Data, Big Data & Analytics Siloed, Multiple Sources Business Outcomes Business Opportunity:
Fast Innovation requires Fast IT Cisco Data Virtualization Puneet Kumar Bhugra Business Solutions Manager 1 Challenge In Data, Big Data & Analytics Siloed, Multiple Sources Business Outcomes Business Opportunity:
Todd Walter Chief Technologist Teradata Corporation
 Todd Walter Chief Technologist Teradata Corporation 10/14/2013 1 The following solely represents the opinions of Todd Walter not the opinions of Teradata Corporation Nothing in this document may be construed
Todd Walter Chief Technologist Teradata Corporation 10/14/2013 1 The following solely represents the opinions of Todd Walter not the opinions of Teradata Corporation Nothing in this document may be construed
Oracle Warehouse Builder 10g Release 2 Integrating Packaged Applications Data
 Oracle Warehouse Builder 10g Release 2 Integrating Packaged Applications Data June 2006 Note: This document is for informational purposes. It is not a commitment to deliver any material, code, or functionality,
Oracle Warehouse Builder 10g Release 2 Integrating Packaged Applications Data June 2006 Note: This document is for informational purposes. It is not a commitment to deliver any material, code, or functionality,
A REVIEW PAPER ON BIG DATA ANALYTICS
 A REVIEW PAPER ON BIG DATA ANALYTICS Kirti Bhatia 1, Lalit 2 1 HOD, Department of Computer Science, SKITM Bahadurgarh Haryana, India bhatia.kirti.it@gmail.com 2 M Tech 4th sem SKITM Bahadurgarh, Haryana,
A REVIEW PAPER ON BIG DATA ANALYTICS Kirti Bhatia 1, Lalit 2 1 HOD, Department of Computer Science, SKITM Bahadurgarh Haryana, India bhatia.kirti.it@gmail.com 2 M Tech 4th sem SKITM Bahadurgarh, Haryana,
TIBCO Data Virtualization for the Energy Industry
 TIBCO Data Virtualization for the Energy Industry USE CASES DESCRIBED: Offshore platform data analytics Well maintenance and repair Cross refinery web data services SAP master data quality TODAY S COMPLEX
TIBCO Data Virtualization for the Energy Industry USE CASES DESCRIBED: Offshore platform data analytics Well maintenance and repair Cross refinery web data services SAP master data quality TODAY S COMPLEX
Performance Comparison of Hive, Pig & Map Reduce over Variety of Big Data
 Performance Comparison of Hive, Pig & Map Reduce over Variety of Big Data Yojna Arora, Dinesh Goyal Abstract: Big Data refers to that huge amount of data which cannot be analyzed by using traditional analytics
Performance Comparison of Hive, Pig & Map Reduce over Variety of Big Data Yojna Arora, Dinesh Goyal Abstract: Big Data refers to that huge amount of data which cannot be analyzed by using traditional analytics
What is Gluent? The Gluent Data Platform
 What is Gluent? The Gluent Data Platform The Gluent Data Platform provides a transparent data virtualization layer between traditional databases and modern data storage platforms, such as Hadoop, in the
What is Gluent? The Gluent Data Platform The Gluent Data Platform provides a transparent data virtualization layer between traditional databases and modern data storage platforms, such as Hadoop, in the
Oracle Database 11g for Data Warehousing & Big Data: Strategy, Roadmap Jean-Pierre Dijcks, Hermann Baer Oracle Redwood City, CA, USA
 Oracle Database 11g for Data Warehousing & Big Data: Strategy, Roadmap Jean-Pierre Dijcks, Hermann Baer Oracle Redwood City, CA, USA Keywords: Big Data, Oracle Big Data Appliance, Hadoop, NoSQL, Oracle
Oracle Database 11g for Data Warehousing & Big Data: Strategy, Roadmap Jean-Pierre Dijcks, Hermann Baer Oracle Redwood City, CA, USA Keywords: Big Data, Oracle Big Data Appliance, Hadoop, NoSQL, Oracle
An Enchanted World: SAS in an Open Ecosystem
 An Enchanted World: SAS in an Open Ecosystem Tuba Islam SAS Global Technology Practice C opyr i g ht 2016, SAS Ins titut e Inc. All rights res er ve d. Diversity can bring power if there is collaboration
An Enchanted World: SAS in an Open Ecosystem Tuba Islam SAS Global Technology Practice C opyr i g ht 2016, SAS Ins titut e Inc. All rights res er ve d. Diversity can bring power if there is collaboration
Oracle Big Data Connectors
 Oracle Big Data Connectors Oracle Big Data Connectors is a software suite that integrates processing in Apache Hadoop distributions with operations in Oracle Database. It enables the use of Hadoop to process
Oracle Big Data Connectors Oracle Big Data Connectors is a software suite that integrates processing in Apache Hadoop distributions with operations in Oracle Database. It enables the use of Hadoop to process
Introduction to K2View Fabric
 Introduction to K2View Fabric 1 Introduction to K2View Fabric Overview In every industry, the amount of data being created and consumed on a daily basis is growing exponentially. Enterprises are struggling
Introduction to K2View Fabric 1 Introduction to K2View Fabric Overview In every industry, the amount of data being created and consumed on a daily basis is growing exponentially. Enterprises are struggling
What is database? Types and Examples
 What is database? Types and Examples Visit our site for more information: www.examplanning.com Facebook Page: https://www.facebook.com/examplanning10/ Twitter: https://twitter.com/examplanning10 TABLE
What is database? Types and Examples Visit our site for more information: www.examplanning.com Facebook Page: https://www.facebook.com/examplanning10/ Twitter: https://twitter.com/examplanning10 TABLE
SQL Maestro and the ELT Paradigm Shift
 SQL Maestro and the ELT Paradigm Shift Abstract ELT extract, load, and transform is replacing ETL (extract, transform, load) as the usual method of populating data warehouses. Modern data warehouse appliances
SQL Maestro and the ELT Paradigm Shift Abstract ELT extract, load, and transform is replacing ETL (extract, transform, load) as the usual method of populating data warehouses. Modern data warehouse appliances
Accelerate your SAS analytics to take the gold
 Accelerate your SAS analytics to take the gold A White Paper by Fuzzy Logix Whatever the nature of your business s analytics environment we are sure you are under increasing pressure to deliver more: more
Accelerate your SAS analytics to take the gold A White Paper by Fuzzy Logix Whatever the nature of your business s analytics environment we are sure you are under increasing pressure to deliver more: more
Integrating Oracle Databases with NoSQL Databases for Linux on IBM LinuxONE and z System Servers
 Oracle zsig Conference IBM LinuxONE and z System Servers Integrating Oracle Databases with NoSQL Databases for Linux on IBM LinuxONE and z System Servers Sam Amsavelu Oracle on z Architect IBM Washington
Oracle zsig Conference IBM LinuxONE and z System Servers Integrating Oracle Databases with NoSQL Databases for Linux on IBM LinuxONE and z System Servers Sam Amsavelu Oracle on z Architect IBM Washington
Oracle Big Data SQL. Release 3.2. Rich SQL Processing on All Data
 Oracle Big Data SQL Release 3.2 The unprecedented explosion in data that can be made useful to enterprises from the Internet of Things, to the social streams of global customer bases has created a tremendous
Oracle Big Data SQL Release 3.2 The unprecedented explosion in data that can be made useful to enterprises from the Internet of Things, to the social streams of global customer bases has created a tremendous
Data 101 Which DB, When. Joe Yong Azure SQL Data Warehouse, Program Management Microsoft Corp.
 Data 101 Which DB, When Joe Yong (joeyong@microsoft.com) Azure SQL Data Warehouse, Program Management Microsoft Corp. The world is changing AI increased by 300% in 2017 Data will grow to 44 ZB in 2020
Data 101 Which DB, When Joe Yong (joeyong@microsoft.com) Azure SQL Data Warehouse, Program Management Microsoft Corp. The world is changing AI increased by 300% in 2017 Data will grow to 44 ZB in 2020
Data Modeling - Conceive, Collaborate, Create. Introduction: The early conceptual beginnings of data modeling trace back to the origins
 Best Practice - Data Modeling Colson 1 Shay Colson S. Dischiave IST 659 September 15, 2009 Data Modeling - Conceive, Collaborate, Create Introduction: The early conceptual beginnings of data modeling trace
Best Practice - Data Modeling Colson 1 Shay Colson S. Dischiave IST 659 September 15, 2009 Data Modeling - Conceive, Collaborate, Create Introduction: The early conceptual beginnings of data modeling trace
Hello, my name is Cara Daly, I am the Product Marketing Manager for Polycom Video Content Management Solutions and today I am going to be reviewing
 Page 1 of 19 Hello, my name is Cara Daly, I am the Product Marketing Manager for Polycom Video Content Management Solutions and today I am going to be reviewing the upcoming changes for our Q2 2013 Solutions
Page 1 of 19 Hello, my name is Cara Daly, I am the Product Marketing Manager for Polycom Video Content Management Solutions and today I am going to be reviewing the upcoming changes for our Q2 2013 Solutions
How Apache Hadoop Complements Existing BI Systems. Dr. Amr Awadallah Founder, CTO Cloudera,
 How Apache Hadoop Complements Existing BI Systems Dr. Amr Awadallah Founder, CTO Cloudera, Inc. Twitter: @awadallah, @cloudera 2 The Problems with Current Data Systems BI Reports + Interactive Apps RDBMS
How Apache Hadoop Complements Existing BI Systems Dr. Amr Awadallah Founder, CTO Cloudera, Inc. Twitter: @awadallah, @cloudera 2 The Problems with Current Data Systems BI Reports + Interactive Apps RDBMS
Cloud Computing 2. CSCI 4850/5850 High-Performance Computing Spring 2018
 Cloud Computing 2 CSCI 4850/5850 High-Performance Computing Spring 2018 Tae-Hyuk (Ted) Ahn Department of Computer Science Program of Bioinformatics and Computational Biology Saint Louis University Learning
Cloud Computing 2 CSCI 4850/5850 High-Performance Computing Spring 2018 Tae-Hyuk (Ted) Ahn Department of Computer Science Program of Bioinformatics and Computational Biology Saint Louis University Learning
Bring Context To Your Machine Data With Hadoop, RDBMS & Splunk
 Bring Context To Your Machine Data With Hadoop, RDBMS & Splunk Raanan Dagan and Rohit Pujari September 25, 2017 Washington, DC Forward-Looking Statements During the course of this presentation, we may
Bring Context To Your Machine Data With Hadoop, RDBMS & Splunk Raanan Dagan and Rohit Pujari September 25, 2017 Washington, DC Forward-Looking Statements During the course of this presentation, we may
Data-Intensive Distributed Computing
 Data-Intensive Distributed Computing CS 451/651 431/631 (Winter 2018) Part 5: Analyzing Relational Data (1/3) February 8, 2018 Jimmy Lin David R. Cheriton School of Computer Science University of Waterloo
Data-Intensive Distributed Computing CS 451/651 431/631 (Winter 2018) Part 5: Analyzing Relational Data (1/3) February 8, 2018 Jimmy Lin David R. Cheriton School of Computer Science University of Waterloo
Data, Information, and Databases
 Data, Information, and Databases BDIS 6.1 Topics Covered Information types: transactional vsanalytical Five characteristics of information quality Database versus a DBMS RDBMS: advantages and terminology
Data, Information, and Databases BDIS 6.1 Topics Covered Information types: transactional vsanalytical Five characteristics of information quality Database versus a DBMS RDBMS: advantages and terminology
Information empowerment for your evolving data ecosystem
 Information empowerment for your evolving data ecosystem Highlights Enables better results for critical projects and key analytics initiatives Ensures the information is trusted, consistent and governed
Information empowerment for your evolving data ecosystem Highlights Enables better results for critical projects and key analytics initiatives Ensures the information is trusted, consistent and governed
Oracle GoldenGate for Big Data
 Oracle GoldenGate for Big Data The Oracle GoldenGate for Big Data 12c product streams transactional data into big data systems in real time, without impacting the performance of source systems. It streamlines
Oracle GoldenGate for Big Data The Oracle GoldenGate for Big Data 12c product streams transactional data into big data systems in real time, without impacting the performance of source systems. It streamlines
UNLEASHING THE VALUE OF THE TERADATA UNIFIED DATA ARCHITECTURE WITH ALTERYX
 UNLEASHING THE VALUE OF THE TERADATA UNIFIED DATA ARCHITECTURE WITH ALTERYX 1 Successful companies know that analytics are key to winning customer loyalty, optimizing business processes and beating their
UNLEASHING THE VALUE OF THE TERADATA UNIFIED DATA ARCHITECTURE WITH ALTERYX 1 Successful companies know that analytics are key to winning customer loyalty, optimizing business processes and beating their
Challenges for Data Driven Systems
 Challenges for Data Driven Systems Eiko Yoneki University of Cambridge Computer Laboratory Data Centric Systems and Networking Emergence of Big Data Shift of Communication Paradigm From end-to-end to data
Challenges for Data Driven Systems Eiko Yoneki University of Cambridge Computer Laboratory Data Centric Systems and Networking Emergence of Big Data Shift of Communication Paradigm From end-to-end to data
Introduction to NoSQL
 Introduction to NoSQL Agenda History What is NoSQL Types of NoSQL The CAP theorem History - RDBMS Relational DataBase Management Systems were invented in the 1970s. E. F. Codd, "Relational Model of Data
Introduction to NoSQL Agenda History What is NoSQL Types of NoSQL The CAP theorem History - RDBMS Relational DataBase Management Systems were invented in the 1970s. E. F. Codd, "Relational Model of Data
Azure Data Factory. Data Integration in the Cloud
 Azure Data Factory Data Integration in the Cloud 2018 Microsoft Corporation. All rights reserved. This document is provided "as-is." Information and views expressed in this document, including URL and
Azure Data Factory Data Integration in the Cloud 2018 Microsoft Corporation. All rights reserved. This document is provided "as-is." Information and views expressed in this document, including URL and
Best practices for building a Hadoop Data Lake Solution CHARLOTTE HADOOP USER GROUP
 Best practices for building a Hadoop Data Lake Solution CHARLOTTE HADOOP USER GROUP 07.29.2015 LANDING STAGING DW Let s start with something basic Is Data Lake a new concept? What is the closest we can
Best practices for building a Hadoop Data Lake Solution CHARLOTTE HADOOP USER GROUP 07.29.2015 LANDING STAGING DW Let s start with something basic Is Data Lake a new concept? What is the closest we can
LOG FILE ANALYSIS USING HADOOP AND ITS ECOSYSTEMS
 LOG FILE ANALYSIS USING HADOOP AND ITS ECOSYSTEMS Vandita Jain 1, Prof. Tripti Saxena 2, Dr. Vineet Richhariya 3 1 M.Tech(CSE)*,LNCT, Bhopal(M.P.)(India) 2 Prof. Dept. of CSE, LNCT, Bhopal(M.P.)(India)
LOG FILE ANALYSIS USING HADOOP AND ITS ECOSYSTEMS Vandita Jain 1, Prof. Tripti Saxena 2, Dr. Vineet Richhariya 3 1 M.Tech(CSE)*,LNCT, Bhopal(M.P.)(India) 2 Prof. Dept. of CSE, LNCT, Bhopal(M.P.)(India)