Module: CLUTO Toolkit. Draft: 10/21/2010
|
|
|
- Lorraine Allison
- 6 years ago
- Views:
Transcription
1 Module: CLUTO Toolkit Draft: 10/21/2010 1) Module Name CLUTO Toolkit 2) Scope The module briefly introduces the basic concepts of Clustering. The primary focus of the module is to describe the usage of CLUTO, a clustering Toolkit, comprised of various algorithms. 3) Learning Objectives At the end of the module, a student will be able to i. Explain the basic concepts of Clustering and its relevance in digital libraries. i Explain the different types of clustering algorithms. Use the CLUTO clustering software package and run programs to cluster objects using CLUTO. 4) 5S Characteristics of the Module i. Streams: Input stream includes an input file containing information about objects to be clustered and their dimensions, clustering program name, and the number of clusters required. Output stream is a file wherein objects are grouped into desired number of clusters using a criterion function. i iv. Structures: Input data is stored either as a matrix file or graph file and output data is stored as a tree file or clustering solution file. Spaces: Feature spaces of objects are used by the vcluster program. The scluster program operates on the similarity space between the objects. Society: End users of the system are those who work in the fields of digital libraries, genetics, bioinformatics, biochemistry, customer services, etc. v. Scenarios: Situations where users submit a set of documents and a similarity criterion to find clusters of related documents. For e.g., grouping a set of documents (objects) based on the terms (dimensions) they contain.
2 5) Level of Effort Required: i. Prior to Class: 2 hours of reading In Class: 3 hours a. 2 hours for learning the basics of clustering and implementation of CLUTO b. 1 hour for class discussions, exercises, and activities 6) Relationship with other modules: Close connections with: i. R Project for statistical computing module R-Project module is used for visualization and statistical analysis. Similarly, the CLUTO module is used to display statistical information about the clusters and display cluster, matrix graphs and tree plots using visualization. Weka-3 module Weka-3 module contains tools for data preprocessing, classification, clustering and visualization. Most of these features are provided by CLUTO as well. 7) Prerequisite knowledge required: Basic knowledge of UNIX commands, statistics and probability. 8) Introductory Remedial Instruction: None 9) Body of Knowledge i. What is clustering? a. Clustering algorithms group a set of documents into subsets or clusters using a similarity or criterion function. b. Documents within a cluster should be as similar as possible, i.e., the intracluster similarity should be high. c. Documents in one cluster should be as dissimilar as possible from documents in other clusters, i.e., the inter-cluster similarity should be low. d. Clustering can be classified into:
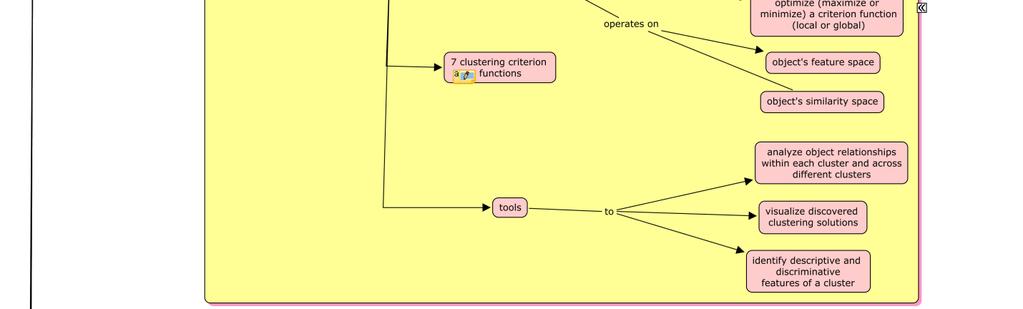
3 i. Flat Clustering and Hierarchical Clustering a. Flat clustering creates a flat set of clusters without any explicit structure that would relate clusters to each other. b. Hierarchical clustering finds successive clusters using previously established clusters. These algorithms usually are either agglomerative ("bottom-up") or divisive ("top-down"). Hard Clustering and Soft Clustering a. Hard clustering computes a hard assignment each document is a member of exactly one cluster. b. The assignment of soft clustering algorithms is soft a document s assignment is a distribution over all clusters. In a soft assignment, a document has fractional membership in several clusters. What is CLUTO? a. CLUTO is a software package for clustering low and high dimensional datasets and for analyzing the characteristics of the various clusters. b. CLUTO uses clustering algorithms to divide data into clusters such that intra-cluster similarity is high and inter-cluster similarity is low. c. CLUTO provides three different classes of clustering algorithms that operate either directly in the object s feature space or in the similarity space. d. Algorithms are based on the partitional, agglomerative, and graph partitioning paradigms. e. CLUTO provides a total of seven different criterion functions. f. CLUTO provides tools for analyzing the discovered clusters to understand the relations between the objects assigned to each cluster and the relations between the different clusters. i CLUTO Programs a. Types of CLUTO Programs: CLUTO consists of two stand-alone programs: i. vcluster: V stands for vector. This program takes actual multidimensional representation of the objects as the input.
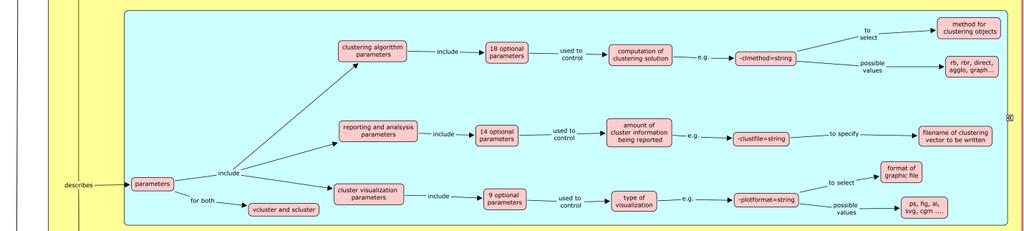
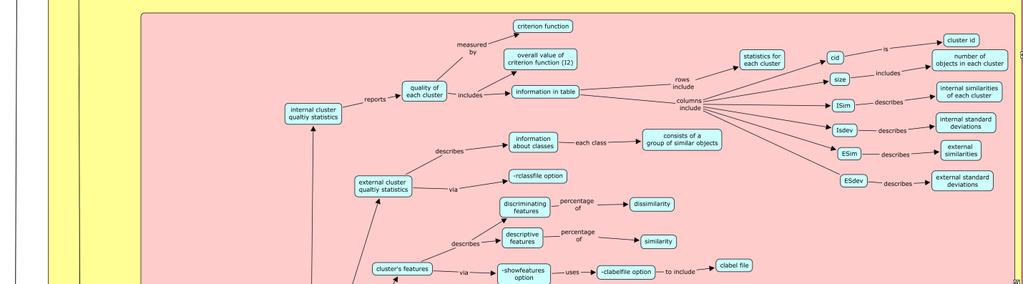
4 scluster: S stands for similarity. This program takes a similarity matrix of the objects as the input. b. Calling Sequence: CLUTO programs are invoked using the following calling sequence: Program-name [optional parameters] file-name NClusters The calling sequence consists of: i. Program-name: vcluster or scluster. Two required parameters: These parameters include a) file-name an input file containing information about objects and their dimensions b) NClusters - the number of clusters required. i Additional optional parameters: These parameters are used to : a) control aspects of the clustering algorithm b) control type of analysis and reporting of clusters and c) control visualization of clusters. c. Statistics: CLUTO programs can be used to display statistical information about: i. Clustering solution. Time taken to perform clustering. iv. Criterion Functions A key feature of a CLUTO clustering algorithms is that the problem is treated as an optimization process which is to maximize or minimize a criterion function. Criterion functions can be broadly classified into four categories: internal, external, hybrid, and graph based criterion functions. These are described and analyzed in [11]. Six criterion functions used for document clustering are described in [6]. CLUTO provides a total of seven different criterion functions that can be used to drive both partitional and agglomerative clustering algorithms. These are described in [2, 10, and 11].
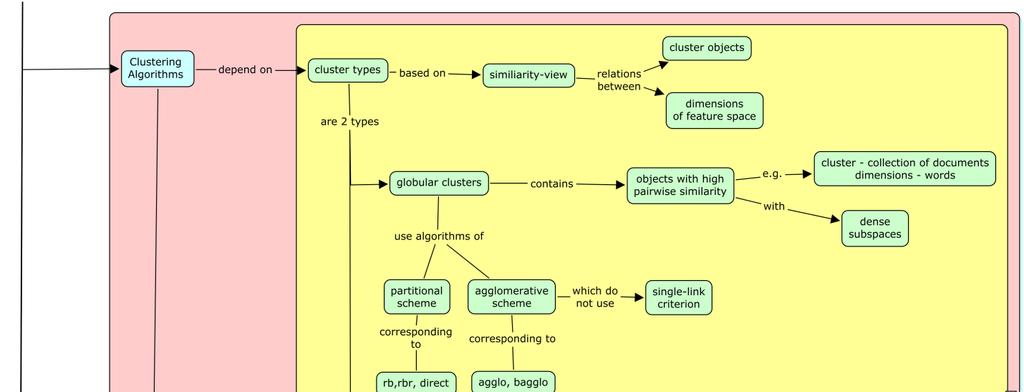
5 Table adapted from CLUTO manual [2] v. CLUTO Algorithms Clustering algorithms used in CLUTO depend on: a. Cluster Types: i. Cluster types are based on similarity-view between the clusters, i.e., the relations between a) cluster objects and b) dimensions of feature space. Clusters are of two types:
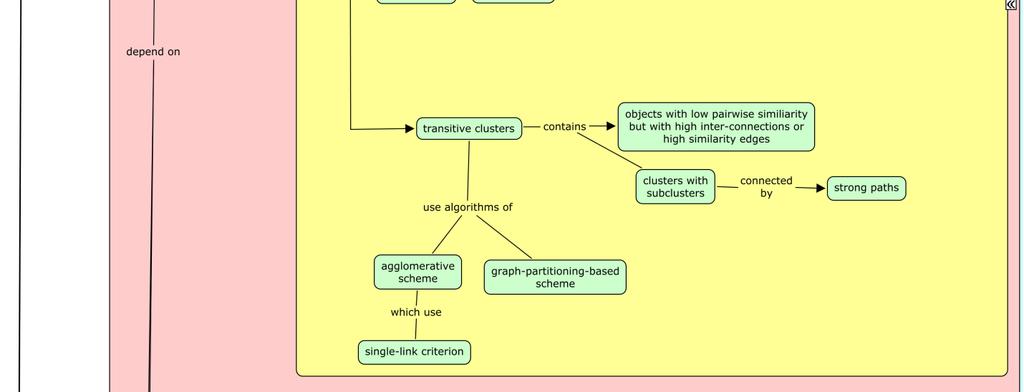
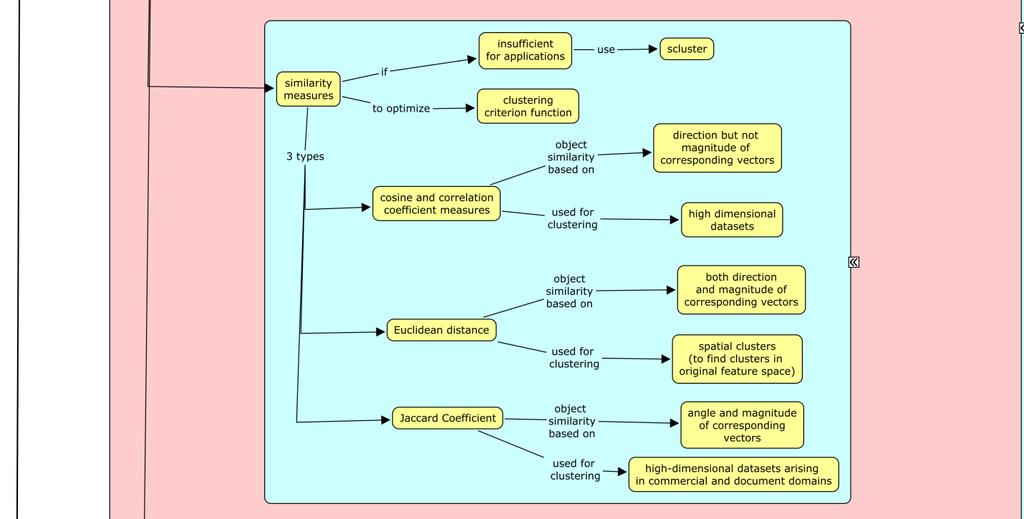
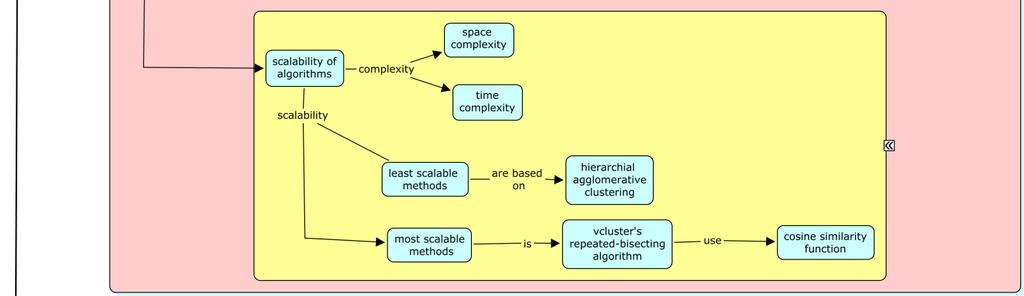
6 b. Similarity Measures: a. Globular clusters: The objects in these clusters have high pair-wise similarities with dense subspaces. b. Transitive clusters: The objects in these clusters have low pair-wise similarities. Each cluster consists of several subclusters connected by strong paths with high similarity edges. The similarity measures used by CLUTO algorithms are: i. Cosine and correlation coefficient measures: The object similarity is based on the direction of the corresponding vectors but not the magnitude. i Euclidean distance: The object similarity is based on both direction and magnitude of the corresponding vectors. Jaccard coefficient: The object similarity is based on angle and magnitude of the corresponding vectors. c. Scalability of Algorithms: The scalability of CLUTO algorithms depends on: i. Space complexity Time complexity vi. History of CLUTO a. CLUTO was developed at Karypis Lab, University of Minnesota Twin Cities. b. The first change to CLUTO, ver.: 1.5 was released on 01/08/2002. Features of agglomerative clustering algorithms, cluster visualization capability, dense input file support were added. c. The latest version of CLUTO, ver.: 2.1.2a was released on 01/09/2007. It included a build for Windows X86_64. d. Details about the specific features of the different releases can be found at:
7 v CLUTO Schematic Diagram CLUTO Schematic Diagram Matrix File Graph file Row label file scluster vcluster Similarity Function Clustering Algorithms Criterion Function Cluster solution file Tree file Row class label file Column label file Figure 1: CLUTO schematic diagram vi Example application areas of CLUTO a. Digital Libraries - To cluster documents (objects) based on the terms (dimensions) they contain. b. Customer Services - Amazon.com may group customers (objects) based on the types of products (nooks, music products - dimensions) they purchase, etc. c. Genetics - To cluster genes (objects) based on their expression levels (dimensions) d. Biochemistry - To cluster proteins (objects) based on the motifs (dimensions) they contain. ix. Features of CLUTO a. Multiple classes of clustering algorithms: partitional, agglomerative, & graph-partitioning based. b. Multiple similarity/distance functions: Euclidean distance, cosine, correlation coefficient, extended Jaccard, user-defined.
8 c. Numerous novel clustering criterion functions and agglomerative merging schemes. d. Traditional agglomerative merging schemes: single-link, complete-link, UPGMA. e. Extensive cluster visualization capabilities and output options: postscript, SVG, gif, xfig, etc. f. Multiple methods for effectively summarizing the clusters: most descriptive and discriminating dimensions, cliques, and frequent item sets. g. Can scale to very large datasets containing hundreds of thousands of objects and tens of thousands of dimensions. x. Relation to IR Concepts CLUTO uses the following IR concepts: a. Similarity functions: Jaccard Coefficient, cosine similarity measure, Euclidean distance. b. Cluster pruning techniques. c. Flat clustering techniques. d. Hierarchical clustering techniques. xi. Input file formats in CLUTO Input files used in CLUTO are of two types: a. Matrix Format i. This is the primary input for CLUTO s vcluster program. i iv. Each row of this matrix represents a single object. Columns correspond to the dimensions (i.e., features) of the objects. Matrix files are classified into two types: a. Dense Matrix Format The first line of the matrix file contains exactly two numbers, both of which are integers. The first integer is the number of rows in the matrix (n) and the second integer is the number of columns in the matrix (m).
9 Each subsequent line contains exactly m space-separated floating point values, such that the ith value corresponds to the ith column of A. Figure 2: Dense Matrix file format b. Sparse Matrix Format The first line contains information about the size of the matrix, while the remaining n lines contain information for each row of A. In CLUTO s sparse matrix format only the non-zero entries of the matrix are stored. The first line of the matrix file contains exactly three numbers, all of which are integers. The first integer is the number of rows in the matrix (n), the second integer is the number of columns in the matrix (m), and the third integer is the total number of non-zeros entries in the n m matrix.
10 Number of rows Number of columns Number of non zero entries Figure 3: Sparse Matrix file format b. Graph Format i. This is the primary input for CLUTO s vcluster program. It is a square matrix. i iv. It specifies the similarity between the objects to be clustered. A value at the (i, j) location of this matrix indicates the similarity between the ith and the jth object. Graph files are classified into two types: a) Dense Graph Format The first line of the file contains exactly one number, which is the number of vertices n of the graph. The remaining n lines store the values of the n columns of the adjacency matrix for each one of the vertices. Each line contains exactly n space-separated floating point values, such that the ith value corresponds to the similarity to the vertex equaling the row number of the current row of the graph.
11 b) Sparse Graph Format The first line of the file contains exactly two numbers, both of which are integers. The first integer is the number of vertices in the graph (n) and the second integer is the number of edges in the graph. The (i + 1)st line of the file contains information about the adjacency structure of the ith vertex. The adjacency structure of each vertex is specified as a space-separated list of pairs. Each pair contains the number of the adjacent vertex followed by the similarity of the corresponding edge. Number of vertices Number of edges The 8 th column has value zero, hence it is not shown Figure 4: Sparse Graph file format x Output file formats in CLUTO Output files used in CLUTO are of two types: a. Clustering File Solution The clustering file of a matrix with n rows consists of n lines with a single number per line. The ith line of the file contains the cluster
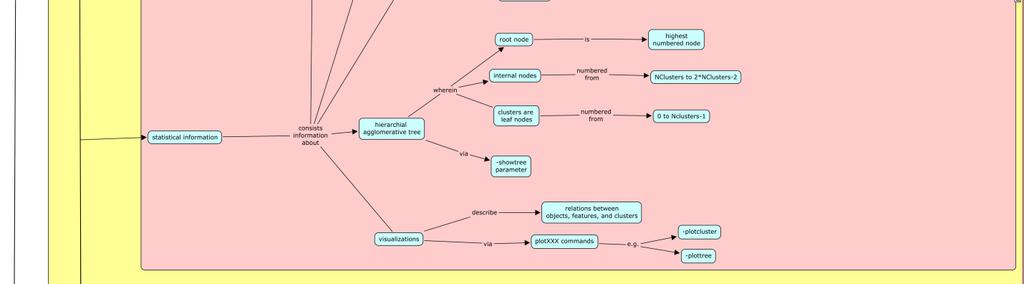
12 b. Tree File number that the ith object/row/vertex belongs to. Cluster numbers run from zero to the number of clusters minus one. The tree produced by performing a hierarchical agglomerative clustering on top of the k-way clustering solution produced by vcluster is stored in a file in the form of a parent array. The ith line contains the parent of the ith node of the tree. Figure 5: Tree file format xi Other Features Two additional features are provided by CLUTO: a. gcluto gcluto is a cross-platform graphical application for clustering lowand high-dimensional datasets and for analyzing the characteristics of the various clusters as shown in figure 5. gcluto provides tools for visualizing the resulting clustering solutions using tree, matrix, and an OpenGL-based mountain visualization as shown in figure 4.

13 Figure 6: gcluto (Mountain View) Adapted from:

14 Figure 7: wcluto (Matrix Visualization) Adapted from: b. wcluto wcluto is a web-enabled data clustering application that is designed for the clustering and data-analysis requirements of gene-expression analysis. Users can upload their datasets, select from a number of clustering methods, perform the analysis on the server, and visualize the final results. The wcluto web-server is hosted by the Center of Computational Genomics and Bioinformatics at the University of Minnesota.



15 10) Concept Map

16
17
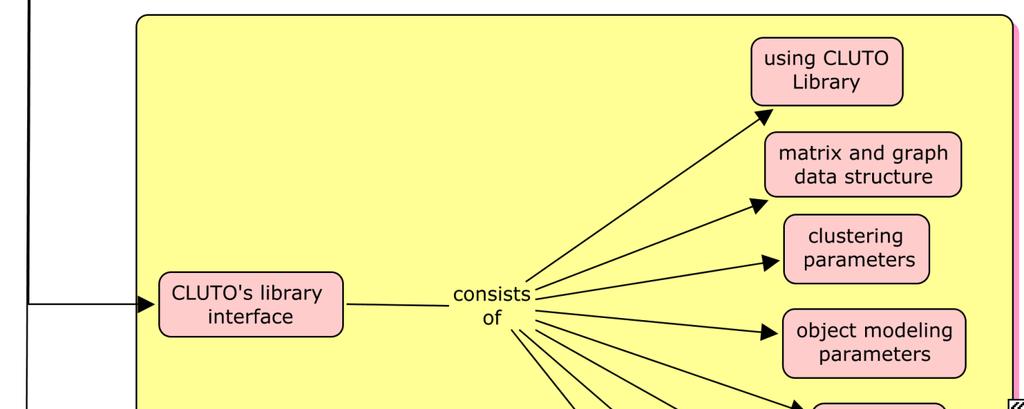

18

19 11) Exercises/Learning Activities i. In-Class exercise 1 (10 minutes) a. This exercise will help you understand the basic concepts of clustering. The links below contain demos to sample clustering algorithms: Sample clustering algorithm using K-means : Sample hierarchical clustering algorithm: b. Select 100 for data size and 5 for the number of clusters and then click on the Initialize button to generate them in random positions. c. Click on Run to begin the simulation. During simulation data positions are fixed. d. Save the results of each experiment as image and add descriptive comments. In-Class exercise 2 (30 minutes) a. Go to the website of the Center for Machine Learning and Intelligent Systems b. Download the IRIS dataset. c. Convert the IRIS dataset format to CLUTO format (.mat file) either manually or using program doc2mat. d. Use the vcluster program to cluster the input dataset into three clusters. e. Build and display a hierarchical agglomerative tree.
20 f. Calculate and display the discriminative and descriptive features of each cluster. g. Every iris has four features (sepal length in cm, sepal width in cm, petal length in cm, petal width in cm). i In-Class Exercise 3 (15 minutes) Use the sports.mat file provided in the cloud to answer the following questions. a. Cluster the input dataset into 10 clusters using the vcluster program and cosine similarity function. b. What clustering algorithm does vcluster use by default? c. Use a partitional and an agglomerative clustering algorithm to perform the clustering. d. Compute clustering by combining both the partitional and agglomerative methods used in c. e. Use the given class file sports.rclass to compute the quality of clustering solution used (Use algorithms used in c. and d.). f. Analyze the output. Which internal characteristic displays internal similarities and which internal characteristic displays external similarities? 12) Evaluation of Learning Outcomes i. Are students familiar with the fundamental concepts, applications and techniques of Clustering? Are students capable of running clustering programs using CLUTO toolkit? This can be determined if a student can successfully run a vcluster/scluster program using appropriate parameters over a given input file and produce an output file with a desired number of clusters. 13) Glossary i. Cluster: A group of objects grouped together by a criterion (similarity) function, often a set of documents. i Feature: Information extracted from an object and used during query processing. Index: A data structure built for the images to speed up searching.
21 iv. Information Retrieval: Field of computer science which studies the retrieval of information (not data) from a collection of written documents. v. Metadata: Informative data about documents or input data. Metadata includes attributes of documents such as author name, date of creation, year of publication, etc. vi. v vi ix. Repository: A physical or digital place where objects are stored for a period of time, from which individual objects can be obtained if they are requested. Vcluster: Stand-alone program that takes as input the actual multidimensional representation of objects to be clustered. Scluster: Stand-alone program that takes as input the similarity matrix (or graph) between the objects to be clustered. Criterion function: A function that maps an event onto a real number representing the economic cost or regret associated with the event. x. Similarity function: A function that defines what objects would belong to a particular cluster. xi. x xi xiv. xv. Feature vector: An n-dimensional vector of numerical features representing an object. Feature space: The vector space associated with feature vectors. Euclidean Distance: The ordinary distance between two points in a vector space. Partitional algorithms: Begin with the whole set and proceed to divide it into successively smaller clusters. Agglomerative algorithms: Begin with each element as a separate cluster and merge them into successively larger clusters. 14) References i. Weblinks: [1] Home Page: [2] Manual: [3] Download Page: [4] Publications: Related research publications:
22 [5] A Segment-based Approach To Clustering Multi-Topic Documents. Andrea Tagarelli and George Karypis. Text Mining Workshop, SIAM Datamining Conference, Department of Computer Science and Engineering, University of Minnesota, Minneapolis. TR # [6] Hierarchical Clustering Algorithms for Document Datasets. Ying Zhao, Goerge Karypis, Usama Fayyad. Data Mining and Knowledge Discovery. Boston:Mar Vol. 10, Iss. 2, p , Department of Computer Science, University of Minnesota, Minneapolis. TR # [7] Topic-Driven Clustering for Document Datasets. Ying Zhao and George Karypis. SIAM International Conference on Data Mining, pp ,2005. Department of Computer Science, University of Minnesota, Minneapolis. TR # [8] Empirical and Theoretical Comparisons of Selected Criterion Functions for Document Clustering. Ying Zhao and George Karypis. Machine Learning, 55, pp , [9] Clustering in Life Sciences. Ying Zhao and George Karypis. In Functional Genomics: Methods and Protocols, M. Brownstein, A. Khodursky and D. Conniffe (editors). Humana Press, [10] Evaluation of Hierarchical Clustering Algorithms for Document Datasets. Ying Zhao and George Karypis. 11th Conference of Information and Knowledge Management (CIKM), pp , [11] Criterion Functions for Document Clustering: Experiments and Analysis. Ying Zhao and George Karypis. Department of Computer Science, University of Minnesota, Minneapolis, MN, TR # [12] A Comparison of Document Clustering Techniques. Michael Steinbach, George Karypis and Vipin Kumar. KDD Workshop on Text Mining, Department of Computer Science / Army HPC Research Center, University of Minnesota, Minneapolis. TR # [13] CHAMELEON: A Hierarchical Clustering Algorithm Using Dynamic Modeling. George Karypis, Eui-Hong Han, Vipin Kumar. IEEE Computer 32(8): 68-75, i Additional reading list for students: [14] CURE: An efficient clustering algorithm for large databases. Sudipto Guha, Rajeev Rastogi, and Kyuseok Shim. In Proceedings of 1998 ACM- SIGMOD International Conference on Management of Data, Page: 73. Place: New York, USA.
23 15) Contributors: Authors: [15] hmetis 1.5: A hypergraph partitioning package. G. Karypis and V. Kumar. Technical report, Department of Computer Science & Engineering, Army HPC Research Center, University of Minnesota, Minneapolis, [16] METIS 4.0: Unstructured graph partitioning and sparse matrix ordering system. G. Karypis and V. Kumar. Technical report, Department of Computer Science, University of Minnesota, Minneapolis, CS_5604: Information Storage and Retrieval- Team 4: i. Vijay, Sony i El Meligy Abdelhamid, Sherif Malayattil, Sarosh Reviewers: Dr. Edward Fox
Introduction to Web Clustering
 Introduction to Web Clustering D. De Cao R. Basili Corso di Web Mining e Retrieval a.a. 2008-9 June 26, 2009 Outline Introduction to Web Clustering Some Web Clustering engines The KeySRC approach Some
Introduction to Web Clustering D. De Cao R. Basili Corso di Web Mining e Retrieval a.a. 2008-9 June 26, 2009 Outline Introduction to Web Clustering Some Web Clustering engines The KeySRC approach Some
Hierarchical Document Clustering
 Hierarchical Document Clustering Benjamin C. M. Fung, Ke Wang, and Martin Ester, Simon Fraser University, Canada INTRODUCTION Document clustering is an automatic grouping of text documents into clusters
Hierarchical Document Clustering Benjamin C. M. Fung, Ke Wang, and Martin Ester, Simon Fraser University, Canada INTRODUCTION Document clustering is an automatic grouping of text documents into clusters
Study and Implementation of CHAMELEON algorithm for Gene Clustering
 [1] Study and Implementation of CHAMELEON algorithm for Gene Clustering 1. Motivation Saurav Sahay The vast amount of gathered genomic data from Microarray and other experiments makes it extremely difficult
[1] Study and Implementation of CHAMELEON algorithm for Gene Clustering 1. Motivation Saurav Sahay The vast amount of gathered genomic data from Microarray and other experiments makes it extremely difficult
Centroid Based Text Clustering
 Centroid Based Text Clustering Priti Maheshwari Jitendra Agrawal School of Information Technology Rajiv Gandhi Technical University BHOPAL [M.P] India Abstract--Web mining is a burgeoning new field that
Centroid Based Text Clustering Priti Maheshwari Jitendra Agrawal School of Information Technology Rajiv Gandhi Technical University BHOPAL [M.P] India Abstract--Web mining is a burgeoning new field that
Mining Quantitative Maximal Hyperclique Patterns: A Summary of Results
 Mining Quantitative Maximal Hyperclique Patterns: A Summary of Results Yaochun Huang, Hui Xiong, Weili Wu, and Sam Y. Sung 3 Computer Science Department, University of Texas - Dallas, USA, {yxh03800,wxw0000}@utdallas.edu
Mining Quantitative Maximal Hyperclique Patterns: A Summary of Results Yaochun Huang, Hui Xiong, Weili Wu, and Sam Y. Sung 3 Computer Science Department, University of Texas - Dallas, USA, {yxh03800,wxw0000}@utdallas.edu
Overview. Data-mining. Commercial & Scientific Applications. Ongoing Research Activities. From Research to Technology Transfer
 Data Mining George Karypis Department of Computer Science Digital Technology Center University of Minnesota, Minneapolis, USA. http://www.cs.umn.edu/~karypis karypis@cs.umn.edu Overview Data-mining What
Data Mining George Karypis Department of Computer Science Digital Technology Center University of Minnesota, Minneapolis, USA. http://www.cs.umn.edu/~karypis karypis@cs.umn.edu Overview Data-mining What
BBS654 Data Mining. Pinar Duygulu. Slides are adapted from Nazli Ikizler
 BBS654 Data Mining Pinar Duygulu Slides are adapted from Nazli Ikizler 1 Classification Classification systems: Supervised learning Make a rational prediction given evidence There are several methods for
BBS654 Data Mining Pinar Duygulu Slides are adapted from Nazli Ikizler 1 Classification Classification systems: Supervised learning Make a rational prediction given evidence There are several methods for
Document Clustering using Feature Selection Based on Multiviewpoint and Link Similarity Measure
 Document Clustering using Feature Selection Based on Multiviewpoint and Link Similarity Measure Neelam Singh neelamjain.jain@gmail.com Neha Garg nehagarg.february@gmail.com Janmejay Pant geujay2010@gmail.com
Document Clustering using Feature Selection Based on Multiviewpoint and Link Similarity Measure Neelam Singh neelamjain.jain@gmail.com Neha Garg nehagarg.february@gmail.com Janmejay Pant geujay2010@gmail.com
CS570: Introduction to Data Mining
 CS570: Introduction to Data Mining Scalable Clustering Methods: BIRCH and Others Reading: Chapter 10.3 Han, Chapter 9.5 Tan Cengiz Gunay, Ph.D. Slides courtesy of Li Xiong, Ph.D., 2011 Han, Kamber & Pei.
CS570: Introduction to Data Mining Scalable Clustering Methods: BIRCH and Others Reading: Chapter 10.3 Han, Chapter 9.5 Tan Cengiz Gunay, Ph.D. Slides courtesy of Li Xiong, Ph.D., 2011 Han, Kamber & Pei.
Clustering Documents in Large Text Corpora
 Clustering Documents in Large Text Corpora Bin He Faculty of Computer Science Dalhousie University Halifax, Canada B3H 1W5 bhe@cs.dal.ca http://www.cs.dal.ca/ bhe Yongzheng Zhang Faculty of Computer Science
Clustering Documents in Large Text Corpora Bin He Faculty of Computer Science Dalhousie University Halifax, Canada B3H 1W5 bhe@cs.dal.ca http://www.cs.dal.ca/ bhe Yongzheng Zhang Faculty of Computer Science
wcluto: A Web-Enabled Clustering Toolkit
 wcluto: A Web-Enabled Clustering Toolkit Matthew Rasmussen, Mukund Deshpande, George Karypis, James Johnson, John A. Crow, and Ernest F. Retzel Department of Computer Science & Center for Computational
wcluto: A Web-Enabled Clustering Toolkit Matthew Rasmussen, Mukund Deshpande, George Karypis, James Johnson, John A. Crow, and Ernest F. Retzel Department of Computer Science & Center for Computational
Data Clustering With Leaders and Subleaders Algorithm
 IOSR Journal of Engineering (IOSRJEN) e-issn: 2250-3021, p-issn: 2278-8719, Volume 2, Issue 11 (November2012), PP 01-07 Data Clustering With Leaders and Subleaders Algorithm Srinivasulu M 1,Kotilingswara
IOSR Journal of Engineering (IOSRJEN) e-issn: 2250-3021, p-issn: 2278-8719, Volume 2, Issue 11 (November2012), PP 01-07 Data Clustering With Leaders and Subleaders Algorithm Srinivasulu M 1,Kotilingswara
USING SOFT COMPUTING TECHNIQUES TO INTEGRATE MULTIPLE KINDS OF ATTRIBUTES IN DATA MINING
 USING SOFT COMPUTING TECHNIQUES TO INTEGRATE MULTIPLE KINDS OF ATTRIBUTES IN DATA MINING SARAH COPPOCK AND LAWRENCE MAZLACK Computer Science, University of Cincinnati, Cincinnati, Ohio 45220 USA E-mail:
USING SOFT COMPUTING TECHNIQUES TO INTEGRATE MULTIPLE KINDS OF ATTRIBUTES IN DATA MINING SARAH COPPOCK AND LAWRENCE MAZLACK Computer Science, University of Cincinnati, Cincinnati, Ohio 45220 USA E-mail:
Comparison of Agglomerative and Partitional Document Clustering Algorithms
 Comparison of Agglomerative and Partitional Document Clustering Algorithms Ying Zhao and George Karypis Department of Computer Science, University of Minnesota, Minneapolis, MN 55455 {yzhao, karypis}@cs.umn.edu
Comparison of Agglomerative and Partitional Document Clustering Algorithms Ying Zhao and George Karypis Department of Computer Science, University of Minnesota, Minneapolis, MN 55455 {yzhao, karypis}@cs.umn.edu
Lesson 3. Prof. Enza Messina
 Lesson 3 Prof. Enza Messina Clustering techniques are generally classified into these classes: PARTITIONING ALGORITHMS Directly divides data points into some prespecified number of clusters without a hierarchical
Lesson 3 Prof. Enza Messina Clustering techniques are generally classified into these classes: PARTITIONING ALGORITHMS Directly divides data points into some prespecified number of clusters without a hierarchical
Clustering Part 4 DBSCAN
 Clustering Part 4 Dr. Sanjay Ranka Professor Computer and Information Science and Engineering University of Florida, Gainesville DBSCAN DBSCAN is a density based clustering algorithm Density = number of
Clustering Part 4 Dr. Sanjay Ranka Professor Computer and Information Science and Engineering University of Florida, Gainesville DBSCAN DBSCAN is a density based clustering algorithm Density = number of
Clustering: Overview and K-means algorithm
 Clustering: Overview and K-means algorithm Informal goal Given set of objects and measure of similarity between them, group similar objects together K-Means illustrations thanks to 2006 student Martin
Clustering: Overview and K-means algorithm Informal goal Given set of objects and measure of similarity between them, group similar objects together K-Means illustrations thanks to 2006 student Martin
ECLT 5810 Clustering
 ECLT 5810 Clustering What is Cluster Analysis? Cluster: a collection of data objects Similar to one another within the same cluster Dissimilar to the objects in other clusters Cluster analysis Grouping
ECLT 5810 Clustering What is Cluster Analysis? Cluster: a collection of data objects Similar to one another within the same cluster Dissimilar to the objects in other clusters Cluster analysis Grouping
University of Florida CISE department Gator Engineering. Clustering Part 4
 Clustering Part 4 Dr. Sanjay Ranka Professor Computer and Information Science and Engineering University of Florida, Gainesville DBSCAN DBSCAN is a density based clustering algorithm Density = number of
Clustering Part 4 Dr. Sanjay Ranka Professor Computer and Information Science and Engineering University of Florida, Gainesville DBSCAN DBSCAN is a density based clustering algorithm Density = number of
[Gidhane* et al., 5(7): July, 2016] ISSN: IC Value: 3.00 Impact Factor: 4.116
![[Gidhane* et al., 5(7): July, 2016] ISSN: IC Value: 3.00 Impact Factor: 4.116](/thumbs/86/94131898.jpg "[Gidhane* et al., 5(7): July, 2016] ISSN: IC Value: 3.00 Impact Factor: 4.116") IJESRT INTERNATIONAL JOURNAL OF ENGINEERING SCIENCES & RESEARCH TECHNOLOGY AN EFFICIENT APPROACH FOR TEXT MINING USING SIDE INFORMATION Kiran V. Gaidhane*, Prof. L. H. Patil, Prof. C. U. Chouhan DOI: 10.5281/zenodo.58632
IJESRT INTERNATIONAL JOURNAL OF ENGINEERING SCIENCES & RESEARCH TECHNOLOGY AN EFFICIENT APPROACH FOR TEXT MINING USING SIDE INFORMATION Kiran V. Gaidhane*, Prof. L. H. Patil, Prof. C. U. Chouhan DOI: 10.5281/zenodo.58632
Datasets Size: Effect on Clustering Results
 1 Datasets Size: Effect on Clustering Results Adeleke Ajiboye 1, Ruzaini Abdullah Arshah 2, Hongwu Qin 3 Faculty of Computer Systems and Software Engineering Universiti Malaysia Pahang 1 {ajibraheem@live.com}
1 Datasets Size: Effect on Clustering Results Adeleke Ajiboye 1, Ruzaini Abdullah Arshah 2, Hongwu Qin 3 Faculty of Computer Systems and Software Engineering Universiti Malaysia Pahang 1 {ajibraheem@live.com}
Gene Clustering & Classification
 BINF, Introduction to Computational Biology Gene Clustering & Classification Young-Rae Cho Associate Professor Department of Computer Science Baylor University Overview Introduction to Gene Clustering
BINF, Introduction to Computational Biology Gene Clustering & Classification Young-Rae Cho Associate Professor Department of Computer Science Baylor University Overview Introduction to Gene Clustering
Data Mining. Dr. Raed Ibraheem Hamed. University of Human Development, College of Science and Technology Department of Computer Science
 Data Mining Dr. Raed Ibraheem Hamed University of Human Development, College of Science and Technology Department of Computer Science 2016 201 Road map What is Cluster Analysis? Characteristics of Clustering
Data Mining Dr. Raed Ibraheem Hamed University of Human Development, College of Science and Technology Department of Computer Science 2016 201 Road map What is Cluster Analysis? Characteristics of Clustering
Clustering. Informal goal. General types of clustering. Applications: Clustering in information search and analysis. Example applications in search
 Informal goal Clustering Given set of objects and measure of similarity between them, group similar objects together What mean by similar? What is good grouping? Computation time / quality tradeoff 1 2
Informal goal Clustering Given set of objects and measure of similarity between them, group similar objects together What mean by similar? What is good grouping? Computation time / quality tradeoff 1 2
ECLT 5810 Clustering
 ECLT 5810 Clustering What is Cluster Analysis? Cluster: a collection of data objects Similar to one another within the same cluster Dissimilar to the objects in other clusters Cluster analysis Grouping
ECLT 5810 Clustering What is Cluster Analysis? Cluster: a collection of data objects Similar to one another within the same cluster Dissimilar to the objects in other clusters Cluster analysis Grouping
Clustering CS 550: Machine Learning
 Clustering CS 550: Machine Learning This slide set mainly uses the slides given in the following links: http://www-users.cs.umn.edu/~kumar/dmbook/ch8.pdf http://www-users.cs.umn.edu/~kumar/dmbook/dmslides/chap8_basic_cluster_analysis.pdf
Clustering CS 550: Machine Learning This slide set mainly uses the slides given in the following links: http://www-users.cs.umn.edu/~kumar/dmbook/ch8.pdf http://www-users.cs.umn.edu/~kumar/dmbook/dmslides/chap8_basic_cluster_analysis.pdf
PESIT- Bangalore South Campus Hosur Road (1km Before Electronic city) Bangalore
 Bangalore") Data Warehousing Data Mining (17MCA442) 1. GENERAL INFORMATION: PESIT- Bangalore South Campus Hosur Road (1km Before Electronic city) Bangalore 560 100 Department of MCA COURSE INFORMATION SHEET Academic
Data Warehousing Data Mining (17MCA442) 1. GENERAL INFORMATION: PESIT- Bangalore South Campus Hosur Road (1km Before Electronic city) Bangalore 560 100 Department of MCA COURSE INFORMATION SHEET Academic
Information Retrieval and Organisation
 Information Retrieval and Organisation Chapter 16 Flat Clustering Dell Zhang Birkbeck, University of London What Is Text Clustering? Text Clustering = Grouping a set of documents into classes of similar
Information Retrieval and Organisation Chapter 16 Flat Clustering Dell Zhang Birkbeck, University of London What Is Text Clustering? Text Clustering = Grouping a set of documents into classes of similar
International Journal of Advanced Research in Computer Science and Software Engineering
 Volume 3, Issue 3, March 2013 ISSN: 2277 128X International Journal of Advanced Research in Computer Science and Software Engineering Research Paper Available online at: www.ijarcsse.com Special Issue:
Volume 3, Issue 3, March 2013 ISSN: 2277 128X International Journal of Advanced Research in Computer Science and Software Engineering Research Paper Available online at: www.ijarcsse.com Special Issue:
Contents. Preface to the Second Edition
 Preface to the Second Edition v 1 Introduction 1 1.1 What Is Data Mining?....................... 4 1.2 Motivating Challenges....................... 5 1.3 The Origins of Data Mining....................
Preface to the Second Edition v 1 Introduction 1 1.1 What Is Data Mining?....................... 4 1.2 Motivating Challenges....................... 5 1.3 The Origins of Data Mining....................
9/29/13. Outline Data mining tasks. Clustering algorithms. Applications of clustering in biology
 9/9/ I9 Introduction to Bioinformatics, Clustering algorithms Yuzhen Ye (yye@indiana.edu) School of Informatics & Computing, IUB Outline Data mining tasks Predictive tasks vs descriptive tasks Example
9/9/ I9 Introduction to Bioinformatics, Clustering algorithms Yuzhen Ye (yye@indiana.edu) School of Informatics & Computing, IUB Outline Data mining tasks Predictive tasks vs descriptive tasks Example
The Effect of Word Sampling on Document Clustering
 The Effect of Word Sampling on Document Clustering OMAR H. KARAM AHMED M. HAMAD SHERIN M. MOUSSA Department of Information Systems Faculty of Computer and Information Sciences University of Ain Shams,
The Effect of Word Sampling on Document Clustering OMAR H. KARAM AHMED M. HAMAD SHERIN M. MOUSSA Department of Information Systems Faculty of Computer and Information Sciences University of Ain Shams,
Multilevel Algorithms for Multi-Constraint Hypergraph Partitioning
 Multilevel Algorithms for Multi-Constraint Hypergraph Partitioning George Karypis University of Minnesota, Department of Computer Science / Army HPC Research Center Minneapolis, MN 55455 Technical Report
Multilevel Algorithms for Multi-Constraint Hypergraph Partitioning George Karypis University of Minnesota, Department of Computer Science / Army HPC Research Center Minneapolis, MN 55455 Technical Report
A Modified Hierarchical Clustering Algorithm for Document Clustering
 A Modified Hierarchical Algorithm for Document Merin Paul, P Thangam Abstract is the division of data into groups called as clusters. Document clustering is done to analyse the large number of documents
A Modified Hierarchical Algorithm for Document Merin Paul, P Thangam Abstract is the division of data into groups called as clusters. Document clustering is done to analyse the large number of documents
Clustering: Overview and K-means algorithm
 Clustering: Overview and K-means algorithm Informal goal Given set of objects and measure of similarity between them, group similar objects together K-Means illustrations thanks to 2006 student Martin
Clustering: Overview and K-means algorithm Informal goal Given set of objects and measure of similarity between them, group similar objects together K-Means illustrations thanks to 2006 student Martin
Text Documents clustering using K Means Algorithm
 Text Documents clustering using K Means Algorithm Mrs Sanjivani Tushar Deokar Assistant professor sanjivanideokar@gmail.com Abstract: With the advancement of technology and reduced storage costs, individuals
Text Documents clustering using K Means Algorithm Mrs Sanjivani Tushar Deokar Assistant professor sanjivanideokar@gmail.com Abstract: With the advancement of technology and reduced storage costs, individuals
Criterion Functions for Document Clustering Experiments and Analysis
 Criterion Functions for Document Clustering Experiments and Analysis Ying Zhao and George Karypis University of Minnesota, Department of Computer Science / Army HPC Research Center Minneapolis, MN 55455
Criterion Functions for Document Clustering Experiments and Analysis Ying Zhao and George Karypis University of Minnesota, Department of Computer Science / Army HPC Research Center Minneapolis, MN 55455
Improving the Efficiency of Fast Using Semantic Similarity Algorithm
 International Journal of Scientific and Research Publications, Volume 4, Issue 1, January 2014 1 Improving the Efficiency of Fast Using Semantic Similarity Algorithm D.KARTHIKA 1, S. DIVAKAR 2 Final year
International Journal of Scientific and Research Publications, Volume 4, Issue 1, January 2014 1 Improving the Efficiency of Fast Using Semantic Similarity Algorithm D.KARTHIKA 1, S. DIVAKAR 2 Final year
Concept Tree Based Clustering Visualization with Shaded Similarity Matrices
 Syracuse University SURFACE School of Information Studies: Faculty Scholarship School of Information Studies (ischool) 12-2002 Concept Tree Based Clustering Visualization with Shaded Similarity Matrices
Syracuse University SURFACE School of Information Studies: Faculty Scholarship School of Information Studies (ischool) 12-2002 Concept Tree Based Clustering Visualization with Shaded Similarity Matrices
Document Clustering: Comparison of Similarity Measures
 Document Clustering: Comparison of Similarity Measures Shouvik Sachdeva Bhupendra Kastore Indian Institute of Technology, Kanpur CS365 Project, 2014 Outline 1 Introduction The Problem and the Motivation
Document Clustering: Comparison of Similarity Measures Shouvik Sachdeva Bhupendra Kastore Indian Institute of Technology, Kanpur CS365 Project, 2014 Outline 1 Introduction The Problem and the Motivation
wcluto: A Web-Enabled Clustering Toolkit 1
 Bioinformatics wcluto: A Web-Enabled Clustering Toolkit 1 Matthew D. Rasmussen, Mukund S. Deshpande, George Karypis*, James Johnson, John A. Crow, and Ernest F. Retzel Department of Computer Science and
Bioinformatics wcluto: A Web-Enabled Clustering Toolkit 1 Matthew D. Rasmussen, Mukund S. Deshpande, George Karypis*, James Johnson, John A. Crow, and Ernest F. Retzel Department of Computer Science and
Administrative. Machine learning code. Supervised learning (e.g. classification) Machine learning: Unsupervised learning" BANANAS APPLES
 Machine learning: Unsupervised learning BANANAS APPLES") Administrative Machine learning: Unsupervised learning" Assignment 5 out soon David Kauchak cs311 Spring 2013 adapted from: http://www.stanford.edu/class/cs276/handouts/lecture17-clustering.ppt Machine
Administrative Machine learning: Unsupervised learning" Assignment 5 out soon David Kauchak cs311 Spring 2013 adapted from: http://www.stanford.edu/class/cs276/handouts/lecture17-clustering.ppt Machine
Unsupervised Learning
 Outline Unsupervised Learning Basic concepts K-means algorithm Representation of clusters Hierarchical clustering Distance functions Which clustering algorithm to use? NN Supervised learning vs. unsupervised
Outline Unsupervised Learning Basic concepts K-means algorithm Representation of clusters Hierarchical clustering Distance functions Which clustering algorithm to use? NN Supervised learning vs. unsupervised
Hierarchical Clustering Algorithms for Document Datasets
 Hierarchical Clustering Algorithms for Document Datasets Ying Zhao and George Karypis Department of Computer Science, University of Minnesota, Minneapolis, MN 55455 Technical Report #03-027 {yzhao, karypis}@cs.umn.edu
Hierarchical Clustering Algorithms for Document Datasets Ying Zhao and George Karypis Department of Computer Science, University of Minnesota, Minneapolis, MN 55455 Technical Report #03-027 {yzhao, karypis}@cs.umn.edu
Using the Kolmogorov-Smirnov Test for Image Segmentation
 Using the Kolmogorov-Smirnov Test for Image Segmentation Yong Jae Lee CS395T Computational Statistics Final Project Report May 6th, 2009 I. INTRODUCTION Image segmentation is a fundamental task in computer
Using the Kolmogorov-Smirnov Test for Image Segmentation Yong Jae Lee CS395T Computational Statistics Final Project Report May 6th, 2009 I. INTRODUCTION Image segmentation is a fundamental task in computer
Similarity Matrix Based Session Clustering by Sequence Alignment Using Dynamic Programming
 Similarity Matrix Based Session Clustering by Sequence Alignment Using Dynamic Programming Dr.K.Duraiswamy Dean, Academic K.S.Rangasamy College of Technology Tiruchengode, India V. Valli Mayil (Corresponding
Similarity Matrix Based Session Clustering by Sequence Alignment Using Dynamic Programming Dr.K.Duraiswamy Dean, Academic K.S.Rangasamy College of Technology Tiruchengode, India V. Valli Mayil (Corresponding
Enhancing Clustering Results In Hierarchical Approach By Mvs Measures
 International Journal of Engineering Research and Development e-issn: 2278-067X, p-issn: 2278-800X, www.ijerd.com Volume 10, Issue 6 (June 2014), PP.25-30 Enhancing Clustering Results In Hierarchical Approach
International Journal of Engineering Research and Development e-issn: 2278-067X, p-issn: 2278-800X, www.ijerd.com Volume 10, Issue 6 (June 2014), PP.25-30 Enhancing Clustering Results In Hierarchical Approach
Analysis and Extensions of Popular Clustering Algorithms
 Analysis and Extensions of Popular Clustering Algorithms Renáta Iváncsy, Attila Babos, Csaba Legány Department of Automation and Applied Informatics and HAS-BUTE Control Research Group Budapest University
Analysis and Extensions of Popular Clustering Algorithms Renáta Iváncsy, Attila Babos, Csaba Legány Department of Automation and Applied Informatics and HAS-BUTE Control Research Group Budapest University
Clustering Algorithms for Data Stream
 Clustering Algorithms for Data Stream Karishma Nadhe 1, Prof. P. M. Chawan 2 1Student, Dept of CS & IT, VJTI Mumbai, Maharashtra, India 2Professor, Dept of CS & IT, VJTI Mumbai, Maharashtra, India Abstract:
Clustering Algorithms for Data Stream Karishma Nadhe 1, Prof. P. M. Chawan 2 1Student, Dept of CS & IT, VJTI Mumbai, Maharashtra, India 2Professor, Dept of CS & IT, VJTI Mumbai, Maharashtra, India Abstract:
Understanding Clustering Supervising the unsupervised
 Understanding Clustering Supervising the unsupervised Janu Verma IBM T.J. Watson Research Center, New York http://jverma.github.io/ jverma@us.ibm.com @januverma Clustering Grouping together similar data
Understanding Clustering Supervising the unsupervised Janu Verma IBM T.J. Watson Research Center, New York http://jverma.github.io/ jverma@us.ibm.com @januverma Clustering Grouping together similar data
Chapter 1, Introduction
 CSI 4352, Introduction to Data Mining Chapter 1, Introduction Young-Rae Cho Associate Professor Department of Computer Science Baylor University What is Data Mining? Definition Knowledge Discovery from
CSI 4352, Introduction to Data Mining Chapter 1, Introduction Young-Rae Cho Associate Professor Department of Computer Science Baylor University What is Data Mining? Definition Knowledge Discovery from
Keywords: hierarchical clustering, traditional similarity metrics, potential based similarity metrics.
 www.ijecs.in International Journal Of Engineering And Computer Science ISSN: 2319-7242 Volume 4 Issue 8 Aug 2015, Page No. 14027-14032 Potential based similarity metrics for implementing hierarchical clustering
www.ijecs.in International Journal Of Engineering And Computer Science ISSN: 2319-7242 Volume 4 Issue 8 Aug 2015, Page No. 14027-14032 Potential based similarity metrics for implementing hierarchical clustering
Data Clustering Hierarchical Clustering, Density based clustering Grid based clustering
 Data Clustering Hierarchical Clustering, Density based clustering Grid based clustering Team 2 Prof. Anita Wasilewska CSE 634 Data Mining All Sources Used for the Presentation Olson CF. Parallel algorithms
Data Clustering Hierarchical Clustering, Density based clustering Grid based clustering Team 2 Prof. Anita Wasilewska CSE 634 Data Mining All Sources Used for the Presentation Olson CF. Parallel algorithms
Unsupervised Data Mining: Clustering. Izabela Moise, Evangelos Pournaras, Dirk Helbing
 Unsupervised Data Mining: Clustering Izabela Moise, Evangelos Pournaras, Dirk Helbing Izabela Moise, Evangelos Pournaras, Dirk Helbing 1 1. Supervised Data Mining Classification Regression Outlier detection
Unsupervised Data Mining: Clustering Izabela Moise, Evangelos Pournaras, Dirk Helbing Izabela Moise, Evangelos Pournaras, Dirk Helbing 1 1. Supervised Data Mining Classification Regression Outlier detection
Workload Characterization Techniques
 Workload Characterization Techniques Raj Jain Washington University in Saint Louis Saint Louis, MO 63130 Jain@cse.wustl.edu These slides are available on-line at: http://www.cse.wustl.edu/~jain/cse567-08/
Workload Characterization Techniques Raj Jain Washington University in Saint Louis Saint Louis, MO 63130 Jain@cse.wustl.edu These slides are available on-line at: http://www.cse.wustl.edu/~jain/cse567-08/
CHAMELEON: A Hierarchical Clustering Algorithm Using Dynamic Modeling
 To Appear in the IEEE Computer CHAMELEON: A Hierarchical Clustering Algorithm Using Dynamic Modeling George Karypis Eui-Hong (Sam) Han Vipin Kumar Department of Computer Science and Engineering University
To Appear in the IEEE Computer CHAMELEON: A Hierarchical Clustering Algorithm Using Dynamic Modeling George Karypis Eui-Hong (Sam) Han Vipin Kumar Department of Computer Science and Engineering University
Notes. Reminder: HW2 Due Today by 11:59PM. Review session on Thursday. Midterm next Tuesday (10/10/2017)
") 1 Notes Reminder: HW2 Due Today by 11:59PM TA s note: Please provide a detailed ReadMe.txt file on how to run the program on the STDLINUX. If you installed/upgraded any package on STDLINUX, you should
1 Notes Reminder: HW2 Due Today by 11:59PM TA s note: Please provide a detailed ReadMe.txt file on how to run the program on the STDLINUX. If you installed/upgraded any package on STDLINUX, you should
DENSITY BASED AND PARTITION BASED CLUSTERING OF UNCERTAIN DATA BASED ON KL-DIVERGENCE SIMILARITY MEASURE
 DENSITY BASED AND PARTITION BASED CLUSTERING OF UNCERTAIN DATA BASED ON KL-DIVERGENCE SIMILARITY MEASURE Sinu T S 1, Mr.Joseph George 1,2 Computer Science and Engineering, Adi Shankara Institute of Engineering
DENSITY BASED AND PARTITION BASED CLUSTERING OF UNCERTAIN DATA BASED ON KL-DIVERGENCE SIMILARITY MEASURE Sinu T S 1, Mr.Joseph George 1,2 Computer Science and Engineering, Adi Shankara Institute of Engineering
PATENT DATA CLUSTERING: A MEASURING UNIT FOR INNOVATORS
 International Journal of Computer Engineering and Technology (IJCET), ISSN 0976 6367(Print) ISSN 0976 6375(Online) Volume 1 Number 1, May - June (2010), pp. 158-165 IAEME, http://www.iaeme.com/ijcet.html
International Journal of Computer Engineering and Technology (IJCET), ISSN 0976 6367(Print) ISSN 0976 6375(Online) Volume 1 Number 1, May - June (2010), pp. 158-165 IAEME, http://www.iaeme.com/ijcet.html
Dimension reduction : PCA and Clustering
 Dimension reduction : PCA and Clustering By Hanne Jarmer Slides by Christopher Workman Center for Biological Sequence Analysis DTU The DNA Array Analysis Pipeline Array design Probe design Question Experimental
Dimension reduction : PCA and Clustering By Hanne Jarmer Slides by Christopher Workman Center for Biological Sequence Analysis DTU The DNA Array Analysis Pipeline Array design Probe design Question Experimental
Hierarchical Clustering Algorithms for Document Datasets
 Data Mining and Knowledge Discovery, 10, 141 168, 2005 c 2005 Springer Science + Business Media, Inc. Manufactured in The Netherlands. Hierarchical Clustering Algorithms for Document Datasets YING ZHAO
Data Mining and Knowledge Discovery, 10, 141 168, 2005 c 2005 Springer Science + Business Media, Inc. Manufactured in The Netherlands. Hierarchical Clustering Algorithms for Document Datasets YING ZHAO
An Unsupervised Technique for Statistical Data Analysis Using Data Mining
 International Journal of Information Sciences and Application. ISSN 0974-2255 Volume 5, Number 1 (2013), pp. 11-20 International Research Publication House http://www.irphouse.com An Unsupervised Technique
International Journal of Information Sciences and Application. ISSN 0974-2255 Volume 5, Number 1 (2013), pp. 11-20 International Research Publication House http://www.irphouse.com An Unsupervised Technique
An Approach to Improve Quality of Document Clustering by Word Set Based Documenting Clustering Algorithm
 ORIENTAL JOURNAL OF COMPUTER SCIENCE & TECHNOLOGY An International Open Free Access, Peer Reviewed Research Journal www.computerscijournal.org ISSN: 0974-6471 December 2011, Vol. 4, No. (2): Pgs. 379-385
ORIENTAL JOURNAL OF COMPUTER SCIENCE & TECHNOLOGY An International Open Free Access, Peer Reviewed Research Journal www.computerscijournal.org ISSN: 0974-6471 December 2011, Vol. 4, No. (2): Pgs. 379-385
HIMIC : A Hierarchical Mixed Type Data Clustering Algorithm
 HIMIC : A Hierarchical Mixed Type Data Clustering Algorithm R. A. Ahmed B. Borah D. K. Bhattacharyya Department of Computer Science and Information Technology, Tezpur University, Napam, Tezpur-784028,
HIMIC : A Hierarchical Mixed Type Data Clustering Algorithm R. A. Ahmed B. Borah D. K. Bhattacharyya Department of Computer Science and Information Technology, Tezpur University, Napam, Tezpur-784028,
Cluster analysis. Agnieszka Nowak - Brzezinska
 Cluster analysis Agnieszka Nowak - Brzezinska Outline of lecture What is cluster analysis? Clustering algorithms Measures of Cluster Validity What is Cluster Analysis? Finding groups of objects such that
Cluster analysis Agnieszka Nowak - Brzezinska Outline of lecture What is cluster analysis? Clustering algorithms Measures of Cluster Validity What is Cluster Analysis? Finding groups of objects such that
Unsupervised Learning : Clustering
 Unsupervised Learning : Clustering Things to be Addressed Traditional Learning Models. Cluster Analysis K-means Clustering Algorithm Drawbacks of traditional clustering algorithms. Clustering as a complex
Unsupervised Learning : Clustering Things to be Addressed Traditional Learning Models. Cluster Analysis K-means Clustering Algorithm Drawbacks of traditional clustering algorithms. Clustering as a complex
Encyclopedia of Data Warehousing and Mining
 Encyclopedia of Data Warehousing and Mining John Wang Montclair State University, USA Volume I A-H IDEA GROUP REFERENCE Hershey London Melbourne Singapore Acquisitions Editor: Development Editor: Senior
Encyclopedia of Data Warehousing and Mining John Wang Montclair State University, USA Volume I A-H IDEA GROUP REFERENCE Hershey London Melbourne Singapore Acquisitions Editor: Development Editor: Senior
Lab of COMP 406. MATLAB: Quick Start. Lab tutor : Gene Yu Zhao Mailbox: or Lab 1: 11th Sep, 2013
 Lab of COMP 406 MATLAB: Quick Start Lab tutor : Gene Yu Zhao Mailbox: csyuzhao@comp.polyu.edu.hk or genexinvivian@gmail.com Lab 1: 11th Sep, 2013 1 Where is Matlab? Find the Matlab under the folder 1.
Lab of COMP 406 MATLAB: Quick Start Lab tutor : Gene Yu Zhao Mailbox: csyuzhao@comp.polyu.edu.hk or genexinvivian@gmail.com Lab 1: 11th Sep, 2013 1 Where is Matlab? Find the Matlab under the folder 1.
Contents. Foreword to Second Edition. Acknowledgments About the Authors
 Contents Foreword xix Foreword to Second Edition xxi Preface xxiii Acknowledgments About the Authors xxxi xxxv Chapter 1 Introduction 1 1.1 Why Data Mining? 1 1.1.1 Moving toward the Information Age 1
Contents Foreword xix Foreword to Second Edition xxi Preface xxiii Acknowledgments About the Authors xxxi xxxv Chapter 1 Introduction 1 1.1 Why Data Mining? 1 1.1.1 Moving toward the Information Age 1
Building a Concept Hierarchy from a Distance Matrix
 Building a Concept Hierarchy from a Distance Matrix Huang-Cheng Kuo 1 and Jen-Peng Huang 2 1 Department of Computer Science and Information Engineering National Chiayi University, Taiwan 600 hckuo@mail.ncyu.edu.tw
Building a Concept Hierarchy from a Distance Matrix Huang-Cheng Kuo 1 and Jen-Peng Huang 2 1 Department of Computer Science and Information Engineering National Chiayi University, Taiwan 600 hckuo@mail.ncyu.edu.tw
CSE 5243 INTRO. TO DATA MINING
 CSE 5243 INTRO. TO DATA MINING Cluster Analysis: Basic Concepts and Methods Huan Sun, CSE@The Ohio State University 09/25/2017 Slides adapted from UIUC CS412, Fall 2017, by Prof. Jiawei Han 2 Chapter 10.
CSE 5243 INTRO. TO DATA MINING Cluster Analysis: Basic Concepts and Methods Huan Sun, CSE@The Ohio State University 09/25/2017 Slides adapted from UIUC CS412, Fall 2017, by Prof. Jiawei Han 2 Chapter 10.
Toward the integration of informatic tools and GRID infrastructure for Assyriology text analysis
 58 Rencontre Assyriologique Internationale (RAI) Private and State 16-20 July 2012 - Leiden Toward the integration of informatic tools and GRID infrastructure for Assyriology text analysis Giovanni Ponti,
58 Rencontre Assyriologique Internationale (RAI) Private and State 16-20 July 2012 - Leiden Toward the integration of informatic tools and GRID infrastructure for Assyriology text analysis Giovanni Ponti,
CSE 5243 INTRO. TO DATA MINING
 CSE 5243 INTRO. TO DATA MINING Cluster Analysis: Basic Concepts and Methods Huan Sun, CSE@The Ohio State University Slides adapted from UIUC CS412, Fall 2017, by Prof. Jiawei Han 2 Chapter 10. Cluster
CSE 5243 INTRO. TO DATA MINING Cluster Analysis: Basic Concepts and Methods Huan Sun, CSE@The Ohio State University Slides adapted from UIUC CS412, Fall 2017, by Prof. Jiawei Han 2 Chapter 10. Cluster
Statistics 202: Data Mining. c Jonathan Taylor. Week 8 Based in part on slides from textbook, slides of Susan Holmes. December 2, / 1
 Week 8 Based in part on slides from textbook, slides of Susan Holmes December 2, 2012 1 / 1 Part I Clustering 2 / 1 Clustering Clustering Goal: Finding groups of objects such that the objects in a group
Week 8 Based in part on slides from textbook, slides of Susan Holmes December 2, 2012 1 / 1 Part I Clustering 2 / 1 Clustering Clustering Goal: Finding groups of objects such that the objects in a group
Outlier Detection and Removal Algorithm in K-Means and Hierarchical Clustering
 World Journal of Computer Application and Technology 5(2): 24-29, 2017 DOI: 10.13189/wjcat.2017.050202 http://www.hrpub.org Outlier Detection and Removal Algorithm in K-Means and Hierarchical Clustering
World Journal of Computer Application and Technology 5(2): 24-29, 2017 DOI: 10.13189/wjcat.2017.050202 http://www.hrpub.org Outlier Detection and Removal Algorithm in K-Means and Hierarchical Clustering
Lecture Notes for Chapter 7. Introduction to Data Mining, 2 nd Edition. by Tan, Steinbach, Karpatne, Kumar
 Data Mining Cluster Analysis: Basic Concepts and Algorithms Lecture Notes for Chapter 7 Introduction to Data Mining, nd Edition by Tan, Steinbach, Karpatne, Kumar What is Cluster Analysis? Finding groups
Data Mining Cluster Analysis: Basic Concepts and Algorithms Lecture Notes for Chapter 7 Introduction to Data Mining, nd Edition by Tan, Steinbach, Karpatne, Kumar What is Cluster Analysis? Finding groups
Contents. List of Figures. List of Tables. List of Algorithms. I Clustering, Data, and Similarity Measures 1
 Contents List of Figures List of Tables List of Algorithms Preface xiii xv xvii xix I Clustering, Data, and Similarity Measures 1 1 Data Clustering 3 1.1 Definition of Data Clustering... 3 1.2 The Vocabulary
Contents List of Figures List of Tables List of Algorithms Preface xiii xv xvii xix I Clustering, Data, and Similarity Measures 1 1 Data Clustering 3 1.1 Definition of Data Clustering... 3 1.2 The Vocabulary
Cluster Analysis. Ying Shen, SSE, Tongji University
 Cluster Analysis Ying Shen, SSE, Tongji University Cluster analysis Cluster analysis groups data objects based only on the attributes in the data. The main objective is that The objects within a group
Cluster Analysis Ying Shen, SSE, Tongji University Cluster analysis Cluster analysis groups data objects based only on the attributes in the data. The main objective is that The objects within a group
Performance Analysis of Data Mining Classification Techniques
 Performance Analysis of Data Mining Classification Techniques Tejas Mehta 1, Dr. Dhaval Kathiriya 2 Ph.D. Student, School of Computer Science, Dr. Babasaheb Ambedkar Open University, Gujarat, India 1 Principal
Performance Analysis of Data Mining Classification Techniques Tejas Mehta 1, Dr. Dhaval Kathiriya 2 Ph.D. Student, School of Computer Science, Dr. Babasaheb Ambedkar Open University, Gujarat, India 1 Principal
Data Mining Cluster Analysis: Advanced Concepts and Algorithms. Lecture Notes for Chapter 8. Introduction to Data Mining, 2 nd Edition
 Data Mining Cluster Analysis: Advanced Concepts and Algorithms Lecture Notes for Chapter 8 Introduction to Data Mining, 2 nd Edition by Tan, Steinbach, Karpatne, Kumar Outline Prototype-based Fuzzy c-means
Data Mining Cluster Analysis: Advanced Concepts and Algorithms Lecture Notes for Chapter 8 Introduction to Data Mining, 2 nd Edition by Tan, Steinbach, Karpatne, Kumar Outline Prototype-based Fuzzy c-means
A FAST CLUSTERING-BASED FEATURE SUBSET SELECTION ALGORITHM
 A FAST CLUSTERING-BASED FEATURE SUBSET SELECTION ALGORITHM Akshay S. Agrawal 1, Prof. Sachin Bojewar 2 1 P.G. Scholar, Department of Computer Engg., ARMIET, Sapgaon, (India) 2 Associate Professor, VIT,
A FAST CLUSTERING-BASED FEATURE SUBSET SELECTION ALGORITHM Akshay S. Agrawal 1, Prof. Sachin Bojewar 2 1 P.G. Scholar, Department of Computer Engg., ARMIET, Sapgaon, (India) 2 Associate Professor, VIT,
Database and Knowledge-Base Systems: Data Mining. Martin Ester
 Database and Knowledge-Base Systems: Data Mining Martin Ester Simon Fraser University School of Computing Science Graduate Course Spring 2006 CMPT 843, SFU, Martin Ester, 1-06 1 Introduction [Fayyad, Piatetsky-Shapiro
Database and Knowledge-Base Systems: Data Mining Martin Ester Simon Fraser University School of Computing Science Graduate Course Spring 2006 CMPT 843, SFU, Martin Ester, 1-06 1 Introduction [Fayyad, Piatetsky-Shapiro
Clustering Large Dynamic Datasets Using Exemplar Points
 Clustering Large Dynamic Datasets Using Exemplar Points William Sia, Mihai M. Lazarescu Department of Computer Science, Curtin University, GPO Box U1987, Perth 61, W.A. Email: {siaw, lazaresc}@cs.curtin.edu.au
Clustering Large Dynamic Datasets Using Exemplar Points William Sia, Mihai M. Lazarescu Department of Computer Science, Curtin University, GPO Box U1987, Perth 61, W.A. Email: {siaw, lazaresc}@cs.curtin.edu.au
Chapter DM:II. II. Cluster Analysis
 Chapter DM:II II. Cluster Analysis Cluster Analysis Basics Hierarchical Cluster Analysis Iterative Cluster Analysis Density-Based Cluster Analysis Cluster Evaluation Constrained Cluster Analysis DM:II-1
Chapter DM:II II. Cluster Analysis Cluster Analysis Basics Hierarchical Cluster Analysis Iterative Cluster Analysis Density-Based Cluster Analysis Cluster Evaluation Constrained Cluster Analysis DM:II-1
Supervised and Unsupervised Learning (II)
") Supervised and Unsupervised Learning (II) Yong Zheng Center for Web Intelligence DePaul University, Chicago IPD 346 - Data Science for Business Program DePaul University, Chicago, USA Intro: Supervised
Supervised and Unsupervised Learning (II) Yong Zheng Center for Web Intelligence DePaul University, Chicago IPD 346 - Data Science for Business Program DePaul University, Chicago, USA Intro: Supervised
Scalable Varied Density Clustering Algorithm for Large Datasets
 J. Software Engineering & Applications, 2010, 3, 593-602 doi:10.4236/jsea.2010.36069 Published Online June 2010 (http://www.scirp.org/journal/jsea) Scalable Varied Density Clustering Algorithm for Large
J. Software Engineering & Applications, 2010, 3, 593-602 doi:10.4236/jsea.2010.36069 Published Online June 2010 (http://www.scirp.org/journal/jsea) Scalable Varied Density Clustering Algorithm for Large
Question Bank. 4) It is the source of information later delivered to data marts.
 It is the source of information later delivered to data marts.") Question Bank Year: 2016-2017 Subject Dept: CS Semester: First Subject Name: Data Mining. Q1) What is data warehouse? ANS. A data warehouse is a subject-oriented, integrated, time-variant, and nonvolatile
Question Bank Year: 2016-2017 Subject Dept: CS Semester: First Subject Name: Data Mining. Q1) What is data warehouse? ANS. A data warehouse is a subject-oriented, integrated, time-variant, and nonvolatile
Conceptual Review of clustering techniques in data mining field
 Conceptual Review of clustering techniques in data mining field Divya Shree ABSTRACT The marvelous amount of data produced nowadays in various application domains such as molecular biology or geography
Conceptual Review of clustering techniques in data mining field Divya Shree ABSTRACT The marvelous amount of data produced nowadays in various application domains such as molecular biology or geography
An Experimental Analysis of Outliers Detection on Static Exaustive Datasets.
 International Journal Latest Trends in Engineering and Technology Vol.(7)Issue(3), pp. 319-325 DOI: http://dx.doi.org/10.21172/1.73.544 e ISSN:2278 621X An Experimental Analysis Outliers Detection on Static
International Journal Latest Trends in Engineering and Technology Vol.(7)Issue(3), pp. 319-325 DOI: http://dx.doi.org/10.21172/1.73.544 e ISSN:2278 621X An Experimental Analysis Outliers Detection on Static
Olmo S. Zavala Romero. Clustering Hierarchical Distance Group Dist. K-means. Center of Atmospheric Sciences, UNAM.
 Center of Atmospheric Sciences, UNAM November 16, 2016 Cluster Analisis Cluster analysis or clustering is the task of grouping a set of objects in such a way that objects in the same group (called a cluster)
Center of Atmospheric Sciences, UNAM November 16, 2016 Cluster Analisis Cluster analysis or clustering is the task of grouping a set of objects in such a way that objects in the same group (called a cluster)
Document Clustering Approach for Forensic Analysis: A Survey
 Document Clustering Approach for Forensic Analysis: A Survey Prachi K. Khairkar 1, D. A. Phalke 2 1, 2 Savitribai Phule Pune University, D Y Patil College of Engineering, Akurdi, Pune, India (411044) Abstract:
Document Clustering Approach for Forensic Analysis: A Survey Prachi K. Khairkar 1, D. A. Phalke 2 1, 2 Savitribai Phule Pune University, D Y Patil College of Engineering, Akurdi, Pune, India (411044) Abstract:
9. Conclusions. 9.1 Definition KDD
 9. Conclusions Contents of this Chapter 9.1 Course review 9.2 State-of-the-art in KDD 9.3 KDD challenges SFU, CMPT 740, 03-3, Martin Ester 419 9.1 Definition KDD [Fayyad, Piatetsky-Shapiro & Smyth 96]
9. Conclusions Contents of this Chapter 9.1 Course review 9.2 State-of-the-art in KDD 9.3 KDD challenges SFU, CMPT 740, 03-3, Martin Ester 419 9.1 Definition KDD [Fayyad, Piatetsky-Shapiro & Smyth 96]
Knowledge Discovery and Data Mining
 Knowledge Discovery and Data Mining Unit # 1 1 Acknowledgement Several Slides in this presentation are taken from course slides provided by Han and Kimber (Data Mining Concepts and Techniques) and Tan,
Knowledge Discovery and Data Mining Unit # 1 1 Acknowledgement Several Slides in this presentation are taken from course slides provided by Han and Kimber (Data Mining Concepts and Techniques) and Tan,
CHAPTER 3 A FAST K-MODES CLUSTERING ALGORITHM TO WAREHOUSE VERY LARGE HETEROGENEOUS MEDICAL DATABASES
 70 CHAPTER 3 A FAST K-MODES CLUSTERING ALGORITHM TO WAREHOUSE VERY LARGE HETEROGENEOUS MEDICAL DATABASES 3.1 INTRODUCTION In medical science, effective tools are essential to categorize and systematically
70 CHAPTER 3 A FAST K-MODES CLUSTERING ALGORITHM TO WAREHOUSE VERY LARGE HETEROGENEOUS MEDICAL DATABASES 3.1 INTRODUCTION In medical science, effective tools are essential to categorize and systematically
Road map. Basic concepts
 Clustering Basic concepts Road map K-means algorithm Representation of clusters Hierarchical clustering Distance functions Data standardization Handling mixed attributes Which clustering algorithm to use?
Clustering Basic concepts Road map K-means algorithm Representation of clusters Hierarchical clustering Distance functions Data standardization Handling mixed attributes Which clustering algorithm to use?
BL5229: Data Analysis with Matlab Lab: Learning: Clustering
 BL5229: Data Analysis with Matlab Lab: Learning: Clustering The following hands-on exercises were designed to teach you step by step how to perform and understand various clustering algorithm. We will
BL5229: Data Analysis with Matlab Lab: Learning: Clustering The following hands-on exercises were designed to teach you step by step how to perform and understand various clustering algorithm. We will
CSE 5243 INTRO. TO DATA MINING
 CSE 5243 INTRO. TO DATA MINING Cluster Analysis: Basic Concepts and Methods Huan Sun, CSE@The Ohio State University 09/28/2017 Slides adapted from UIUC CS412, Fall 2017, by Prof. Jiawei Han 2 Chapter 10.
CSE 5243 INTRO. TO DATA MINING Cluster Analysis: Basic Concepts and Methods Huan Sun, CSE@The Ohio State University 09/28/2017 Slides adapted from UIUC CS412, Fall 2017, by Prof. Jiawei Han 2 Chapter 10.
 http://www.xkcd.com/233/ Text Clustering David Kauchak cs160 Fall 2009 adapted from: http://www.stanford.edu/class/cs276/handouts/lecture17-clustering.ppt Administrative 2 nd status reports Paper review
http://www.xkcd.com/233/ Text Clustering David Kauchak cs160 Fall 2009 adapted from: http://www.stanford.edu/class/cs276/handouts/lecture17-clustering.ppt Administrative 2 nd status reports Paper review
Clustering and Information Retrieval
 Clustering and Information Retrieval Network Theory and Applications Volume 11 Managing Editors: Ding-ZhuDu University o/minnesota, U.S.A. Cauligi Raghavendra University 0/ Southern Califorina, U.S.A.
Clustering and Information Retrieval Network Theory and Applications Volume 11 Managing Editors: Ding-ZhuDu University o/minnesota, U.S.A. Cauligi Raghavendra University 0/ Southern Califorina, U.S.A.
Clustering Tips and Tricks in 45 minutes (maybe more :)
") Clustering Tips and Tricks in 45 minutes (maybe more :) Olfa Nasraoui, University of Louisville Tutorial for the Data Science for Social Good Fellowship 2015 cohort @DSSG2015@University of Chicago https://www.researchgate.net/profile/olfa_nasraoui
Clustering Tips and Tricks in 45 minutes (maybe more :) Olfa Nasraoui, University of Louisville Tutorial for the Data Science for Social Good Fellowship 2015 cohort @DSSG2015@University of Chicago https://www.researchgate.net/profile/olfa_nasraoui