Automating Real-time Seismic Analysis
|
|
|
- Jeremy Davis
- 6 years ago
- Views:
Transcription

1 Automating Real-time Seismic Analysis Through Streaming and High Throughput Workflows Rafael Ferreira da Silva, Ph.D.




2 Do we need seismic analysis? Pegasus 2
")

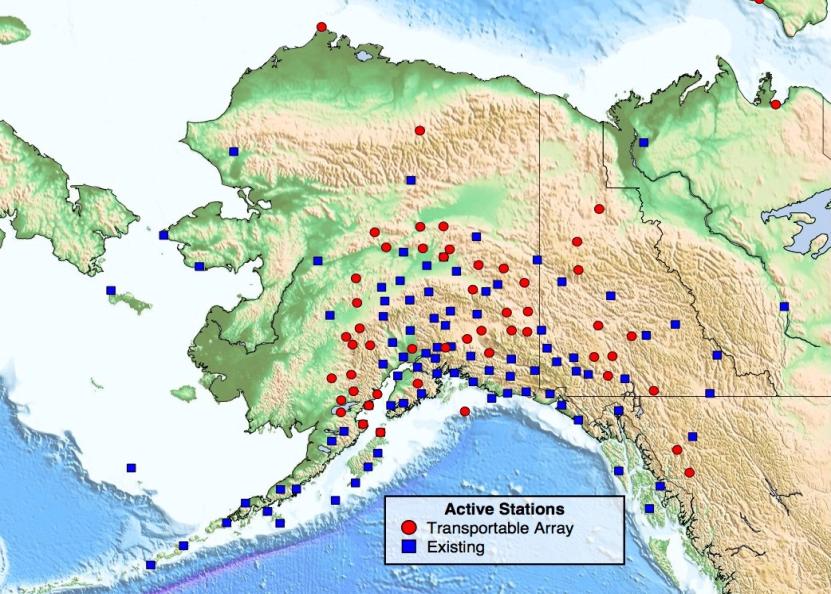
3 USArray A continental-scale Seismic Observatory US Array TA (IRIS Service) 836 stations 394 stations have online data available Pegasus 3



4 The development of reliable risk assessment methods for these hazards requires real-time analysis of seismic data Pegasus 4
5 So, how to efficiently process these data? Pegasus 5








6 Experiment Timeline Scientific Problem Earth Science, Astronomy, Neuroinformatics, Bioinformatics, etc. Computational Scripts Shell scripts, Python, Matlab, etc. Distributed Computing Clusters, HPC, Cloud, Grid, etc. Scientific Result Models, Quality Control, Image Analysis, etc. Analytical Solution Automation Workflows, MapReduce, etc. Monitoring and Debug Fault-tolerance, Provenance, etc. Pegasus 6

7 What is involved in an experiment execution? Pegasus 7

8 Why Scientific Workflows? Automates complex, multi-stage processing pipelines Automate Enables parallel, distributed computations Automatically executes data transfers Reusable, aids reproducibility Recover Records how data was produced (provenance) Handles failures with to provide reliability Keeps track of data and files Debug Pegasus 8
9 Taking a closer look into a workflow DAG directed-acyclic graphs abstract workflow executable workflow optimizations storage constraints job Command-line programs split merge dependency Usually data dependencies pipeline Pegasus 9
10 From the abstraction to execution! stage-in job Transfers the workflow input data abstract workflow executable workflow optimizations storage constraints stage-out job Transfers the workflow output data registration job Registers the workflow output data Pegasus 10
11 Optimizing storage usage abstract workflow executable workflow optimizations storage constraints cleanup job Removes unused data Pegasus 11
 firstjob.uses(firstinputfile, link=link.input) firstjob.uses(firstoutputfile, link=link.output) dax.")
) simuljob.uses(simulinputfile, link=link.input) simuljob.uses(simuloutputfile, line=link.output) dax.")
12 Workflow systems provide tools to generate the abstract workflow dax = ADAG("test_dax") firstjob = Job(name="first_job") firstinputfile = File("input.txt") firstoutputfile = File("tmp.txt") firstjob.addargument("input=input.txt", "output=tmp.txt") firstjob.uses(firstinputfile, link=link.input) firstjob.uses(firstoutputfile, link=link.output) dax.addjob(firstjob) for i in range(0, 5): simuljob = Job(id="%s" % (i+1), name="simul_job ) simulinputfile = File("tmp.txt ) simuloutputfile = File("output.%d.dat" % i) simuljob.addargument("parameter=%d" % i, "input=tmp.txt, output=%s" % simuloutputfile.getname()) simuljob.uses(simulinputfile, link=link.input) simuljob.uses(simuloutputfile, line=link.output) dax.addjob(simuljob) dax.depends(parent=firstjob, child=simuljob) fp = open("test.dax", "w ) dax.writexml(fp) fp.close() abstract workflow Pegasus 12








13 Nimrod Pegasus Which Workflow Management System? Pegasus 13
14 and which model to use? task-oriented stream-based files data transfers via files streams data transfers via memory or message parallelism no concurrency concurrency tasks run concurrently heterogeneous execution tasks can run in heterogeneous resources homogeneous execution tasks should run in homogeneous resources Pegasus 14

15 What does Pegasus provide? Automation Automates pipeline executions Parallel, distributed computations Automatically executes data transfers Heterogeneous resources Task-oriented model Application is seen as a black box Debug Workflow execution and job performance metrics Set of debugging tools to unveil issues Real-time monitoring, graphs, provenance Recovery Job failure detection Checkpoint Files Job Retry Rescue DAGs Optimization Job clustering Data cleanup Pegasus 15
16 and dispel4py? Automation Automates pipeline executions Concurrent, distributed computations Stream-based model Workflow Composition Python Library Grouping (all-to-all, all-to-one, one-to-all) Mapping Sequential Multiprocessing (shared memory) Distributed memory, message passing (MPI) Distributed Real-time (Apache Storm) Apache Spark (Prototype) Optimization Multiple streams (in/out) Avoids I/O (shared memory or message passing) Pegasus 16
17 Pegasus ASTERISM sub-workflow dispel4py workflow Asterism greatly simplifies the effort required to develop data-intensive applications that run across multiple heterogeneous resources distributed in the wide area Pegasus 17
18 Where to run scientific workflows? Pegasus 18
19 High Performance Computing There are several possible configurations shared filesystem Workflow Engine submit host (e.g., user s laptop) typically most HPC sites Pegasus 19
20 Cloud Computing High-scalable object storages object storage Workflow Engine submit host (e.g., user s laptop) Typical cloud computing deployment (Amazon S3, Google Storage) Pegasus 20
21 Grid Computing local data management Workflow Engine Typical OSG sites Open Science Grid submit host (e.g., user s laptop) Pegasus 21
22 And yes you can mix everything! shared filesystem Compute site A Workflow Engine Compute site B submit host (e.g., user s laptop) Pegasus object storage 22


23 How do we use Asterism to automate seismic analysis? Pegasus 23

 Phase 1: data preparation using")
 Phase 2: compute correlation, identifying the")

24 WORKFLOW Seismic Ambient Noise Cross-Correlation Preprocesses and cross-correlates traces (sequences of measurements of acceleration in three dimensions) from multiple seismic stations (IRIS database) Phase 1: data preparation using statistics for extracting information from the noise Phase 1 (pre-process) Phase 2: compute correlation, identifying the time for signals to travel between stations. Infers properties of the intervening rock Phase 2 (cross-correlation) Pegasus 24




25 Seismic Ambient Noise Cross-Correlation Distributed computation framework for event stream processing Designed for massive scalability, supports faulttolerance with a fail fast, auto restart approach to processes Rich array of available spouts specialized for receiving data from all types of sources spout bolt Hadoop of real-time processing, very scalable Pegasus 25
 Compute site B (Apache Storm) output data (~40GB) Pegasus http://pegasus.isi.")
26 Seismic workflow execution input data (~150MB) Compute site A (MPI-based) IRIS database (stations) Phase 1 data transfers between sites performed by Pegasus Phase 2 submit host (e.g., user s laptop) Compute site B (Apache Storm) output data (~40GB) Pegasus 26


27 Southern California Earthquake Center s CyberShake W ORKFLO W Builders ask seismologists: What will the peak ground motion be at my new building in the next 50 years? Seismologists answer this question using Probabilistic Seismic Hazard Analysis (PSHA) 286 sites, 4 models each workflow has 420,000 tasks Pegasus 27
28 A few more workflow features Pegasus 28
29 Performance, why not improve it? workflow restructuring workflow reduction hierarchical workflows pegasus-mpi-cluster clustered job Groups small jobs together to improve performance task small granularity Pegasus 29

30 What about data reuse? workflow restructuring workflow reduction data already available data reuse hierarchical workflows pegasus-mpi-cluster data also available workflow reduction data reuse Jobs which output data is already available are pruned from the DAG Pegasus 30
31 Handling large-scale workflows workflow restructuring workflow reduction hierarchical workflows pegasus-mpi-cluster sub-workflow sub-workflow recursion ends when workflow with only compute jobs is encountered 31
32 Running fine-grained workflows on HPC systems workflow restructuring workflow reduction hierarchical workflows pegasus-mpi-cluster submit host (e.g., user s laptop) HPC System workflow wrapped as an MPI job Allows sub-graphs of a Pegasus workflow to be submitted as monolithic jobs to remote resources Pegasus 32

33 Pegasus Automate, recover, and debug scientific computations. Pegasus Website Get Started Users Mailing List Support HipChat




34 Automating Real-time Seismic Analysis Through Streaming and High Throughput Workflows Thank You Questions? Rafael Ferreira da Silva, Ph.D. Ewa Deelman Rafael Ferreira da Silva Karan Vahi Mats Rynge Rajiv Mayani
Pegasus. Automate, recover, and debug scientific computations. Rafael Ferreira da Silva.
 Pegasus Automate, recover, and debug scientific computations. Rafael Ferreira da Silva http://pegasus.isi.edu Experiment Timeline Scientific Problem Earth Science, Astronomy, Neuroinformatics, Bioinformatics,
Pegasus Automate, recover, and debug scientific computations. Rafael Ferreira da Silva http://pegasus.isi.edu Experiment Timeline Scientific Problem Earth Science, Astronomy, Neuroinformatics, Bioinformatics,
Pegasus. Automate, recover, and debug scientific computations. Mats Rynge
 Pegasus Automate, recover, and debug scientific computations. Mats Rynge rynge@isi.edu https://pegasus.isi.edu Why Pegasus? Automates complex, multi-stage processing pipelines Automate Enables parallel,
Pegasus Automate, recover, and debug scientific computations. Mats Rynge rynge@isi.edu https://pegasus.isi.edu Why Pegasus? Automates complex, multi-stage processing pipelines Automate Enables parallel,
Pegasus. Pegasus Workflow Management System. Mats Rynge
 Pegasus Pegasus Workflow Management System Mats Rynge rynge@isi.edu https://pegasus.isi.edu Automate Why workflows? Recover Automates complex, multi-stage processing pipelines Enables parallel, distributed
Pegasus Pegasus Workflow Management System Mats Rynge rynge@isi.edu https://pegasus.isi.edu Automate Why workflows? Recover Automates complex, multi-stage processing pipelines Enables parallel, distributed
Pegasus. Automate, recover, and debug scientific computations. Mats Rynge https://pegasus.isi.edu
 Pegasus Automate, recover, and debug scientific computations. Mats Rynge rynge@isi.edu https://pegasus.isi.edu Why Pegasus? Automates complex, multi-stage processing pipelines Automate Enables parallel,
Pegasus Automate, recover, and debug scientific computations. Mats Rynge rynge@isi.edu https://pegasus.isi.edu Why Pegasus? Automates complex, multi-stage processing pipelines Automate Enables parallel,
Pegasus Workflow Management System. Gideon Juve. USC Informa3on Sciences Ins3tute
 Pegasus Workflow Management System Gideon Juve USC Informa3on Sciences Ins3tute Scientific Workflows Orchestrate complex, multi-stage scientific computations Often expressed as directed acyclic graphs
Pegasus Workflow Management System Gideon Juve USC Informa3on Sciences Ins3tute Scientific Workflows Orchestrate complex, multi-stage scientific computations Often expressed as directed acyclic graphs
Managing large-scale workflows with Pegasus
 Funded by the National Science Foundation under the OCI SDCI program, grant #0722019 Managing large-scale workflows with Pegasus Karan Vahi ( vahi@isi.edu) Collaborative Computing Group USC Information
Funded by the National Science Foundation under the OCI SDCI program, grant #0722019 Managing large-scale workflows with Pegasus Karan Vahi ( vahi@isi.edu) Collaborative Computing Group USC Information
A Cloud-based Dynamic Workflow for Mass Spectrometry Data Analysis
 A Cloud-based Dynamic Workflow for Mass Spectrometry Data Analysis Ashish Nagavaram, Gagan Agrawal, Michael A. Freitas, Kelly H. Telu The Ohio State University Gaurang Mehta, Rajiv. G. Mayani, Ewa Deelman
A Cloud-based Dynamic Workflow for Mass Spectrometry Data Analysis Ashish Nagavaram, Gagan Agrawal, Michael A. Freitas, Kelly H. Telu The Ohio State University Gaurang Mehta, Rajiv. G. Mayani, Ewa Deelman
Complex Workloads on HUBzero Pegasus Workflow Management System
 Complex Workloads on HUBzero Pegasus Workflow Management System Karan Vahi Science Automa1on Technologies Group USC Informa1on Sciences Ins1tute HubZero A valuable platform for scientific researchers For
Complex Workloads on HUBzero Pegasus Workflow Management System Karan Vahi Science Automa1on Technologies Group USC Informa1on Sciences Ins1tute HubZero A valuable platform for scientific researchers For
Pegasus WMS Automated Data Management in Shared and Nonshared Environments
 Pegasus WMS Automated Data Management in Shared and Nonshared Environments Mats Rynge USC Information Sciences Institute Pegasus Workflow Management System NSF funded project and developed
Pegasus WMS Automated Data Management in Shared and Nonshared Environments Mats Rynge USC Information Sciences Institute Pegasus Workflow Management System NSF funded project and developed
End-to-End Online Performance Data Capture and Analysis of Scientific Workflows
 End-to-End Online Performance Data Capture and Analysis of Scientific Workflows G. Papadimitriou, C. Wang, K. Vahi, R. Ferreira da Silva, A. Mandal, Z. Liu, R. Mayani, M. Rynge, M. Kiran, V. Lynch, R.
End-to-End Online Performance Data Capture and Analysis of Scientific Workflows G. Papadimitriou, C. Wang, K. Vahi, R. Ferreira da Silva, A. Mandal, Z. Liu, R. Mayani, M. Rynge, M. Kiran, V. Lynch, R.
On the Use of Burst Buffers for Accelerating Data-Intensive Scientific Workflows
 On the Use of Burst Buffers for Accelerating Data-Intensive Scientific Workflows Rafael Ferreira da Silva, Scott Callaghan, Ewa Deelman 12 th Workflows in Support of Large-Scale Science (WORKS) SuperComputing
On the Use of Burst Buffers for Accelerating Data-Intensive Scientific Workflows Rafael Ferreira da Silva, Scott Callaghan, Ewa Deelman 12 th Workflows in Support of Large-Scale Science (WORKS) SuperComputing
Frank McKenna. Pacific Earthquake Engineering Research Center
 Frank McKenna Pacific Earthquake Engineering Research Center Example from Prac.ce: The Design Process! 1. Identify or Revise Criteria 2. Generate Trial Design 6. Refine Design Structural Design 3. Develop
Frank McKenna Pacific Earthquake Engineering Research Center Example from Prac.ce: The Design Process! 1. Identify or Revise Criteria 2. Generate Trial Design 6. Refine Design Structural Design 3. Develop
Enabling Large-scale Scientific Workflows on Petascale Resources Using MPI Master/Worker
 Enabling Large-scale Scientific Workflows on Petascale Resources Using MPI Master/Worker Mats Rynge 1 rynge@isi.edu Gideon Juve 1 gideon@isi.edu Karan Vahi 1 vahi@isi.edu Scott Callaghan 2 scottcal@usc.edu
Enabling Large-scale Scientific Workflows on Petascale Resources Using MPI Master/Worker Mats Rynge 1 rynge@isi.edu Gideon Juve 1 gideon@isi.edu Karan Vahi 1 vahi@isi.edu Scott Callaghan 2 scottcal@usc.edu
A Cleanup Algorithm for Implementing Storage Constraints in Scientific Workflow Executions
 2014 9th Workshop on Workflows in Support of Large-Scale Science A Cleanup Algorithm for Implementing Storage Constraints in Scientific Workflow Executions Sudarshan Srinivasan Department of Computer Science
2014 9th Workshop on Workflows in Support of Large-Scale Science A Cleanup Algorithm for Implementing Storage Constraints in Scientific Workflow Executions Sudarshan Srinivasan Department of Computer Science
Part IV. Workflow Mapping and Execution in Pegasus. (Thanks to Ewa Deelman)
") AAAI-08 Tutorial on Computational Workflows for Large-Scale Artificial Intelligence Research Part IV Workflow Mapping and Execution in Pegasus (Thanks to Ewa Deelman) 1 Pegasus-Workflow Management System
AAAI-08 Tutorial on Computational Workflows for Large-Scale Artificial Intelligence Research Part IV Workflow Mapping and Execution in Pegasus (Thanks to Ewa Deelman) 1 Pegasus-Workflow Management System
An exceedingly high-level overview of ambient noise processing with Spark and Hadoop
 IRIS: USArray Short Course in Bloomington, Indian Special focus: Oklahoma Wavefields An exceedingly high-level overview of ambient noise processing with Spark and Hadoop Presented by Rob Mellors but based
IRIS: USArray Short Course in Bloomington, Indian Special focus: Oklahoma Wavefields An exceedingly high-level overview of ambient noise processing with Spark and Hadoop Presented by Rob Mellors but based
Data Analytics with HPC. Data Streaming
 Data Analytics with HPC Data Streaming Reusing this material This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike 4.0 International License. http://creativecommons.org/licenses/by-nc-sa/4.0/deed.en_us
Data Analytics with HPC Data Streaming Reusing this material This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike 4.0 International License. http://creativecommons.org/licenses/by-nc-sa/4.0/deed.en_us
Reduction of Workflow Resource Consumption Using a Density-based Clustering Model
 Reduction of Workflow Resource Consumption Using a Density-based Clustering Model Qimin Zhang, Nathaniel Kremer-Herman, Benjamin Tovar, and Douglas Thain WORKS Workshop at Supercomputing 2018 The Cooperative
Reduction of Workflow Resource Consumption Using a Density-based Clustering Model Qimin Zhang, Nathaniel Kremer-Herman, Benjamin Tovar, and Douglas Thain WORKS Workshop at Supercomputing 2018 The Cooperative
Introduction to MapReduce (cont.)
") Introduction to MapReduce (cont.) Rafael Ferreira da Silva rafsilva@isi.edu http://rafaelsilva.com USC INF 553 Foundations and Applications of Data Mining (Fall 2018) 2 MapReduce: Summary USC INF 553 Foundations
Introduction to MapReduce (cont.) Rafael Ferreira da Silva rafsilva@isi.edu http://rafaelsilva.com USC INF 553 Foundations and Applications of Data Mining (Fall 2018) 2 MapReduce: Summary USC INF 553 Foundations
Data Intensive processing with irods and the middleware CiGri for the Whisper project Xavier Briand
 and the middleware CiGri for the Whisper project Use Case of Data-Intensive processing with irods Collaboration between: IT part of Whisper: Sofware development, computation () Platform Ciment: IT infrastructure
and the middleware CiGri for the Whisper project Use Case of Data-Intensive processing with irods Collaboration between: IT part of Whisper: Sofware development, computation () Platform Ciment: IT infrastructure
MapReduce: Simplified Data Processing on Large Clusters 유연일민철기
 MapReduce: Simplified Data Processing on Large Clusters 유연일민철기 Introduction MapReduce is a programming model and an associated implementation for processing and generating large data set with parallel,
MapReduce: Simplified Data Processing on Large Clusters 유연일민철기 Introduction MapReduce is a programming model and an associated implementation for processing and generating large data set with parallel,
Clouds: An Opportunity for Scientific Applications?
 Clouds: An Opportunity for Scientific Applications? Ewa Deelman USC Information Sciences Institute Acknowledgements Yang-Suk Ki (former PostDoc, USC) Gurmeet Singh (former Ph.D. student, USC) Gideon Juve
Clouds: An Opportunity for Scientific Applications? Ewa Deelman USC Information Sciences Institute Acknowledgements Yang-Suk Ki (former PostDoc, USC) Gurmeet Singh (former Ph.D. student, USC) Gideon Juve
Hadoop 2.x Core: YARN, Tez, and Spark. Hortonworks Inc All Rights Reserved
 Hadoop 2.x Core: YARN, Tez, and Spark YARN Hadoop Machine Types top-of-rack switches core switch client machines have client-side software used to access a cluster to process data master nodes run Hadoop
Hadoop 2.x Core: YARN, Tez, and Spark YARN Hadoop Machine Types top-of-rack switches core switch client machines have client-side software used to access a cluster to process data master nodes run Hadoop
Chapter 5. The MapReduce Programming Model and Implementation
 Chapter 5. The MapReduce Programming Model and Implementation - Traditional computing: data-to-computing (send data to computing) * Data stored in separate repository * Data brought into system for computing
Chapter 5. The MapReduce Programming Model and Implementation - Traditional computing: data-to-computing (send data to computing) * Data stored in separate repository * Data brought into system for computing
Putting it together. Data-Parallel Computation. Ex: Word count using partial aggregation. Big Data Processing. COS 418: Distributed Systems Lecture 21
 Big Processing -Parallel Computation COS 418: Distributed Systems Lecture 21 Michael Freedman 2 Ex: Word count using partial aggregation Putting it together 1. Compute word counts from individual files
Big Processing -Parallel Computation COS 418: Distributed Systems Lecture 21 Michael Freedman 2 Ex: Word count using partial aggregation Putting it together 1. Compute word counts from individual files
Cloud Computing and Hadoop Distributed File System. UCSB CS170, Spring 2018
 Cloud Computing and Hadoop Distributed File System UCSB CS70, Spring 08 Cluster Computing Motivations Large-scale data processing on clusters Scan 000 TB on node @ 00 MB/s = days Scan on 000-node cluster
Cloud Computing and Hadoop Distributed File System UCSB CS70, Spring 08 Cluster Computing Motivations Large-scale data processing on clusters Scan 000 TB on node @ 00 MB/s = days Scan on 000-node cluster
A characterization of workflow management systems for extreme-scale applications
 Accepted Manuscript A characterization of workflow management systems for extreme-scale applications Rafael Ferreira da Silva, Rosa Filgueira, Ilia Pietri, Ming Jiang, Rizos Sakellariou, Ewa Deelman PII:
Accepted Manuscript A characterization of workflow management systems for extreme-scale applications Rafael Ferreira da Silva, Rosa Filgueira, Ilia Pietri, Ming Jiang, Rizos Sakellariou, Ewa Deelman PII:
Lecture 11 Hadoop & Spark
 Lecture 11 Hadoop & Spark Dr. Wilson Rivera ICOM 6025: High Performance Computing Electrical and Computer Engineering Department University of Puerto Rico Outline Distributed File Systems Hadoop Ecosystem
Lecture 11 Hadoop & Spark Dr. Wilson Rivera ICOM 6025: High Performance Computing Electrical and Computer Engineering Department University of Puerto Rico Outline Distributed File Systems Hadoop Ecosystem
MOHA: Many-Task Computing Framework on Hadoop
 Apache: Big Data North America 2017 @ Miami MOHA: Many-Task Computing Framework on Hadoop Soonwook Hwang Korea Institute of Science and Technology Information May 18, 2017 Table of Contents Introduction
Apache: Big Data North America 2017 @ Miami MOHA: Many-Task Computing Framework on Hadoop Soonwook Hwang Korea Institute of Science and Technology Information May 18, 2017 Table of Contents Introduction
The VERCE Architecture for Data-Intensive Seismology
 The VERCE Architecture for Data-Intensive Seismology Iraklis A. Klampanos iraklis.klampanos@ed.ac.uk 1 http://www.verce.eu Overall Objectives VERCE: Virtual Earthquake and Seismology Research Community
The VERCE Architecture for Data-Intensive Seismology Iraklis A. Klampanos iraklis.klampanos@ed.ac.uk 1 http://www.verce.eu Overall Objectives VERCE: Virtual Earthquake and Seismology Research Community
EFFICIENT ALLOCATION OF DYNAMIC RESOURCES IN A CLOUD
 EFFICIENT ALLOCATION OF DYNAMIC RESOURCES IN A CLOUD S.THIRUNAVUKKARASU 1, DR.K.P.KALIYAMURTHIE 2 Assistant Professor, Dept of IT, Bharath University, Chennai-73 1 Professor& Head, Dept of IT, Bharath
EFFICIENT ALLOCATION OF DYNAMIC RESOURCES IN A CLOUD S.THIRUNAVUKKARASU 1, DR.K.P.KALIYAMURTHIE 2 Assistant Professor, Dept of IT, Bharath University, Chennai-73 1 Professor& Head, Dept of IT, Bharath
Data Clustering on the Parallel Hadoop MapReduce Model. Dimitrios Verraros
 Data Clustering on the Parallel Hadoop MapReduce Model Dimitrios Verraros Overview The purpose of this thesis is to implement and benchmark the performance of a parallel K- means clustering algorithm on
Data Clustering on the Parallel Hadoop MapReduce Model Dimitrios Verraros Overview The purpose of this thesis is to implement and benchmark the performance of a parallel K- means clustering algorithm on
Lambda Architecture for Batch and Real- Time Processing on AWS with Spark Streaming and Spark SQL. May 2015
 Lambda Architecture for Batch and Real- Time Processing on AWS with Spark Streaming and Spark SQL May 2015 2015, Amazon Web Services, Inc. or its affiliates. All rights reserved. Notices This document
Lambda Architecture for Batch and Real- Time Processing on AWS with Spark Streaming and Spark SQL May 2015 2015, Amazon Web Services, Inc. or its affiliates. All rights reserved. Notices This document
CloudBATCH: A Batch Job Queuing System on Clouds with Hadoop and HBase. Chen Zhang Hans De Sterck University of Waterloo
 CloudBATCH: A Batch Job Queuing System on Clouds with Hadoop and HBase Chen Zhang Hans De Sterck University of Waterloo Outline Introduction Motivation Related Work System Design Future Work Introduction
CloudBATCH: A Batch Job Queuing System on Clouds with Hadoop and HBase Chen Zhang Hans De Sterck University of Waterloo Outline Introduction Motivation Related Work System Design Future Work Introduction
Streaming data Model is opposite Queries are usually fixed and data are flows through the system.
 1 2 3 Main difference is: Static Data Model (For related database or Hadoop) Data is stored, and we just send some query. Streaming data Model is opposite Queries are usually fixed and data are flows through
1 2 3 Main difference is: Static Data Model (For related database or Hadoop) Data is stored, and we just send some query. Streaming data Model is opposite Queries are usually fixed and data are flows through
STORM AND LOW-LATENCY PROCESSING.
 STORM AND LOW-LATENCY PROCESSING Low latency processing Similar to data stream processing, but with a twist Data is streaming into the system (from a database, or a netk stream, or an HDFS file, or ) We
STORM AND LOW-LATENCY PROCESSING Low latency processing Similar to data stream processing, but with a twist Data is streaming into the system (from a database, or a netk stream, or an HDFS file, or ) We
Write a technical report Present your results Write a workshop/conference paper (optional) Could be a real system, simulation and/or theoretical
 Could be a real system, simulation and/or theoretical") Identify a problem Review approaches to the problem Propose a novel approach to the problem Define, design, prototype an implementation to evaluate your approach Could be a real system, simulation and/or
Identify a problem Review approaches to the problem Propose a novel approach to the problem Define, design, prototype an implementation to evaluate your approach Could be a real system, simulation and/or
Dac-Man: Data Change Management for Scientific Datasets on HPC systems
 Dac-Man: Data Change Management for Scientific Datasets on HPC systems Devarshi Ghoshal Lavanya Ramakrishnan Deborah Agarwal Lawrence Berkeley National Laboratory Email: dghoshal@lbl.gov Motivation Data
Dac-Man: Data Change Management for Scientific Datasets on HPC systems Devarshi Ghoshal Lavanya Ramakrishnan Deborah Agarwal Lawrence Berkeley National Laboratory Email: dghoshal@lbl.gov Motivation Data
A Distributed Data- Parallel Execu3on Framework in the Kepler Scien3fic Workflow System
 A Distributed Data- Parallel Execu3on Framework in the Kepler Scien3fic Workflow System Ilkay Al(ntas and Daniel Crawl San Diego Supercomputer Center UC San Diego Jianwu Wang UMBC WorDS.sdsc.edu Computa3onal
A Distributed Data- Parallel Execu3on Framework in the Kepler Scien3fic Workflow System Ilkay Al(ntas and Daniel Crawl San Diego Supercomputer Center UC San Diego Jianwu Wang UMBC WorDS.sdsc.edu Computa3onal
10 years of CyberShake: Where are we now and where are we going
 10 years of CyberShake: Where are we now and where are we going with physics based PSHA? Scott Callaghan, Robert W. Graves, Kim B. Olsen, Yifeng Cui, Kevin R. Milner, Christine A. Goulet, Philip J. Maechling,
10 years of CyberShake: Where are we now and where are we going with physics based PSHA? Scott Callaghan, Robert W. Graves, Kim B. Olsen, Yifeng Cui, Kevin R. Milner, Christine A. Goulet, Philip J. Maechling,
Cloud Computing 3. CSCI 4850/5850 High-Performance Computing Spring 2018
 Cloud Computing 3 CSCI 4850/5850 High-Performance Computing Spring 2018 Tae-Hyuk (Ted) Ahn Department of Computer Science Program of Bioinformatics and Computational Biology Saint Louis University Learning
Cloud Computing 3 CSCI 4850/5850 High-Performance Computing Spring 2018 Tae-Hyuk (Ted) Ahn Department of Computer Science Program of Bioinformatics and Computational Biology Saint Louis University Learning
Apache Hadoop 3. Balazs Gaspar Sales Engineer CEE & CIS Cloudera, Inc. All rights reserved.
 Apache Hadoop 3 Balazs Gaspar Sales Engineer CEE & CIS balazs@cloudera.com 1 We believe data can make what is impossible today, possible tomorrow 2 We empower people to transform complex data into clear
Apache Hadoop 3 Balazs Gaspar Sales Engineer CEE & CIS balazs@cloudera.com 1 We believe data can make what is impossible today, possible tomorrow 2 We empower people to transform complex data into clear
Spark, Shark and Spark Streaming Introduction
 Spark, Shark and Spark Streaming Introduction Tushar Kale tusharkale@in.ibm.com June 2015 This Talk Introduction to Shark, Spark and Spark Streaming Architecture Deployment Methodology Performance References
Spark, Shark and Spark Streaming Introduction Tushar Kale tusharkale@in.ibm.com June 2015 This Talk Introduction to Shark, Spark and Spark Streaming Architecture Deployment Methodology Performance References
High Performance Data Analytics for Numerical Simulations. Bruno Raffin DataMove
 High Performance Data Analytics for Numerical Simulations Bruno Raffin DataMove bruno.raffin@inria.fr April 2016 About this Talk HPC for analyzing the results of large scale parallel numerical simulations
High Performance Data Analytics for Numerical Simulations Bruno Raffin DataMove bruno.raffin@inria.fr April 2016 About this Talk HPC for analyzing the results of large scale parallel numerical simulations
The Fusion Distributed File System
 Slide 1 / 44 The Fusion Distributed File System Dongfang Zhao February 2015 Slide 2 / 44 Outline Introduction FusionFS System Architecture Metadata Management Data Movement Implementation Details Unique
Slide 1 / 44 The Fusion Distributed File System Dongfang Zhao February 2015 Slide 2 / 44 Outline Introduction FusionFS System Architecture Metadata Management Data Movement Implementation Details Unique
HiTune. Dataflow-Based Performance Analysis for Big Data Cloud
 HiTune Dataflow-Based Performance Analysis for Big Data Cloud Jinquan (Jason) Dai, Jie Huang, Shengsheng Huang, Bo Huang, Yan Liu Intel Asia-Pacific Research and Development Ltd Shanghai, China, 200241
HiTune Dataflow-Based Performance Analysis for Big Data Cloud Jinquan (Jason) Dai, Jie Huang, Shengsheng Huang, Bo Huang, Yan Liu Intel Asia-Pacific Research and Development Ltd Shanghai, China, 200241
Cloud Computing 2. CSCI 4850/5850 High-Performance Computing Spring 2018
 Cloud Computing 2 CSCI 4850/5850 High-Performance Computing Spring 2018 Tae-Hyuk (Ted) Ahn Department of Computer Science Program of Bioinformatics and Computational Biology Saint Louis University Learning
Cloud Computing 2 CSCI 4850/5850 High-Performance Computing Spring 2018 Tae-Hyuk (Ted) Ahn Department of Computer Science Program of Bioinformatics and Computational Biology Saint Louis University Learning
BIG DATA. Using the Lambda Architecture on a Big Data Platform to Improve Mobile Campaign Management. Author: Sandesh Deshmane
 BIG DATA Using the Lambda Architecture on a Big Data Platform to Improve Mobile Campaign Management Author: Sandesh Deshmane Executive Summary Growing data volumes and real time decision making requirements
BIG DATA Using the Lambda Architecture on a Big Data Platform to Improve Mobile Campaign Management Author: Sandesh Deshmane Executive Summary Growing data volumes and real time decision making requirements
Cloud Computing & Visualization
 Cloud Computing & Visualization Workflows Distributed Computation with Spark Data Warehousing with Redshift Visualization with Tableau #FIUSCIS School of Computing & Information Sciences, Florida International
Cloud Computing & Visualization Workflows Distributed Computation with Spark Data Warehousing with Redshift Visualization with Tableau #FIUSCIS School of Computing & Information Sciences, Florida International
Corral: A Glide-in Based Service for Resource Provisioning
 : A Glide-in Based Service for Resource Provisioning Gideon Juve USC Information Sciences Institute juve@usc.edu Outline Throughput Applications Grid Computing Multi-level scheduling and Glideins Example:
: A Glide-in Based Service for Resource Provisioning Gideon Juve USC Information Sciences Institute juve@usc.edu Outline Throughput Applications Grid Computing Multi-level scheduling and Glideins Example:
MapReduce for Data Intensive Scientific Analyses
 apreduce for Data Intensive Scientific Analyses Jaliya Ekanayake Shrideep Pallickara Geoffrey Fox Department of Computer Science Indiana University Bloomington, IN, 47405 5/11/2009 Jaliya Ekanayake 1 Presentation
apreduce for Data Intensive Scientific Analyses Jaliya Ekanayake Shrideep Pallickara Geoffrey Fox Department of Computer Science Indiana University Bloomington, IN, 47405 5/11/2009 Jaliya Ekanayake 1 Presentation
CSE6331: Cloud Computing
 CSE6331: Cloud Computing Leonidas Fegaras University of Texas at Arlington c 2019 by Leonidas Fegaras Cloud Computing Fundamentals Based on: J. Freire s class notes on Big Data http://vgc.poly.edu/~juliana/courses/bigdata2016/
CSE6331: Cloud Computing Leonidas Fegaras University of Texas at Arlington c 2019 by Leonidas Fegaras Cloud Computing Fundamentals Based on: J. Freire s class notes on Big Data http://vgc.poly.edu/~juliana/courses/bigdata2016/
Analytics in the cloud
 Analytics in the cloud Dow we really need to reinvent the storage stack? R. Ananthanarayanan, Karan Gupta, Prashant Pandey, Himabindu Pucha, Prasenjit Sarkar, Mansi Shah, Renu Tewari Image courtesy NASA
Analytics in the cloud Dow we really need to reinvent the storage stack? R. Ananthanarayanan, Karan Gupta, Prashant Pandey, Himabindu Pucha, Prasenjit Sarkar, Mansi Shah, Renu Tewari Image courtesy NASA
Cloud Computing Paradigms for Pleasingly Parallel Biomedical Applications
 Cloud Computing Paradigms for Pleasingly Parallel Biomedical Applications Thilina Gunarathne, Tak-Lon Wu Judy Qiu, Geoffrey Fox School of Informatics, Pervasive Technology Institute Indiana University
Cloud Computing Paradigms for Pleasingly Parallel Biomedical Applications Thilina Gunarathne, Tak-Lon Wu Judy Qiu, Geoffrey Fox School of Informatics, Pervasive Technology Institute Indiana University
CSE 444: Database Internals. Lecture 23 Spark
 CSE 444: Database Internals Lecture 23 Spark References Spark is an open source system from Berkeley Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster Computing. Matei
CSE 444: Database Internals Lecture 23 Spark References Spark is an open source system from Berkeley Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster Computing. Matei
A Parallel R Framework
 A Parallel R Framework for Processing Large Dataset on Distributed Systems Nov. 17, 2013 This work is initiated and supported by Huawei Technologies Rise of Data-Intensive Analytics Data Sources Personal
A Parallel R Framework for Processing Large Dataset on Distributed Systems Nov. 17, 2013 This work is initiated and supported by Huawei Technologies Rise of Data-Intensive Analytics Data Sources Personal
Efficient Dynamic Resource Allocation Using Nephele in a Cloud Environment
 International Journal of Scientific & Engineering Research Volume 3, Issue 8, August-2012 1 Efficient Dynamic Resource Allocation Using Nephele in a Cloud Environment VPraveenkumar, DrSSujatha, RChinnasamy
International Journal of Scientific & Engineering Research Volume 3, Issue 8, August-2012 1 Efficient Dynamic Resource Allocation Using Nephele in a Cloud Environment VPraveenkumar, DrSSujatha, RChinnasamy
Introduction & Motivation Problem Statement Proposed Work Evaluation Conclusions Future Work
 Introduction & Motivation Problem Statement Proposed Work Evaluation Conclusions Future Work Introduction & Motivation Problem Statement Proposed Work Evaluation Conclusions Future Work Today (2014):
Introduction & Motivation Problem Statement Proposed Work Evaluation Conclusions Future Work Introduction & Motivation Problem Statement Proposed Work Evaluation Conclusions Future Work Today (2014):
Building a Data-Friendly Platform for a Data- Driven Future
 Building a Data-Friendly Platform for a Data- Driven Future Benjamin Hindman - @benh 2016 Mesosphere, Inc. All Rights Reserved. INTRO $ whoami BENJAMIN HINDMAN Co-founder and Chief Architect of Mesosphere,
Building a Data-Friendly Platform for a Data- Driven Future Benjamin Hindman - @benh 2016 Mesosphere, Inc. All Rights Reserved. INTRO $ whoami BENJAMIN HINDMAN Co-founder and Chief Architect of Mesosphere,
Using Imbalance Metrics to Optimize Task Clustering in Scientific Workflow Executions
 Using Imbalance Metrics to Optimize Task Clustering in Scientific Workflow Executions Weiwei Chen a,, Rafael Ferreira da Silva a, Ewa Deelman a, Rizos Sakellariou b a University of Southern California,
Using Imbalance Metrics to Optimize Task Clustering in Scientific Workflow Executions Weiwei Chen a,, Rafael Ferreira da Silva a, Ewa Deelman a, Rizos Sakellariou b a University of Southern California,
Scheduling distributed applications can be challenging in a multi-cloud environment due to the lack of knowledge
 ISSN: 0975-766X CODEN: IJPTFI Available Online through Research Article www.ijptonline.com CHARACTERIZATION AND PROFILING OFSCIENTIFIC WORKFLOWS Sangeeth S, Srikireddy Sai Kiran Reddy, Viswanathan M*,
ISSN: 0975-766X CODEN: IJPTFI Available Online through Research Article www.ijptonline.com CHARACTERIZATION AND PROFILING OFSCIENTIFIC WORKFLOWS Sangeeth S, Srikireddy Sai Kiran Reddy, Viswanathan M*,
Scalable Tools - Part I Introduction to Scalable Tools
 Scalable Tools - Part I Introduction to Scalable Tools Adisak Sukul, Ph.D., Lecturer, Department of Computer Science, adisak@iastate.edu http://web.cs.iastate.edu/~adisak/mbds2018/ Scalable Tools session
Scalable Tools - Part I Introduction to Scalable Tools Adisak Sukul, Ph.D., Lecturer, Department of Computer Science, adisak@iastate.edu http://web.cs.iastate.edu/~adisak/mbds2018/ Scalable Tools session
IN-MEMORY DATA FABRIC: Real-Time Streaming
 WHITE PAPER IN-MEMORY DATA FABRIC: Real-Time Streaming COPYRIGHT AND TRADEMARK INFORMATION 2014 GridGain Systems. All rights reserved. This document is provided as is. Information and views expressed in
WHITE PAPER IN-MEMORY DATA FABRIC: Real-Time Streaming COPYRIGHT AND TRADEMARK INFORMATION 2014 GridGain Systems. All rights reserved. This document is provided as is. Information and views expressed in
Chapter 20: Database System Architectures
 Chapter 20: Database System Architectures Chapter 20: Database System Architectures Centralized and Client-Server Systems Server System Architectures Parallel Systems Distributed Systems Network Types
Chapter 20: Database System Architectures Chapter 20: Database System Architectures Centralized and Client-Server Systems Server System Architectures Parallel Systems Distributed Systems Network Types
Scientific Workflows and Cloud Computing. Gideon Juve USC Information Sciences Institute
 Scientific Workflows and Cloud Computing Gideon Juve USC Information Sciences Institute gideon@isi.edu Scientific Workflows Loosely-coupled parallel applications Expressed as directed acyclic graphs (DAGs)
Scientific Workflows and Cloud Computing Gideon Juve USC Information Sciences Institute gideon@isi.edu Scientific Workflows Loosely-coupled parallel applications Expressed as directed acyclic graphs (DAGs)
Embedded Technosolutions
 Hadoop Big Data An Important technology in IT Sector Hadoop - Big Data Oerie 90% of the worlds data was generated in the last few years. Due to the advent of new technologies, devices, and communication
Hadoop Big Data An Important technology in IT Sector Hadoop - Big Data Oerie 90% of the worlds data was generated in the last few years. Due to the advent of new technologies, devices, and communication
Hadoop File System S L I D E S M O D I F I E D F R O M P R E S E N T A T I O N B Y B. R A M A M U R T H Y 11/15/2017
 Hadoop File System 1 S L I D E S M O D I F I E D F R O M P R E S E N T A T I O N B Y B. R A M A M U R T H Y Moving Computation is Cheaper than Moving Data Motivation: Big Data! What is BigData? - Google
Hadoop File System 1 S L I D E S M O D I F I E D F R O M P R E S E N T A T I O N B Y B. R A M A M U R T H Y Moving Computation is Cheaper than Moving Data Motivation: Big Data! What is BigData? - Google
HDFS: Hadoop Distributed File System. CIS 612 Sunnie Chung
 HDFS: Hadoop Distributed File System CIS 612 Sunnie Chung What is Big Data?? Bulk Amount Unstructured Introduction Lots of Applications which need to handle huge amount of data (in terms of 500+ TB per
HDFS: Hadoop Distributed File System CIS 612 Sunnie Chung What is Big Data?? Bulk Amount Unstructured Introduction Lots of Applications which need to handle huge amount of data (in terms of 500+ TB per
Apache Ignite TM - In- Memory Data Fabric Fast Data Meets Open Source
 Apache Ignite TM - In- Memory Data Fabric Fast Data Meets Open Source DMITRIY SETRAKYAN Founder, PPMC https://ignite.apache.org @apacheignite @dsetrakyan Agenda About In- Memory Computing Apache Ignite
Apache Ignite TM - In- Memory Data Fabric Fast Data Meets Open Source DMITRIY SETRAKYAN Founder, PPMC https://ignite.apache.org @apacheignite @dsetrakyan Agenda About In- Memory Computing Apache Ignite
Data Intensive Scalable Computing
 Data Intensive Scalable Computing Randal E. Bryant Carnegie Mellon University http://www.cs.cmu.edu/~bryant Examples of Big Data Sources Wal-Mart 267 million items/day, sold at 6,000 stores HP built them
Data Intensive Scalable Computing Randal E. Bryant Carnegie Mellon University http://www.cs.cmu.edu/~bryant Examples of Big Data Sources Wal-Mart 267 million items/day, sold at 6,000 stores HP built them
EE/CSCI 451: Parallel and Distributed Computation
 EE/CSCI 451: Parallel and Distributed Computation Lecture #12 2/21/2017 Xuehai Qian Xuehai.qian@usc.edu http://alchem.usc.edu/portal/xuehaiq.html University of Southern California 1 Last class Outline
EE/CSCI 451: Parallel and Distributed Computation Lecture #12 2/21/2017 Xuehai Qian Xuehai.qian@usc.edu http://alchem.usc.edu/portal/xuehaiq.html University of Southern California 1 Last class Outline
Before proceeding with this tutorial, you must have a good understanding of Core Java and any of the Linux flavors.
 About the Tutorial Storm was originally created by Nathan Marz and team at BackType. BackType is a social analytics company. Later, Storm was acquired and open-sourced by Twitter. In a short time, Apache
About the Tutorial Storm was originally created by Nathan Marz and team at BackType. BackType is a social analytics company. Later, Storm was acquired and open-sourced by Twitter. In a short time, Apache
Accelerate MySQL for Demanding OLAP and OLTP Use Cases with Apache Ignite. Peter Zaitsev, Denis Magda Santa Clara, California April 25th, 2017
 Accelerate MySQL for Demanding OLAP and OLTP Use Cases with Apache Ignite Peter Zaitsev, Denis Magda Santa Clara, California April 25th, 2017 About the Presentation Problems Existing Solutions Denis Magda
Accelerate MySQL for Demanding OLAP and OLTP Use Cases with Apache Ignite Peter Zaitsev, Denis Magda Santa Clara, California April 25th, 2017 About the Presentation Problems Existing Solutions Denis Magda
DATA SCIENCE USING SPARK: AN INTRODUCTION
 DATA SCIENCE USING SPARK: AN INTRODUCTION TOPICS COVERED Introduction to Spark Getting Started with Spark Programming in Spark Data Science with Spark What next? 2 DATA SCIENCE PROCESS Exploratory Data
DATA SCIENCE USING SPARK: AN INTRODUCTION TOPICS COVERED Introduction to Spark Getting Started with Spark Programming in Spark Data Science with Spark What next? 2 DATA SCIENCE PROCESS Exploratory Data
Deployment Planning Guide
 Deployment Planning Guide Community 1.5.1 release The purpose of this document is to educate the user about the different strategies that can be adopted to optimize the usage of Jumbune on Hadoop and also
Deployment Planning Guide Community 1.5.1 release The purpose of this document is to educate the user about the different strategies that can be adopted to optimize the usage of Jumbune on Hadoop and also
PLATFORM AND SOFTWARE AS A SERVICE THE MAPREDUCE PROGRAMMING MODEL AND IMPLEMENTATIONS
 PLATFORM AND SOFTWARE AS A SERVICE THE MAPREDUCE PROGRAMMING MODEL AND IMPLEMENTATIONS By HAI JIN, SHADI IBRAHIM, LI QI, HAIJUN CAO, SONG WU and XUANHUA SHI Prepared by: Dr. Faramarz Safi Islamic Azad
PLATFORM AND SOFTWARE AS A SERVICE THE MAPREDUCE PROGRAMMING MODEL AND IMPLEMENTATIONS By HAI JIN, SHADI IBRAHIM, LI QI, HAIJUN CAO, SONG WU and XUANHUA SHI Prepared by: Dr. Faramarz Safi Islamic Azad
On the Use of Cloud Computing for Scientific Workflows
 On the Use of Cloud Computing for Scientific Workflows Christina Hoffa 1, Gaurang Mehta 2, Timothy Freeman 3, Ewa Deelman 2, Kate Keahey 3, Bruce Berriman 4, John Good 4 1 Indiana University, 2 University
On the Use of Cloud Computing for Scientific Workflows Christina Hoffa 1, Gaurang Mehta 2, Timothy Freeman 3, Ewa Deelman 2, Kate Keahey 3, Bruce Berriman 4, John Good 4 1 Indiana University, 2 University
Lecture 23 Database System Architectures
 CMSC 461, Database Management Systems Spring 2018 Lecture 23 Database System Architectures These slides are based on Database System Concepts 6 th edition book (whereas some quotes and figures are used
CMSC 461, Database Management Systems Spring 2018 Lecture 23 Database System Architectures These slides are based on Database System Concepts 6 th edition book (whereas some quotes and figures are used
SciSpark 201. Searching for MCCs
 SciSpark 201 Searching for MCCs Agenda for 201: Access your SciSpark & Notebook VM (personal sandbox) Quick recap. of SciSpark Project What is Spark? SciSpark Extensions scitensor: N-dimensional arrays
SciSpark 201 Searching for MCCs Agenda for 201: Access your SciSpark & Notebook VM (personal sandbox) Quick recap. of SciSpark Project What is Spark? SciSpark Extensions scitensor: N-dimensional arrays
Apache Spark is a fast and general-purpose engine for large-scale data processing Spark aims at achieving the following goals in the Big data context
 1 Apache Spark is a fast and general-purpose engine for large-scale data processing Spark aims at achieving the following goals in the Big data context Generality: diverse workloads, operators, job sizes
1 Apache Spark is a fast and general-purpose engine for large-scale data processing Spark aims at achieving the following goals in the Big data context Generality: diverse workloads, operators, job sizes
Automatic Identification of Application I/O Signatures from Noisy Server-Side Traces. Yang Liu Raghul Gunasekaran Xiaosong Ma Sudharshan S.
 Automatic Identification of Application I/O Signatures from Noisy Server-Side Traces Yang Liu Raghul Gunasekaran Xiaosong Ma Sudharshan S. Vazhkudai Instance of Large-Scale HPC Systems ORNL s TITAN (World
Automatic Identification of Application I/O Signatures from Noisy Server-Side Traces Yang Liu Raghul Gunasekaran Xiaosong Ma Sudharshan S. Vazhkudai Instance of Large-Scale HPC Systems ORNL s TITAN (World
Introduction to Grid Computing
 Milestone 2 Include the names of the papers You only have a page be selective about what you include Be specific; summarize the authors contributions, not just what the paper is about. You might be able
Milestone 2 Include the names of the papers You only have a page be selective about what you include Be specific; summarize the authors contributions, not just what the paper is about. You might be able
Distributed File Systems II
 Distributed File Systems II To do q Very-large scale: Google FS, Hadoop FS, BigTable q Next time: Naming things GFS A radically new environment NFS, etc. Independence Small Scale Variety of workloads Cooperation
Distributed File Systems II To do q Very-large scale: Google FS, Hadoop FS, BigTable q Next time: Naming things GFS A radically new environment NFS, etc. Independence Small Scale Variety of workloads Cooperation
Isolation Forest for Anomaly Detection
 Isolation Forest for Anomaly Detection Sahand Hariri PhD Student, MechSE UIUC Matias Carrasco Kind Senior Research Scientist, NCSA LSST Workshop 2018, June 21, NCSA, UIUC Overview Goal: Build a resilient
Isolation Forest for Anomaly Detection Sahand Hariri PhD Student, MechSE UIUC Matias Carrasco Kind Senior Research Scientist, NCSA LSST Workshop 2018, June 21, NCSA, UIUC Overview Goal: Build a resilient
Data Intensive Scalable Computing. Thanks to: Randal E. Bryant Carnegie Mellon University
 Data Intensive Scalable Computing Thanks to: Randal E. Bryant Carnegie Mellon University http://www.cs.cmu.edu/~bryant Big Data Sources: Seismic Simulations Wave propagation during an earthquake Large-scale
Data Intensive Scalable Computing Thanks to: Randal E. Bryant Carnegie Mellon University http://www.cs.cmu.edu/~bryant Big Data Sources: Seismic Simulations Wave propagation during an earthquake Large-scale
Chapter 18: Database System Architectures.! Centralized Systems! Client--Server Systems! Parallel Systems! Distributed Systems!
 Chapter 18: Database System Architectures! Centralized Systems! Client--Server Systems! Parallel Systems! Distributed Systems! Network Types 18.1 Centralized Systems! Run on a single computer system and
Chapter 18: Database System Architectures! Centralized Systems! Client--Server Systems! Parallel Systems! Distributed Systems! Network Types 18.1 Centralized Systems! Run on a single computer system and
Big data systems 12/8/17
 Big data systems 12/8/17 Today Basic architecture Two levels of scheduling Spark overview Basic architecture Cluster Manager Cluster Cluster Manager 64GB RAM 32 cores 64GB RAM 32 cores 64GB RAM 32 cores
Big data systems 12/8/17 Today Basic architecture Two levels of scheduling Spark overview Basic architecture Cluster Manager Cluster Cluster Manager 64GB RAM 32 cores 64GB RAM 32 cores 64GB RAM 32 cores
IBM Data Science Experience White paper. SparkR. Transforming R into a tool for big data analytics
 IBM Data Science Experience White paper R Transforming R into a tool for big data analytics 2 R Executive summary This white paper introduces R, a package for the R statistical programming language that
IBM Data Science Experience White paper R Transforming R into a tool for big data analytics 2 R Executive summary This white paper introduces R, a package for the R statistical programming language that
TITLE: PRE-REQUISITE THEORY. 1. Introduction to Hadoop. 2. Cluster. Implement sort algorithm and run it using HADOOP
 TITLE: Implement sort algorithm and run it using HADOOP PRE-REQUISITE Preliminary knowledge of clusters and overview of Hadoop and its basic functionality. THEORY 1. Introduction to Hadoop The Apache Hadoop
TITLE: Implement sort algorithm and run it using HADOOP PRE-REQUISITE Preliminary knowledge of clusters and overview of Hadoop and its basic functionality. THEORY 1. Introduction to Hadoop The Apache Hadoop
Integration of Workflow Partitioning and Resource Provisioning
 Integration of Workflow Partitioning and Resource Provisioning Weiwei Chen Information Sciences Institute University of Southern California Marina del Rey, CA, USA wchen@isi.edu Ewa Deelman Information
Integration of Workflow Partitioning and Resource Provisioning Weiwei Chen Information Sciences Institute University of Southern California Marina del Rey, CA, USA wchen@isi.edu Ewa Deelman Information
Lightweight Streaming-based Runtime for Cloud Computing. Shrideep Pallickara. Community Grids Lab, Indiana University
 Lightweight Streaming-based Runtime for Cloud Computing granules Shrideep Pallickara Community Grids Lab, Indiana University A unique confluence of factors have driven the need for cloud computing DEMAND
Lightweight Streaming-based Runtime for Cloud Computing granules Shrideep Pallickara Community Grids Lab, Indiana University A unique confluence of factors have driven the need for cloud computing DEMAND
Towards Jungle Computing with Ibis/Constellation
 Towards Jungle Computing with Ibis/Constellation Jason Maassen, Niels Drost Henri Bal, Frank Seinstra Department of Computer Science VU University, Amsterdam, The Netherlands Introduction HPC is entering
Towards Jungle Computing with Ibis/Constellation Jason Maassen, Niels Drost Henri Bal, Frank Seinstra Department of Computer Science VU University, Amsterdam, The Netherlands Introduction HPC is entering
Research challenges in data-intensive computing The Stratosphere Project Apache Flink
 Research challenges in data-intensive computing The Stratosphere Project Apache Flink Seif Haridi KTH/SICS haridi@kth.se e2e-clouds.org Presented by: Seif Haridi May 2014 Research Areas Data-intensive
Research challenges in data-intensive computing The Stratosphere Project Apache Flink Seif Haridi KTH/SICS haridi@kth.se e2e-clouds.org Presented by: Seif Haridi May 2014 Research Areas Data-intensive
Managing Large-Scale Scientific Workflows in Distributed Environments: Experiences and Challenges
 Managing Large-Scale Scientific s in Distributed Environments: Experiences and Challenges Ewa Deelman, Yolanda Gil USC Information Sciences Institute, Marina Del Rey, CA 90292, deelman@isi.edu, gil@isi.edu
Managing Large-Scale Scientific s in Distributed Environments: Experiences and Challenges Ewa Deelman, Yolanda Gil USC Information Sciences Institute, Marina Del Rey, CA 90292, deelman@isi.edu, gil@isi.edu
Oracle Big Data Connectors
 Oracle Big Data Connectors Oracle Big Data Connectors is a software suite that integrates processing in Apache Hadoop distributions with operations in Oracle Database. It enables the use of Hadoop to process
Oracle Big Data Connectors Oracle Big Data Connectors is a software suite that integrates processing in Apache Hadoop distributions with operations in Oracle Database. It enables the use of Hadoop to process
Key aspects of cloud computing. Towards fuller utilization. Two main sources of resource demand. Cluster Scheduling
 Key aspects of cloud computing Cluster Scheduling 1. Illusion of infinite computing resources available on demand, eliminating need for up-front provisioning. The elimination of an up-front commitment
Key aspects of cloud computing Cluster Scheduling 1. Illusion of infinite computing resources available on demand, eliminating need for up-front provisioning. The elimination of an up-front commitment
Planning the SCEC Pathways: Pegasus at work on the Grid
 Planning the SCEC Pathways: Pegasus at work on the Grid Philip Maechling, Vipin Gupta, Thomas H. Jordan Southern California Earthquake Center Ewa Deelman, Yolanda Gil, Sridhar Gullapalli, Carl Kesselman,
Planning the SCEC Pathways: Pegasus at work on the Grid Philip Maechling, Vipin Gupta, Thomas H. Jordan Southern California Earthquake Center Ewa Deelman, Yolanda Gil, Sridhar Gullapalli, Carl Kesselman,
Hadoop/MapReduce Computing Paradigm
 Hadoop/Reduce Computing Paradigm 1 Large-Scale Data Analytics Reduce computing paradigm (E.g., Hadoop) vs. Traditional database systems vs. Database Many enterprises are turning to Hadoop Especially applications
Hadoop/Reduce Computing Paradigm 1 Large-Scale Data Analytics Reduce computing paradigm (E.g., Hadoop) vs. Traditional database systems vs. Database Many enterprises are turning to Hadoop Especially applications
MapReduce Spark. Some slides are adapted from those of Jeff Dean and Matei Zaharia
 MapReduce Spark Some slides are adapted from those of Jeff Dean and Matei Zaharia What have we learnt so far? Distributed storage systems consistency semantics protocols for fault tolerance Paxos, Raft,
MapReduce Spark Some slides are adapted from those of Jeff Dean and Matei Zaharia What have we learnt so far? Distributed storage systems consistency semantics protocols for fault tolerance Paxos, Raft,
Chapter 4:- Introduction to Grid and its Evolution. Prepared By:- NITIN PANDYA Assistant Professor SVBIT.
 Chapter 4:- Introduction to Grid and its Evolution Prepared By:- Assistant Professor SVBIT. Overview Background: What is the Grid? Related technologies Grid applications Communities Grid Tools Case Studies
Chapter 4:- Introduction to Grid and its Evolution Prepared By:- Assistant Professor SVBIT. Overview Background: What is the Grid? Related technologies Grid applications Communities Grid Tools Case Studies