Data Preprocessing. Komate AMPHAWAN
|
|
|
- Barrie Gardner
- 6 years ago
- Views:
Transcription

1 Data Preprocessing Komate AMPHAWAN 1
2 Data cleaning (data cleansing) Attempt to fill in missing values, smooth out noise while identifying outliers, and correct inconsistencies in the data. 2

3 Missing value How can you go about filling in the missing values for this attribute? 3
4 Cause of missing value Incomplete filling data Equipment malfunction (การท างานผ ดปกต ) Inconsistence in deleting data Do not fill data (user think that it s not important) 4
5 Missing value [1] (1) Ignore the tuple done when the class label is missing (assuming the mining task involves classification) not very effective, unless the tuple contains several attributes with missing values especially poor when the percentage of missing values per attribute varies considerably 5
6 Missing value [2] (2) Fill in the missing value manually time-consuming may not be feasible given a large data set with many missing values (3) Use a global constant to fill in the missing value Replace all missing attribute values by the same constant, such as a label like Unknown or. 6
7 Missing value [3] (4) Use the attribute mean to fill in the missing value (5) Use the attribute mean for all samples belonging to the same class as the given tuple if classifying customers according to credit risk, replace the missing value with the average income value for customers in the same credit risk category as that of the given tuple 7
8 Missing value [4] (6) Use the most probable value to fill in the missing value be determined with regression, inference-based tools using a Bayesian formalism, or decision tree induction. Methods 3 to 6 bias the data. The filled-in value may not be correct. 8


9 Noisy data What is Noise? 9
10 Noise is noise means any unwanted sound a random error or variance in a measured variable. Cause of noise Equipment malfunction (การท างานผ ดปกต ) Problems in filling/collecting data: Human error/computer error Data transmission Limited buffer size 10
11 data smoothing techniques [1] Binning smooth a sorted data value by consulting its neighborhood, that is, the values around it. Consist of 3 steps: o sorted values of data o Partition sorted data into buckets, or bins. o perform local smoothing 11
12 Example smoothing by bin means, each value in a bin is replaced by the mean value of the bin In smoothing by bin boundaries, the minimum and maximum values in a given bin are identified as the bin boundaries. Each bin value is then replaced by the closest boundary value. 12
13 data smoothing techniques [2] Regression (การเส อมถอย) smooth by fitting the data to a function, such as with regression. Linear regression involves finding the best line to fit two attributes (or variables), so that one attribute can be used to predict the other. o Y = + x where and are coefficient of regression. Multiple linear regression is an extension of linear regression, where more than two attributes are involved and the data are fit to a multidimensional surface. o Y = b0 + b 1 X 1 + b 2 X b m X m where b 0,,b m are coefficient of regression. 13
14 data smoothing techniques [3] Clustering Outliers may be detected by clustering, where similar values are organized into groups, or clusters. Values that fall outside of the set of clusters may be considered outliers 14
15 Example 15

16 DATA INTEGRATION 16
17 Data Integration [1] Data integration combines data from multiple sources into a coherent (ซ งสอดคล อง) data store, as in data warehousing. These sources may include multiple databases, data cubes, or flat files. Data integration helps to reduce. Data redundancies which may cause data inconsistencies Speed up and improve quality of mining process 17
18 Data Integration [2] Schema integration uses metadata (data of data) to identify entities in data repositories Example ClusID in database A has the same characteristic as CustNumber in database B Checking and modifying data inconsistencies try to smooth the attributes that have the same characteristic but contain different values: Color: black / bk unit: foot / meter 18
19 Data Integration [3] Removing data redundancies may use correlation analysis between two attributes/instance: N is the number of tuples, a i and b i are the respective values of A and B in tuple i, σ A and σ B are the respective standard deviations of A and B. -1 r A,B
20 Data Integration [4] If r A,B is greater than 0, then A and B are positively correlated values of A increase as the values of B increase The higher the value, the stronger the correlation a higher value may indicate that A (or B) may be removed as a redundancy 20
21 Data Integration [5] If r A,B is equal to 0, then A and B are independent and there is no correlation between them. If r A,B is less than 0, then A and B are negatively correlated, the values of one attribute increase as the values of the other attribute decrease. 21

22 DATA TRANSFORMATION 22
23 Data Transformation[1] Data are transformed or consolidated (รวมเป นหน ง) into forms appropriate for mining Smoothing: remove noise from the data. Such techniques include binning, regression, and clustering Aggregation: summarize or aggregate data. o the daily sales data may be aggregated so as to compute monthly and annual total amounts. o used in constructing a data cube for analysis of the data at multiple granularities. 23
24 Data Transformation[2] Generalization: low-level or primitive (raw) data are replaced by higher-level concepts through the use of concept hierarchies. o street can be generalized to city or country. o age may be mapped to concepts, like youth, middleaged, and senior. Normalization: attribute data are scaled so as to fall within a small specified range, such as 1:0 to 1:0, or 0:0 to 1:0. 24
25 Data Transformation[2] Attribute/feature construction: new attributes are constructed and added from the given set of attributes to help the mining process. 25
26 Normalization [1] An attribute is normalized by scaling its values so that they fall within a small specified range, such as 0.0 to 1.0. Techniques min-max normalization z-score normalization, normalization by decimal scaling 26
27 Min-max normalization [1] a linear transformation on the original data. Let min A and max A are the minimum and maximum values of an attribute A. Min-max normalization maps a value, v, of A to v in the range [new_min A,new_max A ] by computing 27
28 Min-max normalization [2] Min-max normalization preserves the relationships among the original data values. It will encounter an out-of-bounds error if a future input case for normalization falls outside of the original data range for A. 28
29 Example of Min-max normalization Suppose that the minimum and maximum values for the attribute income are $12,000 and $98,000, respectively. Try to map income to the range [0.0, 1.0] A value of $73,600 for income is transformed to ((73,600 12,000) /(98,000 12,000)) ( ) + 0 =
30 Z-score (zero-mean) normalization values for an attribute A, are normalized based on the mean and standard deviation of A. A value v of A is normalized to v by computing Z-score is useful when the actual minimum and maximum of attribute A are unknown, or when there are outliers that dominate the min-max normalization. 30
31 Example of z-score normalization Suppose that the mean and standard deviation of the values for the attribute income are $54,000 and $16,000, respectively. A value of $73,600 for income is transformed to (73,600-54,000) 16,000 =
32 Decimal scaling move the decimal point of values of attribute A. The number of decimal points moved depends on the maximum absolute value of A. A value v of A is normalized to v by computing where j is the smallest integer such that Max( v ) < 1 32
33 Example of Decimal scaling Suppose that the recorded values of A range from -986 to 917. The maximum absolute value of A is 986. To normalize by decimal scaling, we therefore divide each value by 1,000 (i.e., j = 3) so that normalizes to and 917 normalizes to
34 Attribute construction New attributes are constructed from the given attributes and added in order to help improve the accuracy and understanding of structure in high-dimensional data. For example, we may add the attribute area based on the attributes height and width. By combining attributes, attribute construction can discover missing information about the relationships between data attributes. 34

35 35
36 Data reduction Reduced representation of the data set that is much smaller in volume, yet closely maintains the integrity (ความสมบ รณ ) of the original data. Strategies Data cube aggregation Attribute subset selection Dimensionality reduction Numerosity reduction Discretization and concept hierarchy generation 36

37 Data Cube Aggregation Data can be aggregated into smaller in volume, without loss of information necessary for the analysis task. 37
38 Example data cube aggregation Sales data for a given branch of AllElectronics for the years 2002 to On the left, the sales are shown per quarter. On the right, the data are aggregated to provide the annual sales. 38

39 Why Attribute Subset Selection is needed? Data sets may contain hundreds of attributes, many of which may be irrelevant/ redundant to the mining task. This can result in discovered patterns of poor quality. irrelevant or redundant attributes can slow down the mining process. 39
40 Attribute subset selection reduce the data set size by removing irrelevant or redundant attributes. Goal: find a minimum set of attributes such that the resulting probability distribution of the data classes is as close as possible to the original distribution obtained using all attributes. Mining process can reduce the number of attributes appearing in the discovered patterns, helping to make the patterns easier to understand. 40
41 How can we find a good subset of the original attributes? Greedy: while searching through attribute space, they always make what looks to be the best choice at the time. best (and worst ) attributes are typically determined using tests of statistical significance 41
42 Greedy heuristic for attribute subset selection. 42
43 Other techniques [1] Stepwise forward selection: starts with an empty set of attributes as the reduced set At each step, the best of the original attributes is determined and added to the reduced set. Stepwise backward elimination: starts with the full set of attributes. At each step, it removes the worst attribute remaining in the set. 43
44 Other techniques [2] Combination of forward selection and backward elimination: at each step, the procedure selects the best attribute and removes the worst from among the remaining attributes. Decision tree induction: constructs a tree where each non-leaf node (a tested attribute), and each leaf node (a class prediction). At each node, the algorithm chooses the best attribute to partition the data into individual classes. 44
 without any loss of information Lossy: approximately 45 reconstruct")
45 Dimensionality Reduction Apply data encoding or transformations to obtain a reduced or compressed representation of the original data. Lossless: reconstruct data (from the original data) without any loss of information Lossy: approximately 45 reconstruct data
 Principal components analysis (PCA)")
46 two popular lossy dimensionality reduction methods Wavelet transforms (Discrete wavelet transform: DWT) Principal components analysis (PCA) 46

47 Can we reduce the data volume by choosing alternative, smaller forms of data representation? NUMEROSITY REDUCTION 47
48 Numerosity reduction technique Parametric: estimate the data, stored only the data parameters, instead of the actual data. (Outliers may also be stored). Log-linear models: estimate discrete multidimensional probability distributions. Nonparametric: store reduced representations of the data Histograms Clustering sampling 48
49 Regression and Log-Linear Models [1] Used to approximate the given data Linear regression: the data are modeled to fit a straight line Multiple linear regression: modeled as a linear function of two or more predictor variables. 49
50 Regression and Log-Linear Models [2] Log-linear models: used to estimate the probability of each point in a multidimensional space for a set of discretized attributes, based on a smaller subset of dimensional combinations. allow a higher-dimensional data space to be constructed from lower-dimensional spaces. useful for dimensionality reduction and data smoothing. 50
51 Histograms Use binning to approximate data distributions. A histogram for an attribute A, partitions the data distribution of A into disjoint subsets/buckets. If each bucket represents only a single attributevalue/frequency pair, the buckets are called singleton buckets. Often, buckets instead represent continuous ranges for the given attribute. 51
52 Example of Histograms a list of prices of commonly sold items at AllElectronics (rounded to the nearest dollar). The numbers have been sorted: 1, 1, 5, 5, 5, 5, 5, 8, 8, 10, 10, 10, 10, 12, 14, 14, 14, 15, 15, 15, 15, 15, 15, 18, 18, 18, 18, 18, 18, 18, 18, 20, 20, 20, 20, 20, 20, 20, 21, 21, 21, 21, 25, 25, 25, 25, 25, 28, 28, 30, 30,
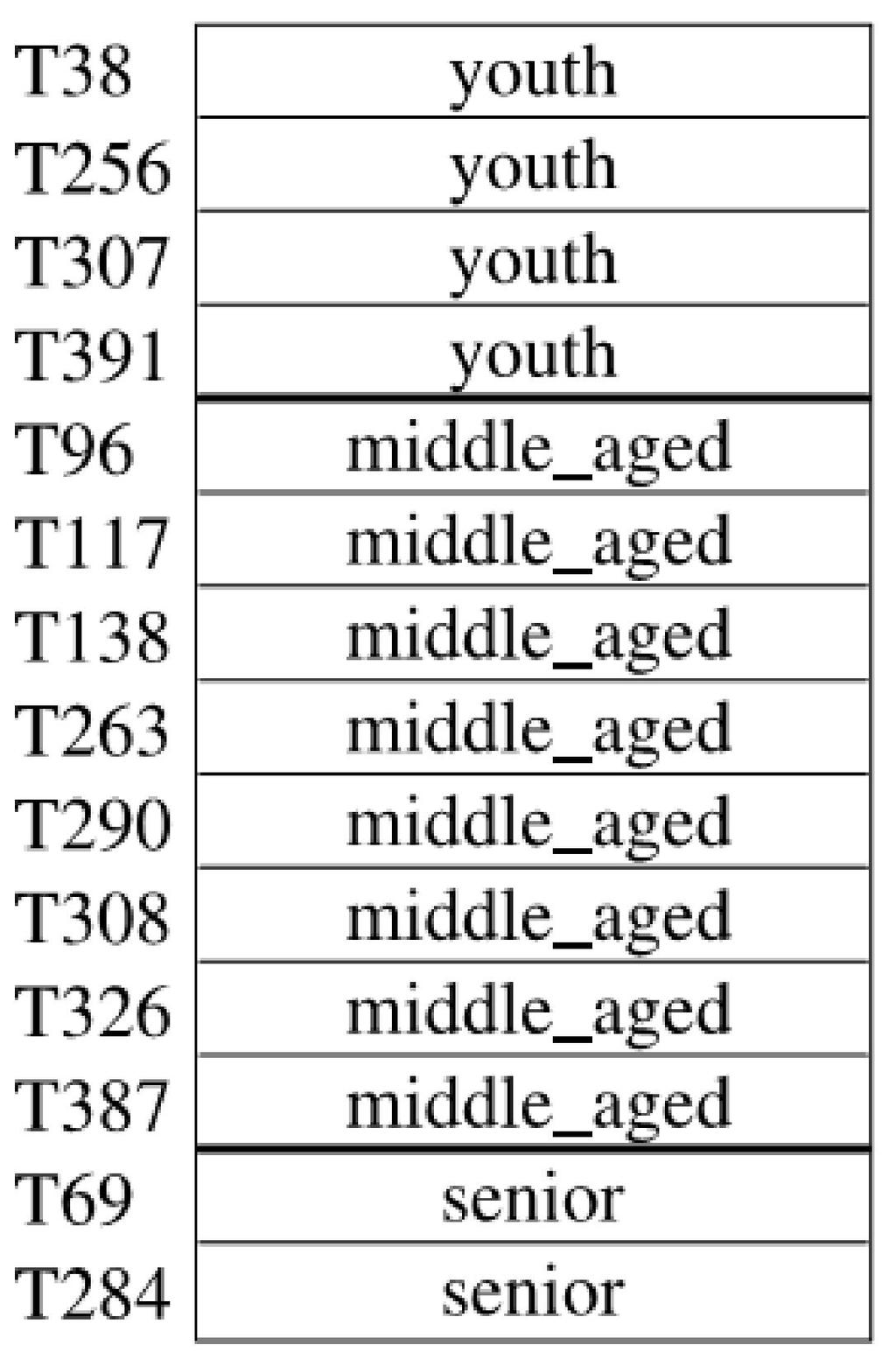
53 Clustering concept partition the objects into clusters, objects within a cluster are similar to one another and dissimilar to objects in other clusters. The quality of a cluster is represented by its Diameter (the maximum distance between any two objects in the cluster). Centroid distance (the average distance of each cluster object from the cluster centroid ) Clustering data reduction, the cluster representations of the data are used to replace the actual data. 53
54 Sampling allows a large data set to be represented by a much smaller random sample (or subset) of the data. Simple random sample without replacement (SRSWOR) of size s Simple random sample with replacement (SRSWR) of size s: Cluster sample Stratified sample 54
55 - Simple random sample without replacement (SRSWOR) of size s - Simple random sample with replacement (SRSWR) of size s: 55
56 56

57 57

58 DATA DISCRETIZATION AND CONCEPT HIERARCHY GENERATION 58
59 Data discretization techniques used to reduce the number of values for a given continuous attribute by dividing the range of the attribute into intervals. Interval labels can then be used to replace actual data values If the discretization process uses class information, then we say it is supervised discretization. Otherwise, it is unsupervised. 59
60 Top-down discretization(splitting) Finding one or a few points (called split points or cut points) to split the entire attribute range, and then repeats this recursively on the resulting intervals. 60
61 bottom-up discretization(merging) considering all of the continuous values as potential split-points, removes some by merging neighborhood values to form intervals, and then recursively applies this process to the resulting intervals. 61
62 Concept hierarchies used to reduce the data by collecting and replacing low-level concepts (such as numerical values for the attribute age) with higher-level concepts (such as youth,middleaged, or senior). detail is lost by such data generalization, the generalized data may be more meaningful and easier to interpret 62
63 63
64 Discretization and Concept Hierarchy Techniques Generation for Numerical Data binning, histogram analysis, entropy-based discretization, χ2-merging, cluster analysis, discretization by intuitive partitioning. 64
65 Entropy-Based Discretization [1] is a supervised, top-down splitting technique explores class distribution information in its calculation and determination of split-points (data values for partitioning an attribute range). To discretize a numerical attribute, A, the method selects the value of A that has the minimum entropy as a split-point, and recursively partitions the resulting intervals to arrive at a hierarchical discretization. 65
66 Basic entropy-based discretization [1] Let D consist of data tuples defined by a set of attributes and a class-label attribute. The class-label attribute provides the class information per tuple. Each value of A can be considered as a split- point to partition the range of A a split-point for A can partition the tuples in D into two subsets satisfying the conditions A split point and A > split point. 66
67 Basic entropy-based discretization [2] How much more information would we still need for a perfect classification, after this partitioning? This amount is called the expected information requirement for classifying a tuple in D based on partitioning by A. where D 1 and D 2 correspond to the tuples in D satisfying the conditions A split point and A > split point, 67 respectively; D is the number of tuples in D.
68 Entropy function is calculated based on the class distribution of the tuples in the set Given m classes, C 1,C 2,,C m, the entropy of D 1 is where p i is the probability of class C i in D 1, determined by dividing the number of tuples of class C i in D 1 by D 1, the total number of tuples in D 1. 68
69 Basic entropy-based discretization [3] When selecting a split-point for attribute A, we want to pick the attribute value that gives the minimum expected information requirement (i.e.,min(infoa(d))) This would result in the minimum amount of expected information (still) required to perfectly classify the tuples after partitioning by A split point and A>split point.
70 Basic entropy-based discretization [4] The process of determining a split-point is recursively applied to each partition obtained, until some stopping criterion is met, such as when the minimum information requirement on all candidate split-points is less than a small threshold, ε, or when the number of intervals is greater than a threshold, max interval.
71 Interval Merging by 2 Analysis ChiMerge is a χ2-based discretization method is a top-down, splitting strategy supervised in that it uses class information for accurate discretization, the relative class frequencies should be fairly consistent within an interval if two adjacent intervals have a very similar distribution of classes, then the intervals can be merged. Otherwise, they should remain separate.
72 ChiMerge is a χ2-based discretization Each distinct value of a numerical attribute A is considered to be one interval. χ2 tests are performed for every pair of adjacent intervals. Adjacent intervals with the least χ2 values are merged together, because low χ2 values for a pair indicate similar class distributions. This merging process proceeds recursively until a predefined stopping criterion is met.
73 The χ2 value (the Pearson χ2 statistic) where o ij is the observed frequency of the joint event (A i,b j ) and e ij is the expected frequency of (A i,b j ), which can be computed as where N is the number of data tuples, count(a=a i ) is the number of tuples having value a i for A, and count(b = b j ) is the number of tuples having value b j for B.
74 Cluster Analysis [1] A clustering algorithm can be applied to discretize a numerical attribute A, by partitioning the values of A into clusters or groups. Clustering takes the distribution of A into consideration, as well as the closeness of data points, and therefore is able to produce highquality discretization results.
75 Cluster Analysis [2] Clustering can be used to generate a concept hierarchy for A by following either a top-down splitting strategy or a bottom-up merging strategy, where each cluster forms a node of the concept hierarchy. each initial cluster or partition may be further decomposed into several subclusters, forming a lower level of the hierarchy Clusters are formed by repeatedly grouping neighboring clusters in order to form higherlevel concepts.
76 Concept Hierarchy Generation for Categorical Data Categorical data are discrete data. Categorical attributes have a finite (but possibly large) number of distinct values, with no ordering among the values. Examples include geographic location, job category, and item type.
77 Specification of a partial ordering of attributes explicitly at the schema level by users or experts Concept hierarchies for categorical attributes typically involve a group of attributes. A user or expert can easily define a concept hierarchy by specifying a partial or total ordering of the attributes at the schema level. o For example, a relational database may contain the attributes: street, city, province, and country. A hierarchy can be defined by specifying the total ordering among these attributes at the schema level, such as street < city < province < country.
78 Specification of a portion of a hierarchy by explicit data grouping specify explicit groupings for a small portion of intermediate-level data. For example, after specifying to form a hierarchy at the schema level, a user could define some intermediate (ตรงกลาง) levels manually, such as o {Alberta, Saskatchewan, Manitoba} prairies (ท งหญ า) Canada and o {British Columbia, prairies Canada} Western Canada.
79 Specification of a set of attributes, but not of their partial ordering Without knowledge of data semantics, how can a hierarchical ordering for an arbitrary set of categorical attributes be found? a concept hierarchy can be automatically generated based on the number of distinct values per attribute in the given attribute set. The attribute with the most distinct values is placed at the lowest level of the hierarchy. The lower the number of distinct values an attribute has, the higher it is in the generated concept hierarchy.
80 Example
81 Specification of only a partial set of attributes the user may have included only a small subset of the relevant attributes in the hierarchy specification. For example, instead of including all of the hierarchically relevant attributes for location, the user may have specified only street and city.
82 Summary [1] Data cleaning routines attempt to fill in missing values, smooth out noise while identifying outliers, and correct inconsistencies in the data. Data integration combines data from multiple sources to form a coherent data store. Metadata, correlation analysis, data conflict detection, and the resolution of semantic heterogeneity contribute toward smooth data integration.
83 Summary [2] Data transformation routines convert the data into appropriate forms for mining. For example, attribute data may be normalized so as to fall between a small range, such as 0:0 to 1:0. Data reduction techniques such as data cube aggregation, attribute subset selection, dimensionality reduction, numerosity reduction, and discretization can be used to obtain a reduced representation of the data while minimizing the loss of information content.
84 Summary [3] Data discretization and automatic generation of concept hierarchies for numerical data can involve techniques such as binning, histogram analysis, entropy-based discretization, χ2 analysis, cluster analysis, and discretization by intuitive partitioning. For categorical data, concept hierarchies may be generated based on the number of distinct values of the attributes defining the hierarchy
85 Summary [4] Although numerous methods of data preprocessing have been developed, data preprocessing remains an active area of research, due to the huge amount of inconsistent or dirty data and the complexity of the problem.
86 Q&A 86
Data Mining. Part 2. Data Understanding and Preparation. 2.4 Data Transformation. Spring Instructor: Dr. Masoud Yaghini. Data Transformation
 Data Mining Part 2. Data Understanding and Preparation 2.4 Spring 2010 Instructor: Dr. Masoud Yaghini Outline Introduction Normalization Attribute Construction Aggregation Attribute Subset Selection Discretization
Data Mining Part 2. Data Understanding and Preparation 2.4 Spring 2010 Instructor: Dr. Masoud Yaghini Outline Introduction Normalization Attribute Construction Aggregation Attribute Subset Selection Discretization
Data Preprocessing Yudho Giri Sucahyo y, Ph.D , CISA
 Obj ti Objectives Motivation: Why preprocess the Data? Data Preprocessing Techniques Data Cleaning Data Integration and Transformation Data Reduction Data Preprocessing Lecture 3/DMBI/IKI83403T/MTI/UI
Obj ti Objectives Motivation: Why preprocess the Data? Data Preprocessing Techniques Data Cleaning Data Integration and Transformation Data Reduction Data Preprocessing Lecture 3/DMBI/IKI83403T/MTI/UI
Data Preprocessing. Slides by: Shree Jaswal
 Data Preprocessing Slides by: Shree Jaswal Topics to be covered Why Preprocessing? Data Cleaning; Data Integration; Data Reduction: Attribute subset selection, Histograms, Clustering and Sampling; Data
Data Preprocessing Slides by: Shree Jaswal Topics to be covered Why Preprocessing? Data Cleaning; Data Integration; Data Reduction: Attribute subset selection, Histograms, Clustering and Sampling; Data
UNIT 2 Data Preprocessing
 UNIT 2 Data Preprocessing Lecture Topic ********************************************** Lecture 13 Why preprocess the data? Lecture 14 Lecture 15 Lecture 16 Lecture 17 Data cleaning Data integration and
UNIT 2 Data Preprocessing Lecture Topic ********************************************** Lecture 13 Why preprocess the data? Lecture 14 Lecture 15 Lecture 16 Lecture 17 Data cleaning Data integration and
Data Preprocessing. Why Data Preprocessing? MIT-652 Data Mining Applications. Chapter 3: Data Preprocessing. Multi-Dimensional Measure of Data Quality
 Why Data Preprocessing? Data in the real world is dirty incomplete: lacking attribute values, lacking certain attributes of interest, or containing only aggregate data e.g., occupation = noisy: containing
Why Data Preprocessing? Data in the real world is dirty incomplete: lacking attribute values, lacking certain attributes of interest, or containing only aggregate data e.g., occupation = noisy: containing
Summary of Last Chapter. Course Content. Chapter 3 Objectives. Chapter 3: Data Preprocessing. Dr. Osmar R. Zaïane. University of Alberta 4
 Principles of Knowledge Discovery in Data Fall 2004 Chapter 3: Data Preprocessing Dr. Osmar R. Zaïane University of Alberta Summary of Last Chapter What is a data warehouse and what is it for? What is
Principles of Knowledge Discovery in Data Fall 2004 Chapter 3: Data Preprocessing Dr. Osmar R. Zaïane University of Alberta Summary of Last Chapter What is a data warehouse and what is it for? What is
2. Data Preprocessing
 2. Data Preprocessing Contents of this Chapter 2.1 Introduction 2.2 Data cleaning 2.3 Data integration 2.4 Data transformation 2.5 Data reduction Reference: [Han and Kamber 2006, Chapter 2] SFU, CMPT 459
2. Data Preprocessing Contents of this Chapter 2.1 Introduction 2.2 Data cleaning 2.3 Data integration 2.4 Data transformation 2.5 Data reduction Reference: [Han and Kamber 2006, Chapter 2] SFU, CMPT 459
CS570: Introduction to Data Mining
 CS570: Introduction to Data Mining Fall 2013 Reading: Chapter 3 Han, Chapter 2 Tan Anca Doloc-Mihu, Ph.D. Some slides courtesy of Li Xiong, Ph.D. and 2011 Han, Kamber & Pei. Data Mining. Morgan Kaufmann.
CS570: Introduction to Data Mining Fall 2013 Reading: Chapter 3 Han, Chapter 2 Tan Anca Doloc-Mihu, Ph.D. Some slides courtesy of Li Xiong, Ph.D. and 2011 Han, Kamber & Pei. Data Mining. Morgan Kaufmann.
Preprocessing Short Lecture Notes cse352. Professor Anita Wasilewska
 Preprocessing Short Lecture Notes cse352 Professor Anita Wasilewska Data Preprocessing Why preprocess the data? Data cleaning Data integration and transformation Data reduction Discretization and concept
Preprocessing Short Lecture Notes cse352 Professor Anita Wasilewska Data Preprocessing Why preprocess the data? Data cleaning Data integration and transformation Data reduction Discretization and concept
3. Data Preprocessing. 3.1 Introduction
 3. Data Preprocessing Contents of this Chapter 3.1 Introduction 3.2 Data cleaning 3.3 Data integration 3.4 Data transformation 3.5 Data reduction SFU, CMPT 740, 03-3, Martin Ester 84 3.1 Introduction Motivation
3. Data Preprocessing Contents of this Chapter 3.1 Introduction 3.2 Data cleaning 3.3 Data integration 3.4 Data transformation 3.5 Data reduction SFU, CMPT 740, 03-3, Martin Ester 84 3.1 Introduction Motivation
Data Preprocessing. Data Mining 1
 Data Preprocessing Today s real-world databases are highly susceptible to noisy, missing, and inconsistent data due to their typically huge size and their likely origin from multiple, heterogenous sources.
Data Preprocessing Today s real-world databases are highly susceptible to noisy, missing, and inconsistent data due to their typically huge size and their likely origin from multiple, heterogenous sources.
By Mahesh R. Sanghavi Associate professor, SNJB s KBJ CoE, Chandwad
 By Mahesh R. Sanghavi Associate professor, SNJB s KBJ CoE, Chandwad Data Analytics life cycle Discovery Data preparation Preprocessing requirements data cleaning, data integration, data reduction, data
By Mahesh R. Sanghavi Associate professor, SNJB s KBJ CoE, Chandwad Data Analytics life cycle Discovery Data preparation Preprocessing requirements data cleaning, data integration, data reduction, data
Data Mining. Data preprocessing. Hamid Beigy. Sharif University of Technology. Fall 1395
 Data Mining Data preprocessing Hamid Beigy Sharif University of Technology Fall 1395 Hamid Beigy (Sharif University of Technology) Data Mining Fall 1395 1 / 15 Table of contents 1 Introduction 2 Data preprocessing
Data Mining Data preprocessing Hamid Beigy Sharif University of Technology Fall 1395 Hamid Beigy (Sharif University of Technology) Data Mining Fall 1395 1 / 15 Table of contents 1 Introduction 2 Data preprocessing
Data Mining. Data preprocessing. Hamid Beigy. Sharif University of Technology. Fall 1394
 Data Mining Data preprocessing Hamid Beigy Sharif University of Technology Fall 1394 Hamid Beigy (Sharif University of Technology) Data Mining Fall 1394 1 / 15 Table of contents 1 Introduction 2 Data preprocessing
Data Mining Data preprocessing Hamid Beigy Sharif University of Technology Fall 1394 Hamid Beigy (Sharif University of Technology) Data Mining Fall 1394 1 / 15 Table of contents 1 Introduction 2 Data preprocessing
Data Mining and Analytics. Introduction
 Data Mining and Analytics Introduction Data Mining Data mining refers to extracting or mining knowledge from large amounts of data It is also termed as Knowledge Discovery from Data (KDD) Mostly, data
Data Mining and Analytics Introduction Data Mining Data mining refers to extracting or mining knowledge from large amounts of data It is also termed as Knowledge Discovery from Data (KDD) Mostly, data
Data Preprocessing. S1 Teknik Informatika Fakultas Teknologi Informasi Universitas Kristen Maranatha
 Data Preprocessing S1 Teknik Informatika Fakultas Teknologi Informasi Universitas Kristen Maranatha 1 Why Data Preprocessing? Data in the real world is dirty incomplete: lacking attribute values, lacking
Data Preprocessing S1 Teknik Informatika Fakultas Teknologi Informasi Universitas Kristen Maranatha 1 Why Data Preprocessing? Data in the real world is dirty incomplete: lacking attribute values, lacking
CS 521 Data Mining Techniques Instructor: Abdullah Mueen
 CS 521 Data Mining Techniques Instructor: Abdullah Mueen LECTURE 2: DATA TRANSFORMATION AND DIMENSIONALITY REDUCTION Chapter 3: Data Preprocessing Data Preprocessing: An Overview Data Quality Major Tasks
CS 521 Data Mining Techniques Instructor: Abdullah Mueen LECTURE 2: DATA TRANSFORMATION AND DIMENSIONALITY REDUCTION Chapter 3: Data Preprocessing Data Preprocessing: An Overview Data Quality Major Tasks
ECT7110. Data Preprocessing. Prof. Wai Lam. ECT7110 Data Preprocessing 1
 ECT7110 Data Preprocessing Prof. Wai Lam ECT7110 Data Preprocessing 1 Why Data Preprocessing? Data in the real world is dirty incomplete: lacking attribute values, lacking certain attributes of interest,
ECT7110 Data Preprocessing Prof. Wai Lam ECT7110 Data Preprocessing 1 Why Data Preprocessing? Data in the real world is dirty incomplete: lacking attribute values, lacking certain attributes of interest,
K236: Basis of Data Science
 Schedule of K236 K236: Basis of Data Science Lecture 6: Data Preprocessing Lecturer: Tu Bao Ho and Hieu Chi Dam TA: Moharasan Gandhimathi and Nuttapong Sanglerdsinlapachai 1. Introduction to data science
Schedule of K236 K236: Basis of Data Science Lecture 6: Data Preprocessing Lecturer: Tu Bao Ho and Hieu Chi Dam TA: Moharasan Gandhimathi and Nuttapong Sanglerdsinlapachai 1. Introduction to data science
Data Mining: Concepts and Techniques. (3 rd ed.) Chapter 3. Chapter 3: Data Preprocessing. Major Tasks in Data Preprocessing
 Chapter 3. Chapter 3: Data Preprocessing. Major Tasks in Data Preprocessing") Data Mining: Concepts and Techniques (3 rd ed.) Chapter 3 1 Chapter 3: Data Preprocessing Data Preprocessing: An Overview Data Quality Major Tasks in Data Preprocessing Data Cleaning Data Integration Data
Data Mining: Concepts and Techniques (3 rd ed.) Chapter 3 1 Chapter 3: Data Preprocessing Data Preprocessing: An Overview Data Quality Major Tasks in Data Preprocessing Data Cleaning Data Integration Data
UNIT 2. DATA PREPROCESSING AND ASSOCIATION RULES
 UNIT 2. DATA PREPROCESSING AND ASSOCIATION RULES Data Pre-processing-Data Cleaning, Integration, Transformation, Reduction, Discretization Concept Hierarchies-Concept Description: Data Generalization And
UNIT 2. DATA PREPROCESSING AND ASSOCIATION RULES Data Pre-processing-Data Cleaning, Integration, Transformation, Reduction, Discretization Concept Hierarchies-Concept Description: Data Generalization And
Data preprocessing Functional Programming and Intelligent Algorithms
 Data preprocessing Functional Programming and Intelligent Algorithms Que Tran Høgskolen i Ålesund 20th March 2017 1 Why data preprocessing? Real-world data tend to be dirty incomplete: lacking attribute
Data preprocessing Functional Programming and Intelligent Algorithms Que Tran Høgskolen i Ålesund 20th March 2017 1 Why data preprocessing? Real-world data tend to be dirty incomplete: lacking attribute
cse634 Data Mining Preprocessing Lecture Notes Chapter 2 Professor Anita Wasilewska
 cse634 Data Mining Preprocessing Lecture Notes Chapter 2 Professor Anita Wasilewska Chapter 2: Data Preprocessing (book slide) Why preprocess the data? Descriptive data summarization Data cleaning Data
cse634 Data Mining Preprocessing Lecture Notes Chapter 2 Professor Anita Wasilewska Chapter 2: Data Preprocessing (book slide) Why preprocess the data? Descriptive data summarization Data cleaning Data
Data Mining: Concepts and Techniques. (3 rd ed.) Chapter 3
 Chapter 3") Data Mining: Concepts and Techniques (3 rd ed.) Chapter 3 Jiawei Han, Micheline Kamber, and Jian Pei University of Illinois at Urbana-Champaign & Simon Fraser University 2011 Han, Kamber & Pei. All rights
Data Mining: Concepts and Techniques (3 rd ed.) Chapter 3 Jiawei Han, Micheline Kamber, and Jian Pei University of Illinois at Urbana-Champaign & Simon Fraser University 2011 Han, Kamber & Pei. All rights
Information Management course
 Università degli Studi di Milano Master Degree in Computer Science Information Management course Teacher: Alberto Ceselli Lecture 03 : 13/10/2015 Data Mining: Concepts and Techniques (3 rd ed.) Chapter
Università degli Studi di Milano Master Degree in Computer Science Information Management course Teacher: Alberto Ceselli Lecture 03 : 13/10/2015 Data Mining: Concepts and Techniques (3 rd ed.) Chapter
Road Map. Data types Measuring data Data cleaning Data integration Data transformation Data reduction Data discretization Summary
 2. Data preprocessing Road Map Data types Measuring data Data cleaning Data integration Data transformation Data reduction Data discretization Summary 2 Data types Categorical vs. Numerical Scale types
2. Data preprocessing Road Map Data types Measuring data Data cleaning Data integration Data transformation Data reduction Data discretization Summary 2 Data types Categorical vs. Numerical Scale types
Chapter 2 Data Preprocessing
 Chapter 2 Data Preprocessing CISC4631 1 Outline General data characteristics Data cleaning Data integration and transformation Data reduction Summary CISC4631 2 1 Types of Data Sets Record Relational records
Chapter 2 Data Preprocessing CISC4631 1 Outline General data characteristics Data cleaning Data integration and transformation Data reduction Summary CISC4631 2 1 Types of Data Sets Record Relational records
ECLT 5810 Data Preprocessing. Prof. Wai Lam
 ECLT 5810 Data Preprocessing Prof. Wai Lam Why Data Preprocessing? Data in the real world is imperfect incomplete: lacking attribute values, lacking certain attributes of interest, or containing only aggregate
ECLT 5810 Data Preprocessing Prof. Wai Lam Why Data Preprocessing? Data in the real world is imperfect incomplete: lacking attribute values, lacking certain attributes of interest, or containing only aggregate
Data Preprocessing. Outline. Motivation. How did this happen?
 Outline Data Preprocessing Motivation Data cleaning Data integration and transformation Data reduction Discretization and hierarchy generation Summary CS 5331 by Rattikorn Hewett Texas Tech University
Outline Data Preprocessing Motivation Data cleaning Data integration and transformation Data reduction Discretization and hierarchy generation Summary CS 5331 by Rattikorn Hewett Texas Tech University
DATA PREPROCESSING. Tzompanaki Katerina
 DATA PREPROCESSING Tzompanaki Katerina Background: Data storage formats Data in DBMS ODBC, JDBC protocols Data in flat files Fixed-width format (each column has a specific number of characters, filled
DATA PREPROCESSING Tzompanaki Katerina Background: Data storage formats Data in DBMS ODBC, JDBC protocols Data in flat files Fixed-width format (each column has a specific number of characters, filled
2 CONTENTS. 3.8 Bibliographic Notes... 45
 Contents 3 Data Preprocessing 3 3.1 Data Preprocessing: An Overview................. 4 3.1.1 Data Quality: Why Preprocess the Data?......... 4 3.1.2 Major Tasks in Data Preprocessing............. 5 3.2
Contents 3 Data Preprocessing 3 3.1 Data Preprocessing: An Overview................. 4 3.1.1 Data Quality: Why Preprocess the Data?......... 4 3.1.2 Major Tasks in Data Preprocessing............. 5 3.2
Data Preprocessing. Erwin M. Bakker & Stefan Manegold. https://homepages.cwi.nl/~manegold/dbdm/
 Data Preprocessing Erwin M. Bakker & Stefan Manegold https://homepages.cwi.nl/~manegold/dbdm/ http://liacs.leidenuniv.nl/~bakkerem2/dbdm/ s.manegold@liacs.leidenuniv.nl e.m.bakker@liacs.leidenuniv.nl 9/26/17
Data Preprocessing Erwin M. Bakker & Stefan Manegold https://homepages.cwi.nl/~manegold/dbdm/ http://liacs.leidenuniv.nl/~bakkerem2/dbdm/ s.manegold@liacs.leidenuniv.nl e.m.bakker@liacs.leidenuniv.nl 9/26/17
A Survey on Data Preprocessing Techniques for Bioinformatics and Web Usage Mining
 Volume 117 No. 20 2017, 785-794 ISSN: 1311-8080 (printed version); ISSN: 1314-3395 (on-line version) url: http://www.ijpam.eu ijpam.eu A Survey on Data Preprocessing Techniques for Bioinformatics and Web
Volume 117 No. 20 2017, 785-794 ISSN: 1311-8080 (printed version); ISSN: 1314-3395 (on-line version) url: http://www.ijpam.eu ijpam.eu A Survey on Data Preprocessing Techniques for Bioinformatics and Web
Data Preprocessing. Data Mining: Concepts and Techniques. c 2012 Elsevier Inc. All rights reserved.
 3 Data Preprocessing Today s real-world databases are highly susceptible to noisy, missing, and inconsistent data due to their typically huge size (often several gigabytes or more) and their likely origin
3 Data Preprocessing Today s real-world databases are highly susceptible to noisy, missing, and inconsistent data due to their typically huge size (often several gigabytes or more) and their likely origin
DEPARTMENT OF INFORMATION TECHNOLOGY IT6702 DATA WAREHOUSING & DATA MINING
 DEPARTMENT OF INFORMATION TECHNOLOGY IT6702 DATA WAREHOUSING & DATA MINING UNIT I PART A 1. Define data mining? Data mining refers to extracting or mining" knowledge from large amounts of data and another
DEPARTMENT OF INFORMATION TECHNOLOGY IT6702 DATA WAREHOUSING & DATA MINING UNIT I PART A 1. Define data mining? Data mining refers to extracting or mining" knowledge from large amounts of data and another
Data Mining: Concepts and Techniques. (3 rd ed.) Chapter 3
 Chapter 3") Data Mining: Concepts and Techniques (3 rd ed.) Chapter 3 Jiawei Han, Micheline Kamber, and Jian Pei University of Illinois at Urbana-Champaign & Simon Fraser University 2013 Han, Kamber & Pei. All rights
Data Mining: Concepts and Techniques (3 rd ed.) Chapter 3 Jiawei Han, Micheline Kamber, and Jian Pei University of Illinois at Urbana-Champaign & Simon Fraser University 2013 Han, Kamber & Pei. All rights
Data Mining: Concepts and Techniques
 Data Mining: Concepts and Techniques Chapter 2 Original Slides: Jiawei Han and Micheline Kamber Modification: Li Xiong Data Mining: Concepts and Techniques 1 Chapter 2: Data Preprocessing Why preprocess
Data Mining: Concepts and Techniques Chapter 2 Original Slides: Jiawei Han and Micheline Kamber Modification: Li Xiong Data Mining: Concepts and Techniques 1 Chapter 2: Data Preprocessing Why preprocess
CS6220: DATA MINING TECHNIQUES
 CS6220: DATA MINING TECHNIQUES 2: Data Pre-Processing Instructor: Yizhou Sun yzsun@ccs.neu.edu September 10, 2013 2: Data Pre-Processing Getting to know your data Basic Statistical Descriptions of Data
CS6220: DATA MINING TECHNIQUES 2: Data Pre-Processing Instructor: Yizhou Sun yzsun@ccs.neu.edu September 10, 2013 2: Data Pre-Processing Getting to know your data Basic Statistical Descriptions of Data
Data Mining. 2.4 Data Integration. Fall Instructor: Dr. Masoud Yaghini. Data Integration
 Data Mining 2.4 Fall 2008 Instructor: Dr. Masoud Yaghini Data integration: Combines data from multiple databases into a coherent store Denormalization tables (often done to improve performance by avoiding
Data Mining 2.4 Fall 2008 Instructor: Dr. Masoud Yaghini Data integration: Combines data from multiple databases into a coherent store Denormalization tables (often done to improve performance by avoiding
Data Preprocessing. Chapter Why Preprocess the Data?
 Contents 2 Data Preprocessing 3 2.1 Why Preprocess the Data?........................................ 3 2.2 Descriptive Data Summarization..................................... 6 2.2.1 Measuring the Central
Contents 2 Data Preprocessing 3 2.1 Why Preprocess the Data?........................................ 3 2.2 Descriptive Data Summarization..................................... 6 2.2.1 Measuring the Central
Data Mining: Concepts and Techniques. Chapter 2
 Data Mining: Concepts and Techniques Chapter 2 Jiawei Han Department of Computer Science University of Illinois at Urbana-Champaign www.cs.uiuc.edu/~hanj 2006 Jiawei Han and Micheline Kamber, All rights
Data Mining: Concepts and Techniques Chapter 2 Jiawei Han Department of Computer Science University of Illinois at Urbana-Champaign www.cs.uiuc.edu/~hanj 2006 Jiawei Han and Micheline Kamber, All rights
Sponsored by AIAT.or.th and KINDML, SIIT
 CC: BY NC ND Table of Contents Chapter 2. Data Preprocessing... 31 2.1. Basic Representation for Data: Database Viewpoint... 31 2.2. Data Preprocessing in the Database Point of View... 33 2.3. Data Cleaning...
CC: BY NC ND Table of Contents Chapter 2. Data Preprocessing... 31 2.1. Basic Representation for Data: Database Viewpoint... 31 2.2. Data Preprocessing in the Database Point of View... 33 2.3. Data Cleaning...
Data Preprocessing. Data Preprocessing
 Data Preprocessing Dr. Sanjay Ranka Professor Computer and Information Science and Engineering University of Florida, Gainesville ranka@cise.ufl.edu Data Preprocessing What preprocessing step can or should
Data Preprocessing Dr. Sanjay Ranka Professor Computer and Information Science and Engineering University of Florida, Gainesville ranka@cise.ufl.edu Data Preprocessing What preprocessing step can or should
University of Florida CISE department Gator Engineering. Data Preprocessing. Dr. Sanjay Ranka
 Data Preprocessing Dr. Sanjay Ranka Professor Computer and Information Science and Engineering University of Florida, Gainesville ranka@cise.ufl.edu Data Preprocessing What preprocessing step can or should
Data Preprocessing Dr. Sanjay Ranka Professor Computer and Information Science and Engineering University of Florida, Gainesville ranka@cise.ufl.edu Data Preprocessing What preprocessing step can or should
2. (a) Briefly discuss the forms of Data preprocessing with neat diagram. (b) Explain about concept hierarchy generation for categorical data.
 Briefly discuss the forms of Data preprocessing with neat diagram. (b) Explain about concept hierarchy generation for categorical data.") Code No: M0502/R05 Set No. 1 1. (a) Explain data mining as a step in the process of knowledge discovery. (b) Differentiate operational database systems and data warehousing. [8+8] 2. (a) Briefly discuss
Code No: M0502/R05 Set No. 1 1. (a) Explain data mining as a step in the process of knowledge discovery. (b) Differentiate operational database systems and data warehousing. [8+8] 2. (a) Briefly discuss
Cse634 DATA MINING TEST REVIEW. Professor Anita Wasilewska Computer Science Department Stony Brook University
 Cse634 DATA MINING TEST REVIEW Professor Anita Wasilewska Computer Science Department Stony Brook University Preprocessing stage Preprocessing: includes all the operations that have to be performed before
Cse634 DATA MINING TEST REVIEW Professor Anita Wasilewska Computer Science Department Stony Brook University Preprocessing stage Preprocessing: includes all the operations that have to be performed before
Jarek Szlichta
 Jarek Szlichta http://data.science.uoit.ca/ Open data Business Data Web Data Available at different formats 2 Data Scientist: The Sexiest Job of the 21 st Century Harvard Business Review Oct. 2012 (c)
Jarek Szlichta http://data.science.uoit.ca/ Open data Business Data Web Data Available at different formats 2 Data Scientist: The Sexiest Job of the 21 st Century Harvard Business Review Oct. 2012 (c)
Data Preprocessing in Python. Prof.Sushila Aghav
 Data Preprocessing in Python Prof.Sushila Aghav Sushila.aghav@mitcoe.edu.in Content Why preprocess the data? Descriptive data summarization Data cleaning Data integration and transformation April 24, 2018
Data Preprocessing in Python Prof.Sushila Aghav Sushila.aghav@mitcoe.edu.in Content Why preprocess the data? Descriptive data summarization Data cleaning Data integration and transformation April 24, 2018
BBS654 Data Mining. Pinar Duygulu. Slides are adapted from Nazli Ikizler, Sanjay Ranka
 BBS654 Data Mining Pinar Duygulu Slides are adapted from Nazli Ikizler, Sanjay Ranka Topics What is data? Definitions, terminology Types of data and datasets Data preprocessing Data Cleaning Data integration
BBS654 Data Mining Pinar Duygulu Slides are adapted from Nazli Ikizler, Sanjay Ranka Topics What is data? Definitions, terminology Types of data and datasets Data preprocessing Data Cleaning Data integration
Data Mining. 3.2 Decision Tree Classifier. Fall Instructor: Dr. Masoud Yaghini. Chapter 5: Decision Tree Classifier
 Data Mining 3.2 Decision Tree Classifier Fall 2008 Instructor: Dr. Masoud Yaghini Outline Introduction Basic Algorithm for Decision Tree Induction Attribute Selection Measures Information Gain Gain Ratio
Data Mining 3.2 Decision Tree Classifier Fall 2008 Instructor: Dr. Masoud Yaghini Outline Introduction Basic Algorithm for Decision Tree Induction Attribute Selection Measures Information Gain Gain Ratio
Data Collection, Preprocessing and Implementation
 Chapter 6 Data Collection, Preprocessing and Implementation 6.1 Introduction Data collection is the loosely controlled method of gathering the data. Such data are mostly out of range, impossible data combinations,
Chapter 6 Data Collection, Preprocessing and Implementation 6.1 Introduction Data collection is the loosely controlled method of gathering the data. Such data are mostly out of range, impossible data combinations,
CS4445 Data Mining and Knowledge Discovery in Databases. A Term 2008 Exam 2 October 14, 2008
 CS4445 Data Mining and Knowledge Discovery in Databases. A Term 2008 Exam 2 October 14, 2008 Prof. Carolina Ruiz Department of Computer Science Worcester Polytechnic Institute NAME: Prof. Ruiz Problem
CS4445 Data Mining and Knowledge Discovery in Databases. A Term 2008 Exam 2 October 14, 2008 Prof. Carolina Ruiz Department of Computer Science Worcester Polytechnic Institute NAME: Prof. Ruiz Problem
Data Mining: Data. Lecture Notes for Chapter 2. Introduction to Data Mining
 Data Mining: Data Lecture Notes for Chapter 2 Introduction to Data Mining by Tan, Steinbach, Kumar Data Preprocessing Aggregation Sampling Dimensionality Reduction Feature subset selection Feature creation
Data Mining: Data Lecture Notes for Chapter 2 Introduction to Data Mining by Tan, Steinbach, Kumar Data Preprocessing Aggregation Sampling Dimensionality Reduction Feature subset selection Feature creation
Data Preparation. Data Preparation. (Data pre-processing) Why Prepare Data? Why Prepare Data? Some data preparation is needed for all mining tools
 Why Prepare Data? Why Prepare Data? Some data preparation is needed for all mining tools") Data Preparation Data Preparation (Data pre-processing) Why prepare the data? Discretization Data cleaning Data integration and transformation Data reduction, Feature selection 2 Why Prepare Data? Why
Data Preparation Data Preparation (Data pre-processing) Why prepare the data? Discretization Data cleaning Data integration and transformation Data reduction, Feature selection 2 Why Prepare Data? Why
Data Mining Concepts & Techniques
 Data Mining Concepts & Techniques Lecture No. 02 Data Processing, Data Mining Naeem Ahmed Email: naeemmahoto@gmail.com Department of Software Engineering Mehran Univeristy of Engineering and Technology
Data Mining Concepts & Techniques Lecture No. 02 Data Processing, Data Mining Naeem Ahmed Email: naeemmahoto@gmail.com Department of Software Engineering Mehran Univeristy of Engineering and Technology
Table Of Contents: xix Foreword to Second Edition
 Data Mining : Concepts and Techniques Table Of Contents: Foreword xix Foreword to Second Edition xxi Preface xxiii Acknowledgments xxxi About the Authors xxxv Chapter 1 Introduction 1 (38) 1.1 Why Data
Data Mining : Concepts and Techniques Table Of Contents: Foreword xix Foreword to Second Edition xxi Preface xxiii Acknowledgments xxxi About the Authors xxxv Chapter 1 Introduction 1 (38) 1.1 Why Data
Data Mining: Concepts and Techniques Classification and Prediction Chapter 6.1-3
 Data Mining: Concepts and Techniques Classification and Prediction Chapter 6.1-3 January 25, 2007 CSE-4412: Data Mining 1 Chapter 6 Classification and Prediction 1. What is classification? What is prediction?
Data Mining: Concepts and Techniques Classification and Prediction Chapter 6.1-3 January 25, 2007 CSE-4412: Data Mining 1 Chapter 6 Classification and Prediction 1. What is classification? What is prediction?
Contents. Foreword to Second Edition. Acknowledgments About the Authors
 Contents Foreword xix Foreword to Second Edition xxi Preface xxiii Acknowledgments About the Authors xxxi xxxv Chapter 1 Introduction 1 1.1 Why Data Mining? 1 1.1.1 Moving toward the Information Age 1
Contents Foreword xix Foreword to Second Edition xxi Preface xxiii Acknowledgments About the Authors xxxi xxxv Chapter 1 Introduction 1 1.1 Why Data Mining? 1 1.1.1 Moving toward the Information Age 1
Web Information Retrieval
 Lucian Blaga University of Sibiu Hermann Oberth Engineering Faculty Computer Science Department Web Information Retrieval First Technical Report PhD title: Data Mining for unstructured data Author: Daniel
Lucian Blaga University of Sibiu Hermann Oberth Engineering Faculty Computer Science Department Web Information Retrieval First Technical Report PhD title: Data Mining for unstructured data Author: Daniel
Data Engineering. Data preprocessing and transformation
 Data Engineering Data preprocessing and transformation Just apply a learner? NO! Algorithms are biased No free lunch theorem: considering all possible data distributions, no algorithm is better than another
Data Engineering Data preprocessing and transformation Just apply a learner? NO! Algorithms are biased No free lunch theorem: considering all possible data distributions, no algorithm is better than another
DEPARTMENT OF COMPUTER SCIENCE AND ENGINEERING
 SHRI ANGALAMMAN COLLEGE OF ENGINEERING & TECHNOLOGY (An ISO 9001:2008 Certified Institution) SIRUGANOOR,TRICHY-621105. DEPARTMENT OF COMPUTER SCIENCE AND ENGINEERING Year / Semester: IV/VII CS1011-DATA
SHRI ANGALAMMAN COLLEGE OF ENGINEERING & TECHNOLOGY (An ISO 9001:2008 Certified Institution) SIRUGANOOR,TRICHY-621105. DEPARTMENT OF COMPUTER SCIENCE AND ENGINEERING Year / Semester: IV/VII CS1011-DATA
Slides for Data Mining by I. H. Witten and E. Frank
 Slides for Data Mining by I. H. Witten and E. Frank 7 Engineering the input and output Attribute selection Scheme-independent, scheme-specific Attribute discretization Unsupervised, supervised, error-
Slides for Data Mining by I. H. Witten and E. Frank 7 Engineering the input and output Attribute selection Scheme-independent, scheme-specific Attribute discretization Unsupervised, supervised, error-
Data Warehousing and Machine Learning
 Data Warehousing and Machine Learning Preprocessing Thomas D. Nielsen Aalborg University Department of Computer Science Spring 2008 DWML Spring 2008 1 / 35 Preprocessing Before you can start on the actual
Data Warehousing and Machine Learning Preprocessing Thomas D. Nielsen Aalborg University Department of Computer Science Spring 2008 DWML Spring 2008 1 / 35 Preprocessing Before you can start on the actual
ECLT 5810 Clustering
 ECLT 5810 Clustering What is Cluster Analysis? Cluster: a collection of data objects Similar to one another within the same cluster Dissimilar to the objects in other clusters Cluster analysis Grouping
ECLT 5810 Clustering What is Cluster Analysis? Cluster: a collection of data objects Similar to one another within the same cluster Dissimilar to the objects in other clusters Cluster analysis Grouping
Preprocessing DWML, /33
 Preprocessing DWML, 2007 1/33 Preprocessing Before you can start on the actual data mining, the data may require some preprocessing: Attributes may be redundant. Values may be missing. The data contains
Preprocessing DWML, 2007 1/33 Preprocessing Before you can start on the actual data mining, the data may require some preprocessing: Attributes may be redundant. Values may be missing. The data contains
Clustering in Data Mining
 Clustering in Data Mining Classification Vs Clustering When the distribution is based on a single parameter and that parameter is known for each object, it is called classification. E.g. Children, young,
Clustering in Data Mining Classification Vs Clustering When the distribution is based on a single parameter and that parameter is known for each object, it is called classification. E.g. Children, young,
MIT 801. Machine Learning I. [Presented by Anna Bosman] 16 February 2018
![MIT 801. Machine Learning I. [Presented by Anna Bosman] 16 February 2018](/thumbs/77/76295965.jpg "MIT 801. Machine Learning I. [Presented by Anna Bosman] 16 February 2018") MIT 801 [Presented by Anna Bosman] 16 February 2018 Machine Learning What is machine learning? Artificial Intelligence? Yes as we know it. What is intelligence? The ability to acquire and apply knowledge
MIT 801 [Presented by Anna Bosman] 16 February 2018 Machine Learning What is machine learning? Artificial Intelligence? Yes as we know it. What is intelligence? The ability to acquire and apply knowledge
COMP 465: Data Mining Classification Basics
 Supervised vs. Unsupervised Learning COMP 465: Data Mining Classification Basics Slides Adapted From : Jiawei Han, Micheline Kamber & Jian Pei Data Mining: Concepts and Techniques, 3 rd ed. Supervised
Supervised vs. Unsupervised Learning COMP 465: Data Mining Classification Basics Slides Adapted From : Jiawei Han, Micheline Kamber & Jian Pei Data Mining: Concepts and Techniques, 3 rd ed. Supervised
ECLT 5810 Clustering
 ECLT 5810 Clustering What is Cluster Analysis? Cluster: a collection of data objects Similar to one another within the same cluster Dissimilar to the objects in other clusters Cluster analysis Grouping
ECLT 5810 Clustering What is Cluster Analysis? Cluster: a collection of data objects Similar to one another within the same cluster Dissimilar to the objects in other clusters Cluster analysis Grouping
Analyse des Données. Master 2 IMAFA. Andrea G. B. Tettamanzi
 Analyse des Données Master 2 IMAFA Andrea G. B. Tettamanzi Université Nice Sophia Antipolis UFR Sciences - Département Informatique andrea.tettamanzi@unice.fr Andrea G. B. Tettamanzi, 2016 1 CM - Séance
Analyse des Données Master 2 IMAFA Andrea G. B. Tettamanzi Université Nice Sophia Antipolis UFR Sciences - Département Informatique andrea.tettamanzi@unice.fr Andrea G. B. Tettamanzi, 2016 1 CM - Séance
Data Mining Course Overview
 Data Mining Course Overview 1 Data Mining Overview Understanding Data Classification: Decision Trees and Bayesian classifiers, ANN, SVM Association Rules Mining: APriori, FP-growth Clustering: Hierarchical
Data Mining Course Overview 1 Data Mining Overview Understanding Data Classification: Decision Trees and Bayesian classifiers, ANN, SVM Association Rules Mining: APriori, FP-growth Clustering: Hierarchical
Analytical model A structure and process for analyzing a dataset. For example, a decision tree is a model for the classification of a dataset.
 Glossary of data mining terms: Accuracy Accuracy is an important factor in assessing the success of data mining. When applied to data, accuracy refers to the rate of correct values in the data. When applied
Glossary of data mining terms: Accuracy Accuracy is an important factor in assessing the success of data mining. When applied to data, accuracy refers to the rate of correct values in the data. When applied
CT75 (ALCCS) DATA WAREHOUSING AND DATA MINING JUN
 DATA WAREHOUSING AND DATA MINING JUN") Q.1 a. Define a Data warehouse. Compare OLTP and OLAP systems. Data Warehouse: A data warehouse is a subject-oriented, integrated, time-variant, and 2 Non volatile collection of data in support of management
Q.1 a. Define a Data warehouse. Compare OLTP and OLAP systems. Data Warehouse: A data warehouse is a subject-oriented, integrated, time-variant, and 2 Non volatile collection of data in support of management
Cse352 Artifficial Intelligence Short Review for Midterm. Professor Anita Wasilewska Computer Science Department Stony Brook University
 Cse352 Artifficial Intelligence Short Review for Midterm Professor Anita Wasilewska Computer Science Department Stony Brook University Midterm Midterm INCLUDES CLASSIFICATION CLASSIFOCATION by Decision
Cse352 Artifficial Intelligence Short Review for Midterm Professor Anita Wasilewska Computer Science Department Stony Brook University Midterm Midterm INCLUDES CLASSIFICATION CLASSIFOCATION by Decision
Data Preprocessing UE 141 Spring 2013
 Data Preprocessing UE 141 Spring 2013 Jing Gao SUNY Buffalo 1 Outline Data Data Preprocessing Improve data quality Prepare data for analysis Exploring Data Statistics Visualization 2 Document Data Each
Data Preprocessing UE 141 Spring 2013 Jing Gao SUNY Buffalo 1 Outline Data Data Preprocessing Improve data quality Prepare data for analysis Exploring Data Statistics Visualization 2 Document Data Each
Statistical Pattern Recognition
 Statistical Pattern Recognition Features and Feature Selection Hamid R. Rabiee Jafar Muhammadi Spring 2012 http://ce.sharif.edu/courses/90-91/2/ce725-1/ Agenda Features and Patterns The Curse of Size and
Statistical Pattern Recognition Features and Feature Selection Hamid R. Rabiee Jafar Muhammadi Spring 2012 http://ce.sharif.edu/courses/90-91/2/ce725-1/ Agenda Features and Patterns The Curse of Size and
Statistical Pattern Recognition
 Statistical Pattern Recognition Features and Feature Selection Hamid R. Rabiee Jafar Muhammadi Spring 2014 http://ce.sharif.edu/courses/92-93/2/ce725-2/ Agenda Features and Patterns The Curse of Size and
Statistical Pattern Recognition Features and Feature Selection Hamid R. Rabiee Jafar Muhammadi Spring 2014 http://ce.sharif.edu/courses/92-93/2/ce725-2/ Agenda Features and Patterns The Curse of Size and
Data Mining: Exploring Data. Lecture Notes for Chapter 3
 Data Mining: Exploring Data Lecture Notes for Chapter 3 1 What is data exploration? A preliminary exploration of the data to better understand its characteristics. Key motivations of data exploration include
Data Mining: Exploring Data Lecture Notes for Chapter 3 1 What is data exploration? A preliminary exploration of the data to better understand its characteristics. Key motivations of data exploration include
MSA220 - Statistical Learning for Big Data
 MSA220 - Statistical Learning for Big Data Lecture 13 Rebecka Jörnsten Mathematical Sciences University of Gothenburg and Chalmers University of Technology Clustering Explorative analysis - finding groups
MSA220 - Statistical Learning for Big Data Lecture 13 Rebecka Jörnsten Mathematical Sciences University of Gothenburg and Chalmers University of Technology Clustering Explorative analysis - finding groups
This tutorial has been prepared for computer science graduates to help them understand the basic-to-advanced concepts related to data mining.
 About the Tutorial Data Mining is defined as the procedure of extracting information from huge sets of data. In other words, we can say that data mining is mining knowledge from data. The tutorial starts
About the Tutorial Data Mining is defined as the procedure of extracting information from huge sets of data. In other words, we can say that data mining is mining knowledge from data. The tutorial starts
Basic Data Mining Technique
 Basic Data Mining Technique What is classification? What is prediction? Supervised and Unsupervised Learning Decision trees Association rule K-nearest neighbor classifier Case-based reasoning Genetic algorithm
Basic Data Mining Technique What is classification? What is prediction? Supervised and Unsupervised Learning Decision trees Association rule K-nearest neighbor classifier Case-based reasoning Genetic algorithm
Gene Clustering & Classification
 BINF, Introduction to Computational Biology Gene Clustering & Classification Young-Rae Cho Associate Professor Department of Computer Science Baylor University Overview Introduction to Gene Clustering
BINF, Introduction to Computational Biology Gene Clustering & Classification Young-Rae Cho Associate Professor Department of Computer Science Baylor University Overview Introduction to Gene Clustering
Feature Selection. CE-725: Statistical Pattern Recognition Sharif University of Technology Spring Soleymani
 Feature Selection CE-725: Statistical Pattern Recognition Sharif University of Technology Spring 2013 Soleymani Outline Dimensionality reduction Feature selection vs. feature extraction Filter univariate
Feature Selection CE-725: Statistical Pattern Recognition Sharif University of Technology Spring 2013 Soleymani Outline Dimensionality reduction Feature selection vs. feature extraction Filter univariate
Data Mining: Exploring Data. Lecture Notes for Chapter 3. Introduction to Data Mining
 Data Mining: Exploring Data Lecture Notes for Chapter 3 Introduction to Data Mining by Tan, Steinbach, Kumar What is data exploration? A preliminary exploration of the data to better understand its characteristics.
Data Mining: Exploring Data Lecture Notes for Chapter 3 Introduction to Data Mining by Tan, Steinbach, Kumar What is data exploration? A preliminary exploration of the data to better understand its characteristics.
Supervised vs. Unsupervised Learning
 Clustering Supervised vs. Unsupervised Learning So far we have assumed that the training samples used to design the classifier were labeled by their class membership (supervised learning) We assume now
Clustering Supervised vs. Unsupervised Learning So far we have assumed that the training samples used to design the classifier were labeled by their class membership (supervised learning) We assume now
Data Mining: Exploring Data. Lecture Notes for Data Exploration Chapter. Introduction to Data Mining
 Data Mining: Exploring Data Lecture Notes for Data Exploration Chapter Introduction to Data Mining by Tan, Steinbach, Karpatne, Kumar 02/03/2018 Introduction to Data Mining 1 What is data exploration?
Data Mining: Exploring Data Lecture Notes for Data Exploration Chapter Introduction to Data Mining by Tan, Steinbach, Karpatne, Kumar 02/03/2018 Introduction to Data Mining 1 What is data exploration?
GUJARAT TECHNOLOGICAL UNIVERSITY MASTER OF COMPUTER APPLICATIONS (MCA) Semester: IV
 Semester: IV") GUJARAT TECHNOLOGICAL UNIVERSITY MASTER OF COMPUTER APPLICATIONS (MCA) Semester: IV Subject Name: Elective I Data Warehousing & Data Mining (DWDM) Subject Code: 2640005 Learning Objectives: To understand
GUJARAT TECHNOLOGICAL UNIVERSITY MASTER OF COMPUTER APPLICATIONS (MCA) Semester: IV Subject Name: Elective I Data Warehousing & Data Mining (DWDM) Subject Code: 2640005 Learning Objectives: To understand
Lecture 7: Decision Trees
 Lecture 7: Decision Trees Instructor: Outline 1 Geometric Perspective of Classification 2 Decision Trees Geometric Perspective of Classification Perspective of Classification Algorithmic Geometric Probabilistic...
Lecture 7: Decision Trees Instructor: Outline 1 Geometric Perspective of Classification 2 Decision Trees Geometric Perspective of Classification Perspective of Classification Algorithmic Geometric Probabilistic...
DI TRANSFORM. The regressive analyses. identify relationships
 July 2, 2015 DI TRANSFORM MVstats TM Algorithm Overview Summary The DI Transform Multivariate Statistics (MVstats TM ) package includes five algorithm options that operate on most types of geologic, geophysical,
July 2, 2015 DI TRANSFORM MVstats TM Algorithm Overview Summary The DI Transform Multivariate Statistics (MVstats TM ) package includes five algorithm options that operate on most types of geologic, geophysical,
Question Bank. 4) It is the source of information later delivered to data marts.
 It is the source of information later delivered to data marts.") Question Bank Year: 2016-2017 Subject Dept: CS Semester: First Subject Name: Data Mining. Q1) What is data warehouse? ANS. A data warehouse is a subject-oriented, integrated, time-variant, and nonvolatile
Question Bank Year: 2016-2017 Subject Dept: CS Semester: First Subject Name: Data Mining. Q1) What is data warehouse? ANS. A data warehouse is a subject-oriented, integrated, time-variant, and nonvolatile
CMPUT 391 Database Management Systems. Data Mining. Textbook: Chapter (without 17.10)
") CMPUT 391 Database Management Systems Data Mining Textbook: Chapter 17.7-17.11 (without 17.10) University of Alberta 1 Overview Motivation KDD and Data Mining Association Rules Clustering Classification
CMPUT 391 Database Management Systems Data Mining Textbook: Chapter 17.7-17.11 (without 17.10) University of Alberta 1 Overview Motivation KDD and Data Mining Association Rules Clustering Classification
Clustering and Visualisation of Data
 Clustering and Visualisation of Data Hiroshi Shimodaira January-March 28 Cluster analysis aims to partition a data set into meaningful or useful groups, based on distances between data points. In some
Clustering and Visualisation of Data Hiroshi Shimodaira January-March 28 Cluster analysis aims to partition a data set into meaningful or useful groups, based on distances between data points. In some
Code No: R Set No. 1
 Code No: R05321204 Set No. 1 1. (a) Draw and explain the architecture for on-line analytical mining. (b) Briefly discuss the data warehouse applications. [8+8] 2. Briefly discuss the role of data cube
Code No: R05321204 Set No. 1 1. (a) Draw and explain the architecture for on-line analytical mining. (b) Briefly discuss the data warehouse applications. [8+8] 2. Briefly discuss the role of data cube
Data warehouses Decision support The multidimensional model OLAP queries
 Data warehouses Decision support The multidimensional model OLAP queries Traditional DBMSs are used by organizations for maintaining data to record day to day operations On-line Transaction Processing
Data warehouses Decision support The multidimensional model OLAP queries Traditional DBMSs are used by organizations for maintaining data to record day to day operations On-line Transaction Processing
Clustering Part 4 DBSCAN
 Clustering Part 4 Dr. Sanjay Ranka Professor Computer and Information Science and Engineering University of Florida, Gainesville DBSCAN DBSCAN is a density based clustering algorithm Density = number of
Clustering Part 4 Dr. Sanjay Ranka Professor Computer and Information Science and Engineering University of Florida, Gainesville DBSCAN DBSCAN is a density based clustering algorithm Density = number of
Preprocessing and Visualization. Jonathan Diehl
 RWTH Aachen University Chair of Computer Science VI Prof. Dr.-Ing. Hermann Ney Seminar Data Mining WS 2003/2004 Preprocessing and Visualization Jonathan Diehl January 19, 2004 onathan Diehl Preprocessing
RWTH Aachen University Chair of Computer Science VI Prof. Dr.-Ing. Hermann Ney Seminar Data Mining WS 2003/2004 Preprocessing and Visualization Jonathan Diehl January 19, 2004 onathan Diehl Preprocessing
SOCIAL MEDIA MINING. Data Mining Essentials
 SOCIAL MEDIA MINING Data Mining Essentials Dear instructors/users of these slides: Please feel free to include these slides in your own material, or modify them as you see fit. If you decide to incorporate
SOCIAL MEDIA MINING Data Mining Essentials Dear instructors/users of these slides: Please feel free to include these slides in your own material, or modify them as you see fit. If you decide to incorporate
What to come. There will be a few more topics we will cover on supervised learning
 Summary so far Supervised learning learn to predict Continuous target regression; Categorical target classification Linear Regression Classification Discriminative models Perceptron (linear) Logistic regression
Summary so far Supervised learning learn to predict Continuous target regression; Categorical target classification Linear Regression Classification Discriminative models Perceptron (linear) Logistic regression
Based on Raymond J. Mooney s slides
 Instance Based Learning Based on Raymond J. Mooney s slides University of Texas at Austin 1 Example 2 Instance-Based Learning Unlike other learning algorithms, does not involve construction of an explicit
Instance Based Learning Based on Raymond J. Mooney s slides University of Texas at Austin 1 Example 2 Instance-Based Learning Unlike other learning algorithms, does not involve construction of an explicit
Machine Learning Techniques for Data Mining
 Machine Learning Techniques for Data Mining Eibe Frank University of Waikato New Zealand 10/25/2000 1 PART VII Moving on: Engineering the input and output 10/25/2000 2 Applying a learner is not all Already
Machine Learning Techniques for Data Mining Eibe Frank University of Waikato New Zealand 10/25/2000 1 PART VII Moving on: Engineering the input and output 10/25/2000 2 Applying a learner is not all Already