UNIT-IV HDFS. Ms. Selva Mary. G
|
|
|
- Dominic Andrews
- 6 years ago
- Views:
Transcription
1 UNIT-IV HDFS
2 HDFS ARCHITECTURE Dataset partition across a number of separate machines Hadoop Distributed File system
3 The Design of HDFS HDFS is a file system designed for storing very large files with streaming data access patterns, running on clusters of commodity hardware. Very large files Very large means files that are hundreds of megabytes, gigabytes, or terabytes in size. There are Hadoop clusters running today that store petabytes of data.
4 Streaming data access most efficient data processing pattern is a write-once, read-many-times pattern. A dataset generated or copied from source, and then various analyses are performed on that dataset over time.
5 Commodity hardware Hadoop doesn t require expensive, highly reliable hardware. It s designed to run on clusters of commodity hardware (commonly available hardware that can be obtained from multiple vendors) for which the chance of node failure across the cluster is high, at least for large clusters.
6 Low-latency data access Applications that require low-latency access to data will not work well with HDFS. HDFS is optimized for delivering a high throughput of data, and this may be at the expense of latency. HBase is currently a better choice for lowlatency access.
7 Lots of small files Namenode holds file system the limit to the number of files in a file system is governed by the amount of memory on the namenode. As a rule of thumb, each file, directory, and block takes about 150 bytes.
8 Features of HDFS It is suitable for the distributed storage and processing. Hadoop provides a command interface to interact with HDFS. The built-in servers of namenode and datanode help users to easily check the status of cluster. HDFS provides file permissions and authentication.
9 Goals of HDFS Fault detection and recovery: Since HDFS includes a large number of commodity hardware, failure of components is frequent. Therefore HDFS should have mechanisms for quick and automatic fault detection and recovery. Huge datasets: HDFS should have hundreds of nodes per cluster Hardware at data: A requested task can be done efficiently, when the computation takes place near the data. Especially where huge datasets are involved, it reduces the network traffic and increases the throughput.
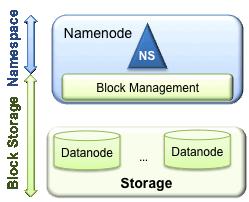
10 HDFS Architecture
11 Namenode The namenode is the commodity hardware that contains operating system and the namenode software. It is software that can be run on commodity hardware. The system having the namenode acts as the master server and it does the following tasks: Manages the file system Regulates client s access to files. It also executes file system operations such as renaming, closing, and opening files and directories.
12 Secondary Namenode HDFS is based on master/slave architecture. Simplifies the overall HDFS architecture. It also creates a single point of failure losing the NameNode effectively means losing HDFS. To somewhat alleviate this problem, Hadoop implements a Secondary NameNode.
13 The Secondary NameNode is not a backup NameNode. It cannot take over the primary NameNode s function. It serves as a checkpointing mechanism for the primary NameNode. In addition to storing the state of the HDFS NameNode, it maintains two on-disk data structures an image file and an edit log. The image file represents metadata state edit log is a transactional log of every filesystem metadata change since the image file was created.
14
15 Datanode The datanode is a commodity hardware having operating system and datanode software. For every node in a cluster, there will be a datanode. These nodes manage the data storage of their system. Datanodes perform read-write operations on the file systems, as per client request. They also perform operations such as block creation, deletion, and replication according to the instructions of the namenode.
16
17 Block A file will be divided into one or more segments and/or stored in individual data nodes. These file segments are called as blocks. In other words, the minimum amount of data that HDFS can read or write is called a Block. The default block size is 64MB, but it can be increased as per the need to change in HDFS configuration.
18 Block advantages First, a file can be larger than any single disk in the network Secondly, making the unit of abstraction a block rather than a file simplifies the storage subsystem (it is easy to calculate how many can be stored on a given disk) Furthermore, blocks fit well with replication for providing fault tolerance and availability. If a block becomes unavailable, a copy can be read from another location
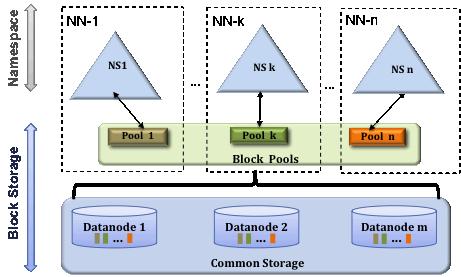
19 HDFS FEDERATION
20 Namespace Consists of directories, files and blocks. It supports file system operations such as create, delete, modify and list files and directories. Block Storage Service, which has two parts: Block Management (performed in the Namenode) Provides Datanode cluster membership by handling registrations Processes block reports and maintains location of blocks. Supports block related operations create, delete and get block location Manages replica placement, block replication Storage - is provided by Datanodes by storing blocks on the local file system and allowing read/write access.
21 The prior HDFS architecture allows only a single namespace for the entire cluster. a single Namenode manages the namespace. HDFS Federation addresses this limitation by adding support for multiple Namenodes/namespaces to HDFS.
22 Multiple Namenodes/Namespaces Federation uses multiple independent Namenodes/ namespaces. The Namenodes are federated; Namenodes are independent and do not require coordination with each other. The Datanodes are used as common storage for blocks Each Datanode registers with all the Namenodes in the cluster. Datanodes send periodic heartbeats and block reports. They also handle commands from the Namenodes.
23
24 Block Pool A Block Pool is a set of blocks that belong to a single namespace. Datanodes store blocks for all the block pools in the cluster. Each Block Pool is managed independently. A Namenode failure does not prevent the Datanode from serving other Namenodes in the cluster. A Namespace and its block pool together are called Namespace Volume. It is a self-contained unit of management. When a Namenode/namespace is deleted, the corresponding block pool at the Datanodes is deleted.
25 ClusterID A ClusterID identifier is used to identify all the nodes in the cluster.
26 Key Benefits Namespace Scalability - allowing more Namenodes to be added to the cluster. Performance - Adding more Namenodes to the cluster scales the file system read/write throughput. Isolation - A single Namenode offers no isolation in a multi user environment. By using multiple Namenodes, different categories of applications and users can be isolated to different namespaces.
27 Hadoop - HDFS Operations Starting HDFS Initially you have to format the configured HDFS file system, open namenode (HDFS server), and execute the following command. $ hadoop namenode -format After formatting the HDFS, start the distributed file system. The following command will start the namenode as well as the data nodes as cluster. $ start-dfs.sh
28 Listing Files in HDFS After loading the information in the server, we can find the list of files in a directory, status of a file, using ls. Given below is the syntax of ls that you can pass to a directory or a filename as an argument. $ $HADOOP_HOME/bin/hadoop fs -ls <args>
29 Inserting Data into HDFS Assume we have data in the file called file.txt in the local system which is ought to be saved in the hdfs file system. Follow the steps given below to insert the required file in the Hadoop file system. Step 1 You have to create an input directory. $ $HADOOP_HOME/bin/hadoop fs -mkdir /user/input Step 2 Transfer and store a data file from local systems to the Hadoop file system using the put command. $ $HADOOP_HOME/bin/hadoop fs -put /home/file.txt /user/input Step 3 You can verify the file using ls command. $ $HADOOP_HOME/bin/hadoop fs -ls /user/input
30 Retrieving Data from HDFS Assume we have a file in HDFS called outfile. Given below is a simple demonstration for retrieving the required file from the Hadoop file system. Step 1 Initially, view the data from HDFS using cat command. $ $HADOOP_HOME/bin/hadoop fs -cat /user/output/outfile Step 2 Get the file from HDFS to the local file system using get command. $ $HADOOP_HOME/bin/hadoop fs -get /user/output/ /home/hadoop_tp/
31 Shutting Down the HDFS You can shut down the HDFS by using the following command. $ stop-dfs.sh
32 Other basic commands Running./bin/hadoop dfs with no additional arguments will list all the commands that can be run with the FsShell system. Furthermore, $HADOOP_HOME/bin/hadoop fs -help commandname will display a short usage summary for the operation in question, if you are stuck.
33 Sr.No Command and description 1. ls <path> Lists the contents of the directory specified by path, showing the names, permissions, owner, size and modification date for each entry. 2. lsr <path> Behaves like -ls, but recursively displays entries in all subdirectories of path. 3. du <path> Shows disk usage, in bytes, for all the files which match path 4. dus <path> Like -du, but prints a summary of disk usage of all files/directories in the path. 5. mv <src><dest> Moves the file or directory indicated by src to dest, within HDFS.
34 Sr.No Command and description 6. cp <src> <dest> Copies the file or directory identified by src to dest, within HDFS. 7. rm <path> Removes the file or empty directory identified by path. 8. rmr <path> Removes the file or directory identified by path. Recursively deletes any child entries (i.e., files or subdirectories of path). 9. put<localsrc> <dest> Copies the file or directory from the local file system identified by localsrc to dest within the DFS. 10. copyfromlocal <localsrc> <dest> Identical to put
35 Sr.No Command and description 11. movefromlocal <localsrc> <dest> Copies the file or directory from the local file system identified by localsrc to dest within HDFS, and then deletes the local copy on success. 12. get [-crc] <src> <localdest> Copies the file or directory in HDFS identified by src to the local file system path identified by localdest. 13. getmerge <src> <localdest> Retrieves all files that match the path src in HDFS, and copies them to a single, merged file in the local file system identified by localdest. 14. cat <filen-ame> Displays the contents of filename on stdout. 15. copytolocal <src> <localdest> Identical to get
36 Sr.No Command and description 16. movetolocal <src> <localdest> Works like -get, but deletes the HDFS copy on success. 17. mkdir <path> Creates a directory named path in HDFS. Creates any parent directories in path that are missing (e.g., mkdir -p in Linux). 18. test -[ezd] <path> Returns 1 if path exists; has zero length; or is a directory or 0 otherwise. 19. stat [format] <path> Prints information about path. Format is a string which accepts file size in blocks (%b), filename (%n), block size (%o), replication (%r), and modification date (%y, %Y). 20. help <cmd-name> Returns usage information for one of the commands listed above. You must omit the leading '-' character in cmd.

37 DATA FLOW - ANATOMY OF A FILE READ
38 Step 1: open() Step 2: DistributedFile system calls the namenode using RPCs determine the locations of the first few blocks in the file. For each block, the namenode returns the addresses of the datanodes that have a copy of that block. Step 3: The DistributedFile system returns an FSDataInputStream The client then calls read() on the stream. Step 4: DFSInputStream has stored the datanode addresses for the first few blocks in the file Connects to the first (closest) datanode for the first block in the file. calls read() repeatedly on the stream.
39 Step 5: End of the block, close the connection to the datanode find the best datanode for the next block. Blocks are read in order Step 6: close(). If error try the next closest one for that block. Remember datanodes that have failed Verifies checksums for the data transferred to it from the datanode. If a corrupted block, attempts to read a replica of the block from another datanode; Reports the corrupted block to the namenode.
40 Finding nearest data node and block
41 distance(/d1/r1/n1, /d1/r1/n1)
42 distance(/d1/r1/n1, /d1/r1/n1) = 0 (processes on the same node) distance(/d1/r1/n1, /d1/r1/n2)
43 distance(/d1/r1/n1, /d1/r1/n1) = 0 (processes on the same node) distance(/d1/r1/n1, /d1/r1/n2) = 2 (different nodes on the same rack)
44 distance(/d1/r1/n1, /d1/r1/n1) = 0 (processes on the same node) distance(/d1/r1/n1, /d1/r1/n2) = 2 (different nodes on the same rack) distance(/d1/r1/n1, /d1/r2/n3)
45 distance(/d1/r1/n1, /d1/r1/n1) = 0 (processes on the same node) distance(/d1/r1/n1, /d1/r1/n2) = 2 (different nodes on the same rack) distance(/d1/r1/n1, /d1/r2/n3) = 4 (nodes on different racks in the same data center)
46 distance(/d1/r1/n1, /d1/r1/n1) = 0 (processes on the same node) distance(/d1/r1/n1, /d1/r1/n2) = 2 (different nodes on the same rack) distance(/d1/r1/n1, /d1/r2/n3) = 4 (nodes on different racks in the same data center) distance(/d1/r1/n1, /d2/r3/n4)
 = 4 (nodes on different racks in the same data center) distance(/d1/r1/n1, /d2/r3/n4) = 6 (nodes in different")
47 distance(/d1/r1/n1, /d1/r1/n1) = 0 (processes on the same node) distance(/d1/r1/n1, /d1/r1/n2) = 2 (different nodes on the same rack) distance(/d1/r1/n1, /d1/r2/n3) = 4 (nodes on different racks in the same data center) distance(/d1/r1/n1, /d2/r3/n4) = 6 (nodes in different data centers)

48 ANATOMY OF A FILE WRITE
49 We re going to consider the case of creating a new file, writing data to it, then closing the file Step 1: create() on DistributedFile system Step 2: RPC call to the namenode to create a new file in the file system s namespace, The namenode performs various checks to make sure the file doesn t already exist the namenode makes a record of the new file; otherwise, file creation fails and the client is thrown an IOException. Step 3: The DistributedFile system returns an FSDataOutputStream for the client to start writing data to. FSDataOutputStream handles communication with the datanodes and namenode. the DFSOutputStream splits it into packets, which it writes to an internal queue called the data queue. The list of datanodes forms a pipeline, assume the replication level is three, so there are three nodes in the pipeline.
50 Step 4: The DataStreamer streams the packets to the first datanode in the pipeline stores each packet and forwards it to the second datanode in the pipeline. the second datanode stores the packet and forwards it to the third (and last) datanode in the pipeline. Step 5: The DFSOutputStream maintains an internal queue of packets that are waiting to be acknowledged by datanodes, called the ack queue. A packet is removed from the ack queue only when it has been acknowledged by all the datanodes in the pipeline. Step 6: When the client has finished writing data, it calls close() on the stream. Step 7: flushes all the remaining packets to the datanode pipeline and waits for acknowledgments before contacting the namenode to signal that the file is complete. The namenode already knows which blocks the file is made up of (because Data Streamer asks for block allocations), so it only has to wait for blocks to be minimally replicated before returning successfully.

51 Replica pipeline
52 Hadoop s default strategy to place the first replica on the same node as the client The second replica is placed on a different rack from the first (off-rack), chosen at random. The third replica is placed on the same rack as the second, but on a different node chosen at random. system tries to avoid placing too many replicas on the same rack. Once the replica locations have been chosen, a pipeline is built. Overall, this strategy gives a good balance among reliability write bandwidth, read performance and block distribution across the cluster (clients only write a single block on the local rack).
53 End of Unit IV
Cloud Computing and Hadoop Distributed File System. UCSB CS170, Spring 2018
 Cloud Computing and Hadoop Distributed File System UCSB CS70, Spring 08 Cluster Computing Motivations Large-scale data processing on clusters Scan 000 TB on node @ 00 MB/s = days Scan on 000-node cluster
Cloud Computing and Hadoop Distributed File System UCSB CS70, Spring 08 Cluster Computing Motivations Large-scale data processing on clusters Scan 000 TB on node @ 00 MB/s = days Scan on 000-node cluster
Hadoop and HDFS Overview. Madhu Ankam
 Hadoop and HDFS Overview Madhu Ankam Why Hadoop We are gathering more data than ever Examples of data : Server logs Web logs Financial transactions Analytics Emails and text messages Social media like
Hadoop and HDFS Overview Madhu Ankam Why Hadoop We are gathering more data than ever Examples of data : Server logs Web logs Financial transactions Analytics Emails and text messages Social media like
The Google File System. Alexandru Costan
 1 The Google File System Alexandru Costan Actions on Big Data 2 Storage Analysis Acquisition Handling the data stream Data structured unstructured semi-structured Results Transactions Outline File systems
1 The Google File System Alexandru Costan Actions on Big Data 2 Storage Analysis Acquisition Handling the data stream Data structured unstructured semi-structured Results Transactions Outline File systems
CS60021: Scalable Data Mining. Sourangshu Bhattacharya
 CS60021: Scalable Data Mining Sourangshu Bhattacharya In this Lecture: Outline: HDFS Motivation HDFS User commands HDFS System architecture HDFS Implementation details Sourangshu Bhattacharya Computer
CS60021: Scalable Data Mining Sourangshu Bhattacharya In this Lecture: Outline: HDFS Motivation HDFS User commands HDFS System architecture HDFS Implementation details Sourangshu Bhattacharya Computer
Hadoop File System S L I D E S M O D I F I E D F R O M P R E S E N T A T I O N B Y B. R A M A M U R T H Y 11/15/2017
 Hadoop File System 1 S L I D E S M O D I F I E D F R O M P R E S E N T A T I O N B Y B. R A M A M U R T H Y Moving Computation is Cheaper than Moving Data Motivation: Big Data! What is BigData? - Google
Hadoop File System 1 S L I D E S M O D I F I E D F R O M P R E S E N T A T I O N B Y B. R A M A M U R T H Y Moving Computation is Cheaper than Moving Data Motivation: Big Data! What is BigData? - Google
Distributed Filesystem
 Distributed Filesystem 1 How do we get data to the workers? NAS Compute Nodes SAN 2 Distributing Code! Don t move data to workers move workers to the data! - Store data on the local disks of nodes in the
Distributed Filesystem 1 How do we get data to the workers? NAS Compute Nodes SAN 2 Distributing Code! Don t move data to workers move workers to the data! - Store data on the local disks of nodes in the
HDFS Architecture. Gregory Kesden, CSE-291 (Storage Systems) Fall 2017
 Fall 2017") HDFS Architecture Gregory Kesden, CSE-291 (Storage Systems) Fall 2017 Based Upon: http://hadoop.apache.org/docs/r3.0.0-alpha1/hadoopproject-dist/hadoop-hdfs/hdfsdesign.html Assumptions At scale, hardware
HDFS Architecture Gregory Kesden, CSE-291 (Storage Systems) Fall 2017 Based Upon: http://hadoop.apache.org/docs/r3.0.0-alpha1/hadoopproject-dist/hadoop-hdfs/hdfsdesign.html Assumptions At scale, hardware
HDFS Access Options, Applications
 Hadoop Distributed File System (HDFS) access, APIs, applications HDFS Access Options, Applications Able to access/use HDFS via command line Know about available application programming interfaces Example
Hadoop Distributed File System (HDFS) access, APIs, applications HDFS Access Options, Applications Able to access/use HDFS via command line Know about available application programming interfaces Example
Distributed Systems 16. Distributed File Systems II
 Distributed Systems 16. Distributed File Systems II Paul Krzyzanowski pxk@cs.rutgers.edu 1 Review NFS RPC-based access AFS Long-term caching CODA Read/write replication & disconnected operation DFS AFS
Distributed Systems 16. Distributed File Systems II Paul Krzyzanowski pxk@cs.rutgers.edu 1 Review NFS RPC-based access AFS Long-term caching CODA Read/write replication & disconnected operation DFS AFS
CS455: Introduction to Distributed Systems [Spring 2018] Dept. Of Computer Science, Colorado State University
![CS455: Introduction to Distributed Systems [Spring 2018] Dept. Of Computer Science, Colorado State University](/thumbs/87/96390739.jpg "CS455: Introduction to Distributed Systems [Spring 2018] Dept. Of Computer Science, Colorado State University") CS 455: INTRODUCTION TO DISTRIBUTED SYSTEMS [HDFS] Circumventing The Perils of Doing Too Much Protect the namenode, you must, from failure What s not an option? Playing it by ear Given the volumes, be
CS 455: INTRODUCTION TO DISTRIBUTED SYSTEMS [HDFS] Circumventing The Perils of Doing Too Much Protect the namenode, you must, from failure What s not an option? Playing it by ear Given the volumes, be
HDFS Architecture Guide
 by Dhruba Borthakur Table of contents 1 Introduction...3 2 Assumptions and Goals...3 2.1 Hardware Failure... 3 2.2 Streaming Data Access...3 2.3 Large Data Sets...3 2.4 Simple Coherency Model... 4 2.5
by Dhruba Borthakur Table of contents 1 Introduction...3 2 Assumptions and Goals...3 2.1 Hardware Failure... 3 2.2 Streaming Data Access...3 2.3 Large Data Sets...3 2.4 Simple Coherency Model... 4 2.5
Dept. Of Computer Science, Colorado State University
 CS 455: INTRODUCTION TO DISTRIBUTED SYSTEMS [HDFS] Circumventing The Perils of Doing Too Much Protect the namenode, you must, from failure What s not an option? Playing it by ear Given the volumes, be
CS 455: INTRODUCTION TO DISTRIBUTED SYSTEMS [HDFS] Circumventing The Perils of Doing Too Much Protect the namenode, you must, from failure What s not an option? Playing it by ear Given the volumes, be
Service and Cloud Computing Lecture 10: DFS2 Prof. George Baciu PQ838
 COMP4442 Service and Cloud Computing Lecture 10: DFS2 www.comp.polyu.edu.hk/~csgeorge/comp4442 Prof. George Baciu PQ838 csgeorge@comp.polyu.edu.hk 1 Preamble 2 Recall the Cloud Stack Model A B Application
COMP4442 Service and Cloud Computing Lecture 10: DFS2 www.comp.polyu.edu.hk/~csgeorge/comp4442 Prof. George Baciu PQ838 csgeorge@comp.polyu.edu.hk 1 Preamble 2 Recall the Cloud Stack Model A B Application
Hadoop Distributed File System(HDFS)
") Hadoop Distributed File System(HDFS) Bu eğitim sunumları İstanbul Kalkınma Ajansı nın 2016 yılı Yenilikçi ve Yaratıcı İstanbul Mali Destek Programı kapsamında yürütülmekte olan TR10/16/YNY/0036 no lu İstanbul
Hadoop Distributed File System(HDFS) Bu eğitim sunumları İstanbul Kalkınma Ajansı nın 2016 yılı Yenilikçi ve Yaratıcı İstanbul Mali Destek Programı kapsamında yürütülmekte olan TR10/16/YNY/0036 no lu İstanbul
Konstantin Shvachko, Hairong Kuang, Sanjay Radia, Robert Chansler Yahoo! Sunnyvale, California USA {Shv, Hairong, SRadia,
 Konstantin Shvachko, Hairong Kuang, Sanjay Radia, Robert Chansler Yahoo! Sunnyvale, California USA {Shv, Hairong, SRadia, Chansler}@Yahoo-Inc.com Presenter: Alex Hu } Introduction } Architecture } File
Konstantin Shvachko, Hairong Kuang, Sanjay Radia, Robert Chansler Yahoo! Sunnyvale, California USA {Shv, Hairong, SRadia, Chansler}@Yahoo-Inc.com Presenter: Alex Hu } Introduction } Architecture } File
A BigData Tour HDFS, Ceph and MapReduce
 A BigData Tour HDFS, Ceph and MapReduce These slides are possible thanks to these sources Jonathan Drusi - SCInet Toronto Hadoop Tutorial, Amir Payberah - Course in Data Intensive Computing SICS; Yahoo!
A BigData Tour HDFS, Ceph and MapReduce These slides are possible thanks to these sources Jonathan Drusi - SCInet Toronto Hadoop Tutorial, Amir Payberah - Course in Data Intensive Computing SICS; Yahoo!
CLOUD-SCALE FILE SYSTEMS
 Data Management in the Cloud CLOUD-SCALE FILE SYSTEMS 92 Google File System (GFS) Designing a file system for the Cloud design assumptions design choices Architecture GFS Master GFS Chunkservers GFS Clients
Data Management in the Cloud CLOUD-SCALE FILE SYSTEMS 92 Google File System (GFS) Designing a file system for the Cloud design assumptions design choices Architecture GFS Master GFS Chunkservers GFS Clients
Google File System (GFS) and Hadoop Distributed File System (HDFS)
 and Hadoop Distributed File System (HDFS)") Google File System (GFS) and Hadoop Distributed File System (HDFS) 1 Hadoop: Architectural Design Principles Linear scalability More nodes can do more work within the same time Linear on data size, linear
Google File System (GFS) and Hadoop Distributed File System (HDFS) 1 Hadoop: Architectural Design Principles Linear scalability More nodes can do more work within the same time Linear on data size, linear
Distributed File Systems II
 Distributed File Systems II To do q Very-large scale: Google FS, Hadoop FS, BigTable q Next time: Naming things GFS A radically new environment NFS, etc. Independence Small Scale Variety of workloads Cooperation
Distributed File Systems II To do q Very-large scale: Google FS, Hadoop FS, BigTable q Next time: Naming things GFS A radically new environment NFS, etc. Independence Small Scale Variety of workloads Cooperation
COSC 6397 Big Data Analytics. Distributed File Systems (II) Edgar Gabriel Spring HDFS Basics
 Edgar Gabriel Spring HDFS Basics") COSC 6397 Big Data Analytics Distributed File Systems (II) Edgar Gabriel Spring 2017 HDFS Basics An open-source implementation of Google File System Assume that node failure rate is high Assumes a small
COSC 6397 Big Data Analytics Distributed File Systems (II) Edgar Gabriel Spring 2017 HDFS Basics An open-source implementation of Google File System Assume that node failure rate is high Assumes a small
COSC 6397 Big Data Analytics. Distributed File Systems (II) Edgar Gabriel Fall HDFS Basics
 Edgar Gabriel Fall HDFS Basics") COSC 6397 Big Data Analytics Distributed File Systems (II) Edgar Gabriel Fall 2018 HDFS Basics An open-source implementation of Google File System Assume that node failure rate is high Assumes a small
COSC 6397 Big Data Analytics Distributed File Systems (II) Edgar Gabriel Fall 2018 HDFS Basics An open-source implementation of Google File System Assume that node failure rate is high Assumes a small
Map-Reduce. Marco Mura 2010 March, 31th
 Map-Reduce Marco Mura (mura@di.unipi.it) 2010 March, 31th This paper is a note from the 2009-2010 course Strumenti di programmazione per sistemi paralleli e distribuiti and it s based by the lessons of
Map-Reduce Marco Mura (mura@di.unipi.it) 2010 March, 31th This paper is a note from the 2009-2010 course Strumenti di programmazione per sistemi paralleli e distribuiti and it s based by the lessons of
Dept. Of Computer Science, Colorado State University
 CS 455: INTRODUCTION TO DISTRIBUTED SYSTEMS [HADOOP/HDFS] Trying to have your cake and eat it too Each phase pines for tasks with locality and their numbers on a tether Alas within a phase, you get one,
CS 455: INTRODUCTION TO DISTRIBUTED SYSTEMS [HADOOP/HDFS] Trying to have your cake and eat it too Each phase pines for tasks with locality and their numbers on a tether Alas within a phase, you get one,
MapReduce. U of Toronto, 2014
 MapReduce U of Toronto, 2014 http://www.google.org/flutrends/ca/ (2012) Average Searches Per Day: 5,134,000,000 2 Motivation Process lots of data Google processed about 24 petabytes of data per day in
MapReduce U of Toronto, 2014 http://www.google.org/flutrends/ca/ (2012) Average Searches Per Day: 5,134,000,000 2 Motivation Process lots of data Google processed about 24 petabytes of data per day in
Distributed Systems. 15. Distributed File Systems. Paul Krzyzanowski. Rutgers University. Fall 2017
 Distributed Systems 15. Distributed File Systems Paul Krzyzanowski Rutgers University Fall 2017 1 Google Chubby ( Apache Zookeeper) 2 Chubby Distributed lock service + simple fault-tolerant file system
Distributed Systems 15. Distributed File Systems Paul Krzyzanowski Rutgers University Fall 2017 1 Google Chubby ( Apache Zookeeper) 2 Chubby Distributed lock service + simple fault-tolerant file system
CS /30/17. Paul Krzyzanowski 1. Google Chubby ( Apache Zookeeper) Distributed Systems. Chubby. Chubby Deployment.
 Distributed Systems. Chubby. Chubby Deployment.") Distributed Systems 15. Distributed File Systems Google ( Apache Zookeeper) Paul Krzyzanowski Rutgers University Fall 2017 1 2 Distributed lock service + simple fault-tolerant file system Deployment Client
Distributed Systems 15. Distributed File Systems Google ( Apache Zookeeper) Paul Krzyzanowski Rutgers University Fall 2017 1 2 Distributed lock service + simple fault-tolerant file system Deployment Client
Distributed Systems. 15. Distributed File Systems. Paul Krzyzanowski. Rutgers University. Fall 2016
 Distributed Systems 15. Distributed File Systems Paul Krzyzanowski Rutgers University Fall 2016 1 Google Chubby 2 Chubby Distributed lock service + simple fault-tolerant file system Interfaces File access
Distributed Systems 15. Distributed File Systems Paul Krzyzanowski Rutgers University Fall 2016 1 Google Chubby 2 Chubby Distributed lock service + simple fault-tolerant file system Interfaces File access
7680: Distributed Systems
 Cristina Nita-Rotaru 7680: Distributed Systems GFS. HDFS Required Reading } Google File System. S, Ghemawat, H. Gobioff and S.-T. Leung. SOSP 2003. } http://hadoop.apache.org } A Novel Approach to Improving
Cristina Nita-Rotaru 7680: Distributed Systems GFS. HDFS Required Reading } Google File System. S, Ghemawat, H. Gobioff and S.-T. Leung. SOSP 2003. } http://hadoop.apache.org } A Novel Approach to Improving
CA485 Ray Walshe Google File System
 Google File System Overview Google File System is scalable, distributed file system on inexpensive commodity hardware that provides: Fault Tolerance File system runs on hundreds or thousands of storage
Google File System Overview Google File System is scalable, distributed file system on inexpensive commodity hardware that provides: Fault Tolerance File system runs on hundreds or thousands of storage
CS November 2017
 Distributed Systems 09r. Map-Reduce Programming on AWS/EMR (Part I) Setting Up AWS/EMR Paul Krzyzanowski TA: Long Zhao Rutgers University Fall 2017 November 21, 2017 2017 Paul Krzyzanowski 1 November 21,
Distributed Systems 09r. Map-Reduce Programming on AWS/EMR (Part I) Setting Up AWS/EMR Paul Krzyzanowski TA: Long Zhao Rutgers University Fall 2017 November 21, 2017 2017 Paul Krzyzanowski 1 November 21,
Distributed Systems. 09r. Map-Reduce Programming on AWS/EMR (Part I) 2017 Paul Krzyzanowski. TA: Long Zhao Rutgers University Fall 2017
 2017 Paul Krzyzanowski. TA: Long Zhao Rutgers University Fall 2017") Distributed Systems 09r. Map-Reduce Programming on AWS/EMR (Part I) Paul Krzyzanowski TA: Long Zhao Rutgers University Fall 2017 November 21, 2017 2017 Paul Krzyzanowski 1 Setting Up AWS/EMR November 21,
Distributed Systems 09r. Map-Reduce Programming on AWS/EMR (Part I) Paul Krzyzanowski TA: Long Zhao Rutgers University Fall 2017 November 21, 2017 2017 Paul Krzyzanowski 1 Setting Up AWS/EMR November 21,
Hadoop Lab 2 Exploring the Hadoop Environment
 Programming for Big Data Hadoop Lab 2 Exploring the Hadoop Environment Video A short video guide for some of what is covered in this lab. Link for this video is on my module webpage 1 Open a Terminal window
Programming for Big Data Hadoop Lab 2 Exploring the Hadoop Environment Video A short video guide for some of what is covered in this lab. Link for this video is on my module webpage 1 Open a Terminal window
BigData and Map Reduce VITMAC03
 BigData and Map Reduce VITMAC03 1 Motivation Process lots of data Google processed about 24 petabytes of data per day in 2009. A single machine cannot serve all the data You need a distributed system to
BigData and Map Reduce VITMAC03 1 Motivation Process lots of data Google processed about 24 petabytes of data per day in 2009. A single machine cannot serve all the data You need a distributed system to
The Google File System
 October 13, 2010 Based on: S. Ghemawat, H. Gobioff, and S.-T. Leung: The Google file system, in Proceedings ACM SOSP 2003, Lake George, NY, USA, October 2003. 1 Assumptions Interface Architecture Single
October 13, 2010 Based on: S. Ghemawat, H. Gobioff, and S.-T. Leung: The Google file system, in Proceedings ACM SOSP 2003, Lake George, NY, USA, October 2003. 1 Assumptions Interface Architecture Single
CPSC 426/526. Cloud Computing. Ennan Zhai. Computer Science Department Yale University
 CPSC 426/526 Cloud Computing Ennan Zhai Computer Science Department Yale University Recall: Lec-7 In the lec-7, I talked about: - P2P vs Enterprise control - Firewall - NATs - Software defined network
CPSC 426/526 Cloud Computing Ennan Zhai Computer Science Department Yale University Recall: Lec-7 In the lec-7, I talked about: - P2P vs Enterprise control - Firewall - NATs - Software defined network
ECE 7650 Scalable and Secure Internet Services and Architecture ---- A Systems Perspective
 ECE 7650 Scalable and Secure Internet Services and Architecture ---- A Systems Perspective Part II: Data Center Software Architecture: Topic 1: Distributed File Systems GFS (The Google File System) 1 Filesystems
ECE 7650 Scalable and Secure Internet Services and Architecture ---- A Systems Perspective Part II: Data Center Software Architecture: Topic 1: Distributed File Systems GFS (The Google File System) 1 Filesystems
Georgia Institute of Technology ECE6102 4/20/2009 David Colvin, Jimmy Vuong
 Georgia Institute of Technology ECE6102 4/20/2009 David Colvin, Jimmy Vuong Relatively recent; still applicable today GFS: Google s storage platform for the generation and processing of data used by services
Georgia Institute of Technology ECE6102 4/20/2009 David Colvin, Jimmy Vuong Relatively recent; still applicable today GFS: Google s storage platform for the generation and processing of data used by services
CS370 Operating Systems
 CS370 Operating Systems Colorado State University Yashwant K Malaiya Spring 2018 Lecture 24 Mass Storage, HDFS/Hadoop Slides based on Text by Silberschatz, Galvin, Gagne Various sources 1 1 FAQ What 2
CS370 Operating Systems Colorado State University Yashwant K Malaiya Spring 2018 Lecture 24 Mass Storage, HDFS/Hadoop Slides based on Text by Silberschatz, Galvin, Gagne Various sources 1 1 FAQ What 2
Authors : Sanjay Ghemawat, Howard Gobioff, Shun-Tak Leung Presentation by: Vijay Kumar Chalasani
 The Authors : Sanjay Ghemawat, Howard Gobioff, Shun-Tak Leung Presentation by: Vijay Kumar Chalasani CS5204 Operating Systems 1 Introduction GFS is a scalable distributed file system for large data intensive
The Authors : Sanjay Ghemawat, Howard Gobioff, Shun-Tak Leung Presentation by: Vijay Kumar Chalasani CS5204 Operating Systems 1 Introduction GFS is a scalable distributed file system for large data intensive
CS370 Operating Systems
 CS370 Operating Systems Colorado State University Yashwant K Malaiya Fall 2017 Lecture 26 File Systems Slides based on Text by Silberschatz, Galvin, Gagne Various sources 1 1 FAQ Cylinders: all the platters?
CS370 Operating Systems Colorado State University Yashwant K Malaiya Fall 2017 Lecture 26 File Systems Slides based on Text by Silberschatz, Galvin, Gagne Various sources 1 1 FAQ Cylinders: all the platters?
Cloud Computing CS
 Cloud Computing CS 15-319 Distributed File Systems and Cloud Storage Part II Lecture 13, Feb 27, 2012 Majd F. Sakr, Mohammad Hammoud and Suhail Rehman 1 Today Last session Distributed File Systems and
Cloud Computing CS 15-319 Distributed File Systems and Cloud Storage Part II Lecture 13, Feb 27, 2012 Majd F. Sakr, Mohammad Hammoud and Suhail Rehman 1 Today Last session Distributed File Systems and
CS435 Introduction to Big Data FALL 2018 Colorado State University. 11/7/2018 Week 12-B Sangmi Lee Pallickara. FAQs
 11/7/2018 CS435 Introduction to Big Data - FALL 2018 W12.B.0.0 CS435 Introduction to Big Data 11/7/2018 CS435 Introduction to Big Data - FALL 2018 W12.B.1 FAQs Deadline of the Programming Assignment 3
11/7/2018 CS435 Introduction to Big Data - FALL 2018 W12.B.0.0 CS435 Introduction to Big Data 11/7/2018 CS435 Introduction to Big Data - FALL 2018 W12.B.1 FAQs Deadline of the Programming Assignment 3
GFS: The Google File System. Dr. Yingwu Zhu
 GFS: The Google File System Dr. Yingwu Zhu Motivating Application: Google Crawl the whole web Store it all on one big disk Process users searches on one big CPU More storage, CPU required than one PC can
GFS: The Google File System Dr. Yingwu Zhu Motivating Application: Google Crawl the whole web Store it all on one big disk Process users searches on one big CPU More storage, CPU required than one PC can
CSE 124: Networked Services Fall 2009 Lecture-19
 CSE 124: Networked Services Fall 2009 Lecture-19 Instructor: B. S. Manoj, Ph.D http://cseweb.ucsd.edu/classes/fa09/cse124 Some of these slides are adapted from various sources/individuals including but
CSE 124: Networked Services Fall 2009 Lecture-19 Instructor: B. S. Manoj, Ph.D http://cseweb.ucsd.edu/classes/fa09/cse124 Some of these slides are adapted from various sources/individuals including but
The Google File System (GFS)
") 1 The Google File System (GFS) CS60002: Distributed Systems Antonio Bruto da Costa Ph.D. Student, Formal Methods Lab, Dept. of Computer Sc. & Engg., Indian Institute of Technology Kharagpur 2 Design constraints
1 The Google File System (GFS) CS60002: Distributed Systems Antonio Bruto da Costa Ph.D. Student, Formal Methods Lab, Dept. of Computer Sc. & Engg., Indian Institute of Technology Kharagpur 2 Design constraints
Introduction to Cloud Computing
 Introduction to Cloud Computing Distributed File Systems 15 319, spring 2010 12 th Lecture, Feb 18 th Majd F. Sakr Lecture Motivation Quick Refresher on Files and File Systems Understand the importance
Introduction to Cloud Computing Distributed File Systems 15 319, spring 2010 12 th Lecture, Feb 18 th Majd F. Sakr Lecture Motivation Quick Refresher on Files and File Systems Understand the importance
Google File System. Arun Sundaram Operating Systems
 Arun Sundaram Operating Systems 1 Assumptions GFS built with commodity hardware GFS stores a modest number of large files A few million files, each typically 100MB or larger (Multi-GB files are common)
Arun Sundaram Operating Systems 1 Assumptions GFS built with commodity hardware GFS stores a modest number of large files A few million files, each typically 100MB or larger (Multi-GB files are common)
TITLE: PRE-REQUISITE THEORY. 1. Introduction to Hadoop. 2. Cluster. Implement sort algorithm and run it using HADOOP
 TITLE: Implement sort algorithm and run it using HADOOP PRE-REQUISITE Preliminary knowledge of clusters and overview of Hadoop and its basic functionality. THEORY 1. Introduction to Hadoop The Apache Hadoop
TITLE: Implement sort algorithm and run it using HADOOP PRE-REQUISITE Preliminary knowledge of clusters and overview of Hadoop and its basic functionality. THEORY 1. Introduction to Hadoop The Apache Hadoop
CSE 124: Networked Services Lecture-16
 Fall 2010 CSE 124: Networked Services Lecture-16 Instructor: B. S. Manoj, Ph.D http://cseweb.ucsd.edu/classes/fa10/cse124 11/23/2010 CSE 124 Networked Services Fall 2010 1 Updates PlanetLab experiments
Fall 2010 CSE 124: Networked Services Lecture-16 Instructor: B. S. Manoj, Ph.D http://cseweb.ucsd.edu/classes/fa10/cse124 11/23/2010 CSE 124 Networked Services Fall 2010 1 Updates PlanetLab experiments
A brief history on Hadoop
 Hadoop Basics A brief history on Hadoop 2003 - Google launches project Nutch to handle billions of searches and indexing millions of web pages. Oct 2003 - Google releases papers with GFS (Google File System)
Hadoop Basics A brief history on Hadoop 2003 - Google launches project Nutch to handle billions of searches and indexing millions of web pages. Oct 2003 - Google releases papers with GFS (Google File System)
Introduction to Map/Reduce. Kostas Solomos Computer Science Department University of Crete, Greece
 Introduction to Map/Reduce Kostas Solomos Computer Science Department University of Crete, Greece What we will cover What is MapReduce? How does it work? A simple word count example (the Hello World! of
Introduction to Map/Reduce Kostas Solomos Computer Science Department University of Crete, Greece What we will cover What is MapReduce? How does it work? A simple word count example (the Hello World! of
The Google File System
 The Google File System Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung Google* 정학수, 최주영 1 Outline Introduction Design Overview System Interactions Master Operation Fault Tolerance and Diagnosis Conclusions
The Google File System Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung Google* 정학수, 최주영 1 Outline Introduction Design Overview System Interactions Master Operation Fault Tolerance and Diagnosis Conclusions
Cloudera Exam CCA-410 Cloudera Certified Administrator for Apache Hadoop (CCAH) Version: 7.5 [ Total Questions: 97 ]
![Cloudera Exam CCA-410 Cloudera Certified Administrator for Apache Hadoop (CCAH) Version: 7.5 [ Total Questions: 97 ]](/thumbs/96/126854374.jpg "Cloudera Exam CCA-410 Cloudera Certified Administrator for Apache Hadoop (CCAH) Version: 7.5 [ Total Questions: 97 ]") s@lm@n Cloudera Exam CCA-410 Cloudera Certified Administrator for Apache Hadoop (CCAH) Version: 7.5 [ Total Questions: 97 ] Question No : 1 Which two updates occur when a client application opens a stream
s@lm@n Cloudera Exam CCA-410 Cloudera Certified Administrator for Apache Hadoop (CCAH) Version: 7.5 [ Total Questions: 97 ] Question No : 1 Which two updates occur when a client application opens a stream
Cloud Computing. Hwajung Lee. Key Reference: Prof. Jong-Moon Chung s Lecture Notes at Yonsei University
 Cloud Computing Hwajung Lee Key Reference: Prof. Jong-Moon Chung s Lecture Notes at Yonsei University Cloud Computing Cloud Introduction Cloud Service Model Big Data Hadoop MapReduce HDFS (Hadoop Distributed
Cloud Computing Hwajung Lee Key Reference: Prof. Jong-Moon Chung s Lecture Notes at Yonsei University Cloud Computing Cloud Introduction Cloud Service Model Big Data Hadoop MapReduce HDFS (Hadoop Distributed
Lecture 12 DATA ANALYTICS ON WEB SCALE
 Lecture 12 DATA ANALYTICS ON WEB SCALE Source: The Economist, February 25, 2010 The Data Deluge EIGHTEEN months ago, Li & Fung, a firm that manages supply chains for retailers, saw 100 gigabytes of information
Lecture 12 DATA ANALYTICS ON WEB SCALE Source: The Economist, February 25, 2010 The Data Deluge EIGHTEEN months ago, Li & Fung, a firm that manages supply chains for retailers, saw 100 gigabytes of information
4/9/2018 Week 13-A Sangmi Lee Pallickara. CS435 Introduction to Big Data Spring 2018 Colorado State University. FAQs. Architecture of GFS
 W13.A.0.0 CS435 Introduction to Big Data W13.A.1 FAQs Programming Assignment 3 has been posted PART 2. LARGE SCALE DATA STORAGE SYSTEMS DISTRIBUTED FILE SYSTEMS Recitations Apache Spark tutorial 1 and
W13.A.0.0 CS435 Introduction to Big Data W13.A.1 FAQs Programming Assignment 3 has been posted PART 2. LARGE SCALE DATA STORAGE SYSTEMS DISTRIBUTED FILE SYSTEMS Recitations Apache Spark tutorial 1 and
Google File System. By Dinesh Amatya
 Google File System By Dinesh Amatya Google File System (GFS) Sanjay Ghemawat, Howard Gobioff, Shun-Tak Leung designed and implemented to meet rapidly growing demand of Google's data processing need a scalable
Google File System By Dinesh Amatya Google File System (GFS) Sanjay Ghemawat, Howard Gobioff, Shun-Tak Leung designed and implemented to meet rapidly growing demand of Google's data processing need a scalable
GFS: The Google File System
 GFS: The Google File System Brad Karp UCL Computer Science CS GZ03 / M030 24 th October 2014 Motivating Application: Google Crawl the whole web Store it all on one big disk Process users searches on one
GFS: The Google File System Brad Karp UCL Computer Science CS GZ03 / M030 24 th October 2014 Motivating Application: Google Crawl the whole web Store it all on one big disk Process users searches on one
HDFS Federation. Sanjay Radia Founder and Hortonworks. Page 1
 HDFS Federation Sanjay Radia Founder and Architect @ Hortonworks Page 1 About Me Apache Hadoop Committer and Member of Hadoop PMC Architect of core-hadoop @ Yahoo - Focusing on HDFS, MapReduce scheduler,
HDFS Federation Sanjay Radia Founder and Architect @ Hortonworks Page 1 About Me Apache Hadoop Committer and Member of Hadoop PMC Architect of core-hadoop @ Yahoo - Focusing on HDFS, MapReduce scheduler,
The Google File System
 The Google File System Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung SOSP 2003 presented by Kun Suo Outline GFS Background, Concepts and Key words Example of GFS Operations Some optimizations in
The Google File System Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung SOSP 2003 presented by Kun Suo Outline GFS Background, Concepts and Key words Example of GFS Operations Some optimizations in
The Google File System
 The Google File System Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung December 2003 ACM symposium on Operating systems principles Publisher: ACM Nov. 26, 2008 OUTLINE INTRODUCTION DESIGN OVERVIEW
The Google File System Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung December 2003 ACM symposium on Operating systems principles Publisher: ACM Nov. 26, 2008 OUTLINE INTRODUCTION DESIGN OVERVIEW
MI-PDB, MIE-PDB: Advanced Database Systems
 MI-PDB, MIE-PDB: Advanced Database Systems http://www.ksi.mff.cuni.cz/~svoboda/courses/2015-2-mie-pdb/ Lecture 10: MapReduce, Hadoop 26. 4. 2016 Lecturer: Martin Svoboda svoboda@ksi.mff.cuni.cz Author:
MI-PDB, MIE-PDB: Advanced Database Systems http://www.ksi.mff.cuni.cz/~svoboda/courses/2015-2-mie-pdb/ Lecture 10: MapReduce, Hadoop 26. 4. 2016 Lecturer: Martin Svoboda svoboda@ksi.mff.cuni.cz Author:
Distributed System. Gang Wu. Spring,2018
 Distributed System Gang Wu Spring,2018 Lecture7:DFS What is DFS? A method of storing and accessing files base in a client/server architecture. A distributed file system is a client/server-based application
Distributed System Gang Wu Spring,2018 Lecture7:DFS What is DFS? A method of storing and accessing files base in a client/server architecture. A distributed file system is a client/server-based application
HADOOP FRAMEWORK FOR BIG DATA
 HADOOP FRAMEWORK FOR BIG DATA Mr K. Srinivas Babu 1,Dr K. Rameshwaraiah 2 1 Research Scholar S V University, Tirupathi 2 Professor and Head NNRESGI, Hyderabad Abstract - Data has to be stored for further
HADOOP FRAMEWORK FOR BIG DATA Mr K. Srinivas Babu 1,Dr K. Rameshwaraiah 2 1 Research Scholar S V University, Tirupathi 2 Professor and Head NNRESGI, Hyderabad Abstract - Data has to be stored for further
Introduction to Hadoop. Owen O Malley Yahoo!, Grid Team
 Introduction to Hadoop Owen O Malley Yahoo!, Grid Team owen@yahoo-inc.com Who Am I? Yahoo! Architect on Hadoop Map/Reduce Design, review, and implement features in Hadoop Working on Hadoop full time since
Introduction to Hadoop Owen O Malley Yahoo!, Grid Team owen@yahoo-inc.com Who Am I? Yahoo! Architect on Hadoop Map/Reduce Design, review, and implement features in Hadoop Working on Hadoop full time since
Hadoop Distributed File System (HDFS) 10/05/2018 1
 10/05/2018 1") Hadoop Distributed File System (HDFS) 1 HDFS Overview A distributed file system uilt on the architecture of Google File System (GS) Shares a similar architecture to many other common distributed storage
Hadoop Distributed File System (HDFS) 1 HDFS Overview A distributed file system uilt on the architecture of Google File System (GS) Shares a similar architecture to many other common distributed storage
GFS Overview. Design goals/priorities Design for big-data workloads Huge files, mostly appends, concurrency, huge bandwidth Design for failures
 GFS Overview Design goals/priorities Design for big-data workloads Huge files, mostly appends, concurrency, huge bandwidth Design for failures Interface: non-posix New op: record appends (atomicity matters,
GFS Overview Design goals/priorities Design for big-data workloads Huge files, mostly appends, concurrency, huge bandwidth Design for failures Interface: non-posix New op: record appends (atomicity matters,
CS 345A Data Mining. MapReduce
 CS 345A Data Mining MapReduce Single-node architecture CPU Machine Learning, Statistics Memory Classical Data Mining Disk Commodity Clusters Web data sets can be very large Tens to hundreds of terabytes
CS 345A Data Mining MapReduce Single-node architecture CPU Machine Learning, Statistics Memory Classical Data Mining Disk Commodity Clusters Web data sets can be very large Tens to hundreds of terabytes
Distributed Systems. GFS / HDFS / Spanner
 15-440 Distributed Systems GFS / HDFS / Spanner Agenda Google File System (GFS) Hadoop Distributed File System (HDFS) Distributed File Systems Replication Spanner Distributed Database System Paxos Replication
15-440 Distributed Systems GFS / HDFS / Spanner Agenda Google File System (GFS) Hadoop Distributed File System (HDFS) Distributed File Systems Replication Spanner Distributed Database System Paxos Replication
! Design constraints. " Component failures are the norm. " Files are huge by traditional standards. ! POSIX-like
 Cloud background Google File System! Warehouse scale systems " 10K-100K nodes " 50MW (1 MW = 1,000 houses) " Power efficient! Located near cheap power! Passive cooling! Power Usage Effectiveness = Total
Cloud background Google File System! Warehouse scale systems " 10K-100K nodes " 50MW (1 MW = 1,000 houses) " Power efficient! Located near cheap power! Passive cooling! Power Usage Effectiveness = Total
The Google File System
 The Google File System By Ghemawat, Gobioff and Leung Outline Overview Assumption Design of GFS System Interactions Master Operations Fault Tolerance Measurements Overview GFS: Scalable distributed file
The Google File System By Ghemawat, Gobioff and Leung Outline Overview Assumption Design of GFS System Interactions Master Operations Fault Tolerance Measurements Overview GFS: Scalable distributed file
Lecture 11 Hadoop & Spark
 Lecture 11 Hadoop & Spark Dr. Wilson Rivera ICOM 6025: High Performance Computing Electrical and Computer Engineering Department University of Puerto Rico Outline Distributed File Systems Hadoop Ecosystem
Lecture 11 Hadoop & Spark Dr. Wilson Rivera ICOM 6025: High Performance Computing Electrical and Computer Engineering Department University of Puerto Rico Outline Distributed File Systems Hadoop Ecosystem
HDFS: Hadoop Distributed File System. Sector: Distributed Storage System
 GFS: Google File System Google C/C++ HDFS: Hadoop Distributed File System Yahoo Java, Open Source Sector: Distributed Storage System University of Illinois at Chicago C++, Open Source 2 System that permanently
GFS: Google File System Google C/C++ HDFS: Hadoop Distributed File System Yahoo Java, Open Source Sector: Distributed Storage System University of Illinois at Chicago C++, Open Source 2 System that permanently
Hadoop. copyright 2011 Trainologic LTD
 Hadoop Hadoop is a framework for processing large amounts of data in a distributed manner. It can scale up to thousands of machines. It provides high-availability. Provides map-reduce functionality. Hides
Hadoop Hadoop is a framework for processing large amounts of data in a distributed manner. It can scale up to thousands of machines. It provides high-availability. Provides map-reduce functionality. Hides
18-hdfs-gfs.txt Thu Oct 27 10:05: Notes on Parallel File Systems: HDFS & GFS , Fall 2011 Carnegie Mellon University Randal E.
 18-hdfs-gfs.txt Thu Oct 27 10:05:07 2011 1 Notes on Parallel File Systems: HDFS & GFS 15-440, Fall 2011 Carnegie Mellon University Randal E. Bryant References: Ghemawat, Gobioff, Leung, "The Google File
18-hdfs-gfs.txt Thu Oct 27 10:05:07 2011 1 Notes on Parallel File Systems: HDFS & GFS 15-440, Fall 2011 Carnegie Mellon University Randal E. Bryant References: Ghemawat, Gobioff, Leung, "The Google File
The Google File System
 The Google File System Sanjay Ghemawat, Howard Gobioff and Shun Tak Leung Google* Shivesh Kumar Sharma fl4164@wayne.edu Fall 2015 004395771 Overview Google file system is a scalable distributed file system
The Google File System Sanjay Ghemawat, Howard Gobioff and Shun Tak Leung Google* Shivesh Kumar Sharma fl4164@wayne.edu Fall 2015 004395771 Overview Google file system is a scalable distributed file system
50 Must Read Hadoop Interview Questions & Answers
 50 Must Read Hadoop Interview Questions & Answers Whizlabs Dec 29th, 2017 Big Data Are you planning to land a job with big data and data analytics? Are you worried about cracking the Hadoop job interview?
50 Must Read Hadoop Interview Questions & Answers Whizlabs Dec 29th, 2017 Big Data Are you planning to land a job with big data and data analytics? Are you worried about cracking the Hadoop job interview?
Google File System. Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung Google fall DIP Heerak lim, Donghun Koo
 Google File System Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung Google 2017 fall DIP Heerak lim, Donghun Koo 1 Agenda Introduction Design overview Systems interactions Master operation Fault tolerance
Google File System Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung Google 2017 fall DIP Heerak lim, Donghun Koo 1 Agenda Introduction Design overview Systems interactions Master operation Fault tolerance
Systems Infrastructure for Data Science. Web Science Group Uni Freiburg WS 2013/14
 Systems Infrastructure for Data Science Web Science Group Uni Freiburg WS 2013/14 MapReduce & Hadoop The new world of Big Data (programming model) Overview of this Lecture Module Background Cluster File
Systems Infrastructure for Data Science Web Science Group Uni Freiburg WS 2013/14 MapReduce & Hadoop The new world of Big Data (programming model) Overview of this Lecture Module Background Cluster File
Google File System 2
 Google File System 2 goals monitoring, fault tolerance, auto-recovery (thousands of low-cost machines) focus on multi-gb files handle appends efficiently (no random writes & sequential reads) co-design
Google File System 2 goals monitoring, fault tolerance, auto-recovery (thousands of low-cost machines) focus on multi-gb files handle appends efficiently (no random writes & sequential reads) co-design
The Evolving Apache Hadoop Ecosystem What it means for Storage Industry
 The Evolving Apache Hadoop Ecosystem What it means for Storage Industry Sanjay Radia Architect/Founder, Hortonworks Inc. All Rights Reserved Page 1 Outline Hadoop (HDFS) and Storage Data platform drivers
The Evolving Apache Hadoop Ecosystem What it means for Storage Industry Sanjay Radia Architect/Founder, Hortonworks Inc. All Rights Reserved Page 1 Outline Hadoop (HDFS) and Storage Data platform drivers
A Distributed Namespace for a Distributed File System
 A Distributed Namespace for a Distributed File System Wasif Riaz Malik wasif@kth.se Master of Science Thesis Examiner: Dr. Jim Dowling, KTH/SICS Berlin, Aug 7, 2012 TRITA-ICT-EX-2012:173 Abstract Due
A Distributed Namespace for a Distributed File System Wasif Riaz Malik wasif@kth.se Master of Science Thesis Examiner: Dr. Jim Dowling, KTH/SICS Berlin, Aug 7, 2012 TRITA-ICT-EX-2012:173 Abstract Due
CS 138: Google. CS 138 XVI 1 Copyright 2017 Thomas W. Doeppner. All rights reserved.
 CS 138: Google CS 138 XVI 1 Copyright 2017 Thomas W. Doeppner. All rights reserved. Google Environment Lots (tens of thousands) of computers all more-or-less equal - processor, disk, memory, network interface
CS 138: Google CS 138 XVI 1 Copyright 2017 Thomas W. Doeppner. All rights reserved. Google Environment Lots (tens of thousands) of computers all more-or-less equal - processor, disk, memory, network interface
Introduction to MapReduce. Instructor: Dr. Weikuan Yu Computer Sci. & Software Eng.
 Introduction to MapReduce Instructor: Dr. Weikuan Yu Computer Sci. & Software Eng. Before MapReduce Large scale data processing was difficult! Managing hundreds or thousands of processors Managing parallelization
Introduction to MapReduce Instructor: Dr. Weikuan Yu Computer Sci. & Software Eng. Before MapReduce Large scale data processing was difficult! Managing hundreds or thousands of processors Managing parallelization
Google File System, Replication. Amin Vahdat CSE 123b May 23, 2006
 Google File System, Replication Amin Vahdat CSE 123b May 23, 2006 Annoucements Third assignment available today Due date June 9, 5 pm Final exam, June 14, 11:30-2:30 Google File System (thanks to Mahesh
Google File System, Replication Amin Vahdat CSE 123b May 23, 2006 Annoucements Third assignment available today Due date June 9, 5 pm Final exam, June 14, 11:30-2:30 Google File System (thanks to Mahesh
Yves Goeleven. Solution Architect - Particular Software. Shipping software since Azure MVP since Co-founder & board member AZUG
 Storage Services Yves Goeleven Solution Architect - Particular Software Shipping software since 2001 Azure MVP since 2010 Co-founder & board member AZUG NServiceBus & MessageHandler Used azure storage?
Storage Services Yves Goeleven Solution Architect - Particular Software Shipping software since 2001 Azure MVP since 2010 Co-founder & board member AZUG NServiceBus & MessageHandler Used azure storage?
Introduction to Hadoop and MapReduce
 Introduction to Hadoop and MapReduce Antonino Virgillito THE CONTRACTOR IS ACTING UNDER A FRAMEWORK CONTRACT CONCLUDED WITH THE COMMISSION Large-scale Computation Traditional solutions for computing large
Introduction to Hadoop and MapReduce Antonino Virgillito THE CONTRACTOR IS ACTING UNDER A FRAMEWORK CONTRACT CONCLUDED WITH THE COMMISSION Large-scale Computation Traditional solutions for computing large
NPTEL Course Jan K. Gopinath Indian Institute of Science
 Storage Systems NPTEL Course Jan 2012 (Lecture 39) K. Gopinath Indian Institute of Science Google File System Non-Posix scalable distr file system for large distr dataintensive applications performance,
Storage Systems NPTEL Course Jan 2012 (Lecture 39) K. Gopinath Indian Institute of Science Google File System Non-Posix scalable distr file system for large distr dataintensive applications performance,
Hadoop/MapReduce Computing Paradigm
 Hadoop/Reduce Computing Paradigm 1 Large-Scale Data Analytics Reduce computing paradigm (E.g., Hadoop) vs. Traditional database systems vs. Database Many enterprises are turning to Hadoop Especially applications
Hadoop/Reduce Computing Paradigm 1 Large-Scale Data Analytics Reduce computing paradigm (E.g., Hadoop) vs. Traditional database systems vs. Database Many enterprises are turning to Hadoop Especially applications
Hadoop MapReduce for Mobile Clouds
 Calhoun: The NPS Institutional Archive Faculty and Researcher Publications Faculty and Researcher Publications Collection 2016 Hadoop MapReduce for Mobile Clouds George, Johnu http://hdl.handle.net/10945/52393
Calhoun: The NPS Institutional Archive Faculty and Researcher Publications Faculty and Researcher Publications Collection 2016 Hadoop MapReduce for Mobile Clouds George, Johnu http://hdl.handle.net/10945/52393
Ceph: A Scalable, High-Performance Distributed File System
 Ceph: A Scalable, High-Performance Distributed File System S. A. Weil, S. A. Brandt, E. L. Miller, D. D. E. Long Presented by Philip Snowberger Department of Computer Science and Engineering University
Ceph: A Scalable, High-Performance Distributed File System S. A. Weil, S. A. Brandt, E. L. Miller, D. D. E. Long Presented by Philip Snowberger Department of Computer Science and Engineering University
The Google File System
 The Google File System Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung Google SOSP 03, October 19 22, 2003, New York, USA Hyeon-Gyu Lee, and Yeong-Jae Woo Memory & Storage Architecture Lab. School
The Google File System Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung Google SOSP 03, October 19 22, 2003, New York, USA Hyeon-Gyu Lee, and Yeong-Jae Woo Memory & Storage Architecture Lab. School
Enhanced Hadoop with Search and MapReduce Concurrency Optimization
 Volume 114 No. 12 2017, 323-331 ISSN: 1311-8080 (printed version); ISSN: 1314-3395 (on-line version) url: http://www.ijpam.eu ijpam.eu Enhanced Hadoop with Search and MapReduce Concurrency Optimization
Volume 114 No. 12 2017, 323-331 ISSN: 1311-8080 (printed version); ISSN: 1314-3395 (on-line version) url: http://www.ijpam.eu ijpam.eu Enhanced Hadoop with Search and MapReduce Concurrency Optimization
NPTEL Course Jan K. Gopinath Indian Institute of Science
 Storage Systems NPTEL Course Jan 2012 (Lecture 41) K. Gopinath Indian Institute of Science Lease Mgmt designed to minimize mgmt overhead at master a lease initially times out at 60 secs. primary can request
Storage Systems NPTEL Course Jan 2012 (Lecture 41) K. Gopinath Indian Institute of Science Lease Mgmt designed to minimize mgmt overhead at master a lease initially times out at 60 secs. primary can request
Performance Enhancement of Data Processing using Multiple Intelligent Cache in Hadoop
 Performance Enhancement of Data Processing using Multiple Intelligent Cache in Hadoop K. Senthilkumar PG Scholar Department of Computer Science and Engineering SRM University, Chennai, Tamilnadu, India
Performance Enhancement of Data Processing using Multiple Intelligent Cache in Hadoop K. Senthilkumar PG Scholar Department of Computer Science and Engineering SRM University, Chennai, Tamilnadu, India
11/5/2018 Week 12-A Sangmi Lee Pallickara. CS435 Introduction to Big Data FALL 2018 Colorado State University
 11/5/2018 CS435 Introduction to Big Data - FALL 2018 W12.A.0.0 CS435 Introduction to Big Data 11/5/2018 CS435 Introduction to Big Data - FALL 2018 W12.A.1 Consider a Graduate Degree in Computer Science
11/5/2018 CS435 Introduction to Big Data - FALL 2018 W12.A.0.0 CS435 Introduction to Big Data 11/5/2018 CS435 Introduction to Big Data - FALL 2018 W12.A.1 Consider a Graduate Degree in Computer Science
Introduction to MapReduce
 Basics of Cloud Computing Lecture 4 Introduction to MapReduce Satish Srirama Some material adapted from slides by Jimmy Lin, Christophe Bisciglia, Aaron Kimball, & Sierra Michels-Slettvet, Google Distributed
Basics of Cloud Computing Lecture 4 Introduction to MapReduce Satish Srirama Some material adapted from slides by Jimmy Lin, Christophe Bisciglia, Aaron Kimball, & Sierra Michels-Slettvet, Google Distributed
Abstract. 1. Introduction. 2. Design and Implementation Master Chunkserver
 Abstract GFS from Scratch Ge Bian, Niket Agarwal, Wenli Looi https://github.com/looi/cs244b Dec 2017 GFS from Scratch is our partial re-implementation of GFS, the Google File System. Like GFS, our system
Abstract GFS from Scratch Ge Bian, Niket Agarwal, Wenli Looi https://github.com/looi/cs244b Dec 2017 GFS from Scratch is our partial re-implementation of GFS, the Google File System. Like GFS, our system
Hadoop An Overview. - Socrates CCDH
 Hadoop An Overview - Socrates CCDH What is Big Data? Volume Not Gigabyte. Terabyte, Petabyte, Exabyte, Zettabyte - Due to handheld gadgets,and HD format images and videos - In total data, 90% of them collected
Hadoop An Overview - Socrates CCDH What is Big Data? Volume Not Gigabyte. Terabyte, Petabyte, Exabyte, Zettabyte - Due to handheld gadgets,and HD format images and videos - In total data, 90% of them collected
Big Data Analytics. Izabela Moise, Evangelos Pournaras, Dirk Helbing
 Big Data Analytics Izabela Moise, Evangelos Pournaras, Dirk Helbing Izabela Moise, Evangelos Pournaras, Dirk Helbing 1 Big Data "The world is crazy. But at least it s getting regular analysis." Izabela
Big Data Analytics Izabela Moise, Evangelos Pournaras, Dirk Helbing Izabela Moise, Evangelos Pournaras, Dirk Helbing 1 Big Data "The world is crazy. But at least it s getting regular analysis." Izabela